Collect a lots of Spark information, solution, debugging etc. Feel Free to open a PR to contribute what you see or your experience on Apache Spark.
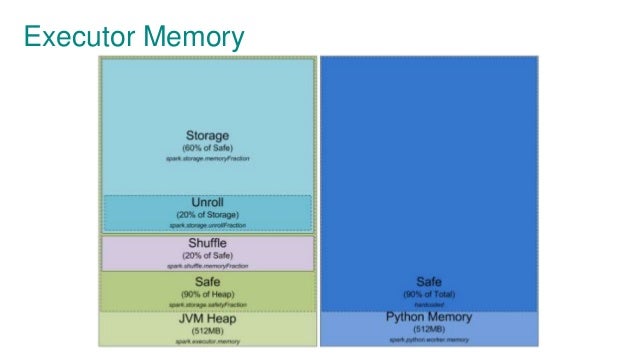
Spark executor memory(ref)
spark-submit --verbose(ref)
- Always add
--verboseoptions onspark-submitto print following information- All default properties
- Command line options
- Settings from spark conf file
Spark Executor on YARN(ref)
- Following is the memory relation config on YARN
- YARN container size -
yarn.nodemanager.resource.memory-mb - Memory Overhead -
spark.yarn.executor.memoryOverhead

- Tune the number of spark.sql.shuffle.partitions
Avoid using jets3t 1.9(ref)
- it's a jar default on hadoop 2.0
- Inexplicably terrible performance
- reduceByKey

- groupByKey

GC policy(ref)
- G1GC is a new feature you can Use
- Used by -XX:+UseG1GC
Join a large Table with a small table(ref)
- Default is ShuffledHashJoin, problem is all the data of big one will be shuffled
- Use BroadcasthashJoin
- it will broadcast the small one to all workers
- Set
spark.sql.autoBroadcastJoinThreshold
- If your task involve a large setup time, use
forEachPartitioninstead - For example: DB connection, Remote Call etc.
- Default Java Serialization is too slow
- Use Kyro
- conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
- It's about /tmp is full, check
spark.local.dirinspark-conf.default - How to fix? Mount more disk space
- spark.local.dir /data/disk1/tmp,/data/disk2/tmp,/data/disk3/tmp,/data/disk4/tmp
java.lang.OutOfMemoryError: GC overhead limit exceeded(ref)
- Too much GC time, you can check on Spark metrics
- How to fix?
- Increase executor heap size by
--executor-memory - Increase
spark.storage.memoryFraction - Change GC policy(ex: use G1GC)
- Increase executor heap size by
shutting down ActorSystem [sparkDriver] java.lang.OutOfMemoryError: Java heap space(ref)
- OOM on Spark driver
- Usually happened when you fetch a huge data to driver(client)
- Spark SQL and Streaming is a typical workload which need large heap on driver
- How to fix?
- Increase
--driver-memory
- Increase
java.lang.NoClassDefFoundError(ref)
- Compiled ok, but got error on run-time
- How to fix?
- Use
--jarsto upload and place on the classpath of your application - Use
--packagesto include comma-sparated list of Maven coordinates of JARs.
EX:--packages com.google.code.gson:gson:2.6.2
This example will add jar of gson to both executor and driver classpath
- Use
- Error message likes:
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 0.0 in stage 0.0 (TID 0) had a not serializable result: com.spark.demo.MyClass Serialization stack:
-object not serializable (class: com.spark.demo.MyClass, value: com.spark.demo.MyClass@6951e281)
-element of array (index: 0)
-array (class [Ljava.lang.Object;, size 6) - How to fix?
- Make
com.spark.demo.MyClassto implementjava.io.Serializable
- Make
- How to fix?
- Upload Spark-assembly.jar to hadoop
- Using
--conf spark.yarn.jarwhen spark-submit orconf.set("spark.yarn.jar","hdfs://hostname:port/spark-assembly-upload-at-1st.jar")in application
java.io.IOException: Resource spark-assembly.jar changed on src filesystem (ref)
- Spark-assembly.jar does exist.
- How to fix?
- Upload Spark-assembly.jar to hadoop
- Using
--conf spark.yarn.jarwhen spark-submit orconf.set("spark.yarn.jar","hdfs://hostname:port/spark-assembly-upload-at-1st.jar")in application


