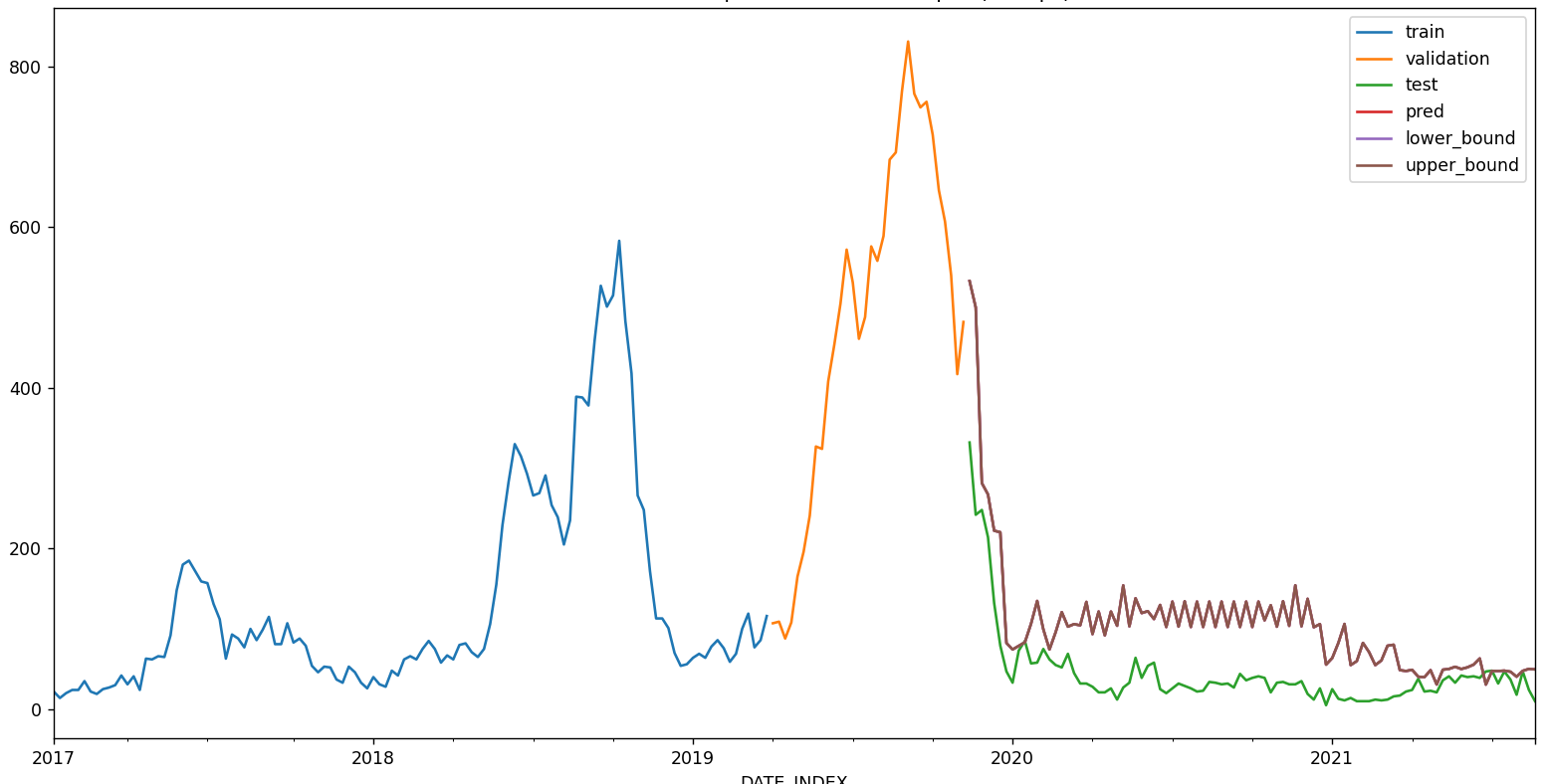
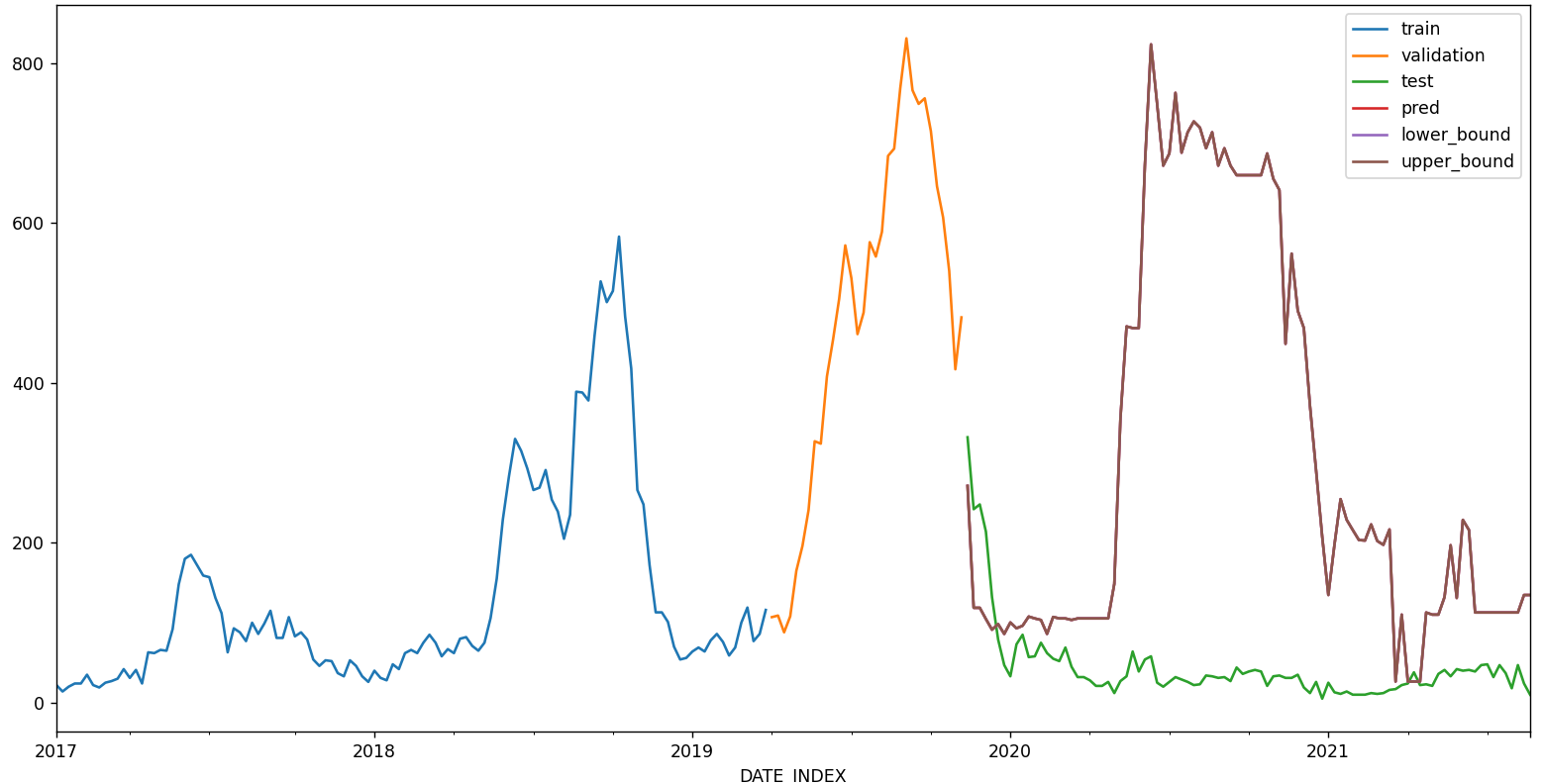
Similarly with the prediction interval, what accounts for these large spikes (I set it as interval=[5, 95],), and why the interval only extends above the predicted values?
The problem space is to predict the number of case count (number of occurrences of an event) in a particular location during the following period. The case count time series (the time unit is weekly) is split into training, validation, and test sets.
