blog's People
Contributors

Stargazers
Watchers

blog's Issues
如何用JavaScript实现一门编程语言 - 保护堆栈
整篇译文的目录章节如下:
- 前言
- λanguage描述
- 写一个解析器(Parser)
- 简单的解释器(Interpreter)
- CPS求值器(CPS Evaluator)
- 保护堆栈
- Continuations
- Yield进阶
- 编译成JS
- 总结
- 真实示例
保护堆栈
CPS求值器中堆栈消耗得更快,因为它持续调用其它函数来推进程序流并且一直没有返回。不要太相信return语句—它们很必要,但在递归非常深的情况下,可能还没等执行到它们就堆栈溢出报错了。
想象一个非常简单程序的堆栈会是什么样子。下面展示了相应的伪代码,其中没包括env是因为对展示堆栈深度不重要。
print(1 + 2 * 3);
## stack:
evaluate( print(1 + 2 * 3), K0 )
evaluate( print, K1 )
K1(print) # it's a var, we fetch it from the environment
evaluate( 1 + 2 * 3, K2 )
evaluate( 2 * 3, K3 )
evaluate( 2, K4 )
K4(2) # 2 is constant so call the continuation with it
evaluate( 3, K5 ) # same for 3, but we're still nesting
K5(3)
K3(6) # the result of 2*3
evaluate( 1, K6 ) # again, constant
K6(1)
K2(7) # the result of 1+2*3
print(K0, 7) # finally get to call print
K0(false) # original continuation. print returns false.只有当最后一个continuation(K0)执行完之后才会轮到一系列无助的return来释放堆栈。对一个如此简单的程序都嵌套这样深,可以想象fib(13)是如何快速地把堆栈空间消耗光的。
堆栈守卫(stack guard)
我们新写的求值器中,堆栈简直就是垃圾。程序每一步后续的计算都需要包裹在传入的回调函数中。所以这也带出一个问题:如果JavaScript能够提供某种方式重置堆栈会怎样?那么我们就可以不时地这样操作,就像某种垃圾回收机制一样,这样深层递归也可以工作。
假设我们有一个GUARD函数可以完成这种重置。它接收两个参数:一个将要调用的函数和一个将要传给它的参数数组。它会检查堆栈,如果嵌套太深则会重置堆栈,然后再调用传入的函数;否则什么都不会做。
使用该函数重写后的求值器如下。因为跟之前代码一样,所以不会解释每种情况;唯一的修改就是在每个函数最前面增加了GUARD函数。
function evaluate(exp, env, callback) {
GUARD(evaluate, arguments);
switch (exp.type) {
case "num":
case "str":
case "bool":
callback(exp.value);
return;
case "var":
callback(env.get(exp.value));
return;
case "assign":
if (exp.left.type != "var")
throw new Error("Cannot assign to " + JSON.stringify(exp.left));
evaluate(exp.right, env, function CC(right){
GUARD(CC, arguments);
callback(env.set(exp.left.value, right));
});
return;
case "binary":
evaluate(exp.left, env, function CC(left) {
GUARD(CC, arguments);
if (exp.operator === '&&') {
if (left === false) {
callback(left);
} else {
evaluate(exp.right, env, function CC(right) {
GUARD(CC, arguments);
callback(right);
});
}
} else if (exp.operator === '||') {
if (left) {
callback(left);
} else {
evaluate(exp.right, env, function CC(right) {
GUARD(CC, arguments);
callback(right);
});
}
} else {
evaluate(exp.right, env, function CC(right) {
GUARD(CC, arguments);
callback(apply_op(exp.operator, left, right));
});
}
});
return;
case "let":
(function loop(env, i){
GUARD(loop, arguments);
if (i < exp.vars.length) {
var v = exp.vars[i];
if (v.def) evaluate(v.def, env, function CC(value){
GUARD(CC, arguments);
var scope = env.extend();
scope.def(v.name, value);
loop(scope, i + 1);
}); else {
var scope = env.extend();
scope.def(v.name, false);
loop(scope, i + 1);
}
} else {
evaluate(exp.body, env, callback);
}
})(env, 0);
return;
case "lambda":
callback(make_lambda(env, exp));
return;
case "if":
evaluate(exp.cond, env, function CC(cond){
GUARD(CC, arguments);
if (cond !== false) evaluate(exp.then, env, callback);
else if (exp.else) evaluate(exp.else, env, callback);
else callback(false);
});
return;
case "prog":
(function loop(last, i){
GUARD(loop, arguments);
if (i < exp.prog.length) evaluate(exp.prog[i], env, function CC(val){
GUARD(CC, arguments);
loop(val, i + 1);
}); else {
callback(last);
}
})(false, 0);
return;
case "call":
evaluate(exp.func, env, function CC(func){
GUARD(CC, arguments);
(function loop(args, i){
GUARD(loop, arguments);
if (i < exp.args.length) evaluate(exp.args[i], env, function CC(arg){
GUARD(CC, arguments);
args[i + 1] = arg;
loop(args, i + 1);
}); else {
func.apply(null, args);
}
})([ callback ], 0);
});
return;
default:
throw new Error("I don't know how to evaluate " + exp.type);
}
}为了可以引用到匿名函数,需要给它们声明一个名字。我使用了CC(代表“current continuation”)。 或者另外一种方法使用arguments.callee,但我们还是不要用废弃的API了。
同样make_lambda只有一行代码改动:
function make_lambda(env, exp) {
if (exp.name) {
env = env.extend();
env.def(exp.name, lambda);
}
function lambda(callback) {
GUARD(lambda, arguments); // <-- this
var names = exp.vars;
var scope = env.extend();
for (var i = 0; i < names.length; ++i)
scope.def(names[i], i + 1 < arguments.length ? arguments[i + 1] : false);
evaluate(exp.body, scope, callback);
}
return lambda;
}GUARD的实现真的非常简单。如何做到从一个深层嵌套调用里立即退出?— 使用异常。所以我们维护了一个限制堆栈最大嵌套层级的全局变量,当达到了这个限制,则抛出异常。我们抛出一个Continuation对象,该对象持有后续计算的信息 — 将要调用的函数及其参数:
var STACKLEN;
function GUARD(f, args) {
if (--STACKLEN < 0) throw new Continuation(f, args);
}
function Continuation(f, args) {
this.f = f;
this.args = args;
}最后需要设置一个循环来捕获Continuation对象。我们还必须借助循环来执行求值器进而使整体方案运作起来。
function Execute(f, args) {
while (true) try {
STACKLEN = 200;
return f.apply(null, args);
} catch(ex) {
if (ex instanceof Continuation)
f = ex.f, args = ex.args;
else throw ex;
}
}Execute接收一个将要运行的函数f及其参数args。函数f最终是在循环中执行,但请注意这里的return—如果执行期间没发生异常,最终程序就会在此结束。STACKLEN会在每次循环开始时被初始化。我发现200是一个合适的值。当捕获到了一个Continuation对象,函数f及其参数args会被恢复为Continuation对象中保存的值,然后继续执行循环。堆栈此时会因异常而被清理,所以又可以继续嵌套执行了。
我们可以像下面这样使用Execute来运行求值器:
Execute(evaluate, [ ast, globalEnv, function(result){
console.log("*** Result:", result);
}]);测试
fib函数不会再失败了:
fib = λ(n) if n < 2 then n else fib(n - 1) + fib(n - 2);
time( λ() println(fib(20)) );可惜尝试fib(27)则会发现其执行时间要比第一版(非CPS)求值器大概慢4倍。但至少可以无限递归下去,如下面例子所示:
sum = λ(n, ret)
if n == 0 then ret
else sum(n - 1, ret + n);
# compute 1 + 2 + ... + 50000
time( λ() println(sum(50000, 0)) );我们的语言事实上要比JavaScript慢很多!设想一下每个变量都必须通过环境对象来查询。尝试优化解释器已经没有意义了 — 没有更多优化空间了。获取更快速度的办法只有将λanguage语言编译成原生JS,这也是我们即将要做的。但首先我们来看一些CPS求值器带来的有趣结果。
如何理解JS中的闭包
如何理解JS中的闭包?
对于函数是一等对象的语言来说,下面两种典型的情况,会存在变量如何取值的问题。
case a. 将函数当参数传递
var x = 15;
function A () {
console.log(x);
}
function B (fn) {
var x = 20;
fn();
}
B(A); // 15, but not 20case b. 将函数作为返回值
function B () {
var x = 10;
function A () {
console.log(x);
}
return A;
}
var x = 20;
B()(); // 10, but not 20从语言实现层面来看,JS中闭包是解决上面两种情况下变量取值的一种机制。
对于闭包常见的描述,比如缓存变量等,只不过是对上面语言实现特性的典型应用。
JS中变量作用域使用的是静态作用域(static scope),在JS引擎解析JS代码时,各个函数能访问到的作用域以及相应的变量已经定了,并且不会再改变。比如上面函数A定义的时候,其能访问到的变量已经定了。对于case a,函数A声明的时候已经决定了其只能访问到全局作用域,并且后续不会发生改变,即始终只能访问到全局变量x和全局函数声明B,访问不到函数B中的局部变量x,不管其后续如何执行,打印出来的结果总是全局变量x的值;对于case b,函数A在函数B执行的时候才被声明,其能访问到的作用域,首先是函数B的局部作用域(局部变量x),然后是全局作用域(全局变量x和全局函数声明B),所以函数A打印的始终是局部变量x的值,而不管其后续如何执行。
通过上面的描述,我们也可以推断闭包名字的由来
闭包(closure)就像是对作用域的一种闭合(closing),在函数定义的时候,其作用域已经决定了,并且后续使用不会再改变,即作用域已经闭合了。
通过case a和case b的对比,我们可以进一步给出闭包更加广义层面的定义,JS中任何一个函数都是闭包,而不仅仅是case b中那种教科书上面狭义的定义,全局函数也是闭包,是对全局作用域的一种闭合。
Reference
如何用JavaScript实现一门编程语言 - 我们得到了什么
整篇译文的目录章节如下:
我们得到了什么
到目前为止,λanguage语言虽然弱小,但(理论上)可以解决任何可计算的问题。得益于聪明的前人 — 阿隆佐·丘奇(Alonzo Church)和阿兰·图灵(Alan Turing)— 证明了λ演算(λ-calculus)和图灵机(Turing machine)是等价的,我们的λanguage语言正是建模了λ演算(λ-calculus)。
这意味着即使λanguage语言缺少了某些特性,我们也可以基于现有的特性来实现它们,或者如果证实实现太困难,也可以基于λanguage语言来实现另一门语言的解释器进而支持这些特性。
循环
循环在已支持递归的情况下是非必需的。我已经展示过一个通过递归实现循环的示例。让我们试一下。
原文中实现了一个功能,可以直接在线编辑运行这些示例中的代码,分为左右两区,左侧为代码编辑区,右侧提供了"Run"按钮来运行示例预览结果,(也可以:CTRL-ENTER来运行,CTRL-L清空输出 — 这些操作需要光标聚焦在左边代码编辑区里才能有效果)。可以使用print/println进行输出。作者推荐大家尽情操作,因为运行功能都实现在本地浏览器中。
但目前译文中,受markdown语法的限制,没办法定制在线编辑运行功能,未来有更好的方式,会及时更新出来。
如果读者朋友们有什么推荐的方式,欢迎留言回复,感谢!!!
print_range = λ(a, b) if a <= b {
print(a);
if a + 1 <= b {
print(", ");
print_range(a + 1, b);
} else println("");
};
print_range(1, 10);然而,如果将range从10增加到1000,就会发现一个问题。我这边当打印600(或某一值)后会显示最大调用栈溢出(“Maximum call stack size exceeded”)。这是因为我们的求值器是递归执行的,会消耗光JavaScript的堆栈。
这是一个很严重的问题,但我们有解决方法。可能很容易想到添加一些迭代关键字,比如 for 或 while,但我们不会这么做。递归很优美,我们不应该弃用它。后面我们会着手来看如何规避这个缺陷。
数据结构(或缺乏的)
我们的λanguage语言似乎只有三种类型:数字,字符串和布尔型。看起来不可能创建复杂的结构,比如对象或列表。但实际我们还有一种类型:函数。事实证明,在λ演算(λ-calculus)中,我们能利用函数来构造任意的数据结构,甚至包括带有继承的对象。
这里演示一下列表
我们期望有一个函数cons,会构建(constructs)一个持有两个值的特殊对象;这个特殊对象我们称为cons cell或者pair。两个持有的值,我们把其中一个叫做car,另外一个叫做cdr,因为数十年期间Lisp也正是如此命名。对于一个给定的cell对象,我们可以使用函数car和cdr来获取对应的值。所以:
x = cons(10, 20);
print(car(x)); # prints 10
print(cdr(x)); # prints 20基于上述这些,很容易来定义一个列表:
一个列表就是一个cell对象,该对象在其car属性中保存了首个(first)元素,在cdr属性中保存了剩下(rest)的元素。但cdr可以保存一个单一值!这个值是一个列表。这个列表的car又保存了它的首个元素,cdr保存了剩下的元素。同样cdr可以再次保存一个单一值!这个值又是一个列表。如此往复。。。
所以这是一个递归的数据结构(通过它自身来定义自身)。还有一个遗留的问题:我们何时停止?直觉上判断,我们应该在cdr为空列表时停止,但空列表又是什么?为此我们将引入一个新的特殊对象叫NIL。可以像cell一样来操作NIL(可以应用car和cdr,但是结果是其自身)— 但它不是一个真正的cell。我们就称其是一个假的cell。至此,下面展示了如何来构建列表1, 2, 3, 4, 5:
x = cons(1, cons(2, cons(3, cons(4, cons(5, NIL)))));
print(car(x)); # 1
print(car(cdr(x))); # 2 in Lisp this is abbrev. cadr
print(car(cdr(cdr(x)))); # 3 caddr
print(car(cdr(cdr(cdr(x))))); # 4 cadddr
print(car(cdr(cdr(cdr(cdr(x)))))); # 5 but no abbreviation for this one.当缺失合适语法的时候看起来就会很糟糕。但我仅仅是为了演示在我们看似受限的λanguage中可以构建这样的数据结构。下面就是相应的定义:
cons = λ(a, b) λ(f) f(a, b);
car = λ(cell) cell(λ(a, b) a);
cdr = λ(cell) cell(λ(a, b) b);
NIL = λ(f) f(NIL, NIL);当第一次看到这样实现的 cons/car/cdr,会发现其中令人不安的事实是甚至都不需要 if(但是不必感到太奇怪,因为在原始的λ演算中就没有 if)。事实上当然没有语言会按这种行为来实现(即不支持 if),虽没有影响语言的完美,但效率太低。大概描述一下上面的代码:
- cons 接收两个值 (a, b) 然后返回持有两个值的函数。那个函数就是“cell对象”。它会接收一个函数参数(f)并用两个存储的值调用它。
- car 接收一个“cell对象”(也就是上面那个函数)并给它传入一个函数进行调用,传入的函数会接收两个参数并返回第一个参数。
- cdr 类似 car, 但是传入的函数会返回第二个参数。
- NIL 模仿一个 cell,它同样是接收一个函数参数(f)的函数,但总是用两个 NIL 来调用这个函数参数(所以 car(NIL) 和 cdr(NIL) 都等于 NIL)。
cons = λ(a, b) λ(f) f(a, b);
car = λ(cell) cell(λ(a, b) a);
cdr = λ(cell) cell(λ(a, b) b);
NIL = λ(f) f(NIL, NIL);
x = cons(1, cons(2, cons(3, cons(4, cons(5, NIL)))));
println(car(x)); # 1
println(car(cdr(x))); # 2
println(car(cdr(cdr(x)))); # 3
println(car(cdr(cdr(cdr(x))))); # 4
println(car(cdr(cdr(cdr(cdr(x)))))); # 5有很多有趣并可以递归实现的列表算法,这很自然,因为列表本身就是递归定义的。例如,下面这个函数会在列表每个元素上应用一个函数:
foreach = λ(list, f)
if list != NIL {
f(car(list));
foreach(cdr(list), f);
};
foreach(x, println);下面是另外一个用随机数构建列表的例子:
range = λ(a, b)
if a <= b then cons(a, range(a + 1, b))
else NIL;
# print the squares of 1..8
foreach(range(1, 8), λ(x) println(x * x));目前为止我们的列表都是不可变的(cell对象一旦创建你就没办法改变car和cdr)。大多数Lisp方言都提供了改变cons cell对象的方法。Scheme中叫set-car! / set-cdr!。Common Lisp中富有提示性的命名为rplaca / rplacd。这次我们更倾向于使用Scheme的命名:
cons = λ(x, y)
λ(a, i, v)
if a == "get"
then if i == 0 then x else y
else if i == 0 then x = v else y = v;
car = λ(cell) cell("get", 0);
cdr = λ(cell) cell("get", 1);
set-car! = λ(cell, val) cell("set", 0, val);
set-cdr! = λ(cell, val) cell("set", 1, val);
# NIL can be a real cons this time
NIL = cons(0, 0);
set-car!(NIL, NIL);
set-cdr!(NIL, NIL);
## test:
x = cons(1, 2);
println(car(x));
println(cdr(x));
set-car!(x, 10);
set-cdr!(x, 20);
println(car(x));
println(cdr(x));上面示例展示了实现复杂可变数据结构的能力。思路非常简单,我也不再赘诉。
我们可以更进一步来实现对象,但是λanguage语言内部不能修改语法使得实现对象变得非常笨重。其它方式是在分词器/解析器中引入新的语法,并可能要在求值器中增加新的语义。很多时候为了取得可接受的性能,这也是所有主流语言的实现方式。下一节我们将来探索增加一些新的语法。
如何用JavaScript实现一门编程语言 - continuations
整篇译文的目录章节如下:
Continuations
至此我们通过CPS(continuation passing style)形式实现了求值器,其中所有函数,无论是λanguage语言定义的,或是JavaScript提供的原始功能函数,第一个参数都是一个将接收求值结果进行调用的回调函数(这个回调函数参数,对于原始功能函数是显式传递的,对于λanguage语言中定义的函数是不可见的,换句话是求值器隐式插入的)。
这个回调函数参数代表了程序所有的未来行为。下一步要做什么的完整描述。我们称其为“the current continuation”,并在代码中使用名字k来指代它。
有一点值得一提,如果我们永远不调用该回调函数即该continuation,程序就暂停了。我们在λanguage语言中还做不到这点,因为make_lambda创建的函数总会调用它们的continuation。但我们可以在原始功能函数中实现这个能力。我引入下面这个原始功能函数来展示如何实现:
globalEnv.def("halt", function(k){});这个函数什么都没有做。它接收了一个continuation参数(k)但没有调用它。
println("foo");
halt();
println("bar");如果删除halt(),就会输出“foo / bar / ***Result: false”(因为最后一个println返回 false)。但存在halt()时,输出只有“foo”。这种情况下甚至没有结果,因为halt()没有调用continuation — 所以我们传给evaluate的回调,即打印***Result结果的函数, 没有执行到。调用函数却永远不知道程序已经暂停了。如果你用的是NodeJS,你很可能已经搬石头砸了自己的脚。
比如说我们想要写一个sleep函数,能够推延程序执行但是不会冻结住浏览器(即没有死循环)。我们可以简单地将其实现为一个原始功能函数:
globalEnv.def("sleep", function(k, milliseconds){
setTimeout(function(){
Execute(k, [ false ]); // continuations expect a value, pass false
}, milliseconds);
});不方便的一点就是我们不得不使用Execute,因为setTimeout将会丢弃当前的执行堆栈。直接调用k(false)的话,代码不会被捕获Continuation异常的循环包裹,第一次发生Continuation异常的时候,程序就会失败。下面是我们如何使用它(多次运行可以发现调用都是并行执行的):
译者:上一节堆栈保护中提到CPS形式更新后的λanguage语言程序的整体执行方案,在Execute内部会设置一个循环保证λanguage语言程序的执行,程序各个Continuation的衔接,是通过将Continuation作为特殊异常抛出,然后循环里捕获到这个异常,会进行Continuaion的衔接设置,达到重置堆栈效果的同时,能保证继续执行后续代码。如果直接调用k(false),则第一次Continuation异常抛出后没有相应的处理机制,程序会直接失败。
let loop (n = 0) {
if n < 10 {
println(n);
sleep(250);
loop(n + 1);
}
};
println("And we're done");这是原生JavaScript做不到的,除非你手工用CPS形式重写代码(并且你不能使用 for 循环):
(function loop(n){
if (n < 10) {
console.log(n);
setTimeout(function(){
loop(n + 1);
}, 250);
} else {
println("And we're done"); // rest of the program goes here.
}
})(0);设想有一些基于NodeJS文件系统API封装实现的原始功能函数,比如:
globalEnv.def("readFile", function(k, filename){
fs.readFile(filename, function(err, data){
// error handling is a bit more complex, ignoring for now
Execute(k, [ data ]); // hope it's clear why we need the Execute
});
});
globalEnv.def("writeFile", function(k, filename, data){
fs.writeFile(filename, data, function(err){
Execute(k, [ false ]);
});
});基于上面的定义,我们可以做下面的事情:
copyFile = λ(source, dest) {
writeFile(dest, readFile(source));
};
copyFile("foo.txt", "bar.txt");并且是异步的。没有回调地狱。
下面是一个更令人费解的例子。我写了下面的原始功能函数:
globalEnv.def("twice", function(k, a, b){
k(a);
k(b);
});它接收两个参数a和b,然后针对每个参数共调用continuation两次。运行一个示例:
println(2 + twice(3, 4));
println("Done");
// output
// 5
// Done
// ***Result: false
// 6
// Done
// ***Result: false如果你之前从没接触过continuation,会觉得输出比较奇怪,我还是把这个疑问留给你自己来思考。一个简短的提示:程序运行一次程序,会给调用者返回两次!
CallCC
目前为止,我们都是通过在JS中写原始功能函数来达到目的。λanguage语言中还没有一种方式能拦截当前的执行。CallCC弥补了这个能力空缺。这个名字是Scheme中call-with-current-continuation的简称(Scheme中也常常拼写为call/cc)。
globalEnv.def("CallCC", function(k, f){
f(k, function CC(discarded, ret){
k(ret);
});
});它将当前continuation具象化为一个可以直接在λanguage语言中调用的函数。这个函数会忽略它自己的continuation (discarded参数)并调用CallCC的continuation。
有了它,我们可以实现许多之前不敢想的操作符(直接通过λanguage语言自身实现,而不是通过JS原始功能函数的方式!),从exceptions到return。我们首先开始实现return。
return实现
foo = λ(return){
println("foo");
return("DONE");
println("bar");
};
CallCC(foo);foo函数接收了一个参数,其有效地充当了JS的return语句( 仅有一点是需要像一个函数一样调用,因为它本质上就是一个函数)。它会丢弃后续的执行(原本会打印“bar”)并提前以传入的返回值("DONE")结束函数。当然,仅在将foo传给CallCC,进而return参数可以被赋值为continuation,这样才能按上述预期执行。我们可以提供一层封装:
with-return = λ(f) λ() CallCC(f);
foo = with-return(λ(return){
println("foo");
return("DONE");
println("bar");
});
foo();上面的优势就是我们目前调用foo时不再需要用CallCC。当然,如果可以不用将return命名为一个函数参数,或者说可以直接使用with-return(译者理解即支持一个return关键字),这将会更好,但是λanguage语言还不允许做语法扩展,至少需要修改解析器才能做到(Lisp语言同样如此)。
简单回溯Easy backtracking
假设我们想实现一个程序,能够找出100以内两个正整数乘积为84的所有数对。这个问题不难,你可能会尝试用两层嵌套循环来解决它,但这里我们会尝试另外一种方法。我们会实现guess和fail两个函数。guess函数将会选一个数字,fail函数反馈需要“尝试其它数字”。我们将会像下面这样使用它们:
a = guess(1); # returns some number >= 1
b = guess(a); # returns some number >= a
if a * b == 84 {
# we have a solution:
print(a); print(" x "); println(b);
};
fail(); # go back to the last `guess` and try another valuefail = λ() false;
guess = λ(current) {
CallCC(λ(k){
let (prevFail = fail) {
fail = λ(){
current = current + 1;
if current > 100 {
fail = prevFail;
fail();
} else {
k(current);
};
};
k(current);
};
});
};
a = guess(1);
b = guess(a);
if a * b == 84 {
print(a); print(" x "); println(b);
};
fail();注意到当a大于84的平方根,或当b大于84/a,继续执行没有意义,可以基于此进一步优化上面的程序。我们可以让guess接收两个参数,start和end,并只在这个范围内取出一个正整数。但针对这个例子我们就此打住,还是继续来看continuations。
ES6 yield
EcmaScript 6将会引入一个神奇的yield操作符,使用之前版本的JavaScript无法实现这个语义,除非将代码整体调整为CPS形式。在λanguage语言中,显式continuation给我们提供了一种方法来实现yield。
但实现yield并不是什么轻松的事情。比我之前预想的要有更多的细节,所以将yield的讨论单独移到了下一章节。这是个进阶话题,对于理解本教程剩余内容不是必须的,但如果想对continuation有更深入的理解,推荐你阅读一下。
Common Lisp中的catch和throw
我们将会实现两种语法结构,catch和throw。可以像下面这样使用:
f1 = λ() {
throw("foo", "EXIT");
print("not reached");
};
println(catch("foo", λ() {
f1();
print("not reached");
})); # prints EXIT解释一下,catch(TAG, function)将定义一个捕获TAG类型异常的hook,然后调用function函数。throw(TAG, value)将跳转到嵌套层级中最近的可以捕获TAG类型异常的catch,然后返回value。 无论catch函数是正常结束或是通过throw结束,hook都会在catch函数结束前被释放掉。
下面简要描述了一种实现。
## with no catch handlers, throw just prints an error.
## even better would be to provide an `error` primitive
## which throws a JavaScript exception. but I'll skip that.
throw = λ(){
println("ERROR: No more catch handlers!");
halt();
};
catch = λ(tag, func){
CallCC(λ(k){
let (rethrow = throw, ret) {
## install a new handler that catches the given tag.
throw = λ(t, val) {
throw = rethrow; # either way, restore the saved handler
if t == tag then k(val)
else throw(t, val);
};
## then call our function and store the result
ret = func();
## if our function returned normally (not via a throw)
## then we will get here. restore the old handler.
throw = rethrow; # XXX
## and return the result.
ret;
};
});
};可以按如下方式测试:
throw = λ(){
println("ERROR: No more catch handlers!");
halt();
};
catch = λ(tag, func){
CallCC(λ(k){
let (rethrow = throw, ret) {
## install a new handler that catches the given tag.
throw = λ(t, val) {
throw = rethrow;
if t == tag then k(val)
else throw(t, val);
};
## then call our function and store the result
ret = func();
## if our function returned normally (not via a throw)
## then we will get here. restore the old handler.
throw = rethrow; # XXX
## and return the result.
ret;
};
});
};
f1 = λ() {
throw("foo", "EXIT");
print("not reached");
};
println(catch("foo", λ() {
f1();
print("not reached");
}));原力黑暗面(The Dark Side of the Force)
上面对catch的描述中,曾提到hook会在catch函数结束前被释放掉。查看代码似乎确实是这样,但CallCC有能力来规避这个行为。哲学上会有两种观点。我完全赞成“权力属于人民”—允许用户有一些颠覆行为或许不是一个坏主意。但对于目前这种特殊情况,如果catch/throw的行为跟用户预期不一致,会给用户带来更多的困惑而不是帮助。
不按常规出牌很简单。你可以调用一个在catch外部存储的contiunation。catch中throw则不会被重置为先前存储的throw处理函数,因为catch甚至无法知道已经退出了当前代码块。例如:
exit = false; # create a global.
x = 0; # guard: don't loop endlessly when calling exit() below
CallCC( λ(k) exit = k );
## exit() will restart from here...
if x == 0 then catch("foo", λ(){
println("in catch");
x = 1; # guard up
exit();
});
println("After catch");
throw("foo", "FOO");上面代码输出两次"After catch",之后输出"ERROR: No more catch handlers!"。正确的行为是只输出一次"After catch",然后输出ERROR。但通过catch外部保存continuation的方式退出函数,catch定义中恢复throw处理函数的逻辑(即上面catch定义代码中标记“XXX”的一行)永远不会执行到,所以旧throw处理函数得不到恢复,catch下面的throw就简单直接跳回catch内部最初定义的hook。
为了能正确的实现exceptions需要delimited continuations。将会在yield实现章节中进行讨论。
这也是众多反对CallCC的争议之一(强调一点:主要是反对CallCC中提供的undelimited continuations)。我还是很喜欢CallCC,如果undelimited continuations能在语言底层被支持并且CallCC不将它们暴露为一等公民,相信这样会更好。另外,我确实发现continuations很令人着迷,如果能很好的理解它,对于实践中实现很多其它有用的数据结构会至关重要。
接下来我们开始实现编译器 — 让程序运转得更快!
W3C CSS Transforms摘译
W3C CSS Transforms
目录
CSS Transforms可以对一个元素进行二维平面或三维空间的变换,如translate, rotate, scale和skew等变换。
下面是对W3C官网CSS Transforms模块的部分摘译,为了理解的连贯性,调整了W3C规范中相关章节的顺序。
5. 二维子集(Two Dimensional Subset)
用户浏览器(UAs)可能不总能渲染出三维变换,那么它们就只能支持该规范的一个二维子集。在这种情况下,三维变换和transform-style、perspective、perspective-origin以及backface-visibility属性将不被支持。三维相关的变换渲染也不会起作用。
对于二维变换情况,矩阵分解采用**Graphics Gems II(Jim Arvo著)书中unmatrix算法的二维简化版本。下面是一个二维的3x3变换矩阵,其中6个参数a~f,分别对应二维变换函数matrix(a, b, c, d, e, f)**的6个参数。
图1 二维变换3x3矩阵
开发者可以很简单的为不支持三维变换的浏览器提供备选变换方案。下面的例子中,transform属性有两次赋值定义。第一次定义包括了两个二维变换函数,第二次定义包括一个二维变换和一个三维变换。
div { transform: scale(2) rotate(45deg); transform: scale(2) rotate3d(0, 0, 1, 45deg); }当浏览器支持三维变换时,第二次属性定义将覆盖第一次的定义,当不支持三维变换时,第二次定义将会失效,浏览器会使用第一种定义。

