Vaani Microphone Check
Abstract
This repo contains a suite of tools used to compare microphones used for the Vaani project.
Introduction
Currently we are using this suite to compare the Nascent Object device microphones to other USB microphones. Generally, when comparing such microphones we will arrange a set of n Nascent Object devices at various distances from a sound source. Next to each such Nascent Object device we will place a Raspberry Pi connected to the other USB microphone we wish to evaluate. The general test set up is as follows:
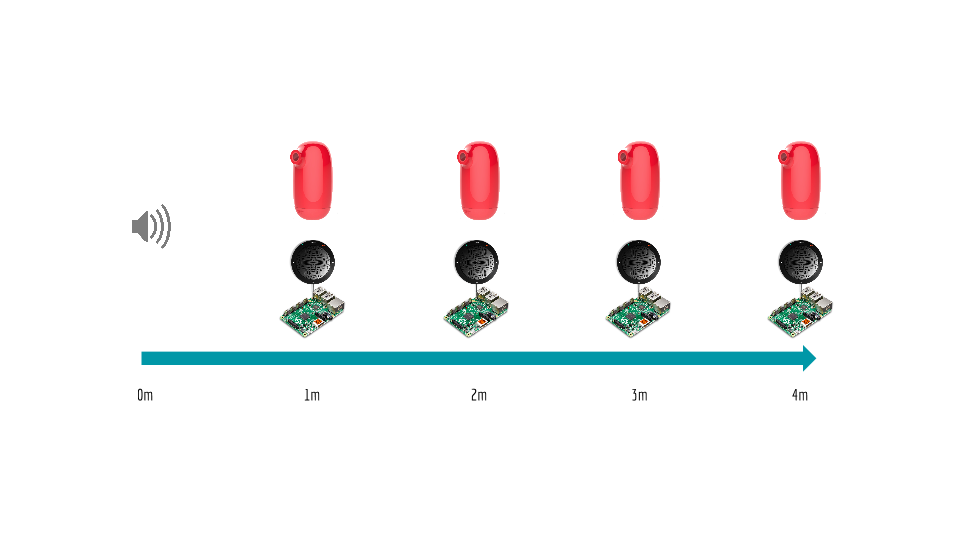
The sound source then "reads" aloud various example sentences, apropos for the Vaani project, and the various devices, Nascent Objects and RPi's, then record the produced audio.
Set-Up
To compare Nascent Object device microphones to other USB microphones we first prepare n Nascent Object devices with the host names vaani-1, vaani-2,...vaani-n. We then place them at specific measured distances from a sound source. (For our current tests we place vaani-1 at 1 meter from the sound source, vaani-2 at 2 meters from the sound source...)
Next we prepare n Raspberry Pi devices with the host names raspberrypi-1, raspberrypi-2,...raspberrypi-n each connected the USB microphone we wish to evaluate. We then place the m-th Raspberry Pi device next to the m-th Nascent Object device, as pictured above.
Next we have all the devices vaani-1, vaani-2,...vaani-n, raspberrypi-1, raspberrypi-2,...raspberrypi-n join the same WiFi network. This allows us, from this WiFi network, to login to vaani-1 using the hostname vaani-1.local, to vaani-2 using the hostname vaani-2.local,..., and to raspberrypi-n using the hostname raspberrypi-n.local.
Next we clone this repository onto a computer connected to the sound source and on the same WiFi network as all of the devices. (We have only tested this with OS X.) This computer must then be configured to ssh into all devices without using a password. (This process is described here[1].)
The final configuration step that must occur is adjusting the audio level of the sound source such that its volume emulates that of conversational speech. To do so one first requires a dB meter. (We used Decibel 10th[2]) One then palces the dB meter at a distance of 1m from the sound source, plays any of the audio files in resources/audio, and then adjusts the volume of the sound source such that the audio files are 65 dB at 1m from the sound source. (65dB at 1m is an approximation of conversational speech[3]).
Execution
Once on has completed all of the set-up steps, execution of the code is straight-forward. One cd's into the vaani.microphone-check directory. Then one calls ./microphone-check as follows
kdaviss-MacBook-Pro:vaani.microphone-check kdavis$ ./microphone-check <n> <corpus>
where <n> is replaced with the number of Nascent Object devices and <corpus>with the corpus one wishes to test. (The various corpora are identified by their directory name under the resources/audio/ directory.
Upon completion, the recordings from the various devices will be placed in the results directory. For the n=3 case the results will appear as follows
results
├── <corpus>
├── no
│ ├── device-1
│ │ ├── add_anemone_nemorosas_to_my_list.wav
| | | ...
│ │ ├── add_anemone_tetonensis_to_my_list_please.wav
│ │ └── can_you_please_add_on_pilsners_to_my_list.wav
│ ├── device-2
│ │ ├── add_anemone_nemorosas_to_my_list.wav
│ │ ├── add_anemone_tetonensis_to_my_list_please.wav
| | | ...
│ │ └── can_you_please_add_on_pilsners_to_my_list.wav
│ └── device-3
│ ├── add_anemone_nemorosas_to_my_list.wav
│ ├── add_anemone_tetonensis_to_my_list_please.wav
| | ...
│ └── can_you_please_add_on_pilsners_to_my_list.wav
└── rpi
├── device-1
│ ├── add_anemone_nemorosas_to_my_list.wav
│ ├── add_anemone_tetonensis_to_my_list_please.wav
| | ...
│ └── can_you_please_add_on_pilsners_to_my_list.wav
├── device-2
│ ├── add_anemone_nemorosas_to_my_list.wav
│ ├── add_anemone_tetonensis_to_my_list_please.wav
| | ...
│ └── can_you_please_add_on_pilsners_to_my_list.wav
└── device-3
├── add_anemone_nemorosas_to_my_list.wav
├── add_anemone_tetonensis_to_my_list_please.wav
| ...
└── can_you_please_add_on_pilsners_to_my_list.wav
where <corpus> is the selected corpus, the rpi directory contains the Raspberry Pi results, and the no directory the Nascent Object results.
Evaluation
Evaluation is done through calculation of the WER on the result and resource sets. (The resource set is located in resource/audio/<corpus>/ and consists of the phrases used to drive the sound source.) Evaluation of the WER on the resource set provides a baseline WER from which the result WER's can be judged, as the resource set WER is not colored by microphones or distances.
Evaluation: Resource Set
To dertermine the WER for resource set, the repository contains a script calculate-wer-baseline that when executed as follows
kdaviss-MacBook-Pro:vaani.microphone-check kdavis$ ./calculate-wer-baseline
passes the resource set speech corpora through a STT engine and measures the WER of the resulting transcripts.
The WER result is then written to files of the form
resources/audio/<corpus>/RESULTS
which contain a single line of the form
WER: 0.1553679653679652
Evaluation: Result Set
To determine the WER for the various microphone/distance pairings of the result set, the repository contains a script calculate-wer that when executed as follows
kdaviss-MacBook-Pro:vaani.microphone-check kdavis$ ./calculate-wer --corpus corpus-1
passes the result set speech corpus-1 through a STT engine and measures the WER of the resulting transcripts.
The WER results are then written to files of the form
results/<corpus-1>/no/device-1/RESULTS
results/<corpus-1>/no/device-2/RESULTS
results/<corpus-1>/no/device-3/RESULTS
...
corresponding to the various microphone/distance pairings for corpus-1. Each such file contains a single line of the form
WER: 0.2053679653679652













