Warning
This plugin has been deprecated in favor of our BigQuery destination for batch exports.
Send events to a BigQuery database on ingestion.
- Visit 'Plugins' in PostHog
- Find this plugin from the repository or install
https://github.com/PostHog/bigquery-plugin - Configure the plugin
- Upload your Google Cloud key
.jsonfile. (See below for permissions and how to retrieve this.) - Enter your Dataset ID
- Enter your Table ID
- Upload your Google Cloud key
- Watch events roll into BigQuery
To set the right permissions up for the BigQuery plugin, you'll need:
- A service account.
- A dataset which has permissions allowing the service account to access it.
Here's how to set these up so that the PostHog plugin has access only to the table it needs:
-
Create a service account. Keep hold of the JSON file at the end of these steps for setting up the plugin, and remember the name too.
-
Create a role which has only the specific permissions the PostHog BigQuery plugin requires (listed below), or use the built in
BigQuery DataOwnerpermission. If you create a custom role, you will need:- bigquery.datasets.get
- bigquery.tables.create
- bigquery.tables.get
- bigquery.tables.list
- bigquery.tables.updateData
-
Create a dataset within a BigQuery project (ours is called
posthog, but any name will do). -
Follow the instructions on granting access to a dataset in BigQuery to ensure your new service account has been granted either the role you created or the "BigQuery Data Owner" permission.
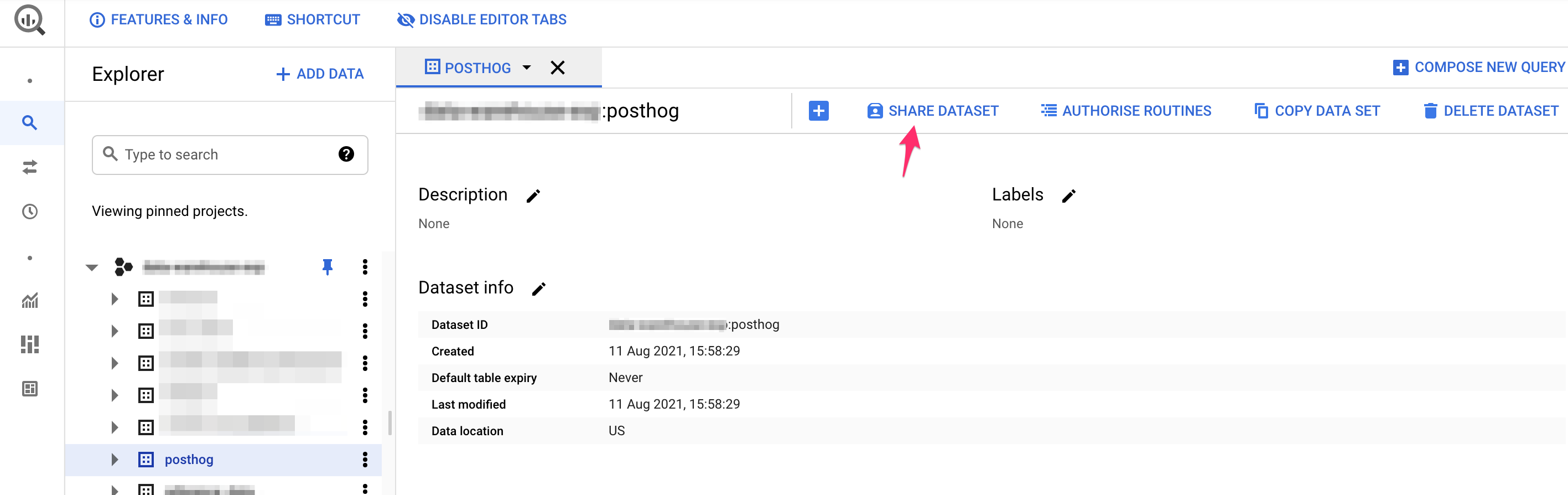
Use the Share Dataset button to share your dataset with your new service account and either the
BigQuery DataOwnerrole, or your custom role created above. In the below, we've used a custom rolePostHog Ingest.
That's it! Once you've done the steps above, your data should start flowing from PostHog to BigQuery.
There's a very rare case when duplicate events appear in BigQuery. This happens due to network errors, where the export seems to have failed, yet it actually reaches BigQuery.
While this shouldn't happen, if you find duplicate events in BigQuery, follow these Google Cloud docs to manually remove the them.
Here is an example query based on the Google Cloud docs that would remove duplicates:
WITH
-- first add a row number, one for each uuid
raw_data AS
(
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY uuid) as ROW_NUMBER
from
`<project_id>.<dataset>.<table>`
WHERE
DATE(timestamp) = '<YYYY-MM-DD>'
),
-- now just filter for one row per uuid
raw_data_deduplicated AS
(
SELECT
* EXCEPT(ROW_NUMBER)
FROM
raw_data
WHERE
ROW_NUMBER = 1
)
SELECT
*
FROM
raw_data_deduplicated
;





















