2021 Project Status: Active development will resume on Saturday the 27th of February.

Note: Version 4 of the add-on is only available for Anki 2.1+. Some features will be missing from the earlier versions.
This is a rewrite of the Incremental Reading add-on, which aims to provide features that support incremental reading in Anki. The idea of working with long-form content within a spaced-repetition program appears to have originated with SuperMemo, which offers an elaborate implementation of the technique (see their help article for more information). This add-on for Anki is comparatively bare-bones, providing a minimal set of tools for iterating over long texts and creating new flashcards from existing ones. For an overview of these features, see below.
- Version 4: GitHub, issue tracker, discussion board
- Version 3: GitHub, discussion board
- Version 2: AnkiWeb, GitHub, manual
- Import content from web feeds (RSS/Atom), webpages, or Pocket (v4 only)
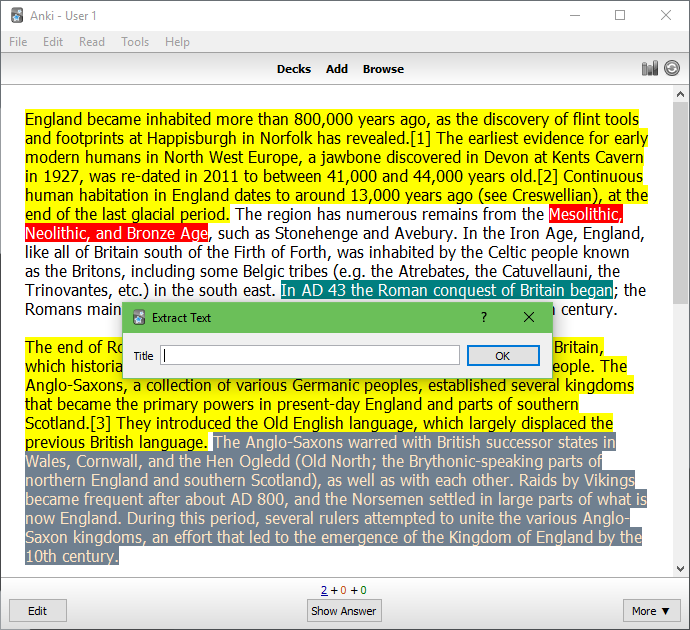
- Extract selected text into a new card by pressing x
- Highlight selected text by pressing h
- Remove selected text by pressing z
- Undo changes to the text by pressing u
- Apply rich text formatting while reading
- Create custom shortcuts to quickly add cards
- Maintain scroll position and zoom on a per-card basis
- Rearrange cards in the built-in organiser
- Control the scheduling of incremental reading cards
- Limit the width of cards (useful on large screens) (v4 only)
- Compatible with Anki 2.1
- Import single webpages (Alt+3)
- Import web feeds (Alt+4)
- Import Pocket articles (Alt+5)
- Apply bold, italics, underline or strikethrough (Ctrl+B, I, U, or S)
- Toggle formatting on and off (Ctrl+Shift+O)
- Choose maximum width of cards (see options: Alt+1)
- Control initial scheduling of extracts (see options: Alt+1)
- Remove unwanted text with a single key-press (z)
- Multi-level undo, for reverting text changes (u)
- New options to control how text is extracted:
- Open the full note editor for each extraction (slow), or simply a title entry box (fast)
- Extract selected text as HTML (retain color and formatting) or plain text (remove all formatting)
- Choose a destination deck for extracts
- New options for several aspects of zoom and scroll functionality:
- Zoom Step (the amount that magnification changes when zooming in or out)
- General Zoom (the zoom level for the deck browser and overview screens)
- Line Step (the amount the page moves up or down when the Up or Down direction keys are used)
- Page Step (same as above, but with the Page Up and Page Down keys)
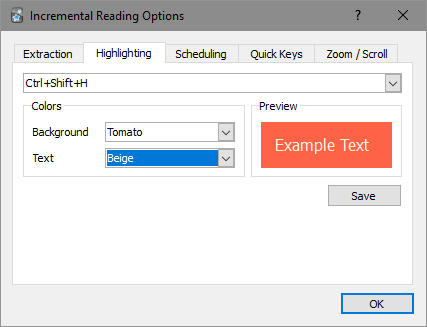
- Highlighting:
- Both the background color and text color used for highlighting can be customized
- A drop-down list of available colors is provided
- A preview is now displayed when selecting highlight colors
- The colors applied to text extracted with x can now be set independently
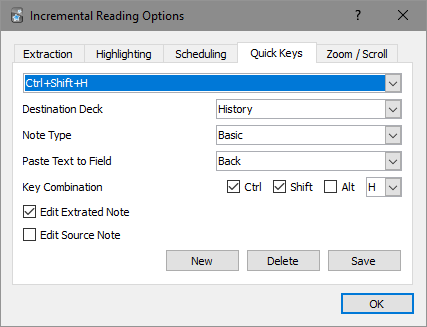
- Quick Keys
- A list of all existing Quick Keys is now shown, to allow easy modification
- Unwanted Quick Keys can be easily deleted
- A plain text extraction option has also been added
- All options have been consolidated into a single tabbed dialog
Note: These are fairly outdated.
You will first need to have Anki installed. Download the relevant installer here.
To install through Anki, navigate to Tools → Add-ons → Get Add-ons..., and enter the code 935264945. To install manually, download the GitHub repository (here) and place the ir folder into your add-ons folder.
Experimentation should lead to a pretty quick understanding of how the add-on works. If in doubt, start with the following:
- Create a new IR note with an article you want to study (the easiest way to do this is to import a webpage, by pressing Alt+3 while on the deck overview screen)
- Set up a shortcut for creating regular Anki cards from IR cards (press Alt+1, or go to the menu, then go to the Quick Keys tab)
- Review the IR card that was created, and extract any text you find interesting (by selecting the text and pressing x)
- Choose Soon or Later when you want to move to the next card (which will be a portion of text you extracted)
- Whenever you want to create a regular Anki note, simply select the desired text and use the shortcut you created earlier
Outdated instructions can be found here. They were written for v2, but the basic behaviour of the add-on is still similar.
If any issues are encountered, please post details to the Anki add-ons forum. It’s best if you post in the existing thread (here) so I receive an email notification. Otherwise, note an issue or make a pull request on GitHub.
Please include the following information in your post:
- The version of Anki you are using (e.g., v2.1.0-beta5; can be found in Help → About...)
- The version of IR you are using (this can be found in Read → About...)
- The operating system you are using
- Details of the problem
- Steps needed to reproduce the problem
Multiple people have contributed to this add-on, and it’s somewhat unclear who to credit for which changes and which licenses to apply.
Tiago Barroso appears to have initiated the project, and he has stated that he releases all of his add-ons under the ISC license. Frank Kmiec later vastly expanded the add-on, but it’s unclear which license his changes were released under. Presuming he didn’t specify one, the AnkiWeb terms and conditions suggest they were automatically released under the AGPL v3. Aleksej’s changes to Frank’s version are multi-licensed under the GPL and ISC licenses.
For the sake of simplicity, my changes are also released under the ISC license. For each author, I have placed a copyright lines where appropriate, with what I believe are correct dates. If I have made a mistake in this respect, please let me know.
Frank Raiser released an Anki 1 add-on under a similar name, but it doesn’t appear to share any code with the current project and functions quite differently. For more information, see Anki Incremental Reading.







































































































































