linzx1993 / linzx1993.github.io Goto Github PK
View Code? Open in Web Editor NEWsimple store
Home Page: https://linzx1993.github.io/
simple store
Home Page: https://linzx1993.github.io/


























































最近的项目度过了开始忙碌的基建期,也慢慢轻松下来,准备记录一下自己最近webpack优化的措施,希望有温故知新的效果。
项目采用的是vue全家桶,构建配置都是基于vue-cli去改进的。关于原始webpack配置大家可以看下这篇文章vue-cli#2.0 webpack配置分析,文章基本对于文件每行代码都做了详细的解释,有助于更好的理解webpack。
项目位置链接
仔细总结了一下,自己的优化基本还是网上流传的那几点
不过经过自己的实践最后三点是对自己项目优化最大的。文章也主要对后面几点详细说明一下
对了,我项目引用了vue全家桶一套,jquery以及两个第三方插件,element-ui,echarts,自己项目的组件大概有40个左右
原来打包一个项目所需要的时间基本在35-40秒左右(第二次有缓存会稍微快一点),但是偶尔来一次大姨妈,时间甚至要到50s左右,我也是醉了。不过大家可以期待一下经过下面这三步优化大概需要多久。
首先为什么要引用Dll?在网上浏览了一些文章后,我发现上除了加快构建速度以外,使用webpack的dll还有一个好处。
Dll打包以后是独立存在的,只要其包含的库没有增减、升级,hash也不会变化,因此线上的dll代码不需要随着版本发布频繁更新。 因为使用Dll打包的基本上都是独立库文件,这类文件有一个特性就是变化不大。当我们正常打包这些库文件到一个app.js里的时候,由于其他业务文件的改变,影响了缓存对构建的优化,导致每次都要重新去npm包里寻找相关文件。而使用了DLL之后,只要包含的库没有升级, 增减,就不需要重新打包。这样也提高了构建速度。
那么如何使用Dll去优化项目呢
首先要建立一个dll的配置文件,引入项目所需要的第三方库。这类库的特点是不需要随着版本发布频繁更新,长期稳定。
const webpack = require('webpack');
const path = require('path');
module.exports = {
entry: {
//你需要引入的第三方库文件
vendor: ['vue','vuex','vue-router','element-ui','axios','echarts/lib/echarts','echarts/lib/chart/bar','echarts/lib/chart/line','echarts/lib/chart/pie',
'echarts/lib/component/tooltip','echarts/lib/component/title','echarts/lib/component/legend','echarts/lib/component/dataZoom','echarts/lib/component/toolbox'],
},
output: {
path: path.join(__dirname, 'dist-[hash]'),
filename: '[name].js',
library: '[name]',
},
plugins: [
new webpack.DllPlugin({
path: path.join(__dirname, 'dll', '[name]-manifest.json'),
filename: '[name].js',
name: '[name]',
}),
]
};
基本配置参数和webpack基本一模一样,相信来看优化的都明白什么意思,我就不解释了。然后执行代码编译文件。(我的配置文件是放在build里面,下方路径根据项目路径需要变动)
webpack -p --progress --config build/webpack.dll.config.js
当运行完执行后,会生成两个新文件在目录同级,一个是生成在dist文件夹下的verdor.js,里面是刚刚入口依赖被压缩后的代码;一个是dll文件夹下的verdor-manifest.json,将每个库进行了编号索引,并且使用的是id而不是name。
接下去你只要去你的webpack配置文件的里的plugin中添加一行代码就ok了。
const manifest = require('./dll/vendor-manifest.json');
...
...,
plugin:[
new webpack.DllReferencePlugin({
context: __dirname,
manifest,
}),
]
这时候再执行webpack命令,可以发现时间直接从40秒锐减到了18-20s左右,整整快了一倍有木有(不知道是不是因为自己依赖库太多了才这样的,手动捂脸)。
一般node.js是单线程执行编译,而happypack则是启动node的多线程进行构建,大大提高了构建速度。使用方法也比较简单。以我项目为例,在插件中new一个新的happypack进程出来,然后再使用使用loader的地方替换成对应的id
var HappyPack = require('happypack');
...
...
modules:{
rules : [
...
{
test: /\.js$/,
loader:[ 'happypack/loader?id=happybabel'],
include: [resolve('src')]
},
...
]
},
...
...
plugin:[
//happypack对对 url-loader,vue-loader 和 file-loader 支持度有限,会有报错,有坑。。。
new HappyPack({
id: 'happybabel',
loaders: ['babel-loader'],
threads: 4,//HappyPack 使用多少子进程来进行编译
}),
new HappyPack({
id: 'scss',
threads: 4,
loaders: [
'style-loader',
'css-loader',
'sass-loader',
],
})
]
这时候再去执行编译webpack的代码,打印出来的console则变成了另外一种提示。而编译时间大概从20s优化到了15s左右(感觉好像没有网上说的那么大,不知道是不是因为本身js比重占据太大的缘故)。
本来是没有第三点的,只不过在搜索网上webpack优化相关文章的时候,看到用人提到把引入文件改成库提供的文件(原理我理解其实就是1.先通过resolve指定文件寻找位置,减小搜索范围;2.直接根据alias找到库提供的文件位置)。
vue-cli配置文件中提示也有提到这一点,就是下面这段代码
resolve: {
//自动扩展文件后缀名,意味着我们require模块可以省略不写后缀名
extensions: ['.js', '.vue', '.json'],
//模块别名定义,方便后续直接引用别名,无须多写长长的地址
alias: {
'vue$': 'vue/dist/vue.esm.js',//就是这行代码,提供你直接引用文件
'@': resolve('src'),
}
},
然后我将其他所有地方关于vue的引用都替换成了vue$之后,比如
// import 'vue';
import 'vue/dist/vue.esm.js';
时间竟然到了12s,也是把我吓了一跳。。。
然后我就把jquery,axios,vuex等等全部给替换掉了。。。不过变化没有特别大,大概优化到了11s左右,美滋滋,O(∩_∩)O~~。如果有缓存的情况下,基本上大概在9s左右
本来是没第四点,刚刚看到公众号推出来一篇文章讲到升级到webpack3的一些新优点,比如Scope Hoisting(webpack2升级到webpack3基本上没有太大问题)。通过添加一个新的插件
// 2017-08-13配合最新升级的webpack3提供的新功能,可以使压缩的代码更小,运行更快
...
plugin : [
new webpack.optimize.ModuleConcatenationPlugin(),
]
不过在添加这行代码之后,构建时间并没有太大变化。因为它的优点是提供js在浏览器中的运行速度。webpack2会把每个处理后的模块用一个函数包裹起来,导致浏览器中的JS执行效率降低,主要是因为闭包函数降低了JS引擎解析速度。
不过在浏览器**的实际效果感觉不出来太大差别
然后还有一个是webpack3中所有的模块支持用ID进行标记,如果重复引用相同的模块
因为要引入代码高亮的highlight.js插件,webpack会引入里面有各个语言的js文件,但是我们项目只需要js,html,css。搜了一下发现网上已经有类似的解决方法了,ContextReplacementPlugin会根据你写的正则去匹配你需要的文件。
而且自己记得webpack3的升级中有个新特性tree shaking就是可以从文件树中去除不必要的文件。
好了基本上感觉就是以上这些效果对项目的优化最大,虽然没有到网上说的那种只要3~4秒时间那么变态,不过感觉基本9-12秒的时间也可以了。
前言:一道从上古流传至今的面试题:浏览器输入一个网址后发生了什么?
按键后的电路原理-》操作系统间的进程通信=》浏览器域名解析=》网络传输=》文件的解析与渲染
今天主要讲的是网络传输其中的一部分,HTTP应用层发出的请求,到传输层TCP/IP传输数据阶段
分享前瞻:
用户通过在浏览器输入网址并回车,或者是点击链接,接着浏览器获取了这个事件。(域名解析,编码规则)
浏览器向服务端发出 TCP 连接请求。(浏览器进程通信,网络寻址)
服务程序接受浏览器的连接请求,并经过 TCP 三次握手建立连接。(TCP握手)
4. 浏览器将请求数据打包成一个 HTTP 协议格式的数据包。( 请求 )
6. 服务端程序拿到这个数据包后,同样以 HTTP 协议格式解包,获取到客户端的意图。
得知客户端意图后进行处理,比如提供静态文件或者调用服务端程序获得动态结果。
服务器将响应结果(可能是 HTML 或者图片等)按照 HTTP 协议格式打包。
服务器将响应数据包推入网络,数据包经过网络传输最终达到到到器。
10. 浏览器拿到数据包后,以 HTTP 协议的格式解包,然后解析数据,假设这里的数据是 HTML 。
GET /index.html
<html>
<body>Hello World</body>
</html>
1、只有请求行(GET请求)
没有 HTTP 请求头和请求体。因为早期内容简单,读取超文本,只需要一个请求行就可以完整表达客户端的需求了。
2、服务器只返回数据,没有返回头信息,结果描述
3、返回的文件内容是 ASCII 字符
因为早期都是 HTML 格式的文件,所以使用 ASCII 字节码来传输是最合适的。
存在的问题:
1、时代发展,文件类型多样化(图片,音视频)
1、增加了 HEAD、POST 等新方法
2、引入状态码,标记可能的错误原因
3、增加请求头和响应头:解决文件类型,编码类型
4、引入缓存机制(Expires)
GET /index.html HTTP1.1
HTTP/1.1 200 OK
HTTP/1.1 404 Not Found
accept: text/html
accept-encoding: gzip, deflate, br
accept-Charset: ISO-8859-1,utf-8
accept-language: zh-CN,zh
content-encoding: br
content-type: text/html; charset=UTF-8
仍未解决的问题:
提问:
1、长连接是如何关闭的?
2、缓存请求头的优先级?
3、你知道
1.多路复用
2.传输方式的优化:二进制的流(流标识符限定了流的总数,上限是 2^31)
3.头压缩:在双端建立key-value的索引表,发送请求头改为发送索引
4.设置请求的优先级
5.服务端的推送
一个域名只使用一个 TCP 长连接和消除队头阻塞问题。可以参考下图:
2.传输方式的优化:二进制的流(流标识符限定了流的总数,上限是 2^31)
3、请求头压缩:在双端建立key-value的索引表,发送请求头改为发送索引
进入到HTTP/2.0后, 前端会发生改变
1、文件打包的变化,例如:雪碧图,JS,CSS文件内联合并
仍未解决的问题
1、基于TCP协议的队头堵塞
当一个流中丢失了过多的包。场景:tcp层对每个数据包都有编号,分为1,2,3 .... tcp保证双向稳定可靠的传输,如果2包数据丢失,1号包和3号包来了,那么在超时重传时间还没有收到2编号数据包,服务端会发送2号数据包,客服端收到之后,发出确认,服务端才会继续发送其他数据,客服端数据才会呈现给上层应用层,这样tcp层的阻塞就发生了
2、IP 地址切换,重连TCP
TCP须重新建连,要再次“握手”,经历“慢启动”,而且之前连接里积累的 HPACK 字典也都消失了,必须重头开始计算,导致带宽浪费和时延。
3、单连接的容错率低于多个连接
提问:浏览器如何知道服务器支持 HTTP/2 呢?
答:TLS 的扩展里,有一个叫“ALPN”(Application Layer Protocol Negotiation)的东西,用来与服务器就 TLS 上跑的应用协议进行“协商”。
| HTTP版本 | 功能 | 特点 |
|---|---|---|
| 0.9(1991) | 1. 仅支持GET2. 服务器只能响应HTML形式字符串 | |
| 1.0(1996) | 1. 新增支持HEAD、POST2. 增加了响应状态码,标记可能的错误原因3. 引入了协议版本号概念4. 引入HTTP请求头概率5. 传输文本不再局限于文本 | 短连接存在HTTP线头阻塞问题 |
| 1.1(1997) | 1. 新增支持PUT、DELETE等新的方法2. 增加了缓存管理与控制3. 明确了连接管理,支持持久连接4. 加入了管道(pipelining)机制(浏览器默认不开启)5. 强制加入HOST请求头6. 支持断点续传 | 是目前互联网上使用最广泛的协议,功能也非常完善存在服务器HTTP线头阻塞问题,常浏览器允许对一个HOST最多建立6个TCP连接,在这6个中发送HTTP请求(诞生了域名分片技术) |
| 2.0(2015) | 1. 废弃pipeline,使用多路复用机制(数据流进行串行传输)2. 采用二进制分帧,不再是纯文本3. 支持首部压缩(HPATCH)4. 支持服务器推送5. 增强了安全性,“事实上”要求加密通信 | 一个HOST只建立一个TCP连接,解决了HTTP线头阻塞,但依然存在TCP线头阻塞问题 |
基于UDP协议的伪TCP协议
1、支持无缝切换网络
2、队头阻塞问题
HTTP2.0的各个流有互相依赖关系,如果前面一个流丢失了,后面被迫阻塞
举例:一个包内包含了某个js的部分内容,如果丢失,包含其余js的包被迫等待缓存在那里
概念名词:请求头,响应头,RTT,TTL
请求行 请求头 请求体
请求头不分大小写
Connection: keep-alive
Connection: close
content-type类型,遵循传统MIME type的类型:标记数据类型
MIME type:标记数据类型、
根据不同的类型做不同的操作
if-Modified-Since :Last-modified
If-None-Match :ETag
location / {
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods 'GET, POST, OPTIONS';
add_header Access-Control-Allow-Headers 'Souche-Security-Token,X-Souche-ServiceChain,If-Modified-Since,Cache-Control,Content-Type,Authorization';
if ($request_method = 'OPTIONS') {
return 204;
}
}
当单个(慢)对象阻止其他/后续的对象前进时
只请求一个JS文件
111111
同时请求一个JS文件和CSS文件
111111 22
1121121
function first() { return "hello"; }
HTTP/1.1 200 OK
Content-Length: 600
.h1 { font-size: 4em; }
func
我们希望能够正确地复用资源块(resource chunks)
TCP报文头
慢启动,拥塞算法,快重传,传输控制算法
参考文章链接
国庆时间看到作者出版了一本正则表达式的书,因为之前一直对正则表达式好奇,于是就去作者的网盘里面下载了这一本书的pdf版观看。最近看完之后觉得这本书真的很不错,弥补了自己很多正则的基础知识。附上链接《JavaScript 正则表达式迷你书》问世了!。
这篇主要记录了一下自己的学习心得
记得之前每次写密码验证的时候,总希望一个正则表达式搞定全部的情况,看完书后觉得原来没有必要。
以密码验证为例出题:
密码长度 6-12 位,由数字、小写字符和大写字母组成,但必须至少包括 2 种字符。大家可以想一下怎么实现。
书中一开始得出了一个非常复杂的正则表达式,但是其实后期维护修改未必简单,而且换一个同事来维护,刚开始理解也很辛苦。
<!--复杂版正则表达式-->
let regex = /(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/;
<!--简单易懂版正则表达式-->
let regex1 = /^[0-9A-Za-z]{6,12}$/; //6-12位的数字、小写字符和大写字母组成
let regex2 = /^[0-9]{6,12}$/; //不包含数字(就是只包含大小写字母)
let regex3 = /^[A-Z]{6,12}$/; //不包含大写字母(就是只包含数字和小写)
let regex4 = /^[a-z]{6,12}$/; //不包含小写字母(就是只包含数字和大写)
function checkPassword (string) {
if (!regex1.test(string)) return false;
if (regex2.test(string)) return false;
if (regex3.test(string)) return false;
if (regex4.test(string)) return false;
return true;
}
可以看到,第一种对于我这种刚开始实战不多的,颇有一点炫技的表现(也有可能是我太菜)。第二种一看,会舒服很多,高可读性和高可维护性。
我个人认为在团队合作中,第二种对于后期伙伴的维护应该是更佳的。
在看书的时候,因为之前正则的基础很薄弱,看见书中频频出现的?用在不同地方实现不一样的效果,我是一脸懵逼,经常要上百度看一下?用在这里表示什么意思。这里小总结一下
表达自身一个“?”字符,但是因为?在正则表达式中的作用太多了,所以当它需要表达自身的时候,需要进行一次转义
\?
这是常见的第一种用法,允许重复匹配的次数,0次或者1次。
例子
let regex1 = /\d*/;
let str = "12345";
str.match(regex); //["12345", index: 0, input: "12345"]
//======使用了?号======//
let regex = /\d?/; //最大允许匹配一次数字
let str = "12345";
str.match(regex); //["1", index: 0, input: "1234"]
这是常见的第二种用法,因为正则表达式默认是贪婪匹配的,所以很多时候我们会在某组匹配字符后加一个问号表示非贪婪匹配
例子
let regex = /\d{1,3}/
let str = "12345";
str.match(regex); //["123", index: 0, input: "12345"]
//======添加了?号======//
let regex = /\d{1,3}?/
let str = "12345";
str.match(regex); //["1", index: 0, input: "1234"]
书中讲到了 这么一句话
正则表达式是匹配模式,要么匹配字符,要么匹配位置。请记住这句话。
关于"位置"这个概念的理解推荐看书中的第二章
而当你匹配位置的时候,两个匹配位置的正则表达式就非常关键了。
(?=p),其中 p 是一个子模式,即 p 前面的位置,或者说,该位置后面的字符要匹配 p。
let result = "hello".replace(/(?=l)/g, '#');
console.log(result); // "he#l#lo"
而 (?!p) 就是 (?=p) 相反的意思,比如:
let result = "hello".replace(/(?!l)/g, '#');
console.log(result); // "#h#ell#o#"
这两个用法在数字格式化的时候有非常大的用处。给大家出个题目吧,如何实现数字的千位分隔符表示。比如讲1234567转化为12,345,678。
大家思考一下
....
....
....
