Este repositório contém uma implementação do algoritmo de Árvore de Decisão do zero usando o algoritmo CART (Árvores de Classificação e Regressão). A árvore de decisão é um algoritmo poderoso amplamente utilizado para construir modelos capazes de lidar tanto com tarefas de classificação quanto de regressão. Essa implementação é escrita em Python e utiliza a biblioteca NumPy para cálculos numéricos eficientes. Além disso possui um suporte para uma visualização de árvores de decisão de modo interativo para fins educacionais.
O algoritmo de Árvore de Decisão constrói um modelo em forma de uma árvore de decisões. Ele particiona recursivamente os dados em subconjuntos com base nos valores das características selecionadas, criando nós de decisão. Em cada nó, o algoritmo identifica a característica que oferece a divisão ótima dos dados, e esse processo continua até que um critério de parada seja atendido. A árvore resultante pode então ser usada para fazer previsões em novos dados.
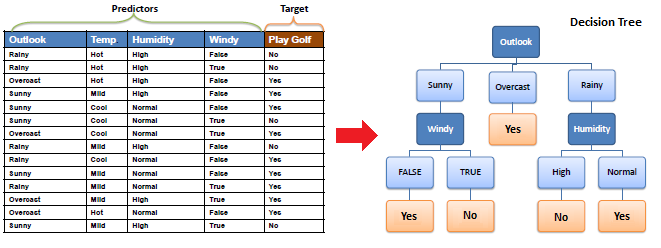
Aqui está uma ilustração do algoritmo de Árvore de Decisão:
O algoritmo CART é um algoritmo popular de árvore de decisão que pode lidar tanto com tarefas de classificação quanto de regressão. O algoritmo CART particiona os dados recursivamente, selecionando uma única característica e limite para dividir os dados com base na medida de impureza de Gini para classificação ou na soma dos erros quadrados para regressão. Esse processo de seleção é repetido até que um critério de parada seja satisfeito.
A tabela a seguir resume o processo do algoritmo CART:
| Passo | Descrição |
|---|---|
| 1. | Selecionar o melhor atributo e o melhor limiar para dividir os dados com base na impureza de Gini ou na soma dos erros quadrados. |
| 2. | Particionar os dados com base no atributo e limiar selecionados. |
| 3. | Repetir os passos 1 e 2 recursivamente para cada subconjunto até que um critério de parada seja atendido. |
| 4. | Criar nós de decisão e nós folha com base nas divisões. |
| 5. | Atribuir a classe majoritária (classificação) ou o valor médio (regressão) aos nós folha. |
Essa implementação do algoritmo particiona os dados em cada nó. A classe principal, DecisionTree, consiste em dois métodos essenciais: fit e predict. O método fit aceita uma matriz numpy X contendo as características de entrada e uma matriz numpy y contendo os valores-alvo correspondentes. Em seguida, ele treina a árvore de decisão usando os dados fornecidos. O método predict aceita uma matriz numpy X de características de entrada e retorna os valores-alvo previstos.
A classe DecisionTree utiliza uma classe Node para representar nós internos da árvore de decisão e uma classe LeafNode para representar os nós folha. A classe Node contém atributos como nós filhos esquerdo e direito, um índice de característica selecionada e um valor limite para particionamento de dados no nó. Por outro lado, a classe LeafNode armazena o valor-alvo para o nó folha.
A principal função recursiva responsável por construir a árvore de decisão é _grow. Essa função recebe os dados de treinamento e uma lista de índices de características como entrada e retorna o nó raiz da árvore de decisão. Além disso, o método _split_data é usado para dividir os dados em subconjuntos esquerdo e direito com base no par (atributo, limiar).
Aqui está um exemplo de árvore de decisão:

Essa árvore de decisão é construída usando o algoritmo CART e pode ser usada para fazer previsões em novos dados.
O Aplicativo Web de Visualização da Árvore de Decisão fornece uma interface intuitiva para interagir com árvores de decisão. Os usuários podem selecionar conjuntos de dados diferentes, configurar hiperparâmetros como a profundidade máxima e o número mínimo de amostras para um nó folha, ajustar a árvore de decisão ao conjunto de dados e visualizar a árvore de decisão resultante. O aplicativo web atualiza dinamicamente a visualização à medida que o usuário interage com os controles.
- Seleção do Conjunto de Dados: Os usuários podem escolher em um menu suspenso o conjunto de dados que desejam usar para treinar a árvore de decisão. Os conjuntos de dados atualmente disponíveis incluem Iris, Wine e Diabetes. Ainda não é possível fazer upload de um dataset específico.
- Controles de Hiperparâmetros: Os usuários podem ajustar a profundidade máxima, o número mínimo de amostras necessárias para dividir um nó interno e o número mínimo de amostras para a criação de nós folhas.
- Botão "Fit": Ao clicar no botão "Fit", a árvore de decisão é treinada usando o conjunto de dados e hiperparâmetros selecionados.
- Botão "Show": Uma visualização interativa da árvore de decisão é gerada.
- Visualização da Árvore de Decisão: O aplicativo web exibe a árvore de decisão como um gráfico, onde cada nó representa um ponto de decisão e cada aresta representa uma divisão com base em uma característica e limite específicos. Os usuários podem passar o mouse sobre os nós para visualizar informações adicionais, como o nome da característica, valor do limiar, valor do critério utilizado, número de observações. Além disso o usuário pode clicar nos nós da árvore e visualizar o subconjunto de dados correspondente.
O aplicativo web é construído usando o framework Dash e incorpora componentes Bootstrap para estilização. A visualização da árvore de decisão é gerada usando objetos de gráficos do Plotly. A classe DecisionTree e classes relacionadas da implementação anterior são utilizadas para treinar a árvore de decisão e extrair as informações necessárias para a visualização.
Essa implementação apresenta as Árvores de Decisão construídas do zero com o algoritmo CART. Ela fornece uma maneira interativa e intuitiva de explorar e entender as árvores de decisão, visualizando a estrutura da árvore e seu processo de tomada de decisão. O código-fonte proporciona um entendimento fácil do funcionamento interno das árvores de decisão.
Uma explicação mais detalhada da implementação do algoritmo pode ser encontrada no meu artigo do Medium referente a esse projeto.



