

CS Course Notes
Home Page: https://junxnone.github.io/csc






𝑚 × 𝑛矩阵乘以𝑛 × t矩阵,变成𝑚 × t矩阵。

矩阵的乘法不满足交换律:𝐴 × 𝐵 ≠ 𝐵 × 𝐴
矩阵的乘法满足结合律。即:𝐴 × (𝐵 × 𝐶) = (𝐴 × 𝐵) × C
在矩阵的乘法中,有一种矩阵起着特殊的作用,如同数的乘法中的 1,我们称 这种矩阵为单位矩阵.它是个方阵,一般用 𝐼 或者 𝐸 表示,本讲义都用 𝐼 代表单位矩阵,从左上角到右下角的对角线(称为主对角线)上的元素均为 1 以外全都为 0。


矩阵的逆:如矩阵𝐴是一个𝑚 × 𝑚矩阵(方阵),如果有逆矩阵,则:

矩阵的转置:设𝐴为𝑚 × 𝑛阶矩阵(即𝑚行𝑛列),第𝑖行𝑗列的元素是𝑎(𝑖,𝑗),即:𝐴 = 𝑎(𝑖,𝑗)
定义𝐴的转置为这样一个𝑛 × 𝑚阶矩阵𝐵,满足𝐵 = 𝑎(𝑗, 𝑖),即 𝑏(𝑖,𝑗) = 𝑎(𝑗, 𝑖)(𝐵的第𝑖行
第𝑗列元素是𝐴的第𝑗行第𝑖列元素),记

single program, multiple data - Programming modelIntel SPMD Program CompilerSymmetric multi-processorNon-uniform memory accesssingle program, multiple dataIntel SPMD Program Compiler
C code 到 SIMD implementation 程序 - xxx.ispc --> xxx.osingle programProgram Instance
Program Instance - N 取决于 SIMD widthone core + SIMD| Interleaved assignment | Blocked assignment |
|---|---|
 |
 |
 |
 |
 |
 |
| System Layers Interface & Implementation |  |
|---|---|
| Thread Programming model |  |
| ISPC Programming model | 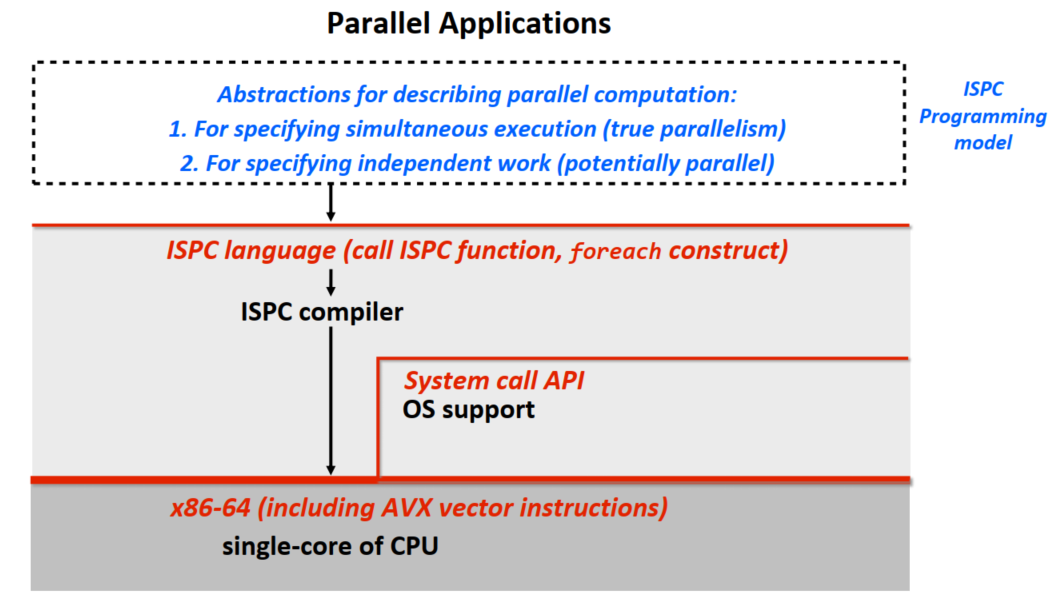 |
Shared Address Space + Message Passing| Model | Description |
|---|---|
| Shared address space | - 共享变量 非结构化数据 - 主动性更强?? |
| Message passing | - 发送/接收消息 - 结构化数据 |
| Data parallel | - SIMD Vector Processor - 通信受 iterations 限制 |
| Shared address space |  |
|---|---|
| SMP HW Implementation |  |
| NUMA HW Implementation |  |
| HW Arch | Description |
|---|---|
| SMP | - 处理器通过 Interconnect 直接访问所有处理器 - 对所有处理器而言, 访问 DRAM 时间相同 |
| NUMA | - 每个处理器拥有自己的Memory - 每个处理器可以通过 Interconnect 访问其他处理器的 Memory- 对本地内存的访问是 low lantency + high bandwidth |
Message Passing Interface| Message passing |  |
|---|
| ISPC-> SPMD/SIMD |  |
|---|
| Streams Programming | Description |
|---|---|
| Benefits | - 函数独立 - data 已知, prefetching 优势 - Cache 优势, 可以减少读写 Memory |
| Drawbacks | Need library of operators to describe complex data flows ??? |

