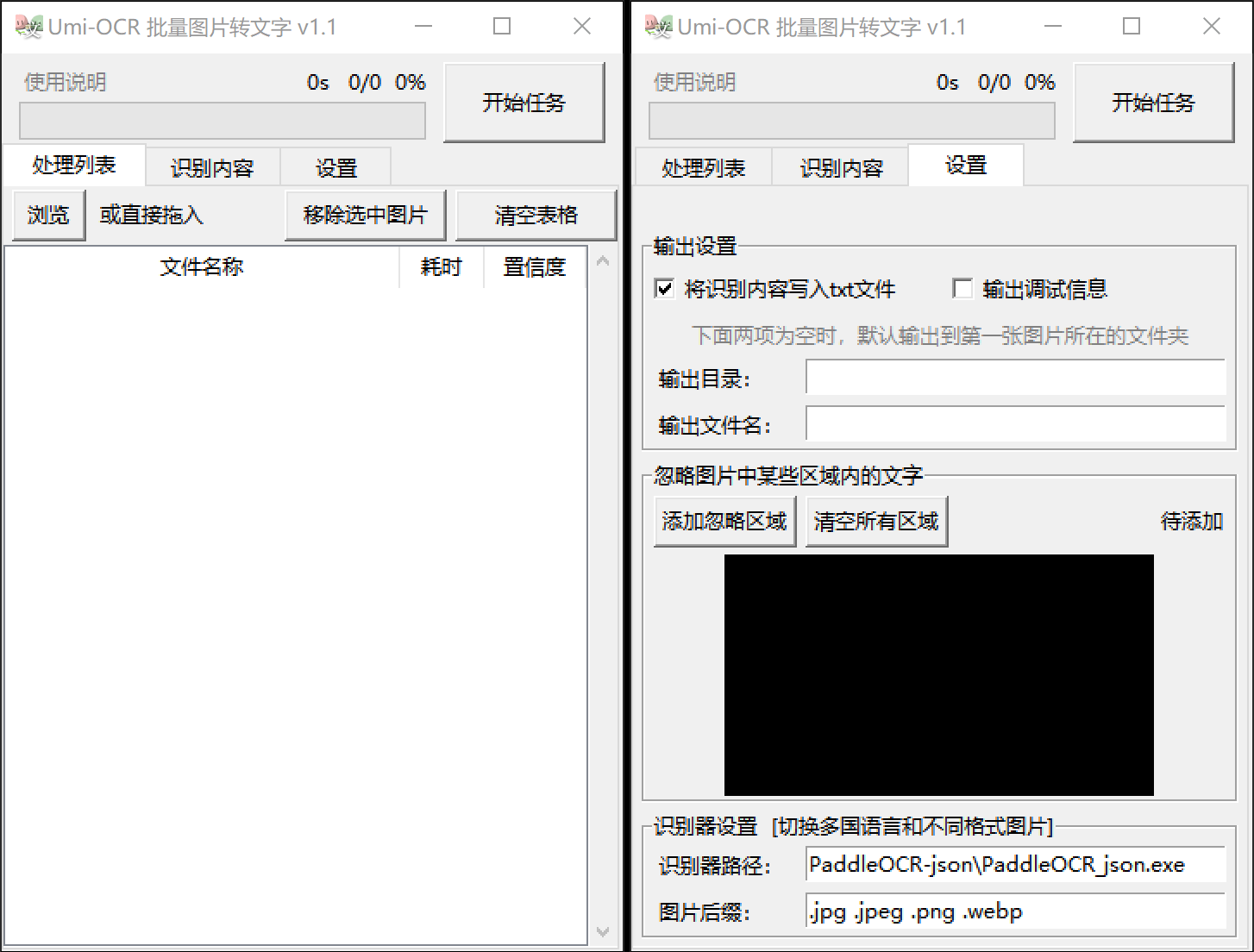
软件用途:批量对本地图片文件进行离线OCR文字识别。win10 x64平台。
本软件是本地图片文件处理工具,没有实时屏幕截图识别的功能。
v1.2版本新功能:支持生成Markdown文件
Github下载: Umi-OCR 批量图片转文字 v1.2.2
蓝奏云下载: https://wwn.lanzoul.com/b036wwa4d 密码:5w36
- 支持 win10 x64 。
- 不建议使用 win7 ,核心c++模块
PaddleOCR-json基本无法运行。如果想尝试,win7 x64 sp1 打满系统升级补丁+安装vc运行库后有小概率能跑起来……
Umi-OCR 批量图片转文字软件 ◁
Umi-CUT 批量图片去黑边/裁剪/压缩软件 (支持Win7)
本软件用于批量导入本地图片,识别图片中的文本,输出到软件面板或本地txt文件。 除了能批量识别普通图片,本软件还有忽略指定区域的特殊功能。
类似含水印的视频截图、含有UI/按钮的游戏截图等,往往只需要提取字幕区域的文本,而避免提取到水印和UI文本。本软件可设置忽略某些区域内的文字,来实现这一目的。尤其是,特别适合用于批量提取Galgame截图中的台词。
当有大量的影视和游戏截图需要整理归档,或者想翻找包含某一段台词/字幕的截图;将这些图片提取出文字、然后Ctrl+F是一个很有效的方法。这是开发本软件的初衷。
本软件使用离线OCR模块 PaddleOCR-json 图片转文字程序 ,使用过程中无需联网。支持更换Paddle官方模型(v2.x版本)或自己训练的模型,支持修改PaddleOCR参数。通过添加不同的语言模型,软件可识别多国语言。
