mansuf / mangadex-downloader Goto Github PK
View Code? Open in Web Editor NEWA command-line tool to download manga from MangaDex, written in Python.
Home Page: https://mangadex-dl.mansuf.link/
License: MIT License
A command-line tool to download manga from MangaDex, written in Python.
Home Page: https://mangadex-dl.mansuf.link/
License: MIT License













































































































I use this to re-update manga I read into komga on a timed basis, but it re-downloads the cover.jpg every time it visits a manga, so my komga directory always shows up as modified. Would it be possible to add an option to only download the cover if it is missing, or even changed?
Why would you add this ugly thing, can you remove it please? I don't see an option to remove them.

Looks ugly
mangadex-dl https://mangadex.org/title/cb77e4a6-3921-43b9-9d64-7d78cd3205ce --save-as tachiyomi
start downloading the manga information along with it
Windows 10 20H2
mangadex-downloader v2.9.0 (https://github.com/mansuf/mangadex-downloader)
Python: 3.10.11
arch: x64
bundled executable: yes
Github releases
No response
mangadex-dl https://mangadex.org/title/cb77e4a6-3921-43b9-9d64-7d78cd3205ce --save-as tachiyomi
No response
I want to download all of my user library from my mangadex account without having any selection interaction first. Sadly i cannot using it with the library:reading or library:plan_to_read when i add the -s --input-pos="*" argument. The error says Error: Manga search results for "library:reading" are empty. I can use just the library but its not downloading my user library, but instead downloading random manga that contain word library in it.
I can download the manga from my mangadex user library account without having imposed to select which manga first.
DietPi (Debian Buster) on Raspberry Pi 3B
2.8.3
PyPI (Python Package Index)
No response
mangadex-dl 'library:reading' --login --login-username ***** --login-password ****** -s --input-pos "*"
No response
On macOS, I have a custom Shortcuts script for automating downloads using the link stored in the clipboard. It's really just a quick GUI to run shell scripts commands, though.

I just updated to v2.6.1 (was on v2.5.x's December release prior), and it seems single & batch commands are creating a downloaded-raw.json file inside the manga's folder.
Is this intentional? (If so, is there a flag to not have it generate it?)
Firstly, thank you very, very much for making this software. It makes the task to archive manga easy.
However, it seems to be missing a feature, which is to solely download all covers that were uploaded to the "Art" section.
My suggestion is to add a switch called "--download-all-covers" or "--only-download-covers" which will download every image from that section. I tried to figure it out by using existing options such as "--use-volume-cover", to no avail. Would be great if the "--cover" switch would work with "--download-all-covers" as well, to select the resolution of the covers.
With this feature, users wouldn't need to stress MangaDex's servers, neither waste their bandwidth.
Thank you.
Sometimes the downloader has not finished downloading images (server connection problem maybe ?) and mark it as finished download (ex: download progress bar stopped at 50% and continue to download the others). This can cause error when converting to specified format (ex: PDF)
[INFO] Downloading Volume. 2 Chapter. 10 page 10
file_sizes: 100%|████████████████████████████| 614k/614k [00:00<00:00, 1.21MB/s]
[INFO] Downloading Volume. 2 Chapter. 10 page 11
file_sizes: 52%|██████████████▌ | 504k/971k [00:15<00:14, 32.6kB/s] <--- The image is not fully downloaded, but the downloader continue to download the others.
[INFO] Downloading Volume. 2 Chapter. 10 page 12
file_sizes: 100%|█████████████████████████████| 948k/948k [00:00<00:00, 968kB/s]
The error looks like this (this one is standalone executable version)
[INFO] Manga "..." has finished download, converting to pdf...
pdf_progress: 41%|██████████████████████████▉ | 11/27 [00:07<00:09, 1.63item/s][ERROR] Unhandled exception, WorkerThreadError: image file is truncated (20 bytes not processed)
Exception in thread Thread-4 (_main):
Traceback (most recent call last):
File "threading.py", line 1009, in _bootstrap_inner
Traceback (most recent call last):
File "threading.py", line 946, in run
File "mangadex_downloader\cli\__init__.py", line 39, in _main
File "mangadex_downloader\format\base.py", line 60, in _main
File "mangadex_downloader\cli\download.py", line 12, in download
File "mangadex_downloader\cli\url.py", line 89, in __call__
File "concurrent\futures\_base.py", line 534, in set_result
concurrent.futures._base.InvalidStateError: FINISHED: <Future at 0x276d3a172b0 state=finished raised OSError>
File "mangadex_downloader\cli\url.py", line 22, in download_manga
File "mangadex_downloader\main.py", line 270, in download
File "mangadex_downloader\format\pdf.py", line 554, in main
File "mangadex_downloader\format\base.py", line 39, in submit
mangadex_downloader.format.base.WorkerThreadError: image file is truncated (20 bytes not processed)
pdf_progress: 41%|██████████████████████████▉ | 11/27 [00:07<00:11, 1.43item/s
If you download a manga where the no description exist, it error's out because it appears as an empty list.
Example manga: "https://mangadex.org/title/35e1c6d0-7352-412a-abad-633ebe05da45/sora-kara-onna-no-ko-ga"
Error Trace:
Traceback (most recent call last):
File "C:\Users\rcgam\AppData\Local\Programs\Python\Python310\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Users\rcgam\AppData\Local\Programs\Python\Python310\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "C:\Users\rcgam\AppData\Local\Programs\Python\Python310\Scripts\mangadex-dl.exe\__main__.py", line 7, in <module>
File "C:\Users\rcgam\AppData\Local\Programs\Python\Python310\lib\site-packages\mangadex_downloader\__main__.py", line 59, in main
_main(sys.argv[1:])
File "C:\Users\rcgam\AppData\Local\Programs\Python\Python310\lib\site-packages\mangadex_downloader\__main__.py", line 45, in _main
download(
File "C:\Users\rcgam\AppData\Local\Programs\Python\Python310\lib\site-packages\mangadex_downloader\main.py", line 89, in download
write_details(manga, details_path)
File "C:\Users\rcgam\AppData\Local\Programs\Python\Python310\lib\site-packages\mangadex_downloader\utils.py", line 35, in write_details
data['description'] = manga.description
File "C:\Users\rcgam\AppData\Local\Programs\Python\Python310\lib\site-packages\mangadex_downloader\manga.py", line 43, in description
return _get_attr(self._attr.get('description'))
File "C:\Users\rcgam\AppData\Local\Programs\Python\Python310\lib\site-packages\mangadex_downloader\manga.py", line 12, in _get_attr
for key, val in data.items():
AttributeError: 'list' object has no attribute 'items'
Add a instance check for manga.__get_attr
def _get_attr(data):
if isinstance(data, dict):
for key, val in data.items():
return val
return data[0] if data else ""
It's appeared that CPU usage has been increased when downloading large chapters in v2.6.0 and upper. Causing application slowing down when downloading.
First, let me tell you about "Download tracking" system that has been added in v2.6.0. It's tracking downloaded chapters and images and it's purpose to check what chapters has been downloaded, so next time you run the application, it only download the chapters that has not been downloaded (latest chapters) without getting rate-limited by MangaDex API (see commit 865b7f5 for more info). Also it verify chapters and images, so if you have corrupted chapters or images, the application will know and will re-download them.
The "Download tracking" system use JSON (JavaScript Object Notation) to store the information about downloaded chapters and images. I use JSON because it's easy to implement it. But, turns out it hurts application performance if it was downloading large chapters (i just tested it out). So yes i was messed up, i'm sorry. I only do basic testing for this project due to limited time i have.
In v2.8.0, i will change the type storage for "Download tracking" system from JSON to SQLite. SQLite handles data efficiently even it's containing large data. If you don't wanna wait for v2.8.0, you can use older version (before v2.6.0). The tracker can be disabled but it's not available yet (see #45)
Would it be possible to add a throttle option of some kind? Like a sleep between pages? I worry that if we hit it too hard eventually they will cloudflare the thing....
After the latest tagged version of v2.5.1, while trying to fix #36, I found that it broke some useful features.
The options which I found not working are:
--use-chapter-title--no-group-nameUsing the same Reproducible command, explained at #36,,
mangadex-downloader "https://mangadex.org/title/296cbc31-af1a-4b5b-a34b-fee2b4cad542/-oshi-no-ko" --language "en" --cover "original" --use-compressed-image --start-chapter 1 --end-chapter 6 --save-as raw --use-chapter-title --no-group-nameIf run, results somewhat like this:

Where the above mentioned command options are ignored by the app:

If I try to download "Chapter 11" from the manga, which has 2 scanlator uploads, both are being downloaded with scanlator's name prefixed in the folder name, but chapter title is still ignored.


