



![]()
An open-source platform for designing and rendering various reports.
jsreport is a reporting server letting developers define reports using javascript templating engines like handlebars. It supports various report output formats like html, pdf, excel, docx, and others. It also includes advanced reporting features like user management, REST API, scheduling, designer, or sending emails.
You can find more information on the official project website https://jsreport.net
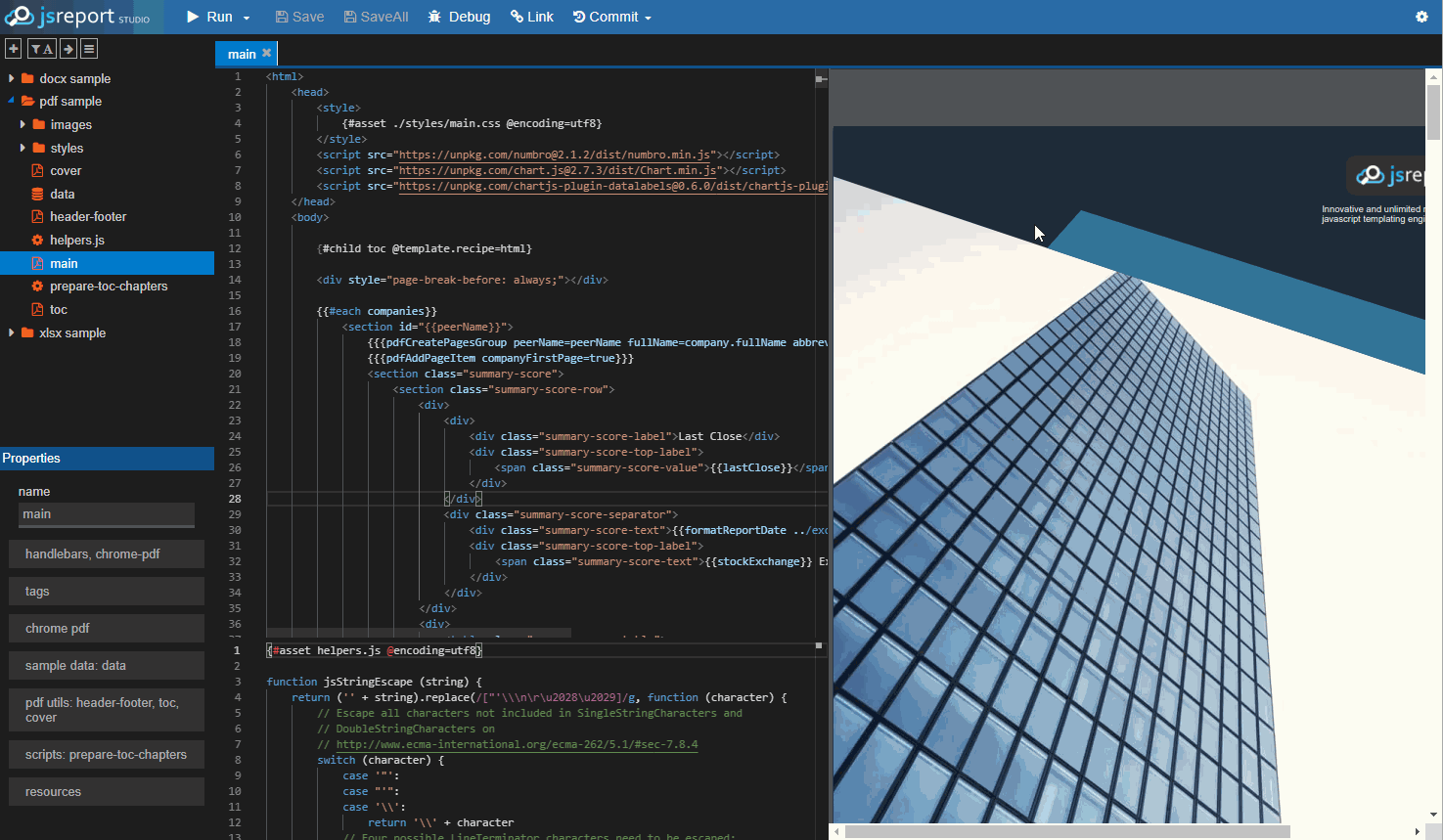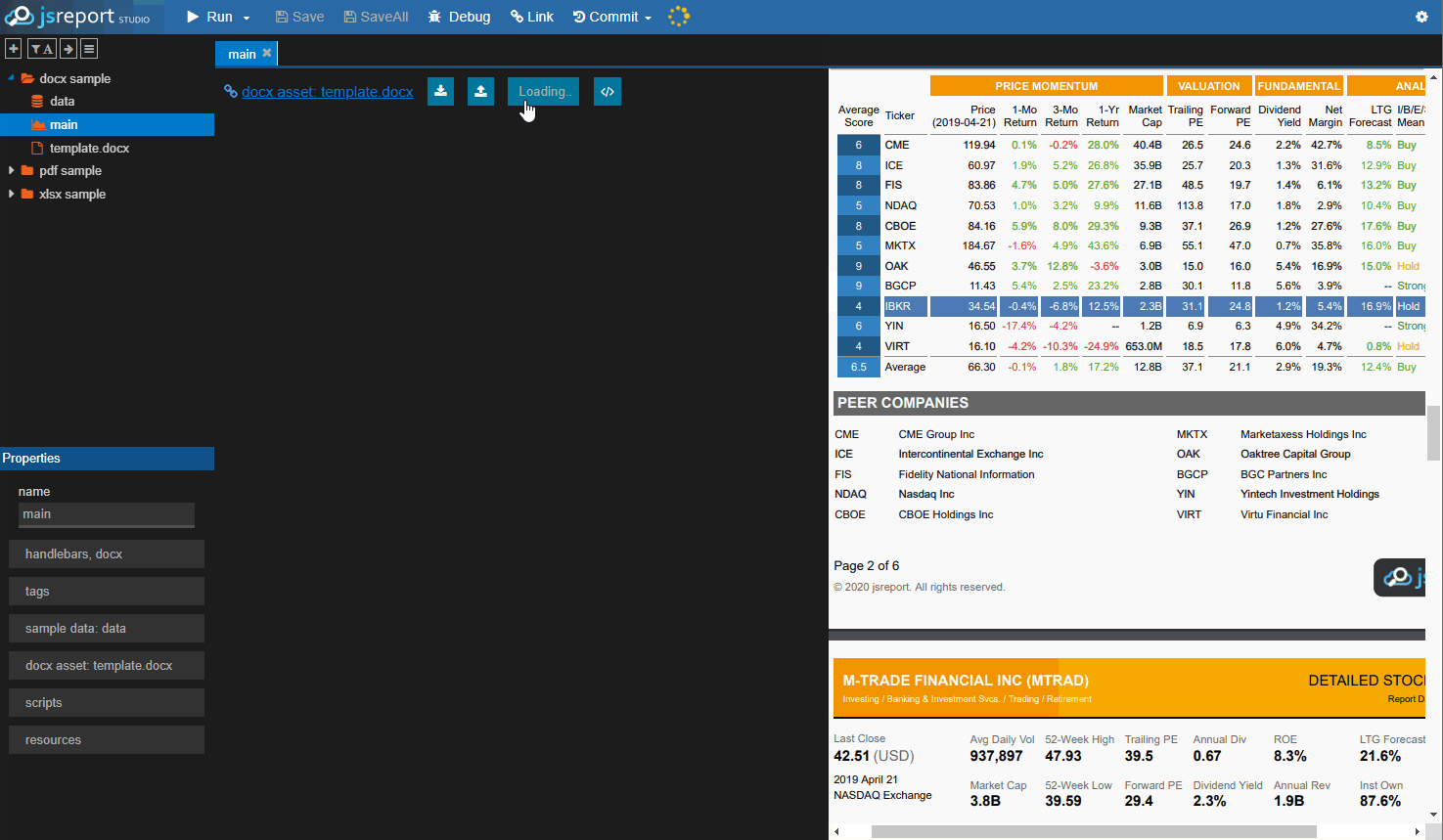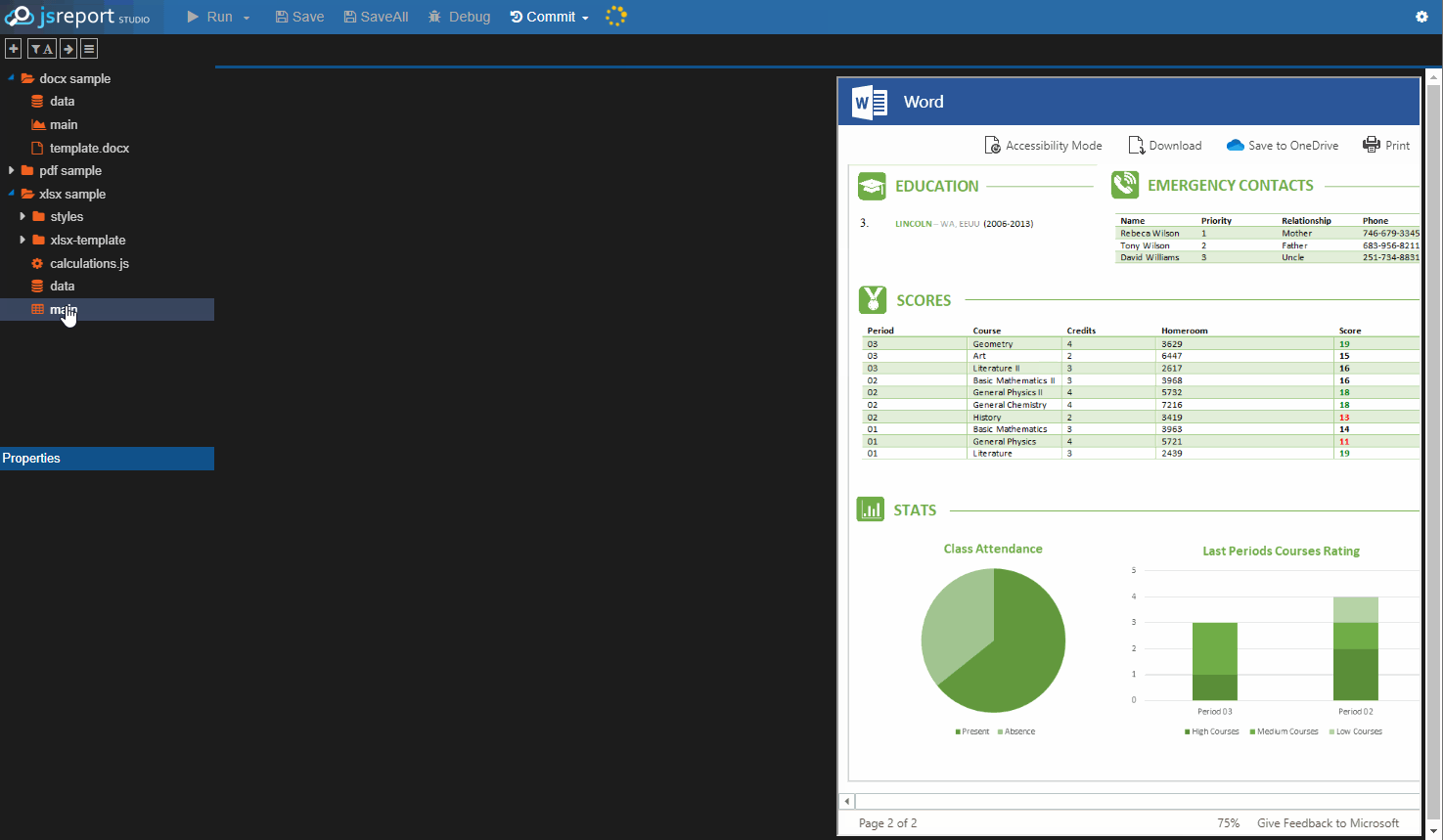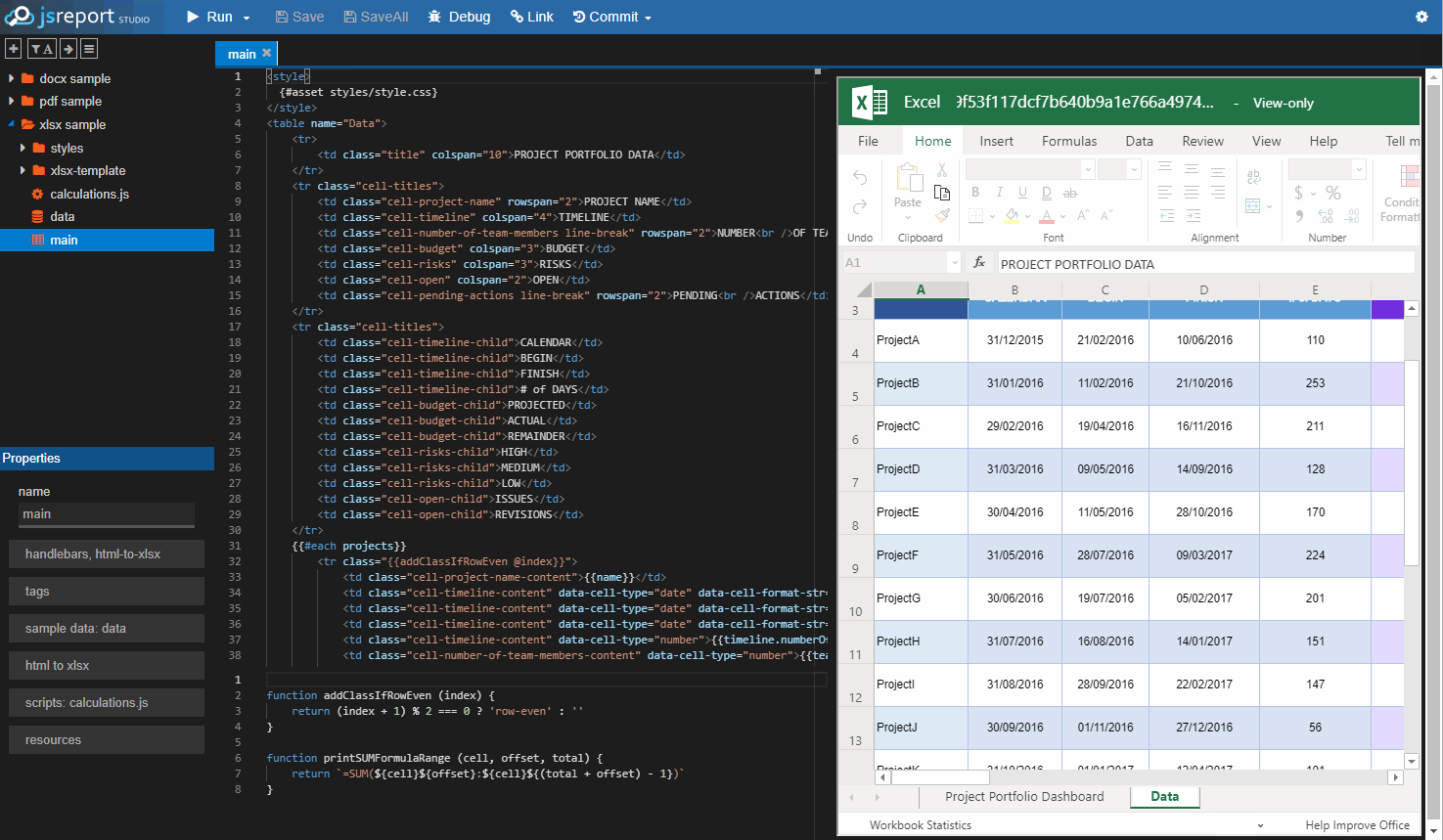
Basic installation from the npm
npm install -g @jsreport/jsreport-cli
jsreport init
jsreport configure
jsreport startYou can also download compiled binary or pull from the official docker images. See https://jsreport.net/on-prem for the details.
See the https://jsreport.net/learn for an overview of concepts, guides, clients, and general documentation.