6. 变换渲染模型(The Transform Rendering Model)
当为元素的transform属性指定了一个非none属性值时,就会在该元素上建立了一个本地坐标系(local coordinate system)。从元素最初始的渲染(未指定transform属性值)到本地坐标系的映射由该元素的变换矩阵(transformation matrix)给定。变换是可累积的,也就是说,元素是在它们祖先的坐标系中建立自己的本地坐标系。从用户的角度来看,就是一个元素会累积应用所有它祖先**‘transform’属性设置的变换,以及自身"transform"属性设置的变换,规范中将这些变换的累积称为元素当前变换矩阵(current transformation matrix, CTM)**。
坐标空间是一个有两个轴的坐标系:X轴是水平向右增加,Y轴是垂直向下增加。三维变换函数将这个坐标空间扩展到三维,增加了垂直于屏幕平面一个Z轴,并且指向观察者。
图2 初始坐标空间示例

变换矩阵是基于**'transform'和'transform-origin'**属性,按照以下步骤计算而来:
- 从单位矩阵开始
- 首先按照**'transform-origin'**属性的X,Y,Z 值进行位移
- 从左至右依次乘以**'transform'**属性中指定的各个变换函数
- 最后再按照**'transform-origin'**属性的X,Y,Z 值的负值进行位移
注意,变换只是影响了元素的显示,不影响元素自身CSS的布局。意味着变化不会影响getClientRects()及getBoundingClientRect()的值。对于基于CSS盒模型布局定位的元素,如果该元素的transform属性为非none,则该元素将成为其所有fixed定位的后代元素的包含块(Containing Block)。
18. 变换函数的元和派生(Transform function primitives and derivatives)
transform中一些变换函数的效果可以通过更具体的变换函数来实现,比如translate的一些操作可以用translateX来实现。此时称translate为元变换,translateX为派生变换。
下面列出了所有二维和三维的元变换以及相应的派生变换。
####二维元变换以及相应的派生变换
| 元变换 | 派生变换 |
|---|---|
| translate() | translateX(), translateY(), translate() |
| rotate()带三个参数 | rotate()带一个或三个参数 |
| scale() | scaleX(), scaleY(),scale() |
####三维元变换以及相应的派生变换
| 元变换 | 派生变换 |
|---|---|
| translate3d() | translateX(), translateY(), translateZ(), translate() |
| scale3d() | scaleX(), scaleY(), scaleZ(), scale() |
| rotate3d() | rotate(), roateX(), rotateY(), rotateZ() |
对于同时具有二维和三维元变换的派生变换,具体是使用二维元变换或三维的元变换,是由上下文环境来决定。
19. 元变换函数和派生变换函数的插值(Interpolation of primitives and derived transform functions)
两个具有相同数量参数的变换函数,会直接进行数值的插值计算,而不需要转换为相同的元变换。插值计算的结果即是带有相同参数的相同变换。对于**rotate3d(), matrix(), matrix3d(), perspective()**有特殊的插值计算规则。
例如,对于变换函数translate(0)和translate(100px),就是两个具有相同数量参数的相同变换,所以它们会直接进行数值上的插值计算。但是对于变换函数translateX(100px)和translate(100px, 0),两个变换既不是相同的变换,使用的参数数量也不同,所以它们就需要先转换为元变换函数,然后才能进行数值上的插值计算。
两个不同的变换,但都是从相同的元变换派生出来的(即相同的派生变换),或者相同的变换,但使用了不同数量的参数,此时两个变换可以进行数值插值计算。需要先将两种变换转换为相同的元变换,然后才能进行数值插值计算。插值计算的结果相当于使用了相同数量参数的相同元变换。
下面的例子,当div发生鼠标hover事件时,会发生从**translateX(100px)到translateY(100px)的3秒过渡变换。此时两个变换都是从相同的元变换translate()派生的,所以需要先将两个变换转换为translate()**元变换,然后才能进行数值插值计算。
div { transform: translateX(100px); } div:hover { transform: translateY(100px); transition: transform 3s; }当发生3秒的transition时,translateX(100px)将会转化为translate(100px, 0),translateY(100px)会转化为translate(0, 100px),然后两个变换才能进行数值的插值计算。
如果两个变换都可以从同一个二维元变换派生,则都会转换为二维元变换。如果其中一个是或者都是三维变换,则会都转换为三维元变换。
下面的例子中,一个二维变换函数经过3秒过渡变换到三维变换函数。两个变换函数的公共元变换为translate3d()。
div { transform: translateX(100px); } div:hover { transform: translateZ(100px); transition: transform 3s; }当发生3s的transition时,translateX(100px)会转化为translate3d(100px, 0, 0),translateZ(100px)会转化为translate3d(0, 0, 100px),然后两个变换才能进行数值的插值计算。
对于**matrix(), matrix3d(), perspective()三种变换将会首先被转化为4x4的矩阵,然后进行矩阵的插值计算。
对于rotate3d()**的插值计算,首先会得到两个变换的单位方向向量,如果相等,则可以直接进行数值的插值计算;否则,就需要先将两种变换转化为4x4的矩阵,然后对矩阵进行插值计算。
17. 变换的插值(Interpolation of Transforms)
当变换函数之间发生过渡时(比如对transforms施加transition属性),就需要对变换函数进行插值计算。从一个初始的变换(from-transform)到一个结束的变换(to-transform),如何进行插值计算需要遵循下面的规则。
I. 当from-transform和to-transform的值都为none
此时没有必要进行计算,保持原值。
||. 当from-transform和to-transform中有一个的值为none
值为none的那个将被替换为恒等变化(Identity Transform functions),然后继续按照下面的规则进行插值计算。
恒等变换(Identity Transform functions) 就是标准里给出的一系列特殊的变换函数,类似线性代数里面的单位矩阵(Identity Matrix),无论怎么施加多少次变换,都不会改变原有的变换,标准里面给出的恒等变换有translate(0)、translate3d(0, 0, 0)、translateX(0)、translateY(0)、translateZ(0)、scale(1)、scaleX(1)、scaleY(1)、scaleZ(1)、rotate(0)、rotate3d(1, 1, 1, 0)、rotateX(0)、rotateY(0)、rotateZ(0)、skew(0, 0)、skewX(0)、skewY(0)、matrix(1, 0, 0, 1, 0, 0)和matrix3d(1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1)。一种特殊的情况是透视(perspective): perspective(infinity),此时M34的值变得无穷小,因此假定它等于单位矩阵。
例如,from-transform为scale(2),to-transform为none, 则none将会被替换为scale(1),然后继续按照下面的规则进行插值。类似的,如果from-transform为none,to-transform为scale(2) rotate(50deg),则from-transform会被替换为scale(1) rotate(0)。
III. 如果from-transform和to-transform中都使用了相同数量的变换函数,并且各个对应的变化是相同的变换或是从相同的元变换派生的变换。
按照元变换函数和派生变换函数的插值里面的步骤,对from-transform和to-transform对应的变换进行插值。计算出的结果作为最终的变换。
例如,from-transform为scale(1) translate(0),to-transform为translate(100px) scale(2),虽然都是用了scale和translate变换,但是对应的变换既不相同也不是从相同的元变换派生出来的,此时就不能按照本条规则来进行插值计算。
IV. 所有其他情况
from-transform和to-transform中使用的变换都会被转化为4x4的矩阵,并进行相应的矩阵插值计算。如果from-transform和to-transform对应的变换矩阵都可以表示成3x2矩阵或者matrix3d矩阵,则元素就按照相应插值计算的矩阵进行变换渲染。在某些特殊的情况下,变化矩阵可能是一个奇异或不可逆矩阵,则元素将不会被渲染。
20. 矩阵的插值(Interpolation of Matrices)
当对两个矩阵进行插值时,首先将矩阵分解为一系列变换操作的值,比如对应的translation、rotation、scale和skew的变换矩阵,然后对各个变换操作对应的矩阵进行数值插值计算,最后将各个变换矩阵重新组合为原始矩阵。
下面的例子中,元素初始变换为rotate(45deg),当发生hover时,将会在X轴和Y轴移动100像素,并旋转1170度。如果设计人员给出下面的写法,很可能是期望看到元素会顺时针旋转3.5圈(1170度)。
<style> div { transform: rotate(45deg); } div:hover { transform: translate(100px, 100px) rotate(1215deg); transition: transform 3s; } </style> <div></div>初始变换**‘rotate(45deg)’和目标变换*'translate(100px, 100px) rotate(1125deg)'完全不同,按照变换的插值* 最后一条规则,两个变换都需要进行矩阵的插值计算。但需要注意,将变换转化为矩阵的过程中,旋转3圈的信息将会丢失掉,所以最终看到的效果只顺时针旋转了半圈(90度)。
为了达到期望的效果,只需要更新上述变换的写法,使前后两个变换满足变换的插值 的第三条规则。初始变换改为**‘translate(0, 0) rotate(45deg)’**,此时就会进行数值的插值计算,从而不会丢失旋转信息,达到期望的效果。
具体的decomposing和recomposing矩阵的算法,见Graphics Gems II。
如何用JavaScript实现一门编程语言 - Token流
整篇译文的目录章节如下:
- 前言
- λanguage描述
- 写一个解析器(Parser)
- 字符流(Character Stream)
- 标记流(Token Stream)
- AST
- 解析器
- 简单的解释器(Interpreter)
- CPS求值器(CPS Evaluator)
- 编译成JS
- 总结
- 真实示例
标记流(Token Stream)
分词器Tokenizer(也叫做词法分析器Lexer)运行在字符流基础上,同样也返回一个具有相同接口的流对象,但是它的peek()/next()函数返回值为一个个标记token。token是有两个属性的对象:type 和 value。下面是我们所支持的token一些示例:
{ type: "punc", value: "(" } // punctuation: parens, comma, semicolon etc.
{ type: "num", value: 5 } // numbers
{ type: "str", value: "Hello World!" } // strings
{ type: "kw", value: "lambda" } // keywords
{ type: "var", value: "a" } // identifiers
{ type: "op", value: "!=" } // operators空白符和注释会被跳过,不会返回token。
为了实现分词器,我们需要更进一步认识λanguage语言的语法。整体思路就是根据当前的字符(input.peek()函数的返回)来决定读取相应类型的token:
- 首先,跳过所有的空格。
- 如果输入流已到结尾,即input.eof()为真,返回空值null。
- 如果遇到井号“#”,则跳过注释(注释所在行结束后,重新开始上面的流程)。
- 如果是引号,则读取字符串。
- 如果是数字字符,则连续读取得到一个数字。
- 如果是一个字母,则读取一个标识符(identifier)或者关键字(keyword)。
- 如果是一种标点符号字符,则返回标点符号token。
- 如果是一种操作符,则返回操作符token。
- 如果上面的情况都不符合,则抛出一个异常input.croak()。
下面的read_next函数作为分词器的核心,实现了上面各描述情况:
function read_next() {
read_while(is_whitespace);
if (input.eof()) return null;
var ch = input.peek();
if (ch == "#") {
skip_comment();
return read_next();
}
if (ch == '"') return read_string();
if (is_digit(ch)) return read_number();
if (is_id_start(ch)) return read_ident();
if (is_punc(ch)) return {
type : "punc",
value : input.next()
};
if (is_op_char(ch)) return {
type : "op",
value : read_while(is_op_char)
};
input.croak("Can't handle character: " + ch);
}这是一个“调度器”函数,next()函数会调用它以获取下一个token。可以注意到它使用到很多针对具体token类型的工具函数,如read_string(),read_number()等。没有理由因为它们而让调度器函数变得复杂,尽管没有其他地方会调用它们。
另外需要注意我们没有一次性把输入流全部消费掉。每次当解析器需要下一个token时,才会读取一个token。当解析发生错误时我们甚至都不会到达流的末尾。
read_ident()函数将会尽可能长的读取可以组成标识符的字符(is_id)。标识符必须以字母,或λ或下划线_开头,剩余部分可以由这三种字符,或数字,或?!-<>=等字符组成。所以foo-bar会被识别为一个标识符(一个vartoken)而不是三个token。这条规则的原因是希望可以使用is-pair或string>=名称来定义函数(抱歉,这是我内心的Lisper在捣乱)。
read_ident()函数也会将标识符和已知的关键字列表进行对比,如果标识符是一个关键字则会返回一个kwtoken,否则返回一个vartoken。
代码更有助于理解上面的描述,下面是λanguage语言分词器的完整实现。附带了一些其他的备注。
function TokenStream(input) {
var current = null;
var keywords = " if then else lambda λ true false ";
return {
next : next,
peek : peek,
eof : eof,
croak : input.croak
};
function is_keyword(x) {
return keywords.indexOf(" " + x + " ") >= 0;
}
function is_digit(ch) {
return /[0-9]/i.test(ch);
}
function is_id_start(ch) {
return /[a-zλ_]/i.test(ch);
}
function is_id(ch) {
return is_id_start(ch) || "?!-<>=0123456789".indexOf(ch) >= 0;
}
function is_op_char(ch) {
return "+-*/%=&|<>!".indexOf(ch) >= 0;
}
function is_punc(ch) {
return ",;(){}[]".indexOf(ch) >= 0;
}
function is_whitespace(ch) {
return " \t\n".indexOf(ch) >= 0;
}
function read_while(predicate) {
var str = "";
while (!input.eof() && predicate(input.peek()))
str += input.next();
return str;
}
function read_number() {
var has_dot = false;
var number = read_while(function(ch){
if (ch == ".") {
if (has_dot) return false;
has_dot = true;
return true;
}
return is_digit(ch);
});
return { type: "num", value: parseFloat(number) };
}
function read_ident() {
var id = read_while(is_id);
return {
type : is_keyword(id) ? "kw" : "var",
value : id
};
}
function read_escaped(end) {
var escaped = false, str = "";
input.next();
while (!input.eof()) {
var ch = input.next();
if (escaped) {
str += ch;
escaped = false;
} else if (ch == "\\") {
escaped = true;
} else if (ch == end) {
break;
} else {
str += ch;
}
}
return str;
}
function read_string() {
return { type: "str", value: read_escaped('"') };
}
function skip_comment() {
read_while(function(ch){ return ch != "\n" });
input.next();
}
function read_next() {
read_while(is_whitespace);
if (input.eof()) return null;
var ch = input.peek();
if (ch == "#") {
skip_comment();
return read_next();
}
if (ch == '"') return read_string();
if (is_digit(ch)) return read_number();
if (is_id_start(ch)) return read_ident();
if (is_punc(ch)) return {
type : "punc",
value : input.next()
};
if (is_op_char(ch)) return {
type : "op",
value : read_while(is_op_char)
};
input.croak("Can't handle character: " + ch);
}
function peek() {
return current || (current = read_next());
}
function next() {
var tok = current;
current = null;
return tok || read_next();
}
function eof() {
return peek() == null;
}
}next()函数并不总会调用read_next()函数,因为之前可能已经读取过(此时read_next()已经调用过,流已经被消费)。所以我们需要一个current变量来保存当前的token。- 我们仅支持常用符号的十进制数字(不支持1E5写法,不支持十六进制,不支持八进制)。如果需要更多的支持,只需要修改
read_number()函数,比较容易实现。 - 和JavaScript不同,字符串中不能出现的未转译字符只有引号本身以及反斜杠。你需要用反斜杠对它们进行转译。否则字符串中可能会包含硬换行符、制表符等。我们不会解析通常的转译符比如\n,\t。同样如果想支持也不难,改动会很小(read_string函数)。
我们现在有了足够强大的工具去轻松地编写解析器,但首先推荐你阅读一下AST的描述。
如何用JavaScript实现一门编程语言 - yield 进阶
整篇译文的目录章节如下:
- 前言
- λanguage描述
- 写一个解析器(Parser)
- 简单的解释器(Interpreter)
- CPS求值器(CPS Evaluator)
- 保护堆栈
- Continuations
- Yield进阶
- 编译成JS
- 总结
- 真实示例
Yield进阶
首先,我们通过一些使用示例来认识yield。
foo = with-yield(λ(yield){
yield(1);
yield(2);
yield(3);
"DONE";
});
println(foo()); # prints 1
println(foo()); # prints 2
println(foo()); # prints 3
println(foo()); # prints DONE调用后,yield会停止函数的执行并返回一个值。到目前非常类似return。当你再次调用函数,会从停止处重新开始执行,就像上面示例中展示的。示例会打印1,2,3,DONE。
一个更真实的用例:
fib = with-yield(λ(yield){
let loop (a = 1, b = 1) {
yield(b);
loop(b, a + b);
};
});
## print the first 50 fibonacci numbers
let loop (i = 0) {
if i < 50 {
println(fib());
loop(i + 1);
};
};fib函数包含了一个无限循环。没有结束的条件。但yield会中断循环并返回当前的数。再次调用函数会从上次停止的地方继续执行,所以我们只需要调用函数50次既可以打印前50个数。
这个程序也会比双递归版本的fib实现快很多,因为其内部会保存前两个值,可以直接计算出下个值并返回。
一次失败的实现尝试
我不会浪费你的时间来做一次失败的尝试,除非能从中得到有价值的经验,所以请忍耐一下。
为了实现yield看起来我们需要保存函数初始的continuation。这样我们才能提前退出,就像 return 的行为一样。然而,真正从yield中返回之前,我们同样需要保存yield自身的continuation,这样后续才能返回到函数中yield接下来要执行的位置。至少看起来应该是这样。我们就按这个思路来尝试实现:
with-yield = λ(func) {
## with-yield returns a function of no arguments
λ() {
CallCC(λ(kret){ # kret is the "return" continuation
let (yield) {
## define yield
yield = λ(value) { # yield takes a value to return
CallCC(λ(kyld){ # kyld is yield's own continuation…
func = kyld; # …save it for later
kret(value); # and return.
});
};
## finally, call the current func, passing it the yield.
func(yield);
};
});
};
};上面是我首次尝试实现yield并且一切看起来都很合理。但当我们用这个定义来运行文中第一个示例,将会进入死循环。如果你愿意可以尝试一下下面的代码,做好需要刷新页面的准备(实际上这里我修改了Execute重清空堆栈的逻辑,使用setTimeout而不是异常捕获的方式,这样你的浏览器就不会被冻结住)。运行后你就会发现首先打印出1,2,3,接着就是打印无穷的“DONE”。
with-yield = λ(func) {
λ() {
CallCC(λ(kret){
let (yield) {
yield = λ(value) {
CallCC(λ(kyld){
func = kyld;
kret(value);
});
};
func(yield);
};
});
};
};
foo = with-yield(λ(yield){
yield(1);
yield(2);
yield(3);
"DONE";
});
println(foo());
println(foo());
println(foo());
println(foo());陷入无限循环的原因很隐晦。但如果你想看一些更离奇的行为,编辑上面代码并将最后四行println改成下面这样:
println(foo());
foo();输出竟然完全一样。再次提醒:你需要这个示例运行后刷新页面,否则它会一直运行下去,直到耗光你电脑的电源和内存。
这里先直白解释一下发生死循环的原因,帮助理解原文。
首先,执行第一行println其中的foo时,最终会第一次调用到func(yield),这时func是最初传入with-yield的函数,所以整体函数后续cps是第一个println处开始直至后续程序;
其次,只有在yield中才会对func重新赋值更新,所以func最后更新至“DONE”之前,就不再变化,即此后执行只会输出“DONE”,并且结合上面一点,执行完之后会跳到第一行println处重新执行整个程序。所以只要执行足够的次数(大于等于代码中yield个数),将程序执行到“DONE”处,即会跳回到第一行println开始死循环,不停地输出“DONE”;
最后,其实只需要两行println就可以“消费”完yield,因为func中能引用到的kret以及yield实际都是第一次定义的,并不是后续定义的,这一块可能需要多断点执行几次好好理解一下,所以只要执行yield其实总会跳到第一行println处打印结果,然后执行第二行foo(),消费下一条yield,但yield中会kret重新回到第一行println,依此往复,直至“DONE”。
确实有点绕,结合下面的原文解释,再反复理解一下:)
问题1:yield永远不再更新
需要注意的一个问题是为第一个yield保存的continuation(按照with-yield的实现,kyld将是接下来要调用的函数)会进行下面的计算:
yield(2);
yield(3);
"DONE";但保存的continuation中yield是什么?跟第一个yield一样,实际会返回到之前保存的第一个kret continuation,将会从那里开始执行并打印结果,这就产生了一个循环。幸运的是有一个简单的修复方法。已足够清晰,我们应该仅创建一次yield,因为第一次函数调用后其创建的yield没办法再更新了(相当于闭包在函数内部创建的变量,外面引用不到,也改变不了);为了能返回到恰当的退出点,我们维护了一个新的return变量:
with-yield = λ(func) {
let (return, yield) {
yield = λ(value) {
CallCC(λ(kyld){
func = kyld;
return(value); # return is set below, on each call to the function
}); # it's always the next return point.
}; #
λ(val) { #
CallCC(λ(kret){ #
return = kret; # <- here
func(val || yield);
});
};
};
};此外,认识到除了第一次之外,其它每次都将yield传给func函数没有意义,改进的新版本允许调用时传递一个值(除了第一次)。这个值将作为yield自身的返回值。
下面代码同样使用foo示例,但仅执行三次println(foo()):
with-yield = λ(func) {
let (return, yield) {
yield = λ(value) {
CallCC(λ(kyld){
func = kyld;
return(value);
});
};
λ(val) {
CallCC(λ(kret){
return = kret;
func(val || yield);
});
};
};
};
foo = with-yield(λ(yield){
yield(1);
yield(2);
yield(3);
"DONE";
});
println(foo());
println(foo());
println(foo());看起来像是可以正确执行了。对比第一版有显著的改进,“print(foo()); foo()”代码不会再死循环了。但如果再增加一行println(foo())会怎么样?会再次发生循环!
问题2:WTF?
这次发生循环的原因会更加深奥一点。与我们continuation不受限的本性(unlimited nature)有关:它们涵盖了程序全部的后续计算行为,恰巧也包含了第一次调用foo()的返回。当从它返回时会发生什么? — 所有一切又重新执行了一遍:
println(foo()); ## yield 1 <----------------- HERE -------------------+
println(foo()); ## yield 2 |
println(foo()); ## yield 3 |
println(foo()); ## we reached "DONE", so the first foo() RETURNS -->--+我们看一下with-yield中的这行代码:
func(val || yield);
#...当通过调用yield退出func函数时,会调用一个continuation,所以并不会执行到#... 这行。但当结束时,到达了函数结尾处(DONE这行),func函数此时将等效于一个返回"DONE"给其初始continuation(即func初始定义函数的continuation)的函数,这个continuation将调用第一个println。第二行的foo()只是循环了一下,所有"DONE"行都是第一行print打印出来的。可以通过下面的代码来验证一下:
println(foo());
println("bar");
println(foo());
println(foo());
foo();上面的输出是:1, bar, 2, 3, DONE, bar, DONE, bar, ....
所以一个可能的修复方式,当“自然”返回时(简单地说就是“结束了”)必须将func设置为其它某值。我们就将其设置为返回“no more continuations”的空函数(什么都不会做)。
val = func(val || yield);
func = λ() "NO MORE CONTINUATIONS";
kret(val);现在不会再循环了,但当运行下述代码时会再次感到困惑:
with-yield = λ(func) {
let (return, yield) {
yield = λ(value) {
CallCC(λ(kyld){
func = kyld;
return(value);
});
};
λ(val) {
CallCC(λ(kret){
return = kret;
val = func(val || yield);
func = λ() "NO MORE CONTINUATIONS";
kret(val);
});
};
};
};
foo = with-yield(λ(yield){
yield(1);
yield(2);
yield(3);
"DONE";
});
println(foo());
println(foo());
println(foo());
println(foo());
我们本期望输出1,2,3,DONE,但同时也输出了三次“NO MORE CONTIUATIONS”。为了弄清楚原因,我们按下面的方式尝试交错输出:
print("A. "); println(foo());
print("B. "); println(foo());
print("C. "); println(foo());
print("D. "); println(foo());
## and the output is:
A. 1
B. 2
C. 3
D. DONE
B. NO MORE CONTINUATIONS
C. NO MORE CONTINUATIONS
D. NO MORE CONTINUATIONS
***Result: false上述输出意味着问题依旧存在:函数正常退出仍然会返回到第一个continuation处;但因函数func目前是空操作,"B."行代码不会触发循环。
原因还是比较绕,原文解释较少,这里面再补充解释下,梳理下执行流程。
一个大的原则还是抓住第一次foo执行。当第一次执行foo时,执行到 val = func(val || yield); 时,func的continuation为with-yield初始化使用的函数整体执行完毕的全部后续行为,所以不管后续程序如何执行,以及kret/return如何赋值,当func被kyld赋值DONE行的continuation后,都会执行完然后跳到 val = func(val || yield); 进行val的赋值及后续行为,接着就是func赋值为空函数等,返回到第一行的println,打印出DONE,后续println都会打印出空函数的返回,即NO MORE CONTINUATIONS。
我们的实现仍然有用,考虑到函数永远不结束仅通过yield退出的情况。下面是一个Fibonacci的例子:
with-yield = λ(func) {
let (return, yield) {
yield = λ(value) {
CallCC(λ(kyld){
func = kyld;
return(value);
});
};
λ(val) {
CallCC(λ(kret){
return = kret;
val = func(val || yield);
func = λ() "NO MORE CONTINUATIONS";
kret(val);
});
};
};
};
fib = with-yield(λ(yield){
let loop (a = 1, b = 1) {
yield(b);
loop(b, a + b);
};
});
## print the first 50 fibonacci numbers
let loop (i = 0) {
if i < 50 {
println(fib());
loop(i + 1);
};
};但如果我们想要一个可靠的实现(函数结束时不会返回到第一次调用的位置),需要引入另一个概念叫做“delimited continuations”。
Delimited continuations: reset 和 shift
我们将通过两个其它的操作符reset和shift来实现yield。它们提供了“delimited continuations” — 那些像普通函数一样返回的continuations。 reset会创建一个“执行帧”(可理解为reset执行时刻的所有上下文信息),shift仅能获取到这个“执行帧”之后的continuation(即reset之后的计算行为),而不是像CallCC那样可以获取到“整个程序的未来计算行为”。
reset和shift都接收一个函数参数。reset函数执行期间,我们能够通过调用shift来给reset的调用位置返回一个值。
首先来看下with-yield会变成什么样:
with-yield = λ(func) {
let (yield) {
## yield uses shift to return a value to the innermost
## reset call. before doing that, it saves its own
## continuation in `func` — so calling func() again will
## resume from where it left off.
yield = λ(val) {
shift(λ(k){
func = k; # save the next continuation
val; # return the currently yielded value
});
};
## from with-yield we return a function with no arguments
## which uses reset to call the original function, passing
## to it the yield (initially) or any other value
## on subsequent calls
λ(val) {
reset( λ() func(val || yield) );
};
}
};注意现在每次函数调用都内嵌在reset中。这可以确保我们不会涵盖程序整体的continuation(即程序全部的后续行为),而仅仅是reset之后的行为。按照定义,现在不可能再发生循环了。当函数正常结束,程序就会继续执行而不会返回到第一次调用的位置。
reset / shift的实现
这些操作符的实现有很强的技巧性,尽管实现代码很短。做好头疼的准备。我会给出两种解决方案。我不是这个方法的作者,可以告诉你在真正理解它们之前我盯着代码看了很久。我是在Oleg Kiselyov的Scheme程序中发现了这个方法。推荐你阅读这些文章来更多地理解这个令人兴奋的概念。
实现为原始功能函数
在这里将它们实现为原始功能函数。在原始功能函数中,当前continuation是显式的(不需要调用CallCC),这在一定程度上更利于理解到底发生了什么。下面是完整的实现:
var pstack = [];
function _goto(f) {
f(function KGOTO(r){
var h = pstack.pop();
h(r);
});
}
globalEnv.def("reset", function(KRESET, th){
pstack.push(KRESET);
_goto(th);
});
globalEnv.def("shift", function(KSHIFT, f){
_goto(function(KGOTO){
f(KGOTO, function SK(k1, v){
pstack.push(k1);
KSHIFT(v);
});
});
});关键之处是reset和shift都使用了_goto,它并不是一个“普通”函数。它没有自己的continuation。_goto接收一个普通函数f并给其传入一个continuation(KGOTO)进行调用。f执行过程中捕获的任意continuation(甚至是使用CallCC捕获的)仅能涵盖到这个KGOTO开始的后续计算行为,因为KGOTO上面没有其它计算了(KGOTO保存在pstack堆栈栈顶)。因此,无论f是正常退出,或通过调用一个continuation退出,最终都会去执行KGOTO — 它会从stack中取出下一个continuation,并应用到之前的计算结果上。
reset会在_goto(th)之前将其自身的continuation(KRESET)压入堆栈。如果不这么做,函数退出后程序就会停止,因为_goto后面没有其它代码了。所以当函数以任意方式退出后,KGOTO都会重新返回到KRESET这里继续执行。
最终shift会以KGOTO这个continuation来调用函数,所以如果正常退出则KGOTO将从pstack栈顶恢复执行,并传给其一个SK函数来返回至shift调用的位置(从而使用shift自己的continuation,KSHIFT)。SK是一个delimited continuation — 能够像一个函数一样返回一个值 — 因此我们也需要将它的continuation(k1)压入堆栈。为了说明其中的区别,我在下面引入了一个shift2原始功能函数,和上面的shift一样,除了没有这一行:pstack.push(k1),试一下这个示例:
println(reset(λ(){
1 + shift( λ(k) k(k(2)) );
}));
println(reset(λ(){
1 + shift2( λ(k) k(k(2)) );
}));shift提供了一个continuation(k),是一个从嵌套层级最近reset开始的delimited continuation。这个例子中continuation就是给shift的结果加1:
1 + [?]当我们调用k时,我们是用值替换了上面的问号(?)。我们调用两次k(k(2))。提供2并继续执行程序,因此内部的k(2)将返回3。所以紧接着的k(3)将提供一个3,同样会替换问号,生成最终的结果4。
shift2是不对的:内部的k(2)永远不会返回。
CallCC-based
如上所述,如果我们仅有CallCC并且没有办法定义原始功能函数,同样可以实现delimited continuation。下面的代码功能与原始功能函数版本基本相同,但因为没有JS数组,它使用了列表list来维护堆栈(像前面章节曾看过的,我们可以直接使用λanguage实现list,尽管这里是使用原生功能函数方式实现的)。因为需要CallCC来获取current continuation(原生功能函数中是一个显式的参数),所以代码比之前版本稍微长了点。
下面代码中最有技巧性的部分是goto的实现形式及其原因,但我要把发掘的乐趣留给你。
pstack = NIL;
goto = false;
reset = λ(th) {
CallCC(λ(k){
pstack = cons(k, pstack);
goto(th);
});
};
shift = λ(f) {
CallCC(λ(k){
goto(λ(){
f(λ(v){
CallCC(λ(k1){
pstack = cons(k1, pstack);
k(v);
});
});
});
});
};
let (v = CallCC( λ(k){ goto = k; k(false) } )) {
if v then let (r = v(), h = car(pstack)) {
pstack = cdr(pstack);
h(r);
}
};基于WebGL的GPGPU指南 - 概述
也是一直在思考前端到底能如何能发力突围的过程中发现了这系列基于WebGL的GPGPU指南的文章,网上大部分 WebGPU 并行计算的文章均引用到了这系列文章,看原文实际应用是Web中针对物理学公式的仿真模拟计算,目前只快速看完前五篇,会陆续整理出来,后续的章节看精力和实际需求斟酌整理。
整理译文的目录章节如下:
超级速度
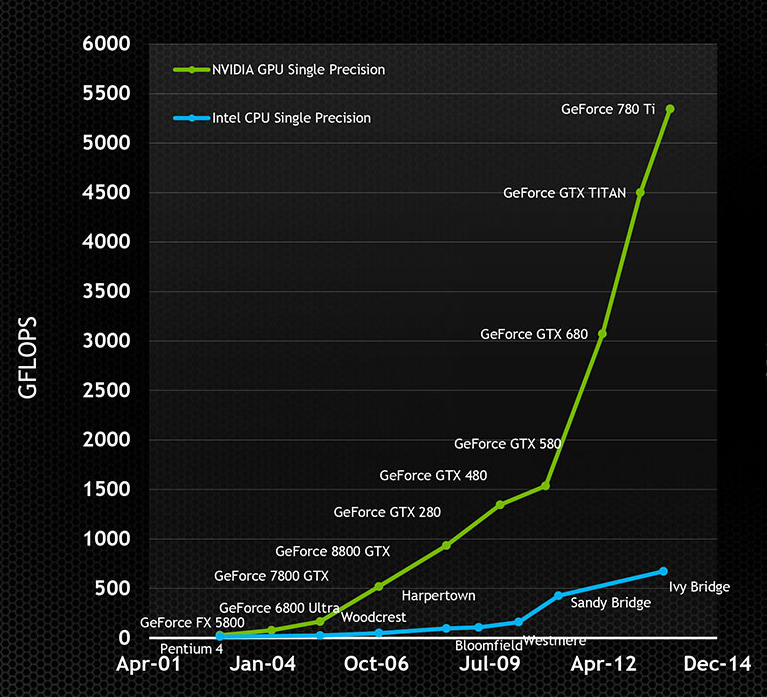
GPU性能远超CPU性能,并且差距越来越大!
上面所展示的性能是针对单精度、32位浮点数的。$GPU$ 能非常好地处理这些数值。然而,使用更高精度的数值,如64位浮点数,会大幅降低性能。实际上,这些更高精度的数值在
等等,什么?WebGL 计算?
现代计算机使用称为着色器
幸运的是,在科学、工程和数学中的大量问题都是可以解决的。
- 在网格上。
- 网格上一个点上的计算不依赖于其它点上正在进行的计算。
 WebGL顶点构建出由片元填充的三角形 |
 看起来就像一个求解数值微分方程的网格 |
着色器
我们如何做到这一点?
将问题映射到