So it's basically forcing --group all to be an absolute option as well.
But selecting a single group with --group XXX is still operational.
So, I get Downloaded Folders (for raw format) as: <Scanlator Group/Uploader Name> <Volume> <Chapter>, which is unexpected.
I should've got folders/files prefixed as <Volume> <Chapter> - <Title>, as it did in the previous tagged versions.
Ubuntu 22.04
mangadex-downloader v2.5.1 (https://github.com/mansuf/mangadex-downloader)
Python: 3.10.6
arch: x64
bundled executable: no
PyPI (Python Package Index)
No response
mangadex-downloader "https://mangadex.org/title/296cbc31-af1a-4b5b-a34b-fee2b4cad542/-oshi-no-ko" --language "en" --cover "original" --use-compressed-image --start-chapter 1 --end-chapter 6 --save-as raw --use-chapter-title --no-group-nameAnd for testing the chapter download with dual scanlator (chapter 11)
mangadex-downloader "https://mangadex.org/title/296cbc31-af1a-4b5b-a34b-fee2b4cad542/-oshi-no-ko" --language "en" --cover "original" --use-compressed-image --start-chapter 10 --end-chapter 12 --save-as raw --use-chapter-title --no-group-nameNo response
Version 0.6.1 on Mac OS version 12.2.1 with Python version 3.10.2
Using the --save-as "cbz-single" switch results in the error below, but using --save-as "cbz" works without an issue. I am not sure if this is an issue on my end due permissions or a missing package, or if it an issue with the app. Thank you.
[ERROR] Unhandled exception, OSError: cannot open resource
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader/cli/__init__.py", line 39, in _main
download(args)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader/cli/download.py", line 12, in download
url(args, args.type)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader/cli/url.py", line 89, in __call__
self.func(self.id, args)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader/cli/url.py", line 22, in download_manga
dl_manga(
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader/main.py", line 270, in download
fmt.main()
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader/format/comic_book.py", line 214, in main
mark_img = get_mark_image(chap_name, cache, index)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader/format/utils.py", line 29, in get_mark_image
font = ImageFont.truetype(font_family, font_size)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/PIL/ImageFont.py", line 844, in truetype
return freetype(font)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/PIL/ImageFont.py", line 841, in freetype
return FreeTypeFont(font, size, index, encoding, layout_engine)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/PIL/ImageFont.py", line 193, in __init__
self.font = core.getfont(
OSError: cannot open resource
Some chapters have a different scanlation groups, is it possible to download all? Thanks!
python3 mangadex.py
[INFO] [MAIN] Fetching "https://mangadex.org/title/14f6bd96-e062-40d6-8fd2-fc6925e54624/aoi-horus-no-hitomi-dansou-no-joou-no-monogatari"
[INFO] [FETCHER] Requesting info to mangadex main website
[INFO] [FETCHER] Checking if ip user are banned or not
[INFO] [FETCHER] Checking if given url manga is exist or not
[INFO] [FETCHER] Retrieving info from mangadex API
Traceback (most recent call last):
File "mangadex.py", line 12, in <module>
info = m.extract_info('https://mangadex.org/title/14f6bd96-e062-40d6-8fd2-fc6925e54624/aoi-horus-no-hitomi-dansou-no-joou-no-monogatari')
File "/home/j/.local/lib/python3.8/site-packages/mangadex_downloader/__init__.py", line 178, in extract_info
data = fetch.get()
File "/home/j/.local/lib/python3.8/site-packages/mangadex_downloader/fetcher.py", line 87, in get
r = requests.get(get_manga_api_url(manga_id))
File "/home/j/.local/lib/python3.8/site-packages/mangadex_downloader/constants.py", line 16, in get_manga_api_url
return BASE_API_URL + '/manga/' + manga_id + '?include=chapters'
TypeError: can only concatenate str (not "NoneType") to str
This is the output.
And this is my mangadex.py file:
from mangadex_downloader import Mangadex
# by default, verbose is False
m = Mangadex(verbose=True)
# if you want to see all information in manga
# plus you want to download it
# do: m.extract_info('give mangadex url here')
# see example below
# this will download all chapters in manga
info = m.extract_info('https://mangadex.org/title/14f6bd96-e062-40d6-8fd2-fc6925e54624/aoi-horus-no-hitomi-dansou-no-joou-no-monogatari')
print(info)
# Output: <MangaData title="My Tiny Senpai From Work" chapters=51 language=jp>
print(info.title)
# Output: 'My Tiny Senpai From Work'
print(info.chapters)
# Output: [{'language': 'English': 'url': ..., 'group': ..., 'uploader': ..., 'volume': ..., 'chapter': ..., 'chapter-id': ...}, ...]
# or, you want to see all information in manga
# but you don't wanna download it
# do: m.extract_info('give mangadex url here', download=False)
# see example belowAny help is appreciated, as I'm not that versed in Python, thanks.
File "C:\Users\Apricot\AppData\Roaming\Python\Python37\site-packages\mangadex_downloader\downloader.py", line 217, in _report
if resp.headers.get('x-cache').startswith('HIT'):
AttributeError: 'NoneType' object has no attribute 'startswith'
getting this error when trying to download manga, any help?
this was the manga page i tried downloading from, it downloads the cover correctly but not the next pages:
https://mangadex.org/title/ada3dca4-fdae-42ca-b867-dae6b860edec/isekai-furin
Hello, it would be nice to be able to download all the titles from a group by only giving the group id to the downloader instead of having to select those one by one.
Thank you very much for your work :)
It would save a lot of time.
I like the features of your work 😍
If it's not too hard, I'd like to ask if you could implement 7-zip compression support for tachiyomi such that we can download as tachiyomi-7zip format with *.7z files.
7-zip can compress files better than Zip, and it can save some storage data (about 3-10% for image files) as-well-as reduce downloadable size for individual chapters/volumes when hosted on certain website/server.
Didn't notice this before v2.8.2, so assuming this is a regression in the newest version.
The error log is included below:
[INFO] Checking url = https://mangadex.org/chapter/1e864547-08c0-405a-b465-1c6d32dfe7bd
[INFO] Found chapter None from manga "The girl I was interested in was a Two-Mouthed Youkai."
[INFO] Download directory is set to "/Users/scheris/Downloads/The girl I was interested in was a Two-Mouthed Youkai"
[INFO] Using raw format
[ERROR] Unhandled exception, AttributeError: 'NoneType' object has no attribute 'images'
Traceback (most recent call last):
File "/opt/homebrew/lib/python3.11/site-packages/mangadex_downloader/cli/__init__.py", line 73, in _main
download(args)
File "/opt/homebrew/lib/python3.11/site-packages/mangadex_downloader/cli/download.py", line 33, in download
url(args, args.type)
File "/opt/homebrew/lib/python3.11/site-packages/mangadex_downloader/cli/url.py", line 161, in __call__
self.func(self.id, args)
File "/opt/homebrew/lib/python3.11/site-packages/mangadex_downloader/cli/url.py", line 116, in download_chapter
dl_chapter(*args)
File "/opt/homebrew/lib/python3.11/site-packages/mangadex_downloader/main.py", line 206, in download_chapter
fmt.main()
File "/opt/homebrew/lib/python3.11/site-packages/mangadex_downloader/format/raw.py", line 59, in main
for im_info in file_info.images:
^^^^^^^^^^^^^^^^
AttributeError: 'NoneType' object has no attribute 'images'
Should have downloaded normally, like if I remove --no-track and it works as expected.
macOS 13.2.1 (M1)
2.8.2
PyPI (Python Package Index)
No response
mangadex-dl --no-track --use-compressed-image https://mangadex.org/chapter/1e864547-08c0-405a-b465-1c6d32dfe7bd
No response
I run this on Fedora 37, on the stock Python3 package (version Python 3.11.2).
When trying to download a manga (so far I've tried Uzumaki and The Decagon House Murders, having similar results for both) I'm unable to download anything appart from the cover art and the download.db file.
I'm using the commands below:
https://mangadex.org/title/f4cfbb1c-766e-49db-ae80-1a5db3cbcc1b/uzumaki
https://mangadex.org/title/0c0b19c8-efde-4a65-b98a-9c7fc79fd173/the-decagon-house-murders
I am not able to do anything to get the full manga. Am I doing something wrong or is there an issue with the package? According to the docs, what I'm typing should work ok.
BTW thank you for this fantastic tool!
To download the full manga.
Fedora 37, Python3 version 3.11.2
mangadex-downloader v2.8.1 (https://github.com/mansuf/mangadex-downloader)
Python: 3.11.2
arch: x64
bundled executable: no
PyPI (Python Package Index)
No response
https://mangadex.org/title/f4cfbb1c-766e-49db-ae80-1a5db3cbcc1b/uzumaki
https://mangadex.org/title/0c0b19c8-efde-4a65-b98a-9c7fc79fd173/the-decagon-house-murders
No response
The downloaded-cbz.json doesn't seem to track certain chapters of this manga correctly: https://mangadex.org/title/9d3d3403-1a87-4737-9803-bc3d99db1424. This may be due to a special character used in some titles.
It will re-download chapters 20, 27, 28, 29, 34, and 37 every time the command is run, even if all chapters have been downloaded before. I've noticed that these particular chapters have a right single quotation mark in the titles rather than straight apostrophes, and have garbled titles in the downloaded-cbz.json, like "She’s the Only One I Refuse to Share.cbz". The cbz will still be downloaded with the correct title.
If this is the cause, there may also be problems with other special characters in chapter titles.
This is the command's output:
[INFO] Checking url = https://mangadex.org/title/9d3d3403-1a87-4737-9803-bc3d99db1424
[INFO] Using English language
[INFO] Fetching all chapters...
[INFO] Downloading cover manga The Guy She Was Interested in Wasn't a Guy at All
[INFO] Not downloading cover manga, since "cover" is none
[INFO] Download directory is set to "C:\Users\User\mangadex-dl\manga\The Guy She Was Interested in Wasn't a Guy at All"
[INFO] Using cbz format
[INFO] Preparing to download...
[INFO] Getting images from chapter 20
[INFO] Downloading Chapter. 20 - When It Comes to His Niece, There’s No Spending Too Much page 1
file_sizes: 100%|███████████████████████████| 2.22M/2.22M [00:04<00:00, 536kB/s]
[INFO] Downloading Chapter. 20 - When It Comes to His Niece, There’s No Spending Too Much page 2
file_sizes: 100%|███████████████████████████| 2.50M/2.50M [00:03<00:00, 682kB/s]
[INFO] Downloading Chapter. 20 - When It Comes to His Niece, There’s No Spending Too Much page 3
file_sizes: 100%|███████████████████████████| 2.84M/2.84M [00:04<00:00, 657kB/s]
[INFO] Downloading Chapter. 20 - When It Comes to His Niece, There’s No Spending Too Much page 4
file_sizes: 100%|███████████████████████████| 2.36M/2.36M [00:07<00:00, 307kB/s]
[INFO] Ch. 20 - When It Comes to His Niece, There’s No Spending Too Much has finished download, converting to cbz...
cbz_progress: 100%|████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 95.30item/s]
[INFO] Getting images from chapter 27
[INFO] Downloading Chapter. 27 - I’m the Only One Who Knows Who My Crush (A Girl) Is page 1
file_sizes: 100%|███████████████████████████| 2.66M/2.66M [00:03<00:00, 836kB/s]
[INFO] Downloading Chapter. 27 - I’m the Only One Who Knows Who My Crush (A Girl) Is page 2
file_sizes: 100%|███████████████████████████| 2.32M/2.32M [00:02<00:00, 785kB/s]
[INFO] Downloading Chapter. 27 - I’m the Only One Who Knows Who My Crush (A Girl) Is page 3
file_sizes: 100%|███████████████████████████| 2.74M/2.74M [00:03<00:00, 761kB/s]
[INFO] Downloading Chapter. 27 - I’m the Only One Who Knows Who My Crush (A Girl) Is page 4
file_sizes: 100%|███████████████████████████| 2.21M/2.21M [00:04<00:00, 538kB/s]
[INFO] Ch. 27 - I’m the Only One Who Knows Who My Crush (A Girl) Is has finished download, converting to cbz...
cbz_progress: 100%|███████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 105.32item/s]
[INFO] Getting images from chapter 28
[INFO] Downloading Chapter. 28 - Someone’s Going to Get Blinded page 1
file_sizes: 100%|███████████████████████████| 2.30M/2.30M [00:18<00:00, 126kB/s]
[INFO] Downloading Chapter. 28 - Someone’s Going to Get Blinded page 2
file_sizes: 100%|███████████████████████████| 2.46M/2.46M [00:13<00:00, 182kB/s]
[INFO] Downloading Chapter. 28 - Someone’s Going to Get Blinded page 3
file_sizes: 100%|███████████████████████████| 3.03M/3.03M [00:18<00:00, 160kB/s]
[INFO] Downloading Chapter. 28 - Someone’s Going to Get Blinded page 4
file_sizes: 100%|███████████████████████████| 3.04M/3.04M [00:10<00:00, 294kB/s]
[INFO] Ch. 28 - Someone’s Going to Get Blinded has finished download, converting to cbz...
cbz_progress: 100%|████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 88.94item/s]
[INFO] Getting images from chapter 29
[INFO] Downloading Chapter. 29 - She’s the Only One I Refuse to Share page 1
file_sizes: 100%|███████████████████████████| 2.67M/2.67M [00:03<00:00, 760kB/s]
[INFO] Downloading Chapter. 29 - She’s the Only One I Refuse to Share page 2
file_sizes: 100%|███████████████████████████| 2.12M/2.12M [00:02<00:00, 733kB/s]
[INFO] Downloading Chapter. 29 - She’s the Only One I Refuse to Share page 3
file_sizes: 100%|███████████████████████████| 3.29M/3.29M [00:05<00:00, 562kB/s]
[INFO] Downloading Chapter. 29 - She’s the Only One I Refuse to Share page 4
file_sizes: 100%|███████████████████████████| 2.60M/2.60M [00:04<00:00, 625kB/s]
[INFO] Ch. 29 - She’s the Only One I Refuse to Share has finished download, converting to cbz...
cbz_progress: 100%|████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 90.97item/s]
[INFO] Getting images from chapter 34
[INFO] Downloading Chapter. 34 - Most Likely, It’s Not Her Imagination page 1
file_sizes: 100%|███████████████████████████| 2.64M/2.64M [00:14<00:00, 179kB/s]
[INFO] Downloading Chapter. 34 - Most Likely, It’s Not Her Imagination page 2
file_sizes: 100%|███████████████████████████| 2.70M/2.70M [00:06<00:00, 395kB/s]
[INFO] Downloading Chapter. 34 - Most Likely, It’s Not Her Imagination page 3
file_sizes: 100%|███████████████████████████| 3.03M/3.03M [00:05<00:00, 525kB/s]
[INFO] Downloading Chapter. 34 - Most Likely, It’s Not Her Imagination page 4
file_sizes: 100%|███████████████████████████| 2.61M/2.61M [00:09<00:00, 273kB/s]
[INFO] Ch. 34 - Most Likely, It’s Not Her Imagination has finished download, converting to cbz...
cbz_progress: 100%|████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 83.38item/s]
[INFO] Getting images from chapter 37
[INFO] Downloading Chapter. 37 - The World’s Most Beautiful Sound page 1
file_sizes: 100%|███████████████████████████| 2.85M/2.85M [00:09<00:00, 291kB/s]
[INFO] Downloading Chapter. 37 - The World’s Most Beautiful Sound page 2
file_sizes: 100%|███████████████████████████| 2.89M/2.89M [00:05<00:00, 487kB/s]
[INFO] Downloading Chapter. 37 - The World’s Most Beautiful Sound page 3
file_sizes: 100%|███████████████████████████| 2.82M/2.82M [00:04<00:00, 567kB/s]
[INFO] Downloading Chapter. 37 - The World’s Most Beautiful Sound page 4
file_sizes: 100%|███████████████████████████| 3.46M/3.46M [00:12<00:00, 282kB/s]
[INFO] Ch. 37 - The World’s Most Beautiful Sound has finished download, converting to cbz...
cbz_progress: 100%|████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 77.16item/s]
[INFO] 'Ch. 1.cbz' is verified and no need to re-download
[INFO] 'Ch. 2.cbz' is verified and no need to re-download
[INFO] 'Ch. 3.cbz' is verified and no need to re-download
[INFO] 'Ch. 4.cbz' is verified and no need to re-download
[INFO] 'Ch. 5.cbz' is verified and no need to re-download
[INFO] 'Ch. 6.cbz' is verified and no need to re-download
[INFO] 'Ch. 7.cbz' is verified and no need to re-download
[INFO] 'Ch. 8 - The Type of Girl Who Makes a Pass When She's Panicking.cbz' is verified and no need to re-download
[INFO] 'Ch. 9 - She Doesn't Have Friends, but She Felt Happy All the Same.cbz' is verified and no need to re-download
[INFO] 'Ch. 9.1 - Character Bios.cbz' is verified and no need to re-download
[INFO] 'Ch. 10.cbz' is verified and no need to re-download
[INFO] 'Ch. 10.1 - The Two of Them After Being Caught in the Rain.cbz' is verified and no need to re-download
[INFO] 'Ch. 11.cbz' is verified and no need to re-download
[INFO] 'Ch. 12.cbz' is verified and no need to re-download
[INFO] 'Ch. 13 - Girls With an Extreme Gap.cbz' is verified and no need to re-download
[INFO] 'Ch. 14 - Today Too, the Gyaru Is Involved With the Gloomy Girl.cbz' is verified and no need to re-download
[INFO] 'Ch. 15 - The Gloomy Girl in My Class Was Super Cool.cbz' is verified and no need to re-download
[INFO] 'Ch. 16 - The Voice of Her Crush (Actually a Girl) Is Unforgettable.cbz' is verified and no need to re-download
[INFO] 'Ch. 17 - Caught in The Storm.cbz' is verified and no need to re-download
[INFO] 'Ch. 18 - The Guy She Was Interested in Wasn't a Guy At All.cbz' is verified and no need to re-download
[INFO] 'Ch. 18.1 - The Two of Them Shopping on a Day Off, Five Years From Now (Hopefully).cbz' is verified and no need to re-download
[INFO] 'Ch. 19 - A New Semester of Don't Ask, Don't Tell.cbz' is verified and no need to re-download
[INFO] 'Ch. 20 - When It Comes to His Niece, There’s No Spending Too Much.cbz' is verified and no need to re-download
[INFO] 'Ch. 21 - Come On, Just Face Her.cbz' is verified and no need to re-download
[INFO] 'Ch. 22 - The Girl at the CD Store.cbz' is verified and no need to re-download
[INFO] 'Ch. 22.1 - Maybe It Would Be Like This if the Two of Them Moved in Together... Do Your Best!.cbz' is verified and no need to re-download
[INFO] 'Ch. 23 - Stop Right There!.cbz' is verified and no need to re-download
[INFO] 'Ch. 24 - I'll Keep Chasing You!.cbz' is verified and no need to re-download
[INFO] 'Ch. 25 - Feels Like a Dream.cbz' is verified and no need to re-download
[INFO] 'Ch. 26 - The Guy She Liked Was a Girl Friend.cbz' is verified and no need to re-download
[INFO] 'Ch. 26.1 - I Kind of Wanted to Make Some Goods That These Two Might Have.cbz' is verified and no need to re-download
[INFO] 'Ch. 27 - I’m the Only One Who Knows Who My Crush (A Girl) Is.cbz' is verified and no need to re-download
[INFO] 'Ch. 28 - Someone’s Going to Get Blinded.cbz' is verified and no need to re-download
[INFO] 'Ch. 29 - She’s the Only One I Refuse to Share.cbz' is verified and no need to re-download
[INFO] 'Ch. 30 - If It's These Two.cbz' is verified and no need to re-download
[INFO] 'Ch. 31 - An Unexpected Encounter With Her Crush (A Girl).cbz' is verified and no need to re-download
[INFO] 'Ch. 32 - Telepathy.cbz' is verified and no need to re-download
[INFO] 'Ch. 33 - Wish, and You Shall Receive.cbz' is verified and no need to re-download
[INFO] 'Ch. 34 - Most Likely, It’s Not Her Imagination.cbz' is verified and no need to re-download
[INFO] 'Ch. 35 - Peacemaker.cbz' is verified and no need to re-download
[INFO] 'Ch. 36 - Trouble Chaser.cbz' is verified and no need to re-download
[INFO] 'Ch. 37 - The World’s Most Beautiful Sound.cbz' is verified and no need to re-download
[INFO] 'Ch. 37.1 - Smoothly (Valentine's day twitter pic - Landscape and portrait orientation).cbz' is verified and no need to re-download
[INFO] Waiting for chapter read marker to finish
[INFO] Download finished for manga "The Guy She Was Interested in Wasn't a Guy at All"
[INFO] Cleaning up...
And this is the downloaded-cbz.json (renamed to txt so I could upload it):
It should properly verify the chapters are downloaded and not redownload anything.
Windows 10 21H1
mangadex-downloader v2.7.1 (https://github.com/mansuf/mangadex-downloader)
Python: 3.10.9
arch: x64
bundled executable: yes
Github releases
No response
mangadex-dl "https://mangadex.org/title/9d3d3403-1a87-4737-9803-bc3d99db1424" --language en --use-chapter-title --no-group-name --cover none --save-as cbz --folder manga
The command is run from a batch file.
Download bug and come to an alt after some time. I guess this is a bug on mangadex-downloader as the size of the image is way too big to be the true size but could come from mangadex.