即 


即:

求导数后得到:

更新参数:



……
……
面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。
当两个特征有较大的数量级差异时,绘制代价函数的等高线图能,看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。
解决的方法是尝试将所有特征的尺度都尽量缩放到-1到1之间。
线性回归并不适用于所有数据,有时我们需要曲线来适应我们的数据,比如二次方模型或者三次方模型:

多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要。
对代价函数求导
对于那些不可逆的矩阵(通常是因为特征之间不独立,如同时包含英尺为单位的尺寸和米为单位的尺寸两个特征,也有可能是特征数量大于训练集的数量),正规方程方法是不能用的。
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率a | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量n大时也能较好适用 | 需要计算 如果特征数量n较大则运算代价大,因为矩阵逆的计算时间复杂度为 如果特征数量n较大则运算代价大,因为矩阵逆的计算时间复杂度为 ,通常来说当n小于10000 时还是可以接受的 ,通常来说当n小于10000 时还是可以接受的 |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
多处理器的计算机 --> 云计算Power Density Wall
| Microprocessor Trend Data |
|---|
 |
SuperComputer VS Cloud System(Data Center)| VS | SuperComputers | Cloud System(Data Center Clusters) |
|---|---|---|
| 目标应用 | Few, Big tasks | Many small tasks |
| 硬件 | - 定制化 - 高可靠性 - 低延迟连接 |
- 消费级 - 低成本 - 吞吐量优化连接 |
| Run-Time System | - Minimal - 静态调度 |
- 高可靠性 - 动态调度 |
| Application Programming | - Low-level, processor-centric model - Programmer manages resources |
- High level, data-centric model - Let run-time system manage resources |
speedup = 执行时间(1 Processor) / 执行时间(N Processors)Performance per areaPerformance per WattLe vent se lève, il faut tenter de vivre.
This is a Course Notes. Supported By the Template Wiki
 |
 |
|---|
core->ALUs 执行 相同的指令8x data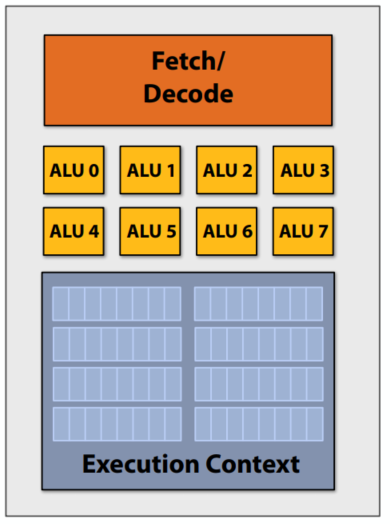 |