The test period is between 2020-07-01 to 2021-08-21. If I make a 4-week rolling prediction (future_prediction_n_step = 4), it looks like this
import sys
import math
import pandas as pd
import config
import data_import
import feature_engineering as feat_eng
import glob
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import hts
import correlation as corr
from lightgbm import LGBMRegressor
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge, Lasso
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.pipeline import make_pipeline
from skforecast.ForecasterAutoreg import ForecasterAutoreg
from skforecast.ForecasterAutoregMultiOutput import ForecasterAutoregMultiOutput
from skforecast.model_selection import grid_search_forecaster
from skforecast.model_selection import backtesting_forecaster
# Modelling and Forecasting
# ==============================================================================
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import make_pipeline
from skforecast.ForecasterAutoreg import ForecasterAutoreg
from skforecast.ForecasterAutoregMultiOutput import ForecasterAutoregMultiOutput
from skforecast.model_selection import grid_search_forecaster
from skforecast.model_selection import backtesting_forecaster
from joblib import dump, load
# Print/graph output setting
save_switch = False # WARNING: Will overwrite existing files with the same filename
print_switch = True
graph_switch = True
sole_graph_switch = False
if sole_graph_switch:
graph_switch = False # if sole_graph_switch == `True`, automatically disable `graph_switch`
prediction_interval_switch = True
log_transform_outcome = False
# Forecasting parameters
autoregressive_n_lag = 104 # number of lags (weeks) used for autoregression
horizontal_threshold_n_case = 100 # this horizontal_threshold_n_case is nullified if set to 0
curr_random_state = 888
lags_grid = [1, 4, 8, 26, 55, 120] # lags used as autoregressive predictor
curr_performance_metric = 'mean_absolute_error' # 'mean_absolute_error' # 'mean_squared_error' # 'mean_absolute_percentage_error'
selected_predictor_option_set = 1
param_grid_option = 0 # search grid for hyperparameter optimization
# Moving average setting
slow_ma_n_wk = 60
medium_ma_n_wk = 30
fast_ma_n_wk = 2
smoothing_ma_n_wk = 2
# Date setting
outer_start_date = '2017-01-07' # '2017-01-07'
outer_end_date = '2021-08-21' # '2021-08-21'
end_train = '2019-06-01' # '2019-02-28'
end_validation = '2020-07-01'
restrict_outer_date_switch = True # if `True`, apply the `outer_start_date` and `outer_end_date` to slice and form the "total" data
# Climate lag setting
avg_precipitation_lag = 0 # positive value, i.e., +4, means the current value will move 4 weeks into the future
avg_temp_lag = 0
avg_relative_humidity_lag = 0
avg_specific_humidity_lag = 0
climate_lag_switch = True # if `True`, apply the above lags to the corresponding climate var
climate_moving_avg_n_wk = 4
climate_moving_avg_switch = True # if `True`, turn the climate variables into smooth average
def log_transform(curr_num):
if curr_num > 0:
return math.log(curr_num)
else:
return curr_num
def main(location, future_prediction_n_step):
# Setup
# =====================================================================================================
# Initial setup
plt.cla()
# Data import and preprocessing
df = data_import.import_single_country_ref_data(input_filename=data_filename)
df = df.asfreq('W-Sat') # this line isn't really necessary
df = df.sort_index()
assert len(df) > 0, 'Error: DataFrame has no data'
# Feature set
# =====================================================================================================
# Log transformation of outcome (case count)
if log_transform_outcome:
df['REPORTED_CASES'] = df['REPORTED_CASES'].apply(log_transform)
# Data preparation for predictive modeling
feature_column = ['AVG_PREC', 'AVG_TEMP', 'AVG_REL_HUM', 'AVG_SP_HUM']