The image to be a smaller size and after a few retry to download correctly
2.0.0
git clone && pip install .
No response
mangadex-downloader "library" --input-pos "*" --use-chapter-title --login --login-username "*******" --login-password "********" --cover "original" --delay-requests 1.5 --save-as raw --path "D:\Manga\mangadex"
...for easier navigation. I feel there should be an optional flag to put chapters into "Volume n" folders if "pdf" or "cbz" flags are present. Or if, for example, "pdf-chapters" or "cbz-chapters" flags are there, group them into "Volume n.pdf" files. Sort of like middle ground between downloading all the chapters into the same folder and making a large pdf file with all the chapters.
Like so:

and

I have discovered your project this evening and was astounded by how flawlessly it works (except for missing arial fonts, which is fixable on my part). Thank you for your work!
since you've already created a downloaded json.file.
maybe you can add more meta data to it? like for instance the download ID, link, or more important: manga description,tags, last update, last download time etc.
this would be easy to reuse the json file in a script to fill up a series metadata and redownload at set times with a script.
I was updating a manga and the code stopped executing as soon as it tried to update the cover image. Here are all the displayed messages:
[INFO] Using English language
[INFO] Downloading cover manga Yofukashi no Uta
file_sizes: 0%| | 0.00/138k [00:00<?, ?B/s][ERROR] Unhandled exception, FileExistsError: [WinError 183] Cannot create a file when that file already exists: 'Ongoing - Hiatus\Yofukashi no Uta\cover.jpg.temp' -> 'Ongoing - Hiatus\Yofukashi no Uta\cover.jpg'
Traceback (most recent call last):
File "mangadex_downloader\cli_init_.py", line 57, in _main
File "mangadex_downloader\cli\download.py", line 21, in download
File "mangadex_downloader\cli\url.py", line 167, in call
File "mangadex_downloader\cli\url.py", line 81, in download_manga
File "mangadex_downloader\main.py", line 407, in download
File "mangadex_downloader\utils.py", line 60, in download
File "mangadex_downloader\downloader.py", line 138, in download
FileExistsError: [WinError 183] Cannot create a file when that file already exists: 'Ongoing - Hiatus\Yofukashi no Uta\cover.jpg.temp' -> 'Ongoing - Hiatus\Yofukashi no Uta\cover.jpg'
The command line I used was:
..\mangadex-dl\mangadex-dl "OngoingList.txt" --folder ".\Ongoing - Hiatus" --use-chapter-title --no-group-name
I have run this command line previously without issue, and this was the only manga in the list that had this occur, so I presume the cover image on Mangadex was updated. I updated from 1.6.2 to 1.7.2 and the error occurred again. I can confirm that page images are replaced when the ones I have are different from what is on the server. I was able to get the manga to update after deleting the existing cover.jpg.
while trying yo test the new use-volume-cover option, i get an error if the series has no volumes grouping
mangadex-dl -v
mangadex-downloader v2.6.1 (https://github.com/mansuf/mangadex-downloader)
Python: 3.9.16
arch: x64
bundled executable: no
command:
mangadex-dl https://mangadex.org/title/0210cda7-341d-4cdb-bbbb-3cf31e5f5f5c/a-mediocre-senior-brother --save-as cbz-volume --use-volume-cover --language "en" --use-chapter-title --folder /downloads/
exception
mangadex_downloader.errors.MangaDexException: Failed to find volume cover for volume None (manga_id: 0210cda7-341d-4cdb-bbbb-3cf31e5f5f5c). Please report this issue to https://github.com/mansuf/mangadex-downloader/issues
if there is no vuolume, then just use the main cover
docker : python:3.9-alpine
mangadex-downloader v2.6.1 (https://github.com/mansuf/mangadex-downloader)
Python: 3.9.16
arch: x64
bundled executable: no
PyPI (Python Package Index)
No response
mangadex-dl https://mangadex.org/title/0210cda7-341d-4cdb-bbbb-3cf31e5f5f5c/a-mediocre-senior-brother --save-as cbz-volume --use-volume-cover --language "en" --use-chapter-title --folder /downloads/
No response
There is list of cover representing each volumes in MangaDex.

Maybe we can use that in first page in any volume formats, instead of placing chapter info (or cover) in first page.
However, the chapter cover (info) is still can be added after volume cover. But, it's gonna be changed to optional feature (default to be disabled). So --no-chapter-info will get deprecated and wil be replaced with --use-chapter-cover instead.
Also add option to enable creation volume cover (--use-volume-cover / -uvc)
Maybe I haven't seen it, but are there more options on chapter-cover creation (esp when save as cbz-volume is used?)
the current chaptertitle+cover is in landscape and mess up my pretty library