 |
|---|
Instruction stream coherence - 指令流的连续性影响 SIMD 的效率Divergent/Divergence - 发散执行, 指缺乏连续性
in-order 部分独立, Out-of-Order 部分共享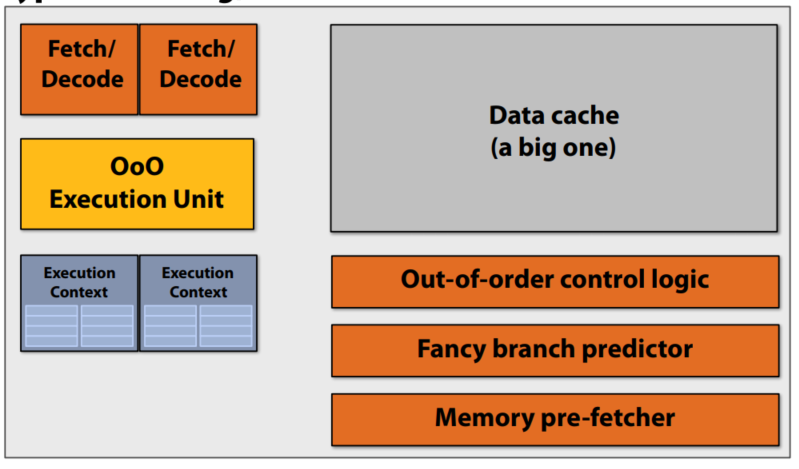 |
 |
|---|
| Interleaved multi-threading |
|---|
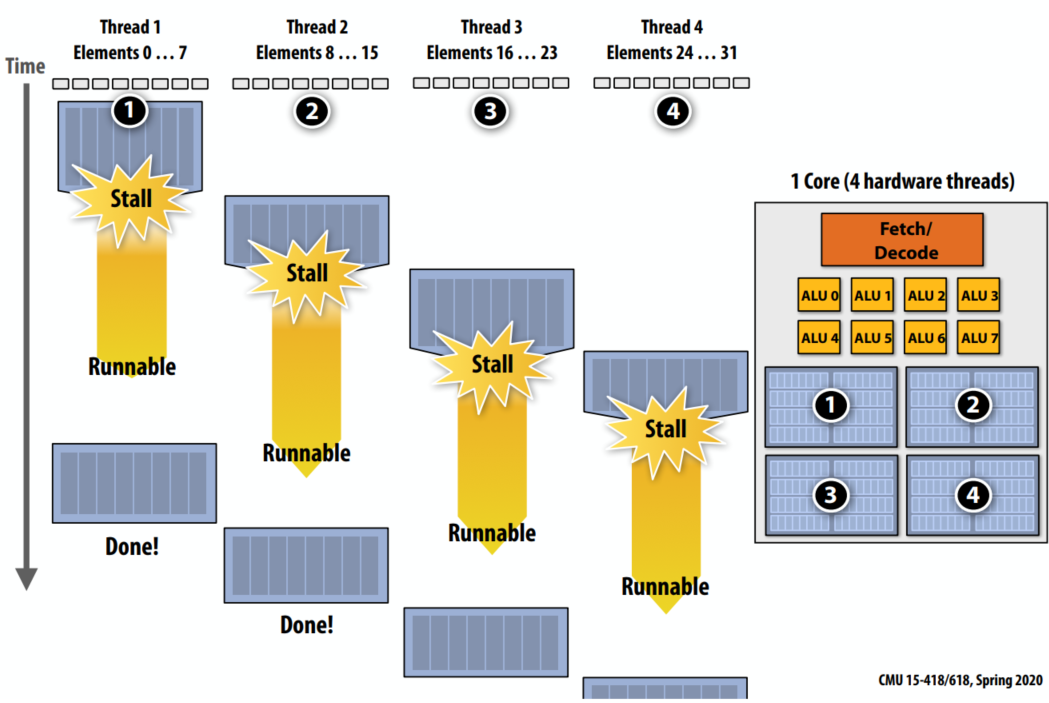 |
prefetching, multi-threading is a latency hiding, not a latency reducing technique ??
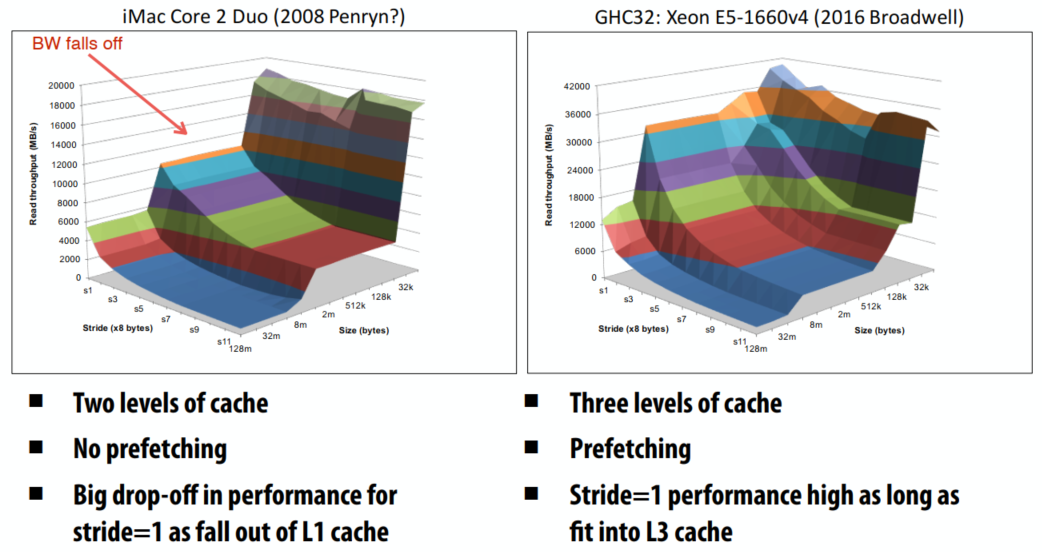
读取延迟读取最大速度Cache 有效减少了 内存访问时间L12 VS L123 + Prefetching |
|---|
 |
| Processors | 用途 | 并行方法 | 调度 | Cores | Hardware | 编程困难度 |
|---|---|---|---|---|---|---|
| CPU | 序列化的 code | ILP | 硬件调度 | <100 | 昂贵复杂 | 容易 |
| GPU | 很多独立的 task | 线程及数据并行 | 软件调度 | > 1000 | 简单便宜 | 困难 |
| FPGA | 信号处理/神经网络/... | |||||
| VPU | 神经网络 |
