本repo记录项目总结,原创文件,翻译等,文件已迁移到issue。
喜欢请star,订阅请watch,欢迎讨论.
内容会同步至 语雀博客 和 前端进制 微信公众号
- issue 为原创文件
- 项目中的目录代码片段和参考资源
- closed issue一般为项目中遇到的问题解决方法
本作品由jiangtao创作,采用知识共享署名-非商业性使用-相同方式共享 3.0 **大陆许可协议进行许可。凡是转载的文章,翻译的文章,或者由其他作者投稿的文章,版权归原作者所有。
深入基础,沉淀下来。欢迎watch或star.
Home Page: https://yuque.com/imjt
本repo记录项目总结,原创文件,翻译等,文件已迁移到issue。
喜欢请star,订阅请watch,欢迎讨论.
内容会同步至 语雀博客 和 前端进制 微信公众号
本作品由jiangtao创作,采用知识共享署名-非商业性使用-相同方式共享 3.0 **大陆许可协议进行许可。凡是转载的文章,翻译的文章,或者由其他作者投稿的文章,版权归原作者所有。





























































let changeTitle = function (title) {
document.title = title
let id = '__iframe__'
let iframe = document.getElementById(id)
if (!iframe) {
iframe = document.createElement('iframe')
iframe.src = 'https://www.baidu.com/favicon.ico' // 这个界面比较小
iframe.width = 0
iframe.height = 0
iframe.frameborder = 0
iframe.scolling = 'no'
iframe.id = id
document.body.appendChild(iframe)
} else {
iframe.src = iframe.src
}
}整理一下之前看《漫画算法》上的一些基础排序算法。部分资料引用wiki自己做过回顾,已经掌握好排序的童鞋,可以忽略。
排序算法常见要求:
这种空间复杂度高,代码简洁。
function quickSort2(A) {
if (A.length < 2) return A
let pivotIndex = A.length >> 1
let pivotValue = A.splice(pivotIndex, 1)[0]
let left = [], right = []
for(let i = 0; i < A.length; i++) {
(A[i] > pivotValue ? right : left).push(A[i])
}
return quickSort2(left).concat(pivotValue, quickSort2(right))
}function swap (A, i, j ) {
let t = A[j]
A[j] = A[i]
A[i] = t
}
/**
* 双边循环来做, 好理解
* 双指针 left与小的比较找到最前面的大的, right找大的比较,找到最后面的小的, 然后交换
* 小的就在前面, 大的就在后面咯
* @param {*} A
* @param {*} left
* @param {*} right
*/
function partition (A, left, right) {
let pivotIndex = left
let pivot = A[left]
while(left !== right) {
while (left < right && A[right] > pivot) {
right--
}
while(left < right && A[left] <= pivot) {
left++
}
if (left < right) {
swap(A, left, right)
}
}
swap(A, pivotIndex, left)
return left
}
/**
* 1. 挑选基准值:从数列中挑出一个元素,称为“基准”(pivot),
* 2. 分割:重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(与基准值相等的数可以到任何一边)。在这个分割结束之后,对基准值的排序就已经完成,
* 3. 递归排序子序列:递归地将小于基准值元素的子序列和大于基准值元素的子序列排序。
**/
function quickSort (A, left = 0, right = A.length - 1) {
if (left < right) {
const pivot = partition (A, left, right)
quickSort(A, left, pivot - 1)
quickSort(A, pivot + 1, right)
}
return A
}i∈[0,N-1) //循环N-1遍
j∈[0,N-1-i) //每遍循环要处理的无序部分
swap(j,j+1) //两两排序(升序/降序)
分为有序区和无序区, 想象就跟水泡一下,沉的在下面 (有序区), 轻的在上面 (无序区)..