下载压缩包并解压全部文件即可,无需安装。
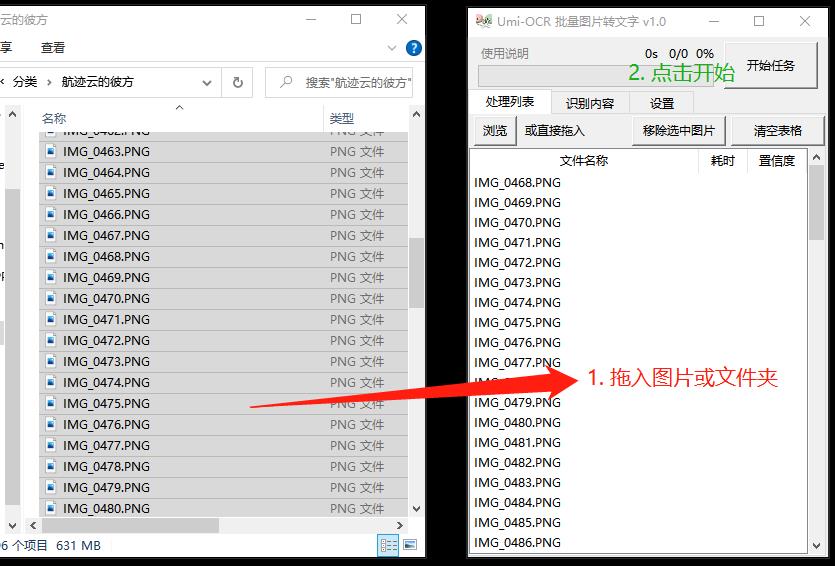
- 打开主程序,将任意 图片/文件夹 拖入窗口中的白色背景表格区域,或点击左上方的 浏览 选择图片。
- 若拖入文件夹,则加载文件夹下所有 符合后缀(见后) 的图片文件。
- 点击右上方 开始任务 ,等待进度条走完。
- 任务进行中,可随时点击 终止任务(原开始任务按钮)来停止,但下次开始时依然会从头开始。
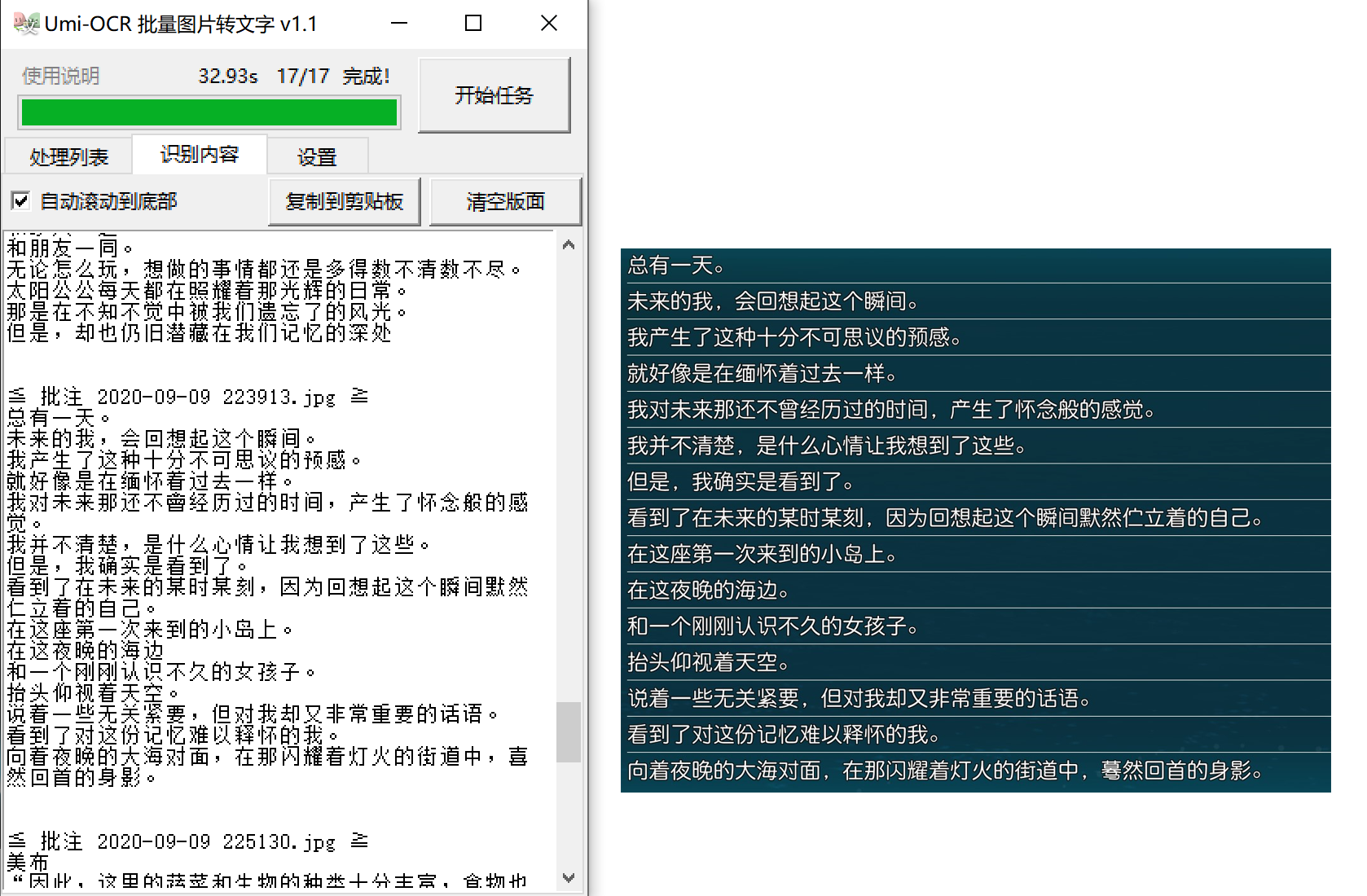
- 点击 识别内容 选项卡查看输出文字,或者前往 第一张图片的目录 查看识别结果txt文件。
- 识别内容选项卡中,可一键将全部文本 复制到剪贴板 。
点击 设置 选项卡,配置参数。大部分设置项(除去输出目录、文件名,忽略区域参数)会自动保存,下次打开还是这个样。
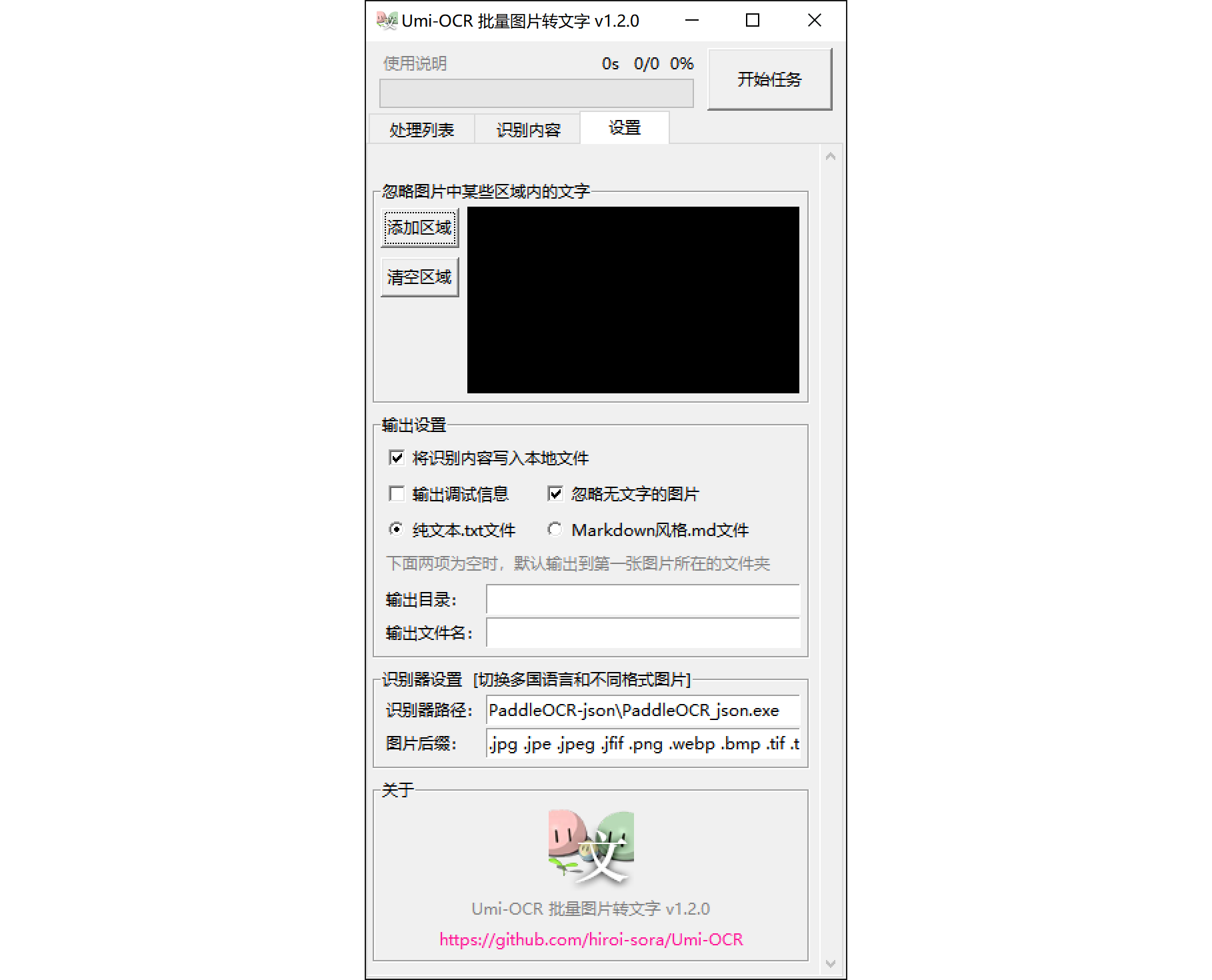
- 点击 添加区域 展开配置忽略区的新窗口。具体配置方式见后。
- 点击 清空区域 清空已配置的所有忽略区域参数。
- 已添加区域后,上方标题文字提示当前忽略区域的 生效分辨率 。
- 将 识别内容写入本地文件 取消勾选后,不会再生成本地文件,只能在 识别内容 选项卡中查看输出信息。
- 输出调试信息 若勾选,则会额外输出程序工作状态的内容。
- 忽略无文字的图片 若勾选,则不含文字(或文字全被忽略区域屏蔽掉)的图片名称不会出现在输出信息中。
- 若想生成一份用于浏览的markdown文件,则建议取消勾选。
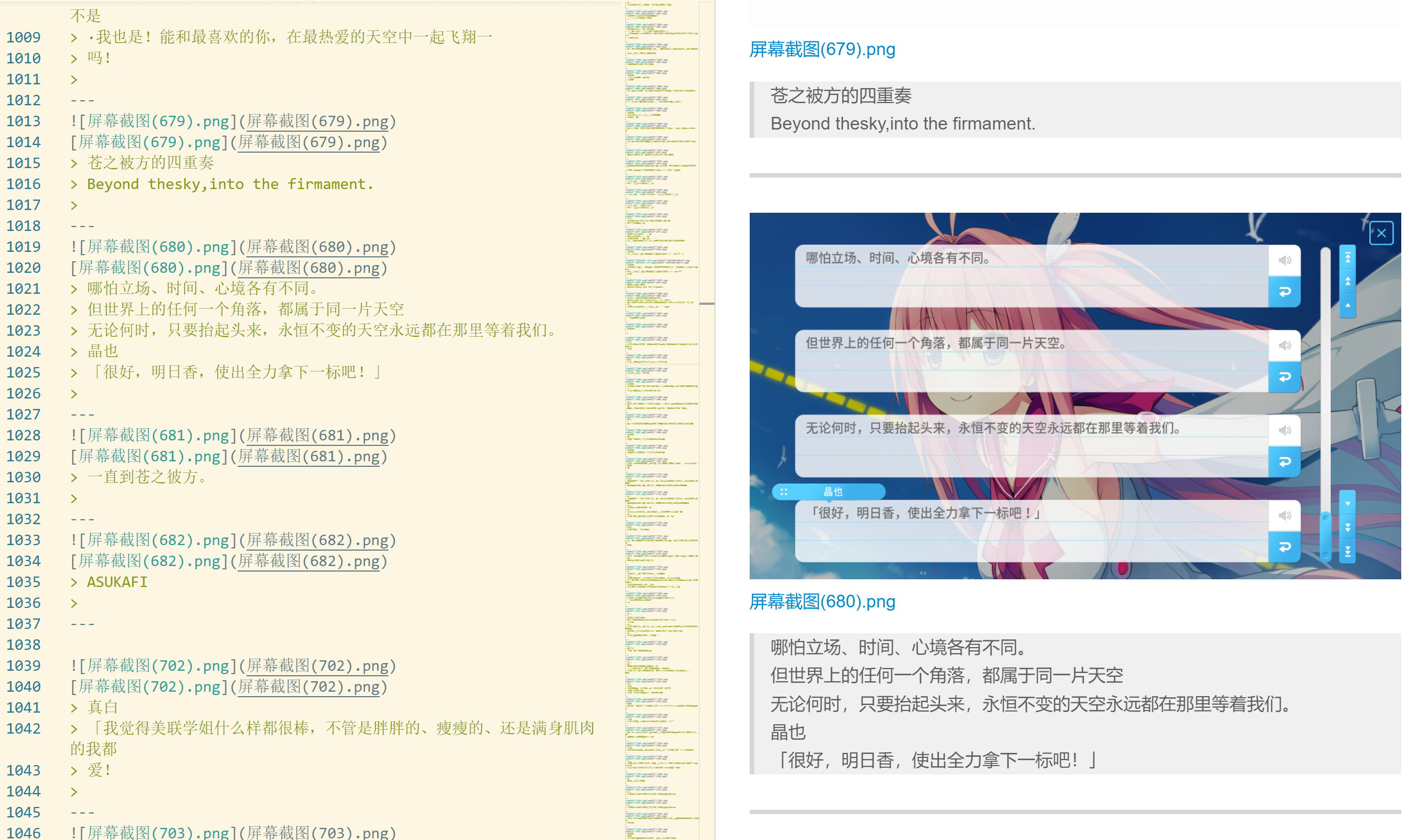
