pines-cheng / blog Goto Github PK
View Code? Open in Web Editor NEW技术博客
Home Page: https://pines-cheng.github.io/blog/
技术博客
Home Page: https://pines-cheng.github.io/blog/




















































































































































最近在做React 图片懒加载的,原本以为比较简单,轻轻松松就能搞定,结果碰到了一系列的问题,可谓是一波三折,不过经过这次折腾,对图片懒加载及相关的实现有了更深刻的了解,特此记录一下。
一开始的时候,没打算自己造轮子。直接在网上搜索到了 react-lazyload 的库,用上以后,demo测试也没问题,可是在商品列表却没生效。于是直接去看源码找原因。
图片懒加载一般涉及到的流程为:滚动容器 -> 绑定事件 -> 检测边界 -> 触发事件 -> 图片加载
import React from 'react';
import ReactDOM from 'react-dom';
import LazyLoad from 'react-lazyload';
import MyComponent from './MyComponent';
const App = () => {
return (
<div className="list">
<LazyLoad height={200}>
<img src="tiger.jpg" /> /*
Lazy loading images is supported out of box,
no extra config needed, set `height` for better
experience
*/
</LazyLoad>
<LazyLoad height={200} once >
/* Once this component is loaded, LazyLoad will
not care about it anymore, set this to `true`
if you're concerned about improving performance */
<MyComponent />
</LazyLoad>
<LazyLoad height={200} offset={100}>
/* This component will be loaded when it's top
edge is 100px from viewport. It's useful to
make user ignorant about lazy load effect. */
<MyComponent />
</LazyLoad>
<LazyLoad>
<MyComponent />
</LazyLoad>
</div>
);
};
ReactDOM.render(<App />, document.body);react-lazyload 有一个props为 overflow,默认为false。
if (this.props.overflow) { // overflow 为true,向上查找滚动容器
const parent = scrollParent(ReactDom.findDOMNode(this));
if (parent && typeof parent.getAttribute === 'function') {
const listenerCount = 1 + (+parent.getAttribute(LISTEN_FLAG));
if (listenerCount === 1) {
parent.addEventListener('scroll', finalLazyLoadHandler, passiveEvent);// finalLazyLoadHandler 及passiveEvent 见下面
}
parent.setAttribute(LISTEN_FLAG, listenerCount);
}
} else if (listeners.length === 0 || needResetFinalLazyLoadHandler) { // 否则直接绑定window
const { scroll, resize } = this.props;
if (scroll) {
on(window, 'scroll', finalLazyLoadHandler, passiveEvent);
}
if (resize) {
on(window, 'resize', finalLazyLoadHandler, passiveEvent);
}
}通过源码可以看到,这里当 overflow 为true时,调用 scrollParent 获取滚动容器,否者直接将滚动事件绑定在 window。
scrollParent 代码如下:
/**
* @fileOverview Find scroll parent
*/
export default (node) => {
if (!node) {
return document.documentElement;
}
const excludeStaticParent = node.style.position === 'absolute';
const overflowRegex = /(scroll|auto)/;
let parent = node;
while (parent) {
if (!parent.parentNode) {
return node.ownerDocument || document.documentElement;
}
const style = window.getComputedStyle(parent); //获取节点的所有样式
const position = style.position;
const overflow = style.overflow;
const overflowX = style['overflow-x'];
const overflowY = style['overflow-y'];
if (position === 'static' && excludeStaticParent) {
parent = parent.parentNode;
continue;
}
if (overflowRegex.test(overflow) && overflowRegex.test(overflowX) && overflowRegex.test(overflowY)) {
return parent;
}
parent = parent.parentNode;
}
return node.ownerDocument || node.documentElement || document.documentElement;
};这段代码比较简单,可以看到,scrollParent 默认是迭代向上查找 parentNode 样式的 overflow ,直到找到第一个 overflow 为 auto 或 scroll 的节点。然后返回该节点,作为滚动容器。
看到这里,我就基本知道商品列表懒加载无效的原因了,react-lazyload 仅支持 overflow 的滚动方式,而商品列表由于特殊原因,选用了 transform 的滚动方式。那是否有必要对其进行一下改造呢?接下来,我们继续往下看。
上面的 passiveEvent 如下,在您的触摸和滚轮事件侦听器上设置 passive 选项可提升滚动性能。
// if they are supported, setup the optional params
// IMPORTANT: FALSE doubles as the default CAPTURE value!
const passiveEvent = passiveEventSupported ? { capture: false, passive: true } : false;详细可以参考:移动Web滚动性能优化: Passive event listeners
这里对 scroll 事件的回调函数 finalLazyLoadHandler 进行了节流或去抖的处理,时间是300毫秒。看起来还不错。
if (!finalLazyLoadHandler) {
if (this.props.debounce !== undefined) {
finalLazyLoadHandler = debounce(lazyLoadHandler, typeof this.props.debounce === 'number' ?
this.props.debounce :
300);
delayType = 'debounce';
} else if (this.props.throttle !== undefined) {
finalLazyLoadHandler = throttle(lazyLoadHandler, typeof this.props.throttle === 'number' ?
this.props.throttle :
300);
delayType = 'throttle';
} else {
finalLazyLoadHandler = lazyLoadHandler;
}lazyLoadHandler 如下:
const lazyLoadHandler = () => {
for (let i = 0; i < listeners.length; ++i) {
const listener = listeners[i];
checkVisible(listener); //检测元素是否可见,并设置组件的props:visible
}
// Remove `once` component in listeners
purgePending(); //移除一次性组件的监听
};这里大家千万不要被函数方法名 checkVisible 给迷惑,这里绝仅仅做了函数名字面意义的事情,而是做了一大堆的事。包括检测是否可见,设置组件 props,更新监听list,还有 component.forceUpdate!也是够了。。。
/**
* Detect if element is visible in viewport, if so, set `visible` state to true.
* If `once` prop is provided true, remove component as listener after checkVisible
*
* @param {React} component React component that respond to scroll and resize
*/
const checkVisible = function checkVisible(component) {
const node = ReactDom.findDOMNode(component);
if (!node) {
return;
}
const parent = scrollParent(node);
const isOverflow = component.props.overflow &&
parent !== node.ownerDocument &&
parent !== document &&
parent !== document.documentElement;
const visible = isOverflow ?
checkOverflowVisible(component, parent) :
checkNormalVisible(component);
if (visible) { //组件是否可见
// Avoid extra render if previously is visible
if (!component.visible) {
if (component.props.once) {
pending.push(component); //如果只触发一次,则放入pending的列表,然后在purgePending中移除监听
}
component.visible = true; //设置组件的props为true
component.forceUpdate(); //强制更新
}
} else if (!(component.props.once && component.visible)) {
component.visible = false;
if (component.props.unmountIfInvisible) {
component.forceUpdate();
}
}
};检测组件滚动到可见位置的方法如下:
/**
* Check if `component` is visible in overflow container `parent`
* @param {node} component React component
* @param {node} parent component's scroll parent
* @return {bool}
*/
const checkOverflowVisible = function checkOverflowVisible(component, parent) {
const node = ReactDom.findDOMNode(component);
let parentTop;
let parentHeight;
try {
({ top: parentTop, height: parentHeight } = parent.getBoundingClientRect());
} catch (e) {
({ top: parentTop, height: parentHeight } = defaultBoundingClientRect);
}
const windowInnerHeight = window.innerHeight || document.documentElement.clientHeight;
// calculate top and height of the intersection of the element's scrollParent and viewport
const intersectionTop = Math.max(parentTop, 0); // intersection's top relative to viewport
const intersectionHeight = Math.min(windowInnerHeight, parentTop + parentHeight) - intersectionTop; // height
// check whether the element is visible in the intersection
let top;
let height;
try {
({ top, height } = node.getBoundingClientRect());
} catch (e) {
({ top, height } = defaultBoundingClientRect);
}
const offsetTop = top - intersectionTop; // element's top relative to intersection
const offsets = Array.isArray(component.props.offset) ?
component.props.offset :
[component.props.offset, component.props.offset]; // Be compatible with previous API
return (offsetTop - offsets[0] <= intersectionHeight) &&
(offsetTop + height + offsets[1] >= 0);
};看起来好像代码比较多,其实核心方法就一个:getBoundingClientRect() 。Element.getBoundingClientRect() 方法返回元素的大小及其相对于视口的位置。
通过 getBoundingClientRect 方法获取组件的滚动位置(top height等),然后经过一系列计算,就可以判断组件是否已经鼓动到合适的位置上了。
至此,react-lazyload 的代码我们已经大致看完了,总结一下这个库的缺点吧:
overflow 滚动component.visible = true; 违背React原则,太暴力component.forceUpdate() ,在滚动列表长,滚动速度快的时候,可能会有性能隐患getBoundingClientRect 性能不太好LazyLoad 是一个快速的,轻量级的,灵活的图片懒加载库,本质是基于 img 标签的 srcset 属性。
HTML
<img alt="..."
data-src="../img/44721746JJ_15_a.jpg"
width="220" height="280">Javascript
var myLazyLoad = new LazyLoad();入口文件,这里主要是 this._setObserver 方法和 this.update 方法。
var LazyLoad = function LazyLoad(instanceSettings, elements) {
this._settings = _extends({}, defaultSettings, instanceSettings);
this._setObserver();
this.update(elements);
};_setObserver 方法,核心是执行 new IntersectionObserver() 。
IntersectionObserver 是浏览器原生提供的构造函数,接受两个参数:onIntersection 是可见性变化时的回调函数,option是配置对象(该参数可选)。
构造函数的返回值 this._observer 是一个观察器实例。实例的 observer 方法可以指定观察哪个 DOM 节点。
onIntersection 回调用于在图片可见时设置 src 加载图片。
下面可以看到,滚动容器默认为 ducument,否则需手动传一个 DOM 节点 进来。
_setObserver: function _setObserver() {
var _this = this;
if (!("IntersectionObserver" in window)) { // IntersectionObserver 方法不存在,直接返回
return;
}
var settings = this._settings;
var onIntersection = function onIntersection(entries) {
entries.forEach(function (entry) {
if (entry.intersectionRatio > 0) { // intersectionRatio:目标元素的可见比例,即intersectionRect占boundingClientRect的比例,完全可见时为1,完全不可见时小于等于0
var element = entry.target;
revealElement(element, settings); // 设置img的src
_this._observer.unobserve(element); // 停止观察
}
});
_this._elements = purgeElements(_this._elements);
};
this._observer = new IntersectionObserver(onIntersection, { // 获取观察器实例IntersectionObserver对象
root: settings.container === document ? null : settings.container, // 滚动容器默认为document
rootMargin: settings.threshold + "px"
});
},其中 revealElement 方法如下:
var revealElement = function revealElement(element, settings) {
if (["IMG", "IFRAME"].indexOf(element.tagName) > -1) {
addOneShotListeners(element, settings);
addClass(element, settings.class_loading);
}
setSources(element, settings); // 设置img的src
setData(element, "was-processed", true);
callCallback(settings.callback_set, element);
};
update 方法,获取需要懒加载的 img 元素,指定观察节点。
update: function update(elements) {
var _this2 = this;
var settings = this._settings;
var nodeSet = elements || settings.container.querySelectorAll(settings.elements_selector); // 获取所有需要懒加载的的img元素
this._elements = purgeElements(Array.prototype.slice.call(nodeSet)); // nodeset to array for IE compatibility
if (this._observer) {
this._elements.forEach(function (element) {
_this2._observer.observe(element); // 开始观察
});
return;
}
// Fallback: load all elements at once
this._elements.forEach(function (element) {
revealElement(element, settings);
});
this._elements = purgeElements(this._elements);
},检测可见这里使用的是 IntersectionObserver 。
传统的实现方法是,监听到scroll事件后,调用目标元素(绿色方块)的 getBoundingClientRect() 方法,得到它对应于视口左上角的坐标,再判断是否在视口之内。这种方法的缺点是,由于scroll事件密集发生,计算量很大,容易造成性能问题。
目前有一个新的 IntersectionObserver API ,可以自动"观察"元素是否可见,Chrome 51+ 已经支持。由于可见(visible)的本质是,目标元素与视口产生一个交叉区,所以这个 API 叫做"交叉观察器"。
详细可见文章下面的参考。
下面的代码很好懂,无非就是将 data-src 的值赋给 src 而已,这样,图片就开始加载了。
var setSourcesForPicture = function setSourcesForPicture(element, settings) {
var dataSrcSet = settings.data_srcset;
var parent = element.parentNode;
if (parent.tagName !== "PICTURE") {
return;
}
for (var i = 0, pictureChild; pictureChild = parent.children[i]; i += 1) {
if (pictureChild.tagName === "SOURCE") {
var sourceSrcset = getData(pictureChild, dataSrcSet);
if (sourceSrcset) {
pictureChild.setAttribute("srcset", sourceSrcset);
}
}
}
};改懒加载库一共只有两百多行代码,且没有任何依赖。使用 IntersectionObserver 配合 data-src 也极大的提升了性能。不过缺点如下:
IntersectionObserver 兼容性不好,不支持 IntersectionObserver 的浏览器,直接一次性显示图片。
作为一个不轻易造轮子的程序员,最后我还是选用了 verlok/lazyload ,不过添加 IntersectionObserver 的 polyfill。 顺便提一下,IntersectionObserver 的polyfill 也是基于 getBoundingClientRect 实现的。
然后将第一个库的 scrollParent 方法移植了过来,自动查找父节点的滚动容器,完美!
与桌面应用不同,网络应用不需要单独的安装过程:只需输入网址,便可启动和运行 - 这是网络的一个关键特色。不过,要做到这一步,我们通常需要获取几十个(有时甚至是几百个)不同的资源,所有这些资源加起来的数据量高达几兆字节,并且必须在短短几百毫秒内汇聚起来,以实现我们想要达到的即时网络体验。
在满足上述要求的前提下实现即时网络体验绝非易事,优化内容效率至关重要的原因就在于此:避免不必要的下载、通过各种压缩技术优化每个资源的传送编码以及尽可能利用缓存来避免多余的下载。
除了避免不必要的资源下载,在提高网页加载速度上您可以采取的最有效措施就是,通过优化和压缩其余资源来最大限度减小总下载大小。
压缩冗余或不必要数据的最佳方法是将其全部消除。我们不能只是删除任意数据,但在某些环境中,我们可能对数据格式及其属性有内容特定了解,往往可以在不影响其实际含义的情况下显著减小负载的大小。
通用压缩程序(例如设计用于压缩任意文本的压缩程序)在压缩以上网页时可能同样可以取得相当不错的效果,但永远别指望它能去除注释、折叠 CSS 规则或者进行大量的其他内容特定优化。正因如此,预处理/源码压缩/环境感知优化才会成为功能如此强大的工具。
注:举个有说服力的例子,JQuery 内容库未压缩开发版本的大小现已接近大约 300KB。而压缩(移除注解等内容)后同一内容库的大小仅为原来的大约 1/3:大约 100KB。
Gzip 是一种可以作用于任何字节流的通用压缩程序。它会在后台记忆一些之前看到的内容,并尝试以高效方式查找并替换重复的数据片段。(欲知详情,请参阅浅显易懂的 GZIP 低阶说明。)GZIP 对基于文本的内容的压缩效果最好,在压缩较大文件时往往可实现高达 70-90% 的压缩率,而如果对已经通过替代算法压缩过的资产(例如,大多数图片格式)运行 GZIP,则效果甚微,甚至毫无效果。
| 内容库 | 大小 | 压缩后大小 | 压缩比率 |
|---|---|---|---|
| jquery-1.11.0.js | 276 KB | 82 KB | 70% |
| jquery-1.11.0.min.js | 94 KB | 33 KB | 65% |
| angular-1.2.15.js | 729 KB | 182 KB | 75% |
| bootstrap-3.1.1.css | 118 KB | 18 KB | 85% |
上表显示了 GZIP 压缩对几种最流行的 JavaScript 内容库和 CSS 框架可实现的压缩率。压缩率范围为 60% 至 88%,将文件压缩源码后(产生文件名中包含“.min”的文件),再使用 GZIP 进行压缩,可进一步提高压缩率。
HTML5 Boilerplate 项目包含所有最流行服务器的 配置文件样例,其中为每个配置标志和设置都提供了详细的注解。要为您的服务器确定最佳配置,请执行以下操作: 在列表中找到您喜爱的服务器。 查找 GZIP 部分。 * 确认您的服务器配置了推荐的设置。
可通过以下这种快速而又简单的方法了解 GZIP 的实用效果:打开 Chrome DevTools,然后检查“Network”面板中的“Size / Content”列:“Size”表示资产的传送大小,“Content”表示资产的未压缩大小。对于上例中的 HTML 资产,GZIP 在传送时节省了 98.8KB。
最后,尽管大多数服务器会在向用户提供这些资产时自动对其进行压缩,但某些 CDN 需要特别注意和手动操作,以确保 GZIP 资产得到提供。务请审核您的网站并确保资产确实 得到压缩。
Tips:
图像优化既是一门艺术,也是一门科学:说它是一门艺术,是因为单个图像的压缩并不存在明确的最佳方案,说它是一门科学,则是因为有许多发展成熟的方法和算法都能够显著缩减图像的大小。找到图像的最佳设置需要在许多方面进行认真分析:格式能力、编码数据的内容、质量、像素尺寸等。
首先要问问自己,要实现所需的效果,是否确实需要图像。好的设计应该简单,而且始终可以提供最佳性能。如果您可以消除图像资源(与 HTML、CSS、JavaScript 以及网页上的其他资产相比,需要的字节数通常更大),这种优化策略就始终是最佳策略。不过,如果使用得当,图像传达的信息也可能胜过千言万语,因此需要由您来找到平衡点。
接下来您应该考虑是否存在某种替代技术,能够以更高效的方式实现所需的效果:
高 DPI (HiDPI) 屏幕可以产生绚丽的效果,但也有一个明显的折衷之处:图像资产需要更多的细节,才能对更高的设备像素数加以利用。好在矢量图像最适用于这项任务,因为它们在任何分辨率下都能渲染出清晰的效果。为了渲染出更丰富的细节,我们可能会招致更大的处理开销,但基础资产是相同的,并且与分辨率无关。
另一方面,因为光栅图像是以像素为单位编码图像数据,所以面临的挑战要大得多。因此,像素数越大,光栅图像的文件大小就越大。
如果我们将物理屏幕的分辨率加倍,总像素数将增加四倍:双倍的水平像素数乘以双倍的垂直像素数。因此,如果是“2x”的屏幕,所需的像素数不只是加倍,而是增加到原来的四倍!
那么,这有何实际意义呢?我们可以通过高分辨率屏幕提供绚丽的图像,这可以作为产品的一大特色。不过,高分辨率屏幕也需要高分辨率图像:尽可能优先使用矢量图像,因为它们与分辨率无关,并且能够始终提供清晰的效果,而如果需要使用光栅图像,请借助 srcset 和 picture 提供并优化每个图像的多个变体。
矢量图像最适用于包含几何形状的图像,矢量图像与缩放和分辨率无关。
所有现代浏览器都支持可缩放矢量图形 (SVG),这种基于 XML 的图片格式适用于二维图形:我们可以将 SVG 标记直接嵌入网页,也可将其作为外部资源嵌入网页。然后,可通过大多数基于矢量的绘图软件创建一个 SVG 文件,或直接在您喜欢的文本编辑器中手动创建。
<?xml version="1.0" encoding="utf-8"?>
<!-- Generator: Adobe Illustrator 17.1.0, SVG Export Plug-In . SVG Version: 6.00 Build 0) -->
<svg version="1.2" baseProfile="tiny" id="Layer_1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink"
x="0px" y="0px" viewBox="0 0 612 792" xml:space="preserve">
<g id="XMLID_1_">
<g>
<circle fill="red" stroke="black" stroke-width="2" stroke-miterlimit="10" cx="50" cy="50" r="40"/>
</g>
</g>
</svg>上例渲染的是一个具有黑色轮廓和红色背景的简单圆形,并且是从 Adobe Illustrator 导出。您可以看出,它包含大量元数据,例如图层信息、注解和 XML 命名空间,而在浏览器中渲染资产时通常不需要这些数据。因此,通过 svgo 之类的工具将您的 SVG 文件缩小绝对有益。
svgo 能够将上面这个由 Illustrator 生成的 SVG 文件的大小减少 58%,使其从 470 个字节缩小到 199 个字节。而且,由于 SVG 是一种基于 XML 的格式,因此我们还可以应用 GZIP 压缩来减小其传送大小 - 确保将您的服务器配置为对 SVG 资产进行压缩!
光栅图像就是一个 2 维“像素”栅格,例如,100x100 像素的图像是 10,000 个像素的序列,而每个像素又存储有“RGBA”值:(R) 红色通道、(G) 绿色通道、(B) 蓝色通道和 (A) alpha(透明度)通道。
在内部,浏览器为每个通道分配 256 个值(色阶),也就是每个通道 8 位 (2 ^ 8 = 256),每个像素 4 个字节(4 个通道 x 8 位 = 32 位 = 4 个字节)。因此,如果我们知道栅格尺寸,就能轻易计算出文件大小:
| 尺寸 | 像素 | 文件大小 |
|---|---|---|
| 100 x 100 | 10,000 | 39 KB |
| 200 x 200 | 40,000 | 156 KB |
| 300 x 300 | 90,000 | 351 KB |
| 500 x 500 | 250,000 | 977 KB |
| 800 x 800 | 640,000 | 2500 KB |
100x100 像素图像的文件大小只有 39KB,可能似乎不是什么大问题,但对于更大的图像,文件大小会迅速暴增,并使图像资产的下载既速度缓慢又开销巨大。幸运的是,目前为止我们所描述是“未压缩”图片格式。我们可以采取什么措施来减小图片文件的大小呢?
一个简单的策略是将图像的“位深”从每个通道 8 位减少为更小的调色板:每个通道 8 位为每个通道提供 256 个值,共计提供 16777216 (2563) 种颜色。如果我们将调色板减少为 256 色,会出现什么情况?那样的话,RGB 通道一共只需要 8 位,每个像素立即可以节约两个字节,与原来每个像素 4 个字节的格式相比,通过压缩节约了 50% 的字节!
注:从左至右 (PNG):32 位(16M 色)、7 位(128 色)、5 位(32 色)。包含渐变色过渡的复杂场景(渐变、天空等)需要较大的调色板,以避免在 5 位资产中产生马赛克天空之类的视觉伪影。另一方面,如果图像只使用几种颜色,较大的调色板只会浪费宝贵的位数!
接下来,在优化了各个像素中存储的数据之后,我们可以多动动脑筋,看看能不能对相邻像素也做做优化:其实,许多图像(尤其是照片)的大量相邻像素都具有相似的颜色 - 例如,天空、重复的纹理等。压缩程序可以利用这些信息采用“增量编码”,在这种编码方式下,并不为每个像素单独存储值,而是存储相邻像素之间的差异:如果相邻像素相同,则增量为“零”,我们只需存储一位!但是这显然还不够...
人眼对不同颜色的敏感度是不同的:为此,我们可以通过减小或增大这些颜色的调色板来优化颜色编码。“相邻”像素构成二维栅格,这意味着每个像素都有多个相邻像素:我们可以利用这一点进一步改进增量编码。我们不再只是关注每个像素直接相邻的像素,而是着眼于更大块的相邻像素,并使用不同设置对不同的像素块进行编码。当然还不止这些...
您可以看出,图像优化很快就会复杂(或者有趣起来,全凭您怎么看了),这也是学术和商业研究都很活跃的一个领域。由于图像占据了大量字节,因此开发更好的图像压缩方法具有极大价值!如果您很想了解更多信息,请访问 Wikipedia 网页,或查看 WebP 压缩方法白皮书中 提供的实例。
人眼对不同颜色的敏感度不同,这意味着我们可以使用较少的位数来编码某些颜色。因此,典型的图像优化过程由两个高级步骤组成:
第一步是可选步骤,具体算法将取决于特定的图片格式,但一定要了解,任何图像都可通过有损压缩步骤来减小其大小。 实际上,不同图片格式(例如 GIF、PNG、JPEG 以及其他格式)之间的差异在于它们在执行有损和无损压缩步骤时所使用(或省略)特定算法的组合。
除了不同的有损和无损压缩算法外,不同的图片格式还支持不同的功能,例如动画和透明度 (alpha) 通道。因此,需要将所需视觉效果与功能要求相结合来为特定图像选择“正确的格式”。
| 格式 | 透明度 | 动画 | 浏览器 |
|---|---|---|---|
| GIF | 支持 | 支持 | 所有 |
| PNG | 支持 | 不支持 | 所有 |
| JPEG | 不支持 | 不支持 | 所有 |
| JPEG | XR | 支持 | 支持 |
| WebP | 支持 | 支持 | Chrome、Opera、Android |
获得普遍支持的图片格式有三种:GIF、PNG 和 JPEG。除了这些格式外,一些浏览器还支持较新的格式(例如 WebP 和 JPEG XR),它们的总体压缩率更高,提供的功能也更多。那么,您应该使用哪一种格式呢?
最后,为每一项资产确定了最佳图片格式及其设置之后,请考虑增加一个以 WebP 和 JPEG XR 格式编码的变体。这两种格式均为新格式,并且遗憾的是,它们没有(尚未)得到所有浏览器的普遍支持,但尽管如此,它们仍可为较新的客户端显著降低文件大小,例如,平均来说,与可比的 JPEG 图像相比,WebP 可将文件大小减小 30%。
由于 WebP 和 JPEG XR 均未得到普遍支持,您需要向应用或服务器添加额外的逻辑来提供相应的资源:
最后请注意,如果您使用 Webview 在本机应用中渲染内容,就可以完全控制客户端,并可独占使用 WebP!Facebook、Google+ 以及许多其他应用都使用 WebP 来提供其应用内的所有图像 - 实现的文件大小缩减定然物有所值。如需了解有关 WebP 的更多信息,请观看 Google I/O 2013 上的演讲 WebP:部署更快速、更小并且更绚丽的图像。
图像优化可归结为两个标准:优化编码每个图像像素所使用的字节数,和优化总像素数:图像的文件大小就是总像素数与编码每个像素所使用字节数的乘积。不多不少。
图像优化既是一门艺术,也是一门科学:说它是一门艺术,是因为单个图像的压缩并不存在明确的最佳方案,说它是一门科学,则是因为有一些发展成熟的方法和算法有助于显著缩减图像的大小。
在您努力优化图像时,要记住以下这些技巧和方法:
Unicode 字体可能包含数千种字形。字体格式有四种:WOFF2、WOFF、EOT 和 TTF。
目前网络上使用的字体容器格式有四种:EOT、TTF、WOFF 和 WOFF2。遗憾的是,尽管选择范围很广,但仍然缺少在所有新旧浏览器上都能使用的单一通用格式:EOT 只有 IE 支持,TTF 获得了部分 IE 支持,WOFF 获得了最广泛的支持,但在某些较旧的浏览器上不受支持,而 WOFF 2.0 支持对许多浏览器来说尚未实现。
我们需要提供多种格式才能实现一致的体验:
注:考虑使用 Zopfli 压缩处理 EOT、TTF 和 WOFF 格式。Zopfli 是一种兼容 zlib 的压缩工具,提供的文件大小压缩率比 gzip 高大约 5%。
字体延迟加载带有一个可能会延迟文本渲染的重要隐藏影响:浏览器必须构建渲染树(它依赖 DOM 和 CSSOM 树),然后才能知道需要使用哪些字体资源来渲染文本。因此,字体请求的处理将远远滞后于其他关键资源请求的处理,并且在获取资源之前,可能会阻止浏览器渲染文本。
网页内容的首次绘制(可在渲染树构建后不久完成)与字体资源请求之间的“竞赛”产生了“空白文本问题”,出现该问题时,浏览器会在渲染网页布局时遗漏所有文本。
不同浏览器之间实际行为有所差异:
Font Loading API 提供了一种脚本编程接口来定义和操纵 CSS 字体,追踪其下载进度,以及替换其默认延迟下载行为。例如,如果您确定将需要特定字体变体,您可以定义它并指示浏览器启动对字体资源的立即获取:
var font = new FontFace("Awesome Font", "url(/fonts/awesome.woff2)", {
style: 'normal', unicodeRange:'U+000-5FF', weight:'400'
});
font.load(); // don't wait for the render tree, initiate an immediate fetch!
font.ready().then(function() {
// apply the font (which may re-render text and cause a page reflow)
// after the font has finished downloading
document.fonts.add(font);
document.body.style.fontFamily = "Awesome Font, serif";
// OR... by default the content is hidden,
// and it's rendered after the font is available
var content = document.getElementById("content");
content.style.visibility = "visible";
// OR... apply your own render strategy here...
});并且,由于您可以检查字体状态(通过 check() 方法)并追踪其下载进度,因此您还可以为在网页上渲染文本定义一种自定义策略:
最重要的是,您还可以混用和匹配上述策略来适应网页上的不同内容。例如,在获得字体前延迟某些部分的文本渲染;使用后备字体,然后在字体下载完成后进行重新渲染;指定不同的超时,等等。
注:在某些浏览器上,Font Loading API 仍处于开发阶段。可以考虑使用 FontLoader polyfill 或 webfontloader 内容库来提供类似功能,尽管附加的 JavaScript 依赖关系会产生开销。
使用 Font Loading API 消除“空白文本问题”的简单替代策略是将字体内容内联到 CSS 样式表内:
内联策略不那么灵活,不允许您为不同的内容定义自定义超时或渲染策略,但不失为是一种适用于所有浏览器并且简单而又可靠的解决方案。为获得最佳效果,请将内联字体分成独立的样式表,并为它们提供较长的 max-age。这样一来,在您更新 CSS 时,就不会强制访问者重新下载字体。
注:有选择地使用内联。回想一下,@font-face 使用延迟加载行为来避免下载多余的字体变体和子集的原因。此外,通过主动式内联增加 CSS 的大小将对您的关键渲染路径产生不良影响。浏览器必须下载所有 CSS,然后才能构造 CSSOM,构建渲染树,以及将页面内容渲染到屏幕上。
字体资源通常是不会频繁更新的静态资源。因此,它们非常适合较长的 max-age 到期 - 确保您为所有字体资源同时指定了条件 ETag 标头和最佳 Cache-Control 策略。
您无需在 localStorage 中或通过其他机制存储字体,其中的每一种机制都有各自的性能缺陷。 浏览器的 HTTP 缓存与 Font Loading API 或 webfontloader 内容库相结合,实现了最佳并且最可靠的机制来向浏览器提供字体资源。
与普遍的观点相反,使用网页字体不需要延迟网页渲染,也不会对其他性能指标产生不良影响。在充分优化的情况下使用字体可大幅提升总体用户体验:出色的品牌推广,改进的可读性、易用性和可搜索性,并一直提供可扩展的多分辨率解决方案,能够出色地适应各种屏幕格式和分辨率。不要害怕使用网页字体!
不过,直接实现可能招致下载内容庞大和不必要的延迟。您需要通过对字体资产本身及其在网页上的获取和使用方式进行优化来为浏览器提供协助的环节。
//HTML标签转义(< -> <)
function html2Escape(sHtml) {
return sHtml.replace(/[<>&"]/g,function(c){
return {'<':'<','>':'>','&':'&','"':'"'}[c];
});
}这个实现原理是:innerText(textContent) 会获取纯文本内容,忽略 html 节点标签,而 innerHTML 会显示标签内容。
我们先将需转义的内容赋值给 innerText(textContent),再获取它的 innerHTML 属性,这时获取到的就是转义后文本内容。
//HTML标签转义(< -> <)
function html2Escape(sHtml) {
var temp = document.createElement("div");
(temp.textContent != null) ? (temp.textContent = sHtml) : (temp.innerText = sHtml);
var output = temp.innerHTML;
temp = null;
return output;
}反转义的方法为先将转义文本赋值给 innerHTML,然后通过 innerText(textContent) 获取转义前的文本内容。
//HTML标签反转义(< -> <)
function escape2Html(str) {
var temp = document.createElement("div");
temp.innerHTML = str;
var output = temp.innerText || temp.textContent;
temp = null;
return output;
}渲染一个网页,浏览器需要完成的步骤:
我们的演示网页看起来可能很简单,实际上却需要完成相当多的工作。如果 DOM 或 CSSOM 被修改,您只能再执行一遍以上所有步骤,以确定哪些像素需要在屏幕上进行重新渲染。
浏览器渲染页面前需要先构建 DOM 和 CSSOM 树。因此,我们需要确保尽快将 HTML 和 CSS 都提供给浏览器。
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>让我们从可能的最简单情况入手:一个包含一些文本和一幅图片的普通 HTML 页面。浏览器如何处理此页面?
整个流程的最终输出是我们这个简单页面的文档对象模型 (DOM),浏览器对页面进行的所有进一步处理都会用到它。
浏览器每次处理 HTML 标记时,都会完成以上所有步骤:将字节转换成字符,确定令牌,将令牌转换成节点,然后构建 DOM 树。这整个流程可能需要一些时间才能完成,有大量 HTML 需要处理时更是如此。
需要快速温习相关内容,请查看 Chrome DevTools 文档;如果您未接触过 DevTools,建议学习 Codeschool Discover DevTools 课程。
如果您打开 Chrome DevTools 并在页面加载时记录时间线,就可以看到执行该步骤实际花费的时间。在上例中,将一堆 HTML 字节转换成 DOM 树大约需要 5 毫秒。对于较大的页面,这一过程需要的时间可能会显著增加。创建流畅动画时,如果浏览器需要处理大量 HTML,这很容易成为瓶颈。
DOM 树捕获文档标记的属性和关系,但并未告诉我们元素在渲染后呈现的外观。那是 CSSOM 的责任。
在浏览器构建我们这个简单页面的 DOM 时,在文档的 head 部分遇到了一个 link 标记,该标记引用一个外部 CSS 样式表:style.css。由于预见到需要利用该资源来渲染页面,它会立即发出对该资源的请求,并返回以下内容:
body { font-size: 16px }
p { font-weight: bold }
span { color: red }
p span { display: none }
img { float: right }与处理 HTML 时一样,我们需要将收到的 CSS 规则转换成某种浏览器能够理解和处理的东西。因此,我们会重复 HTML 过程,不过是为 CSS 而不是 HTML:
CSS 字节转换成字符,接着转换成令牌和节点,最后链接到一个称为“CSS 对象模型”(CSSOM) 的树结构内:
CSSOM 为何具有树结构?为页面上的任何对象计算最后一组样式时,浏览器都会先从适用于该节点的最通用规则开始(例如,如果该节点是 body 元素的子项,则应用所有 body 样式),然后通过应用更具体的规则(即规则“向下级联”)以递归方式优化计算的样式。
以上面的 CSSOM 树为例进行更具体的阐述。span 标记内包含的任何置于 body 元素内的文本都将具有 16 像素字号,并且颜色为红色 — font-size 指令从 body 向下级联至 span。不过,如果某个 span 标记是某个段落 (p) 标记的子项,则其内容将不会显示。
还请注意,以上树并非完整的 CSSOM 树,它只显示了我们决定在样式表中替换的样式。每个浏览器都提供一组默认样式(也称为“User Agent 样式”),即我们不提供任何自定义样式时所看到的样式,我们的样式只是替换这些默认样式(例如默认 IE 样式)。
要了解 CSS 处理所需的时间,您可以在 DevTools 中记录时间线并寻找“Recalculate Style”事件:与 DOM 解析不同,该时间线不显示单独的“Parse CSS”条目,而是在这一个事件下一同捕获解析和 CSSOM 树构建,以及计算的样式的递归计算。
我们的小样式表需要大约 0.6 毫秒的处理时间,影响页面上的 8 个元素 — 虽然不多,但同样会产生开销。不过,这 8 个元素从何而来呢?CSSOM 和 DOM 是独立的数据结构!都是独立的对象,分别网罗文档不同方面的信息:一个描述内容,另一个则是描述需要对文档应用的样式规则。结果证明,浏览器隐藏了一个重要步骤。接下来,让我们谈一谈将 DOM 与 CSSOM 关联在一起的渲染树。
CSSOM 树和 DOM 树合并成渲染树,然后用于计算每个可见元素的布局,并输出给绘制流程,将像素渲染到屏幕上。优化上述每一个步骤对实现最佳渲染性能至关重要。
第一步是让浏览器将 DOM 和 CSSOM 合并成一个“渲染树”,网罗网页上所有可见的 DOM 内容,以及每个节点的所有 CSSOM 样式信息。
为构建渲染树,浏览器大体上完成了下列工作:
终输出的渲染同时包含了屏幕上的所有可见内容及其样式信息。有了渲染树,我们就可以进入“布局”阶段。
到目前为止,我们计算了哪些节点应该是可见的以及它们的计算样式,但我们尚未计算它们在设备视口内的确切位置和大小---这就是“布局”阶段,也称为“自动重排”。
为弄清每个对象在网页上的确切大小和位置,浏览器从渲染树的根节点开始进行遍历。让我们考虑下面这样一个简单的实例:
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Critial Path: Hello world!</title>
</head>
<body>
<div style="width: 50%">
<div style="width: 50%">Hello world!</div>
</div>
</body>
</html>布局流程的输出是一个“盒模型”,它会精确地捕获每个元素在视口内的确切位置和尺寸:所有相对测量值都转换为屏幕上的绝对像素。
以上网页的正文包含两个嵌套 div:第一个(父)div 将节点的显示尺寸设置为视口宽度的 50%,---父 div 包含的第二个 div---将其宽度设置为其父项的 50%;即视口宽度的 25%。
最后,既然我们知道了哪些节点可见、它们的计算样式以及几何信息,我们终于可以将这些信息传递给最后一个阶段:将渲染树中的每个节点转换成屏幕上的实际像素。这一步通常称为“绘制”或“栅格化”。
上述步骤都需要浏览器完成大量工作,所以相当耗时。不过,Chrome DevTools 可以帮助我们对上述所有三个阶段进行深入的了解。让我们看一下最初“hello world”示例的布局阶段:
执行渲染树构建、布局和绘制所需的时间将取决于文档大小、应用的样式,以及运行文档的设备:文档越大,浏览器需要完成的工作就越多;样式越复杂,绘制需要的时间就越长(例如,单色的绘制开销“较小”,而阴影的计算和渲染开销则要“大得多”)。
最后将在视口中看到下面的网页:
本质都是为了解决异步action的问题
Redux Saga可以理解为一个和系统交互的常驻进程,其中,Saga可简单定义如下:
Saga = Worker + Watcher
saga特点:
LLT(long live transcation)等业务场景。takeLatest/takeEvery/throttle方法,可以便利的实现对事件的仅关注最近事件、关注每一次、事件限频cancel/delay方法,可以便利的取消、延迟异步请求race(effects),[…effects]方法来支持竞态和并行场景Redux Saga适用于对事件操作有细粒度需求的场景,同时他们也提供了更好的可测试性。
这里有一个简单的需求,登录页面,使用redux-thunk与async / await。组件可能看起来像这样,像平常一样分派操作。
组件部分二者应该是大同小异:
import { login } from 'redux/auth';
class LoginForm extends Component {
onClick(e) {
e.preventDefault();
const { user, pass } = this.refs;
this.props.dispatch(login(user.value, pass.value));
}
render() {
return (<div>
<input type="text" ref="user" />
<input type="password" ref="pass" />
<button onClick={::this.onClick}>Sign In</button>
</div>);
}
}
export default connect((state) => ({}))(LoginForm);登录的action文件
// auth.js
import request from 'axios';
import { loadUserData } from './user';
// define constants
// define initial state
// export default reducer
export const login = (user, pass) => async (dispatch) => {
try {
dispatch({ type: LOGIN_REQUEST });
let { data } = await request.post('/login', { user, pass });
await dispatch(loadUserData(data.uid));
dispatch({ type: LOGIN_SUCCESS, data });
} catch(error) {
dispatch({ type: LOGIN_ERROR, error });
}
}
// more actions...更新用户数据的页面:
// user.js
import request from 'axios';
// define constants
// define initial state
// export default reducer
export const loadUserData = (uid) => async (dispatch) => {
try {
dispatch({ type: USERDATA_REQUEST });
let { data } = await request.get(`/users/${uid}`);
dispatch({ type: USERDATA_SUCCESS, data });
} catch(error) {
dispatch({ type: USERDATA_ERROR, error });
}
}
// more actions...export function* loginSaga() {
while(true) {
const { user, pass } = yield take(LOGIN_REQUEST) //等待 Store 上指定的 action LOGIN_REQUEST
try {
let { data } = yield call(request.post, '/login', { user, pass }); //阻塞,请求后台数据
yield fork(loadUserData, data.uid); //非阻塞执行loadUserData
yield put({ type: LOGIN_SUCCESS, data }); //发起一个action,类似于dispatch
} catch(error) {
yield put({ type: LOGIN_ERROR, error });
}
}
}
export function* loadUserData(uid) {
try {
yield put({ type: USERDATA_REQUEST });
let { data } = yield call(request.get, `/users/${uid}`);
yield put({ type: USERDATA_SUCCESS, data });
} catch(error) {
yield put({ type: USERDATA_ERROR, error });
}
}我们使用形式yield call(func,… args)调用api函数。调用不会执行效果,它只是创建一个简单的对象,如{type:’CALL’,func,args}。执行被委托给redux-saga中间件,该中间件负责执行函数并且用其结果恢复generatorr。
相比Redux Thunk,使用Redux Saga有几处明显的变化:
dispatch(action creator),而是dispatch(pure action)ES6 Generator语法,简化异步代码语法除开上述这些不同点,Redux Saga真正的威力,在于其提供了一系列帮助方法,使得对于各类事件可以进行更细粒度的控制,从而完成更加复杂的操作。
const iterator = loginSaga()
assert.deepEqual(iterator.next().value, take(LOGIN_REQUEST))
// resume the generator with some dummy action
const mockAction = {user: '...', pass: '...'}
assert.deepEqual(
iterator.next(mockAction).value,
call(request.post, '/login', mockAction)
)
// simulate an error result
const mockError = 'invalid user/password'
assert.deepEqual(
iterator.throw(mockError).value,
put({ type: LOGIN_ERROR, error: mockError })
)注意,我们通过简单地将模拟数据注入迭代器的下一个方法来检查api调用结果。模拟数据比模拟函数更简单。
通过yield take(ACTION)可以方便自由的对action进行拦截和过滤。Thunks由每个新动作的动作创建者调用(例如LOGIN_REQUEST)。即动作被不断地推送到thunk,并且thunk不能控制何时停止处理那些动作。
假设例如我们要添加以下要求:
你将如何实现这一点与thunk?同时还为整个流程提供全面的测试覆盖?
可是如果你使用redux-saga:
function* authorize(credentials) {
const token = yield call(api.authorize, credentials)
yield put( login.success(token) )
return token
}
function* authAndRefreshTokenOnExpiry(name, password) {
let token = yield call(authorize, {name, password})
while(true) {
yield call(delay, token.expires_in)
token = yield call(authorize, {token})
}
}
function* watchAuth() {
while(true) {
try {
const {name, password} = yield take(LOGIN_REQUEST)
yield race([
take(LOGOUT),
call(authAndRefreshTokenOnExpiry, name, password)
])
// user logged out, next while iteration will wait for the
// next LOGIN_REQUEST action
} catch(error) {
yield put( login.error(error) )
}
}
}在上面的例子中,我们使用race表示了并发要求。
authAndRefreshTokenOnExpiry后台任务。authAndRefreshTokenOnExpiry在调用(授权,{token})调用的中间被阻止,它也将被取消。取消自动向下传播。有时候我们需要在几个ajax请求执行完之后,再执行对应的操作。redux-thunk需要借助第三方的库,而redux-saga是直接实现的。
import { call } from 'redux-saga/effects'
// 正确写法, effects 将会同步执行
const [users, repos] = yield [
call(fetch, '/users'),
call(fetch, '/repos')
]当我们需要 yield 一个包含 effects 的数组, generator 会被阻塞直到所有的 effects 都执行完毕,或者当一个 effect 被拒绝 (就像 Promise.all 的行为)。
在redux-saga中,我们可以使用了辅助函数 takeEvery 在每个 action 来到时派生一个新的任务。 这多少有些模仿 redux-thunk 的行为:举个例子,每次一个组件调用 fetchProducts Action 创建器(Action Creator),Action 创建器就会发起一个 thunk 来执行控制流。
在现实情况中,takeEvery 只是一个在强大的低阶 API 之上构建的辅助函数。 在这一节中我们将看到一个新的 Effect,即 take。take 让我们通过全面控制 action 观察进程来构建复杂的控制流成为可能。
让我们开始一个简单的 Saga 例子,这个 Saga 将监听所有发起到 store 的 action,然后将它们记录到控制台。
使用 takeEvery('')( 代表通配符模式),我们就能捕获发起的所有类型的 action。
import { takeEvery } from 'redux-saga'
function* watchAndLog(getState) {
yield* takeEvery('*', function* logger(action) {
console.log('action', action)
console.log('state after', getState())
})
}现在我们知道如何使用 take Effect 来实现和上面相同的功能:
import { take } from 'redux-saga/effects'
function* watchAndLog(getState) {
while(true) {
const action = yield take('*')
console.log('action', action)
console.log('state after', getState())
})
}take 就像我们更早之前看到的 call 和 put。它创建另一个命令对象,告诉 middleware 等待一个特定的 action。 正如在 call Effect 的情况中,middleware 会暂停 Generator,直到返回的 Promise 被 resolve。 在 take 的情况中,它将会暂停 Generator 直到一个匹配的 action 被发起了。 在以上的例子中,watchAndLog 处于暂停状态,直到任意的一个 action 被发起。
注意,我们运行了一个无限循环的 while(true)。记住这是一个 Generator 函数,它不具备 从运行至完成 的行为(run-to-completion behavior)。 Generator 将在每次迭代上阻塞以等待 action 发起。
一个简单的例子,假设在我们的 Todo 应用中,我们希望监听用户的操作,并在用户初次创建完三条 Todo 信息时显示祝贺信息。
import { take, put } from 'redux-saga/effects'
function* watchFirstThreeTodosCreation() {
for(let i = 0; i < 3; i++) {
const action = yield take('TODO_CREATED')
}
yield put({type: 'SHOW_CONGRATULATION'})
}与 while(true) 不同,我们运行一个只迭代三次的 for 循环。在 take 初次的 3 个 TODO_CREATED action 之后, watchFirstThreeTodosCreation Saga 将会使应用显示一条祝贺信息然后中止。这意味着 Generator 会被回收并且相应的监听不会再发生。
一旦任务被 fork,可以使用 yield cancel(task) 来中止任务执行。取消正在运行的任务,将抛出 SagaCancellationException 错误。
为了对 action 队列进行防抖动,可以在被 fork 的任务里放置一个 delay。
const delay = (ms) => new Promise(resolve => setTimeout(resolve, ms))
function* handleInput(input) {
// 500ms 防抖动
yield call(delay, 500)
...
}
function* watchInput() {
let task
while(true) {
const { input } = yield take('INPUT_CHANGED')
if(task)
yield cancel(task)
task = yield fork(handleInput, input)
}
}在上面的示例中,handleInput 在执行之前等待了 500ms。如果用户在此期间输入了更多文字,我们将收到更多的 INPUT_CHANGED action。 并且由于 handleInput 仍然会被 delay 阻塞,所以在执行自己的逻辑之前它会被 watchInput 取消。
一个 effect 就是一个纯文本 JavaScript 对象,包含一些将被 saga middleware 执行的指令。
使用 redux-saga 提供的工厂函数来创建 effect。 举个例子,你可以使用 call(myfunc, 'arg1', 'arg2') 指示 middleware 调用 myfunc('arg1', 'arg2') 并将结果返回给 yield 了 effect 的那个 Generator。
从 Saga 内触发异步操作(Side Effect)总是由 yield 一些声明式的 Effect 来完成的 (你也可以直接 yield Promise,但是这会让测试变得困难。使用 Effect 诸如 call 和 put,与高阶 API 如 takeEvery 相结合,让我们实现与 redux-thunk 同样的东西, 但又有额外的易于测试的好处。
一个 task 就像是一个在后台运行的进程。在基于 redux-saga 的应用程序中,可以同时运行多个 task。通过 fork 函数来创建 task:
function* saga() {
...
const task = yield fork(otherSaga, ...args)
...
}指的是一种使用两个单独的 Saga 来组织控制流的方式。
Watcher: 监听发起的 action 并在每次接收到 action 时 fork 一个 worker。
Worker: 处理 action 并结束它。
示例:
function* watcher() {
while(true) {
const action = yield take(ACTION)
yield fork(worker, action.payload)
}
}
function* worker(payload) {
// ... do some stuff
}创建一条 Effect 描述信息,指示 middleware 等待 Store 上指定的 action。 Generator 会暂停,直到一个与 pattern 匹配的 action 被发起。
用以下规则来解释 pattern:
take(action => action.entities) 会匹配那些 entities 字段为真的 action)。action.type === pattern 时被匹配(例如,take(INCREMENT_ASYNC))。take([INCREMENT, DECREMENT]) 会匹配 INCREMENT 或 DECREMENT 类型的 action)。用于触发 action,功能上类似于dispatch。
创建一条dispatch Effect 描述信息,指示 middleware 发起一个 action 到 Store。
直接使用dispatch:
//...
function* fetchProducts(dispatch)
const products = yield call(Api.fetch, '/products')
dispatch({ type: 'PRODUCTS_RECEIVED', products })
}该解决方案与我们在上一节中看到的从 Generator 内部直接调用函数,有着相同的缺点。如果我们想要测试 fetchProducts 接收到 AJAX 响应之后执行 dispatch, 我们还需要模拟 dispatch 函数。
相反,我们需要同样的声明式的解决方案。只需创建一个对象来指示 middleware 我们需要发起一些 action,然后让 middleware 执行真实的 dispatch。 这种方式我们就可以同样的方式测试 Generator 的 dispatch:只需检查 yield 后的 Effect,并确保它包含正确的指令。
redux-saga 为此提供了另外一个函数 put,这个函数用于创建 dispatch Effect。
import { call, put } from 'redux-saga/effects'
//...
function* fetchProducts() {
const products = yield call(Api.fetch, '/products')
// 创建并 yield 一个 dispatch Effect
yield put({ type: 'PRODUCTS_RECEIVED', products })
}现在,我们可以像上一节那样轻易地测试 Generator:
import { call, put } from 'redux-saga/effects'
import Api from '...'
const iterator = fetchProducts()
// 期望一个 call 指令
assert.deepEqual(
iterator.next().value,
call(Api.fetch, '/products'),
"fetchProducts should yield an Effect call(Api.fetch, './products')"
)
// 创建一个假的响应对象
const products = {}
// 期望一个 dispatch 指令
assert.deepEqual(
iterator.next(products).value,
put({ type: 'PRODUCTS_RECEIVED', products }),
"fetchProducts should yield an Effect put({ type: 'PRODUCTS_RECEIVED', products })"
)用于调用异步逻辑,支持 promise 。
创建一条 Effect 描述信息,指示 middleware 调用 fn 函数并以 args 为参数。fn 既可以是一个普通函数,也可以是一个 Generator 函数。
middleware 调用这个函数并检查它的结果。
如果结果是一个 Generator 对象,middleware 会执行它,就像在启动 Generator (startup Generators,启动时被传给 middleware)时做的。 如果有子级 Generator,那么在子级 Generator 正常结束前,父级 Generator 会暂停,这种情况下,父级 Generator 将会在子级 Generator 返回后继续执行,或者直到子级 Generator 被某些错误中止, 如果是这种情况,将在父级 Generator 中抛出一个错误。
如果结果是一个 Promise,middleware 会暂停直到这个 Promise 被 resolve,resolve 后 Generator 会继续执行。 或者直到 Promise 被 reject 了,如果是这种情况,将在 Generator 中抛出一个错误。
当 Generator 中抛出了一个错误,如果有一个 try/catch 包裹当前的 yield 指令,控制权将被转交给 catch。 否则,Generator 会被错误中止,并且如果这个 Generator 被其他 Generator 调用了,错误将会传到调用的 Generator。
yield fork(fn ...args) 的结果是一个 Task 对象 —— 一个具备某些有用的方法和属性的对象
创建一条 Effect 描述信息,指示 middleware 以 无阻塞调用 方式执行 fn。
fork 类似于 call,可以用来调用普通函数和 Generator 函数。但 fork 的调用是无阻塞的,在等待 fn 返回结果时,middleware 不会暂停 Generator。 相反,一旦 fn 被调用,Generator 立即恢复执行。
fork 与 race 类似,是一个中心化的 Effect,管理 Sagas 间的并发。
创建一条 Effect 描述信息,指示 middleware 在多个 Effect 之间执行一个 race(类似 Promise.race([...]) 的行为)。
redux-saga的其他详细API列举如下,API详解可以查看API 参考