more control on how the covers are generated would be nice (i'd just opt for the title in the cover itself, maybe with some transparant black bakground for readability)
$ /home/mxdl/venv/bin/mangadex-dl -dr 1 -ngn --language en --save-as cbz --folder /comics/Manga https://mangadex.org/title/78abd677-3058-4a71-8dd4-1d687e5a1e64/how-to-kill-a-god --start-chapter 50 --end-chapter 51
Error: 'None' is not valid value, available values are ['cloudflare', 'cloudflare-security', 'cloudflare-family', 'opendns', 'opendns-family', 'adguard', 'adguard-family', 'adguard-unfiltered', 'quad9', 'quad9-unsecured', 'google']In some mangas, such as https://mangadex.org/title/3f28c47a-bf8d-4e79-83ca-2e64fe906372, the program fails to convert to float and ends prematurely due to a chapter being a string (in this case "EXTRA"). The error is on line 149 on the file "chapter.py" and the hack I made seems to fix it.
try:
num_chap = float(chapter.chapter)
except:
print(f"{chapter.chapter}is not an integer, continue")
break
I'm trying to make the cbz format use some compression (because default is no compression, deflated : 0), but despite setting the MANGADEXDL_ZIP_COMPRESSION_LEVEL environment variable, nothing happens.
I expected it to use the configured compression level, yet nothing happens.
Win10
mangadex-downloader v2.8.3 (https://github.com/mansuf/mangadex-downloader)
Python: 3.10.10
arch: x64
bundled executable: yes
Github releases
No response
in cmd:
set MANGADEXDL_ZIP_COMPRESSION_LEVEL=1
mangadex-dl.exe https://mangadex.org/chapter/9f20eb08-abe9-4fb6-acde-5f85049fe24d --save-as cbz
Same results with setting it as permanent env var.
Why is no compression even the default? Deflated level 1 is producing a noticeable difference with jpegs (like 230kb -> 191kb), while higher levels doesn't do much (deflated L9 189kb, other compression type are also similar).
I'd guess that deflated level 1 has negligible impact on compression and decompression speeds, and there are no compatibility issues either, I don't see drawbacks with it.
So I'm not sure what the issue is with reading the env variable or how easy it would be fix, but adding compression by default or at least as a parameter would be also helpful.
Hey. I've installed the latest version and tried to download manga in cbz-volume format.
Here is the log: https://pastebin.com/p0wDSLYN
The problem occurs not with that particular manga, but with any when saving in cbz-volume format. Saving in other formats works properly.
Environment Information:
mangadex-dl = latest commit from GitHub (as of 67db5fe)
Operating System = macOS 12.3 Monterey (Intel)
Python Version = 3.10 (installed from the pkg from python.org)
Installation Method:
GitHub latest commit = git clone https://github.com/mansuf/mangadex-downloader.git && cd mangadex-downloader && python3 ./setup.py install
I was attempting to download groups separately for one chapter, as its group naming was causing issues for me and the downloader (treated as same group, though it had 2 group names)
mangadex-dl --save-as cbz --type chapter "b753b4b6-cc2f-4d47-ad32-634ce70f1399"
This command was used to save a chapter. I tested multiple chapters with the same result.
[INFO] Found chapter 1 from manga "Karakai Jouzu no Takagi-san"
[INFO] Using cbz format
[ERROR] Unhandled exception, TypeError: BaseFormat.__init__() missing 1 required positional argument: 'kwargs_iter_chapter_img'
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader-0.6.1-py3.10.egg/mangadex_downloader/cli/__init__.py", line 41, in _main
download(args)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader-0.6.1-py3.10.egg/mangadex_downloader/cli/download.py", line 12, in download
url(args, args.type)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader-0.6.1-py3.10.egg/mangadex_downloader/cli/url.py", line 126, in __call__
self.func(self.id, args)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader-0.6.1-py3.10.egg/mangadex_downloader/cli/url.py", line 72, in download_chapter
dl_chapter(*args)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/mangadex_downloader-0.6.1-py3.10.egg/mangadex_downloader/main.py", line 414, in download_chapter
fmt = fmt_class(
TypeError: BaseFormat.__init__() missing 1 required positional argument: 'kwargs_iter_chapter_img'
This is the received error.
So I can use --save-as raw-volume --start-chapter ## --no-chapter-info --login
I've went ahead and downloaded everything that is out for all the manga I currently read. I would like to make a "download updates" batch script to just grab the newest stuff. Currently all the manga is set to "completed" in MD, which IIRC should update to "reading" when a new chapter comes out. Could the script login, then grab all the latest for whatever is marked as unread, download it all as a raw-volume, then mark it all as read?
I hope I explained this right lol
Thanks for a great tool!!!!
Because I love you.
I would like to suggest reducing the number of logging messages and progress bars by replacing them by up stacked progression bars. More precisely,
Only print relevant messages on the console e.g., when starting a download or when a chapter / volume / part is completed depending on the merging procedure. For instance, when saving the output as cbz-volume, I am only interested when the whole is done and not when each page of each chapter is done. Such messages should be logged in DEBUG mode only.
By default, the logging verbosity should be rather WARNING than INFO, or it should be possible to suppress info messages. I haven't looked at the source code itself, but is there a way to configure the logger (if it is actually a logger) using an environment variable?
For progression bars, since tqdm supports stacked bars, it would be easier and cleaner to have a progression bar for the 1) volume (progression over the chapters), 2) the chapter volume (progression over the pages) and 3) the page download as it is currently. It should be possible to only show the volume progression or the volume + chapter or all bars.
I'll be happy to contribute to that but I'll need to dive into the code beforehand.
Having too many messages makes the terminal output quite unreadable. I have no idea about the ETA and I also have no idea which manga I am currently downloading if I am using the file:URL syntax.
Version 1.0.0 (I just installed it today)
Install via Python PIP
OS: Linux Mint 20.3
Python Version: 3.8.10
Command: mangadex-dl --login-username (redacted) --login-password (redacted) --save-as tachiyomi --cover original --unsafe https://mangadex.org/title/c1d990dd-9ff2-4e47-b93d-5e56e34c5069/digimon-xros-wars
I know tachiyomi is supposed to be default but I was seeing it using raw format so I enforced it.
I'm not sure what is triggering this. If I restart the download it will go down and skip the files it grabbed then pickup just fine where it left off.
[ERROR] Unhandled exception, AttributeError: 'NoneType' object has no attribute 'startswith'
Traceback (most recent call last):
File "/home/shinji/.local/lib/python3.8/site-packages/mangadex_downloader/cli/__init__.py", line 35, in _main
download(args)
File "/home/shinji/.local/lib/python3.8/site-packages/mangadex_downloader/cli/download.py", line 12, in download
url(args, args.type)
File "/home/shinji/.local/lib/python3.8/site-packages/mangadex_downloader/cli/url.py", line 144, in __call__
self.func(self.id, args)
File "/home/shinji/.local/lib/python3.8/site-packages/mangadex_downloader/cli/url.py", line 66, in download_manga
dl_manga(*args)
File "/home/shinji/.local/lib/python3.8/site-packages/mangadex_downloader/main.py", line 331, in download
fmt.main()
File "/home/shinji/.local/lib/python3.8/site-packages/mangadex_downloader/format/tachiyomi.py", line 61, in main
success = downloader.download()
File "/home/shinji/.local/lib/python3.8/site-packages/mangadex_downloader/downloader.py", line 172, in download
self._report(resp, length, round((t2 - t1) * 1000), False)
File "/home/shinji/.local/lib/python3.8/site-packages/mangadex_downloader/downloader.py", line 254, in _report
if resp.headers.get('x-cache').startswith('HIT'):
AttributeError: 'NoneType' object has no attribute 'startswith'
PS Y:\Books> .\mangadex-dl_x64_v2.7.1\mangadex-dl\mangadex-dl.exe --login
MangaDex username / email => neonfire
MangaDex password =>
[INFO] Logging in to MangaDex
[ERROR] Login to MangaDex failed, reason: User / Password does not match
[ERROR] User / Password does not match
PS Y:\Books>
I just tried the saved pass I had, then went and reset it as well. Waited after reset before trying again. Just won't work. I can log out and back in of MD's website without issue. Also tried with the --login-username --login-password options
to log in
Win 11
x64-v2.7.1
Github releases
No response
.\mangadex-dl_x64_v2.7.1\mangadex-dl\mangadex-dl.exe --login
No response
If you happen to download a manga and have certain chapters/volumes/etc.. already, it will mention it has cancelled the downlooad but it keeps an empty folder around for it. I mainly use it for cbz, so not sure if it's just for that save type.
The info log

