Hi~ I'm KaKa_Xie 👋
I'm a 5 years working engineer who likes to write some daily blogs.
- Read more about My Blogs
- Read more about My Issue Blogs
- Some shared articles in 掘金
- Ping me by Email: [email protected]
【持续更新】以 issue 的形式来记录笔记
Hi~ I'm KaKa_Xie 👋
I'm a 5 years working engineer who likes to write some daily blogs.







通俗地讲就是验证当前用户的身份,证明“你是你自己”(比如:你每天上下班打卡,都需要通过指纹打卡,当你的指纹和系统里录入的指纹相匹配时,就打卡成功)
互联网中的认证:
用户授予第三方应用访问该用户某些资源的权限
你在安装手机应用的时候,APP 会询问是否允许授予权限(访问相册、地理位置等权限)
你在访问微信小程序时,当登录时,小程序会询问是否允许授予权限(获取昵称、头像、地区、性别等个人信息)
实现授权的方式有:cookie、session、token、OAuth
实现认证和授权的前提是需要一种媒介(证书) 来标记访问者的身份
在战国时期,商鞅变法,发明了照身帖。照身帖由官府发放,是一块打磨光滑细密的竹板,上面刻有持有人的头像和籍贯信息。国人必须持有,如若没有就被认为是黑户,或者间谍之类的。
在现实生活中,每个人都会有一张专属的居民身份证,是用于证明持有人身份的一种法定证件。通过身份证,我们可以办理手机卡/银行卡/个人贷款/交通出行等等,这就是认证的凭证。
在互联网应用中,一般网站(如掘金)会有两种模式,游客模式和登录模式。游客模式下,可以正常浏览网站上面的文章,一旦想要点赞/收藏/分享文章,就需要登录或者注册账号。当用户登录成功后,服务器会给该用户使用的浏览器颁发一个令牌(token),这个令牌用来表明你的身份,每次浏览器发送请求时会带上这个令牌,就可以使用游客模式下无法使用的功能。
HTTP 是无状态的协议(对于事务处理没有记忆能力,每次客户端和服务端会话完成时,服务端不会保存任何会话信息):每个请求都是完全独立的,服务端无法确认当前访问者的身份信息,无法分辨上一次的请求发送者和这一次的发送者是不是同一个人。所以服务器与浏览器为了进行会话跟踪(知道是谁在访问我),就必须主动的去维护一个状态,这个状态用于告知服务端前后两个请求是否来自同一浏览器。而这个状态需要通过 cookie 或者 session 去实现。
cookie 存储在客户端: cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。
cookie 是不可跨域的: 每个 cookie 都会绑定单一的域名,无法在别的域名下获取使用,一级域名和二级域名之间是允许共享使用的(靠的是 domain)。
cookie 重要的属性
| 属性 | 说明 |
|---|---|
| conte | conte |
| name=value | 键值对,设置 Cookie 的名称及相对应的值,都必须是字符串类型 - 如果值为 Unicode 字符,需要为字符编码。 - 如果值为二进制数据,则需要使用 BASE64 编码。 |
| domain | 指定 cookie 所属域名,默认是当前域名 |
| path | 指定 cookie 在哪个路径(路由)下生效,默认是 '/'。 如果设置为 /abc,则只有 /abc 下的路由可以访问到该 cookie,如:/abc/read。 |
| maxAge | cookie 失效的时间,单位秒。如果为整数,则该 cookie 在 maxAge 秒后失效。如果为负数,该 cookie 为临时 cookie ,关闭浏览器即失效,浏览器也不会以任何形式保存该 cookie 。如果为 0,表示删除该 cookie 。默认为 -1。 - 比 expires 好用。 |
| expires | 过期时间,在设置的某个时间点后该 cookie 就会失效。 一般浏览器的 cookie 都是默认储存的,当关闭浏览器结束这个会话的时候,这个 cookie 也就会被删除 |
| secure | 该 cookie 是否仅被使用安全协议传输。安全协议有 HTTPS,SSL 等,在网络上传输数据之前先将数据加密。默认为 false。 当 secure 值为 true 时,cookie 在 HTTP 中是无效,在 HTTPS 中才有效。 |
| httpOnly | 如果给某个 cookie 设置了 httpOnly 属性,则无法通过 JS 脚本 读取到该 cookie 的信息,但还是能通过 Application 中手动修改 cookie,所以只是在一定程度上可以防止 XSS 攻击,不是绝对的安全 |

session 认证流程:
用户第一次请求服务器的时候,服务器根据用户提交的相关信息,创建对应的 Session
请求返回时将此 Session 的唯一标识信息 SessionID 返回给浏览器
浏览器接收到服务器返回的 SessionID 信息后,会将此信息存入到 Cookie 中,同时 Cookie 记录此 SessionID 属于哪个域名
当用户第二次访问服务器的时候,请求会自动判断此域名下是否存在 Cookie 信息,如果存在自动将 Cookie 信息也发送给服务端,服务端会从 Cookie 中获取 SessionID,再根据 SessionID 查找对应的 Session 信息,如果没有找到说明用户没有登录或者登录失效,如果找到 Session 证明用户已经登录可执行后面操作。
根据以上流程可知,SessionID 是连接 Cookie 和 Session 的一道桥梁,大部分系统也是根据此原理来验证用户登录状态。
安全性: Session 比 Cookie 安全,Session 是存储在服务器端的,Cookie 是存储在客户端的。
存取值的类型不同:Cookie 只支持存字符串数据,想要设置其他类型的数据,需要将其转换成字符串,Session 可以存任意数据类型。
有效期不同: Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭(默认情况下)或者 Session 超时都会失效。
存储大小不同: 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie,但是当访问量过多,会占用过多的服务器资源。
访问资源接口(API)时所需要的资源凭证
简单 token 的组成: uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,token 的前几位以哈希算法压缩成的一定长度的十六进制字符串)
特点:
token 的身份验证流程:

每一次请求都需要携带 token,需要把 token 放到 HTTP 的 Header 里
基于 token 的用户认证是一种服务端无状态的认证方式,服务端不用存放 token 数据。用解析 token 的计算时间换取 session 的存储空间,从而减轻服务器的压力,减少频繁的查询数据库
token 完全由应用管理,所以它可以避开同源策略
另外一种 token——refresh token
refresh token 是专用于刷新 access token 的 token。如果没有 refresh token,也可以刷新 access token,但每次刷新都要用户输入登录用户名与密码,会很麻烦。有了 refresh token,可以减少这个麻烦,客户端直接用 refresh token 去更新 access token,无需用户进行额外的操作。

Access Token 的有效期比较短,当 Acesss Token 由于过期而失效时,使用 Refresh Token 就可以获取到新的 Token,如果 Refresh Token 也失效了,用户就只能重新登录了。
Refresh Token 及过期时间是存储在服务器的数据库中,只有在申请新的 Acesss Token 时才会验证,不会对业务接口响应时间造成影响,也不需要向 Session 一样一直保持在内存中以应对大量的请求。
Session 是一种记录服务器和客户端会话状态的机制,使服务端有状态化,可以记录会话信息。而 Token 是令牌,访问资源接口(API)时所需要的资源凭证。Token 使服务端无状态化,不会存储会话信息。
Session 和 Token 并不矛盾,作为身份认证 Token 安全性比 Session 好,因为每一个请求都有签名还能防止监听以及重放攻击,而 Session 就必须依赖链路层来保障通讯安全了。如果你需要实现有状态的会话,仍然可以增加 Session 来在服务器端保存一些状态。
所谓 Session 认证只是简单的把 User 信息存储到 Session 里,因为 SessionID 的不可预测性,暂且认为是安全的。而 Token ,如果指的是 OAuth Token 或类似的机制的话,提供的是 认证 和 授权 ,认证是针对用户,授权是针对 App 。其目的是让某 App 有权利访问某用户的信息。这里的 Token 是唯一的。不可以转移到其它 App 上,也不可以转到其它用户上。Session 只提供一种简单的认证,即只要有此 SessionID ,即认为有此 User 的全部权利。是需要严格保密的,这个数据应该只保存在站方,不应该共享给其它网站或者第三方 App。所以简单来说:如果你的用户数据可能需要和第三方共享,或者允许第三方调用 API 接口,用 Token 。如果永远只是自己的网站,自己的 App,用什么就无所谓了。
JSON Web Token(简称 JWT)是目前最流行的跨域认证解决方案。
是一种认证授权机制。
JWT 是为了在网络应用环境间传递声明而执行的一种基于 JSON 的开放标准(RFC 7519)。JWT 的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源。比如用在用户登录上。
可以使用 HMAC 算法或者是 RSA 的公/私秘钥对 JWT 进行签名。因为数字签名的存在,这些传递的信息是可信的。
阮一峰老师的 JSON Web Token 入门教程 讲的非常通俗易懂,这里就不再班门弄斧了

JWT 认证流程:
Authorization: Bearer <token>服务端的保护路由将会检查请求头 Authorization 中的 JWT 信息,如果合法,则允许用户的行为
因为 JWT 是自包含的(内部包含了一些会话信息),因此减少了需要查询数据库的需要
因为 JWT 并不使用 Cookie 的,所以你可以使用任何域名提供你的 API 服务而不需要担心跨域资源共享问题(CORS)
因为用户的状态不再存储在服务端的内存中,所以这是一种无状态的认证机制
相同:
区别:
Token:服务端验证客户端发送过来的 Token 时,还需要查询数据库获取用户信息,然后验证 Token 是否有效。
JWT: 将 Token 和 Payload 加密后存储于客户端,服务端只需要使用密钥解密进行校验(校验也是 JWT 自己实现的)即可,不需要查询或者减少查询数据库,因为 JWT 自包含了用户信息和加密的数据。
因为存储在客户端,容易被客户端篡改,使用前需要验证合法性
不要存储敏感数据,比如用户密码,账户余额
使用 httpOnly 在一定程度上提高安全性
尽量减少 cookie 的体积,能存储的数据量不能超过 4kb
设置正确的 domain 和 path,减少数据传输
cookie 无法跨域
一个浏览器针对一个网站最多存 20 个 Cookie,浏览器一般只允许存放 300 个 Cookie
移动端对 cookie 的支持不是很好,而 session 需要基于 cookie 实现,所以移动端常用的是 token
将 session 存储在服务器里面,当用户同时在线量比较多时,这些 session 会占据较多的内存,需要在服务端定期的去清理过期的 session
当网站采用集群部署的时候,会遇到多台 web 服务器之间如何做 session 共享的问题。因为 session 是由单个服务器创建的,但是处理用户请求的服务器不一定是那个创建 session 的服务器,那么该服务器就无法拿到之前已经放入到 session 中的登录凭证之类的信息了。
当多个应用要共享 session 时,除了以上问题,还会遇到跨域问题,因为不同的应用可能部署的主机不一样,需要在各个应用做好 cookie 跨域的处理。
sessionId 是存储在 cookie 中的,假如浏览器禁止 cookie 或不支持 cookie 怎么办? 一般会把 sessionId 跟在 url 参数后面即重写 url,所以 session 不一定非得需要靠 cookie 实现
移动端对 cookie 的支持不是很好,而 session 需要基于 cookie 实现,所以移动端常用的是 token
如果你认为用数据库来存储 token 会导致查询时间太长,可以选择放在内存当中。比如 redis 很适合你对 token 查询的需求。
token 完全由应用管理,所以它可以避开同源策略
token 可以避免 CSRF 攻击(因为不需要 cookie 了)
移动端对 cookie 的支持不是很好,而 session 需要基于 cookie 实现,所以移动端常用的是 token
git 内置了对命令非常详细的解释,可以供我们快速查阅
# 查找可用命令
$ git help
# 查找所有可用命令
$ git help -a
# 在文档当中查找特定的命令
# git help <命令>
$ git help add
$ git help commit
$ git help init显示索引文件(也就是当前工作空间)和当前的头指针指向的提交的不同
# 显示分支,未跟踪文件,更改和其他不同
$ git status
# 查看其他的git status的用法
$ git help status获取某些文件,某些分支,某次提交等 git 信息
# 显示commit历史,以及每次commit发生变更的文件
$ git log --stat
# 搜索提交历史,根据关键词
$ git log -S [keyword]
# 显示某个commit之后的所有变动,每个commit占据一行
$ git log [tag] HEAD --pretty=format:%s
# 显示某个commit之后的所有变动,其"提交说明"必须符合搜索条件
$ git log [tag] HEAD --grep feature
# 显示某个文件的版本历史,包括文件改名
$ git log --follow [file]
$ git whatchanged [file]
# 显示指定文件相关的每一次diff
$ git log -p [file]
# 显示过去5次提交
$ git log -5 --pretty --oneline
# 显示所有提交过的用户,按提交次数排序
$ git shortlog -sn
# 显示指定文件是什么人在什么时间修改过
$ git blame [file]
# 显示暂存区和工作区的差异
$ git diff
# 显示暂存区和上一个commit的差异
$ git diff --cached [file]
# 显示工作区与当前分支最新commit之间的差异
$ git diff HEAD
# 显示两次提交之间的差异
$ git diff [first-branch]...[second-branch]
# 显示今天你写了多少行代码
$ git diff --shortstat "@{0 day ago}"
# 比较暂存区和版本库差异
$ git diff --staged
# 比较暂存区和版本库差异
$ git diff --cached
# 仅仅比较统计信息
$ git diff --stat
# 显示某次提交的元数据和内容变化
$ git show [commit]
# 显示某次提交发生变化的文件
$ git show --name-only [commit]
# 显示某次提交时,某个文件的内容
$ git show [commit]:[filename]
# 显示当前分支的最近几次提交
$ git reflog
# 查看远程分支
$ git br -r
# 创建新的分支
$ git br <new_branch>
# 查看各个分支最后提交信息
$ git br -v
# 查看已经被合并到当前分支的分支
$ git br --merged
# 查看尚未被合并到当前分支的分支
$ git br --no-merged添加文件到当前工作空间中。如果你不使用 git add 将文件添加进去,那么这些文件也不会添加到之后的提交之中
# 添加一个文件
$ git add test.js
# 添加一个子目录中的文件
$ git add /path/to/file/test.js
# 支持正则表达式
$ git add ./*.js
# 添加指定文件到暂存区
$ git add [file1] [file2] ...
# 添加指定目录到暂存区,包括子目录
$ git add [dir]
# 添加当前目录的所有文件到暂存区
$ git add .
# 添加每个变化前,都会要求确认
# 对于同一个文件的多处变化,可以实现分次提交
$ git add -prm 和上面的 add 命令相反,从工作空间中去掉某个文件
# 移除 HelloWorld.js
$ git rm HelloWorld.js
# 移除子目录中的文件
$ git rm /pather/to/the/file/HelloWorld.js
# 删除工作区文件,并且将这次删除放入暂存区
$ git rm [file1] [file2] ...
# 停止追踪指定文件,但该文件会保留在工作区
$ git rm --cached [file]管理分支,可以通过下列命令对分支进行增删改查切换等
# 查看所有的分支和远程分支
$ git branch -a
# 创建一个新的分支
$ git branch [branch-name]
# 重命名分支
# git branch -m <旧名称> <新名称>
$ git branch -m [branch-name] [new-branch-name]
# 编辑分支的介绍
$ git branch [branch-name] --edit-description
# 列出所有本地分支
$ git branch
# 列出所有远程分支
$ git branch -r
# 新建一个分支,但依然停留在当前分支
$ git branch [branch-name]
# 新建一个分支,并切换到该分支
$ git checkout -b [branch]
# 新建一个分支,指向指定commit
$ git branch [branch] [commit]
# 新建一个分支,与指定的远程分支建立追踪关系
$ git branch --track [branch] [remote-branch]
# 切换到指定分支,并更新工作区
$ git checkout [branch-name]
# 切换到上一个分支
$ git checkout -
# 建立追踪关系,在现有分支与指定的远程分支之间
$ git branch --set-upstream [branch] [remote-branch]
# 合并指定分支到当前分支
$ git merge [branch]
# 选择一个commit,合并进当前分支
$ git cherry-pick [commit]
# 删除分支
$ git branch -d [branch-name]
# 删除远程分支
$ git push origin --delete [branch-name]
$ git branch -dr [remote/branch]
# 切换到某个分支
$ git co <branch>
# 创建新的分支,并且切换过去
$ git co -b <new_branch>
# 基于branch创建新的new_branch
$ git co -b <new_branch> <branch>
# 把某次历史提交记录checkout出来,但无分支信息,切换到其他分支会自动删除
$ git co $id
# 把某次历史提交记录checkout出来,创建成一个分支
$ git co $id -b <new_branch>
# 删除某个分支
$ git br -d <branch>
# 强制删除某个分支 (未被合并的分支被删除的时候需要强制)
$ git br -D <branch>将当前工作空间更新到索引所标识的或者某一特定的工作空间
# 检出一个版本库,默认将更新到master分支
$ git checkout
# 检出到一个特定的分支
$ git checkout branchName
# 新建一个分支,并且切换过去,相当于"git branch <名字>; git checkout <名字>"
$ git checkout -b newBranch远程同步的远端分支
# 下载远程仓库的所有变动
$ git fetch [remote]
# 显示所有远程仓库
$ git remote -v
# 显示某个远程仓库的信息
$ git remote show [remote]
# 增加一个新的远程仓库,并命名
$ git remote add [shortname] [url]
# 查看远程服务器地址和仓库名称
$ git remote -v
# 添加远程仓库地址
$ git remote add origin git@ github:xxx/xxx.git
# 设置远程仓库地址(用于修改远程仓库地址)
$ git remote set-url origin git@ github.com:xxx/xxx.git
# 删除远程仓库
$ git remote rm <repository>
# 上传本地指定分支到远程仓库
# 把本地的分支更新到远端origin的master分支上
# git push <远端> <分支>
# git push 相当于 git push origin master
$ git push [remote] [branch]
# 强行推送当前分支到远程仓库,即使有冲突
$ git push [remote] --force
# 推送所有分支到远程仓库
$ git push [remote] --all# 恢复暂存区的指定文件到工作区
$ git checkout [file]
# 恢复某个commit的指定文件到暂存区和工作区
$ git checkout [commit] [file]
# 恢复暂存区的所有文件到工作区
$ git checkout .
# 重置暂存区的指定文件,与上一次commit保持一致,但工作区不变
$ git reset [file]
# 重置暂存区与工作区,与上一次commit保持一致
$ git reset --hard
# 重置当前分支的指针为指定commit,同时重置暂存区,但工作区不变
$ git reset [commit]
# 重置当前分支的HEAD为指定commit,同时重置暂存区和工作区,与指定commit一致
$ git reset --hard [commit]
# 重置当前HEAD为指定commit,但保持暂存区和工作区不变
$ git reset --keep [commit]
# 新建一个commit,用来撤销指定commit
# 后者的所有变化都将被前者抵消,并且应用到当前分支
$ git revert [commit]
# 恢复最后一次提交的状态
$ git revert HEAD
# 暂时将未提交的变化移除,稍后再移入
$ git stash
$ git stash pop
# 列所有stash
$ git stash list
# 恢复暂存的内容
$ git stash apply
# 删除暂存区
$ git stash drop将当前索引的更改保存为一个新的提交,这个提交包括用户做出的更改与信息
# 提交暂存区到仓库区附带提交信息
$ git commit -m [message]
# 提交暂存区的指定文件到仓库区
$ git commit [file1] [file2] ... -m [message]
# 提交工作区自上次commit之后的变化,直接到仓库区
$ git commit -a
# 提交时显示所有diff信息
$ git commit -v
# 使用一次新的commit,替代上一次提交
# 如果代码没有任何新变化,则用来改写上一次commit的提交信息
$ git commit --amend -m [message]
# 重做上一次commit,并包括指定文件的新变化
$ git commit --amend [file1] [file2] ...# 显示工作目录和索引的不同
$ git diff
# 显示索引和最近一次提交的不同
$ git diff --cached
# 显示工作目录和最近一次提交的不同
$ git diff HEAD可以在版本库中快速查找
可选配置:
# 感谢Travis Jeffery提供的以下用法:
# 在搜索结果中显示行号
$ git config --global grep.lineNumber true
# 是搜索结果可读性更好
$ git config --global alias.g "grep --break --heading --line-number"
# 在所有的java中查找variableName
$ git grep 'variableName' -- '*.java'
# 搜索包含 "arrayListName" 和, "add" 或 "remove" 的所有行
$ git grep -e 'arrayListName' --and \( -e add -e remove \)显示这个版本库的所有提交
# 显示所有提交
$ git log
# 显示某几条提交信息
$ git log -n 10
# 仅显示合并提交
$ git log --merges
# 查看该文件每次提交记录
$ git log <file>
# 查看每次详细修改内容的diff
$ git log -p <file>
# 查看最近两次详细修改内容的diff
$ git log -p -2
#查看提交统计信息
$ git log --stat合并就是将外部的提交合并到自己的分支中
# 将其他分支合并到当前分支
$ git merge branchName
# 在合并时创建一个新的合并后的提交
# 不要 Fast-Foward 合并,这样可以生成 merge 提交
$ git merge --no-ff branchName重命名或移动一个文件
# 重命名
$ git mv test.js test2.js
# 移动
$ git mv test.js ./new/path/test.js
# 改名文件,并且将这个改名放入暂存区
$ git mv [file-original] [file-renamed]
# 强制重命名或移动
# 这个文件已经存在,将要覆盖掉
$ git mv -f myFile existingFile# 列出所有tag
$ git tag
# 新建一个tag在当前commit
$ git tag [tag]
# 新建一个tag在指定commit
$ git tag [tag] [commit]
# 删除本地tag
$ git tag -d [tag]
# 删除本地所有tag
git tag | xargs git tag -d
# 删除远端所有tag
git tag -l | xargs -n 1 git push --delete origin
# 删除远程tag
$ git push origin :refs/tags/[tagName]
# 查看tag信息
$ git show [tag]
# 提交指定tag
$ git push [remote] [tag]
# 提交所有tag
$ git push [remote] --tags
# 新建一个分支,指向某个tag
$ git checkout -b [branch] [tag]从远端版本库合并到当前分支
# 从远端origin的master分支更新版本库
# git pull <远端> <分支>
$ git pull origin master
# 抓取远程仓库所有分支更新并合并到本地,不要快进合并
$ git pull --no-ff$ git ci <file>
$ git ci .
# 将git add, git rm和git ci等操作都合并在一起做
$ git ci -a
$ git ci -am "some comments"
# 修改最后一次提交记录
$ git ci --amend将一个分支上所有的提交历史都应用到另一个分支上
不要在一个已经公开的远端分支上使用 rebase.
# 将experimentBranch应用到master上面
# git rebase <basebranch> <topicbranch>
$ git rebase master experimentBranch将当前的头指针复位到一个特定的状态。这样可以使你撤销 merge、pull、commits、add 等
这是个很强大的命令,但是在使用时一定要清楚其所产生的后果
# 使 staging 区域恢复到上次提交时的状态,不改变现在的工作目录
$ git reset
# 使 staging 区域恢复到上次提交时的状态,覆盖现在的工作目录
$ git reset --hard
# 将当前分支恢复到某次提交,不改变现在的工作目录
# 在工作目录中所有的改变仍然存在
$ git reset dha78as
# 将当前分支恢复到某次提交,覆盖现在的工作目录
# 并且删除所有未提交的改变和指定提交之后的所有提交
$ git reset --hard dha78as# 生成一个可供发布的压缩包
$ git archive
# 打补丁
$ git apply ../sync.patch
# 测试补丁能否成功
$ git apply --check ../sync.patch
# 查看Git的版本
$ git --version2 月份发布的 Chrome 80 版本中默认屏蔽了第三方的 Cookie,在灰度期间,就导致了阿里系的很多应用都产生了问题,为此还专门成立了小组,推动各 BU 进行改造,目前阿里系基本已经改造完成。所有的前端团队估计都收到过通知,也着实加深了一把大家对于 Cookie 的理解,所以很可能就此出个面试题,而即便不是面试题,当问到 HTTP 相关内容的时候,不妨也扯到这件事情来,一能表明你对前端时事的跟进,二还能借此引申到前端安全方面的内容,为你的面试加分。
所以本文就给大家介绍一下浏览器的 Cookie 以及这个"火热"的 SameSite 属性。
一般我们都会说 “HTTP 是一个无状态的协议”,不过要注意这里的 HTTP 其实是指 HTTP 1.x,而所谓无状态协议,简单的理解就是即使同一个客户端连续两次发送请求给服务器,服务器也识别不出这是同一个客户端发送的请求,这导致的问题就比如你加了一个商品到购物车中,但因为识别不出是同一个客户端,你刷新下页面就没有了……
为了解决 HTTP 无状态导致的问题,后来出现了 Cookie。不过这样说可能会让你产生一些误解,首先无状态并不是不好,有优点,但也会导致一些问题。而 Cookie 的存在也不是为了解决通讯协议无状态的问题,只是为了解决客户端与服务端会话状态的问题,这个状态是指后端服务的状态而非通讯协议的状态。
那我们来看下 Cookie,引用下维基百科:
Cookie(复数形态 Cookies),类型为「小型文本文件」,指某些网站为了辨别用户身份而储存在用户本地终端上的数据。
作为一段一般不超过 4KB 的小型文本数据,它由一个名称(Name)、一个值(Value)和其它几个用于控制 Cookie 有效期、安全性、使用范围的可选属性组成,这些涉及的属性我们会在后面会介绍。
我们可以在浏览器的开发者工具中查看到当前页面的 Cookie:

尽管我们在浏览器里查看到了 Cookie,这并不意味着 Cookie 文件只是存放在浏览器里的。实际上,Cookies 相关的内容还可以存在本地文件里,就比如说 Mac 下的 Chrome,存放目录就是 ~/Library/Application Support/Google/Chrome/Default,里面会有一个名为 Cookies 的数据库文件,你可以使用 sqlite 软件打开它:

存放在本地的好处就在于即使你关闭了浏览器,Cookie 依然可以生效。
那 Cookie 是怎么设置的呢?简单来说就是
我们以 https://main.m.taobao.com/ 为例来看下这个过程:
我们在请求返回的 Response Headers 可以看到 Set-Cookie 字段:

然后我们查看下 Cookie:

我们刷新一遍页面,再看下这个请求,可以在 Request Headers 看到 cookie 字段:

在下面这张图里我们可以看到 Cookies 相关的一些属性:

这里主要说一些大家可能没有注意的点:
Name/Value
用 JavaScript 操作 Cookie 的时候注意对 Value 进行编码处理。
Expires
Expires 用于设置 Cookie 的过期时间。比如:
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;当 Expires 属性缺省时,表示是会话性 Cookie,像上图 Expires 的值为 Session,表示的就是会话性 Cookie。当为会话性 Cookie 的时候,值保存在客户端内存中,并在用户关闭浏览器时失效。需要注意的是,有些浏览器提供了会话恢复功能,这种情况下即使关闭了浏览器,会话期 Cookie 也会被保留下来,就好像浏览器从来没有关闭一样。
与会话性 Cookie 相对的是持久性 Cookie,持久性 Cookies 会保存在用户的硬盘中,直至过期或者清除 Cookie。这里值得注意的是,设定的日期和时间只与客户端相关,而不是服务端。
Max-Age
Max-Age 用于设置在 Cookie 失效之前需要经过的秒数。比如:
Set-Cookie: id=a3fWa; Max-Age=604800;Max-Age 可以为正数、负数、甚至是 0。
如果 max-Age 属性为正数时,浏览器会将其持久化,即写到对应的 Cookie 文件中。
当 max-Age 属性为负数,则表示该 Cookie 只是一个会话性 Cookie。
当 max-Age 为 0 时,则会立即删除这个 Cookie。
假如 Expires 和 Max-Age 都存在,Max-Age 优先级更高。
Domain
Domain 指定了 Cookie 可以送达的主机名。假如没有指定,那么默认值为当前文档访问地址中的主机部分(但是不包含子域名)。
像淘宝首页设置的 Domain 就是 .taobao.com,这样无论是 a.taobao.com 还是 b.taobao.com 都可以使用 Cookie。
在这里注意的是,不能跨域设置 Cookie,比如阿里域名下的页面把 Domain 设置成百度是无效的:
Set-Cookie: qwerty=219ffwef9w0f; Domain=baidu.com; Path=/; Expires=Wed, 30 Aug 2020 00:00:00 GMTPath
Path 指定了一个 URL 路径,这个路径必须出现在要请求的资源的路径中才可以发送 Cookie 首部。比如设置 Path=/docs,/docs/Web/ 下的资源会带 Cookie 首部,/test 则不会携带 Cookie 首部。
Domain 和 Path 标识共同定义了 Cookie 的作用域:即 Cookie 应该发送给哪些 URL。
Secure 属性
标记为 Secure 的 Cookie 只应通过被 HTTPS 协议加密过的请求发送给服务端。使用 HTTPS 安全协议,可以保护 Cookie 在浏览器和 Web 服务器间的传输过程中不被窃取和篡改。
HTTPOnly
设置 HTTPOnly 属性可以防止客户端脚本通过 document.cookie 等方式访问 Cookie,有助于避免 XSS 攻击。
SameSite
SameSite 是最近非常值得一提的内容,因为 2 月份发布的 Chrome80 版本中默认屏蔽了第三方的 Cookie,这会导致阿里系的很多应用都产生问题,为此还专门成立了问题小组,推动各 BU 进行改造。
作用
我们先来看看这个属性的作用:
SameSite 属性可以让 Cookie 在跨站请求时不会被发送,从而可以阻止跨站请求伪造攻击(CSRF)。
属性值
SameSite 可以有下面三种值:
Strict 仅允许一方请求携带 Cookie,即浏览器将只发送相同站点请求的 Cookie,即当前网页 URL 与请求目标 URL 完全一致。
Lax 允许部分第三方请求携带 Cookie
None 无论是否跨站都会发送 Cookie
之前默认是 None 的,Chrome80 后默认是 Lax。
跨域和跨站
首先要理解的一点就是跨站和跨域是不同的。同站(same-site)/跨站(cross-site)」和第一方(first-party)/第三方(third-party)是等价的。但是与浏览器同源策略(SOP)中的「同源(same-origin)/跨域(cross-origin)」是完全不同的概念。
同源策略的同源是指两个 URL 的协议/主机名/端口一致。例如,https://www.taobao.com/pages/...,它的协议是 https,主机名是 www.taobao.com,端口是 443。
同源策略作为浏览器的安全基石,其「同源」判断是比较严格的,相对而言,Cookie 中的「同站」判断就比较宽松:只要两个 URL 的 eTLD+1 相同即可,不需要考虑协议和端口。其中,eTLD 表示有效顶级域名,注册于 Mozilla 维护的公共后缀列表(Public Suffix List)中,例如,.com、.co.uk、.github.io 等。eTLD+1 则表示,有效顶级域名+二级域名,例如 taobao.com 等。
举几个例子,www.taobao.com 和 www.baidu.com 是跨站,www.a.taobao.com 和 www.b.taobao.com 是同站,a.github.io 和 b.github.io 是跨站(注意是跨站)。
改变
接下来看下从 None 改成 Lax 到底影响了哪些地方的 Cookies 的发送?直接来一个图表:

从上图可以看出,对大部分 web 应用而言,Post 表单,iframe,AJAX,Image 这四种情况从以前的跨站会发送三方 Cookie,变成了不发送。
Post 表单:应该的,学 CSRF 总会举表单的例子。
iframe:iframe 嵌入的 web 应用有很多是跨站的,都会受到影响。
AJAX:可能会影响部分前端取值的行为和结果。
Image:图片一般放 CDN,大部分情况不需要 Cookie,故影响有限。但如果引用了需要鉴权的图片,可能会受到影响。
除了这些还有 script 的方式,这种方式也不会发送 Cookie,像淘宝的大部分请求都是 jsonp,如果涉及到跨站也有可能会被影响。
问题
我们再看看会出现什么的问题?举几个例子:
天猫和飞猪的页面靠请求淘宝域名下的接口获取登录信息,由于 Cookie 丢失,用户无法登录,页面还会误判断成是由于用户开启了浏览器的“禁止第三方 Cookie”功能导致而给与错误的提示
淘宝部分页面内嵌支付宝确认付款和确认收货页面、天猫内嵌淘宝的登录页面等,由于 Cookie 失效,付款、登录等操作都会失败
阿里妈妈在各大网站比如今日头条,网易,微博等投放的广告,也是用 iframe 嵌入的,没有了 Cookie,就不能准确的进行推荐
一些埋点系统会把用户 id 信息埋到 Cookie 中,用于日志上报,这种系统一般走的都是单独的域名,与业务域名分开,所以也会受到影响。
一些用于防止恶意请求的系统,对判断为恶意请求的访问会弹出验证码让用户进行安全验证,通过安全验证后会在请求所在域种一个 Cookie,请求中带上这个 Cookie 之后,短时间内不再弹安全验证码。在 Chrome80 以上如果因为 Samesite 的原因请求没办法带上这个 Cookie,则会出现一直弹出验证码进行安全验证。
天猫商家后台请求了跨域的接口,因为没有 Cookie,接口不会返回数据
……
如果不解决,影响的系统其实还是很多的……
解决
解决方案就是设置 SameSite 为 none。
以 Adobe 网站为例:https://www.adobe.com/sea/,查看请求可以看到:

不过也会有两点要注意的地方:
HTTP 接口不支持 SameSite=none
如果你想加 SameSite=none 属性,那么该 Cookie 就必须同时加上 Secure 属性,表示只有在 HTTPS 协议下该 Cookie 才会被发送。
需要 UA 检测,部分浏览器不能加 SameSite=none
IOS 12 的 Safari 以及老版本的一些 Chrome 会把 SameSite=none 识别成 SameSite=Strict,所以服务端必须在下发 Set-Cookie 响应头时进行 User-Agent 检测,对这些浏览器不下发 SameSite=none 属性
Cookie 主要用于以下三个方面:
如果被问到话,可以从大小、安全、增加请求大小等方面回答。
通常情况下当们在初次使用 Git 的时候,需要设置一些个人信息&git alias等,从而提高一些 git 方面的效率。
个人信息
这样我们在 commit 的时候能把个人信息附带上
git alias 别名
配置以后可以用简短的命令代替默认命令,而且还可以自定义一些个性 git <命令>
路径都是默认路径
Mac:
vim ~/.gitconfigWindows:
vim /c/Users/${自己电脑的用户名}/.gitconfig # 在Git Bash Here中才可以使用 vim下面的 alias 是我个人习惯,可以根据自己的习惯进行修改
[user]
name = KaKa_Xie
email = [email protected]
[alias]
sta = status
com = commit
mer = merge
reb = rebase
che = checkout
swi = switch
br = branch
unstage = reset HEAD --
last = log -1 HEAD
# --pretty[=<format>],<format> can be one of oneline, short, medium, full, fuller, reference, email, raw
lp = log --pretty=oneline
# %Cred: switch color to red;
# %Creset: reset color;
# %cI: committer date, strict ISO 8601 format
# %cr: committer date, relative
# %ae email
# %s subject
# %n newline
# %C(...) color specification
# lg = log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%ci) %C(bold blue)<%an>%Creset <%ae>'
lg = log --color --graph --pretty=format:'%Cred%h%Creset%C(yellow)%d%Creset %s %Cgreen%ci'
lg5 = log -5 --color --graph --pretty=format:'%Cred%h%Creset%C(yellow)%d%Creset %s %Cgreen%ci'
lg10 = log -10 --color --graph --pretty=format:'%Cred%h%Creset%C(yellow)%d%Creset %s %Cgreen%ci %C(bold blue)<%an>'
# [color]
# branch = auto
# diff = auto
# status = auto
# ui = auto
[color "branch"]
current = magenta
local = yellow
remote = cyan
# git status 的颜色配置
[color "status"]
changed = green # 已变更的文件
added = yellow # 已暂存的文件 git add .
untracked = cyan # 未跟踪的文件 新增的文件
[color "diff"]
meta = yellow
frag = magenta bold
commit = yellow bold
old = red bold
new = green bold
whitespace = red reverse
[color "diff-highlight"]
oldNormal = red bold
oldHighlight = red bold 52
newNormal = green bold
newHighlight = green bold 22
[core]
# https://git-scm.com/book/zh/v2/自定义-Git-配置-Git
excludesfile = /Users/${用户名}/.gitignore_global # git config --global core.excludesfile ~/.gitignore_global会自动生成路径
ignorecase = false # 开启敏感模式
pager = less # 分页器 默认是less
[pager]
# branch, log, diff等支持paper
branch = false # 当启用了zsh shell之后 执行git相关操作(log,branch)时会进入vim模式,一旦按q退出以后,就会导致上次操作的查询的结果被清空.设置了这个以后就可以避免了
git lg 效果如下:

# 全局设置
git config --global user.name "kaka" # 设置Git的用户名
git config --global user.email "[email protected]" # 设置Git的邮箱
# 项目本地设置
git config user.name "user2"
git config user.email "[email protected]"
# 查看
git config --get-all user.name # 获取所有的Git名字
git config --get-all user.email # 获取所有的Git邮箱
git config --get user.name # 获取本地git用户名
git config --global --list # 查看当前用户(global)配置
git config --local --list # 查看当前仓库配置信息
git config --system --list # 查看系统config
git config --list # 会查询到全局跟项目本地的所有配置之前有个项目后端把前端的项目文件路径给存起来了,以便动态注册路由,但是由于文件夹命名不规范(大驼峰)便改成了小驼峰,导致文件夹名字变更未被 git 当做变更而记录,最后就导致后端回来的路径跟实际项目路径不一致从而导致动态路由注册失败引发 bug!
git 默认不区分文件名大小写变化!!

