![]()
Canonical features for OpenStreetMap, collected manually and via the NSI Collector planet scan.
The goal of this project is to maintain a canonical list of commonly used features for suggesting consistent spelling and tagging in OpenStreetMap.
👉 Watch the video from our talk at State of the Map US 2019 to learn more about this project!
You can browse the name-suggestion-index and check Wikidata links for accuracy at https://nsi.guide.
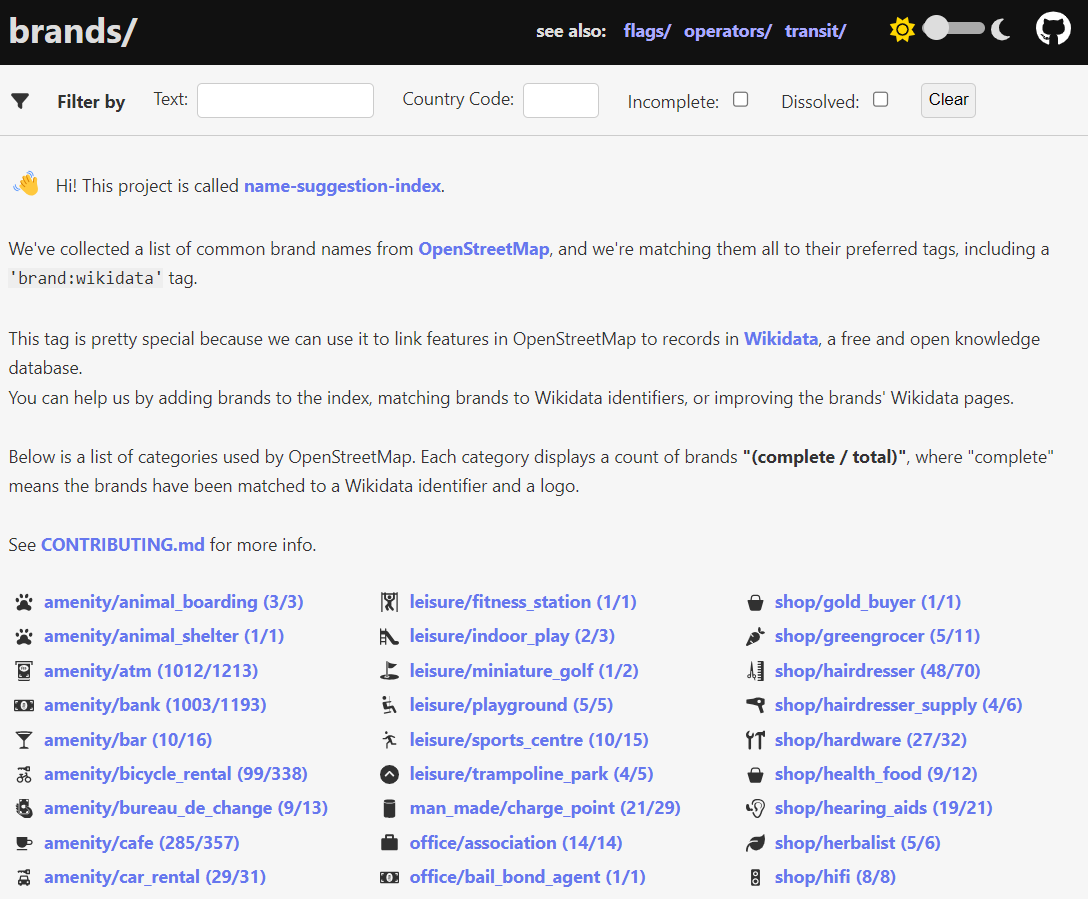
When mappers create features in OpenStreetMap, they are not always consistent about how they
name and tag things. For example, we may prefer McDonald's tagged as amenity=fast_food
but we see many examples of other spellings (Mc Donald's, McDonalds, McDonald’s) and
taggings (amenity=restaurant).
Building a canonical feature index allows two very useful things:
- We can suggest the most "correct" way to tag things as users create them while editing.
- We can scan the OSM data for "incorrect" features and produce lists for review and cleanup.
