librarycarpentry / lc-fair-research Goto Github PK
View Code? Open in Web Editor NEWLibrary Carpentry: FAIR Data & Software
Home Page: https://librarycarpentry.org/lc-fair-research
License: Other
Library Carpentry: FAIR Data & Software
Home Page: https://librarycarpentry.org/lc-fair-research
License: Other

































































The challenge below is taken from the Sprint GoogleDoc.
Activity suggestion:
Pick an article using Crossref API to view the metadata (e.g. http://api.crossref.org/v1/works/10.1371/journal.pone.0237703).
Alternative: Check the metadata of a Zenodo Record (which uses DataCite).
How could we improve the metadata?
Solution:
Trick: To visualize more clearly the JSON results of Crossref API in the browser, use a browser extension such as JSONview
Is anyone interested in expanding on these exercises and reviewing them? You could also add them to the main lesson under Findable. Don't forget to add the solution to the lesson.
Don't forget to check out the comments in the google doc.
Any further comments on these challenges please add them to this issue!
If your Maintainer team has decided not to participate in the June 2019 lesson release, please close this issue.
To have this lesson included in the 18 June 2019 release, please confirm that the following items are true:
When all checkboxes above are completed, this lesson will be added to the 18 June lesson release. Please leave a comment on carpentries/lesson-infrastructure#26 or contact Erin Becker with questions ([email protected]).
This is a suggestion for all lessons: when citing articles, datasets, or other research objects, let's use their persistent identifiers when they have one.
As a follow-up to #11, lesson contributors should be requested to use persistent identifiers (PIDs) to articles, datasets and other research objects.
I suppose (and suggested in #38 (comment)) that the pull request template has a message or checklist item reminding authors to use PIDs or that an automatic check is run on the contents.
Consider the utility of creating a public zotero library and exporting it to a bibliography page in this lesson under the Extras menu.
@zkamvar
We need to update style for this lesson so that jump lists (anchors for different sections) becomes automatically available for different levels of headings.
Please see TIBHannover/2018-07-09-FAIR-Data-and-Software#10 for a discussion of whether to transfer it somewhere, maybe here, or keep on developing it as Google Slides.
Learning objectives are the highest level and focus on what the learner will learn.
Learning objectives are the highest level and focus on what the learner will learn.
I wanted to open this up for discussion before anyone started work on it: the Introduction episode references the "research lifecycle" and then uses this illustration which instead calls it the "scientific lifecycle". Given the generally narrower usage of the word "science" in English (usually referring to only the natural sciences) than other European languages (where it is mostly a proper synonym for "research"), should we change "science" to "research" here? Or perhaps clarify our definition of "science"?
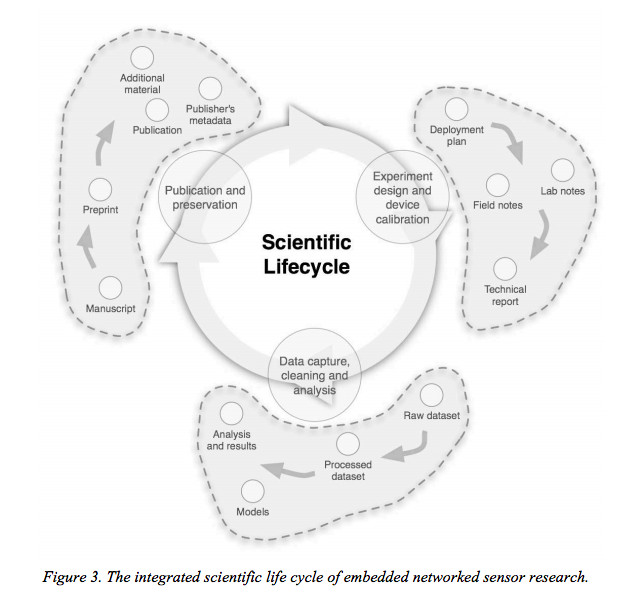
In light of the myriad of "Research Data Life cycle figures" available including https://www.dcc.ac.uk/guidance/curation-lifecycle-model
I would like to create one specifically for this lesson and would, therefore, like to ask you to add what you think is should be included under the following themes:
1- Planning:
2- Managing:
3- Sharing
4- Preservation and Publication
Please feel free to edit/add as you see fit.
Learning objectives are the highest level and focus on what the learner will learn.
