jl749 / lamb_optimizer Goto Github PK
View Code? Open in Web Editor NEWhttps://arxiv.org/pdf/1904.00962.pdf
https://arxiv.org/pdf/1904.00962.pdf

https://mcneela.github.io/machine_learning/2019/09/03/Writing-Your-Own-Optimizers-In-Pytorch.html

self.state contains current parameters as dictdefault_dict# LAMB example
{tensor(layer1_weight):
{'step': 1,
'exp_avg': tensor([...]),
'exp_avg_sq': tensor([...]),
'weight_norm': tensor(0.0233),
'adam_norm': tensor(3.1622),
'trust_ratio': tensor(0.0074)}
... for every param}
self.default contains originally initialized config values{'lr': 0.0025, 'betas': (0.9, 0.999), 'eps': 1e-06, 'weight_decay': 0.01}
class SGD(Optimizer):
r"""Implements stochastic gradient descent (optionally with momentum).
Nesterov momentum is based on the formula from
`On the importance of initialization and momentum in deep learning`__.
Args:
params (iterable): iterable of parameters to optimize or dicts defining
parameter groups
lr (float): learning rate
momentum (float, optional): momentum factor (default: 0)
weight_decay (float, optional): weight decay (L2 penalty) (default: 0)
dampening (float, optional): dampening for momentum (default: 0)
nesterov (bool, optional): enables Nesterov momentum (default: False)
Example:
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
>>> optimizer.zero_grad()
>>> loss_fn(model(input), target).backward()
>>> optimizer.step()
__ http://www.cs.toronto.edu/%7Ehinton/absps/momentum.pdf
.. note::
The implementation of SGD with Momentum/Nesterov subtly differs from
Sutskever et. al. and implementations in some other frameworks.
Considering the specific case of Momentum, the update can be written as
.. math::
v = \rho * v + g \\
p = p - lr * v
where p, g, v and :math:`\rho` denote the parameters, gradient,
velocity, and momentum respectively.
This is in contrast to Sutskever et. al. and
other frameworks which employ an update of the form
.. math::
v = \rho * v + lr * g \\
p = p - v
The Nesterov version is analogously modified.
"""
def __init__(self, params, lr=required, momentum=0, dampening=0,
weight_decay=0, nesterov=False):
defaults = dict(lr=lr, momentum=momentum, dampening=dampening,
weight_decay=weight_decay, nesterov=nesterov)
if nesterov and (momentum <= 0 or dampening != 0):
raise ValueError("Nesterov momentum requires a momentum and zero dampening")
super(SGD, self).__init__(params, defaults)
def __setstate__(self, state):
super(SGD, self).__setstate__(state)
for group in self.param_groups:
group.setdefault('nesterov', False)
def step(self, closure=None):
"""Performs a single optimization step.
Arguments:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad.data
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = d_p.clone()
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(1 - dampening, d_p)
if nesterov:
d_p = d_p.add(momentum, buf)
else:
d_p = buf
p.data.add_(-group['lr'], d_p)
return losszero_grad()
https://stackoverflow.com/questions/48001598/why-do-we-need-to-call-zero-grad-in-pytorch
e.g.
train ResNet50 with ImageNet dataset for 80 epochs
80 * 1.3M images * 7.7B ops per img
Data Parallelism (large batch training)
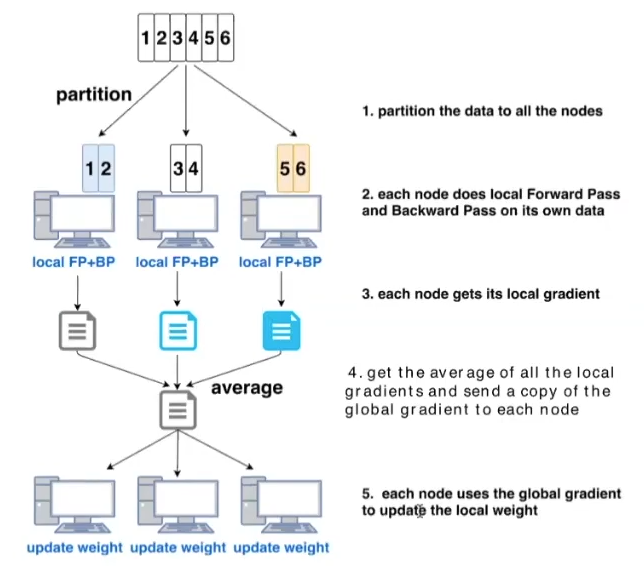
Communication optimization
Model Parallelism
process more samples (imgs) per iteration (scale training of deep neural networks to larger numbers of accelerators and reduce the training time)
but what are the costs?
before we talk about it. let's look into Flatness, Generalization and SGD (https://www.inference.vc/sharp-vs-flat-minima-are-still-a-mystery-to-me/)
the loss surface of deep nets tends have many local minima. (different generalization performance)
"Interestingly, stochastic gradient descent (SGD) with small batchsizes appears to locate minima with better generalization properties than large-batch SGD." (https://medium.com/geekculture/why-small-batch-sizes-lead-to-greater-generalization-in-deep-learning-a00a32251a4f)
how do we predict generalization properties?
Hochreiter and Schmidhuber (1997): suggested that the flatness of the minimum is a good measure (e.g. think why we use cosine annealing)