The jsreport official distribution in npm, docker, or compiled binary includes the most commonly used extensions. However, the list of available extensions is much longer, and you may want to install some of the missing ones as well. See the list of available packages here or in the documentation.
You are also not limited to extensions we provide to you. You can implement your extensions. See the Implementing custom extension article.
You can find documentation for adapting this jsreport distribution using nodejs and also information for integrating it into an existing nodejs application in the article adapting jsreport.
The official jsreport distribution wires the most popular extensions into the ready-to-use package. However, if you are skilled, you are free to start from the ground using jsreport-core.
We use yarn to manage the monorepo. The basic workflow is the following
git clone https://github.com/jsreport/jsreport
yarn install
yarn startThe tests for the individual package runs the following way
yarn workspace @jsreport/jsreport-scripts test
The studio extensions development with the hot reload can be started using
set NODE_ENV=jsreport-development&&yarn start
- adding more features to docx/pptx/xlsx recipes
- pdf compression
- version control extension direct git integration and improvements
- studio editor intellisense
- html-to-xlsx - images, filters...
More in the backlog.
Missing a feature? Submit a feature request.
We update vulnerable jsreport dependencies based on npm and Snyk audits during every release. Please wait until we release the next version when you notice a security warning in your audit. There is no need to create a ticket for it. In case you see a direct impact on jsreport security that you can replicate, please send us an email to [email protected] and we will make sure it's fixed ASAP. Note there is no need to panic when there is a vulnerability mentioned in the audit because it is the most likely in the code path that is not used. A typical example of a vulnerability is an eventual DDoS attack through a dependency parsing some internal config, which in fact can't happen and isn't a vulnerability at all.
Copyright (C) 2024 Jan Blaha
Do you want to use jsreport for a personal purpose, in a school project or a non-profit organization? Then you don't need the author's permission, just go on and use it. You can use jsreport without the author's permission also when having a maximum 5 templates stored in jsreport storage.
For commercial projects using more than 5 stored report templates see Pricing page.
Under any of the licenses, free or not, you are allowed to download the source code and make your own edits.
In every case, there are no warranties of any kind provided:
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.





