For episode 2, Findable (https://librarycarpentry.org/lc-fair-research/02-findable/index.html), here is some suggested text for “Choosing the right repository”
Funding agencies are another resource for recommendations on choosing a data repository. National Institutes of Health, for example, provides a list of Open Domain-Specific Data Sharing Repositories
Journals may also have requirements specifying which data repositories are to be used for sharing data associated with a published article. For example, the author guidelines for Systematic Biology state that "All data files and online-only appendices should be uploaded to Dryad", and "All nucleotide sequence data and alignments must be submitted to GenBank or EMBL before the paper can be published. In addition, all data matrices and resulting trees must be submitted to TreeBASE."
Learning objectives are the highest level and focus on what the learner will learn.
The idea below is taken from the Sprint GoogleDoc.
Is anyone interested in expanding on these exercises and reviewing them? Don't forget to add the solution to the lesson.
Don't forget to check out the comments in the google doc.
Any further comments on this exercise please add them to this issue!
Learning objectives are the highest level and focus on what the learner will learn.
[…] collection of guiding principles to make data Findable, Accessible, Interoperable, and Re-usable. This module provides a number of lessons to ensure that a researcher’s data is properly managed and published to ensure it enables reproducible research.
The original repo is a bit sleepy, but I worked in two different forks on some minor fixes and a new exercise. Please see the little bubbles on https://github.com/ReproNim/module-FAIR-data/network.
The challenges below are taken from the Sprint GoogleDoc.
Challenge 1:
arXiv is a preprint repository for physics, math, computer science and related disciplines. It allows researchers to share and access their work before it is formally published.
Go to arXiv and
Does arXiv use a DOI?
Compare these two papers:
https://arxiv.org/abs/2008.09350
https://arxiv.org/abs/2008.00287
which one of them has a persistent identifier?
Challenge 2:
Look at this paper [link]. Click on the ‘pdf’ link to download it. Do a full-text search by using control + F or command + F and search for ‘http’. Did the author use DOIs for their data and software?
Challenge 3:
What is the problem with referring to your code and software only with a URL [example] without providing a DOI?
Is anyone interested in expanding on these exercises and reviewing them? You could also add them to the main lesson under Findable. Don't forget to add the solution to the lesson.
Don't forget to check out the comments in the google doc.
Any further comments on these challenges please add them to this issue!
Some of us teach postgraduate students and researchers, some of us teach librarians, some of us teach data stewards and people supporting research infrastructure.
We know that it's good to have a crossover audience who can inform each other, but without detailed knowledge of our different learner profiles, it's difficult to diagnose exactly the problems we want to fix.
Fleshing out learner personas will help us understand our target audience and better understand which activities are best going to suit them.
Hi @maneesha can you create a lesson team for the FAIR lesson and invite:
Thanks!
Here are some resources that are reusable that will complement the licenses episode.
To be added here: https://github.com/LibraryCarpentry/lc-fair-research/blob/gh-pages/_episodes/06-licenses.md
Learning objectives are the highest level and focus on what the learner will learn.
The FAIR principles were originally developed for research data: discussions as to how (or even if) they apply to software are still ongoing in the wider research community. Issue raised by @nehamoopen during a Zoom call.
Two suggestions were made:
Learning objectives are the highest level and focus on what the learner will learn.
The challenge below is taken from the Sprint GoogleDoc.
ORCID + DOI Autoupdate.
Suggestion:
Register for an ORCID account and activate it if you don't have one (if you don't want to have an official ORCID iD, you can also use the Sandbox environment https://sandbox.orcid.org/)
Apply desired privacy settings to the data in your ORCID profile
Use the Search & Link Tool/Wizard to connect your ORCID with Crossref Metadata Search and DataCite. See if there're already works authored by you that you can import from the wizard.
Upload a work (e.g. your most recent presentation) to Zenodo or Figshare (both use DataCite DOIs). Remember to fill in the metadata correctly and add your ORCID iD to it.
Wait a couple of minutes to see the work appearing in your ORCID Record.
Comment: Zenodo mints a DOI for each uploaded version and another one for the complete collection of version. If we only upload one work, it looks like if two DOIs were minted for the same object. This leads to a duplicate in the ORCID Record, but can be seen as an opportunity to explain the "combine" option in ORCID. https://orcid.org/blog/2020/06/18/new-features-alert-combining-work-items
Is anyone interested in expanding on these exercises and reviewing them? You could also add them to the main lesson under Findable. Don't forget to add the solution to the lesson.
Don't forget to check out the comments in the google doc.
Any further comments on these challenges please add them to this issue!
This exercise example is specific to interoperability of oceanographic data, if that is appropriate.
Using the data server ERDDAP, along with the Climate and Forecast conventions, combine temperature data from multiple sources and make a profile or timeseries plot.
Maybe building off this example jupyter notebook, but reducing some of the complexity with xarray and the various functions introduced.
