RATS: Realtime Ad Target System. A data pipeline that ingests real time social media comment data and processes it with real time SQL queries.
In this project I :
- Implemented a data pipeline called RATS : Real time Ad Target System on AWS.
- Selected best posts to place ads on a stream of reddit.com comment data for selected target categories.
- Ingested more than 1 Tb of data through Kafka and then processed it with Spark Structured Streaming to implement SQL queries on real time data with 600 ms latency.
- Leveraged kafka consumer groups and multiple partitions to increase writes by more than 3 times and reduced latency by a factor of 10 by tuning spark.
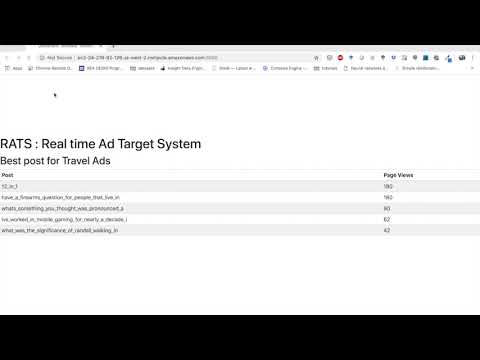
Video of the system demo here: Shows the posts with the highest page views updated in real time.
Setup cluster with pegasus on AWS.
Create a VPC
Create a public subnet within the VPC for 11 instances ( remember to increase the Elastic IP limit)
Install virtual environments on instances with python3, Tmux and kafka-python
Cluster specs :
-
Kafka cluster - 4 nodes m4.large
-
Spark cluster - 1 master, 4 slaves m4.2xlarge
-
PostgreSQL instance m4.xlarge
-
Instance for running producer and consumer m4.4xlarge
Real time ad bidding industry requires high throughput pipelines that can process social media or user web session data with ultra low latencies. In this project I designed a pipeline to process real time streams of social media comment data to figure out the best place to post ads.
Data is ingested through AWS S3 by a python producer into a Kafka topic. This data is then fed to Spark Structured Streaming for aggregation using Real time Spark SQL queries. The data is ingested into a new Kafka topic and then python consumers write the data to a PostgreSQL database.

Reddit.com comment dataset downloaded from Pushshift
Each month dataset is ~ 8 GB compressed and 150 GB uncompressed.
Each comment is stored in json format with the multiple keys of which following are used:
- post
- subreddit
- body
- timestamp
- author
A wildcard is used to filter for certain words on the body of the comment. In the following example, I use a few handpicked keywords to filter for Travel ads. The keywords could be improved by analyzing the user click behaviour.
Here line corresponds to input streaming dataframe where comments are filtered according to keywords from the body of the comment.
lines = spark.sql("SELECT * FROM updates WHERE body LIKE '%vacation%'\
OR body LIKE '%holiday%'\
OR body LIKE '%beach%'\
OR body LIKE '%urope%'\
OR body LIKE '%trip%'\
OR body LIKE '%tired%'\
OR body LIKE '%work%'\
OR body LIKE '%fatigue%'\
OR body LIKE '%overwork%'\
OR body LIKE '%party%'\
OR body LIKE '%fun%'\
OR body LIKE '%weekend%'\
OR body LIKE '%ecember%'\
OR body LIKE '%ummer%'\
OR body LIKE '%ingapore%'\
OR body LIKE '%alaysia%'\
OR body LIKE '%hailand%'\
OR body LIKE '%affari%'\
OR body LIKE '%kids%'\
OR body LIKE '%lions%'\
OR body LIKE '%event%'\
OR body LIKE '%ingapore%'\
OR body LIKE '%bored%'\
OR body LIKE '%happy%'\
OR body LIKE '%excited%'\
OR body LIKE '%sad%'\
OR body LIKE '%breakup%'\
OR body LIKE '%wedding%'\
OR body LIKE '%visit%'\
OR body LIKE '%no time%'\
OR body LIKE '%car%'\
OR body LIKE '%road%'\
OR body LIKE '%bonus%'\
OR body LIKE '%tan%'\
OR body LIKE '%road-trip%'\
OR body LIKE '%girl friend%'\
OR body LIKE '%bus%'\
OR body LIKE '%train%'\
OR body LIKE '%motel%'\
OR body LIKE '%visit%'\
OR body LIKE '%mother%'\
OR body LIKE '%father%'\
OR body LIKE '%parents%'\
OR body LIKE '%thanks giving%'\
OR body LIKE '%long week%'")Increasing producer throughput Each producer sends data to kafka at the rate of 700 messages/s (acks = 1, as I dont want to loose any messages). To increase the throughput (messages/s) I increased the the number of producers parallely writing to multiple kafka partitions.

Increasing consumer throughput Each consumer can write to postgres at a rate of ~1000 messages/s. To increase the write speed I used multiple kafka partitions and multiple consumers in a consumer group.

-
Set failondataloss: false in spark structured streaming source. Incase streaming application shuts downdue to lost data in kafka or missing offsets.(low retention period or no replication of topics across brokers)
-
Set retention period to a low number: Due to the size of the data source.
- To reduce latency use continuous trigger( 1 ms), this mode does not support aggregations.