RFC2616规定的47种http报文首部字段中与缓存相关的字段。
在 http1.0 时代,给客户端设定缓存方式可通过两个字段——Pragma和Expires来规范。虽然这两个字段早可抛弃,但为了做http协议的向下兼容,你还是可以看到很多网站依旧会带上这两个字段。
当该字段值为no-cache的时候(事实上现在RFC中也仅标明该可选值),会知会客户端不要对该资源读缓存,即每次都得向服务器发一次请求才行。
有了Pragma来禁用缓存,自然也需要有个东西来启用缓存和定义缓存时间,对http1.0而言,Expires就是做这件事的首部字段。 Expires的值对应一个GMT(格林尼治时间),比如Mon, 22 Jul 2002 11:12:01 GMT来告诉浏览器资源缓存过期时间,如果还没过该时间点则不发请求。
如果Pragma头部和Expires头部同时存在,则起作用的会是Pragma,有兴趣的同学可以自己试一下。
需要注意的是,响应报文中Expires所定义的缓存时间是相对服务器上的时间而言的,其定义的是资源“失效时刻”,如果客户端上的时间跟服务器上的时间不一致(特别是用户修改了自己电脑的系统时间),那缓存时间可能就意义了。
针对上述的“Expires时间是相对服务器而言,无法保证和客户端时间统一”的问题,http1.1新增了 Cache-Control 来定义缓存过期时间。注意:若报文中同时出现了 Expires 和 Cache-Control,则以 Cache-Control 为准。
也就是说优先级从高到低分别是 Pragma -> Cache-Control -> Expires 。
Cache-Control也是一个通用首部字段,这意味着它能分别在请求报文和响应报文中使用。在RFC中规范了 Cache-Control 的格式为:
"Cache-Control" ":" cache-directive
作为请求首部时,cache-directive 的可选值有:
作为响应首部时,cache-directive 的可选值有:
Cache-Control 允许自由组合可选值,例如:
Cache-Control: max-age=3600, must-revalidate
它意味着该资源是从原服务器上取得的,且其缓存(新鲜度)的有效时间为一小时,在后续一小时内,用户重新访问该资源则无须发送请求。 当然这种组合的方式也会有些限制,比如 no-cache 就不能和 max-age、min-fresh、max-stale 一起搭配使用。
上述的首部字段均能让客户端决定是否向服务器发送请求,比如设置的缓存时间未过期,那么自然直接从本地缓存取数据即可(在chrome下表现为200 from cache),若缓存时间过期了或资源不该直接走缓存,则会发请求到服务器去。
我们现在要说的问题是,如果客户端向服务器发了请求,那么是否意味着一定要读取回该资源的整个实体内容呢?
我们试着这么想——客户端上某个资源保存的缓存时间过期了,但这时候其实服务器并没有更新过这个资源,如果这个资源数据量很大,客户端要求服务器再把这个东西重新发一遍过来,是否非常浪费带宽和时间呢?
答案是肯定的,那么是否有办法让服务器知道客户端现在存有的缓存文件,其实跟自己所有的文件是一致的,然后直接告诉客户端说“这东西你直接用缓存里的就可以了,我这边没更新过呢,就不再传一次过去了”。
为了让客户端与服务器之间能实现缓存文件是否更新的验证、提升缓存的复用率,Http1.1新增了几个首部字段来做这件事情。
服务器将资源传递给客户端时,会将资源最后更改的时间以“Last-Modified: GMT”的形式加在实体首部上一起返回给客户端。
Last-Modified: Fri, 22 Jul 2016 01:47:00 GMT
客户端会为资源标记上该信息,下次再次请求时,会把该信息附带在请求报文中一并带给服务器去做检查。
这样保证不向客户端重复发出资源,也保证当服务器有变化时,客户端能够得到最新的资源。一个304响应比一个静态资源通常小得多,这样就节省了网络带宽。
示例为 If-Modified-Since: Thu, 31 Mar 2016 07:07:52 GMT
该请求首部告诉服务器如果客户端传来的最后修改时间与服务器上的一致,则直接回送304 和响应报头即可。
当前各浏览器均是使用的该请求首部来向服务器传递保存的 Last-Modified 值。
该值告诉服务器,若Last-Modified没有匹配上(资源在服务端的最后更新时间改变了),则应当返回412(Precondition Failed) 状态码给客户端。 Last-Modified 存在一定问题,如果在服务器上,一个资源被修改了,但其实际内容根本没发生改变,会因为Last-Modified时间匹配不上而返回了整个实体给客户端(即使客户端缓存里有个一模一样的资源)。
为了解决上述Last-Modified可能存在的不准确的问题,Http1.1还推出了 ETag 实体首部字段。 服务器会通过某种算法,给资源计算得出一个唯一标志符(比如md5标志),在把资源响应给客户端的时候,会在实体首部加上“ETag: 唯一标识符”一起返回给客户端。例如:
Etag: "5d8c72a5edda8d6a:3239"
客户端会保留该 ETag 字段,并在下一次请求时将其一并带过去给服务器。服务器只需要比较客户端传来的ETag跟自己服务器上该资源的ETag是否一致,就能很好地判断资源相对客户端而言是否被修改过了。
那么客户端是如何把标记在资源上的 ETag 传回给服务器的呢?请求报文中有两个首部字段可以带上 ETag 值:
示例为 If-None-Match: "5d8c72a5edda8d6a:3239"
需要注意的是,如果资源是走分布式服务器(比如CDN)存储的情况,需要这些服务器上计算ETag唯一值的算法保持一致,才不会导致明明同一个文件,在服务器A和服务器B上生成的ETag却不一样。
几种字段的对比:
| 头部 | 优势和特点 | 劣势和问题 |
|---|---|---|
| Expires | 1、HTTP 1.0 产物,可以在HTTP 1.0和1.1中使用,简单易用。2、以时刻标识失效时间。 | 1、时间是由服务器发送的(UTC),如果服务器时间和客户端时间存在不一致,可能会出现问题。2、存在版本问题,到期之前的修改客户端是不可知的。 |
| Cache-Control | 1、HTTP 1.1 产物,以时间间隔标识失效时间,解决了Expires服务器和客户端相对时间的问题。2、比Expires多了很多选项设置。 | 1、HTTP 1.1 才有的内容,不适用于HTTP 1.0 。2、存在版本问题,到期之前的修改客户端是不可知的。 |
| Last-Modified | 1、不存在版本问题,每次请求都会去服务器进行校验。服务器对比最后修改时间如果相同则返回304,不同返回200以及资源内容。 | 1、只要资源修改,无论内容是否发生实质性的变化,都会将该资源返回客户端。例如周期性重写,这种情况下该资源包含的数据实际上一样的。2、以时刻作为标识,无法识别一秒内进行多次修改的情况。3、某些服务器不能精确的得到文件的最后修改时间。 |
| ETag | 1、可以更加精确的判断资源是否被修改,可以识别一秒内多次修改的情况。2、不存在版本问题,每次请求都回去服务器进行校验。 | 1、计算ETag值需要性能损耗。2、分布式服务器存储的情况下,计算ETag的算法如果不一样,会导致浏览器从一台服务器上获得页面内容后到另外一台服务器上进行验证时发现ETag不匹配的情况。 |
我们可以把刷新/访问界面的手段分成三类,在浏览器中,有时候你会发现通过不同的手段访问/刷新界面页面的呈现速度是不一样的,那么它们到底有什么区别呢?
返回响应码是 200 OK (from cache),浏览器发现该资源已经缓存了而且没有过期(通过Expires头部或者Cache-Control头部),没有跟服务器确认,而是直接使用了浏览器缓存的内容。其中响应内容和之前的响应内容一模一样,例如其中的Date时间是上一次响应的时间。
F5的作用和直接在URI输入栏中输入然后回车是不一样的,F5会让浏览器无论如何都发一个HTTP Request给Server,即使先前的响应中有Expires头部。所以,当我在当前 腾讯课堂 网页中按F5的时候,浏览器会发送一个HTTP Request给Server,但是包含这样的Headers:
Cache-Control: max-age=0
If-Modified-Since: Fri, 15 Jul 2016 04:11:51 GMT
其中Cache-Control是Chrome强制加上的,而If-Modified-Since是因为获取该资源的时候包含了Last-Modified头部,浏览器会使用If-Modified-Since头部信息重新发送该时间以确认资源是否需要重新发送。 实际上Server没有修改这个index.css文件,所以返回了一个304(Not Modified),这样的响应信息很小,所消耗的route-trip不多,网页很快就刷新了。
上面的例子中没有ETag,如果Response中包含ETag,F5引发的Http Request中也是会包含If-None-Match的。
Ctrl+F5要的是彻底的从Server拿一份新的资源过来,所以不光要发送HTTP request给Server,而且这个请求里面连If-Modified-Since/If-None-Match都没有,这样就逼着Server不能返回304,而是把整个资源原原本本地返回一份,这样,Ctrl+F5引发的传输时间变长了,自然网页Refresh的也慢一些。我们可以看到该操作返回了200,并刷新了相关的缓存控制时间。
实际上,为了保证拿到的是从Server上最新的,Ctrl+F5不只是去掉了If-Modified-Since/If-None-Match,还需要添加一些HTTP Headers。
按照HTTP/1.1协议,Cache不光只是存在Browser终端,从Browser到Server之间的中间节点(比如Proxy)也可能扮演Cache的作用,为了防止获得的只是这些中间节点的Cache,需要告诉他们,别用自己的Cache敷衍我,往Upstream的节点要一个最新的copy吧。
在Chrome 51 中会包含两个头部信息, 作用就是让中间的Cache对这个请求失效,这样返回的绝对是新鲜的资源。
Cache-Control: no-cache
Pragma: no-cache
综上对各种HTTP缓存控制头部的对比以及用户可能出现的浏览器刷新行为的讨论,当我们在一个项目上做http缓存的应用时,我们实际上还是会把上述提及的大多数首部字段均使用上。
Expires用时刻来标识失效时间,不免收到时间同步的影响,而Cache-Control使用时间间隔很好的解决了这个问题。 但是 Cache-Control 是 HTTP1.1 才有的,不适用于 HTTP1.0,而 Expires 既适用于 HTTP1.0,也适用于 HTTP1.1,所以说在大多数情况下同时发送这两个头会是一个更好的选择,当客户端两种头都能解析的时候,会优先使用 Cache-Control。
二者都是通过某个标识值来请求资源, 如果服务器端的资源没有变化,则自动返回 HTTP 304 (Not Changed)状态码,内容为空,这样就节省了传输数据量。而当资源发生比那话后,返回和第一次请求时类似。从而保证不向客户端重复发出资源,也保证当服务器有变化时,客户端能够得到最新的资源。
其中Last-Modified使用文件最后修改作为文件标识值,它无法处理文件一秒内多次修改的情况,而且只要文件修改了哪怕文件实质内容没有修改,也会重新返回资源内容;ETag作为“被请求变量的实体值”,其完全可以解决Last-Modified头部的问题,但是其计算过程需要耗费服务器资源。
Expires和Cache-Control都有一个问题就是服务端作为的修改,如果还在缓存时效里,那么客户端是不会去请求服务端资源的(非刷新),这就存在一个资源版本不符的问题,而强制刷新一定会发起HTTP请求并返回资源内容,无论该内容在这段时间内是否修改过;而Last-Modified和Etag每次请求资源都会发起请求,哪怕是很久都不会有修改的资源,都至少有一次请求响应的消耗。
对于所有可缓存资源,指定一个Expires或Cache-Control max-age以及一个Last-Modified或ETag至关重要。同时使用前者和后者可以很好的相互适应。
前者不需要每次都发起一次请求来校验资源时效性,后者保证当资源未出现修改的时候不需要重新发送该资源。而在用户的不同刷新页面行为中,二者的结合也能很好的利用HTTP缓存控制特性,无论是在地址栏输入URI然后输入回车进行访问,还是点击刷新按钮,浏览器都能充分利用缓存内容,避免进行不必要的请求与数据传输。
同学们是否还记得我们在讨论用户刷新页面行为中体积的index.css文件,它实际上被命名为index.03d344bd.css。而细心的同学也会发现它的Expires和Cache-Control时间出奇的长,这难道不会导致用户无法得到其最近的内容吗?
其做法实际上很简单,它把服务侧ETag的那一套理论搬到了前端来使用。 页面的静态资源以版本形式发布,常用的方法是在文件名或参数带上一串md5或时间标记符:
https://hm.baidu.com/hm.js?e23800c454aa573c0ccb16b52665ac26
http://tb1.bdstatic.com/tb/_/tbean_safe_ajax_94e7ca2.js
http://img1.gtimg.com/ninja/2/2016/04/ninja145972803357449.jpg
可以看到上面的例子中有不同的做法,有的在URI后面加上了md5参数,有的将md5值作为文件名的一部分,有的将资源放在特性版本的目录中。
那么在文件没有变动的时候,浏览器不用发起请求直接可以使用缓存文件;而在文件有变化的时候,由于文件版本号的变更,导致文件名变化,请求的url变了,自然文件就更新了。这样能确保客户端能及时从服务器收取到新修改的文件。通过这样的处理,增长了静态资源,特别是图片资源的缓存时间,避免该资源很快过期,客户端频繁向服务端发起资源请求,服务器再返回304响应的情况(有Last-Modified/Etag)。
大部分代码都是一般代码。通过建立一大组库和辅助函数来解决一般问题,剩下的只是让你的程序与众不同的核心部分。
这个技巧有帮助的原因是它使程序员关注小而定义良好的问题,这些问题已经同项目的其他部分脱离。其结果是,对于这些子问题的解决方案倾向于更加完整和正确。你也可以在以后重用它们。
应该把代码组织得一次只做一件事情。
如果你有很难读的代码,尝试把它所做的所有任务列出来。其中一些任务可以很容易地变成单独的函数(或类)。其他的可以简单地成为一个函数中的逻辑“段落”。具体如何拆分这些任务没有它们已经分开这个事实那样重要。难的是要准确地描述你的程序所做的所有这些小事情。
如果你不能把一件事解释给你祖母听的话说明你还没有真正理解它。
当把一件复杂的事向别人解释时,那些小细节很容易就会让他们迷惑。把一个想法用自然语言解释是个很有价值的能力,因为这样其他知识没有你这么渊博的人才可以理解它。这需要把一个想法精炼成最重要的概念。这样做不仅帮助他人理解,而且也帮助你自己把这个想法想得更清晰。
在你把代码“展示”给读者时也应使用同样的技巧。我们接受代码是你解释程序所做事情的主要手段这一关点。所以代码应当用自然语言编写。
最好读的代码就是没有代码。
当你开始一个项目,自然会很兴奋并且想着你希望实现的所有很酷的功能。但是程序员倾向于高估有多少功能真的对于他们的项目来讲是必不可少的。很多功能结果没有完成,或者没有用到,也可能只是让程序更复杂。
程序员还倾向于低估实现一个功能所要花的工夫。我们乐观地估计了实现一个粗糙原型所要花的时间,但是忘记了在将来代码库的维护、文件以及后增的“重量”所带来的额外时间。
不是所有的程序都需要运行得快,100%准确,并且能处理所有的输入。如果你真的仔细检查你的需求,有时你可以把它削减成一个简单的问题,只需要较少的代码。
怎么说“减少需求”和“解决更简单的问题”的好处都不为过。需求常常以微妙的方式互相影响。这意味着解决一半的问题可能只需要花四分之一的工夫。
最好的解决办法就是“让你的代码库越小,越轻量级越好”,就算你的项目在增长。那么你就要:
很多时候,程序员就是不知道现有的库可以解决他们的问题。或者有时,它们忘了库可以做什么。知道你的库能做什么以便你可以使用它,这一点很重要。
这里有一条比较中肯的建议:每隔一段时间,花15分钟来阅读标准库中的所有函数/模块/类型的名字。这包括C++标准模板库(STL)、Java API、Python内置的模块以及其他内容。
这样做的目的不是记住整个库。这只是为了了解有什么可以用的,以便下次你写新代码时会想:“等一下,这个听起来和我在API中见到的东西有点像……” 我们相信提前做这种准备很快就会得到回报,起码因为你会更倾向于使用库了。
一个常被引用的统计结果是一个平均水平的软件工程师每天写出10行可以放到最终产品中的代码。当程序员们刚一听到这个,他们根本不相信——“10行代码?我一分钟就写出来了!”
这里的关键词是“最终产品中的”。在一个成熟的库中,每一行代码都代表相当大量的设计、调试、重写、文档、优化和测试。任何经受了这样达尔文进化过程一样的代码行就是很有价值的。这就是为什么重用库有这么大的好处,不仅节省时间,还少写了代码。
你可以通过以下方法避免编写新代码:
正则表达式(Regular Expression)是一种处理字符串匹配的语言。
很可能你使用过 Windows/Dos 下用于文件查找的通配符(wildcard),也就是 * 和 ? 。如果你想查找某个目录下的所有的Word文档的话,你会搜索 *.doc。在这里,* 会被解释成任意的字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求 —— 当然,代价就是更复杂——比如你可以编写一个正则表达式,用来查找所有以0开头,后面跟着2-3个数字,然后是一个连字号 “-”,最后是7或8位数字的字符串(像010-12345678或0376-7654321)。
JavaScript 同样也对正则表达式有很好的支持,RegExp 是 JavaScript 中的内置“类”,通过使用RegExp,用户可以自己定义模式来对字符串进行匹配。而 JavaScrip t中的 String 对象的 replace 方法也支持使用正则表达式对串进行匹配,一旦匹配,还可以通过调用预设的回调函数来进行替换。
学习正则表达式的最好方法是从例子开始,理解例子之后再自己对例子进行修改,实验。下面给出了不少简单的例子,并对它们作了详细的说明。
假设你在一篇英文小说里查找hi,你可以使用正则表达式hi。
这几乎是最简单的正则表达式了,它可以精确匹配这样的字符串:由两个字符组成,前一个字符是 h ,后一个是i。
通常,处理正则表达式的工具会提供一个忽略大小写的选项,如果选中了这个选项,它可以匹配 hi,HI,Hi,hI 这四种情况中的任意一种。
不幸的是,很多单词里包含hi这两个连续的字符,比如 him,history,high 等等。用hi来查找的话,这里边的hi也会被找出来。如果要精确地查找hi这个单词的话,我们应该使用 \bhi\b。
\b 是正则表达式规定的一个特殊代码(好吧,某些人叫它元字符,metacharacter),代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是\b并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。
如果需要更精确的说法,\b 匹配这样的位置:它的前一个字符和后一个字符不全是(一个是,一个不是或不存在)\w。
假如你要找的是hi后面不远处跟着一个 Lucy,你应该用 \bhi\b.*\bLucy\b。
这里,.是另一个元字符,匹配除了换行符以外的任意字符。*同样是元字符,不过它代表的不是字符,也不是位置,而是数量——它指定*前边的内容可以连续重复使用任意次以使整个表达式得到匹配。
因此,.*连在一起就意味着任意数量的不包含换行的字符。现在 \bhi\b.*\bLucy\b 的意思就很明显了:先是一个单词hi,然后是任意个任意字符(但不能是换行),最后是Lucy这个单词。
换行符就是\n,ASCII编码为10(十六进制0x0A)的字符。
如果同时使用其它元字符,我们就能构造出功能更强大的正则表达式。比如下面这个例子:
0\d\d-\d\d\d\d\d\d\d\d 匹配这样的字符串:以0开头,然后是两个数字,然后是一个连字号“-”,最后是8个数字(也就是**的电话号码。当然,这个例子只能匹配区号为3位的情形)。
这里的\d是个新的元字符,匹配一位数字(0,或1,或2,或……)。- 不是元字符,只匹配它本身——连字符(或者减号,或者中横线,或者随你怎么称呼它)。
为了避免那么多烦人的重复,我们也可以这样写这个表达式:0\d{2}-\d{8}。这里\d后面的 {2}({8}) 的意思是前面 \d 必须连续重复匹配2次(8次)。
| 操作符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| * , +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^ , $ , \anymetacharacter | 位置和顺序 |
**元字符,是一些数学符号,在正则表达式中有特定的含义,而不仅仅表示其“字面”上的含义。**比如星号(*),表示一个集合的零到多次重复,而问号(?)表示零次或一次。如果你需要使用元字符的字面意义,则需要转义。
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
\ba\w*\b 匹配以字母a开头的单词——先是某个单词开始处(\b),然后是字母a,然后是任意数量的字母或数字(\w*),最后是单词结束处(\b)。\d+ 匹配1个或更多连续的数字。这里的 + 是和 * 类似的元字符,不同的是 *匹配重复任意次(可能是0次),而+ 则匹配重复1次或更多次。\b\w{6}\b 匹配刚好6个字符的单词和忽略大小写的选项类似,有些正则表达式处理工具还有一个处理多行的选项。如果选中了这个选项,^和$的意义就变成了匹配行的开始处和结束处。
你已经看过了前面的 *,+,{2},{5,12} 这几个匹配重复的方式了。下面是正则表达式中所有的限定符(指定数量的代码,例如 *,{5,12} 等)
| 代码/语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
Windows\d+ 匹配Windows后面跟1个或更多数字^\w+ 匹配一行的第一个单词(或整个字符串的第一个单词,具体匹配哪个意思得看选项设置)特殊字符,主要是指注入空格,制表符,其他进制(十进制之外的编码方式)等,它们的特点是以转义字符()为前导。如果需要引用这些特殊字符的字面意义,同样需要转义。
| 字符 | 含义 |
|---|---|
| 字符本身 | 匹配字符本身 |
| \r | 匹配回车 |
| \n | 匹配换行 |
| \t | 制表符 |
| \f | 换页 |
| \x# | 匹配十六进制数 |
| \cX | 匹配控制字符 |
要想查找数字,字母或数字,空白是很简单的,因为已经有了对应这些字符集合的元字符,但是如果你想匹配没有预定义元字符的字符集合(比如元音字母 a,e,i,o,u),应该怎么办?
很简单,你只需要在方括号里列出它们就行了,像 [aeiou] 就匹配任何一个英文元音字母,[.?!] 匹配标点符号(.或?或!)。
我们也可以轻松地指定一个字符范围,像 [0-9] 代表的含意与\d就是完全一致的:一位数字;同理 [a-z0-9A-Z_] 也完全等同于 \w(如果只考虑英文的话)。
下面是一个更复杂的表达式:\(?0\d{2}[) -]?\d{8}。
这个表达式可以匹配几种格式的电话号码,像(010)88886666,或 022-22334455,或 02912345678等。我们对它进行一些分析吧:首先是一个转义字符 \( , 它能出现 0 次或 1 次 (?),然后是一个 0,后面跟着2个数字 (\d{2}),然后是)或 - 或 空格 中的一个,它出现 1 次或不出现 (?),最后是 8 个数字 (\d{8})。
使用工具可视化显示如下:
“(”和“)”也是元字符,后面的分组节里会提到,所以在这里需要使用 转义。
不幸的是,刚才那个表达式也能匹配 010)12345678 或 (022-87654321 这样的 “不正确” 的格式。要解决这个问题,我们需要用到分枝条件。正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用 | 把不同的规则分隔开。 听不明白?没关系,看例子:
0\d{2}-\d{8}|0\d{3}-\d{7} 这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。
\(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8} 这个表达式匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔。你可以试试用分枝条件把这个表达式扩展成也支持4位区号的。
\d{5}-\d{4}|\d{5}这个表达式用于匹配美国的邮政编码。美国邮编的规则是5位数字,或者用连字号间隔的9位数字。之所以要给出这个例子是因为它能说明一个问题:使用分枝条件时,要注意各个条件的顺序。 如果你把它改成 \d{5}|\d{5}-\d{4} 的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。原因是匹配分枝条件时,将会从左到右地测试每个条件,如果满足了某个分枝的话,就不会去再管其它的条件了。
我们已经提到了怎么重复单个字符(直接在字符后面加上限定符就行了);但如果想要重复多个字符又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了, 你也可以对子表达式进行其它一些操作(后面会有介绍)。
(\d{1,3}\.){3}\d{1,3} 是一个简单的IP地址匹配表达式。要理解这个表达式,请按下列顺序分析它:\d{1,3} 匹配1到3位的数字,(\d{1,3}\.){3} 匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字(\d{1,3})。
不幸的是,它也将匹配 256.300.888.999 这种不可能存在的IP地址。如果能使用算术比较的话,或许能简单地解决这个问题,但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
理解这个表达式的关键是理解 2[0-4]\d|25[0-5]|[01]?\d\d?,这里我就不细说了,你自己应该能分析得出来它的意义。
IP地址中每个数字都不能大于255. 经常有人问我, 01.02.03.04 这样前面带有0的数字, 是不是正确的IP地址呢? 答案是: 是的, IP 地址里的数字可以包含有前导 0 (leading zeroes).
有时需要查找不属于某个能简单定义的字符类的字符。比如想查找除了数字以外,其它任意字符都行的情况,这时需要用到反义:
| 代码/语法 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
\S+ 匹配不包含空白符的字符串。<a[^>]+> 匹配用尖括号括起来的以a开头的字符串。使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
后向引用 用于重复搜索前面某个分组匹配的文本。例如,\1 代表分组1匹配的文本。难以理解?请看示例:
\b(\w+)\b\s+\1\b 可以用来匹配重复的单词,像 go go, 或者 kitty kitty。这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字 (\b(\w+)\b) ,这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符 (\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(\1)。
你也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:(?<Word>\w+) (或者把尖括号换成'也行:(?'Word'\w+)) ,这样就把 \w+ 的组名指定为Word了。要反向引用这个分组捕获的内容,你可以使用\k<Word> ,所以上一个例子也可以写成这样:\b(?<Word>\w+)\b\s+\k<Word>\b。
使用小括号的时候,还有很多特定用途的语法。下面列出了最常用的一些:
| 分类 | 代码/语法 | 说明 |
|---|---|---|
| 捕获 | (exp) | 匹配exp,并捕获文本到自动命名的组里 |
| 捕获 | (?exp) | 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp) |
| 捕获 | (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号 |
| 零宽断言 | (?=exp) | 匹配exp前面的位置 |
| 零宽断言 | (?<=exp) | 匹配exp后面的位置 |
| 零宽断言 | (?!exp) | 匹配后面跟的不是exp的位置 |
| 零宽断言 | (?<!exp) | 匹配前面不是exp的位置 |
| 注释 | (?#comment) | 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 |
(?:exp) 这样的语法来剥夺一个分组对组号分配的参与权.接下来的四个用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像 \b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。最好还是拿例子来说明吧:
断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配。
(?=exp) 也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式 exp。比如 \b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=exp) 也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式 exp。比如 (?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找 reading a book时,它匹配 ading。
假如你想要给一个很长的数字中每三位间加一个逗号(当然是从右边加起了),你可以这样查找需要在前面和里面添加逗号的部分:((?<=\d)\d{3})+\b ,用它对 1234567890 进行查找时结果是 234567890。
前面我们提到过怎么查找不是某个字符或不在某个字符类里的字符的方法(反义)。但是如果我们只是想要确保某个字符没有出现,但并不想去匹配它时怎么办?例如,如果我们想查找这样的单词--它里面出现了字母q,但是q后面跟的不是字母u,我们可以尝试这样:
\b\w*q[^u]\w*\b 匹配包含后面不是字母u的字母q的单词。但是如果多做测试(或者你思维足够敏锐,直接就观察出来了),你会发现,如果q出现在单词的结尾的话,像 Iraq,Benq,这个表达式就会出错。这是因为 [^u] 总要匹配一个字符,所以如果q是单词的最后一个字符的话,后面的[^u]将会匹配q后面的单词分隔符(可能是空格,或者是句号或其它的什么),后面的 \w*\b 将会匹配下一个单词,于是 \b\w*q[^u]\w*\b 就能匹配整个 Iraq fighting。
负向零宽断言能解决这样的问题,因为它只匹配一个位置,并不消费任何字符。 现在,我们可以这样来解决这个问题:\b\w*q(?!u)\w*\b。
零宽度负预测先行断言(?!exp),断言此位置的后面不能匹配表达式exp。例如:\d{3}(?!\d) 匹配三位数字,而且这三位数字的后面不能是数字;\b((?!abc)\w)+\b 匹配不包含连续字符串abc的单词。
同理,我们可以用 (?<!exp),零宽度负回顾后发断言 来断言此位置的前面不能匹配表达式exp:(?<![a-z])\d{7} 匹配前面不是小写字母的七位数字。
一个更复杂的例子:(?<=<(\w+)>).*(?=<\/\1>) 匹配不包含属性的简单HTML标签内里的内容。
(?<=<(\w+)>) 指定了这样的前缀:被尖括号括起来的单词(比如可能是<b>),然后是 .* (任意的字符串),最后是一个后缀 (?=<\/\1>)。注意后缀里的 \/,它用到了前面提过的字符转义;\1则是一个反向引用,引用的正是捕获的第一组,前面的 (\w+) 匹配的内容,这样如果前缀实际上是 <b> 的话,后缀就是 </b> 了。整个表达式匹配的是 <b> 和 </b> 之间的内容(再次提醒,不包括前缀和后缀本身)。
小括号的另一种用途是通过语法 (?#comment) 来包含注释。例如:2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)。
要包含注释的话,最好是启用“忽略模式里的空白符”选项,这样在编写表达式时能任意的添加空格,Tab,换行,而实际使用时这些都将被忽略。启用这个选项后,在#后面到这一行结束的所有文本都将被当成注释忽略掉。例如,我们可以前面的一个表达式写成这样:
(?<= # 断言要匹配的文本的前缀
<(\w+)> # 查找尖括号括起来的字母或数字(即HTML/XML标签)
) # 前缀结束
.* # 匹配任意文本
(?= # 断言要匹配的文本的后缀
<\/\1> # 查找尖括号括起来的内容:前面是一个"/",后面是先前捕获的标签
) # 后缀结束
**当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。**以这个表达式为例:a.*b ,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索 aabab 的话,它会匹配整个字符串 aabab。这被称为 贪婪匹配。
有时,我们更需要 **懒惰匹配 **,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号 ? 。这样 .*? 就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b 匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
| 代码/语法 | 说明 |
|---|---|
| *? | 重复任意次, 但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
| 修饰符 | 描述 |
|---|---|
| i | 忽略大小写开关 |
| g | 全局搜索开关 |
| m | 多行搜索开关(重定义^与$的意义) |
有时我们需要匹配像( 100 * ( 50 + 15 ) )这样的可嵌套的层次性结构,这时简单地使用 \(.+\) 则只会匹配到最左边的左括号和最右边的右括号之间的内容(这里我们讨论的是贪婪模式,懒惰模式也有下面的问题)。假如原来的字符串里的左括号和右括号出现的次数不相等,比如( 5 / ( 3 + 2 ) ) ),那我们的匹配结果里两者的个数也不会相等。有没有办法在这样的字符串里匹配到最长的,配对的括号之间的内容呢?
为了避免(和(把你的大脑彻底搞糊涂,我们还是用尖括号代替圆括号吧。现在我们的问题变成了如何把 xx <aa aa> yy这样的字符串里,最长的配对的尖括号内的内容捕获出来?
这里需要用到以下的语法构造:
(?'group') 把捕获的内容命名为group,并压入堆栈(Stack)(?'-group') 从堆栈上弹出最后压入堆栈的名为group的捕获内容,如果堆栈本来为空,则本分组的匹配失败(?(group)yes|no) 如果堆栈上存在以名为group的捕获内容的话,继续匹配yes部分的表达式,否则继续匹配no部分(?!) 零宽负向先行断言,由于没有后缀表达式,试图匹配总是失败我们需要做的是每碰到了左括号,就在压入一个"Open",每碰到一个右括号,就弹出一个,到了最后就看看堆栈是否为空--如果不为空那就证明左括号比右括号多,那匹配就应该失败。正则表达式引擎会进行回溯(放弃最前面或最后面的一些字符),尽量使整个表达式得到匹配。
< #最外层的左括号
[^<>]* #最外层的左括号后面的不是括号的内容
(
(
(?'Open'<) #碰到了左括号,在黑板上写一个"Open"
[^<>]* #匹配左括号后面的不是括号的内容
)+
(
(?'-Open'>) #碰到了右括号,擦掉一个"Open"
[^<>]* #匹配右括号后面不是括号的内容
)+
)*
(?(Open)(?!)) #在遇到最外层的右括号前面,判断黑板上还有没有没擦掉的"Open";如果还有,则匹配失败
> #最外层的右括号
平衡组的一个最常见的应用就是匹配HTML,下面这个例子可以匹配嵌套的
<div[^>]*>[^<>]*(((?'Open'<div[^>]*>)[^<>]*)+((?'-Open'</div>)[^<>]*)+)*(?(Open)(?!))</div>.
网络上有很多可视化的正则表达式学习或调试的工具,有些还能自动生成测试案例等。如下面一个邮箱校验的正则表达式:
//Email正则
/^([A-Za-z0-9_\-\.])+\@([A-Za-z0-9_\-\.])+\.([A-Za-z]{2,4})$/.test("[email protected]");
//输出 true
// 1.邮箱以a-z、A-Z、0-9开头,最小长度为1.
// 2.如果左侧部分包含-、_、.则这些特殊符号的前面必须包一位数字或字母。
// 3.@符号是必填项
// 4.右则部分可分为两部分,第一部分为邮件提供商域名地址,第二部分为域名后缀,现已知的最短为2位。
// 最长的为6为。
// 5.邮件提供商域可以包含特殊字符-、_、.
/^[a-z0-9]+([._\\-]*[a-z0-9])*@([a-z0-9]+[-a-z0-9]*[a-z0-9]+.){1,63}[a-z0-9]+$/.test("[email protected]");
可视化
保罗·格雷厄姆出身于一个中产阶级家庭,本科就读于康奈尔大学,研究生阶段去了哈佛大学。他有一套完整的创业哲学,他的创业公式是:
他说:创始人本身比他的创意更重要。
他认为:所有的东西都在变成软件。
它的作者是美国互联网界举足轻重、有“创业教父”之称的哈佛大学计算机博士保罗·格雷厄姆(Paul Graham)。本书是他的文集。保罗·格雷厄姆.
1984年,《新闻周刊》的记者史蒂文·利维出版了历史上第一本介绍黑客的著作——《黑客:计算机革命的英雄》(Hackers: Heroes of the Computer Revolution)。在该书中,他进一步将黑客的价值观总结为六条“黑客伦理”(hacker ethic),直到今天这几条伦理都被视为这方面的最佳论述。
根据这六条“黑客伦理”,黑客价值观的核心原则可以概括成这样几点:分享、开放、**、计算机的自由使用、进步。
TODO:
meta标签是HTML语言HEAD区的一个辅助性标签。
meta常用于定义页面的说明,关键字,最后修改日期,和其它的元数据。这些元数据将服务于浏览器(如何布局或重载页面),搜索引擎和其它网络服务。
mata 标签包含全局属性
Note: 全局属性
name在标签里又特殊的含义,itempro属性不能和name,http-equiv和charset 属性设置在同一个meta标签。
声明网页的字符编码:
<meta charset="UTF-8">
content属性的内容是htp-equiv或name属性的值,具体取决于你用哪一个。
该属性可以包含HTTP头的名称,属性的英文全称为http-equivalent。它定义了可以改变server和user-agent行为的指令。该指令的值在content属性内定义,可以是以下之一:
定义页面的默认语言。它可以被任何元素上的lang属性所覆盖。
禁止浏览器从本地计算机的缓存中访问页面内容。如:
<meta http-equiv="Pragma" content="no-cache">
可以用于设定网页的到期时间。一旦网页过期,必须到服务器上重新传输。
指定请求和响应遵循的缓存机制。共有以下几种用法:
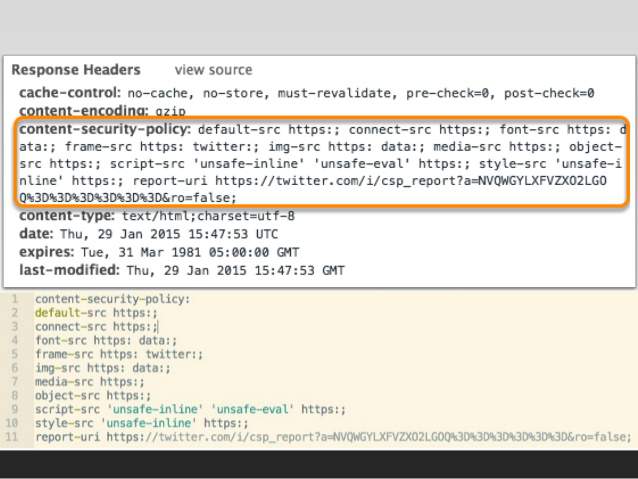
允许页面作者定义当前页面的内容策略。内容策略主要指定允许的服务器地址和脚本端点,这有助于防止cross-site scripting 攻击。
CSP 的实质就是白名单制度,开发者明确告诉客户端,哪些外部资源可以加载和执行,等同于提供白名单。它的实现和执行全部由浏览器完成,开发者只需提供配置。
CSP 大大增强了网页的安全性。攻击者即使发现了漏洞,也没法注入脚本,除非还控制了一台列入了白名单的可信主机。
两种方法可以启用 CSP。一种是通过 HTTP 头信息的Content-Security-Policy的字段。
Content-Security-Policy: script-src 'self'; object-src 'none';
style-src cdn.example.org third-party.org; child-src https:
另一种是通过网页的标签。
<meta http-equiv="Content-Security-Policy" content="script-src 'self'; object-src 'none'; style-src cdn.example.org third-party.org; child-src https:">
上面代码中,CSP 做了如下配置:
启用后,不符合 CSP 的外部资源就会被阻止加载。
更多介绍可见:Content Security Policy 入门教程
定义文档的MIME类型,后跟其字符编码。
该指令指定:
<meta http-equiv="refresh" content="2;URL=http://www.github.com/"> //意思是2秒后跳转到github
定义页面的cookie,对应的content值必须遵循IETF HTTP Cookie Specification
不要使用这条指令,使用HTTP头的Set-Cookie替代
用于告知浏览器以何种版本来渲染页面。
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"/> //指定IE和Chrome使用最新版本渲染当前页面
name属性的定义是属于document-level metadata,不能和以下属性同时设置: itemprop, http-equiv 或 charset。
该元数据名称与content属性包含的值相关联。 name属性的可能值为:
定义在网页中运行的应用程序的名称。
用于标注网页作者。
包括一个关于页面内容的缩略而精准的描述。一些浏览器,如Firefox和Opera,会使用这个当做网页书签的默认描述。
用于标明网页是什么软件做的。
用于告诉搜索引擎,你网页的关键字
如果页面不是经常更新,为了减轻搜索引擎爬虫对服务器带来的压力,可以设置一个爬虫的重访时间。如果重访时间过短,爬虫将按它们定义的默认时间来访问。举例:
<meta name="revisit-after" content="7 days" >
renderer是为双核浏览器准备的,用于指定双核浏览器默认以何种方式渲染页面。比如说360浏览器。举例:
<meta name="renderer" content="webkit"> //默认webkit内核
<meta name="renderer" content="ie-comp"> //默认IE兼容模式
<meta name="renderer" content="ie-stand"> //默认IE标准模式
referrer 控制document发起的Request请求中附加的Referer HTTP header,相应的值在content中:
| content | 含义 |
|---|---|
| no-referrer | 不发送HTTP Referer头 |
| origin | 发送document的origin |
| no-referrer-when-downgrade | 将origin作为referer发送到和当前页面同等安全的URLs(https-> https),但不会将origin发送到不安全的URLS(https-> http)。这是默认行为。 |
| origin-when-crossorigin | same-origin的请求,发送的完整URL(剥离参数),但在其他情况下只发送origin |
| unsafe-URL | same-origin 或 cross-origin的请求,将发送完整的URL(剥离参数) |
robots用来告诉爬虫哪些页面需要索引,哪些页面不需要索引。
| 值 | 描述 | Used By |
|---|---|---|
| index | 允许robot索引本页面(默认) | All |
| noindex | 不允许robot索引本页面 | All |
| follow | 允许搜索引擎继续通过此网页的链接索引搜索其它的网页(默认) | All |
| nofollow | 搜索引擎不继续通过此网页的链接索引搜索其它的网页 | All |
| none | 相当于noindex,nofollow | |
| noodp | 禁止使用Open Directory Project描述(如果有的话)作为搜索引擎结果中的页面描述。 | Google, Yahoo, Bing |
| noarchive | 要求搜索引擎不缓存页面内容 | Google, Yahoo, Bing |
| nosnippet | 禁止在搜索引擎结果中显示该页面的任何描述。 | Google, Bing |
| noimageindex | 要求此页面不作为引用页面的索引图像的显示。 | |
| nocache | 和noarchive同义 | Bing |
提供了关于viewport初始大小的大小的提示。仅供移动设备使用。
| 值 | content取值 | 描述 |
|---|---|---|
| width | 整数或device-width | 定义viewport的像素宽度,或允许viewport适应设备的屏幕宽度。 |
| height | 整数或device-height | 定义viewport的高度。没有任何浏览器使用(???) |
| initial-scale | 0.0 - 10.0 | 定义设备宽度(纵向模式下的设备宽度或横向模式下的设备高度)与viewport大小之间的比例。 |
| maximum-scale | 0.0 - 10.0 | 定义最大的缩放级别。它必须大于或等于minimum-scale,否则视为未定义。浏览器设置可以忽略此规则,iOS10 +默认情况下忽略它。 |
| minimum-scale | 0.0 - 10.0 | 定义最小的缩放级别。它必须小于或等于maximum-scale,否则视为未定义。浏览器设置可以忽略此规则,iOS10 +默认情况下忽略它。 |
| user-scalable | yes 或 no | 如果设置为no,用户将无法放大网页。默认值为yes。浏览器设置可以忽略此规则,iOS10 +默认情况下忽略它。 |
<meta name=”viewport” content=”initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no”/>
你可以设置一段时间后对页面进行刷新操作。meta http-equiv=”refresh”可以指定浏览器延迟一段时间自动刷新页面。下面的meta-tag指定浏览器每5秒自动刷新一次。
<meta http-equiv=”refresh” content=”5″ />
我们可以使用refresh meta标签对页面进行重定向。下面的例子将在5秒后访问www.25xt.com
<meta http-equiv=”refresh” content=”5;url=’http://www.25xt.com’” />
当我们在本地测试网页的时候,没有及时更新新内容,可能就是有浏览器缓存。这个时候,我们只要通过使用Meta标签禁用浏览器缓存,可以解决。通用代码如下:
<meta http-equiv="expires" content="0">
<meta http-equiv="pragma" content="no-cache">
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="Cache-Control" content="no-siteapp"/>
<meta content=”telephone=no” name=”format-detection” />
SSH(Secure Shell)是一个提供数据通信安全、远程登录、远程指令执行等功能的安全网络协议,由芬兰赫尔辛基大学研究员Tatu Ylönen,于1995年提出,其目的是用于替代非安全的Telnet、rsh、rexec等远程Shell协议。之后SSH发展了两个大版本SSH-1和SSH-2。
通过使用SSH,你可以把所有传输的数据进行加密,这样"中间人"这种攻击方式就不可能实现了,而且也能够防止 DNS欺骗 和 IP欺骗。使用SSH,还有一个额外的好处就是传输的数据是经过压缩的,所以可以加快传输的速度。SSH有很多功能,它既可以代替Telnet,又可以为FTP、Pop、甚至为PPP提供一个安全的"通道"。
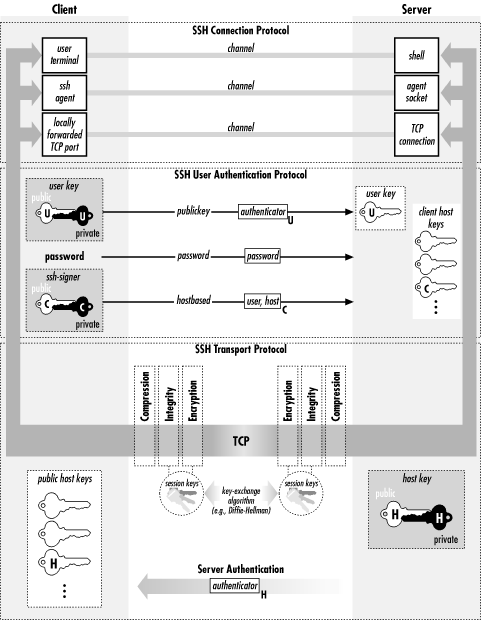
SSH为一项创建在应用层和传输层基础上的安全协议,为计算机上的 Shell 提供安全的传输和使用环境。
SSH协议框架中最主要的部分是三个协议:
传输层协议(The Transport Layer Protocol):传输层协议提供服务器认证,数据机密性,信息完整性等的支持。用户认证协议(The User Authentication Protocol):用户认证协议为服务器提供客户端的身份鉴别。连接协议(The Connection Protocol):连接协议将加密的信息隧道复用成若干个逻辑通道,提供给更高层的应用协议使用。SSH-AUTH是SSH里面用于验证客户端身份的协议。我们在用ssh命令输入密码的那一步实际上就是在这个阶段。可以看到的是,虽然传输的是用户名和密码,但是由于这个协议建立在SSH-TRANS之上,所以内容都是加密的,可以放心的传输。
而SSH-CONN是真正的应用协议。在这里可以定义各种不同的协议,其中我们经常使用的scp、sftp还有正常的remote shell都是定义在这里的一种协议实现。这里的各种应用协议都要首先经过SSH-AUTH的验证之后才可以使用。
这个三个协议之间的关系可以用下面这幅图来说明:

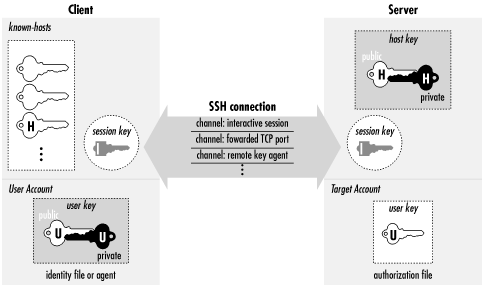
SSH从安全和性能两方面综合考虑,结合使用了 Public Key/Private key(公钥/私钥) 和 Secret Key(密钥)。
Public Key/Private key:非对称加密,安全,但效率低,不适合大规模进行数据的加密和解密操作Secret Key:对称机密,高效,但安全性相对较低,Key的分发尤其不方便对密码学基础知识和数字签名了解,可以参考阮一峰的博文
SSH-2 通过 MD5 和 SHA-1 实现该功能,SSH-1 使用 CRC-32OpenSSH 通过在 know-hosts 中存储主机名和 host key 对服务端身份进行认证 服务端验证请求者身份:提供安全性较弱的用户密码方式,和安全性更强的 per-user public-key signatures;此外SSH还支持与第三方安全服务系统的集成,如 Kerberos等Forwarding 操作:Port Forwarding;X Forwarding;Agent ForwardingSSH结合使用了Public Key/Private key和Secret Key:
Public Key/Private key(非对称加密)用于在建立安全通道前在客户端和服务端之间传输 Secret Key和进行身份认证;Secret Key(对称加密)则用来作为SSH会话的安全保证,对数据进行加密和解密。SSH可以处理4种密钥:
| 名称 | 生命周期 | 创建 | 类型 | 描述 |
|---|---|---|---|---|
| Host Key | 持久化 | 服务端 | Public Key | Host Key是服务器用来证明自己身份的一个永久性的非对称密钥 |
| User Key | 持久化 | 用户 | Public Key | User Key 是客户端用来证明用户身份的一个永久性的非对称密钥(一个用户可以有多个密钥/身份标识) |
| Server Key | 默认为1小时 | 服务端 | Public Key | Server Key 是SSH-1协议中使用的一个临时的非对称密钥,每隔一定的间隔(默认是一个小时)都会在服务器重新生成。用于对Session Key进行加密(仅SSH-1协议有,SSH-2对其进行了增强,这里Server Key作为一个概念便于在流程中进行描述) |
| Session Key | 客户端 | 会话(Session) | Secret Key | Session Key是一个随机生成的对称密钥,用户SSH客户端和服务器之间的通信进行加密,会话结束时,被销毁 |
SSH框架:
在进行有意义的会话之前,SSH客户端和服务器必须首先建立一条安全连接。该连接可以允许双方共享密钥、密码,最后可以相互传输任何数据。
现在我们介绍SSH-1协议是如何确保网络连接的安全性的。SSH-1客户端和服务器从阿卡似乎经过很多个步骤,协商使用加密算法,生成并共享一个会话密钥,最终建立一条安全连接:
每个阶段均涉及到客户端与服务端的多次交互,通过这些交互过程完成包括证书传输、算法协商、通道加密等过程。
这个步骤没什么好说的,就是向服务器的TCP端口(约定是22)发送连接请求。
这些协议是以 ASCII 字符串表示,例如:SSH-1.5-1.2.27,其意义为SSH协议,版本号是V1.5,SSH1实现版本为1.2.27。可以使用 Telnet 客户端连接到一个SSH服务器端口是看到这个字符串:
➜ telnet 192.168.1.200 22
Trying 192.168.1.200...
Connected to doc.dinghuo123.com.
Escape character is '^]'.
SSH-2.0-OpenSSH_6.0p1 Debian-4+deb7u6
如果客户端和服务器确定其协议版本号是兼容的,那么连按就继续进行,否则,双方都可能决定中断连接。例如,如果一个只使用 SSH-1 的客户端连接到一个只使用 SSH-2 的服务器上,那么客户端就会断开连接并打印一条错误消息。实际上还可能执行其他操作:例如,只使用SSH-2的服务器可以调用SSH-1服务器来处理这次连接请求。
协议版本号交换过程一旦完成,客户端和服务器都立即从下层的 TCP 连接切换到基于子报文的协议。每个报文都包含一个32位的字段,1 - 8字节的填充位[ 用来防止已知明文攻击unknown-plaintext attack ],一个1字节的报文类型代码, 报文有效数据和一个4字节的完整性检査字段。
服务器向客户端发送以下信息(现在还沒有加密):
主机密钥(Host Key),用于后面证明服务器主机的身份服务器密钥(Server Key),用来帮助建立安全连接检测字节(check bytes)。客户端在下一次响应中必须包括这些检测字节,否則服务器就会拒绝接收响应信息,这种方法可以防止某些 IP伪装攻击(IP spoofing attack)。此时,双方都要计算一个通用的 128 位会话标识符(Session ID)。它在某些协议中用来惟一标识这个 SSH 会话。该值是 主机密钥(Host Key)、服务器密钥(Server Key)和检测字节(check bytes)一起应用 MD5散列函数 得到的结果。
当客户端接收到 主机密钥(Host Key)时,它要进行询问:“之前我和这个服务器通信过吗?如果通信过,那么它的主机密钥是什么呢?”要回答这个问题,客户端就要査阅自己的已知名主机数据库。如果新近到达的主机密钥可以和数据库中以前的一个密钥匹,那么就没有问题了。
但是,此时还存在两种可能:已知名主机数据库中没有这个服务器,也可能有这个服务器但是其主机密钥不同。在这两种情况中,客户端要选择是信任这个新近到达的密钥还是拒绝接受该密钥。此时就需要人的指导参与了,例如,客户端用户可能被提示要求确定是接受还是拒绝该密钥。
The authenticity of host 'ssh-server.example.com (12.18.429.21)' can't be established.
RSA key fingerprint is 98:2e:d7:e0:de:9f:ac:67:28:c2:42:2d:37:16:58:4d.
Are you sure you want to continue connecting (yes/no)?
如果客户端拒绝接受这个主机密钥,那么连接就中止了。让我们假设客户端接受该密钥,现在继续介绍。
现在客户端为双方都支持的 bulk箅法 随机生成一个新密钥,称为 会话密钥(Session Key)。其目的是对客户端和服务器之间发送的数据进行加密和解密。所需要做的工作是把这个 会话密钥(Session Key)发送给服务器,双方就可以启用加密并开始安全通信了。
当然,客户端不能简单地把会话密钥(Session Key)发送给服务器。此时数据还没有进行加密,如果第三方中途截获了这个密钥,那么他就可以解密客户端和服务器之间的消息。此后你就和安全性无缘了。因此客户端必须安全地发送会话密钥(Session Key)。 这是通过两次加密实现的:一次使用服务器的公共主机密钥(Host Key),一次使用服务器密钥(Server Key)。
这个步骤确保只有服务器可以读取会话密钥(Session Key)。在会话密钥(Session Key)经过两次加密之后,客户端就将其发送给服务器,同时还会发送检测字节和所选定的算法(这些算法是从第4步中服务器支持的算法列表中挑选出来的)。
在发送会话密钥之后,双方开始使用密钥和所选定的 bulk算法 对会话数据进行加密,但是在开始继续发送其他数据之前,客户端要等待服务器发来一个确认消息,该消息(以及之后的所有数据)都必须使用这个会话密钥(Session Key)加密。这是最后一歩,它提供了服务器认证:只有目的服务器才可以解密 会话密钥(Session Key),因为它是使用前面的 主机密钥(Host Key)(这个密钥已经对已知名主机列表进行了验证)进行加密的。
如果没有会话密钥(Session Key),假冒的服务器就不能解密以后的协议通信,也就不能生成有效的通信,客户端会注意到这一点并中断连接。
注意服务器认址是隐含的;并没有显式交换来验证服务器主机密钥(Host Key)。因此客户端在继续发送数椐之前,必须等待服务器使用新会话密钥(Session Key)作出有意义的响应。 从而在处理之前验证服务的身份,虽然 SSH-1 协议在这点上并没有什么特殊 . 但是 SSH-2 需要服务器认证时显示地地交换会话密钥(Session Key)。
使用服务器密钥(Server Key)对会话密钥(Session Key)再进行一次加密就提供了一种称为完美转发安全性的特性。这就是说不存在永久性密钥泄露的可能,因为它不会危害到其他部分和以后SSH会话的安全性。如果我们只使用服务器主机密钥(Host Key)来保护会话密钥(Session Key), 那么主机密钥(Host Key)的泄露就会危害到以后的通倍,并允许解密原来记录下来的会话。使用服务器密钥(Server Key)再加密次就消除了这种缺点,因为服务器密钥(Server Key)是临时的,它不会保存到磁盘上,而且会周期性地更新(缺省情况下,一小时更新一次)。如果一个入侵者已经获取了服务器的私钥,那么他必须还要执行中间人攻击或服务器欺骗攻击才能对会话造成损害。
由于客户端和服务器现在都知道会话密钥(Session Key),而其他人都不知道,因此他们就可以相互发送加密消息(使用他们一致同意的 bulk算法 )并对其进行解密了。而且,客户端还可以完成服务器认证。我们现在就已经准备好开始客户端认证了。
SSH提供多种客户端认证方式。
SSH-1:
SSH-2:
这里之讨论我们经常使用的的 Password 和 Public Key 方式。
此时安全通道已经及建立,之后的所有内容都通过 Session Key 加密后进行传输。
Password 方式既客户端提供用户和密码,服务端对用户和密码进行匹配,完成认证。类Unix系统中,如 OpenSSH 的框架,一般通过系统的本地接口完成认证。
Password 的优势是简单,无需任何而外的配置就可以使用。缺点密码不便于记忆,过于简单的密码容易被暴力破解。
Public Key 认证的基本原理是基于非对称加密方式,分别在服务端对一段数据通过公钥进行加密,如果客户端能够证明其可以使用私钥对这段数据进行解密,则可以说明客户端的身份。因为服务端需要使用客户端生成的密钥对的公钥对数据首先加密,所以需要先将公钥存储到服务端的密钥库(Auhtorized Key)。还记得Github中使用git协议push代码前需要先添加SSH KEY吗?
下面详细介绍一个通过 Public Key 进行客户端认证的过程。
Public Key 的认证请求,并发送 RSA Key 的模数作为标识符。(如果想深入了解RSA Key详细 --> 维基百科)~/.ssh/authorized_keys 文件中),以及其拥有的访问权限。如果没有则断开连接Session ID 生成一个MD5值发送给服务端。 结合 Session ID 的目的是为了避免攻击者采用 重放攻击(replay attack)。文章同步于Github Pines-Cheng/blog
CDN(内容分发网络)全称是 Content Delivery Network,建立并覆盖在承载网之上、由分布在不同区域的边缘节点服务器群组成的分布式网络,替代传统以 WEB Server 为中心的数据传输模式。
作用是将源内容发布到边缘节点,配合精准的调度系统;将用户的请求分配至最适合他的节点,使用户可以以最快的速度取得他所需的内容,有效解决Internet网络拥塞状况,提高用户访问的响应速度。
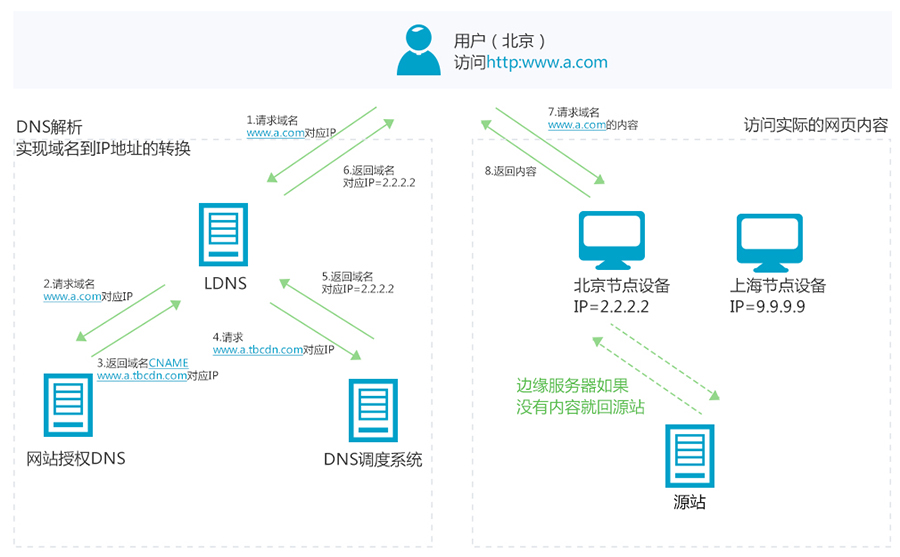
用户通过浏览器等方式访问网站的过程如图所示:
用户在自己的浏览器中输入要访问的网站域名。
浏览器向 本地DNS服务器 请求对该域名的解析。
本地DNS服务器中如果缓存有这个域名的解析结果,则直接响应用户的解析请求。
本地DNS服务器中如果没有关于这个域名的解析结果的缓存,则以递归方式向整个DNS系统请求解析,获得应答后将结果反馈给浏览器。
浏览器得到域名解析结果,就是该域名相应的服务设备的 IP地址 。
浏览器向服务器请求内容。
服务器将用户请求内容传送给浏览器。
在网站和用户之间加入 CDN 以后,用户不会有任何与原来不同的感觉。最简单的 CDN 网络有一个 DNS 服务器和几台缓存服务器就可以运行了。一个典型的 CDN 用户访问调度流程如图所示:
当用户点击网站页面上的内容URL,经过本地DNS系统解析,DNS 系统会最终将域名的解析权交给 CNAME 指向的 CDN 专用 DNS 服务器。
CDN 的 DNS 服务器将 CDN 的全局负载均衡设备 IP 地址返回用户。
用户向 CDN 的全局负载均衡设备发起内容 URL 访问请求。
CDN 全局负载均衡设备根据用户 IP 地址,以及用户请求的内容URL,选择一台用户所属区域的区域负载均衡设备,告诉用户向这台设备发起请求。
基于以下这些条件的综合分析之后,区域负载均衡设备会向全局负载均衡设备返回一台缓存服务器的IP地址:
全局负载均衡设备把服务器的 IP 地址返回给用户。
用户向缓存服务器发起请求,缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果这台缓存服务器上并没有用户想要的内容,而区域均衡设备依然将它分配给了用户,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器将内容拉到本地。
**DNS 服务器根据用户 IP 地址,将域名解析成相应节点的缓存服务器IP地址,实现用户就近访问。**使用 CDN 服务的网站,只需将其域名解析权交给 CDN 的全局负载均衡(GSLB)设备,将需要分发的内容注入 CDN,就可以实现内容加速了。
使用CDN后的http请求处理流程如下图,其中左边为DNS解析过程,右边为内容访问过程:
CDN基于这样的原理:
CDN 公司在整个互联网上部署数以百计的CDN服务器(Cache),这些服务器通常在运营商的 IDC (互联网数据中心Internet Data Center)中,尽量靠近接入网络和用户。CDN在Cache中复制内容,当内容的提供者更新内容时,CDN 向Cache重新分发这些被刷新的内容。CDN提供一种机制,当用户请求内容时,该内容能够由以最快速度交付的Cache 来向用户提供,这个挑选"最优"的过程就叫做负载均衡。被选中的最优 Cache 可能最靠近用户,或者有一条与用户之间条件最好的路径。
从功能上划分,典型的 CDN 系统架构由分发服务系统、负载均衡系统和运营管理系统三大部分组成,如图所示:
该系统的主要作用是实现将内容从内容源中心向边缘的推送和存储,承担实际的内容数据流的全网分发工作和面向最终用户的数据请求服务。分发服务系统最基本的工作单元就是许许多多的 Cache设备(缓存服务器),Cache 负责直接响应最终用户的访问请求,把缓存在本地的内容快速地提供给用户。同时 Cache 还负责与源站点进行内容同步,把更新的内容以及本地没有的内容从源站点获取并保存在本地。
一般来说,根据承载内容类型和服务种类的不同,分发服务系统会分为多个子服务系统,如网页加速子系统、流媒体加速子系统、应用加速子系统等。每个子服务系统都是一个分布式服务集群,由一群功能近似的、在地理位置上分布部署的 Cache 或 Cache 集群组成,彼此间相互独立。每个子服务系统设备集群的数量根据业务发展和市场需要的不同,少则几十台,多则可达上万台,对外形成一个整体,共同承担分发服务工作。Cache 设备的数量、规模、总服务能力是衡量一个 CDN 系统服务能力的最基本的指标。
分发服务系统在承担内容的更新、同步和响应用户需求的同时,还需要向上层的调度控制系统提供每个Cache设备的健康状况信息、响应情况,有时还需要提供内容分布信息,以便调度控制系统根据设定的策略决定由哪个Cache(组)来响应用户的请求最优。
负载均衡系统是一个 CDN 系统的神经中枢,主要功能是负责对所有发起服务请求的用户进行访问调度,确定提供给用户的最终实际访问地址。大多数 CDN 系统的负载均衡系统是分级实现的,这里以最基本的两级调度体系进行简要说明。一般而言,两级调度体系分为全局负载均衡(GSLB)和本地负载均衡(SLB)。
其中,全局负载均衡(GSLB)主要根据 用户就近性原则,通过对每个服务节点进行"最优"判断,确定向用户提供服务的 Cache 的物理位置。最通用的 GSLB 实现方法是基于DNS解析的方式实现,也有一些系统采用了应用层重定向等方式来解决。本地负载均衡(SLB)主要负责节点内部的设备负载均衡,当用户请求从 GSLB 调度到 SLB 时,SLB 会根据节点内各 Cache 设备的实际能力或内容分布等因素对用户进行重定向,常用的本地负载均衡方法有基于4层调度、基于7层调度、链路负载调度等。
CDN的运营管理系统与一般的电信运营管理系统类似,分为运营管理和网络管理两个子系统。
运营管理子系统是CDN系统的业务管理功能实体,负责处理业务层面的与外界系统交互所必需的一些收集、整理、交付工作,包含客户管理、产品管理、计费管理、统计分析等功能。
网络管理子系统实现对CDN系统的网络设备管理、拓扑管理、链路监控和故障管理,为管理员提供对全网资源进行集中化管理操作的界面,通常是基于Web方式实现的。
CDN 系统设计的首要目标是尽量减少用户的访问响应时间,为达到这一目标,CDN 系统应该尽量将用户所需要的内容存放在距离用户最近的位置。也就是说,负责为用户提供内容服务的 Cache 设备应部署在物理上的网络边缘位置,我们称这一层为CDN边缘层。CDN 系统中负责全局性管理和控制的设备组成 中心层,中心层同时保存着最多的内容副本,当边缘层设备未命中时,会向中心层请求,如果在中心层仍未命中,则需要中心层向源站回源。
不同CDN系统设计之间存在差异,中心层可能具备用户服务能力,也可能不直接提供服务,只向下级节点提供内容。如果CDN网络规模较大,边缘层设备直接向中心层请求内容或服务会造成中心层设备压力过大,就要考虑在边缘层和中心层之间部署一个区域层,负责一个区域的管理和控制,也保存部分内容副本供边缘层访问。
如图是一个典型的CDN系统三级部署示意图:
节点是 CDN 系统中最基本的部署单元,一个CDN系统由大量的、地理位置上分散的 POP(point-of-presence)节点组成,为用户提供就近的内容访问服务。
CDN 节点网络主要包含 CDN 骨干点和 POP 点。CDN 骨干点和 CDN POP 点在功能上不同。
POP(point-of-presence)节点,CDN POP点主要作为直接向用户提供服务的节点。但是,从节点构成上来说,无论是CDN骨干点还是CDN POP点,都由Cache设备和本地负载均衡设备构成。
在一个节点中,Cache设备和本地负载均衡设备的连接方式有两种:一种是旁路方式,一种是穿越方式。
如图所示:
在穿越方式下,SLB(Server Load Balancer,负载均衡 一般由 L4-7 交换机实现,SLB 向外提供可访问的 公网IP地址(VIP,每台Cache仅分配私网IP地址,该台SLB下挂的所有Cache构成一个服务组。所有用户请求和媒体流都经过该SLB设备,再由SLB设备进行向上向下转发。SLB实际上承担了 NAT(Network Address Translation,网络地址转换)功能,向用户屏蔽了Cache设备的IP地址。这种方式是CDN系统中应用较多的方式,优点是具有较高的安全性和可靠性,缺点是L4-7交换机通常较为昂贵。另外,当节点容量大时,L4-7交换机容易形成性能瓶颈。不过近年来,随着 LVS (Linux Virtual Server,即Linux虚拟服务器) 等技术的兴起,SLB设备价格有了大幅下降。
在旁路方式下,有两种 SLB 实现方式:
在CDN系统中,不仅分发服务系统和调度控制系统是分布式部署的,运营管理系统也是分级分布式部署的,每个节点都是运营管理数据的生成点和采集点,通过日志和网管代理等方式上报数据。可以说,CDN本身就是一个大型的具有**控制能力的分布式服务系统。
当下的互联网应用都包含大量的静态内容,但静态内容以及一些准动态内容又是最耗费带宽的,特别是针对全国甚至全世界的大型网站,如果这些请求都指向主站的服务器的话,不仅是主站服务器受不了,单端口500M左右的带宽也扛不住,所以大多数网站都需要CDN服务。
根本上的原因是,访问速度对互联网应用的用户体验、口碑、甚至说直接的营收都有巨大的影响,任何的企业都渴望自己站点有更快的访问速度。而HTTP传输时延对web的访问速度的影响很大,在绝大多数情况下是起决定性作用的,这是由TCP/IP协议的一些特点决定的。物理层上的原因是光速有限、信道有限,协议上的原因有丢包、慢启动、拥塞控制等。
这就是你使用CDN的第一个也是最重要的原因:为了加速网站的访问。
除了加速网站的访问之外,CDN还有一些作用:
互联不互通、区域ISP地域局限、出口带宽受限制等种种因素都造成了网站的区域性无法访问。CDN加速可以覆盖全球的线路,通过和运营商合作,部署IDC资源,在全国骨干节点商,合理部署CDN边缘分发存储节点,充分利用带宽资源,平衡源站流量。阿里云在国内有500+节点,海外300+节点,覆盖主流国家和地区不是问题,可以确保CDN服务的稳定和快速。
CDN的负载均衡和分布式存储技术,可以加强网站的可靠性,相当无无形中给你的网站添加了一把保护伞,应对绝大部分的互联网攻击事件。防攻击系统也能避免网站遭到恶意攻击。
当某个服务器发生意外故障时,系统将会调用其他临近的健康服务器节点进行服务,进而提供接近100%的可靠性,这就让你的网站可以做到永不宕机。
投入使用CDN加速可以实现网站的全国铺设,你根据不用考虑购买服务器与后续的托管运维,服务器之间镜像同步,也不用为了管理维护技术人员而烦恼,节省了人力、精力和财力。
CDN加速厂商一般都会提供一站式服务,业务不仅限于CDN,还有配套的云存储、大数据服务、视频云服务等,而且一般会提供7x24运维监控支持,保证网络随时畅通,你可以放心使用。并且将更多的精力投入到发展自身的核心业务之上。
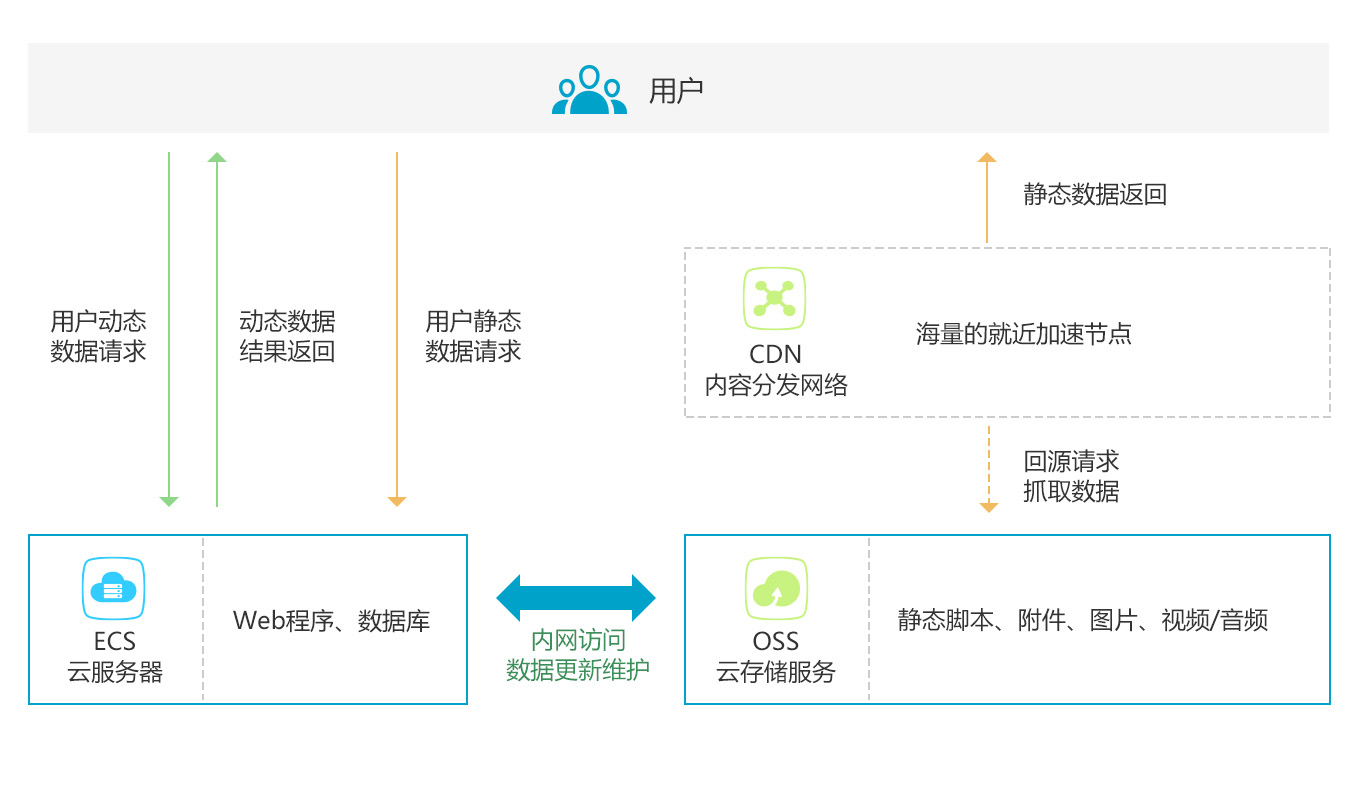
站点或者应用中大量静态资源的加速分发,建议将站点内容进行动静分离,动态文件可以结合云服务器ECS,静态资源如各类型图片、html、css、js文件等,建议结合 对象存储OSS 存储海量静态资源,可以有效加速内容加载速度,轻松搞定网站图片、短视频等内容分发。
支持各类文件的下载、分发,支持在线点播加速业务,如mp4、flv视频文件或者平均单个文件大小在20M以上,主要的业务场景是视音频点播、大文件下载(如安装包下载)等,建议搭配对象存储OSS使用,可提升回源速度,节约近2/3回源带宽成本。
视频流媒体直播服务,支持媒资存储、切片转码、访问鉴权、内容分发加速一体化解决方案。结合弹性伸缩服务,及时调整服务器带宽,应对突发访问流量;结合媒体转码服务,享受高速稳定的并行转码,且任务规模无缝扩展。
移动APP更新文件(apk文件)分发,移动APP内图片、页面、短视频、UGC等内容的优化加速分发。提供httpDNS服务,避免DNS劫持并获得实时精确的DNS解析结果,有效缩短用户访问时间,提升用户体验。
其实,CDN本身就是一种DNS劫持,只不过是良性的。 不同于黑客强制DNS把域名解析到自己的钓鱼IP上,CDN则是让DNS主动配合,把域名解析到临近的服务器上。
劫持通常分为两类:
域名劫持,又称DNS劫持,通常是指域名指向到非正常IP(恶意IP),该恶意IP通过反向代理的方式,在能返回网页正常内容的情况,可能插入恶意代码、监听网民访问、劫持敏感信息等操作。通常验证一个域名是否被劫持的方法是PING一个域名,如果发现PING出来的IP不是您的服务器真实IP,则可以确定被劫持了(当然如果使用了知道创宇云安全等安全加速平台,得到的IP为平台IP,并非劫持)
数据劫持,通常由电信运营商中某些员工等勾结犯罪分子,在公网中进行数据支持,插入,此类情况极隐蔽,不会改变用户域名解析IP,而是直接数据流经运营商宽带时在网页中挺入内容,此类情况,建议网页启用HTTPS加密,可以解决这一问题(通信是加密的,运营商无法插入恶意内容)
某运营商对新浪首页的广告强制插入:
如果使用CDN服务时,当源站向CDN返回被劫持的内容时,此时CDN将获取到的并不是正确的网页内容(而是经运营商篡改强制植入广告的页面),此时可能导致该内容在CDN中长时间缓存,发现这种问题,可以清理CDN缓存后,一般即可恢复正常。
遇到劫持现象,可以向工信部投诉:http://www.chinatcc.gov.cn:8080/cms/shensus/
可参考:
CDN边缘节点缓存策略因服务商不同而不同,但一般都会遵循http标准协议,通过http响应头中的 Cache-control: max-age的字段来设置CDN边缘节点数据缓存时间。
当客户端向CDN节点请求数据时,CDN节点会判断缓存数据是否过期,若缓存数据并没有过期,则直接将缓存数据返回给客户端;否则,CDN节点就会向源站发出回源请求(back to the source request),从源站拉取最新数据,更新本地缓存,并将最新数据返回给客户端。
CDN服务商一般会提供基于文件后缀、目录多个维度来指定CDN缓存时间,为用户提供更精细化的缓存管理。
CDN缓存时间会对回源率产生直接的影响。若CDN缓存时间较短,CDN边缘节点上的数据会经常失效,导致频繁回源,增加了源站的负载,同时也增大的访问延时;若CDN缓存时间太长,会带来数据更新时间慢的问题。开发者需要增对特定的业务,来做特定的数据缓存时间管理。
CDN边缘节点对开发者是透明的,相比于浏览器 Ctrl+F5 的强制刷新来使浏览器本地缓存失效,开发者可以通过CDN服务商提供的“刷新缓存”接口来达到清理CDN边缘节点缓存的目的。这样开发者在更新数据后,可以使用 刷新缓存 功能来强制CDN节点上的数据缓存过期,保证客户端在访问时,拉取到最新的数据。
可参考:
和其他许多编程语言一样,JavaScript使用分号(;)将语句分隔 开。这对增强代码的可读性和整洁性是非常重要的:缺少分隔符,一条语句的结束 就成了下一条语句的开始,反之亦然。在JavaScript中,如果语句各自独占一行,通 常可以省略语句之间的分号(程序结尾或右花括号“}”之前的分号也可以省略)。
许多JavaScript程序员(包括本书中的示例代码)使用分号来明确标记语句的结束, 即使在并不完全需要分号的时候也是如此。另一种风格就是,在任何可以省略分号 的地方都将其省略,只有在不得不用的时候才使用分号。不管采用哪种编程风格, 关于JavaScript中可选分号的问题有几个细节需要注意。
考虑如下代码,因为两条语句用两行书写,第一个分号是可以省略掉的:
a=3;
b=4;
如果按照如下格式书写,第一个分号则不能省略掉:
a=3;b=4;
需要注意的是,JavaScript并不是在所有换行处都填补分号:只有在缺少了分号 就无法正确解析代码的时候,JavaScript才会填补分号。 换句话讲(类似下面代码中的两处异常),如果当前语句和随后的非空格字符不能当成一个整体来解析的话, JavaScript就在当前语句行结束处填补分号。看一下如下代码:
var a
a
=
3 console.log(a)
JavaScript将其解析为:
var a;a=3;console.log(a);
JavaScript给第一行换行处添加了分号,因为如果没有分号,JavaScript就无法解析代码 var a a。第二个a可以单独当做一条语句“a;”,但JavaScript并没有给第二行结 尾填补分号,因为它可以和第三行内容一起解析成 “a=3;”。
这些语句的分隔规则会导致一些意想不到的情形,这段代码写成了两行,看起来是两条独立的语句:
var y=x+f
(a+b).toString()
但第二行的圆括号却和第一行的f组成了一个函数调用,JavaScript会把这段代 码看做:
var y=x+f(a+b).toString();
而这段代码的本意并不是这样。为了能让上述代码解析为两条不同的语句,必须手动填写行尾的显式分号。
通常来讲,如果一条语句以“(”、“[”、“/”、“+”或“-”开始,那么它极有可能和前一条语句合在一起解析。
以“/”、“+”和“-”开始的语句并不常见,而以“(”和“[”开始的 语句则非常常见,至少在一些JavaScript编码风格中是很普遍的。有些程序员喜欢保守地在语句前加上一个分号(有些代码合并工具也是这么干的),这样哪怕之前的语句被修改了、分号被误删除了,当 前语句还是会正确地解析:
var x=0//这里省略了分号
;[x,x+1,x+2].forEach(console.log)//前面的分号保证了正确地语句解析
如果当前语句和下一行语句无法合并解析,JavaScript则在第一行后填补分号, 这是通用规则,但有两个例外。第一个例外是在涉及 return、break 和 continue 语句的场景中。如果这三个关键字后紧跟着换行,JavaScript则会在换行 处填补分号。例如,这段代码:
return
true;
JavaScript会解析成:
return;true;
而代码的本意是这样:
return true;
也就是说,在 return、break 和 continue 和随后的表达式之间不能有换行。如果添加了换行,程序则只有在极特殊的情况下才会报错,而且程序的调试非常不方便。
第二个例外是在涉及“++”和“——”运算符的时候。这些运算符可以 作为表达式的前缀,也可以当做表达式的后缀。如果将其用做后缀表达式,它和表 达式应当在同一行。否则,行尾将填补分号,同时“++”或“——”将会作为下一行代 码的前缀操作符并与之一起解析,例如,这段代码:
x
++
y
这段代码将解析为“x;++y”,而不是“x++;y”。
在实际的工作中,我们可能还有些疑惑,当有多个选择器作用在一个元素上时,哪个规则最终会应用到元素上?其实这是通过层叠机制来控制的,这也和样式继承(元素从其父元素那里获得属性值)有关。
CSS 是 Cascading Style Sheets 的缩写,这暗示层叠(cascade)的概念是很重要的。在最基本的层面上,它表明CSS规则的顺序很重要,但它比那更复杂。什么选择器在层叠中胜出取决于三个因素(这些都是按重量级顺序排列的——前面的的一种会否决后一种):
在CSS中,有一个特别的语法可以让一条规则总是优先于其他规则:!important。把它加在属性值的后面可以使这条声明有无比强大的力量。
注意: 重载这个 !important 声明的唯一方法是在后面的源码或者是一个拥有更高特殊性的源码中包含相同的 !important 特性的声明。
知道 !important存在是很有用的,这样当你在别人的代码中遇到它时,你就知道它是什么了。但是!我们建议你千万不要使用它,除非你绝对必须使用它。您可能不得不使用它的一种情况是,当您在CMS中工作时,您不能编辑核心的CSS模块,并且您确实想要重写一种不能以其他方式覆盖的样式。 但是,如果你能避免的话,不要使用它。由于 !important 改变了层叠正常工作的方式,因此调试CSS问题,尤其是在大型样式表中,会变得非常困难。
要注意一个CSS声明的重要性取决于它被指定在什么样式表内——用户可以设置自定义样式表覆盖开发商的样式,例如用户可能有视力障碍,想设置字体大小对所有网页的访问是双倍的正常大小,以便更容易阅读。
相互冲突的声明将按以下顺序适用,后一种将覆盖先前的声明:
Web开发者的样式表覆盖用户的样式表是合理的,所以设计可以保持预期,但是有时候用户有很好的理由来重写web开发人员样式,如上所述,这可以通过在用户的规则中使用 !important。
特殊性基本上是衡量选择器的具体程度的一种方法——它能匹配多少元素。如上面所示的示例所示,元素选择器具有很低的特殊性。类选择器具有更高特殊性,所以将战胜元素选择器。ID选择器有甚至更高的专用性, 所以将战胜类选择器。
一个选择器具有的专用性的量是用四种不同的值(或组件)来衡量的,它们可以被认为是千位,百位,十位和个位——在四个列中的四个简单数字:
ID选择器就 在该列中加1分。类选择器、属性选择器、或者 伪类 就在该列中加1分。元素选择器 或 伪元素 就在该列中加1分。注意: 通用选择器 (*), 复合选择器 (+, >, ~, ' ') 和否定伪类 (:not) 在专用性中无影响。
示例
| 选择器 | 千位 | 百位 | 十位 | 个位 | 合计值 |
|---|---|---|---|---|---|
| h1 | 0 | 0 | 0 | 1 | 0001 |
| #important | 0 | 1 | 0 | 0 | 0100 |
| h1 + p::first-letter | 0 | 0 | 0 | 3 | 0003 |
| li > a[href*="zh-CN"] > .inline-warning | 0 | 0 | 2 | 2 | 0022 |
#important div > div > a:hover, 在一个元素的 <style> 属性里 |
1 | 1 | 1 | 3 | 1113 |
注意: 如果多个选择器具有相同的重要性和专用性,则选择哪一个选择器取决于 Source order(源代码次序)。
如果多个相互竞争的选择器具有相同的重要性和专用性,那么第三个因素将帮助决定哪一个规则获胜——后面的规则将战胜先前的规则。
CSS继承是我们需要研究的最后一部分,以获取所有信息并了解什么样式应用于元素。其**是,应用于某个元素的一些属性值将由该元素的子元素继承,而有些则不会。
哪些属性默认被继承哪些不被继承大部分符合常识。如果你想确定,你可以 参考CSS参考资料—— 每个单独的属性页都会从一个汇总表开始,其中包含有关该元素的各种详细信息,包括是否被继承。
继承属性是CSS最基本的内容之一,一般不会特别考虑,但是还是要记住的是:
CSS为处理继承提供了三种特殊的通用属性值:
inherit。inherit,否则就是表现得像 initial。层叠样式表这个名字很贴切。 CSS所采用的方法就是让样式层叠在一起,这是通过结合继承和特殊性做到的•。CSS2.1 的层叠规则相当简单。
!important 的规则的权重要高于没有 !important 标志的规则。按来源对应用到给定元素的所有声明排序。共有3种来源:创作人员、读者和用户代理。正常情况下,创作人员的样式要胜过读者的样式。有 !important 标志的读者样式要强于所有其他样式,这包括有 !important 标志的创作人员样式。创作人员样式和读者样式都比用户代理的默认样式要强。公司出于自身隐私保护需要,不想把自己的代码开源到包管理区,但是又急需一套完整包管工具,来管理越来越多的组件、模块和项目。对于前端,最熟悉的莫过于npm,bower等;但是bower的市场兼容性明显没有npm强壮,加之commonjs规范的日益成熟。npm应该是前端包管理的不二选择。
公司对于搭建本地私有npm库有如下要求:
Sinopia 是一个零配置的私有的带缓存功能的npm包管理工具,作者是是rlidwka,一个大神,也是一只猫~ 往社区内贡献过很多代码,包括 jshttp, markdown-it 等等,也是 Node.js 核心代码库的活跃贡献者。
使用sinopia,你不用安装CouchDB或MYSQL之类的数据库,Sinopia有自己的迷你数据库,如果要下载的包不存在,它将自动去你配置的npm地址上去下载,而且硬盘中只缓存你现在过的包,以节省空间。
sinopia有以下几个优势值得关注:
嗯,这种方式可行,也最简单,但真真的太烂了,姑且不说不能使用 semver,关键还是 url 太丑,如果是强迫症真的没法忍~
暂且不论 cnpm 只是作为镜像使用,其实这个方案缺点就挺多的,用的人多,速度不一定快,缓存,关键是不支持发布包以及登陆、注册,再加上配置过于复杂。而且,还需要安装数据库。
土豪啊,我还能说什么呢。。。但是问题是,npm在国内访问慢,还是不是的无法访问,花钱也买不到好的服务,何必呢。
首先,你要自己配置nodejs及npm的环境,然后运行
npm install -g sinopia
$ sinopia
warn --- config file - .....\AppData\Roaming\sinopia\config.yaml
warn --- http address - http://localhost:4873/
然后打开:http://localhost:4873/

如果能正常显示,说明安装成功。
当然,你也可以使用pm2或其他的守护进程进行管理,具体步骤如下:
安装pm2:npm install -g pm2
启动:pm2 start `which sinopia`
更多高级的pm2使用方法可以查看pm2电子书,相当详细,强烈推荐。
Sinopia的特点是,你在哪个目录运行,它的就会在对应的目录下创建自己的文件。目录下默认有两个文件:config.yaml和storage ,htpasswd 是添加用户之后自动创建的。
root@debian:/usr/local/apps/sinopia# ls
config.yaml htpasswd storage
其中config.yaml是用来配置访问权限,代理,文件存储路径等所有配置信息的,htpasswd用来保存用户的账号密码等息息,storage是用来存放npm包的。
#
# This is the default config file. It allows all users to do anything,
# so don't use it on production systems.
#
# Look here for more config file examples:
# https://github.com/rlidwka/sinopia/tree/master/conf
#
# path to a directory with all packages
storage: ./storage //npm包存放的路径
auth:
htpasswd:
file: ./htpasswd //保存用户的账号密码等信息
# Maximum amount of users allowed to register, defaults to "+inf".
# You can set this to -1 to disable registration.
max_users: -1 //默认为1000,改为-1,禁止注册
# a list of other known repositories we can talk to
uplinks:
npmjs:
url: http://registry.npm.taobao.org/ //默认为npm的官网,由于国情,修改 url 让sinopia使用 淘宝的npm镜像地址
packages: //配置权限管理
'@*/*':
# scoped packages
access: $all
publish: $authenticated
'*':
# allow all users (including non-authenticated users) to read and
# publish all packages
#
# you can specify usernames/groupnames (depending on your auth plugin)
# and three keywords: "$all", "$anonymous", "$authenticated"
access: $all
# allow all known users to publish packages
# (anyone can register by default, remember?)
publish: $authenticated
# if package is not available locally, proxy requests to 'npmjs' registry
proxy: npmjs
# log settings
logs:
- {type: stdout, format: pretty, level: http}
#- {type: file, path: sinopia.log, level: info}
# you can specify listen address (or simply a port)
listen: 0.0.0.0:4873 ////默认没有,只能在本机访问,添加后可以通过外网访问。
storage: 仓库保存的路径
web: 是否支持WEB接口
auth: 验证相关
uplinks: 配置上游的npm服务器,主要是用于请求的仓库不存在时去上游服务器拉取
packages: 配置模块/包的发布(publish)、下载(access)的权限等
listen: 配置监听端口与主机名
max_users: -1表示我们将最大用户数设置为-1,表示禁用 npm adduser 命令来创建用户,不过我们仍然可以通过当前目录下的 htpasswd 文件来初始化用户。
示例:
yorkie:{SHA}?????????????????=:autocreated 2016-02-05T15:33:46.238Z
weflex:{SHA}????????????????=:autocreated 2016-02-05T15:39:19.960Z
james:{SHA}????????????????=:autocreated 2016-02-05T17:59:05.041Z
上面的加密算法也很简单,就是简单的SHA1哈稀之后再转换成 Base64 输出就好,后面跟着的只是表示时间。
配置大致分为两个部分,一个是以 @weflex/* 为开头的,另一个则是通配符 *。
这个当然就是对 package.json 中的 name 字段进行匹配,比如 @weflex/app 将匹配第一个配置,而 express 则匹配第二个。
这里这么配置的意义在于:一般团队或者公司的私有项目,会采用不同的权限控制,于是这里借用了 NPM 的 scoped name 即 @Company 的形式,例如 @weflex/app 即表示 WeFlex 下属的 app 项目了。
接下来,每一个命名过滤器(filter)下都有三项基本设置:
access: 表示哪一类用户可以对匹配的项目进行安装(install)
publish: 表示哪一类用户可以对匹配的项目进行发布(publish)
proxy: 如其名,这里的值是对应于 uplinks 的
对于1和2的值,我们通常有以下一些可选的配置:
$all 表示所有人都可以执行对应的操作
$authenticated 表示只有通过验证的人可以执行对应操作
$anonymous 表示只有匿名者可以进行对应操作(通常无用)
或者也可以指定对应于之前我们配置的用户表 htpasswd 中的一个或多个用户,这样就明确地指定哪些用户可以执行匹配的操作
配置完成后,再运行:
$ sinopia -c config.yml
强烈推荐使用nrm来管理自己的代理。
全局安装nrm可以快速修改,切换,增加npm镜像地址。
$ npm install -g nrm # 安装nrm
$ nrm add XXXXX http://XXXXXX:4873 # 添加本地的npm镜像地址
$ nrm use XXXX # 使用本址的镜像地址
$ nrm --help # 查看nrm命令帮助
$ nrm list # 列出可用的 npm 镜像地址
$ nrm use taobao # 使用`淘宝npm`镜像地址
安装完成.之后你通过npm install 安装的包,sinopia都会帮你缓存到本地了.试一下吧。
mkdir test && cd test
npm install lodash # sinopia发现本地没有 lodash包,就会从 taobao镜像下载
rm -rf node-modules # 删除目录
npm insatll lodash # 第二次安装就会从缓存下载了,速度很快
创建新用户
1.确保自己已经切换到配置的代理
➜ ~ nrm ls
npm ---- https://registry.npmjs.org/
cnpm --- http://r.cnpmjs.org/
taobao - http://registry.npm.taobao.org/
nj ----- https://registry.nodejitsu.com/
rednpm - http://registry.mirror.cqupt.edu.cn
npmMirror https://skimdb.npmjs.com/registry
* sinopia http://192.168.1.200:4873/
2.运行npm adduser,填写信息,注册账号。如果已经有账号,直接运行npm login即可。
➜ ~ npm adduser
Username: test
Password:
3.运行$ npm publish发布新包。
通过一些例子来学习正则表达式摘录,js正则函数match、exec、test、search、replace、split
//去除首尾的‘/’
input = input.replace(/^\/*|\/*$/g,'');'javascript:;'.match(/^(javascript\s*\:|#)/);
//["javascript:", "javascript:", index: 0, input: "javascript:;"]var str = "access_token=dcb90862-29fb-4b03-93ff-5f0a8f546250; refresh_token=702f4815-a0ff-456c-82ce-24e4d7d619e6; account_uid=1361177947320160506170322436";
str.match(/account_uid=([^\=]+(\;)|(.*))/ig);var str = 'asdf html-webpack-plugin for "index/index.html" asdfasdf';
str.match(/html-webpack-plugin for \"(.*)\"/ig);
console.log(RegExp.$1) //=>index/index.html'css/[hash:8].index-index.css'.replace(/\[(?:(\w+):)?(contenthash|hash)(?::([a-z]+\d*))?(?::(\d+))?\]/ig,'(.*)');
//=> css/(.*).index-index.cssvar str = '<!DOCTYPE html><html manifest="../../cache.manifest" lang="en"><head><meta charset="UTF-8">';
str.replace(/<html[^>]*manifest="([^"]*)"[^>]*>/,function(word){
return word.replace(/manifest="([^"]*)"/,'manifest="'+url+'"');
}).replace(/<html(\s?[^\>]*\>)/,function(word){
if(word.indexOf('manifest')) return word;
return word.replace('<html','<html manifest="'+url+'"');
});
//原:<!DOCTYPE html><html manifest="../../cache.manifest" lang="en"><head><meta charset="UTF-8">
//替换成=> <!DOCTYPE html><html manifest="cache.manifest" lang="en"><head><meta charset="UTF-8">'max_length(12)'.match(/^(.+?)\((.+)\)$/)
// ["max_length(12)", "max_length", "12", index: 0, input: "max_length(12)"]var name = "Doe, John";
name.replace(/(\w+)\s*, \s*(\w+)/, "$2 $1");
//=> "John Doe"var str = 'asfdf === sdfaf ##'
str.match(/[^===]+(?=[===])/g) // 截取 ===之前的内容
str.replace(/\n/g,'') // 替换字符串中的 \n 换行字符// 精确到1位小数
/^[1-9][0-9]*$|^[1-9][0-9]*\.[0-9]$|^0\.[0-9]$/.test(1.2);
// 精确到2位小数
/^[0-9]+(.[0-9]{2})?$/.test(1.221);// 必须是包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
/^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$/.test("weeeeeeeW2");
//密码强度正则,最少6位,包括至少1个大写字母,1个小写字母,1个数字,1个特殊字符
/^.*(?=.{6,})(?=.*\d)(?=.*[A-Z])(?=.*[a-z])(?=.*[!@#$%^&*? ]).*$/.test("diaoD123#");
//输出 true/^[\u4e00-\u9fa5]{0,}$/.test("但是d"); //false
/^[\u4e00-\u9fa5]{0,}$/.test("但是"); //true
/^[\u4e00-\u9fa5]{0,}$/.test("但是"); //true/[\u4E00-\u9FA5]/.test("但是d") //true/^\w+$/.test("ds2_@#"); // false//身份证号(18位)正则
/^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$/.test("42112319870115371X");
//输出 false“yyyy-mm-dd“ 格式的日期校验,已考虑平闰年。
//日期正则,简单判定,未做月份及日期的判定
var dP1 = /^\d{4}(\-)\d{1,2}\1\d{1,2}$/;
//输出 true
console.log(dP1.test("2017-05-11"));
//输出 true
console.log(dP1.test("2017-15-11"));
//日期正则,复杂判定
var dP2 = /^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$/;
//输出 true
console.log(dP2.test("2017-02-11"));
//输出 false
console.log(dP2.test("2017-15-11"));
//输出 false
console.log(dP2.test("2017-02-29"));
// true var strRegex = "(.jpg|.gif|.txt)";
var re=new RegExp(strRegex);
if (re.test(str)){
}
/(.jpg|.gif)+(\?|\#|$)/.test('a/b/c.jpgsss'); //=> false
/(.jpg|.gif)+(\?|\#|$)/.test('a/b/c.jpg?'); //=> true//用户名正则,4到16位(字母,数字,下划线,减号)
/^[a-zA-Z0-9_-]{4,16}$/.test("diaodiao");
//输出 true/^\d+$/.test("42"); //正整数正则 -> 输出 true
/^-\d+$/.test("-42"); //负整数正则 -> 输出 true
/^-?\d+$/.test("-42"); //整数正则 -> 输出 true
/^[0-9]+$/.test(25.5455) //正整数正则 -> 输出 false
// 浮点数
/^(?:[-+])?(?:[0-9]+)?(?:\.[0-9]*)?(?:[eE][\+\-]?(?:[0-9]+))?$/.test(0.2)可以是整数也可以是浮点数
/^\d*\.?\d+$/.test("42.2"); //正数正则 -> 输出 true
/^-\d*\.?\d+$/.test("-42.2"); //负数正则 -> 输出 true
/^-?\d*\.?\d+$/.test("-42.2"); //数字正则 -> 输出 true//Email正则
/^([A-Za-z0-9_\-\.])+\@([A-Za-z0-9_\-\.])+\.([A-Za-z]{2,4})$/.test("[email protected]");
//输出 true
// 1.邮箱以a-z、A-Z、0-9开头,最小长度为1.
// 2.如果左侧部分包含-、_、.则这些特殊符号的前面必须包一位数字或字母。
// 3.@符号是必填项
// 4.右则部分可分为两部分,第一部分为邮件提供商域名地址,第二部分为域名后缀,现已知的最短为2位。
// 最长的为6为。
// 5.邮件提供商域可以包含特殊字符-、_、.
/^[a-z0-9]+([._\\-]*[a-z0-9])*@([a-z0-9]+[-a-z0-9]*[a-z0-9]+.){1,63}[a-z0-9]+$/.test("[email protected]");// 国家代码(2到3位)-区号(2到3位)-电话号码(7到8位)-分机号(3位)
/^(([0\+]\d{2,3}-)?(0\d{2,3})-)(\d{7,8})(-(\d{3,}))?$/.test('021-5055455')//手机号正则
/^1[34578]\d{9}$/.test("13611778887");
//输出 true
//* 13段:130、131、132、133、134、135、136、137、138、139
//* 14段:145、147
//* 15段:150、151、152、153、155、156、157、158、159
//* 17段:170、176、177、178
//* 18段:180、181、182、183、184、185、186、187、188、189
//* 国际码 如:**(+86)
/^((\+?[0-9]{1,4})|(\(\+86\)))?(13[0-9]|14[57]|15[012356789]|17[03678]|18[0-9])\d{8}$/.test("13611778887");//URL正则
/^((https?|ftp|file):\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/.test("http://wangchujiang.com");
//输出 true
//获取url中域名、协议正则 'http://xxx.xx/xxx','https://xxx.xx/xxx','//xxx.xx/xxx'
/^(http(?:|s)\:)*\/\/([^\/]+)/.test("http://www.baidu.com");
/^((http|https):\/\/(\w+:{0,1}\w*@)?(\S+)|)(:[0-9]+)?(\/|\/([\w#!:.?+=&%@!\-\/]))?$/.test('https://www.baidu.com/s?wd=@#%$^&%$#')
// 必须有协议
/^[a-zA-Z]+:\/\//.test("http://www.baidu.com");//ipv4地址正则
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/.test("192.168.130.199");
//输出 true//RGB Hex颜色正则
/^#?([a-fA-F0-9]{6}|[a-fA-F0-9]{3})$/.test("#b8b8b8");
//输出 true//QQ号正则,5至11位
/^[1-9][0-9]{4,10}$/.test("398188661");//输出 true//微信号正则,6至20位,以字母开头,字母,数字,减号,下划线
/^[a-zA-Z]([-_a-zA-Z0-9]{5,19})+$/.test("jslite"); //输出 true//车牌号正则
/^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$/.test("沪B99116") //输出 true// HEX 颜色正则
/^#?([0-9a-fA-F]{3}|[0-9a-fA-F]{6})$/.test("#ccb2b2")在很久很久以前,我们访问各种网站都是简单而直接的,用户的请求通过互联网发送到服务提供方,服务提供方直接将信息反馈给用户。
后来,GFW 就出现了,他像一个收过路费的强盗一样夹在了在用户和服务之间,每当用户需要获取信息,都经过了 GFW,GFW将它不喜欢的内容统统过滤掉,于是客户当触发 GFW 的过滤规则的时候,就会收到 Connection Reset 这样的响应内容,而无法接收到正常的内容。
GFW 内部结构:
GFW 列表可以参考这里:gfwlist/gfwlist
聪明的人们想到了利用境外服务器代理的方法来绕过 GFW 的过滤,其中包含了各种HTTP代理服务、Socks服务、VPN服务等。
SSH(Secure Shell)是一个提供数据通信安全、远程登录、远程指令执行等功能的安全网络协议,由芬兰赫尔辛基大学研究员Tatu Ylönen,于1995年提出,其目的是用于替代非安全的Telnet、rsh、rexec等远程Shell协议。之后SSH发展了两个大版本SSH-1和SSH-2。
想深入了解SSH的原理,可以查看 O‘RELLY的 《SSH: The Secure Shell - The Definitive Guide》,这是一本非常不错的书。
那么我们来看看搭建一个SSH隧道翻墙,究竟有多简单。首先你需要有一台支持SSH的墙外服务器,此服务器啥都不需要,只要能SSH连接即可。
客户端SSH执行如下命令:
ssh -D 7001 username@remote-host
上述命令中-D表示动态绑定,7001表示本地SOCKS代理的侦听端口,可以改成别的,后面的 username@remote-host就是你登录远程服务器的用户名和主机。当然,这个命令后会提示输入密码,就是username这个用户的密码(除非你配置了SSH公钥认证,可以不输入密码),这样隧道就打通了。
由于 ssh 本身就是基于 RSA 加密技术,所以 GFW 无法从数据传输的过程中的加密数据内容进行关键词分析,避免了被重置链接的问题,但由于创建隧道和数据传输的过程中,ssh 本身的特征是明显的,所以 GFW 一度通过分析连接的特征进行干扰,导致 ssh 存在被定向进行干扰的问题。
至于干扰的原理,shadowsocks的作者 @clowwindy 认为:
从校长最近的论文上上看,GFW 最近弄的是先检测首部特征判断 SSL 和 SSH,然后统计包长度和方向,用实现训练好的模型去判断承载的流量是否为 HTTP。如果你用 SSH 翻墙,或者你的操作行为发的数据包过于接近 HTTP,就会被 reset。反过来,如果你想用 SSH 翻墙,只要在用来翻墙的那个 ssh 连接里做些别的操作(比如反复 tail 一个长文件,这样会不停的输出;或者用管道不停的往 ssh 里写命令,这样会不停的输入),就可以让这个模型失效,从而不会被判定为翻墙。
随着时代的发展以及企业规模的发展壮大,企业网络也在不断发生变化。例如,一家总部设在北京的企业,可能会在上海、广州和深圳等地都设有分支机构,因此需要把各个分支机构连接在一起,以便共享资源、协同工作,提高工作效率。但传统的专线联网方式价格昂贵,一般中小企业难以负担。这时低成本的VPN技术就孕育而生了。VPN(Virtual Private Network)即虚拟专用网络,它可以利用廉价接入的公共网络(主要使用Inter-net)来传输私有数据,相较于传统的专线连网方式具有成本优势,因此被很多企业和电信运营商采用。
VPN 比shadowsocks更加底层,它通过操作系统的接口直接虚拟出一张网卡,后续整个操作系统的网络通讯都将通过这张虚拟的网卡进行收发。这和任何一个代理的实现思路都差不多,应用层并不知道网卡是虚拟的,这样vpn虚拟网卡将以中间人的身份对数据进行加工,从而实现各种神奇的效果。具体来说,vpn是通过编写一套网卡驱动并注册到操作系统实现的虚拟网卡,这样数据只要经过网卡收发就可以进行拦截处理。
VPN和SSH隧道翻墙有如下区别:
简单理解的话,shadowsocks 是将原来 ssh 创建的 Socks5 协议拆开成 server 端和 client 端,所以下面这个原理图基本上和利用 ssh tunnel 大致类似。
代理自动配置(Proxy auto-config,简称PAC) 是一种网页浏览器技术,用于定义浏览器该如何自动选择适当的代理服务器来访问一个网址。
一个PAC文件包含一个JavaScript形式的函数 FindProxyForURL(url, host)。这个函数返回一个包含一个或多个访问规则的字符串。用户代理根据这些规则适用一个特定的代理其或者直接访问。当一个代理服务器无法响应的时候,多个访问规则提供了其他的后备访问方法。浏览器在访问其他页面以前,首先访问这个PAC文件。PAC文件中的URL可能是手工配置的,也可能是是通过网页的 网络代理自发现协议(Web Proxy Autodiscovery Protocol) 自动配置的。
上面是从维基百科摘录的关于PAC的解释,我做了一个简单的图片解释什么是PAC:
简单的讲,PAC就是一种配置,它能让你的浏览器智能判断哪些网站走代理,哪些不需要走代理。点击 Shadowsocks 的菜单,选择 编辑自动模式的 PAC,如下图
在上面的目录下有两个文件,一个是 gfwlist.js,还有一个是
user-rule.txt,确保当前的模式为自动代理模式,打开系统设置-->网络,点击高级,查看代理选项卡,如下图
Shadowsocks 的全局模式,是设置你的系统代理的代理服务器,使你的所有http/socks数据经过代理服务器的转发送出。而只有支持 socks 5或者使用系统代理的软件才能使用 Shadowsocks(一般的浏览器都是默认使用系统代理)。
而PAC模式就是会在你连接网站的时候读取PAC文件里的规则,来确定你访问的网站有没有被墙,如果符合,那就会使用代理服务器连接网站,而PAC列表一般都是从 GFWList 更新的。GFWList 定期会更新被墙的网站(不过一般挺慢的)。
简单地说,在全局模式下,所有网站默认走代理。而PAC模式是只有被墙的才会走代理,推荐PAC模式,如果PAC模式无法访问一些网站,就换全局模式试试,一般是因为PAC更新不及时(也可能是GFWList更新不及时)导致的。
还有,说一下Chrome不需要 Proxy SwitchyOmega 和 Proxy SwitchySharp 插件,这两个插件的作用就是,快速切换代理,判断网站需不需要使用某个代理的(shadowsocks已经有pac模式了,所以不需要这个)。如果你只用shadowsocks的话,就不需要这个插件了!
经过代理服务器的IP会被更换。连接 Shadowsocks 需要知道IP、端口、账号密码和加密方式。但是Shadowsocks因为可以自由换端口,所以定期换端口就可以有效避免IP被封!
本地浏览器SOCKS服务器通常是用来做代理的,它通过TCP连接把目标主机和客户端连接在一起, 并转发所有的流量。SOCKS代理能在任何端口,任何协议下运行(额,好想有点不对, 这货是运行在session层,所以在他之下的层他就无法代理了)。SOCKS V4只支持 TCP连接,而SOCKS V5在其基础上增加了安全认证以及对UDP协议的支持(也就是说, SOCKS5支持密码认证以及转发UDP流量,注意,HTTP是不支持转发UDP的)。
SOCKS代理在任何情况下都不会中断server与client之间的数据(这是由这种协议的 特性决定的,毕竟非明文,但是在SOCKS代理服务器上还是可以还原出TCP和UDP的原始 流量的),当你的防火墙不允许你上网的时候,你就可以通过SOCKS代理来上网(这里的 意思是,如果GFW把google屏蔽了,你就可以通过一台海外的SOCKS代理服务器上谷歌)。
大多数的浏览器都支持SOCKS代理(这篇文章是三年前的,抱歉,谷歌第一条就是它)。( 浏览器上网的时候需要与目标主机建立TCP连接,这个时候浏览器就会告诉SOCKS代理,它想 与目标主机进行通讯,然后SOCKS代理就会转发浏览器的数据,并向目标主机发出请求,然 后再把返回的数据转发回来。)(关于shadowsocks的一点题外话:虽然github上的源码 没了,但是耐不住民间私货多呀。shadowsocks有server端和client端,这两个都是用 来转发数据的,但是由于其所处的位置不同,所以功能也不同,client即本地运行的程序, 监听1080端口,并将数据转发到远在他乡的SOCKS服务器,由于这种转发是加密的,在会话层, 所以GFW过滤的难度很大,所以才派人巴拉巴拉让作者删除源码,嗯,一定是这样的。然后server 那边收到数据后,会原原本本的把数据再向目标请求,收到反馈后再返回给本地client的1080端口, 这样,我们向本地的1080请求资源,本地向SOCKS服务器请求资源,SOCKS服务器向目标请求资源, 这一条TCP连接就这样建立起来了。)但是,但是,但是,SOCKS代理原则上是可以还原真实数据的, 所以,第三方的代理也许不是很可靠。
HTTP代理跟上面原理类似,用处也基本相同,都是让处于防火墙下的主机与外界建立连接,但是它与SOCKS代理不同的是,HTTP代理可以中断连接(即在中间截断数据流),因为HTTP代理是以HTTP请求为基础的 而这些请求大多以明文形式存在,所以HTTP代理可以在Client和下游服务器中间窃听,修改数据。但也正 由于HTTP代理只能处理HTTP请求,所以它对HTTP请求的处理也是很舒服的(原文中是smart)。而也由于 HTTP代理可以获取你的HTTP请求,所以HTTP代理服务器那边就可以根据你提交的数据来把那些资源缓存下来,提升访问的速度(用户亲密度+1)。有好多ISP都用HTTP代理,而不管用户那边的浏览器是怎样配置的,因为不管用户们怎么配置,他们总是要访问80端口,而这些80端口们又掌握在ISP们的手中。(原文完全不是这样说的= =。原文是说,互联网提供商们把流量都通过了HTTP代理,这样代理服务器中就有了缓存,访问的速度会快一些。)
(我来举个栗子:假如你的HTTP代理是Goagent,监听本地127.0.0.1:8080,此刻假设你已经把浏览器 的代理设置为:127.0.0.1:8080,那么你在浏览器中,所有的POST,GET,以及其他的请求,都会通过 本地的代理转发给远程的服务器,然后再通过远程的服务器去请求你所请求的这些资源,大家知道,HTTP协议是通过明文传输的,无论是在本地还是远程的服务器上,都是可以监听到这些流量的,所以才会有GFW的存在……HTTP协议属于应用层,而SOCKS协议属于传输层,ps:传输层在应用层之下,这就决定了两者的能力大小。)
随着前端这几年的风生水起,CSS作为前端的三剑客之一,各种技术方案也是层出不穷。从CSS prepocessor(SASS、LESS、Stylus)到后来的后起之秀 PostCSS,再到 CSS Modules、Styled-Component 等。有人维护了一份完整的 CSS in JS 技术方案的对比,里面已经有将近50种技术方案。CSS Modules就是其中一种。
要弄懂CSS Modules是什么,可以先看官方介绍:GitHub – css-modules/css-modules: Documentation about css-modules
通过上面介绍可以看出,CSS Modules既不是官方标准,也不是浏览器的特性,而是在构建步骤(例如使用Webpack或Browserify)中对CSS类名选择器限定作用域的一种方式(通过hash实现类似于命名空间的方法)。例如我们在buttons.js里引入buttons.css文件,并使用.btn的样式,在其他组件里是不会被.btn影响的,除非它也引入了buttons.css.
JS已经全面实现了模块化,但是css还处于探索阶段。为什么我们需要css模块化?主要由一下几个原因。
CSS的规则都是全局的,任何一个组件的样式规则,都对整个页面有效。现在的前端工程大多是基于组件开发,随着工程的页面数量好复杂度的提升,相信写css的人都会遇到样式冲突(污染)的问题。一般我们会采用一下几种方法:
可是以上方案只是降低了全局冲突的概率,并不能彻底解决全局冲突的问题。并且,实现方式也不够优雅,还增加了代码的复杂和冗余。
CSS 模块化的解决方案有很多,但主要有三类。
规范化CSS的模块化解决方案(比如BEM BEM — Block Element Modifier ,OOCSS,AMCSS,SMACSS,SUITCSS)
但存在以下问题:
彻底抛弃 CSS,用 JavaScript 写 CSS 规则,并内联样式。styled-components 就是其中代表。styled-components可以让CSS真正意义地写到JS里面,同时让标签更具有语意化,这跟HTML5新标签**相同;该框架让样式也具备组件化**,让前端完全面向组件化编程,就像java的包装类型。
但存在以下问题:
使用JS编译原生的CSS文件,使其具备模块化的能力,代表是 CSS Modules。
CSS Module还是JS和CSS分离的写法,不会改变大家的书写习惯,CSS Module只需修改构建代码和使用模块依赖引入className的方式即可使用,且支持less和sass的语法,
使用CSS Modules可以让组件className控制权转交给JS,我们不会去关心命名冲突污染等问题,同时可以灵活控制生成的命名,样式代码不用修改即可让使用CSS语法的旧项目零成本接入。
CSS Modules 能最大化地结合现有 CSS 生态(预处理器/后处理器等)和 JS 模块化能力,几乎零学习成本。只要你使用 Webpack,可以在任何项目中使用。是目前最好的 CSS 模块化解决方案。
CSS Modules配置非常简单,如果你使用webpack,只需要在配置文件中改动一行即可。
// webpack.config.js
css?modules&localIdentName=[name]__[local]-[hash:base64:5]
加上 modules 即为启用,localIdentName 是设置生成样式的命名规则。
css
/* components/Button.css */
.normal { /* normal 相关的所有样式 */ }
js
// components/Button.js
import styles from './Button.css';
console.log(styles);
buttonElem.outerHTML = `<button class=${styles.normal}>Submit</button>`上例中 console 打印styles的结果是:
Object {
normal: 'button--normal-abc53',
disabled: 'button--disabled-def886',
}
注意到 button--normal-abc53 是 CSS Modules 按照 localIdentName 自动生成的 class 名。其中的 abc53 是按照给定算法生成的序列码。经过这样混淆处理后,class 名基本就是唯一的,大大降低了项目中样式覆盖的几率。同时在生产环境下修改规则,生成更短的 class 名,可以提高 CSS 的压缩率。
CSS Modules 对 CSS 中的 class 名都做了处理,使用对象来保存原 class 和混淆后 class 的对应关系。
import React from 'react';
import styles from './table.css';
export default class Table extends React.Component {
render () {
return <div className={styles.table}>
<div className={styles.row}>
</div>
</div>;
}
}
渲染结果:
<div class="table__table___32osj">
<div class="table__row___2w27N">
</div>
</div>
babel-plugin-react-css-modules 可以实现使用styleName属性自动加载CSS模块。只需要把className换成styleName即可获得CSS局部作用域的能力,babel插件来自动进行语法树解析并最终生成className。改动成本极小,不会增加JSX的复杂度,也不会给项目带来额外的负担。
import React from 'react';
import styles from './table.css';
class Table extends React.Component {
render () {
return <div styleName='table'>
</div>;
}
}
export default Table;
CSS Modules 很好的解决了 CSS 目前面临的模块化难题。支持与 CSS处理器搭配使用,能充分利用现有技术积累。如果你的产品中正好遇到类似问题,非常值得一试。
在前端工程的的打包史中,common文件向来都不是一个好处理的方面。在这一块,webpack提供了CommonsChunkPlugin来处理这个事情,但是在由于文档的模棱两可,再加上各种配置选项的多样性和某些bug,这一块还是有不少坑的。
所谓工欲善其事必先利其器,我们既然想做common方面的优化,那么首先肯定要知道打包后的文件体积庞大的主要原因。说到这里就不得不提到一个相当好用的工具:webpack-bundle-analyzer
它既是一个webpack插件,又是一个命令行工具。能够将webpack包的内容转换成可缩放的树状图,方便进行交互分析。恩。。。就是这玩意:

npm install --save-dev webpack-bundle-analyzer
在 webpack.config.js中:
var BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
// ...
plugins: [new BundleAnalyzerPlugin()]
// ...
默认配置如下:
new BundleAnalyzerPlugin({
// Can be `server`, `static` or `disabled`.
// In `server` mode analyzer will start HTTP server to show bundle report.
// In `static` mode single HTML file with bundle report will be generated.
// In `disabled` mode you can use this plugin to just generate Webpack Stats JSON file by setting `generateStatsFile` to `true`.
analyzerMode: 'server',
// Host that will be used in `server` mode to start HTTP server.
analyzerHost: '127.0.0.1',
// Port that will be used in `server` mode to start HTTP server.
analyzerPort: 8888,
// Path to bundle report file that will be generated in `static` mode.
// Relative to bundles output directory.
reportFilename: 'report.html',
// Automatically open report in default browser
openAnalyzer: true,
// If `true`, Webpack Stats JSON file will be generated in bundles output directory
generateStatsFile: false,
// Name of Webpack Stats JSON file that will be generated if `generateStatsFile` is `true`.
// Relative to bundles output directory.
statsFilename: 'stats.json',
// Options for `stats.toJson()` method.
// For example you can exclude sources of your modules from stats file with `source: false` option.
// See more options here: https://github.com/webpack/webpack/blob/webpack-1/lib/Stats.js#L21
statsOptions: null,
// Log level. Can be 'info', 'warn', 'error' or 'silent'.
logLevel: 'info'
})
第一步:
webpack --profile --json > stats.json
第二步:
webpack --profile --json | Out-file 'stats.json' -Encoding OEM
执行成功后,你将看到以下动态网页:
在这里顺便放上线上文件加载waterfall,作为对比。
通过图表可以看到,在以下配置下:
config.plugins.push(new CommonsChunkPlugin('commons', 'js/commons.[hash].bundle.js'));
打包出来的文件还是有很多问题的:
import {ImgBigSwiper} from 'components/src/index'; 这种写法会导致将components里面的所有组件全部打包进页面的js。应该这样写:import ImgBigSwiper from 'components/src/ImgBigSwiper';挨个引入,见webpack将ES6编译成CommonJs后只引入用到的模块在这个过程中,会发现一个有趣的事情。就是index.html页面的script加载分为以下两个部分:
......
<script type="text/javascript" src="//res.dinghuo123.com/src/common/ueditor/ueditor.config.js"></script>
<script type="text/javascript" src="//res.dinghuo123.com/src/common/ueditor/ueditor.config.js"></script>
<script type="text/javascript" src="//res.dinghuo123.com/src/common/ueditor/ueditor.config.js"></script>
......
<script>
document.write('<script src="https://resource.dinghuo123.com/dist/ydhv2/webpack.assets.js?v=' + Math.random() + '"><\/script>');
document.write('<script src="' + window.WEBPACK_ASSETS['commons'].js + '"><\/script>');
document.write('<script src="//res.dinghuo123.com/src/common/ueditor/ueditor.config.js"><\/script>');
document.write('<script src="' + window.WEBPACK_ASSETS['index'].js + '"><\/script>');
</script>
然后你会发现,是上面一块的script并行加载完,才并行加载下一个script标签的内容。大家可以思考一下为什么。
进过调整之后的CommonsChunkPlugin配置:
config.plugins.push(new CommonsChunkPlugin({
name: 'commons',
minChunks: Infinity // 随着 入口chunk 越来越多,这个配置保证没其它的模块会打包进 公共chunk
}));
config.plugins.push(new CommonsChunkPlugin({
async:'antd',
minChunks(module) {
var context = module.context;
return context && context.indexOf('antd/dist') >= 0;
}
}));
config.plugins.push(new CommonsChunkPlugin({
async:'echarts',
minChunks(module) {
var context = module.context;
return context && (context.indexOf('echarts') >= 0 || context.indexOf('zrender') >= 0);
}
}));
这里用到了minChunks和async两个配置。
其中第一name的commons是一个entry入口,里面是一个依赖包的数组。minChunks设置为Infinity这个配置保证没其它的模块会打包进 公共chunk。因为说实话,CommonsChunkPlugin的commons分析实在是不怎么只能,还是手动控制会更好一些。
当然,你可以传入一个 function ,以添加定制的逻辑(默认是 chunk 的数量),这个函数会被 CommonsChunkPlugin 插件回调,并且调用函数时会传入 module 和 count 参数。
module 参数代表每个 chunks 里的模块,这些 chunks 是你通过 name/names 参数传入的。
当你想要对 CommonsChunk 如何决定模块被打包到哪里的算法有更为细致的控制, 这个配置就会非常有用。
如果设置为 true,一个异步的 公共chunk 会作为 options.name 的子模块,和 options.chunks 的兄弟模块被创建。它会与 options.chunks 并行被加载。可以通过提供想要的字符串,而不是 true 来对输出的文件进行更换名称。
还是先看打包分析的结果吧:
通过上面分析可以看到:
tree-shaking的探索Vendor and code splitting in webpack 2
webpack 按需打包加载
weboack Split app and vendor code
awesome-webpack-cn

在 ES6 中增加了对类对象的相关定义和操作(比如 class 和 extends ),这就使得我们在多个不同类之间共享或者扩展一些方法或者行为的时候,变得并不是那么优雅。这个时候,我们就需要一种更优雅的方法来帮助我们完成这些事情。
在面向对象(OOP)的设计模式中,decorator被称为装饰模式。OOP的装饰模式需要通过继承和组合来实现,而Python除了能支持 OOP 的 decorator 外,直接从语法层次支持 decorator。
如果你熟悉 python 的话,对它一定不会陌生。那么我们先来看一下 python 里的装饰器是什么样子的吧:
def decorator(f):
print "my decorator"
return f
@decorator
def myfunc():
print "my function"
myfunc()
# my decorator
# my function这里的 @decorator 就是我们说的装饰器。在上面的代码中,我们利用装饰器给我们的目标方法执行前打印出了一行文本,并且并没有对原方法做任何的修改。代码基本等同于:
def decorator(f):
def wrapper():
print "my decorator"
return f()
return wrapper
def myfunc():
print "my function"
myfunc = decorator(myfuc)通过代码我们也不难看出,装饰器 decorator 接收一个参数,也就是我们被装饰的目标方法,处理完扩展的内容以后再返回一个方法,供以后调用,同时也失去了对原方法对象的访问。当我们对某个应用了装饰以后,其实就改变了被装饰方法的入口引用,使其重新指向了装饰器返回的方法的入口点,从而来实现我们对原函数的扩展、修改等操作。
ES7 中的 decorator 同样借鉴了这个语法糖,不过依赖于 ES5 的 Object.defineProperty 方法 。
Object.defineProperty() 方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性, 并返回这个对象。
该方法允许精确添加或修改对象的属性。通过赋值来添加的普通属性会创建在属性枚举期间显示的属性(for...in 或 Object.keys 方法), 这些值可以被改变,也可以被删除。这种方法允许这些额外的细节从默认值改变。默认情况下,使用 Object.defineProperty() 添加的属性值是不可变的。
Object.defineProperty(obj, prop, descriptor)obj:要在其上定义属性的对象。prop:要定义或修改的属性的名称。descriptor:将被定义或修改的属性描述符。在ES6中,由于 Symbol类型 的特殊性,用 Symbol类型 的值来做对象的key与常规的定义或修改不同,而Object.defineProperty 是定义 key为 Symbol 的属性的方法之一。
对象里目前存在的属性描述符有两种主要形式:数据描述符和存取描述符。
描述符必须是这两种形式之一;不能同时是两者。
数据描述符和存取描述符均具有以下可选键值:
当且仅当该属性的 configurable 为 true 时,该属性描述符才能够被改变,同时该属性也能从对应的对象上被删除。默认为 false。
enumerable定义了对象的属性是否可以在 for...in 循环和 Object.keys() 中被枚举。
当且仅当该属性的 enumerable 为 true 时,该属性才能够出现在对象的枚举属性中。默认为 false。
数据描述符同时具有以下可选键值:
该属性对应的值。可以是任何有效的 JavaScript 值(数值,对象,函数等)。默认为 undefined。
当且仅当该属性的 writable 为 true 时,value 才能被赋值运算符改变。默认为 false。
存取描述符同时具有以下可选键值:
一个给属性提供 getter 的方法,如果没有 getter 则为 undefined。该方法返回值被用作属性值。默认为 undefined。
一个给属性提供 setter 的方法,如果没有 setter 则为 undefined。该方法将接受唯一参数,并将该参数的新值分配给该属性。默认为 undefined。
如果一个描述符不具有value,writable,get 和 set 任意一个关键字,那么它将被认为是一个数据描述符。如果一个描述符同时有(value或writable)和(get或set)关键字,将会产生一个异常。
@testable
class MyTestableClass {
// ...
}
function testable(target) {
target.isTestable = true;
}
MyTestableClass.isTestable // true上面代码中,@testable 就是一个装饰器。它修改了 MyTestableClass这 个类的行为,为它加上了静态属性isTestable。testable 函数的参数 target 是 MyTestableClass 类本身。
基本上,装饰器的行为就是下面这样。
@decorator
class A {}
// 等同于
class A {}
A = decorator(A) || A;也就是说,装饰器是一个对类进行处理的函数。装饰器函数的第一个参数,就是所要装饰的目标类。
如果觉得一个参数不够用,可以在装饰器外面再封装一层函数。
function testable(isTestable) {
return function(target) {
target.isTestable = isTestable;
}
}
@testable(true)
class MyTestableClass {}
MyTestableClass.isTestable // true
@testable(false)
class MyClass {}
MyClass.isTestable // false上面代码中,装饰器 testable 可以接受参数,这就等于可以修改装饰器的行为。
注意,装饰器对类的行为的改变,是代码编译时发生的,而不是在运行时。这意味着,装饰器能在编译阶段运行代码。也就是说,装饰器本质就是编译时执行的函数。
前面的例子是为类添加一个静态属性,如果想添加实例属性,可以通过目标类的 prototype 对象操作。
下面是另外一个例子。
// mixins.js
export function mixins(...list) {
return function (target) {
Object.assign(target.prototype, ...list)
}
}
// main.js
import { mixins } from './mixins'
const Foo = {
foo() { console.log('foo') }
};
@mixins(Foo)
class MyClass {}
let obj = new MyClass();
obj.foo() // 'foo'上面代码通过装饰器 mixins,把Foo对象的方法添加到了 MyClass 的实例上面。
装饰器不仅可以装饰类,还可以装饰类的属性。
class Person {
@readonly
name() { return `${this.first} ${this.last}` }
}上面代码中,装饰器 readonly 用来装饰“类”的name方法。
装饰器函数 readonly 一共可以接受三个参数。
function readonly(target, name, descriptor){
// descriptor对象原来的值如下
// {
// value: specifiedFunction,
// enumerable: false,
// configurable: true,
// writable: true
// };
descriptor.writable = false;
return descriptor;
}
readonly(Person.prototype, 'name', descriptor);
// 类似于
Object.defineProperty(Person.prototype, 'name', descriptor);另外,上面代码说明,装饰器(readonly)会修改属性的 描述对象(descriptor),然后被修改的描述对象再用来定义属性。
装饰器只能用于类和类的方法,不能用于函数,因为存在函数提升。
另一方面,如果一定要装饰函数,可以采用高阶函数的形式直接执行。
function doSomething(name) {
console.log('Hello, ' + name);
}
function loggingDecorator(wrapped) {
return function() {
console.log('Starting');
const result = wrapped.apply(this, arguments);
console.log('Finished');
return result;
}
}
const wrapped = loggingDecorator(doSomething);core-decorators.js是一个第三方模块,提供了几个常见的装饰器,通过它可以更好地理解装饰器。
autobind 装饰器使得方法中的this对象,绑定原始对象。
readonly 装饰器使得属性或方法不可写。
override 装饰器检查子类的方法,是否正确覆盖了父类的同名方法,如果不正确会报错。
import { override } from 'core-decorators';
class Parent {
speak(first, second) {}
}
class Child extends Parent {
@override
speak() {}
// SyntaxError: Child#speak() does not properly override Parent#speak(first, second)
}
// or
class Child extends Parent {
@override
speaks() {}
// SyntaxError: No descriptor matching Child#speaks() was found on the prototype chain.
//
// Did you mean "speak"?
}deprecate 或 deprecated 装饰器在控制台显示一条警告,表示该方法将废除。
import { deprecate } from 'core-decorators';
class Person {
@deprecate
facepalm() {}
@deprecate('We stopped facepalming')
facepalmHard() {}
@deprecate('We stopped facepalming', { url: 'http://knowyourmeme.com/memes/facepalm' })
facepalmHarder() {}
}
let person = new Person();
person.facepalm();
// DEPRECATION Person#facepalm: This function will be removed in future versions.
person.facepalmHard();
// DEPRECATION Person#facepalmHard: We stopped facepalming
person.facepalmHarder();
// DEPRECATION Person#facepalmHarder: We stopped facepalming
//
// See http://knowyourmeme.com/memes/facepalm for more details.
//suppressWarnings 装饰器抑制 deprecated 装饰器导致的 console.warn() 调用。但是,异步代码发出的调用除外。
@testable
class Person {
@readonly
@nonenumerable
name() { return `${this.first} ${this.last}` }
}从上面代码中,我们一眼就能看出,Person类是可测试的,而name方法是只读和不可枚举的。
实际开发中,React 与 Redux 库结合使用时,常常需要写成下面这样。
class MyReactComponent extends React.Component {}
export default connect(mapStateToProps, mapDispatchToProps)(MyReactComponent);有了装饰器,就可以改写上面的代码。装饰
@connect(mapStateToProps, mapDispatchToProps)
export default class MyReactComponent extends React.Component {}相对来说,后一种写法看上去更容易理解。
菜单点击时,进行事件拦截,若该菜单有新功能更新,则弹窗显示。
/**
* @description 在点击时,如果有新功能提醒,则弹窗显示
* @param code 新功能的code
* @returns {function(*, *, *)}
*/
const checkRecommandFunc = (code) => (target, property, descriptor) => {
let desF = descriptor.value;
descriptor.value = function (...args) {
let recommandFuncModalData = SYSTEM.recommandFuncCodeMap[code];
if (recommandFuncModalData && recommandFuncModalData.id) {
setTimeout(() => {
this.props.dispatch({type: 'global/setRecommandFuncModalData', recommandFuncModalData});
}, 1000);
}
desF.apply(this, args);
};
return descriptor;
};在 React 项目中,我们可能需要在向后台请求数据时,页面出现 loading 动画。这个时候,你就可以使用装饰器,优雅地实现功能。
@autobind
@loadingWrap(true)
async handleSelect(params) {
await this.props.dispatch({
type: 'product_list/setQuerypParams',
querypParams: params
});
}loadingWrap 函数如下:
export function loadingWrap(needHide) {
const defaultLoading = (
<div className="toast-loading">
<Loading className="loading-icon"/>
<div>加载中...</div>
</div>
);
return function (target, property, descriptor) {
const raw = descriptor.value;
descriptor.value = function (...args) {
Toast.info(text || defaultLoading, 0, null, true);
const res = raw.apply(this, args);
if (needHide) {
if (get('finally')(res)) {
res.finally(() => {
Toast.hide();
});
} else {
Toast.hide();
}
}
};
return descriptor;
};
}问题:这里大家可以想想看,如果我们不希望每次请求数据时都出现 loading,而是要求只要后台请求时间大于 300ms 时,才显示loading,这里需要怎么改?
连接管理是一个 HTTP 的关键话题:打开和保持连接在很大程度上影响着网站和 Web 应用程序的性能。在 HTTP/1.x 里有好些个模型:
短连接(short-lived connections),持久连接(persistent connections), 和HTTP 管道(HTTP pipelining)。
HTTP 的传输协议主要依赖于 TCP 来提供从客户端到服务器端之间的连接。

在早期,HTTP 使用一个简单的模型来处理这样的连接—— 短连接。这些连接的生命周期是短暂的:每发起一个请求时都会创建一个新的连接,并在收到应答时立即关闭。
这个简单的模型对性能有先天的限制:打开每一个 TCP 连接都是相当耗费资源的操作。客户端和服务器端之间需要交换好些个消息。当请求发起时,网络延迟和带宽都会对性能造成影响。现代浏览器往往要发起很多次请求(十几个或者更多)才能拿到所需的完整信息,证明了这个早期模型的效率低下。
有两个新的模型在 HTTP/1.1 诞生了。首先是长连接模型,它会保持连接去完成多次连续的请求,减少了不断重新打开连接的时间。然后是 HTTP Pipelining,它还要更先进一些,多个连续的请求甚至都不用等待立即返回就可以被发送,这样就减少了耗费在网络延迟上的时间。
要注意的一个重点是 HTTP 的连接管理适用于两个连续节点之间的连接,如 hop-by-hop,而不是 end-to-end。当模型用于从客户端到第一个代理服务器的连接和从代理服务器到目标服务器之间的连接时(或者任意中间代理)效果可能是不一样的。HTTP 协议头受不同连接模型的影响,比如 Connection 和 Keep-Alive,就是 hop-by-hop 协议头,它们的值是可以被中间节点修改的。
HTTP 最早期的模型,也是 HTTP/1.0 的默认模型,是短连接。每一个 HTTP 请求都由它自己独立的连接完成;这意味着发起每一个 HTTP 请求之前都会有一次 TCP 握手,而且是连续不断的。
TCP 协议握手本身就是耗费时间的,所以 TCP 可以保持更多的热连接来适应负载。短连接破坏了 TCP 具备的能力,新的冷连接降低了其性能。
这是 HTTP/1.0 的默认模型(如果没有指定 Connection 协议头,或者是值被设置为 close)。而在 HTTP/1.1 中,只有当 Connection 被设置为 close 时才会用到这个模型。
短连接有两个比较大的问题:创建新连接耗费的时间尤为明显,另外 TCP 连接的性能只有在该连接被使用一段时间后(热连接)才能得到改善。为了缓解这些问题,持久连接(persistent connections) 的概念便被设计出来了,甚至在 HTTP/1.1 之前。或者这被称之为一个 keep-alive 连接。
HTTP/1.1(以及 HTTP/1.0 的各种增强版本)允许 HTTP 设备在事务处理结束之后将 TCP 连接保持在打开状态,以便为未来的 HTTP 请求重用现存的连接。在事务处理结束之后仍然保持在打开状态的 TCP 连接被称为持久连接。非持久连接会在每个事务结束之后关闭。持久连接会在不同事务之间保持打开状态,直到客户端或服务器决定将其关闭为止。
一个 持久连接 会保持一段时间,重复用于发送一系列请求,节省了新建 TCP 连接握手的时间,还可以利用 TCP 的性能增强能力。当然这个连接也不会一直保留着:连接在空闲一段时间后会被关闭(服务器可以使用 Keep-Alive 协议头来指定一个最小的连接保持时间)。
重用已对目标服务器打开的空闲持久连接,就可以避开缓慢的连接建立阶段。而且, 已经打开的连接还可以避免慢启动的拥塞适应阶段,以便更快速地进行数据的传输。
持久连接也还是有缺点的;就算是在空闲状态,它还是会消耗服务器资源,而且在重负载时,还有可能遭受 DoS attacks 攻击。这种场景下,可以使用非持久连接,即尽快关闭那些空闲的连接,也能对性能有所提升。
HTTP/1.0 里默认并不适用 持久连接。把 Connection 设置成 close 以外的其它参数都可以让其保持 持久连接,通常会设置为 retry-after。
在 HTTP/1.1 里,默认就是持久连接的,协议头都不用再去声明它(但我们还是会把它加上,万一某个时候因为某种原因要退回到 HTTP/1.0 呢)。
持久连接与并行连接配合使用可能是最高效的方式。现在,很多 Web 应用程序都会打开少量的并行连接,其中的每一个都是持久连接。
那些不理解 Connection 首部,而且不知道在沿着转发链路将其发送出去之前,应该将该首部删除的代理。很多老的或简单的代理都 是 盲中继(blind relay),它们只是将字节从一个连接转发到另一个连接中去,不对 Connection 首部进行特殊的处理。

默认情况下,HTTP 请求是按顺序发出的。下一个请求只有在当前请求收到应答过后才会被发出。由于会受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
流水线是在同一条长连接上发出连续的请求,而不用等待应答返回。这样可以避免连接延迟。理论上讲,性能还会因为两个 HTTP 请求有可能被打包到一个 TCP 消息包中而得到提升。就算 HTTP 请求不断的继续,尺寸会增加,但设置 TCP 的 最大分段大小 MSS (Maximum Segment Size) 选项,任然足够包含一系列简单的请求。
并不是所有类型的 HTTP 请求都能用到流水线:只有 idempotent 方式,比如 GET、HEAD、PUT 和 DELETE 能够被安全的重试:如果有故障发生时,流水线的内容要能被轻易的重试。
今天,所有遵循 HTTP/1.1 的代理和服务器都应该支持流水线,虽然实际情况中还是有很多限制:一个很重要的原因是,任然没有现代浏览器去默认支持这个功能。
HTTP 流水线在现代浏览器中并不是默认被启用的:
- Web 开发者并不能轻易的遇见和判断那些搞怪的 代理服务器 的各种莫名其妙的行为。
- 正确的实现流水线式复杂的:传输中的资源大小,多少有效的 往返时延 RTT(Round-Trip Time) 会被用到,还有有效带宽,流水线带来的改善有多大的影响范围。不知道这些的话,重要的消息可能被延迟到不重要的消息后面。这个重要性的概念甚至会演变为影响到页面布局!因此 HTTP 流水线在大多数情况下带来的改善并不明显。
- 流水线受制于 队头阻塞 Head-of-line blocking (HOL blocking) 问题。
由于这些原因,流水线已经被更好的算法给代替,如 multiplexing,已经用在 HTTP/2。
在HTTP/2中,客户端向某个域名的服务器请求页面的过程中,只会创建一条TCP连接,即使这页面可能包含上百个资源。而之前的HTTP/1.x一般会创建6-8条TCP连接来请求这100多个资源。单一的连接应该是HTTP2的主要优势,单一的连接能减少TCP握手带来的时延(如果是建立在SSL/TLS上面,HTTP2能减少很多不必要的SSL握手,大家都知道SSL握手很慢)。
另外我们知道,TCP协议有个滑动窗口,有慢启动这回事,就是说每次建立新连接后,数据先是慢慢地传,然后滑动窗口慢慢变大,才能较高速度地传,这下倒好,这条连接的滑动窗口刚刚变大,http1.x就创个新连接传数据(这就好比人家HTTP2一直在高速上一直开着,你HTTP1.x是一辆公交车走走停停)。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。
所以,HTTP2中用一条单一的长连接,避免了创建多个TCP连接带来的网络开销,提高了吞吐量。
HTTP/2 是基于帧(frame)的协议。采用分帧是为了将重要信息都封装起来, 让协议的解析方可以轻松阅读、解析并还原信息。帧(frame) 是HTTP/2中数据传输的最小单位,因此帧不仅要细分表达HTTP/1.x中的各个部份,也优化了HTTP/1.x表达得不好的地方,同时还增加了HTTP/1.x表达不了的方式。
HTTP/2 帧结构如下:

HTTP/2 规范对流(stream)的定义是:HTTP/2 连接上独立的、双向的帧序列交换。你可以将流看作在连接上的一系列帧,它们构成了单独的 HTTP 请求和响应。如果客户端想要发出请求,它会开启一个新的流。然后,服务器将在这个流上回复。这与 h1 的请求 / 响应流程类似,重要的区别在于,因为有分帧,所以多个请求和响应可以交错,而不会互相阻塞。流 ID(帧首部的第 6~9 字节)用来标识帧所属的流。
特点如下:
一张图表示如下:
就是说在一个TCP连接上,我们可以向对方不断发送一个个的消息,这里每一个消息看成是一帧,而每一帧有个stream identifier 的字段标明这一帧属于哪个 流,然后在对方接收时,根据 stream identifier 拼接每个 流 的所有帧组成一整块数据。我们把 HTTP/1.x 每个请求都当作一个 流,那么请求化成多个流,请求响应数据切成多个帧,不同流中的帧交错地发送给对方,这就是HTTP/2中的 多路复用。
从上图我们可以留意到:
多路复用让HTTP连接变得很廉价,只需要创建一个新流即可,这不需要多少时间,而在 HTTP/1.x 时代却要经历三次握手时间或者队首阻塞等问题。而且创建新流默认是无限制的,也就是可以无限制的并行请求下载。不过,HTTP/2 还是提供了 SETTINGS_MAX_CONCURRENT_STREAMS 字段在 SETTINGS 帧 上设置,可以限制并发流数目,标准上建议不要低于 100 以保证性能。
实际的传输可能是这样的:
只看到 帧(Frame),没有 流(Stream)嘛。
需要抽象化一些,就好理解了:
HTTP/1.x 一次请求-响应,建立一个连接,用完关闭;每一个小组任务都需要建立一个班级,多个小组任务多个班级,1:1比例HTTP/1.1 Pipeling 解决方式为,若干个小组任务排队串行化单线程处理,后面小组任务等待前面小组任务完成才能获得执行机会,一旦有任务处理超时等,后续任务只能被阻塞,毫无办法,也就是人们常说的线头阻塞HTTP/2 多个小组任务可同时并行(严格意义上是并发)在班级内执行。一旦某个小组任务耗时严重,但不会影响到其它小组任务正常执行摘自 MDN web docs
选择器是 CSS 规则的一部分且位于 CSS 声明块前。
选择器可以被分为以下类别:
简单选择器(Simple selectors):通过元素类型、class 或 id 匹配一个或多个元素。属性选择器(Attribute selectors):通过 属性 / 属性值 匹配一个或多个元素。伪类(Pseudo-classes):匹配处于确定状态的一个或多个元素,比如被鼠标指针悬停的元素,或当前被选中或未选中的复选框,或元素是 DOM 树中一父节点的第一个子节点。伪元素(Pseudo-elements):匹配处于相关的确定位置的一个或多个元素,例如每个段落的第一个字,或者某个元素之前生成的内容。组合器(Combinators):这里不仅仅是选择器本身,还有以有效的方式组合两个或更多的选择器用于非常特定的选择的方法。例如,你可以只选择 divs 的直系子节点的段落,或者直接跟在 headings 后面的段落。多用选择器(Multiple selectors):这些也不是单独的选择器;这个思路是将以逗号分隔开的多个选择器放在一个 CSS 规则下面, 以将一组声明应用于由这些选择器选择的所有元素。此选择器只是一个选择器名和指定的HTML元素名的不区分大小写的匹配。这是选择所有指定类型的最简单方式。
类选择器由一个点“.”以及类后面的类名组成。类名是在HTML class文档元素属性中没有空格的任何值。由你自己选择一个名字。同样值得一提的是,文档中的多个元素可以具有相同的类名,而单个元素可以有多个类名(以空格分开多个类名的形式书写)。
ID选择器由哈希/磅符号 (#)组成,后面是给定元素的ID名称。 任何元素都可以使用id属性设置唯一的ID名称。 由你自己选择的ID是什么。 这是选择单个元素的最有效的方式。
重要提示:一个ID名称必须在文件中是唯一的。关于重复ID的行为是不可预测的,比如在一些浏览器只是第一个实例计算,其余的将被忽略。
通用选择(*)是最终的王牌。它允许选择在一个页面中的所有元素。由于给每个元素应用同样的规则几乎没有什么实际价值,更常见的做法是与其他选择器结合使用。
重要提示:使用通用选择时小心。因为它适用于所有的元素,在大型网页利用它可以对性能有明显的影响:网页可以显示比预期要慢。不会有太多的情况下,您想使用此选择。
在CSS中,组合器允许您将多个选择器组合在一起,这允许您在其他元素中选择元素,或者与其他元素相邻。四种可用的类型是:
| Combinators | Select |
|---|---|
| A,B | 匹配满足A(和/或)B的任意元素. |
| A B | 匹配任意元素,满足条件:B是A的后代结点(B是A的子节点,或者A的子节点的子节点) |
| A > B | 匹配任意元素,满足条件:B是A的直接子节点 |
| A + B | 匹配任意元素,满足条件:B是A的下一个兄弟节点(AB有相同的父结点,并且B紧跟在A的后面) |
| A ~ B | 匹配任意元素,满足条件:B是A之后的兄弟节点中的任意一个(AB有相同的父节点,B在A之后,但不一定是紧挨着A) |
注:相邻兄弟选择器和通用兄弟选择器只会“向后”选择,DOM结构靠前的兄弟元素不在选择范围内。
这里有一个简单的例子来展示这些工作是如何工作的:
<section>
<h2>Heading 1</h2>
<p>Paragraph 1</p>
<p>Paragraph 2</p>
<div>
<h2>Heading 2</h2>
<p>Paragraph 3</p>
<p>Paragraph 4</p>
</div>
</section>section p {
color: blue;
}
section > p {
background-color: yellow;
}
h2 + p {
text-transform: uppercase;
}
h2 ~ p {
border: 1px dashed black;
}CSS样式的HTML如下所示:
<iframe src="https://mdn.github.io/learning-area/css/introduction-to-css/css-selectors/combinators.html" class="live-sample-frame" width="100%" frameborder="0" height="270"></iframe>选择器是这样工作的:
<p> 元素——前两个 <p> 都是 <section> 元素的直接子元素,而后面的两个 <p> 元素是 <section> 元素的孙子元素(它们在 <div>里面)。因此,所有的段落文本都是蓝色的。<p> 元素,这两个元素是 <section> 元素的直接子元素(但后两个 <p>元素不是,它们不是直接的子元素)。所以只有前两段有黄色的背景色。<h2> 元素之后直接相连的 <p> 元素—— 在本例中是第一和第三段。因此,这些文本都是大写的。<h2> 元素的 <p> 元素 ——在这种情况下,所有的段落符合此条件。因此,所有的这些都有一个虚线的边界。属性选择器是一种特殊类型的选择器,它根据元素的 属性和属性值来匹配元素。它们的通用语法由方括号([]) 组成,其中包含属性名称,后跟可选条件以匹配属性的值。 属性选择器可以根据其匹配属性值的方式分为两类: 存在和值属性选择器 和 子串值属性选择器。
这些属性选择器尝试匹配精确的属性值:
这种情况的属性选择器也被称为“伪正则选择器”,因为它们提供类似 regular expression 的灵活匹配方式(但请注意,这些选择器并不是真正的正则表达式):
一个 CSS 伪类(pseudo-class) 是一个以冒号(:)作为前缀的关键字,当你希望样式在特定状态下才被呈现到指定的元素时,你可以往元素的选择器后面加上对应的伪类(pseudo-class)。你可能希望某个元素在处于某种状态下呈现另一种样式,例如当鼠标悬停在元素上面时,或者当一个 checkbox 被禁用或被勾选时,又或者当一个元素是它在 DOM 树中父元素的第一个孩子元素时。
:active:any:checked:default:dir():disabled:empty:enabled:first:first-child:first-of-type:fullscreen:focus:hover:indeterminate:in-range:invalid:lang():last-child:last-of-type:left:link:not():nth-child():nth-last-child():nth-last-of-type():nth-of-type():only-child:only-of-type:optional:out-of-range:read-only:read-write:required:right:root:scope:target:valid:visited伪元素(Pseudo-element)跟伪类很像,但它们又有不同的地方。它们都是关键字 —— 但这次伪元素前缀是两个冒号 (::) —— 同样是添加到选择器后面达到指定某个元素的某个部分。
该文章来自于电影互联网之子 The Internet's Own Boy: The Story of Aaron Swartz (2014)的豆瓣影评:如果亚伦·斯沃茨出生在**,原文的地址应该在Github上的blog,已无法访问。
虽然是两年前的文章,但是对比电影及Aaron Swartz的身平,结合自身经历,这一切糅合在一起,依然是感慨良多。
我在斯沃茨的经历中看见了我,但即使除去所努力的年限还没到斯沃茨的26年之外,我所做的事情完全还成不是和斯是一个数量级的。就像我所宣称的我从来不相信天赋一样——我见识过这个世界上最顶尖的人才,他们的才能在于有方法的持之以恒的努力加上对所追求事物的热情,天赋只是弱者给自己的借口,强者给弱者的谎言——我不觉得如果把我放在斯的位置上,我所完成的会更差。我敬佩斯在其所在领域内的努力,也希望自己以后有机会能够参与到这么一些让世界变得更好的运动中来,但在观看这部纪录片时我会不由自主地对比我和斯的境遇,然后把这个对比放在**的大背景中,那么,开始吧。
在所有的一切之前,致敬,亚伦·斯沃茨。
本文从一个90后所在的大多数普通家庭的情况来对比“斯如果出生在**”这一假想,如果这个**家庭是高级知识分子、名牌大学教授又或者是经济实力雄厚的有文化的人士,那么这些对比也未必成立,也没有意义的。因为绝大多数的**家庭不是这种情况。广义上来讲也是斯奋斗的领域——**普通家庭并没有对
有质量的知识的获取途经,所以他们只能依靠高考这一条路。
斯3岁开始接触电脑,我也是类似的年纪,可能是4岁。就像影片里斯的兄弟所讲,他们都喜欢电脑,但是只有斯真正进入了这个领域。我是大学才真正开始成为一个计算机玩家,在此之前我都是一个电脑玩家。斯没有传记存在,我暂时也没有时间去调查斯的背景,但从一个电脑的玩家进入一个计算机的玩家,大概要
迈过两条坎:
这两点结合在一起是如何找到高质量的相关信息,而这一条,如果斯出生在**,
其能够获取的信息的质量不止会下降一个等级,待我慢慢道来。
首先90后出生的孩子一般情况下在比较小的时候都不会有一台电脑,这一点我不在此列。而即使家里有一台电脑,为了让孩子好好学习不沉迷游戏,家长一般情况下也不会让孩子上网——我在此列。相信许多同辈们都有这样的经历。
而这些判断已经是家长已经被信息时代遗弃的表现——他们根本不知道互联网是现在社会上最大的阶层资源间的multiplier(恕想不到翻译)。作为没有什么资源的普通民众,这就是你四两拨千斤的武功心法。
这又要谈到阶级了,我们从高考说起。高考简单来看是人才选拔,但高考的背后是**稀缺的资源造成的一种畸形的用于留出上下阶层流通通道而保持社会稳定的资源分配方式(想象有多少家庭唯一的希望就是孩子上一个好大学):高考以残废绝大多数考生的学习兴趣为代价生产出这个社会运转需要的少部分人才,这
部分人才对上层**阶级有相当的使用价值并可能被吸收成为其阶层的一员。
如果没有互联网,高考就只是唯一的通道了。但互联网使得知识,这一原本仅仅能够通过正规教育来传播的稀缺资源变得能够以极低的成本大规模传播,于是互联网成为了一个人改变自己最大的multiplier。在网上你可以获得所有你需要的知识,前提一旦你被引领入门。而家长们根本不知道有这么一扇门存在。在他们看来电脑和互联网只会让孩子对游戏、网络游戏上瘾。是的,游戏是能够让人上瘾的东西,根据神经学的理论,老鼠只要能够在大脑获得足够的刺激,它能够忽略进食直到死去。而游戏能够给予了人们这种刺激,这种在极短的时间内出现的虚拟的刺激还不能让人类演化出相应的天然分辨真假手段——因为他们本质是一样
的。但究其本因,还是家长们不能给孩子们展示这门后的东西,让他们看见计算机和互联网神奇的世界,这个世界会远远超过游戏的吸引力。即使是我的大学的一位信息科学院的教授也做不到——因为他也不明白,只是传统地做研究,并不是一个黑客。
所以,对于下层阶级的孩子们来说,一开始,他们便失去了如此宝贵的财富。
那么,为什么家长们不能呢?
现在有了知乎、豆瓣这些比较有质量的中文网站来获取一些有质量的信息。在这些网站没有存在之前,中文的网络环境可谓是一塌糊涂——绝大多数只是一些只会占沙发、点赞、灌水的用户。你如何期待他们创造出一个良好的网络环境?在一开始的时候我只是以为这是**的网络环境差,但是慢慢我才意识到这其实是中
国的整个国家的公民素质有待提升。
同样的问题存在在**的教材上,包括大学教材。有个叫童哲的巴黎高师学物理的孩子建立了一个叫万门大学的互联网大学,旨在教大 学 代 数?!这个世界疯了吧,大学里的教授是干什么吃的?
然而事实是,整个**的大学教授基本没有什么人有心思在教学上,因为这根本和他们评职称没有关系。教材的写作多数情况下也是和出版社基于利益的合作,且许多情况下是挂着教授的名字让教授的学生来写。在出版界也多是如此——我接触的技术书籍以市场投机的心理出版为多,内容一塌糊涂,浪费纸张。当然,也
有好的著作,不会被我一棒子打死。比如《数学之美》、《程序员的自我修养》等等,都是倾注心力有情怀的好书。
因此,**的资料质量很差。我相信即使是约翰纳什来看**大学的线性代数课本也会失去对数学的兴趣的。
真正的学习需要直接去英文的环境里学习。这里面水比较深,举几个现在想到的例子:在网络环境上google group上一个严肃的有良好氛围的讨论平台,Quora的答案水平在很大程度上是超越知乎的,而绝大多数的MOOC课程都是英文的。
所以,我问这门一个简单的问题:有多少家长能够教孩子真正的英语?另外说一句,不要依靠学校的英语教育,只要不是全国范围内都称得上最好的学校,其他的学校的老师都不能算是会英语,包括大学。所以,没有人在一开始给你引路。
斯如果在**长大,在20岁之前他都在准备高考。而相信以他的性格,他一定是个差生。
好了,即使假设我们学了英语,能够学习这些有质量的英文内容。我们仍然有一个难以逾越的鸿沟。**没有一个社区来让人参与。
斯最初的成名战是参与RSS的设计和实现——一个家里的wiki并不是什么大事情,会一些网络基本编程的人都能够完成,难点在于让他成为世界的wikipedia,所以这里我并不把这视为斯的成名战,只能是练手的玩具。
斯能够在14岁参与一个被世界上所有人的使用的工具的建设,其基本要素大概如下:RSS不是一项复杂的技术,更多的是一项规范,所以斯能够贡献;美国有很多这样的社区,他们需要大量的人,所以斯能够加入。
而**已经远远地落后在世界后边,而社区这种东西并没有在**广泛形成,即使是现在。并且社区由于和自组织相似这么一种组织,其是被打击、压制的对象。所以,即使斯成为了一个学习了高等数学、矩阵代数、计算理论的少年天才,他的归宿一般也就是去清华、北大好好上个学。
在**创业?还是Reddit这种充满争议的网站?想,都不要想。
最后,谈一谈斯用互联网的力量来阻止法案的通过。这一段看得真的是激动人心也唏嘘不已。这一伟大的创举的完成草率的分析大概也要这么一些条件:
It is just not possible at all.
在HTTP的发展过程中,出现了很多HTTP版本,其中的大部分协议都是向下兼容的。在进行HTTP请求时,客户端在请求时会告诉服务器它采用的协议版本号,而服务器则会在使用相同或者更早的协议版本进行响应。
这是HTTP最早大规模使用的版,现已过时。在这个版本中 只有GET一种请求方法,在HTTP通讯也没有指定版本号,也不支持请求头信息。该版本不支持POST等方法,因此客户端向服务器传递信息的能力非常有限。
这个版本是第一个在HTTP通讯中指定版本号的协议版本,HTTP/1.0至今仍被广泛采用,特别是在代理服务器中。
HTTP/1.0支持:GET、POST、HEAD三种HTTP请求方法。
HTTP/1.1是当前正在使用的版本。该版本默认采用持久连接,并能很好地配合代理服务器工作。还支持以管道方式同时发送多个请求,以便降低线路负载,提高传输速度。
HTTP/1.1新增了:OPTIONS、PUT、DELETE、TRACE、CONNECT五种HTTP请求方法。
这个版本是最新发布的版本,于今年5月(2015年5月)做HTTP标准正式发布。HTTP/2通过支持请求与相应的多路重用来减少延迟,通过压缩HTTP头字段将协议开销降到最低,同时增加了对请求优先级和服务器端推送的支持。
OPTIONS 方法用于确定 Web 服务器的一般功能,或者 Web 服务器处理特定资源的能力。
GET 是最常用的方法。通常用于请求服务器发送某个资源。HTTP/1.1 要求服务器 实现此方法。
HEAD 方法与 GET 方法的行为很类似,但服务器在响应中只返回首部。不会返回实 体的主体部分。这就允许客户端在未获取实际资源的情况下,对资源的首部进行检查。使用 HEAD,可以:
服务器开发者必须确保返回的首部与 GET 请求所返回的首部完全相同。遵循 HTTP/1.1 规范,就必须实现 HEAD 方法。
与 GET 从服务器读取文档相反,PUT 方法会向服务器写入文档。有些发布系统允 许用户创建 Web 页面,并用 PUT 直接将其安装到 Web 服务器上去。
PUT 方法的语义就是让服务器用请求的主体部分来创建一个由所请求的 URL 命名的新文档,或者,如果那个 URL 已经存在的话,就用这个主体来替代它。
因为 PUT 允许用户对内容进行修改,所以很多 Web 服务器都要求在执行 PUT 之前,用密码登录。
和POST方法一样,PUT方法也改变了资源的状态,所以是 非安全 的。但是有一点和POST不同,它是 幂等 的,这是为什么呢?想想setter函数吧,重复调用,只要参数是一样的,表述就是不变的。
POST 方法起初是用来向服务器输入数据的 3。实际上,通常会用它来支持 HTML 的表单。表单中填好的数据通常会被送给服务器,然后由服务器将其发送到它要去 的地方(比如,送到一个服务器网关程序中,然后由这个程序对其进行处理)。