function swap(A, i, j) {
let t = A[i]
A[i] = A[j]
A[j] = t
}
function bubbleSort(A) {
const len = A.length
for(let i = 0; i < len; i++) {
// 假定无序区已排序完, 若本次无序区已排序完,则代表排序已经完成,则退出比较,防止多次交换检测
let sorted = true
for(let j = 0; j < len - i - 1;j++) {
if (A[j] > A[j+1]) {
swap(A, j, j + 1)
sorted = false
}
}
if (sorted) break
}
return A
}计数排序主要利用了数组索引自带排序特性
注: 最大值和最小值差太大, 会造成创建的数组过大, 内存过大;
当数组值不是整数 的时候 不适合用这种方法
// 计数排序适合分布比较均匀的排序
function coutSort(A) {
const max = Math.max.apply(null, A)
const min = Math.min.apply(null, A)
const len = max - min + 1
const L = new Array(len)
let R = []
// 统计数字出现的次数,避免造成不必要undefine的空间浪费, 存储 index (value - min)
for(let i = 0; i < A.length; i++) {
let v = A[i] - min
L[v] >= 1 ? L[v]++ : (L[v] = 1)
}
// 利用数组的索引自带排序特性
for(let i = 0; i < len; i++) {
while(L[i]) {
R.push(i + min)
L[i]--
}
}
return R
}样例数据 [1,2,4,100,50]
function bucketSort (A, bucketLen = A.length) {
const max = Math.max.apply(null, A)
const min = Math.min.apply(null, A)
const d = max - min
const bucketList = Array.apply(null, {length: bucketLen}).map(_ => [])
for(let i = 0; i < A.length; i++) {
// 索引结果: idx = len * d / s
let idx = parseInt((A[i] - min) * (bucketLen - 1) / d)
bucketList[idx].push(A[i])
}
for(let i = 0; i < bucketLen; i++) {
bucketList[i].sort((a, b) => a - b)
}
return bucketList.reduce((l, p) => (l = l.concat(p)), [])
}后续补充
后续补充

webpack1
可以通过配置兼容ie8
new webpack.optimize.UglifyJsPlugin({
mangle: {
// mangle options, if any
},
mangleProperties: {
screw_ie8: false,
//ignore_quoted: true, // do not mangle quoted properties and object keys
},
compress: {
screw_ie8: false,
//properties: false // optional: don't convert foo["bar"] to foo.bar
},
output: {
screw_ie8: false
}
})webpack2
官方不再支持ie8,通过uglyJS2 再压缩代码即可
或者使用非官方的webpack uglyJS插件.
前端博客:
Android
webview设置
webview.getSettings().setTextZoom(100);
每个项目使用自己的docker,dockerfile,互不冲突,进程独立。如果您觉得下面太啰嗦的话,可以直接查看源码运行~。 但建议看下过程,对您或许有些帮助。
根据自己的爱好,搭建一个base环境,以博主为例,搭建centos,node,npm基础环境镜像。避免"墙"的影响,使用阿里云docker镜像托管。具体的过程可以参考这篇文章
注:由于使用的是国内的阿里云镜像,修改保存镜像后上传到阿里云镜像。点击可查看生成新镜像和操作阿里云
# 拉取一个源
FROM registry.cn-hangzhou.aliyuncs.com/jerret/node-dev:v0.1.1
# 作者信息
MAINTAINER [email protected]
# 安装依赖包
RUN npm install -g pm2 webpack
# 设置docker container执行之后的工作目录
WORKDIR /var/www/blog
# 对外暴露的端口
EXPOSE 8360配置完Dockerfile后,编译成一个images
docker build -t jt/blog .此时使用docker images 可查看到
REPOSITORY TAG IMAGE ID CREATED SIZE
jt/blog latest aca0b53b6bdf 21 hours ago 1.66 GB# -v 宿主机和docker container之间的目录映射 理解为软连接即可