答案
let regex = /(?!^)(?=(\d{3})+$)/g;
"12345678".replace(regex1,","); // "12,345,678"
具体实现看不懂还是推荐去看原书,作者写的很好,我相信对大家帮助肯定也很大。
还有最后一种不怎么常见(可能是没怎么见过)的用法(?:),表示非捕获模式。我是这么理解的(不知道自己理解的对不对),就是当你遇到匹配的字符时,它并没有马上捕获匹配的内容,并且记录下拉,而是继续匹配下去作为为整体匹配服务。讲的不好,大家还是看例子实在吧(手动捂脸)。
例子
let regex = /(?:a)(b)(c)/; "abcabc".match(regex)
//结果 ["abc", "b", "c"]
// m[0] 是/(?:a)(b)(c)/匹配到的整个字符串,这里包括了a
// m[1] 是捕获组1,即(b)匹配的子字符串substring or sub sequence
// m[2] 是捕获组2,即(c)匹配到的
大家可以注意到第一个括号里面的a并没有被提取出来,但是整体匹配的字符时有a的。这就是我理解的非捕获模式,为整体存在的匹配。
性能和效率始终是绕不开的一环,文中提到回溯造成原因我感觉主要是由2点造成的,
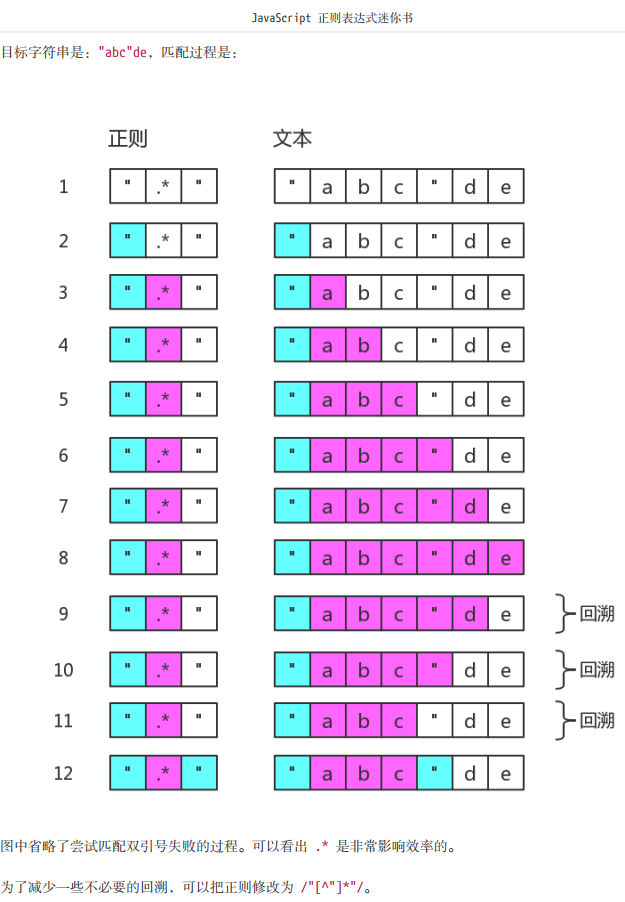
先说第一种情况,贪婪匹配造成的回溯,举个书中的例子
let str = '"abc"de';
let regex = /".*"/;
str.match(regex); // ['"abc"', index: 0, input: '"abc"de']
当用此正则表达式去匹配字符串的时候,发现最后无法完成整体匹配的时候,会不断回吐一个字符再次去尝试整体正确的匹配。大家可以结合下图理解。
书中最后讲到回溯是非常影响效率的,但是自己在写例子测试的时候,发现其实时间基本上没有任何差别,不知道是不是因为自己测试的正则比较简单,还是浏览器现在对于正则的优化做的比较好,总之没有达到书中说的到非常影响效率的程度。
效率对比例子
function test(){
let str = '"abc"dddddddddddddddddddddddddddddde';
let regex = /".*"/;
};
console.time()
for(var i = 0;i< 1000000000;i++){test()}
console.timeEnd()
//default: 2321.663818359375ms
//========修改为减少贪婪回溯的写法========//
function test(){
let str = '"abc"dddddddddddddddddddddddddddddde';
let regex = /"[^"]]*"/;
};
console.time()
for(var i = 0;i< 1000000000;i++){test()}
console.timeEnd()
//default: 2327.2890625ms
对于这种回溯的解决方法来说:
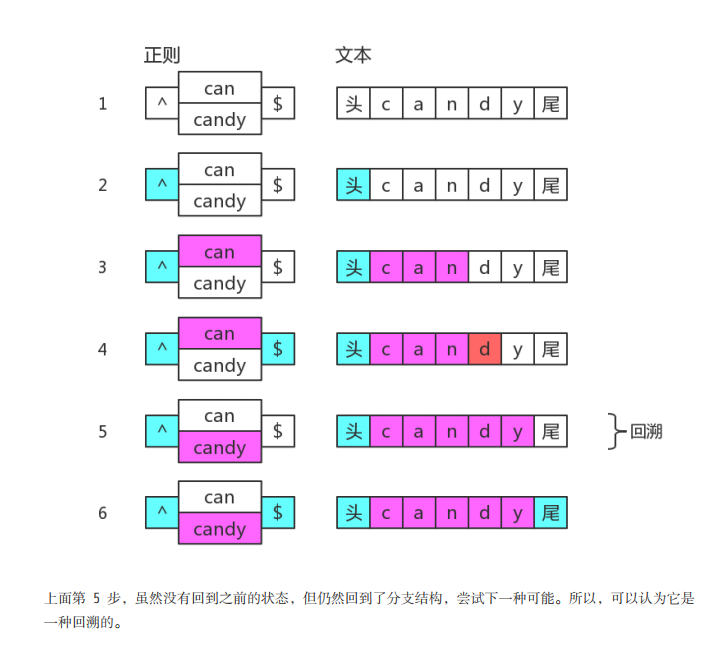
然而并不是所有回溯的情况都是由贪婪造成的。比如当我们在使用分支匹配的时候。
例子
let str = 'candy';
let regex =/can|candy/;
str.match(regex); //["can", index: 0, input: "candy"]
当我们用/can|candy/去匹配字符串 "candy",得到的结果是 "can",因为分支会
一个一个尝试,如果前面的满足了,后面就不会再试验了。但是如果我们的目标字符串是“candy”的时候,那怎么办呢。
例子
let str = 'candy';
let regex = /^(?:can|candy)$/;
str.match(regex); //["candy", index: 0, input: "candy"]
大家可以先看图理解一下懒惰造成的回溯
字符串对象和正则对象提供了很多跟正则有关的基础方法,很多方法都都有很好的使用场景。
比如我在表单验证的场景里,用户每次输入值我需要进行判断用户是否输入正确,我可是使用regex.test()方法来确定是否给用户提示
只允许输入数字
<input onkeyup="test(this.value)" />
function test(value){
let regex = /[^\d]/g;
if(regex.test(value))console.log("请输入数字")
}
这个replace方法用处实在是太大了,已经到了可以单开一篇的地步了,大家可以前往这里去看MDN上replace的文档,这里就不详细介绍了。这里写个简单的例子
最简单的模板编译
let str = '我是{{name}},年龄{{age}},性别{{sex}}';
let obj = {
name:'姓名',
age:18,
sex: '男'
}
let strEnd = str.replace(/\{\{(.+?)\}\}/g,function (match, m1) {
return obj(m1)
})
// "我是姓名,年龄18,性别undefined"
这个方法感觉和indexOf效率有一些相似,都是寻找符合匹配的下标。不过indexOf方法是为字符串使用的,而search是为正则表达式实现的
let str = 'abc123456';
let regex = /\d/;
console.log(str.search(regex)); // 3
字符串的split方法同样支持正则表达式进行切割
var regex = /,/;
var string = "html,css,javascript";
console.log( string.split(regex) );
这个方法更多是为了提取匹配内容而存在的。当你的正则表达式里面有小括号()的存在时,match方法可以帮你提取出字符串中符合括号正则的表达式。
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
console.log( string.match(regex) );
// ["2017-06-26", "2017", "06", "26", index: 0, input: "2017-06-26"]
我靠,再开个坑,一定要记得写
算法算法,一个这两年被人念叨最多的词汇,但很多时候身为一个前端人员完全感受不到其所在,所以一直对此也很是懵逼。这段时间也是无聊,于是看了一本算法图解的书,还是很能感受到其中的一些魅力所在的额
二分查找算法,是本书的第一个算法,用于有序数据的快速查找。
链表相对于数组的优势
| 1 | 数组 | 链表 |
|---|---|---|
| 插入 | O(n),需要从第一个开始查找到最后一个才能插入 | O(1)随便扔一个地方 |
| 读取 | O(1)直接知道数据位置在哪里 | O(n)需要知道前面的才能知道后面的 |
| 删除 | O(n)遍历所有的一个个开始删除 | O(1)直接修改每个项所代表的索引 |
快速查找排序算法:最常见的排序算法,举例描述:先找出一个数组中最小的,推出到新数组中,然后来n次遍历,得出由小到大的新数组。时间复杂度为O(n2);
主要讲解了基本的栈和递归调用,最后讲到的高级递归主题尾递归需要看一下
因为最近在写项目的UI库,遇到自定义滚动条这一个槛还是卡了我挺久的,主要卡在了如何自动监听内容变化并更新滚动条高度。市面上基本所有的滚动条插件都没有实现这一点,最后面扒了element的源码才最终解决。本文主要讲的也是这个。
首先,我们先把需要实现的功能先确定下来。
前面两点依靠原生滚动条其实比较简单,但是在第三点上实在是卡了我好久,想了好久都没有想出来。最后还是看了element源码才实现成功。
接下去我会以垂直滚动条为例(水平滚动条基本同理),实现一个自定义的滚动条出来。我争取把其中原理细节讲清楚。
开始我们先把HTML和样式写好
<div class="scrollbar">
<div class="scrollbar-content">
<ul class="box">
<li>11111</li><li>11111</li><li>11111</li><li>11111</li>
<li>11111</li><li>11111</li><li>11111</li><li>11111</li>
<li>11111</li><li>11111</li><li>11111</li><li>11111</li>
<li>11111</li><li>11111</li><li>11111</li><li>11111</li>
</ul>
</div>
<div class='scrollbar-bar'>
<div ref="thumb" class="scrollbar-thumb"></div>
</div>
</div>
滚动条的框架如上面所示,接下午我会以简称wrap,bar,thumb进行简称
wrap :内容区域包裹框bar : 包裹区域中自定义滚动条的滚动框thumb :自定义滚动条开始之前要大家可以先记住一点,我们并不是不用原生滚动条,实际上我们所有的操作都需要依靠原生滚动条才能实现。只不过它隐藏在了暗处,而让UI更好看的自定义滚动条出现在明处。
第一步我们先将原生的滚动条隐藏掉。但是这里涉及到第一个问题,那就是不同浏览器的下滚动条宽度是不一样的。我们需要准确的知道,如果wrap产生了滚动条,那它的宽度是多少。
先写一个获取到区域内滚动条的宽度(scrollWidth)的回调函数getScrollWidth,获取到滚动条高度之后,
function getScrollWidth(){
const outer = document.createElement("div");
outer.className = "el-scrollbar__wrap";
outer.style.width = '100px';
outer.style.visibility = "hidden";
outer.style.position = "absolute";
outer.style.top = "-9999px";
document.body.appendChild(outer);
const widthNoScroll = outer.offsetWidth;
outer.style.overflow = "scroll";
const inner = document.createElement("div");
inner.style.width = "100%";
outer.appendChild(inner);
const widthWithScroll = inner.offsetWidth;
outer.parentNode.removeChild(outer);
scrollBarWidth = widthNoScroll - widthWithScroll;
return scrollBarWidth;
}
获取到滚动条的宽度scrollBarWidth之后,通过再来设置wrap的css样式,通过marginRight将滚动条移动到视线之外
wrap.style.overflow = scroll;
wrap.style.marginRight = -scrollWidth + "px";
第二步我们需要计算出滚动条的高度。计算方法也很简单,元素高度scrollHieght/内容高度clientHeight,得出来的就是滚动条所占的百分比。
因为内容高度经常变更,我们可以写一个更新滚动条高度的回调函数updateThumb,方便后期s随时调用。
function updateThumb(){
let heightPercentage = (wrap.clientHeight * 100 / wrap.scrollHeight);
thumb.style.height = heightPercentage + "%";
}
到了这一步,基本上一个滚动条的基本样式已经出来了。接下去我们要实现它的使用功能。
到这里我们已经可以看到成型的滚动条的UI界面了,但是仍然缺少滚动和拖动的功能。关键点是在于如何去监听滚动条的变化。
还记得文章开头说过,我们所有功能的实现都依赖隐藏起来的原生滚动条。如果大家理解了我上面说的话,那么问题就简单了。当我们开始滑动滚轮的时候,隐藏在暗处的原生滚动条也会同时滚动,此时便会触发原生滚动条的scroll事件。
这里可以再详细说明下。只要元素的scrollTop发生变化,就必然会触发scroll事件。所以我们操作滚轮,其实本质上是改变元素的scrollTop。
所以我们只需要写一个相应的回调函数handleScroll,在每次触发回调的时候,实时修改我们自定义滚动条的样式就行了。
function handleScroll(){
this.moveY = (wrap.scrollTop *100 / wrap.clientHeight);
//通过计算出来的百分比,然后对滚动条执行translate移动
thumb.style.transform = "translateY" + moveY;
},
wrap.addEventListener('scroll',handleScroll);
接下去我们实现第二个功能。当我们点击滚动框的一个位置时,滚动条也会跳到这个位置,同时内容位置也会发生改变。
第一步先获得点击的y坐标,然后计算出和滚动框bar顶部的距离,再算出占滚动框的百分比,这个百分比就是滚动条的高度
function clickTrackHandle(e){
//获得点击位置与滚动框顶部之间的距离
const offset = Math.abs(e.target.getBoundingClientRect().top - e.clientY)
//让点击位置处于滚动条的中间
const thumbHalf = thumb.offsetHeight / 2;
//计算出滚动条在滚动框的百分比位置
const thumbPositionPercentage = (offset - thumbHalf) * 100 / wrap.offsetHeight;
//通过改变scrollTop来操作。所有操作滚动条的最后一步都是通过handleScroll来实现
wrap.scrollTop = (thumbPositionPercentage * wrap.scrollHeight / 100);
}
bar.addEventListener("click",clickTrackHandle);
只要scrollTop值发生变化就会触发我们上一步写的回调。
接下来我们再去实现手动拖拽滚动条去实现移动内容,这个知识点就是拖拽的知识点,不过在看源码的时候发现element的习惯很好,他是在当你点击滚动条的时候绑定拖拽,然后松开的时候取消绑定。
function mouseMoveDocumentHandler(){}; //实时记录滚动条位置的拖拽函数
//当点击滚动条时
document.addEventListener("mousedown",mouseMoveDocumentHandler);
document.onselectstart = false; //同时阻止选中
//当松开滚动条时
document.removeEventListener("mousedown",mouseMoveDocumentHandler);
document.onselectstart = null; //同时阻止选中
因为这一块代码比较多,就不贴文章里,大家可以直接链接里看就是了。
查看拖动滚动条的效果
第二章讲的主要都是实现滚动条功能,这一章讲的是纠结😖我很久的功能。
因为滚动条的高度并不是我们一开始能够确定的,它需要在dom内容渲染出来之后才能确定。而且有时候随着内容的变化,还需要实时改变滚动条的高度。再看了市面上的滚动条之后,发现基本都没有满足这一功能。
事实上缺少了这一点,使用起来是缺少视觉交互的。举个例子,加入一个原来有滚动条的元素因为内容减少导致了滚动条小时,但是自定义滚动条因为没有检测到变化仍然存在,那就会给用户造成困扰。
我不希望每次更新内容都要通过加一步回调函数来更新一下滚动条,而是希望它自己实时更新。在网上没有找到答案之后,最终去翻了element源码,研究了好久,总算找到了想要的答案。
关键点就在于我能前面之前说的那一句话——如果我们改变元素的scrollTop,是会触发scroll事件。
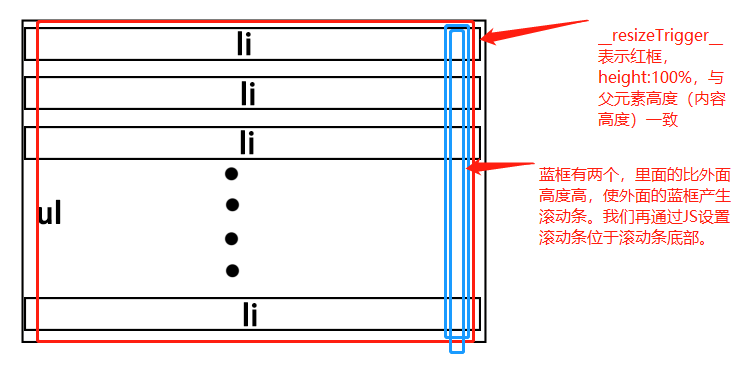
大家想象一个情景,如果滚动条永远出现在最底部,比如下图
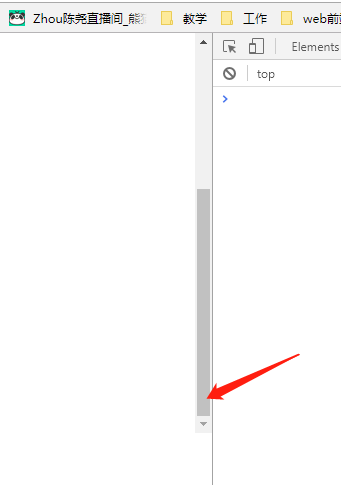
那么只要我内容发生了一点变化,滚动条必然会变长或者变短。那么在滚动条长度变化时,scrollTop自然发生了改变(滚动条消失则scrollTop变为0),那么就会触发scroll的回调函数,那么我们就自动监测到了啊😊。
在明白了这一点后,却又冒出来一个问题。正常情况下,滚动条不可能出现在最底部啊,那怎么办呢?