注: POST 用于向服务器发送数据。PUT 用于向服务器上的资源(例如文件)中存储数据。
客户端发起一个请求时,这个请求可能要穿过防火墙、代理、网关或其他一些应用 程序。每个中间节点都可能会修改原始的 HTTP 请求。TRACE 方法允许客户端在 最终将请求发送给服务器时,看看它变成了什么样子。
TRACE 请求会在目的服务器端发起一个“环回”诊断。行程最后一站的服务器会 弹回一条 TRACE 响应,并在响应主体中携带它收到的原始请求报文。这样客户端 就可以查看在所有中间 HTTP 应用程序组成的请求 / 响应链上,原始报文是否,以及如何被毁坏或修改过。

TRACE 方法主要用于诊断;也就是说,用于验证请求是否如愿穿过了请求 / 响应链。它也是一种很好的工具,可以用来查看代理和其他应用程序对用户请求所产生 效果。
尽管 TRACE 可以很方便地用于诊断,但它确实也有缺点,它假定中间应用程序对 各种不同类型请求(不同的方法——GET、HEAD、POST 等)的处理是相同的。
很多 HTTP 应用程序会根据方法的不同做出不同的事情——比如,代理可能会将 POST 请求直接发送给服务器,而将 GET 请求发送给另一个 HTTP 应用程序(比如 Web 缓存)。TRACE 并不提供区分这些方法的机制。通常,中间应用程序会自行决定对 TRACE 请求的处理方式。
TRACE 请求中不能带有实体的主体部分。TRACE 响应的实体主体部分包含了响应服务器收到的请求的精确副本。
当 TRACE 请求到达目的服务器时,16 整条请求报文都会被封装在一条 HTTP 响应 的主体中回送给发送端。当 TRACE 响应到达时,客户端可以检查服务器收到的确切报文,以及它所经过的代理列表(在 Via 首部)。TRACE 响应的 Content-Type 为 message/http,状态为 200 OK。

Via 首部字段列出了与报文途经的每个中间节点(代理或网关)有关的信息。报文每经过一个节点,都必须将这个中间节点添加到 Via 列表的末尾。
代理也可以用 Via 首部来检测网络中的路由循环。代理应该在发送一条请求之前, 在 Via 首部插入一个与其自身有关的独特字符串,并在输入的请求中查找这个字符 串,以检测网络中是否存在路由循环。
Via 首部字段包含一个由逗号分隔的 路标(waypoint)。每个路标都表示一个独立的 代理服务器或网关,且包含与那个中间节点的协议和地址有关的信息。下面是一个 带有两个路标的 Via 首部实例:
Via = 1.1 cache.joes-hardware.com, 1.1 proxy.irenes-isp.net
Via 首部的正规语法如下所示:
Via = "Via" ":" 1#( waypoint )
waypoint = ( received-protocol received-by [ comment ] )
received-protocol = [ protocol-name "/" ] protocol-version
received-by = ( host [ ":" port ] ) | pseudonym
注意,每个 Via 路标中最多包含 4 个组件:一个可选的协议名(默认为 HTTP)、一 个必选的协议版本、一个必选的节点名和一个可选的描述性注释。
OPTIONS 方法请求 Web 服务器告知其支持的各种功能。可以询问服务器通常支持哪些方法,或者对某些特殊资源支持哪些方法。(有些服务器可能只支持对一些特殊类型的对象使用特定的操作)。
通过使用 OPTIONS,客户端可以在与服务器进行交互之前,确定服务器的能力,这样它就可以更方便地与具备不同特性的代理和服务器进行互操作了。
这为客户端应用程序提供了一种手段,使其不用实际访问那些资源就能判定访问各种资源的最优方式。

如果 OPTIONS 请求的 URI 是个星号(*),请求的就是整个服务器所支持的功能。
比如:
OPTIONS * HTTP/1.1
如果 URI 是个实际资源地址,OPTIONS 请求就是在查询那个特定资源的可用特性:
OPTIONS http://www.joes-hardware.com/index.html HTTP/1.1
如果成功,OPTIONS方法就会返回一个包含了各种首部字段的200 OK响应,这些 字段描述了服务器所支持的,或资源可用的各种可选特性。HTTP/1.1 在响应中唯一 指定的首部字段是 Allow 首部,这个首部用于描述服务器所支持的各种方法(或者 服务器上的特定资源)。OPTIONS 允许在可选的响应主体中包含更多的信息,但并没有对这种用法进行定义。
Allow 实体首部字段列出了请求 URI 标识的资源所支持的方法列表,如果请求 URI为 * 的话,列出的就是整个服务器所支持的方法列表。例如:
Allow: GET, HEAD, PUT
可以将 Allow 首部作为请求首部,建议在新的资源上支持某些方法。并不要求服务 器支持这些方法,但应该在相应的响应中包含一个 Allow 首部,列出它实际支持的方法。
因为客户端可能已经通过其他途径与原始服务器进行了交流,所以即使代理无法理解指定的所有方法,也不能对 Allow 首部字段进行修改。
顾名思义,DELETE 方法所做的事情就是请服务器删除请求 URL 所指定的资源。 但是,客户端应用程序无法保证删除操作一定会被执行。因为 HTTP 规范允许服务 器在不通知客户端的情况下撤销请求。

和POST方法一样,DELETE方法也改变了资源的状态,所以是非安全的。但是有一点和POST不同,它是幂等的,也就是说,就算是服务器在前一个请求中已经删除了资源,它也必须返回200.这就意味着,我们在实现服务端的该方法是,需要跟踪已经删除的资源,否则就会返回404的。
CONNECT方法是HTTP/1.1协议预留的,能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接与非加密的HTTP代理服务器的通信。
PATCH方法出现的较晚,它在2010年的 RFC 5789 PATCH Method for HTTP 标准中被定义。PATCH请求与PUT请求类似,同样用于资源的更新。二者有以下两点不同:
HTTP 报文是在 HTTP 应用程序之间发送的数据块。这些数据块以一些文本形式的 元信息(meta-information)开头,这些信息描述了报文的内容及含义,后面跟着可选的数据部分。
HTTP 使用术语 流入(inbound) 和 流出(outbound) 来描述事务处理(transaction) 的方向。报文流入源端服务器,工作完成之后,会流回用户的 Agent 代理中。
HTTP 报文会像河水一样流动。不管是请求报文还是响应报文,所有报文都会向 下游(downstream)流动。所有报文的发送者都在接收者的上游 (upstream)。
HTTP 报文是简单的格式化数据块。每条报文都包含一条来自客户端的请求,或者一条来自服务器的响应。它们由三个部分组成:对报文进行描述的 起始行(start line)、包含属性的 首部(header) 块,以及可选的包含数据的 主体(body) 部分。
HTTP-message = start-line
*( header-field CRLF )
CRLF
[ message-body ]
所有的HTTP报文都可以分为两类:请求报文(request message) 和 响应报文 (response message)。请求和响应报文的基本报文结构相同。
请求报文的格式:
<method> <request-URL> <version>
<headers>
<entity-body>
响应报文的格式(注意,只有起始行的语法有所不同):
<version> <status> <reason-phrase>
<headers>
<entity-body>
起始行和首部就是由行分隔的 ASCII 文本。每行都以一个由两个字符组成的行终止序列作为结束,其中包括一个回车符(ASCII 码 13)和一个换行符(ASCII 码 10)。 这个行终止序列可以写做 CRLF。
curl -i www.baidu.com/index.html
HTTP/1.1 200 OK
Server: bfe/1.0.8.18
Date: Wed, 04 Apr 2018 02:39:19 GMT
Content-Type: text/html
Content-Length: 2381
Last-Modified: Mon, 23 Jan 2017 13:27:56 GMT
Connection: Keep-Alive
ETag: "588604dc-94d"
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Pragma: no-cache
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
Accept-Ranges: bytes
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>所有的 HTTP 报文都以一个起始行作为开始。请求报文的起始行说明了要做些什么。
响应报文的起始行说明发生了什么。
请求报文请求服务器对资源进行一些操作。请求报文的起始行,或称为请求行,包含了一个方法和一个请求 URL,还包含 HTTP 的版本。所有这些字段都由空格符分隔。
响应报文承载了状态信息和操作产生的所有结果数据,将其返回给客户端。响应报文的起始行,或称为响应行,包含了响应报文使用的 HTTP 版本、数字状态码,以 及描述操作状态的文本形式的原因短语。
请求的起始行以方法作为开始,方法用来告知服务器要做些什么。比如,在行 “GET /specials/saw-blade.gif HTTP/1.0”中,方法就是 GET。
状态码是在每条响应报文的起始行中返回的。会返回一个数字状态和一个可读的状态。数字码便于程序进行差错处理,而原因短语则更便于人们理解。方法是用来告诉服务器做什么事情的,状态码则用来告诉客户端,发生了什么事情。
| 整体范围 | 已定义范围 | 分类 |
|---|---|---|
| 100 ~ 199 | 100 ~ 101 | 信息提示 |
| 200~299 | 200~206 | 成功 |
| 300 ~ 399 | 300 ~ 305 | 重定向 |
| 400 ~ 499 | 400 ~ 415 | 客户端错误 |
| 500 ~ 599 | 500 ~ 505 | 服务器错误 |
原因短语是响应起始行中的最后一个组件。它为状态码提供了文本形式的解释。比如,在行 HTTP/1.0 200 OK 中,OK 就是原因短语。
版本号会以 HTTP/x.y 的形式出现在请求和响应报文的起始行中。
跟在起始行后面的就是零个、一个或多个 HTTP 首部字段。
HTTP 首部字段向请求和响应报文中添加了一些附加信息。本质上来说,它们只是一些名 / 值对的列表。
HTTP 规范定义了几种首部字段。应用程序也可以随意发明自己所用的首部。HTTP 首部可以分为以下几类。
每个 HTTP 首部都有一种简单的语法:名字后面跟着冒号( :),然后跟上可选的空格,再跟上字段值,最后是一个 CRLF。
HTTP 报文的第三部分是可选的实体主体部分。实体的主体是 HTTP 报文的负荷。 就是 HTTP 要传输的内容。
HTTP 报文可以承载很多类型的数字数据:图片、视频、HTML 文档、软件应用程 序、信用卡事务、电子邮件等。
现在,我们对一些基本 HTTP 方法进行更为深入的讨论。
GET 是最常用的方法。通常用于请求服务器发送某个资源。HTTP/1.1 要求服务器 实现此方法。
HEAD 方法与 GET 方法的行为很类似,但服务器在响应中只返回首部。不会返回实体的主体部分。这就允许客户端在未获取实际资源的情况下,对资源的首部进行检查。使用 HEAD,可以:

与 GET 从服务器读取文档相反,PUT 方法会向服务器写入文档。有些发布系统允 许用户创建 Web 页面,并用 PUT 直接将其安装到 Web 服务器上去。

PUT 方法的语义就是让服务器用请求的主体部分来创建一个由所请求的 URL 命名的新文档,或者,如果那个 URL 已经存在的话,就用这个主体来替代它。
因为 PUT 允许用户对内容进行修改,所以很多 Web 服务器都要求在执行 PUT 之前,用密码登录。
POST 方法起初是用来向服务器输入数据的。实际上,通常会用它来支持 HTML 的表单。表单中填好的数据通常会被送给服务器,然后由服务器将其发送到它要去的地方。
POST 用于向服务器发送数据。PUT 用于向服务器上的资源(例如文件)中存储数据。
客户端发起一个请求时,这个请求可能要穿过防火墙、代理、网关或其他一些应用 程序。每个中间节点都可能会修改原始的 HTTP 请求。TRACE 方法允许客户端在最终将请求发送给服务器时,看看它变成了什么样子。
TRACE 请求会在目的服务器端发起一个“环回”诊断。行程最后一站的服务器会 弹回一条 TRACE 响应,并在响应主体中携带它收到的原始请求报文。这样客户端就可以查看在所有中间 HTTP 应用程序组成的请求 / 响应链上,原始报文是否,以 及如何被毁坏或修改过。

TRACE 方法主要用于诊断;也就是说,用于验证请求是否如愿穿过了请求 / 响应 链。它也是一种很好的工具,可以用来查看代理和其他应用程序对用户请求所产生效果。
TRACE 请求中不能带有实体的主体部分。TRACE 响应的实体主体部分包含了响应服务器收到的请求的精确副本。
OPTIONS 方法请求 Web 服务器告知其支持的各种功能。可以询问服务器通常支持 哪些方法,或者对某些特殊资源支持哪些方法。(有些服务器可能只支持对一些特殊 类型的对象使用特定的操作)。
这为客户端应用程序提供了一种手段,使其不用实际访问那些资源就能判定访问各种资源的最优方式。

顾名思义,DELETE 方法所做的事情就是请服务器删除请求 URL 所指定的资源。 但是,客户端应用程序无法保证删除操作一定会被执行。因为 HTTP 规范允许服务 器在不通知客户端的情况下撤销请求。

HTTP 被设计成字段可扩展的,这样新的特性就不会使老的软件失效了。扩展方法指的就是没有在 HTTP/1.1 规范中定义的方法。服务器会为它所管理的资源实现一些 HTTP 服务,这些方法为开发者提供了一种扩展这些 HTTP 服务能力的手段。
首部和方法配合工作,共同决定了客户端和服务器能做什么事情。
有些首部提供了与报文相关的最基本的信息,它们被称为通用首部。
允许客户端和服务器指定与请求 / 响应连接有关的选项
提供日期和时间标志,说明报文是什么时间创建的
给出了发送端使用的 MIME 版本
如果报文采用了分块传输编码(chunked transfer encoding)方式,就可 以用这个首部列出位于报文拖挂(trailer)部分的首部集合
告知接收端为了保证报文的可靠传输,对报文采用了什么编码方式
给出了发送端可能想要“升级”使用的新版本或协议
显示了报文经过的中间节点(代理、网关)
用于随报文传送缓存指示
另一种随报文传送指示的方式,但并不专用于缓存
提供了运行客户端的机器的 IP 地址
提供了客户端用户的 E-mail 地址
给出了接收请求的服务器的主机名和端口号
提供了包含当前请求 URI 的文档的 URL
提供了与客户端显示器的显示颜色有关的信息
给出了客户端 CPU 的类型或制造商
提供了与客户端显示器(屏幕)能力有关的信息
给出了运行在客户端机器上的操作系统名称及版本
提供了客户端显示器的像素信息
将发起请求的应用程序名称告知服务器
Accept 首部为客户端提供了一种将其喜好和能力告知服务器的方式。
告诉服务器能够发送哪些媒体类型
告诉服务器能够发送哪些字符集
告诉服务器能够发送哪些编码方式
告诉服务器能够发送哪些语言
告诉服务器可以使用哪些扩展传输编码
有时客户端希望为请求加上某些限制。
比如,如果客户端已经有了一份文档副本, 就希望只在服务器上的文档与客户端拥有的副本有所区别时,才请求服务器传输文档。通过条件请求首部,客户端就可以为请求加上这种限制,要求服务器在对请求进行响应之前,确保某个条件为真。
允许客户端列出某请求所要求的服务器行为
如果实体标记与文档当前的实体标记相匹配,就获取这份文档
除非在某个指定的日期之后资源被修改过,否则就限制这个请求
如果提供的实体标记与当前文档的实体标记不相符,就获取文档
允许对文档的某个范围进行条件请求
除非在某个指定日期之后资源没有被修改过,否则就限制这个请求
如果服务器支持范围请求,就请求资源的指定范围
HTTP 本身就支持一种简单的机制,可以对请求进行质询 / 响应认证。这种机制要 求客户端在获取特定的资源之前,先对自身进行认证,这样就可以使事务稍微安全 一些。
包含了客户端提供给服务器,以便对其自身进行认证的数据
客户端用它向服务器传送一个令牌——它并不是真正的安全首部,但确实隐含了安全功能。
用来说明请求端支持的 cookie 版本
随着因特网上代理的普遍应用,人们定义了几个首部来协助其更好地工作。
在通往源端服务器的路径上,将请求转发给其他代理或网关的最大次数——与 TRACE 方法一同使用
与 Authorization 首部相同,但这个首部是在与代理进行认证时使用的
与 Connection 首部相同,但这个首部是在与代理建立连接时使用的
(从最初创建开始)响应持续时间
服务器为其资源支持的请求方法列表
如果资源不可用的话,在此日期或时间重试
服务器应用程序软件的名称和版本
对 HTML 文档来说,就是 HTML 文档的源端给出的标题
比原因短语中更详细一些的警告报文
如果资源有多种表示方法——比如,如果服务器上有某文档的法语和德语译稿, HTTP/1.1 可以为服务器和客户端提供对资源进行协商的能力。
对此资源来说,服务器可接受的范围类型
服务器查看的其他首部的列表,可能会使响应发生变化;也就是说,这是一个首部列表,服务器会根据这些首部的内容挑选出最适合的资源版本发 送给客户端
我们已经看到过安全请求首部了,本质上这里说的就是 HTTP 的质询 / 响应认证机制的响应侧。
来自代理的对客户端的质询列表
不是真正的安全首部,但隐含有安全功能;可以在客户端设置一个令牌,
以便服务器对客户端进行标识
与 Set-Cookie 类似,RFC 2965 Cookie 定义
来自服务器的对客户端的质询列表
列出了可以对此实体执行的请求方法
告知客户端实体实际上位于何处;用于将接收端定向到资源的(可能是新的)位置(URL)上去
内容首部提供了与实体内容有关的特定信息,说明了其类型、尺寸以及处理它所需 的其他有用信息。比如,Web 浏览器可以通过查看返回的内容类型,得知如何显示对象。
解析主体中的相对 URL 时使用的基础 URL
对主体执行的任意编码方式
理解主体时最适宜使用的自然语言
主体的长度或尺寸
资源实际所处的位置
主体的 MD5 校验和
在整个资源中此实体表示的字节范围
这个主体的对象类型
通用的缓存首部说明了如何或什么时候进行缓存。实体的缓存首部提供了与被缓存 实体有关的信息——比如,验证已缓存的资源副本是否仍然有效所需的信息,以及 更好地估计已缓存资源何时失效所需的线索。
与此实体相关的实体标记
实体不再有效,要从原始的源端再次获取此实体的日期和时间
这个实体最后一次被修改的日期和时间
从收到 HTML、CSS 和 JavaScript 字节到对其进行必需的处理,从而将它们转变成渲染的像素这一过程中有一些中间步骤,优化性能其实就是了解这些步骤中发生了什么, 即关键渲染路径。优化关键渲染路径是指优先显示与当前用户操作有关的内容。
通过优化关键渲染路径,我们可以显著缩短首次渲染页面的时间。 此外,了解关键渲染路径还可以为构建高性能交互式应用打下基础。
渲染一个网页,浏览器需要完成的步骤:
我们的演示网页看起来可能很简单,实际上却需要完成相当多的工作。*如果 DOM 或 CSSOM 被修改,您只能再执行一遍以上所有步骤,以确定哪些像素需要在屏幕上进行重新渲染。
优化关键渲染路径就是指最大限度缩短执行上述第 1 步至第 5 步耗费的总时间。 这样一来,就能尽快将内容渲染到屏幕上,此外还能缩短首次渲染后屏幕刷新的时间,即为交互式内容实现更高的刷新率。
发现和解决关键渲染路径性能瓶颈需要充分了解常见的陷阱。 让我们踏上实践之旅,找出常见的性能模式,从而帮助您优化网页。
让我们定义一下用来描述关键渲染路径的词汇:
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Critical Path: No Style</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>我们将从基本 HTML 标记和单个图像(无 CSS 或 JavaScript)开始。让我们在 Chrome DevTools 中打开 Network 时间线并检查生成的资源瀑布:
当 HTML 内容可用后,浏览器会解析字节,将它们转换成令牌,然后构建 DOM 树。请注意,为方便起见,DevTools 会在底部报告 DOMContentLoaded 事件的时间(216 毫秒),该时间同样与蓝色垂直线相符。HTML 下载结束与蓝色垂直线 (DOMContentLoaded) 之间的间隔是浏览器构建 DOM 树所花费的时间 — 在本例中仅为几毫秒。
请注意,我们的“趣照”并未阻止 domContentLoaded 事件。这证明,我们构建渲染树甚至绘制网页时无需等待页面上的每个资产:并非所有资源都对快速提供首次绘制具有关键作用。事实上,当我们谈论关键渲染路径时,通常谈论的是 HTML 标记、CSS 和 JavaScript。图像不会阻止页面的首次渲染,不过,我们当然也应该尽力确保系统尽快绘制图像!
即便如此,系统还是会阻止图像上的 load 事件(也称为 onload):DevTools 会在 335 毫秒时报告 onload 事件。回想一下,onload 事件标记的点是网页所需的所有资源均已下载并经过处理的点,这是加载微调框可以在浏览器中停止微调的点(由瀑布中的红色垂直线标记)。
T0 与 T1 之间的时间捕获的是网络和服务器处理时间。在最理想的情况下(如果 HTML 文件较小),我们只需一次网络往返便可获取整个文档。由于 TCP 传输协议工作方式的缘故,较大文件可能需要更多次的往返。因此,在最理想的情况下,上述网页具有单次往返(最少)关键渲染路径。
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>我们同样需要一次网络往返来获取 HTML 文档,然后检索到的标记告诉我们还需要 CSS 文件;这意味着,浏览器需要返回服务器并获取 CSS,然后才能在屏幕上渲染网页。因此,这个页面至少需要两次往返才能显示出来。CSS 文件同样可能需要多次往返,因此重点在于最少。
这里有:
我们同时需要 HTML 和 CSS 来构建渲染树。所以,HTML 和 CSS 都是关键资源:CSS 仅在浏览器获取 HTML 文档后才会获取,因此关键路径长度至少为两次往返。两项资源相加共计 9KB 的关键字节。
现在,让我们向组合内额外添加一个 JavaScript 文件。
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
<script src="app.js"></script>
</body>
</html>我们添加了 app.js,它既是网页上的外部 JavaScript 资源,又是一种解析器阻止(即关键)资源。更糟糕的是,为了执行 JavaScript 文件,我们还需要进行阻止并等待 CSSOM;回想一下,JavaScript 可以查询 CSSOM,因此在下载 style.css 并构建 CSSOM 之前,浏览器将会暂停。
即便如此,如果我们实际查看一下该网页的“网络瀑布”,就会注意到 CSS 和 JavaScript 请求差不多是同时发起的;浏览器获取 HTML,发现两项资源并发起两个请求。
因此,上述网页具有以下关键路径特性:
现在,我们拥有了三项关键资源,关键字节总计达 11 KB,但我们的关键路径长度仍是两次往返,因为我们可以同时传送 CSS 和 JavaScript。了解关键渲染路径的特性意味着能够确定哪些是关键资源,此外还能了解浏览器如何安排资源的获取时间。让我们继续探讨示例。
内联 JavaScript:
我们减少了一个请求,但 onload 和 domContentLoaded 时间实际上没有变化。为什么呢?怎么说呢,我们知道,这与 JavaScript 是内联的还是外部的并无关系,因为只要浏览器遇到 script 标记,就会进行阻止,并等到 CSSOM 构建完毕。此外,在我们的第一个示例中,浏览器是并行下载 CSS 和 JavaScript,并且差不多是同时完成。在此实例中,内联 JavaScript 代码并无多大意义。但是,我们可以通过多种策略加快网页的渲染速度。
向 script 标记添加“async”属性来解除对解析器的阻止:
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
<script src="app.js" async></script>
</body>
</html>异步(外部)JavaScript:
解析 HTML 之后不久即会触发 domContentLoaded 事件;浏览器已得知不要阻止 JavaScript,并且由于没有其他阻止解析器的脚本,CSSOM 构建也可同步进行了。
异步脚本具有以下几个优点:
因此,我们优化过的网页现在恢复到了具有两项关键资源(HTML 和 CSS),最短关键路径长度为两次往返,总关键字节数为 9 KB。
如果 CSS 样式表只需用于打印,那会如何呢?
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet" media="print">
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
<script src="app.js" async></script>
</body>
</html>因为 style.css 资源只用于打印,浏览器不必阻止它便可渲染网页。所以,只要 DOM 构建完毕,浏览器便具有了渲染网页所需的足够信息。因此,该网页只有一项关键资源(HTML 文档),并且最短关键渲染路径长度为一次往返。
为尽快完成首次渲染,我们需要最大限度减小以下三种可变因素:
关键资源是可能阻止网页首次渲染的资源。这些资源越少,浏览器的工作量就越小,对 CPU 以及其他资源的占用也就越少。
同样,关键路径长度受所有关键资源与其字节大小之间依赖关系图的影响:某些资源只能在上一资源处理完毕之后才能开始下载,并且资源越大,下载所需的往返次数就越多。
最后,浏览器需要下载的关键字节越少,处理内容并让其出现在屏幕上的速度就越快。要减少字节数,我们可以减少资源数(将它们删除或设为非关键资源),此外还要压缩和优化各项资源,确保最大限度减小传送大小。
优化关键渲染路径的常规步骤如下:
作为每个可靠性能策略的基础,准确的评估和检测必不可少。 无法评估就谈不上优化。本文说明了评估 CRP(关键渲染路径) 性能的不同方法。
因为 style.css 资源只用于打印,浏览器不必阻止它便可渲染网页。所以,只要 DOM 构建完毕,浏览器便具有了渲染网页所需的足够信息。因此,该网页只有一项关键资源(HTML 文档),并且最短关键渲染路径长度为一次往返。
关键请求链这个概念源自关键渲染路径 (CRP) 优化策略。 CRP 通过确定优先加载的资源以及加载顺序,允许浏览器尽可能快地加载页面。
在 Lighthouse 的 Chrome 扩展程序版本中,您的报告将生成一个类似如下的图表:
Initial navigation
|---lighthouse/ (developers.google.com)
|---/css (fonts.googleapis.com) - 1058.34ms, 72.80KB
|---css/devsite-googler-buttons.css (developers.google.com) - 1147.25ms, 70.77KB
|---jsi18n/ (developers.google.com) - 1155.12ms, 71.20KB
|---css/devsite-google-blue.css (developers.google.com) - 2034.57ms, 85.83KB
|---2.2.0/jquery.min.js (ajax.googleapis.com) - 2699.55ms, 99.92KB
|---contributors/kaycebasques.jpg (developers.google.com) - 2841.54ms, 84.74KB
|---MC30SXJEli4/photo.jpg (lh3.googleusercontent.com) - 3200.39ms, 73.59KB
此图表表示页面的关键请求链。从 lighthouse/ 到 /css 的路径形成一条链。 从 lighthouse/ 到 css/devsite-googler-buttons.css 的路径形成另一条链。 以此类推。审查的最高得分体现了这些链条的数量。 例如,上面的图表的分数为七分。
该图表也详细列出下载每个资源花了多少时间,以及下载每个资源所需的字节数。
您可以根据此图表利用以下方式提升您的 CRP:
优化以上任一因素都可提升页面加载速度。
详情请参阅关键请求链
结合使用 Navigation Timing API 和页面加载时发出的其他浏览器事件,您可以捕获并记录任何页面的真实 CRP 性能。
上图中的每一个标签都对应着浏览器为其加载的每个网页追踪的细粒度时间戳。
那么,这些时间戳有什么含义呢?
HTML 规范中规定了每个事件的具体条件:应在何时触发、应满足什么条件等等。对我们而言,我们将重点放在与关键渲染路径有关的几个关键里程碑上:
要以最快速度完成首次渲染,需要最大限度减少网页上关键资源的数量并(尽可能)消除这些资源,最大限度减少下载的关键字节数,以及优化关键路径长度。
为了最大限度减少浏览器渲染网页的工作量,应延迟任何非必需的脚本(即对构建首次渲染的可见内容无关紧要的脚本)。
CSS 是构建渲染树的必备元素,首次构建网页时,JavaScript 常常受阻于 CSS。确保将任何非必需的 CSS 都标记为非关键资源(例如打印和其他媒体查询),并应确保尽可能减少关键 CSS 的数量,以及尽可能缩短传送时间。
尽早在 HTML 文档内指定所有 CSS 资源,以便浏览器尽早发现 标记并尽早发出 CSS 请求。
一个样式表可以使用 CSS import (@import) 指令从另一样式表文件导入规则。不过,应避免使用这些指令,因为它们会在关键路径中增加往返次数:只有在收到并解析完带有 @import 规则的 CSS 样式表之后,才会发现导入的 CSS 资源。
初学者对React可能满怀期待,觉得React可能完爆其它一切框架,甚至不切实际地认为React可能连原生的渲染都能完爆——对框架的狂热确实会出现这样的不切实际的期待。让我们来看看React的官方是怎么说的。React官方文档在Advanced Performanec这一节,这样写道:
One of the first questions people ask when considering React for a project is whether their application will be as fast and responsive as an equivalent non-React version
显然React自己也其实只是想尽量达到跟非React版本相当的性能。
react的组件渲染分为初始化渲染和更新渲染。
在初始化渲染的时候会调用根组件下的所有组件的render方法进行渲染,如下图(绿色表示已渲染,这一层是没有问题的):
但是当我们要更新某个子组件的时候,如下图的绿色组件(从根组件传递下来应用在绿色组件上的数据发生改变):
我们的理想状态是只调用关键路径上组件的render,如下图:
但是react的默认做法是调用所有组件的render,再对生成的虚拟DOM进行对比,如不变则不进行更新。这样的render和虚拟DOM的对比明显是在浪费,如下图(黄色表示浪费的render和虚拟DOM对比)
Tips:
- 拆分组件是有利于复用和组件优化的。
- 生成虚拟DOM并进行比对发生在render()后,而不是render()前。
componentWillReceiveProps(object nextProps):当挂载的组件接收到新的props时被调用。此方法应该被用于比较this.props 和 nextProps以用于使用this.setState()执行状态转换。(组件内部数据有变化,使用state,但是在更新阶段又要在props改变的时候改变state,则在这个生命周期里面)shouldComponentUpdate(object nextProps, object nextState): -boolean 当组件决定任何改变是否要更新到DOM时被调用。作为一个优化实现比较this.props 和 nextProps 、this.state 和 nextState ,如果React应该跳过更新,返回false。componentWillUpdate(object nextProps, object nextState):在更新发生前被立即调用。你不能在此调用this.setState()。componentDidUpdate(object prevProps, object prevState): 在更新发生后被立即调用。(可以在DOM更新完之后,做一些收尾的工作)Tips:
- React的优化是基于
shouldComponentUpdate的,该生命周期默认返回true,所以一旦prop或state有任何变化,都会引起重新render。
react在每个组件生命周期更新的时候都会调用一个shouldComponentUpdate(nextProps, nextState)函数。它的职责就是返回true或false,true表示需要更新,false表示不需要,默认返回为true,即便你没有显示地定义 shouldComponentUpdate 函数。这就不难解释上面发生的资源浪费了。
为了进一步说明问题,我们再引用一张官网的图来解释,如下图( SCU表示shouldComponentUpdate,绿色表示返回true(需要更新),红色表示返回false(不需要更新);vDOMEq表示虚拟DOM比对,绿色表示一致(不需要更新),红色表示发生改变(需要更新)):
根据渲染流程,首先会判断shouldComponentUpdate(SCU)是否需要更新。如果需要更新,则调用组件的render生成新的虚拟DOM,然后再与旧的虚拟DOM对比(vDOMEq),如果对比一致就不更新,如果对比不同,则根据最小粒度改变去更新DOM;如果SCU不需要更新,则直接保持不变,同时其子元素也保持不变。
react官方提供一个插件React.addons.Perf可以帮助我们分析组件的性能,以确定是否需要优化。
打开console面板,先输入Perf.start()执行一些组件操作,引起数据变动,组件更新,然后输入Perf.stop()。(建议一次只执行一个操作,好进行分析)
再输入Perf.printInclusive查看所有涉及到的组件render,如下图(官方图片):
或者输入Perf.printWasted()查看下不需要的的浪费组件render,如下图(官方图片):
优化前:
优化后:
react-perf-tool为React应用提供了一种可视化的性能检测方案,该工程同样是基于React.addons,但是使用图表来显示结果,更加方便。
var PureRenderMixin = require('react-addons-pure-render-mixin');
React.createClass({
mixins: [PureRenderMixin],
render: function() {
return <div className={this.props.className}>foo</div>;
}
});var shallowCompare = require('react-addons-shallow-compare');
export class SampleComponent extends React.Component {
shouldComponentUpdate(nextProps, nextState) {
return shallowCompare(this, nextProps, nextState);
}
render() {
return <div className={this.props.className}>foo</div>;
}
}es7装饰器的写法:
import pureRender from "pure-render-decorator"
...
@pureRender
class Person extends Component {
render() {
console.log("我re-render了");
const {name,age} = this.props;
return (
<div>
<span>姓名:</span>
<span>{name}</span>
<span> age:</span>
<span>{age}</span>
</div>
)
}
}pureRender很简单,就是把传进来的component的shouldComponentUpdate给重写掉了,原来的shouldComponentUpdate,无论怎样都是return ture,现在不了,我要用shallowCompare比一比,shallowCompare代码及其简单,如下:
function shallowCompare(instance, nextProps, nextState) {
return !shallowEqual(instance.props, nextProps) || !shallowEqual(instance.state, nextState);
}
shallowEqual其实只比较props的第一层子属性是不是相同,如果props是如下
{
detail: {
name: "123",
age: "123"
}
}他只会比较props.detail ===nextProps.detail,导致在传入复杂的数据的情况下,优化失效。
我们也可以在 shouldComponentUpdate() 中使用使用 deepCopy 和 deepCompare 来避免无必要的 render(),但 deepCopy 和 deepCompare 一般都是非常耗性能的。
Immutable Data 就是一旦创建,就不能再被更改的数据。对 Immutable 对象的任何修改或添加删除操作都会返回一个新的 Immutable 对象。
Immutable 实现的原理是 Persistent Data Structure(持久化数据结构),也就是使用旧数据创建新数据时,要保证旧数据同时可用且不变。同时为了避免 deepCopy 把所有节点都复制一遍带来的性能损耗,Immutable 使用了 Structural Sharing(结构共享),即如果对象树中一个节点发生变化,只修改这个节点和受它影响的父节点,其它节点则进行共享。请看下面动画:
Immutable 则提供了简洁高效的判断数据是否变化的方法,只需 === 和 is 比较就能知道是否需要执行 render(),而这个操作几乎 0 成本,所以可以极大提高性能。修改后的 shouldComponentUpdate 是这样的:
import { is } from 'immutable';
shouldComponentUpdate: (nextProps = {}, nextState = {}) => {
const thisProps = this.props || {}, thisState = this.state || {};
if (Object.keys(thisProps).length !== Object.keys(nextProps).length ||
Object.keys(thisState).length !== Object.keys(nextState).length) {
return true;
}
for (const key in nextProps) {
if (!is(thisProps[key], nextProps[key])) {
return true;
}
}
for (const key in nextState) {
if (thisState[key] !== nextState[key] || !is(thisState[key], nextState[key])) {
return true;
}
}
return false;
}这是一个facebook/immutable-js的react pure render mixin 的库,可以简化很多写法。
使用react-immutable-render-mixin可以实现装饰器的写法。
import React from 'react';
import { immutableRenderDecorator } from 'react-immutable-render-mixin';
@immutableRenderDecorator
class Test extends React.Component {
render() {
return <div></div>;
}
}###参考文章
Immutable 详解及 React 中实践
为了避免一定程度的浪费,react官方还在0.14版本中加入了无状态组件,
这种组件没有状态,没有生命周期,只是简单的接受 props 渲染生成 DOM 结构。无状态组件非常简单,开销很低,如果可能的话尽量使用无状态组件。比如使用箭头函数定义:
// es6
const HelloMessage = (props) => <div> Hello {props.name}</div>;
render(<HelloMessage name="John" />, mountNode);因为无状态组件只是函数,所以它没有实例返回,这点在想用 refs 获取无状态组件的时候要注意,参见DOM 操作。
大部分使用mixin和class extends的地方,高阶组件都是更好的方案——毕竟
组合优于继承。
使用ES6编写React应用(4):使用高阶组件替代Mixins
Mixin 已死,Composition **
同构基于服务端渲染,却不止是服务端渲染。
React在减少重复渲染方面确实是有一套独特的处理办法,那就是virtual DOM,但显示在首次渲染的时候React绝无可能超越原生的速度。因此,我们在做优化的时候,接下来可以做的事情就是:
React同构直出优化总结
腾讯新闻React同构直出优化实践
正则表达式 (regular expression)是一个描述字符模式的对象。JavaScript的 RegExp类 表示正则表达式,String 和 RegExp 都定义了方法,后者使用正则表达式进行强大的模式匹配和文本检索与替换功能。
JavaScript 的正则表达式语法是 Perl5 的正则表达式语法的大型子集,所以对于有Perl编程经验的程序员来说,学习JavaScript 中的正则表达式是小菜一碟。
JavaScript中的正则表达式用 RegExp对象 表示,可以使用 RegExp() 构造函数来创建 RegExp 对象。
不过RegExp对象更多的是通过一种特殊的直接量语法来创建。就像通过引号包裹字符的方式来定义字符串直接量一样,正则表达式直接量定义为包含在一对斜杠 (/) 之间的字符,例如:
var pattern=/s$/;运行这段代码创建一个新的 RegExp 对象,并将它赋值给变量 pattern。这个特殊的 RegExp 对象用来匹配所有以字母 “s” 结尾的字符串。用构造函数 RegExp() 也可以定义个与之等价的正则表达式,代码如下:
var pattern=new RegExp(“s$”);正则表达式直接量则与此不同,ECMAScript 3 规范规定,一个正则表达式直接量会在执行到它时转换为一个RegExp对象,同一段代码所表示正则表达式直接量的每次运算都返回同一个对象。
ECMAScript 5 规范则做了相反的规定,同一段代码所 表示的正则表达式直接量的每次运算都返回新对象。IE一直都是按照ECMAScript 5 规范实现的,多数最新版本的浏览器也开始遵循ECMAScript 5。
一般匹配重复字符是尽可能多地匹配,而且允许后续的正则表达式继续匹配。因此,我们称之为 “贪婪的”匹配。
我们同样可以使用正则表达式进行 非贪婪匹配。
只须在待匹配的字符后跟随一个问号即可: “??”、“+?”、“*?”或“{1,5}?”。
比如,正则表达式/a+/可以匹配一个或多个连续的字母 a。当使用 “aaa” 作为匹配字符串时,正则表达式会匹配它的三个字符。但 是 /a+?/ 也可以匹配一个或多个连续字母 a,但它是尽可能少地匹配。我们同样 将 “aaa” 作为匹配字符串,但后一个模式只能匹配第一个a。
使用非贪婪的匹配模式所得到的结果可能和期望并不一致。考虑以下正则表达式 /a+b/,它可以匹配一个或多个a,以及一个b。当使用 “aaab” 作为匹配字符串时, 它会匹配整个字符串。
现在再试一下非贪婪匹配的版本 /a+?b/,它匹配尽可能少的 a 和一个 b。当用它来匹配 “aaab” 时,你期望它能匹配一个 a 和最后一个 b。但实际上, 这个模式却匹配了整个字符串,和该模式的贪婪匹配一模一样。
这是因为正则表达式的模式匹配总是会寻找字符串中第一个可能匹配的位置。由于该匹配是从字符串的第一个字符开始的,因此在这里不考虑它的子串中更短的匹配。
正则表达式的语法还包括指定选择项、子表达式分组和引用前一子表达式的特殊字符。
字符 “|” 用于分隔供选择的字符。例如,/ab|cd|ef/ 可以匹配字符串“ab”,也 可以匹配字符串“cd”,还可以匹配字符串 “ef”。/\d{3}|[a-z]{4}/ 匹配的是三位数字或 者四个小写字母。
注意,选择项的尝试匹配次序是从左到右,直到发现了匹配项。如果左边的选择项匹配,就忽略右边的匹配项,即使它产生更好的匹配。因此,当正则表达式 /a|ab/ 匹配字符串 “ab” 时,它只能匹配第一个字符。
正则表达式中的圆括号有多种作用。
一个作用是把单独的项组合成子表达式, 以便可以像处理一个独立的单元那样用 “|”、“*”、“+” 或者 “?” 等来对单元内的项进行处理。例如, /java(script)?/ 可以匹配字符串“java”,其后可以有 “script” 也可以没有。/(ab|cd)+|ef/ 可以匹配字符串 “ef”,也可以匹配字符串“ab”或“cd”的一次或多次重复。
在正则表达式中,圆括号的另一个作用是在完整的模式中定义子模式。
当一个正则表达式成功地和目标字符串相匹配时,可以从目标串中抽出和圆括号中的子模式相匹配的部分。例如,假定我们正在检索的模式是一个或多个小写字母后面跟随了一位或多位数字, 则可以使用模式 /[a-z]+\d+/。但假定我们真正关心的是每个匹配尾部的数字,那么如果将模式的数字部分放在括号中 (/[a-z]+(\d+)/) ,就可以从检索到的匹配中抽取数字 了,之后我们会有详尽的解释。
带圆括号的表达式的另一个用途是允许在同一正则表达式的后部引用前面的子表达式。
这是通过在字符 “\” 后加一位或多位数字来实现的。这个数字指定了带圆括 号的子表达式在正则表达式中的位置。例如,\1引用的是第一个带圆括号的子表达 式,\3 引用的是第三个带圆括号的子表达式。
注意,因为子表达式可以嵌套另一个子表达式,所以它的位置是参与计数的左括号的位置。例如,在下面的正则表达式 中,嵌套的子表达式 ([Ss]cript) 可以用 \2来指代:
/([Jj]ava([Ss]cript)?)\sis\s(fun\w*)/
对正则表达式中前一个子表达式的引用,并不是指对子表达式模式的引用,而指的是与那个模式相匹配的文本的引用。这样,引用可以用于实施一条约束,即一个字符串各个单独部分包含的是完全相同的字符。
例如,下面的正则表达式匹配的就是位于单引号或双引号之内的 0 个或多个字符。但是,它并不要求左侧和右侧的引号匹配(即,加入的两个引号都是单引号或都是双引号):
/[’”][^’”]*[’”]/如果要匹配左侧和右侧的引号,可以使用如下的引用:
/([’”])[^’”]*\1/\1 匹配的是第一个带圆括号的子表达式所匹配的模式。在这个例子中,存在这样一条约束,那就是左侧的引号必须和右侧的引号相匹配。
正则表达式不允许用双引号括起的内容中有单引号,反之亦然。不能在字符类中使用这种引用,所以下面的写法是非法的:
/([’”])[^\1]*\1/同样,在正则表达式中不用创建带数字编码的引用,也可以对子表达式进行分组。它不是以 “(” 和 “)” 进行分组,而是以 “(?:”和“)” 来进行分组,比如,考虑下面这个模式:
/([Jj]ava(?:[Ss]cript)?)\sis\s(fun\w*)/这里,子表达式 (?:[Ss]cript) 仅仅用于分组,因此复制符号”?”可以应用到各个分 组。这种改进的圆括号并不生成引用,所以在这个正则表达式中,\2 引用了与 (fun\W*) 匹配的文本。
下图对正则表达式的选择、分组和引用运算符做了总结:
任意正则表达式都可以作为锚点条件。如果在符号 “(?=”和“)” 之间加入一个表 达式,它就是一个 先行断言 ,用以说明圆括号内的表达式必须正确匹配,但并不是真正意义上的匹配。
比如,要匹配一种常用的程序设计语言的名字,但只在其后有冒号时才匹配,可以使用 /[Jj]ava([Ss]cript)?(?=\:)/。这个正则表达式可以匹 配“JavaScript:The Definitive Guide”中的“JavaScript”,但是不能匹配“Java in a Nutshell”中的“Java”,因为它后面没有冒号。

带有 “(?!” 的断言是负向先行断言,用以指定接下来的字符都不必匹配。
例如, /Java(?!Script)([A-Z]\w*)/可以匹配“Java”后跟随一个大写字母和任意多个ASCII 单词,但Java后面不能跟随“Script”。它可以匹配“JavaBeans”,但不能匹配“Javanese”;它不匹配“JavaScript”,也不能匹配“JavaScripter”。

String支持4种使用正则表达式的方法。
最简单的是 search()。它的参数是一个正则表达式,返回第一个与之匹配的子串的起始位置,如果找不到匹配的子串,它将 返回 -1。比如,下面的调用返回值为 4:
“JavaScript”.search(/script/i);如果 search() 的参数不是正则表达式,则首先会通过RegExp构造函数将它转换成正则表达式,
search() 方法不支持全局检索,因为它忽略正则表达式参数中的修饰符g。
replace()方法用以执行检索与替换操作。其中第一个参数是一个正则表达式, 第二个参数是要进行替换的字符串。这个方法会对调用它的字符串进行检索,使用指定的模式来匹配。
如果正则表达式中设置了修饰符 g,那么源字符串中所有与模式匹配的子串都将替换成第二个参数指定的字符串;如果不带修饰符 g,则只替换所匹配的第一个子串。
如果replace()的第一个参数是字符串而不是正则表达式,则 replace()将直接搜索这个字符串,而不是像search()一样首先通过RegExp()将它转换为正则表达式。
比如,可以使用下面的方法,利用 replace() 将文本中的所有 javascript(不区分大小写) 统一替换为“JavaScript”:
//将所有不区分大小写的javascript都替换成大小写正确的JavaScript
text.replace(/javascript/gi,“JavaScript”);但 replace() 的功能远不止这些。回忆一下前文所提到的,正则表达式中使用圆括号括起来的子表达式是带有从左到右的索引编号的,而且正则表达式会记忆与每个子表达式匹配的文本。
如果在替换字符串中出现了$加数字,那么 replace() 将用与指定的子表达式相匹配的文本来替换这两个字符。这是一个非常有用的特性。
比 如,可以用它将一个字符串中的英文引号替换为中文半角引号:
//一段引用文本起始于引号,结束于引号
//中间的内容区域不能包含引号
var quote=/”([^”]*)”/g;//用中文半角引号替换英文引号,同时要保持引号之间的内容(存储在$1中)没有被修改
text.replace(quote,’“$1”’);最值得注意的是,replace()方法的第二个参数 可以是函数,该函数能够动态地计算替换字符串。
match() 方法是最常用的String正则表达式方法。它的唯一参数就是一个正则表达式(或通过RegExp()构造函数将其转换为正则表达式),返回的是一个由匹配结果组成的数组。
如果该正则表达式设置了修饰符g,则该方法返回的数组包含字符 串中的所有匹配结果。例如:
“1 plus 2 equals 3”.match(/\d+/g)//返回[“1”,“2”,“3”]如果这个正则表达式没有设置修饰符 g, match() 就不会进行全局检索,它只检索第一个匹配。但即使 match() 执行的不是全局检索,它也返回一个数组。
在这种情况下,数组的第一个元素就是匹配的字符串,余下的元素则是正则表达式中用圆括号括起来的子表达式。
因此,如果 match() 返回一个数组a,那么 a[0] 存放的是完整的匹配,a[1]存放的则是与第一个用圆括号括起来的表达式相匹配的子串,以此类推。为了和方法 replace() 保持一致, a[n] 存放的是 $n的内容。
split() 这个方法用以将调用 它的字符串拆分为一个子串组成的数组,使用的分隔符是split()的参数,例如:
“123,456,789”.split(“,”);//返回[“123”,“456”,“789”]split() 方法的参数也可以是一个正则表达式,这使得 split() 方法异常强大。例如,可以指定分隔符,允许两边可以留有任意多的空白符:
“1,2,3,4,5”.split(/\s*,\s*/);//返回[“1”,“2”,“3”,“4”,“5”]每个RegExp对象都包含5个属性。
g。ignoreCase 也是一个只读的布尔值,用以说明正则表达式是否带有修饰符 i。multiline 是一个只读的布尔值,用以说明正则表达式是否带有修饰符 m。lastIndex,它是一个可读/写的整数。如果匹配模式带有g修饰符, 这个属性存储在整个字符串中下一次检索的开始位置,这个属性会被 exec()和 test() 方法用到,下面会讲到。RegExp对象定义了两个用于执行模式匹配操作的方法。
RegExp最主要的执行模式匹配的方法是 exec() ,exec()方法对一个指定的字符串执行一个正则表达 式,简言之,就是在一个字符串中执行匹配检索。
如果它没有找到任何匹配,它就 返回null,但如果它找到了一个匹配,它将返回一个数组,就像match() 方法为非全局检索返回的数组一样。
和
match()方法不同,不管正则表达式是否具有全局修饰符g,exec()都会返回一样的数组。
当调用exec()的正则表达式对象具有修饰符 g 时,它将把当前正则表达式对象的 lastIndex 属性设置为紧挨着匹配子串的字符位置。当同一个正则表达式第二次调用
exec()时,它将从lastIndex属性所指示的字符处开始检索。
var pattern = /Java/g;
var text = "JavaScript is more fun than Java!";
result = pattern.exec(text)
//结果
//["Java", index: 0, input: "JavaScript is more fun than Java!"]
pattern.lastIndex //4如果 exec() 没有发现任何匹配结果,它会将 lastIndex 重置为0(在任何时候都可以将 lastIndex属性设置为0。
每当在字符串中找最后一个匹配项后,在使用这个RegExp对象开始新的字符串查找之前,都应当将 lastIndex 设置为0)。这种特殊的行为使我们可以在用正则表达式匹配字符串的过程中反复调用 exec(),比如:
var pattern = /Java/g;
var text = "JavaScript is more fun than Java!";
var result;
while ((result = pattern.exec(text)) != null) {
alert("Matched '" + result[0] + "'" +
" at position " + result.index +
"; next search begins at " + pattern.lastIndex);
}另外一个RegExp方法是 test() ,它比 exec() 更简单一些。它的参数是一个字符串,用 test() 对某个字符串进行检测,如果包含正则表达式的一个匹配结果,则返回 true :
var pattern=/java/i;
pattern.test(“JavaScript”);//返回true调用 test() 和调用 exec() 等价,当 exec() 的返回结果不是null时,test()返回true。由于这种等价性,当一个全局正则表达式调用方法 test() 时,它的行为和 exec() 相同。
因为它从 lastIndex 指定的位置处开始检索某个字符串,如果它找到了一个匹配结果,那么它就立即设置 lastIndex 为当前匹配子串的结束位置。这样一来,就可以使用test() 来遍历字符串,就像用 exec() 方法一样。
与 exec() 和 test() 不同, String方法 search()、replace() 和 match() 并不会用到 lastIndex 属性。
实际上, String 方法只是简单地将 lastIndex 属性值重置为0。
如果让一 个带有修饰符 g 的正则表达式对多个字符串执行 exec()或test(),要么在每个字符串中找出所有的匹配以便将 lastIndex 自动重置为零,要么显式将 lastIndex 手动设置为 0(当最后一次检索失败时需要手动设置 lastIndex )。
如果忘了手动设置 lastIndex 的值,那么下一次对新字符串进行检索时,执行检索的起始位置可能就不是字符串的开始位置,而可能是任意位置。
当然,如果RegExp不带有修饰符g,则不必担心会发生这种情况。
同样要记住,在 ECMAScript 5中,正则表达式直接量的每次计算都会创建一个新的 RegExp对象,每个新 RegExp对象 具有各自的 lastIndex属性,这势必会大大减少“残留” lastIndex 对程序造成的意外影响。
HTTP/1 已经支撑我们走到今天,但是现代 Web 应用的需求迫使我们关注其设计缺陷。下面是它面临的一些比较重要的问题;这自然也是设计 HTTP/2 要解决的核心问题。
并没有“HTTP/1”这种专业术语;此处这一用法(还有 h1),是对 HTTP/1.0 (RFC 1945)和 HTTP/1.1(RFC 2616)的简称。
浏览器很少只从一个域名获取一份资源。大多数时候,它希望能同时获取许多资源。设想这样一个网站,它把所有图片放在单个特定域名下。HTTP/1 并未提供机制来同时请求这些资源。如果仅仅使用一个连接,它需要发起请求、等待响应,之后才能发起下一个请求。
h1 有个特性叫 管道化(pipelining),允许一次发送一组连续的请求,而不用等待应答返回。这样可以避免连接延迟。但是该特性只能按照发送顺序依次接收响应。而且,管道化备受互操作性和部署的各种问题的困扰,基本没有实用价值。
在请求应答过程中,如果出现任何状况,剩下所有的工作都会被阻塞在那次请求应答之后。这就是 队头阻塞 (Head-of-line blocking或缩写为HOL blocking),它会阻碍网络传输和 Web 页面渲染,直至失去响应。
为了防止这种问题,现代浏览器会针对单个域名开启 6 个连接,通过各个连接分别发送请求。它实现了某种程度上的并行,但是每个连接仍会受到 队头阻塞 的影响。另外,这也没有高效利用有限的设备资源。
传输控制协议(TCP) 的设计思路是:对假设情况很保守,并能够公平对待同一网络的不同流量的应用。它的避免拥塞机制被设计成即使在最差的网络状况下仍能起作用,并且如果有需求冲突也保证相对公平。这是它取得成功的原因之一。
它的成功并不是因为传输数据最快,而是因为它是最可靠的协议之一,涉及的核心概念就是 拥塞窗口(congestion window) 。拥塞窗口是指,在接收方确认数据包之前,发送方可以发出的 TCP 包的数量。 例如,如果拥塞窗口指定为 1,那么发送方发出 1 个数据包之后,只有接收方确认了那个包,才能发送下一个。
一般来讲,每次发送一个数据包并不是非常低效。TCP 有个概念叫 慢启动(Slow Start), 它用来探索当前连接对应拥塞窗口的合适大小。慢启动的设计目标是为了让新连接搞清楚当前网络状况,避免给已经拥堵的网络继续添乱。它允许发送者在收到每个确认回复后额外发送 1 个未确认包。这意味着新连接在收到 1 个确认回复之后,可以发送 2 个数据包; 在收到 2 个确认回复之后,可以发 4 个;以此类推。这种几何级数增长很快就会到达协议规定的发包数上限,这时候连接将进入拥塞避免阶段,

