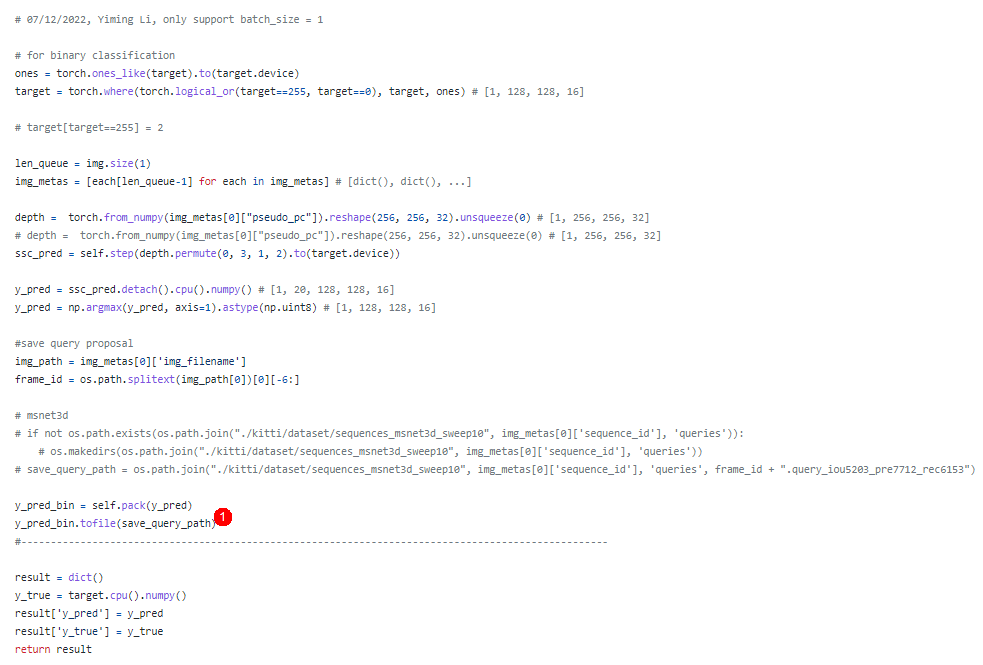
Hello @RoboticsYimingLi , Now I am reproducing Your fantastic VoxFormer
But, when stage-1 study is well done, stage-2 make error like below
my compute spec is
Tesla A100(80G) 4 GPUS
CUDA 11.3 torch 1.10.1
Please Tell me solution... I can't do anything now...
Error Message
error in ms_deformable_im2col_cuda: an illegal memory access was encountered
Traceback (most recent call last):
File "./tools/train.py", line 261, in
main()
File "./tools/train.py", line 250, in main
custom_train_model(
File "/home/hamyo/SSC/mmdetection3d/VoxFormer/projects/mmdet3d_plugin/voxformer/apis/train.py", line 27, in custom_train_model
custom_train_detector(
File "/home/hamyo/SSC/mmdetection3d/VoxFormer/projects/mmdet3d_plugin/voxformer/apis/mmdet_train.py", line 200, in custom_train_detector
runner.run(data_loaders, cfg.workflow)
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/mmcv/runner/epoch_based_runner.py", line 127, in run
epoch_runner(data_loaders[i], **kwargs)
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/mmcv/runner/epoch_based_runner.py", line 50, in train
self.run_iter(data_batch, train_mode=True, **kwargs)
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/mmcv/runner/epoch_based_runner.py", line 29, in run_iter
outputs = self.model.train_step(data_batch, self.optimizer,
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/mmcv/parallel/distributed.py", line 52, in train_step
output = self.module.train_step(*inputs[0], **kwargs[0])
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/mmdet/models/detectors/base.py", line 237, in train_step
losses = self(**data)
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/hamyo/SSC/mmdetection3d/VoxFormer/projects/mmdet3d_plugin/voxformer/detectors/voxformer.py", line 108, in forward
return self.forward_train(**kwargs)
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/mmcv/runner/fp16_utils.py", line 98, in new_func
return old_func(*args, **kwargs)
File "/home/hamyo/SSC/mmdetection3d/VoxFormer/projects/mmdet3d_plugin/voxformer/detectors/voxformer.py", line 138, in forward_train
losses_pts = self.forward_pts_train(img_feats, img_metas, target)
File "/home/hamyo/SSC/mmdetection3d/VoxFormer/projects/mmdet3d_plugin/voxformer/detectors/voxformer.py", line 93, in forward_pts_train
outs = self.pts_bbox_head(img_feats, img_metas, target)
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/hamyo/SSC/mmdetection3d/VoxFormer/projects/mmdet3d_plugin/voxformer/dense_heads/voxformer_head.py", line 95, in forward
seed_feats = self.cross_transformer.get_vox_features(
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/mmcv/runner/fp16_utils.py", line 98, in new_func
return old_func(*args, **kwargs)
File "/home/hamyo/SSC/mmdetection3d/VoxFormer/projects/mmdet3d_plugin/voxformer/modules/transformer.py", line 136, in get_vox_features
bev_embed = self.encoder(
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/mmcv/runner/fp16_utils.py", line 98, in new_func
return old_func(*args, **kwargs)
File "/home/hamyo/SSC/mmdetection3d/VoxFormer/projects/mmdet3d_plugin/voxformer/modules/encoder.py", line 205, in forward
output = layer(
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/hamyo/SSC/mmdetection3d/VoxFormer/projects/mmdet3d_plugin/voxformer/modules/encoder.py", line 372, in forward
query = self.attentions[attn_index](
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/mmcv/runner/fp16_utils.py", line 186, in new_func
return old_func(*args, kwargs)
File "/home/hamyo/SSC/mmdetection3d/VoxFormer/projects/mmdet3d_plugin/voxformer/modules/deformable_cross_attention.py", line 171, in forward
slots[j, index_query_per_img] += queries[j, i, :len(index_query_per_img)]
RuntimeError: CUDA error: an illegal memory access was encountered
terminate called after throwing an instance of 'c10::CUDAError'
what(): CUDA error: an illegal memory access was encountered