WebGL GPGPU实现的基本结构
画布(Canvas)
与
其次,我们不需要将画布附加到 DOM 上,只需创建画布并用它获取一个
几何形状
我们希望使用尽可能简单的几何形状来进行计算。顶点和几何形状的唯一目的就是针对画布中每个像素点生成对片段着色器的调用。几乎总是会使用两个能覆盖完整画布的三角形作为几何形状,正如图中所示。
片段
简单的几何形状被光栅化。它被划分成与原始画布上的像素相对应的片段。我们使用没有投影的简单几何形状,以便片段能直接映射到像素。
输入纹理
在
我们按照画布尺寸来创建一个纹理。所以,对于一个
代码
现在事情变得非常有趣。当进行渲染时,针对几何形状中的每个片段都会调用片段着色器,并产生一个像素值
输出纹理
将片段着色器的结果绘制到屏幕上对于计算来说并不是非常有用。相反,我们将其写入另一个纹理。这种作为离屏渲染目标使用的纹理,被称为帧缓冲对象
输出纹理的尺寸与画布和输入纹理相同。实际上,通过交换输入和输出纹理来进行另一次渲染是一种常见做法。
你可能会问“第一个纹理从哪里来?”,有两种可能性。第一种是直接从片段着色器创建纹理。考虑假如上面流程中没有输入纹理,片段着色器仅使用
减速带(Speed Bumps)
这种技术对于大多数
为了能够尽可能简单地阐明通用方法,我们首先将解释强劲桌面平台上的一个矩阵乘法示例,然后展示如何将代码适配到不太顺畅的移动平台。
如何用JavaScript实现一门编程语言 - 简单的解释器(Interpreter)
整篇译文的目录章节如下:
- 前言
- λanguage描述
- 写一个解析器(Parser)
- 简单的解释器(Interpreter)
- CPS求值器(CPS Evaluator)
- 编译成JS
- 总结
- 真实示例
简单的解释器(Interpreter)
作者原文提到的bug此译文中已修复,主要是指在解释器,CPS求值器及CPS编译器章节中:像 a() && b() 或者 a() || b() 的表达式两侧都会求值。这样处理是不对的,是否对 b() 求值依赖 a() 的求值结果。通过将 || 及 && 两个二元操作符的处理逻辑替换为 if 表达式来修复。
一个简单的解释器
总结一下:目前为止我们写了3个函数:InputStream,TokenStream和parse。我们可以通过下面的方式得到一块代码的AST:
var ast = parse(TokenStream(InputStream(code)));实现解释器要比解析器简单。仅仅需要遍历AST,按正常顺序执行表达式即可。
环境
准确执行的关键是能够正确地维护环境 - 一个持有各种变量绑定的结构体。环境会作为我们求值函数的一个参数。每次遇到一个 lambda 节点,我们必须用新变量(函数参数)来扩展环境,并使用运行时传入的值来初始化这些变量。如果参数将外层作用域(这里我会交换地使用作用域scope和环境environment两个词)的同名变量覆盖了,我们必须在函数结束时小心地将变量恢复为之前的值。
实现上述机制最简单的方式就是利用JavaScript的原型继承(prototype inheritance)。当进入一个函数时,我们创建一个新的环境,其原型设置为外层环境(父辈环境),函数体基于新的环境来求值。这样当退出函数时,我们不需要做任何事情 - 外层环境(env)已经包含了可能被覆盖的任何同名变量绑定,不用再做任何恢复操作。
下面是环境(Environment)对象的定义:
function Environment(parent) {
this.vars = Object.create(parent ? parent.vars : null);
this.parent = parent;
}
Environment.prototype = {
extend: function() {
return new Environment(this);
},
lookup: function(name) {
var scope = this;
while (scope) {
if (Object.prototype.hasOwnProperty.call(scope.vars, name))
return scope;
scope = scope.parent;
}
},
get: function(name) {
if (name in this.vars)
return this.vars[name];
throw new Error("Undefined variable " + name);
},
set: function(name, value) {
var scope = this.lookup(name);
// let's not allow defining globals from a nested environment
if (!scope && this.parent)
throw new Error("Undefined variable " + name);
return (scope || this).vars[name] = value;
},
def: function(name, value) {
return this.vars[name] = value;
}
};一个环境对象有一个父辈属性parent指向父辈作用域。对于全局作用域(global scope)这个属性是null。环境对象上还有一个vars属性持有各种变量绑定。为了能通过原型继承得到当前的变量绑定,对于顶层全局作用域,vars初始化为Object.create(null),对于子作用域,会初始化为Object.create(parent.vars)。
环境对象支持下面这些方法:
- extend() — 创建一个子作用域。
- lookup(name) — 寻找给定名字的变量所定义的作用域。
- get(name) — 得到变量的当前值。如果变量未定义会抛出一个错误。
- set(name, value) — 设置一个变量的值。需要寻找变量定义的真实作用域。如果没有找到该作用域,并且也不在全局作用域,会抛出错误。
- def(name, value) — 在当前作用域上创建一个变量。
求值函数(evaluate function)
现在有了环境,我们可以来处理主要的问题了。函数是一个大的switch语句,通过节点类型调度执行各节点的求值逻辑。我来一一解说每一种情况。
function evaluate(exp, env) {
switch (exp.type) {对于常量节点,直接返回它们的值:
case "num":
case "str":
case "bool":
return exp.value;从环境中取出变量的值。记住 var 节点的value属性记录了变量的名字。
case "var":
return env.get(exp.value);对于赋值节点,我们需要检查左侧是否是一个 var 节点(如果不是,则抛出一个错误;我们现在还不支持其他类型节点的赋值)。然后可以使用env.set来给变量设置值。注意变量值需要事先通过递归调用求值函数来得到。
case "assign":
if (exp.left.type != "var")
throw new Error("Cannot assign to " + JSON.stringify(exp.left));
return env.set(exp.left.value, evaluate(exp.right, env));一个二元表达式 binary 节点需要应用一个操作符到两个操作数上。我们后面会来写apply_op函数,相当简单。同样,我们需要递归调用求值函数来计算左右操作数:
case "binary":
var left = evaluate(exp.left, env);
if (exp.operator === "&&") {
return left !== false && evaluate(exp.right, env);
}
if (exp.operator === "||") {
return left !== false ? left : evaluate(exp.right, env);
}
return apply_op(exp.operator,
left,
evaluate(exp.right, env));一个函数 lambda 节点实际是通过一个JavaScript闭包实现,所以在JavaScript中可以像普通函数一样调用。写了一个make_lambda函数,后续会进行定义:
case "lambda":
return make_lambda(env, exp);if 节点求值很简单:首先对条件condition求值。如果值不是 false,则继续对 then 分支求值。否则,如果有 else 分支,则对其求值,否则返回 false。
case "if":
var cond = evaluate(exp.cond, env);
if (cond !== false) return evaluate(exp.then, env);
return exp.else ? evaluate(exp.else, env) : false;prog 节点是一个表达式序列。按顺序对每个表达式求值,并返回最后一个表达式的值。如果表达式序列为空,则返回值为false。
case "prog":
var val = false;
exp.prog.forEach(function(exp){ val = evaluate(exp, env) });
return val;call 节点求值需要调用一个函数。首先对func属性求值,应该返回一个普通的JS函数,接着对args属性求值,并传给前面返回的函数来调用。
case "call":
var func = evaluate(exp.func, env);
return func.apply(null, exp.args.map(function(arg){
return evaluate(arg, env);
}));永远不应该执行到这里,只有当我们解析器中增加了新的节点类型,并且忘记更新求值函数,才会执行到这个分支,抛出一个清晰的错误。
default:
throw new Error("I don't know how to evaluate " + exp.type);
}
}上面就是求值函数的核心,正如你所看到的,是不是相当简单。我们还需要写两个函数,首先开始最简单的apply_op:
function apply_op(op, a, b) {
function num(x) {
if (typeof x != "number")
throw new Error("Expected number but got " + x);
return x;
}
function div(x) {
if (num(x) == 0)
throw new Error("Divide by zero");
return x;
}
switch (op) {
case "+" : return num(a) + num(b);
case "-" : return num(a) - num(b);
case "*" : return num(a) * num(b);
case "/" : return num(a) / div(b);
case "%" : return num(a) % div(b);
// pre-process in evaluate avoid imporperly expression evaluation
// for a() && b() or a() || b()
// case "&&": return a !== false && b;
// case "||": return a !== false ? a : b;
case "<" : return num(a) < num(b);
case ">" : return num(a) > num(b);
case "<=" : return num(a) <= num(b);
case ">=" : return num(a) >= num(b);
case "==" : return a === b;
case "!=" : return a !== b;
}
throw new Error("Can't apply operator " + op);
}函数接受操作符和参数。通过一个swtich语句来来应用操作符。不像JavaScript,将任意操作符应用到任意参数进而判断操作是否合理,我们要求数字型操作符的操作数需要是数字,除数不能是0,通过使用num和div小工具函数来保证这些。对于字符串我们将会定义其它的工具函数。
make_lambda
make_lambda函数有一点巧妙:
function make_lambda(env, exp) {
function lambda() {
var names = exp.vars;
var scope = env.extend();
for (var i = 0; i < names.length; ++i)
scope.def(names[i], i < arguments.length ? arguments[i] : false);
return evaluate(exp.body, scope);
}
return lambda;
}正如你看到的,make_lambda返回一个引用了环境对象和将要求值表达式的普通JavaScript函数。闭包创建的时候什么都不会做,但当被调用时,在创建时保存的环境对象将会由函数参数/传值所扩展(如果传递的值少于函数表达式定义时的参数个数,未被赋值的参数将初始化为 false)。接着在新的作用域下对表达式的函数体进行求值。
原始功能函数(Primitive functions)
你可能察觉到 λanguage 语言没有提供与外界交互的方式。某些代码示例中使用了print和println函数,但是它们还未定义。这些需要定义为原始功能函数(也就是说,我们通过JavaScript实现它们,并插入到全局环境)。
所有功能汇集到一起,有了下面的测试程序:
// some test code here
var code = "sum = lambda(x, y) x + y; print(sum(2, 3));";
// remember, parse takes a TokenStream which takes an InputStream
var ast = parse(TokenStream(InputStream(code)));
// create the global environment
var globalEnv = new Environment();
// define the "print" primitive function
globalEnv.def("print", function(txt){
console.log(txt);
});
// run the evaluator
evaluate(ast, globalEnv); // will print 5下载
可以下载到目前为止的代码lambda-eval.js。能够在NodeJS下执行 - 将代码传入标准输入来求值,例如:
echo 'sum = lambda(x, y) x + y; println(sum(2, 3));' | node lambda-eval1.js下一节我们来看一下 λanguage 的玩法。
如何用JavaScript实现一门编程语言 - 真实示例
整篇译文的目录章节如下:
真实示例
我以少量例子来结束本教程,也希望它们能展示出λanguage语言可以比ES5做得更好。我知道ES6就在眼前, 但其还需要数年(未来N年)才可能得到广泛支持 — 当下我们只有两个选择,一个是写一个成功的浏览器提供替代JavaScript的方案(可能性为0),或者将一门更好的语言编译成JavaScript(成功的概率100%)。
- catDir(pathname) — 一个函数会递归遍历目录树并打印每个文件的内容,除了以点号开始的文件(即隐藏文件)。
- copyTreeSeq(srcdir, destdir) — 一个函数会递归拷贝一个目录树。
- copyTree(srcdir, destdir) — 上面拷贝目录树函数的并行版本。它一次拷贝多个文件所以会快很多。
- In fairness to Node — 写了一个parallelEach抽象并丢掉错误处理(失败情况)尝试使得纯NodeJS代码尽可能看起来更好。
- Exceptions — 演示了一个可以支持跨异步调用的简单异常系统。
原始功能函数
本节的示例需要下面的原始功能函数库。将其保存为"library.lambda"并确保在需要它的程序之前引入它,例如:
cat library.lambda program.lambda | node lambda.js所有原始功能函数都将接收continuation(k)作为第一个参数。并请注意其中一些需要使用Execute来调用回调函数。因为它们会调用异步API,所以Execute中的循环将在结果生成之前就结束了。你在写原始功能函数时一定要切记这点 — 如果你不会立即调用continuation,请使用Execute。
## primitives
## these assignments are required so that we create globals.
readFile = false;
readDir = false;
writeFile = false;
makeDir = false;
symlink = false;
readlink = false;
fstat = false;
lstat = false;
isFile = false;
isDirectory = false;
isSymlink = false;
pathJoin = false;
pathBasename = false;
pathDirname = false;
forEach = false;
length = false;
arrayRef = false;
arraySet = false;
stringStartsWith = false;
parallel = false;
cons = false;
isCons = false;
car = false;
cdr = false;
NIL = false;
setCar = false;
setCdr = false;
RESET = false;
SHIFT = false;
js:raw "(function(){
// filesystem
var fs = require('fs');
var path = require('path');
readFile = function(k, filename) {
fs.readFile(filename, function(err, data){
if (err) throw new Error(err);
Execute(k, [ data ]);
});
};
readDir = function(k, dirname) {
fs.readdir(dirname, function(err, files){
if (err) throw new Error(err);
Execute(k, [ files ]);
});
};
writeFile = function(k, filename, data) {
fs.writeFile(filename, data, function(err){
if (err) throw new Error(err);
Execute(k, [ false ]);
});
};
makeDir = function(k, dirname) {
fs.mkdir(dirname, function(err){
if (err) throw new Error(err);
Execute(k, [ false ]);
});
};
symlink = function(k, src, dest) {
fs.symlink(src, dest, function(err){
if (err) throw new Error(err);
Execute(k, [ false ]);
});
};
readlink = function(k, path) {
fs.readlink(path, function(err, target){
if (err) throw new Error(err);
Execute(k, [ target ]);
});
};
fstat = function(k, pathname) {
fs.stat(pathname, function(err, stat){
if (err && err.code != 'ENOENT') throw new Error(err);
Execute(k, [ err ? false : stat ]);
});
};
lstat = function(k, pathname) {
fs.lstat(pathname, function(err, stat){
if (err && err.code != 'ENOENT') throw new Error(err);
Execute(k, [ err ? false : stat ]);
});
};
isFile = function(k, stat) {
k(stat.isFile());
};
isDirectory = function(k, stat) {
k(stat.isDirectory());
};
isSymlink = function(k, stat) {
k(stat.isSymbolicLink());
};
pathJoin = function(k) {
k(path.join.apply(path, [].slice.call(arguments, 1)));
};
pathBasename = function(k, x) {
k(path.basename(x));
};
pathDirname = function(k, x) {
k(path.dirname(x));
};
// lists
function Cons(car, cdr) {
this.car = car;
this.cdr = cdr;
}
isCons = function(k, thing) {
k(thing instanceof Cons);
};
cons = function(k, car, cdr) {
k(new Cons(car, cdr));
};
car = function(k, cell) {
k(cell.car);
};
cdr = function(k, cell) {
k(cell.cdr);
};
setCar = function(k, cell, car) {
k(cell.car = car);
};
setCdr = function(k, cell, cdr) {
k(cell.cdr = cdr);
};
NIL = {};
NIL.car = NIL;
NIL.cdr = NIL;
// arrays
length = function(k, thing) {
k(thing.length);
};
arrayRef = function(k, array, index) {
k(array[index]);
};
arraySet = function(k, array, index, value) {
k(array[index] = value);
};
// strings
stringStartsWith = function(k, str, prefix) {
k(str.substr(0, prefix.length) == prefix);
};
parallel = function(k, f){
var n = 0, result = [], i = 0;
f(function(){ if (i == 0) k(false) }, pcall);
function pcall(kpcall, chunk){
var index = i++;
n++;
chunk(function(rchunk){
n--;
result[index] = rchunk;
if (n == 0) Execute(k, [ result ]);
});
kpcall(false);
}
};
// delimited continuations
var pstack = [];
function _goto(f) {
f(function KGOTO(r){
var h = pstack.pop();
h(r);
});
}
RESET = function(KRESET, th){
pstack.push(KRESET);
_goto(th);
};
SHIFT = function(KSHIFT, f){
_goto(function(KGOTO){
f(KGOTO, function SK(k1, v){
pstack.push(k1);
KSHIFT(v);
});
});
};
})()";
forEach = λ(array, f)
let (n = length(array))
let loop (i = 0)
if (i < n) {
f(arrayRef(array, i), i);
loop(i + 1);
};catDir
我抛出一个简单的问题。查找并打印一个目录下的文件!完成一个函数,递归遍历一个目录并打印下面除了以点号开头的每个文件的内容。NodeJS中,要使用异步API。
换句话说,我们正在寻求(几乎)相当于下面命令的功能:
find . -type f -exec cat {} \;区别是它不应该搜寻以点号开头的目录,并应该排除以点号开头的文件。我将很乐观:用Node完成这个功能会更容易,相对于去探索如何使用find命令工具来完成。
NodeJS实现
如果有一定的经验,写一个原始Node程序来完成这个功能不会太难,但看起来不太美观:
"use strict";
var fs = require("fs");
var path = require("path");
function catDir(dirname, callback) {
fs.readdir(dirname, function(err, files){
if (err) throw new Error(err);
(function loop(i){
if (i < files.length) {
var f = files[i];
if (f.charAt(0) != ".") {
var fullname = path.join(dirname, f);
fs.stat(fullname, function(err, stat){
if (err) throw new Error(err);
if (stat.isDirectory()) {
catDir(fullname, function(){
loop(i + 1);
});
} else if (stat.isFile()) {
fs.readFile(fullname, "utf8", function(err, data){
if (err) throw new Error(err);
process.stdout.write(String(data));
loop(i + 1);
});
}
});
} else {
loop(i + 1);
}
} else {
callback();
}
})(0);
});
}
console.time("catDir");
catDir("/home/mishoo/work/my/uglifyjs2/", function(){
// rest of the program goes here.
console.timeEnd("catDir");
});λanguage实现
看看吧,既简洁又优雅。实际上仍使用了异步API,虽然看起来好像没有 — 换句话说,catDir不会阻塞进程。但没有回调地狱。
catDir = λ(dirname) {
forEach(readDir(dirname), λ(f){
if !stringStartsWith(f, ".") {
let (fullname = pathJoin(dirname, f),
stat = fstat(fullname)) {
if isDirectory(stat) {
catDir(fullname);
} else if isFile(stat) {
print(readFile(fullname));
}
}
}
});
};
catDir("/home/mishoo/work/my/uglifyjs2/");说明:
- 程序需要一个原始功能函数库。
- λanguage语言在一些语法上还相当局限,比如不能直接进行 f.charAt(0) != ".",所以我写了一个 stringStartsWith 作为原始功能函数,并使用了新增加的求反运算符(再说一遍,也是一个语法糖)。
- readDir 和 readFile 函数也都是原始功能函数,它们会分别调用NodeJS “fs”模块中的相应函数。同样它们使用的都是异步版本。fstat也是一样的情况。
- 你可能会提出反对我在作弊,使用了forEach,而在JavaScript中使用了一个丑陋的loop函数,但这就是问题所在:λanguage中我们可以使用看起来像同步的循环;JavaScript中却不能(即使用辅助工具库如async.eachSeries,仍需要将剩下代码嵌在一个continuation中传给抽象的循环)。
- 与纯NodeJS相比的速度差别可以忽略不计。有趣的是,即使我禁用了优化器,性能也不会降低很多。这就是比JavaScript慢10倍的循环也不应该吓到你 — 在真实app中,这些循环往往不会是瓶颈;如果变成了瓶颈,你也可以实现原始功能函数。
串行copyTree
下面是另一个问题,与第一个问题差不多相同的难度。我们想实现一个目录拷贝函数。它接收两个参数:源目录(必须存在且必须是一个目录)和目标路径(必须不存在,将会被创建)。
我们仍处于“说教模式” — 这个函数也不是完美的。它不会考虑文件权限或者恰当的错误处理。同样,它会将源文件读入内存然后写入目标位置(正确的做法应当是分块读取,以支持比RAM容量大的文件)。
NodeJS实现
首先,下面是完整恐怖的NodeJS版本:
function copyTreeSeq(srcdir, destdir, callback) {
fs.mkdir(destdir, function(err){
if (err) throw new Error(err);
fs.readdir(srcdir, function(err, files){
if (err) throw new Error(err);
(function loop(i){
function next(err) {
if (err) throw new Error(err);
loop(i + 1);
}
if (i < files.length) {
var f = files[i];
var fullname = path.join(srcdir, f);
var dest = path.join(destdir, f);
fs.lstat(fullname, function(err, stat){
if (err) throw new Error(err);
if (stat.isSymbolicLink()) {
fs.readlink(fullname, function(err, target){
if (err) throw new Error(err);
fs.symlink(target, dest, next);
});
} else if (stat.isDirectory()) {
copyTreeSeq(fullname, dest, next);
} else if (stat.isFile()) {
fs.readFile(fullname, function(err, data){
if (err) throw new Error(err);
fs.writeFile(dest, data, next);
});
} else {
next();
}
});
} else {
callback();
}
})(0);
});
});
}之所以将它命名为copyTreeSeq,因为尽管使用了异步API,但它还是以串行的方式来运行的 — 也就是说,每次仅拷贝一个文件。
λanguage实现
λanguage语言版本很简单,仍然完全是异步的并且和NodeJS版本代码运作的一样好:
copyTreeSeq = λ(srcdir, destdir) {
makeDir(destdir);
forEach(readDir(srcdir), λ(f){
let (fullname = pathJoin(srcdir, f),
dest = pathJoin(destdir, f),
stat = lstat(fullname)) {
if isSymlink(stat) {
symlink(readlink(fullname), dest);
} else if isDirectory(stat) {
copyTreeSeq(fullname, dest);
} else if isFile(stat) {
writeFile(dest, readFile(fullname));
}
}
});
};我通过拷贝一个RAM文件系统中包含2676个嵌套子目录的路径,共11012个文件(180M),来测试上述程序。λanguage程序耗时3.6s,纯NodeJS程序耗时3.5s,也就是Node会快大概2%。现在再来看看代码。2%的速度是否能挽救代码的丑陋?
但注意,这个代码是串行的 — 每次仅拷贝一个文件。既然我们的文件系统操作是异步的,可以尝试每次并行拷贝多个文件。我之前不相信会有多大差别,但事实差别很大:纯NodeJS和λanguage的并行版本都要快大概3倍。
copyTree并行版本
下面是目录拷贝函数的并行版本实现。区别就是不用等待当前文件拷贝完成才开始下一个文件的拷贝,会同时处理多个文件。两种语言版本实现都比它们串行版本快了大概3倍。
NodeJS实现
如何在NodeJS中实现并行似乎比在λanguage语言中更加明显。使用Node,回调函数由你传入,并知道调用者会立即继续执行,所以这开放了一个可以使用for循环的可能。但我们必须谨慎处理保证直到所有文件都被处理后才最终调用callback回调函数。NodeJS的并行版本和串行版本一样丑陋:
function copyTree(srcdir, destdir, callback) {
fs.mkdir(destdir, function(err){
if (err) throw new Error(err);
fs.readdir(srcdir, function(err, files){
if (err) throw new Error(err);
var count = files.length;
function next(err) {
if (err) throw new Error(err);
if (--count == 0) callback();
}
if (count == 0) {
callback();
} else {
files.forEach(function(f){
var fullname = path.join(srcdir, f);
var dest = path.join(destdir, f);
fs.lstat(fullname, function(err, stat){
if (err) throw new Error(err);
if (stat.isSymbolicLink()) {
fs.readlink(fullname, function(err, target){
if (err) throw new Error(err);
fs.symlink(target, dest, next);
});
} else if (stat.isDirectory()) {
copyTree(fullname, dest, next);
} else if (stat.isFile()) {
fs.readFile(fullname, function(err, data){
if (err) throw new Error(err);
fs.writeFile(dest, data, next);
});
} else {
next();
}
});
});
}
});
});
}使用forEach循环开始并行拷贝目录下面的所有文件。回调函数(next)需要保证所有文件都已拷贝完成才最终调用最顶层callback。除此之外,还需要校验如果目录没有文件则直接调用callback。
λanguage实现
我们需要一个原始功能函数来完成λanguage语言的并行版本。那是因为我们基于异步Node API的包装程序仅在执行完成后才会调用它们的回调函数,所以默认我们的程序只能串行执行。
我实现了一个原始功能函数,它会接收一个函数参数,并给该函数参数传入叫做pcall的单一参数。pcall接收一个函数参数并对其进行“异步”调用 — 也就是说,当函数参数还在运行的过程中,pcall就会立即重新开始执行。最终,parallel() 调用仅在其函数体中所有pcall结束后才返回。如果听起来很复杂,看下面的用法可能会有一定的启发:
copyTree = λ(srcdir, destdir) {
makeDir(destdir);
parallel(λ(pcall){
forEach(readDir(srcdir), λ(f){
pcall(λ(){
let (fullname = pathJoin(srcdir, f),
dest = pathJoin(destdir, f),
stat = lstat(fullname)) {
if isSymlink(stat) {
symlink(readlink(fullname), dest);
} else if isDirectory(stat) {
copyTree(fullname, dest);
} else if isFile(stat) {
writeFile(dest, readFile(fullname));
}
}
});
});
});
};所以相对于串行版本字面上的改动很少:将forEach循环包装到一个parallel的调用中,然后使用pcall处理每个文件。我们不需要计算有多少文件并随机地调用回调函数;原始功能函数会处理所有事情。代码看起来像是串行的,但实际是并行运行的!
一个组合了parallel和forEach的原始功能函数将可以编写出更优雅的代码,并且不难实现;但parallel看起来更通用。
可能会有人争论λanguage代码之所以出色是因为对并行的抽象,如果NodeJS做了类似的抽象也可以同样出色。在某种程度上确实如此,但也不会跟上面代码一样清晰简洁。
原始功能函数:parallel
我将稍微讨论一下parallel的实现。下面是实现代码:
parallel = js:raw "function(k, f){
var n = 0, result = [], i = 0;
f(function(){ if (i == 0) k(false) }, pcall);
function pcall(kpcall, chunk){
var index = i++;
n++;
chunk(function(rchunk){
n--;
result[index] = rchunk;
