me-ica / mapca Goto Github PK
View Code? Open in Web Editor NEWA Python implementation of the moving average principal components analysis methods from GIFT
License: GNU General Public License v2.0
A Python implementation of the moving average principal components analysis methods from GIFT
License: GNU General Public License v2.0











Originally, we wanted to have the function operate on images and the class operate on arrays, in case we could get rid of the spatial elements of the algorithm (see #5). Since that's not possible anymore, the way we pass around a 3D shape tuple and a 1D mask vector is more than a little awkward. We can just move the image-related code from the function to the class and pass in a data image and a mask image to clean up the interface.
If the subsampling function operates on images, it will be easier to use nilearn's functions for masking/unmasking the data. See #32.
How do you all feel about using nilearn.image.resample_img() for utils.subsampling()? I am working on #29, and I think it would be easier have a function that downsamples and returns images instead of arrays.
As of today, tests fail due to the following error:
Package make is not available, but is referred to by another package.
This may mean that the package is missing, has been obsoleted, or
is only available from another source
E: Package 'make' has no installation candidate
Exited with code exit status 100
As discussed in tedana #636, the maPCA in tedana currently does not normalize data before performing PCA.
@tsalo already added the normalize option when he restructured the toolbox to be sklearn compatible. However, as I mentioned in the PR, I think we should add an if statement that checks the data is already z-scored and normalizes the data when it isn't. I'd remove the normalize option and do the normalization by default.
Currently we pass around shape_3d (a three-element tuple with the shape of the image) and mask_vec (a 1D array indicating whether a given voxel falls within the mask) throughout the MovingAveragePCA class, and I would love to support 2D data, if that's possible.
n_features_ from sklearn's PCA is deprecated and has to be updated to n_features_in_.
/export/home/mflores/.conda/envs/tedana/lib/python3.9/site-packages/sklearn/utils/deprecation.py:101: FutureWarning: Attribute `n_features_` was deprecated in version 1.2 and will be removed in 1.4. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)Working on #59 has made me realize we probably want to increase the minimum Python version we support if we want to stay compatible with new versions of scikit-learn.
I would also follow the installation changes we did in tedana and move everything to the project.toml file.
We'll want to deploy to PyPi to make it easier to use this package in tedana and other tools.
I believe we should add a documentation page that clearly explains what the algorithm does.
I think it would make it easier to understand for users of tedana especially, as we receive some questions about it in Neurostars (see this post for example).
It looks like utils._kurtn(arr) can be replaced with scipy.stats.kurtosis(arr, axis = 0, fisher = True).
Any cons with making this replacement?
Few other notes:
_kurtn converts an input with shape (2,3,4) into (3,1). I was expecting the output shape to be (3,4). Is this intentional?mapca/mapca/tests/test_utils.py
Lines 93 to 99 in 0d01a2b
_kurtn says that the kurtosis is calculated along the second dimension, but the code is calculating kurtosis along every dimension except the second dimension.Lines 317 to 329 in 0d01a2b
Tedana has dropped duecredit and uses bibtex instead now, but due to maPCA, tedana users still see a duecredit warning.
maPCA should do the same to avoid confusion among tedana users.
I have a dataset where the number of components with any criterion were sometimes way to high or low. This is an issue that has been reported by others. I've identified one reason this is happening.
The MAPCA algorithm depends on estimating the spatial dependence of voxels and then running a cost function on a sparse sampling of the voxels that are far enough apart to be independent & identically distributed (i.i.d.). That is, if neighboring voxels have dependence, then apply the cost function to every other voxel in 3D space (i.e. use 1/(2^3) of the total voxels).
