META: This is a sketch of a blogpost. Please help improve it!
Scaling Lookout: Device Push via Microservices
We're starting to roll out a new way to push commands to devices. It's designed to be secure and simple; our simple design provided easy affordance for composability, scalability, and reliability.
As a short introduction, we started with two Rails apps.
The big Rails app was responsible for the vast majority of application logic. The small Rails app was responsible for ingesting credentials for Google/Apple/etc push services and using those services to ping devices. It held no long-term state. The devices, upon receiving the ping, would then go back to the big Rails app and ask for its commands.
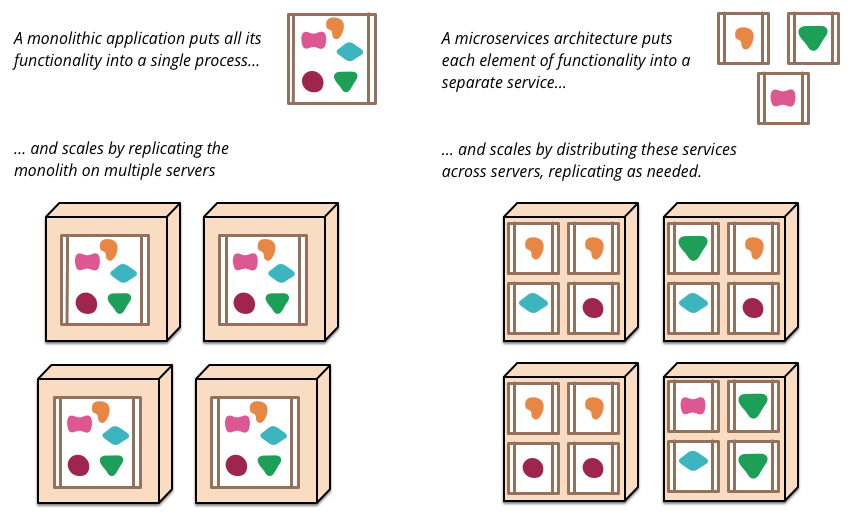
We are breaking our monolithic app into a variety of different services.
Our top-level engineering design goals, for device push as well as for all other engineering projects, are simplicity, composability, scalability, and reliability.
Simplicity helps us reason about each part of the system. Composability helps each well-defined part work as a whole. Scalability helps us with growth as a company. Horizontal and vertical scalability, especially for this sort of a linear problem, comes from a decoupled design. Reliability helps us build systems on top of this infrastructure. Durability, high availability, and fault tolerance all help to achieve reliability.
SIMPLICITY
Rich Hickey talks at length about simplicity. FIXME links
Simplicity is different from easiness.
"Simple" (sim-plect-) means "single plait" or "one fold", which is no fold at all, and is how many "twists" something has. "Easy", as best we can tell, comes from the same root as "adjacent", which is "nearby" in ability or access.
Querying a relational database with an object-relational mapper is easy, for anyone who writes server code. It's very close to pre-existing knowledge, but it twists together relational algebra, object models, stored values, time, two different programming languages, global locks, and much more. An append-only log is simple; the lack of mutation, for instance, means that the values readable in the log are not tied together with a notion of time.
"Simple", furthermore, is an objective term, based on how many things are plaited together, woven together in the code. "Easy" is a relative term, based on who declares something easy, and the entire personal history behind that declaration. What had been easy one day might be difficult the next, depending on what things are available.
Our old small Rails app was easy. It was an Apache+Passenger+Rails stack, using ActiveRecord to talk to MySQL. This stack is use in many places throughout our architecture. We are familiar with using each component, to varying degrees, and familiar with deploying it. The Rails app can modify any state at any time. We can add ever more responsibilities into this one Rails app. Integration testing has all the pieces right near by, in one box.
But we got into this mess because the large application that this talks to was built exactly the same way. Simplicity is breaking that box apart. Simplicity means that command storage is its own small component, which is separate from push token storage, which is separate from message signing, which is separate from GCM/APNS/ADM device push API requests. Message passing enforces strict separations between components. (Many layers of encapsulation are broken when a global database is conscripted to also be everyone's queue.)
http://martinfowler.com/articles/microservices/images/sketch.png
When we break the components apart, we get Sinatra + nginx in front, mainly for routing through our small API. Sinatra has the benefit of being both simple (not intertwined with many other components) as well as easy.
When we try to scale our service we can immediately see the benefits of simplicity.
If our Rails app is a monolithic box, and we need to scale up one component, we have no choice but to deploy more monolithic boxes. If another component is 10x over-provisioned, there's no straightforward way to deploy 46% of the Rails app. Everything is in the same box, and the bigger the box gets the more difficult it gets to reason about shared state.
When we try to scale up a highly-used component, it is its own small Sinatra app, and deploying 10x of those is much more lightweight and understandable, and our load balancer can route to many more upstreams, and we have better separation of concerns.
We also wanted to avoid the complexity that comes from mixing transactional queries and analytical queries.
The old small Rails app had an admin page, full of the current state of every device ping. The admin page was a reminder of many anti-patterns that we hoped to avoid. First, the state was all backed in a database, and the asynchronous job processing generated invalid SQL (due to inscrutable race conditions in old thread-unsafe versions of ActiveRecord). Second, the global state of the world provided only partial insight; for instance, we could not tell the mean and standard deviation of the time to send a ping. (Our best guess was that it was "relatively fast", which is unsatisfyingly qualitative.) Also, we could not correlate the state with the state of any other components of the application (like whatever was causing the pings to be sent, to gauge overall round trip speeds).