if (n == 0) Execute(k, [ result ]);
});
kpcall(false);
}
}";k是parallel自身的continuation。f是接收pcall参数进行调用的函数。f接收一个执行 if (i == 0) k(false) 的continuation — 这在当f函数体中没有pcall调用的情况下很必要;我们直接调用顶层parallel的continuation(k)并传入结果false。
pcall算是一个循规蹈矩的函数:接收一个continuation(kpcall)和一个将运行的函数(chunk)。它调用chunk后会立即调用它自身的continuation(传入false;我们此时并没有一个有意义的结果)。所以,如果chunk是异步的,它将与程序剩余部分并行运行(即kpcall所代表的)。
pcall做了一些管家工作来记录它被调用了多少次。在最后一次调用(即 n == 0 )时,它会执行顶层parallel的continuation,并给它传入结果数组(这个结果数组对于我们copyTree例子没有用,但通常情况下可能会有用)。
希望尝试一下吗?下面的dostuff函数是“异步”的 — 它仅仅会在timeout时间片段后打印txt文本内容并将其返回。对比两种情况下的区别(是否使用parallel)。
dostuff = λ(txt, timeout) {
sleep(timeout);
println(txt);
txt;
};
println("## without parallel:");
time(λ(){
dostuff("Foo", 1000);
dostuff("Bar", 500);
dostuff("Baz", 200);
});
println("## with parallel:");
result = time(λ(){
parallel(λ(pcall){
pcall( λ() dostuff("Foo", 1000) );
pcall( λ() dostuff("Bar", 500) );
pcall( λ() dostuff("Baz", 200) );
});
});
println("## all done, result is:");
println(result);注意到非并行版本调用的耗时是每个任务耗时的总和,也就是1700ms;并行版本的耗时粗略为最长任务的耗时(1000ms)。在所有pcall调用结束后,结果会以恰当的顺序被收集到一个数组中并返回。
copyTree的问题
如果你尝试在包含数千个文件的目录中执行,可能会惊讶碰到“EMFILE”的异常。发生这个异常是因为我们达到了文件系统允许同时打开文件数目的限制。幸运的是,仅仅通过更新原始功能函数就能非常简单地修复这个问题。下面是更新后的新版本:
PCALLS = 1000;
parallel = js:raw "function(k, f){
var n = 0, result = [], i = 0;
f(function(){ if (i == 0) k(false) }, pcall);
function pcall(kpcall, chunk){
n++;
if (PCALLS <= 0) {
setTimeout(function(){
n--;
Execute(pcall, [ kpcall, chunk ]);
}, 5);
} else {
PCALLS--;
var index = i++;
chunk(function(rchunk){
PCALLS++;
n--;
result[index] = rchunk;
if (n == 0) Execute(k, [ result ]);
});
kpcall(false);
}
}
}";一个全局变量PCALLS保存了每次允许并行调用的最大数量。当到达了最大并行数量,我们会5ms后进行重试。我发现1000对PCALLS是一个不错的值(如果设置的太小容易饿死并可能比同步版本更慢)。
这就是所有内容了,λanguage实现的copyTree保持不变 — 仅需要在原始功能函数中节流pcall的调用,将其并行运行的数量限制在1000以内。我们的程序依然保持优雅并看起来像是串行的,但它很快,并行执行并能处理任意数量规模的目录。
修复NodeJS版本实现
我想说下面的代码是至今为止最丑陋的:
var PCALLS = 1000;
function copyTree(srcdir, destdir, callback) {
fs.mkdir(destdir, function(err){
if (err) throw new Error(err);
fs.readdir(srcdir, function(err, files){
if (err) throw new Error(err);
var count = files.length;
function next(err) {
PCALLS++;
if (err) throw new Error(err);
if (--count == 0) callback();
}
if (count == 0) {
callback();
} else {
(function loop(i){
if (PCALLS <= 0) {
setTimeout(function(){
loop(i);
}, 5);
} else if (i < files.length) {
PCALLS--;
var f = files[i];
var fullname = path.join(srcdir, f);
var dest = path.join(destdir, f);
fs.lstat(fullname, function(err, stat){
if (err) throw new Error(err);
if (stat.isSymbolicLink()) {
fs.readlink(fullname, function(err, fullname){
if (err) throw new Error(err);
fs.symlink(fullname, dest, next);
});
} else if (stat.isDirectory()) {
copyTree(fullname, dest, next);
} else if (stat.isFile()) {
fs.readFile(fullname, function(err, data){
if (err) throw new Error(err);
fs.writeFile(dest, data, next);
});
} else {
next();
}
});
loop(i + 1);
}
})(0);
}
});
});
}糟透了,是不是?我们在下一节通过类似parallel函数的抽象来将其变得稍微好一点。
公平对待Node
好吧,也许我有点夸张了。我想指出的是,想避免回调地狱但也想使用异步和并行计算的唯一解决方案就是语言本身要支持显式的continuation。我并没有试图隐藏在Node中手动编写异步代码的丑陋之处,但也许我们可以做些什么。
一方面,校验错误的代码 if (err) throw new Error(err) 到处可见。为了公平起见(λanguage中它们被Node API的包装程序处理),我将丢掉它们,但如果你曾使用NodeJS写过程序,你知道它们不可能被丢掉(除非实现类似的API包装处理程序)。另一方面,我将写一个parallelEach帮助函数(下面你会看到为什么async库中的async.eachLimit不能继续使用)。
这次实现的代码看起来确实更漂亮了,可能是我们在NodeJS中能做到的最好的了;但仍然没有λanguage语言版本一样好。
function copyTree(srcdir, destdir, callback) {
fs.mkdir(destdir, function(err){
fs.readdir(srcdir, function(err, files){
parallelEach(files, function(f, next){
var fullname = path.join(srcdir, f);
var dest = path.join(destdir, f);
fs.lstat(fullname, function(err, stat){
if (stat.isSymbolicLink()) {
fs.readlink(fullname, function(err, target){
fs.symlink(target, dest, next);
});
} else if (stat.isDirectory()) {
copyTree(fullname, dest, next);
} else if (stat.isFile()) {
fs.readFile(fullname, function(err, data){
fs.writeFile(dest, data, next);
});
} else {
next();
}
});
}, callback);
});
});
}async.eachLimit不能正确工作的原因(我事实也确实试过)是因为它不允许做全局的限制。每次递归进入copyTree我们会进入另一个拥有自己局部limit限制的async.eachLimit,但这也意味着运行的任务可能潜在地增加一倍(并且它们也可以递归下去)。 我们很快就触发了“EMFILE”错误。所以,我自己重新实现了这部分代码抽象,并不十分复杂:
var PCALLS = 1000;
function parallelEach(a, f, callback) {
if (a.length == 0) {
callback();
return;
}
var count = a.length;
(function loop(i){
if (i < a.length) {
if (PCALLS <= 0) {
setTimeout(function(){
loop(i);
}, 5);
} else {
PCALLS--;
f(a[i], function(err){
if (err) throw new Error(err);
PCALLS++;
if (--count == 0)
callback();
});
loop(i + 1);
}
}
})(0);
}错误处理(Error handling)
在上一小节代码中我丢掉了 if (err) throw new Error(err) 代码行。因为它禁止了错误恢复,所以这种“处理”错误的方式是无意义的。我们仅仅抛出错误,然后中断掉程序(除非你设置一个全局的捕获处理程序,但全局也意味着它将没有足够的上下文信息来很好地从错误中恢复)。
然而,如果你曾使用NodeJS认真做过一些事情,就会知道这些代码在每个回调函数中都非常必要。除此之外,除了将错误抛出,另一个好想法是将错误传给之前的回调函数(或者处理该错误,并酌情恢复)。NodeJS中的惯例是将错误error作为第一个参数,结果result作为第二个参数。所以我们需要在每个回调函数中插入这行,并插在最前面:if (err) return callback(err)。退一步说,这很粗糙。
λanguage语言中的异常
得益于显式的continuation,λanguage语言中我们可以实现支持跨异步调用的异常系统。
我们将在这里实现一个基本的系统 — 两个原始功能函数,TRY和THROW(全部大写,为了避免与JavaScript本身的try和throw关键字冲突)。下面是可能的用法:
TRY(
λ() {
let (data = readFile("/tmp/notexists")) {
print("File contents:");
print(data);
}
}
## "ENOENT" means file not found
, "ENOENT", λ(info){
print("File not found:", info);
}
## generic handler
, true, λ(info, code){
print("Some error. Code:", code, "info:", info);
}
);看起来很丑陋是因为我们没有给解析器扩展语法 — TRY和THROW都是普通的函数。但如果我们想要代码更优雅,当然可以修改解析器。
如果你想测试这个实例,请下载支持异常的原始功能函数库。
TRY接收一个函数及一堆错误处理程序。每个错误处理程序之前必须有错误代码(所以参数数量应该总是奇数的)。如果传入true而不是一个错误代码,则对应处理程序将被用来处理前面未处理的错误。为了能实现这点,当错误发生时,需要修改原始功能函数来调用THROW(而不是JS的throw):
readFile = function(k, filename) {
fs.readFile(filename, function(err, data){
if (err) return Execute(THROW, [ k, err.code, filename ]);
Execute(k, [ data ]);
});
};当然需要在Execute循环中来调用THROW。
你可以在浏览器中试着运行一下:
TRY(
λ(){
sleep(500);
THROW("foo", "Info for foo");
println("Not reached");
},
"foo", λ(info){
println("Got foo:");
println(info);
"HANDLED";
}
);请注意TRY,会像一个普通函数一样返回一个值。在没有错误抛出时,它的结果就是函数的结果,否则就是匹配的错误处理程序的结果,所以你可以像下面例子这样写:
data = TRY(λ(){ readFile("/foo/bar.data"); }, "ENOENT", λ(){ "default data"; # in case file was not found });
我们系统的美妙之处就是允许我们仅在需要的地方才来关注错误,而不是每个函数都需要(像NodeJS每个函数都需要)。我的意思是就像try/catch一样。例如,copyTreeSeq函数并不需要关心错误,因为调用者可以将调用整体包裹在一个TRY中:
copied = TRY(
λ(){ copyTreeSeq(source, destination); true },
## generic error handler
true, λ(code, info){ print("Some error occurred", code, info); false }
);
## .. our program resumes from here either way.
## `copied` will be true if the operation was successful.原生NodeJS中为了确认操作是否成功,需要在每个回调函数前面增加一行代码 if (err) return callback(err)。通过fs API进一步封装也不能抽象优化这一点。
我们这里实现的异常系统在面对并行时将展现出不足。对并行版本copyTree的恰当支持需要更多的思考。。。
实现
下面将 TRY 和 THROW 实现为原始功能函数:
var exhandlers = [];
window.THROW = function(discarded, code, info) {
while (exhandlers.length > 0) {
var frame = exhandlers.pop();
for (var i = 0; i < frame.length; ++i) {
var x = frame[i];
if (x.code === true || x.code === code) {
x.handler(x.continuation, info, code);
return;
}
}
}
throw new Error('No error handler for [' + code + '] ' + info);
};
window.TRY = function(k, f) {
var frame = [];
for (var i = 2; i < arguments.length;) {
var x = {
code: arguments[i++],
handler: arguments[i++],
continuation: k
};
if (typeof x.handler != 'function')
throw new Error('Exception handler must be a function!');
frame.push(x);
}
exhandlers.push(frame);
f(function(result){
exhandlers.pop();
k(result);
});
};实现很简单且可靠因为没有对外暴露像CallCC的原始功能函数。我们通过exhandlers维护了函数执行帧的堆栈。TRY将压入新函数帧,包含了新的一组错误处理程序。THROW弹出一函数帧并执行第一个匹配的错误处理程序。它传给错误处理程序的continuation(x.continuation)是TRY中压入的某一错误处理程序的continuation — 所以THROW并不会return,而是跳转到之前设定的某一位置(就像大多数编程语言中的异常一样)。当没有更多可用的函数帧,THROW将通过抛出一个硬编码的JS错误来中断程序。
顺便提一下,这里也应该解释了为什么通常异常的代价很高,无论做了多大程度的优化,进入try块时都将做一些类似上述的事情。
结束
希望本教程值得你花费时间。
感谢任何反馈。
如何用JavaScript实现一门编程语言 - 字符流
整篇译文的目录章节如下:
- 前言
- λanguage描述
- 写一个解析器(Parser)
- 字符流(Character Stream)
- 标记流(Token Stream)
- AST
- 解析器
- 简单的解释器(Interpreter)
- CPS求值器(CPS Evaluator)
- 编译成JS
- 总结
- 真实示例
字符流(Character Stream)
本节算是最小的一部分。我们将要创建一个“流对象”,该对象提供了从字符串读取字符的一些操作。流对象实现了下面4个方法:
- peek() — 返回下一个字符,但是不会将其从流中删除。
- next() — 返回下一个字符,同时将其从流中删除。
- eof() — 当且仅当流中没有更多字符时返回true。
- croak(msg) — 抛出错误throw new Error(msg).
之所以包括最后一个方法,是因为流可以很容易地追踪当前位置(如行/列),这对错误信息的显示很重要。
你可以根据自己的需要任意添加其它的方法,上述方法对于本教程已经足够了。
字符输入流是与字符打交道的,所以*next()/peek()*等函数的返回值都是字符(JS中没有字符char类型,就是单一字符的字符串)。
下面是流对象的完整代码, 这里称其为InputStream。足够简单,理解起来应该不会有问题。
function InputStream(input) {
var pos = 0, line = 1, col = 0;
return {
next : next,
peek : peek,
eof : eof,
croak : croak,
};
function next() {
var ch = input.charAt(pos++);
if (ch == "\n") line++, col = 0; else col++;
return ch;
}
function peek() {
return input.charAt(pos);
}
function eof() {
return peek() == "";
}
function croak(msg) {
throw new Error(msg + " (" + line + ":" + col + ")");
}
}请注意它不是一个标准的类对象(通过new创建的那种)。你只需要通过var stream = InputStream(string)就可以得到一个流对象。
接下来,我们将基于流对象去抽象实现另外一个功能:分词器(the tokenizer)。
如何用JavaScript实现一门编程语言 - 增加新的结构
整篇译文的目录章节如下:
增加新的结构
我们语言的语法还是有点少见。例如没有办法定义新变量。正如之前提过的,我们需要使用一个立即执行函数IIFE,就像下面这样(有点无聊的例子,没想出更好的):
(λ(x, y){
(λ(z){ ## it gets worse when one of the vars depends on another
print(x + y + z);
})(x + y);
})(2, 3);我们想增加一个 let 关键字从而可以像下面这样定义变量:
let (x = 2, y = 3, z = x + y) print(x + y + z);每个变量的定义,都可以引用到前面定义的变量。let关键字可以被转换成下面的代码片段:
(λ(x){
(λ(y){
(λ(z){
print(x + y + z);
})(x + y);
})(3);
})(2);上面的转换可以直接在解析器中完成而不需要求值器的任何改动。我们可以直接将整个转换操作转变为 call 和 lambda 节点,而不需要增加一个专门的 let 节点。这意味着我们的语言没有增加任何语义 — 这被称为“语法糖”(syntactic sugar),其中转变为AST节点的操作就是熟知的“脱糖”(desugaring)。
既然无论怎样都要修改解析器,我们还是增加一个专用的 let 节点进而求值的效率可以更高(我们只需要扩展作用域,没有必要创建闭包并立即调用它们)。
我们会额外支持一种Scheme中很受欢迎的“命名let”(named let)语法。这样我们能以更简单的方式来定义循环表达式:
print(let loop (n = 10)
if n > 0 then n + loop(n - 1)
else 0);上面是一个计算 10 + 9 + ... + 0 累加和的递归循环。目前我们语言的能力只能按下面的方式实现:
print((λ(loop){
loop = λ(n) if n > 0 then n + loop(n - 1)
else 0;
loop(10);
})());为了能进一步简化,我们将增加命名函数(named functions)的概念。这样我们就可以按照下面的方式实现:
print((λ loop (n) if n > 0 then n + loop(n - 1)
else 0)
(10));总结一下,我们需要做的修改:
- lambda关键字后面支持一个可选的名字。如果指定了名字,则函数执行的环境必须定义这个名字并指向该函数。正如JavaScript中的命名函数表达式一样。
- 支持一个新的 let 关键字。紧接着关键字会有一个可选的名字及被圆括号包裹并由逗号分隔的变量定义列表(该列表也可能为空),其中变量定义形式如 foo = EXPRESSION。 let 关键字定义体是一个单一的表达式(显然也可以是{}包裹的表达式组)。
解析器更新(Parser changes)
首先,稍微改动一下分词器,需要将 let 加入到关键字列表中:
var keywords = " let if then else lambda λ true false ";还需要更改解析器中的parse_lambda函数来支持可选的函数名字:
function parse_lambda() {
return {
type: "lambda",
name: input.peek().type == "var" ? input.next().value : null, // this line
vars: delimited("(", ")", ",", parse_varname),
body: parse_expression()
};
}现在来定义 let 的解析:
function parse_let() {
skip_kw("let");
if (input.peek().type == "var") {
var name = input.next().value;
var defs = delimited("(", ")", ",", parse_vardef);
return {
type: "call",
func: {
type: "lambda",
name: name,
vars: defs.map(function(def){ return def.name }),
body: parse_expression(),
},
args: defs.map(function(def){ return def.def || FALSE })
};
}
return {
type: "let",
vars: delimited("(", ")", ",", parse_vardef),
body: parse_expression(),
};
}上述函数处理了两种情况。如果紧接着 let 解析到了一个 var token,则其为“命名let”(named let)。其定义形式为被圆括号包裹并由逗号分隔,所以可以用 delimited 函数并传入parse_vardef(下文中定义了该工具函数)来解析该定义。接着返回一个调用命名函数表达式的 call 节点(即节点整体为一个IIFE)。命名函数的参数名字为 let 中定义的变量,call 节点会负责传递参数值。函数体则是通过 parse_expression() 解析完成。
如果不是“命名let”,则返回一个 let 节点,持有 vars 和 body 属性。vars 的结构为 { name: VARIABLE, def: AST },会由下面函数从 let 定义列表中解析获得:
function parse_vardef() {
var name = parse_varname(), def;
if (is_op("=")) {
input.next();
def = parse_expression();
}
return { name: name, def: def };
}我们还需要考虑在调度器(parse_atom)中解析到 let 关键字的情况,所以增加了下面一行代码:
// can be before the one handling parse_if
if (is_kw("let")) return parse_let();求值器更新(Evaluator changes)
既然我们倾向于修改AST而不是进行“脱糖”操作(即直接转换为已有的AST节点),所以必须要更新求值器。
为了支持可选的函数名字,下面是更新后make_lambda函数:
function make_lambda(env, exp) {
if (exp.name) { // these
env = env.extend(); // lines
env.def(exp.name, lambda); // are
} // new
function lambda() {
var names = exp.vars;
var scope = env.extend();
for (var i = 0; i < names.length; ++i)
scope.def(names[i], i < arguments.length ? arguments[i] : false);
return evaluate(exp.body, scope);
}
return lambda;
}如果有函数名字,则当闭包创建的时侯会立即扩展作用域,并定义该名字指向新创建的闭包。剩下的不变。
最终,为了支持 let AST节点,我们在求值函数中增加了下面的分支:
case "let":
exp.vars.forEach(function(v){
var scope = env.extend();
scope.def(v.name, v.def ? evaluate(v.def, env) : false);
env = scope;
});
return evaluate(exp.body, env);注意每个定义的变量都需要扩展作用域,如果有初始化代码,则其求值结果会作为初始值,否则初始值为false。接着对let定义体进行求值。
测试
println(let loop (n = 100)
if n > 0 then n + loop(n - 1)
else 0);
let (x = 2, y = x + 1, z = x + y)
println(x + y + z);
# errors out, the vars are bound to the let body
# print(x + y + z);
let (x = 10) {
let (x = x * 2, y = x * x) {
println(x); ## 20
println(y); ## 400
};
println(x); ## 10
};结论
λanguage语言整体都是我们自己实现的,所以上面的更新不会太难。但如果语言是其他人实现并且我们拿不到源码;更难的情况,如果是大家都已经安装的标准语言,并且需要遵从特定(严格)的语法?比如JavaScript语言。设想一下你需要给JavaScript增加一个新的语法结构 — 能做到吗?可能门都没有,即使你能将其提议给维护JS的那些大佬,提议也需要等待数年才会被考虑,接受,标准化然后广泛实现。在JavaScript中,我们就像囚徒一样(除非在JS基础上实现自己的语言)。
前面曾说过我将会讨论为什么Lisp是一门伟大的语言:Lisp中不需要改变解析器/求值器/编译器就能增加语法结构,这使得我们不需要将这些结构强加给所有语言用户,也不用花费数年来等待某些委员会采纳提议并由其他组织实现这些提议。Lisp即自由。如果Lisp没有命名函数或者 let 语法结构,我们就可以通过比上面更少的代码来增加实现,并且它们就跟其它内置语法结构一样。
如何用JavaScript实现一门编程语言 - 写一个解析器(Parser)
整篇译文的目录章节如下:
- 前言
- λanguage描述
- 写一个解析器(Parser)
- 简单的解释器(Interpreter)
- CPS求值器(CPS Evaluator)
- 编译成JS
- 总结
- 真实示例
写一个解析器(Parser)
编写一个语言解析器是一个相对稍复杂的任务。本质上,它是通过检测字符的方式将一块代码片段转化成抽象语法树(Abstract Syntax Tree,AST)。AST是程序在内存中的结构化展现,“抽象”意味着不用关心源代码具体是由什么字符组成,只需要把程序的语义表达出来即可。我写了一个单独的章节来描述我们的AST。
例如,对于下面的程序代码:
sum = lambda(a, b) {
a + b;
};
print(sum(1, 2));我们的解析器将会生成如下的AST(一个JavaScript对象):
{
type: "prog",
prog: [
// 第一个表达式:
{
type: "assign",
operator: "=",
left: { type: "var", value: "sum" },
right: {
type: "lambda",
vars: [ "a", "b" ],
body: {
// the body should be a "prog", but because
// it contains a single expression, our parser
// reduces it to the expression itself.
type: "binary",
operator: "+",
left: { type: "var", value: "a" },
right: { type: "var", value: "b" }
}
}
},
// 第二个表达式:
{
type: "call",
func: { type: "var", value: "print" },
args: [{
type: "call",
func: { type: "var", value: "sum" },
args: [ { type: "num", value: 1 },
{ type: "num", value: 2 } ]
}]
}
]
}写解析器的一个主要难点在于如何恰当的组织代码。解析器工作层面要更高,不仅仅是如何从字符串读取字符。下面是将复杂度做到可控的几点建议:
- 多拆分些函数,保证函数足够小。每个函数保证只做好一件事即可。
- 不要试图使用正则表达式去做解析。效果不好。虽然正则表达式对词法分析器能起到作用,但我建议将它们限制在非常简单的处理上。
- 不要试图去猜测。当不确定如何解析某部分时,就当成错误抛出来(需要确保错误信息包含了错误发生的行列位置)。
为了便于理解,会将实现代码分成三部分,各部分会进一步拆分成许多小的函数:
- 字符流
- Token流(分词器Lexer)
- 解析器
如何用JavaScript实现一门编程语言 - 编译器优化
整篇译文的目录章节如下:
优化器(Optimizer)
作者原文提到的bug此译文中已修复,主要是指在解释器,CPS求值器及CPS编译器章节中:像 a() && b() 或者 a() || b() 的表达式两侧都会求值。这样处理是不对的,是否对 b() 求值依赖 a() 的求值结果。通过将 || 及 && 两个二元操作符的处理逻辑替换为 if 表达式来修复。
优化器
— 细节决定成败 —
优化CPS形式的代码是许多学术研究的主题。但即使不知道很多理论,我们仍然可以进行一些明显的改进。对于fib函数,相对于之前的版本大概会有3倍的提速:
fib = λ(n) if n < 2 then n else fib(n - 1) + fib(n - 2);
time( λ() println(fib(27)) );像我们写的其它代码一样,优化器会递归遍历AST,依据一些规则,将表达式尽可能转换为更简单的形式。这种方法很有效直至到达了数学家们所谓的“不动点”:optimize(ast) == ast。也就是说,至此AST不能进一步简化了。为了实现这点,我们使用一个changes变量,优化开始前将其重置为0,每次AST简化的同时递增该变量。当changes保持为0,意味着优化完成。
示例
fib函数
下面你可以看到fib函数所经历的一系列简化。虽然我使用了JavaScript代码来展示说明,但请记住优化器接收的是一个AST返回的也是一个AST;make_js只在最后被调用一次。
优化器本身并没有特别被优化 — 每一轮可以做更多的事情,但我更倾向于一次只做一次修改,当changes > 0时返回未被修改的原表达式(后面我会给出详细原因)。
- 初始代码,to_cps返回的代码。
fib = function β_CC(β_K1, n) {
GUARD(arguments, β_CC);
(function β_CC(β_I2) {
GUARD(arguments, β_CC);
n < 2 ? β_I2(n) : fib(function β_CC(β_R4) {
GUARD(arguments, β_CC);
fib(function β_CC(β_R5) {
GUARD(arguments, β_CC);
β_I2(β_R4 + β_R5);
}, n - 2);
}, n - 1);
})(function β_CC(β_R3) {
GUARD(arguments, β_CC);
β_K1(β_R3);
});
};- 展开IIFE。β_I2(if节点的continuation)成为了所在函数的一个变量。
fib = function β_CC(β_K1, n) {
var β_I2;
GUARD(arguments, β_CC);
β_I2 = function β_CC(β_R3) {
GUARD(arguments, β_CC);
β_K1(β_R3);
}, n < 2 ? β_I2(n) : fib(function β_CC(β_R4) {
GUARD(arguments, β_CC);
fib(function β_CC(β_R5) {
GUARD(arguments, β_CC);
β_I2(β_R4 + β_R5);
}, n - 2);
}, n - 1);
};- “尾部调用优化”。这里并没有真正进行TCO,但最终结果是一样的。可以发现β_I2实际上等同于β_K1,所以将不需要的函数闭包删除。
fib = function β_CC(β_K1, n) {
var β_I2;
GUARD(arguments, β_CC);
β_I2 = β_K1, n < 2 ? β_I2(n) : fib(function β_CC(β_R4) {
GUARD(arguments, β_CC);
fib(function β_CC(β_R5) {
GUARD(arguments, β_CC);
β_I2(β_R4 + β_R5);
}, n - 2);
}, n - 1);
};- 变量消除。既然β_I2与β_K1相同,β_I2出现的地方都可以用β_K1来替换,赋值语句就可以删除了。
fib = function β_CC(β_K1, n) {
var β_I2;
GUARD(arguments, β_CC);
β_K1, n < 2 ? β_K1(n) : fib(function β_CC(β_R4) {
GUARD(arguments, β_CC);
fib(function β_CC(β_R5) {
GUARD(arguments, β_CC);
β_K1(β_R4 + β_R5);
}, n - 2);
}, n - 1);
};- 删除无用代码。既然β_I2不再需要,var语句也可以删除。 同样一个无意义的β_K1也可以删除。
fib = function β_CC(β_K1, n) {
GUARD(arguments, β_CC);
n < 2 ? β_K1(n) : fib(function β_CC(β_R4) {
GUARD(arguments, β_CC);
fib(function β_CC(β_R5) {
GUARD(arguments, β_CC);
β_K1(β_R4 + β_R5);
}, n - 2);
}, n - 1);
};- 丢掉一些GUARD调用。当一个函数立即调用另外一个函数,就有机会来让下一个函数再重置堆栈,考虑到我们目前堆栈嵌套限制相当小(200次调用),所以可以承受住少数函数不保护堆栈。
[**XXX: 需要更多的测试来确保这是合理的;速度增益是很显著的。**同时我们也丧失了无限的递归能力,尽管正确的尾递归函数仍可以运行。]
fib = function β_CC(β_K1, n) {
GUARD(arguments, β_CC);
n < 2 ? β_K1(n) : fib(function(β_R4) {
fib(function(β_R5) {
β_K1(β_R4 + β_R5);
}, n - 2);
}, n - 1);
};- 没有更多的转换。到达了不动点,至此停止。
fib = function β_CC(β_K1, n) {
GUARD(arguments, β_CC);
n < 2 ? β_K1(n) : fib(function(β_R4) {
fib(function(β_R5) {
β_K1(β_R4 + β_R5);
}, n - 2);
}, n - 1);
};let节点
下面示例中我将不会展示全部中间步骤,只展示初始和最终形式。
输入代码:
(λ(){
let (a = 2, b = 5) {
print(a + b);
};
})();转换:

输入代码:
(λ(){
let (a = 2) {
let (a = 3) {
print(a);
};
print(a);
};
})();转换:

实现概览
如前所述,优化器将接收AST并逐步简化节点,直到没有更多可能的简化为止。不像我们之前写的其它AST遍历器,这个优化器是具有“破坏性”的 — 可能会修改输入的源AST,而不是创建一个新的。关键的简化动作如下:
- 丢掉无用的闭包:λ(x){ y(x) } → y。
- 尽可能丢掉没有被使用的变量。
- 在所在函数内部展开IIFE。
- 计算常量表达式:a = 2 + 3 * 4 → a = 14。
- 同样,如果if节点的条件是常量,将if替换为恰当的分支。
- 丢掉prog节点中没有副作用的表达式。
- 只要有可能使用unguarded: true标识lambda节点。
一些优化可能是“级联”的 — 例如,将一个变量替换为另一个,则被替换的变量就可能可以丢掉。因此完成任意的改动后进行反复处理优化很重要。
make_scope
因为与环境耦合在一起(有时引入变量,有时又要删除它们),我们需要一个精确的方式来确定变量之间的联系。就像“变量x都被什么引用”?为了实现这个能力,我写了一个帮助函数make_scope。它会遍历AST,恰当地创建Environment实例,并对一些节点进行如下标识:
- "lambda" — 既然它们会创建新环境,每个lambda节点将获得一个env属性指向其环境。同样每个lambda节点会获得一个locs属性 — 当前函数所有“局部”变量的名字数组(最终代码中使用var定义)。
- "var" — 变量节点将获得一个env属性指向定义该变量的环境,以及一个def属性指向一个definition对象。
环境会为每个变量存储一个definition对象,并且为了方便,每个var节点的def属性将指向该definition对象。该对象包含了下面的信息:
{
refs: [/* array of "var" nodes pointing to this definition */],
assigned: integer, // how many times is this var assigned to?
cont: true or false, // is this a continuation argument?
}这个信息使得优化器可以进行想做的优化。例如,如果一个变量被赋值和被引用的次数相同,意味着没有任何地方在使用该变量的值(因为每次赋值都算一次引用)— 所以可以将它丢掉。或者,当需要将变量X替换为变量Y时,我们可以遍历X的refs并将每个引用节点的名字修改为Y。
我们给lambda节点增加的locs属性将用来存储展开IIFE过程中得到的变量。如果locs已存在,则make_scope会保留它(并会谨慎地在环境中定义得到的变量),否则将其初始化为空数组。JS代码生成器(js_lambda中)将为那些变量名字(如果存在的话)引入一个var语句(所以js_lambda也需要修改)。
我第一次尝试的时侯是在开始的时侯调用一次make_scope,然后让优化器维护每个简化中所有env和def等其它属性,优势是在一轮优化中就可以做多个简化。但这个代码太复杂,最终放弃了。当前代码会在每轮优化之前调用make_scope,然后优化器在每次简化后不会做其它操作(这是必要的,这样我们就不会操作过时的作用域信息)。
optimize函数
如之前所说,优化器每轮优化开展之前将先调用make_scope,并如此反复直到没有更多可能的优化。最终,在返回优化过的表达式之前,会将顶层作用域保存到env属性中。下面是入口函数:
function optimize(exp) {
do {
var changes = 0;
var defun = exp;
make_scope(exp);
exp = opt(exp);
} while (changes);
return exp;
function opt(exp) {
if (changes) return exp;
switch (exp.type) {
case "num" :
case "str" :
case "bool" :
case "var" : return exp;
case "binary" : return opt_binary (exp);
case "assign" : return opt_assign (exp);
case "if" : return opt_if (exp);
case "prog" : return opt_prog (exp);
case "call" : return opt_call (exp);
case "lambda" : return opt_lambda (exp);
}
throw new Error("I don't know how to optimize " + JSON.stringify(exp));
}
... // the opt_* functions here
}我们不需要关心let节点,因为CPS转换器中已将它们脱糖展开为IIFE了。
那些“容易”的节点(常量和变量)直接按原样返回。
每个opt_*函数将对当前表达式的成员递归调用opt函数。
opt_binary将优化二元表达式:会对left和right节点分别调用opt,然后校验它们是否是常量 — 如果是,则对表达式求值并替换结果。
opt_assign同样将同时优化left和right节点。然后校验潜在的可进行的优化。
opt_if将依次优化cond,then以及else节点。当condition可以确定时(一个常量表达式)则会相应地返回then或else。
opt_prog会重复一些CPS转换器中已经做过的工作,比如丢掉没有副作用的表达式;这里仍旧有用是因为优化是相互级联的(即使to_cps返回了紧凑的代码,这里仍旧可能经过一些优化最终得到了没有副作用的表达式)。
opt_call优化函数调用。如果我们调用的是一个匿名lambda函数(IIFE),将会跳转至opt_iife(查看代码)函数,它会将函数参数和函数体在当前程序展开。这可能是我们做的最巧妙(且最有效)的优化工作了。
opt_lambda将优化仅会以相同参数调用另一个函数的一类函数。如果事实并非如此,它会将未使用变量从locs中丢掉,然后进一步优化函数体。
实现代码
我不打算详细介绍所有函数实现。点击下面的显示代码来查看完整的代码(默认隐藏了起来,不希望滚动条把你吓跑)。
显示代码
function optimize(exp) {
var changes, defun;
do {
changes = 0;
make_scope(exp);
exp = opt(exp);
} while (changes);
make_scope(exp);
return exp;
function opt(exp) {
if (changes) return exp;
switch (exp.type) {
case "num" :
case "str" :
case "bool" :
case "var" : return exp;
case "binary" : return opt_binary (exp);
case "assign" : return opt_assign (exp);
case "if" : return opt_if (exp);
case "prog" : return opt_prog (exp);
case "call" : return opt_call (exp);
case "lambda" : return opt_lambda (exp);
}
throw new Error("I don't know how to optimize " + JSON.stringify(exp));
}
function changed() {
++changes;
}
function is_constant(exp) {
return exp.type == "num"
|| exp.type == "str"
|| exp.type == "bool";
}
function num(exp) {
if (exp.type != "num")
throw new Error("Not a number: " + JSON.stringify(exp));
return exp.value;
}
function div(exp) {
if (num(exp) == 0)
throw new Error("Division by zero: " + JSON.stringify(exp));
return exp.value;
}
function opt_binary(exp) {
exp.left = opt(exp.left);
exp.right = opt(exp.right);
if (is_constant(exp.left) && is_constant(exp.right)) {
switch (exp.operator) {
case "+":
changed();
return {
type: "num",
value: num(exp.left) + num(exp.right)
};
case "-":
changed();
return {
type: "num",
value: num(exp.left) - num(exp.right)
};
case "*":
changed();
return {
type: "num",
value: num(exp.left) * num(exp.right)
};
case "/":
changed();
return {
type: "num",
value: num(exp.left) / div(exp.right)
};
case "%":
changed();
return {
type: "num",
value: num(exp.dleft) % div(exp.right)
};
case "<":
changed();
return {
type: "bool",
value: num(exp.left) < num(exp.right)
};
case ">":
changed();
return {
type: "bool",
value: num(exp.left) > num(exp.right)
};
case "<=":
changed();
return {
type: "bool",
value: num(exp.left) <= num(exp.right)
};
case ">=":
changed();
return {
type: "bool",
value: num(exp.left) >= num(exp.right)
};
case "==":
changed();
if (exp.left.type != exp.right.type)
return FALSE;
return {
type: "bool",
value: exp.left.value === exp.right.value
};
case "!=":
changed();
if (exp.left.type != exp.right.type)
return TRUE;
return {
type: "bool",
value: exp.left.value !== exp.right.value
};
case "||":
changed();
if (exp.left.value !== false)
return exp.left;
return exp.right;
case "&&":
changed();
if (exp.left.value !== false)
return exp.right;
return FALSE;
}
}
return exp;
}
function opt_assign(exp) {
if (exp.left.type == "var") {
if (exp.right.type == "var" && exp.right.def.cont) {
// the var on the right never changes. we can safely
// replace references to exp.left with references to
// exp.right, saving one var and the assignment.
changed();
exp.left.def.refs.forEach(function(node){
node.value = exp.right.value;
});
return opt(exp.right); // could be needed for the result.
}
if (exp.left.def.refs.length == exp.left.def.assigned && exp.left.env.parent) {
// if assigned as many times as referenced and not a
// global, it means the var is never used, drop the
// assignment but keep the right side for possible
// side effects.
changed();
return opt(exp.right);
}
}
exp.left = opt(exp.left);
exp.right = opt(exp.right);
return exp;
}
function opt_if(exp) {
exp.cond = opt(exp.cond);
exp.then = opt(exp.then);
exp.else = opt(exp.else || FALSE);
if (is_constant(exp.cond)) {
changed();
if (exp.cond.value !== false)
return exp.then;
return exp.else;
}
return exp;
}
function opt_prog(exp) {
if (exp.prog.length == 0) {
changed();
return FALSE;
}
if (exp.prog.length == 1) {
changed();
return opt(exp.prog[0]);
}
if (!has_side_effects(exp.prog[0])) {
changed();
return opt({
type : "prog",
prog : exp.prog.slice(1)
});
}
if (exp.prog.length == 2) return {
type: "prog",
prog: exp.prog.map(opt)
};
// normalize
return opt({
type: "prog",
prog: [
exp.prog[0],
{ type: "prog", prog: exp.prog.slice(1) }
]
});
}
function opt_call(exp) {
// IIFE-s will be optimized away by defining variables in the
// containing function. However, we don't unwrap into the
// global scope (that's why checking for env.parent.parent).
var func = exp.func;
if (func.type == "lambda" && !func.name) {
if (func.env.parent.parent)
return opt_iife(exp);
// however, if in global scope we can safely unguard it.
func.unguarded = true;
}
return {
type : "call",
func : opt(func),
args : exp.args.map(opt)
};
}
function opt_lambda(f) {
// λ(x...) y(x...) ==> y
TCO: if (f.body.type == "call" &&
f.body.func.type == "var" &&
f.body.func.def.assigned == 0 &&
f.body.func.env.parent &&
f.vars.indexOf(f.body.func.value) < 0 &&
f.vars.length == f.body.args.length) {
for (var i = 0; i < f.vars.length; ++i) {
var x = f.body.args[i];
if (x.type != "var" || x.value != f.vars[i])
break TCO;
}
changed();
return opt(f.body.func);
}
f.locs = f.locs.filter(function(name){
var def = f.env.get(name);
return def.refs.length > 0;
});
var save = defun;
defun = f;
f.body = opt(f.body);
if (f.body.type == "call")
f.unguarded = true;
defun = save;
return f;
}
// (λ(foo, bar){...body...})(fooval, barval)
// ==>
// foo = fooval, bar = barval, ...body...
function opt_iife(exp) {
changed();
var func = exp.func;
var argvalues = exp.args.map(opt);
var body = opt(func.body);
function rename(name) {
var sym = name in defun.env.vars ? gensym(name + "$") : name;
defun.locs.push(sym);
defun.env.def(sym, true);
func.env.get(name).refs.forEach(function(ref){
ref.value = sym;
});
return sym;
}
var prog = func.vars.map(function(name, i){
return {
type : "assign",
operator : "=",
left : { type: "var", value: rename(name) },
right : argvalues[i] || FALSE
};
});
func.locs.forEach(rename);
prog.push(body);
return opt({
type: "prog",
prog: prog
});
}
}
function make_scope(exp) {
var global = new Environment();
exp.env = global;
(function scope(exp, env) {
switch (exp.type) {
case "num":
case "str":
case "bool":
break;
case "var":
var s = env.lookup(exp.value);
if (!s) {
exp.env = global;
global.def(exp.value, { refs: [], assigned: 0 });
} else {
exp.env = s;
}
var def = exp.env.get(exp.value);
def.refs.push(exp);
exp.def = def;
break;
case "assign":
scope(exp.left, env);
scope(exp.right, env);
if (exp.left.type == "var")
exp.left.def.assigned++;
break;
case "binary":
scope(exp.left, env);
scope(exp.right, env);
break;
case "if":
scope(exp.cond, env);
scope(exp.then, env);
if (exp.else)
scope(exp.else, env);
break;
case "prog":
exp.prog.forEach(function(exp){
scope(exp, env);
});
break;
case "call":
scope(exp.func, env);
exp.args.forEach(function(exp){
scope(exp, env);
});
break;
case "lambda":
exp.env = env = env.extend();
if (exp.name)
env.def(exp.name, { refs: [], func: true, assigned: 0 });
exp.vars.forEach(function(name, i){
env.def(name, { refs: [], farg: true, assigned: 0, cont: i == 0 });
});
if (!exp.locs) exp.locs = [];
exp.locs.forEach(function(name){
env.def(name, { refs: [], floc: true, assigned: 0 });
});
scope(exp.body, env);
break;
default:
throw new Error("Can't handle node " + JSON.stringify(exp));
}
})(exp, global);
return exp.env;
}
var FALSE = { type: "bool", value: false };
var TRUE = { type: "bool", value: true };如何用JavaScript实现一门编程语言 - λanguage描述
整篇译文的目录章节如下:
整篇译文的目录章节如下:
- 前言
- λanguage描述
- 写一个解析器(Parser)
- 简单的解释器(Interpreter)
- CPS求值器(CPS Evaluator)
- 编译成JS
- 总结
- 真实示例
λanguage描述
一切开始之前,我们应该对要取得的目标有一个清晰的认识。使用严格的语法来描述λanguage语言不失为一个好想法,但本教程中,我尽量保证描述更通俗,比如下面的示例:
# this is a comment
println("Hello World!");
println(2 + 3 * 4);
# functions are introduced with `lambda` or `λ`
fib = lambda (n) if n < 2 then n else fib(n - 1) + fib(n - 2);
println(fib(15));
print-range = λ(a, b) # `λ` is synonym to `lambda`
if a <= b then { # `then` here is optional as you can see below
print(a);
if a + 1 <= b {
print(", ");
print-range(a + 1, b);
} else println(""); # newline
};
print-range(1, 5);注意上面标识符名称(print-range)可以包含减号"-"。这纯属个人的喜好:我总是喜欢在操作符前后加上空格,不是特别喜欢驼峰命名,并且短中划线比下划线要更好点。创造自己的编程语言的好处就是可以按照自己的喜好来实现。:)
输出如下:
Hello World!
14
610
1, 2, 3, 4, 5λanguage语言虽然看起来有点像JavaScript,但是它们不一样。首先,λanguage中只有表达式而没有语句。一个表达式会返回一个值并且可以用来代替任何其它表达式。花括号“{}”用来创建一个表达式序列,其中用分号“;”来分割各个表达式,表达式序列本身也是表达式,它的值是最后一个表达式的值。下面是一个有效的程序:
a = {
fib(10); # has no side-effects, but it's computed anyway
fib(15) # the last semicolon can be missing
};
print(a); # prints 610通过关键字lambda或者λ(两者是同义词)引入函数。紧跟着关键字后面必须是由圆括号()包裹且由逗号,分隔的变量列表(也可以为空),像JavaScript一样,这些变量就是函数参数名称。函数体是一个单一的表达式,也可以是一个由“{}”包裹的表达式序列。没有return语句(因为λanguage不支持语句),所以函数体中最后一个表达式的值会被返回给调用者(caller)。
没有var关键字。可以使用JavaScript程序员所谓的“IIFE”来引入新变量。使用lambda将变量声明为参数。跟JavaScript一样,在λanguage语言中,变量同样拥有函数作用域,函数都是闭包。
甚至if关键字本身就是一个表达式。在JavaScript中需要使用三目运算符达到下面的效果:
a = foo() ? bar() : baz(); // JavaScript
a = if foo() then bar() else baz(); # λanguage上面print-range代码片段可以看到,当分支是以左花括号{开始的时候,then关键字可以省略,否则是必需的。如果有选择分支的话,则else关键字是必需的。与函数体类似,then和else关键字的分支体也是一个单一的表达式,同样可以是一个由花括号{}包裹的,且分号;分割的表达式序列。当条件为false并且没有选择分支的时候,if表达式的值为false。说到这,false是λanguage语言中代表假值(falsy value)的唯一一个关键字:
if foo() then print("OK");上面的代码当且仅foo()的值不为false时才会打印OK。考虑到语言的完整性,也有一个true关键字,任何不为false(按照JavaScript的===操作符判断)的条件(包括数字0和空字符串“”)都会被解析为true。
另外需要注意的是,if的条件不要求必须用圆括号包裹。虽然加上了也不会错(左圆括号(代表一个表达式的开始),但总有些多余。
整个程序会假定被包裹在花括号{}中来解析,所以需要在每个表达式后面加上分号;(最后一个表达式可以除外)。
好了,上面就是我们的λanguage语言。它不一定算是一个好编程语言。语法看起来很小巧,但是会有缺陷。有许多缺失的特性,比如对象或数组,我们不会投入过多精力在上面,因为它们不是必须的。如果能够理解本教程所有的内容,你可以轻易的实现这些特性。
下一节我们将要来写一个λanguage语言的解析器。
如何用JavaScript实现一门编程语言 - 解析器
整篇译文的目录章节如下:
解析器(Parser)
解析器会按照上一节AST中的描述创建出各种类型的AST节点。
得益于前面的分词器,解析器可以直接操作标记流而不用处理单个字符。为了降低复杂度,它同样定义了很多工具函数。这里首先讨论一下构成解析器的主要函数。我们从一个上层的lambda解析器开始讲起:
function parse_lambda() {
return {
type: "lambda",
vars: delimited("(", ")", ",", parse_varname),
body: parse_expression()
};
}解析标记流的过程中,当遇到lambda关键字则会调用上面的函数,所以它关心的就是解析参数名字:被圆括号包裹并由逗号分隔。相比于直接将代码实现在parse_lambda中,我更倾向于写一个delimited函数,delimited接收start,stop,separator及parser四个参数,parser是一个函数,会解析start和stop之间的标记。上面parse_lambda中将parse_varname函数传递给parser,parse_varname函数在解析到非变量时会抛出错误。parse_lambda函数体是一个表达式,所以可通过parse_expression解析得到。
delimited是一个相对底层的函数:
function delimited(start, stop, separator, parser) {
var a = [], first = true;
skip_punc(start);
while (!input.eof()) {
if (is_punc(stop)) break;
if (first) first = false; else skip_punc(separator);
if (is_punc(stop)) break; // the last separator can be missing
a.push(parser());
}
skip_punc(stop);
return a;
}正如你所看到的,它使用了更多的工具函数:is_punc和skip_punc。当前token如果是给定的符号,is_punc会返回true(不会消耗掉当前token),skip_punc会确认token是给定的符号(否则会抛错)并将其从输入流中丢弃。
解析整体程序(prog节点)的函数可能是最简单的:
function parse_toplevel() {
var prog = [];
while (!input.eof()) {
prog.push(parse_expression());
if (!input.eof()) skip_punc(";");
}
return { type: "prog", prog: prog };
}由于不支持语句,所以我们就简单通过不停地调用parse_expression()函数来读取输入流中的表达式。使用skip_punc(";")因为表达式要求由分号分隔。
另外一个简单的示例:parse_if():
function parse_if() {
skip_kw("if");
var cond = parse_expression();
if (!is_punc("{")) skip_kw("then");
var then = parse_expression();
var ret = { type: "if", cond: cond, then: then };
if (is_kw("else")) {
input.next();
ret.else = parse_expression();
}
return ret;
}parse_if中通过skip_kw(判断当前token如果不是给定的关键字会抛出错误)跳过if关键字 ,通过parse_expression()来读取条件。接下来,如果条件成立分支(consequent branch)不是以左花括号“{”开始,则要求有then关键字(如果不要求then关键字,这样的语法可能会太罕见)。分支就是表达式,所以我们通过parse_expression()解析它们。else 分支是可选的,所以需要先检测关键字是否存在再来决定是否解析它。
有很多小工具函数的好处就是能很大程度上保持代码简洁。我们几乎像使用了专门用做解析的高级语言一样来实现解析器。所有这些小工具函数是“互斥的”,例如,parse_atom()函数是主要的调度者 — 基于当前的token来调用其它函数。其中一个就是parse_if()(当前token为 if 时会被调用) ,并且它会进一步调用parse_expression()。但parse_expression()会再次调用parse_atom()。之所以没有发生死循环,是因为每步处理中,每个函数都会至少消费掉一个token。
上述类型的解析器叫做“递归下降解析器”(recursive descent parser),也可能算是可以手写实现的最简单类型。
更低层次:parse_atom()和parse_expression()
parse_atom()依据当前的token完成了主要的调度工作:
function parse_atom() {
return maybe_call(function(){
if (is_punc("(")) {
input.next();
var exp = parse_expression();
skip_punc(")");
return exp;
}
// This is the proper place to implement unary operators.
// Following is the code for boolean negation, which is present
// in the final version of lambda.js, but I'm leaving it out
// here since support for it is not implemented in the interpreter
// nor compiler, in this tutorial:
//
// if (is_op("!")) {
// input.next();
// return {
// type: "not",
// body: parse_atom()
// };
// }
if (is_punc("{")) return parse_prog();
if (is_kw("if")) return parse_if();
if (is_kw("true") || is_kw("false")) return parse_bool();
if (is_kw("lambda") || is_kw("λ")) {
input.next();
return parse_lambda();
}
var tok = input.next();
if (tok.type == "var" || tok.type == "num" || tok.type == "str")
return tok;
unexpected();
});
}如果解析到了一个开括号,则其必定是一个括号表达式 — 因此首先会跳过开括号,然后调用parse_expression()并预期以闭括号结尾。如果解析到了某个关键字,则会调用对应关键字的解析函数。如果解析到了一个常量或者标识符,则会原样返回token。如果所有情况都未满足,则会调用unexpected()抛出一个错误。
当期望是一个原子表达式(atomic expression)但是解析到了“{”,解析器会调用parse_prog来解析整个序列的表达式。正如下面所定义的。它做了一些小的优化 — 如果prog节点为空,则直接返回 FALSE。如果程序只包含一个表达式,则返回表达式的解析结果。否则返回一个包含表达式的"prog"节点。
// we're going to use the FALSE node in various places,
// so I'm making it a global.
var FALSE = { type: "bool", value: false };
function parse_prog() {
var prog = delimited("{", "}", ";", parse_expression);
if (prog.length == 0) return FALSE;
if (prog.length == 1) return prog[0];
return { type: "prog", prog: prog };
}下面是parse_expression()函数。 与parse_atom()相反,这个函数将会使用maybe_binary()来尽可能地向右扩展一个表达式,将会在下面解释。
function parse_expression() {
return maybe_call(function(){
return maybe_binary(parse_atom(), 0);
});
}maybe_*函数
这些函数会根据表达式后面跟随的具体内容来决定是用另外一个节点来包裹表达式,还是直接按原样返回表达式。
maybe_call()非常简单。接收一个解析当前表达式的函数。如果在那个表达式后解析到一个“(”符号,则其必定是一个调用“call”节点,将会由parse_call()来处理(包含在下面代码中)。可以再次注意到delimited()如何被用来读取参数列表。
function maybe_call(expr) {
expr = expr();
return is_punc("(") ? parse_call(expr) : expr;
}
function parse_call(func) {
return {
type: "call",
func: func,
args: delimited("(", ")", ",", parse_expression)
};
}操作符优先级
maybe_binary(left, my_prec) 用来组合类似 1 + 2 * 3 的二元表达式。能正确解析它们的技巧就是要准确地定义操作符的优先级,如下:
var PRECEDENCE = {
"=": 1,
"||": 2,
"&&": 3,
"<": 7, ">": 7, "<=": 7, ">=": 7, "==": 7, "!=": 7,
"+": 10, "-": 10,
"*": 20, "/": 20, "%": 20,
};上述定义意味着 * 要比 + 有更强的约束,所以对一个表达式,比如 1 + 2 * 3,必须被解析为 (1 + (2 * 3)) 而不是 ((1 + 2) * 3),后者是按通常从左到右(left-to-right)顺序解析的结果。
这里的技巧就是读一个原子表达式(只有1)并将它(作为左参数)和当前的优先级(my_prec)一起传给maybe_binary()。maybe_binary将会解析紧跟着的内容。如果没有解析到运算符,或者运算符的优先级更低,则直接原样返回左参数。
如果解析到一个更高优先级的运算符,则会将左参数包裹到一个新的二元表达式"binary"节点中,并在新的优先级(*)上对右参数重复上面的技巧:
function maybe_binary(left, my_prec) {
var tok = is_op();
if (tok) {
var his_prec = PRECEDENCE[tok.value];
if (his_prec > my_prec) {
input.next();
var right = maybe_binary(parse_atom(), his_prec) // (*);
var binary = {
type : tok.value == "=" ? "assign" : "binary",
operator : tok.value,
left : left,
right : right
};
return maybe_binary(binary, my_prec);
}
}
return left;
}需要注意的是在返回二元表达式之前,为了能将表达式包裹到另一个紧跟着的具有更高优先级的表达式中,必须在旧的优先级(my_prec)上也调用maybe_binary。如果这些难以理解,请一遍遍反复阅读代码(也许可以在脑中尝试某些输入表达式的执行)直到搞明白了。
最终,由于my_prec初始化为0,任何运算符都会构建出一个二元表达式"binary"节点(或当运算符为=时构建一个赋值"assign"节点)。解析器中还有另外一些其它的函数,所以我将整体解析函数放到了下面。点击“显示代码”来显示所有的代码(大约150行)。
显示代码
var FALSE = { type: "bool", value: false };
function parse(input) {
var PRECEDENCE = {
"=": 1,
"||": 2,
"&&": 3,
"<": 7, ">": 7, "<=": 7, ">=": 7, "==": 7, "!=": 7,
"+": 10, "-": 10,
"*": 20, "/": 20, "%": 20,
};
return parse_toplevel();
function is_punc(ch) {
var tok = input.peek();
return tok && tok.type == "punc" && (!ch || tok.value == ch) && tok;
}
function is_kw(kw) {
var tok = input.peek();
return tok && tok.type == "kw" && (!kw || tok.value == kw) && tok;
}
function is_op(op) {
var tok = input.peek();
return tok && tok.type == "op" && (!op || tok.value == op) && tok;
}
function skip_punc(ch) {
if (is_punc(ch)) input.next();
else input.croak("Expecting punctuation: \"" + ch + "\"");
}
function skip_kw(kw) {
if (is_kw(kw)) input.next();
else input.croak("Expecting keyword: \"" + kw + "\"");
}
function skip_op(op) {
if (is_op(op)) input.next();
else input.croak("Expecting operator: \"" + op + "\"");
}
function unexpected() {
input.croak("Unexpected token: " + JSON.stringify(input.peek()));
}
function maybe_binary(left, my_prec) {
var tok = is_op();
if (tok) {
var his_prec = PRECEDENCE[tok.value];
if (his_prec > my_prec) {
input.next();
return maybe_binary({
type : tok.value == "=" ? "assign" : "binary",
operator : tok.value,
left : left,
right : maybe_binary(parse_atom(), his_prec)
}, my_prec);
}
}
return left;
}
function delimited(start, stop, separator, parser) {
var a = [], first = true;
skip_punc(start);
while (!input.eof()) {
if (is_punc(stop)) break;
if (first) first = false; else skip_punc(separator);
if (is_punc(stop)) break;
a.push(parser());
}
skip_punc(stop);
return a;
}
function parse_call(func) {
return {
type: "call",
func: func,
args: delimited("(", ")", ",", parse_expression),
};
}
function parse_varname() {
var name = input.next();
if (name.type != "var") input.croak("Expecting variable name");
return name.value;
}
function parse_if() {
skip_kw("if");
var cond = parse_expression();
if (!is_punc("{")) skip_kw("then");
var then = parse_expression();
var ret = {
type: "if",
cond: cond,
then: then,
};
if (is_kw("else")) {
input.next();
ret.else = parse_expression();
}
return ret;
}
function parse_lambda() {
return {
type: "lambda",
vars: delimited("(", ")", ",", parse_varname),
body: parse_expression()
};
}
function parse_bool() {
return {
type : "bool",
value : input.next().value == "true"
};
}
function maybe_call(expr) {
expr = expr();
return is_punc("(") ? parse_call(expr) : expr;
}
function parse_atom() {
return maybe_call(function(){
if (is_punc("(")) {
input.next();
var exp = parse_expression();
skip_punc(")");
return exp;
}
if (is_punc("{")) return parse_prog();
if (is_kw("if")) return parse_if();
if (is_kw("true") || is_kw("false")) return parse_bool();
if (is_kw("lambda") || is_kw("λ")) {
input.next();
return parse_lambda();
}
var tok = input.next();
if (tok.type == "var" || tok.type == "num" || tok.type == "str")
return tok;
unexpected();
});
}
function parse_toplevel() {
var prog = [];
while (!input.eof()) {
prog.push(parse_expression());
if (!input.eof()) skip_punc(";");
}
return { type: "prog", prog: prog };
}
function parse_prog() {
var prog = delimited("{", "}", ";", parse_expression);
if (prog.length == 0) return FALSE;
if (prog.length == 1) return prog[0];
return { type: "prog", prog: prog };
}
function parse_expression() {
return maybe_call(function(){
return maybe_binary(parse_atom(), 0);
});
}
}致谢
我是在学习Marijn Haverbeke的parse-js库(Common Lisp)时明白了如何去写一个有意义的解析器。 上面的解析器仿照他的代码,尽管是为了解析一个更简单的语言。
如何用JavaScript实现一门编程语言 - AST
整篇译文的目录章节如下:
AST
正如前面所描述的,解析器将会构建出一个能准确表达程序语义的数据结构。一个AST节点就是一个普通的JavaScript对象,该对象有一个指定节点类型的type属性和依赖具体节点类型的额外信息。
简而言之:
- num { type: "num", value: NUMBER } // 数字型变量节点
- str { type: "str", value: STRING } // 字符串型变量节点
- bool { type: "bool", value: true or false } // 布尔型变量节点
- var { type: "var", value: NAME } // 标识符节点
- lambda { type: "lambda", vars: [ NAME... ], body: AST } // 函数声明节点
- call { type: "call", func: AST, args: [ AST... ] } // 函数调用节点
- if { type: "if", cond: AST, then: AST, else: AST } // 条件节点
- assign { type: "assign", operator: "=", left: AST, right: AST } // 赋值节点
- binary { type: "binary", operator: OPERATOR, left: AST, right: AST } // 二元表达式节点
- prog { type: "prog", prog: [ AST... ] } // 表达式序列节点
- let { type: "let", vars: [ VARS... ], body: AST } // 块级作用于变量节点
示例:
数字型变量Numbers("num")
字符串型变量Strings("str")
布尔型变量Booleans("bool")
标识符Identifiers("var")
函数声明Functions("lambda")
函数调用Function calls("call")
条件Conditionals("if")
else分支是可选的:
赋值Assignment("assign")
二元表达式Binary expressions("binary")
表达式序列Sequences("prog")
块级作用域变量Block scoped variables("let")












