![]()
This is an R package for analyzing and visualizing data from Microsoft Workplace Analytics. For analyzing data from Microsoft Viva Insights, please see our other package vivainsights.
-
Run prebuilt analysis and visualizations off advanced insights data with settings for HR variables, privacy threshold, etc.
-
Generate prebuilt interactive HTML reports, which cover specific areas e.g. collaboration, connectivity
-
Leverage advanced analytics functions, such as text mining and hierarchical clustering, which are built for Workplace Analytics metrics
-
Integrate analysis of Leader Insights data with your R workflow seamlessly
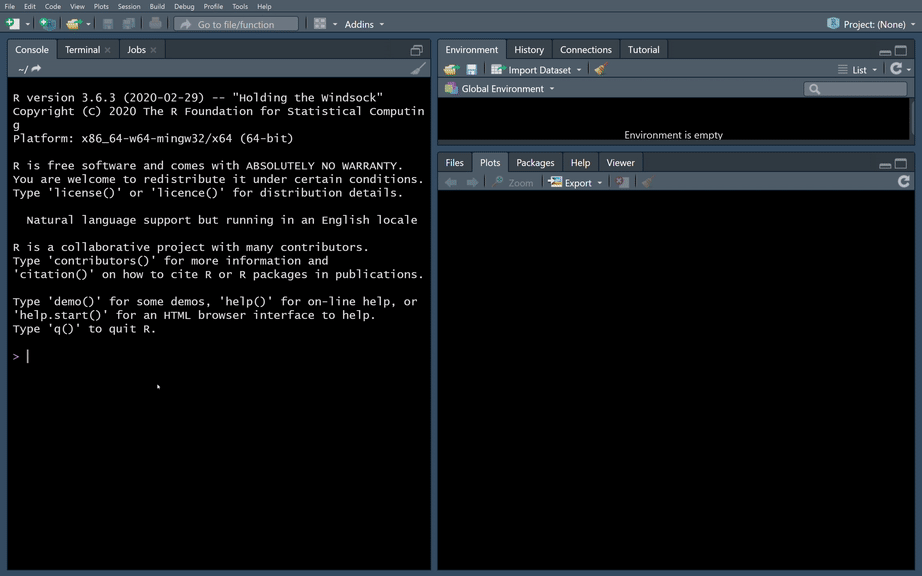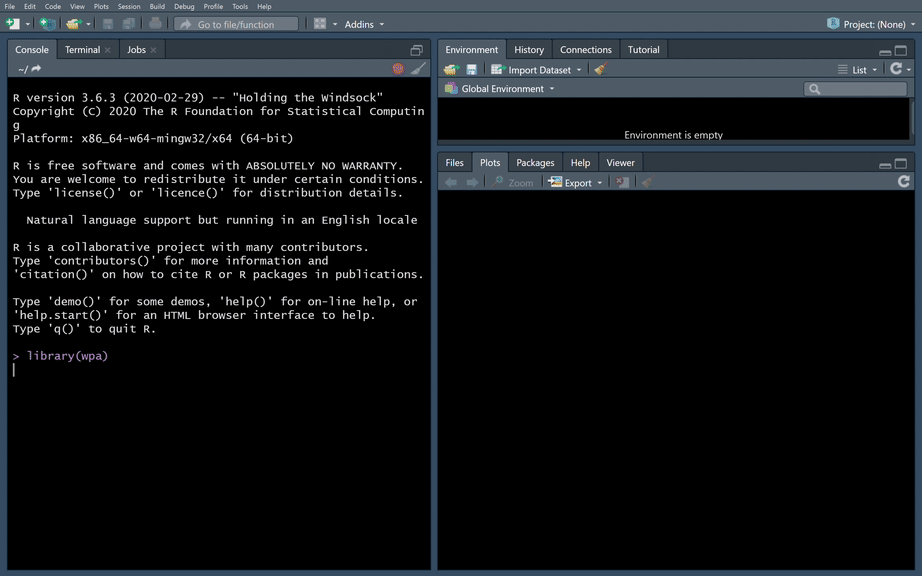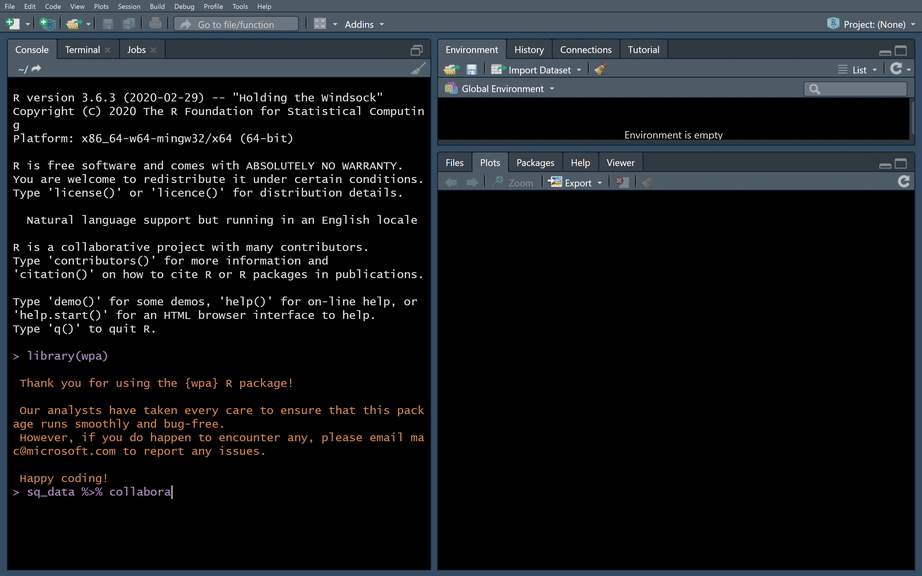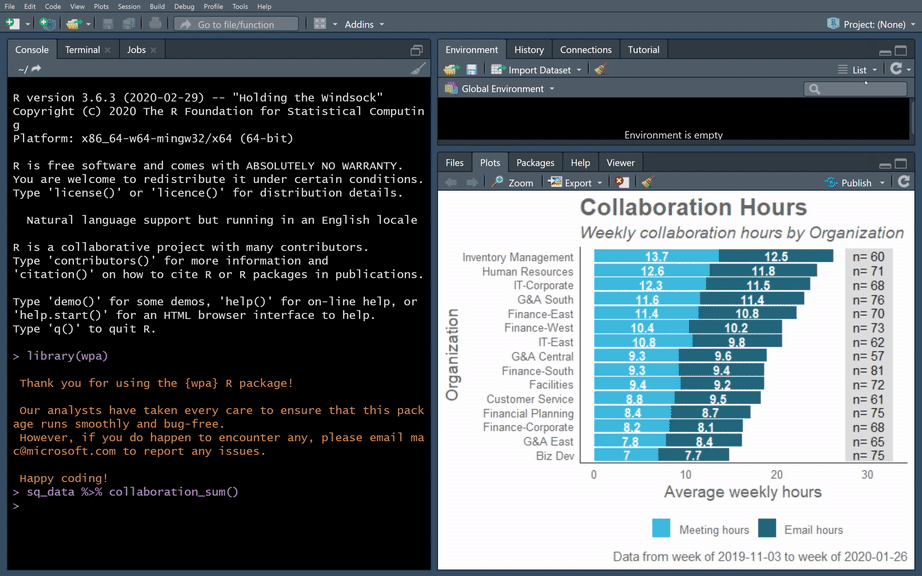
Here is an example of wpa in action:
To get started with the package, please see the following links:
Also check out our package cheat sheet for a quick glimpse of what wpa offers:

We welcome contributions to the package!
If you would like contribute code to the repo, please read our Contributor Guide and Developer Guide. This documentation should provide you all the information you will need to get started.
If you would like to log an issue or submit a feature request, please create a new issue or comment on an existing issue on GitHub Issues on this repo.
Please do not report security vulnerabilities through public GitHub issues. Please read our Security document for more details.
See NEWS.md for the package changelog.
- Viva Insights R library - new implementation
- Viva Insights Python library
- Viva RMarkdown Report Marketplace
- Viva Insights Sample Code
- Viva Insights Zoom Integration
- Viva Insights OData Query Download
We would ask you to please read the Microsoft Open Source Code of Conduct prior to engaging with this package.
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
⭐ Please star this repository to keep us going!
Contributors to the GitHub repo:

See the full list of our contributors here.


![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")



![microsoft-github-policy-service[bot] avatar](https://avatars.githubusercontent.com/in/95686?v=4 "microsoft-github-policy-service[bot]")














