element选择了自己造一个置于底部的滚动条来满足自己需求。
<script>
const ul = document.getElementById("ul");
const resizeTrigger = document.createElement("div");
resizeTrigger.className = "resize-triggers";
resizeTrigger.innerHTML = '<div class="expand-trigger"><div><div></div></div></div>';
ul.appendChild(resizeTrigger);
const resetTrigger = function (element) {
const trigger = element.__resizeTrigger__;
const expand = trigger.firstElementChild;
const expandChild = expand.firstElementChild;
expandChild.style.height = expand.offsetHeight + 1 + 'px';
expand.scrollTop = expand.scrollHeight;
};
ul.addEventListener("scroll",function(){
resetTrigger(this);
},true)
</script>
ul是我们包裹内容的DOM元素。
配合着css来看,第一段JS我们创建出了resizeTrigger这个div,并且我们将他的height:100%。这样子如果内容发生变化,resizeTrigger永远和父元素ul同时改变高度。这里设置成高度100%非常重要,这样子才能主动同步到内容的变化。
注意到resizeTrigger里面还有有一个父子元素expand和expandChild。在第二段JS的resetTrigger函数中。然后设置expandChild的高度超过父元素expand的高度,促使expand产生滚动条。然后我们再将滚动条的scrollTop设置为最大,这样子滚动条就会出现在滚动区域resizeTrigger的最底部了。
现在我们做到了将滚动条设置在了最底部,所以只要内容发生了变化,那么滚动条的scrollTop必然也会发生变化。
最后一段代码就是scroll的监听。当监听到scrollTop值发生变化时,触发相应的回调函数。
所以这块代码最后的逻辑其实是这样的。内容改变 --> ul高度改变--> resizeTrigger高度改变 --> expand滚动条的scrollTop发生变化 --> 触发scroll的回调函数,在函数里面调整再次调整滚动条的高度,保证滚动条高度正确。
通过这三段代码,我们也基本实现了自动监听内容变化来更新滚动条。
简单画了个配图来帮助理解逻辑
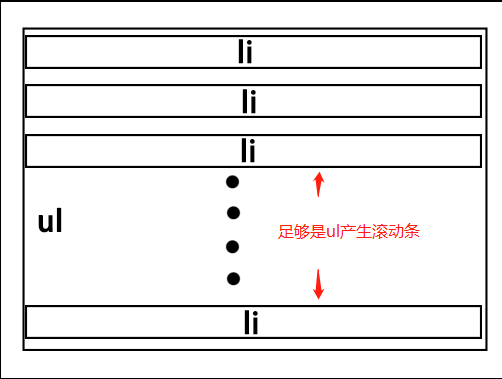
通过两个小蓝框产生的滚动条来帮助监听内容变化
经过以上3大步基本上是可以实现一个自定义的滚动条的。上面的代码是面向原生js的。在我们的项目里面,实现第4点是通过封装成一个scrollbar的的组件,在项目里面进行使用。
这一条要求因为不同框架实现方式都不一样,所以就不详细贴代码了,不过最终原理肯定还是一致的。因为自己项目用的是一个Vue框架,所以是个Vue组件,有需求可以自己去看。
好了文章就到此结束了,在看人家源码的过程中也学到了许多。比如使用JSX来编写组件;scroll监听其实就是判断scrollTop;比如通过自己造滚动条的方法监听scrollTop来实现自动更新。最后通过写文章,对一些新的知识点理解还是加深了许多。
最新项目中有用promise几个api,对代码结构看起来的确很爽。然后想着去网上找了几篇promise库源码解析的文章。但是看了几篇,感觉还是不能够很理解,然后看到一篇翻译文章有说道q.js库的作者有对promise实现的递进讲解,看了一下,还不错,
Q.js作者源码分析:Q.js作者promise递进讲解实现
网上找的promise源码翻译。文章有些地方翻译的很好,但是对比原文发现少了一些内容,所以读起来很不顺畅。所以自己根据原文也翻译了一遍。对了,本文适合用过promise的人阅读。如果你还没有接触过。可以右转阮一峰的promise讲解
假如你正在写一个函数不立即返回值,而是等待几秒钟后才返回执行结果,你会怎么写呢?思考几秒钟。
最简单的做法自然是写一个回调函数依靠定时器来返回值,比如下面这个
var oneOneSecondLater = function (callback) {
setTimeout(function () {
callback(1);
}, 1000);
};
这是一个很简单解决问题的方法,但是还有改进的地方,比如能够添加代码执行错误时给出提示。
var maybeOneOneSecondLater = function (callback, errback) {
setTimeout(function () {
//进行判断情况,是执行成功的回调,还是执行错误的回调
if (Math.random() < .5) {
callback(1);
} else {
errback(new Error("Can't provide one."));
}
}, 1000);
};
一般的做法是提供一个能同时返回值并且能抛出错误的工具。上面这个例子则演示同时提供回调和错误处理。但是这种写法实在是太定制化了,并不好。
所以考虑到大多数的情况,代替最简单的返回值和抛出异常,我们更希望函数通常会返回一个对象用来表示最后执行成功或者失败的结果,而这个返回的对象就是promise。从名字上理解,promise表示承诺,那么最终这个promise(承诺)是要被resolve(履行,执行)掉的。
接下去我们开始迭代设计promise。我们先设计一个具有“then”方法的promise模型,通过“then”方法,我们能注册回调函数并且延迟执行。
var maybeOneOneSecondLater = function () {
var callback;
setTimeout(function () {
callback(1);
}, 1000);
return {
then: function (_callback) {
callback = _callback;
}
};
};
maybeOneOneSecondLater().then(callback1);
代码写好了。但是大家仔细观察发现该方案仍然还有两个缺点
敲黑板,注意注意,接下去开始慢慢搭建promise了。
正常情况下,我们希望可以接收任何数量的回调,且不管是否超时,仍然可以继续注册回调。为了实现这些,我们将创建一个包含两个功能的promise对象。
我们暂时设计了一个defer对象,他的返回值一个包含两部分的对象(这个对象就是promise),一个用来注册观察者(就是"then方法添加回调),一个用来通知所有的观察者执行代码(就是resolve去执行之前添加的所有回调)。
当promise没有被resolve之前,所有回调函数会存储在一个"pengding"的数组中。
当promise被resolve之后,立即执行之前存储的所有回调函数,当回调函数全部执行完毕之后,我们将根据"pengding"来区分状态。
let defer = () => {
let pending = [],value;
return {
resolve(_value){
value = _value
for(let i = 0;i < pending.length; i++){
pending[i](value)
}
pending = undefined;
},
then(_callback){
if(pending){
pending.push(_callback)
}else{
_callback();
}
}
}
}
let oneOneSecondLater = () => {
let result = defer();
setTimeout(()=> {
result.resolve(1);
}, 1000);
return result;
};
oneOneSecondLater().then(callback);
这开始的第一步很关键啊,因为此时我们已经可以做到
但是还有一些问题,比如
那么接下来我们先修正第一个问题
let defer = () => {
let pending = [],value
return {
resolve(_value){
if(pending){
value = _value
for(let i = 0;i < pending.length; i++){
pending[i](value)
}
pending = undefined;
}else{
throw new Error("A promise can only be resolved once.")
}
},
then(_callback){
if(pending){
pending.push(_callback)
}else{
_callback();
}
}
}
}
好,现在我们已经保证不能重复defer.resolve()的问题了,那么我们还希望可以实现通过链式调用来添加回调。可是目前要只能通过defer().then(callback1),defer().then(callback2),defer().then(callback3)这种方式添加回调,这显然不是我们想要的方式。接下来我们将一步一步实现。
但是在实现链式回调之前,为了后期结构,我们希望对我们的promise进行职责区分,一个注册观察者,一个执行观察者。根据最少授权原则,我们希望如果授权给某人一个promise,这里只允许他增加观察者;如果授权给某人resolver,他应当仅仅能决定什么时候给出解决方案。因为大量实验表明任何任何不可避免的越权行为会导致后续的改动变得很难维护。(其实就是希望把添加回调的then功能移植到promise中,从defer.then转变成defer.promise.then,保证功能的纯粹性)
let defer = () => {
let pending = [],value;
return {
resolve(_value){
if(pending){
value = _value
for(let i = 0;i < pending.length; i++){
pending[i](value)
}
pending = undefined;
}else{
throw new Error("A promise can only be resolved once.")
}
},
promise: {
then (callback) {
if (pending) {
pending.push(callback);
} else {
callback(value);
}
}
}
}
}
当职责分离完之后,我们就可以接下去实现一步关键的改造
上文说道要实现链式回调,我们首先要能在下一个回调函数里接受上一个回调的值。依靠上一步的职责分离的基础,我们接下来要跨非常大的一步,就是使用旧的promise去驱动新的promise。我们希望通过promise组合的使用,来实现值的传递。
举个例子,让你写一个相加的函数,接受两个回调函数返回的数字相加。大家可以考虑如何实现。
var twoOneSecondLater = function (callback) {
var a, b;
var consider = function () {
if (a === undefined || b === undefined)return;
callback(a + b);
};
oneOneSecondLater(function (_a) {
a = _a;
consider();
});
oneOneSecondLater(function (_b) {
b = _b;
consider();
});
};
twoOneSecondLater(function (c) {
// c === 2
});
上面这个方法虽然做到了,但是这个方法是脆弱的,因为我们在执行相加函数时,需要额外的代码去判断相加的数字是否有效。
于是我们希望用更少的代码去实现上面的需求,比如就像下面这样
//上面的函数如果用更少的步骤来表达就是
var a = oneOneSecondLater();
var b = oneOneSecondLater();
var c = a.then(function (a) {
return b.then(function (b) {
return a + b;
});
});
上面这个例子其实想表达的就是实现callback返回值的传递,如callback1的返回值传给callback2,将callback2的返回值传给callback3。
为了实现上面例子的这种效果,我们要实现以下几点
我们实现一个函数可以将获得的值传给下一个回调使用
let ref = (value) => {
return {
then(callback){
callback(value);
}
}
}
不过考虑到有时候返回的值不仅仅是一个值,而且还可能是一个promise函数,所以我们需要加个判断
let ref = (value) => {
if(value && typeof value.then === "function"){
return value;
}
return {
then(callback){
callback(value);
}
}
}
这样子我们在使用中就不需要考虑传入的值是一个普通值还是一个promise了。
接下来,为了能使then方法也能返回一个promise,我们来改造下then方法;我们强制将callback的返回值传入下一个promise并立即返回。
这个例子存储了回调的值,并在下一个回调中执行了。但是上面第三点没有实现,因为返回值可能是一个promise,那么我们继续改进一下方法
let ref = (value) => {
if(value && typeof value.then === "function"){
return value;
}
return {
then(callback){
return ref(callback(value));
}
}
}
通过这一步增强之后,基本上就可以做到获得上一个回调值并不断链式调用下去了。
接下去我们考虑到一种比较复杂的情况,就是defer中存储的回调会在未来某个时间调用。于是我们需要在defer里面将回调进行一次封装,我们将回调中执行完后通过then方法去驱动下一个promise并传递一个返回值。
此外,resolve方法应该能处理本身是一个promise的情况,resolve可以将值传递给promise。因为不管是ref还是defer都可以返回一个then方法。如果promise是ref类型的,将会通过then(callback)立即执行回调。如果是promise是defer类型的,callback暂时被存储起来,依靠下一个then(callback)调用才能执行;所以变成了callback可以监听一个新的promise以便能获取完全执行后的value。
根据以上要求,得出了下面最终版的promise
let isPromise = (value) => {
return value && typeof value.then === "function";
};
let ref = (value) => {
if (value && typeof value.then === "function")
return value;
return {
then (callback) {
return ref(callback(value));
}
};
};
let defer = () => {
let pending = [], value;
return {
resolve: function (_value) {
if (pending) {
value = ref(_value); // values wrapped in a promise
for (let i = 0, ii = pending.length; i < ii; i++) {
let callback = pending[i];
value.then(callback); // then called instead
}
pending = undefined;
}
},
promise: {
then: function (_callback) {
let result = defer();
// callback is wrapped so that its return
// value is captured and used to resolve the promise
// that "then" returns
let callback = function (value) {
result.resolve(_callback(value));
};
if (pending) {
pending.push(callback);
} else {
value.then(callback);
}
return result.promise;
}
}
};
};
let a = defer();
a.promise.then(function(value){console.log(value);return 2}).then(function(value){console.log(value)});
a.resolve(1);
将defer分为两个部分,一个是promise,一个是resolve
到了这一步基本上的promise功能已经实现了,可以链式调用,可以在自己控制在未来某个时间resolve。接下去就是功能的增强和补足了。
这一块回调基本上就写完了,看了很久原文的描述,对着代码理解作者想表达的意思。不过英语不太好,写的磕磕绊绊。╮(╯▽╰)╭,感觉还是有些地方写的不对。希望有人能够纠错出来。
为了实现错误消息的传递,我们还需要一个错误的回调函数(errback)。就像promise完全执行时调用callback一样,它会告知执行errback以及告诉我们拒绝的原因。
实现一个类似于前面ref的函数。
let reject = (reason) => {
return {
then(callback,errback){
return ref(errback(reason);
}
}
}
最简单的实现方法是当监听到返回值时,立即执行代码
reject("Meh.").then((value) => {},(reason) => {
throw new Error(reason);
}
那么接下来我们改进原来promsie这个API,引入“errback”。
为了将错误回调添加到代码中,defer需要添加一种新的容器来添加成功回调和错误回调。因此之前那个存储在数组(pending)中的只有一种待处理回调函数,我们需要重新设计一个同时包含成功回调和错误回调的数组([callback,errback]),根据then传入的参数决定调用哪个。
var defer = function () {
var pending = [], value;
return {
resolve: function (_value) {
if (pending) {
value = ref(_value);
for (var i = 0, ii = pending.length; i < ii; i++) {
// apply the pending arguments to "then"
value.then.apply(value, pending[i]);
}
pending = undefined;
}
},
promise: {
then: function (_callback, _errback) {
var result = defer();
var callback = function (value) {
result.resolve(_callback(value));
};
var errback = function (reason) {
result.resolve(_errback(reason));
};
if (pending) {
pending.push([callback, errback]);
} else {
value.then(callback, errback);
}
return result.promise;
}
}
};
};
let ref = (value) => {
if (value && typeof value.then === "function")
return value;
return {
then: function (callback) {
return ref(callback(value));
}
};
};
let reject = (reason) => {
return {
then: function (callback, errback) {
return ref(errback(reason));
}
};
};
代码写完了,但是仍然还有地方可以改进。
比如作者说到这一步有一个问题,就是如果按照上面这么写,那么所有的then函数就必须提供错误回调函数(_errback),如果不提供就会出错。所以最简单的解决方法是提供一个默认的回调函数。甚至文中还说,如果仅仅是对错误回调有需要,那么忽略不写成功回调(_callback)也是可以的。所以为了满足需求,我们为_callback和_errback都提供一个默认的回调函数。(好吧,其实我就是觉得这是一个好的库的容错处理)
var defer = function () {
...
return{
...
promise : {
then: function (_callback, _errback) {
var result = defer();
// 提供一个默认的成功回调和错误回调
_callback = _callback || function (value) {
// 默认执行
return value;
};
_errback = _errback || function (reason) {
// 默认拒绝
return reject(reason);
};
var callback = function (value) {
result.resolve(_callback(value));
};
var errback = function (reason) {
result.resolve(_errback(reason));
};
if (pending) {
pending.push([callback, errback]);
} else {
value.then(callback, errback);
}
return result.promise;
}
}
}
}
}
好了,现在我们已经实现了接收构造或者隐含的错误回调这一步的完成版
我们还有需要需要提高的地方就是要保证callbacks和errbacks在未来他们被调用的时候,应该是和注册时的顺序是保持一致的。这将显著降低异步编程中流程控制出错可能性。文中举了一个有趣的小例子.
var blah = function () {
var result = foob().then(function () {
return barf();
});
var barf = function () {
return 10;
};
return result;
};
上面这个函数在执行后会出现两种情况,一是抛出一个异常,二是顺利执行并返回了值10。而决定是哪个结果的是foob()是否在正确顺序里。因为我们希望哪怕回调在未来被延迟执行了,它能够执行成功。
下面添加了一个enqueue方法,我的理解就是依靠setTimeout的异步将所有回调按照顺序添加到任务队列中,保证按照顺序执行代码。
let enqueue = (callback) => {
setTimeout(callback,1)
}
let enqueue = (callback) => {
//process.nextTick(callback); // NodeJS
setTimeout(callback, 1); // Naïve browser solution
};
let defer = function () {
let pending = [], value;
return {
resolve: function (_value) {
if (pending) {
value = ref(_value);
for (let i = 0, ii = pending.length; i < ii; i++) {
enqueue(function () {
value.then.apply(value, pending[i]);
});
}
pending = undefined;
}
},
promise: {
then: function (_callback, _errback) {
let result = defer();
_callback = _callback || function (value) {
return value;
};
_errback = _errback || function (reason) {
return reject(reason);
};
let callback = function (value) {
result.resolve(_callback(value));
};
let errback = function (reason) {
result.resolve(_errback(reason));
};
if (pending) {
pending.push([callback, errback]);
} else {
// XXX
enqueue(function () {
value.then(callback, errback);
});
}
return result.promise;
}
}
};
};
let ref = function (value) {
if (value && value.then)
return value;
return {
then: function (callback) {
let result = defer();
// XXX
enqueue(function () {
result.resolve(callback(value));
});
return result.promise;
}
};
};
let reject = function (reason) {
return {
then: function (callback, errback) {
var result = defer();
// XXX
enqueue(function () {
result.resolve(errback(reason));
});
return result.promise;
}
};
};
虽然将需要的回调依照次序添加到了队列中
作者有考虑到一些新的问题,比如
于是我们需要找个机会then的回调函数,为了保证当回调函数中程序出错时,可以转入到报错函数中。(其实又是一个库的容错处理,保证代码出错时不中断程序的执行)。
用when方法封装下promise以此阻止错误发生,确保不会有哪些突发性的错误,包括哪些非必需的事件流控制,并且也能使callback和errback各自保持独立。
var when = function (value, _callback, _errback) {
var result = defer();
var done;
_callback = _callback || function (value) {
return value;
};
_errback = _errback || function (reason) {
return reject(reason);
};
var callback = function (value) {
try {
return _callback(value);
} catch (reason) {
return reject(reason);
}
};
var errback = function (reason) {
try {
return _errback(reason);
} catch (reason) {
return reject(reason);
}
};
enqueue(function () {
ref(value).then(function (value) {
if (done)
return;
done = true;
result.resolve(ref(value).then(callback, errback));
}, function (reason) {
if (done)
return;
done = true;
result.resolve(errback(reason));
});
});
return result.promise;
};
现在这一步来看,promise已经成为了一个具有接受消息功能的类了。Deferred promise根据获得的消息来执行对应的回调函数,返回对应的值。当你接收到完全成功执行的值,则在then中执行成功的回调函数返回msg;获得错误的值则在then中执行错误回调函数,返回错误的原因
因此我们基本可以认为promise这个类可以接受任何的值,包括"then/when"这些信息。这对于一些非立即执行函数的监听非常有用。举个例子,当你发了一个网络请求,等待返回值才能执行函数。我们等待这个请求的往返的过程中浪费了许多时间,而promise仿佛在电脑中另外开了一个线程进行监听这些返回值,然后执行对应的回调函数(这个例子是自己理解举的,非原文,如有不对,欢迎改正)。
翻到这里有点崩溃了,捂下脑子,接下去感觉有点头疼了,以后再补吧,因为基本形态的promise已经出来。接下去是另外一种需求的promise了
接下来我们要包装一种新型的promise,这套promise基于一些能发送任意消息的方法之上,可以满足 "get", "put", "post"能发送相应的消息,并且能根据返回结果中执行相应的promise。
第一次尝试翻译,真的是个体力活,花了快2天的时间,整个人都是炸的。不过所幸是比以前明白了一些恭喜。
原文大概讲解了基本的promise构成,但是现在还是有许多方法并没有分析,接下去我按照自己的想法去实现以下promise.all方法。如果写的不好,欢迎大家指正,帮我进步一下,谢谢。(手动捂脸)
好像自从使用框架之后,对jquery的依赖越来越低了,其好像已经慢慢作为一个工具库的存在了。新项目商量之下,为了减小文件大小,干脆直接不用jquery,对于一些需要的工具函数直接从jquery提取到一个自己写的工具文件tool.js中。在提取的过程中,也慢慢理解了jquery一些工具函数的源码
深拷贝和浅拷贝的使用场景不同,并没有好坏之分,像对一些基本数据类型,直接可以使用浅拷贝对处理数据。但是对于基本引用类型如嵌套对象,数组(包含着对象的数组),那么就需要使用到深拷贝了。
不想看前面深浅拷贝对比的,可以直接拉到第二章看jquery源码实现
原生js也有一些提供拷贝的函数,比如数组的Array.slice(0),Array.concat(),对象的Object.create(),Object.assign()等等,但是都是浅拷贝,遇到二维数组,嵌套对象就通通失败了(以前不懂的时候,真的被坑的不要不要的啊)。
比如下面这个例子,都是在只有基本数据类型的情况下,使用浅拷贝就可以了。
let arr = [1,2,34,5,67,8,9];
let cloneArr = arr.slice(4);
console.log(cloneArr); // [67, 8, 9]
cloneArr[0] = 100; // 修改cloneArr
console.log(arr); // [1,2,34,5,67,8,9],修改cloneArr不影响原数组arr
----------------
let obj = {a : 1,b : 2,c : 3,};
let cloneObj = Object.assign({},obj);// 将拷贝的属性值拷贝到目标对象,然后返回目标对象
console.log(cloneObj); // cloneObj = {a : 1,b : 2,c : 3,};
cloneObj.a = 444; //修改对象
console.log(obj); // obj = {a : 1,b : 2,c : 3,}; 修改拷贝对象不影响源对象
但是如果以上例子将基本数据类型换成引用类型Object和Array呢?