v1.2版本新功能生成文件可选择两种风格:纯文本.txt文件 和 Markdown风格.md文件 。前者可用于查找等一般用途。后者在编辑器或浏览器中渲染为图文并茂的页面,可用于浏览和欣赏图集。v1.2.2版本新功能可勾选任务完成后用系统默认编辑器打开输出文件或输出文件夹(不生成本地文件时无效)。- 输出目录 和 输出文件名 设置生成的文件的位置和名称。
- 当拖入第一张图片且这两项设置为空时,自动设置输出路径为第一张图片的父目录,输出文件名为
[转文字]_{父目录}.txt。除非要自定目录和名称,否则这两项默认留空即可。
- 当拖入第一张图片且这两项设置为空时,自动设置输出路径为第一张图片的父目录,输出文件名为
- 软件 处理列表 标签页的 清空表格 按钮,除了会清空已导入的图片列表,还会清空 输出目录 和 输出文件名 设置。这样下次拖入新图片时,就能在新的位置存放输出文件。
- 识别器路径 配置当前使用的识别器exe程序。
- 图片后缀 配置软件允许载入的图片后缀,不同后缀以空格分隔,必须全为小写。
正常情况下无需改动。
- 如果你有必要添加新的图片后缀,要保证该图片同时满足c++模块的
PaddleOCR和python的PIL均可识别。比如 .gif 图片,虽然PIL可以识别,但PaddleOCR无法识别,载入gif文件会导致软件任务失败,因此不允许载入 .gif 。 - 不在许可后缀范围内的文件,拖入软件也不会被载入。目前默认的图片后缀为:
.jpg .jpe .jpeg .jfif .png .webp .bmp .tif .tiff