# 开启区分大小写
git config core.ignorecase falsegit config的文档提示Config file location
--global use global config file
--system use system config file
--local use repository config file
--worktree use per-worktree config file
-f, --file <file> use given config file
--blob <blob-id> read config from given blob object
Action
--get get value: name [value-regex]
--get-all get all values: key [value-regex]
--get-regexp get values for regexp: name-regex [value-regex]
--get-urlmatch get value specific for the URL: section[.var] URL
--replace-all replace all matching variables: name value [value_regex]
--add add a new variable: name value
--unset remove a variable: name [value-regex]
--unset-all remove all matches: name [value-regex]
--rename-section rename section: old-name new-name
--remove-section remove a section: name
-l, --list list all
-e, --edit open an editor
--get-color find the color configured: slot [default]
--get-colorbool find the color setting: slot [stdout-is-tty]
Type
-t, --type <> value is given this type
--bool value is "true" or "false"
--int value is decimal number
--bool-or-int value is --bool or --int
--bool-or-str value is --bool or string
--path value is a path (file or directory name)
--expiry-date value is an expiry date
Other
-z, --null terminate values with NUL byte
--name-only show variable names only
--includes respect include directives on lookup
--show-origin show origin of config (file, standard input, blob, command line)
--show-scope show scope of config (worktree, local, global, system, command)
--default <value> with --get, use default value when missing entry通过 git config + Config file location + Action 的组合形式
git config --system --list通过 git config + Action
git config --get core.ignorecase....
npm help <key>
npm help confignpm root -gnpm list -g # 全部层级关系展开
npm list -g --depth 0 # 0 表示只查看一级的,1表示两级,以此类推。npm install npm -g
npm install npm@latest -g # 这将安装最新的官方测试版 npm。
npm install npm@next -g # 要安装将来发布的版本npm config list # 配置详情,可以看到npm的安装路劲和node 安装的地方# https://registry.npm.taobao.org/
npm config set registry <URL>首先看个例子:
let a = { name: '张三' }
let b = a
b.name = '李四'
console.log('a:', a) // 李四
console.log('b:', b) // 李四
var a = [1, 2, 3]
var b = a
b.push(4)
console.log('a:', a) //1,2,3,4
console.log('b:', b) //1,2,3,4因为在 JavaScript 中,对象跟数组属于引用数据类型,指针都会指向同一个,所以一改都改.
如何各改各的呢?(深拷贝)
let a = { name: '张三' }
let b = { ...a }
b.name = '李四'
console.log('a:', a) // {name: "张三"}
console.log('b:', b) // {name: "李四"}
let a = [1, 2]
let b = [...a]
b[1] = 3
console.log('a:', a) // [1, 2]
console.log('b:', b) // [1, 3]let a = { name: '张三' }
let b = {}
b = JSON.parse(JSON.stringify(a))
b.name = '李四'
console.log('a:', a) // {name: "张三"}
console.log('b:', b) // {name: "李四"}
let a = [1, 2]
let b = []
b = JSON.parse(JSON.stringify(a))
b[1] = 3
console.log('a:', a) // [1,2]
console.log('b:', b) // [3]
- 正则会被处理为空对象
- 具备函数/symbol/undefined 属性值直接被干掉
- BigInt 还处理不了,会报错 // Uncaught TypeError: Do not know how to serialize a BigInt
- 日期对象最后还是字符串
let obj = {
a:1,
b:/^$/,
c:undefined,
d:new Date()
}
console.log(JSON.parse(JSON.stringify(obj)))
// 结果如下
{
a:1,
b:{},
d:"2020-11-20T07:04:10.653Z"
}function deepCopy(param) {
if (!param) return param
if (param instanceof Date) return new Date(param)
if (param instanceof RegExp) return new RegExp(param)
// 数组和对象都会被判断为 'object'
if (typeof param !== "object") return param
// const blankArrOrObj = param instanceof Array ? [] : {}
// 或者
const blankArrOrObj = Array.isArray(param) ? [] : {}
// tips: for in 如果是数组那么就是 (index in arr) 如果是 对象 则就是 (key in obj)
for (const keyOrIndex in param) {
blankArrOrObj[keyOrIndex] = typeof param[keyOrIndex] === 'object'
? deepCopy(param[keyOrIndex])
: param[keyOrIndex]
}
return blankArrOrObj
}
// 对象
let a = { name: '张三' }
b = deepCopy(a)
b.name = '李四'
console.log('a:', a) // {name: "张三"}
console.log('b:', b) // {name: "李四"}
// 简单数组
let a = [1, 2]
b = deepCopy(a)
b[1] = 3
console.log('a:', a) // [1,2]
console.log('b:', b) // [3]
// 对象数组
let a = [{ name: 'x'}, { name: 'y' }]
b = deepCopy(a)
b[1].name = 'z'
console.log('a:', a) // [{ name: 'x'}, { name: 'y' }]
console.log('b:', b) // [{ name: 'x'}, { name: 'z' }]从根本上来讲,Git 是一个内容寻址的文件系统,其次才是一个版本控制系统。记住这点,对于理解 Git 的内部原理及其重要。所谓“内容寻址的文件系统”,意思是根据文件内容的 hash 码来定位文件。这就意味着同样内容的文件,在这个文件系统中会指向同一个位置,不会重复存储。
Git 对象包含三种:数据对象、树对象、提交对象。Git 文件系统的设计思路与 linux 文件系统相似,即将文件的内容与文件的属性分开存储,文件内容以“装满字节的袋子”存储在文件系统中,文件名、所有者、权限等文件属性信息则另外开辟区域进行存储。在 Git 中,数据对象相当于文件内容,树对象相当于文件目录树,提交对象则是对文件系统的快照。
下面的章节,会分别对每种对象进行说明。开始说明之前,先初始化一个 Git 文件系统:
$ mkdir git-test
$ cd git-test
$ git init接下来的操作都会在 git-test 这个目录中进行。
数据对象是文件的内容,不包括文件名、权限等信息。Git 会根据文件内容计算出一个 hash 值,以 hash 值作为文件索引存储在 Git 文件系统中。由于相同的文件内容的 hash 值是一样的,因此 Git 将同样内容的文件只会存储一次。git hash-object 可以用来计算文件内容的 hash 值,并将生成的数据对象存储到 Git 文件系统中:
$ echo 'version 1' | git hash-object -w --stdin
83baae61804e65cc73a7201a7252750c76066a30
$ echo 'version 2' | git hash-object -w --stdin
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
$ echo 'new file' | git hash-object -w --stdin
fa49b077972391ad58037050f2a75f74e3671e92上面示例中,-w 表示将数据对象写入到 Git 文件系统中,如果不加这个选项,那么只计算文件的 hash 值而不写入;--stdin 表示从标准输入中获取文件内容,当然也可以指定一个文件路径代替此选项。
上面讲数据对象写入到 Git 文件系统中,那如何读取数据对象呢?git cat-file 可以用来实现所有 Git 对象的读取,包括数据对象、树对象、提交对象的查看:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30
version 1
$ git cat-file -t 83baae61804e65cc73a7201a7252750c76066a30
blob上面示例中,-p 表示查看 Git 对象的内容,-t 表示查看 Git 对象的类型。
通过这一节,我们能够对 Git 文件系统中的数据对象进行读写。但是,我们需要记住每一个数据对象的 hash 值,才能访问到 Git 文件系统中的任意数据对象,这显然是不现实的。数据对象只是解决了文件内容存储的问题,而文件名的存储则需要通过下一节的树对象来解决。
树对象是文件目录树,记录了文件获取目录的名称、类型、模式信息。使用 git update-index 可以为数据对象指定名称和模式,然后使用 git write-tree 将树对象写入到 Git 文件系统中:
$ git update-index --add --cacheinfo 100644 83baae61804e65cc73a7201a7252750c76066a30 test.txt
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579--add 表示新增文件名,如果第一次添加某一文件名,必须使用此选项;--cacheinfo <mode> <object> <path>是要添加的数据对象的模式、hash 值和路径,<path>意味着为数据对象不仅可以指定单纯的文件名,也可以使用路径。另外要注意的是,使用 git update-index 添加完文件后,一定要使用 git write-tree 写入到 Git 文件系统中,否则只会存在于 index 区域。
树对象仍然可以使用 git cat-file 查看:
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree上面表示这个树对象只有 test.txt 这个文件,接下来我们将 version 2 的数据对象指定为 test.txt,并添加一个新文件 new.txt:
$ git update-index --cacheinfo 100644 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index --add --cacheinfo 100644 fa49b077972391ad58037050f2a75f74e3671e92 new.txt
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341查看树对象 0155eb,可以发现这个树对象有两个文件了:
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt我们甚至可以使用 git read-tree,将已添加的树对象读取出来,作为当前树的子树:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614--prefix 表示把子树对象放到哪个目录下。查看树对象,可以发现当前树对象有一个文件夹和两个文件:
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt最终,整个树对象的结构如下图:

树对象解决了文件名的问题,而且,由于我们是分阶段提交树对象的,树对象可以看做是开发阶段源代码目录树的一次次快照,因此我们可以是用树对象作为源代码版本管理。但是,这里仍然有问题需要解决,即我们需要记住每个树对象的 hash 值,才能找到个阶段的源代码文件目录树。在源代码版本控制中,我们还需要知道谁提交了代码、什么时候提交的、提交的说明信息等,接下来的提交对象就是为了解决这个问题的。
提交对象是用来保存提交的作者、时间、说明这些信息的,可以使用 git commit-tree 来将提交对象写入到 Git 文件系统中:
$ echo 'first commit' | git commit-tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
db1d6f137952f2b24e3c85724ebd7528587a067a上面 commit-tree 除了要指定提交的树对象,也要提供提交说明,至于提交的作者和时间,则是根据环境变量自动生成,并不需要指定。这里需要提醒一点的是,读者在测试时,得到的提交对象 hash 值一般和这里不一样,这是因为提交的作者和时间是因人而异的。
提交对象的查看,也是使用 git cat-file:
$ git cat-file -p db1d6f137952f2b24e3c85724ebd7528587a067a
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author jingsam <[email protected]> 1528022503 +0800
committer jingsam <[email protected]> 1528022503 +0800
first commit上面是属于首次提交,那么接下来的提交还需要指定使用-p 指定父提交对象,这样代码版本才能成为一条时间线:
$ echo 'second commit' | git commit-tree 0155eb4229851634a0f03eb265b69f5a2d56f341 -p db1d6f137952f2b24e3c85724ebd7528587a067a
d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c使用 git cat-file 查看一下新的提交对象,可以看到相比于第一次提交,多了 parent 部分:
$ git cat-file -p d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c
tree 0155eb4229851634a0f03eb265b69f5a2d56f341
parent db1d6f137952f2b24e3c85724ebd7528587a067a
author jingsam <[email protected]> 1528022722 +0800
committer jingsam <[email protected]> 1528022722 +0800
second commit最后,我们再将树对象 3c4e9c 提交:
$ echo 'third commit' | git commit-tree 3c4e9cd789d88d8d89c1073707c3585e41b0e614 -p d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c
3ac728ac62f0a7b5ac201fd3ed1f69165df8be31使用 git log 可以查看整个提交历史:
$ git log --stat 3ac728ac62f0a7b5ac201fd3ed1f69165df8be31
commit 3ac728ac62f0a7b5ac201fd3ed1f69165df8be31
Author: jingsam <[email protected]>
Date: Sun Jun 3 18:47:29 2018 +0800
third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c
Author: jingsam <[email protected]>
Date: Sun Jun 3 18:45:22 2018 +0800
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit db1d6f137952f2b24e3c85724ebd7528587a067a
Author: jingsam <[email protected]>
Date: Sun Jun 3 18:41:43 2018 +0800
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)最终的提交对象的结构如下图:

Git 中的数据对象解决了数据存储的问题,树对象解决了文件名存储问题,提交对象解决了提交信息的存储问题。从 Git 设计中可以看出,Linus 对一个源代码版本控制系统做了很好的抽象和解耦,每种对象解决的问题都很明确,相比于使用一种数据结构,无疑更灵活和更易维护。
前端项目通常会包括多个 npm script,对多个命令进行编排是很自然的需求,有时候需要将多个命令串行,即脚本遵循严格的执行顺序;有时候则需要让它们并行来提高速度,比如不相互阻塞的 npm script。社区中也有比 npm 内置的多命令运行机制更好用的解决方案:npm-run-all。
通常来说,前端项目会包含 js、css、less、scss、json、markdown 等格式的文件,为保障代码质量,给不同的代码添加检查是很有必要的,代码检查不仅保障代码没有低级的语法错误,还可确保代码都遵守社区的最佳实践和一致的编码风格,在团队协作中尤其有用,即使是个人项目,加上代码检查,也会提高你的效率和质量。
我通常会给前端项目加上下面 4 种代码检查:
js 代码检查,1.1 中有详细的配置步骤;css、less、scss;json 文件语法检查,踩过坑的同学会清楚,json 文件语法错误会知道导致各种失败;Markdown 文件最佳实践检查,个人偏好;需要注意的是,html 代码也应该检查,但是工具支持薄弱,就略过不表。此外,为代码添加必要的单元测试也是质量保障的重要手段,常用的单测技术栈是:
包含了基本的代码检查、单元测试命令的 package.json 如下:
{
"name": "hello-npm-script",
"version": "0.1.0",
"main": "index.js",
"scripts": {
"lint:js": "eslint *.js",
"lint:css": "stylelint *.less",
"lint:json": "jsonlint --quiet *.json",
"lint:markdown": "markdownlint --config .markdownlint.json *.md",
"test": "mocha tests/"
},
"devDependencies": {
"chai": "^4.1.2",
"eslint": "^4.11.0",
"jsonlint": "^1.6.2",
"markdownlint-cli": "^0.5.0",
"mocha": "^4.0.1",
"stylelint": "^8.2.0",
"stylelint-config-standard": "^17.0.0"
}
}在我们运行测试之前确保我们的代码都通过代码检查会是比较不错的实践,这也是让多个 npm script 串行的典型用例,实现方式也比较简单,只需要用 && 符号把多条 npm script 按先后顺序串起来即可,具体到我们的项目,修改如下图所示:
diff --git a/package.json b/package.json
index c904250..023d71e 100644
--- a/package.json
+++ b/package.json
@@ -8,7 +8,7 @@
- "test": "mocha tests/"
+ "test": "npm run lint:js && npm run lint:css && npm run lint:json && npm run lint:markdown && mocha tests/"
},然后直接执行 npm test 或 npm t,从输出可以看到子命令的执行顺序是严格按照我们在 scripts 中声明的先后顺序来的:
eslint ==> stylelint ==> jsonlint ==> markdownlint ==> mocha

需要注意的是,串行执行的时候如果前序命令失败(通常进程退出码非 0),后续全部命令都会终止,我们可以尝试在 index.js 中引入错误(删掉行末的分号):
diff --git a/index.js b/index.js
index ab8bd0e..b817ea4 100644
--- a/index.js
+++ b/index.js
@@ -4,7 +4,7 @@ const add = (a, b) => {
}
return NaN;
-};
+}
module.exports = { add };然后重新运行 npm t,结果如下,npm run lint:js 失败之后,后续命令都没有执行:

在严格串行的情况下,我们必须要确保代码中没有编码规范问题才能运行测试,在某些时候可能并不是我们想要的,因为我们真正需要的是,代码变更时同时给出测试结果和测试运行结果。这就需要把子命令的运行从串行改成并行,实现方式更简单,把连接多条命令的 && 符号替换成 & 即可。
代码变更如下:
diff --git a/package.json b/package.json
index 023d71e..2d9bd6f 100644
--- a/package.json
+++ b/package.json
@@ -8,7 +8,7 @@
- "test": "npm run lint:js && npm run lint:css && npm run lint:json && npm run lint:markdown && mocha tests/"
+ "test": "npm run lint:js & npm run lint:css & npm run lint:json & npm run lint:markdown & mocha tests/"
}重新运行 npm t,我们得到如下结果:

细心的同学可能已经发现上图中哪里不对,npm run lint:js 的结果在进程退出之后才输出,如果你自己运行,不一定能稳定复现这个问题,但 npm 内置支持的多条命令并行跟 js 里面同时发起多个异步请求非常类似,它只负责触发多条命令,而不管结果的收集,如果并行的命令执行时间差异非常大,上面的问题就会稳定复现。怎么解决这个问题呢?
答案也很简单,在命令的增加 & wait 即可,这样我们的 test 命令长这样:
npm run lint:js & npm run lint:css & npm run lint:json & npm run lint:markdown & mocha tests/ & wait加上 wait 的额外好处是,如果我们在任何子命令中启动了长时间运行的进程,比如启用了 mocha 的 --watch 配置,可以使用 ctrl + c 来结束进程,如果没加的话,你就没办法直接结束启动到后台的进程。
有强迫症的同学可能会觉得像上面这样用原生方式来运行多条命令很臃肿,幸运的是,我们可以使用 npm-run-all 实现更轻量和简洁的多命令运行。
用如下命令将 npm-run-all 添加到项目依赖中:
npm i npm-run-all -D然后修改 package.json 实现多命令的串行执行:
diff --git a/package.json b/package.json
index b3b1272..83974d6 100644
--- a/package.json
+++ b/package.json
@@ -8,7 +8,8 @@
- "test": "npm run lint:js & npm run lint:css & npm run lint:json & npm run lint:markdown & mocha tests/ & wait"
+ "mocha": "mocha tests/",
+ "test": "npm-run-all lint:js lint:css lint:json lint:markdown mocha"
},npm-run-all 还支持通配符匹配分组的 npm script,上面的脚本可以进一步简化成:
diff --git a/package.json b/package.json
index 83974d6..7b327cd 100644
--- a/package.json
+++ b/package.json
@@ -9,7 +9,7 @@
- "test": "npm-run-all lint:js lint:css lint:json lint:markdown mocha"
+ "test": "npm-run-all lint:* mocha"
},如何让多个 npm script 并行执行?也很简单:
diff --git a/package.json b/package.json
index 7b327cd..c32da1c 100644
--- a/package.json
+++ b/package.json
@@ -9,7 +9,7 @@
- "test": "npm-run-all lint:* mocha"
+ "test": "npm-run-all --parallel lint:* mocha"
},并行执行的时候,我们并不需要在后面增加 & wait,因为 npm-run-all 已经帮我们做了。
TIP#5:npm-run-all 还提供了很多配置项支持更复杂的命令编排,比如多个命令并行之后接串行的命令,感兴趣的同学请阅读文档,自己玩儿。
Git 中的数据对象、树对象和提交对象的 hash 方法原理是一样的,可以描述为:
header = "<type> " + content.length + "\0"
hash = sha1(header + content)上面公式表示,Git 在计算对象 hash 时,首先会在对象头部添加一个 header 。这个 header 由 3 部分组成:第一部分表示对象的类型,可以取值 blob、 tree、 commit 以分别表示数据对象、树对象、提交对象;第二部分是数据的字节长度;第三部分是一个空字节,用来将 header 和 content 分隔开。将 header 添加到 content 头部之后,使用 sha1 算法计算出一个 40 位的 hash 值。
在手动计算 Git 对象的 hash 时,有两点需要注意:
header 中第二部分关于数据长度的计算,一定是字节的长度而不是字符串的长度;header + content 的操作并不是字符串级别的拼接,而是二进制级别的拼接。各种 Git 对象的 hash 方法相同,不同的在于:
blob,树对象是 tree,提交对象是 commit;接下来分别讲数据对象、树对象和提交对象的具体的 hash 方法。
数据对象的格式如下:
blob <content length><NULL><content>从上一篇文章中我们知道,使用 git hash-object 可以计算出一个 40 位的 hash 值,例如:
$ echo -n "what is up, doc?" | git hash-object --stdin
bd9dbf5aae1a3862dd1526723246b20206e5fc37注意,上面在 echo 后面使用了-n 选项,用来阻止自动在字符串末尾添加换行符,否则会导致实际传给 git hash-object 是 what is up, doc?\n,而不是我们直观认为的 what is up, doc?。
为验证前面提到的 Git 对象 hash 方法,我们使用 openssl sha1 来手动计算 what is up, doc?的 hash 值:
$ echo -n "blob 16\0what is up, doc?" | openssl sha1
bd9dbf5aae1a3862dd1526723246b20206e5fc37可以发现,手动计算出的 hash 值与 git hash-object 计算出来的一模一样。
在 Git 对象 hash 方法的注意事项中,提到header中第二部分关于数据长度的计算,一定是字节的长度而不是字符串的长度。由于 what is up, doc?只有英文字符,在 UTF8 中恰好字符的长度和字节的长度都等于 16,很容易将这个长度误解为字符的长度。假设我们以中文来试验:
$ echo -n "中文" | git hash-object --stdin
efbb13322ba66f682e179ebff5eeb1bd6ef83972
$ echo -n "blob 2\0中文" | openssl sha1
d1dc2c3eed26b05289bddb857713b60b8c23ed29我们可以看到,git hash-object 和 openssl sha1 计算出来的 hash 值根本不一样。这是因为中文两个字符作为 UTF 格式存储后的字符长度不是 2,具体是多少呢?可以使用 wc 来计算:
$ echo -n "中文" | wc -c
6中文字符串的字节长度是 6,重新手动计算发现得出的 hash 值就能对应上了:
$ echo -n "blob 6\0中文" | openssl sha1
efbb13322ba66f682e179ebff5eeb1bd6ef83972树对象的内容格式如下:
tree <content length><NUL><file mode> <filename><NUL><item sha>...需要注意的是,<item sha> 部分是二进制形式的 sha1 码,而不是十六进制形式的 sha1 码。
我们从上一篇文章摘出一个树对象做实验,其内容如下:
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt我们首先使用 xxd 把 83baae61804e65cc73a7201a7252750c76066a30 转换成为二进制形式,并将结果保存为 sha1.txt 以方便后面做追加操作:
$ echo -n "83baae61804e65cc73a7201a7252750c76066a30" | xxd -r -p > sha1.txt
$ cat tree-items.txt
���a�Ne�s� rRu
vj0%接下来构造 content 部分,并保存至文件 content.txt:
$ echo -n "100644 test.txt\0" | cat - sha1.txt > content.txt
$ cat content.txt
100644 test.txt���a�Ne�s� rRu
vj0%计算 content 的长度:
$ cat content.txt | wc -c
36
那么最终该树对象的内容为:
```bash
$ echo -n "tree 36\0" | cat - content.txt
tree 36100644 test.txt���a�Ne�s� rRu
vj0%最后使用 openssl sha1 计算 hash 值,可以发现和实验的 hash 值是一样的:
$ echo -n "tree 36\0" | cat - content.txt | openssl sha1
d8329fc1cc938780ffdd9f94e0d364e0ea74f579提交对象的格式如下:
commit <content length><NUL>tree <tree sha>
parent <parent sha>
[parent <parent sha> if several parents from merges]
author <author name> <author e-mail> <timestamp> <timezone>
committer <author name> <author e-mail> <timestamp> <timezone>
<commit message>我们从上一篇文章摘出一个提交对象做实验,其内容如下:
$ echo 'first commit' | git commit-tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
db1d6f137952f2b24e3c85724ebd7528587a067a
$ git cat-file -p db1d6f137952f2b24e3c85724ebd7528587a067a
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author jingsam <[email protected]> 1528022503 +0800
committer jingsam <[email protected]> 1528022503 +0800
first commit这里需要注意的是,由于echo 'first commit'没有添加-n 选项,因此实际的提交信息是first commit\n。使用 wc 计算出提交内容的字节数:
$ echo -n "tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author jingsam <[email protected]> 1528022503 +0800
committer jingsam <[email protected]> 1528022503 +0800
first commit\n" | wc -c
163那么,这个提交对象的 header 就是commit 163\0,手动把头部添加到提交内容中:
commit 163\0tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author jingsam <[email protected]> 1528022503 +0800
committer jingsam <[email protected]> 1528022503 +0800
first commit\n使用 openssl sha1 计算这个上面内容的 hash 值:
$ echo -n "commit 163\0tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author jingsam <[email protected]> 1528022503 +0800
committer jingsam <[email protected]> 1528022503 +0800
first commit\n" | openssl sha1
db1d6f137952f2b24e3c85724ebd7528587a067a可以看见,与实验的 hash 值是一样的。
这篇文章详细地分析了 Git 中的数据对象、树对象和提交对象的 hash 方法,可以发现原理是非常简单的。数据对象和提交对象打印出来的内容与存储内容组织是一模一样的,可以很直观的理解。对于树对象,其打印出来的内容和实际存储是有区别的,增加了一些实现上的难度。例如,使用二进制形式的 hash 值而不是直观的十六进制形式,我现在还没有从已有资料中搜到这么设计的理由,这个问题留待以后解决。
npm 目前支持一下几种类型的依赖包管理
dependenciesdevDependenciespeerDependenciesoptionalDependenciesbundledDependencies / bundleDependencies "dependencies": {
"lodash": "^4.17.19"
},
"devDependencies": {
"@babel/cli": "^7.1.0"
},
"peerDependencies": {},
"optionalDependencies": {},
"bundledDependencies": []dependencies应用依赖,或者叫做业务依赖,是我们最常用的一种。这种依赖是应用发布后上线所需要的,也就是说其中的依赖项属于线上代码的一部分。比如框架 react,第三方的组件库 ant-design 等。可通过下面的命令来安装:
npm i ${packageName} -SdevDependencies开发环境依赖。这种依赖只在项目开发时所需要,比如构建工具 webpack、gulp,单元测试工具 jest、mocha 等。可通过下面的命令来安装:
npm i ${packageName} -DpeerDependencies同行依赖。这种依赖的作用是提示宿主环境去安装插件在peerDependencies中所指定依赖的包,用于解决插件与所依赖包不一致的问题。
听起来可能没有那么好理解,举个例子来说明下。[email protected]只是提供了一套基于react的ui组件库,但它要求宿主环境需要安装指定的react版本,所以你可以看到 node_modules 中 antd 的package.json中有这么一项配置:
"peerDependencies": {
"react": ">=16.0.0",
"react-dom": ">=16.0.0"
}它要求宿主环境安装大于等于16.0.0版本的react,也就是antd的运行依赖宿主环境提供的该范围的react安装包。
在安装插件的时候,peerDependencies 在
npm 2.x和npm 3.x中表现不一样。npm2.x 会自动安装同等依赖,npm3.x 不再自动安装,会产生警告!手动在package.json文件中添加依赖项可以解决。
optionalDependencies可选依赖。这种依赖中的依赖包即使安装失败了,也不影响整个安装的过程。需要注意的是,optionalDependencies会覆盖dependencies中的同名依赖包,所以不要在两个地方都写。
在实际项目中,如果某个包已经失效,我们通常会寻找它的替代方案。不确定的依赖会增加代码判断和测试难度,所以这个依赖项还是尽量不要使用。
bundledDependencies / bundleDependencies打包依赖。如果在打包发布时希望一些依赖包也出现在最终的包里,那么可以将包的名字放在 bundledDependencies 中,bundledDependencies 的值是一个字符串数组,如:
{
"name": "test",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"mysql2": "^2.1.0"
},
"devDependencies": {
"sequelize": "^5.21.3"
},
"bundledDependencies": ["mysql2", "sequelize"]
}执行打包命令 npm pack,在生成的 sequelize-test-1.0.0.tgz 包中,将包含 mysql2 和 sequelize。
需要注意的是,在 bundledDependencies 中指定的依赖包,必须先在 dependencies 和 devDependencies 声明过,否则打包会报错。
为了在软件版本号中包含更多意义,反映代码所做的修改,产生了语义化版本,软件的使用者能从版本号中推测软件做的修改。npm 包使用语义化版控制,我们可安装一定版本范围的 npm 包,npm 会选择和你指定的版本相匹配 的 (latest)最新版本安装。
npm 采用了semver规范作为依赖版本管理方案。版本号由三部分组成:主版本、次版本号、补丁版本号。变更不同的版本号,代表不同的意义:
主版本号(major):软件做了不兼容的变更(breaking change 重大变更)次版本号(minor):添加功能或者废弃功能,向下兼容,修订号必须归零补丁版本号(patch):bug 修复,向下兼容下面让我们来看下常用的几个版本格式:
"compression": "1.7.4"表示精确版本号。任何其他版本号都不匹配。在一些比较重要的线上项目中,建议使用这种方式锁定版本。
"typescript": "^3.4.3"表示兼容补丁和小版本更新的版本号。官方的定义是能够兼容除了最左侧的非 0 版本号之外的其他变化。这句话不是很好理解,举几个例子大家就明白了:
"^3.4.3" 等价于 `">= 3.4.3 < 4.0.0"。即只要最左侧的 "3" 不变,其他都可以改变。所以 "3.4.5", "3.6.2" 都可以兼容。
"^0.4.3" 等价于 ">= 0.4.3 < 0.5.0"。因为最左侧的是 "0",那么只要第二位 "4" 不变,其他的都兼容,比如 "0.4.5" 和 "0.4.99"。
"^0.0.3" 等价于 ">= 0.0.3 < 0.0.4"。大版本号和小版本号都为 "0" ,所以也就等价于精确的 "0.0.3"。
"mime-types": "~2.1.24"表示只兼容补丁更新的版本号。关于 ~ 的定义分为两部分:如果列出了小版本号(第二位),则只兼容补丁(第三位)的修改;如果没有列出小版本号,则兼容第二和第三位的修改。我们分两种情况理解一下这个定义:
"~2.1.24" 列出了小版本号 "1",因此只兼容第三位的修改,等价于 ">= 2.1.24 < 2.2.0"。
"~2.1" 也列出了小版本号 "2",因此和上面一样兼容第三位的修改,等价于 ">= 2.1.0 < 2.2.0"。
"~2" 没有列出小版本号,可以兼容第二第三位的修改,因此等价于 ">= 2.0.0 < 3.0.0"
"underscore-plus": "1.x" "uglify-js": "3.4.x"除了上面的x、X还有*和(空),这些都表示使用通配符的版本号,可以匹配任何内容。具体来说:
"*" 、"x" 或者 (空) 表示可以匹配任何版本。
"1.x", "1.*" 和 "1" 表示匹配主版本号为 "1" 的所有版本,因此等价于 ">= 1.0.0 < 2.0.0"。
"1.2.x", "1.2.*" 和 "1.2" 表示匹配版本号以 "1.2" 开头的所有版本,因此等价于 ">= 1.2.0 < 1.3.0"。
"css-tree": "1.0.0-alpha.33" "@vue/test-utils": "1.0.0-beta.29"有时候为了表达更加确切的版本,还会在版本号后面添加标签或者扩展,来说明是预发布版本或者测试版本等。常见的标签有:
| 标签 | 含义 | 补充 |
|---|---|---|
| demo | demo 版本 | 可能用于验证问题的版本 |
| dev | 开发版 | 开发阶段用的,bug 多,体积较大等特点,功能不完善 |
| alpha | α 版本 | 预览版,或者叫内部测试版;一般不向外发布,会有很多 bug;一般只有测试人员使用。 |
| beta | 测试版(β 版本) | 测试版,或者叫公开测试版;这个阶段的版本会一直加入新的功能;在 alpha 版之后推出。 |
| gamma | (γ)伽马版本 | 较 α 和 β 版本有很大的改进,与稳定版相差无几,用户可使用 |
| trial | 试用版本 | 本软件通常都有时间限制,过期之后用户如果希望继续使用,一般得交纳一定的费用进行注册或购买。有些试用版软件还在功能上做了一定的限制。 |
| csp | 内容安全版本 | js 库常用 |
| rc | 最终测试版本 | 可能成为最终产品的候选版本,如果未出现问题则可发布成为正式版本 |
| latest | 最新版 | 不指定版本和标签,npm 默认安最新版 |
| stable | 稳定版 |
我们都知道,执行npm install后,依赖包被安装到了node_modules中。虽然在实际开发中我们无需十分关注里面具体的细节,但了解node_modules中的内容可以帮助我们更好的理解npm安装依赖包的具体机制。
在 npm 的早期版本中,npm 处理依赖的方式简单粗暴,以递归的方式,严格按照 package.json 结构以及子依赖包的 package.json 结构将依赖安装到他们各自的 node_modules 中。
举个例子,我们的项目ts-axios现在依赖了两个模块: axios、body-parser:
{
"name": "ts-axios",
"dependencies": {
"axios": "^0.19.0",
"body-parser": "^1.19.0"
}
}axios 依赖了 follow-redirects 和 is-buffer 模块:
{
"name": "axios",
"dependencies": {
"follow-redirects": "1.5.10",
"is-buffer": "^2.0.2"
}
}body-parser 依赖了 bytes 和 content-type 等模块:
{
"name": "body-parser",
"dependencies": {
"bytes": "3.1.0",
"content-type": "~1.0.4",
"..."
}
}那么,执行 npm install 后,得到的 node_modules 中模块目录结构就是下面这样的:

这样的方式优点很明显, node_modules 的结构和 package.json 结构一一对应,层级结构明显,并且保证了每次安装目录结构都是相同的。
但是,试想一下,如果你依赖的模块非常之多,你的 node_modules 将非常庞大,嵌套层级非常之深:
从上图这种情况,我们不难得出嵌套结构拥有以下缺点:
为了解决以上问题,npm 在 3.x 版本做了一次较大更新。其将早期的嵌套结构改为扁平结构。
安装模块时,不管其是直接依赖还是子依赖的依赖,优先将其安装在 node_modules 根目录。
还是上面的依赖结构,我们在执行 npm install 后将得到下面的目录结构:

此时我们若在模块中又依赖了 [email protected] 版本:
{
"name": "ts-axios",
"dependencies": {
"axios": "^0.19.0",
"body-parser": "^1.19.0",
"is-buffer": "^2.0.1"
}
}当安装到相同模块时,判断已安装的模块版本是否符合新模块的版本范围,如果符合则跳过,不符合则在当前模块的 node_modules 下安装该模块。
此时,我们在执行 npm install 后将得到下面的目录结构:

对应的,如果我们在项目代码中引用了一个模块,模块查找流程如下:
假设我们又依赖了一个包 axios2@^0.19.0,而它依赖了包 is-buffer@^2.0.3,则此时的安装结构是下面这样的:

所以 npm 3.x 版本并未完全解决老版本的模块冗余问题,甚至还会带来新的问题。
我们在 package.json 通常只会锁定大版本,这意味着在某些依赖包小版本更新后,同样可能造成依赖结构的改动,依赖结构的不确定性可能会给程序带来不可预知的问题。
为了解决 npm install 的不确定性问题,在 npm 5.x 版本新增了 package-lock.json 文件,而安装方式还沿用了 npm 3.x 的扁平化的方式。
package-lock.json 的作用是锁定依赖结构,即只要你目录下有 package-lock.json 文件,那么你每次执行 npm install 后生成的 node_modules 目录结构一定是完全相同的。
例如,我们有如下的依赖结构:
{
"name": "ts-axios",
"dependencies": {
"axios": "^0.19.0"
}
}在执行 npm install 后生成的 package-lock.json 如下:
{
"name": "ts-axios",
"version": "0.1.0",
"dependencies": {
"axios": {
"version": "0.19.0",
"resolved": "https://registry.npmjs.org/axios/-/axios-0.19.0.tgz",
"integrity": "sha512-1uvKqKQta3KBxIz14F2v06AEHZ/dIoeKfbTRkK1E5oqjDnuEerLmYTgJB5AiQZHJcljpg1TuRzdjDR06qNk0DQ==",
"requires": {
"follow-redirects": "1.5.10",
"is-buffer": "^2.0.2"
},
"dependencies": {
"debug": {
"version": "3.1.0",
"resolved": "https://registry.npmjs.org/debug/-/debug-3.1.0.tgz",
"integrity": "sha512-OX8XqP7/1a9cqkxYw2yXss15f26NKWBpDXQd0/uK/KPqdQhxbPa994hnzjcE2VqQpDslf55723cKPUOGSmMY3g==",
"requires": {
"ms": "2.0.0"
}
},
"follow-redirects": {
"version": "1.5.10",
"resolved": "https://registry.npmjs.org/follow-redirects/-/follow-redirects-1.5.10.tgz",
"integrity": "sha512-0V5l4Cizzvqt5D44aTXbFZz+FtyXV1vrDN6qrelxtfYQKW0KO0W2T/hkE8xvGa/540LkZlkaUjO4ailYTFtHVQ==",
"requires": {
"debug": "=3.1.0"
}
},
"is-buffer": {
"version": "2.0.3",
"resolved": "https://registry.npmjs.org/is-buffer/-/is-buffer-2.0.3.tgz",
"integrity": "sha512-U15Q7MXTuZlrbymiz95PJpZxu8IlipAp4dtS3wOdgPXx3mqBnslrWU14kxfHB+Py/+2PVKSr37dMAgM2A4uArw=="
},
"ms": {
"version": "2.0.0",
"resolved": "https://registry.npmjs.org/ms/-/ms-2.0.0.tgz",
"integrity": "sha1-VgiurfwAvmwpAd9fmGF4jeDVl8g="
}
}
}
}
}最外面的两个属性 name 、version 同 package.json 中的 name 和 version ,用于描述当前包名称和版本。
dependencies 是一个对象,对象和 node_modules 中的包结构一一对应,对象的 key 为包名称,值为包的一些描述信息:
version: 包唯一的版本号resolved: 安装来源integrity: 表明包完整性的 hash 值(验证包是否已失效)requires: 依赖包所需要的所有依赖项,与子依赖的 package.json 中dependencies的依赖项相同。dependencies: 依赖包 node_modules 中依赖的包,与顶层的 dependencies 一样的结构这里注意,并不是所有的子依赖都有 dependencies 属性,只有子依赖的依赖和当前已安装在根目录的 node_modules 中的依赖冲突之后,才会有这个属性。
通过以上几个步骤,说明package-lock.json文件和node_modules目录结构是一一对应的,即项目目录下存在package-lock.json可以让每次安装生成的依赖目录结构保持相同。
在开发一个应用时,建议把package-lock.json文件提交到代码版本仓库,从而让你的团队成员、运维部署人员或CI系统可以在执行npm install 时安装的依赖版本都是一致的。
脚本功能是 npm 最强大、最常用的功能之一。
npm 允许在package.json文件中使用scripts字段来定义脚本命令。以vue-cli3为例:
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"lint": "vue-cli-service lint",
"test:unit": "vue-cli-service test:unit"
}这样就可以通过npm run serve脚本替代vue-cli-service serve脚本来启动项目,而无需每次都敲一遍冗长的脚本。
这里我们参考一下阮老师的文章:
npm 脚本的原理非常简单。每当执行 npm run,就会自动新建一个 Shell,在这个 Shell 里面执行指定的脚本命令。因此,只要是 Shell(一般是 Bash)可以运行的命令,就可以写在 npm 脚本里面。
比较特别的是,npm run 新建的这个 Shell,会将当前目录的 node_modules/.bin 子目录加入 PATH 变量,执行结束后,再将 PATH 变量恢复原样。
在原有脚本后面加上 -- 分隔符, 后面再加上参数,就可以将参数传递给 script 命令了,比如 eslint 内置了代码风格自动修复模式,只需给它传入 --fix 参数即可,我们可以这样写:
"scripts": {
"lint": "vue-cli-service lint --fix",
}除了第一个可执行的命令,以空格分割的任何字符串(除了一些 shell 的语法)都是参数,并且都能通过process.argv属性访问。
process.argv属性返回一个数组,其中包含当启动 Node.js 进程时传入的命令行参数。 第一个元素是process.execPath,表示启动 node 进程的可执行文件的绝对路径名。第二个元素为当前执行的 JavaScript 文件路径。剩余的元素为其他命令行参数。
如果 npm 脚本里面需要执行多个任务,那么需要明确它们的执行顺序。
如果是串行执行,即要求前一个任务执行成功之后才能执行下一个任务。使用&&符号连接。
npm run script1 && npm run script2串行命令执行过程中,只要一个命令执行失败,则整个脚本将立刻终止。
如果是并行执行,即多个任务可以同时执行。使用&符号来连接。
npm run script1 & npm run script2这里的钩子和vue或react里面的生命周期有点相似。
npm 脚本有pre和post两个钩子。在执行 npm scripts 命令(无论是自定义还是内置)时,都经历了 pre 和 post 两个钩子,在这两个钩子中可以定义某个命令执行前后的命令。
比如,在用户执行npm run build的时候,会自动按照下面的顺序执行。
npm run prebuild && npm run build && npm run postbuild当然,如果没有指定prebuild、postbuild,会默默的跳过。如果想要指定钩子,必须严格按照 pre 和 post 前缀来添加。
npm 脚本有一个非常强大的功能,就是可以使用 npm 的内部变量。
在执行npm run脚本时,npm 会设置一些特殊的env环境变量。其中 package.json 中的所有字段,都会被设置为以npm_package_ 开头的环境变量。比如 package.json 中有如下字段内容:
{
"name": "sequelize-test",
"version": "1.0.0",
"description": "sequelize测试",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"mysql2": "^2.1.0",
"sequelize": "^5.21.3"
}
}那么,变量npm_package_name返回sequelize-test,变量npm_package_description返回 sequelize 测试。也就是:
// 这两个是在node环境环境执行 非浏览器
// test.js 执行 node test.js
console.log(process.env.npm_package_name) // sequelize-test
console.log(process.env.npm_package_description) // sequelize测试npm 从以下来源获取配置信息(优先级由高到低):
命令行npm run dev --foo=bar执行上述命令,会将配置项foo的值设为bar,通过process.env.npm_config_foo可以访问其配置值。这个时候的 foo 配置值将覆盖所有其他来源存在的 foo 配置值。
环境变量如果 env 环境变量中存在以npm_config_为前缀的环境变量,则会被识别为 npm 的配置属性。比如,环境变量中的npm_config_foo=bar 将会设置配置参数 foo 的值为 "bar"。
如果只指定了参数名却没有指定任何值的配置参数,其值将会被设置为 true。
npmrc文件通过修改 npmrc 文件可以直接修改配置。系统中存在多个 npmrc 文件,这些 npmrc 文件被访问的优先级从高到低的顺序为:
项目配置文件只作用在本项目下。在其他项目中,这些配置不生效。通过创建这个.npmrc 文件可以统一团队的 npm 配置规范。路径为/path/to/my/project/.npmrc。
用户配置文件默认为~/.npmrc/,可通过npm config get userconfig查看存放的路径。
全局配置文件通过npm config get globalconfig可以查看具体存放的路径。
npm 内置的配置文件这是一个不可更改的内置配置文件,为了维护者以标准和一致的方式覆盖默认配置。mac下的路径为/path/to/npm/npmrc。
默认配置通过npm config ls -l查看 npm 内部的默认配置参数。如果命令行、环境变量、所有配置文件都没有配置参数,则使用默认参数值。
setnpm config set <key> <value> [-g|--global]
npm config set registry <url> # 指定下载 npm 包的来源,默认为 https://registry.npmjs.org/ ,可以指定私有源设置配置参数 key 的值为 value,如果省略 value,key 会被设置为 true。
getnpm config get <key>查看配置参数 key 的值。
deletenpm config delete <key>删除配置参数 key
listnpm config list [-l] [--json]查看所有设置过的配置参数。使用 -l 查看所有设置过的以及默认的配置参数。使用 --json 以 json 格式查看。
npm config edit在编辑器中打开 npmrc 文件,使用 --global 参数打开全局 npmrc 文件。
URI: (Uniform Resource Identifier)统一资源标识符
URL: (Uniform Resource Locator)统一资源定位符: 不仅标识了 Web 资源,还指定了操作或者获取方式,同时指出了主要访问机制和网络位置。
URN: (Uniform Resource Name)统一资源名称: 用特定命名空间的名字标识资源。使用 URN 可以在不知道其网络位置及访问方式的情况下讨论资源。
URI 可以被分为 URL、URN 或两者的组合。
这是一个 URI: http://bitpoetry.io/posts/hello.html#intro
URL 是 URI 的一个子集: 告诉我们访问网络位置的方式。在我们的例子中,URL 应该为: http://bitpoetry.io/posts/hello.html
URN 是 URI 的一个子集,包括名字(给定的命名空间内),但是不包括访问方式,应该为: bitpoetry.io/posts/hello.html#intro
encodeURIComponent() <=> decodeURIComponent()
encodeURI() <=> decodeURI()
encodeURIComponent() 和 encodeURI() 都是对 URI 进行编码。
encodeURIComponent() 不转义的字符: A-Z a-z 0-9 - _ . ! ~ * ( )
encodeURI(): 只对空格进行转义
var set1 = ';,/?:@&=+$' // 保留字符
var set2 = "-_.!~*'()" // 不转义字符
var set3 = '#' // 数字标志
var set4 = 'ABC abc 123' // 字母数字字符和空格
console.log(encodeURI(set1)) // ;,/?:@&=+$
console.log(encodeURI(set2)) // -_.!~*'()
console.log(encodeURI(set3)) // #
console.log(encodeURI(set4)) // ABC%20abc%20123 (the space gets encoded as %20)
console.log(encodeURIComponent(set1)) // %3B%2C%2F%3F%3A%40%26%3D%2B%24
console.log(encodeURIComponent(set2)) // -_.!~*'()
console.log(encodeURIComponent(set3)) // %23
console.log(encodeURIComponent(set4)) // ABC%20abc%20123 (the space gets encoded as %20)encodeURI: 适用于 url 跳转时。
encodeURIComponent: 适用于 url 作为参数传递时,对参数解码。
'http://www.我.com?a=?' // 想把?传给服务器'
encodeURI('http://www.我.com?a=?') //"http://www.%E6%88%91.com?a=?"
// 服务器收到的a值为空,因为?是URL保留字符。此时我们需要用encodeURIComponent来编码!
// encodeURIComponent会编码所有的URL保留字,所以不适合编码URL。如:当我们把编码过的/folder1/folder2/default.html发送到服务器时时,由于‘/’也将被编码,服务器将无法正确识别。
encodeURIComponent('http://www.我.com') //"http%3A%2F%2Fwww.%E6%88%91.com"
encodeURI('http://www.我.com') + '?a=' + encodeURIComponent('?')encodeURI(),encodeURIComponent()使用场景
你知道 URL、URI 和 URN 三者之间的区别吗?
encodeURI、encodeURIComponent、btoa 及其应用场景
本小节会介绍 3 个知识点:给 npm script 传递参数以减少重复的 npm script;增加注释提高 npm script 脚本的可读性;控制运行时日志输出能让你专注在重要信息上。
eslint 内置了代码风格自动修复模式,只需给它传入 --fix 参数即可,在 scripts 中声明检查代码命令的同时你可能也需要声明修复代码的命令,面对这种需求,大多数同学可能会忍不住复制粘贴,如下:
diff --git a/package.json b/package.json
index c32da1c..b6fb03e 100644
--- a/package.json
+++ b/package.json
@@ -5,6 +5,7 @@
"lint:js": "eslint *.js",
+ "lint:js:fix": "eslint *.js --fix",在 lint:js 命令比较短的时候复制粘贴的方法简单粗暴有效,但是当 lint:js 命令变的很长之后,难免后续会有人改了 lint:js 而忘记修改 lint:js:fix(别问我为啥,我就是踩着坑过来的),更健壮的做法是,在运行 npm script 时给定额外的参数,代码修改如下:
diff --git a/package.json b/package.json
--- a/package.json
+++ b/package.json
@@ -5,6 +5,7 @@
"lint:js": "eslint *.js",
+ "lint:js:fix": "npm run lint:js -- --fix",要格外注意 --fix 参数前面的 -- 分隔符,意指要给 npm run lint:js 实际指向的命令传递额外的参数。
运行效果如下图:

上图第 2 个红色框里面是实际执行的命令,可以看到 --fix 参数附加在了后面。
TIP#6:如果你不想单独声明
lint:js:fix命令,在需要的时候直接运行:npm run lint:js -- --fix来实现同样的效果。
问题来了,如果我想为 mocha 命令增加 --watch 模式方便在开发时立即看到测试结果,该怎么做呢?相信读到这里你心中已经有了答案。
如果 package.json 中的 scripts 越来越多,或者出现复杂的编排命令,你可能需要给它们添加注释以保障代码可读性,但 json 天然是不支持添加注释的,下面是 2 种比较 trick 的方式。
第一种方式是,package.json 中可以增加 // 为键的值,注释就可以写在对应的值里面,npm 会忽略这种键,比如,我们想要给 test 命令添加注释,按如下方式添加:
diff --git a/package.json b/package.json
--- a/package.json
+++ b/package.json
@@ -10,6 +10,7 @@
+ "//": "运行所有代码检查和单元测试",
"test": "npm-run-all --parallel lint:* mocha"这种方式的明显不足是,npm run 列出来的命令列表不能把注释和实际命令对应上,如果你声明了多个,npm run 只会列出最后那个,如下图:

另外一种方式是直接在 script 声明中做手脚,因为命令的本质是 shell 命令(适用于 linux 平台),我们可以在命令前面加上注释,具体做法如下:
diff --git a/package.json b/package.json
--- a/package.json
+++ b/package.json
@@ -10,8 +10,7 @@
- "//": "运行所有代码检查和单元测试",
- "test": "npm-run-all --parallel lint:* mocha"
+ "test": "# 运行所有代码检查和单元测试 \n npm-run-all --parallel lint:* mocha"注意注释后面的换行符 \n 和多余的空格,换行符是用于将注释和命令分隔开,这样命令就相当于微型的 shell 脚本,多余的空格是为了控制缩进,也可以用制表符 \t 替代。这种做法能让 npm run 列出来的命令更美观,但是 scripts 声明阅读起来不那么整齐美观。

上面两种方式都有明显的缺陷,个人建议的更优方案还是把复杂的命令剥离到单独的文件中管理,在单独的文件中可以自由给它添加注释,详见后续章节。
在运行 npm script 出现问题时你需要有能力去调试它,某些情况下你需要让 npm script 以静默的方式运行,这类需求可通过控制运行时日志输出级别来实现。
日志级别控制参数有好几个,简单举例如下:
默认日志输出级别
即不加任何日志控制参数得到的输出,可能是你最常用的,能看到执行的命令、命令执行的结果。
显示尽可能少的有用信息
结合其他工具调用 npm script 的时候比较有用,需要使用 --loglevel silent,或者 --silent,或者更简单的 -s 来控制,这个日志级别的输出实例如下(只有命令本身的输出,读起来非常的简洁):

如果执行各种 lint script 的时候启用了 -s 配置,代码都符合规范的话,你不会看到任何输出,这就是没有消息是最好的消息的由来,哈哈!
排查脚本问题的时候比较有用,需要使用 --loglevel verbose,或者 --verbose,或者更简单的 -d 来控制,这个日志级别的输出实例如下(详细打印出了每个步骤的参数、返回值,下面的截图只是部分):


由于当年太年轻,资历不够深!!!导致文件命名不规范,现在想更正文件夹名字(
common => COMMON),结果发现一个很奇特的现象! git 对文件(夹)名的大小写不敏感!!!!引发了一些问题。最终经过查阅资料得以解决,遂!写下这篇帖子记录一下。走~跟着渣渣一起吃着花生 🥜 喝着啤酒 🍺 燥起来~

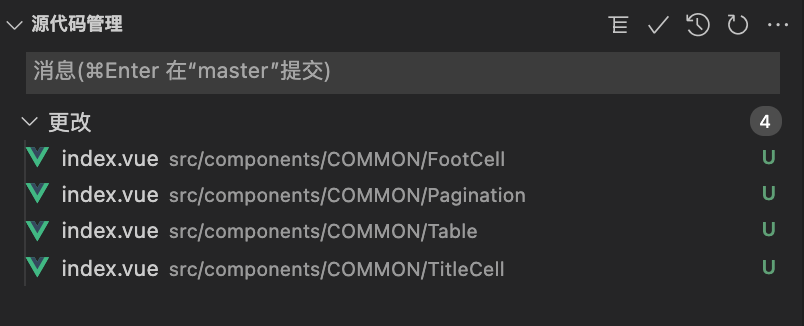
master 分支的代码及文件目录情况
# master分支原始目录
.
├── main.js
└── src
└── components
└── common
├── FootCell
│ └── index.vue
├── Pagination
│ └── index.vue
├── Table
│ └── index.vue
└── TitleCell
└── index.vue// main.js
const files = require.context('../components/common', true, /\.vue$/)user1 分支:feature/user1
user2 分支:feature/user2
此时分别有两个用户user1和user2在各自的电脑上拉取了这个项目。
文件名的变更未同步到远端,但是引用路径却同步到远端了!
user1 不知道 git 大小写不敏感,user2 可知可不知,反正最后都!会!知!道!!!

因为 这里
git大小写不敏感所以只进行文件名变更(大小写)的话,不会被git检测到,所以必须要改动一个文件,让git检测到变更。才能进行commit!刚好文件名的变更导致了引用路径也需要变更!因此本次可以进行提交
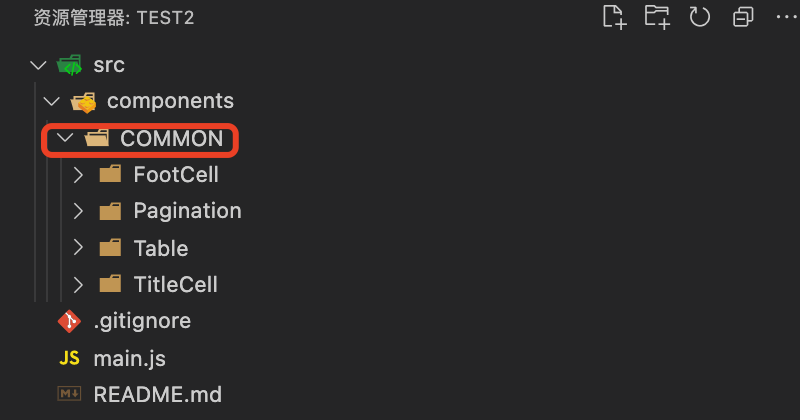
由于被绿太狠了,心情不太好就开始了*操作坑队友!common => COMMON结果如下:
# common => COMMON
.
├── main.js
└── src
└── components
└── COMMON
├── FootCell
│ └── index.vue
├── Pagination
│ └── index.vue
├── Table
│ └── index.vue
└── TitleCell
└── index.vue// main.js
const files = require.context('../components/common', true, /\.vue$/)最后并把代码提交到了远端,并且告诉 user2 代码有更新
pull 代码user2于是乎就先pull然后merge了一下,把 user1 的代码同步到自己的分支,结果如下:
# 此时 common => common 没有变化!!!
.
├── main.js
└── src
└── components
└── common
├── FootCell
│ └── index.vue
├── Pagination
│ └── index.vue
├── Table
│ └── index.vue
└── TitleCell
└── index.vue// main.js 有变化!!!
const files = require.context('../components/COMMON', true, /\.vue$/)这个时候,“报应”来的太突然,项目报错了!引用的路径是COMMON而实际项目的路径是common

然后user2就好奇为啥会是这种情况,文件名没有变化??于是乎开启了探索之路~~
因为
user1被绿了一波,心情不好搞事情,害得user2引发了 bug,但是刚好激发了user2的好奇心。
为啥user1的是 COMMON,到我这里是 common???
最后user2查到了答案! 原来是 git 对文件名的大小写不敏感,才会引发这个问题。好了那么接下来就是这么去解决这个问题呢??
温馨提示
因为
git默认不区分大小写,所以如果只更改文件名的话git并不会检测到文件有变化,固!无法进行commit,所以这次测试在更改文件名的时候附带的改动了其他地方,以便提交!
既然user2已经知道了 git 默认大小写不敏感,那就让他敏感呗。多简单!
git config core.ignorecase false # 让你变的敏感
其实
user1压根就没有把文件名更改同步到到远端!(所以开头才说,他不知道git大小写不敏感!但是文件引用路径变更了,这个就导致其他人(user2)因为文件路径改变导致项目报错)
切分支 checkout
git che master拉代码 pull
git pull这个时候就会发现项目无法启动,因为
main.js中的文件路径引用已经由common => COMMON了,但实际文件名依旧是common
common => COMMON
暂存 add
git add .提交 commit
git commit -m user2手动同步更新文件名
推送 push
# 这一步是替user1,将文件名变更同步到远端,供user3……等使用
#(此时如果其他用户是之前拉取的分支那么也会出现本篇文章所描述的问题!)
# 方法嘛~~ 就是当前文章~~哈哈哈
git push切分支 checkout
git che feature/user2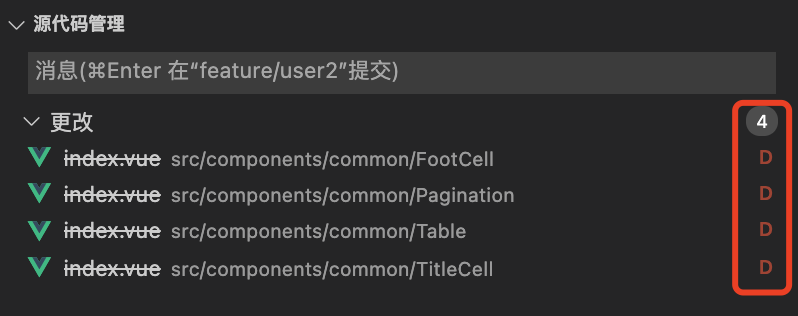

merge master 到 feature/user2 分支
git merge master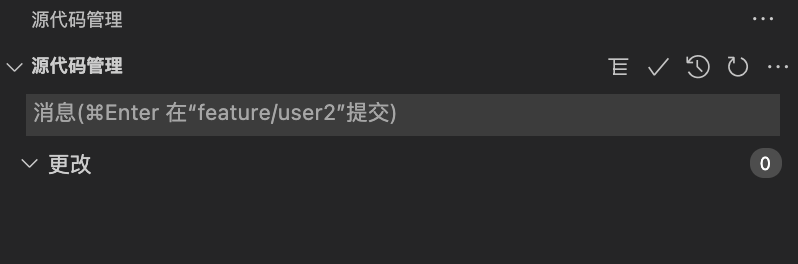
commit 记录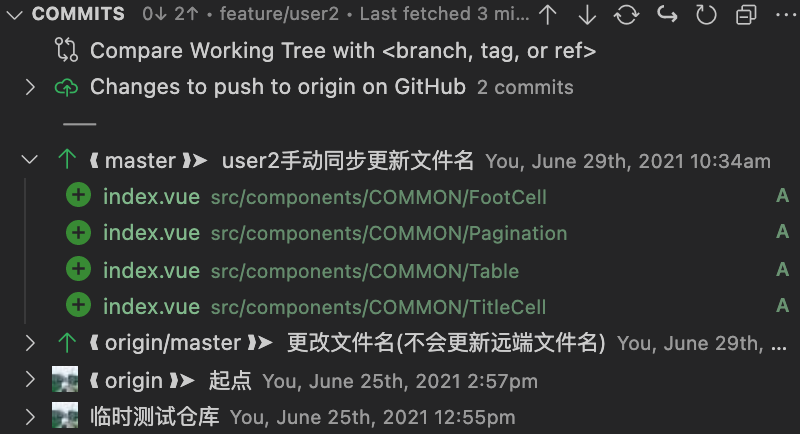
文件名变更实际已经同步到远端了,且引用路径也同步到了远端!
这次user1 知道 git 大小写不敏感, user2 同样可知可不知,于是一开始就逼迫她,让她变得敏感再敏感!

user1 的分支:feature/user1git config core.ignorecase false # emmmmm……俺敏感了common => COMMON
更改引用路径
// 旧
const files = require.context('../components/common', true, /\.vue$/)
// 新
const files = require.context('../components/COMMON', true, /\.vue$/)暂存 add
git add .提交 commit
git commit -m <msg>git checkout master


merge 结果如下:
git merge feature/user1 # user1的分支合并到本地master

推送 push
git push # 推送到远端masteruser2 的分支:feature/user2git config core.ignorecase false切分支 checkout
git checkout master拉代码 pull
git pull # 更新 master 分支结果如下:
# 结果 error
KaKa:test2 xxx$ git pull
更新 5f318b9..5174f2e
error: 工作区中下列未跟踪的文件将会因为合并操作而被覆盖:
src/components/COMMON/FootCell/index.vue
src/components/COMMON/Pagination/index.vue
src/components/COMMON/Table/index.vue
src/components/COMMON/TitleCell/index.vue
请在合并前移动或删除。
正在终止
注意!上面那个问题一旦触发,那么你接下来所有的操作比如
check,switch,pull等操作都会报这个错误!!
其实上面已经告诉你怎么操作了,按照提示 删除或者移动原有的common文件夹,然后再pull(check,switch)即可解决
结果如下图:
common文件名已经变更为COMMON
如果上一步问题解决了那么这一步就没什么异常了,user2 的分支代码已经被更新了
切分支 checkout
git checkout feature/user2merge 代码
git merge master # 更新 feature/user2 分支commit 记录如下图:


git config core.ignorecase true # git 默认不敏感切分支 checkout
git checkout master拉代码 pull
git pull # 更新 master 分支结果如下图:

惊不惊喜意不意外?

虽然远端的文件名已经由common => COMMON,但是当user2 执行pull的时候本地的文件名依旧还是老的common
先更改文件名
common => COMMON
再切换分支:
git checkout feature/user2COMMON文件夹变成空的了
最后执行 merge 后的变化如下:
git merge masterCOMMON文件夹又有内容了

commit记录如下:


删除文件夹 rm
git rm <文件夹路径> -r # -r 表示递归删除文件 rm
git rm <文件路径>git config core.ignorecase falsecommon => common copy
复制副本以后不能直接将 common copy 改成 COMMON (此时 common 还存在)
git rm ./src/components/common -r # -r 表示递归common copy => COMMON
看到这里有的同学该问了为啥不拷贝副本 common copy 以后立马直接对其变更名字(common copy => COMMON),然后执行第3步操作呢????问的好啊。鼓掌 👏

看到这个结果·····

其实本人也是很想这么操作的,可是现在回头想想,在不区分大小写的情况下:
common === COMMON // true,所以上面的提示是没有问题的 我个人认为
在这一步 你将遇到如下错误信息导致切换分支失败 (跟上面的还不太一样)
check 出问题
KaKa:test xxxx$ git che master
error: 工作区中下列未跟踪的文件将会因为检出操作而被覆盖:
src/components/common/FootCell/index.vue
src/components/common/Pagination/index.vue
src/components/common/Table/index.vue
src/components/common/TitleCell/index.vue
请在切换分支前移动或删除。
正在终止此时的项目结构是这样子的:
.
├── README.md
├── main.js
└── src
└── components
└── COMMON <= # 重点!这里!!! 并没有 common
├── FootCell
│ └── index.vue
├── Pagination
│ └── index.vue
├── Table
│ └── index.vue
└── TitleCell
└── index.vue
```并没有common文件夹!!那么就无解了??但是否定的!那我们就:
把COMMON=> common
再删除common


