Recommender-Hadoop
Writing scalable recommender system with Hadoop. Implementation of very simple "people we might know" recommender algorithm on Apache Hadoop
Our first try on making People you might know feature of facebook on Apache Hadoop and sorting the recommended friends based on the number of mutual friends they have.(From highest to lowest)
####Our graph contains the input file with the first character of every line as source and the following characters as their neighbors connecting them.
#####Note that if there's a node from A to B then there's a node from B to A also.
Our Input File
A B
B A D C
C B D E I
D B C H
E C G F
F E H
H F D I
G E
I C H
Note - I have created 2 Mappers and Reducers and we run 2 jobs and the output of the first job becomes the input of the next job.
The Input file and the First Job Running:
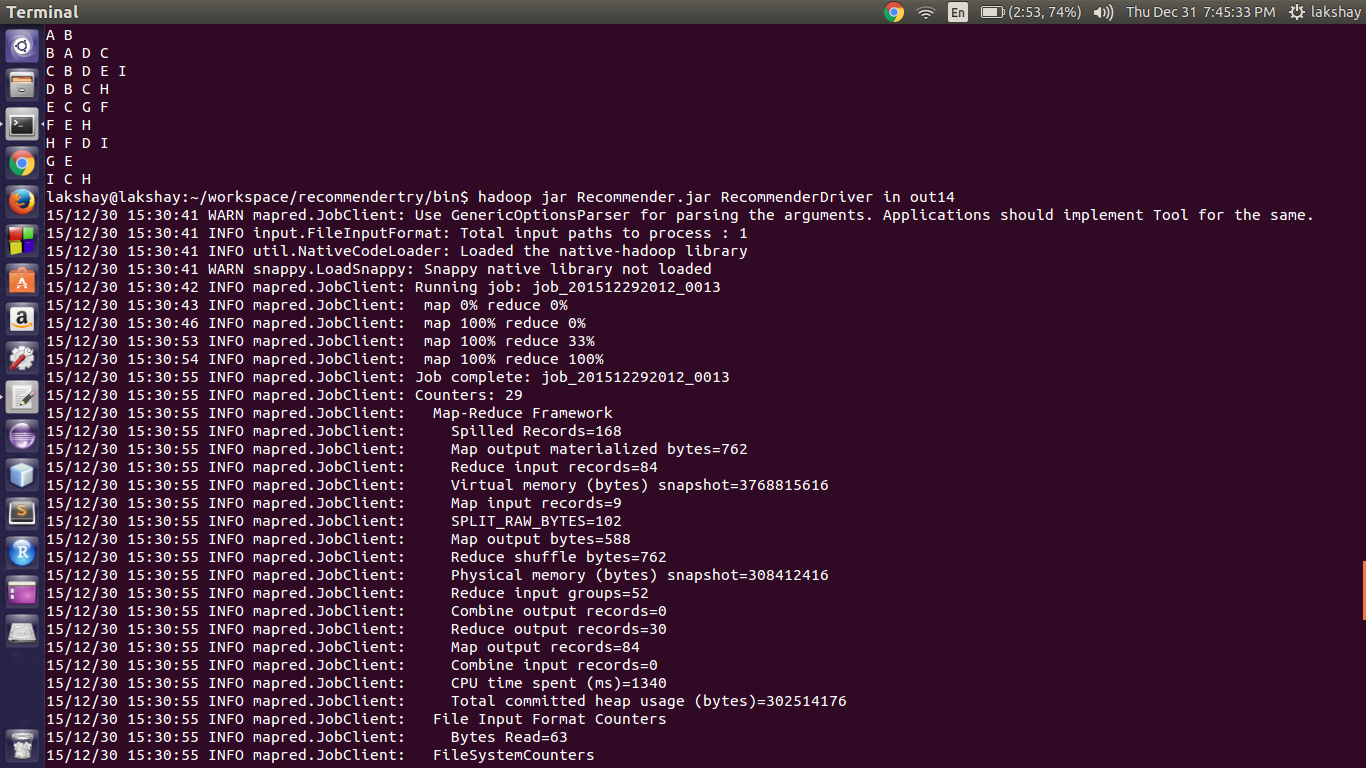
so the Output of the first Reducer is this:
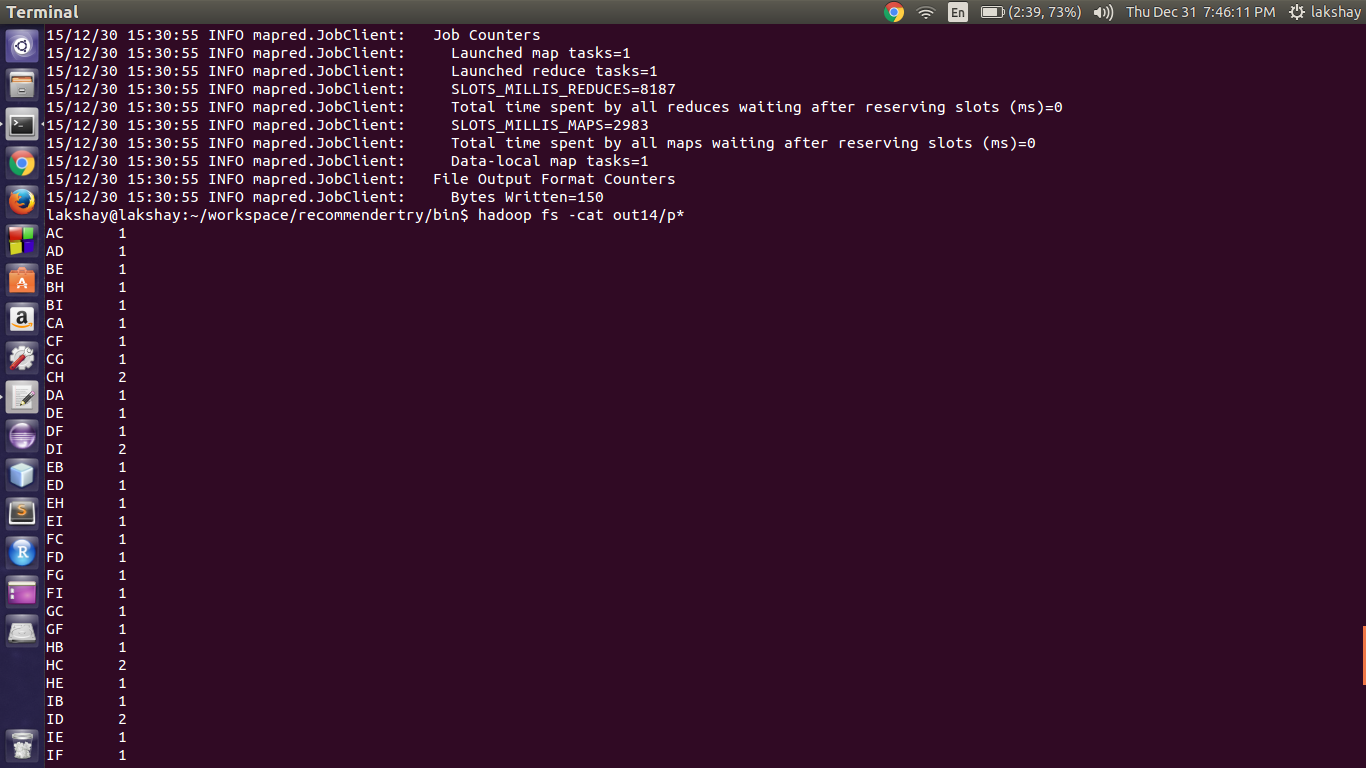
This output becomes the input to the Second Mapper
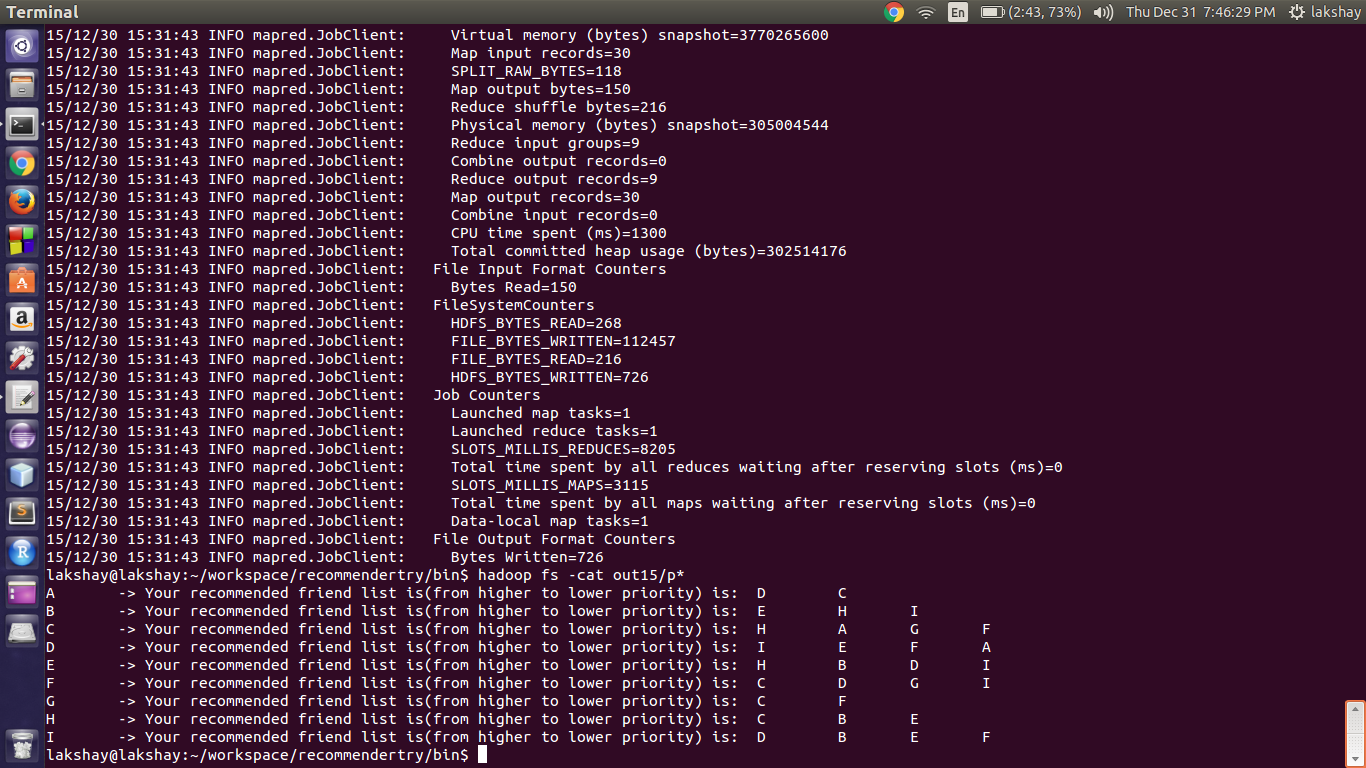
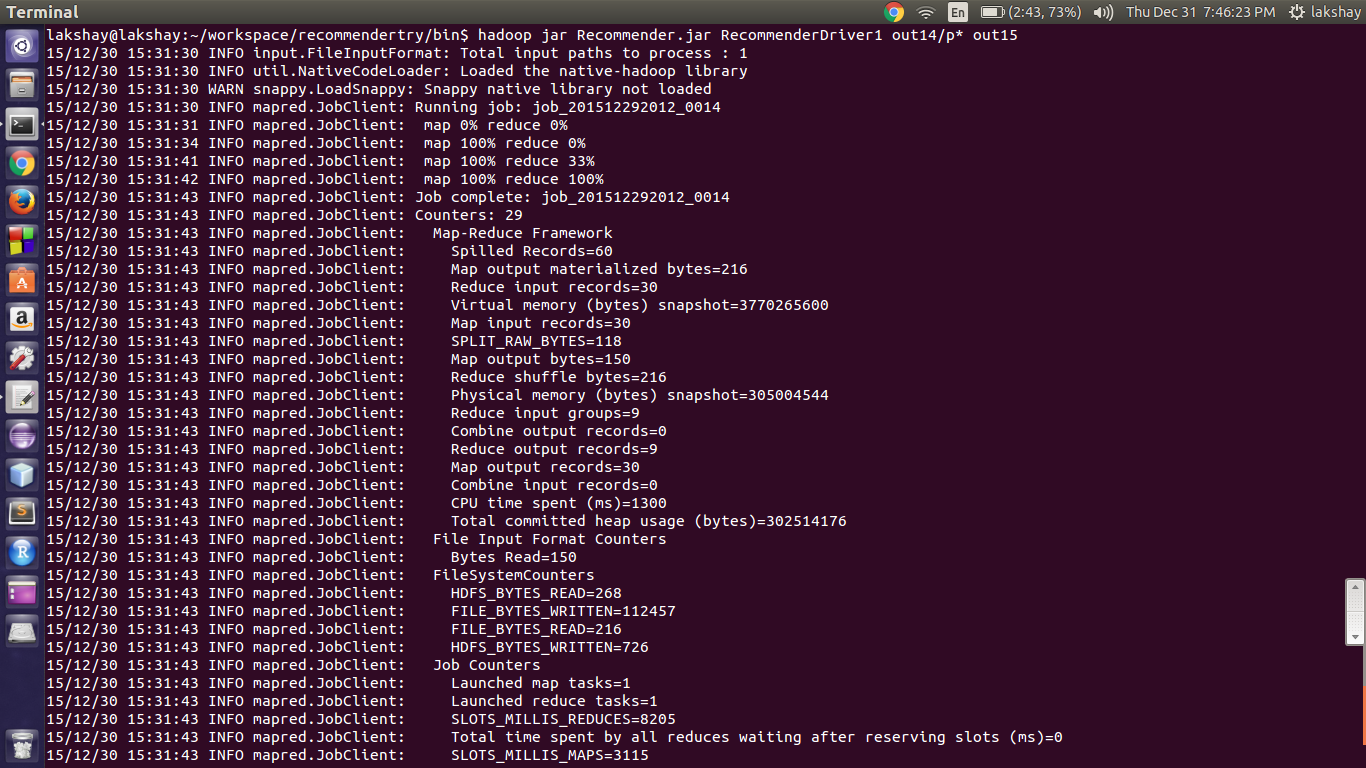
In our case the output of the first Map Reduce job is contained in out14/part-r-00000 and we give the same file as the input to the next mapReduce job and the output file of the next Mapreduce job is out15
Now running the second MapReduce job by writing the command ** hadoop jar Recommender.jar RecommenderDriver1 out14/p* out15**
Note that the jar file name is Recommenderand the name of the driver class of the second MapReduce job is RecommenderDriver1.
##Output of the Job
The Output of the Recommender System suggest us the list of friends with whom I am not a friend and can be friend with. The list of friends are sorted in the order with the highest number of mutual friends between the two friends to the lowest.