忽略区域是本软件特色功能。可用于批量识别视频截图时排除右上角水印的干扰,批量识别游戏截图时排除UI与按钮的干扰,让识别结果只留下干净的台词文本。
“忽略区域”是指图片上指定位置与大小的矩形区域,完全处于这些区域内的文字块,将被排除。
- 点击 设置 选项卡中的 添加忽略区域 ,进入忽略区域选择窗口。
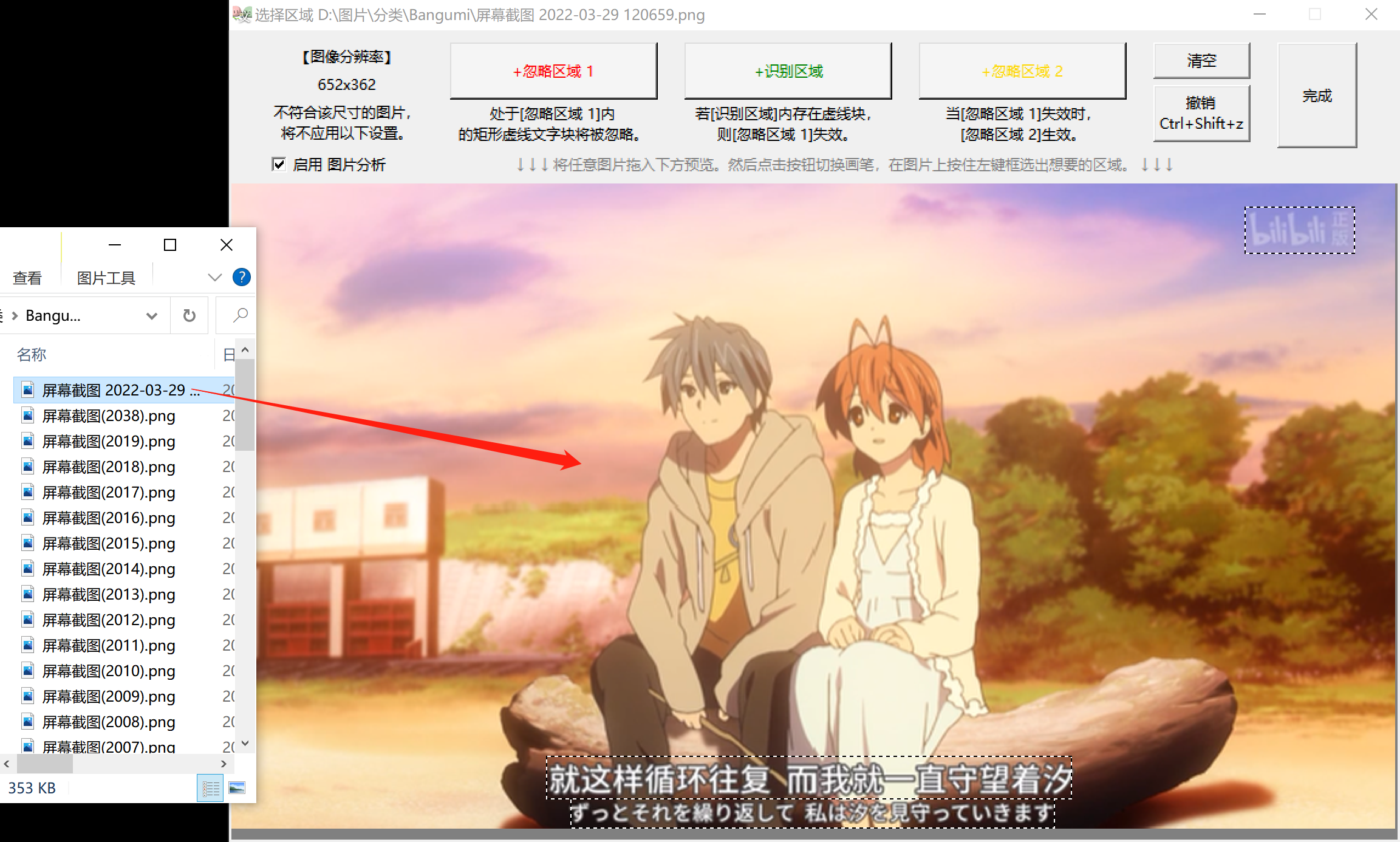
- 将任意图片 拖入 该窗口,可预览该图片。将新图片拖入窗口可切换预览,但已绘制的忽略区域不会消失;可切换不同图片来仔细调整忽略区域。
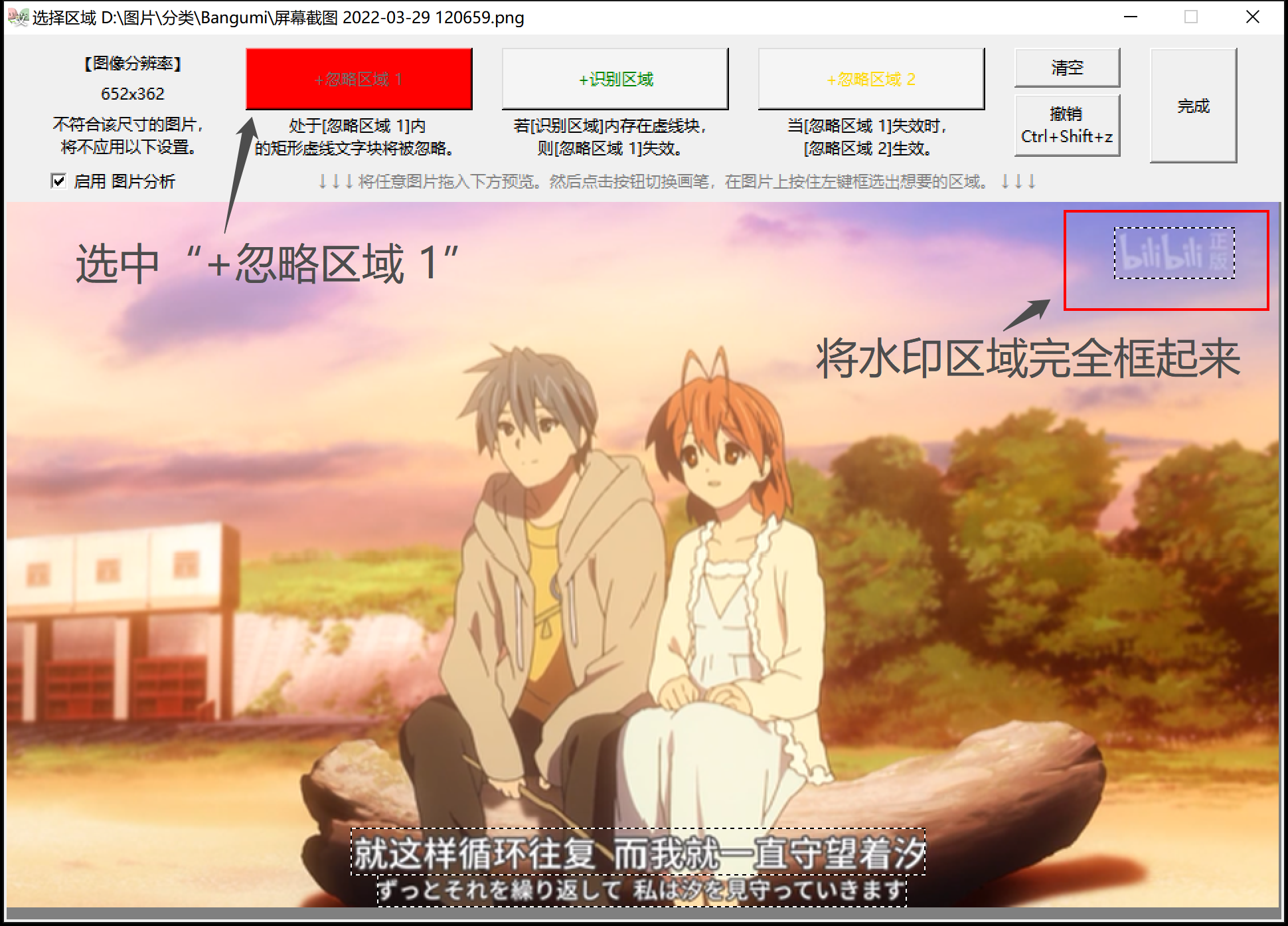
- 绘制 忽略区域 :拖入图片后,点击选中左起第一按钮 +忽略区域 1 ,然后在图片上按住左键拖拽,绘制矩形区域。可 撤销 步骤。
- 绘制完后,点击 完成 返回软件主窗口。若不想应用此次绘制,则右上角X,取消。
简单案例见下。
- 打开忽略区域设置窗口,拖入任一张截图。
稍等约1秒,面板上会显示出图片,识别到的文字区域会被虚线框起来。发现右上角的水印也被识别到了。
- 点击选择 +忽略区域 1 ,鼠标按住,绘制矩形完全包裹住水印区域,范围可以大一些。
- 点击 完成 。返回主窗口, 开始任务 。
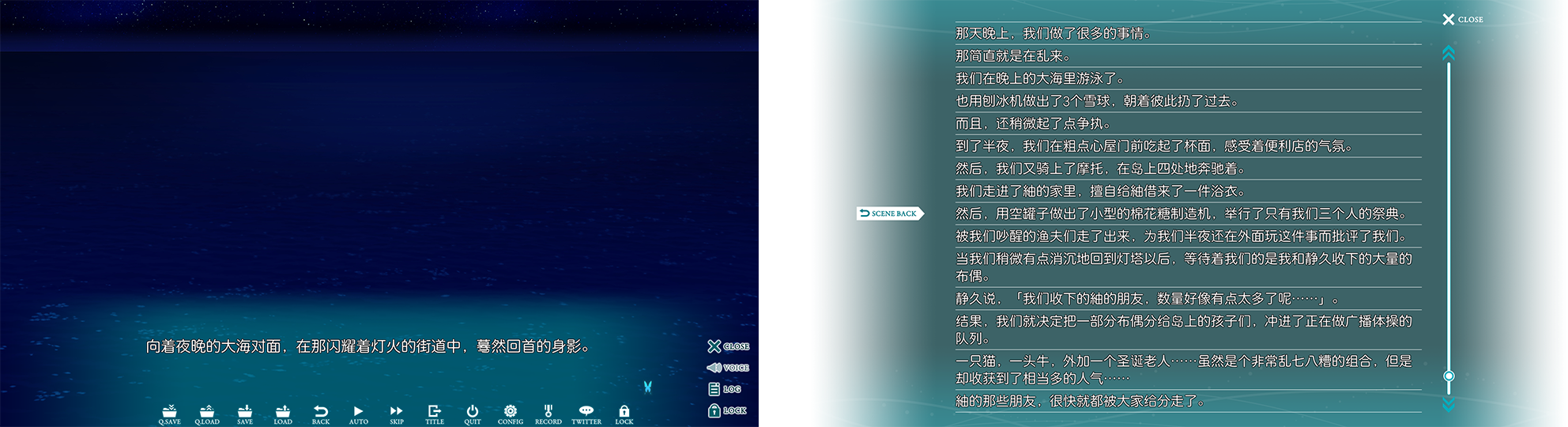
- 假设有一组游戏截图,主要分为两类图片,这两类图片的文字位置和UI位置不太相同:
- A类(上图左)为对话模式,字数少,要保留的台词文本在画面下方,要排除的UI分布于底端。
- B类(上图右)为历史文本模式,字数多,从上到下都有要保留的文本(与A类UI位置有重合),要排除的UI分布在两侧。
- 拖入一张A类图片。选择 +忽略区域 1 ,绘制矩形包裹住要排除的 底端UI 。
