A single node image classifier that classifies cat vs not cat images in python using logistic regression.
To run:
Train: $python main.py train (Training process time depends upon number of iterations in main.py)
Test: $python main.py test
Classify: $python main.py classify path_to_image_file
(try to classify images provided in root directory not-cat:[1.jpg,2.jpg,3.jpg] cat:[cat1.jpg,cat2.jpg, cat3.jpg])
NOTE: The accuracy is not too high (the model might classify image of Elon Musk as a CAT and cat image as NOT-CAT, try it out) because regularization parameters are not considered. It's just a simple program with single neural node that classifies images.
The basic idea behind a perceptron is to consider the weighted sum of input features and apply an activation function. And the system learns and optimizes the weights to minimize error with each iteration and get close to the true value for training samples. After training is done you use the trained weights to predict output for unseen data. This is called supervised learning as system sees the input features and their true class during training to learn weights. Here the inputs are pixel values from the images in training data set.
Something like this:

The activation function here is called heaviside or step function.
Step function is not what we require for task at hand.
We will use sigmoid function.
Here:
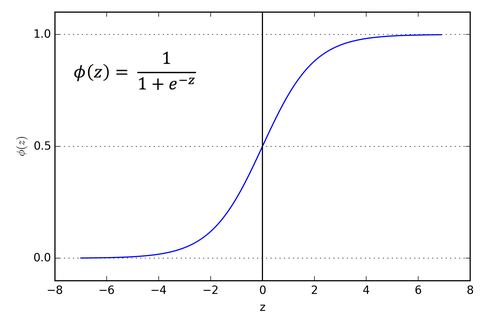
So instead of heaviside or step we use a sigmoid activation function which is real-valued and differentiable (you need this to find gradients). The sigmoid function squashes the weighted inputs and gives a value in range 0 to 1. Which can be used for binary classification if the value crosses a certain threshold say >0.5 for class 1 otherwise class 0.
The inputs includes pixels from 3 color channels (RGB) which we reshape in one column vector for one sample (see main.py):

Just a dog image for your understanding (See! I am not biased towards cats !)
There is one more important component involved and it's called bias.
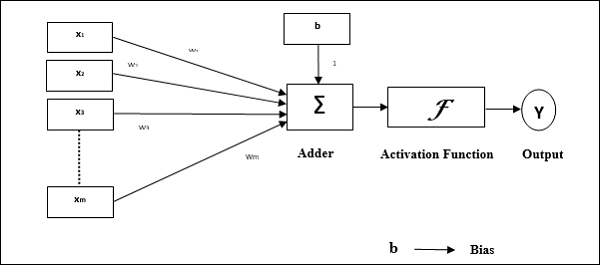
The bias input is 1 but it has it's own weight. The system tries to learn and optimize bias weight as well.
So after considering all components we get something lilke this:
The step function at the end is used to decide class of the output value from previous step. Say if input to step <= 0.5 -> class 0 otherwise class 1.
The aim is to minimize error or just say optimize the weights so that the output is close to the actual value of the input training sample. The optimizer used here is Gradient Descent.
Gradient descent works by calculating the derivative or slope of the cost function wrt the weights to get the gradient and then use that gradient to update weights by a little amount in a direction opposite of the gradient. So if gradient is negative then we need to move towards zero slope and that can be done by increasing the weight . Similarly if slope is positive at a particular weight point that means we need to move in a direction that decreases the error which is a direction towards decreasing weight.
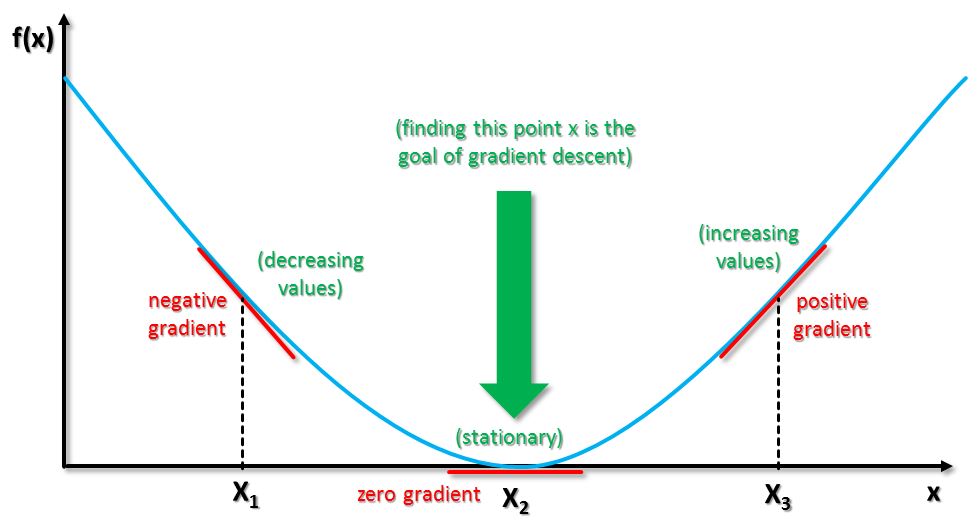
Here X axis is weight axis and Y axis represents error.
So if you are at X1 then move towards X2. If at X3 then move towards X2
After the iterations are over for Gradient descent.. the final weights and bias are used to classify new unseen images.
The data set was taken from Coursera.
Images taken from Google image search and here are the links:
https://deeplearning4j.org/img/perceptron_node.png
https://sebastianraschka.com/images/faq/logisticregr-neuralnet/sigmoid.png
http://i2.wp.com/blog.hackerearth.com/wp-content/uploads/2017/01/Capture-15.png
https://www.tutorialspoint.com/artificial_neural_network/images/perceptron.jpg
https://qph.ec.quoracdn.net/main-qimg-1b0c3d6b6c008626f30e93e107c93b2a
http://www.big-data.tips/wp-content/uploads/2016/06/gradient-types.jpg



{kind=link}