https://arxiv.org/pdf/1703.04933.pdf
https://vimeo.com/237275513
However, flatness is sensitive to reparametrization (Dinh et al (2017)): we can reparametrize a neural network without changing its outputs (observational equivalence) while making sharp minima look arbitrarily flat and vice versa. --> flatness alone cannot explain or predict good generalization
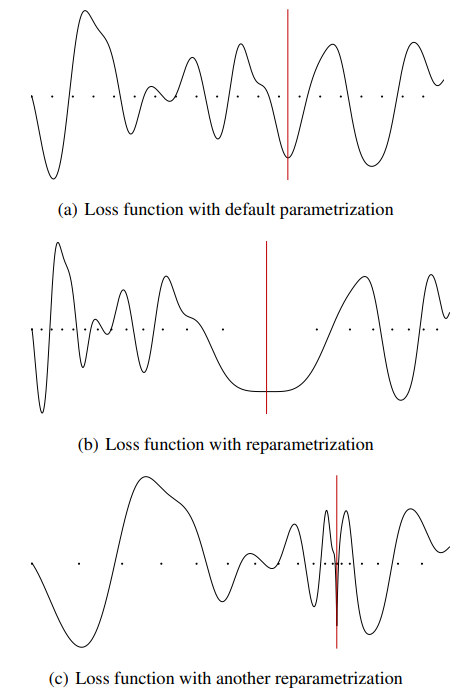

e.g. ReLU

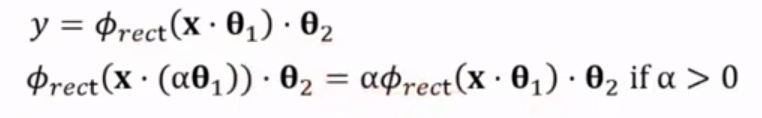
different parameters but same output
e.g. input @ A @ B == input @ -A @ -B
e.g. alpha-scale transform
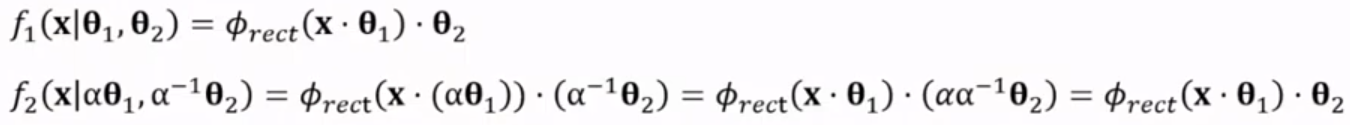
epsilon-flatness (Hochreiter and Schmidhuber (1997))

blue line represent Θ's flatness
epsilon-sharpness (Keskar et al. (2017))
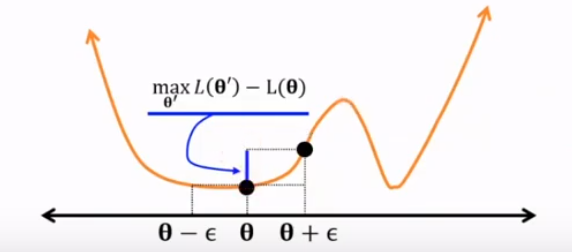
https://arxiv.org/pdf/1609.04836.pdf
https://medium.com/geekculture/why-small-batch-sizes-lead-to-greater-generalization-in-deep-learning-a00a32251a4f
large-batch methods tend to converge to sharp minimizers. In contrast, small-batch methods consistently converge to flat minimizers (this is due to the inherent noise in the gradient estimation)

sharp minima causes generalization gap between training and testing.
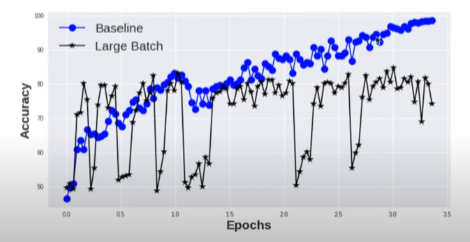
e.g. LSTM on MNIST dataset (baseline_batch: 256, large_batch: 8192)

cross entropy loss against the sharpness (network F & network C)
as our learners mature (loss reduces) the sharpness on the Large Batch learners increases
“For larger values of the loss function, i.e., near the initial point, SB and LB method yield similar values of sharpness. As the loss function reduces, the sharpness of the iterates corresponding to the LB method rapidly increases, whereas for the SB method the sharpness stays relatively constant initially and then reduces, suggesting an exploration phase followed by convergence to a flat minimizer.”

"Look at how quickly the networks converge to their testing accuracies"
if training-testing gap was due to a overfitting, we would not see the consistently lower performance of the LB methods. Instead by stopping earlier, we would avoid overfitting, and the performances(LB_testing <--> SB_testing) would be closer. (this is not what we observed) ==> "generalization gap is not due to over-fitting"
smaller batches are generally known to regularize, noise in the sample gradients pushes the iterates out of the basin of attraction of sharp minimizers
the noise in large-batch is not sufficient to cause ejection from the initial basin leading to convergence to a sharper minimizer
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.