最后执行 git check master
忽略执行删除后的文件变更,直接 git checkout master
merge 出问题
KaKa-3:test xxxx$ git merge feature/user1
更新 5f318b9..24b399d
error: 工作区中下列未跟踪的文件将会因为合并操作而被覆盖:
src/components/COMMON/FootCell/index.vue
src/components/COMMON/Pagination/index.vue
src/components/COMMON/Table/index.vue
src/components/COMMON/TitleCell/index.vue
请在合并前移动或删除。
正在终止并没有COMMON,处理方法同上:
把common=> COMMON
再删除COMMON


最后git merge feature/user1就可以了~
commit 记录如下图:

git config core.ignorecase truecommon => COMMON
然而尴尬的一幕它发生了!!!如下图:


卧槽! Git 并没有检测到 文件有变化!
这种情况要么放弃,要么开启敏感模式!如果开启那就是情况一了

此时 user2的master 分支初始目录如下:
.
├── README.md
├── main.js
└── src
└── components
└── common
├── FootCell
│ └── index.vue
├── Pagination
│ └── index.vue
├── Table
│ └── index.vue
└── TitleCell
└── index.vuegit config core.ignorecase falseKaKa:test2 xxxx$ git pull
更新 5f318b9..24b399d
error: 工作区中下列未跟踪的文件将会因为合并操作而被覆盖:
src/components/COMMON/FootCell/index.vue
src/components/COMMON/Pagination/index.vue
src/components/COMMON/Table/index.vue
src/components/COMMON/TitleCell/index.vue
请在合并前移动或删除。
正在终止不出所料 会跟开头讲的 状况一致,这里就不重复赘述了,参考上面的即可解决。
commit 记录如下图:
git config core.ignorecase truepull 最新代码如下图

同前面所说,变更都过来了,唯独文件名由于本地的大小写不敏感,所以没有自动变更名字
common => COMMON
切分支 checkout
git checkout feature/user2merge 代码
git merge mastercommit 记录如下图:
综上的出来的结论就是多人协作开发的时候存在已下情况
第一种方式
user1 两种, user2 两种,总共四种情况。且文件都被标记为A
都未开启敏感模式(绝大多数都是这个情况)
这种情况可想而知,远端的文件名一直都是 common 而非 COMMON,所有人乃至以后都会一直存在这个问题(自己本地需要去手动的更改文件名),
都开启了敏感模式
这种情况 user2 在同步更新 master 分支代码的时候会遇到 error,根据提示删除或移动文件位置即可!(删除最简单直观)
修改方(user1)开起了敏感模式,被通知方(user2)未开启
虽然文件名已经被改动且同步到了远端,但是当 user2 (master)拉取的时候会发现自己本地的文件名依旧是 common 未改动。这个时候只需要手动的去更改文件名,然后 merge 到 user2 的分支即可
修改方(user1)未开启敏感模式,被通知方(user2)开启了
user1 自以为文件名已经更改成功且同步到了远端,实际并没有同步到远端,user2 自己手动更改,更改后 push 到远端,这样所有人的文件引用路径错误问题都能得到解决
第二种方式
通过git rm 这个操作来处理。通过这种方式变更文件会被标记为R
已上所有内容都是经过好几遍测试,一边实践一边记录的形式来撰写的,最后也反复检查了好几遍,目测没有什么问题,如果有问题了就请留言告知吧~

在开发过程中我们经常会看到文件变更后末尾都会有
A,U,M,D,R等符号,那么这些符号到底什么含义呢?
| 标识 | 作用 |
|---|---|
A |
增加的文件. (git add .) U 变成 A |
C |
文件的一个新拷贝. |
D |
删除的一个文件. |
M |
文件的内容或者 mode 被修改了. |
R |
文件名被修改了。 |
T |
文件的类型被修改了。 |
U |
新增文件 未被 git 跟踪记录 |
X |
未知状态。 |
| 标识 | 作用 |
|---|---|
| 绿色 | 未加入版本控制 U 已经加入版本控制(git add .) A 被重命名(git rm xxx -r)R |
| 金黄色 | 加入版本控制,已提交,有改动(修改部分)M |
| 白色 | 加入版本控制,已提交,无改动。 |
| 灰色 | 版本控制已忽略文件。 |
这篇文章是针对浏览器的 JavaScript 脚本,Node.js 大同小异,这里不涉及到 Node.js 的场景。当然 Node.js 作为服务端语言,必然更关注内存泄漏的问题。
用户一般不会在一个 Web 页面停留比较久,即使有一点内存泄漏,重载页面内存也会跟着释放。而且浏览器也有自动回收内存的机制,所以我们前端其实并没有像 C、C++ 这类语言一样,特别关注内存泄漏的问题。
但是如果我们对内存泄漏没有什么概念,有时候还是有可能因为内存泄漏,导致页面卡顿。了解内存泄漏,如何避免内存泄漏,也是我们提升前端技能的必经之路。
俗话说好记忆不如烂笔头,所以本人就总结了一些内存泄漏相关的知识,避免一些低级的内存泄漏问题。
在硬件级别上,计算机内存由大量触发器组成。每个触发器包含几个晶体管,能够存储一个位。单个触发器可以通过唯一标识符寻址,因此我们可以读取和覆盖它们。因此,从概念上讲,我们可以把我们的整个计算机内存看作是一个巨大的位数组,我们可以读和写。
这么底层的概念,了解下就好,绝大多数数情况下,JavaScript 语言作为一门高级语言,无需我们使用二进制进直接进行读和写。
内存也是有生命周期的,不管什么程序语言,一般可以按顺序分为三个周期:
分配期
分配所需要的内存
使用期
使用分配到的内存(读、写)
释放期
不需要时将其释放和归还
内存分配 -> 内存使用 -> 内存释放。
在计算机科学中,内存泄漏指由于疏忽或错误造成程序未能释放已经不再使用的内存。内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。
如果内存不需要时,没有经过生命周期的释放期,那么就存在内存泄漏。
内存泄漏简单理解:无用的内存还在占用,得不到释放和归还。比较严重时,无用的内存会持续递增,从而导致整个系统卡顿,甚至崩溃。
像 C 语言这样的底层语言一般都有底层的内存管理接口,比如
malloc()和free()。相反,JavaScript 是在创建变量(对象,字符串等)时自动进行了分配内存,并且在不使用它们时“自动”释放。 释放的过程称为垃圾回收。这个“自动”是混乱的根源,并让 JavaScript(和其他高级语言)开发者错误的感觉他们可以不关心内存管理。
JavaScript 内存管理机制和内存的生命周期是一一对应的。首先需要分配内存,然后使用内存,最后释放内存。
其中 JavaScript 语言 不需要程序员手动 分配内存,绝大部分情况下也不需要手动释放内存,对 JavaScript 程序员来说通常就是使用内存(即使用变量、函数、对象等)。
JavaScript 定义变量就会自动分配内存的。我们只需了解 JavaScript 的内存是自动分配的就足够了。
看下内存自动分配的例子:
// 给数值变量分配内存
let number = 123
// 给字符串分配内存
const string = 'xianshannan'
// 给对象及其包含的值分配内存
const object = {
a: 1,
b: null
}
// 给数组及其包含的值分配内存(就像对象一样)
const array = [1, null, 'abra']
// 给函数(可调用的对象)分配内存
function func(a) {
return a
}使用值的过程实际上是对分配内存进行读取与写入的操作。读取与写入可能是写入一个变量或者一个对象的属性值,甚至传递函数的参数。
根据上面的内存自动分配例子,我们继续内存使用的例子:
// 写入内存
number = 234
// 读取 number 和 func 的内存,写入 func 参数内存
func(number)前端界一般称垃圾内存回收为 GC(Garbage Collection,即垃圾回收)。
内存泄漏一般都是发生在这一步,JavaScript 的内存回收机制虽然能回收绝大部分的垃圾内存,但是还是存在回收不了的情况,如果存在这些情况,需要我们手动清理内存。
以前一些老版本的浏览器的 JavaScript 回收机制没那么完善,经常出现一些 bug 的内存泄漏,不过现在的浏览器基本都没这些问题了,已过时的知识这里就不做深究了。
这里了解下现在的 JavaScript 的垃圾内存的两种回收方式,熟悉下这两种算法可以帮助我们理解一些内存泄漏的场景。
这是最初级的垃圾收集算法。此算法把“对象是否不再需要”简化定义为“对象有没有其他对象引用到它”。如果没有引用指向该对象(零引用),对象将被垃圾回收机制回收。
看下下面的例子,“这个对象”的内存被回收了吗?
// “这个对象”分配给 a 变量
var a = {
a: 1,
b: 2
}
// b 引用“这个对象”
var b = a
// 现在,“这个对象”的原始引用 a 被 b 替换了
a = 1当前执行环境中,“这个对象”内存还没有被回收的,需要手动释放“这个对象”的内存(当然是还没离开执行环境的情况下),例如:
b = null
// 或者 b = 1,反正替换“这个对象”就行了这样引用的"这个对象"的内存就被回收了。
ES6 把引用有区分为强引用和弱引用,这个目前只有再 Set 和 Map 中才有。
强引用才会有引用计数叠加,只有引用计数为 0 的对象的内存才会被回收,所以一般需要手动回收内存(手动回收的前提在于标记清除法还没执行,还处于当前执行环境)。
而弱引用没有触发引用计数叠加,只要引用计数为 0,弱引用就会自动消失,无需手动回收内存。
当变量进入执行环境时标记为“进入环境”,当变量离开执行环境时则标记为“离开环境”,被标记为“进入环境”的变量是不能被回收的,因为它们正在被使用,而标记为“离开环境”的变量则可以被回收
环境可以理解为我们的作用域,但是全局作用域的变量只会在页面关闭才会销毁。
// 假设这里是全局变量
// b 被标记进入环境
var b = 2
function test() {
var a = 1
// 函数执行时,a 被标记进入环境
return a + b
}
// 函数执行结束,a 被标记离开环境,被回收
// 但是 b 就没有被标记离开环境
test()JavaScript 的内存回收机制虽然能回收绝大部分的垃圾内存,但是还是存在回收不了的情况。程序员要让浏览器内存泄漏,浏览器也是管不了的。
下面有些例子是在执行环境中,没离开当前执行环境,还没触发标记清除法。所以你需要读懂上面 JavaScript 的内存回收机制,才能更好理解下面的场景。
// 在全局作用域下定义
function count(number) {
// basicCount 相当于 window.basicCount = 2
basicCount = 2
return basicCount + number
}不过在 eslint 帮助下,这种场景现在基本没人会犯了,eslint 会直接报错,了解下就好。
无用的计时器忘记清理是新手最容易犯的错误之一。
就拿一个 vue 组件来做例子。
<template>
<div></div>
</template>
<script>
export default {
methods: {
refresh() {
// 获取一些数据
}
},
mounted() {
setInterval(function() {
// 轮询获取数据
this.refresh()
}, 2000)
}
}
</script>上面的组件销毁的时候,setInterval 还是在运行的,里面涉及到的内存都是没法回收的(浏览器会认为这是必须的内存,不是垃圾内存),需要在组件销毁的时候清除计时器,如下:
<template>
<div></div>
</template>
<script>
export default {
methods: {
refresh() {
// 获取一些数据
}
},
mounted() {
this.refreshInterval = setInterval(function() {
// 轮询获取数据
this.refresh()
}, 2000)
},
beforeDestroy() {
clearInterval(this.refreshInterval)
}
}
</script>无用的事件监听器忘记清理是新手最容易犯的错误之一。
还是继续使用 vue 组件做例子。
<template>
<div></div>
</template>
<script>
export default {
mounted() {
window.addEventListener('resize', () => {
// 这里做一些操作
})
}
}
</script>上面的组件销毁的时候,resize 事件还是在监听中,里面涉及到的内存都是没法回收的(浏览器会认为这是必须的内存,不是垃圾内存),需要在组件销毁的时候移除相关的事件,如下:
<template>
<div></div>
</template>
<script>
export default {
mounted() {
this.resizeEventCallback = () => {
// 这里做一些操作
}
window.addEventListener('resize', this.resizeEventCallback)
},
beforeDestroy() {
window.removeEventListener('resize', this.resizeEventCallback)
}
}
</script>如果对 Set 不熟悉,可以看这里。
如下是有内存泄漏的(成员是引用类型的,即对象):
let map = new Set()
let value = { test: 22 }
map.add(value)
value = null需要改成这样,才没内存泄漏:
let map = new Set()
let value = { test: 22 }
map.add(value)
map.delete(value)
value = null有个更便捷的方式,使用 WeakSet,WeakSet 的成员是弱引用,内存回收不会考虑到这个引用是否存在。
let map = new WeakSet()
let value = { test: 22 }
map.add(value)
value = null如果对 Map 不熟悉,可以看这里。
如下是有内存泄漏的(键值是引用类型的,即对象):
let map = new Map()
let key = new Array(5 _ 1024 _ 1024)
map.set(key, 1)
key = null需要改成这样,才没内存泄漏:
let map = new Map()
let key = new Array(5 _ 1024 _ 1024)
map.set(key, 1)
map.delete(key)
key = null有个更便捷的方式,使用 WeakMap,WeakMap 的键名是弱引用,内存回收不会考虑到这个引用是否存在。
let map = new WeakMap()
let key = new Array(5 _ 1024 _ 1024)
map.set(key, 1)
key = null这个跟上面的被遗忘的事件监听器的道理是一样的。
假设订阅发布事件有三个方法 emit 、on 、off 三个方法。
还是继续使用 vue 组件做例子。
<template>
<div @click="onClick"></div>
</template>
<script>
import customEvent from 'event'
export default {
methods: {
onClick() {
customEvent.emit('test', { type: 'click' })
}
},
mounted() {
customEvent.on('test', data => {
// 一些逻辑
console.log(data)
})
}
}
</script>上面的组件销毁的时候,自定义 test 事件还是在监听中,里面涉及到的内存都是没法回收的(浏览器会认为这是必须的内存,不是垃圾内存),需要在组件销毁的时候移除相关的事件,如下:
<template>
<div @click="onClick"></div>
</template>
<script>
import customEvent from 'event'
export default {
methods: {
onClick() {
customEvent.emit('test', { type: 'click' })
}
},
mounted() {
customEvent.on('test', data => {
// 一些逻辑
console.log(data)
})
},
beforeDestroy() {
customEvent.off('test')
}
}
</script>首先看下这个代码:
function closure() {
const name = 'xianshannan'
return () => {
return name
.split('')
.reverse()
.join('')
}
}
const reverseName = closure()
// 这里调用了 reverseName
reverseName()上面有没有内存泄漏?
上面是没有内存泄漏的,因为 name 变量是要用到的(非垃圾)。这也是从侧面反映了闭包的缺点,内存占用相对高,量多了会有性能影响。
但是改成这样就是有内存泄漏的:
function closure() {
const name = 'xianshannan'
return () => {
return name
.split('')
.reverse()
.join('')
}
}
const reverseName = closure()在当前执行环境未结束的情况下,严格来说,这样是有内存泄漏的,name 变量是被 closure 返回的函数调用了,但是返回的函数没被使用,这个场景下 name 就属于垃圾内存。name 不是必须的,但是还是占用了内存,也不可被回收。
当然这种也是极端情况,很少人会犯这种低级错误。这个例子可以让我们更清楚的认识内存泄漏。
每个页面上的 DOM 都是占用内存的,假设有一个页面 A 元素,我们获取到了 A 元素 DOM 对象,然后赋值到了一个变量(内存指向是一样的),然后移除了页面的 A 元素,如果这个变量由于其他原因没有被回收,那么就存在内存泄漏,如下面的例子:
class Test {
constructor() {
this.elements = {
button: document.querySelector('#button'),
div: document.querySelector('#div'),
span: document.querySelector('#span')
}
}
removeButton() {
document.body.removeChild(this.elements.button)
// this.elements.button = null
}
}
const a = new Test()
a.removeButton()上面的例子 button 元素 虽然在页面上移除了,但是内存指向换为了 this.elements.button,内存占用还是存在的。所以上面的代码还需要这样写: this.elements.button = null,手动释放这个内存。
内存泄漏时,内存一般都是会周期性的增长,我们可以借助谷歌浏览器的开发者工具进行判别。
这里不进行详细的开发者工具使用说明,详细看谷歌开发者工具,不过谷歌浏览器是不断迭代更新的,有些文档落后了,界面长得不一样。
本人测试的谷歌版本为:版本 76.0.3809.100(正式版本) (64 位)。
这里针对下面例子进行一步一步的排查和找到问题出现在哪里:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
</head>
<body>
<div id="app">
<button id="run">运行</button>
<button id="stop">停止</button>
</div>
<script>
const arr = []
for (let i = 0; i < 200000; i++) {
arr.push(i)
}
let newArr = []
function run() {
newArr = newArr.concat(arr)
}
let clearRun
document.querySelector('#run').onclick = function() {
clearRun = setInterval(() => {
run()
}, 1000)
}
document.querySelector('#stop').onclick = function() {
clearInterval(clearRun)
}
</script>
</body>
</html>上面例子的代码可以直接运行的,怎么运行我就不多说了。
访问上面的代码页面,打开谷歌开发者工具,切换至 Performance 选项,勾选 Memory 选项。
在页面上点击运行按钮,然后在开发者工具上面点击左上角的录制按钮,10 秒后在页面上点击停止按钮,5 秒后停止内存录制。得到的内存走势如下:

由上图可知,10 秒之前内存周期性增长,10 后点击了停止按钮,内存平稳,不再递增。
我们可以使用内存走势图判断当前页面是否有内存泄漏。经过测试上面的代码 20000 个数组项改为 20 个数组项,内存走势也一样能看出来。
上一步确认是内存泄漏问题后,我们继续利用谷歌开发者工具进行问题查找。
访问上面的代码页面,打开谷歌开发者工具,切换至 Memory 选项。页面上点击运行按钮,然后点击开发者工具左上角录制按钮,录制完成后继续点击录制,知道录制完三个为止。然后点击页面的停止按钮,再连续录制 3 次内存(不要清理之前的录制)。下图就是进行这些步骤后的截图:

从这里也可以看出,点击运行按钮后,内存在不断递增。点击停止按钮后,内存就平稳了。虽然我们也可以使用这样的方式来判别是否存在内存泄漏,但是不够第一步的方法便捷,走势图也更直观。
然后第二步的主要目的来了,记录 JavaScript 堆内存才是内存录制的主要目的,我们可以看到哪个堆占用的内存更高。
在刚才的录制中选择 Snapshot 3 ,然后按照 Shallow Size 进行逆序排序(不了解的可以看内存术语),如下:

从内存记录中,发现 array 对象占用最大,展开后发现,第一个 object elements 占用最大,选择这个 object elements 后可以在下面看到 newArr 变量,然后点击 test:23,只要是高亮下划线的地方都可以进去看看 (测试页面是 test.html),可以跳转到 newArr 附近。

前置条件:
Mac 系统环境下
当执行如下命令时:
$ gitk --all
zsh: command not found: gitk
我是从上而下一步一步操作的,最终也成功了,但是你可以尝试下从
第2步操作直接安装gitk,有可能会成功 😹
已下部分操作基于 brew 命令操作,如果没有安装 brew 包管理的请自行
百度||谷歌进行安装 🤪
$ git --version
git version 2.17.2 (Apple Git-113)
$ which git
/usr/bin/git/usr/bin/git 则说明 git 为 Mac 原生老版本,升级最新的 git,可通过 brew 安装
brew install git执行如下命令:
$ brew link git
Warning: Already linked: /usr/local/Cellar/git/2.29.2
To relink:
brew unlink git && brew link git上面的 Warning 是正常的提示(已经是最新的 git 了),写博客前没注意老版本输出是什么样子的,如果不是已上格式,按照提示执行
brew unlink git && brew link git即可
确认下默认设置,不同于原生的/usr/bin/git
$ which git
# 说明是新版的git路径
/usr/local/bin/git$ gitk
#注:Terminal用的是zsh,所以报这个错
zsh: command not found: gitk安装:
brew install git-gui你可能会输出:
Warning: git-gui 2.29.2 is already installed, it's just not linked
You can use `brew link git-gui` to link this version.根据上述提示执行:
$ brew link git-gui
Linking /usr/local/Cellar/git-gui/2.29.2...
Error: Could not symlink bin/git-gui
Target /usr/local/bin/git-gui
already exists. You may want to remove it:
rm '/usr/local/bin/git-gui'
To force the link and overwrite all conflicting files:
brew link --overwrite git-gui
To list all files that would be deleted:
brew link --overwrite --dry-run git-gui再次根据上述提示执行:
$ brew link --overwrite git-gui
Linking /usr/local/Cellar/git-gui/2.29.2... 6 symlinks created
# 这个命令我没有执行,用的是上面这个
$ brew link --overwrite --dry-run git-gui安装完成确认路径是否为/usr/local/bin/gitk
$ which gitk
/usr/local/bin/gitkpackage.json 中的 main 字段指向的是 Library 的入口,通常有 3 个选择:
src/index.js;dist/library.js;dist/library.min.js。引用 Library 的方式也分为两种:
script 标签直接引用,适用于简单页面;require 或 import 方式引用,需要借助打包工具打包,适用于复杂页面。本文探讨一下 main 字段如何指定,才能兼顾各种引用方式。
第一种方式指向源码入口,这种情况仅适用于 require 方式引用。由于指向的是源代码,需要库使用者借助打包工具如 webpack,自行对库进行打包。此方式存在以下问题:
1.webpack 配置 babel-loader 一般会排除 node_modules,意味着不会对 library 进行转译,可能会导致打包后的代码中包含 ES6 代码,造成低版本浏览器兼容问题; 2.如果 library 的编译需要一些特别的 loader 或 loader 配置,使用者需要在自己的配置中加上这些配置,否则会造成编译失败; 3.使用者的打包工具需要收集 library 的依赖,造成打包编译速度慢,影响开发体验。
总的来说,第一种方式需要使用者自行对 library 进行编译打包,对使用者造成额外的负担,因此源代码入口文件不适宜作为库的入口。但是,如果 library 的目标运行环境只是 node 端,由于 node 端不需要对源代码进行编译打包,所以这种情况下可以使用 src/index.js 作为库入口。
开发版本的主要作用是便于调试,文件体积并不是开发版本所关心的问题,这是因为开发版本通常是托管在 localhost 上,文件大小基本没影响。
开发版本主要通过以下手段来方便调试,提升开发体验:
babel 转译,即使用者不再需要对 library 进行这两步工作了,提高编译打包的效率;其中第 3 点是通过库代码中添加如下类似代码实现的:
if (process.env.NODE_ENV === 'development') {
console.warn('Some useful warnings.')
}生成开发版本的似乎,webpack 的 DefinePlugin 会将 process.env.NODE_ENV 替换为 development,所以以上代码变为:
if ('development' === 'development') {
console.warn('Some useful warnings.')
}这就表示上述条件一直成立,warning 信息会显示出来。
最近和 iview 的开发者争论一件事,即在生成 library 的开发版本的时候,NODE_ENV 应该设置为 development 还是 production。他们认为应该设置为 production,理由是可以减小开发版本的体积。假设 DefinePlugin 将 process.env.NODE_ENV 替换为 production,之前的示例代码会变为:
if ('production' === 'development') {
console.warn('Some useful warnings.')
}这就意味着你使用库开发应用时,不会看到任何警告信息,这不利于提前发现错误。可能有的人会说,我的源代码中没有 if (process.env.NODE_ENV === 'development') {}这类代码,所以设置为 production 也不会有任何问题呀。殊不知,虽然你的源代码中这种没有这类提示代码,但是你的 devependencies 里面可能会有啊,这样做就会关闭依赖中的 warning 信息。
可能又有疑问:“引用开发版本的包体积很大,岂不是让我的应用打包上线版本很大?”其实完全不用担心,因为应用打包为上线版本时,会经过两个额外的工作:
DefinePlugin 将 process.env.NODE_ENV 替换为 production,关闭所有警告信息;UglifyJsPlugin 对应用代码进行 minify,减小应用体积。同时会删除 if ('production' === 'development') {}这类永远不会执行的代码,进一步减小应用体积。所以,在开发时应用开发版本,不必担心最后的应用体积。但是如果开发时是以 script 标签的方式引用库的开发版本,上线时应该替换为响应的发布版本。
发布版本追求的是尽量减小体积,因为相比于 JS 引擎解析的时间,网络传输是最慢的,所以要通过减小库的体积,减少网络传输的时间。
减小发布版本的文件体积,主要是通过将 process.env.NODE_ENV 设置为 production,然后再使用 UglifyJsPlugin 对应用代码进行 minify 以及删除永不执行的代码。
那么将库的发布版本作为入口文件合不合适呢?显然不合适,因为发布版本的是经过高度压缩精简的,代码完全不可读,应用开发阶段难以调试。
发布版本是适用于在应用上线时,通过 script 标签形式引用。
通过上面的分析,可以发现将库的开发版本作为库的入口才是正确合理的做法,即设置"main": "dist/library.js"。而作为库的开发者,也要遵循约定,生成库的开发版本的时候,使用 development 环境变量,保留警告信息。
首先来搞清楚什么是 Git 引用,前文讲了 Git 提交对象的哈希、存储原理,理论上我们只要知道该对象的 hash 值,就能往前推出整个提交历史,例如:
$ git log --pretty=oneline 3ac728ac62f0a7b5ac201fd3ed1f69165df8be31
3ac728ac62f0a7b5ac201fd3ed1f69165df8be31 third commit
d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c second commit
db1d6f137952f2b24e3c85724ebd7528587a067a first commit现在问题来了,提交对象的这 40 位 hash 值不好记忆,Git 引用相当于给 40 位 hash 值取一个别名,便于识别和读取。Git 引用对象都存储在 .git/refs 目录下,该目录下有 3 个子文件夹 heads、tags 和 remotes,分别对应于 HEAD 引用、标签引用和远程引用,下面分别讲一讲每种引用的原理。
HEAD 引用是用来指向每个分支的最后一次提交对象,这样切换到一个分支之后,才能知道分支的“尾巴”在哪里。HEAD 引用存储在 .git/refs/heads 目录下,有多少个分支,就有相应的同名 HEAD 引用对象。例如代码库里面有 master 和 test 两个分支,那么 .git/refs/heads 目录下就存在 master 和 test 两个文件,分别记录了分支的最后一次提交。
HEAD 引用的内容就是提交对象的 hash 值,理论上我们可以手动地构造一个 HEAD 引用:
$ echo "3ac728ac62f0a7b5ac201fd3ed1f69165df8be31" > .git/refs/heads/masterGit 提供了一个专有命令 update-ref,用来查看和修改 Git 引用对象,当然也包括 HEAD 引用:
$ git update-ref refs/heads/master 3ac728ac62f0a7b5ac201fd3ed1f69165df8be31
$ git update-ref refs/heads/master
3ac728ac62f0a7b5ac201fd3ed1f69165df8be31上面的命令我们将 master 分支的 HEAD 指向了 3ac728ac62f0a7b5ac201fd3ed1f69165df8be31,现在用 git log 查看下 master 的提交历史,可以发现最后一次提交就是所更新的 hash 值:
$ git log --pretty=oneline master
3ac728ac62f0a7b5ac201fd3ed1f69165df8be31 (HEAD -> master) third commit
d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c second commit
db1d6f137952f2b24e3c85724ebd7528587a067a first commit同理,可以使用同样的方法更新 test 分支的 HEAD:
$ git update-ref refs/heads/test d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c
$ git log --pretty=oneline test
d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c (test) second commit
db1d6f137952f2b24e3c85724ebd7528587a067a first commit.git/refs/heads 目录下存储了每个分支的 HEAD,那怎么知道代码库当前处于哪个分支呢?这就需要一个代码库级别的 HEAD 引用。.git/HEAD 这个文件就是整个代码库级别的 HEAD 引用。我们先查看一下 .git/HEAD 文件的内容:
$ cat .git/HEAD
ref: refs/heads/master我们发现 .git/HEAD 文件的内容不是 40 位 hash 值,而像是指向 .git/refs/heads/master。尝试切换到 test:
$ git checkout test
$ cat .git/HEAD
ref: refs/heads/test切换分支后,.git/HEAD 文件的内容也跟着指向 .git/refs/heads/test。.git/HEAD 也是 HEAD 引用对象,与一般引用不同的是,它是“符号引用”。符号引用类似于文件的快捷方式,链接到要引用的对象上。
Git 提供专门的命令 git symbolic-ref ,用来查看和更新符号引用:
$ git symbolic-ref HEAD refs/heads/master
$ git symbolic-ref HEAD refs/heads/test至此,我们分析了两种 HEAD 引用,一种是分支级别的 HEAD 引用,用来记录各分支的最后一次提交,存储在.git/refs/heads 目录下,使用 git update-ref 来维护;一种是代码库级别的 HEAD 引用,用来记录代码库所处的分支,存储在 .git/HEAD 文件,使用 git symbolic-ref 来维护。
标签引用,顾名思义就是给 Git 对象打标签,便于记忆。例如,我们可以将某个提交对象打 v1.0 标签,表示是 1.0 版本。标签引用都存储在 .git/refs/tags 里面。
标签引用和 HEAD 引用本质是 Git 引用对象,同样使用 git update-ref 来查看和修改:
$ git update-ref refs/tags/v1.0 d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c
$ cat .git/refs/tags/v1.0
d4d2c6cffb408d978cb6f1eb6cfc70e977378a5c还有一种标签引用称为“附注引用”,可以为标签添加说明信息。上面的标签引用打了一个 v1.0 的标签表示发布 1.0 版本,有时候发布软件的时候除了版本号信息,还要写更新说明。附注引用就是用来实现打标签的同时,也可以附带说明信息。
附注引用是怎么实现的呢?与常规标签引用不同的是,它不直接指向提交对象,而是新建一个 Git 对象存储到 .git/objects 中,用来记录附注信息,然后附注标签指向这个 Git 对象。
使用 git tag 建立一个附注标签:
$ git tag -a v1.1 3ac728ac62f0a7b5ac201fd3ed1f69165df8be31 -m "test tag"
$ cat .git/refs/tags/v1.1
8be4d8e4e8e80711dd7bae304ccfa63b35a6eb8c使用 git cat-file 来查看附注标签所指向的 Git 对象:
$ git cat-file -p 8be4d8e4e8e80711dd7bae304ccfa63b35a6eb8c
object 3ac728ac62f0a7b5ac201fd3ed1f69165df8be31
type commit
tag v1.1
tagger jingsam <[email protected]> 1529481368 +0800
test tag可以看到,上面的 Git 对象存储了我们填写的附注信息。
总之,普通的标签引用和附注引用同样都是存储的是 40 位 hash 值,指向一个 Git 对象,所不同的是普通的标签引用是直接指向提交对象,而附注标签是指向一个附注对象,附注对象再指向具体的提交对象。
另外,本质上标签引用并不是只可以指向提交对象,实际上可以指向任何 Git 对象,即可以给任何 Git 对象打标签。
远程引用,类似于 .git/refs/heads 中存储的本地仓库各分支的最后一次提交,在 .git/refs/remotes 是用来记录多个远程仓库各分支的最后一次提交。
我们可以使用 git remote 来管理远程分支:
$ git remote add origin [email protected]:jingsam/git-test.git上面添加了一个 origin 远程分支,接下来我们把本地仓库的 master 推送到远程仓库上:
$ git push origin master
Counting objects: 9, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (9/9), 720 bytes | 360.00 KiB/s, done.
Total 9 (delta 0), reused 0 (delta 0)
To github.com:jingsam/git-test.git
* [new branch] master -> master这时候在 .git/refs/remotes 中的远程引用就会更新:
$ cat .git/refs/remotes/origin/master
3ac728ac62f0a7b5ac201fd3ed1f69165df8be31和本地仓库的 master 比较一下,发现是一模一样的,表示远程分支和本地分支是同步的:
$ cat .git/refs/heads/master
3ac728ac62f0a7b5ac201fd3ed1f69165df8be31由于远程引用也是 Git 引用对象,所以理论上也可以使用 git update-ref 来手动维护。但是,我们需要先把代码与远程仓库进行同步,在远程仓库中找到对应分支的 HEAD,然后使用 git update-ref 进行更新,过程比较麻烦。而我们在执行 git pull 或 git push 这样的高层命令的时候,远程引用会自动更新。
到这里,三种 Git 引用都已分析完毕。总的来说,三种 Git 引用都统一存储到 .git/refs 目录下,Git 引用中的内容都是 40 位的 hash 值,指向某个 Git 对象,这个对象可以是任意的 Git 对象,可以是数据对象、树对象、提交对象。三种 Git 引用都可以使用 git update-ref 来手动维护。
三种 Git 引用对象所不同的是,分别存储于.git/refs/heads、.git/refs/tags、.git/refs/remotes,存储的文件夹不同,赋予了引用对象不同的功能。HEAD 引用用来记录本地分支的最后一次提交,标签引用用来给任意 Git 对象打标签,远程引用正式用来记录远程分支的最后一次提交。
git checkout -b xxx # 在当前所处的分支基础之上创建xxx分支
git checkout -b xxx yyy # 在yyy分支的基础之上创建新xxx分支2.1 删除本地
git branch -d xxx yyy zzz # 支持删除多个分支
git branch -D xxx yyy zzz # 强制删除 -D是--delete --force的缩写2.2 删除远端
支持多个分支删除
-d <分支名> || --delete <分支名>
git push origin -d <分支名1> <分支名2> # 删除远端分支(只需要分支名不需要带有remotes)结果如下:
KaKa:xxx-project kaka-mac$ git push origin -d test01 test02
To http://10.0.11.37:80/kaka/xxx-project.git
- [deleted] test01
- [deleted] test02错误示例:
直接使用<分支名>,不要使用remotes/origin/<分支名>
KaKa:xxx-project kaka-mac$ git push origin -d remotes/origin/test01 remotes/origin/test02
error: 无法删除 'remotes/origin/test01':远程引用不存在
error: 无法删除 'remotes/origin/test02':远程引用不存在
error: 推送一些引用到 'http://10.0.11.37:80/kaka/xxx-project.git' 失败:<分支名>
git push origin :<分支名1> :<分支名2> …… :<分支N>结果如下:
KaKa:xxx-project kaka$ git push origin :test01 :test02
To http://10.0.11.37:80/kaka/xxx-project.git
- [deleted] test01
- [deleted] test02
2.3 删除本地已失效的分支
有时候远端分支已经删除了,git branch -a的时候还能看到,这个时候就可以执行下面这个命令,来更新git branch -a的状态
git remote show origin # 可以查看remote地址,远程分支,还有本地分支与之相对应关系等信息
git remote prune origin # 删除本地版本库上那些失效的远程追踪分支clean
# 删除 untracked files
git clean -f
# 连 untracked 的目录也一起删掉
git clean -fd
# 连 gitignore 的untrack 文件/目录也一起删掉 (慎用,一般这个是用来删掉编译出来的 .o之类的文件用的)
git clean -xfd
# 在用上述 git clean 前,墙裂建议加上 -n 参数来先看看会删掉哪些文件,防止重要文件被误删
git clean -nxfd
git clean -nf
git clean -nfdrm
# 删除文件夹
git rm <文件夹路径> -r # -r 表示递归
# 删除文件
git rm <文件路径> git rm ./src/components/common -r # 删除common文件夹二者应该有区别~具体区别又搞不太清楚···😂 rm我的使用场景就是 Git 大小写不敏感时,若想更改文件名(驼峰转换)这个时候会用到这个命令。clean是当我对项目进行撤销变更的时候,执行git checkout .后那些未被跟踪的文件(untracked files)无法撤销,这个时候就可以使用clean命令来进行删除!
4.1 撤销工作区域中的修改
git checkout .4.2 撤销工作区中指定文件的修改
filename: ./package.json || package.json || src/App.vue
git checkout -- filename # 路径是从项目的根目录开始这里撤销的操作都是被 Git tracked 的文件,将所有变动过的文件还原上一次 commit 状态,但是对于新增的文件(U-untracked)则无任何撤销作用,这个时候就需要使用 git clean命令来 删除 untracked的文件,具体参考上步操作(删除文件)
5.1 回退到指定版本HEAD形式
# 这种情况文件修改变更还在
git reset HEAD^ # 上一个
git reset HEAD^^ # 上上一个
git reset HEAD~n # n:1,2,3,4……
# 这种情况文件变更都不在(还原成初始状态)
git reset --hard HEAD~1
git update-ref -d HEAD # 撤销第一次commit,因为已上的操作都无法撤销第一个commit5.2 回退到指定版本直接版本号形式
git reset xxxxxx # 取消某一次提交且做的修改还在
git reset --hard xxxxxx # 取消某一次提交且做的修改全部丢失如何后悔了!可以使用命令 git reflog 来查看你的每一次操作日志,该命令可以输出对应的版本号的操作记录
# 查看版本库的历史记录
git log
# 查看版本库的历史记录,美化输出
git log --pretty=oneline
# 查看版本库的历史记录,只显示前 5 条
git log -5
git log -5 --pretty=onelinegit commit -a # 进入多行编辑模式
git commit -m 'x' # 输入引号 和内容以后 就可以直接回车换行了
git commit --amend -m 'xxx' # 修改上一次提交的 message
git rebase -i <hash-id> # 利用这一步的 r, reword <commit>, 将要修改的某次commit之前的pick换成r 保存会进入下一步重新更改commit msg了# 创建
git tag v1.0 # 创建标签(默认在最新的commit上)
git tag v0.9 6224937 # 在指定commit上创建标签
git tag -a v0.1 -m "version 0.1 released" 3628164 # 在指定commit上创建有备注的标签(-a指定标签名)
# 展示
git show <tagname> # 可以查看标签的文字说明
# 查看
git tag # 查看所有标签
# 获取远端tag
git fetch --tags
# 将制定tag推送到远端
git push origin <tagname>
# 将所有tag推送到远端
git push --tags
git push origin --tags
# 删除本地
git tag -d <tagname> # 删除tag
# 删除远端分支
git push origin :refs/tags/<tagname>
# 删除本地所有tag
git tag | xargs git tag -d
# 删除远端所有tag
git tag -l | xargs -n 1 git push --delete origin# 本地 & 本地
git diff develop master # 比较develop & master分支的区别
# 本地 & 远端分支
git diff develop origin/master(1)git stash save <message> # 执行存储时,添加备注,方便查找,只有git stash 也要可以的,但查找时不方便识别。
(2)git stash list # 查看stash了哪些存储
(3)git stash show # 显示做了哪些改动,默认show第一个存储,如果要显示其他存贮,后面加stash@{$num},比如第二个 git stash show stash@{1}
(4)git stash show -p # 显示第一个存储的改动,如果想显示其他存存储,命令:git stash show stash@{$num} -p ,比如第二个:git stash show stash@{1} -p
(5)git stash apply # 应用某个存储,但不会把存储从存储列表中删除,默认使用第一个存储,即stash@{0},如果要使用其他个,git stash apply stash@{$num} , 比如第二个:git stash apply stash@{1}
(6)git stash pop # 命令恢复之前缓存的工作目录,将缓存堆栈中的对应stash删除,并将对应修改应用到当前的工作目录下,默认为第一个stash,即stash@{0},如果要应用并删除其他stash,命令:git stash pop stash@{$num} ,比如应用并删除第二个:git stash pop stash@{1}
(7)git stash drop stash@{$num} # 丢弃stash@{$num}存储,从列表中删除这个存储
(8)git stash clear # 删除所有缓存的stashgitk --all # 查看 `git树图`&`diff`如果查看到界面中文乱码,执行如下命令即可
git config --global gui.encoding utf-8 # 转换成简体中文其他博客:
1.Git 撤销修改和版本回退·CSDN
npm 出现之前:前端依赖项是保存到存储库中并手动下载的
2010:npm 发布并支持 nodejs
2012:npm 的使用量急剧增加——主要是由于 Browserifys 浏览器的支持
2012:npm 有了一个竞争对手 bower,它完全支持浏览器
2012-2016:前端项目的依赖项数量成倍增加
2012-2016:构建和安装前端应用变得越来越慢
2012-2016:大量(重复的)依赖项存储在神奇的 node_modules 内的嵌套文件夹中 ☢️
2012-2016:rm -rf node_modules 成为前端开发人员最常用的命令。
2015:bower 输给了 npm
2015:node_modules 被修改为扁平化的文件结构!
2016: left-pad 成为当时的新闻头条
2016: yarn 发布
2016:npm 发布 shrinkwrap
2017:npm 5 发布
2018:npm ci 发布
2018:npm 6 发布 ♀️
2019:tink 开始进入 beta 模式
...
yarn init --yes # 简写 -y
npm init --yes # 简写 -yyarn add <package> [--dev/-D] // 不带-D默认生产环境
yarn add [package]@[version] #带版本
npm install XXX --save 可以简写成npm i XXX -S --------> 安装项目依赖
npm install XXX --save-dev可以简写成npm i XXX -D ------> 安装开发依赖npm config get registry // 查看npm当前镜像源
npm config set registry https://registry.npm.taobao.org/ // 设置npm镜像源为淘宝镜像
yarn config get registry // 查看yarn当前镜像源
yarn config set registry https://registry.npm.taobao.org/ // 设置yarn镜像源为淘宝镜像
镜像源地址部分如下:
npm --- https://registry.npmjs.org/
cnpm --- https://r.cnpmjs.org/
taobao --- https://registry.npm.taobao.org/yarn global add [package]
npm install [package] -gyarn remove <packageName>
npm uninstall <packageName> -Syarn global remove <packageName>
npm uninstall -g <packageName>yarn
npm install || npm iyarn upgrade # 升级所有依赖项,不记录在 package.json 中
npm update # npm 可以通过 ‘--save|--save-dev’ 指定升级哪类依赖
yarn upgrade webpack # 升级指定包
npm update webpack --save-dev # npm
yarn upgrade --latest # 忽略版本规则,升级到最新版本,并且更新 package.jsonyarn global list --depth=0 # 限制依赖的深度
npm list -g --depth=0yarn cache clean
npm cache clean --forceyarn info <package...>
npm v <package...> versions //缩写npm, yarn 做了哪些优化并行安装: 无论 npm 还是 yarn 在执行包的安装时,都会执行一系列任务。 npm 是按照队列执行每个 package ,也就是说必须要等到当前 package 安装完成之后,才能继续后面的安装。而 yarn 是同步执行所有任务,提高了性能。
离线模式: 如果之前已经安装过一个软件包,用 yarn 再次安装时之间从缓存中获取,就不用像 npm 那样再从网络下载了。
安装版本统一: 为了防止拉取到不同的版本,yarn 有一个锁定文件 (lock file) 记录了被确切安装上的模块的版本号。每次只要新增了一个模块,yarn 就会创建(或更新)yarn.lock 这个文件。这么做就保证了,每一次拉取同一个项目依赖时,使用的都是一样的模块版本。
更好的语义化: yarn 改变了一些 npm 命令的名称,比如 yarn add/remove,比 npm 原本的 install/uninstall要更清晰。
注意 cnpm 不支持 package-lock
,
使用
cnpm install时候,并不会生成package-lock.json文件。cnpm install的时候,就算你项目中有package-lock.json文件,cnpm 也不会识别,仍会根据 package.json 来安装。所以这就是为什么之前你用npm安装产生了package-lock.json,后面的人用 cnpm 来安装,可能会跟你安装的依赖包不一致。
因此,尽量不要直接使用 cnpm install 安装项目依赖包。但是为了解决直接使用 npm install 速度慢的问题,可以设置 npm 代理解决。
# 设置淘宝镜像代理
npm config set registry https://registry.npm.taobao.org
# 查看已设置代理
npm config get registry首先要知道自己的电脑有个全局的 .gitconfig 文件里面有个 email,这个是关键后面要用到!
$ vim ~/.gitconfig[user]
name = "xiehuaqiang"
email = [email protected] # 后面要用到!
[alias]
sta = status
com = commit
che = checkout
br = branch
unstage = reset HEAD --
last = log -1 HEAD
[color]
branch = auto
diff = auto
status = auto
ui = auto
[color "branch"]
current = magenta
local = yellow
remote = cyan就在根据 GitHub 官网设置 ssh 完以后,出现了一个问题,就是从 GitHub 上通过 ssh 的形式来 clone 的时候死活不成功!提示如下 ↓
Mr-Xies-Mac-Pro:test kaka$ git clone [email protected]:***/**_demo.git
Cloning into 'html_demo'...
[email protected]: Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.因为生成 ssh 的时候配置的 email 地址跟全局的不一致!导致无法 git clone 下来!
so easy~
就是修改全局的 git 配置中的 email,让他跟生成 ssh 时设置的一致就 ojbk 了
$ git config --global user.email '[email protected]'结论:以后多个仓库地址(GitHub GitLab)最好用一个邮箱!不论是全局的还是本地的
第一步:
$ ssh-keygen -t rsa -b 4096 -C "[email protected]" # 这是GitHub官网的命令
$ ssh-keygen -t rsa -C "[email protected]" # 其他情况第二步 设置公钥秘钥的文件名 (为了以后扩展有多个仓库 自己 || 公司的)
Enter file in which to save the key (/Users/kaka/.ssh/id_rsa): id_rsa_home第三步 一路回车
最后会生成 id_rsa_home, id_rsa_home.pub
+---[RSA 4096]----+
| [email protected] |
| oB+OB+= . |
| o++=Oo+... |
| + +...o. . |
| . S o . |
| + . ..|
| . o o+|
| . E|
| |
+----[SHA256]-----+第四步 查看公钥
$ cat id_rsa_home.pub# 公钥
ssh-rsa AAAAB3NzaC1yc2EAAAADAQA……ssh-add -D # delete cached keys
ssh-add -l # 查看添加哪些第一步 生成代理 (自己的理解)
$ eval `ssh-agent -s` || eval "$(ssh-agent -s)" # 两种写法都可以
> Agent pid 8833 # 输出第二步 写入代理
$ ssh-add -K ~/.ssh/id_rsa_home
> Identity added: /Users/kaka/.ssh/id_rsa_home ([email protected]) # 输出第三步 查看代理
$ ssh-add -l
4096 SHA256:tp……qA3ERkSoU [email protected] (RSA) # 输出第二步声明:
If you're using macOS Sierra 10.12.2 or later, you will need to modify your ~/.ssh/config file to automatically load keys into the ssh-agent and store passphrases in your keychain
Host *
AddKeysToAgent yes
UseKeychain yes
IdentityFile ~/.ssh/id_rsa_home第一步 将 ssh key 添加到 GitHub 账户
第二步 检验是否设置成功
$ ssh -T [email protected] # 配置文件中的地址
Hi Popxie! You've successfully authenticated, but GitHub does not provide shell access' # 输出第三步 git clone project
如果 clone 不下来 请将公钥重新添加一次。(我写完这篇文档以后发现还是不行,就重新添加了一下,然后就 ojbk 了)
# 家
Host home.github.com
HostName github.com
AddKeysToAgent yes
UseKeychain yes
PreferredAuthentications publickey
IdentityFile ~/.ssh/id_rsa_home
#公司
Host company.xx.yy.com
HostName xx.yy.com
PreferredAuthentications publickey
IdentityFile ~/.ssh/id_rsa_company数据对象、树对象和提交对象都是存储在.git/objects 目录下,目录的结构如下:
.git
|-- objects
|-- 01
| |-- 55eb4229851634a0f03eb265b69f5a2d56f341
|-- 1f
| |-- 7a7a472abf3dd9643fd615f6da379c4acb3e3a
|-- 83
|-- baae61804e65cc73a7201a7252750c76066a30从上面的目录结构可以看出,Git 对象的 40 位 hash 分为两部分:头两位作为文件夹,后 38 位作为对象文件名。所以一个 Git 对象的存储路径规则为:
.git/objects/hash[0, 2]/hash[2, 40]这里就产生了一个疑问:为什么 Git 要这么设计目录结构,而不直接用 Git 对象的 40 位 hash 作为文件名?原因是有两点:
FAT32 限制单目录下的最大文件数量是 65535 个,如果使用 U 盘拷贝 Git 文件就可能出现问题。在在 Git 内部原理之 Git 对象哈希中,我们知道 Git 对象会在原内容前加个一个头部:
store = header + contentGit 对象在存储前,会使用 zlib 的 deflate 算法进行压缩,即简要描述为:
zlib_store = zlib.deflate(store)压缩后的 zlib_store 按照 Git 对象的路径规则存储到.git/objects 目录下。
总结下 Git 对象存储的算法步骤:
content 长度,构造 header ;header 添加到 content 前面,构造 Git 对象;sha1 算法计算 Git 对象的 40 位 hash 码;zlib 的 deflate 算法压缩 Git 对象;Git 对象存储到.git/objects/hash[0, 2]/hash[2, 40]路径下;接下来,我们使用 Nodejs 来实现 git hash-object -w 的功能,即计算 Git 对象的 hash 值并存储到 Git 文件系统中:
const fs = require('fs')
const crypto = require('crypto')
const zlib = require('zlib')
function gitHashObject(content, type) {
// 构造header
const header = `${type} ${Buffer.from(content).length}\0`
// 构造Git对象
const store = Buffer.concat([Buffer.from(header), Buffer.from(content)])
// 计算hash
const sha1 = crypto.createHash('sha1')
sha1.update(store)
const hash = sha1.digest('hex')
// 压缩Git对象
const zlib_store = zlib.deflateSync(store)
// 存储Git对象
fs.mkdirSync(`.git/objects/${hash.substring(0, 2)}`)
fs.writeFileSync(`.git/objects/${hash.substring(0, 2)}/${hash.substring(2, 40)}`, zlib_store)
console.log(hash)
}
// 调用入口
gitHashObject(process.argv[2], process.argv[3])最后,测试下能否正确存储 Git 对象:
$ node index.js 'hello, world' blob
8c01d89ae06311834ee4b1fab2f0414d35f01102
$ git cat-file -p 8c01d89ae06311834ee4b1fab2f0414d35f01102
hello, world由此可见,我们生成了一个合法的 Git 数据对象,证明算法是正确的。
语义版本控制的概念很简单:所有的版本都有 3 个数字:x.y.z。
当发布新的版本时,不仅仅是随心所欲地增加数字,还要遵循以下规则:
该约定在所有编程语言中均被采用,每个npm软件包都必须遵守该约定,这一点非常重要,因为整个系统都依赖于此。
为什么这么重要?
因为 npm 设置了一些规则,可用于在 package.json 文件中选择要将软件包更新到的版本(当运行 npm update 时)。
规则使用了这些符号:
^ 插入号~ 波浪号>>=<<==-||这些规则的详情如下:
^: 如果写入的是 ^0.13.0,则当运行 npm update 时,会更新到补丁版本和次版本:即 0.13.1、0.14.0、依此类推。~: 如果写入的是 〜0.13.0,则当运行 npm update 时,会更新到补丁版本:即 0.13.1 可以,但 0.14.0 不可以。>: 接受高于指定版本的任何版本。>=: 接受等于或高于指定版本的任何版本。<=: 接受等于或低于指定版本的任何版本。<: 接受低于指定版本的任何版本。=: 接受确切的版本。-: 接受一定范围的版本。例如:2.1.0 - 2.6.2。||: 组合集合。例如 < 2.1 || > 2.6。可以合并其中的一些符号,例如 1.0.0 || >=1.1.0 <1.2.0,即使用 1.0.0 或从 1.1.0 开始但低于 1.2.0 的版本。
还有其他的规则:
如果 npm 脚本里面需要执行多个任务,那么需要明确它们的执行顺序。
如果是并行执行(即同时的平行执行),可以使用&符号。
npm run script1.js & npm run script2.js如果是继发执行(即只有前一个任务成功,才执行下一个任务),可以使用&&符号。
npm run script1.js && npm run script2.js这两个符号是 Bash 的功能。
每当我们开发完一个功能分支以后,在合并到
master分支以后,会附带的将开发期间所有的commit记录一并 merge 到了远端,若为一个人开发还好问题不大,一旦牵扯多个人协同开发的话,就会导致master分支commit记录严重混乱,"交叉感染",commit记录不清晰。
理想情况下master分支commit记录应尽量做到干净清晰,一个commit为一个功能(但是这个commit会包含这个功能分支的所有commit记录),方便出问题了进行整体回滚,以及有个清晰的树状图(git log --graph)
test 分支创建一个新的功能分支,用来模拟两个人开发
user1 和 user2 来表示user1 和 user2 分别轮流交叉提交 commit,用来模拟最终 merge 到 test 分支 commit 记录交叉混乱的情况
user1 & user2 分别进行的 4 次提交 如上图所示
commit记录"交叉混乱",视觉上看着并不是很爽朗
merge 后的 commit 是按照 commit 的时间自上而下的排序,所以看着会比较不清爽