for col in feature_column:
df.rename(columns={col: 'X_' + col}, inplace=True) # signal which are predictors
# Standardize the features
tagged_feature_column = ['X_AVG_PREC', 'X_AVG_TEMP', 'X_AVG_REL_HUM', 'X_AVG_SP_HUM']
std_scaler = StandardScaler()
for col in tagged_feature_column:
df[col + '_STD_SCALER'] = std_scaler.fit_transform(df[[col]])
df.drop(tagged_feature_column, axis=1, inplace=True) # remove unecessary columns
# Feature engineering - extract month
df['X_MONTH'] = df['DATE_INDEX_COPY'].dt.strftime('%m')
df['X_MONTH'] = df['X_MONTH'].astype('category')
# Feature engineering - moving averages
df[f'X_MA_{slow_ma_n_wk}'] = df['REPORTED_CASES'].rolling(window=slow_ma_n_wk).mean()
df[f'X_MA_{medium_ma_n_wk}'] = df['REPORTED_CASES'].rolling(window=medium_ma_n_wk).mean()
df[f'X_MA_{fast_ma_n_wk}'] = df['REPORTED_CASES'].rolling(window=fast_ma_n_wk).mean()
df[f'X_SMOOTH_MA_{smoothing_ma_n_wk}'] = df['REPORTED_CASES'].rolling(window=smoothing_ma_n_wk).mean()
# Feature engineering - case proportion
df['CASE_PER_100K_POPULATION'] = df[f'X_SMOOTH_MA_{smoothing_ma_n_wk}'] / df['POPULATION_2020'] * 100000
# Add the REPORTED_CASES time-series (imputed missing) of the adjacent states and map to `df`
adjacent_adm1_list = config.adjacent_states_per_adm1[location]
adjacent_adm1_varname_list = []
for curr_adm1 in adjacent_adm1_list:
adm1_varname = f'X_REPORTED_CASES_{curr_adm1.upper()}'
adjacent_adm1_varname_list.append(adm1_varname)
df_adjacent_adm1 = df_mexico_full[df_mexico_full['ADM1_NAME'] == curr_adm1]
df_adjacent_adm1 = df_adjacent_adm1[['REPORTED_CASES']]
df = df.merge(df_adjacent_adm1, left_index=True, right_index=True)
df.rename({'REPORTED_CASES_y': adm1_varname, 'REPORTED_CASES_x': 'REPORTED_CASES'}, axis=1, inplace=True)
# Apply lags (in weeks) for climate variables
if climate_lag_switch:
df['X_AVG_PREC_STD_SCALER'] = df['X_AVG_PREC_STD_SCALER'].rolling(window=climate_moving_avg_n_wk).mean()
df['X_AVG_TEMP_STD_SCALER'] = df['X_AVG_TEMP_STD_SCALER'].rolling(window=climate_moving_avg_n_wk).mean()
df['X_AVG_REL_HUM_STD_SCALER'] = df['X_AVG_REL_HUM_STD_SCALER'].rolling(window=climate_moving_avg_n_wk).mean()
df['X_AVG_SP_HUM_STD_SCALER'] = df['X_AVG_SP_HUM_STD_SCALER'].rolling(window=climate_moving_avg_n_wk).mean()
# Predictor groups
climate_varname_list = ['X_AVG_PREC_STD_SCALER', 'X_AVG_TEMP_STD_SCALER', 'X_AVG_REL_HUM_STD_SCALER',
'X_AVG_SP_HUM_STD_SCALER']
ma_varname_list = [f'X_MA_{slow_ma_n_wk}', f'X_MA_{medium_ma_n_wk}', f'X_MA_{fast_ma_n_wk}']
# Turn climate variables into their respective moving averages
if climate_moving_avg_switch:
df['X_AVG_PREC_STD_SCALER'] = df['X_AVG_PREC_STD_SCALER'].shift(avg_precipitation_lag)
df['X_AVG_TEMP_STD_SCALER'] = df['X_AVG_TEMP_STD_SCALER'].shift(avg_temp_lag)
df['X_AVG_REL_HUM_STD_SCALER'] = df['X_AVG_REL_HUM_STD_SCALER'].shift(avg_relative_humidity_lag)
df['X_AVG_SP_HUM_STD_SCALER'] = df['X_AVG_SP_HUM_STD_SCALER'].shift(avg_specific_humidity_lag)
# Selection of predictor combinations
if selected_predictor_option_set == 1:
exogenous_varname_list = []
elif selected_predictor_option_set == 2:
exogenous_varname_list = climate_varname_list
elif selected_predictor_option_set == 3:
exogenous_varname_list = adjacent_adm1_varname_list
elif selected_predictor_option_set == 4:
exogenous_varname_list = ma_varname_list
elif selected_predictor_option_set == 5:
exogenous_varname_list = climate_varname_list + adjacent_adm1_varname_list
elif selected_predictor_option_set == 6:
exogenous_varname_list = climate_varname_list + ma_varname_list + adjacent_adm1_varname_list
# Impute missing values in Exogenous Vars; using last available value
for varname in (climate_varname_list + ma_varname_list + adjacent_adm1_varname_list):
df[varname] = df[varname].ffill() # backward fill - impute using the closest past value
df[varname] = df[varname].bfill() # forward fill - inpute using the cloest future value