The empty folders that remain

No empty folders to be left behind when a chapter or anything is skipped.
mangadex-downloader v2.0.1 (https://github.com/mansuf/mangadex-downloader)
Python: 3.10.5
arch: x64
bundled executable: no
PyPI (Python Package Index)
No response
Obviously only reproducible if you have the 1st chapter of the manga already in the folder, then running the command again.
mangadex-dl "xxxxxxxxxx" --save-as "cbz" --no-group-name --use-alt-details --start-chapter=1 --end-chapter=1
When trying to download new or update existing manga series that are located on my Samba file server, mangadex-dl throws the error "[ERROR] Unhandled exception, OperationalError: database is locked"
Console output from trying to update existing manga on Samba server:
mangadex-dl -lang "en" --save-as "cbz" --path "/mnt/W/Manga/Manga/" --group "all" https://mangadex.org/title/de9e3b62-eac5-4c0a-917d-ffccad694381/sometimes-even-reality-is-a-lie
[INFO] Checking url = https://mangadex.org/title/de9e3b62-eac5-4c0a-917d-ffccad694381/sometimes-even-reality-is-a-lie
[INFO] Using English language
[INFO] Fetching all chapters...
[INFO] Downloading cover manga Sometimes Even Reality Is a Lie!
[INFO] File exist and replace is False, cancelling download...
[INFO] Download directory is set to "/mnt/W/Manga/Manga/Sometimes Even Reality Is a Lie!"
[INFO] Using cbz format
[ERROR] Unhandled exception, OperationalError: database is locked
Traceback (most recent call last):
File "/home/x/.local/lib/python3.8/site-packages/mangadex_downloader/cli/__init__.py", line 73, in _main
download(args)
File "/home/x/.local/lib/python3.8/site-packages/mangadex_downloader/cli/download.py", line 33, in download
url(args, args.type)
File "/home/x/.local/lib/python3.8/site-packages/mangadex_downloader/cli/url.py", line 161, in __call__
self.func(self.id, args)
File "/home/x/.local/lib/python3.8/site-packages/mangadex_downloader/cli/url.py", line 95, in download_manga
dl_manga(*args)
File "/home/x/.local/lib/python3.8/site-packages/mangadex_downloader/main.py", line 163, in download
download_manga(manga, base_path)
File "/home/x/.local/lib/python3.8/site-packages/mangadex_downloader/main.py", line 123, in download_manga
m.tracker = get_tracker(save_as, path)
File "/home/x/.local/lib/python3.8/site-packages/mangadex_downloader/tracker/__init__.py", line 156, in get_tracker
return _migrate_legacy_tracker(fmt, path)
File "/home/x/.local/lib/python3.8/site-packages/mangadex_downloader/tracker/__init__.py", line 92, in _migrate_legacy_tracker
new_tracker = DownloadTrackerSQLite(fmt, path)
File "/home/x/.local/lib/python3.8/site-packages/mangadex_downloader/tracker/sqlite.py", line 59, in __init__
self._load()
File "/home/x/.local/lib/python3.8/site-packages/mangadex_downloader/tracker/sqlite.py", line 296, in _load
cur.execute(cmd_script)
sqlite3.OperationalError: database is locked
Just to note - my Samba file server runs Ubuntu 18.04.6 LTS (GNU/Linux 4.15.0-204-generic x86_64)
Permissions for the directories that the above manga resides:
Linux Mint ls -l in /mnt/W/Manga/:
drwxrwxrwx 2 x x 0 Feb 25 10:02 Manga
Linux Mint ls -l in /mnt/W/Manga/Manga/:
drwxrwxrwx 2 x x 0 Feb 28 14:39 'Sometimes Even Reality Is a Lie!'
Ubuntu Server ls -l for the same directories:
drwxr-sr-x 23 x x 4096 Feb 25 10:02 Manga
drwxr-sr-x 2 x x 4096 Feb 28 14:39 'Sometimes Even Reality Is a Lie!'
I have create mask = 0777 set in smb.conf, so folder perms shouldn't be an issue here.
After running mangadex-dl and getting the error, there is an empty download.db file (0B) that is created in the download directory:
-rwxrwxrwx 1 x x 0 Feb 28 14:39 download.db
The above error only happens when setting the path to my file server. Saving locally still works perfectly fine. This was a local successful test (initial download):
mangadex-dl -lang "en" --save-as "cbz" --path "/home/x/Documents/Mangas/" --group "all" https://mangadex.org/title/91d7344d-04ff-43a9-a871-0727bb00663f/godzilla-vs-spacegodzilla
[INFO] Checking url = https://mangadex.org/title/91d7344d-04ff-43a9-a871-0727bb00663f/godzilla-vs-spacegodzilla
[INFO] Using English language
[INFO] Fetching all chapters...
[INFO] Downloading cover manga Godzilla vs. SpaceGodzilla
file_sizes: 100%|████████████████████████████| 208k/208k [00:00<00:00, 3.29MB/s]
[INFO] Download directory is set to "/home/x/Documents/Mangas/Godzilla vs. SpaceGodzilla"
[INFO] Using cbz format
[INFO] Preparing to download...
[INFO] Getting images from chapter 1
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 1
file_sizes: 100%|████████████████████████████| 181k/181k [00:00<00:00, 2.83MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 2
file_sizes: 100%|████████████████████████████| 258k/258k [00:00<00:00, 8.13MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 3
file_sizes: 100%|████████████████████████████| 181k/181k [00:00<00:00, 2.41MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 4
file_sizes: 100%|████████████████████████████| 214k/214k [00:00<00:00, 27.3MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 5
file_sizes: 100%|████████████████████████████| 143k/143k [00:00<00:00, 57.9MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 6
file_sizes: 100%|████████████████████████████| 197k/197k [00:00<00:00, 9.66MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 7
file_sizes: 100%|████████████████████████████| 164k/164k [00:00<00:00, 25.6MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 8
file_sizes: 100%|████████████████████████████| 120k/120k [00:00<00:00, 18.0MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 9
file_sizes: 100%|████████████████████████████| 124k/124k [00:00<00:00, 56.1MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 10
file_sizes: 100%|████████████████████████████| 140k/140k [00:00<00:00, 47.4MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 11
file_sizes: 100%|████████████████████████████| 127k/127k [00:00<00:00, 46.3MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 12
file_sizes: 100%|████████████████████████████| 138k/138k [00:00<00:00, 98.4MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 13
file_sizes: 100%|████████████████████████████| 115k/115k [00:00<00:00, 49.0MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 14
file_sizes: 100%|████████████████████████████| 115k/115k [00:00<00:00, 17.8MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 15
file_sizes: 100%|████████████████████████████| 154k/154k [00:00<00:00, 38.6MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 16
file_sizes: 100%|████████████████████████████| 117k/117k [00:00<00:00, 32.5MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 17
file_sizes: 100%|████████████████████████████| 146k/146k [00:00<00:00, 42.9MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 18
file_sizes: 100%|████████████████████████████| 160k/160k [00:00<00:00, 46.0MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 19
file_sizes: 100%|████████████████████████████| 151k/151k [00:00<00:00, 33.8MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 20
file_sizes: 100%|████████████████████████████| 137k/137k [00:00<00:00, 53.9MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 21
file_sizes: 100%|████████████████████████████| 168k/168k [00:00<00:00, 7.76MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 22
file_sizes: 100%|████████████████████████████| 131k/131k [00:00<00:00, 33.4MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 23
file_sizes: 100%|████████████████████████████| 120k/120k [00:00<00:00, 6.25MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 24
file_sizes: 100%|████████████████████████████| 110k/110k [00:00<00:00, 6.25MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 1 page 25
file_sizes: 100%|████████████████████████████| 119k/119k [00:00<00:00, 44.1MB/s]
[INFO] [Chinatown KM] Vol. 1 Ch. 1 has finished download, converting to cbz...
cbz_progress: 100%|█████████████████████████| 25/25 [00:00<00:00, 1780.08item/s]
[INFO] Getting images from chapter 2
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 1
file_sizes: 100%|████████████████████████████| 217k/217k [00:00<00:00, 31.9MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 2
file_sizes: 100%|████████████████████████████| 128k/128k [00:00<00:00, 16.6MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 3
file_sizes: 100%|████████████████████████████| 163k/163k [00:00<00:00, 9.53MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 4
file_sizes: 100%|████████████████████████████| 234k/234k [00:00<00:00, 14.2MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 5
file_sizes: 100%|████████████████████████████| 130k/130k [00:00<00:00, 70.8MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 6
file_sizes: 100%|████████████████████████████| 124k/124k [00:00<00:00, 53.7MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 7
file_sizes: 100%|████████████████████████████| 139k/139k [00:00<00:00, 55.1MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 8
file_sizes: 100%|████████████████████████████| 165k/165k [00:00<00:00, 27.7MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 9
file_sizes: 100%|████████████████████████████| 152k/152k [00:00<00:00, 25.8MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 10
file_sizes: 100%|████████████████████████████| 158k/158k [00:00<00:00, 9.42MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 11
file_sizes: 100%|████████████████████████████| 296k/296k [00:00<00:00, 15.1MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 12
file_sizes: 100%|████████████████████████████| 149k/149k [00:00<00:00, 42.1MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 13
file_sizes: 100%|█████████████████████████████| 133k/133k [00:00<00:00, 161kB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 14
file_sizes: 100%|████████████████████████████| 159k/159k [00:00<00:00, 16.2MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 15
file_sizes: 100%|████████████████████████████| 139k/139k [00:00<00:00, 40.5MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 16
file_sizes: 100%|████████████████████████████| 122k/122k [00:00<00:00, 46.0MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 17
file_sizes: 100%|████████████████████████████| 122k/122k [00:00<00:00, 37.2MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 2 page 18
file_sizes: 100%|████████████████████████████| 287k/287k [00:00<00:00, 17.3MB/s]
[INFO] [Chinatown KM] Vol. 1 Ch. 2 has finished download, converting to cbz...
cbz_progress: 100%|█████████████████████████| 18/18 [00:00<00:00, 1385.76item/s]
[INFO] Getting images from chapter 3
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 1
file_sizes: 100%|████████████████████████████| 217k/217k [00:00<00:00, 15.7MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 2
file_sizes: 100%|████████████████████████████| 136k/136k [00:00<00:00, 50.6MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 3
file_sizes: 100%|████████████████████████████| 178k/178k [00:00<00:00, 61.8MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 4
file_sizes: 100%|████████████████████████████| 136k/136k [00:00<00:00, 37.6MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 5
file_sizes: 100%|████████████████████████████| 131k/131k [00:00<00:00, 8.88MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 6
file_sizes: 100%|████████████████████████████| 138k/138k [00:00<00:00, 19.0MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 7
file_sizes: 100%|████████████████████████████| 153k/153k [00:00<00:00, 15.8MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 8
file_sizes: 100%|████████████████████████████| 128k/128k [00:00<00:00, 56.3MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 9
file_sizes: 100%|████████████████████████████| 150k/150k [00:00<00:00, 16.2MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 10
file_sizes: 100%|████████████████████████████| 137k/137k [00:00<00:00, 53.4MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 11
file_sizes: 100%|████████████████████████████| 181k/181k [00:00<00:00, 60.6MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 12
file_sizes: 100%|████████████████████████████| 133k/133k [00:00<00:00, 9.21MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 13
file_sizes: 100%|████████████████████████████| 139k/139k [00:00<00:00, 9.26MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 14
file_sizes: 100%|████████████████████████████| 169k/169k [00:00<00:00, 50.0MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 15
file_sizes: 100%|████████████████████████████| 148k/148k [00:00<00:00, 17.6MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 16
file_sizes: 100%|████████████████████████████| 149k/149k [00:00<00:00, 39.7MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 17
file_sizes: 100%|████████████████████████████| 143k/143k [00:00<00:00, 54.4MB/s]
[INFO] Downloading [Chinatown KM] Volume. 1 Chapter. 3 page 18
file_sizes: 100%|████████████████████████████| 145k/145k [00:00<00:00, 60.8MB/s]
[INFO] [Chinatown KM] Vol. 1 Ch. 3 has finished download, converting to cbz...
cbz_progress: 100%|█████████████████████████| 18/18 [00:00<00:00, 1863.08item/s]
[INFO] Waiting for chapter read marker to finish
[INFO] Download finished for manga "Godzilla vs. SpaceGodzilla"
[INFO] Cleaning up...
Re-running the command (update):
mangadex-dl -lang "en" --save-as "cbz" --path "/home/x/Documents/Mangas/" --group "all" https://mangadex.org/title/91d7344d-04ff-43a9-a871-0727bb00663f/godzilla-vs-spacegodzilla
[INFO] Checking url = https://mangadex.org/title/91d7344d-04ff-43a9-a871-0727bb00663f/godzilla-vs-spacegodzilla
[INFO] Using English language
[INFO] Fetching all chapters...
[INFO] Downloading cover manga Godzilla vs. SpaceGodzilla
[INFO] File exist and replace is False, cancelling download...
[INFO] Download directory is set to "/home/x/Documents/Mangas/Godzilla vs. SpaceGodzilla"
[INFO] Using cbz format
[INFO] Preparing to download...
[INFO] '[Chinatown KM] Vol. 1 Ch. 1.cbz' is verified and no need to re-download
[INFO] '[Chinatown KM] Vol. 1 Ch. 2.cbz' is verified and no need to re-download
[INFO] '[Chinatown KM] Vol. 1 Ch. 3.cbz' is verified and no need to re-download
[INFO] Waiting for chapter read marker to finish
[INFO] Download finished for manga "Godzilla vs. SpaceGodzilla"