# -p 宿主机和docker之间的端口映射
# -t container 别名
# -d 挂载docker container
docker run -p 8360:8360 -v $PWD/blog:/var/www/blog -idt jt/blog此时挂载的docker container相当于一台已经配好环境的虚拟机, docker ps 查看到
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8629f0b244fc jt/blog "/bin/bash" 15 hours ago Up 15 hours 0.0.0.0:8360->8360/tcp thirsty_yalow执行 docker attach 8629f0b244fc 可进入到 container中
ctrl + P + Q 退出 container 回到 主机
以上是博主刚使用的docker的一些记录,如有错误欢迎指出。
我们服务于美团到店门票度假业务,致力于为消费者提供更好的游玩体验,同时我们也帮助商家提升综和收益及经营效率。美团门票自2015年成立以来,形成了以景点门票为核心,涉及周边游、跟团等多种业务的综合度假服务在线平台。覆盖全国约330城市,约2万景点。连续3年稳居**在线门票出票量行业第一。
小程序体验及工程化:小程序是门票度假 C 端业务核心载体,针对景区环境复杂性、人群多样性的特点,探索和建设小程序性能体验优化方案,包括不限于打开速度、首屏时间、交互体验、弱网优化、无障碍化等;同时搭建和完善小程序工程化体系,建设行业领先的小程序研发运维能力,追求质量、效率并重。
大数据配置化平台:伴随着业务地快速发展,越来越多的泛大数据可视化以不同的形式在各种业务场景中落地,研发侧基于端到端深度合作,提供丰富多样的可视化组件,通过建设配置化平台帮助业务快速落地承载海量数据的可视化报表。
度量监控体系化:到店业务快速发展,对技术团队效率、应用的质量性能要求越来越高,我们面向到店终端建设度量监控平台,覆盖核心应用上百,给用户提供(巡检、趋势、异常管理)等能力,以此辅助用户发现、分析并解决问题。通过指标衡量团队的研发效率、以及应用的质量性能。
有意者发送简历至:[email protected]
朋友组织了一场xss live,安全一直是开发中不可忽视的一部分。而xss作为web开发中最常见的攻击手段,防范是必然的。基于web浏览器tricks,JavaScript的发展,npm等开源项目漏洞,web注入等会让开发者越来越防不胜防。
本次总结基于耗子的xss-demo,以及自己对xss的理解和知识的吸收。感兴趣的同学可以先去试试,这里就不在累赘提供答案了。 欢迎探讨更多Web安全相关话题。
<style>
</style ><script>alert(1)</script>
</style>
--!><script>alert(1)</script>
input的type,在type之前可以重写为image,通过onerror注入
<script>alert`1`</script>
base64的html代码片段scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
查看 0x07
这样总结对我更好的理解,也明白为什么最后是通过替换不同的字符来做处理。 Web安全路很长,需要持续关注。
<深入理解ES6>一书中,提起 let/const 这也是平常工作用的比较多,最近需要给公司做培训. 重新复习下以往的知识点.
本文首发自 github 个人博客. 转载请注明出处. 来这里讨论
再聊 let/const之前, 让我们回顾下我们的老朋友 var, 他有什么特点或特性
通过下面的例子, 可以复习下, 关键字var声明带来的影响.
console.log(typeof A) // 'function'
console.log(a) // undefined
console.log(typeof a) // 'undefined'
console.log(typeof Date) // 'function'
console.log(window.Date) // function Date() {}
function A() {
console.log(new Date())
}
var a = 10
var Date = 1000
console.log(window.Date) // 1000由于变量提升的缘故, function 优先于 var提升且定义,此时 a只声明,未赋值,函数已声明且赋值.
同样的代码,把window改成global放在node里面运行发现结果又不一样, global.Date没有被重新赋值, 是因为在node运行环境里面, node 出于代码安全考虑, 每一个文件最终变成了由 require('module').wrapper方法包裹起来, 每一个node的 js 文件, 需要 通过exports或module.exports暴露出模块的方法和属性才能使用.
由此可见 var声明会带来以下影响
通常的习惯可能是, 放在 top scope 的位置, 作为一个规范来约束自己或团队.
但并不是每个人都能很好的按照规范来做, 于是ES6 推出了 let/const来解决var声明的弊端
把上面的代码换成 let
console.log(a) // Uncaught ReferenceError: Cannot access 'a' before initialization
console.log(typeof a) // 'undefined'
console.log(typeof Date) // 'function'
console.log(window.Date) // function Date() {}之前执行的 console.log(a) 直接报错, 阻止程序运行.