基于WebGL的GPGPU指南 - 初始化矩阵
整理译文的目录章节如下:
初始化矩阵
现在已经有了一个精美封装的库,我们在一个示例问题上应用一下。矩阵初始化是一个很好的例子,因为它能直接将一个矩阵映射到一个网格,并且片段着色器可以直接根据行列索引计算矩阵元素而不使用输入纹理。这使得初始化比后续的计算示例会稍微简单一些。这种初始化条件的设置在我们将要研究的许多问题中也很常见。
问题大部分代码在另一个文件MatrixInitializer.js中,我们将在下面几段内容中进行介绍。这种模块化使得页面上的代码简短且易于理解。
这段代码汇集了我们一直在讨论的许多概念,并将它们组合成一个完整的应用程序。
"use strict";
var bufferStatus;
var framebuffer;
var gpgpUtility;
var initializer;
var matrixColumns;
var matrixRows;
var texture;
matrixColumns = 128;
matrixRows = 128;
gpgpUtility = new vizit.utility.GPGPUtility(matrixColumns, matrixRows, { premultipliedAlpha: false });
if (GPGPUtility.isFloatingTexture())
{
// Height and width are set in the constructor.
texture = gpgpUtility.makeTexture(WebGLRenderingContext.FLOAT, null);
framebuffer = gpgpUtility.attachFrameBuffer(texture);
bufferStatus = gpgpUtility.frameBufferIsComplete();
if (bufferStatus.isComplete)
{
initializer = new MatrixInitializer(gpgpUtility);
initializer.initialize(matrixColumns, matrixRows);
// Delete resources no longer in use.
initializer.done();
// Tests, terminate on first failure.
initializer.test( 0, 0)
&& initializer.test( 10, 12)
&& initializer.test(100, 100);
}
else
{
alert(bufferStatus.message);
}
}
else
{
alert("Floating point textures are not supported.");
}画布尺寸是根据问题规模来指定的,这个例子中是矩阵的列数
创建画布和
在
后面章节我们将展示当浮点纹理不可用时如何将浮点值打包到四个无符号字节
我们需要纹理作为
到目前为止,我们还没有涉及到任何问题特定的代码,但已经可以确保我们的设置可以在此系统上工作。
当
- 我们可以创建浮点纹理
- 我们可以写入或渲染浮点纹理
当
矩阵初始化阶段在MatrixInitializer.js中,定义了一个
function MatrixInitializer(gpgpUtility_)
{
/** WebGLRenderingContext */
var gl;
var gpgpUtility;
var heightHandle;
var positionHandle;
var program;
var textureCoordHandle;
var widthHandle;
.
.
.
gpgpUtility = gpgpUtility_;
gl = gpgpUtility.getGLContext();
program = this.createProgram(gl);
}我们将要解决的所有问题的几何形状和顶点着色器都是相同的。这使得程序可以得到相当大的简化。我们使用一个标准的顶点着色器,并提供片段着色器,这是所有问题具体代码所在的地方。我们通过将第一个参数置为
/**
* Compile shaders and link them into a program, then retrieve references to the
* attributes and uniforms. The standard vertex shader, which simply passes on the
* physical and texture coordinates, is used.
*
* @returns {WebGLProgram} The created program object.
* @see {https://www.khronos.org/registry/webgl/specs/1.0/#5.6|WebGLProgram}
*/
this.createProgram = function (gl)
{
var fragmentShaderSource;
var program;
// Note that the preprocessor requires the newlines.
fragmentShaderSource = "#ifdef GL_FRAGMENT_PRECISION_HIGH\n"
+ "precision highp float;\n"
+ "#else\n"
+ "precision mediump float;\n"
+ "#endif\n"
+ ""
+ "uniform float height;"
+ "uniform float width;"
+ ""
+ "varying vec2 vTextureCoord;"
+ ""
+ "vec4 computeElement(float s, float t)"
+ "{"
+ " float i = floor(width*s);"
+ " float j = floor(height*t);"
+ " return vec4(i*1000.0 + j, 0.0, 0.0, 0.0);"
+ "}"
+ ""
+ "void main()"
+ "{"
+ " gl_FragColor = computeElement(vTextureCoord.s, vTextureCoord.t);"
+ "}";
// Null first argument to createProgram => use the standard vertex shader
program = gpgpUtility.createProgram(null, fragmentShaderSource);
// position and textureCoord are attributes from the standard vertex shader
positionHandle = gpgpUtility.getAttribLocation(program, "position");
gl.enableVertexAttribArray(positionHandle);
textureCoordHandle = gpgpUtility.getAttribLocation(program, "textureCoord");
gl.enableVertexAttribArray(textureCoordHandle);
// Height and width are the problem specific variables
heightHandle = gpgpUtility.getUniformLocation(program, "height");
widthHandle = gpgpUtility.getUniformLocation(program, "width");
return program;
}片段着色器将纹素设置为
/**
* Runs the program to do the actual work. On exit the framebuffer &
* texture are populated with the values computed in the fragment shader.
* Use gl.readPixels to retrieve texture values.
*/
this.initialize = function(width, height)
{
gl.useProgram(program);
gpgpUtility.getStandardVertices();
gl.vertexAttribPointer(
positionHandle, // The attribute
3, // The three (x,y,z) elements in each value
gl.FLOAT, // The data type, so each position is three floating point numbers
gl.FALSE, // Are values normalized - unused for float
20, // Stride, the spacing, in bytes, between beginnings of successive values
0); // Offset 0, data starts at the beginning of the array
gl.vertexAttribPointer(
textureCoordHandle, // The attribute
2, // The two (s,t) elements in each value
gl.FLOAT, // The data type, so each position is two floating point numbers
gl.FALSE, // Are values normalized - unused for float
20, // Stride, the spacing, in bytes, between beginnings of successive values
12); // Offset 12 bytes, data starts after the positional data
gl.uniform1f(widthHandle, width);
gl.uniform1f(heightHandle, height);
gl.drawArrays(gl.TRIANGLE_STRIP, 0, 4);
};在完成了初始化工作需要的所有计算之后,我们调用
/**
* Invoke to clean up resources specific to this program. We leave the texture
* and frame buffer intact as they are used in followon calculations.
*/
this.done = function ()
{
gl.deleteProgram(program);
};当然,与任何合理的代码一样,我们以一组测试用例作为结束。这些测试也作为从
/**
* Read back the i, j pixel and compare it with the expected value. The expected value
* computation matches that in the fragment shader.
*
* @param i {integer} the i index of the matrix.
* @param j {integer} the j index of the matrix.
*/
this.test = function(i, j)
{
var buffer;
var expected;
var passed;
// One each for RGBA component of a pixel
buffer = new Float32Array(4);
// Read a 1x1 block of pixels, a single pixel
gl.readPixels(
i, // x-coord of lower left corner
j, // y-coord of lower left corner
1, // width of the block
1, // height of the block
gl.RGBA, // Format of pixel data.
gl.FLOAT,// Data type of the pixel data, must match makeTexture
buffer); // Load pixel data into buffer
expected = i*1000.0 + j;
passed = (buffer[0] === expected);
if (!passed)
{
alert("Read " + buffer[0] + " at (" + i + ", " + j + "), expected " + expected + ".");
}
return passed;
};- 这个未初始化的纹理内存是WebGL早期安全问题的来源。现在要求清除这个内存。
- 从长远来看,这些其它纹理组件可以用于将整数打包到一组单字节通道中,或者优化浮点纹理方法。
基于WebGL的GPGPU指南 - 减速带
整理译文的目录章节如下:
减速带
浮点纹理
使用浮点纹理进行通用GPU计算(GPGPU)的主要问题集中在以下几方面:
- 创建浮点纹理
- 写入浮点纹理
- 从GPU读取浮点纹理
这些问题在意料之中,因为浮点纹理在GPGPU处理中至关重要,但在计算机图形学中却不属于主流。幸运的是,由于这些问题彼此关联密切,因此它们的解决方案也密切相关。如果我们无法使用浮点纹理解决某个步骤,我们则可以使用纹理储存浮点数的方式来解决。
许多情况下,运行模拟及显示结果都完全在GPU上完成。对于这些情况,无法从GPU读取浮点纹理的问题将无关紧要。事实上,我预计有些人会认为这一节内容是多余的。如果你只对数值技术感兴趣,或者你的目标受众始终使用更强大的系统,那么这一节内容确实不是必需的。然而,对于希望触及广泛受众的教学设计人员或开发人员来说,这些材料是必不可少的。
下面这个图表涵盖了决定是否需要使用无符号字节纹理的主要要素,以及将它们纳入项目的过程。

我们是否需要担心浮点数转化?
幸运的是1 过程中的每个决策点都已经建立对应的测试。这意味着这个过程可以自动化,并且根据测试结果加载不同的程序。
我们已经开发了始终使用浮点纹理决策点的代码示例。下一步将解决即使能够从片段着色器读写浮点值,但ReadPixels无法从GPU读回浮点像素的情况。顺便说一下,这正是我手机的情况,配备了Adreno 220 GPU。这要求我们将输出纹理中的每个浮点数打包到一个UNSIGNED_BYTE RGBA纹理元素(texel)中。然后将这些纹理元素读回到CPU,并解构成浮点数。
最终情况是涉及无法使用浮点纹理的场景。可能是因为OES_texture_float扩展不可用,进而无法创建浮点纹理,或者是因为CheckFramebufferStatus状态未完成,我们无法将计算结果写入(渲染到)浮点纹理。在任何一种情况下,我们都会将中间结果存储在UNSIGNED_BYTE RGBA纹理中。在每一步计算结尾,我们将浮点结果转换为无符号字节,然后在下一步计算开始时,我们再将无符号字节转换为浮点数。这些每次计算中的多次转换将会导致在性能方面要付出很高的代价。
当我们使用无符号字节纹理时,我们希望当浮点格式和RGBA无符号字节相互数据转换时,不会丢失信息,即尽可能少地损失精度。

一个IEEE 754标准的浮点数

相同位打包到一个RGBA无符号字节纹素
你可能已经注意到字节顺序是ABGR而不是RGBA。这是因为Intel、ARM和大多数目标平台是小端序(little endian),在这种情况下字节顺序是反向的。
一旦理解了浮点数中各个位的含义后,提取这些位并不困难。IEEE 754浮点表示将一个数映射为
如果WebGL支持位运算,分解这个公式可能会更容易。我们仍然可以通过纯粹的数学操作来分解它。
我们从一段提取浮点数值符号位的代码片段开始。
float sgn;
sgn = step(0.0, -value);
value = abs(value);GLSL中的step函数,当第二个参数小于第一个参数时会返回0,否则返回1。但真正有趣的是:”为什么使用函数而不是if或三元运算符,或者if-then-else?”,通常情况下,GPU被设计为在多个着色器上以完全相同的方式并行运行相同的代码。因此,if语句和分支结构并不能被很好地处理,在合理情况下应避免使用。GLSL有许多类似的函数,如step和clamp,可以用来实现条件执行的效果2。
下一步是提取指数。数字通常是
float exponent;
exponent = floor(log2(value));我们可以用
float mantissa;
mantissa = value*pow(2.0, -exponent)-1;现在我们已经恢复了尾数,可以从指数中去除偏移量或偏置。
exponent = exponent+127.0;我们还可以将结果的第一个 (
vec4 result = vec4(0,0,0,0);
result.r = 128.0*sgn + floor(exponent/2.0);第二个 (
result.g = (exponent - floor(exponent/2.0) * 2.0) * 128.0 + floor(mantissa * 128.0);蓝色 (
result.b = floor((mantissa - floor(mantissa * 128.0) / 128.0) * 32768.0);截至目前,应该意识到了我们重复计算了多个表达式,意味着有必要进行重构。
vec4 result = vec4(0,0,0,0);
result.a = floor(exponent/2.0);
exponent = exponent - result.a*2.0;
result.a = result.a + 128.0*sgn;
result.b = floor(mantissa * 128.0);
mantissa = mantissa - result.b / 128.0;
result.b = result.b + exponent*128.0;
result.g = floor(mantissa*32768.0);
mantissa = mantissa - result.g/32768.0;
result.r = floor(mantissa*8388608.0);基于这块代码,我们可以构建一个将浮点数转换为无符号字节纹理的程序 ToUnsignedBytes。查看前面的过程图,我们可以当帧缓冲状态检查通过时来调用这个程序,但在计算后我们暂无法将像素读回到CPU。
// Tests, terminate on first failure.
success = initializer.test(0, 0) &&
initializer.test(10, 12) &&
initializer.test(100, 100);
if (!success) {
renderToUnsignedBytes(texture);
}/**
* Accepts a passed in texture, which is assumed to contain single floating point
* values, and packs each texture element in the corresponding RGBA element of the
* newly created texture.
*
* @param {WebGLTexture} A texture previously populated with floating point values.
*/
function renderToUnsignedBytes(texture) {
unsignedByteTexture = gpgpUtility.makeTexture(WebGLRenderingContext.UNSIGNED_BYTE, null);
unsignedByteFramebuffer = gpgpUtility.attachFrameBuffer(unsignedByteTexture);
bufferStatus = gpgpUtility.frameBufferIsComplete();
if (bufferStatus.isComplete) {
unsignedByteConverter = new ToUnsignedBytes(gpgpUtility);
unsignedByteConverter.convert(matrixColumns, matrixRows, texture);
// Delete resources no longer in use.
unsignedByteConverter.done();
// Tests, terminate on first failure.
success = unsignedByteConverter.test(0, 0) &&
unsignedByteConverter.test(10, 12) &&
unsignedByteConverter.test(100, 100);
} else {
alert(bufferStatus.message);
}
}测试方法从GPU读回这些数据,比较宽慰的是,这个过程非常简单。
// One each for RGBA component of a pixel
buffer = new Uint8Array(4);
// Read a 1x1 block of pixels, a single pixel
gl.readPixels(i, // x-coord of lower left corner
j, // y-coord of lower left corner
1, // width of the block
1, // height of the block
gl.RGBA, // Format of pixel data.
gl.UNSIGNED_BYTE, // Data type of the pixel data, must match makeTexture
buffer); // Load pixel data into buffer
floatingPoint = new Float32Array(buffer.buffer);Uint8Array(4) 是一个由4个无符号8位整数组成的数组。这跟我们加载到纹理中的4个无符号字节完全匹配。要从这些字节重新得到浮点数,只需使用
为了在计算中使用无符号字节纹理,我们还需要在着色器内部读回数据。这意味着需要逆转一下用来将数字打包到RGBA字节中的过程。
相同位打包到一个RGBA无符号字节纹素
一个IEEE 754标准的浮点数
这次我们从纹素中解包各个RGBA字节到一个浮点数中。
我们再次从符号开始,这是alpha字节中最左边的位。
float sgn;
// sgn will be 0 or -1;
sgn = -step(128.0, texel.a);
texel.a += 128.0*sgn;Next we pull out the exponent. Starting with the last bit to make it easy to trim the bit from the blue byte.
接下来提取指数。从蓝色字节的最后一位开始,以便于剪除该位。
float exponent;
exponent = step(128.0, texel.b);
texel.b -= exponent*128.0;
// Multiple by 2 => left shift by one bit.
exponent += 2.0*texel.a -127.0剩下未处理的位都是尾数部分。
float mantissa;
mantissa = texel.b*65536.0 + texel.g*256.0 + texel.r;最后,将所有部分组合成完整的结果,参考之前使用的相同公式。
float value;
value = sgn * exp2(exponent)*(1.0 + mantissa * exp2(-23.0));通用使用模式将是读取纹理数据,解包数据,执行计算,然后将结果打包成可以存储在纹理中的形式。
精度
几乎同样常见的一个问题就是GPU所能支持的精度,即用多少位来存储浮点数。在片段着色器开头的代码块已经隐含地传达了这一点。
#ifdef GL_FRAGMENT_PRECISION_HIGH
precision highp float;
#else
precision mediump float;
#endif较低精度的表示方法简单地使用更少的比特位来表示一个数字。这个例子展示了一个16位IEEE浮点数。可以将其与上面的32位浮点数进行比较。