# Dataset splitting
# =====================================================================================================
# Splitting datasets into train-val-test
if restrict_outer_date_switch:
df = df.loc[outer_start_date: outer_end_date]
df_train = df.loc[: end_train, :]
df_val = df.loc[end_train:end_validation, :]
df_test = df.loc[end_validation:, :]
# Time series plot
if graph_switch:
fig, ax = plt.subplots(figsize=(12, 4))
df_train.REPORTED_CASES.plot(ax=ax, label='train', linewidth=1)
df_val.REPORTED_CASES.plot(ax=ax, label='validation', linewidth=1)
df_test.REPORTED_CASES.plot(ax=ax, label='test', linewidth=1)
ax.set_title(f'Reported cases in {location}')
ax.legend()
if log_transform_outcome:
plt.ylabel('log scale')
plt.show()
# Boxplot for annual seasonality
if graph_switch:
fig, ax = plt.subplots(figsize=(7, 3.5))
df['MONTH'] = df.index.month # WARNING: coarse way to extract month, testing for now
df.boxplot(column='REPORTED_CASES', by='MONTH', ax=ax, )
df.groupby('MONTH')['REPORTED_CASES'].median().plot(style='o-', linewidth=0.8, ax=ax)
ax.set_ylabel('Reported cases')
ax.set_title(f'Reported cases in {location} by month')
fig.suptitle('')
plt.show()
# Autocorrelation plot
if graph_switch:
fig, ax = plt.subplots(figsize=(7, 3))
plot_acf(df.REPORTED_CASES, ax=ax, lags=180)
plt.show()
# Partial autocorrelation plot
if graph_switch:
fig, ax = plt.subplots(figsize=(7, 3))
plot_pacf(df.REPORTED_CASES, ax=ax, lags=112, method='ywm')
plt.show()
if print_switch:
print(f"Train dates : {df_train.index.min()} --- {df_train.index.max()}")
print(f"Validation dates : {df_val.index.min()} --- {df_val.index.max()}")
print(f"Test dates : {df_test.index.min()} --- {df_test.index.max()}")
print(f"Mean outcome: {df['REPORTED_CASES'].mean()}")
# Forecasting classifier set up (without grid search)
# =====================================================================================================
print('=====================================================================================================')
print('Start of forecasting (without grid search)')
# Initialize forecaster
forecaster = ForecasterAutoreg(
regressor=XGBRegressor(random_state=curr_random_state),
lags=autoregressive_n_lag
)
# Declare predictors and outcome
forecaster.fit(
y=df.loc[:end_validation, 'REPORTED_CASES'],
exog=df.loc[:end_validation, exogenous_varname_list]
)
# Backtest
metric, predictions = backtesting_forecaster(
forecaster=forecaster,
y=df.REPORTED_CASES,
initial_train_size=len(df.loc[:end_validation]),
fixed_train_size=False,
steps=future_prediction_n_step,
metric=curr_performance_metric,
refit=False,
verbose=False
)
# Plot backtesting and print results
if graph_switch:
fig, ax = plt.subplots(figsize=(12, 3.5))
df.loc[predictions.index, 'REPORTED_CASES'].plot(ax=ax, linewidth=2, label='real')
predictions.plot(linewidth=2, label='prediction', ax=ax)
ax.set_title(f'Prediction vs real reported cases in {location} ({future_prediction_n_step}-week)')
ax.legend()
if log_transform_outcome:
plt.ylabel('log scale')
plt.show()
if print_switch:
print(f'Backtest error metric: {metric}')
print('Predictor importance:', forecaster.get_feature_importance())
print('End of forecasting (without grid search)')
# Forecasting classifier set up (with grid search)
# =====================================================================================================
print('=====================================================================================================')
print('Start of forecasting (with grid search)')
# Hyperparameter Grid search
forecaster = ForecasterAutoreg(
regressor=XGBRegressor(random_state=curr_random_state),
lags=autoregressive_n_lag # This value will be replaced in the grid search
)
# Regressor's hyperparameters
if param_grid_option == 0:
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [5, 10, 30],
'learning_rate': [0.01, 0.1]
