monocongo / climate_indices Goto Github PK
View Code? Open in Web Editor NEWClimate indices for drought monitoring
Home Page: https://monocongo.github.io/climate_indices/
License: Other
Climate indices for drought monitoring
Home Page: https://monocongo.github.io/climate_indices/
License: Other


![deepsource-autofix[bot] avatar](https://avatars.githubusercontent.com/in/57168?v=4 "deepsource-autofix[bot]")

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")


























































































































CodeFactor found an issue: Complex Method
It's currently on:
process_nclimdiv.py:59-233
Commit 211a632
Since there's nothing nClimGrid or nClimDiv specific to the processing codes we should make them more generic for the type of time series being processed: grid, division, or station. Most likely once we've written the station processor code (process_stations.py) then there'll likely be quite a bit of code that can reasonably be factored out to a parent class and/or a core processing module (perhaps in indices.py, maybe better so as to not introduce object-oriented features into the code which may make numba optimization more difficult). Once this is complete it will make it easier in the future to create additional time series type processors using the approach used in the new/refactored processor codes.
Resolution of this issue should be three new files:
process_divisions.py
process_grid.py
process_stations.py
...as well as an updated indices.py
Refactor the process_nclimdiv.py code to use object-oriented approach, using process_nclimgrid.py as an example. Eliminates globals other than a single shared file lock.
environment.yml is no longer used/included, update README to reflect current state of affairs
https://docs.readthedocs.io/en/latest/getting_started.html
http://ericholscher.com/blog/2016/mar/15/dont-use-markdown-for-technical-docs/
These indices were originally written for monthly inputs, update to facilitate usage of daily inputs.
Functions that may need attention:
compute.transform_fitted_gamma()
compute.transform_fitted_pearson()
indices.spi_gamma()
indices.spi_pearson()
indices.spei_gamma()
indices.spei_pearson()
indices.percentage_of_normal()
Code coverage information is not being generated and reported to Coveralls, as evidenced by the Coveralls page for the project continually reporting no data available. Suspected errors or incomplete configuration for coverage, (perhaps focus on .coveragerc file?), update to fix.
This is done/complete once we see some movement of the coverage percentage on the README's Coveralls badge, this is currently unaffected by settings that should be taking effect, such as pragma: no cover comments, etc. (stuck at 12%)
Investigate whether or not this code's logic follows closely what is described in the relevant literature (Palmer 1965, Wells 2004).
If so then look into how the code can be simplified and/or modularized further. Use vectorization where possible. Reduction of cyclomatic complexity encouraged where reasonable.
If not then address the divergence from accepted/established algorithm, remeasure, repeat.
CodeFactor found an issue: Complex Method
It's currently on:
palmer.py:989-1169
Commit fdd08e5
Create files and infrastructure necessary for Travis CI, including badge in README file.
CodeFactor found an issue: Using the global statement
It's currently on:
pdinew.py:649
I'm an associate editor with the Journal of Open Research Software and just wanted to reach out to ask if you'd considered publishing a software article so that you can get academic credit (i.e. citations) for all the hard work involved in releasing and maintaining your software?
Palmer-specific code was commented out at last commit of this code, replace so we can again compute PDSI etc. with this processing script.
Actual license is GPLv3.
Maybe a more liberal license (MIT, BSD,...) would be a better option to let people adopt the package.
Create develop branch in order to have a staging area for latest code that is under development. A to-be-determined practice can then be put into place for the promotion of code into the master branch, maybe with the master branch serving as the more or less static place where the latest released/tagged version resides?
The initial year of the dataset is used in some of the index calculations, and this value can be determined from the NetCDF but we're currently not doing this, using hard-coded value of 1895 instead.
For example in scripts/process/process_grid.py@master L#68
Integrate with static code analysis, code coverage, and CI services. Include badges on README file.
Travis CI
CodeFactor
Coverage/codecov.io/Coveralls
Investigate whether or not this code's logic follows closely what is described in the relevant literature (Palmer 1965, Wells 2004).
If so then look into how the code can be simplified and/or modularized further. Use vectorization where possible. Reduction of cyclomatic complexity encouraged where reasonable.
If not then address the divergence from accepted/established algorithm, remeasure, repeat.
CodeFactor found an issue: Complex Method
It's currently on:
palmer.py:1501-1634
Commit fdd08e5
Create a script (scripts/process/process_grid_spi.py) for use creating SPI indiecs datasets from input precipitation datasets. Initial usage will be for CMORPH SPI, taking NetCDF input as created from ingest_cmorph.
We already have a pip install working, do the same for Anaconda environments, so we can issue a command such as
$ conda install indices_python
Guidance on how this is done: http://conda-test.pydata.org/docs/build_tutorials/pkgs.html
The content of README.md and docs/index.rst is duplicated and difficult to keep in sync. We'll move most of the content into the index.rst file in order to then reduce the README to a summary and a link to the documentation on readthedocs.io, which is where the content in index.rst is made available in a nice format.
I think with the new changes in setup.py the following can be done:
# environment.yml contains the dependencies, for an environment named 'indices_python'
- conda env create -q -f environment.yml
- source activate indices_python