一个IEEE 754标准的16位浮点数
最明显的区别之一是指数偏移量变为15,变小了很多。
看起来大多数情况下可以通过上面ifdef定义浮点数精度的方式来解决这些差异。然而,重要的是要考虑降低的精度是否能为模拟提供所需的准确性。
注释
- 好吧,可能也包含了一些接下来要讨论的内容。
- OpenGL ES着色语言内置函数
如何用JavaScript实现一门编程语言 - CPS求值器(CPS Evaluator)
整篇译文的目录章节如下:
- 前言
- λanguage描述
- 写一个解析器(Parser)
- 简单的解释器(Interpreter)
- CPS求值器(CPS Evaluator)
- 编译成JS
- 总结
- 真实示例
CPS求值器(CPS Evaluator)
作者原文提到的bug此译文中已修复,主要是指在解释器,CPS求值器及CPS编译器章节中:像 a() && b() 或者 a() || b() 的表达式两侧都会求值。这样处理是不对的,是否对 b() 求值依赖 a() 的求值结果。通过将 || 及 && 两个二元操作符的处理逻辑替换为 if 表达式来修复。
CPS求值器(CPS Evaluator)
我们的语言有两个问题:(1) 递归受限于JS的堆栈,所以没有有效的方式做遍历;(2) 很慢。我们这里先解决第一个问题,遗憾的是以语言变得更慢为代价。我们将以CPS(Continuation-Passing Style)形式来重写求值器。
什么是CPS?
在NodeJS中你总会如下操作:
fs.readFile("file.txt", "utf8", function CC(error, data){
// this callback is the "continuation"
// instead of returning a value by using `return`,
// readFile will invoke our callback with the data.
});程序执行的每一步,你都需要调用回调函数才能得以持续执行。CPS使得程序控制流变得“清晰” — 你不用return,你不用throw,你不用break 或 continue。没有任意的跳转。你甚至不能直接将 for 或者 while 循环和异步函数组合使用。如果真是这样,为什么语言中还要有这些关键字?
手工写CPS形式的程序很不直观且易出错,但我们也不得不以这种方式来重写求值器。
求值函数(The evaluate function)
CPS形式的evaluate函数将接收三个参数:表达式exp(AST形式),环境env,以及接收结果的回调函数callback。下面是代码实现,我会像之前一样对每种情况进行解释:
function evaluate(exp, env, callback) {
switch (exp.type) {对于常量节点,直接返回它们的值。但请记住,我们需要调用callback来传值,而不是return。
case "num":
case "str":
case "bool":
callback(exp.value);
return;var节点的处理同样简单: 从环境中获取变量的值,并将其传给callback。
case "var":
callback(env.get(exp.value));
return;对于assign节点,我们首先需要对right表达式进行求值。直接调用evaluate并传入一个回调函数,回调函数中就可以获取到结果(即right表达式的求值)。然后设置变量并用设置结果(实际就是变量的值)来调用顶层的callback。
case "assign":
if (exp.left.type != "var")
throw new Error("Cannot assign to " + JSON.stringify(exp.left));
evaluate(exp.right, env, function(right){
callback(env.set(exp.left.value, right));
});
return;类似地,对于二元表达式binary节点,首先需要对left节点求值,然后对right节点求值,最后将两节点基于操作符运算后的结果传递给callback。和之前一样,我们递归调用evaluate并传入一个回调函数来继续执行后续步骤。
case "binary":
evaluate(exp.left, env, function(left){
if (exp.operator === "&&") {
if (left === false) {
callback(left);
} else {
evaluate(exp.right, env, function(right){
callback(right);
});
}
} else if (exp.operator === "||") {
if (left) {
callback(left);
} else {
evaluate(exp.right, env, function(right){
callback(right);
});
}
} else {
evaluate(exp.right, env, function(right){
callback(apply_op(exp.operator, left, right));
});
}
});
return;let节点看起来要更复杂一点,但实际上非常简单。 我们有许多变量定义,它们可能不包含def(初始值)属性,此时默认会初始值为 false;当该属性存在时,则需要递归调用evaluate函数对其求值。
如果你用过NodeJS,你可能已经解决过很多类似的问题。由于使用了回调,我们不能直接使用for,而是需要一个接一个逐个计算表达式(想象一下evaluate函数可能不是立即返回,而是异步的)。下面的循环函数(立即调用的)接收环境对象env及当前变量定义索引i来进行计算。
如果i等于vars.length则意味着计算结束并且环境中已经有了所有变量定义(defs),此时再来执行evaluate(exp.body, env, callback)。需要注意这次我们没有直接来调用callback,而是将其传给evaluate函数作为exp.body执行之后的延续,即其将负责继续执行后续工作。
否则i小于vars.length的情况,则会用evaluate求值当前的定义,并传入一个回调函数用刚求值的变量定义来扩展环境,然后进行下一次循环loop(scope, i + 1)。
case "let":
(function loop(env, i){
if (i < exp.vars.length) {
var v = exp.vars[i];
if (v.def) evaluate(v.def, env, function(value){
var scope = env.extend();
scope.def(v.name, value);
loop(scope, i + 1);
}); else {
var scope = env.extend();
scope.def(v.name, false);
loop(scope, i + 1);
}
} else {
evaluate(exp.body, env, callback);
}
})(env, 0);
return;我们再次使用了一个独立的函数来处理lambda节点,下面我会进行介绍。
case "lambda":
callback(make_lambda(env, exp));
return;对于if节点的执行,首先要对条件求值。如果求值不是 false 则对 then 分支求值,否则进一步判断 else 分支,如果其存在则求值,否则给callback传入 false。在then/else分支处理中可以再次注意到,我们同样没有调用callbcak,而是将其传给了evaluate,负责起表达式计算后续的工作。
case "if":
evaluate(exp.cond, env, function(cond){
if (cond !== false) evaluate(exp.then, env, callback);
else if (exp.else) evaluate(exp.else, env, callback);
else callback(false);
});
return;prog节点的处理类似let节点,但会更简单因为不需要定义变量并扩展环境。两种节点都有相同的处理模式:使用一个loop函数处理索引i。当i与prog.length相等时,则求值结束,直接返回最后一个表达式的求值结果(当然这里的返回,还是通过调用callback并传值的方式)。可以注意到我们是通过将last传给loop的方式来获取它的值(prog.body为空的情况,last初始值为false)。
case "prog":
(function loop(last, i){
if (i < exp.prog.length) evaluate(exp.prog[i], env, function(val){
loop(val, i + 1);
}); else {
callback(last);
}
})(false, 0);
return;对于call节点,我们需要先后对func和arguments求值。同let和prog节点一样,再次使用了一个loop函数来类似地处理它们,只不过这次会将结果构造成一个数组。数组的第一个值必须是callback,因为make_lambda返回的闭包函数也都是CPS形式的,所以它们都是通过调用回调并传结果而不是使用return。
case "call":
evaluate(exp.func, env, function(func){
(function loop(args, i){
if (i < exp.args.length) evaluate(exp.args[i], env, function(arg){
args[i + 1] = arg;
loop(args, i + 1);
}); else {
func.apply(null, args);
}
})([ callback ], 0);
});
return;和之前一样的收尾,如果我们不知道如何继续,则抛出一个错误。
default:
throw new Error("I don't know how to evaluate " + exp.type);
}
}你可能注意到上面每个case分支都以一个return结束。 但没有返回值;结果都传给了callback。如果有可能,我们期望执行永远不会返回case分支;但这就是JS的工作方式。我们需要return语句来确保不会进入到下一个分支。
新make_lambda
在这个版本的求值器中,所有函数接收的第一个参数都是“continuation” — 一个将被传入结果并调用的回调函数。求值器总会插入这个参数,紧接着是运行时传入的其它参数。下面是新make_lambda的代码实现:
function make_lambda(env, exp) {
if (exp.name) {
env = env.extend();
env.def(exp.name, lambda);
}
function lambda(callback) {
var names = exp.vars;
var scope = env.extend();
for (var i = 0; i < names.length; ++i)
scope.def(names[i],
i + 1 < arguments.length
? arguments[i + 1]
: false);
evaluate(exp.body, scope, callback);
}
return lambda;
}仅仅做了略微的改动。使用新变量绑定(参数arguments产生的)来扩展环境。同时需要考虑第一个参数是callback(arguments使用了i + 1索引的原因)。最终像之前一样,在新环境作用域下通过evaluate对函数体求值,但是需要传入callback而不是直接返回结果。
顺便需要注意这里是唯一使用for进行循环的地方。因为当call节点求值时所有参数都已经计算出来了—不需要再对每个参数求值并传入一个回调函数来获取参数值。
原始功能函数(Primitives)
对于CPS求值器,原始功能函数均会将callback作为第一个参数。定义原始功能函数时我们必须记住这一点。下面是针对新版本的一些简单测试代码:
var code = "sum = lambda(x, y) x + y; print(sum(2, 3));";
var ast = parse(TokenStream(InputStream(code)));
var globalEnv = new Environment();
// define the "print" primitive function
globalEnv.def("print", function(callback, txt){
console.log(txt);
callback(false); // call the continuation with some return value
// if we don't call it, the program would stop
// abruptly after a print!
});
// run the evaluator
evaluate(ast, globalEnv, function(result){
// the result of the entire program is now in "result"
});小测试
我们再次使用fib函数:
fib = λ(n) if n < 2 then n else fib(n - 1) + fib(n - 2);
time( λ() println(fib(10)) );如果增加n至fib(27),我们将得到一个“堆栈溢出”错误。事实上,目前堆栈会增长的更快,所以当前的求值器最多只能计算到fib(12)(至少在我的浏览器上是这样,你们的可能会有变动)。非常令人失望,下一节会展示如何规避这个问题。
如何用JavaScript实现一门编程语言 - 总结
整篇译文的目录章节如下:
总结
为了能真正完成本教程,我又进一步给λanguage增加了一些特性实现和修复(非核心的,但有了更好),但这里并没有给出具体描述。下面可以下载到完整的代码。
可以通过NodeJS运行程序。从标准输入STDIN读取λanguage源程序并编译执行。会从标准错误输出编译结果,并在标准输出给出程序执行结果。使用示例:
cat primitives.lambda program.lambda | node lambda.js最终的改动点如下:
- 支持求反运算符(!)。它之所以非核心是因为可以简单地通过一个函数实现:
not = λ(x) if x then false else true;
not(1 < 0) # ⇒ true然后,给它分配一个专用AST节点进而可以生成更高效的代码(一个函数调用意味着需要GURAD或诸如此类的)。
- 增加了一个 js:raw 关键字。通过它可以在输出中插入任意JavaScript代码(仅仅指完整的表达式,而非语句)。使用示例是很容易在λanguage语言中定义原始功能函数:
length = js:raw "function(k, thing){
k(thing.length);
}";
arrayRef = js:raw "function(k, array, index){
k(array[index]);
}";
arraySet = js:raw "function(k, array, index, newValue){
k(array[index] = newValue);
}";
array = js:raw "function(k){
k([].slice.call(arguments, 1));
}";我的语法高亮配置给这个关键字使用了一个红色,因为它是危险的。可能不是太危险,但你需要知道使用它意味着什么:你传给 js:raw 的代码不会被校验并将原封不动地输出到JS中。例如下面代码中,优化器不能判断你访问了局部变量,并会将 x = 10 丢弃:

这不是一个bug。是意料之中会发生的。
-
为布尔表达式生成更好的代码 — make_js,像我们写得那样,可能很容易输出类似代码 (a < 0 ? true : false) !== false,但明显可以简化成 a < 0。这可能不会提升速度,但至少看起来不会那么傻。
-
修复 && 和 || 运算符的语义使得 false 是λanguage中唯一的假值。
-
为全局变量生成 var 声明并基于严格模式"use strict"对最终输出代码进行求值(严格模式下似乎会有大概 5-10% 的速度提升)。
我们是否已经接近一门真实的编程语言了?
不论相信与否,λanguage相当接近Scheme语言了。我曾答应我们不是在实现一门Lisp,我遵守了诺言。但大部分工作已经完成了:我们有了一个不错的CPS转换器和优化器。如果想实现Scheme,剩下的就是写一个Scheme解析器来生成兼容的AST,以及一轮预编译来完成宏扩展。还有核心库的一堆原始功能函数。应该不会有太多的工作。
待增加特性
如果我们想针对λanguage语言有进一步的工作,下面是一些应该考虑的点。
变量名字
JavaScript生成器原样保留了变量的名字,但这通常并不是一个好主意(不用说这是一个bug,因为我们允许标识符名称中出现JavaScript认为非法的字符)。我们至少应该全局增加前缀并替换非法字符。我考虑的前缀是“λ_”。
可变参数列表
任何实用的语言都将需要像JavaScript arguments类似的支持。我们可以简单地通过增加一些语法来支持它,例如:
foo = λ(first, second, rest...) {
## rest here is an array with arguments after second
};但等等,在λanguage语言中数组是什么?(下一小节list中会讲到)。
似乎有倾向认为我们已经可以使用“arguments”名字(因为JS中我们保持了相同的变量名字),但这不会正常工作:to_cps和优化器会认为其是一个全局变量,可能造成混乱。
在不牺牲太多代码大小的情况下实现上面的语法,我们可以使用GURAD函数。示例输出:
foo = function CC(first, second) {
var rest = GUARD(arguments, CC, 2); // returns arguments starting at index 2
};与这个特性相关,我们同样需要一个与Function.prototype.apply等价的特性。
数组和对象
可以很容易地将它们定义为原始功能函数,就像在上面 js:raw 中做得那样。然而,在语法层面实现它们将会生成更高效的代码,同时会赋予我们更熟悉的语法;a[0] = 1 毫无疑问要比 arraySet(a, 0, 1) 更友好。
我想避免的一件事就是歧义。例如,JavaScript中花括号用来表示代码块和字面量对象。规则就是“当左花括号处于语句的位置,则其为一个代码块;当处于一个表达式中时,就是一个对象字面量”。但λanguage中并没有语句(这也是一个特性)并且花括号意味着一个表达式序列。我希望保持这种状态,所以不会使用 { ... } 来表示一个对象字面量。
“点”符号
与前一条相关,我们应该支持通过点符号访问对象的属性。这种用法太普遍了,而不容忽视。
我期望像JavaScript那样支持“方法”是有挑战的(比如:支持 this 关键字)。原因是我们所有函数都会转换成CPS形式(所有函数调用都会将continuation作为第一个参数插入进来)。如果我们打算支持类似JS的方法,我们怎么判断是在调用一个CPS形式的函数(例如:λanguage语言写的)而不是一个普通函数(例如:来自某些JS库)?这点值得思考。
语法(分隔符)
要求prog节点中表达式必须以分号分隔有点太苛刻。例如:按目前的解析器规则,下面的程序是非法的:
if foo() {
bar()
} # ← error
print("DONE")问题出在井号#一行。即使以一个右花括号结束,紧接着它还应该有一个分号(因为if是一个表达式,并以一个右花括号结束)。如果之前使用过JavaScript,这并不很直观;可能更希望放松规则,并认为右花括号后面的分号是可选的。但又很棘手,因为下面的代码也是一个有效的程序:
a = {
foo();
bar();
fib
}
(6);上面代码的结果是调用foo(),bar(),并将 fib(6) 的结果赋值给变量a。多么滑稽的语法,但你知道吗,绝大多数中缀语言都有类似古怪的语法,比如下面代码是一个语法合法的JS程序;尝试运行并不会出现解析错误,但当你调用foo()时会发现有个明显的运行时错误:
function foo() {
a = {
foo: 1,
bar: 2,
baz: 3
}
(10);
}异常
我们可以在reset和shift操作符或者其它原始功能函数基础上实现一个异常系统。
继续…
即使没有TODO中罗列的特性,λanguage语言已经相当强大,我将以一些样例来结束整篇教程,会对比在NodeJS和λanguage中如何来实现一些小程序。继续阅读。
基于WebGL的GPGPU指南 - 各阶段实现
整理译文的目录章节如下:
各阶段实现
在上一节中,我们将通用GPGPU实现拆分为六个小概念。现在我们将为其中五个概念编写代码,光栅化步骤则会由GPU自动完成。当然,我们会将代码组织成清晰、模块化且高度可复用的函数。就像乐高积木一样,我们可以通过组装这些函数来设计构建自己的实现。
我们将方法放在GPGPUtility类中。构造函数提供了定义函数的上下文。具体来说,函数将使用这里定义的实例变量,例如高度
/**
* Set of functions to facilitate the setup and execution of GPGPU tasks.
*
* @param {integer} width_ The width (x-dimension) of the problem domain.
* Normalized to s in texture coordinates.
* @param {integer} height_ The height (y-dimension) of the problem domain.
* Normalized to t in texture coordinates.
*
* @param {WebGLContextAttributes} attributes_ A collection of boolean values to enable or disable various WebGL features.
* If unspecified, STANDARD_CONTEXT_ATTRIBUTES are used.
* @see STANDARD_CONTEXT_ATTRIBUTES
* @see{@link https://www.khronos.org/registry/webgl/specs/latest/1.0/#5.2}
*/
GPGPUtility = function (width_, height_, attributes_)
{
var attributes;
var canvas;
/** @member {WebGLRenderingContext} gl The WebGL context associated with the canvas. */
var gl;
var canvasHeight, canvasWidth;
var problemHeight, problemWidth;
var standardVertexShader;
var standardVertices;
/** @member {Object} Non null if we enable OES_texture_float. */
var textureFloat;
/**
⋮ The code in the following paragraphs goes here.
*/
canvasHeight = height_;
problemHeight = canvasHeight;
canvasWidth = width_;
problemWidth = canvasWidth;
attributes = typeof attributes_ === 'undefined' ? GPGPUtility.STANDARD_CONTEXT_ATTRIBUTES : attributes_;
canvas = this.makeGPCanvas(canvasWidth, canvasHeight);
gl = this.getGLContext();
// Attempt to activate the extension, returns null if unavailable
textureFloat = gl.getExtension('OES_texture_float');
};
// Disable attributes unused in computations.
GPGPUtility.STANDARD_CONTEXT_ATTRIBUTES = { alpha: false, depth: false, antialias: false };画布(Canvas)
即使第一步中我们已可以看到与常规
/**
* Create a canvas for computational use. Computations don't
* require attachment to the DOM.
*
* @param {integer} width The width (x-dimension) of the problem domain.
* @param {integer} height The height (y-dimension) of the problem domain.
*
* @returns {HTMLCanvasElement} A canvas with the given height and width.
*/
this.makeGPCanvas = function (width, height)
{
var canvas;
canvas = document.createElement('canvas');
canvas.width = width;
canvas.height = height;
return canvas;
};当获取WebGL上下文时,我们提供一组属性来禁用不会使用的功能。如果没有显式提供这些属性,会默认禁用一组标准功能。
// Disable attributes unused in computations.
GPGPUtility.STANDARD_CONTEXT_ATTRIBUTES = { alpha: false, depth: false, antialias: false };
/**
* Get a 3d context, webgl or experimental-webgl. The context presents a
* javascript API that is used to draw into it. The webgl context API is
* very similar to OpenGL for Embedded Systems, or OpenGL ES.
*
* @returns {WebGLRenderingContext} A manifestation of OpenGL ES in JavaScript.
*/
this.getGLContext = function ()
{
// Only fetch a gl context if we haven't already
if(!gl)
{
gl = canvas.getContext("webgl", attributes)
|| canvas.getContext('experimental-webgl', attributes);
}
return gl;
};几何形状

一个三角形带中的四个顶点覆盖了整个画布。x 和 y 是归一化的设备坐标。s 和 t 是纹理坐标。
覆盖画布最简单的几何形状是一个矩形,每个角都有一个顶点。幸运的是,在归一化设备坐标中,画布的各角坐标为
回想一下,问题网格与画布像素和纹理元素都是精确匹配的。这意味着我们也要将纹理附加到画布各角上。这可能有点令人困惑,因为纹理坐标是另一种坐标系。纹理坐标的范围从
/**
* Return a standard geometry with texture coordinates for GPGPU calculations.
* A simple triangle strip containing four vertices for two triangles that
* completely cover the canvas. The included texture coordinates range from
* (0, 0) in the lower left corner to (1, 1) in the upper right corner.
*
* @returns {Float32Array} A set of points and textures suitable for a two triangle
* triangle fan that forms a rectangle covering the canvas
* drawing surface.
*/
this.getStandardGeometry = function ()
{
// Sets of x,y,z(=0),s,t coordinates.
return new Float32Array([
-1.0, 1.0, 0.0, 0.0, 1.0, // upper left
-1.0, -1.0, 0.0, 0.0, 0.0, // lower left
1.0, 1.0, 0.0, 1.0, 1.0, // upper right
1.0, -1.0, 0.0, 1.0, 0.0]);// lower right
};创建纹理
普通纹理中的像素颜色数据,红
OES_texture_float是
// Non null if we enable OES_texture_float
var textureFloat;
// Attempt to activate the extension, returns null if unavailable
textureFloat = gl.getExtension('OES_texture_float');
/**
* Check if floating point textures are available. This is an optional feature,
* and even if present are usually not usable as a rendering target.
*/
this.isFloatingTexture = function()
{
return textureFloat != null;
};既然现在我们已启用了浮点纹理,那就来创建一个。我们使用
我们设置了一些选项可以使纹理更适合存储计算数据。将
如果我们读取超过纹理边缘的值,则希望得到边缘的值。我们通过将
/**
* Create a width x height texture of the given type for computation.
* Width and height must be powers of two.
*
* @param {WebGLRenderingContext} The WebGL context for which we will create the texture.
* @param {integer} width The width of the texture in pixels. Normalized to s in texture coordinates.
* @param {integer} height The height of the texture in pixels. Normalized to t in texture coordinates.
* @param {number} type A valid texture type. FLOAT, UNSIGNED_BYTE, etc.
* @param {number[] | null} data Either texture data, or null to allocate the texture but leave the texels undefined.
*
* @returns {WebGLTexture} A reference to the created texture on the GPU.
*/
this.makeTexture = function (gl, width, height, type, data)
{
var texture;
// Create the texture
texture = gl.createTexture();
// Bind the texture so the following methods effect this texture.
gl.bindTexture(gl.TEXTURE_2D, texture);
gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_MIN_FILTER, gl.NEAREST);
gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_MAG_FILTER, gl.NEAREST);
gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_WRAP_S, gl.CLAMP_TO_EDGE);
gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_WRAP_T, gl.CLAMP_TO_EDGE);
// Pixel format and data for the texture
gl.texImage2D(
gl.TEXTURE_2D, // Target, matches bind above.
0, // Level of detail.
gl.RGBA, // Internal format.
width, // Width - related to s on textures.
height, // Height - related to t on textures.
0, // Always 0 in OpenGL ES.
gl.RGBA, // Format for each pixel.
type, // Data type for each chanel.
data); // Image data in the described format, or null.
// Unbind the texture.
gl.bindTexture(gl.TEXTURE_2D, null);
return texture;
};输出纹理
通常来说,片段着色器的结果会绘制到屏幕上并且

由于与画布尺寸匹配对齐,纹理的几何形状定义非常清晰。
纹理的
纹理元素之间的
在片段着色器中,我们可以访问到纹理坐标,从这个坐标可以准确地知道正在写入哪个纹理元素。具体来说,
最后,我们将纹理设置为渲染目标。
/**
* Create and bind a framebuffer, then attach a texture.
*
* @param {WebGLRenderingContext} gl The WebGL context associated with the framebuffer and texture.
* @param {WebGLTexture} texture The texture to be used as the buffer in this framebuffer object.
*
* @returns {WebGLFramebuffer} The framebuffer
*/
this.attachFrameBuffer = function (gl, texture)
{
var frameBuffer;
// Create a framebuffer
frameBuffer = gl.createFramebuffer();
// Make it the target for framebuffer operations - including rendering.
gl.bindFramebuffer(gl.FRAMEBUFFER, frameBuffer);
// Our texture is the target of rendering ops now.
gl.framebufferTexture2D(
gl.FRAMEBUFFER, // The target is always a FRAMEBUFFER.
gl.COLOR_ATTACHMENT0, // We are providing the color buffer.
gl.TEXTURE_2D, // This is a 2D image texture.
texture, // The texture.
0); // 0, we aren't using MIPMAPs
return frameBuffer;
};为了确保帧缓冲区对象可用,我们还必须调用
/**
* Check the framebuffer status. Return false if the framebuffer is not complete,
* That is if it is not fully and correctly configured as required by the current
* hardware. True indicates that the framebuffer is ready to be rendered to.
*
* @returns {boolean} True if the framebuffer is ready to be rendered to. False if not.
*/
this.frameBufferIsComplete = function ()
{
var message;
var status;
var value;
status = gl.checkFramebufferStatus(gl.FRAMEBUFFER);
switch (status)
{
case gl.FRAMEBUFFER_COMPLETE:
value = true;
break;
case gl.FRAMEBUFFER_UNSUPPORTED:
message = "Framebuffer is unsupported";
value = false;
break;
case gl.FRAMEBUFFER_INCOMPLETE_ATTACHMENT:
message = "Framebuffer incomplete attachment";
value = false;
break;
case gl.FRAMEBUFFER_INCOMPLETE_DIMENSIONS:
message = "Framebuffer incomplete (missmatched) dimensions";
value = false;
break;
case gl.FRAMEBUFFER_INCOMPLETE_MISSING_ATTACHMENT:
message = "Framebuffer incomplete missing attachment";
value = false;
break;
default:
message = "Unexpected framebuffer status: " + status;
value = false;
}
return {isComplete: value, message: message};
};如何用JavaScript实现一门编程语言 - 前言
之前看到一篇较完整的关于如何使用JavaScript实现一门编程语言的博文,虽然作者本人(UglifyJS作者)声称是简单的教程,但里面很多概念思考还是很值得学习,比如对continuation的讨论,yield以及reset/shift等的实现讨论等。所以尝试将全部文章译成中文,供更多对语言原理感兴趣的同学学习,翻译过程尽量保证原文风格,但限于Markdown语法的支持,后续章节一些定制化的脚本功能不能在线实时交互,原文请查看。
整篇译文的目录章节如下:
前言
这是一本关于如何实现一门编程语言的教程。如果你曾经写过解释器(interpreter)或者编译器(compiler),那么本教程对你来说可能不会涉及新的知识概念。但如果你是使用正则表达式(regexps)来分析一门编程语言,还是建议你至少可以阅读解析章节。 让我们写出错误更少的代码!
本教程是按照由浅入深的编写顺序。除非你对某个主题已经非常了解,否则不推荐跳跃式阅读。如果对某些概念不能理解,随时可以参考之前的章节。同时非常期望得到你的问题和反馈!
本教程的目标受众是普通的JavaScript和NodeJS程序员。
我们将会学到什么
- 什么是解析器(parser),如何写出一个
- 如何写一个解释器(interpreter)
- 为什么Continuations很重要
- 写一个编译器(Compiler)
- 如何把代码转化成CPS类型(continuation-passing style)
- 一些基本的优化技巧
- 我们实现的λanguage语言能给普通的JavaScript带来哪些新特性的示例
这期间我会讨论到为什么Lisp是一门如此伟大的语言。不过,我们实现的语言不是Lisp。除了宏(macros)功能之外,它几乎和Scheme一样强大,拥有更丰富的语法(众所周知的经典中缀表达式)。但Lisp强大之处也正是宏(macros),是其它语言不能征服的终极堡垒(除非他们叫做Lisp方言)。【是的,我知道SweetJS...,但也差了一点】
首先,让我们来创造一门编程语言吧。
如何用JavaScript实现一门编程语言 - JS代码生成器
整篇译文的目录章节如下:
编译成JS
为了λanguage语言能更有效率,应将其转换成以JavaScript目标语言实现的程序,而不是直接对AST解析求值。接着我们通过 eval 或 new Function (或用一个 <script> 标签加载) 来运行它,我向你保证速度提升一定会非常显著。我将这个转换工作分成三个部分:
- JS代码生成器(code generator)
- 转换为CPS形式
- 优化
以代码生成部分开始讲解看起来可能会有点奇怪,直觉上它应该是“最后阶段”。之所以这样安排是因为代码生成会有助于实现和调试后续的部分。后续部分实现后也仅需要对代码生成器做小的调整即可。
JS代码生成器(code generator)
从AST生成JS代码非常简单。参照我们最初一版求值器的结构,make_js是一个接收AST的递归函数。这里环境对象的用处不大,因为这次我们不会执行AST,而是将其转化为等价功能的JavaScript代码,并以字符串形式返回。
代码入口看起来像下面这样:
function make_js(exp) {
return js(exp);
function js(exp) {
switch (exp.type) {
case "num" :
case "str" :
case "bool" : return js_atom (exp);
case "var" : return js_var (exp);
case "binary" : return js_binary (exp);
case "assign" : return js_assign (exp);
case "let" : return js_let (exp);
case "lambda" : return js_lambda (exp);
case "if" : return js_if (exp);
case "prog" : return js_prog (exp);
case "call" : return js_call (exp);
default:
throw new Error("Dunno how to make_js for " + JSON.stringify(exp));
}
}
// NOTE, all the functions below will be embedded here.
}js函数基于当前节点的类型进行调度,直接调用相应的生成器。
function js_atom(exp) {
return JSON.stringify(exp.value); // cheating ;-)
}目前而言,我们将原样输出变量名,这并不完全正确:λanguage语言中允许变量名中包含负号字符,但这在JS中并不合法。为了后面能更容易解决这个问题,所有变量名都会经过一个make_var函数处理,这样后面就可以统一一处修改:
function make_var(name) {
return name;
}
function js_var(exp) {
return make_var(exp.value);
}对于二元运算符,分别编译左、右操作数,并用操作符进行拼接即可。需要注意的是我们最外层整体用括号进行了包裹,不用担心输出的美化—可以使用UglifyJS完成美化工作。
function js_binary(exp) {
return "(" + js(exp.left) + exp.operator + js(exp.right) + ")";
}仔细的读者会发现此处与求值器相比存在一些bug:求值器里会确保数字类型的操作符将接受恰当类型的操作数,并且不会发生除0的情况;同时&&和||的语义(关于falsy假值的认定)也与原生JS有些许的不同。我们后续再来关心这些问题。
// assign nodes are compiled the same as binary
function js_assign(exp) {
return js_binary(exp);
}lambda节点同样相当简单。就是输出一个JavaScript函数表达式。我们用括号包裹一下,避免可能的错误,输出function关键字,紧接着如果有函数名则输出函数名,然后是参数列表。函数体是一个单一的表达式,返回其结果。
function js_lambda(exp) {
var code = "(function ";
if (exp.name)
code += make_var(exp.name);
code += "(" + exp.vars.map(make_var).join(", ") + ") {";
code += "return " + js(exp.body) + " })";
return code;
}使用立即执行函数IIFE来处理let节点。有点大材小用,我们可以做得更好,但目前不想耗费更多精力。用IIFE处理let节点非常简单:如果vars属性为空,则编译body属性。否则为第一个变量/定义创建一个IIFE节点(一个call节点),如果变量/定义为空则返回一个FALSE节点 — 最后编译IIFE节点。这叫做“脱糖desugaring”。
function js_let(exp) {
if (exp.vars.length == 0)
return js(exp.body);
var iife = {
type: "call",
func: {
type: "lambda",
vars: [ exp.vars[0].name ],
body: {
type: "let",
vars: exp.vars.slice(1),
body: exp.body
}
},
args: [ exp.vars[0].def || FALSE ]
};
return "(" + js(iife) + ")";
}我们使用JavaScript的三目运算符来编译if节点。我们仍旧坚定λanguage语言中仅有false一个假值的事实(所以仅当条件不是false时才会执行then节点)。如果没有else节点,就默认编译一个FALSE节点。
与求值器不同,根据条件仅会执行then或else,这里两种分支必须都要遍历来生成代码 — 原因很明显,此时还不能知道条件的执行结果。
function js_if(exp) {
return "("
+ js(exp.cond) + " !== false"
+ " ? " + js(exp.then)
+ " : " + js(exp.else || FALSE)
+ ")";
}最后,prog和call — 非常简单的节点。对于prog节点,我们直接使用JavaScript中的逗号操作符即可。逗号操作符可以完美满足我们的诉求,对表达式序列顺序求值并返回最后一个表达式的求值。
function js_prog(exp) {
return "(" + exp.prog.map(js).join(", ") + ")";
}
function js_call(exp) {
return js(exp.func) + "(" + exp.args.map(js).join(", ") + ")";
}上面就是代码生成器的全部!
原始功能函数和用法
这次生成的程序实际使用的是JavaScript变量,所以原生功能函数就是全局JS变量或函数。下面是一个基本的使用示例:
// the "print" primitive
window.print = function(txt) {
console.log(txt);
};
// some test code here
var code = "sum = lambda(x, y) x + y; print(sum(2, 3));";
// get the AST
var ast = parse(TokenStream(InputStream(code)));
// get JS code
var code = make_js(ast);
// additionally, if you want to see the beautified JS code using UglifyJS
// (or possibly other tools such as acorn/esprima + escodegen):
console.log( UglifyJS.parse(code).print_to_string({ beautify: true }) );
// execute it
eval(code); // prints 5后面你可以看到它的真实使用案例。
测试
还记得我们求值器的第一个版本(目前最快的版本)需要花费1S多时间来计算fib(27)?(大概比JS慢了300倍)。下面是其编译成JS的版本:
fib = λ(n) if n < 2 then n else fib(n - 1) + fib(n - 2);
time( λ() println(fib(27)) );就和手写的JS代码一样块(译者多次尝试仅需要4~7ms,在线示例)。你可以从浏览器终端中看到生成的代码(console.log打印出来的)。
很可能我们想就此打住 — 因为已经“和JS一样快”了。但“和JS一样好”,同样并不足够好。没有了continuations,递归再次成为瓶颈。我们这里所做的最好也仅能称其为一个“转译器”。
编译器是将一门源语言转换成一门目标语言。例如,C++转换到汇编语言。或者λanguage到JavaScript。编译器真正做的不是代码生成,而是给源语言提供很多特性使其比目标语言更加强大。
接下来我们将继续把AST转化成CPS形式。
如何用JavaScript实现一门编程语言 - 编译器示例及改进
整篇译文的目录章节如下:
示例
接下来的示例将解析源代码、转换为CPS形式并生成最终的JavaScript代码。你可以看到λanguage语言是如何正确地转换为CPS形式的JavaScript代码。输出代码的缩进等是借助UglifyJS完成的(查看页面源码可以发现这些示例实际上是浏览器生成的)。可以通过下面的代码来完成转换:
var ast = parse(TokenStream(InputStream(code)));
var cps = to_cps(ast, function(x){ return x });
var out = make_js(cps);
// get beautified output:
out = UglifyJS.parse(out).print_to_string({ beautify: true });我们传给to_cps的“toplevel continuation”会原样返回传入的AST节点。
下面示例中你将发现return关键字是无意义的,跟CPS求值器中的效果一样,函数都不会return,相反会将结果传入continuation调用进行后续的计算。
函数调用
可以看到每个函数调用中是如何将包裹了程序后续行为的continuation作为第一个参数插入的。