let arr = [1,2,{a : 3},{b : 4},5];
let cloneArr = arr.slice(2);
console.log(cloneArr); // [{a : 3},{b : 4},5];
cloneArr[0].a = 100; // 修改cloneArr
console.log(arr); // [1,2,{a : 100},{b : 4},5],修改cloneArr影响原数组arr
----------------
let obj = {a : {aa : 1},b : {bb : 2},c : 3,};
let cloneObj = Object.assign({},obj);// 将拷贝的属性值拷贝到目标对象,然后返回目标对象
console.log(cloneObj); // cloneObj = {a : {aa : 1},b : {bb : 2},c : 3,};
cloneObj.a.aa = 100; //修改对象
console.log(obj); // obj = {a : {aa : 100},b : {bb : 2},c : 3,}; 修改拷贝对象影响到了源对象
为什么会这样子,原因其实也不复杂。js内存分为栈内存和堆内存。所有的基本数据类型都是存储在栈内存中,而引用类型则是存储在堆内存中,提供了一个地址放在了栈内存中。当我们要获取引用类型的值时,先从栈内存获得地址,再根据地址去堆内存中获得值。因此也叫按引用访问。
(去网上浅拷贝了一张图片,因为拷贝了一个图片地址)
而我们上面例子中,每个数组和对象每个属性存储的引用类型obj其实是个地址,我们只是简单的拷贝了属性值,其实就是拷贝了一个地址。所以我们在新对象里进行修改时,由于是通过同一个地址修改了值。因为和原对象共用了一个地址,所以自然就修改了原对象的值了。
前面解析了浅拷贝。因为我们项目对大型数据处理占据了大头,其中不可避免的会经常用到深拷贝这块。那么深拷贝是怎么实现的。
其实也很简单,就是根据地址找到你堆内存中的值,不断递归深入拷贝下去,直到为基本数据类型为止,接下去就贴上深拷贝代码。
在讲jquey前,还有一个很暴力的方式JSON.parse()和JSON.stringify();缺点是
let obj = {
a: 1,
b: 2,
c: [1,2,3],
d: function() {
console.log("asdfghj");
}
};
let result1 = JSON.stringify(target);
console.log(result1); // 输出结果为"{"a":1,"b":2,"c":[1,2,3]}",函数直接没了
--------------------------------------------
const obj = {
foo: {
name: 'foo',
bar: {
name: 'bar'
baz: {
name: 'baz',
aChild: null // 待会将指向obj.bar
}
}
}
}
obj.foo.bar.baz.aChild = obj.foo // foo->bar->baz->aChild->foo形成环
JSON.stringify(obj) // => TypeError: Converting circular personucture to JSON
好了,最后贴上jquery深拷贝的代码和自己一些理解的注释
$.fn.extend = function () {
//jquery喜欢在初始定义好所有的变量
let options,// 被拷贝的对象
name,// 遍历时的属性
src,// 返回对象本身的属性值
copy,// 需要拷贝的内容
copyIsArray,// 判断是否为数组
clone,// 返回拷贝的内容
target = arguments[0] || {},
i = 1,
length = arguments.length,
deep = false;// 默认为浅拷贝
//target 是传入的第一个参数,表示是否要深递归
if(typeof target === 'boolean'){
deep = target;
//既然为boolean,则此处初始化target为第二个参数或者空对象
target = arguments[i] || {};
// 如果传了类型为 boolean 的第一个参数,i 则从 2 开始
i ++
}
//如果传入的第一个参数不是对象或者其他,初始化为一个空对象
if(typeof target !== 'object' && $.isFunction(target)){
target = {};
}
//如果只传入了一个参数,表示是jquery静态方法,直接返回自身
if(i === length){
target = this;
i --;
}
for(; i < length; i ++){
if((options = arguments[i]) !== null ){
for( name in options){
src = target[name];//获得源对象的值
copy = options[name];//获得要拷贝对象的值
//说是为了避免无限循环,例如 extend(true, target, {'target':target});
if(target === copy) continue;
//如果是数据正确,且是一个纯粹的对象(纯粹的对象指的是 通过 "{}" 或者 "new Object" 创建的)或者是一个数组的话
if(deep && copy && ($.isPlainObject(copy) || (copyIsArray = Array.isArray(copy)))){
//如果是一个数组的话
if(copyIsArray){
copyIsArray = false;
clone = src && Array.isArray(src) ? src : [];//判断源对象是不是数组,如果不是,直接变为空数组,拷贝属性高优先原则
} else {
clone = src && $.isPlainObject(src) ? src : {};//判断原对象属性是否有值,如果有的话,直接返回原值,否则新建一个空对象
}
//继续深拷贝下去
target[name] = $.extend(deep,clone,copy);
}else if(copy !== undefined){
//如果不为空,则不是需要深拷贝的数据和对象,而是string,data,boolean等等,可以直接赋值
target[name] = copy;
}
}
}
}
// 返回新的拷贝完的对象
return target;
}
在看上段代码中,又发现了几个好方法在业务中会用到的,可以让代码更严谨
//判断数据类型
//判断是否为纯正的数据对象
isPlainObject: function( obj ) {
//如果数据不正确,不是对象类型,或者是dom对象,window对象,则直接返回false
if ( !obj || jQuery.type(obj) !== "object" || obj.nodeType || jQuery.isWindow( obj ) ) {
return false;
}
//这段代码是为了兼容IE89存在的,查看是否有constructor属性,如果没有必然是数据对象
try {
if ( obj.constructor &&
!core_hasOwn.call(obj, "constructor") &&
!core_hasOwn.call(obj.constructor.prototype, "isPrototypeOf") ) {
return false;
}
} catch ( e ) {
return false;
}
//对象中key的顺序会将自身属性排在最前面遍历,如果最后一个还是自身属性,则必然所有属性都是自己的
var key;
for ( key in obj ) {}
return key === undefined || core_hasOwn.call( obj, key );
},
以上基本就是jquery.extend代码的解析了。extend是jquery中一个极其重要的方法,jquery本身就用它扩展了许多静态方法和实例方法
摘要:因为项目刚开始用的vue框架,所以早期也研究了一下他的代码看过相关文章的解析,说说也能说个七七八八。不过今天再去看以前的demo的时候,发现忽然一知半解了,说明当时可能也没有理解透,所以写篇文章让自己理解的更深一些。
好吧,事实上在我条理清晰的写完文章之后,时隔4个月,还是忘记的七七八八了
本篇文章大多数知识点实在学习了这篇Vue.js双向绑定的实现原理之后避免遗忘,所以写这个温故知新,加强理解。
如果稍微看过相关文章的人都知道vue的实现是依靠Object.defineproperty()来实现的。每个对象都有自己内置的set和get方法,当每次使用set时,去改变引用该属性的地方,从而实现数据的双向绑定。简单举例
const obj = {};
Object.defineProperty(obj,'hello',{
get(value){
console.log("啦啦啦,方法被调用了");
},
set(newVal,oldVal){
console.log("set方法被调用了,新的值为" + newVal)
}
})
obj.hello; //get方法被调用了
obj.hello = "1234"; //set方法被调用了
基于这个原理,如果想实现显示文字根据输入input变化,实现一个简单版的。
<input type="text" id="a"/>
<span id="b"></span>
<script>
const obj = {};
Object.defineProperty(obj,'hello',{
get(){
console.log("啦啦啦,方法被调用了");
},
set(newVal){
document.getElementById('a').value = newVal;
document.getElementById('b').innerHTML = newVal;
}
})
document.addEventListener('keyup',function(e){
obj.hello = e.target.value;
})
</script>
上面这个实例实现的效果是:随着文本框输入文字的变化,span会同步显示相同的文字内容。同时在控制台用js改变obj.hello,视图也会更新。这样就实现了view->model,model->view的双向绑定。
我们最终实现下面vue的效果
<div id="app">
<input type="text" v-model="text"/>
</div>
<script>
const vm = new Vue({
id : "app",
data : {
text : "hello world"
}
})
</script>
1.输入框的文本与文本节点的data数据绑定
2.输入框的内容发生变化时,data中的数据也发生变化,实现view->model的变化
3.data中的数据发生变化时,文本节点的内容同步发生变化,实现model->view的变化
要实现1的要求,则又涉及到了dom的编译,其中有一个DocumentFragment的知识点。
众所周知,vue吸收了react虚拟DOM的优点,使用DocumentFragment处理节点,其性能和速度远胜于直接操作dom。vue进行编译时,就是将所有挂载在dom上的子节点进行劫持到使用DocumentFragment处理节点,等到所有操作都执行完毕,将DocumentFragment再一模一样返回到挂载的目标上。
先实现一段劫持函数,将要操作的dom全部劫持到DocumentFragment中,然后再append会原位置。
<div id="app">
<input type="text" v-model="text"/>
</div>
<script>
const app = document.getElementById("app");
const nodetoFragment = (node) => {
const flag = document.createDocumentFragment();
let child;
while(child = node.firstChild){
flag.appendChild(child);//不断劫持挂载元素下的所有dom节点到创建的DocumentFragment
}
return flag
}
const dom = nodetoFragment(app);
</script>
当已经获取到所有的dom元素之后,则需要对数据进行初始化绑定,这里简单涉及到了模板的编译。
// 编译HTML模板
const compile = (node,vm) => {
const regex = /\{\{(.*)\}\}/;//为临时正则表达式,为demo而生
//如果节点类型为元素的话
if(node.nodeType === 1){
const attrs = node.attributes;
for(let i = 0;i < attrs.length; i++){
let attr = attrs[i];
if(attr.nodeName === "v-model"){
let name = attr.nodeValue;
node.addEventListener("input",function (e) {
vm.data[name] = e.target.value;
})
node.value = vm.data[name];
node.removeAttribute("v-model");
}
}
}
//如果节点类型为文本的话
if(node.nodeType === 3){
if(regex.test(node.nodeValue)){
let name = RegExp.$1;//获取匹配的字符串,又学到了。。。
name = name.trim();
node.nodeValue = vm.data[name];
}
}
};
//劫持挂载元素到虚拟dom
let nodeToFragment = (node,vm) => {
const flag = document.createDocumentFragment();
let child;
while(child = node.firstChild){
compile(child,vm);//绑定数据,插入到虚拟DOM中
flag.appendChild(child);
}
return flag;
};
//初始化
class Vue {
constructor(option){
this.data = option.data;
let id = option.el;
let dom = nodeToFragment(document.getElementById(id),this);
document.getElementById(id).appendChild(dom);
}
}
const vm = new Vue({
el : "app",
data : {
text : "hello world"
}
})
通过以上代码先实现了第一个要求,文本框和文本节点已经出现了hello woeld了
接下来我们要实现数据双向绑定的第一步,即view->model的绑定。根据之前那个简单的例子看到,我们可以通过input事件实时获取input中的值,接着将通过Object.defineProperty这个方法将data中的text设置为vm的访问器属性。当我们将获取到的input值设置vm.data.text时,通过set方法,实现了数据层的绑定。在这一步,set中要做的操作是更新属性的值。
let defineReactive = (obj,key,val) => {
Object.defineProperty(obj,key,{
get(val){
return val;
}
set(newVal,oldVal){
if(newVal === oldVal) return;
val = newVal;
console.log(`我获取到了新${val},并成功设置`);
}
})
};
//监听所有data传递进来的数据,将他们绑定到原型vm上面
let observe = (obj,vm) => {
Object.keys(obj).forEach((key)=>{
defineReactive(vm.data,key,obj[key]);
})
};
text 属性变化了,set方法触发了,可以通过view层的改变实时改变数据,可是并没有改变文本节点的数据。一个新的知识点:订阅发布模式。
订阅发布模式定义了一种一对多的关系,让多个观察者同时监听一个主题对象,这个主体对象的改变会通知所有观察者对象。
发布者发出通知=>主题对象收到通知并推送给订阅者=>订阅者执行操作
// 三个订阅者
let sub1 = {updata(){console.log(1);}};
let sub2 = {updata(){console.log(2);}};
let sub3 = {updata(){console.log(3);}};
// 一个主题发布器
class Dep{
constructor(){
this.subs = [sub1,sub2,sub3];
}
notify(){
subs.forEach((sub) => {
sub.updata();
})
}
}
const dep = new Dep();
// 一个发布者
const pub = {
publish(){
dep.notipy();
}
};
pub.publish();
上图为一个简单实例,发布者执行发布命令,所有这个主题的订阅者执行更新操作。接下去我们要做的就是,当set方法触发后,input作为发布者,改变了text属性;而文本节点作为订阅者,在收到消息后执行更新操作。
每次new一个新的vue对象时,主要是做了两件事,一件是监听数据:observer(监听数据),第二个是编译HTML,nodeToFragement(id)。
在监听数据的过程中,会为data中的每一个属性生成一个主题对象。
而在编译HTML的过程中,会为每个与数据绑定的相关节点生成一个订阅者watcher,订阅者watcher会将自己订阅到相应属性的dep中。
在前面的方法中已经实现了:修改输入框内容=>再时间回调中修改属性值=>触发属性的set方法。
接下来要做的是发出通知dep.notify=>发出订阅者的uodate方法=>更新视图。
那么如何将watcher添加到关联属性的dep中呢。
编译HTML过程中,为每一个与data关联的节点生成一个watcher,那么watcher中又发生了什么?
// 每一个属性节点的watcher
class Watcher{
constructor(vm,node,name){
Dep.target = this;
this.name = name;
this.node = node;
this.vm = vm;
this.update();
Dep.target = null;
}
update(){
//获得最新值,然后更新视图
this.get();
this.node.nodeValue = this.value;
}
get(){
this.value = this.vm.data[this.name];
}
}
在编译HTML的过程中,生成watcher
let complie = (node,vm){
......