这种机制需要几次往返数据请求才能得知最佳拥塞窗口大小。但在解决性能问题时,就这 区区几次数据往返也是非常宝贵的时间(成本)。现代操作系统一般会取 4~10 个数据包作为初始拥塞窗口大小。如果你把一个数据包设置为最大值下限 1460 字节(也就是 最大有效负载),那么只能先发送 5840 字节(假定拥塞窗口为 4),然后就需要等待接收确认回复。
如今的 Web 页面平均大小约 2MB,包括 HTML 和所有依赖的资源。在理想情况下, 这需要大约 9 次往返请求来传输完整个页面。除此之外,浏览器一般会针对同一个域名开启 6 个并发连接,每个连接都免不了拥塞窗口调节。
上面提到的那些数字是怎么得出来的?这个时候了解一些数学知识很有必要,有助于估算对网络传输的影响,看看到底是增加还是减少了传输字节数。假设拥塞窗口的大 小每次往返请求之后会翻一番,每个数据包承载 1460 字节。在理想情况下,呈现出等比数列。
直到第 9 次,2MB 数据才能全部发完。不过,这过度简化了现实情况。在窗口大小达 到 1024 个数据包时,要么会触发一个叫
ssthresh(慢启动阈值)的上限值,要么窗口 会自动缩小;不管哪种情况,几何级数增长都会终止。不过,用于粗略估算时,这种简单方法已经够用了。
前面提到过,因为 h1 并不支持多路复用,所以浏览器一般会针对指定域名开启 6 个并发 连接。这意味着拥塞窗口波动也会并行发生 6 次。TCP 协议保证那些连接都能正常工作, 但是不能保证它们的性能是最优的。
虽然 h1 提供了压缩被请求内容的机制,但是消息首部却无法压缩。消息首部可不能忽略, 尽管它比响应资源小很多,但它可能占据请求的绝大部分(有时候可能是全部)。如果算 上 cookie,有个几千字节就很正常了。
据 HTTP 历史存档记录,2016 年末,请求首部一般集中在 460 字节左右。对于包含 140 个 资源的普通Web 页面,意味着它在发起的所有请求中大约占 63KB。
想想之前关于 TCP 拥塞窗口管理的讨论,发送该页面相关的所有请求可能需要 3~4 轮往返,因此网络延迟的损耗会被迅速放大。此外,上行带宽通常会受到网络限制,尤其是在移动网络环境中,于是拥塞窗口机制根本来不及起作用,导致更多的请求和响应。
消息首部压缩的缺失也容易导致客户端到达带宽上限,对于低带宽或高拥堵的链路尤其如此。体育馆效应(Stadium Effect) 就是一个经典例子。如果成千上万人同一时间出现在同一地点(例如重大体育赛事),会迅速耗尽无线蜂窝网络带宽。这时候,如果能压缩请求首部,把请求变得更小,就能够缓解带宽压力,降低系统的总负载。
如果浏览器针对指定域名开启了多个 socket(每个都会受队头阻塞问题的困扰),开始请求资源,这时候浏览器能指定优先级的方式是有限的:要么发起请求,要么不发起。
然而 Web 页面上某些资源会比另一些更重要,这必然会加重资源的 排队效应。这是因为浏览器为了先请求优先级高的资源,会推迟请求其他资源。
但是优先级高的资源获取之后,在处理的过程中,浏览器并不会发起新的资源请求,所以服务器无法利用这段时间发送优先级低的资源,总的页面下载时间因此延长了。还会出现这样的情况:一个高优先级资源被浏览器发现,但是受制于浏览器处理的方式,它被排在了一个正在获取的低优先级资源之后。
虽然第三方资源不是 HTTP/1 特有的问题,但鉴于它日益增长的性能问题,我们也把它列在这里。
如今的 Web 页面上请求的很多资源完全独立于站点服务器的控制,我们称这些为 第三方资源。现代 Web 页面加载时长中往往有一半消耗在第三方资源上。虽然有很多技巧能把第三方资源对页面性能的影响降到最低,但是很多第三方资源都不在 Web 开发者的控制范围内,所以很可能其中有些资源的性能很差,会延迟甚至阻塞页面渲染。
任何关于 Web 性能的讨论,只要没有提到第三方资源引起的问题,都不算完整。(令人扫兴的是, h2 对此也束手无策。)
第三方资源究竟让页面慢多少? Akamai 的 Foundry 团队的研究显示,第三方资源的影响非常大,平均累计占到页面整体加载时间的一半 1。这份报告提出了新的用于跟踪第三方资源影响的指标,称为
3rd Party Trailing Ratio。它测量的是请求并展现第三方内容对页面渲染时间的影响程度。
局域网(local area network,LAN)。
广域网(wide area network,WAN)。
目前使用的两种典型的广域 网:点到点广域网和交换式广域网。
在电路交换网络(circuit-switched network)中,两个端系统之间总是存在一条专用的连接(称 为电路),交换机只能使其变成活跃或非活跃状态。
分组交换网络:在一个计算机网络中,两个端点之间使用被称为分组(packet)的数据块进行通信。分组交换网络中的路由器具有能够存储和转发分组的队列。
协议(protocol)定义了发送者、接收 者和所有中间设备为了高效通信需要遵循的规则。当通信简单时,我们可能只是需要一个简单的协 议;当通信复杂时,我们可能需要把任务划分到不同层,每层需要一个协议,也就是说需要协议分层(protocol layering)。
原则:第一个原则就是如果想要双向通信,那么我们需要每一层能够 实现两个相反的任务,每个方向上一个。第二个原则是两端每一层中的两个对象应该相同。
TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/互联网协议)
应用层、传输层和网 络层的任务是端到端的(end-to-end)。但是,数据链路层和物理层的任务是点到点的(hop-to-hop), 其中一个跳步是一个主机或路由器。也就是说,高三层的任务范围是互联网,低两层的任务范围是 链路。

两个应用层之间的逻辑连接是端到端的。两个应用层之间仿佛存在一座桥梁一样相互交消息(message)。应用层的通信处于两个进程(该层正在运行的两个程序)之间。
超级文本传输协议(Hypertext Transfer Protocol,HTTP)是访问万维网(World Wide Web, WWW)的载体。简单邮件传输协议(Simple Mail Transfer Protocol,SMTP)是电子邮件(e-mail) 服务的主要协议。文件传输协议(File Transfer Protocol,FTP)用于将文件从一台主机传输到另一 台主机。远程登录(Terminal Network,TELNET)和安全外壳(Secure Shell,SSH)用于访问远端 的站点。简单网络管理协议(Simple Network Management Protocol,SNMP)对 Internet 全局或局部进行管理。域名系统(Domain Name System,DNS)使其他的协议能够查询一台计算 机的网络层地址。因特网组管理协议(Internet Group Management Protocol,IGMP)用于管理一个 组的成员资格。传输层的逻辑连接也是端到端的。源主机的传输层从应用层得到消息(message),封装成传输层的分组( TCP 中称为段(segment),在 UDP 中称为用户数据报(user datagram)),然后进行发送。通过逻辑(想象的)连接,分组到达目 的主机的传输层。传输层有多个协议,这意味着每个应用程序可以使用与它的需求最匹 配的协议。
传输层在有效载荷基础上增加传输层头部,其中包括了希望进行通信的源和目的应用程序的标识符和一些投递该消息需 要的更多信息,例如进行流量控制、差错控制和拥塞控制需要的信息。
Internet 中有几个传输层协议,每个都是为一些特定的任务设计的。
传输控制协议(Transmission Control Protocol,TCP)是一个面向连接的协议,它在传输数据之前,首先在两台主机的传输层之间建立一条逻辑连接。TCP 协议在两个 TCP 层之间创建一个管道,以便传输字节流。TCP 协议提供流量控制(匹配源主机的发送数据速率与目的主机的接 收数据速率,以防止目的主机溢出)、差错控制(保证数据段无差错到达目的地和重新发送受损的 数据段)、拥塞控制(减少由于网络拥塞造成的数据段丢失)。用户数据报协议(User Datagram Protocol,UDP)是一种无连接协议,它传输用户数据报之前不需要创建逻辑 连接。在 UDP 中,每个用户数据报是一个独立的实体,它和前一个或后一个用户数据报没有关系(无连接就是这个意思)。UDP 是一种比较简单的协议,它不提供流量控制、差错控制或拥塞控制。 它的简单性(意味着小的额外开销)对某些应用程序具有吸引力,这些应用程序发送较短的消息且 不能容忍 TCP 在分组损坏或丢失时使用重发机制。流控制传输协议(Stream Control Transmission Protocol,SCTP)是一种新协议,它是为多媒体出现的新应用设计的。网络层负责在源计算机和目的计算机之间创建一个连接。网络层的通信是主机到主机的。可是, 由于从源主机到目的主机可能存在多个路由器,因此路径上的路由器负责为每个分组选择最好的路径。我们可以说网络层负责主机到主机的通信,并且指挥分组通过合适的路由器。
网络层把传输层分组作为数据或有效载荷,并且在该有效载荷上添加自己的头部。头部包 含源和目的主机的地址,以及用于头部差错检查、分片的信息等其他一些信息。其结果为一个称为 **数据报(datagram)**的网络层分组。
需要这一层的原因之一是在不同的层次之间分割不同的任务。原因之二是路由器不需要应用层和传输层。 分割任务允许我们在路由器上加载较少的协议。
nternet 的网络层包括其主要协议:因特网协议(Internet Protocol,IP),因特网协议定义了在 网络层称为数据报的分组格式。IP 同时定义了在这一层使用的地址格式和结构。与此同时,IP 负 责从源主机把一个分组路由到目的主机。这种功能主要是通过每个路由器都将数据报转发到路径上 的下一个路由器而实现的。
IP 是一个无连接的协议,不提供流量控制、差错控制和拥塞控制服务。这意味着如果一个应 用需要这些服务,那么应用需要依赖于传输层协议。网络层也包括单播(一对一)和多播(一对多) 路由协议。虽然路由协议不参加路由(路由是 IP 的责任),但是它为路由器创建转发路由表,为转 发处理提供帮助。
网络层也包含一些帮助 IP 转发和进行路由工作的辅助协议。在路由一个分组时,因特网控制 报文协议(Internet Control Message Protocol,ICMP)帮助 IP 报告遇到的问题。因特网组管理协议 (Internet Group Management Protocol,IGMP)协助 IP 进行多任务处理。动态主机配置协议(Dynamic Host Configuration Protocol,DHCP)帮助 IP 获取一台主机的网络层地址。在网络层地址已知时, 地址解析协议(Address Resolution Protocol,ARP)帮助 IP 寻找一台主机或一台路由器的链路层地址。
我们已经知道一个互联网是多个链路(LAN 和 WAN)通过路由器连接而构成的。从主机传输 数据报到目的地可能存在多个交叠的链路集。路由器负责选择最好的链路进行传输。
数据链路层把网络层分组作为数据或有效载荷,并且添加上自己的头部。该头部包含主机或下一跳步(路由器)的链路层地址。其结果为一个称为**帧(frame)**的链路层分组。该帧被传递 到物理层进行传输。
TCP/IP 没有为数据链路层定义任何特定的协议。它支持所有标准的和私有的协议。能够接管数据报并携带它穿过链路的任何协议都能满足网络层的要求。数据链路层接管一个数据报并将它封 装在一个称为**帧(frame)**的分组中。每个链路层协议可能提供不同的服务。有些链路层协议提供完整的检查和纠错,有些只提供纠 错。
我们可以说物理层负责携带一个帧中单独的比特穿过链路。尽管物理层位于 TCP/IP 协议簇的 最底层,但是由于在物理层之下存在另外一个隐藏的传输介质层,因此两个设备物理层之间的通信 仍然是逻辑通信数据链路层接收的一个帧的比特需要被变换,然后通过传输介质传输。但是我们可以认为两个设备物理层之间的逻辑单元是一个比特(bit)。将一个比特变换成一个信号存在多种协议。
层次、地址与分组名之间存在一定的关系。

[email protected] 一样的电子邮件地 址。MAC 地址(MAC address),是本地定义的地址。每个链路层地址用于在网络(LAN 或 WAN)中定义一个特定的主机或路由器。由于 TCP/IP 协议簇在一些层次使用多个协议,因此我们在源端需要进行多路复用 (multiplexing),在目的端需要进行多路分解(demultiplexing)。在这种情况下,多路复用的意思是一个协议能够封装来自多个上层协议的分组(一次一个);多路分解的意思是一个协议能够进行解封装, 并且将分组投递到多个上层协议(一次一个)。
为了进行多路复用和多路分解,协议需要一个用于标识被封装的分组属于哪种协议的头部字段。
Internet 标准是一个彻底通过测试的规范,该规范对从事互联网工作的人员非常有用。Internet 标准是一个必须遵循的正式的规则。经过严格的过程,一个规范才能达到 Internet 标准的某一状态。 规范开始于 Internet 草案。一个 Internet 草案(Internet draft)是一个工作文档(该项工作正在进行中),没有官方的状态,具有 6 个月的生命周期。在 Internet 管理机构建议下,草案可以作为请求评论(Request for Comment,RFC)文档发布。
在一个 RFC 生命周期中,它会处于 6 个成熟阶段(maturity levels)之一:建议标准(proposed standard)、草案标准(draft standard)、Internet 标准(Internet standard)、历史的(historic)、实验性 的(experimental)和信息性的(informational)。
RFC 分为 5 个要求的级别(requirement level):要求的(required)、推荐的(recommended)、可选的(elective)、限制使用的(limited use)和不推荐的(not recommended)。
好书强烈推荐

推荐电影:模仿游戏 The Imitation Game (2014)
数据加密标准(英语:Data Encryption Standard,缩写为 DES)是一种对称密钥加密块密码算法,1976年被美国联邦政府的国家标准局确定为联邦资料处理标准(FIPS),随后在国际上广泛流传开来。它基于使用56位密钥的对称算法。这个算法因为包含一些机密设计元素,相对短的密钥长度以及怀疑内含美国国家安全局(NSA)的后门而在开始时有争议,DES因此受到了强烈的学院派式的审查,并以此推动了现代的块密码及其密码分析的发展。
DES现在已经不是一种安全的加密方法,主要因为它使用的56位密钥过短。1999年1月,distributed.net与电子前哨基金会合作,在22小时15分钟内即公开破解了一个DES密钥。也有一些分析报告提出了该算法的理论上的弱点,虽然在实际中难以应用。为了提供实用所需的安全性,可以使用DES的派生算法3DES来进行加密,虽然3DES也存在理论上的攻击方法。在2001年,DES作为一个标准已经被高级加密标准(AES)所取代。另外,DES已经不再作为国家标准科技协会(前国家标准局)的一个标准。
图中的⊕符号代表异或(XOR)操作。“F函数”将数据半块与某个子密钥进行处理。然后,一个F函数的输出与另一个半块异或之后,再与原本的半块组合并交换顺序,进入下一个回次的处理。在最后一个回次完成时,两个半块需要交换顺序,这是费斯妥结构的一个特点,以保证加解密的过程相似。

高级加密标准(英语:Advanced Encryption Standard,缩写:AES),在密码学中又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准。这个标准用来替代原先的DES,已经被多方分析且广为全世界所使用。经过五年的甄选流程,高级加密标准由美国国家标准与技术研究院(NIST)于2001年11月26日发布于FIPS PUB 197,并在2002年5月26日成为有效的标准。2006年,高级加密标准已然成为对称密钥加密中最流行的算法之一。
不同于它的前任标准DES,Rijndael使用的是代换-置换网络,而非Feistel架构。AES在软件及硬件上都能快速地加解密,相对来说较易于实现,且只需要很少的内存。作为一个新的加密标准,目前正被部署应用到更广大的范围。
严格地说,AES和Rijndael加密法并不完全一样(虽然在实际应用中两者可以互换),因为Rijndael加密法可以支持更大范围的区块和密钥长度:AES的区块长度固定为128比特,密钥长度则可以是128,192或256比特;而Rijndael使用的密钥和区块长度均可以是128,192或256比特。加密过程中使用的密钥是由Rijndael密钥生成方案产生。
大多数AES计算是在一个特别的有限域完成的。
AES加密过程是在一个4×4的字节矩阵上运作,这个矩阵又称为“体(state)”,其初值就是一个明文区块(矩阵中一个元素大小就是明文区块中的一个Byte)。(Rijndael加密法因支持更大的区块,其矩阵行数可视情况增加)加密时,各轮AES加密循环(除最后一轮外)均包含4个步骤:
分组密码(block cipher) 流密码(stream cipher)
最早出现的工作模式,ECB,CBC,OFB和CFB可以追溯到1981年[4]。2001年,NIST修订了其早先发布的工作模式任务栏表,加入了AES,并加入了CTR模式[5]。最后,在2010年1月,NIST加入了XTS-AES[6],而其余的可信模式并没有为NIST所认证。例如CTS是一种密文窃取的模式,许多常见的密码学运行库提供了这种模式。
ECB,CBC,OFB,CFB,CTR和XTS模式仅仅提供了机密性;为了保证加密信息没有被意外修改或恶意篡改,需要采用分离的消息验证码,例如CBC-MAC。密码学社区认识到了对专用的保证完整性的方法的需求,NIST因此提出了HMAC,CMAC和GMAC。HMAC在2002年通过了认证[7],CMAC在2005年通过[8],GMAC则在2007年被标准化[9]。
在发现将认证模式与加密模式联合起来的难度之后,密码学社区开始研究结合了加密和认证的单一模式,这种模式被称为认证加密模式(AE,Authenticated Encryption),或称为authenc。AE模式的例子包括CCM[10],GCM[11],CWC,EAX,IAPM和OCB。
初始化向量(IV,Initialization Vector)是许多任务作模式中用于将加密随机化的一个位块,由此即使同样的明文被多次加密也会产生不同的密文,避免了较慢的重新产生密钥的过程。
初始化向量与密钥相比有不同的安全性需求,因此IV通常无须保密,然而在大多数情况中,不应当在使用同一密钥的情况下两次使用同一个IV。对于CBC和CFB,重用IV会导致泄露明文首个块的某些信息,亦包括两个不同消息中相同的前缀。对于OFB和CTR而言,重用IV会导致完全失去安全性。另外,在CBC模式中,IV在加密时必须是无法预测的;特别的,在许多实现中使用的产生IV的方法,例如SSL2.0使用的,即采用上一个消息的最后一块密文作为下一个消息的IV,是不安全的[12]。
###电子密码本(ECB)
最简单的加密模式即为电子密码本(Electronic codebook,ECB)模式。需要加密的消息按照块密码的块大小被分为数个块,并对每个块进行独立加密。
本方法的缺点在于同样的明文块会被加密成相同的密文块;因此,它不能很好的隐藏数据模式。在某些场合,这种方法不能提供严格的数据保密性,因此并不推荐用于密码协议中。下面的例子显示了ECB在密文中显示明文的模式的程度:该图像的一个位图版本(左图)通过ECB模式可能会被加密成中图,而非ECB模式通常会将其加密成右图。
右图是使用CBC,CTR或任何其它的更安全的模式加密左图可能产生的结果——与随机噪声无异。注意右图看起来的随机性并不能表示图像已经被安全的加密;许多不安全的加密法也可能产生这种“随机的”输出。
ECB模式也会导致使用它的协议不能提供数据完整性保护,易受到重放攻击的影响,因此每个块是以完全相同的方式解密的。例如,“梦幻之星在线:蓝色脉冲”在线电子游戏使用ECB模式的Blowfish密码。在密钥交换系统被破解而产生更简单的破解方式前,作弊者重复通过发送加密的“杀死怪物”消息包以非法的快速增加经验值。
1976年,IBM发明了密码分组链接(CBC,Cipher-block chaining)模式[14]。在CBC模式中,每个明文块先与前一个密文块进行异或后,再进行加密。在这种方法中,每个密文块都依赖于它前面的所有明文块。同时,为了保证每条消息的唯一性,在第一个块中需要使用初始化向量。
CBC是最为常用的工作模式。它的主要缺点在于加密过程是串行的,无法被并行化,而且消息必须被填充到块大小的整数倍。解决后一个问题的一种方法是利用密文窃取。
注意在加密时,明文中的微小改变会导致其后的全部密文块发生改变,而在解密时,从两个邻接的密文块中即可得到一个明文块。因此,解密过程可以被并行化,而解密时,密文中一位的改变只会导致其对应的明文块完全改变和下一个明文块中对应位发生改变,不会影响到其它明文的内容。
密文反馈(CFB,Cipher feedback)模式类似于CBC,可以将块密码变为自同步的流密码;工作过程亦非常相似,CFB的解密过程几乎就是颠倒的CBC的加密过程:
上述公式是描述的是最简单的CFB,在这种模式下,它的自同步特性仅仅与CBC相同,即若密文的一整块发生错误,CBC和CFB都仍能解密大部分数据,而仅有一位数据错误。若需要在仅有了一位或一字节错误的情况下也让模式具有自同步性,必须每次只加密一位或一字节。可以将移位寄存器作为块密码的输入,以利用CFB的自同步性。
为了利用CFB制作一种自同步的,可以处理任意位情况错误的流密码,需要使用一个与块的大小相同的移位寄存器,并用IV将寄存器初始化。然后,将寄存器内容使用块密码加密,然后将结果的最高x位与明文的x进行异或,以产生密文的x位。下一步将生成的x位密文移入寄存器中,并对下面的x位明文重复这一过程。解密过程与加密过程相似,以IV开始,对寄存器加密,将结果的高x与密文异或,产生x位明文,再将密文的下面x位移入寄存器。
输出反馈模式(Output feedback, OFB)可以将块密码变成同步的流密码。它产生密钥流的块,然后将其与明文块进行异或,得到密文。与其它流密码一样,密文中一个位的翻转会使明文中同样位置的位也产生翻转。这种特性使得许多错误校正码,例如奇偶校验位,即使在加密前计算,而在加密后进行校验也可以得出正确结果。
注意:CTR模式(Counter mode,CM)也被称为ICM模式(Integer Counter Mode,整数计数模式)和SIC模式(Segmented Integer Counter)。
与OFB相似,CTR将块密码变为流密码。它通过递增一个加密计数器以产生连续的密钥流,其中,计数器可以是任意保证长时间不产生重复输出的函数,但使用一个普通的计数器是最简单和最常见的做法。使用简单的、定义好的输入函数是有争议的:批评者认为它“有意的将密码系统暴露在已知的、系统的输入会造成不必要的风险”[18]。目前,CTR已经被广泛的使用了,由输入函数造成的问题被认为是使用的块密码的缺陷,而非CTR模式本身的弱点[19]。无论如何,有一些特别的攻击方法,例如基于使用简单计数器作为输入的硬件差错攻击[20]。
CTR模式的特征类似于OFB,但它允许在解密时进行随机存取。由于加密和解密过程均可以进行并行处理,CTR适合运用于多处理器的硬件上。

MD5,SHA-1
可以保证消息的完整性,但不能对消息进行认证。

消息码是一种与密钥相关联的单向散列函数。












React在减少重复渲染方面确实是有一套独特的处理办法,那就是虚拟DOM,但显然在首次渲染的时候React绝无可能超越原生的速度,或者一定能将其它的框架比下去。尤其是在优化前的React,每次数据变动都会执行render,大大影响了性能,特别是在移动端。
在初始化渲染时,我们需要渲染整个应用
(绿色 = 已渲染节点)
我们想更新一部分数据。这些改变只和一个叶子节点相关(绿色的)
我们只想渲染通向叶子节点的关键路径上的这几个节点(绿色的)
如果你不告诉 React 别这样做,它便会如此
(橘黄色 = 浪费的渲染)
从上图可以看见,组件除了必要渲染的三个节点外,还渲染了其他不必要渲染的节点,这对性能是一个很大的浪费。如果对于复杂的页面,这将导致页面的整体体验效果非常差。因此要提高组件的性能,就应该想尽一切方法减少不必要的渲染。
React的生命周期如下,还没熟悉的同学可以去熟悉一下。