The idea below is taken from the Sprint GoogleDoc.
Is anyone interested in expanding on this exercise and reviewing it?. Don't forget to add the solution to the lesson.
Don't forget to check out the comments in the google doc.
Any further comments on this, please add them to this issue!
Only the "Findable" lesson has questions listed. These might need review and questions need to be added for the other lessons as well.
The links in this line item in CONTRIBUTING.md are broken.
If you wish to change this lesson, please work in https://github.com/swcarpentry/FIXME, which can be viewed at https://swcarpentry.github.io/FIXME.
Determining learning objectives will help how the content on each page is shaped.
Learning objectives could be drawn from any number of existing FAIR training materials.
The Reference page under "Extras" is a useful lesson tool, but requires all the episodes to have clear key points to draw from.
It could also be useful to rename "References" to Glossary, to avoid confusion with any user expecting a bibliography or list of references.
In the first sentence under "Description" on page https://librarycarpentry.org/Top-10-FAIR//2019/09/09/nanotechnology/, the word "interoperability" is currently misspelled as "interopera_bility" and should be fixed.
I'm a member of The Carpentries Core Team and I'm submitting this issue on behalf of another member of the community. In most cases, I won't be able to follow up or provide more details other than what I'm providing below.
I would like contribute to the new FAIR Data lesson as part of the checkout process:
https://librarycarpentry.org/lc-fair-research/01-introduction/index.html
I've read the whole lesson and I believe it is very well done already.
My suggestion: In the penultimate section of the Introduction "How does "FAIR" translate to your institution or workplace?" the first question goes: "Does your institutional data management policy refer to FAIR principles?"
· There are many research institutions and libraries that do not yet have a data management policy and/or might not be planning to get one in the near future so this question could alienate some participants. It would be better to change the wording to something along the lines of: "If your institution has a data management policy, does it refer to the FAIR principles?" OR "Does your institution have a data management policy that refers to the FAIR principles?"
I'm a member of The Carpentries staff and I'm submitting this issue on behalf of another member of the community. In most cases, I won't be able to follow up or provide more details other than what I'm providing below.
I noticed that in the lesson https://librarycarpentry.org/lc-fair-research/07-assessment/index.html under the "Planning" section there was a heading for Data and Software Management Plans, but no supporting text or links. I would like to recommend the following text and links as resources for Data Management Plans:
Here are two sites that help you create Data Management Plans
DMPonline - https://dmponline.dcc.ac.uk/
DMPTool - https://dmptool.org/
Many organizations and funding agencies provide sample Data Management Plans. For example, the Inter-university Consortium for Political and Social Research (ICPSR) provides a sample data plan for data deposited in its repository - https://www.icpsr.umich.edu/web/pages/datamanagement/dmp/plan.html.
@Karvovskaya and I wanted some feedback on the exercises for the Findable episode before we start fleshing it out. Suggestions for improvement, incl. how to do them totally differently are welcome!
I've organized the exercises according to the (sub-)principles for some structure.
F1: (Meta) data are assigned globally unique and persistent identifiers / DOIs
Challenge 1:
Compare these two papers from arXiv - a preprint repository for physics, math, computer science, and related disciplines which allow researchers to share and access their work before it is formally published:
https://arxiv.org/abs/2008.09350
https://arxiv.org/abs/2008.00287
Which one of them has a persistent identifier?
Challenge 2:
Look at this paper [link to be included]. Click on the ‘pdf’ link to download it. Do a full-text search by using control + F or command + F and search for ‘http’. Did the author use DOIs for their data and software?
Challenge 3:
What is the problem with referring to your code and software only with a URL [example to be included] without providing a DOI?
F2: Data are described with rich metadata
F3: Metadata clearly and explicitly include the identifier of the data they describe
We could provide an exercise where a dataset/software is provided, and learners have to extract + fill out metadata fields based on that? If possible, it would be nice to allow for ‘correctly’ typed answers only - so no typos, etc. because those little errors affect the links between content.
Example exercise for inspiration: https://sites.uwm.edu/dltre/metadata/exercises/
The depth of this exercise can range from something simple like the three images in the previous link, or we could have sample exercises that follow specific schemes/standards like DDI, DataCite, discipline-specific standards.
Also, this is what is currently on the lesson website: Automatic ORCID profile update when DOI is minted RelatedIdentifiers linking papers, data, software in Zenodo
F4: (Meta)data are registered or indexed in a searchable resource
Perhaps we could use Zenodo’s Sandbox for learners to ‘upload’ the data + metadata?
We could also provide some example datasets/software and have learners select the most appropriate (discipline-specific) repository from a list we give them/they can search for the repo themselves.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.