//如果节点类型为文本的话
if(node.nodeType === 3){
if(regex.test(node.nodeValue)){
let name = RegExp.$1;
name = name.trim();
node.nodeValue = vm.data[name];
//在编译过程中,每发现一个属性,则新建一个watcher
new Watcher(vm,node,name);//在此处添加订阅者
}
}
}
首先将自己赋给了一个全局变量Dep.target;然后执行了update方法,进而执行了get方法,读取了vm的访问器属性,从而触发了访问器属性的get方法,get方法将相应的watcher添加到对应访问器属性的dep中。再次,获取属性的值,然后更新视图。最后将dep.target设置为空,是因为这是个全局变量也是watcher与dep之间唯一的桥梁,任何时间都只能保证只有一个值。
(其实就是说全局一个主题,每个订阅者和发布者都是通过这个主题进行沟通。当执行代码时,这个主题接受到一个发布通知,通知完所有订阅者,然后注销掉,用于下一个通知发布。啰嗦了一段就是想讲为什么要设置Dep.target = null)。
// 一个主题发布器
class Dep(){
constructor(){
this.subs = [];
}
notify(){
this.subs.forEach((sub) => {
sub.update();
}
}
addSub(sub){
this.subs.push(sub);
}
}
let defineReactive = (obj,key,val) => {
let dep = new Dep();
Object.defineProperty(obk,key,{
get(){
//在此处将所有的监测器watcher添加进发布器,每一个属性都有自己的发布器
if(dep.target) dep.addSub(dep.target);
}
set(newVal,oldVal){
if(newVal === oldVal) return;
val = newVal;
dep.notify();
}
})
}
至此,hello world 双向绑定就基本实现了。文本内容会随输入框内容同步变化,在控制器中修改 vm.text 的值,会同步反映到文本内容中。
记得以前看过一句话,说市面上任何的UI库都无法满足一个产品的所有需求。
事实上的确如此,产品需求总是千奇百怪。正如我公司现在的产品,引用的是elemen-ui的库,但是无法级联多选,下拉多选的展现形式不对,穿梭框无法上下移动等各种需求逼迫我们只能自己去写组件实现了。
自己手写实现了两个组件之后,先写一篇记录一些坑和学会的新东西
之前在写angular的父子组件传递数据,子组件可以修改父组件传递进来的数据。不过在Vue中子组件不允许修改父组件穿进来的值,以vue举例来说
<!--父组件HTML内容-->
<children-component :value="data"></children-component>
<!--父组件的js内容-->
export default({
data(){
return {
data : [1,2,3,4]
}
}
})
<!--子组件的js内容-->
export default({
props : ["value"],
created : {
this.value = [5,6,7,8];
}
})
此举会引发一个非常常见的报错,

那么解决方法是什么呢,那就要看你需求了。比如传进来的是一个渲染列表,我需要的只是修改渲染的数据,那么可以emit出去,然后在父组件重新赋值,通过双向绑定,触发子组件的再次渲染。
<!--父组件HTML内容-->
<children-component :value="data" @changeProp="changeData"></children-component>
<!--父组件的js内容-->
export default({
data(){
return {
data : [1,2,3,4]
}
},
methods : {
changeData(value){
this.data = value;
}
}
})
<!--子组件的js内容-->
export default({
props : ["value"],
created : {
this.$emit("changeProp",[5,6,7,8])
}
})
例子写的比较简单,其实原理就是emit一个数据到父组件上去,然后在父组件中接受到这个传递上来的新值,将data赋予新值,然后重新传递到了子组件,起到一个变向修改子组件的效果。
被人提醒到一个方法是用.sync,这个方法也是可以的。之前一直以为是被废弃就没用,才发现它其实是在的。看了一下.synv文档,发现这其实是一个语法糖的形式展现出来。如文档所示
<!--日常使用语法糖形态-->
<comp :foo.sync="bar"></comp>
<!--↓↓↓↓↓真实形态↓↓↓↓↓↓-->
<comp :foo="bar" @update:foo="val => bar = val"></comp>
<!--子组件js代码-->
this.$emit('update:foo', newValue)
个人感觉Vue框架其实还是不赞同直接修改数据,但是它帮你定义了一个update事件,让你在子组件可以直接显式调用,不需要自己去定义事件这么麻烦了。大家还是把自定义事件用在一些事件上吧。
但是你每次父子组件传递数据时,都要父子处定义一个事件是很麻烦的,vue则为每个组件提供了一个默认v-model的语法糖。
<!--父组件HTML内容-->
<children-component v-mode="data" ></children-component>
<!--父组件的js内容-->
export default({
data(){
return {
data : [1,2,3,4]
}
},
watch : {
//可以在此处监听子组件传递上来的数据
data(n,o){
console.log(n,o); //[5,6,7,8],[1,2,3,4]
}
}
})
<!--子组件的js内容-->
export default({
<!--大家注意我下面这行代码是打了注释的,说明我在子组件没有定义任何属性-->
// props : ["value"]
<!--并且我接下去直接在代码中使用了this.value(一个完全没有定义过的value)。-->
created : {
console.log(this.value);
this.$emit("input",[5,6,7,8]); //当我想改变传进来值的时候
}
})
因为之前一直使用ng-model来用于表单组件的传递,所以开始对于v-mode也是这个印象,不过后面看了element-ui的源码才发现我想简单了,然后网上搜了一下对于这个语法糖的解释。
//注意,该组件不是表单组件
<children-component :value="data" @input="data = arguments[0]"></children-component>
看了这行代码大家心里估计也能明白的差不多了,其实Vue只是帮我们把父组件上的两段声明合二为一了,同时再帮我们在子组件处直接省略了定义。语法糖说到底就是帮我们省力的嘛。
因为在父子组件传递数据的时候,我们会通过在父组件写属性名将属性传递进去,理论上你可以写任何一个属性名a,value,list,data,但是有几个关键字已经被Vue内部保留了,比如下面的key。
<children-component :key="data" :value="list"></children-component>
<!--父组件的js内容-->
export default({
data(){
return {
data : [1,2,3,4],
list : [1,2,4,5]
}
},
})
<!--子组件的js内容-->
export default({
// props : ["value","key"]
created : {
console.log(this.value);
console.log(this.key);
}
})

当然如果我不在props里面写入key这个属性的话,是不会报错的。
然后想起项目中在写下拉框组件时,如果你对自己以前写的option组件进行repeat的时候,key会作为一个关键字进行标记,不传key的话,vue会给出黄色提醒,不是报错,比如
<demo-select :optionList="optionList">
<demo-option v-for="option in optionList" :key="option.value" :value="option.value">{{option.label}}</demo-option>
</demo-select>
<!--父组件的js内容-->
export default({
data(){
return {
optionList : [{label:1,value:1},{label:2,value:2},{label:3,value:3}],
}
},
})
<!--子组件的js内容-->
export default({
// props : ["value","key"]
created : {
console.log(this.value);
console.log(this.key);
}
})
如果我在对需要repeat的子组件中没有添加:key这个属性的话,则会给出上面的提醒。原因呢,文档里面也有述说,作为每个VNODE唯一标识的id,用于diff对比时更高的效率。不过这是另一个话题了。
好了回到开头,总结性话语就是不要写key传递属性。不过不知道还有没有什么其他的属性我还没有碰到的
如果一个UI组件内部还分了好几层(3层左右),且有不止一个事件或者属性需要传递,那么单纯的props和@+事件传递就没有那么方便了。这时候我们会选择$emit,$broadcast和$on。基本使用用法就不介绍了,见官方文档。主要讲其中的一个坑。如果同一个事件$emit,$broadcast和$on不是由同一个组件调用的话,那么传递的值是接收不到的
<parent-component>
<children-component></children-component>
</parent-component>
<!--父组件的js内容-->
export default({
mounted(){
this.$on("change",function(value){console.log("接收到了子组件传递上来的信息" + value)});
//此处this指向的父组件
}
})
<!--子组件的js内容-->
export default({
mounted(){
this.$emit("change",11111); //此处this指向的子组件
}
})
在上面这一段代码,子组件通过$emit传递一个值上去,但是他是通过调自己(非父组件)用$emit方法。而父组件也是调用自身的$on方法,那么这个$on方法是接收不到传递上来的值的。因为两个组件的this分别指是自己,不是同一个。
如果我们把子组件进行修改一下
<parent-component>
<children-component></children-component>
</parent-component>
<!--父组件的js内容-->
export default({
mounted(){
//此处this指向的父组件
this.$on("change",function(value){console.log("接收到了子组件传递上来的信息" + value)});
}
})
<!--子组件的js内容-->
export default({
computed(){
rootParent(){
return this.$parent;
}
}
mounted(){
this.rootParent.$emit("change",11111); //获取到是同一个组件之后进行调用
}
})
这样子就可以成功传递了。但是如果组件内部有好几层的话,直接通过this.$parent.$parent去获取上层父组件比较麻烦。我们希望可以做到不管组件有几层,我都可以直接一步直接获取到父组件进行调用$emit或者$broadcast。那么我们需要单独封装一个方法写在一个文件里面,然后使用的时候进行Mixins合并就好了。
//Emitter.js 文件
export default {
methods: {
//三个属性分别是父组件名,事件名,传递值
dispatch(componentName, eventName, params) {
var parent = this.$parent || this.$root;
var name = parent.$options.componentName;
while (parent && (!name || name !== componentName)) {
parent = parent.$parent;
if (parent) {
name = parent.$options.componentName;
}
}
if (parent) {
parent.$emit.apply(parent, [eventName].concat(params));
}
},
broadcast(componentName, eventName, params) {
broadcast.call(this, componentName, eventName, params);
}
}
};
//然后在引用文件进行引入并且调用
import Emitter from "Emitter.js"
export default {
mixins: [Emitter],
mounted(){
this.dispatch('parentComponent',"change",1111)
}
}
假如我们写好了一些组件,接下去肯定还要引入和使用吧。但是你写了这么多组件,在每个地方一个个引用想要的是一件很麻烦的事情。我们最好是在一个初始的地方一次性全部引入,然后在用的地方直接使用
(当然全部引入的话,无可避免的会引入和打包不需要的东西,不过这是公共组件库的烦恼,我们自己写的肯定会全部用到)。
// 在文件开头初始引入所有的组件文件
import b from "./components/common/b.vue"
import c from "./components/common/c.vue"
const components = [b,c];
const install = function (Vue, opts = {}) {
components.map(component => {
Vue.component(component.name, component);
});
};
export default install
然后直接在启动的main.js文件里面引入就好
import ui from "install.js"
Vue.use(ui);
然后你就可以随意在任何一个组件里面直接调用了,比自己之前在每个组件里重复调用要方便一点。
<b v-model="data1"></b>
<c v-model="data2"></c>
好了,暂时到这里,都是自己的踩得坑和心得,希望对大家有所帮助吧,接下去还有的话再补充好了。
数组应该是我们在写程序中应用到最多的数据结构了,相比于无序的对象,有序的数组帮我们在处理数据时,实在是帮了太多的忙了。今天刚好看到一篇Array.include的文章,忽然发现经过几个ES3,ES5,ES6,ES7几个版本的更迭,发现在代码中用到了好多数组的方法,所以准备全部列出来,也是给自己加深印象
ES3中的方法毫无疑问大家已经烂熟在心了,不过中间有些细节可以回顾加深一下记忆,比如是否修改原数组返回新数组,执行方法之后的返回值是什么,某些参数的意义是否搞混等等。熟悉的的可以直接快速浏览或者跳过。
Array.join()方法是将一个数组里面的所有元素转换成字符串,然后再将他们连接起来返回一个新数组。可以传入一个可选的字符串来分隔结果字符串中的所有元素。如果没有指定分隔字符串,就默认使用逗号分隔。
let a = [1,2,3,4,5,6,7];
let b = a.join(); // b = "1,2,3,4,5,6,7";
let c = a.a.join(" "); // b = "1 2 3 4 5 6 7";
方法Array.join()恰好与String.split()相反,后者是通过将一个字符串分隔成几个元素来创建数组
Array.reverse()方法将颠倒数组中元素的顺序并返回一个颠倒后的数组。它在原数组上执行这一操作,所以说并不是创建了一个新数组,而是在已存在的数组中对元素进行重排。
let a = [1,2,3,4,5,6,7];
a.reverse(); // a = [7,6,5,4,3,2,1]
Array.sort()是在原数组上进行排序,返回排序后的数组。如果调用方法时不传入参数,那么它将按照字母顺序对数组元素进行排序,说得更精确点,是按照字符编码的顺序进行排序。要实现这一点,首先应把数组的元素都转换成字符串(如有必要),以便进行比较。
如果数组中有未定义的元素,这些元素将放在数组的末尾
let a = [1,12,23,14,,undefined,null,NaN,56,6,7,"a",{},[]];
a.sort(); //[[], 1, 12, 14, 23, 56, 6, 7, "NaN", {}, "a", null,undefined,undefined × 1]
//返回的NaN已经是一个字符串,说明在比较过程中将其转化成了字符串进行比较
仔细看可以发现,上面顺序并没有按照数字大小进行排序。如果想按照其他标准进行排序,就需要提供比较函数。该函数比较前后两个值,然后返回一个用于说明这两个值的相对顺序的数字。比较函数应该具有两个参数 a 和 b,其返回值如下:
let a = [1,12,23,14,,undefined,null,NaN,56,6,7,"a",{},[]];
a.sort((a,b) => {return a - b}); //[null, Array(0), NaN, Object, 1, 6, 7, 12, 14, 23, 56, "a",undefined, undefined × 1]
Array.concat() 方法用于连接两个或多个参数(数组,字符串等),该方法不会改变现有的数组,而会返回连接多个参数的一个新数组。如果传入的参数是数组,那么它将被展开,将元素添加到返回的数组中。但要注意,concat并不能递归的展开一个元素为数组的参数。
let a = [1,2,3];
let b = a.concat(4,5,[6,7,[9,10]]); // b = [1,2,3,4,5,6,7,[9,10]]];
Array.slice() 方法可从已有的数组中返回指定的一个片段(slice),或者说是子数组。它是从原数组中截取了一个片段,并返回到了一个新数组。
Array.slice(a,b) 它有两个参数a,b
| 参数 | 描述 |
|---|---|
| a | 必选。规定从何处开始选取。如果是负数,那么它规定从数组尾部开始算起的位置。也就是说,-1 指最后一个元素,-2 指倒数第二个元素,以此类推。 |
| b | 可选。规定从何处结束选取。该参数是数组片断结束处的数组下标。如果没有指定该参数,那么切分的数组包含从 start 到数组结束的所有元素。如果这个参数是负数,那么它规定的是从数组尾部开始算起的元素。 |
let a = [1,2,3,4,5,7,8];
let b = a.slice(3); // [4, 5, 7, 8]
let c = a.slice(3,5); // [4, 5]
let d = a.slice(-5,-2); // [3, 4, 5]
let d = a.slice(2,1); // []
请注意,该方法并不会修改数组,而是返回一个新的子数组。如果想删除数组中的一段元素,应该使用下面这个方法 Array.splice()。
Array.splice() 方法从数组中添加/删除元素,然后返回被删除的元素。它在原数组上修改数组,并不像slice和concat那样创建新数组。注意,虽然splice和slice名字非常相似,但是执行的却是完全不同的操作。
| 参数 | 描述 |
|---|---|
| index | 必选,整数。规定添加/删除项目的位置,使用负数可从数组结尾处倒着寻找位置。 |
| howmany | 可选,整数。要删除的元素数量。如果设置为 0,则不会删除元素。如果没有选择,则默认从index开始到数组结束的所有元素 |
| item1, ..., itemX | 可选。向数组添加新的元素。 |
let a = [1,2,3,4,5,7,8];
let b = a.splice(3); // a = [1,2,3] b = [4, 5, 7, 8]
-----------------------------------------------------------
let c = [1,2,3,4,5,7,8];
let d = c.splice(3,5); // c = [1,2] d = [3,4,5,7,8]
-----------------------------------------------------------
let e = [1,2,3,4,5,7,8];
let f = e.splice(3,2,111,222,[1,2]); // e = [1, 2, 3, 111, 222,[1,2], 7, 8] f = [4,5]
大家要记住slice()和splice()两个方法第二个参数代表的意义是不一样的。虽然这很基础,可是有时候还是会弄混。
Array.push() 方法可向数组的末尾添加一个或多个元素,并返回新的长度。
Array.pop()方法用于删除并返回数组的最后一个元素。如果数组已经为空,则 pop() 不改变数组,并返回 undefined 值。
let a = [1,2,3,4,5];
let b = a.pop(); //a = [1,2,3,4] b = 5
let c = a.push(1,3,5); // a = [1,2,3,4,1,3,5] c = 7
上面两个方法都是直接对原数组进行操作。通过上面两个方法可以实现一个先进后出的栈。
unshift,shift()的方法行为和push(),pop()非常相似,只不过他们是对数组的头部元素进行插入和删除。
Array.unshift() 方法可向数组的头部添加一个或多个元素,并返回新的长度。
Array.shift()方法用于删除并返回数组的第一个元素。如果数组已经为空,则 pop() 不改变数组,并返回 undefined 值。
let a = [1,2,3,4,5];
let b = a.shift(); //a = [2,3,4,5] b = 1
let c = a.unshift(1,3,5); // a = [1,3,5,2,3,45] c = 7
和所有javascript的对象一样,数组也有toString()方法,这个方法可以将数组的每一个元素转化成字符串(如果必要的话,就调用元素的toString()方法),然后输出字符串的列表,字符串之间用逗号隔开。(用我的话来理解,其实就是遍历数组元素调用每个元素自身的toString()方法,然后用逗号连接)
toString()的返回值和没有参数的join()方法返回的字符串相同
let a = let e = [1,undefined,null,Boolean,{},[],function(){console.log(1);}];
let b = a.toString(); // b = "1,,,function Boolean() { [native code] },[object Object],,function (){console.log(1);}"
注意,输出的结果中,返回的数组值周围没有括号。
toLocaleString方法是toString()方法的本地化版本。它是使用地区特定的分隔符把生成的字符串连接起来,形成一个字符串。
虽然是两个方法,但是一般元素两个方法的输出结果却基本是一样的,去网上找了相关文章,发现只有两种情况比较有区分,一个是时间,一个是4位数字以上的数字,举例如下
let a = 1111;
let b = a.toLocaleString(); // b = "1,111"
let c = a.toString(); // c = "1111";
-------------------------------------------------------
let date = new Date();
let d = date.toString(); // d = "Sun Sep 03 2017 21:52:18 GMT+0800 (**标准时间)"
let e = date.toLocaleString(); //e = "2017/9/3 下午9:52:18"
好吧,这个api和数组关系不大。。。主要还是和数组中元素自身有关。啊哈哈,尴尬。
Array.valueOf()方法在日常中用的比较少,该方法继承与Object。javascript中许多内置对象都针对自身重写了该方法,数组Array.valueOf()直接返回自身。
let a = [1,"1",{},[]];
let b = a.valueOf();
a === b; // true
好啦,关于ES3的方法就不详细描述了,我相信大家基本上都已经完全是烂熟于心的那种,唯一可能需要加强记忆的就是一些参数含义,返回数据这些了。
2.Array在ES5新增的方法中接受两个参数,第一个参数都是function类型,必选,默认有传参,这些参数分别是:
第二个参数是当执行回调函数时指向的this(参考对象),不提供默认为window,严格模式下为undefined。
以forEach举例
语法
array.forEach(callback, thisArg)
array.forEach(callback(currentValue, index, array){
//do something
}, thisArg)
例子:
//demo,注意this指向
//我这个demo没有用箭头函数来测试
let a = ['a', 'b', 'c'];
a.forEach(function(currentValue, index, array){
this.info(currentValue, index, array);
},{info:function(value,index,array){
console.log(`当前值${value},下标${index},数组${array}`)}
});
function info(value,index,array){
console.log(`外放方法 : 当前值${value},下标${index},数组${array}`)}
}
// 当前值a,下标0,数组a,b,c
// 当前值b,下标1,数组a,b,c
// 当前值c,下标2,数组a,b,c
3.ES5中的所有关于遍历的方法按升序为数组中含有效值的每一项执行一次callback函数,那些已删除(使用delete方法等情况)或者未初始化的项将被跳过(但不包括那些值为 undefined 的项)(例如在稀疏数组上)。
例子:数组哪些项被跳过了
function logArrayElements(element, index, array) {
console.log(`a[${index}] = ${element}`);
}
let xxx; //定义未赋值
let a = [1,2,"", ,undefined,xxx,3];
delete a[1]; // 移除 2
a.forEach(logArrayElements);
// a[0] = 1
// 注意索引1被跳过了,因为在数组的这个位置没有项 被删除了
// a[2] = ""
// 注意索引3被跳过了,因为在数组的这个位置没有项,可以理解成没有被初始化
// a[4] = undefined
// a[5] = undefined
// a[6] = 3
好了,上面3点基本上是ES5中所有方法的共性,下面就不重复述说了。开始正文解析每个方法的不同了
Array.forEach() 为每个数组元素执行callback函数;不像map() 或者reduce() ,它总是返回 undefined值,并且不可链式调用。典型用例是在一个链的最后执行副作用。
注意: 没有办法中止或者跳出 forEach 循环,除了抛出一个异常。如果你需要跳出函数,推荐使用Array.some。如果可以,新方法 find() 或者findIndex() 也可被用于真值测试的提早终止。