[INFO] Cleaning up...
The expected result was for mangadex-dl to download/update comic series located on the file server like the local test above.
Versions 2.7.x would save to the file server without issue.
Linux Mint 20.3 Cinnamon
Release v2.8.0
No development versions have been installed or used.
Other
mangadex-dl was initially installed via PyPI 3 versions ago (v.2.7.0 I believe). Updated to v2.8.0 today via the 'mangadex-dl --update' command. Had to manually update 'requests-doh' and 'requests' via PIP after update.
mangadex-dl -lang "en" --save-as "cbz" --path "/mnt/W/Manga/Manga/" --group "all" https://mangadex.org/title/de9e3b62-eac5-4c0a-917d-ffccad694381/sometimes-even-reality-is-a-lie
mangadex-dl --update console output from today, including PIP requirements errors that required manual updates:
Collecting mangadex-downloader
Downloading mangadex_downloader-2.8.0-py3-none-any.whl (3.1 MB)
|████████████████████████████████| 3.1 MB 1.3 MB/s
Requirement already satisfied, skipping upgrade: Pillow==9.3.0 in /home/x/.local/lib/python3.8/site-packages (from mangadex-downloader) (9.3.0)
Requirement already satisfied, skipping upgrade: requests[socks] in /usr/lib/python3/dist-packages (from mangadex-downloader) (2.22.0)
Requirement already satisfied, skipping upgrade: pathvalidate in /home/x/.local/lib/python3.8/site-packages (from mangadex-downloader) (2.5.2)
Requirement already satisfied, skipping upgrade: tqdm in /home/x/.local/lib/python3.8/site-packages (from mangadex-downloader) (4.64.1)
Requirement already satisfied, skipping upgrade: beautifulsoup4 in /usr/lib/python3/dist-packages (from mangadex-downloader) (4.8.2)
Collecting requests-doh==0.3.0
Downloading requests_doh-0.3.0-py3-none-any.whl (9.4 kB)
Requirement already satisfied, skipping upgrade: packaging in /usr/lib/python3/dist-packages (from mangadex-downloader) (20.3)
Requirement already satisfied, skipping upgrade: pyjwt in /usr/lib/python3/dist-packages (from mangadex-downloader) (1.7.1)
Requirement already satisfied, skipping upgrade: PySocks!=1.5.7,>=1.5.6 in /home/x/.local/lib/python3.8/site-packages (from requests[socks]->mangadex-downloader) (1.7.1)
Collecting dnspython[doh]==2.3.0
Downloading dnspython-2.3.0-py3-none-any.whl (283 kB)
|████████████████████████████████| 283 kB 48.4 MB/s
Requirement already satisfied, skipping upgrade: requests-toolbelt<0.11.0,>=0.9.1; extra == "doh" in /home/x/.local/lib/python3.8/site-packages (from dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (0.9.1)
Requirement already satisfied, skipping upgrade: httpx>=0.21.1; python_full_version >= "3.6.2" and extra == "doh" in /home/x/.local/lib/python3.8/site-packages (from dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (0.23.3)
Requirement already satisfied, skipping upgrade: h2>=4.1.0; python_full_version >= "3.6.2" and extra == "doh" in /home/x/.local/lib/python3.8/site-packages (from dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (4.1.0)
Requirement already satisfied, skipping upgrade: sniffio in /home/x/.local/lib/python3.8/site-packages (from httpx>=0.21.1; python_full_version >= "3.6.2" and extra == "doh"->dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (1.3.0)
Requirement already satisfied, skipping upgrade: certifi in /usr/lib/python3/dist-packages (from httpx>=0.21.1; python_full_version >= "3.6.2" and extra == "doh"->dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (2019.11.28)
Requirement already satisfied, skipping upgrade: rfc3986[idna2008]<2,>=1.3 in /home/x/.local/lib/python3.8/site-packages (from httpx>=0.21.1; python_full_version >= "3.6.2" and extra == "doh"->dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (1.5.0)
Requirement already satisfied, skipping upgrade: httpcore<0.17.0,>=0.15.0 in /home/x/.local/lib/python3.8/site-packages (from httpx>=0.21.1; python_full_version >= "3.6.2" and extra == "doh"->dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (0.16.3)
Requirement already satisfied, skipping upgrade: hpack<5,>=4.0 in /home/x/.local/lib/python3.8/site-packages (from h2>=4.1.0; python_full_version >= "3.6.2" and extra == "doh"->dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (4.0.0)
Requirement already satisfied, skipping upgrade: hyperframe<7,>=6.0 in /home/x/.local/lib/python3.8/site-packages (from h2>=4.1.0; python_full_version >= "3.6.2" and extra == "doh"->dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (6.0.1)
Requirement already satisfied, skipping upgrade: idna; extra == "idna2008" in /usr/lib/python3/dist-packages (from rfc3986[idna2008]<2,>=1.3->httpx>=0.21.1; python_full_version >= "3.6.2" and extra == "doh"->dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (2.8)
Requirement already satisfied, skipping upgrade: h11<0.15,>=0.13 in /home/x/.local/lib/python3.8/site-packages (from httpcore<0.17.0,>=0.15.0->httpx>=0.21.1; python_full_version >= "3.6.2" and extra == "doh"->dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (0.14.0)
Requirement already satisfied, skipping upgrade: anyio<5.0,>=3.0 in /home/x/.local/lib/python3.8/site-packages (from httpcore<0.17.0,>=0.15.0->httpx>=0.21.1; python_full_version >= "3.6.2" and extra == "doh"->dnspython[doh]==2.3.0->requests-doh==0.3.0->mangadex-downloader) (3.6.2)
ERROR: requests-doh 0.3.0 has requirement requests==2.28.2, but you'll have requests 2.22.0 which is incompatible.
Installing collected packages: dnspython, requests-doh, mangadex-downloader
Attempting uninstall: dnspython
Found existing installation: dnspython 2.2.1
Uninstalling dnspython-2.2.1:
Successfully uninstalled dnspython-2.2.1
Attempting uninstall: requests-doh
Found existing installation: requests-doh 0.2.3
Uninstalling requests-doh-0.2.3:
Successfully uninstalled requests-doh-0.2.3
Attempting uninstall: mangadex-downloader
Found existing installation: mangadex-downloader 2.7.2
Uninstalling mangadex-downloader-2.7.2:
Successfully uninstalled mangadex-downloader-2.7.2
Successfully installed dnspython-2.3.0 mangadex-downloader-2.8.0 requests-doh-0.3.0
requests-doh and requests threw an incompatibility error (version mismatch) during the update. I had to update them manually using python3 -m pip install --force-reinstall requests==2.28.1 and python3 -m pip install --force-reinstall requests-doh==0.3.0
/etc/fstab entry in Linux Mint for the file server:
//192.168.1.93/ga7pesh2 /mnt/W cifs username=x,password=xxxxxxxxxx,uid=1000,gid=1000,iocharset=utf8,rw,file_mode=0777,dir_mode=0777,sec=ntlmv2,nounix 0 0
Would it be possible for this program to have an optional flag to add the chapter title to the final file name? I feel that such a feature would be useful for certain file organizing schemes. Of course, this should be optional because there are bound to be many chapters with long titles.
It would be very nice to have a config file inside the main folder, so i can just set --save-as cbz and --path "" and especially --no-group-name so i dont have to write it every time i download something.
It would greatly ease the usability.
We can now embed the covers from "Art" in the volumes by using --use-volume-cover which is amazing.
However for example with "Rising of the SHield Hero" there are covers in like 10 different languages:
https://mangadex.org/title/0f237a5f-07ad-4e43-bbd9-2a320694434d/tate-no-yuusha-no-nariagari?tab=art
It seems to grab the first one it can find for every volume. Which is sometimes Russian, sometimes Japanese, etc.. It's a real mess honestly to see each volume do a lottery on which language it'll use for a cover.
It'd be a real great quality of life if in some way the user could choose the locale "en", "jp" or somehow to define which language the covers should prefer.
It would fix the somewhat messy multiple cover languages that we're currently getting when a manga has multiple language art covers.
details.json doesnt get downloaded if im using --save-as format-volume/single. works if im saving as format without volume/single.
download details.json
Windows 10 20H2
mangadex-downloader v2.9.0 (https://github.com/mansuf/mangadex-downloader)
Python: 3.10.11
arch: x64
bundled executable: yes
Github releases
No response
mangadex-dl.exe --save-as "cbz-volume" --write-tachiyomi-info --use-volume-cover "https://mangadex.org/title/897959ff-cc94-4627-a9c5-ac13af5ba89f/reversible"
No response
Greetings. Appreciate your work on mangadex-downloader, that's a handy tool!
Earlier there was a request for grouping volume chapters files into standalone volume files:
#13 (comment)
For some reason only pdf-volume format was added, while there are people who prefer cbz.
When downloading a volume with PDF conversion enabled it will error out with OSError: image file is truncated (34 bytes not processed)
This is a well know error, with already implemented error handling. But that error handling doesn't work in my case.
The problematic piece of code, in mangadex_downloader/format/pdf.py:
def check_truncated(self, img):
# Pillow won't load truncated images
# See https://github.com/python-pillow/Pillow/issues/1510
# Image reference: https://mangadex.org/chapter/1615adcb-5167-4459-8b12-ee7cfbdb10d9/16
err = None
try:
img.load()
except OSError as e:
err = e
else:
return False
if err and 'broken data stream' in str(err):
ImageFile.LOAD_TRUNCATED_IMAGES = True
elif err:
# Other error
raise err
# Load it again
img.load()
return True
In my case it enters the elif, instead of the conditional that was meant to deal with this issue. What I did is I just moved ImageFile.LOAD_TRUNCATED_IMAGES = True before fist img.load() and it fixed this issue. I guess you could alter the if statement so this would work too.
Conditional meant to handle this error to catch it.
Solus 4.3 (Linux)
mangadex-downloader v2.8.0 (https://github.com/mansuf/mangadex-downloader)
Python: 3.10.9
arch: x64
bundled executable: no
PyPI (Python Package Index)
No response
mangadex-dl --save-as pdf-volume --start-chapter 4 https://mangadex.org/title/34f45c13-2b78-4900-8af2-d0bb551101f4/dorohedoro
Full error log:
[INFO] Vol. 4 has finished download, converting to pdf...
pdf_progress: 1%|▋ | 1/186 [00:00<00:30, 6.14item/s][ERROR] We have problem in queue worker
Traceback (most recent call last):
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/utils.py", line 214, in run
job()
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 491, in <lambda>
worker.submit(lambda: self.convert(images, pdf_file))
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 390, in convert
im.save(
File "/home/jacek/.local/lib/python3.10/site-packages/PIL/Image.py", line 2353, in save
save_handler(self, fp, filename)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 108, in _save_all
self._save(im, fp, filename, save_all=True)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 190, in _save
truncated = self.check_truncated(im)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 100, in check_truncated
raise err
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 90, in check_truncated
img.load()
File "/home/jacek/.local/lib/python3.10/site-packages/PIL/ImageFile.py", line 254, in load
raise OSError(
OSError: image file is truncated (34 bytes not processed)
Stack (most recent call last):
File "/usr/lib/python3.10/threading.py", line 973, in _bootstrap
self._bootstrap_inner()
File "/usr/lib/python3.10/threading.py", line 1016, in _bootstrap_inner
self.run()
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/utils.py", line 216, in run
log.error("We have problem in queue worker", exc_info=err, stack_info=True)
[ERROR] Unhandled exception, OSError: image file is truncated (34 bytes not processed)
Traceback (most recent call last):
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/cli/__init__.py", line 73, in _main
download(args)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/cli/download.py", line 33, in download
url(args, args.type)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/cli/url.py", line 161, in __call__
self.func(self.id, args)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/cli/url.py", line 95, in download_manga
dl_manga(*args)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/main.py", line 163, in download
download_manga(manga, base_path)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/main.py", line 133, in download_manga
fmt.main()
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/base.py", line 539, in main
self.download_volumes(worker, volumes)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 491, in download_volumes
worker.submit(lambda: self.convert(images, pdf_file))
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/utils.py", line 196, in submit
raise err
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/utils.py", line 214, in run
job()
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 491, in <lambda>
worker.submit(lambda: self.convert(images, pdf_file))
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 390, in convert
im.save(
File "/home/jacek/.local/lib/python3.10/site-packages/PIL/Image.py", line 2353, in save
save_handler(self, fp, filename)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 108, in _save_all
self._save(im, fp, filename, save_all=True)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 190, in _save
truncated = self.check_truncated(im)
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 100, in check_truncated
raise err
File "/home/jacek/.local/lib/python3.10/site-packages/mangadex_downloader/format/pdf.py", line 90, in check_truncated
img.load()
File "/home/jacek/.local/lib/python3.10/site-packages/PIL/ImageFile.py", line 254, in load
raise OSError(
OSError: image file is truncated (34 bytes not processed)
pdf_progress: 1%|█
Sometimes, a Manga is uploaded by multiple Scanlation groups.
And if the Manga is Licensed to a Publisher (like MangaPlus, etc.), a redirect link is also given on the specific Chapter.
For Example, See: https://mangadex.org/title/296cbc31-af1a-4b5b-a34b-fee2b4cad542/-oshi-no-ko?page=4
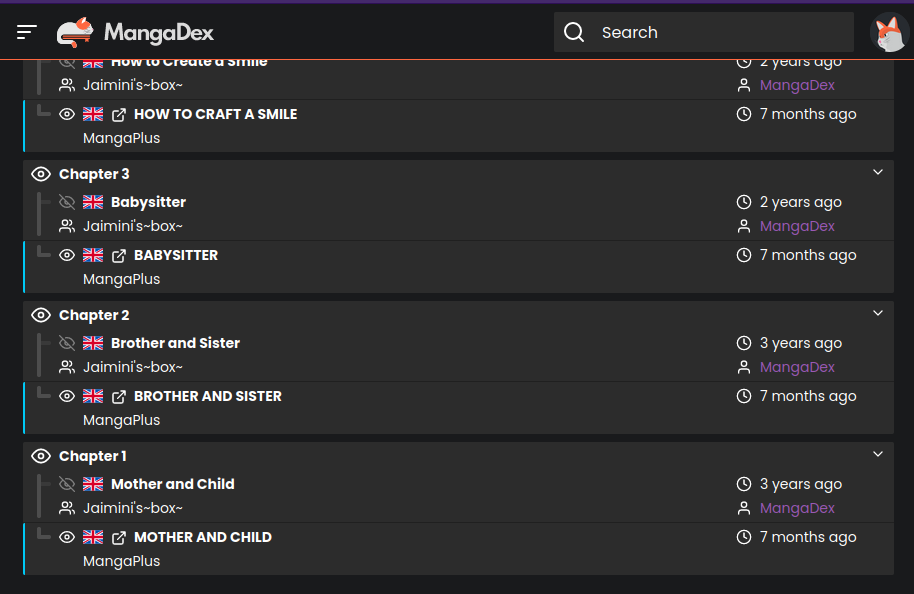
The Chapters 1 through 6 has two uploader, the first is Licensed and the second is the scanlation group's upload.
The App always tries to download from the first uploader link. If the link has no image, it just skips the chapter without trying other uploader link from the same chapter.