}
elif param_grid_option == 1:
param_grid = {
'n_estimators': [10, 50, 100, 250, 500],
'max_depth': [3, 5, 10, 25, 30, 45],
'learning_rate': [0.01, 0.05, 0.1]
}
elif param_grid_option == 2:
param_grid = {
'n_estimators': [10, 25, 50, 100, 250, 500, 1000],
'max_depth': [3, 5, 8, 10, 25, 30, 45],
'learning_rate': [0.005, 0.01, 0.05, 0.1, 0.3]
}
results_grid = grid_search_forecaster(
forecaster=forecaster,
y=df.loc[:end_validation, 'REPORTED_CASES'],
exog=df.loc[:end_validation, exogenous_varname_list],
param_grid=param_grid,
lags_grid=lags_grid,
steps=future_prediction_n_step,
metric=curr_performance_metric,
refit=False,
initial_train_size=len(df[:end_train]),
fixed_train_size=False,
return_best=True,
verbose=False
)
if print_switch:
print(f'Grid optimization results: {results_grid}')
print(f'Trainer attributes: {forecaster}')
# Backtest with test data and prediction intervals
metric, predictions = backtesting_forecaster(
forecaster=forecaster,
y=df.REPORTED_CASES,
initial_train_size=len(df.REPORTED_CASES[:end_validation]),
fixed_train_size=False,
steps=future_prediction_n_step,
metric=curr_performance_metric,
interval=[5, 95],
n_boot=500,
in_sample_residuals=True,
verbose=False
)
if print_switch:
print('Backtesting error metric:', metric)
predictions.head(5)
if graph_switch:
fig, ax = plt.subplots(figsize=(12, 3.5))
df.loc[predictions.index, 'REPORTED_CASES'].plot(linewidth=2, label='real', ax=ax)
ax.set_title(f'Prediction vs real reported cases in {location} ({future_prediction_n_step}-week)')
predictions.iloc[:, 0].plot(linewidth=2, label='prediction', ax=ax)
if prediction_interval_switch:
ax.fill_between(
predictions.index,
predictions.iloc[:, 1],
predictions.iloc[:, 2],
alpha=0.3,
color='red',
label='prediction interval'
)
ax.legend()
if log_transform_outcome:
plt.ylabel('log scale')
plt.show()
if sole_graph_switch: # mapping the predicted values to the entire time-series
if prediction_interval_switch:
fig, ax = plt.subplots(figsize=(18, 6))
df_train['REPORTED_CASES'].plot(ax=ax, label='train')
df_val['REPORTED_CASES'].plot(ax=ax, label='validation')
df_test['REPORTED_CASES'].plot(ax=ax, label='test')
predictions.plot(ax=ax, label='pred')
ax.set_title(f'Prediction vs real reported cases in {location} ({future_prediction_n_step}-week)')
ax.legend()
if log_transform_outcome:
plt.ylabel('log scale')
if save_switch:
plt.savefig(
output_dir + f'/predicted_graph_{location}_{future_prediction_n_step}week_with_interval.png',
dpi=300)
else:
plt.show()
else:
fig, ax = plt.subplots(figsize=(18, 6))
df_train['REPORTED_CASES'].plot(ax=ax, label='train')
df_val['REPORTED_CASES'].plot(ax=ax, label='validation')
df_test['REPORTED_CASES'].plot(ax=ax, label='test')
predictions.iloc[:, 0].plot(ax=ax, label='pred')
ax.set_title(f'Prediction vs real reported cases in {location} ({future_prediction_n_step}-week)')
ax.legend()
if log_transform_outcome:
plt.ylabel('log scale')
if save_switch:
plt.savefig(output_dir + f'/predicted_graph_{location}_{future_prediction_n_step}week.png', dpi=300)
else:
plt.show()
# Predicted interval coverage
inside_interval = np.where(
(df.loc[end_validation:, 'REPORTED_CASES'] >= predictions["lower_bound"]) & \
(df.loc[end_validation:, 'REPORTED_CASES'] <= predictions["upper_bound"]),
True,
False
)
coverage = inside_interval.mean()
if print_switch:
print(f"Predicted interval coverage: {round(100 * coverage, 2)} %")
print('Predictor importance:', forecaster.get_feature_importance())
if __name__ == '__main__':
loop_location_switch = False # can be 'True' or 'False'
if loop_location_switch == True:
all_adm1_list = config.adjacent_states_per_adm1.keys()
n_forecast_week_list = [12, 16, 20, 24, 32, 52]
for adm1 in all_adm1_list:
for n_week in n_forecast_week_list:
main(location=adm1, future_prediction_n_step=n_week)
else:
adm1 = config.selected_adm1
main(location=adm1, future_prediction_n_step=24)