- 拖入一张B类图片。选择 +识别区域 ,绘制矩形包裹住 小部分要保留的文本 。注意只要该区域内含有任意保留文本即可,不需要画得很大,不需要包裹住所有保留文本;不能与A类图中 可能存在的任何文本 重合。
- 然后选择 +忽略区域 2 ,绘制矩形包裹住B类图要排除的 两侧UI 。
- 点击 完成 。返回主窗口, 开始任务 。
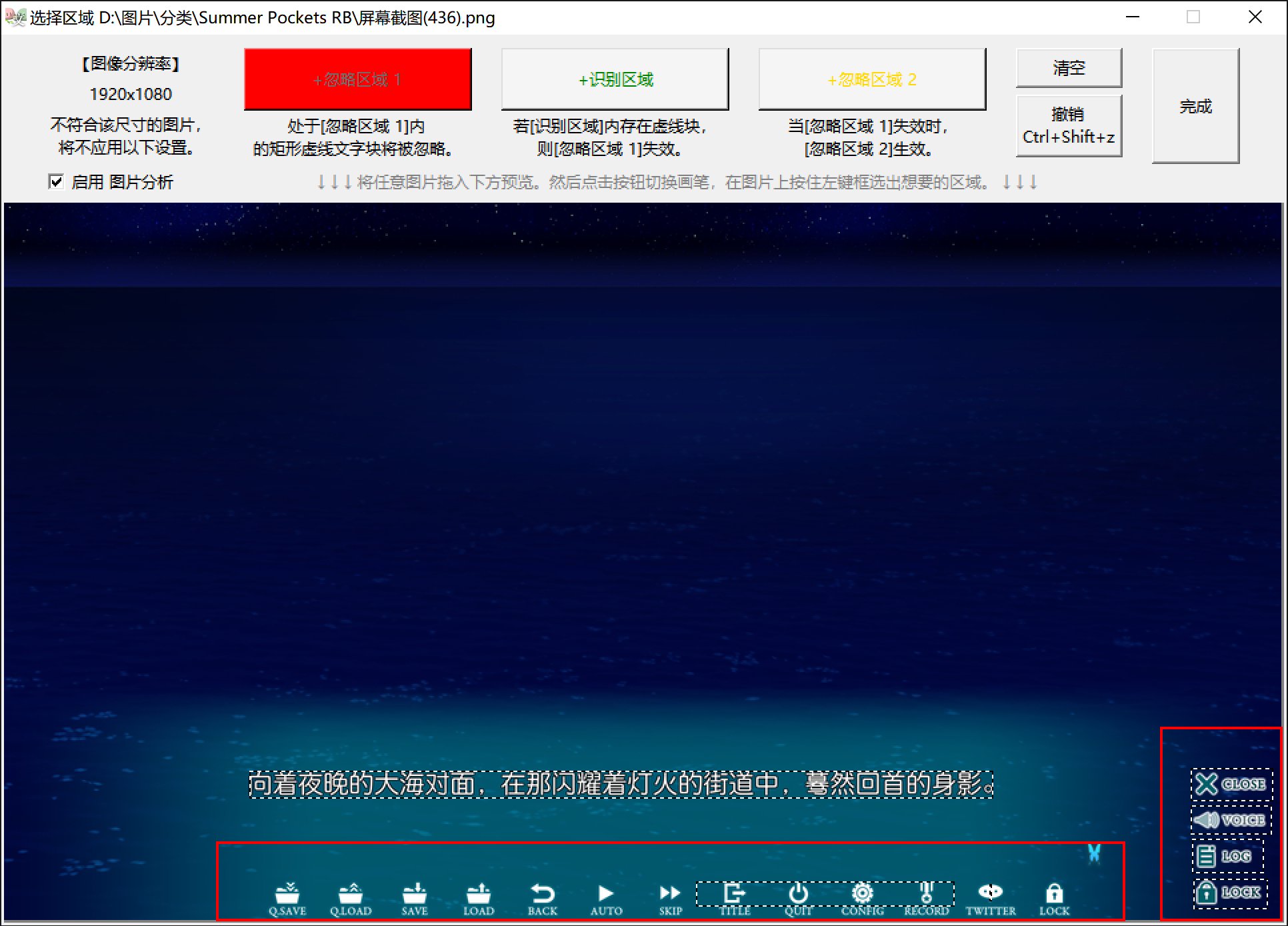
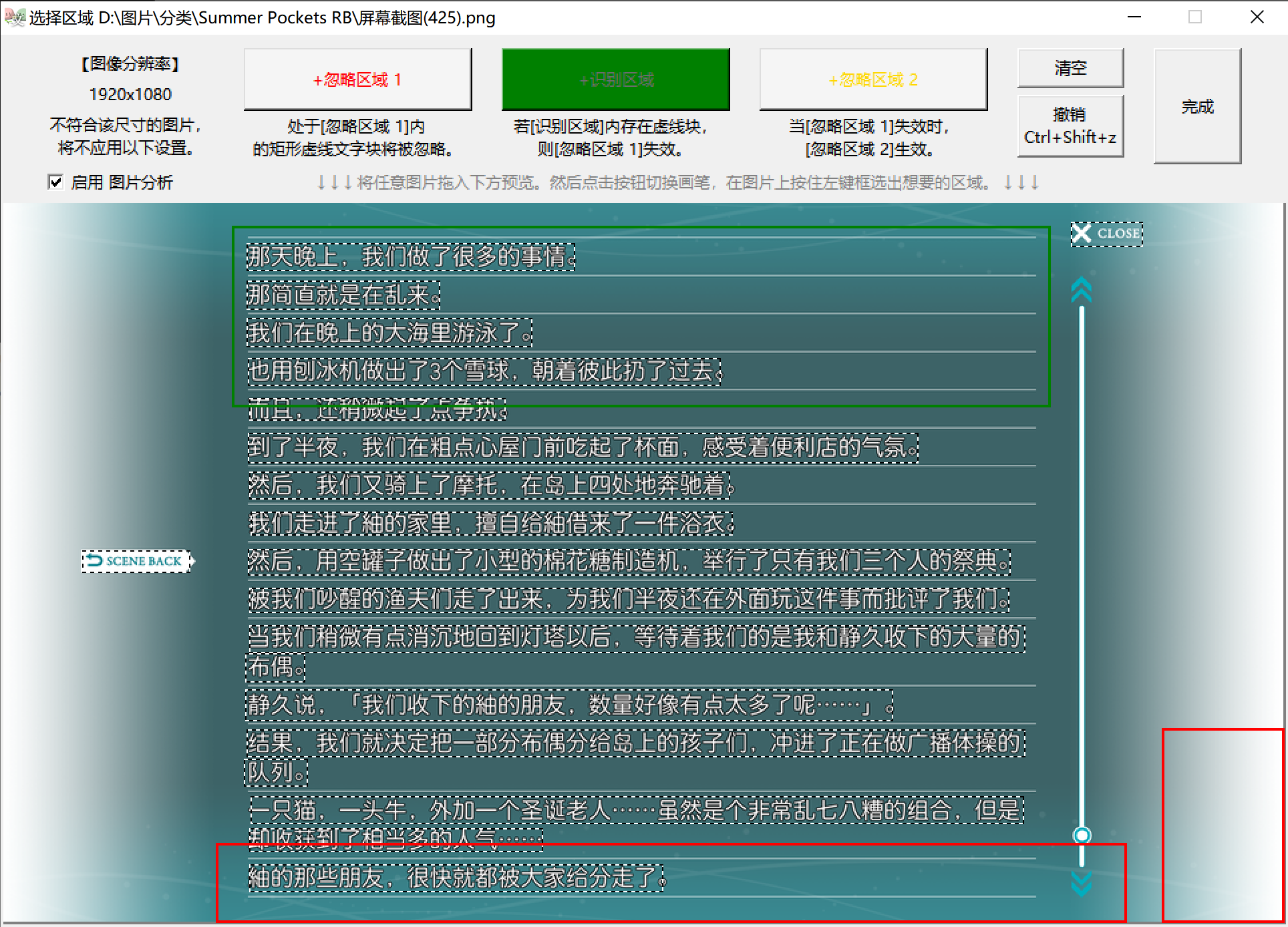
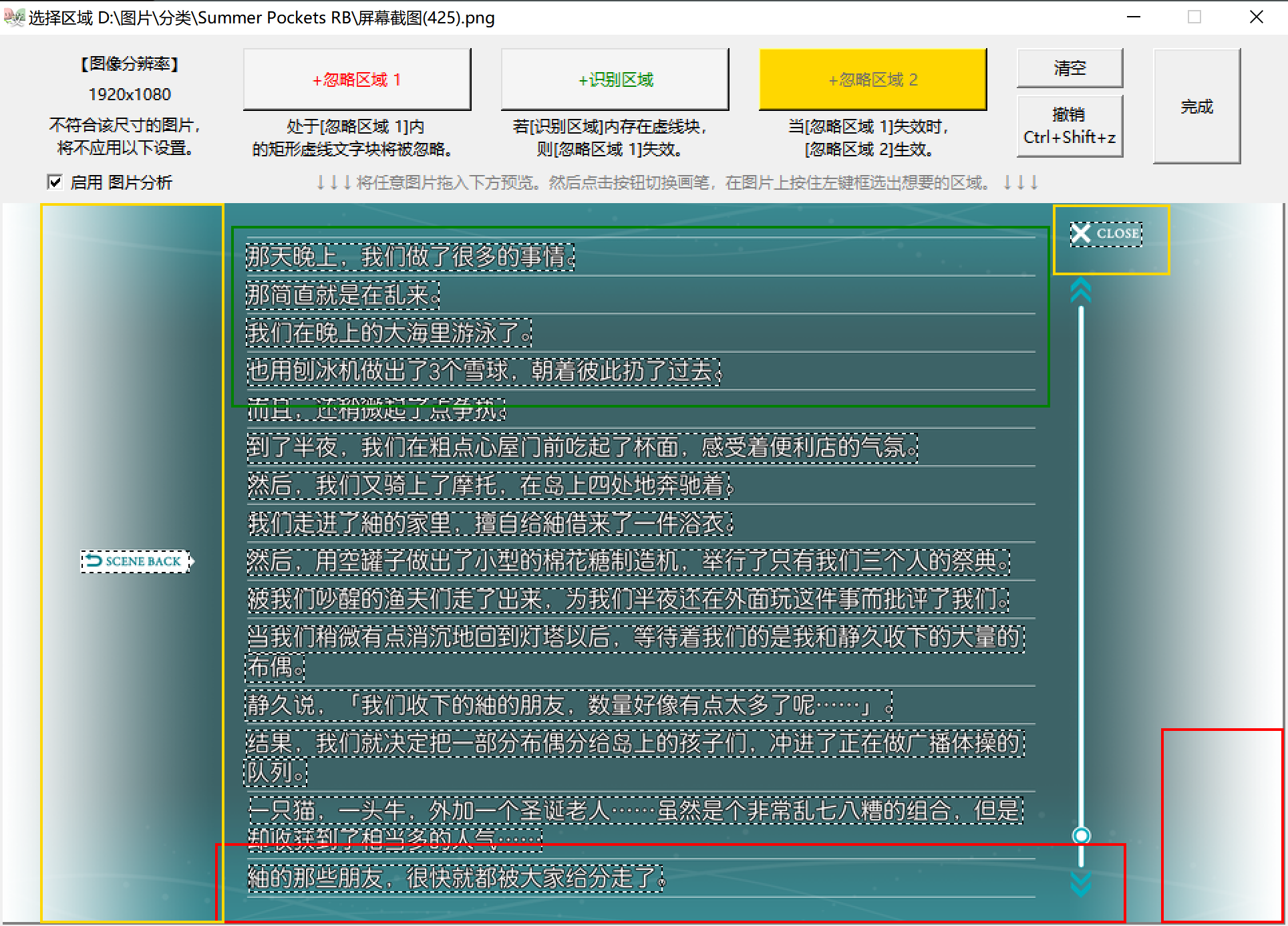
-
忽略区域1 :正常情况下,处于 忽略区域1 内的文字 不会 输出。
-
识别区域 :当识别区域内存在文本时,忽略区域1失效 ;即处于忽略区域1内的文字也 会 被输出。
-
忽略区域2 :当 忽略区域1失效 时,忽略区域2才生效;即处于区域1内的文字 会 输出、区域2内的文字 不会 输出。
识别区域 忽略区域1 忽略区域2 × 不存在文字 √ 生效 × 失效 √ 存在文字 × 失效 √ 生效 -
“忽略区域配置”只针对一种分辨率生效。假如配置的分辨率是1920x1080,那么批量识别图片时,只有符合1920x1080的图片才会排除干扰文本。
-
拖入预览的图片必须分辨率相同。假如先拖入1920x1080的图片,再拖入其它分辨率的图片;软件会弹窗警告。只有点击 清空 删除当前已配置的忽略区域,才能拖入其他分辨率图片,并应用此分辨率。
软件自带日文识别库,将 识别器路径 修改为 PaddleOCR-json\PaddleOCR_json_jp.exe 即可。