例子:如果数组在迭代时被修改了
下面的例子输出"one", "two", "three"。当到达包含值"two"的项时,整个数组添加了一个项在第一位,这导致所有的元素下移一个位置。此时在下次执行回调中,因为元素 "two"符合条件,结果一直增加元素,直到遍历次数完毕。forEach()不会在迭代之前创建数组的副本。
let a = ["one", "two", "three"];
let b = a.forEach((value,index,arr) => {
if (value === "two") {
a.unshift("zero");
}
return "new" + value
});
// one,0,["one", "two", "three"]
// two,1,["one", "two", "three"]
// two,2,["zero", "one", "two", "three"]
// two,3,["zero","zero", "one", "two", "three"]
看完例子可以发现,使用 forEach 方法处理数组时,数组元素的范围是在callback方法第一次调用之前就已经确定了。在 forEach 方法执行的过程中:原数组中新增加的元素将不会被 callback 访问到;若已经存在的元素被改变或删除了,则它们的传递到 callback 的值是 forEach 方法遍历到它们的那一个索引时的值。
ES5中所有API在数组被修改时都遵从这个原则,以下不再重复
Array.map 方法会给原数组中的每个元素都按顺序调用一次callback函数。callback每次执行后的返回值(没有指定返回值则返回undefined)组合起来形成一个新数组。
例子:返回每个元素的平方根的数组
let a = [1,4,9];
let b = a.map((value) => {
return Math.sqrt(value); //如果没有return,则默认返回undefined
});
// b= [1,2,3]
Array.filter()为数组中的每个元素调用一次 callback 函数,并利用所有使得 callback 返回 true 或 等价于 true 的值 的元素创建一个新数组。那些没有通过 callback 测试的元素会被跳过,不会被包含在新数组中
例子:数组去重
let a = [1,2,3,4,32,6,79,0,1,1,8];
let b = a.filter((value,index,arr) => {
return arr.indexOf(value) === index;
});
// b = [1, 2, 3, 4, 32, 6, 79, 0, 8]
Array.some 为数组中的每一个元素执行一次 callback 函数,直到找到一个使得 callback 返回一个“真值”(即可转换为布尔值 true 的值)。如果找到了这样一个值,some 将会立即返回 true。否则,some 返回 false。callback 只会在那些”有值“的索引上被调用,不会在那些被删除或从来未被赋值的索引上调用。
例子:查看数组内是否含有大于0的元素
let a = [-1,4,9];
let b = a.some((value) => {
return value > 0; //如果没有return,则默认返回undefined,将无法告诉some判断
});
// b = true
some方法可以理解成拥有跳出功能的forEach()函数,可以用在在一些需要中断函数的地方
Array.every() 方法为数组中的每个元素执行一次 callback 函数,直到它找到一个使 callback 返回 false(表示可转换为布尔值 false 的值)的元素。如果发现了一个这样的元素,every 方法将会立即返回 false。否则,callback 为每一个元素返回 true,every 就会返回 true。callback 只会为那些已经被赋值的索引调用。不会为那些被删除或从来没被赋值的索引调用。
例子:检测所有数组元素的大小,是否都大于0
let a = [-1,4,9];
let b = a.every((value) => {
return value > 0; //如果没有return,则默认返回undefined
});
// b = false
Array.indexOf()使用严格相等(strict equality,即===)进行判断searchElement与数组中包含的元素之间的关系。
Array.indexOf()提供了两个参数,第一个searchElement代表要查询的元素,第二个代表fromIndex表示从哪个下标开始查找,默认为0。
语法
arr.indexOf(searchElement)
arr.indexOf(searchElement, fromIndex = 0)
Array.indexOf()会返回首个被找到的元素在数组中的索引位置; 若没有找到则返回 -1
例子:
let array = [2, 5, 9];
array.indexOf(2); // 0
array.indexOf(7); // -1
array.indexOf(9, 2); // 2
array.indexOf(2, -1); // -1
array.indexOf(2, -3); // 0
Array.lastIndexOf()就不细说了,其实从名字大家也可以看出来,indexOf是正向顺序查找,lastIndexOf是反向从尾部开始查找,但是返回的索引下标仍然是正向的顺序索引
。
语法
arr.lastIndexOf(searchElement, fromIndex = arr.length - 1)
需要注意的是,只是查找的方向相反,fromIndex和返回的索引都是正向顺序的,千万不要搞混了(感觉我这么一说,大家可能搞混了,捂脸)。
例子:各种情况下的的indexOf
var array = [2, 5, 9, 2];
var index = array.lastIndexOf(2); // index = 3
index = array.lastIndexOf(7); // index = -1
index = array.lastIndexOf(2, 3); // index = 3
index = array.lastIndexOf(2, 2); // index = 0
index = array.lastIndexOf(2, -2); // index = 0
index = array.lastIndexOf(2, -1); // index = 3
Array.reduce() 为数组中的每一个元素依次执行回调函数,最后返回一个函数累计处理的结果。
语法
array.reduce(function(accumulator, currentValue, currentIndex, array), initialValue)
reduce的回调函数中的参数与前面的不同,多了第一个参数,是上一次的返回值
例子:数组求和
let sum = [0, 1, 2, 3].reduce(function (o,n) {
return o + n;
});
// sum = 6
对了,当回调函数第一次执行时,accumulator 和 currentValue 的取值有两种情况:
例子:reduce数组去重
[1,2,3,4,5,6,78,4,3,2,21,1].reduce(function(accumulator,currentValue){
if(accumulator.indexOf(currentValue) > -1){
return accumulator;
}else{
accumulator.push(currentValue);
return accumulator;
}
},[])
注意 :如果数组为空并且没有提供initialValue, 会抛出TypeError 。如果数组仅有一个元素并且没有提供initialValue, 或者有提供initialValue但是数组为空,那么此唯一值将被返回并且callback不会被执行。
Array.reduceRight() 为数组中的每一个元素依次执行回调函数,方向相反,从右到左,最后返回一个函数累计处理的结果。
因为这个方法和reduce方法基本是一模一样的,除了方法相反,所以就不详细的再写一遍了
之所以将这个方法放在最后,是因为这个方法和前面的不太一致,是用于确定传递的值是否是一个 Array,使用方法也很简单
例子
let a = Array.isArray([1,2,3]); //true
let b = Array.isArray(document.getElementsByTagName("body")); //类数组也为false
不过感觉除非是临时判断,不然一般也不会用这个方法去判断,一般还是下面这种万金油型的吧。
Object.prototype.toString.call([]).slice(8, -1) === "Array";//true
好啦,关于ES5的方法基本上就讲到这里了,感觉自己在深入去看了一些文章之后,还是有一些额外的收获的。比如对reduce这个平时不常用的方法了解更加深刻了,感觉之前很多遍历收集数据的场景其实用reduce更加方便。
不同于es5主要以遍历方法为主,es6的方法是各式各样的,不过必须要说一句,在性能上,es6的效率基本上是最低的。
英文名字叫做Spread syntax,中文名字叫做扩展运算符。这个方法我不知道怎么描述,感觉更像是原有concat()方法的增强,可以配合着解构一起使用,大家还是直接看例子感受以下吧
例子:简单拷贝数组
//如果是ES5
let c = [7,8,9].concat(a);
//如果是ES6
let a = [1,23,4,5,6];
let b = [7,8,9,...a]; // b = [7, 8, 9, 1, 23, 4, 5, 6]
----------------------------------------------------------
//浅拷贝
let c = [{a : 1}];
let d = [...c]
d[0].a = 2
c[0].a // 2
可以看到这个方法对于引用类型仍然是浅复制,所以对于数组的深拷贝还是需要用额外的方法,可以看我另外一篇文章
Array.of()方法可以将传入参数以顺序的方式返回成一个新数组的元素。
let a = Array.of(1, 2, 3); // a = [1, 2, 3]
其实,刚看到这个api和他的用途,还是比较懵逼的,因为看上去这个方法就是直接将传入的参数变成一个数组之外,就没有任何区别了,那么我为什么不直接用以前的写法去实现类似的效果呢,比如 let = [1,2,3];而且看上去也更加直接。然后我去翻了下最新的ECMAScript草案,其中有这么一句话
The of function is an intentionally generic factory method; it does not require that its this value be the Array constructor. Therefore it can be transferred to or inherited by other constructors that may be called with a single numeric argument.
自己理解了一下,其实大概意思就是说为了弥补Array构造函数传入单个函数的不足,所以出了一个of这个更加通用的方法,举个例子
let a = new Array(1);//a = [undefined × 1]
let b = new Array(1,2);// b = [1,2]
大家可以注意到传入一个参数和传入两个参数的结果,完全是不一样的,这就很尴尬了。而为了避免这种尴尬,es6则出了一种通用的of方法,不管你传入了几个参数,都是一种相同类型的输出结果。
不过我好奇的是,如果只传入几个参数,为什么不直接let a = [1,2,3];效率和直观性也更加的高。如果要创建一个长度的数组,我肯定还是选let a = new Array(10000),这种形式,实在没有感觉到Array.of的实用场景,希望大家可以给我点指导。
Array.from()方法从一个类似数组(拥有一个 length 属性和若干索引属性的任意对象)或可迭代的对象(String, Array, Map, Set和 Generator)中创建一个新的数组实例。
我们先查看Array.from()的语法
语法
Array.from(arrayLike, mapFn, thisArg)
从语法中,我们可以看出Array.from()最基本的功能是将一个类数组的对象转化成数组,然后通过第二个和第三个参数可以对转化成功后的数组再次执行一次遍历数据map方法,也就是Array.from(obj).map(mapFn, thisArg)。
对了额外说一句,这个方法的性能很差,和直接的for循环的性能对比了一下,差了百倍不止。
例子 :将一串数字字符串转化为数组
let a = Array.from("242365463432",(value) => return value * 2);
//a = [4, 8, 4, 6, 12, 10, 8, 12, 6, 8, 6, 4]
Array.copyWithin方法,在当前数组内部,将指定位置的成员浅复制到其他位置(会覆盖原有成员),然后返回当前数组。也就是说,使用这个方法,会修改当前数组。
这个方法有点复杂,光看描述可能大家未必能轻易理解,大家可以先看下语法,再看demo配合理解,而且自己没有想到这个方法合适的应用场景。网上也没又看到相关使用场景。但是讲道理,这个方法设计出来,肯定是经过深思熟虑的,如果大家有想到,欢迎评论给我,谢谢。
语法
arr.copyWithin(target, start, end)
//arr.copyWithin(目标索引, 源开始索引, 结束源索引)
例子
// 将3-4号位复制到0号位
[1, 2, 3, 4, 5].copyWithin(0, 3, 4); // [4, 2, 3, 4, 5]
// 将2-5号位复制到0号位
[1, 2, 3, 4, 5].copyWithin(0, 2, 5); //[3, 4, 5, 4, 5]
// 将1-4号位复制到4号位
[1, 2, 3, 4, 5].copyWithin(4, 1, 4); //[1, 2, 3, 4, 2]
复制遵循含头不含尾原则
第一个是常规的例子,大家可以对比看第二个可以发现,这个方法是先浅复制了数组一部分暂时存储起来,然后再从目标索引处开始一个个覆盖后面的元素,直到这段复制的数组片段全部粘贴完。
再看第三个例子,可以发现当复制的数据片段从目标索引开始粘贴时,如果超过了长度,它将停止粘贴,这说明它不会改变数据的 length,但是会改变数据本身的内容。
Array.copyWithin可以理解成复制以及粘贴序列这两者是为一体的操作;即使复制和粘贴区域重叠,粘贴的序列也会有拷贝来的值。
Array.find()方法返回数组中满足提供的测试函数的第一个元素的值。否则返回 undefined。
Array.findIndex() 方法返回数组中满足提供的测试函数的第一个元素的值的索引。否则返回 -1。
这两个方法其实使用非常相似,使用场景有点像ES5中Array.some,都是在找到第一个满足条件的时候,跳出循环,区别的是,三种返回的值完全不一样,我想这也许是为什么要在ES6中增加这两个API的原因吧,可以理解成是数组的方法的补足。
例子:三个方法各自的返回值
let a = [1,2,3,4,5].find((item)=>{return item > 3}); // a = 4 返回第一个符合结果的值
let b = [1,2,3,4,5].findIndex((item)=>{return item > 3}); // b = 3 返回第一个符合结果的下标
let c = [1,2,3,4,5].some((item)=>{return item > 3}); // c = true 返回是否有符合条件的Boolean值
-----------------不满足条件--------------------
let a = [1,2,3,4,5].find((item)=>{return item > 6}); // a = undefined
let b = [1,2,3,4,5].findIndex((item)=>{return item > 6}); // b = -1
let c = [1,2,3,4,5].some((item)=>{return item > 6}); // c = false
注意:find()和findIndex()方法无法判断NaN,可以说是内部用 ===判断,不同于ES7中的include方法。不过这个判断方式是另外一个话题,不在本文详述了,感兴趣的同学可以去查一下。
其实还可以发现,Array.find() 方法只是返回第一个符合条件的元素,它的增强版是es5中Array.filter()方法,返回所有符合条件的元素到一个新数组中。可以说是当用find方法时考虑跟多的是跳出吧。
我感觉这4个方法配合相应的回调函数基本上可以完全覆盖大多数需要数组判断的场景了,大家觉得呢?
Array.fill()方法用一个固定值填充一个数组中从起始索引到终止索引内的全部元素,返回原数组
这个方法的使用也非常简单,大家基本上看个语法和demo就能懂了。需要注意的是,这个方法是返回数组本身,还有一点就是,类数组不能调用这个方法,刚刚自己去改了MDN上面的文档。
语法
arr.fill(value)
arr.fill(value, startIndex)
arr.fill(value, startIndex, endIndex)
例子
let a = new Array(10);
a.fill(1); // a = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1];
let b = [1,2,34,5,6,7,8].fill(3,4); //b = [1, 2, 34, 5, 3, 3, 3];
let c = [1,2,34,5,6,7,8].fill(3,2,5); // c = [1, 2, 3, 3, 3, 7, 8];
个人感觉这个方法初始化数组挺有用的,自己每次测试数据时,只要new Array(10000).fill(1),比以前遍历直观方便多了
Array.entries()将数组转化成一个中包含每个索引的键/值对的Array Iterator对象
Array.keys()将数组转化成一个中包含每个索引的键的Array Iterator对象
Array.values()将数组转化成一个中包含每个索引的值的Array Iterator对象。
Array.values()方法chrome浏览器并不支持,
之所以将这三个方法放在一起是有原因的额,大家可以看这三个方法其实都是一个数组转化为一种新的数据类型——返回新的Array Iterator对象,唯一区别的是转化之后的元素不一样。跟他们的名字一样,entries()方法转化为全部的键值对,key()方法转化为键,value()保留值。
例子:观察各个迭代器遍历输出的东西
Array.entries()
let a = [1,2,3].entries();
for(let i of a){console.log(i);}
//[0, 1]
//[1, 2]
//[2, 3]
Array.keys()
let b = [1,2,3].keys();
for(let i of b){console.log(i);}
//0
//1
//2
Array.values()
let c = [1,2,3].values();
for(let i of c){console.log(i);}
//1
//2
//3
关于迭代器这个东西,自己说不上什么,因为自己没有亲自用过,如果大家有什么见解课可以评论给我,我来补充和学习一下
Array.includes方法返回一个布尔值,表示某个数组是否包含给定的值,如果包含,则返回true,否则返回false,与字符串的includes方法类似。
这个方法大家可以看作是ES5中Array.indexOf的语义增强版,“includes”这个是否包含的意思,直接返回Boolean值,比起原来的indexOf是否大于-1,显得更加直观,我就是判断有没有包含哪个值
对了,Array.includes()相比起indexOf这个方法还有一个增强之处是可以判断NaN。
语法,使用方法和indexof一模一样
arr.includes(searchElement)
arr.includes(searchElement, fromIndex)
例子
let array = [2, 5, 9];
array.includes(2); // true
array.includes(7); // false
array.includes(9, 2); // true
array.includes(2, -1); // false
array.includes(2, -3); // true
[NaN].includes(NaN); // true
方法还真是tmd多啊,感觉基本上应该是更新完了,前后两星期花了我4天时间吧,还是挺累的。不过收货还是很多,比如知道了ES5的方法基本上都有第二个this指向的参数,重新认识了reduce方法,感觉自己之前很多场景用reduce更好,重新熟悉了一些ES6的方法可以试用有些场景
如果能看到最后的,感觉你也是够累的,哈哈哈。
记得4月新出了webpack4,这个月刚好没什么事情,用webpack4又重新去搭了一遍自己的项目。在搭项目的途中,忽然对webpack模块化之后的代码起了兴趣,于是想搞清楚我们引入的文件到底是怎么运行的。
所谓的基本版,就是我只引入了一个test.js,代码只有一行var a = 1。打包之后,发现生成的文件main.js并没有多少代码,只有90行不到。
截取出真正执行的代码就更加少了,只有下面4行。我们接下去就从这几行代码中看下打包出来的文件的执行流程是怎么样的。
(function(modules) {
//新建一个对象,记录导入了哪些模块
var installedModules = {};
// The require function 核心执行方法
function __webpack_require__(moduleId){/*内容暂时省略*/}
// expose the modules object (__webpack_modules__) 记录传入的modules作为私有属性
__webpack_require__.m = modules;
// expose the module cache 缓存对象,记录了导入哪些模块
__webpack_require__.c = installedModules;
// Load entry module and return exports 默认将传入的数组第一个元素作为参数传入,这个s应该是start的意思了
return __webpack_require__(__webpack_require__.s = 0);
})([(function(module, exports, __webpack_require__) {
/* 0 */
var a = 1;
/***/ })
/******/ ])首先很明显,整个文件是个自执行函数。传入了一个数组参数modules。
这个自执行函数内部一开始新建了一个对象installedModules,用来记录打包了哪些模块。
然后新建了函数__webpack_require__,可以说整个自执行函数最核心的就是__webpack_require__。__webpack_require__有许多私有属性,其中就有刚刚新建的installedModules。
最后自执行函数return了__webpack_require__,并传入了一个参数0。因为__webpack_require__的传参变量名称叫做moduleId,那么传参传进来的也就是*模块id**。所以我大胆猜测这个0可能是某个模块的id。
这时候我瞄到下面有一行注释/* 0 */。可以发现webpack会在每一个模块导入的时候,会在打包模块的顶部写上一个id的注释。那么刚才那个0就能解释了,就是我们引入的那个模块,由于是第一个模块,所以它的id是0。
那么当传入了moduleId之后,__webpack_require__内部发生了什么?
function __webpack_require__(moduleId) {
// Check if module is in cache
// 检查缓存对象中是否有这个id,判断是否首次引入
if(installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// Create a new module (and put it into the cache) 添加到.c缓存里面
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// Execute the module function 执行通过moduleId获取到的函数
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// Flag the module as loaded
// 表示module对象里面的模块加载了
module.l = true;
// Return the exports of the module
return module.exports;
}首先通过moduleId判断这个模块是否引入过。如果已经引入过的话,则直接返回。否则installedModules去记录下这次引入。这样子如果别的文件也要引入这个模块的话,避免去重复执行相同的代码。
然后通过modules[moduleId].call去执行了引入的JS文件。
看完这个函数之后,大家可以发现其实webpack打包之后的文件并没有什么很复杂的内容嘛。当然这很大一部分原因是因为我们的场景太简单了,那么接下来就增加一点复杂性。
接下来我修改一下webpack入口,单个入口同时下引入三个个文件
entry: [path.resolve(__dirname, '../src/test.js'),path.resolve(__dirname, '../src/test2.js'),path.resolve(__dirname, '../src/test3.js')],三个文件的内容分别为var a = 1,var b = 2,var c = 3。接下来我们可以看看打包之后的代码
打包之后的文件main.js核心内容并没有发生变化,和上面一模一样。但是这个自执行函数传入的参数却发生了变化。
(function(modules) {
/*这部分内容省略,和前面一模一样*/
})([
/* 0 */
/***/ (function(module, exports, __webpack_require__) {
__webpack_require__(1);
__webpack_require__(2);
module.exports = __webpack_require__(3);
/***/ }),
/* 1 */
/***/ (function(module, exports, __webpack_require__) {
var a = 1;
/***/ }),
/* 2 */
/***/ (function(module, exports, __webpack_require__) {
var b = 2;
/***/ })
/* 3 */
/***/ (function(module, exports, __webpack_require__) {
var c = 3;
/***/ })
/******/ ]);前面说过,自执行函数默认将传入的参数数组的第一个元素传入__webpack_require__执行代码。
我们可以看一下传入第一个参数的内容,在上一章中是我们引入的文件内容var a = 1,但是这里却不是了。而是按模块引入顺序执行函数__webpack_require__(1),__webpack_require__(2),__webpack_require__(3),通过__webpack_require__函数去执行了我们引入的代码。
大家可以先想一下这里的1,2,3是怎么来的,为什么可以函数调用的时候,直接传参1,2,3
不过到这里还不明白,module.exports到底起了什么作用,如果起作用,为什么又只取最后一个呢?
