Realizamos en Google Cloud Platform (GCP) el despliegue de un modelo de machine learning (ML) para predecir la potabilidad del agua. En un principio, tanto el análisis de datos como la evaluación de modelos y su performance fue hecho en un trabajo previo de data sciences. Se ha tomado como base para iniciar todo el desarrollo en dataset Water Quality publicado en Kaggle.
La implementación está orientada a usuarios externos a la empresa u organismo, como ser un ente de control para estar al tanto de la operación. O clientes finales, para estar al tanto de la calidad del servicio.
La fuente de los datos iniciales han sido resultados de laboratorio de múltiples muestras. Lo cual suma una dificultad extra en cuanto a la fiabilidad de la información a emplear en la etapa de análisis de datos. También el dataset original posee la clase a predecir desbalanceada, lo cual suma una consideración extra a la hora de realizar entrenamientos.
La principal métrica de refererencia es precision, dado que se busca evitar los falsos positivos, por tratarse de una cuestión de salud pública. Más incluso que el hecho de detectar agua potable (recall alto).
En cuanto al modelo puesto en producción, la arquitectura desarrollada se divide en dos partes:
- Operación de planta: realiza inferencias de forma directa; los datos son provistos por la instrumentación de la planta potabilizadora principalmente. También de los registros permanentes de la operatoria (en caso de no ser posible instrumentar digitalemnte algún parámetro del dataset).
- Control de calidad: ensayos de laboratorio de muestras periódicas. Este proceso está desacoplado del de inferencias, ya que se trata controlar la performance del modelo de ML. Los resultados se guardan en el dataset original para reentrenamiento.
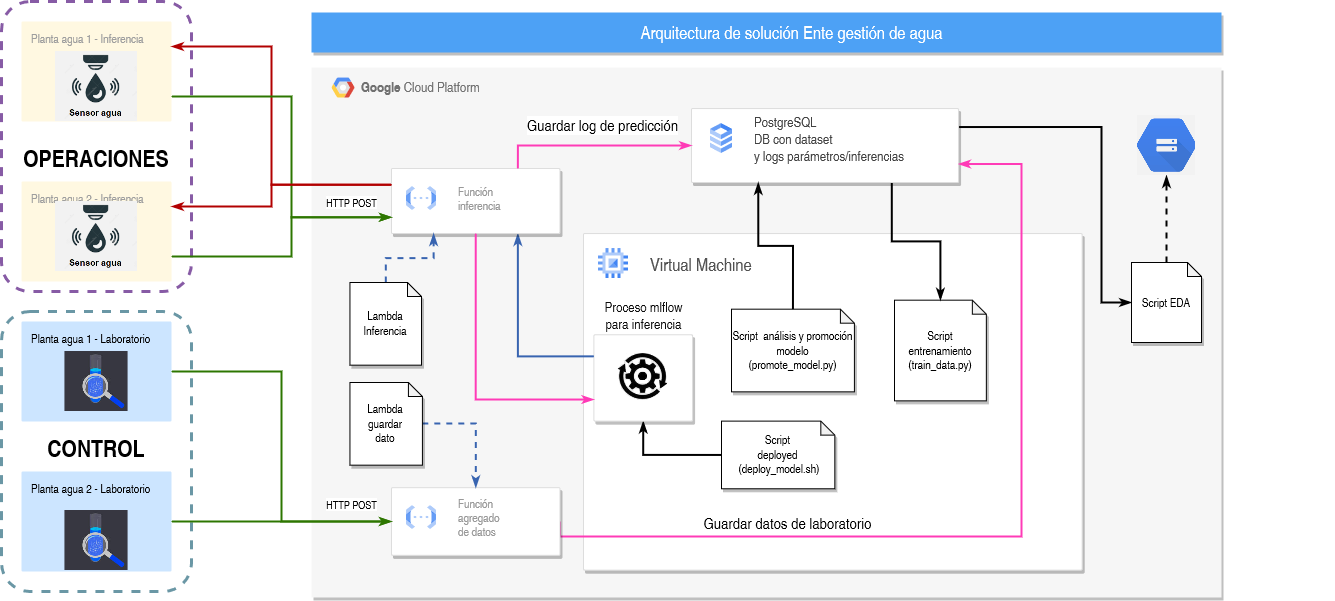
- Bucket
Se guarda la notebook que se utiliza para hacer el análisis exploratorio de datos (EDA por sus siglas en inglés) del modelo de agua, verificando si es necesario modificar el algoritmo de entrenamiento. - Base de datos PostreSQL
Se utiliza para guardar el dataset con todas las features de agua y los nuevos datos que van ingresando al sistema a medida que se certifican los nuevos ensayos de laboratorio. Además se guarda en la misma un log de datos de inferencias y toda la configuración (metadata) utilizada por mlflow para el control y registro de métricas de las ejecuciones. Cuenta con dos esquemas:- Esquema public: utilizado para gestionar la metadata utilizada por mlflow. La misma cuenta internamente con varias tablas.
- Esquema water: para gestionar los datos del negocio. Posee dos tablas:
- water_potability: tiene las muestras analizadas y la indicación si la misma es potable o no según sus features asociadas.
- water_inferences: tiene un log de las predicciones del modelo, junto a los valores de las features analizadas, el resultado inferido, la fecha de inferencia y el sensor que hizo la solicitud.
- Virtual Machine
Es la encargada de servir el modelo y hacer el reentrenamiento del mismo, para que en caso que otro modelo performe mejor, cambiarlo y dejar en producción el más adecuado. Internamente cuenta con los siguientes scripts:- Train_data.py: realiza el entrenamiento de todos los modelos utilizando un gridSerachCV. Toma el dataset de una carpeta local en formato csv (copia de la base de datos almacenada también en la nube) y guarda cada ejecución de los modelos utilizando mlflow y la base de datos mencionada anteriormente. Modelos a entrenas:
- Random Forest.
- Decission Tree.
- SVM.
- Regresión logística.
- reTrainModel.sh: es el encargado de hacer el reentrenamiento. Está configurado para ejecutarse todos los días. El mismo copia los datos de la base de datos y ejecuta el script de train_data.py para reentrenar el modelo completo.
- promote_model.py: se ejecuta luego de reTrainModel.sh. Es el encargado de analizar todas las corridas realizadas, analizando la métrica de precisión. El modelo que mejor performa es promovido a producción.
- Train_data.py: realiza el entrenamiento de todos los modelos utilizando un gridSerachCV. Toma el dataset de una carpeta local en formato csv (copia de la base de datos almacenada también en la nube) y guarda cada ejecución de los modelos utilizando mlflow y la base de datos mencionada anteriormente. Modelos a entrenas:
- Lambda Functions
Utilizadas para la interacción con el modelo productivo. Se implementaron dos:}- Lambda_Inferencia: es la encargada de hacer inferencias contra el modelo. Recibe los datos de solicitud de los sensores, hace la inferencia comunicándose con la máquina virtual, guarda un log en la tabla water_inferences de la base de datos y retorna el valor predicho al sensor.
- Lambda_agregado: permite el agregado de nuevos datos a la tabla water_potability de la base de datos, que corresponde a las muestras de laboratorio realizadas por el personal de planta. Esta lambda es accedida solo por personal habilitado por el ente regulador.