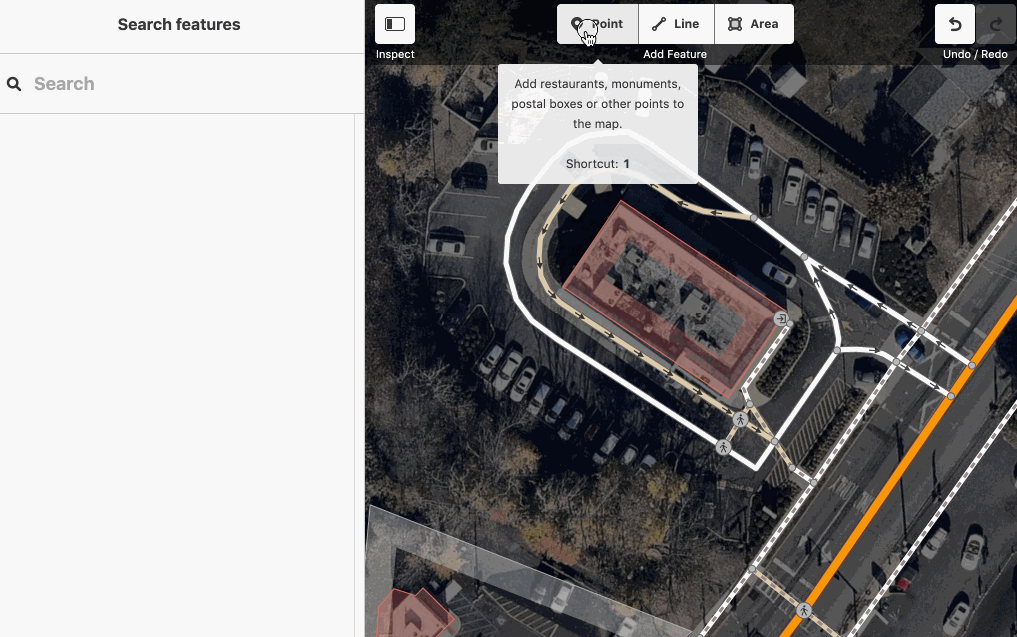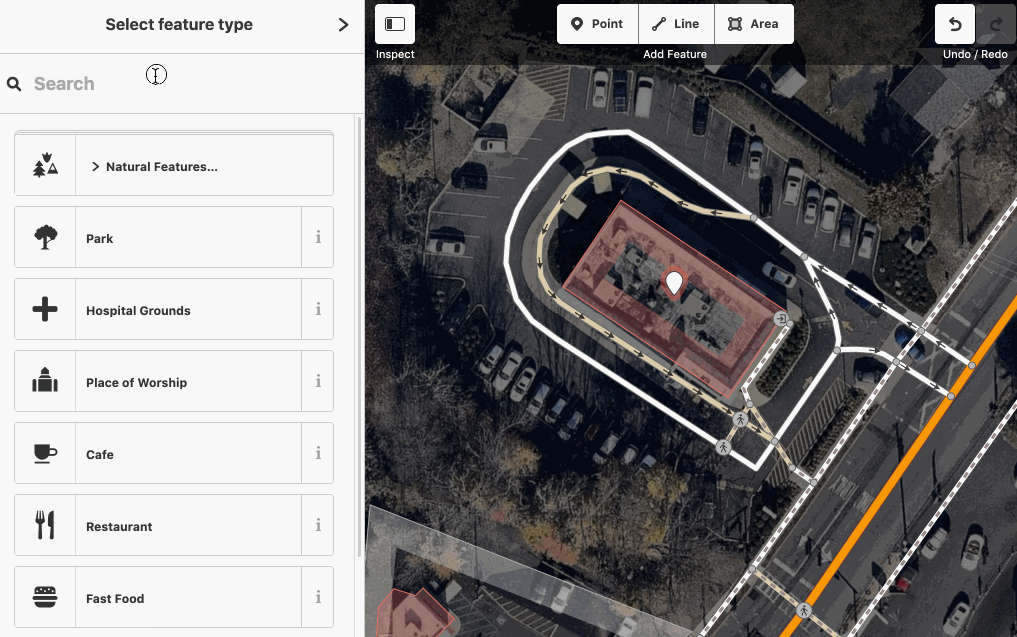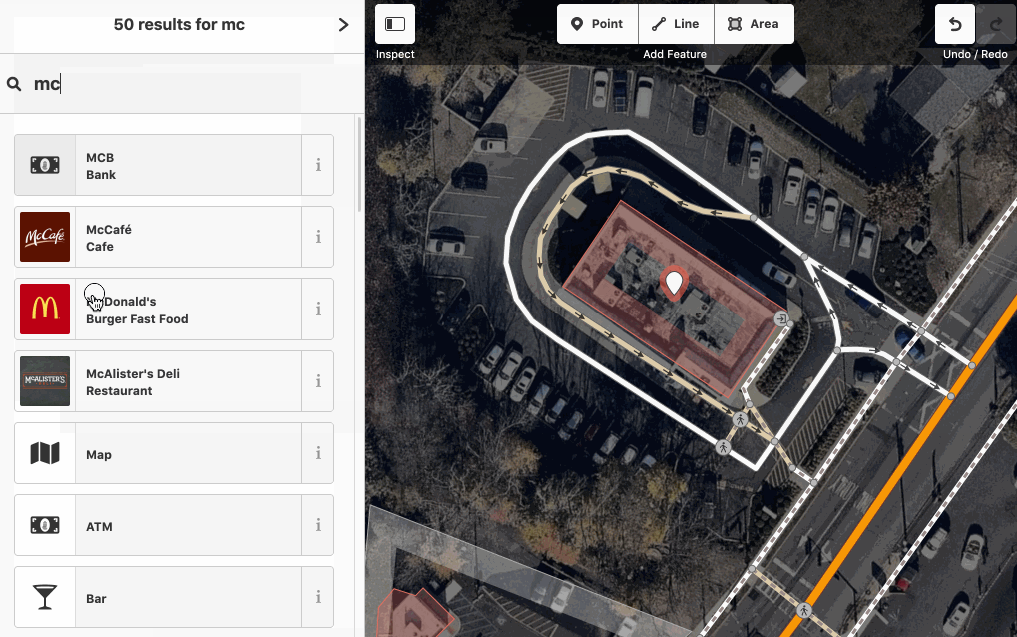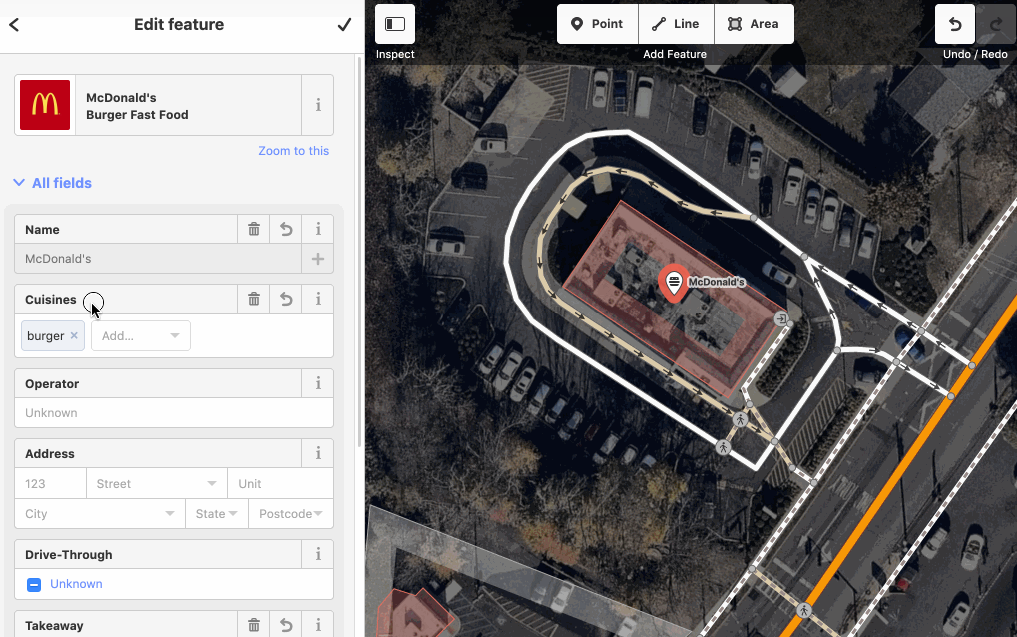
The name-suggestion-index is in use in iD when adding a new item
Currently used in:
- Rapid
- iD (see above)
- Vespucci
- JOSM presets available
- Osmose
- osmfeatures
- Go Map!!
- StreetComplete
- Every Door
- All The Places
See the project wiki for details.
We're always looking for help!
- Read the Code of Conduct and remember to be kind to one another.
- See the project wiki for info about how to contribute to this index.
If you have any questions or want to reach out to a maintainer, ping @bhousel, @1ec5, or @tas50 on:
- OpenStreetMap US Slack (
#poior#generalchannels)
name-suggestion-index is available under the 3-Clause BSD License. See the LICENSE.md file for more details.


























































































































