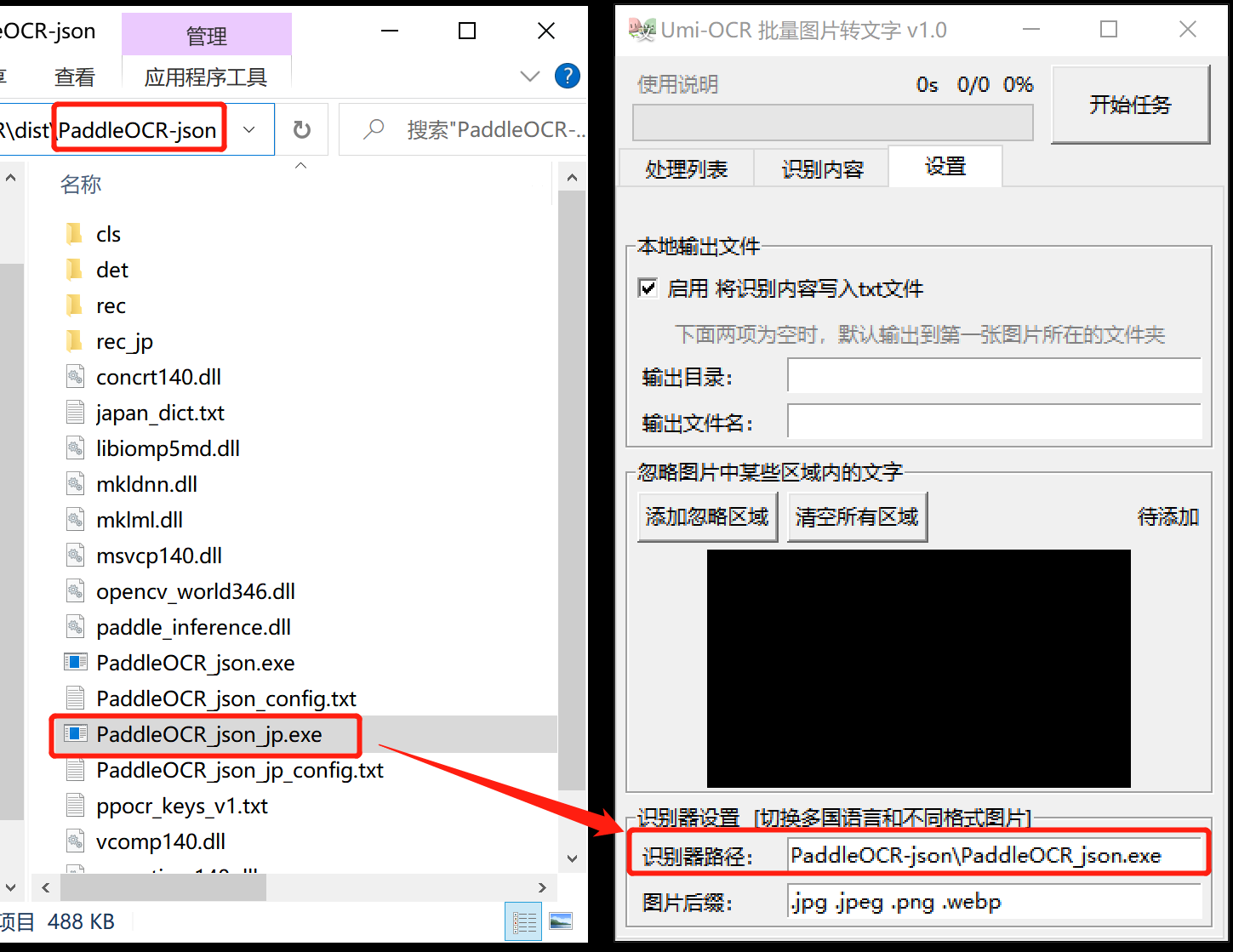
建议对Paddle比较熟悉或爱折腾的朋友阅读,普通用户请跳过此条
以法文为例:
- 前往 PP-OCR系列 多语言识别模型列表 下载对应的 推理模型
french_mobile_v2.0_rec_infer.tar和 字典文件french_dict.txt。 - 在
PaddleOCR-json目录下创建文件夹rec_fr,将解压后的三个模型文件放进去。字典文件可直接放在目录下。 - 复制一份识别器
PaddleOCR_json.exe,命名为PaddleOCR_json_fr.exe - 复制一份配置单
PaddleOCR_json_config.txt,命名为PaddleOCR_json_fr_config.txt - 打开配置单
PaddleOCR_json_fr_config.txt,将# rec config相关的两个配置项改为:# rec config rec_model_dir rec_fr char_list_file french_dict.txt - 保存文件,打开软件,将 识别器路径 改为
PaddleOCR-json\PaddleOCR_json_fr.exe。
软件附带的模型可能过时,可以重新下载PaddleOCR的最新官方模型,享受更精准的识别质量。或者使用自己训练的模型。
- 下载模型
- 前往PaddleOCR下载一组推理模型(非训练模型)。中英文超轻量PP-OCRv2模型 体积小、速度快,中英文通用PP-OCR server模型 体积大、精度高。一般来说,轻量模型的精度已经非常不错,无需使用标准模型。