- python setup.py install
script:
# run all tests with coverage
- export NUMBA_DISABLE_JIT=1 # disable numba JIT
- coverage run --source=indices_python -m unittest tests/test_*.pyuse this:
- conda env create -n indices_python
- source activate indices_python
- pip install .
script:
# run all tests with coverage
- export NUMBA_DISABLE_JIT=1 # disable numba JIT
- coverage run --source=indices_python setup.py testI don't send a PR because maybe you will need some trial'n'error and maybe it is easier if you do direct commits to check if it is working.
Since these aren't available (yet?) on Windows we should do a conditional import and/or bypass of pynco in order to not break a run on Windows.
Compare results of new code against operational results from NCEI climate divisions with the following variables computed:
For each division:
Write the code in a fashion that makes it easy to refactor out a base class for reuse with code that will do this for grids, so we can do a similar comparison using WRCC/WWDT PRISM datasets.
The utils module is missing from the imports in process_grid.py.
Add indices used within NACEM
We need an SPI that can be computed on a daily basis, using a sliding X-days scale rather than the X-month(s) scale with a calendar month granularity that's currently in place for all the scaled indices (SPI, SPEI, PNP, etc.) Once this is complete for SPI it should be straightforward to flesh this out for the other scaled indices as well.
SPI processing results show missing values in locations where we expect data. See attached image result of recent CMORPH SPI processing (gamma with missing data vs. Pearson3)
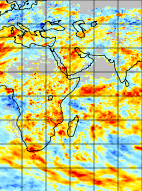
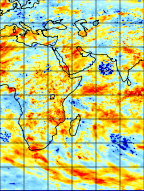
AppVeyor was included in the webhooks(?) for this project, and an attempt was made to remove this integration once it appeared to me that AppVeyor was primarily for .NET projects. It looks like the dis-integration is incomplete because we still see an AppVeyor error included in the checks on the project, causing a red X to appear next to the repo name. Further look at other AppVeyor Python projects shows that AppVeyor is also useful for Python so we should instead fully integrate in order to investigate whether or not AppVeyor is a good service to have tied to the project as it appears to be.
Extend unit tests from a base class that'll contain commonly used fixtures, primarily numpy arrays we should match when computing indices and intermediates in the unit tests. This will eliminate code duplication and allow for keeping fixture data in a single class.
It is not pretty clear which python versions are supported right now.
As it is a new package I think you should support most moder python versions, Python >= 3.5, but it should be clariffied somewhere (docs, readme, trove classifiers in setup.py,...)
I've added python 3.5 and 3.6 in #64 but it hould be ammended iy you have other plans.
Helpful, but it takes forever and provides limited value.
Per advice from UCAR/MetPy team, in order to facilitate wider use/adoption of the package.
Compare the results of the PDSI code against the dataset recently provided by Dai: https://catalog.data.gov/dataset/global-monthly-dai-palmer-drought-severity-index
A paper describes how the Tweedie distribution fitting can be used for drought monitoring using streamflow data: Statistical distributions for monthly aggregations of precipitation and streamflow in drought indicator applications; Svensson, Hannaford, and Prosdocimi, 2017
This is probably best tackled by creating a function in compute.py named transform_fitted_tweedie(), along the same lines as the existing transform_fitted_gamma() and transform_fitted_pearson() functions. Then these can be used to create spi_tweedie() in the indices.py module.
Credit to Curtis Riganti for highlighting the utility of this additional fitting. Thanks!
Dr. Dai's PDSI dataset is here: https://rda.ucar.edu/datasets/ds299.0/
Ascertain his code if possible in order to look much closer at where numbers bifurcate.
You are using pycurl to perform file downloading. I think you could easily remove this dependency using urllib included in the stdlib so users don't have to install a third party dependency.
Even, you could remove the retrieve_file function from the utils module as you could use directly the following:
Now you have:
from indices_python.utils import retrieve_file
retrieve_file(url, local_file)You could remove retrieve_file function and pycurl dependency and do the same using:
from urllib import request
request.urlretrieve(url, local_file)So less dependencies, less code, less tests using a battle tested stdlib functionality. WIN-WIN.
This is probably nice to have, and perhaps relevant to the issue of scaling/packing data (to be addressed in another issue).
Create ufuncs using numba's vectorize decorator where possible.
Travis CI builds current take 4 minutes or so, and this can perhaps be reduced significantly by adopting new build practices such as dependency caching.
Look into why shell-True is being used, hopefully not required and can be removed
CodeFactor found an issue: subprocess call with shell=True identified, security issue.
It's currently on:
process_nclimgrid.py:666
Change name in order to more uniquely/accurately reflect the nature of the project. Suggestions are very welcome!
Remove and/or replace references to a 'develop' branch since this approach is not currently being used.
The repository is a little bit messy right now.
Folders like misc, notebooks, example_inputs or scripts should be rethinked.
Do you want to provide examples of library usage? Try to organize misc, notebooks, example_inputs or scripts all in notebooks in the notebooks folder.
Do you have other plans for these folders? Just try to clarify about it and separate what is the library itself from what is documentation/examples, tests, ci,...
Test files are currently using a somewhat convoluted mechanism to provide what is essentially absolute imports, and it smells like a bad hack.
Eliminate the need for context.py in tests/test_*.py files.
Low hanging fruit:
compute._error_function()
compute._pearson3cdf()
compute._pearson_fit_ufunc()
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.