因为其中的 shouldComponentUpdate 是优化的关键。React的重复渲染优化的核心其实就是在shouldComponentUpdate里面做数据比较。在优化之前,shouldComponentUpdate是默认返回true的,这导致任何时候触发任何的数据变化都会使component重新渲染。这必然会导致资源的浪费和性能的低下——你可能会感觉比较原生的响应更慢。
React性能优化的关键在于shouldComponentUpdate,
在上面的示例中,因为 C2 的 shouldComponentUpdate 返回 false,React 就不需要生成新的虚拟 DOM,也就不需要更新 DOM,注意 React 甚至不需要调用 C4 和 C5 的 shouldComponentUpdate。
C1 和 C3 的 shouldComponentUpdate 返回 true,所以 React 需要向下到叶子节点检查它们,C6 返回 true,因为虚拟 DOM 不相等,需要更新 DOM。最后感兴趣的是 C8,对于这个节点,React 需要计算虚拟 DOM,但是因为它和旧的相等,所以不需要更新 DOM。
在传入组件的props和state只有一层时,我们可以直接使用 React.PureComponent,它会自动帮我们进行浅比较(shallow-compare),从而控制shouldComponentUpdate的返回值。
但是,当传入props或state不止一层,或者未array和object时,浅比较(shallow-compare)就失效了。当然我们也可以在 shouldComponentUpdate() 中使用使用 deepCopy 和 deepCompare 来避免无必要的 render(),但 deepCopy 和 deepCompare 一般都是非常耗性能的。这个时候我们就需要 Immutable。
JavaScript 中的对象一般是可变的(Mutable),因为使用了引用赋值,新的对象简单的引用了原始对象,改变新的对象将影响到原始对象。如
foo={a: 1};
bar=foo;
bar.a=2你会发现此时 foo.a 也被改成了 2。虽然这样做可以节约内存,但当应用复杂后,这就造成了非常大的隐患,Mutable 带来的优点变得得不偿失。为了解决这个问题,一般的做法是使用 shallowCopy(浅拷贝)或 deepCopy(深拷贝)来避免被修改,但这样做造成了 CPU 和内存的浪费。
而Immutable 可以很好地解决这些问题。
Immutable Data 就是一旦创建,就不能再被更改的数据。对 Immutable 对象的任何修改或添加删除操作都会返回一个新的 Immutable 对象。Immutable 实现的原理是 Persistent Data Structure(持久化数据结构),也就是使用旧数据创建新数据时,要保证旧数据同时可用且不变。同时为了避免 deepCopy 把所有节点都复制一遍带来的性能损耗,Immutable 使用了 Structural Sharing(结构共享),即如果对象树中一个节点发生变化,只修改这个节点和受它影响的父节点,其它节点则进行共享。
可以看看下面这个经典的动画:
Immutable.js本质上是一个JavaScript的持久化数据结构的库 ,但是由于同期的React太火,并且和React在性能优化方面天衣无缝的配合,导致大家常常把它们两者绑定在一起。
Immutable.js是Facebook 工程师 Lee Byron 花费 3 年时间打造,但没有被默认放到 React 工具集里(React 提供了简化的 Helper)。它内部实现了一套完整的 Persistent Data Structure,且数据结构和方法非常丰富(完全不像JS出身的好不好)。像 Collection、List、Map、Set、Record、Seq。有非常全面的map、filter、groupBy、reduce、find函数式操作方法。同时 API 也尽量与 Object 或 Array 类似。 Immutable.js 压缩后下载有 16K。
其中有 3 种最重要的数据结构说明一下:(Java 程序员应该最熟悉了)
Map:键值对集合,对应于 Object,ES6 也有专门的 Map 对象List:有序可重复的列表,对应于 ArraySet:无序且不可重复的列表简单示例
import { Map } from "immutable";
const map1 = Map({ a: 1, b: 2, c: 3 });
const map2 = map1.set('b', 50);
map1.get('b'); // 2
map2.get('b'); // 50seamless-immutable是另一套持久化数据结构的库,它并没有实现完整的 Persistent Data Structure,而是使用 Object.defineProperty(因此只能在 IE9 及以上使用)扩展了 JavaScript 的 Array 和 Object 对象来实现,只支持 Array 和 Object 两种数据类型,API 基于与 Array 和 Object ,因此许多不用改变自己的使用习惯,对代码的入侵非常小。同时,它的代码库也非常小,压缩后下载只有 2K。
简单示例
// 使用 seamless-immutable.js 后
import Immutable from 'seamless-immutable';
var array = Immutable(["totally", "immutable", {hammer: "Can’t Touch This"}]);
array[1] = "I'm going to mutate you!"
array[1] // "immutable"
array[2].hammer = "hm, surely I can mutate this nested object..."
array[2].hammer // "Can’t Touch This"
for (var index in array) { console.log(array[index]); }
// "totally"
// "immutable"
// { hammer: 'Can’t Touch This' }
JSON.stringify(array) // '["totally","immutable",{"hammer":"Can’t Touch This"}]'seamless-immutable的实现依赖于ECMAScript 5 的一些特性,如Object.defineProperty 和 Object.freeze,因此会在浏览器兼容性方面有所欠缺:
不过这不是问题啦,可以使用 polyfill es-shims/es5-shim 来解决。
虽然 Immutable.js 尽量尝试把 API 设计的原生对象类似,有的时候还是很难区别到底是 Immutable 对象还是原生对象,容易混淆操作。
Immutable 中的 Map 和 List 虽对应原生 Object 和 Array,但操作非常不同,比如你要用 map.get('key')而不是 map.key,array.get(0) 而不是 array[0]。另外 Immutable 每次修改都会返回新对象,也很容易忘记赋值。
当使用外部库的时候,一般需要使用原生对象,也很容易忘记转换。
当然也有一些办法来避免类似问题发生:
Immutable.fromJS 而不是 Immutable.Map 或 Immutable.List 来创建对象,这样可以避免 Immutable 和原生对象间的混用。但是还有一个致命的问题是,对现有代码的改造,使用 Immutable.js 成本实在太大。
而seamless-immutable虽然数据结构和API不如Immutable.js丰富,但是对于只想使用Immutable Data来对React进行优化以避免重复渲染的我们来说,已经是绰绰有余了。而且Array和Object原生的方法等都可以直接使用,原有项目改动极小。
由于seamless-immutable的实现依赖于ECMAScript 5 和原生的Array、Object天然的兼容性,导致其在React中的使用非常简单,只要注意三点就可以达到效果:
初始化state数据的时候,使用Immutable的初始化方式。
import Immutable from 'seamless-immutable';
state: {
orderList: Immutable([]),
}修改state数据的时候,同样也要注意:
saveOrderList(state, {payload: items}) {
return {...state, orderList: Immutable(items)};
}使用pure-render-decorator,真是方便、快捷又优雅。当然,由于decorator属于ES7的特性,babel还需要自己配置。
import React from 'react';
import pureRender from 'pure-render-decorator';
@pureRender
class OrderListView extends React.Component {
render() {
const {orderList} = this.props;
return (
<div>
{
orderList.map((item) => {
return (
<div key={item.orderNum}>
<div>{item.orderNum}</div>
<div>{item.createTime}</div>
<div>{item.contact}</div>
<hr/>
</div>
);
})
}
</div>
);
}
}
export default OrderListView;
怎么样,传说中的React的SCU的优化就是这么简单,赶紧去试试吧。
可能你学会了如何使用 Webpack ,也大致知道其工作原理,可是你想过 Webpack 输出的 bundle.js 是什么样子的吗? 为什么原来一个个的模块文件被合并成了一个单独的文件?为什么 bundle.js 能直接运行在浏览器中?
下面通过 Webpack 构建一个采用 CommonJS 模块化编写的项目,该项目有个网页会通过 JavaScript 在网页中显示 Hello,Webpack。
运行构建前,先把要完成该功能的最基础的 JavaScript 文件和 HTML 建立好,需要如下文件:
页面入口文件 index.html
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<div id="app"></div>
<!--导入 Webpack 输出的 JavaScript 文件-->
<script src="./dist/bundle.js"></script>
</body>
</html>JS 工具函数文件 show.js
// 操作 DOM 元素,把 content 显示到网页上
function show(content) {
window.document.getElementById('app').innerText = 'Hello,' + content;
}
// 通过 CommonJS 规范导出 show 函数
module.exports = show;JS 执行入口文件 main.js
// 通过 CommonJS 规范导入 show 函数
const show = require('./show.js');
// 执行 show 函数
show('Webpack');Webpack 在执行构建时默认会从项目根目录下的 webpack.config.js 文件读取配置,所以你还需要新建它,其内容如下:
const path = require('path');
module.exports = {
// JavaScript 执行入口文件
entry: './main.js',
output: {
// 把所有依赖的模块合并输出到一个 bundle.js 文件
filename: 'bundle.js',
// 输出文件都放到 dist 目录下
path: path.resolve(__dirname, './dist'),
}
};一切文件就绪,在项目根目录下执行 webpack 命令运行 Webpack 构建,你会发现目录下多出一个 dist 目录,里面有个 bundle.js 文件, bundle.js 文件是一个可执行的 JavaScript 文件,它包含页面所依赖的两个模块 main.js 和 show.js 及内置的 webpackBootstrap 启动函数。 这时你用浏览器打开 index.html 网页将会看到 Hello,Webpack。
Webpack 是一个打包模块化 JavaScript 的工具,它会从 main.js 出发,识别出源码中的模块化导入语句, 递归的寻找出入口文件的所有依赖,把入口和其所有依赖打包到一个单独的文件中。 从 Webpack2 开始,已经内置了对 ES6、CommonJS、AMD 模块化语句的支持。
先来看看由最简单的项目构建出的 bundle.js 文件内容,代码如下:
(
// webpackBootstrap 启动函数
// modules 即为存放所有模块的数组,数组中的每一个元素都是一个函数
function (modules) {
// 安装过的模块都存放在这里面
// 作用是把已经加载过的模块缓存在内存中,提升性能
var installedModules = {};
// 去数组中加载一个模块,moduleId 为要加载模块在数组中的 index
// 作用和 Node.js 中 require 语句相似
function __webpack_require__(moduleId) {
// 如果需要加载的模块已经被加载过,就直接从内存缓存中返回
if (installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// 如果缓存中不存在需要加载的模块,就新建一个模块,并把它存在缓存中
var module = installedModules[moduleId] = {
// 模块在数组中的 index
i: moduleId,
// 该模块是否已经加载完毕
l: false,
// 该模块的导出值
exports: {}
};
// 从 modules 中获取 index 为 moduleId 的模块对应的函数
// 再调用这个函数,同时把函数需要的参数传入
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// 把这个模块标记为已加载
module.l = true;
// 返回这个模块的导出值
return module.exports;
}
// Webpack 配置中的 publicPath,用于加载被分割出去的异步代码
__webpack_require__.p = "";
// 使用 __webpack_require__ 去加载 index 为 0 的模块,并且返回该模块导出的内容
// index 为 0 的模块就是 main.js 对应的文件,也就是执行入口模块
// __webpack_require__.s 的含义是启动模块对应的 index
return __webpack_require__(__webpack_require__.s = 0);
})(
// 所有的模块都存放在了一个数组里,根据每个模块在数组的 index 来区分和定位模块
[
/* 0 */
(function (module, exports, __webpack_require__) {
// 通过 __webpack_require__ 规范导入 show 函数,show.js 对应的模块 index 为 1
const show = __webpack_require__(1);
// 执行 show 函数
show('Webpack');
}),
/* 1 */
(function (module, exports) {
function show(content) {
window.document.getElementById('app').innerText = 'Hello,' + content;
}
// 通过 CommonJS 规范导出 show 函数
module.exports = show;
})
]
);以上看上去复杂的代码其实是一个立即执行函数,可以简写为如下:
(function(modules) {
// 模拟 require 语句
function __webpack_require__() {
}
// 执行存放所有模块数组中的第0个模块
__webpack_require__(0);
})([/*存放所有模块的数组*/])
bundle.js 能直接运行在浏览器中的原因在于输出的文件中通过 __webpack_require__ 函数定义了一个可以在浏览器中执行的加载函数来模拟 Node.js 中的 require 语句。
原来一个个独立的模块文件被合并到了一个单独的 bundle.js 的原因在于浏览器不能像 Node.js 那样快速地去本地加载一个个模块文件,而必须通过网络请求去加载还未得到的文件。 如果模块数量很多,加载时间会很长,因此把所有模块都存放在了数组中,执行一次网络加载。
如果仔细分析 __webpack_require__ 函数的实现,你还有发现 Webpack 做了缓存优化: 执行加载过的模块不会再执行第二次,执行结果会缓存在内存中,当某个模块第二次被访问时会直接去内存中读取被缓存的返回值。
在给单页应用做按需加载优化时,一般采用以下原则:
被分割出去的代码的加载需要一定的时机去触发,也就是当用户操作到了或者即将操作到对应的功能时再去加载对应的代码。 被分割出去的代码的加载时机需要开发者自己去根据网页的需求去衡量和确定。
由于被分割出去进行按需加载的代码在加载的过程中也需要耗时,你可以预言用户接下来可能会进行的操作,并提前加载好对应的代码,从而让用户感知不到网络加载时间。
用 Webpack 实现按需加载
Webpack 内置了强大的分割代码的功能去实现按需加载,实现起来非常简单。
举个例子,现在需要做这样一个进行了按需加载优化的网页:
网页首次加载时只加载 main.js 文件,网页会展示一个按钮,main.js 文件中只包含监听按钮事件和加载按需加载的代码。
当按钮被点击时才去加载被分割出去的 show.js 文件,加载成功后再执行 show.js 里的函数。
其中 main.js 文件内容如下:
window.document.getElementById('btn').addEventListener('click', function () {
// 当按钮被点击后才去加载 show.js 文件,文件加载成功后执行文件导出的函数
import(/* webpackChunkName: "show" */ './show').then((show) => {
show('Webpack');
})
});show.js 文件内容如下:
module.exports = function (content) {
window.alert('Hello ' + content);
};代码中最关键的一句是 import(/* webpackChunkName: "show" */ './show'),Webpack 内置了对 import(*) 语句的支持,当 Webpack 遇到了类似的语句时会这样处理:
在使用 import() 分割代码后,你的浏览器并且要支持 Promise API 才能让代码正常运行, 因为 import() 返回一个 Promise,它依赖 Promise。对于不原生支持 Promise 的浏览器,你可以注入 Promise polyfill。
/* webpackChunkName: "show" */的含义是为动态生成的 Chunk 赋予一个名称,以方便我们追踪和调试代码。 如果不指定动态生成的 Chunk 的名称,默认名称将会是 [id].js。/* webpackChunkName: "show" */是在 Webpack3 中引入的新特性,在 Webpack3 之前是无法为动态生成的 Chunk 赋予名称的。
在采用了按需加载的优化方法时,Webpack 的输出文件会发生变化。
例如把源码中的 main.js 修改为如下:
// 异步加载 show.js
import('./show').then((show) => {
// 执行 show 函数
show('Webpack');
});重新构建后会输出两个文件,分别是执行入口文件 bundle.js 和 异步加载文件 0.bundle.js。
其中 0.bundle.js 内容如下:
// 加载在本文件(0.bundle.js)中包含的模块
webpackJsonp(
// 在其它文件中存放着的模块的 ID
[0],
// 本文件所包含的模块
[
// show.js 所对应的模块
(function (module, exports) {
function show(content) {
window.document.getElementById('app').innerText = 'Hello,' + content;
}
module.exports = show;
})
]
);bundle.js 内容如下:
(function (modules) {
/***
* webpackJsonp 用于从异步加载的文件中安装模块。
* 把 webpackJsonp 挂载到全局是为了方便在其它文件中调用。
*
* @param chunkIds 异步加载的文件中存放的需要安装的模块对应的 Chunk ID
* @param moreModules 异步加载的文件中存放的需要安装的模块列表
* @param executeModules 在异步加载的文件中存放的需要安装的模块都安装成功后,需要执行的模块对应的 index
*/
window["webpackJsonp"] = function webpackJsonpCallback(chunkIds, moreModules, executeModules) {
// 把 moreModules 添加到 modules 对象中
// 把所有 chunkIds 对应的模块都标记成已经加载成功
var moduleId, chunkId, i = 0, resolves = [], result;
for (; i < chunkIds.length; i++) {
chunkId = chunkIds[i];
if (installedChunks[chunkId]) {
resolves.push(installedChunks[chunkId][0]);
}
installedChunks[chunkId] = 0;
}
for (moduleId in moreModules) {
if (Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
modules[moduleId] = moreModules[moduleId];
}
}
while (resolves.length) {
resolves.shift()();
}
};
// 缓存已经安装的模块
var installedModules = {};
// 存储每个 Chunk 的加载状态;
// 键为 Chunk 的 ID,值为0代表已经加载成功
var installedChunks = {
1: 0
};
// 模拟 require 语句,和上面介绍的一致
function __webpack_require__(moduleId) {
// ... 省略和上面一样的内容
}
/**
* 用于加载被分割出去的,需要异步加载的 Chunk 对应的文件
* @param chunkId 需要异步加载的 Chunk 对应的 ID
* @returns {Promise}
*/
__webpack_require__.e = function requireEnsure(chunkId) {
// 从上面定义的 installedChunks 中获取 chunkId 对应的 Chunk 的加载状态
var installedChunkData = installedChunks[chunkId];
// 如果加载状态为0表示该 Chunk 已经加载成功了,直接返回 resolve Promise
if (installedChunkData === 0) {
return new Promise(function (resolve) {
resolve();
});
}
// installedChunkData 不为空且不为0表示该 Chunk 正在网络加载中
if (installedChunkData) {
// 返回存放在 installedChunkData 数组中的 Promise 对象
return installedChunkData[2];
}
// installedChunkData 为空,表示该 Chunk 还没有加载过,去加载该 Chunk 对应的文件
var promise = new Promise(function (resolve, reject) {
installedChunkData = installedChunks[chunkId] = [resolve, reject];
});
installedChunkData[2] = promise;
// 通过 DOM 操作,往 HTML head 中插入一个 script 标签去异步加载 Chunk 对应的 JavaScript 文件
var head = document.getElementsByTagName('head')[0];
var script = document.createElement('script');
script.type = 'text/javascript';
script.charset = 'utf-8';
script.async = true;
script.timeout = 120000;
// 文件的路径为配置的 publicPath、chunkId 拼接而成
script.src = __webpack_require__.p + "" + chunkId + ".bundle.js";
// 设置异步加载的最长超时时间
var timeout = setTimeout(onScriptComplete, 120000);
script.onerror = script.onload = onScriptComplete;
// 在 script 加载和执行完成时回调
function onScriptComplete() {
// 防止内存泄露
script.onerror = script.onload = null;
clearTimeout(timeout);
// 去检查 chunkId 对应的 Chunk 是否安装成功,安装成功时才会存在于 installedChunks 中
var chunk = installedChunks[chunkId];
if (chunk !== 0) {
if (chunk) {
chunk[1](new Error('Loading chunk ' + chunkId + ' failed.'));
}
installedChunks[chunkId] = undefined;
}
};
head.appendChild(script);
return promise;
};
// 加载并执行入口模块,和上面介绍的一致
return __webpack_require__(__webpack_require__.s = 0);
})
(
// 存放所有没有经过异步加载的,随着执行入口文件加载的模块
[
// main.js 对应的模块
(function (module, exports, __webpack_require__) {
// 通过 __webpack_require__.e 去异步加载 show.js 对应的 Chunk
__webpack_require__.e(0).then(__webpack_require__.bind(null, 1)).then((show) => {
// 执行 show 函数
show('Webpack');
});
})
]
);这里的 bundle.js 和上面所讲的 bundle.js 非常相似,区别在于:
多了一个 webpack_require.e 用于加载被分割出去的,需要异步加载的 Chunk 对应的文件;
多了一个 webpackJsonp 函数用于从异步加载的文件中安装模块。
在使用了 CommonsChunkPlugin 去提取公共代码时输出的文件和使用了异步加载时输出的文件是一样的,都会有 webpack_require.e 和 webpackJsonp。 原因在于提取公共代码和异步加载本质上都是代码分割。
构建网络应用的过程中,我们经常需要与服务器进行持续的通讯以保持双方信息的同步。通常这种持久通讯在不刷新页面的情况下进行,消耗一定的内存资源常驻后台,并且对于用户不可见。在 WebSocket 出现之前,我们有一下解决方案:
当前Web应用中较常见的一种持续通信方式,通常采取 setInterval 或者 setTimeout 实现。例如如果我们想要定时获取并刷新页面上的数据,可以结合Ajax写出如下实现:
setInterval(function() {
$.get("/path/to/server", function(data, status) {
console.log(data);
});
}, 10000);上面的程序会每隔10秒向服务器请求一次数据,并在数据到达后存储。这个实现方法通常可以满足简单的需求,然而同时也存在着很大的缺陷:在网络情况不稳定的情况下,服务器从接收请求、发送请求到客户端接收请求的总时间有可能超过10秒,而请求是以10秒间隔发送的,这样会导致接收的数据到达先后顺序与发送顺序不一致。于是出现了采用 setTimeout 的轮询方式:
function poll() {
setTimeout(function() {
$.get("/path/to/server", function(data, status) {
console.log(data);
// 发起下一次请求
poll();
});
}, 10000);
}程序首先设置10秒后发起请求,当数据返回后再隔10秒发起第二次请求,以此类推。这样的话虽然无法保证两次请求之间的时间间隔为固定值,但是可以保证到达数据的顺序。
上面两种传统的轮询方式都存在一个严重缺陷:程序在每次请求时都会新建一个HTTP请求,然而并不是每次都能返回所需的新数据。当同时发起的请求达到一定数目时,会对服务器造成较大负担。这时我们可以采用长轮询方式解决这个问题。
长轮询与以下将要提到的服务器发送事件和WebSocket不能仅仅依靠客户端JavaScript实现,我们同时需要服务器支持并实现相应的技术。
长轮询的基本**是在每次客户端发出请求后,服务器检查上次返回的数据与此次请求时的数据之间是否有更新,如果有更新则返回新数据并结束此次连接,否则服务器 hold住此次连接,直到有新数据时再返回相应。而这种长时间的保持连接可以通过设置一个较大的HTTP timeout` 实现。下面是一个简单的长连接示例:
服务器(PHP):
<?php
// 示例数据为data.txt
$filename= dirname(__FILE__)."/data.txt";
// 从请求参数中获取上次请求到的数据的时间戳
$lastmodif = isset( $_GET["timestamp"])? $_GET["timestamp"]: 0 ;
// 将文件的最后一次修改时间作为当前数据的时间戳
$currentmodif = filemtime($filename);
// 当上次请求到的数据的时间戳*不旧于*当前文件的时间戳,使用循环"hold"住当前连接,并不断获取文件的修改时间
while ($currentmodif <= $lastmodif) {
// 每次刷新文件信息的时间间隔为10秒
usleep(10000);
// 清除文件信息缓存,保证每次获取的修改时间都是最新的修改时间
clearstatcache();
$currentmodif = filemtime($filename);
}
// 返回数据和最新的时间戳,结束此次连接
$response = array();
$response["msg"] =Date("h:i:s")." ".file_get_contents($filename);
$response["timestamp"]= $currentmodif;
echo json_encode($response);
?>客户端:
function longPoll (timestamp) {
var _timestamp;
$.get("/path/to/server?timestamp=" + timestamp)
.done(function(res) {
try {
var data = JSON.parse(res);
console.log(data.msg);
_timestamp = data.timestamp;
} catch (e) {}
})
.always(function() {
setTimeout(function() {
longPoll(_timestamp || Date.now()/1000);
}, 10000);
});
}长轮询可以有效地解决传统轮询带来的带宽浪费,但是每次连接的保持是以消耗服务器资源为代价的。尤其对于Apache+PHP 服务器,由于有默认的 worker threads 数目的限制,当长连接较多时,服务器便无法对新请求进行相应。
服务器发送事件(以下简称SSE)是HTML 5规范的一个组成部分,可以实现服务器到客户端的单向数据通信。通过 SSE ,客户端可以自动获取数据更新,而不用重复发送HTTP请求。一旦连接建立,“事件”便会自动被推送到客户端。服务器端SSE通过 事件流(Event Stream) 的格式产生并推送事件。事件流对应的 MIME类型 为 text/event-stream ,包含四个字段:event、data、id和retry。event表示事件类型,data表示消息内容,id用于设置客户端 EventSource 对象的 last event ID string 内部属性,retry指定了重新连接的时间。
服务器(PHP):
<?php
header("Content-Type: text/event-stream");
header("Cache-Control: no-cache");
// 每隔1秒发送一次服务器的当前时间
while (1) {
$time = date("r");
echo "event: ping\n";
echo "data: The server time is: {$time}\n\n";
ob_flush();
flush();
sleep(1);
}
?>客户端中,SSE借由 EventSource 对象实现。EventSource 包含五个外部属性:onerror, onmessage, onopen, readyState、url,以及两个内部属性:reconnection time与 last event ID string。在onerror属性中我们可以对错误捕获和处理,而 onmessage 则对应着服务器事件的接收和处理。另外也可以使用 addEventListener 方法来监听服务器发送事件,根据event字段区分处理。
客户端:
var eventSource = new EventSource("/path/to/server");
eventSource.onmessage = function (e) {
console.log(e.event, e.data);
}
// 或者
eventSource.addEventListener("ping", function(e) {
console.log(e.event, e.data);
}, false);SSE相较于轮询具有较好的实时性,使用方法也非常简便。然而SSE只支持服务器到客户端单向的事件推送,而且所有版本的IE(包括到目前为止的Microsoft Edge)都不支持SSE。如果需要强行支持IE和部分移动端浏览器,可以尝试 EventSource Polyfill(本质上仍然是轮询)。SSE的浏览器支持情况如下图所示:
| >>>>>>>>>>>> | 传统轮询 | 长轮询 | 服务器发送事件 | WebSocket |
|---|---|---|---|---|
| 浏览器支持 | 几乎所有现代浏览器 | 几乎所有现代浏览器 | Firefox 6+ Chrome 6+ Safari 5+ Opera 10.1+ | IE 10+ Edge Firefox 4+ Chrome 4+ Safari 5+ Opera 11.5+ |
| 服务器负载 | 较少的CPU资源,较多的内存资源和带宽资源 | 与传统轮询相似,但是占用带宽较少 | 与长轮询相似,除非每次发送请求后服务器不需要断开连接 | 无需循环等待(长轮询),CPU和内存资源不以客户端数量衡量,而是以客户端事件数衡量。四种方式里性能最佳。 |
| 客户端负载 | 占用较多的内存资源与请求数。 | 与传统轮询相似。 | 浏览器中原生实现,占用资源很小。 | 同Server-Sent Event。 |
| 延迟 | 非实时,延迟取决于请求间隔。 | 同传统轮询。 | 非实时,默认3秒延迟,延迟可自定义。 | 实时。 |
| 实现复杂度 | 非常简单。 | 需要服务器配合,客户端实现非常简单。 | 需要服务器配合,而客户端实现甚至比前两种更简单。 | 需要Socket程序实现和额外端口,客户端实现简单。 |
WebSocket 协议在2008年诞生,2011年成为国际标准。所有浏览器都已经支持了。
WebSocket同样是HTML 5规范的组成部分之一,现标准版本为 RFC 6455。WebSocket 相较于上述几种连接方式,实现原理较为复杂,用一句话概括就是:客户端向 WebSocket 服务器通知(notify)一个带有所有 接收者ID(recipients IDs) 的事件(event),服务器接收后立即通知所有活跃的(active)客户端,只有ID在接收者ID序列中的客户端才会处理这个事件。由于 WebSocket 本身是基于TCP协议的,所以在服务器端我们可以采用构建 TCP Socket 服务器的方式来构建 WebSocket 服务器。
这个 WebSocket 是一种全新的协议。它将 TCP 的 Socket(套接字)应用在了web page上,从而使通信双方建立起一个保持在活动状态连接通道,并且属于全双工(双方同时进行双向通信)。
其实是这样的,WebSocket 协议是借用 HTTP协议 的 101 switch protocol 来达到协议转换的,从HTTP协议切换成WebSocket通信协议。
它的最大特点就是,服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息,是真正的双向平等对话,属于服务器推送技术的一种。其他特点包括:
WebSocket协议被设计来取代现有的使用HTTP作为传输层的双向通信技术,并受益于现有的基础设施(代理、过滤、身份验证)。
本协议有两部分:握手和数据传输。
来自客户端的握手看起来像如下形式:
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Origin: http://example.com
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
来自服务器的握手看起来像如下形式:
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
Sec-WebSocket-Protocol: chat
来自客户端的首行遵照 Request-Line 格式。 来自服务器的首行遵照 Status-Line 格式。
Request-Line 和 Status-Line 制品定义在 RFC2616。
一旦客户端和服务器都发送了它们的握手,且如果握手成功,接着开始数据传输部分。 这是一个每一端都可以的双向通信信道,彼此独立,随意发生数据。
一个成功握手之后,客户端和服务器来回地传输数据,在本规范中提到的概念单位为“消息”。 在线路上,一个消息是由一个或多个帧的组成。 WebSocket 的消息并不一定对应于一个特定的网络层帧,可以作为一个可以被一个中间件合并或分解的片段消息。
一个帧有一个相应的类型。 属于相同消息的每一帧包含相同类型的数据。 从广义上讲,有文本数据类型(它被解释为 UTF-8 RFC3629文本)、二进制数据类型(它的解释是留给应用)、和控制帧类型(它是不准备包含用于应用的数据,而是协议级的信号,例如应关闭连接的信号)。这个版本的协议定义了六个帧类型并保留10以备将来使用。
首先,客户端发起协议升级请求。可以看到,采用的是标准的 HTTP 报文格式,且只支持GET方法。
GET / HTTP/1.1
Host: localhost:8080
Origin: http://127.0.0.1:3000
Connection: Upgrade
Upgrade: websocket
Sec-WebSocket-Version: 13
Sec-WebSocket-Key: w4v7O6xFTi36lq3RNcgctw==
重点请求首部意义如下:
Connection: Upgrade:表示要升级协议
Upgrade: websocket:表示要升级到 websocket 协议。
Sec-WebSocket-Version: 13:表示 websocket 的版本。如果服务端不支持该版本,需要返回一个 Sec-WebSocket-Versionheader ,里面包含服务端支持的版本号。
Sec-WebSocket-Key:与后面服务端响应首部的 Sec-WebSocket-Accept 是配套的,提供基本的防护,比如恶意的连接,或者无意的连接。
服务端返回内容如下,状态代码101表示协议切换。到此完成协议升级,后续的数据交互都按照新的协议来。
HTTP/1.1 101 Switching Protocols
Connection:Upgrade
Upgrade: websocket
Sec-WebSocket-Accept: Oy4NRAQ13jhfONC7bP8dTKb4PTU=
Sec-WebSocket-Accept 根据客户端请求首部的 Sec-WebSocket-Key 计算出来。
计算公式为:
将 Sec-WebSocket-Key 跟 258EAFA5-E914-47DA-95CA-C5AB0DC85B11 拼接。
通过 SHA1 计算出摘要,并转成 base64 字符串。
伪代码如下:
>toBase64( sha1( Sec-WebSocket-Key + 258EAFA5-E914-47DA-95CA-C5AB0DC85B11 ) )
WebSocket 客户端、服务端通信的最小单位是 帧(frame),由 1 个或多个帧组成一条完整的 消息(message)。
发送端:将消息切割成多个帧,并发送给服务端;
接收端:接收消息帧,并将关联的帧重新组装成完整的消息;
用于数据传输部分的报文格式是通过本节中详细描述的 ABNF 来描述。
下面给出了 WebSocket 数据帧的统一格式。熟悉 TCP/IP 协议的同学对这样的图应该不陌生。
从左到右,单位是比特。比如 FIN、RSV1各占据 1 比特,opcode占据 4 比特。
内容包括了标识、操作代码、掩码、数据、数据长度等。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+
针对前面的格式概览图,这里逐个字段进行讲解,如有不清楚之处,可参考协议规范,或留言交流。
如果是 1,表示这是 消息(message)的最后一个分片(fragment),如果是 0,表示不是是 消息(message)的最后一个 分片(fragment)。
一般情况下全为 0。当客户端、服务端协商采用 WebSocket 扩展时,这三个标志位可以非 0,且值的含义由扩展进行定义。如果出现非零的值,且并没有采用 WebSocket 扩展,连接出错。
操作代码,Opcode 的值决定了应该如何解析后续的 数据载荷(data payload)。如果操作代码是不认识的,那么接收端应该 断开连接(fail the connection)。可选的操作代码如下:
%x0:表示一个延续帧。当 Opcode 为 0 时,表示本次数据传输采用了数据分片,当前收到的数据帧为其中一个数据分片。
%x1:表示这是一个文本帧(frame)
%x2:表示这是一个二进制帧(frame)
%x3-7:保留的操作代码,用于后续定义的非控制帧。
%x8:表示连接断开。
%x8:表示这是一个 ping 操作。
%xA:表示这是一个 pong 操作。
%xB-F:保留的操作代码,用于后续定义的控制帧。
表示是否要对数据载荷进行掩码操作。从客户端向服务端发送数据时,需要对数据进行掩码操作;从服务端向客户端发送数据时,不需要对数据进行掩码操作。
如果服务端接收到的数据没有进行过掩码操作,服务端需要断开连接。
如果 Mask 是 1,那么在 Masking-key 中会定义一个 掩码键(masking key),并用这个掩码键来对数据载荷进行反掩码。所有客户端发送到服务端的数据帧,Mask 都是 1。
单位是字节。为 7 位,或 7+16 位,或 1+64 位。
假设数 Payload length === x,如果
x 为 0~126:数据的长度为 x 字节。
x 为 126:后续 2 个字节代表一个 16 位的无符号整数,该无符号整数的值为数据的长度。
x 为 127:后续 8 个字节代表一个 64 位的无符号整数(最高位为 0),该无符号整数的值为数据的长度。
此外,如果 payload length 占用了多个字节的话,payload length 的二进制表达采用 网络序(big endian,重要的位在前)。
所有从客户端传送到服务端的数据帧,数据载荷都进行了掩码操作,Mask 为 1,且携带了 4 字节的 Masking-key。如果 Mask 为 0,则没有 Masking-key。
备注:载荷数据的长度,不包括 mask key 的长度。
载荷数据:包括了扩展数据、应用数据。其中,扩展数据 x 字节,应用数据 y 字节。
扩展数据:如果没有协商使用扩展的话,扩展数据数据为 0 字节。所有的扩展都必须声明扩展数据的长度,或者可以如何计算出扩展数据的长度。此外,扩展如何使用必须在握手阶段就协商好。如果扩展数据存在,那么载荷数据长度必须将扩展数据的长度包含在内。
应用数据:任意的应用数据,在扩展数据之后(如果存在扩展数据),占据了数据帧剩余的位置。载荷数据长度 减去 扩展数据长度,就得到应用数据的长度。
掩码键(Masking-key)是由客户端挑选出来的 32 位的随机数。掩码操作不会影响数据载荷的长度。掩码、反掩码操作都采用如下算法:
首先,假设:
original-octet-i:为原始数据的第 i 字节。
transformed-octet-i:为转换后的数据的第 i 字节。
j:为i mod 4的结果。
masking-key-octet-j:为 mask key 第 j 字节。
算法描述为: original-octet-i 与 masking-key-octet-j 异或后,得到 transformed-octet-i。
j = i MOD 4
transformed-octet-i = original-octet-i XOR masking-key-octet-j
一旦 WebSocket 客户端、服务端建立连接后,后续的操作都是基于数据帧的传递。
WebSocket 根据 opcode 来区分操作的类型。比如0x8表示断开连接,0x0-0x2 表示数据交互。
WebSocket 的每条消息可能被切分成多个数据帧。当 WebSocket 的接收方收到一个数据帧时,会根据FIN的值来判断,是否已经收到消息的最后一个数据帧。
FIN=1 表示当前数据帧为消息的最后一个数据帧,此时接收方已经收到完整的消息,可以对消息进行处理。FIN=0,则接收方还需要继续监听接收其余的数据帧。
此外,opcode 在数据交换的场景下,表示的是数据的类型。0x01表示文本,0x02表示二进制。而0x00比较特殊,表示延续帧(continuation frame),顾名思义,就是完整消息对应的数据帧还没接收完。
WebSocket 为了保持客户端、服务端的实时双向通信,需要确保客户端、服务端之间的 TCP 通道保持连接没有断开。然而,对于长时间没有数据往来的连接,如果依旧长时间保持着,可能会浪费包括的连接资源。
但不排除有些场景,客户端、服务端虽然长时间没有数据往来,但仍需要保持连接。这个时候,可以采用心跳来实现。
发送方 ->接收方:ping
接收方 ->发送方:pong
ping、pong 的操作,对应的是 WebSocket 的两个控制帧,opcode分别是 0x9、0xA。
一旦发送或接收到一个Close控制帧,这就是说,_WebSocket 关闭阶段握手已启动,且 WebSocket 连接处于 CLOSING 状态。
当底层TCP连接已关闭,这就是说 WebSocket连接已关闭 且 WebSocket 连接处于 CLOSED 状态。 如果 TCP 连接在 WebSocket 关闭阶段已经完成后被关闭,WebSocket连接被说成已经 完全地 关闭了。
如果WebSocket连接不能被建立,这就是说,WebSocket连接关闭,但不是 完全的 。
当关闭一个已经建立的连接(例如,当在打开阶段握手已经完成后发送一个关闭帧),端点可以表明关闭的原因。 由端点解释这个原因,并且端点应该给这个原因采取动作,本规范是没有定义的。 本规范定义了一组预定义的状态码,并指定哪些范围可以被扩展、框架和最终应用使用。 状态码和任何相关的文本消息是关闭帧的可选的组件。
当发送关闭帧时端点可以使用如下预定义的状态码。
| 状态码 | 名称 | 描述 |
|---|---|---|
| 0–999 | 保留段, 未使用. | |
| 1000 | CLOSE_NORMAL | 正常关闭; 无论为何目的而创建, 该链接都已成功完成任务. |
| 1001 | CLOSE_GOING_AWAY | 终端离开, 可能因为服务端错误, 也可能因为浏览器正从打开连接的页面跳转离开. |
| 1002 | CLOSE_PROTOCOL_ERROR | 由于协议错误而中断连接. |
| 1003 | CLOSE_UNSUPPORTED | 由于接收到不允许的数据类型而断开连接 (如仅接收文本数据的终端接收到了二进制数据). |
| 1004 | 保留. 其意义可能会在未来定义. | |
| 1005 | CLOSE_NO_STATUS | 保留. 表示没有收到预期的状态码. |
| 1006 | CLOSE_ABNORMAL | 保留. 用于期望收到状态码时连接非正常关闭 (也就是说, 没有发送关闭帧). |
| 1007 | Unsupported Data | 由于收到了格式不符的数据而断开连接 (如文本消息中包含了非 UTF-8 数据). |
| 1008 | Policy Violation | 由于收到不符合约定的数据而断开连接. 这是一个通用状态码, 用于不适合使用 1003 和 1009 状态码的场景. |
| 1009 | CLOSE_TOO_LARGE | 由于收到过大的数据帧而断开连接. |
| 1010 | Missing Extension | 客户端期望服务器商定一个或多个拓展, 但服务器没有处理, 因此客户端断开连接. |
| 1011 | Internal Error | 客户端由于遇到没有预料的情况阻止其完成请求, 因此服务端断开连接. |
| 1012 | Service Restart | 服务器由于重启而断开连接. |
| 1013 | Try Again Later | 服务器由于临时原因断开连接, 如服务器过载因此断开一部分客户端连接. |
| 1014 | 由 WebSocket 标准保留以便未来使用. | |
| 1015 | TLS Handshake | 保留. 表示连接由于无法完成 TLS 握手而关闭 (例如无法验证服务器证书). |
| 1016–1999 | 由 WebSocket 标准保留以便未来使用. | |
| 2000–2999 | 由 WebSocket 拓展保留使用. | |
| 3000–3999 | 可以由库或框架使用.不应由应用使用. 可以在 IANA 注册, 先到先得. | |
| 4000–4999 | 可以由应用使用. |
WebSocket 对象提供了用于创建和管理 WebSocket 连接,以及可以通过该连接发送和接收数据的 API。
WebSocket 构造器方法接受一个必须的参数和一个可选的参数:
WebSocket WebSocket(in DOMString url, in optional DOMString protocols);
WebSocket WebSocket(in DOMString url,in optional DOMString[] protocols);url
表示要连接的URL。这个URL应该为响应WebSocket的地址。
protocols 可选
可以是一个单个的协议名字字符串或者包含多个协议名字字符串的数组。这些字符串用来表示子协议,这样做可以让一个服务器实现多种 WebSocket子协议(例如你可能希望通过制定不同的协议来处理不同类型的交互)。如果没有制定这个参数,它会默认设为一个空字符串。
构造器方法可能抛出以下异常:SECURITY_ERR 试图连接的端口被屏蔽。
var ws = new WebSocket('ws://localhost:8080');执行上面语句之后,客户端就会与服务器进行连接。
| 属性名 | 类型 | 描述 |
|---|---|---|
| binaryType | DOMString | 一个字符串表示被传输二进制的内容的类型。取值应当是"blob"或者"arraybuffer"。"blob"表示使用DOM Blob 对象,而"arraybuffer"表示使用 ArrayBuffer 对象。 |
| bufferedAmount | unsigned long | 调用 send() 方法将多字节数据加入到队列中等待传输,但是还未发出。该值会在所有队列数据被发送后重置为 0。而当连接关闭时不会设为0。如果持续调用send(),这个值会持续增长。只读。 |
| extensions | DOMString | 服务器选定的扩展。目前这个属性只是一个空字符串,或者是一个包含所有扩展的列表。 |
| onclose | EventListener | 用于监听连接关闭事件监听器。当 WebSocket 对象的readyState 状态变为 CLOSED 时会触发该事件。这个监听器会接收一个叫close的 CloseEvent 对象。 |
| onerror | EventListener | 当错误发生时用于监听error事件的事件监听器。会接受一个名为“error”的event对象。 |
| onmessage | EventListener | 一个用于消息事件的事件监听器,这一事件当有消息到达的时候该事件会触发。这个Listener会被传入一个名为"message"的 MessageEvent 对象。 |
| onopen | EventListener | 一个用于连接打开事件的事件监听器。当readyState的值变为 OPEN 的时候会触发该事件。该事件表明这个连接已经准备好接受和发送数据。这个监听器会接受一个名为"open"的事件对象。 |
| protocol | DOMString | 一个表明服务器选定的子协议名字的字符串。这个属性的取值会被取值为构造器传入的protocols参数。 |
| readyState | unsigned short | 连接的当前状态。取值是 Ready state constants 之一。 只读。 |
| url | DOMString | 传入构造器的URL。它必须是一个绝对地址的URL。只读。 |
实例对象的 onopen 属性,用于指定连接成功后的回调函数。
ws.onopen = function () {
ws.send('Hello Server!');
}如果要指定多个回调函数,可以使用addEventListener方法。
ws.addEventListener('open', function (event) {
ws.send('Hello Server!');
});实例对象的 onclose 属性,用于指定连接关闭后的回调函数。
ws.onclose = function(event) {
var code = event.code;
var reason = event.reason;
var wasClean = event.wasClean;
// handle close event
};
ws.addEventListener("close", function(event) {
var code = event.code;
var reason = event.reason;
var wasClean = event.wasClean;
// handle close event
});实例对象的 onmessage 属性,用于指定收到服务器数据后的回调函数。
ws.onmessage = function(event) {
var data = event.data;
// 处理数据
};
ws.addEventListener("message", function(event) {
var data = event.data;
// 处理数据
});注意,服务器数据可能是文本,也可能是 二进制数据(blob对象或Arraybuffer对象)。
ws.onmessage = function(event){
if(typeof event.data === String) {
console.log("Received data string");
}
if(event.data instanceof ArrayBuffer){
var buffer = event.data;
console.log("Received arraybuffer");
}
}除了动态判断收到的数据类型,也可以使用 binaryType 属性,显式指定收到的二进制数据类型。
// 收到的是 blob 数据
ws.binaryType = "blob";
ws.onmessage = function(e) {
console.log(e.data.size);
};
// 收到的是 ArrayBuffer 数据
ws.binaryType = "arraybuffer";
ws.onmessage = function(e) {
console.log(e.data.byteLength);
};这些常量是 readyState 属性的取值,可以用来描述 WebSocket 连接的状态。
| 常量 | 值 | 描述 |
|---|---|---|
| CONNECTING | 0 | 连接还没开启。 |
| OPEN | 1 | 连接已开启并准备好进行通信。 |
| CLOSING | 2 | 连接正在关闭的过程中。 |
| CLOSED | 3 | 连接已经关闭,或者连接无法建立。 |
关闭 WebSocket 连接或停止正在进行的连接请求。如果连接的状态已经是 closed,这个方法不会有任何效果
void close(in optional unsigned short code, in optional DOMString reason);code 可选
一个数字值表示关闭连接的状态号,表示连接被关闭的原因。如果这个参数没有被指定,默认的取值是1000 (表示正常连接关闭)。 请看 CloseEvent 页面的 list of status codes来看默认的取值。
reason 可选
一个可读的字符串,表示连接被关闭的原因。这个字符串必须是不长于123字节的UTF-8 文本(不是字符)。
可能抛出的异常
unpaired surrogates。通过 WebSocket 连接向服务器发送数据。
void send(in DOMString data);
void send(in ArrayBuffer data);
void send(in Blob data); data:要发送到服务器的数据。
可能抛出的异常:
unpaired surrogates 的字符串。发送文本的例子。
ws.send('your message');发送 Blob 对象的例子。
var file = document
.querySelector('input[type="file"]')
.files[0];
ws.send(file);发送 ArrayBuffer 对象的例子。
// Sending canvas ImageData as ArrayBuffer
var img = canvas_context.getImageData(0, 0, 400, 320);
var binary = new Uint8Array(img.data.length);
for (var i = 0; i < img.data.length; i++) {
binary[i] = img.data[i];
}
ws.send(binary.buffer);WebSocket 服务器的实现,可以查看维基百科的列表。
常用的 Node 实现有以下三种。
WebSocket 是基于 TCP 的独立的协议。它与 HTTP 唯一的关系是它的握手是由 HTTP 服务器解释为一个 Upgrade 请求。
WebSocket协议试图在现有的 HTTP 基础设施上下文中解决现有的双向HTTP技术目标;同样,它被设计工作在HTTP端口80和443,也支持HTTP代理和中间件,
HTTP服务器需要发送一个“Upgrade”请求,即101 Switching Protocol到HTTP服务器,然后由服务器进行协议转换。
前面提到了,Sec-WebSocket-Key/Sec-WebSocket-Accept 在主要作用在于提供基础的防护,减少恶意连接、意外连接。
作用大致归纳如下:
避免服务端收到非法的 websocket 连接(比如 http 客户端不小心请求连接 websocket 服务,此时服务端可以直接拒绝连接)
确保服务端理解 websocket 连接。因为 ws 握手阶段采用的是 http 协议,因此可能 ws 连接是被一个 http 服务器处理并返回的,此时客户端可以通过 Sec-WebSocket-Key 来确保服务端认识 ws 协议。(并非百分百保险,比如总是存在那么些无聊的 http 服务器,光处理 Sec-WebSocket-Key,但并没有实现 ws 协议。。。)
用浏览器里发起 ajax 请求,设置 header 时,Sec-WebSocket-Key 以及其他相关的 header 是被禁止的。这样可以避免客户端发送 ajax 请求时,意外请求协议升级(websocket upgrade)
可以防止反向代理(不理解 ws 协议)返回错误的数据。比如反向代理前后收到两次 ws 连接的升级请求,反向代理把第一次请求的返回给 cache 住,然后第二次请求到来时直接把 cache 住的请求给返回(无意义的返回)。
Sec-WebSocket-Key 主要目的并不是确保数据的安全性,因为 Sec-WebSocket-Key、Sec-WebSocket-Accept 的转换计算公式是公开的,而且非常简单,最主要的作用是预防一些常见的意外情况(非故意的)。
WebSocket 协议中,数据掩码的作用是增强协议的安全性。但数据掩码并不是为了保护数据本身,因为算法本身是公开的,运算也不复杂。除了加密通道本身,似乎没有太多有效的保护通信安全的办法。
那么为什么还要引入掩码计算呢,除了增加计算机器的运算量外似乎并没有太多的收益(这也是不少同学疑惑的点)。
答案还是两个字:安全。但并不是为了防止数据泄密,而是为了防止早期版本的协议中存在的代理缓存污染攻击(proxy cache poisoning attacks)等问题。
来自于O'Reilly免费的电子书:Software Architecture Patterns
分层架构是最常见的架构,也被称为n层架构。多年以来,许多企业和公司都在他们的项目中使用这种架构,它已经几乎成为事实标准,因此被大多数架构师、开发者和软件设计者所熟知。比如MVC。
分层架构的一个特性就是关注分离(separation of concerns)。在层中的组件只负责本层的逻辑。组件的划分很容易让它们实现自己的角色和职责,也比较容易地开发,测试管理和维护。
我们需要这样的冗余,即使业务层没有处理业务规则,也要通过业务层来调用数据层,这叫分层隔离。对于某些功能,如果我们从表现层直接访问数据层,那么数据层后续的任何变动都将影响到业务层和表现层。
注意分层的开闭原则。如果某层是关闭的,那么每个请求都要经过着一层。相反,如果该层是开放的,那么请求可以绕过这一层,直接到下一层。
分层隔离有利于降低整个应用程序的复杂度。某些功能并不需要经过每一层,这时我们需要根据开闭原则来简化实现。
分层架构是SOLID原则的通用架构,当我们不确定哪种架构更合适的时候,分层架构将是一个很好的起点。我们需要注意防止架构陷入污水池反模式(architecture sinkhole anti-pattern)。
在这个模式中,请求流只是简单的 穿过层次,不留一点云彩,或者说只留下一阵⻘青烟。比如说界面层响应了一个获得数据的请求。响应层把这 个请求传递给了业务层,业务层也只是传递了这个请求到持久层,持久层对数据库做简单的SQL查询获得用户的数据。这个数据按照原理返回,不会有任何的二次处理,返回到界面上。
每个分层架构或多或少都可能遇到这种场景。关键在于这样的请求有多少。80-20原则可以帮助你确定架构是 否处于反污水模式。大概有百分之二十的请求仅仅是做简单的穿越,百分之八十的请求会做一些业务逻辑操 作。然而,如果这个比例反过来,大部分的请求都是仅仅穿过层,不做逻辑操作。那么开放一些架构层会比较好。不过由于缺少了层次隔离,项目会变得难以控制。
分层架构可以演变为巨石应用(Monolith),导致代码库难以维护。
将所有功能都部署在一个web容器中运行的系统就叫做巨石型应用。巨石型应用有很多好处:IDE都是为开发单个应用设计的、容易测试——在本地就可以启动完整的系统、容易部署——直接打包为一个完整的包,拷贝到web容器的某个目录下即可运行。
但是,上述的好处是有条件的:应用不那么复杂。对于大规模的复杂应用,巨石型应用会显得特别笨重:
我们看一下淘宝前几年的架构的例子:
这是一个标准的分层的架构。每一层中又可以详细的分成更细的层,比如服务层。
围着着这个主架构还有一些外围的产品。比如监控和审计。
事件驱动架构(Event Driven Architecture)是一种流行的分布式异步架构模式,用于创建可伸缩的应用程序。这种模式是自适应的,可用于小规模或者大规模的应用程序。它由高度解耦的,单一目的的事件处理组件组成,可以异步地接收和处理事件。
它包括两个主要的拓扑结构:调停者拓扑(Mediator Topology) 和 代理者拓扑(Broker Topology)。Mediator拓扑结构需要你在一个事件通过mediator时精心安排好几个步骤,而broker拓扑结构无需mediator,而是由你串联起几个事件。这两种拓扑架构的特征和实现有很大的不同,所以你需要知道哪一个适合你。
Mediator拓扑结构适合有多个步骤的事件,需要安排处理层次。
例如购买一只股票,首先会校验这个交易,校验股票交易是否符合各种规定,将它交给一个经纪人,计算佣金,最后确认交易。所有这些都安排好各个步骤的顺序,决定它们是否串行还是并行。
通常,架构主要包含4种组件,事件队列(Event Queue)、调停者(Mediator)、事件通道(Event Channel)和事件处理器(Event Processor)。客户端创建事件,并将其发送到事件队列,调停者接收事件并将其传递给事件通道。事件通道将事件传递给事件处理器,事件最终由事件处理器处理完成。
事件流是这样开始的: 客户端发送一个事件到事件队列(event queues)中,它用来将事件传送给event mediator。Event mediator收到初始的事件后,会发送额外的一些异步事件给event channels来执行处理的每个步骤。Event processors监听event channels,接收事件并处理一些业务逻辑。
事件调停者不会处理也不知道任何业务逻辑,它只编排事件。事件调停者知道每种事件类型的必要步骤。业务逻辑或者处理发生在事件处理器中,事件通道、消息队列或者消息主题用于传递事件给事件处理器。事件处理器是自包含和独立的,解耦于架构。理想情况下,每种事件处理器应只负责处理一种事件类型。
这里有两种事件:初始事件和处理事件。Mediator会将初始事件编排成处理事件。它没有具体的业务逻辑,只是一个协调者,负责将初始事件转化成一个或者多个处理事件。
在事件驱动架构中有十几个甚至几百个事件队列都很正常。模式本身没有限定事件队列的实现方式。它可能是一个消息队列,一个web service或者其它。
event channels 既可以是消息队列,也可以是消息topic,大部分是消息topic,这样可以由多个消息处理器(event processor)处理同一个消息。
消息处理器包含实际的业务逻辑。每个消息处理器都是自包含的,独立的,高度解耦的,执行单一的任务。这种模式可能有一些变种。作为架构师,你应该理解每个实现的细节,确保这种解决方案适合你的需求。有一些开源的框架实现了这种架构,如Spring Integration, Apache Camel, 或者 Mule ESB。
不像调停者拓扑,代理者拓扑不使用任何集中的编排,它没有中心的Mediator。而是在事件处理器之间使用简单的队列或者集线器,事件处理器知道处理事件的下一个事件处理器。所有的事件串联起来通过一个轻量级的消息broker如RabbitMQ,ActiveMQ,HornetQ等。如果你的消息比较简单,不需要重新编排,就可以使用这种结构。
如图所示,它包含两个组件broker和 event processor。broker中的event channel可以是消息队列,消息topic或者它们的复合形式。每个event processor负责处理事件,发布新的事件。
在新浪微博的早期架构中,微博发布使用同步推模式,用户发表微博后系统会立即将这条微博插入到数据库所有粉丝的订阅列表中,当用户量比较大时,特别是明星用户发布微博时,会引起大量的数据库写操作,超出数据库负载,系统性能急剧下降,用户响应延迟加剧。
后来新浪微博改用异步推拉结合的模式,用户发表微博后系统将微博写入消息队列后立即返回,用户响应迅速,消息队列消费者任务将微博推送给所有当前在线粉丝的订阅列表中,非在线用户登录后再根据关注列表拉取微博订阅列表。
因其分布式和异步的性质,事件驱动架构的实现相对复杂,主要是由于它的异步和分布式特性。我们需要面对很多问题,比如网络分区、调停者失败、重新连接逻辑等。由于这是一个分布式且异步的模式,如果你需要事务,那就麻烦了,你得需要一个事务协调器。分布式系统中的事务非常难以管理,很难找到标准的工作单位模式。
一个考虑是这种模式对于单一的逻辑缺乏原子事务。所以你需要将原子事务交给一个事件处理器执行,跨事件处理器的原子事务是很困难的。
最困难的设计之一是事件处理器的创建,维护和管理。事件通常有特殊的约定(数据值和格式)。
微内核架构(Microkernel architecture)模式也被称为插件架构(plugin architecture)模式。可以用来实现基于产品的应用, 比如Eclipse,在微内核的基础上添加一些插件,就可以提供不同的产品,如C++, Java等。
微内核包含两个组件: core system 和 plug-in modules。应用逻辑被分隔成核心系统和插件模块,可以提供可扩展的,灵活的,特性隔离的功能。
这种模式非常适合桌面应用程序,但是也可以在Web应用程序中使用。事实上,许多不同的架构模式可以作为整个系统的一个插件。对于产品型应用程序来说,如果我们想将新特性和功能及时加入系统,微内核架构是一种不错的选择。
微内核的架构模式可以嵌入到其它的架构模式之中。微内核架构通过插件还可以提供逐步演化的功能和增量开发。所以如果你要开发基于产品的应用,微内核是不二选择。
尽管微服务的概念还相当新,但它确实已经快速地吸引了大量的眼球,以替代整体应用和面向服务架构(SOA)。其中的一个核心概念是具备高可伸缩性、易于部署和交付的独立部署单元(Separately Deployable Units)。最重要的概念是包含业务逻辑和处理流程的服务组件(Service Component)
不管你使用何种实现风格和拓扑,有几个通用的核心概念应用在这种架构模式上。首先是分隔发布单元(separately deployed units)。
如图所示,每一个微内核的组件都被分隔成一个独立的单元。微服务包含服务组件(service component)。不要考虑微内核的单个服务,而是最好考虑服务组件,从粒度上讲它可以是单一的模块或者一个一个大的应用程序,代表单一功能(提供天气预报或者图片存储)。
正确设计服务组件的粒度是一个很大的挑战。
另一个关键概念是微内核是分布式的。这意味着服务组件可能是远程方法(通过JMS, AMQP, REST, SOAP, RMI......等等)。分布式意味着这种模式可以建立大规模的应用。
另一个值得兴奋的特性是它可以从其它有问题的架构模式中演化出来,而不是直接创建出来等待问题发生。当你遇到一些无法解决的问题,特别是互联网企业的规模扩大时,是很好的引入微服务架构的时机。
一般会从两个模式中演化:
SOA不是不好,但是太昂贵了,不好理解和实现。
这张图从三个维度概括了一个系统的扩展过程:
从y轴这个方向扩展,才能将巨型应用分解为一组不同的服务,例如订单管理中心、客户信息管理中心、商品管理中心等等。
有很多实现微服务的方式。最通用最流行的三个方式是:
API REST-based 适合网站提供小规模的,自包含的服务。很多互联网网站都提供这样的服务,比如OAuth2服务。
application REST-based不同于上面的架构,客户端看到的是web界面或者富客户端程序,而不是调用API。UI层独立发布,可以访问服务组件。
中心消息模式,它类似前面的模式,但是使用一个轻量级的消息broker取代RESTful的服务调用。这个轻量级的broker不会执行服务的编排,传输和路由,这和SOA不同,不要把它看作SOA的简化版
内部服务之间的通信方式有两种:基于HTTP协议的同步机制(REST、RPC);基于消息队列的异步消息处理机制(AMQP-based message broker)。
Dubbo是阿里巴巴开源的分布式服务框架,属于同步调用,当一个系统的服务太多时,需要一个注册中心来处理服务发现问题,例如使用ZooKeeper这类配置服务器进行服务的地址管理:服务的发布者要向ZooKeeper发送请求,将自己的服务地址和函数名称等信息记录在案;服务的调用者要知道服务的相关信息,具体的机器地址在ZooKeeper查询得到。这种同步的调用机制足够直观简单,只是没有“订阅——推送”机制。
AMQP-based的代表系统是Kafka、RabbitMQ等。这类分布式消息处理系统将订阅者和消费者解耦合,消息的生产者不需要消费者一直在线;消息的生产者只需要把消息发送给消息代理,因此也不需要服务发现机制。
两种通信机制都有各自的优点和缺点,实际中的系统经常包含两种通信机制。例如,在分布式数据管理中,就需要同时用到同步HTTP机制和异步消息处理机制。
微服务架构解决了无架构的整体编码的应用的问题以及SOA的问题。同时它还可以提供实时的产品发布。它是一个分布式架构,也会有上面分布式的问题。
基于空间的架构有时候也被成为基于云的架构。
大部分的基于web的应用的业务流都是一样的。 客户端的请求发送给web服务器,然后是应用服务器,最后是数据库服务器。对于用户很小时不会有问题,但是负载增大时就会遇到瓶颈(想想抢火车票)。首先是web服务器撑不住,web服务器能撑住应用服务器又不行,然后是数据库服务器。通常解决方案是增加web服务器,便宜,简单,但很多情况下负载会传递给应用服务器,然后传递给数据库服务器。有时候增加数据库服务器也没有办法,因为数据库也有锁,有事务的限制。
基于空间的架构用来解决规模和并发的问题。
基于空间的架构最小化限制应用规模的影响。这个模式来自于tuple space, 分布式共享内存想法。要想大规模,就要移除中心数据库的限制,使用可复制的内存网格。应用数据保存在所有活动的处理单元的内存中,处理单元根据应用规模可以加入和移除。因为没有中心数据库,所以数据库的瓶颈可以解决。
这种模式有两个组件:处理单元processing unit 和 虚拟化中间件virtualized middleware。
处理单元包含应用程序。小的应用程序可以使用一个处理单元,大的应用程序可以被分隔成几个处理单元。处理单元还包括数据网格。
虚拟化中间件负责管理和通信。处理数据的同步和请求。
基于空间的架构是一个复杂而昂贵的模式。对于小型的负载可变的web应用很适合,但是对于大型的关系型数据库应用不是太适合。
你好,以issue的方式提交blog很有趣,请问这是怎么实现的?非前端开发不是很了解,谢谢!
程序员之间的互相尊重体现在他所写的代码中。他们对工作的尊重也体现在那里。
在《Clean Code》一书中Bob大叔认为在代码阅读过程中人们说脏话的频率是衡量代码质量的唯一标准。这也是同样的道理。
这样,代码最重要的读者就不再是编译器、解释器或者电脑了,而是人。写出的代码能让人快速理解、轻松维护、容易扩展的程序员才是专业的程序员。
可读性基本定理:代码的写法应当使别人理解它所需的时间最小化。
本书的余下部分将讨论如何把“易读”这条原则应用在不同的场景中。但是请记住,当你犹豫不决时,可读性基本定理总是先于本书中任何其他条例或原则。
我们在程序中见到的很多名字都很模糊,例如tmp。就算是看上去合理的词,如size或者get,也都没有装入很多信息。本章会告诉你如何把信息装入名字中。
“把信息装入名字中”包括要选择非常专业的词,并且避免使用“空洞”的词。
例如,“get”这个词就非常不专业,例如在下面的例子中:
def GetPage(url): ...
“get”这个词没有表达出很多信息。这个方法是从本地的缓存中得到一个页面,还是从数据库中,或者从互联网中?如果是从互联网中,更专业的名字可以是FetchPage()或者Download-Page()。
下面是一个BinaryTree类的例子:
class BinaryTree
{
int Size();
...
};
你期望Size()方法返回什么呢?树的高度,节点数,还是树在内存中所占的空间?
问题是Size()没有承载很多信息。更专业的词可以是Height()、NumNodes()或者MemoryBytes()。
另外一个例子,假设你有某种Thread类:
class Thread
{
void Stop();
...
}
Stop()这个名字还可以,但根据它到底做什么,可能会有更专业的名字。例如,你可以叫它Kill(),如果这是一个重量级操作,不能恢复。或者你可以叫它Pause(),如果有方法让它Re-sume()。
要勇于使用同义词典或者问朋友更好的名字建议。英语是一门丰富的语言,有很多词可以选择。
下面是一些例子,这些单词更有表现力,可能适合你的语境:
但别得意忘形。在PHP中,有一个函数可以explode()一个字符串。这是个很有表现力的名字,描绘了一幅把东西拆成碎片的景象。但这与split()有什么不同?(这是两个不一样的函数,但很难通过它们的名字来猜出不同点在哪里。)
清晰和精确比装可爱好。
使用像tmp、retval和foo这样的名字往往是“我想不出名字”的托辞。与其使用这样空洞的名字,不如挑一个能描述这个实体的值或者目的的名字。
例如,下面的JavaScript函数使用了retval:
var euclidean_norm = function(v) {
var retval = 0.0;
for (var i = 0; i < v.length; i += 1)
retval += v[i] * v[i];
return Math.sqrt(retval);
};当你想不出更好的名字来命名返回值时,很容易想到使用retval。但retval除了“我是一个返回值”外并没有包含更多信息(这里的意义往往也是很明显的)。
好的名字应当描述变量的目的或者它所承载的值。在本例中,这个变量正在累加v的平方。因此更贴切的名字可以是sum_squares。这样就提前声明了这个变量的目的,并且可能会帮忙找到缺陷。
例如,想象如果循环的内部被意外写成:
retval += v[i];如果名字换成sum_squares这个缺陷就会更明显:
sum_squares += v[i]; //我们要累加的"square"在哪里?缺陷!retval这个名字没有包含很多信息。用一个描述该变量的值的名字来代替它。
如果你要使用像tmp、it或者retval这样空泛的名字,那么你要有个好的理由。
在给变量、函数或者其他元素命名时,要把它描述得更具体而不是更抽象。
例如,假设你有一个内部方法叫做ServerCanStart(),它检测服务是否可以监听某个给定的TCP/IP端口。然而Server-CanStart()有点抽象。CanListenOnPort()就更具体一些。这个名字直接地描述了这个方法要做什么事情。
我们前面提到,一个变量名就像是一个小小的注释。尽管空间不是很大,但不管你在名中挤进任何额外的信息,每次有人看到这个变量名时都会同时看到这些信息。
因此,如果关于一个变量有什么重要事情的读者必须知道,那么是值得把额外的“词”添加到名字中的。例如,假设你有一个变量包含一个十六进制字符串:
string id; // Example: "af84ef845cd8"
如果让读者记住这个ID的格式很重要的话,你可以把它改名为hex_id。
如果你的变量是一个度量的话(如时间长度或者字节数),那么最好把名字带上它的单位。例如,这里有些JavaScript代码用来度量一个网页的加载时间:
var start = (new Date()).getTime(); // top of the page
...
var elapsed = (new Date()).getTime() - start; // bottom of the page
document.writeln("Load time was: " + elapsed + " seconds");这段代码里没有明显的错误,但它不能正常运行,因为get-Time()会返回毫秒而非秒。通过给变量结尾追加_ms,我们可以让所有的地方更明确:
var start_ms = (new Date()).getTime(); // top of the page...
var elapsed_ms = (new Date()).getTime() - start_ms; // bottom of the page
document.writeln("Load time was: " + elapsed_ms / 1000 + " seconds");除了时间,还有很多在编程时会遇到的单位。下表列出一些没有单位的函数参数以及带单位的版本:
| 函数参数 | 带单位的参数 |
|---|---|
| Start(int delay) | delay → delay_secs |
| CreateCache(int size) | size → size_mb |
| ThrottleDownload(float limit) | limit → max_kbps |
| Rotate(float angle) | angle → degrees_cw |
这种给名字附带额外信息的技巧不仅限于单位。在对于这个变量存在危险或者意外的任何时候你都该采用它。
例如,很多安全漏洞来源于没有意识到你的程序接收到的某些数据还没有处于安全状态。在这种情况下,你可能想要使用像 untrustedUrl 或者 unsafeMessageBody 这样的名字。在调用了清查不安全输入的函数后,得到的变量可以命名为 trustedUrl 或者 safeMessageBody 。
但你不应该给程序中每个变量都加上像 unescaped_ 或者 _utf8 这样的属性。如果有人误解了这个变量就很容易产生缺陷,尤其是会产生像安全缺陷这样可怕的结果,在这些地方这种技巧最有用武之地。基本上,如果这是一个需要理解的关键信息,那就把它放在名字里。
作用域 小的标识符(对于多少行其他代码可见)也不用带上太多信息。也就是说,因为所有的信息(变量的类型、它的初值、如何析构等)都很容易看到,所以可以用很短的名字。如果一个标识符有较大的作用域,那么它的名字就要包含足够的信息以便含义更清楚。
所以经验原则是:团队的新成员是否能理解这个名字的含义?如果能,那可能就没有问题。例如,对程序员来讲,使用eval来代替evaluation,用doc来代替document,用str来代替string是相当普遍的。因此如果团队的新成员看到FormatStr()可能会理解它是什么意思,然而,理解BEManager可能有点困难。
有时名字中的某些单词可以拿掉而不会损失任何信息。例如,Convert To String()就不如To String()这个更短的名字,而且没有丢失任何有用的信息。同样,不用DoServeLoop(),ServeLoop()也一样清楚。
对于下划线、连字符和大小写的使用方式也可以把更多信息装到名字中。对不同的实体使用不同的格式就像语法高亮显示的形式一样,能帮你更容易地阅读代码。
要多问自己几遍:“这个名字会被别人解读成其他的含义吗?”要仔细审视这个名字。
假设你在写一段操作数据库结果的代码:
results = Database.all_objects.filter("year <= 2011")
结果现在包含哪些信息?
这里的问题是“filter”是个二义性单词。我们不清楚它的含义到底是“挑出”还是“减掉”。最好避免使用“filter”这个名字,因为它太容易误解。
假设你有个函数用来剪切一个段落的内容:
# Cuts off the end of the text, and appends "..."
def Clip(text, length):
...
你可能会想象到Clip()的两种行为方式:
第二种方式(截掉)的可能性最大,但还是不能肯定。与其让读者乱猜代码,还不如把函数的名字改成Truncate(text,length)。
然而,参数名length也不太好。如果叫max_length的话可能会更清楚。这样也还没有完。就算是max_length这个名字也还是会有多种解读:
如你在前一章中所见,这属于应当把单位附加在名字后面的那种情况。在本例中,我们是指“字符数”,所以不应该用max_length,而要用max_chars。
命名极限最清楚的方式是在要限制的东西前加上max_或者min_。
下面是另一个例子,你没法判断它是“少于”还是“少于且包含”:
print integer_range(start=2, stop=4)
# Does this print [2,3] or [2,3,4] (or something else)?
尽管start是个合理的参数名,但stop可以有多种解读。对于这样包含的范围(这种范围包含开头和结尾),一个好的选择是first/last。
例如:
set.PrintKeys(first="Bart", last="Maggie")
不像stop,last这个名字明显是包含的。除了first/last,min/max这两个名字也适用于包含的范围,如果它们在上下文中“听上去合理”的话。
对于命名包含/排除范围典型的编程规范是使用begin/end。
但是end这个词有点二义性。例如,在句子“我读到这本书的end部分了”,这里的end是包含的。遗憾的是,英语中没有一个合适的词来表示“刚好超过最后一个值”。
因为对begin/end的使用是如此常见(至少在C++标准库中是这样用的,还有大多数需要“分片”的数组也是这样用的),它已经是最好的选择了。
通常来讲,加上像is、has、can或should这样的词,可以把布尔值变得更明确。
例如,SpaceLeft() 函数听上去像是会返回一个数字,如果它的本意是返回一个布尔值,可能 HasSapceLeft() 个这名字更好一些。
最后,最好避免使用反义名字。
例如,不要用:bool disable_ssl = false;
而更简单易读(而且更紧凑)的表示方式是:bool use_ssl = true;
有些名字之所以会让人误解是因为用户对它们的含义有先入为主的印象,就算你的本意并非如此。在这种情况下,最好放弃这个名字而改用一个不会让人误解的名字。
很多程序员都习惯了把以get开始的方法当做轻量级访问器这样的用法,它只是简单地返回一个内部成员变量。如果违背这个习惯很可能会误导用户。
以下是一个用Java写的例子,请不要这样做:
public class StatisticsCollector {
public void addSample(double x) {}
public double getMean() {
// Iterate through all samples and return total / num_samples
}
}在这个例子中,getMean()的实现是要遍历所有经过的数据并同时计算中值。如果有大量的数据的话,这样的一步可能会有很大的代价!但一个容易轻信的程序员可能会随意地调用get-Mean(),还以为这是个没什么代价的调用。
相反,这个方法应当重命名为像computeMean()这样的名字,后者听起来更像是有些代价的操作。(另一种做法是,用新的实现方法使它真的成为一个轻量级的操作。)
下面是一个来自C++标准库中的例子。曾经有个很难发现的缺陷,使得我们的一台服务器慢得像蜗牛在爬,就是下面的代码造成的:
void ShrinkList( list<Node> & list, int max_size )
{
while ( list.size() > max_size )
{
FreeNode( list.back() );
list.pop_back();
}
}这里的“缺陷”是,作者不知道list.size()是一个O(n)操作——它要一个节点一个节点地历数列表,而不是只返回一个事先算好的个数,这就使得ShrinkList()成了一个O(n2)操作。
这段代码从技术上来讲“正确”,事实上它也通过了所有的单元测试。但当把ShrinkList()应用于有100万个元素的列表上时,要花超过一个小时来完成!
可能你在想:“这是调用者的错,他应该更仔细地读文档。”有道理,但在本例中,list.size()不是一个固定时间的操作,这一点是出人意料的。所有其他的C++容器类的size()方法都是时间固定的。
假使 size() 的名字是 countSize() 或者 countElements() ,很可能就会避免相同的错误。C++标准库的作者可能是希望把它命名为 size() 以和所有其他的容器一致,就像 vector 和 map 。但是正因为他们的这个选择使得程序员很容易误把它当成一个快速的操作,就像其他的容器一样。谢天谢地,现在最新的C++标准库把size()改成了O(1)。
不会误解的名字是最好的名字——阅读你代码的人应该理解你的本意,并且不会有其他的理解。遗憾的是,很多英语单词在用来编程时是多义性的,例如 filter、length和limit。
在你决定使用一个名字以前,要吹毛求疵一点,来想象一下你的名字会被误解成什么。最好的名字是不会误解的。
好的源代码应当“看上去养眼”。本章会告诉大家如何使用好的留白、对齐及顺序来让你的代码变得更易读。确切地说,有三条原则:
在这里中,我们只关注可以改进代码的简单 审美 方法。这些类型的改变很简单并且常常能大幅地提高可读性。有时大规模地重构代码(例如拆分出新的函数或者类)可能会更有帮助。我们的观点是好的审美与好的设计是两种独立的**。最好是同时在两个方向上努力做到更好。
使代码“看上去漂亮”通常会带来不限于表面层次的改进,它可能会帮你把代码的结构做得更好。
如: React生命周期的顺序。
一致的风格比“正确”的风格更重要。
注释的目的是尽量帮助读者了解得和作者一样多。
不要为那些从代码本身就能快速推断的事实写注释。
一个好的名字比一个好的注释更重要,因为在任何用到这个函数的地方都能看得到它。
通常来讲,你不需要“拐杖式注释”——试图粉饰可读性差的代码的注释。写代码的人常常把这条规则表述成:好代码>坏代码+好注释。
很多好的注释仅通过“记录你的想法”就能得到,也就是那些你在写代码时有过的重要想法。
电影中常有“导演评论”部分,电影制作者在其中给出自己的见解并且通过讲故事来帮助你理解这部电影是如何制作的。同样,你应该在代码中也加入注释来记录你对代码有价值的见解。
代码始终在演进,并且在这过程中肯定会有瑕疵。不要不好意思把这些瑕疵记录下来。
例如,当代码需要改进时:
// TODO: 采用更快算法
或者当代码没有完成时:
// TODO(dustin):处理除JPEG以外的图像格式
有几种标记在程序员中很流行:
重要的是你应该可以随时把代码将来应该如何改动的想法用注释记录下来。这种注释给读者带来对代码质量和当前状态的宝贵见解,甚至可能会给他们指出如何改进代码的方向。
当定义常量时,通常在常量背后都有一个关于它是什么或者为什么它是这个值的“故事”。
有些常量不需要注释,因为它们的名字本身已经很清楚(例如SECONDS_PER_DAY)。但是在我们的经验中,很多常量可以通过加注释得以改进。这不过是匆匆记下你在决定这个常量值时的想法而已。
了解通过网络收集资源的阶段至关重要。这是解决加载问题的基础,也是前端性能优化的关键点之一。
所有网络请求都被视为资源。通过网络对它们进行检索时,资源具有不同生命周期。Resource Timing API 为网络事件(如重定向的开始和结束事件, DNS查找的开始和结束事件, 请求开始, 响应开始和结束时间等)生成有 高分辨率时间戳( high-resolution timestamps ) 的资源加载时间线, 并提供了资源大小和资源类型。
通过Resource Timing API可以获取和分析应用资源加载的详细网络计时数据, 应用程序可以使用时间度量标准来确定加载特定资源所需要的时间,比如 XMLHttpRequest、<SVG>、图片、或者脚本。
出于隐私保护的原因,在获得资源的 Resource Timing 详情时有 跨域限制 。
Resource Timing API 提供了与接收各个资源的时间有关的大量详细信息。请求生命周期的主要阶段包括:
startTime。redirectStart 也会开始。fetchStart 时间。domainLookupStart 时间在 DNS 请求开始时采集。domainLookupEnd 时间在 DNS 请求结束时采集。connectStart 在初始连接到服务器时采集。secureConnectionStart 将在握手(确保连接安全)开始时开始。connectEnd 将在到服务器的连接完成时采集。requestStart 会在对某个资源的请求被发送到服务器后立即采集。responseStart 是服务器初始响应请求的时间。responseEnd 是请求结束并且数据完成检索的时间。要查看 Network 面板中给定条目完整的耗时信息,您有三种选择。
此代码可以在 DevTools 的 Console 中运行。 它将使用 Resource Timing API 检索所有资源。 然后,它将通过查找是否存在名称中包含“style.css”的条目对条目进行过滤。 如果找到,将返回相应条目。
performance.getEntriesByType('resource').filter(item => item.name.includes("style.css"))如果某个请求正在排队,则指示:
请求等待发送所用的时间。 可以是等待 Queueing 中介绍的任何一个原因。 此外,此时间包含代理协商所用的任何时间。
与代理服务器连接协商所用的时间。
执行 DNS 查询所用的时间。 页面上的每一个新域都需要完整的往返才能执行 DNS 查询。
建立连接所用的时间,包括 TCP 握手/重试和协商 SSL 的时间。
完成 SSL 握手所用的时间。
发出网络请求所用的时间。 通常不到一毫秒。
等待初始响应所用的时间,也称为至第一字节的时间。 此时间将捕捉到服务器往返的延迟时间,以及等待服务器传送响应所用的时间。
接收响应数据所用的时间。
Performance 接口 可以获取到当前页面与性能相关的信息。它是 High Resolution Time API 的一部分,同时也融合了 Performance Timeline API、Navigation Timing API、 User Timing API 和 Resource Timing API。
该类型的对象可以通过调用只读属性 Window.performance 来获得。
注意:除了以下指出的情况外,该接口及其成员在 Web Worker 中可用。此外,还需注意,性能 markers 和 measures 是依赖上下文的。如果你在主线程(或者其他 worker)中创建了一个 mark,那么它在 worker 线程中是不可用的;反之亦然。
通过 Network 面板可以发现大量可能的问题。查找这些问题需要很好地了解客户端与服务器如何通信,以及协议施加的限制。
最常见问题是一系列已被加入队列或已被停止的条目。这表明正在从单个网域检索太多的资源。在 HTTP 1.0/1.1 连接上,Chrome 会将每个主机强制设置为最多六个 TCP 连接。如果您一次请求十二个条目,前六个将开始,而后六个将被加入队列。最初的一半完成后,队列中的第一个条目将开始其请求流程。
要为传统的 HTTP 1 流量解决此问题,您需要实现 域分片。也就是在您的应用上设置多个子域,以便提供资源。然后,在子域之间平均分配正在提供的资源。
注意:HTTP 1 连接的修复结果不会应用到 HTTP 2 连接上。事实上,前者的结果会影响后者。 如果您部署了 HTTP 2,请不要对您的资源进行域分片,因为它与 HTTP 2 的操作方式相反。在 HTTP 2 中,到服务器的单个 TCP 连接作为多路复用连接。这消除了 HTTP 1 中的六个连接限制,并且可以通过单个连接同时传输多个资源。
又称:大片绿色
等待时间长表示至第一字节的时间 (TTFB) 漫长。建议将此值控制在 200 毫秒以下。长 TTFB 会揭示两个主要问题之一。
要解决长 TTFB,首先请尽可能缩减网络。理想的情况是将应用托管在本地,然后查看 TTFB 是否仍然很长。如果仍然很长,则需要优化应用的响应速度。可以是优化数据库查询、为特定部分的内容实现缓存,或者修改您的网络服务器配置。很多原因都可能导致后端缓慢。您需要调查您的软件并找出未满足您的性能预算的内容。
如果本地托管后 TTFB 仍然漫长,那么问题出在您的客户端与服务器之间的网络上。很多事情都可以阻止网络遍历。客户端与服务器之间有许多点,每个点都有其自己的连接限制并可能引发问题。测试时间是否缩短的最简单方法是将您的应用置于其他主机上,并查看 TTFB 是否有所改善。
又称:大片蓝色
如果您看到 Content Download 阶段花费了大量时间,则提高服务器响应或串联不会有任何帮助。首要的解决办法是减少发送的字节数。
每天都有数以亿计的各种媒体对象经由 HTTP 传送,如图像、文本、影片以及软件程序等。HTTP 要确保它所承载的“货物”满 足以下条件:
HTTP 实体首部描述了 HTTP 报文的内容。HTTP/1.1 版定义了以下 10 个基本字体首部字段。
除非使用了分块编码,否则 Content-Length 首部就是带有实体主体的报文必须使用的。使用 Content-Length 首部是为了能够检测出服务器崩溃而导致的报文截尾,并对共享持久连接的多个报文进行正确分段。
Content-Length 首部指示出报文中实体主体的字节大小。这个大小是包含了所有内容编码的。如果主体进行了内容编码,Content-Length 首部说明的就是 编码后(encoded) 的主体的字节长度,而不是未编码的原始主体的长度。
没有 Content-Length 的话,客户端无法区分到底是报文结束时正常的连接关闭,还是报文传输中由于服务器崩溃而导致的连接关闭。客户端需要通过 Content-Length 来检测 报文截尾。
Content-Length 首部对于持久连接是必不可少的。如果响应通过持久连接传送, 就可能有另一条 HTTP 响应紧随其后。客户端通过 Content-Length 首部就可以知道报文在何处结束,下一条报文从何处开始。因为连接是持久的,客户端无法依赖 连接关闭来判别报文的结束。
有一种情况下,使用持久连接时可以没有 Content-Length 首部,即采用
分块编码(chunked encoding)时。在分块编码的情况下,数据是分为一系列的块来发送的,每块都有大小说明。哪怕服务器在生成首部的时候不知道整个实体的大小(通常是因为实体是动态生成的),仍然可以使用分块编码传输若干已知大小的块。
服务器使用 Content-MD5 首部发送对实体主体运行 MD5 算法的结果。只有产生响应的原始服务器可以计算并发送 Content-MD5 首部。如果一份文档使用 gzip 算法进 行压缩,然后用分块编码发送,那么就对整个经 gzip 压缩的主体进行 MD5 计算。
Content-Type 首部字段说明了实体主体的 MIME 类型。6MIME 类型是标准化的 名字,用以说明作为货物运载实体的基本媒体类型(比如:HTML 文件、Microsoft Word 文档或是 MPEG 视频等)。客户端应用程序使用 MIME 类型来解释和处理其内容。
Content-Type 首部说明的是原始实体主体的媒体类型。例如, 如果实体经过内容编码的话,Content-Type 首部说明的仍是编码之前的实体主体的类型。
Content-Type 首部还支持可选的参数来进一步说明内容的类型。charset(字符集)参数就是个例子,它说明把实体中的比特转换为文本文件中的字符的方法:
Content-Type: text/html; charset=iso-8859-4
MIME 中的 multipart(多部分)电子邮件报文中包含多个报文,它们合在一起作 为单一的复杂报文发送。每一部分都是独立的,有各自的描述其内容的集;不同的 部分之间用分界字符串连接在一起。
HTTP 也支持多部分主体。不过,通常只用在下列两种情形之一:提交填写好的表格,或是作为承载若干文档片段的范围响应。
内容编码,是对报文的主体进行的可逆变换。内容编码是和内容的具体格式细节紧密相关的。例如,你可能会用 gzip 压缩文本文件,但不是 JPEG 文 件,因为 JPEG 这类东西用 gzip 压缩的不够好。
HTTP 定义了一些标准的内容编码类型,并允许用扩展编码的形式增添更多的编码。 由 互联网号码分配机构(IANA)对各种编码进行标准化,它给每个内容编码算法分配了唯一的代号。Content-Encoding 首部就用这些标准化的代号来说明编码时使 用的算法。
毫无疑问,我们不希望服务器用客户端无法解码的方式来对内容进行编码。为了避免服务器使用客户端不支持的编码方式,客户端就把自己支持的内容编码方式列表放在请求的 Accept-Encoding 首部里发出去。
如果 HTTP 请求中没有包含 Accept-Encoding 首部,服务器就可以假设客户端能够接受任何编码方式(等价 于发送 Accept-Encoding: *)。
客户端可以给每种编码附带 Q(质量)值参数来说明编码的优先级。Q 值的范围从0.0 到 1.0,0.0 说明客户端不想接受所说明的编码,1.0 则表明最希望使用的编码。 “*”表示“任何其他方法”。决定在响应中回送什么内容给客户端是个更通用的过程,而选择使用何种内容编码则是此过程的一部分。
compress;q=0.5, gzip;q=1.0 gzip;q=1.0, identity; q=0.5, *;q=0
传输编码也是作用在实体主体上的可逆变换,但使用它们是由于架构方面的原因,同内容的格式无关。使用传输编码是为了改变 报文中的数据在网络上传输的方式。
HTTP 协议中只定义了下面两个首部来描述和控制传输编码。
下面的例子中,请求使用了 TE 首部来告诉服务器它可以接受分块编码(如果是 HTTP/1.1 应用程序的话,这就是必须的)并且愿意接受附在分块编码的报文结尾上 的拖挂:
GET /new_products.html HTTP/1.1
Host: www.joes-hardware.com
User-Agent: Mozilla/4.61 [en] (WinNT; I) TE: trailers, chunked
...
对它的响应中包含 Transfer-Encoding 首部,用于告诉接收方已经用分块编码对
报文进行了传输编码:
HTTP/1.1 200 OK Transfer-Encoding: chunked Server: Apache/3.0
...
在这个起始首部之后,报文的结构就将发生改变。
传输编码的值都是大小写无关的。HTTP/1.1 规定在 TE 首部和 Transfer-Encoding 首部中使用传输编码值。最新的 HTTP 规范只定义了一种传输编码,就是分块编码。
分块编码把报文分割为若干个大小已知的块。块之间是紧挨着发送的,这样就不需要在发送之前知道整个报文的大小了。
要注意的是,分块编码是一种传输编码,因此是报文的属性,而不是主体的属性。
若客户端和服务器之间不是持久连接,客户端就不需要知道它正在读取的主体的长度,而只需要读到服务器关闭主体连接为止。
当使用持久连接时,在服务器写主体之前,必须知道它的大小并在 Content- Length 首部中发送。如果服务器动态创建内容,就可能在发送之前无法知道主体的长度。
分块编码为这种困难提供了解决方案,只要允许服务器把主体逐块发送,说明每块的大小就可以了。因为主体是动态创建的,服务器可以缓冲它的一部分,发送其大小和相应的块,然后在主体发送完之前重复这个过程。服务器可以用大小为 0 的块作为主体结束的信号,这样就可以继续保持连接,为下一个响应做准备。
客户端也可以发送分块的数据给服务器。因为客户端事先不知道服务器是否接受分块编码(这是因为服务器不会在给客户端的响应中发送 TE 首部),所以客户端必须做好服务器用411 Length Required(需要Content-Length首部)响应来拒绝分块请求的准备。