因为好奇如果多入口多文件是怎么样的,接下去我又将入口改了一下,变成了下面这样
entry: {
index1: [path.resolve(__dirname, '../src/test1.js')],
index2: [path.resolve(__dirname, '../src/test2.js'),path.resolve(__dirname, '../src/test3.js')],
},打包生成了index1.js和index2.js。发现index1.js和第一章讲的一样,index2.js和第二个文件一样。并没有什么让我很意外的东西。
在前面的打包文件中,我们发现每个模块id似乎是和引入顺序有关的。而在我们日常开发环境中,必然会引入各种公共文件,那么webpack会怎么处理这些id呢
于是我们在配置文件中新增了webpack.optimize.SplitChunksPlugin插件。
在
webpack2和3版本中是webpack.optimize.CommonsChunkPlugin插件。但是在webpack4进行了一次优化改进,想要了解的可以看一下这篇文章webpack4:代码分割CommonChunkPlugin的寿终正寝。所以这里的代码将是使用webpack4打包出来的。
然后修改一下配置文件中的入口,我们开了两个入口,并且两个入口都引入了test3.js这个文件
entry: {
index1: [path.resolve(__dirname, '../src/test.js'),path.resolve(__dirname, '../src/test3.js')],
index2: [path.resolve(__dirname, '../src/test2.js'),path.resolve(__dirname, '../src/test3.js')],
},可以看到,打包后生成了3个文件。
<script type="text/javascript" src="scripts/bundle.4474bdd2169853ce33a7.js"></script>
<script type="text/javascript" src="scripts/index1.4474bdd2169853ce33a7.js"></script>
<script type="text/javascript" src="scripts/index2.4474bdd2169853ce33a7.js"></script>首先bundle.js(文件名自己定义的)很明显是一个公共文件,里面应该有我们提取test3.js出来的内容。打开文件后,发现里面的代码并不多,只有下面几行。
(window["webpackJsonp"] = window["webpackJsonp"] || []).push([[2],{
/***/ 2:
/***/ (function(module, exports, __webpack_require__) {
var c = 1;
/***/ })
}]);
单纯看文件内容,我们大概能推测出几点:
webpackJsonp的数组2,应该是这个模块的id{模块id:模块内容}的对象。模块内容就是我们test3.js,被一个匿名函数包裹在
webpack2中,采用的是{文件路径:模块内容}的对象形式。不过在升级到webpack3中优化采用了数字形式,为了方便提取公共模块。
注意到一点,这个文件中的2并不像之前一样作为注释的形式存在了,而是作为属性名。但是它为什么直接就将这个模块id命名为2呢,目前来看,应该是这个模块是第二个引入的。带着这个想法,我接下去看了打包出来的index1.js文件
截取出了真正执行并且有用的代码出来。
// index1.js
(function(modules) { // webpackBootstrap
// install a JSONP callback for chunk loading
function webpackJsonpCallback(){
/*暂时省略内容*/
return checkDeferredModules
}
function checkDeferredModules(){/*暂时省略内容*/}
// The module cache
var installedModules = {};
// object to store loaded and loading chunks
// undefined = chunk not loaded, null = chunk preloaded/prefetched
// Promise = chunk loading, 0 = chunk loaded
var installedChunks = {
0: 0
};
var deferredModules = []; //
var jsonpArray = window["webpackJsonp"] = window["webpackJsonp"] || [];
var oldJsonpFunction = jsonpArray.push.bind(jsonpArray);
jsonpArray.push = webpackJsonpCallback;
jsonpArray = jsonpArray.slice();
for(var i = 0; i < jsonpArray.length; i++){
webpackJsonpCallback(jsonpArray[i]);
}
var parentJsonpFunction = oldJsonpFunction;
// add entry module to deferred list
deferredModules.push([0,2]);
// run deferred modules when ready
return checkDeferredModules();
})([
/* 0 */
/***/ (function(module, exports, __webpack_require__) {
__webpack_require__(1);
module.exports = __webpack_require__(2);
/***/ }),
/* 1 */
/***/ (function(module, exports, __webpack_require__) {
var a = 1;
/***/ })
/******/ ]);在引入webpack.optimize.SplitChunksPlugin之后,核心代码在原来基础上新增了两个函数webpackJsonpCallback和checkDeferredModules。然后在原来的installedModules基础上,多了一个installedModules,用来记录了模块的运行状态;一个deferredModules,暂时不知道干嘛,看名字像是存储待执行的模块,等到后面用到时再看。
此外,还有这个自执行函数最后一行代码调用形式不再像之前一样。之前是通过调用__webpack_require__(0),现在则变成了checkDeferredModules。那么我们便顺着它现在的调用顺序再去分析一下现在的代码。
在分析了不同之后,接下来就按照运行顺序来查看代码,首先能看到一个熟悉的变量名字webpackJsonp。没错,就是刚才bundle.js中暴露到全局的那个数组。由于在html中先引入了bundle.js文件,所以我们可以直接从全局变量中获取到这个数组。
前面已经简单分析过window["webpackJsonp"] 了,就不细究了。接下来这个数组进行了一次for循环,将数组中的每一个元素传参给了方法webpackJsonpCallback。而在这里的演示中,传入就是我们bundle.js中一个包含模块信息的数组[[2],{2:fn}}]。
接下来就看webpackJsonpCallback如何处理传进来的参数了
/******/ function webpackJsonpCallback(data) {
/******/ var chunkIds = data[0]; // 模块id
/******/ var moreModules = data[1]; // 提取出来的公共模块,也就是文件内容
/******/ var executeModules = data[2]; // 需要执行的模块,但演示中没有
/******/ // add "moreModules" to the modules object,
/******/ // then flag all "chunkIds" as loaded and fire callback
/******/ var moduleId, chunkId, i = 0, resolves = [];
/******/
/******/ for(;i < chunkIds.length; i++) {
/******/ chunkId = chunkIds[i];
/******/ if(installedChunks[chunkId]) {
/******/ resolves.push(installedChunks[chunkId][0]);
/******/ }
/******/ installedChunks[chunkId] = 0;
/******/ }
/******/ for(moduleId in moreModules) {
/******/ if(Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
/******/ modules[moduleId] = moreModules[moduleId];
/******/ }
/******/ }
/******/ if(parentJsonpFunction) parentJsonpFunction(data);
/******/
/******/ while(resolves.length) {
/******/ resolves.shift()();
/******/ }
/******/
/******/ // add entry modules from loaded chunk to deferred list
/******/ deferredModules.push.apply(deferredModules, executeModules || []);
/******/
/******/ // run deferred modules when all chunks ready
/******/ return checkDeferredModules();
/******/ };这个函数中主要干了两件事情,分别是在那两个for循环中。
一是在installedChunks对象记录引入的公共模块id,并且将这个模块标为已经导入的状态0。
installedChunks[chunkId] = 0;然后在另一个for循环中,设置传参数组modules的数据。我们公共模块的id是2,那么便设置modules数组中索引为2的位置为引入的公共模块函数。
modules[moduleId] = moreModules[moduleId];
//这段代码在我们的例子中等同于 modules[2] = (function(){/*test3.js公共模块中的代码*/})
其实当看到这段代码时,心里就有个疑问了。因为
index1.js中设置modulesp[2]这个操作并不是一个push操作,如果说数组索引为2的位置已经有内容了呢?暂时保留着心中的疑问,继续走下去。心中隐隐感觉到这个打包后的代码其实并不是一个独立的产物了。
我们知道modules是传进来的一个数组参数,在第二个章节中可以看到,我们会在最后执行函数__webpack_require__(0),然后依顺序去执行所有引入模块。
不过这次却和以前不一样了,可以看到webpackJsonpCallback最后返回的代码是checkDeferredModules。前面也说了整个自执行函数最后返回的函数也是checkDeferredModules,可以说它替代了__webpack_require__(0)。接下去就去看看checkDeferredModules发生了什么
/******/ function checkDeferredModules() {
/******/ var result;
/******/ for(var i = 0; i < deferredModules.length; i++) {
/******/ var deferredModule = deferredModules[i];
/******/ var fulfilled = true;
/******/ for(var j = 1; j < deferredModule.length; j++) {
/******/ var depId = deferredModule[j];
/******/ if(installedChunks[depId] !== 0) fulfilled = false;
/******/ }
/******/ if(fulfilled) {
/******/ deferredModules.splice(i--, 1);
/******/ result = __webpack_require__(__webpack_require__.s = deferredModule[0]);
/******/ }
/******/ }
/******/ return result;
/******/ }这个函数关键点似乎是在deferredModules,但是我们刚才webpackJsonpCallback唯一涉及到这个的只有这么一句,并且executeModules其实是没有内容的,所以可以说是空数组。
deferredModules.push.apply(deferredModules, executeModules || []);
既然没有内容,那么webpackJsonpCallback就只能结束函数了。回到主线程,发现下面马上是两句代码,得,又绕回来了。
// add entry module to deferred list
deferredModules.push([0,2]);
// run deferred modules when ready
return checkDeferredModules();
不过现在就有deferredModules这个数组终于有内容了,一次for循环下来,最后去执行我们模块的代码仍然是这一句
result = __webpack_require__(__webpack_require__.s = deferredModule[0]);很熟悉,有木有,最后还是回到了__webpack_require__,然后就是熟悉的流程了
__webpack_require__(1);
module.exports = __webpack_require__(2);
但是当我看到这个内容竟然有这行代码时__webpack_require__(2);还是有点崩溃的。为什么?因为它代码明确直接执行了__webpack_require__(2)。但是2这个模块id是通过在全局属性webpackJsonp获得的,代码不应该明确知道的啊。
我原来以为的运行过程是,每个js文件通过全局变量webpackJsonp获得到公共模块id,然后push到自执行函数传参数组modules。那么等到真正执行的时候,会按照for循环依次执行数组内的每个函数。它不会知道有1,2这种明确的id的。
为什么我会这么想呢?因为我一开始认为每个js文件都是独立的,想交互只能通过全局变量来。既然是独立的,我自然不知道公共模块id是
2事实上,webpackJsonp的确是验证了我的想法。
可惜结果跟我想象的完全不一样,在index1.js直接指定执行哪些模块。这只能说明一个事情,其实webpack内部已经将所有的代码顺序都确定好了,而不是在js文件中通过代码来确定的。事实上,当我去查看index2.js文件时,更加确定了我的想法。
/******/ (function(modules) {/*内容和index1.js一样*/})
/************************************************************************/
/******/ ([
/* 0 */,
/* 1 */,
/* 2 */,
/* 3 */
/***/ (function(module, exports, __webpack_require__) {
__webpack_require__(4);
module.exports = __webpack_require__(2);
/***/ }),
/* 4 */
/***/ (function(module, exports, __webpack_require__) {
var b = 2;
/***/ })
/******/ ]);
//# sourceMappingURL=index2.19eeab4e90ee99ee1ce4.js.map
仔细查看自执行函数的传参数组,发现它的第0,1,2位都是undefined。我们知道这几个数字其实就是每个模块本身的Id。而这几个id恰恰就是index1.js和bundle.js中的模块。理论上来说在浏览器下运行,index2.js应该无法得知的,但是事实却完全相反。
走到这一步,我对webpack打包后的代码也没有特别大的欲望了,webpack内部实现才是更重要的了。好了,不说了,我先去看网上webpack的源码解析了,等我搞明白了,再回来写续集。
单页应用在随着框架的诞生已经是大趋势,自己平时在项目中也已经用了不少vur-router的代码了。用久了自然对其中的实现好奇了起来,于是想着自己能不能做出一个简单的vue-router。一开始扒了源码研究,实在是看不懂。于是从一篇篇文章开始慢慢补充起自己的基础。
如果使用过vue-router的人应该知道,Router插件是通过切换hash值来切换页面的。而浏览器则提供了一个hashchange的回调方法监听的hash值的变化。我们可以就这个原生API实现一个简单的前端路由。
之所以用这个API作为我们第一个出场嘉宾,其好处是可以兼容低版本的IE8浏览器
<a href="#/">home</a>
<a href="#/router1">router1</a>
<a href="#/router2">router2</a>
<div id="content"></div>
--------
class Router {
constructor(router = {}){
this.router = router;
this.init();
}
refresh(){
let url = window.location.hash.slice(1) || "/";
if(this.router[url]){
this.router[url]();
}else{
throw new Error("It isn't a router name that registered");
}
}
init(){
window.addEventListener("hashchange",this.refresh.bind(this),false);
}
}
function changeContent(text){
document.getElementById("content").innerText = text;
}
let router = new Router({
"/"(){
changeContent('home')
},
'/router1'(){
changeContent('router1')
},
'/router1'(){
changeContent('router2')
}
})
当浏览器监听到hash值发生改变之后,自动调用对应路由提供的回调,这样子就出现了一个简单的单页路由demo。
随着HTML5的发布,我们则多了一个新的选择history。
浏览器原生的history对象为我们提供了一些新的方法如下,具体意思基本上也可以做
history.go(); //加载 history 列表中的某个具体页面。
history.back(); //加载 history 列表中的前一个 URL,等同于history.go(-1)。
history.foward(); //加载 history 列表中的下一个 URL,等同于history.go(1)。
history.pushState(state,title,url); //添加一条页面地址记录
history.replaceState(state,title,url); //更新当前的历史地址记录
这里再额外说一句pushState方法和replaceState的区别,从网上找了一张图来表示
pushState()是在history栈中添加一个地址并同时跳往该地址,replaceState()是直接替换当前地址为新地址。
每当你使用pushState()或者replaceState()方法时,会触发popstate事件的回调
然后我们以这两个方法为基础,重新写一个Router的类
<a href="#/">home</a>
<a href="#/router1">router1</a>
<a href="#/router2">router2</a>
<div id="content"></div>
--------
class Router{
constructor(router = {}){
this.router = router;
this.init();
}
route(path,cb){
this.router[path] = cb || function () {
throw new Error("please give a callback");
};
}
refresh(state){
let url = state.path || "/";
if(this.router[url]){
this.router[url]();
}else{
throw new Error("It's not register router");
}
}
route(path,cb){
this.router[path] = cb || function () {
throw new Error("please give a callback");
};
}
init(){
let _this = this;
window.addEventListener("popstate",function (event) {
this.refresh(event.state || {});
}.bind(this))
document.querySelectorAll("a").forEach(a => {
a.addEventListener("click",function (e) {
e.preventDefault();
let path = link.slice(1) || "/";
let link = a.getAttribute("href");
_this.refresh({path : path} || {});
if(e.target.getAttribute("type") === 'replace'){
window.history.replaceState({'path':path},path,e.target.hre;
} else {
window.history.pushState({'path' : path},path,e.target.href);
}
})
},false);
//首次进入路由
let path = window.location.hash.slice(1) || '/';
this.refresh({path : path} || {});
}
}
function changeContent(text){
document.getElementById('content').innerHTML = text;
}
let router = new Router({
'/'(){
changeContent("home");
},
'/router1'(){
changeContent("router1");
},
'/router2'(){
changeContent("router2");
}
})
router.route('/router3',function(){
changeContent('路由3');
})
开坑 -- 2018-1-7
预计结束 -- 2018-1-15
完了,读不完vue-router的源码了
半个月前看到一篇文章将eventEmitter,看完之后心血来潮自己写了一个。晚上睡觉前忽然想到还可以尝试实现vue中emitter。于是,故事就这么开始了。
我们先看一张图,看下EventEmitter需要实现哪些功能
可以看到一个EventEmitter类的内容其实并不杂乱。根据这张图来看,我们大致可以分为以下几个模块。
EventEmitter初始属性
addEventListener模块
emit模块
removeEventListener模块
listeners,eventNames
工具函数和兼容性函数
基本上按照上面这个顺序,就可以写出来一个基本的的eventEmitter的类了。
推荐大家可以先自己尝试写一写,这样子等下看成熟库的源码可以得到的收获更多。
然后去网上找了一个成熟库的源码进行对比,果然发现了一些问题需要改善😳。
点这里。写完之后,可以看下看EventEmitter类源码怎么实现的。
具体代码就不分析了😂😂,稍微对主线讲解一下吧。因为源码并不复杂,沉下心花个半小时肯定能全部看懂。
作者一开始新建一个_events对象,这个对象会在后期存取我们监听器。然后设定了一个监听器允许的最大事件,避免内存泄露的可能性。
function EventEmitter() {
if (!this._events || !Object.prototype.hasOwnProperty.call(this, '_events')) {
this._events = objectCreate(null);
this._eventsCount = 0;
}
this._maxListeners = this._maxListeners || undefined;
}
然后添加事件,在真实场景中,我们会在html中获取需要添加哪些监听器type,和对应的方法listener
function _addListener(target, type, listener, prepend) {
var m;
var events;
var existing;
if (typeof listener !== 'function')
throw new TypeError('"listener" argument must be a function');
events = target._events;
if (!events) {
events = target._events = objectCreate(null);
target._eventsCount = 0;
} else {
if (events.newListener) {
target.emit('newListener', type,
listener.listener ? listener.listener : listener);
events = target._events;
}
existing = events[type];
}
if (!existing) {
existing = events[type] = listener;
++target._eventsCount;
} else {
if (typeof existing === 'function') {
existing = events[type] =
prepend ? [listener, existing] : [existing, listener];
} else {
if (prepend) {
existing.unshift(listener);
} else {
existing.push(listener);
}
}
}
return target;
}
当我们事件添加完毕之后,则是通过emit进行调用
EventEmitter.prototype.emit = function emit(type) {
var er, handler, len, args, i, events;
events = this._events;
if (events)
doError = (doError && events.error == null);
else if (!doError)
return false;
handler = events[type];
if (!handler)
return false;
if (isFn) handler.call(self);
else {
var len = handler.length;
var listeners = arrayClone(handler, len);
for (var i = 0; i < len; ++i)
listeners[i].call(self);
}
}
return true;
};
主线代码就这样,更多细节我是真的推荐大家全看源码的。因为这400多行的代码真的不复杂。反倒是源码中间还是有很多细节可以值得细细品味的。
我们可以看到网上许多库(比如vue)都是使用Object.create(null)来创建对象,而不是使用{}来新建对象。这是为什么呢🤔?