表达式序列 (prog)

条件(Conditionals)
注意下面两个 if 示例是如何完全一样地完成了编译。这很有趣并也预示着一个问题。

下面示例展示连续多个 if 会编译成什么:

函数(lambda)

还有一点,输出代码中传给add的continuation的作用就是传入结果并调用dup的continuation — β_K(β_R)。所以整个函数可以直接替换为 β_K:
dup = function(β_K_1, x) {
return add(β_K_1, x, x);
};这是一个应该完成的重要且简单的优化。
Let

fib函数
仅为了展示一个更有意义的程序示例:

结论
为了得到一个不错的语言我们还需要修复一些问题。在此之上,我们会重新回归考虑递归限制的问题 — 我们将直接复用CPS求值器中构建的基础结构:Execute,Continuation和GUARD,所以修复相当容易。下一节我们将直接在CPS转换器以及JS代码生成器中修复一系列问题。
改进
下面我们将会对CPS转换器及代码生成器做一些轻微的修改。
prog节点
我们从一个简单的函数开始,cps_prog — 想法就是当第一个表达式没有副作用时,没有必要再将其输出。下面的帮助函数将决定一个AST节点是否会产生副作用。该函数并不完美;这里的金科玉律就是小心为上。如果确定不了,就认为是有副作用的。
例如,判断assign或call节点是否有副作用并不容易。变量定义中的赋值操作会产生副作用,但如果定义的变量从未使用或立即被重新赋值,则都可以丢弃。另一方面,如果被调用的函数是“纯函数”,则函数调用也可能没有副作用,但没有简单的方式来证明这一点。既然不容易确保是否有副作用,就认为它们都有副作用。
function has_side_effects(exp) {
switch (exp.type) {
case "call":
case "assign":
return true;
case "num":
case "str":
case "bool":
case "var":
case "lambda":
return false;
case "binary":
return has_side_effects(exp.left)
|| has_side_effects(exp.right);
case "if":
return has_side_effects(exp.cond)
|| has_side_effects(exp.then)
|| (exp.else && has_side_effects(exp.else));
case "let":
for (var i = 0; i < exp.vars.length; ++i) {
var v = exp.vars[i];
if (v.def && has_side_effects(v.def))
return true;
}
return has_side_effects(exp.body);
case "prog":
for (var i = 0; i < exp.prog.length; ++i)
if (has_side_effects(exp.prog[i]))
return true;
return false;
}
return true;
}期望上面的函数已经足够清晰而不需要进一步解释。有了这个函数,cps_prog变成下面这样:
function cps_prog(exp, k) {
return (function loop(body){
if (body.length == 0) return k(FALSE);
if (body.length == 1) return cps(body[0], k);
if (!has_side_effects(body[0]))
return loop(body.slice(1));
return cps(body[0], function(first){
if (has_side_effects(first)) return {
type: "prog",
prog: [ first, loop(body.slice(1)) ]
};
return loop(body.slice(1));
});
})(exp.prog);
}所以,对于前两种情况的处理跟之前相同:如果表达式序列为空则返回false,如果只有一个表达式则进行编译因为我们需要其编译结果。但如果至少有两个表达式时,会进一步校验:能否在编译时确定第一个表达式没有副作用?如果确定没有则将其丢弃—甚至不会编译它—直接对剩余部分进行编译。如果有副作用,还会在其continuation中进一步校验其结果是否有副作用(因为结果可能仅是一个普通变量),并仅当有副作用时才会包含其结果。
if节点
之前的cps_if中各分支都进行编译,导致连续的if语句会增加大量的代码输出。一种修复方法(代价相当大)是将程序剩余部分包裹到一个continuation里,我们将if节点转换为接收一个continuation参数的IIFE表达式。IIFE函数体将使用if表达式的编译结果来调用continuation。
下面是一个采用上面方案的 λ 到 λ 转化示例:

上面的转换确实会增加一些开销,但至少代码增长是线性而不是指数型的(比如,你不会在输出中看到两个print(a))。
下面是更新后的 cps_if:
function cps_if(exp, k) {
return cps(exp.cond, function(cond){
var cvar = gensym("I");
var cast = make_continuation(k);
k = function(ifresult) {
return {
type: "call",
func: { type: "var", value: cvar },
args: [ ifresult ]
};
};
return {
type: "call",
func: {
type: "lambda",
vars: [ cvar ],
body: {
type: "if",
cond: cond,
then: cps(exp.then, k),
else: cps(exp.else || FALSE, k)
}
},
args: [ cast ]
};
});
}我们不得不为continuation起一个名字(cvar)。将程序剩余部分编译为cast的continuation后,我们将k赋值为一个会调用cast(可通过cvar引用到)的call节点,并会将if表达式(then和else分支)的编译结果传给cast进行调用。就是目前传给各分支中的k。
增加堆栈保护并丢弃return
为了实现这个功能需要对代码生成器做一点小改动。更新后的js_lambda如下:
function js_lambda(exp) {
var code = "(function ";
var CC = exp.name || "β_CC";
code += make_var(CC);
code += "(" + exp.vars.map(make_var).join(", ") + ")";
code += "{ GUARD(arguments, " + CC + "); " + js(exp.body) + " })";
return code;
}如果编译的函数没有命名,则默认函数名为"β_CC",所以可以将其传给GUARD。我翻转了GUARD的参数,因为它们会增加很多输出(可以看到虽然删除了return语句,但同时需要增加这些guard语句)— 并提供一个更长的常量字符串使得输出代码能够在使用gzip后得到更好的压缩。
经过这些“改进”,fib函数的输出看起来很“混乱”:

试着运行一下:
fib = λ(n) if n < 2 then n else fib(n - 1) + fib(n - 2);
time( λ() println(fib(27)) );根据我的测试,看起来比最初一版求值器实现快了6倍,比CPS求值器快了30倍。同时也比手写的JS慢了大概30倍。导致其慢的原因,除了引入CPS转换的开销,还有就是堆栈保护。遗憾的是没有方法还规避这些开销。如果JS代码生成器中放弃了使用GUARD,上面的例子将会堆栈溢出。
另一方面开销增加来自于if节点的处理方式。对于上面的例子完全没有必要,因为if表达式是函数中的最后一项(它的continuation就是调用fib函数的continuation)。
下一章节我们将写一个优化器来进一步改善输出代码的质量。
基于WebGL的GPGPU指南 - 矩阵乘法
整理译文的目录章节如下:
矩阵乘法
我们已经完成了矩阵的初始化。进一步可以做的最简单但有趣的操作是矩阵平方。
其中
在深入研究代码之前,我们再来看一下预期的GPGPU应用程序的结构。
WebGL GPGPU实现的基本结构
我们将从画布(canvas)开始自底向上地构建整个程序。要计算结果矩阵
var gpgpUtility;
var matrixColumns;
var matrixRows;
matrixColumns = 128;
matrixRows = 128;
gpgpUtility = new vizit.utility.GPGPUtility(matrixColumns, matrixRows);纹理的
纹理元素之间的
在片段着色器中,我们可以访问到纹理坐标,从这个坐标可以准确地知道正在写入哪个纹理元素。具体来说,
几何形状再次是完全覆盖画布的标准三角形。由这个画布加几何形状组合生成的片段为矩阵
我们将初始化步骤中的渲染目标
/**
* Runs the program to do the actual work. On exit the framebuffer &
* texture are populated with the square of the input matrix, m. Use
* gl.readPixels to retrieve texture values.
*
* @param m {WebGLTexture} A texture containing the elements of m.
* @param mSquared {WebGLTexture} A texture to be incorporated into a fbo,
* the target for our operations.
*/
this.square = function(m, mSquared)
{
var m2FrameBuffer;
// Create and bind a framebuffer
m2FrameBuffer = gpgpUtility.attachFrameBuffer(mSquared);
gl.useProgram(program);
gpgpUtility.getStandardVertices();
gl.vertexAttribPointer(positionHandle, 3, gl.FLOAT, gl.FALSE, 20, 0);
gl.vertexAttribPointer(textureCoordHandle, 2, gl.FLOAT, gl.FALSE, 20, 12);
gl.activeTexture(gl.TEXTURE0);
gl.bindTexture(gl.TEXTURE_2D, m);
gl.uniform1i(textureHandle, 0);
gl.drawArrays(gl.TRIANGLE_STRIP, 0, 4);
};
我们设置几何形状以便每个
方程右侧
#ifdef GL_FRAGMENT_PRECISION_HIGH
precision highp float;
#else
precision mediump float;
#endif
uniform sampler2D m;
varying vec2 vTextureCoord;
void main()
{
float i, j;
float value = 0.0;
i = vTextureCoord.s;
j = vTextureCoord.t;
for(float k=0.0; k<128.0; ++k)
{
value += texture2D(m, vec2(i, k/128.0)).r * texture2D(m, vec2(k/128.0, j)).r;
}
gl_FragColor.r = value;
}GLSL(特别是WebGL使用的GLSL版本)有一个有趣的要求,即循环的界限必须是固定的。根据GLSL规范附录A控制流(Control Flow)章节,循环的最大迭代次数需要在编译时确定。这意味着我们需要为不同大小的矩阵编写不同的着色器。
另一种方法是设置一个非常大的循环索引,并在完成时跳出循环,类似于下面的方法:
uniform sampler2D m;
uniform float mSize;
varying vec2 vTextureCoord;
void main()
{
float i, j;
float value = 0.0;
i = vTextureCoord.s;
j = vTextureCoord.t;
for(float k=0.0; k<2048.0; ++k)
{
if (k >= mSize)
{
break;
}
value += texture2D(m, vec2(i, k/mSize)).r * texture2D(m, vec2(k/mSize, j)).r;
}
gl_FragColor.r = value;虽然这种方法可以让你拥有一个适用于多种情况的单一着色器,但仍存在一些问题。许多GPU,尤其是老款GPU,会展开循环,并执行所有真假条件路径,然后丢弃不需要的结果。这会导致意料之外的大内存消耗以及糟糕的执行时间。
问题: 你将如何修改这个算法来实现两个不同尺寸矩阵相乘?
下面表格是这段代码的运行结果。同时将GPU计算结果与JavaScript的64位计算结果进行了比较。通常情况下这些结果不会匹配。
GPGPU结果与JavaScript 64位结果相比较
| 坐标 | GPU结果 | 正确期望值 | 相对误差 |
|---|---|---|---|
| (1, 1) | 8819015680 | 8819016128 | 5.1e-8 |
| (10, 12) | 81986330624 | 81986337536 | 8.4e-8 |
| (20, 30) | 163327934464 | 163327923840 | 6.5e-8 |
| (100, 100) | 814771535872 | 814771692800 | 1.9e-7 |
| (101, 101) | 822925459456 | 822925428928 | 3.7e-8 |
| (127, 127) | 1035012341760 | 1035012424256 | 8.0e-8 |
这就引出了关于GPU计算的一个重要问题。WebGL中你不会看到64位(双精度)浮点数。最多只能看到32位(单精度)甚至24位或16位浮点数。针对问题和示例选择足够的精度非常重要,就像许多教学模拟的情况一样。
一道面试题目引发的思考
起因
多列布局是前端一个经典的反复被提及的面试题目,最典型的即两列,左列定宽菜单栏,右列变宽为内容区域。
通常得到的答案无外乎左列浮动定宽,然后右列或浮动,或设置外边距,或绝对定位等等。偶尔会有面试者给出设置右列overflow属性的答案,心里就会有些惊喜,继而会继续追问,为什么这么设置就能实现效果,期待能有进一步惊喜,但基本大部分面试者都止步于这样设置,并不清楚原因。非常少的面试者会提到这样设置能够触发块级格式化上下文(Block Formatting Conext, BFC),如果继续追问触发BFC的原因,几乎没有一个面试者能给出比较满意的答案。
本文就是由这道面试题目引发的一些思考。针对设置overflow属性这一方法,做进一步的探讨。
overflow属性
overflow属性最常见的一个使用场景就是规定当内容溢出元素框时发生的事情。可能的值如下:
- visible 默认值。元素内容不会被裁剪,元素框之外的内容仍然会呈现。
- hidden 元素内容会被裁剪,并且元素 框之外的内容是不可见的。
- scroll 元素内容会被裁剪,但是浏览器会显示滚动条以便查看其余的内容。
- auto 浏览器自动处理元素内容的溢出,如果元素内容被裁剪,则浏览器会显示滚动条以便查看其余的内容。
- inherit 规定应该从父元素继承 overflow 属性的值。
除此之外,也会经常看到通过overflow属性实现的一些效果,比如清除浮动,以及上面提到的两栏布局的实现。这些效果的实现,可能跟overflow属性的本意相差甚远,就像两种不相关的事务被硬生生的牵扯到了一起。其实不然,CSS Spec规范文档中还明确记录着overflow属性的另外一个重要作用。
overflow属性跟布局的关系
The CSS2.1 spec mandates that overflow other than visible establish a new "block formatting context".
CSS2.1规范中已经明确提出,设置overflow属性(非visible)能触发块级格式化上下文(Block Formatting Conext, BFC)。
BFC是个很大的话题,此处不展开,这里给出一个简化不精确的解释,BFC概念的引入,一定程度是为了特殊情况下布局计算的方便,元素触发BFC之后,其作用就相当于一个根容器,其内部的子元素会跟外界完全隔离开,子元素布局以及尺寸相关的计算都会以该元素容器为基础。
为什么overflow非visible值会触发BFC?
首先,设置overflow属性为visible的话,是一种默认情况,就相当于正常默认的布局,所有超出元素框的内容仍然会正常显示,不会被裁剪,也不会出现滚动条。但对于其它几种值的话(hidden, scroll, auto),元素的内容可能会被裁剪,此时,对于某些情况下可能出现的特殊布局处理就会出现争议。
比如对于垂直方向紧贴着的两个元素A和B,其中元素A中浮动的子元素可能会遮住元素B的部分文字区域,此时如果元素B的overflow属性设置为visible,则内容会包裹在元素A浮动子元素的周围,这种情况比较容易理解,如下图。
图1 overflow属性设置为visible

但当元素B的overflow属性设置为非visible的值时,各版本规范的规定就会出现差异。
CSS2.0规范规定,设置非visible属性值后,元素B的内容仍然包裹浮动元素,如图2所示。
图2 overflow属性设置为novisible,CSS2.0规范中的处理

此后如果元素B内容发生滚动,每次滚动行为,元素B中发生折叠的内容(图3中元素B中文字内容滚动后发生变化)全部要重新计算重绘,实际上这将会带来很大的性能问题,对滚动体验也会造成比较大的影响。
图3 overflow属性设置为novisible,CSS2.0规范中发生滚动时的处理

但这里存在进一步的疑问,即使按此规范的约定,元素B内容滚动时存在性能以及体验问题,但是非visible属性中的hidden值,难以理解,元素内容已经被裁剪掉了,为什么跟其它值auto, scroll归为一类?这里面就存在一个误区,overflow设置为hidden值并不代表内容不可滚动,此时浏览器只不过没有提供可滚动的UI,被"裁剪"掉的内容可以通过JavaScript脚本来控制滚动,这也是脚本模拟滚动条的基础。比如,可以通过JavaScript脚本设置元素的scrollTop实现图4的效果,更友好的方式可以自定义一个滚动条。
图4 overflow属性设置为hidden,CSS2.0规范中发生滚动时的处理

事实上各大浏览器厂商也都没有遵照CSS2.0来实现这一部分规范。取而代之,实现的是CSS2.1中的规范内容,即当元素B的overflow属性设置为非visible值时会触发BFC,元素B会创建自己的块级格式化上下文,并会被整体推向右侧,如图5所示。
图5 overflow属性设置为nonvisible,CSS2.1规范中的处理

备注 上面各图均来自于参考文献3
收尾
事实上,一些常见的其它布局技巧也都是基于上述的原理点,比如overflow属性非visible值可以用于清除浮动。如果一个面试者,能够比较清楚地讲出上面的各点,相信每个面试官心里面都会比较惊喜,上面只是自己的一些想法,可能会有些许的钻牛角尖,但单从这种对细节的钻研把控程度,候选人就一定不会太差,对候选人来说必然会有很大程度的加分。
上面只是针对两列布局这道题目一种方案的单方面探讨,这种方案有哪些优缺点等等都未提及,如果对每种方案都进行类似程度的拓展,将会发现这其中会涵盖很多前端知识点,所以看似简单的题目其实并不简单。越发觉得前端领域的水很深,伙伴们一起来努力探索实践吧!
参考文献
如何用JavaScript实现一门编程语言 - 我们有多快?
整篇译文的目录章节如下:
我们有多快?
简单回答:非常慢(dog slow)!
但来测试一下。我们将使用计算斐波那契数列的双递归函数,因为它不需要太多的栈空间但执行时间会随着 n 的规模增长曾现指数级增长。我们将会对比这个函数在普通JavaScript及λanguage语言下的执行时间。
我在当前环境定义了下面的原始功能函数;
globalEnv.def("fibJS", function fibJS(n){
if (n < 2) return n;
return fibJS(n - 1) + fibJS(n - 2);
});
globalEnv.def("time", function(fn){
var t1 = Date.now();
var ret = fn();
var t2 = Date.now();
println("Time: " + (t2 - t1) + "ms");
return ret;
});time接收一个函数,并会打印出该函数的执行时间。执行下面的程序:
fib = λ(n) if n < 2 then n else fib(n - 1) + fib(n - 2);
print("fib(10): ");
time( λ() println(fib(10)) );
print("fibJS(10): ");
time( λ() println(fibJS(10)) );
println("---");
print("fib(20): ");
time( λ() println(fib(20)) );
print("fibJS(20): ");
time( λ() println(fibJS(20)) );
println("---");
print("fib(27): ");
time( λ() println(fib(27)) );
print("fibJS(27): ");
time( λ() println(fibJS(27)) );在我的机器上,使用Google Chrome,最后的 n (27) ,λanguage语言执行超过了1秒,JavaScript却只用了4毫秒。显然这完全无法接受。
我们可以并将λanguage语言编译成JavaScript。为了弥补只能使用递归的情况,我们可以增加循环关键字(for / while),增加对象或数组等复杂数据结构,甚至异常 — 所有这些都可以被底层JavaScript语言所支撑。但这又有什么意义呢?JS同样有它的缺点,只是在它上面强加另一种语法不会给我们带来任何引以为豪的成就。
所以本教程中我投入了更多的思考,接下来将会介绍一个CPS(Continuation-Passing Style)求值器,会先后尝试 Continuations 以及一个与JavaScript同样有效率但拥有更强语义能力的编译器。
我们要试着做得比宿主语言(JavaScript)更好。速度很重要,但不是唯一的目标。
如何用JavaScript实现一门编程语言 - CPS转换器
整篇译文的目录章节如下:
CPS转换器(transformer)
作者原文提到的bug此译文中已修复,主要是指在解释器,CPS求值器及CPS编译器章节中:像 a() && b() 或者 a() || b() 的表达式两侧都会求值。这样处理是不对的,是否对 b() 求值依赖 a() 的求值结果。通过将 || 及 && 两个二元操作符的处理逻辑替换为 if 表达式来修复。
转换代码为CPS形式
为了能够使用不受限制的递归和continuation,我们将像在解释器章节中做的一样:实现一个“CPS求值器”。求值器本身是按照continuation-passing-style形式编写,接收一个计算表达式和一个接收结果的回调函数。但这里我们只进行编译,而不会求值,所以这个回调函数指代什么并不特别明显。
下面是本篇代码的一些转换示例。选择通过λanguage语言而不是AST进行表达,因为这样更容易理解,但需要澄清一点:CPS转换器接收一个AST输入,并返回一个兼容且等价的AST输出,区别在于输出的AST是CPS形式的。它并不会返回一个字符串形式的λanguage或JavaScript程序,这是代码生成器完成的。
在下面示例中,TC代表“toplevel continuation” — 它将接收整个程序的结果。你可以认为其是“最后的返回”。

实现
to_cps函数将接收一个AST以及一个回调函数作为输入。程序主入口点看起来像下面这样:
function to_cps(exp, k) {
return cps(exp, k);
function cps(exp, k) {
switch (exp.type) {
case "num" :
case "str" :
case "bool" :
case "var" : return cps_atom (exp, k);
case "assign" :
case "binary" : return cps_binary (exp, k);
case "let" : return cps_let (exp, k);
case "lambda" : return cps_lambda (exp, k);
case "if" : return cps_if (exp, k);
case "prog" : return cps_prog (exp, k);
case "call" : return cps_call (exp, k);
default:
throw new Error("Dunno how to CPS " + JSON.stringify(exp));
}
}
// NOTE, the functions defined below must be placed here.
}看起来和代码生成器类似,但所有函数都接收一个额外的k参数,它将编译程序的剩余部分 — continuation。k返回的AST作用于当前表达式的值,因此需要将值传给k — 但需要比CPS求值器中更抽象的方式来思考:这里我们并没有运行程序,仅仅是进行编译。所以我们操作的不是值,而是代表值和运算的AST。
所以cps_*函数必须调用k(或者将其传递下去)来“执行”程序的剩余部分(事实上是编译剩余程序并得到代表当前节点continuation的AST节点),但它们也必须返回当前调用表达式的AST节点。这是与CPS求值器的另一个不同点,CPS求值器对所有分支都返回undefined,而这里我们返回AST。希望解释完所有cps_*转换器后这些描述会变得清晰。
原子值Atomic values
我们将那些不需要依赖其它代码就可以求值的值称为“原子值”。它们既可以是常量,也可以是变量。我们直接将当前AST节点传给continuation(并返回其结果!)。
function cps_atom(exp, k) {
return k(exp);
}binary 和 assign
对于二元运算,我们必须在编译left和right后才能调用其continuation,所以按照这个顺序分别编译,最后将代表等价二元操作的AST节点传给k进行调用(但此时left和right已经是求值后的原子结果):
function cps_binary(exp, k) {
return cps(exp.left, function(left) {
if (exp.operator === '&&') {
if (left.value === false) {
return k(left);
}
return cps(exp.right, function(right) {
return k(right);
});
} else if (exp.operator === '||') {
if (left.value === true) {
return k(left);
}
return cps(exp.right, function(right) {
return k(right);
});
}
return cps(exp.right, function(right) {
return k({
type: exp.type,
operator: exp.operator,
left: left,
right: right
})
});
});
}let节点
我们将let节点转换为立即调用函数表达式(IIFE),然后针对IIFE进行CPS转换。这意味着CPS转换后在AST节点中不会有let节点了(意味着代码生成器中可以将js_let删掉)。
function cps_let(exp, k) {
if (exp.vars.length == 0)
return cps(exp.body, k);
return cps({
type: "call",
args: [ exp.vars[0].def || FALSE ],
func: {
type: "lambda",
vars: [ exp.vars[0].name ],
body: {
type: "let",
vars: exp.vars.slice(1),
body: exp.body
}
}
}, k);
}lambda节点
首先很清晰的一点,lambda节点的continuation应该是一个lambda节点,比如代码a = λ(x) x + 1;,对λ节点求值的continuation是将其赋值给a,所以continuation将会接收到一个函数。
但将一个函数转换为CPS形式是什么意思?上面代码示例编译的结果是:TC(a = λ(K, x){ K(x + 1) }); (其中TC是赋值表达式的continuation)。所以lambda节点增加其continuation(K)作为第一个参数,并且其body会被编译成将结果传入K进行调用的方式。我们必须引入一个新的变量(当然不会仅使用K)并确保变量名字不会与程序内其它变量冲突。我们可以很严谨地实现,但这里我们假定通过在变量名前面增加"β_"前缀就可以避免可能的变量冲突(事实上确实可行,因为λanguage语言的解析器中,β不是一个合法的字符)。
所以,一共有下面这些步骤:
- 引入一个唯一的变量名(用cont来存储)。
- 调用cps编译函数体,参数continuation会将最终结果传入cont进行调用。
- 传入一个新lambda节点来调用顶层的k,该节点拥有更新过的参数列表(将cont作为第一个参数)以及转换为CPS形式的函数体。
function cps_lambda(exp, k) {
var cont = gensym("K");
var body = cps(exp.body, function(body){
return { type: "call",
func: { type: "var", value: cont },
args: [ body ] };
});
return k({ type: "lambda",
name: exp.name,
vars: [ cont ].concat(exp.vars),
body: body });
}gensym函数(代表“generate symbol”)应该返回一个唯一的变量名。
// these are global
var GENSYM = 0;
function gensym(name) {
if (!name) name = "";
name = "β_" + name;
return name + (++GENSYM);
}与其他cps_*函数相比(除了cps_atom),cps_lambda是唯一一个在函数实现主体而不是其自身continuation中调用后续continuation(k)的函数。正是因为lambda实际上是原子值。
if节点
if的编译比较简单:
function cps_if(exp, k) {
return cps(exp.cond, function(cond){
return {
type: "if",
cond: cond,
then: cps(exp.then, k),
else: cps(exp.else || FALSE, k),
};
});
}所以就是编译condition,并传入将返回恰当AST节点(也是一个if节点)的continuation。continuation中会将k作为编译then/else分支的continuation。我们后面会发现这里会有一点小问题。
call节点
call节点必须先对调用的函数进行转换,然后依次对参数进行转换。我们创建一个数组来存储每个参数对应的AST节点,进而完成call节点的编译输出。我们会将程序剩余部分的continuation作为第一个参数,该continuation是make_continuation基于k生成的。
function cps_call(exp, k) {
return cps(exp.func, function(func){
return (function loop(args, i){
if (i == exp.args.length) return {
type : "call",
func : func,
args : args
};
return cps(exp.args[i], function(value){
args[i + 1] = value;
return loop(args, i + 1);
});
})([ make_continuation(k) ], 0);
});
}continuation是一个函数,会将call节点返回的值传给程序的剩余部分(k的编译输出):
function make_continuation(k) {
var cont = gensym("R");
return { type : "lambda",
vars : [ cont ],
body : k({ type : "var",
value : cont }) };
}prog节点
处理很简单:如果表达式序列为空则返回false(也就是说以一个FALSE节点来调用程序剩余部分)。如果仅有一个表达式则以其值来调用程序剩余部分。如果更多则首先编译第一个表达式,然后递归编译剩余的表达式。
function cps_prog(exp, k) {
return (function loop(body){
if (body.length == 0) return k(FALSE);
if (body.length == 1) return cps(body[0], k);
return cps(body[0], function(first){
return {
type: "prog",
prog: [ first, loop(body.slice(1)) ]
};
});
})(exp.prog);
}可以注意到prog最终返回的AST包含两个表达式(其中第二个可能是另一个prog)。这跟lists的定义方式很相似。AST与前面的代码生成器仍然兼容,可能会稍长一点。
接下来一节中,我们会看一些CPS转换器的示例并指出其中存在的问题。
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.