Exception raised from create_event_internal at /opt/conda/conda-bld/pytorch_1639180588308/work/c10/cuda/CUDACachingAllocator.cpp:1211 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x42 (0x7fdede183d62 in /home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #1: + 0x1c613 (0x7fdf236a1613 in /home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/lib/libc10_cuda.so)
frame #2: c10::cuda::CUDACachingAllocator::raw_delete(void) + 0x1a2 (0x7fdf236a2022 in /home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/lib/libc10_cuda.so)
frame #3: c10::TensorImpl::release_resources() + 0xa4 (0x7fdede16d314 in /home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #4: + 0x295359 (0x7fdf776a3359 in /home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #5: + 0xadb231 (0x7fdf77ee9231 in /home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #6: THPVariable_subclass_dealloc(_object) + 0x292 (0x7fdf77ee9532 in /home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #7: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4d386f]
frame #8: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4e55cb]
frame #9: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4e55cb]
frame #10: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4e0800]
frame #11: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4f16a8]
frame #12: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4f1691]
frame #13: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4f1691]
frame #14: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4f1691]
frame #15: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4f1691]
frame #16: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4f1691]
frame #17: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4f1691]
frame #18: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4f1691]
frame #19: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x4c9280]
frame #20: PyDict_SetItemString + 0x52 (0x5823a2 in /home/hamyo/anaconda3/envs/voxformer/bin/python)
frame #21: PyImport_Cleanup + 0x93 (0x5a7623 in /home/hamyo/anaconda3/envs/voxformer/bin/python)
frame #22: Py_FinalizeEx + 0x71 (0x5a6751 in /home/hamyo/anaconda3/envs/voxformer/bin/python)
frame #23: Py_RunMain + 0x112 (0x5a21f2 in /home/hamyo/anaconda3/envs/voxformer/bin/python)
frame #24: Py_BytesMain + 0x39 (0x57a799 in /home/hamyo/anaconda3/envs/voxformer/bin/python)
frame #25: __libc_start_main + 0xe7 (0x7fdfb1900c87 in /lib/x86_64-linux-gnu/libc.so.6)
frame #26: /home/hamyo/anaconda3/envs/voxformer/bin/python() [0x57a64d]
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 53769 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 53771 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 53772 closing signal SIGTERM
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: -6) local_rank: 1 (pid: 53770) of binary: /home/hamyo/anaconda3/envs/voxformer/bin/python
Traceback (most recent call last):
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/distributed/launch.py", line 193, in
main()
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/distributed/launch.py", line 189, in main
launch(args)
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/distributed/launch.py", line 174, in launch
run(args)
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/distributed/run.py", line 710, in run
elastic_launch(
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/distributed/launcher/api.py", line 131, in call
return launch_agent(self._config, self._entrypoint, list(args))
File "/home/hamyo/anaconda3/envs/voxformer/lib/python3.8/site-packages/torch/distributed/launcher/api.py", line 259, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
./tools/train.py FAILED
Failures:
<NO_OTHER_FAILURES>
Root Cause (first observed failure):
[0]:
time : 2024-04-20_00:00:00
host : server-45
rank : 1 (local_rank: 1)
exitcode : -6 (pid: 53770)
error_file: <N/A>
traceback : Signal 6 (SIGABRT) received by PID 53770