Object.create()这个API我就不介绍了,不清楚的推荐上MDN先了解一下
我们可以先在chrome的控制台上打印Object.create({})创建的对象是什么样子的:
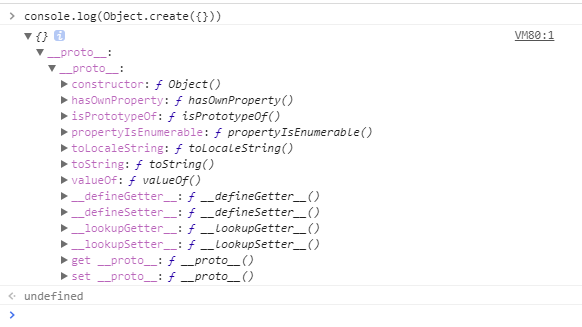
可以看到新创建出来的对象继承了Object原型链上所有的方法。
我们可以再看一下使用Object.create(null)创建出来的对象:

没有任何属性,显示No properties。
区别很明显,我们获得了一个非常纯净的对象。那么问题来了,这样对象有什么好处呢🤔?
首先我们需要知道无论是var a = {}还是Object.create({}),他们返回的对象都是继承自Object的原型,而原型是可以修改的。但是假如有别的库或者开发者在页面上修改了Object的原型,那么你也会继承下来修改后的原型方法,这个可能就不是我们想要的了。
随手在一个csdn的网页控制台写个例子,没想到就出现这个问题
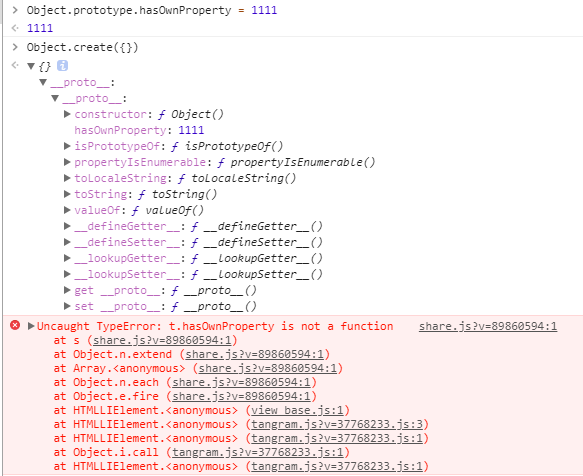
而如果我们自己在每个库开头新建一个干净的对象,我们可以自己改写这个对象的原型方法进行复用和继承,既不会影响他人,也不会被他人影响。
在源码中看到了这么一段代码,作者亲自打了注释说1.5倍速度快于原生。
// About 1.5x faster than the two-arg version of Array#splice().
function spliceOne(list, index) {
for (var i = index, k = i + 1, n = list.length; k < n; i += 1, k += 1)
list[i] = list[k];
list.pop();
}
splice的效率慢我是知道,但是作者说1.5倍快我就要亲自试验下了。
看他方法,缺陷应该是数组长度越长,所需时间越长;下标越靠近开始,所需时间越长。于是我用了不同长度的数组,不同下标去进行反复测试100次。
// 测试的代码是这么写的,如果不合理请指教
var arr = [];for(let i = 0;i < 50000;i++){arr.push(i)}
console.time();
spliceOne(arr,1)
// arr.splice(1,1)
// arr.splice(49995,1)
// spliceOne(arr,49995)
console.timeEnd()
//在数据长度是5的情况下,下标为1,splice效率快33%
//在数据长度是500的情况下,下标为1,splice效率快75%
//在数据长度是50000的情况下,下标为1,splice效率快95%
//在数据长度是5的情况下,下标为4,spliceOne效率快20%
//在数据长度是500的情况下,下标为45,spliceOne效率快50%
//在数据长度是50000的情况下,下标为49995,spliceOne效率快50%
因为源码是针对node.js的,不知道是不是浏览器内部对splice做过优化。作者的方法在特定情况下的确是做到了更快,还是很厉害的。👍👍👍🤕
源码作者专门为emit不同数量参数写了不同的方法,有emitNone,emitOne,emitTwp,emitThree,emitMany。
如果按照我来写,最多也就分成emitNone和emitMany两个方法。但是作者应该是为了更高的效率,尽可能减少for循环这种代码。这也是我这种不怎么写库的人迟钝的地方。节约的十几行代码在压缩之后,重要性是低于性能上的损耗的。
在写完EventEmitter之后,仍然感觉特别单调。然后睡觉的时候忽然在想,是不是可以正好将自己写好这个类套进到vue里面呢?有了实际场景,就知道自己写的东西到底能干什么,有什么问题。不然空有理论也是没有任何进步的。
之前网上也有很多文章解析了vue如何实现双向绑定。事实上在编译html的过程中实现了的不仅仅是数据双向绑定,添加事件监听器也是这一过程做的。只是网上关于事件监听的文章却几乎没有。
按照我一开始的想法,应该是先编译HTML获取所有的属性,判断出哪些属性是绑定事件,哪些是数据绑定。
<template>
<div id="app" :data="data" @click="test" @change="test2">test内容</div>
</>
<script>
var vue = {
methods: {
test(){alert(123)},
test2(){console.log(456)}
}
}
var onRE = /^@|^v-on:/;
function compile(node) {
var reg = /\{\{(.*)\}\}/;
//节点类型为元素
if(node.nodeType === 1){
var attr = node.attributes;
for(var i = 0;i < attr.length; i ++){
console.log(attr[i])
}
}
}
compile(window.app)
</script>
于是自己先写出了第一段代码,希望依靠原生node的方法attributes去获取DOM元素上所有的属性
但是等到获取之后,才发现获取到的每个属性attr[i]竟然是一个神奇的对象类型[object Attr],表现形式是@click=test。虽然表现很像是字符串,但是个 NamedNodeMap。靠根本不知道怎么用嘛😂😂😂
去网上找了资料之后,才知道他是怎么获取key和value的。
var onRE = /^@/;
function compile(node) {
var reg = /\{\{(.*)\}\}/;
//节点类型为元素
if(node.nodeType === 1){
var attr = node.attributes;
for(var i = 0;i < attr.length; i ++){
if(onRE.test(attr[i].nodeName)){
var value = attr[i].nodeValue;
}
}
}
}
compile(window.app)
只是文章里面说DOM4规定中已经不推荐使用这个属性了😢ㄟ( ▔, ▔ )ㄏ。想了想放弃了,还是乖乖去看了一下vue的源码是怎么实现的吧。
因为想着vue肯定也是先编译HTML,所以直接找到了源码中的html-parse模块。
vue先定义了一个parseHTML的方法,传进来需要编译的html模板,也就是我们的template。然后通过一个属性正则表达式一步步去match出模板字符串内的所有属性,最后返回了一个包含所有属性的数组attrs。
然后vue会对得到的数组attrs进行遍历判断,这个属性是v-for?还是change?还是src等等。当获取到的属性为@click或者v-on:click这种事件之后,然后通过方法addHandler去添加事件监听器。我们也就可以在开发中使用emit了。
当然vue中间还会有很多操作。比如会接着将这个属性数组以及tag传入到一个
createASTElement函数里面进行生成一棵AST树渲染成真实的dom等等。只不过这并不是我们本篇文章需要讨论的内容了
我们接下去就按照vue的流程来实现绑定事件。首先我们定义好我们的html内容。
<template>
<div id="app" :data="data" @click="test" @change="test2">test内容</div>
</>
<script>
var vue = {
data(){
return {data:1}
}
methods: {
test(){alert(123)},
test2(){console.log(456)}
}
}
</script>
在我们就要开始进行编译之前,我们准备好所有需要用到的正则,新建好一个eventEmitter类
var attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/;
var ncname = '[a-zA-Z_][\\w\\-\\.]*';
const qnameCapture = `((?:${ncname}\\:)?${ncname})`
const startTagOpen = new RegExp(`^<${qnameCapture}`)
var startTagClose = /^\s*(\/?)>/;
var onRE = /^@|^v-on:/;
var eventEmitter = new EventEmitter()
const app = document.getElementById("app")
然后开始写我们的编译函数。前面已经说了,我们传进模板,然后依据正则一步步match出所有的属性.
function compiler(html){
html = trim(html) //因为模板换行有空格,所以需要先去除开头的空格
let index = html.match(startTagOpen)[0].length
html = html.substring(index)
const match = {
attrs: [],
attrList: []
}
let end, attr;
//编译完整个html标签
//如果多层dom,vue有循环,但是测试就不搞那么复杂了
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
match.attrs.push(attr)
index = attr.length
html = html.substring(attr[0].length)
}
return match
}
解释一下编译过程吧。先根据开头标签的正则,找到需要编译的html。然后截取出除开始标签<div的剩余字符串。
接下来继续对字符串判断。依靠属性正则表达式,判断这段html标签内有没有属性,如果有的话,从字符串中截取(类似于splice效果)出来。
继续不断循环字符串,直到遇到闭合标签/div>为止。然后结束编译,返回数组。
编译完成后我们已经获取到了模板里面所有的属性,但是现在存储起来的属性表现形式是一个match出来的数组,并不是一个方便开发者使用的map形式。所以接下来我们要处理一下我们获得的数组。
function processAttrs(match){
let l = match.attrs.length
for (var i = 0; i < l; i++) {
var args = match.attrs[i];
// hackish work around FF bug https://bugzilla.mozilla.org/show_bug.cgi?id=369778
if (args[0].indexOf('""') === -1) {
if (args[3] === '') { delete args[3]; }
if (args[4] === '') { delete args[4]; }
if (args[5] === '') { delete args[5]; }
}
var value = args[3] || args[4] || args[5] || '';
match.attrList[i] = {
name: args[1],
value: value
};
}
return match
}
通过这一步,我们已经获取到了一个attrList,并且存储起来了一个个表现为map形式的属性。然后我们要遍历这些属性,判断哪些是需要绑定的方法,哪些使我们不需要的属性。如果是需要绑定的方法,我们通过addHandler函数来添加事件监听器。
function processHandler(match){
let attrList = match.attrList, l = attrList.length
let name, value
for(let i = 0; i < l; i ++){
name = attrList[i].name
value = attrList[i].value
if(onRE.test(name)){
name = name.replace(onRE, '');
addHandle(vue, name, value, false);
}
}
}
function addHandle(target, name, value, prepend){
let handler = target.methods[value]
eventEmitter.addListener(name, handler, prepend)
eventEmitter.emit("click")
}
走到这里整个流程就已经结束了。接下去每次进入页面去进行初始化编译就好了。
function parseHTML(html){
const match = compiler(html)
processAttrs(match)
processHandler(match)
}
如果想尝试触发我们之前绑定的事件,在vue中是子组件向父组件触发。这里就不搞父子组件这么麻烦了。我们可以直接在JS里面调用emit来进行验证
eventEmitter.emit("click")
文章结束了,日常总结一下吧。实现整个eventEmitter的代码其实并不复杂,尤其在源码非常简洁的情况下,基本上认真看个十几分钟就能明白整个轮廓。~~然后我没有仔细看vue中的实现是怎么样的,不过我猜测应该相似度很高。~~过了一个星期去看了一下vue的代码,内部实现4个模块emit,off,on,once。其中代码并没有像我们的eventEmitter一样细致到参数数量的区别对待,也能理解,毕竟人家主要实现框架功能。
vue的event源码位置在eventsMixin(src/core/instance/events.js)
后面看vue提取属性还是花了更多的时间,原来还以为可以自己通过attribute属性来实现的。没想到最后还是参考了vue,再看的途中,也明白了vue编译html的整个过程,以及每个过程实现了哪些内容。
其实看源码可以学到的东西都很多,最直接的就是知道怎么实现一个功能。此外呢?其实此外是是更多的。比如编码习惯,比如防御性代码怎么写,比如结尾处理代码怎么写,比这不就看到有方法比原生API的效率还快。这些都是看源码的乐趣所在。
看完之后,以后妈妈再也不用担心面试考eventEmitter了
为什么要强调前端篇,因为看到有一部分技术文章更是讲到了硬件方面的知识,因为自己目前能力有限,所以更着重于前端这一块。
到现在也看了许多的技术文章了,今天第一次下笔写文章,主要是为了加深自己这方面的印象,二来指不定在自己写的过程中会遇到一些自己以前没有注意过的新问题。
当用户在网址栏输入信息的时候,当用户输入url时,浏览器会从本地地址中调取缓存的历史记录,来减少用户需要输入的文字。还有一种情况是输入非url时,类似于chrome浏览器,它会将你输入的字符进行转换为非ASCII码的Unicode字符作为后缀添加在url后面进行搜索。
由于用户更擅于记住域名和主机名,而计算机更擅于处理一组纯数字的IP地址,这时DNS服务则应运而生。DNS协议提供通过域名查找IP地址或逆向IP地址反查找域名的服务。
当用户确认输入好之后信息后,点击回车确认,浏览器首先会从本地DNS缓存(chrome://net-internals/#dns)中读取当前网址所对应的域名;如果缓存中没有找到,则去本机中的gethostbyname库函数进行查询(不同操作系统中的函数不同),会在本机host文件中查看是否有对应的域名;如果gethostbyname库没有找到,则会向本地DNS服务器发一条DNS查询请求,通常是在缓存在本地路由器或运营商的服务器;如果还没有找到,则会一直向上寻找从运营商服务器到全球最顶部13台dns根域名服务器,然后依次返回到本机。(好像亚洲唯一一台在日本,不知道是不是几年第一个浏览器页面在日本诞生,瞎猜猜)
由于早期的 DNS 查询结果是一个512字节的 UDP 数据包。这个包最多可以容纳13个服务器的地址,因此就规定全世界有13个根域名服务器,编号从a.root-servers.net一直到m.root-servers.net。但是为了保证根域名服务器的可用性,服务器运营商会部署多个节点。所以,根域名服务器其实不止13台。据统计,截止2016年1月,全世界共有 517 台根域名服务器
当用户获得域名之后,主机开始发送TCP/IP请求,即经典的三次握手。
第一次握手。第一次向服务器发送码SYN=1,随机产生一个seqnumber(sequence number)码(1234567),表示请求建立连接;
第二次握手。当服务器接收到确认联机的信息后,向主机发送一个ACKnumber=(主机的seqnumber+1),SYN(synchorinize)=1,ACK(acknowledgment)=1,并随机产生一个seqnumber=(7654321)的包。
第三次握手。主机会检查收到acknumber是否正确,即是否为第一次发送的seqnumber+1,一级ACK码是否为1,主机如果收到SYN和ACK都为1则表示确认连接。
完成三次握手,主机开始与服务器发送数据。如果在这三次握手中任何一个环节出了问题,TCP协议会再次以相同的顺序发送数据包。当然除了3次握手,TCP协议还有其他各种手段保证通信的可靠性。
这里涉及到一个知识点,就是为什么要三次而不是两次握手。看过几篇文章的表述,用自己理解的语言来说下。关键是在于第三次请求,假设第三次请求因为某些原因没有及时发送到服务端,而服务端再过了一段时间之后才获取到这个延迟请求,会将此误认为一个新的连接请求,但实际上这并不是一个新的运输连接。结果服务器苦苦等着客户端不可能发送过的数据,从而浪费了许多服务器资源。而如果有了三次握手,服务端如果不收到第三次请求,就知道客户端不会发送请求。
当文件传输完毕后,浏览器开始渲染页面。这里浏览器有一个渲染引擎,即我们常说的各种浏览器内核,比如Safari的webkit,chrome的Blink,IE的edge,另外一个则是js引擎,例如有chrome的V8引擎,IE的EdgeJScript,FireFox的SpiderMonkey(firefox的第一款引擎世界的第一款引擎,js之父所写)。
服务器和客户端都可以发出中断请求
当一个请求发完之后,则开始了四次挥手。
第一次挥手:由服务器先发送了一个FIN码,随机产生一个序号i,用来关闭主动方到被动方的传输,告诉主机我不会再给你发送数据了(当然在FIN码发送之前发出去的数据,如果没有收到对应的ACK确认报文,则依然会重发这些数据)。此时主机仍然在可以接受数据
第二次挥手:主机收到FIN码之后,发出一个ACK给服务器,确认序号为收到序号i+1(与SYN相同,一个FIN占用一个序号)
第三次挥手:被动关闭方发送一个FIN码,用来关闭被动方和主动方的数据连接,也就是告诉主动关闭方,我的数据已经发送完了,不会再给你主动发送数据了。
第四次挥手:主动关闭方收到FIN码之后,发送一个ACK给被动关闭方,确认序号为收到序号i+1。至此,完成4次挥手
用我自己的理解来说就是,
(1) 客户端发出一个FIN码,产生一个序号i用来关闭主动到被动方的数据连接,
(2) 服务器收到一个FIN码后,它发回一个ACK,确认序号为收到的序号i+1,
(3) 服务器关闭了被动关闭方和主动关闭方的数据连接,并发送一个FIN码给主动关闭方
(4) 客户端收到确认的ACK报文后,并将确认序号设置为收到序号i+1
这里有一个问题在于为什么挥手比牵手多了一次动作。我的理解就是多了一个关闭连接的操作。互相不发送数据是半关闭,互相关闭连接是真正关闭。
首先开始根据html文件开始构建最初的DOM树,然后根据获取的css文件的样式表,形成CSSOM,这时候结合dom和CSSOM,创建出来一颗渲染树。在渲染树中,每一个字符串都是一个独立的渲染节点,每一个渲染节点都是经过计算的,叫做布局("layout")。如果此时获取到js文件并开始执行时,渲染过程则会停止(渲染和执行js不能同时执行)。在js执行过程中,会有相关代码会导致浏览器的重绘(repaint)和回流(reflow),这是首屏渲染应该注意的地方。
众所周知,现在许多提高页面性能的方法都是有一条都是减少dom的操作,而dom操作影响的直接结果一般都是说dom的变化引起了dom结构的改变,导致了页面的重排,这个引起的过程可以叫做回流。引起回流的情况有许多,列几项典型举例下:
常见的优化方法网上也是一搜一大堆,不过大多数方法核心点是在于尽可能减少直接影响的次数,列几项典型举例下:
幸运的是现代浏览器引擎有时候会积累足够的变化,或一定时间,或一个线程结束才发生一次变化。不过好的规范应该在编写代码时就注意到。
咦,好像写完了,感觉不会那么少啊,以后想起来再来继续补充吧
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