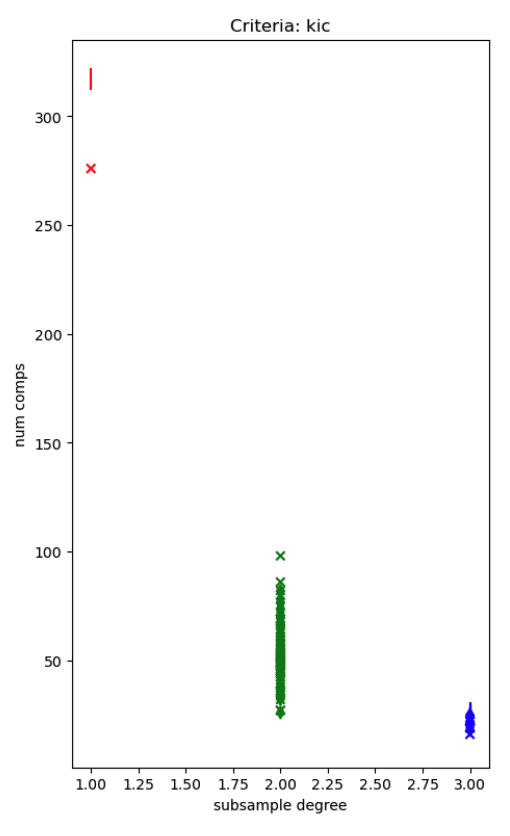
I made a branch of mapca which outputted a lot more logging including this subsampling factor: sub_iid_sp_median The attached figure shows this subsampling factor on the x axis and the estimated number of components on the y axis. The different markers are different run types, but all have 300-350 volumes. When the subsampling factor is 1 (i.e. use every voxel) the number of components estimation always fails by giving way too many components. When the subsampling factor is 3 (1/27 of the total voxels used for estimation) the number of components estimation fails by being way too low. I'm Given the very large range of estimated components when the subsampling factor is 2, I suspect there are other issues, but this discrete parameter should be constant for data collected within the same acquisition parameters and bad things happen when it's not.
I'm starting to think about options for completely different approaches for estimating the number of components, but I wanted to document this here. As an intermediate step, we might want to add a few more values, such as this subsamplign factor, into logging.
As a tangent, I realized mapca used a LGR but it wasn't writing out the log. In my above branch, I changed the LGR declaration to "general" and changed a few other things. MAPCA still didn't output it's own log, but then the LGR output from mapca was included in the tedana log.
https://github.com/handwerkerd/mapca/blob/a03727b3346c0f92380b5a1699b7c001d43c6956/mapca/mapca.py#L31
We need to incorporate information for the appropriate license from GIFT.
@jbteves pointed out in ME-ICA/tedana#702 that there are some commented lines that we should probably remove. There's no problem with losing the original code, since the lines will remain in the history.
The title is quite self-explanatory: we have to cite the ma PCA paper, reference the GIFT package and add a link to their website.
I copied the relevant tests from tedana over but we'll need to set up CI with workflows for the unit tests, coverage, and linting.
While working on the integration test, I saw there is a little bug in the code that probably comes from losing the context we had in tedana.
Basically, we are not considering that the data has been masked when giving shape3d to fit_transform(). We're currently giving the original dimensions when it should be the masked ones.
Edit: The error comes from the fact that apply_mask from nilearn only keeps the values inside the mask, while mapca in tedana keeps everything.
I thought #11 would fix the Codecov issue but apparently, it didn't.
The CircleCI config looks good to me. I'll probably look into it tomorrow.
This stems from ME-ICA/tedana#849 and is related to #42. Basically, I think it would be awesome if we had some idea of how many components are "typical" for the different criteria, depending on a few factors, such as (1) number of volumes, (2) temporal resolution, and (3) spatial resolution. We could then plot and share those results in the MAPCA documentation, much like how the tedana documentation includes distributions of typical ME-EPI parameters in the literature.
@eurunuela in #26, it looks like you commented out code that generated a Scaler within the subsampling procedure, and instead reused the one for the general scaling:
Lines 174 to 177 in 6c1d58c
My concern is that re-fitting self.scaler_ based on new data will make it invalid for rescaling data back to the original scale, as here:
Lines 331 to 332 in 6c1d58c
Does that make sense, or was there a specific reason you got rid of the original approach? Apologies for not noticing this in #26 and bringing it up while that PR was open.
Stems from #29. Now that the class operates on images, we should try to work through the code and replace any manual masking/unmasking/reshaping with nilearn's functions.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.