instruction-level parallelism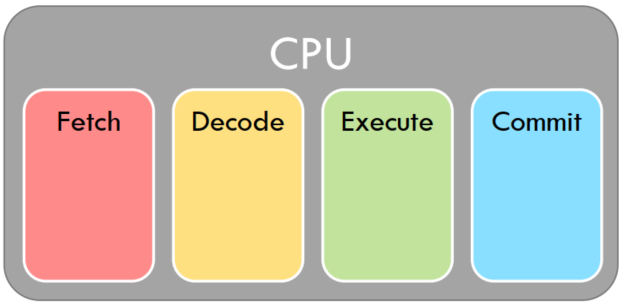 |
 |
|---|
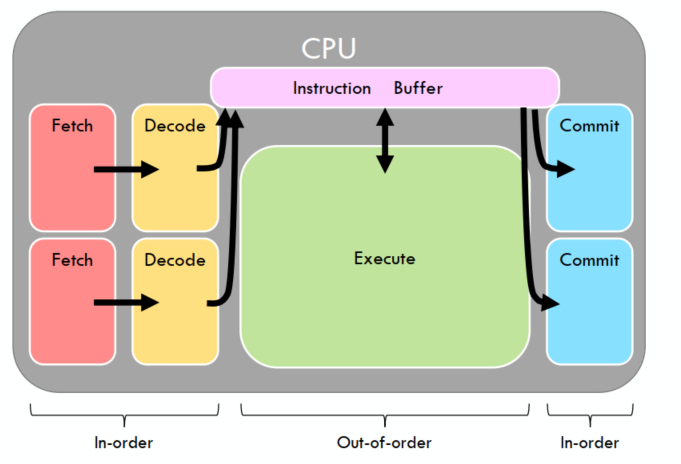
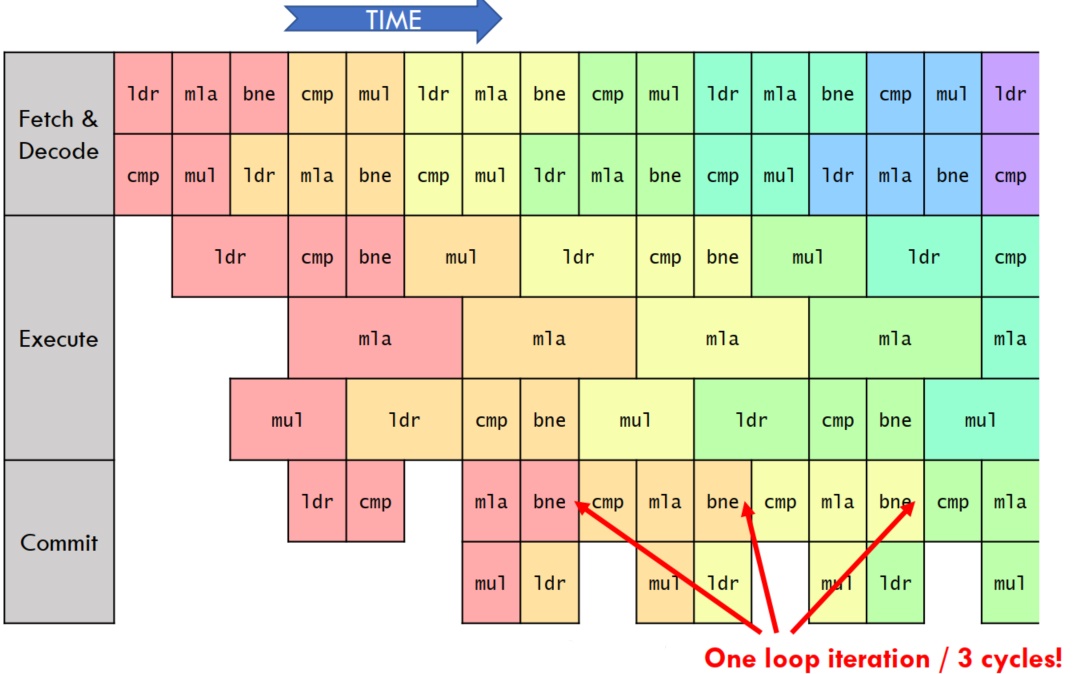
Fetch/Decode/Execute/Commit - 4X Speedup |
 |
|---|
NOP 指令, 以等到前一条指令 commitR3, 后一条指令执行时要读 R3, 后一条指令执行时,前一条指令还没有 commit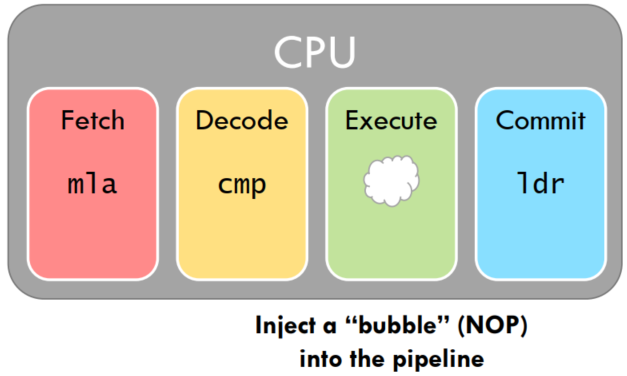 |
 |
|---|
 |
 |
|---|
Static instruction sequence 预取指令, 预取到错误指令
 |
 |
|---|
rolling back
95% 猜对??
执行已经准备好的指令read-after-writeCritical Path - 迭代中最长路径Execution Unit 数量(并行执行指令的个数)/Structural hazards |
 |
|---|
 |
 |
|---|
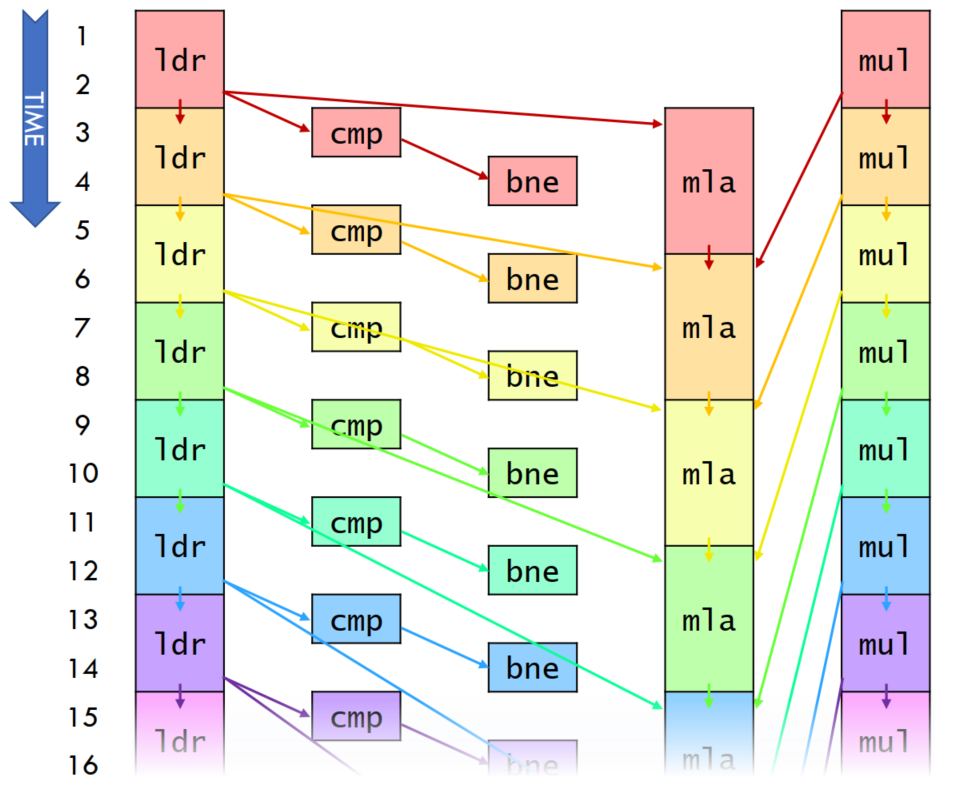
- ldr, mul execute in 2 cycles
- cmp, bne execute in 1 cycle
- mla executes in 3 cycles
- 每个循环执行 3 cycles, 一共 5 条指令
- IPC(Instructions per cycle)
= 5/3 =1.66... > 1(perfect pipeling)