git log 前后对比 如上图所示

git log --graph 前后对比 如上图所示
这里以user1操作为例,user2同理
使用
git rebase -i xxxx命令

user1 rebase 前后对比 如上图所示
git push -f友情提示: 如果对变基不是很清楚,建议在变基之前对'
user1'的分支进行备份
通常情况下,一个新的功能分支不可能一直暂存在本地而不提交远端,就样子就会造成多次的 commit 都会被提交到远端,最终 merge 到 test 分支的时候也会附带的把之前的多次 commit 记录一并给提交上去了。而我们期望的是:简化 commit 记录,在 merge 到 test 之前将之前的 commit 都合并为一个
但是git rebase命令多用于未提交到远端之前进行 commit 合并操作。
所以就有了友情提示做个备份,以免操作失误不好挽回的局面。
948aa5a940eda8b7d92181a2cd0a272ebec38352 (HEAD -> feature/user1-test, origin/feature/user1-test) add user1.4
60e6ec8520c94dcc54f8f76ab96ba393fe4e19b7 add user1.3
fba4e9588c28d7dd076e5f8abc63a711bb1f0235 add user1.2
d01d268ddf308d7fd612a9c5db2d27f7dc1bfd27 add user1.1
e6edcd464317c119c4cfa3cb2b7a354003db9788 (origin/test, origin/master, test, master) 修复you dont know js图片路径引入问题由上可知我们要将add user1.1 ~ add user1.4合并为一个 commit,所以我们要选择的起点是 e6edcd464
1.git rebase -i e6edcd464会弹出以下提示
pick d01d268 add user1.1
pick fba4e95 add user1.2
pick 60e6ec8 add user1.3
pick 948aa5a add user1.4
# 变基 e6edcd4..948aa5a 到 948aa5a(4 个提交)
#
# 命令:
# p, pick <提交> = 使用提交
# r, reword <提交> = 使用提交,但修改提交说明
# e, edit <提交> = 使用提交,进入 shell 以便进行提交修补
# s, squash <提交> = 使用提交,但融合到前一个提交
# f, fixup <提交> = 类似于 "squash",但丢弃提交说明日志
# x, exec <命令> = 使用 shell 运行命令(此行剩余部分)
# b, break = 在此处停止(使用 'git rebase --continue' 继续变基)
# d, drop <提交> = 删除提交
# l, label <label> = 为当前 HEAD 打上标记
# t, reset <label> = 重置 HEAD 到该标记
# m, merge [-C <commit> | -c <commit>] <label> [# <oneline>]
# . 创建一个合并提交,并使用原始的合并提交说明(如果没有指定
# . 原始提交,使用注释部分的 oneline 作为提交说明)。使用
# . -c <提交> 可以编辑提交说明。
#
# 可以对这些行重新排序,将从上至下执行。
#
# 如果您在这里删除一行,对应的提交将会丢失。
#
# 然而,如果您删除全部内容,变基操作将会终止。2.将user1.2~user1.4合并到user1.1
pick d01d268 add user1.1
s fba4e95 add user1.2 ↑
s 60e6ec8 add user1.3 ↑
s 948aa5a add user1.4 ↑ # s 表示向上合并,所以p(ick)都会在上 s(quash)在下,否则会出问题哈,不信可以自己尝试[狗头]
:wq //退出保存3.退出保存后进入如下页面
# 这是一个 4 个提交的组合。
# 这是第一个提交说明:
add user1.1
# 这是提交说明 #2:
add user1.2
# 这是提交说明 #3:
add user1.3
# 这是提交说明 #4:
add user1.4
# 请为您的变更输入提交说明。以 '#' 开始的行将被忽略,而一个空的提交
# 说明将会终止提交
:wq //退出保存4.直接 :wq退出保存走默认的即可
5.最终效果前后对比
如上图所示

But 这个时候 vscode 左下角会有提示告诉你 当前分支落后远端分支 4 次 commit,且有一个未提交的 commit 如上图所示

因为这个分支是自己的,所以可以强制将当前变基后的分支 push 到远端覆盖,结果 如上图所示
这种情况呢包含在情况一中,只是没有了强制 push 这一步,也不会出现落后远端分支 4 次 commit 的情况。
所以不再重复赘述~~
最终变基合并后的效果 如上图所示:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.