- 注意只能使用v2.x版模型,不能使用v1.1版。v1版模型每个压缩包内有model和params两个文件,v2版则是每组三个文件;不能混用。
- 放置模型
- 将下载下来的方向分类器(如
ch_ppocr_mobile_v2.0_cls_infer.tar)、检测模型(如ch_PP-OCRv2_det_infer.tar)、识别模型(如ch_PP-OCRv2_rec_infer.tar)解压,将文件分别放到对应文件夹cls、det、rec。 - 打开PaddleOcr_json.exe。若无报错,则模型文件已正确加载。“Active code page: 65001”是正常现象。
- 调整配置
[exe名称]_config.txt是全局配置文件,可设置模型位置、识别参数等。调整它也许能获得更高的识别精度和效率。具体参考官方文档。- 如果修改了exe名称,也需要同步修改配置文件名的前缀。
用它跑完了我珍藏的7000多张各类截图文件,效果十分满意。
跟半年前使用百度云在线OCR接口(标准文字识别)跑的对比:
- Umi-OCR使用轻量模型时速度很快,平均识别耗时<1s(使用笔记本低压u)。在线OCR受限于网络,耗时>1s。
- Umi-OCR对符号的正确识别率更高,比如能正确识别中文逗号。在线OCR的结果中,很大一部分中文逗号被识别为英文。
- 对于文字内容,Umi-OCR与在线OCR的准确度几乎没有差异。都能满足所需。
- 排除UI与水印干扰,是Umi-OCR的独有技能。理论上在线OCR的高精度识别接口也能做到,
不过那玩意死贵死贵。