如果客户端的 TE 首部中说明它可以接受拖挂的话,就可以在分块的报文最后加上拖挂。产生原始响应的服务器也可以在分块的报文最后加上拖挂。拖挂的内容是可选的元数据,客户端不一定需要理解和使用(客户端可以忽略并丢弃拖挂中的内容)。
拖挂中可以包含附带的首部字段,它们的值在报文开始的时候可能是无法确定的 (例如,必须要先生成主体的内容)。Content-MD5 首部就是一个可以在拖挂中发送的首部,因为在文档生成之前,很难算出它的 MD5。
除了 Transfer-Encoding、Trailer 以及 Content-Length 首部之外,其他 HTTP 首部都可以作为拖挂发送。
当文档在客户端“过期”之后(也就是说,客户端不再认为该副本有效),客户端必须从服务器请求一份新的副本。不过,如果该文档在服务器上并未发生改变,客户 端也就不需要再接收一次了——继续使用缓存的副本即可。
这种特殊的请求,称为 条件请求(conditional request),要求客户端使用 验证码 (validator)
来告知服务器它当前拥有的版本号,并仅当它的当前副本不再有效时才要求发送新的副本。
服务器应当告知客户端能够将内容缓存多长时间,在这个时间之内就是新鲜的。 服务器可以用这两个首部之一来提供这种信息: Expires(过期) 和 Cache- Control(缓存控制)。
客户端和服务器为了能正确使用 Expires 首部,它们的时钟必须同步。
HTTP 为客户端提供了一种方法,仅当资源改变时才请求副本, 这种特殊请求称为有条件的请求。有条件的请求是标准的 HTTP 请求报文,但仅当某个特定条件为真时才执行。
例如,某个缓存服务器可能发送下面的有条件 GET 报文给服务器,仅当文件 /announce.html 从 2002 年 6 月 29 日(这是缓存的文档最后 被作者修改的时间)之后发生改变的情况下才发送它:
GET /announce.html HTTP/1.0
If-Modified-Since: Sat, 29 Jun 2002, 14:30:00 GMT
有条件的请求是通过以“If-”开头的有条件的首部来实现的。
每个有条件的请求都通过特定的验证码来发挥作用。验证码是文档实例的一个特殊属性,用它来测试条件是否为真。从概念上说,你可以把验证码看作文件的序列号、 版本号,或者最后发生改变的日期时间。
HTTP把验证码分为两类:弱验证码(weak validators)和 强验证码(strong validators)。 弱验证码不一定能唯一标识资源的一个实例,而强验证码必须如此。
最后修改时间(If-Modified-Since)被当作弱验证码,因为尽管它说明了资源最后被修改的时间,但它的描述精度最大就是 1 秒。
ETag 首部被当作强验证码,因为每当资源内容改变时,服务器都可以在 ETag 首部放置不同的值。
有时候,客户端和服务器可能需要采用不那么精确的实体标记验证方法。例如,某服务器可能想对一个很大、被广泛缓存的文档进行一些美化修饰,但不想在缓存服务器再验证时产生很大的传输流量。在这种情况下,该服务器可以在标记前面加上“W/”前缀来广播一个“弱”实体标记。
关于客户端如何要求服务器只在资源的客户端副本不再有效的情况下才发送其副本, 我们已经清楚地理解了。HTTP 还进一步锦上添花:它允许客户端实际上只请求文 档的一部分,或者说某个范围。
有了范围请求,HTTP 客户端可以通过请求曾获取失败的实体的一个范围(或者说一部分),来恢复下载该实体。当然这有一个前提,那就是从客户端上一次请求该实 体到这次发出范围请求的时段内,该对象没有改变过。例如:
GET /bigfile.html HTTP/1.1
Host: www.joes-hardware.com
Range: bytes=4000-
User-Agent: Mozilla/4.61 [en] (WinNT; I) ...
在本例中,客户端请求的是文档开头 4000 字节之后的部分(不必给出结尾字节数, 因为请求方可能不知道文档的大小)。在客户端收到了开头的 4000 字节之后就失败的情况下,可以使用这种形式的范围请求。
并不是所有服务器都接受范围请求,但很多服务器可以。服务器可以通过在响应中包含 Accept-Ranges 首部的形式向客户端说明可以接受的范围请求。这个首部的值是计算范围的单位,通常是以字节计算的。例如:
HTTP/1.1 200 OK
Date: Fri, 05 Nov 1999 22:35:15 GMT Server: Apache/1.2.4
Accept-Ranges: bytes
涉及范围请求的一系列 HTTP 事务的例子:

Range 首部在流行的 点对点(Peer-to-Peer,P2P) 文件共享客户端软件中得到广泛应用,它们从不同的对等实体同时下载多媒体文件的不同部分。
如果客户端有一个页面的已过期副本,就要请求页面的最新实例。若改变的地方比较少,与其发送完整的新页面给客户端,客户端更愿意服务器只发送页面发生改变的部分,这样就可以更快地得到最新的页面。
差异编码是 HTTP 协议的一个扩展,它通过交换对象改变的部分而不是完整的对象来优化传输性能。差异编码也是一类实例操控,因为它依赖客户端和服务器之间针对特定的对象实例来交换信息。RFC 3229 描述了差异编码。
如果客户端想告诉服务器它愿意接受该页面的差异,只要发送 A-IM 首部 就可以了。A-IM 是 Accept-Instance-Manipulation(接受实例操控) 的缩写。
在 A-IM 首部中,客户端会说明它知道哪些算法可以把差异应用于老版本而得到最新版本。
服务端发送回下面这些内容:一个特殊的响应代码—— 226 IM Used,告知客户端它正在发送的是所请求对象的实例操控,而不是那个完整的对象自身;一个 IM(Instance-Manipulation 的缩写) 首部,说明用于计算差异的算法;新的 ETag 首部 和 Delta-Base 首部,说明用于计算差异的基线文档的 ETag。

服务器侧的“差异生成器”根据基线文档和该文档的最新实例,用客户端在 A-IM 首部中指明的算法计算它们之间的差异。客户端侧的“差异应用器” 得到差异,将其应用于基线文档,得到文档的最新实例。例如,如果产生差异的算 法是 Unix 系统的 diff-e 命令,客户端就可以用 Unix 系统中的文本编辑器 ed 提供的 功能来应用差异。
文档每个实例的唯一标识符。由服务器在响应中发送;客户端在后继请求的 If-Match 首部和 If-None-Match 首部中可以使用它
客户端发送的请求首部,当且仅当客户端的文档版本与服务器不同时,才向服务器请求该文档
客户端请求首部,说明可以接受的实例操控类型
服务器响应首部,说明作用在响应上的实例操控的类型。当响应代码是226 IM Used 时,会发送这个首部
服务器响应首部,说明用于计算差异的基线文档的 ETag 值(应当与客户端请求
中的 If-None-Match 首部里的 ETag 相同)
人们会用 Web 事务来处理一些很重要的事情。如果没有强有力的安全保证,人们就 无法安心地进行网络购物或使用银行业务。如果无法严格限制访问权限,公司就不 能将重要的文档放在 Web 服务器上。Web 需要一种安全的 HTTP 形式。
目前已存在一些提供认证(基本认证和 摘要认证 )和报文完整性检查(摘要 qop="auth-int")的轻量级方法。对很多网络事务来说,这些方法都是很好用的, 但对大规模的购物、银行事务,或者对访问机密数据来说,并不足够强大。这些更 为重要的事务需要将 HTTP 和数字加密技术结合起来使用,才能确保安全。
HTTP 的安全版本要高效、可移植且易于管理,不但能够适应不断变化的情况而且还应 该能满足社会和政府的各项要求。我们需要一种能够提供下列功能的 HTTP 安全技术。
在这个数字加密技术的入门介绍中,我们会讨论以下内容。
密码学基于一种名为密码(cipher)的秘密代码。密码是一套编码方案——一种特 殊的报文编码方式和一种稍后使用的相应解码方式的结合体。加密之前的原始报文通常被称为 明文(plaintext 或 cleartext)。使用了密码之后的编码报文通常被称作 密文(ciphertext)。
用密码来生成保密信息已经有数千年了。传说 尤利乌斯·凯撒(Julius Caesar) 曾使用过一种三字符循环移位密码,报文中的每个字符都由字母表中三个位置之后的字符来取代。在现代的字母表中,“A”就应该由“D”来取代,“B”就应该由“E” 来取代,以此类推。
随着技术的进步,人们开始制造一些机器,这些机器可以用复杂得多的密码来快速、 精确地对报文进行编解码。这些密码机不仅能做一些简单的旋转,它们还可以替换 字符、改变字符顺序,将报文切片切块,使代码的破解更加困难。
往往在现实中,编码算法和编码机都可能会落入敌人的手中,所以大部分机器上都有一些号盘,可以将其设置为大量不同的值以改变密码的工作方式。即使机器被盗,没有正确的号盘设置(密钥值),解码器也无法工作。
这些密码参数被称为 密钥(key)。要在密码机中输入正确的密钥,解密过程才能正确进行。密码密钥会让一个密码机看起来好像是多个虚拟密码机一样,每个密码机 都有不同的密钥值,因此其行为都会有所不同。
给定一段明文报文 P、一个编码函数 E 和一个数字编码密钥 e,就可以生成一段经 过编码的密文 C。通过解码函数 D 和解码密钥 d,可以将密文 C 解 码为原始的明文 P。当然,编 / 解码函数都是互为反函数的,对 P 的编码进行解码 就会回到原始报文 P 上去。

很多数字加密算法都被称为 对称密钥(symmetric-key) 加密技术,这是因为它们在编码时使用的密钥值和解码时 一样(e=d)。我们就将其统称为密钥 k。

流行的对称密钥加密算法包括:DES、Triple-DES、RC2 和 RC4。
保持密钥的机密状态是很重要的。在很多情况下,编 / 解码算法都是众所周知的,因此密钥就是唯一保密的东西了。好的加密算法会迫使攻击者试遍每一个可能的密钥,才能破解代码。用暴力去尝试 所有的密钥值称为 枚举攻击(enumeration attack)。
对称密钥加密技术的缺点之一就是发送者和接收者在互相对话之前,一定要有一个共享的保密密钥。
比如 Alice(A)、Bob(B)和 Chris(C)都想与 Joe 的 五金商店(J) 对话。A、B 和 C 都要建立自己与 J 之间的保密密钥。A 可能需要密钥 KAJ,B 可能需要密钥 KBJ,C 可能需要密钥 KCJ。每对通信实体都需要自己的私有密钥。如果有 N 个节点, 每个节点都要和其他所有 N-1 个节点进行安全对话,总共大概会有 N2 个保密密钥: 这将是一个管理噩梦。
公开密钥加密技术没有为每对主机使用单独的加密 / 解密密钥,而是使用了两个非对称密钥:一个用来对主机报文编码,另一个用来对主机报文解码。
所有公开密钥非对称加密系统所面临的共同挑战是,要确保即便有人拥有了下面所有的线索,也无法计算出保密的私有密钥:
RSA算法 就是一个满足了所有这些条件的流行的公开密钥加密系统,它是在 MIT 发明的,后来由 RSA 数据安全公司将其商业化。即使有了公共密钥、任意一段明文、用公共密钥对明文编码之后得到的相关密文、RSA 算法自身,甚至 RSA 实现 的源代码,破解代码找到相应的私有密钥的难度仍相当于对一个极大的数进行质因数分解的困难程度,这种计算被认为是所有计算机科学中最难的问题之一。因此, 如果你发现了一种能够快速地将一个极大的数字分解为质因数的方法,就不仅能够入侵瑞士银行的账户系统,而且还可以获得图灵奖了。
任何人只要知道了其公开密钥,就可以向一台公共服务器发送安全报文,所以非对称的公开密钥加密系统是很好用的。两个节点无须为了进行安全的通信而先交换私有密钥。
但公开密钥加密算法的计算可能会很慢。实际上它混合使用了对称和非对称策略。 比如,比较常见的做法是在两节点间通过便捷的公开密钥加密技术建立起安全通信, 然后再用那条安全的通道产生并发送临时的随机对称密钥,通过更快的对称加密技 术对其余的数据进行加密。(SSH和HTTPS都是这样的)
除了加 / 解密报文之外,还可以用加密系统对报文进行签名(sign),以说明是谁编写的报文,同时证明报文未被篡改过。这种技术被称为数字签名(digital signing)。
数字签名是附加在报文上的特殊加密校验码。数字签名通常是用 非对称公开密钥技术产生的。因为只有所有者才知道其私有密钥, 所以可以将作者的私有密钥当作一种“指纹”使用。

RSA 加密系统将解码函数 D 作为签名函数使用,是因为 D 已经将私有密钥作为输入使用了。注意, 解码函数只是一个函数,因此,可以将其用于任意的输入。同样,在 RSA 加密系统中,以任意顺序 应用 D 和 E 函数时,两者都会相互抵消。因此 E(D(stuff)) = stuff,就像 D(E(stuff)) = stuff 一样。
私钥和公钥是一对,都可以加解密,配对使用。RSA 的原理,两个大质数(p,q)乘积(n)难以逆向求解,所以 pq 是对等的,公钥和私钥也是对等的。
因特网上的“ID 卡”——数字证书。数字证书(通常被称作“certs”,有点像 certs 牌薄荷糖)中包含了由某个受信任组织担保的用户或公司的相关信息。
数字证书中还包含一组信息,所有这些信息都是由一个官方的 证书颁发机构(CA) 以数字方式签发的。
而且,数字证书通常还包括对象的 公开密钥,以及对象和所用签名算法的描述性信息。任何人都可以创建一个数字证书,但并不是所有人都能够获得受人尊敬的签发 权,从而为证书信息担保,并用其私有密钥签发证书。典型的证书结构如图所示。

不幸的是,数字证书没有单一的全球标准。就像不是所有印刷版 ID 卡都在同样的位 置包含了同样的信息一样,数字证书也有很多略有不同的形式。 不过好消息就是现 在使用的大多数证书都以一种标准格式—— X.509 v3,来存储它们的信息。X.509 v3 证书提供了一种标准的方式,将证书信息规范至一些可解析字段中。不同类型的证 书有不同的字段值,但大部分都遵循X.509 v3结构。
基于 X.509 证书的签名有好几种,(其中)包括 Web 服务器证书、客户端电子邮件 证书、软件代码签名证书和证书颁发机构证书。
通过 HTTPS 建立了一个安全 Web 事务之后,现代的浏览器都会自动获取所连接服 务器的数字证书。如果服务器没有证书,安全连接就会失败。
浏览器收到证书时会对签名颁发机构进行检查。如果这个机构是个很有权威的公共签名机构,浏览器可能已经知道其公开密钥了(浏览器会预先安装很多签名颁发机构的证书)。
如果对签名颁发机构一无所知,浏览器就无法确定是否应该信任这个签名颁发机构, 它通常会向用户显示一个对话框,看看他是否相信这个签名发布者。签名发布者可 能是本地的 IT 部门或软件厂商。
HTTPS 是最流行的 HTTP 安全形式。它是由网景公司首创的,所有主要的浏览器和 服务器都支持此协议。
使用 HTTPS 时,所有的 HTTP 请求和响应数据在发送到网络之前,都要进行加密。 HTTPS 在 HTTP 下面提供了一个传输级的密码安全层——可以使用 SSL,也可以使用其后继者—— 传输层安全(Transport Layer Security,TLS)。由于 SSL 和 TLS 非常类似,所以我们不太严格地用术语 SSL 来表示 SSL 和 TLS。

不使用SSL/TLS的HTTP通信,就是不加密的通信。所有信息明文传播,带来了三大风险。
窃听风险(eavesdropping):第三方可以获知通信内容。篡改风险(tampering):第三方可以修改通信内容。冒充风险(pretending):第三方可以冒充他人身份参与通信。SSL/TLS协议是为了解决这三大风险而设计的,希望达到:
SSL(Secure Socket Layer)是安全套接层,TLS(Transport Layer Security)是传输层安全协议,建立在SSL3.0协议规范,是 SSL3.0 的后续版本。SSL 直到 3.0版本才大规模的部署和应用。 TLS 版本相比于 SSL 变化明显的是支持的加密算法不同。当前最新使用的是TLS1.2协议。1.3版本还在草案阶段。
现在,安全 HTTP 是可选的。请求一个客户端(比如 Web 浏览器)对某 Web 资源执行某事务时,它会去检查 URL 的方案:
SSL 是个二进制协议,与 HTTP 完全不同,其流量是承载在另一个端口上的(SSL 通常是由端口 443 承载的)。如果 SSL 和 HTTP 流量都从端口 80 到达,大部分 Web 服务器会将二进制 SSL 流量理解为错误的 HTTP 并关闭连接。将安全服务进一步整 合到 HTTP 层中去就无需使用多个目的端口了,在实际中这样不会引发严重的问题。
开始加密通信之前,客户端和服务器首先必须建立连接和交换参数,这个过程叫做握手(handshake)。假定客户端叫做爱丽丝,服务器叫做鲍勃,整个握手过程可以用下图说明。
握手阶段分成五步:
随机数(Client random),以及客户端支持的加密方法。服务器生成的随机数(Server random)。随机数(Premaster secret),并使用数字证书中的公钥,加密这个随机数,发给鲍勃。Premaster secret)。对话密钥(session key),用来加密接下来的整个对话过程。上面的五步,画成一张图,就是下面这样:
握手阶段有三点需要注意:
对话密钥(session key) 加密(对称加密),服务器的公钥和私钥只用于加密和解密 对话密钥(session key)(非对称加密),无其他作用。整个握手阶段都不加密(也没法加密),都是明文的。因此,如果有人窃听通信,他可以知道双方选择的加密方法,以及三个随机数中的两个。整个通话的安全,只取决于 第三个随机数(Premaster secret)能不能被破解。
虽然理论上,只要服务器的公钥足够长(比如2048位),那么 Premaster secret 可以保证不被破解。但是为了足够安全,我们可以考虑把握手阶段的算法从默认的 RSA算法,改为 Diffie-Hellman算法(简称DH算法)。
采用 DH算法 后,Premaster secret 不需要传递,双方只要交换各自的参数,就可以算出这个随机数。
上图中,第三步和第四步由传递 Premaster secret 变成了传递 DH算法 所需的参数,然后双方各自算出 Premaster secret。这样就提高了安全性。
SSL 支持双向认证,将服务器证书承载回客户端,再将客户端的证书回送给服务器。 而现在,浏览时并不经常使用客户端证书。大部分用户甚至都没有自己的客户端证书。服务器可以要求使用客户端证书,但实际中很少出现这种情况。
SSL 自身不要求用户检查 Web 服务器证书,但大部分现代浏览器都会对证书进行简 单的完整性检查,并为用户提供进行进一步彻查的手段。网景公司提出的一种 Web 服务器证书有效性算法是大部分浏览器有效性验证技术的基础。验证步骤如下所述:
日期检测 首先,浏览器检查证书的起始日期和结束日期,以确保证书仍然有效。如果证书 过期了,或者还未被激活,则证书有效性验证失败,浏览器显示一条错误信息。签名颁发者可信度检测 每个证书都是由某些 证书颁发机构(CA) 签发的,它们负责为服务器担保。证书有不同的等级,每种证书都要求不同级别的背景验证。比如,如果申请某个电 子商务服务器证书,通常需要提供一个营业的合法证明。签名检测 一旦判定签名授权是可信的,浏览器就要对签名使用签名颁发机构的公开密钥, 并将其与校验码进行比较,以查看证书的完整性。站点身份检测 为防止服务器复制其他人的证书,或拦截其他人的流量,大部分浏览器都会试着 去验证证书中的域名与它们所对话的服务器的域名是否匹配。服务器证书中通常 都包含一个域名,但有些 CA 会为一组或一群服务器创建一些包含了服务器名称 列表或通配域名的证书。如果主机名与证书中的标识符不匹配,面向用户的客户 端要么就去通知用户,要么就以表示证书不正确的差错报文来终止连接。SSL 是个复杂的二进制协议。除非你是密码专家,否则就不应该直接发送原始的 SSL 流量。幸运的是,借助一些商业或开源的库,编写 SSL 客户端和服务器并不十 分困难。
OpenSSL 是 SSL 和 TLS 最常见的开源实现。OpenSSL 项目由一些志愿者合作开发, 目标是开发一个强壮的、具有完备功能的商业级工具集,以实现 SSL 和 TLS 协议以 及一个全功能的通用加密库。可以从 http://www.openssl.org 上获得 OpenSSL 的相 关信息,并下载相应软件。
强烈推荐一本书:HTTP 权威指南
Git 每次提交代码,都要写 Commit message(提交说明),否则就不允许提交。但是,一般来说,commit message 应该清晰明了,说明本次提交的目的。
不过话说回来,作为最具个人创造力和最会利用工具的物种——程序猿,最好是能有规范和工具的约束。否者的话,你可能看到以下的commit message:
目前,社区有多种 Commit message 的写法规范。本文介绍Angular 规范是目前使用最广的写法,比较合理和系统化,并且有配套的工具。前前端框架Angular.js采用的就是该规范。如下图:
比如,下面的命令显示上次发布后的变动,每个commit占据一行。你只看行首,就知道某次 commit 的目的。
$ git log <last tag> HEAD --pretty=format:%s
$ git log <last release> HEAD --grep feature
Change Log 是发布新版本时,用来说明与上一个版本差异的文档,详见后文。
每次提交,Commit message 都包括三个部分:header,body 和 footer。
<type>(<scope>): <subject>
<BLANK LINE>
<body>
<BLANK LINE>
<footer>
其中,header 是必需的,body 和 footer 可以省略。
不管是哪一个部分,任何一行都不得超过72个字符(或100个字符)。这是为了避免自动换行影响美观。
Header部分只有一行,包括三个字段:type(必需)、scope(可选)和subject(必需)。
用于说明 commit 的类别,只允许使用下面7个标识。
如果type为feat和fix,则该 commit 将肯定出现在 Change log 之中。其他情况(docs、chore、style、refactor、test)由你决定,要不要放入 Change log,建议是不要。
scope用于说明 commit 影响的范围,比如数据层、控制层、视图层等等,视项目不同而不同。
例如在Angular,可以是$location, $browser, $compile, $rootScope, ngHref, ngClick, ngView等。
如果你的修改影响了不止一个scope,你可以使用*代替。
subject是 commit 目的的简短描述,不超过50个字符。
其他注意事项:
Body 部分是对本次 commit 的详细描述,可以分成多行。下面是一个范例。
More detailed explanatory text, if necessary. Wrap it to
about 72 characters or so.
Further paragraphs come after blank lines.
- Bullet points are okay, too
- Use a hanging indent
有两个注意点:
Footer 部分只用于以下两种情况:
如果当前代码与上一个版本不兼容,则 Footer 部分以BREAKING CHANGE开头,后面是对变动的描述、以及变动理由和迁移方法。
BREAKING CHANGE: isolate scope bindings definition has changed.
To migrate the code follow the example below:
Before:
scope: {
myAttr: 'attribute',
}
After:
scope: {
myAttr: '@',
}
The removed `inject` wasn't generaly useful for directives so there should be no code using it.
如果当前 commit 针对某个issue,那么可以在 Footer 部分关闭这个 issue 。
Closes #234
还有一种特殊情况,如果当前 commit 用于撤销以前的 commit,则必须以revert:开头,后面跟着被撤销 Commit 的 Header。
revert: feat(pencil): add 'graphiteWidth' option
This reverts commit 667ecc1654a317a13331b17617d973392f415f02.
Body部分的格式是固定的,必须写成This reverts commit <hash>.,其中的hash是被撤销 commit 的 SHA 标识符。
如果当前 commit 与被撤销的 commit,在同一个发布(release)里面,那么它们都不会出现在 Change log 里面。如果两者在不同的发布,那么当前 commit,会出现在 Change log 的Reverts小标题下面。
可以使用典型的git工作流程或通过使用CLI向导Commitizen来添加提交消息格式。
npm install -g commitizen
然后,在项目目录里,运行下面的命令,使其支持 Angular 的 Commit message 格式。
commitizen init cz-conventional-changelog --save --save-exact
以后,凡是用到git commit命令,一律改为使用git cz。这时,就会出现选项,用来生成符合格式的 Commit message。
validate-commit-msg 用于检查项目的 Commit message 是否符合Angular规范。
该包提供了使用githooks来校验commit message的一些二进制文件。在这里,我推荐使用husky,只需要添加"commitmsg": "validate-commit-msg"到你的package.json中的nam scripts即可.
当然,你还可以通过定义配置文件.vcmrc来自定义校验格式。详细使用请见文档 validate-commit-msg
如果你的所有 Commit 都符合 Angular 格式,那么发布新版本时, Change log 就可以用脚本自动生成。生成的文档包括以下三个部分:
每个部分都会罗列相关的 commit ,并且有指向这些 commit 的链接。当然,生成的文档允许手动修改,所以发布前,你还可以添加其他内容。
conventional-changelog 就是生成 Change log 的工具,运行下面的命令即可。
$ npm install -g conventional-changelog
$ cd my-project
$ conventional-changelog -p angular -i CHANGELOG.md -w
Commit message 和 Change log 编写指南
Angular.js Git Commit Guidelines
把条件、循环以及其他对控制流的改变做得越“自然”越好。运用一种方式使读者不用停下来重读你的代码。
相对于追求最小化代码行数,一个更好的度量方法是最小化人们理解它所需的时间。
我的经验是,do语句是错误和困惑的来源……我倾向于把条件放在“前面我能看到的地方”。其结果是,我倾向于避免使用do语句。
通常来讲提早返回可以减少嵌套并让代码整洁。“保护语句”(在函数顶部处理简单的情况时)尤其有用。
当你对代码做改动时,从全新的角度审视它,把它作为一个整体来看待。
嵌套的代码块需要更加集中精力去理解。每层新的嵌套都需要读者把更多的上下文“压入栈”。应该把它们改写成更加“线性”的代码来避免深嵌套。
在循环中,与提早返回类似的技术是continue:
与if(...)return;在函数中所扮演的保护语句一样,这些if(...) continue;语句是循环中的保护语句。
然而在实践中,编程语言和库的结构让代码在“幕后”运行,或者让流程难以理解。
下面是一些例子:
| 编程结构 | 高层次程序流程是如何变得不清晰的 |
|---|---|
| 线程 | 不清楚什么时间执行什么代码 |
| 信号量/中断处理程序 | 有些代码随时都有可能执行 |
| 异常 | 可能会从多个函数调用中向上冒泡一样地执行 |
| 函数指针和匿名函数 | 很难知道到底会执行什么代码,因为在编译时还没有决定 |
| 虚方法 | object.virtualMethod()可能会调用一个未知子类的代码 |
把你的超长表达式拆分成更容易理解的小块。
拆分表达式最简单的方法就是引入一个额外的变量,让它来表示一个小一点的子表达式。这个额外的变量有时叫做“解释变量”,因为它可以帮助解释子表达式的含义。
即使一个表达式不需要解释(因为你可以看出它的含义),把它装入一个新变量中仍然有用。我们把它叫做总结变量,它的目的只是用一个短很多的名字来代替一大块代码,这个名字会更容易管理和思考。
如果你学过“电路”或者“逻辑”课,你应该还记得德摩根定理。对于一个布尔表达式,有两种等价的写法:
如果你记不住这两条定理,一个简单的小结是“分别取反,转换与/或”(反向操作是“提出取反因子”)。
有时,你可以使用这些法则来让布尔表达式更具可读性。例如,如果你的代码是这样的:
if (!(file_exists && !is_protected)) Error("Sorry, could not read file.");那么可以把它改写成:
if (!file_exists || is_protected) Error("Sorry, could not read file.");变量的草率运用如何让程序更难理解。确切地说,我们会讨论三个问题:
让你的变量对尽量少的代码行可见。
很多编程语言提供了多重作用域/访问级别,包括模块、类、函数以及语句块作用域。通常越严格的访问控制越好,因为这意味着该变量对更少的代码行“可见”。
从某种意义上来讲,类的成员变量就像是在该类的内部世界中的“小型全局变量”。尤其对大的类来讲,很难跟踪所有的成员变量以及哪个方法修改了哪个变量。这样的小型全局变量越少越好。
另一个对类成员访问进行约束的方法是“尽量使方法变成静态的”。静态方法是让读者知道“这几行代码与那些变量无关”的好办法。
或者还有一种方式是“把大的类拆分成小一些的类”。这种方法只有在这些小一些的类事实上相互独立时才能发挥作用。如果你只是创建两个类来互相访问对方的成员,那你什么目的也没达到。
RAIL 是一种以用户为中心的性能模型。每个网络应用均具有与其生命周期有关的四个不同方面,且这些方面以不同的方式影响着性能:
RAIL核心**是以用户为中心;最终目标不是让您的网站在任何特定设备上都能运行很快,而是使用户满意。主要包含以下几个方面:
让用户成为您的性能工作的中心。用户花在网站上的大多数时间不是等待加载,而是在使用时等待响应。下表是用户时间与用户反应的关系:
| 延迟 | 用户反应 |
|---|---|
| 0 - 16 毫秒 | 人们特别擅长跟踪运动,如果动画不流畅,他们就会对运动心生反感。 用户可以感知每秒渲染 60 帧的平滑动画转场。也就是每帧 16 毫秒(包括浏览器将新帧绘制到屏幕上所需的时间),留给应用大约 10 毫秒的时间来生成一帧。 |
| 0 - 100 毫秒 | 在此时间窗口内响应用户操作,他们会觉得可以立即获得结果。时间再长,操作与反应之间的连接就会中断。 |
| 100 - 300 毫秒 | 用户会遇到轻微可觉察的延迟。 |
| 300 - 1000 毫秒 | 在此窗口内,延迟感觉像是任务自然和持续发展的一部分。对于网络上的大多数用户,加载页面或更改视图代表着一个任务。 |
| 1000+ 毫秒 | 超过 1 秒,用户的注意力将离开他们正在执行的任务。 |
| 10,000+ 毫秒 | 用户感到失望,可能会放弃任务;之后他们或许不会再回来。 |
在用户注意到滞后之前您有 100 毫秒的时间可以响应用户输入。这适用于大多数输入,不管他们是在点击按钮、切换表单控件还是启动动画。但不适用于触摸拖动或滚动。
如果您未响应,操作与反应之间的连接就会中断。用户会注意到。
尽管很明显应立即响应用户的操作,但这并不总是正确的做法。使用此 100 毫秒窗口执行其他开销大的工作,但需要谨慎,以免妨碍用户。如果可能,请在后台执行工作。
对于需要超过 500 毫秒才能完成的操作,请始终提供反馈。
如果动画帧率发生变化,您的用户确实会注意到。您的目标就是每秒生成 60 帧,每一帧必须完成以下所有步骤:
从纯粹的数学角度而言,每帧的预算约为 16 毫秒(1000 毫秒 / 60 帧 = 16.66 毫秒/帧)。 但因为浏览器需要花费时间将新帧绘制到屏幕上,只有 10 毫秒来执行代码。
在像动画一样的高压点中,关键是不论能不能做,什么都不要做,做最少的工作。 如果可能,请利用 100 毫秒响应预先计算开销大的工作,这样您就可以尽可能增加实现 60fps 的可能性。
如需了解详细信息,请参阅渲染性能。
利用空闲时间完成推迟的工作。例如,尽可能减少预加载数据,以便您的应用快速加载,并利用空闲时间加载剩余数据。
推迟的工作应分成每个耗时约 50 毫秒的多个块。如果用户开始交互,优先级最高的事项是响应用户。
要实现小于 100 毫秒的响应,应用必须在每 50 毫秒内将控制返回给主线程,这样应用就可以执行其像素管道、对用户输入作出反应,等等。
以 50 毫秒块工作既可以完成任务,又能确保即时的响应。
在 1 秒钟内加载您的网站。否则,用户的注意力会分散,他们处理任务的感觉会中断。
侧重于优化关键渲染路径以取消阻止渲染。
要根据 RAIL 指标评估您的网站,请使用 Chrome DevTools Timeline 工具记录用户操作。然后根据这些关键 RAIL 指标检查 Timeline 中的记录时间。
| RAIL 步骤 | 关键指标 | 用户操作 |
|---|---|---|
| 响应 | 输入延迟时间(从点按到绘制)小于 100 毫秒。 | 用户点按按钮(例如打开导航)。 |
| 动画 | 每个帧的工作(从 JS 到绘制)完成时间小于 16 毫秒。 | 用户滚动页面,拖动手指(例如,打开菜单)或看到动画。 拖动时,应用的响应与手指位置有关(例如,拉动刷新、滑动轮播)。 此指标仅适用于拖动的持续阶段,不适用于开始阶段。 |
| 空闲 | 主线程 JS 工作分成不大于 50 毫秒的块。 | 用户没有与页面交互,但主线程应足够用于处理下一个用户输入。 |
| 加载 | 页面可以在 1000 毫秒内就绪。 | 用户加载页面并看到关键路径内容。 |
React 因为性能好而被广为周知,但这并不意味着我们能够把这个当作是理所当然。让你的React应用更快的关键Tips之一就是优化你的 render 函数.
我曾经创建过一个简单的测试,来比较下面不同条件下的 render() 函数的速度:
对于那些不耐烦,只是想阅读结果的人来说,这是以下测试中得出的最重要的结论:
Stateless (functional) components 并不比有状态组件 stateful (class) components快Pure components 更快,因为使用shouldComponentUpdatedevelopment 模式下的渲染性能比 production 模式下慢 2–8x倍development 模式下的渲染性能比 0.14 慢 2x 倍很惊讶?
与每个基准一样,弄懂结果的关键是先理解方法。让我们花一些时间来解释我在这里做了什么,为什么要这么做。
目标是创建一个非常简单的测试来迭代 render() 函数。我创建了包含三种组件之一的父组件:
shouldComponentUpdate 返回 false// Stateful component
class Stateful extends Component {
render () {
return <div>Hello Cmp1: stateful</div>;
}
}
// Pure stateful with disabled updates
class Pure extends Component {
shouldComponentUpdate() {
return false;
}
render () {
return <div>Hello Cmp2: stateful, pure, no updates</div>;
}
}
// Stateless component
function Stateless() {
return <div>Hello Cmp3: stateless</div>;
}测试的组件很简单,并没有改变DOM。
顶层的组件将三种类型的组件每种循环渲染100,000次。同时使用浏览器自带的 Performance.now功能,统计从初始渲染到最后渲染的时间来衡量渲染时间。遗憾的是,我们不能使用React官方提供的的Perf函数来统计,因为它们不能用在生产环境中。
虽然始终传递props以确保更新,但目标组件保持渲染的数据相同。这样我们可以保证与纯组件的一致性。 DOM不会从这些组件中更新,从而保证其他API(例如布局呈现引擎)的干扰达到最小。
所有的JavaScript代码都运行在纯ES6中,没有转换步骤(没有转换为ES5)
测试运行的浏览器为Chrome 51 (包含常用的插件,如一系列的 dev tools, 1Password, Pocket等), 一个纯粹的Chrome Canary 54 (没有插件,没有历史记录,完全全新的) 和 Firefox 46. OS X 10.11,主机环境为一台2.6 GHz Intel Core i7 处理器的MBP.所有呈现的数据都是取所有浏览器运行结果的平均值。
TJ Holowaychuk’s 的观点中,值得一提的是不安装任何插件的浏览器能够产生一个明显更好的结果。这就是我们使用一个纯粹的Chrome Canary配置的原因。无论怎样,我们普通的用户通常都会在浏览器安装几个插件,我们并不知道这个会导致多大的性能损失。
执行这些类型的基准测试时的精确度并不容易实现。有时测试会运行速度更慢或更快,导致结果产生偏差。这就是为什么我多次运行测试,并统计了所有的结果。您单次测试的结果可能会有所不同。
所有的 源码 都在Github上,欢迎check out. 每个框架对应一个文件夹,你能够在里面运行常见的 npm i && npm start命令。这些应用运行在不同的端口,因此他们能够被同时执行。 readme 文件 提供了更详尽的说明。
我们已经有了这些前提,现在,让我们来讨论一下这些发现。
根据React 0.14和React 15,无状态(functional)组件与常规的基于类的状态组件一样快。
您会注意到,React 0.14中的测试显示无状态组件与状态组件性能有5%的差异,但我认为这是统计误差。
但是,当整个生命周期被剥离,且没有引用,没有状态管理,无状态组件为何不会更快?
根据 Dan Abramov的说法,无状态组件内部封装在一个类中,当前并没有进行任何的优化,
@ggrgur There is no “optimized” support for them yet because stateless component is wrapped in a class internally. It's same code path.
React团队已经承诺将对于无状态组件的优化,我确信在React的未来版本之一中将实现。
抛开复杂构建优化问题,React应用程序性能调优的关键在于知道什么时候渲染,什么时候不渲染。
这里有一个例子:假设您正在创建一个下拉菜单,并希望通过设置状态来展开它expanded:true。这种情况下,你必须要渲染整个块,包括下拉列表中的所有列表项才能更改css值吗?千万不要这么干!
这种情况下,shouldComponentUpdate 是你最好的朋友, 赶紧用上它。如果你能够使用shouldComponentUpdate进行优化,就不要使用无状态组件。您可以使用Shallow Compare函数来简化流程,但如果这成为React组件核心功能的一部分,我也不会感到惊讶。
更新:从React 15.3开始,React.PureComponent是一个新的基类,可以替代使用Shallow Compare插件或Pure Render mixin的场景。
最初的基准测试是在没有添加任何逻辑到render函数的情况下,进行了渲染性能的比较。而一旦添加了计算,Pure Components的优势就会更加明显。我们可以将其视为一种缓存的方法。
我这么直接原因之一是看到开发人员不关心改善渲染,因为虚拟DOM将在这方面做了一些处理。但是显然,在涉及到虚拟DOM的diff算法之前,应用的速度还有大量的提升空间。
我不想说你应该在所有的地方使用shouldComponentUpdate。添加大量的逻辑或在组件很少输出相同的HTML代码的地方使用它,就会增加不必要的复杂度。你应该知道这种生命周期方法的力量,并且合理的使用它。
阻止不必要的渲染只是其中一方面。上述结果告诉我们如何提高渲染性能?
下图显示了render()函数对应用程序性能的影响。渲染是复杂操作的开始,最终导致优化的DOM更新。
render越简单,更新越快:
以下是优化render阶段的几个提示:
正如您的应用程序可能在render阶段包含业务逻辑计算一样,React还添加了helpers来增强您的开发体验。让我们看看它们是如何影响性能的。
React代码默认为development模式。令人惊讶的是,development环境下的渲染显着较慢。
在构建应用程序时将其指定为production模式的方法是定义环境变量NODE_ENV = production。当然,你只会在生产环境下用到这个,因为development 模式将提供更好的调试体验。
以下是您在Webpack配置中自动执行此变量的方法:
module.exports = {
plugins: [
new webpack.DefinePlugin({
‘process.env’: {NODE_ENV: ‘”production”’}
})
],
}这样做不仅能够优化你的render性能,还能够提供更小的体积。
别忘了使用UglifyJS plugin剔除不必要的代码,下面是一个使用例子:
plugins: [
new webpack.optimize.UglifyJsPlugin({
sourceMap: false,
warnings: false,
}),
],我们看到React 15在development模式下与之前的版本相比要慢得多。他们在生产中的比较结果又如何呢?
React 15 重要更新 是框架与DOM交互的核心变化。 innerHTML 被替换成 document.createElement,现代浏览器中更快捷的选择。
不再支持Internet Explorer 8可能意味着一些内部流程更加优化。
React 15在渲染过程中真的更快,但只有在构建模式为production时才能生效。development模式实际上相当慢,主要是因为包含了太多的帮助调试和优化代码的函数。
值得注意的是,这些发现是基于React 15与React-DOM 15的。React Native的development模式下结果可能会有显着差异。也许你可以运行类似的测试,并与社区分享结果。
性能开始于在React应用程序中优化render block。该基准测试比较了创建和优化组件的三种方法。你得对他们的使用场景和优缺点了然于心。
可能还有许多其他的基准测试方法,因此绝对不要把你在这里学到的一切当作理所当然。如果您有其他想法欢迎贡献。
Grgur是Modus Create的一名软件架构师,专门从事JavaScript性能,React JS和Sencha框架。如果这篇文章有帮助,也许他16年的从财富100强到政府和初创公司的经验可以帮助你的项目。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.