So we pared down the app to only processing transactions, and all historical insight comes from our event log. Once we stopped generating HTML, we could ditch all of our HTML templates and Javascript and things like XSS protections, and our app became smaller, more performant, and easier to understand. Further, once we shipped the complete event log to a centralized place, we had a much richer view of the world, and were able to answer basic performance-related questions like determining the standard deviation of processing time to ping a device.
We chose the simplicity of an event log over the ease of global state in the app, and the benefits made the choice obvious.
SIMPLE SECURITY
The security requirements are prevention of forgery, prevention of Man-In-The-Middle attacks, prevention of replay attacks, and prevention of eavesdropping. We wanted all of those guarantees while keeping with a simple design.
All of Lookout's inter-service API calls require a JWT, signed by a service's private RSA key, and the public keys are all held in a central repository we call Keymaster.
We attempt to thwart forgery/MITM/eavesdropping by enforcing that all API calls to the push service are made with JWTs signed by our inbound's private key and encrypted with our public key, and these JWTs contain the API endpoint's parameters of command payload and the specific service's feature; the response is a unique tracking id for the payload on the message bus.
We prevent replay attacks by having a table of each device's incrementing counter server-side, and keeping a durable counter device-side, and before payloads go into command storage they are re-encapsulated into another JWT with the counter, and devices must verify that the counter encapsulated with the command is strictly greater than its internal counter.
We prevent forgery by keeping private keys for each feature of each service, correlating the inbound feature's service with the inbound Keymaster signature's key.
We prevent forgery/MITM/replay/eavesdropping by enforcing that devices fetch their commands with Keymaster tokens and internal counters, and then all commands with higher counters get returned for client-side verification.
SIMPLICITY GOALS: HOW WELL WE ACHIEVED THEM
We constructed a push service that was stateless, event-driven, with loosely-coupled waterfall queues that were used by microservices. Our message encapsulation and signing succeeds at keeping device payloads secure, but one of our data store backend choices let to tighter coupling, which we'll discuss later. FIXME are we going to be discussing Chef and Micropush owning env mgmt or is that just us being dumm about things
COMPOSABLE
"Agile and XP have shown us that refactoring and tests [ASK AKUHN ABOUT THE QUOTE] lets us make change with zero impact. I never knew that; I still do not know that." -- Rich Hickey
"When things are intertwined together, we lose the ability to take them in isolation." -- Rich Hickey
When trying to compose two pieces of software, the only way forward is to fundamentally understand and control what the software does. Relying on tests to guide your implementation is like relying on freeway guardrails to get you where you're going. They'll stop you from driving off of a cliff, but they won't stop you from taking the road in the wrong direction, or from wrecking your car in the process.
When things are intertwined together, we lose the ability to take them in isolation.
We have four different isolated services, which (in the ensemble) comprise the push service: message signing, command storage, push token storage, and asynchronous device push API requests.
First, a device registers its push tokens with token storage.
~message signing~
~command storage~
~async workers~
~token storage~ <---- Device
Next, a service will want to send the device a command. We receive the request with a keymaster token, encapsulate the command with the device's counter and sign it with the service's feature key, and generate a message id.
Service <----> message signing
|
v
~command storage~ ----> Device
|
v
~async workers~ ----> Push Services
^ |
| v
~token storage~ <---- Device
We will store the command, and a job will start to ping a device.
Service <----> message signing
|
v
~command storage~ ----> Device
|
v
~async workers~ ----> Push Services
^ |
| v
~token storage~ <---- Device
The device receives the command.
Service <----> message signing
|
v
~command storage~ ----> Device
|
v
~async workers~ ----> Push Services
^ |
| v
~token storage~ <---- Device
Our simple security model composes well.
The inbound request is wrapped with a signed and encrypted Keymaster token with a payload and a feature and a priority. This prevents forgery and eavesdropping. Further, because the request was signed and encrypted, we are more resilient to vulnerabilities in the security of our TLS transport, we are better able to write these innocuous pseudo-random bytes to a message bus, and we can use external cloud machines to serve / compute on sensitive data for devices.
SCALABILITY
The Apache+Passenger+Rails stack is easy. Everything is in the one-size-fits-all box. To scale up, just put more boxes out there.
Not only does this waste space, but it also becomes progressively harder to understand.
The Sinatra+nginx stack is simple. Everything is in its own box. To scale up, add more boxes.
Asynchronous workers are usually under low load, as is message signing. Give this three boxes. Token storage receives push tokens from all existing devices, so that has higher CPU and network needs. Command storage not only receives devices checking in for their messages on a ping, but also every single device daily. (We wanted to poll to ensure devices would receive commands, even if there were bugs that would stop devices from getting pinged.) Command storage has higher outbound bandwidth requirements, and stricter latency requirements (we assume there are no race conditions between devices receive push tokens from the operating system and Lookout services trying to contact devices).
Because our system is made of small boxes loosely joined, we can add another box that has a message bus like Kafka, and it is straightforward to connect the pieces to use that. (As a thought experiment, consider how much of a bungle it would be trying to scale asynchronous job processing if each worker had to perform large OLAP queries on one large global OLTP database.)
RELIABILITY
"Simplicity is a prerequisite for reliability." -- Dijkstra
We want high availability, from database to application, we want to be tolerant of partial failures, we want zero downtime (be it deploys or outages), and we want to be multi-datacenter.
...


{kind=link}