- 本软件工作流程是python调用c++编译的识别器exe程序,识别器exe再加载模型文件和必要的dll链接库,完成图片识别工作。因此可切换不同exe识别器和模型文件,实现切换多国语言的识别。而且,c++识别器比python版PaddleOCR具有更高的性能。
- 启动任务时,运行tk的主线程创建了一个新线程和一个事件循环。耗时量大的OCR任务在新线程中执行,对tk界面的修改由事件循环提交到主线程中执行。
大概是这么回事?反正能跑起来就对了。无论任务跑得多满,界面都不会卡,除非实在顶不住。 PaddleOCR_json.exe接收输入一个本地图片路径,以json格式字符串输出这张图片的识别结果,如此循环往复。具体见 PaddleOCR-json 图片转文字程序- 使用
pyinstaller打包,参数为pyinstaller -F -w -i icon/icon.ico -n "Umi-OCR 批量图片转文字" main.py
- 输出内容可选为markdown风格并嵌入图片路径。
- 设置项能保存。
- 自动打开输出文件or文件夹。
- 对图片重命名。
低(有)优(生)先(之)级(年):
- 忽略区域能保存预设。
- 缩减离线OCR模块的体积。
- 添加新功能:可选任务完成后自动打开输出文件或目录。
- 更新PaddleOCR-json模块至
v1.1.1,修正了可能得到错误包围盒的漏洞。
- 可选生成Markdown风格的图文并茂的.md文件,作为索引使用有更佳的观感。当然也可以继续选择生成纯文本.txt文件。
- 修改设置面板的样式,改为滚动面板以容纳更多设置选项。
- 用户修改配置项后可自动保存。
- 修正了漏洞:退出 [忽略区域窗口] 时,OCR子进程未关闭。
- 添加新功能:[忽略区域窗口] 以虚线框 展示识别出的文字块。
- “梦开始的地方”