If any specific chapter has multiple uploader, and if the first link returns no image, then app should try to download from second link of the same chapter if scanlator group is not fixed by command line.
Also, please note that if I use --group all in command line, then each and every uploads for all chapters are downloaded as the command expects it from.
But I don't want to write the group name in the files as-well-as want to skip the chapter links which are redirecting to non-mangadex links automatically, no matter what filters are added in the command line.
Ubuntu 22.04 LTS (on Github Actions)
mangadex-downloader v2.5.0 (https://github.com/mansuf/mangadex-downloader)
Python: 3.10.6
arch: x64
bundled executable: no
PyPI (Python Package Index)
No response
mangadex-downloader "https://mangadex.org/title/296cbc31-af1a-4b5b-a34b-fee2b4cad542/-oshi-no-ko" --language "en" --cover "original" --use-compressed-image --start-chapter 1 --end-chapter 6 --save-as raw --use-chapter-title --no-group-nameEven if I skip --no-group-name in the above command, the app skips all the chapters as no image are returned from the links.
As a way to help organize files for some programs, and have a cleaner look, it would be nice to add one or more leading zeroes for files and folders.
For example, instead of:
page 8.jpg
page 9.jpg
page 10.jpg
...
page 105.jpg
Have the files titled:
page 008.jpg
page 009.jpg
page 010.jpg
page 105.jpg
Some programs display the pages out of order without this.
Previously, the app has self-generated chapter info (cover). But it was ugly and not look good.