issue width of processor
一个程序被认为能从经验 E 中学习,解决任务 T,达到性能度量值 P
当且仅当,有了经验 E 后,经过 P 评判,程序在处理 T 时的性能有所提升。
———— Tom Mitchell(卡内基梅隆大学)
监督学习(Supervised Learning)指的就是我们给学习算法一个数据集。这个数据集由“正确答案”组成。运用学习算法,算出更多的正确答案。
Label研究一组随机变量(Y1 ,Y2 ,…,Yi)和另一组(X1,X2,…,Xk)变量之间关系的统计分析方法
根据特征使用算法预测类别
无监督学习(Unsupervised Learning)中没有任何的标签或者是有相同的标签或者就是没标签。
无监督学习算法可能会把这些数据分成几个不同的簇。
| 定义 | 描述 |
|---|---|
| 输入(特征/面积) | |
| 输出(房价) | |
| 假设(Hypothesis)/(房价和面积的关系函数) | |
|
|
参数, 算法计算出最佳参数,更好的拟合数据 |
代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。



梯度下降是一个用来求函数最小值的算法。
开始时我们随机选择一个参数的组合,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到找到一个局部最小值(local minimum)。
因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
批量梯度下降(batch gradient descent)算法的公式为:

其中α是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。

在梯度下降的每一步中,我们都用到了所有的训练样本,在梯度下降中,在计算微分求导项时,我们需要进行求和运算,所以,在每一个单独的梯度下降中,我们最终都要计算这样一个东西,这个项需要对所有m个训练样本求和。因此,批量梯度下降法这个名字说明了我们需要考虑所有这一"批"训练样本,而事实上,有时也有其他类型的梯度下降法,不是这种"批量"型的,不考虑整个的训练集,而是每次只关注训练集中的一些小的子集。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.