Then it was removed later in v2.0.0 and use MangaDex generated instead.

Using @NidokingMaster idea, we can create new self-generated chapter info (cover) using Pillow library.

from PIL import Image, ImageDraw, ImageFont, ImageFilter, ImageEnhance
import requests
import textwrap
def draw_multiple_line_text(image, text, font, text_color, text_start_height):
'''
From unutbu on [python PIL draw multiline text on image](https://stackoverflow.com/a/7698300/395857)
'''
draw = ImageDraw.Draw(image)
image_width, image_height = image.size
y_text = text_start_height
lines = textwrap.wrap(text, width=19)
for line in lines:
line_width, line_height = font.getsize(line)
draw.text(((image_width - line_width) / 2, y_text),
line, font=font, fill=text_color)
y_text += line_height
def main():
# get image from MangaDex
r = requests.get("https://mangadex.org/covers/0bd72573-7512-4a38-b9fe-ae00a4776fdd/9aab4ff4-68da-4a74-8036-987a1f69d6b8.jpg", stream=True)
image = Image.open(r.raw)
# resize image to fixed 1000px width (keeping aspect ratio) so font sizes and text heights match for all covers
aspect_ratio = image.height / image.width
new_width = 1000
new_height = new_width * aspect_ratio
image = image.resize((int(new_width), int(new_height)), Image.LANCZOS)
# apply blur and darken filters
image = image.filter(ImageFilter.GaussianBlur(6))
image = ImageEnhance.Brightness(image).enhance(0.3)
text_color = (255, 255, 255)
title_font = ImageFont.truetype("arialbd.ttf", size=100)
title_text_start_height = 50
title_text = "You Weren't My Sister, but My Fiancée?"
chinfo_font = ImageFont.truetype("arial.ttf", size=60)
chinfo_text_start_height = 650
chinfo_text = "Vol. 1 Ch. 3"
scanlated_font = ImageFont.truetype("ariali.ttf", size=25)
scanlated_text_start_height = 1100
scanlated_text = "scanlated by:"
group_font = ImageFont.truetype("arialbd.ttf", size=50)
group_text_start_height = 1140
group_text = "ToruScans"
# draw Title text
draw_multiple_line_text(image, title_text, title_font, text_color, title_text_start_height)
# draw Volume/chapter info
draw_multiple_line_text(image, chinfo_text, chinfo_font, text_color, chinfo_text_start_height)
# draw "scanlated by:" text
draw_multiple_line_text(image, scanlated_text, scanlated_font, text_color, scanlated_text_start_height)
# draw scanlation group
draw_multiple_line_text(image, group_text, group_font, text_color, group_text_start_height)
image.save('pil_text.png')
if __name__ == "__main__":
main()
References:
This new chapter info (cover) looks good than the previous self-generated one and we don't have to rely on MangaDex for chapter info (cover) creation. Because who knows MangaDex embed server is down (og.mangadex.org, see #40 (comment)).
Is there a flag that will allow us to only download the newest "n" chapters?
I would like to run this script automatically once a week, and download the newest, say 5, chapters from each release I'm following. Right now I only see how to download a set number range which wouldn't work as you need to know the chapter number and change it each time.
It would be useful to have a chapters parameter in the MangaDex.download() function which allows the user to pass a list of specific chapters to download
So you could just search for certain year and highest rating and download the first 3 chapters from all those manga to then test read what you like to read further all from your CLI :)
Maybe the workflow could be like: mangadex-dl -s -sf "year=2022" -sf "rating=8-10" then the first 100 are presented in descending rating and you can say download the first 1-3 chapters from the first 10-100 manga from best rated to worst.
That would be brilliant for quickly finding new manga and test them.
Greatly enhances workflow of finding new manga to read.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.