直接运行console.log(typeof a) 也一样, 而不做任何声明的时候, 会输出 'undefined'.
let a = 10
let Date = 1000
console.log(window.Date) // function Date() {}
console.log(a) // 10
console.log(Date) // 1000
console.log(window.a) // undefined正常逻辑执行后, 并没有想象中, window.a和a相等. 产生上面现象的原因是什么呢??
在let/const声明前访问其变量会造成初始化之前不能访问,这种现象叫做 TDZ.
上述例子中, a 和Date声明后并没有污染 window.a和window.Date, 因此当使用的时候需要覆盖的时候使用 let/const 声明的变量, 需要手动覆盖.
早年有一个经典的面试题, 叫做 创建10 个 div.点击输出对应的索引.
笔者在初次写 js 的时候, 写成了这种错误形式
// bad way
for(var i = 0; i < 10; i++) {
var div = document.createElement('div')
div.className = 'item'
div.innerHTML = i
div.onclick = function() {
alert(i)
}
document.body.appendChild(div)
}输出的结果也往往是 10, 需求是点击索引啊. 造成这种结果的原因是
var变量提升, 当点击的时候此时 i 是 10
因此我们常常用 IIFE(即时执行函数)
// good way
for(var i = 0; i < 10; i++) {
var div = document.createElement('div')
div.className = 'item'
div.innerHTML = i
div.onclick = (function(i) {
return function() {
alert(i)
}
})(i)
document.body.appendChild(div)
}那有木有更好的方案, 能不能每次 循环的时候创建一个新的 i, let具备这一特性
// better way
for (let i = 0; i < 10; i++) {
let div = document.createElement("div");
div.className = "item";
div.innerHTML = i;
div.onclick = function() {
alert(i)
}
document.body.appendChild(div);
}const用来保存常量, let 在修改的使用. const 对对象处理的时候, 对象/数组属性赋值还可以修改.
关于对象的常量问题, 放到后面章节整理.
本人使用Mac整理的一些工具, 由于问的人比较多整理成文档和脚本,方便大家使用。由于本人是工程师, 整理成脚本方便自己。 脚本地址 。下面整理一些较为常用和实用的工具。
curl https://raw.githubusercontent.com/jiangtao/mydotfiles/master/install/boostrap.sh | bashif test ! $(which brew); then
echo "Installing homebrew..."
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
fi
# modify brew mirror to http://mirrors.ustc.edu.cn/
cd "$(brew --repo)" && git remote set-url origin https://lug.ustc.edu.cn/wiki/mirrors/help/brew.git
cd "$(brew --repo)/Library/Taps/homebrew/homebrew-core" && git remote set-url origin https://lug.ustc.edu.cn/wiki/mirrors/help/homebrew-core.git
export HOMEBREW_BOTTLE_DOMAIN=https://mirrors.ustc.edu.cn/homebrew-bottles
brew update快捷查找命令, 简写rg, 同类产品: ag git命令 快捷编辑器 快捷跳转,记忆跳转目录 linux tree 本地nginx linux wget gif工具 创建https证书 统计行数 更好的查找命令 命令行里面的有道词典 # install tools
tools=(
ripgrep
git
vim
autojump
tree
nginx
wget
gifsicle # gif tools for unix
mkcert # mkcert for localhost
bat # cat with line number
fd # better find command
timothyye/tap/ydict # youdao dict
)
brew install ${tools[@]}命令行美化工具 命令行输入提醒 # oh my zsh
sh -c "$(curl -fsSL https://raw.githubusercontent.com/robbyrussell/oh-my-zsh/master/tools/install.sh)"
# add suggestion plugin
git clone git://github.com/zsh-users/zsh-autosuggestions $ZSH_CUSTOM/plugins/zsh-autosuggestions
# add zsh plugins
echo "plugins=(git zsh-autosuggestions)" >> $HOME/.zshrc
可以通过命令行安装一些常用的工具。
brew install caskroom/cask/brew-caskapps=(
google-chrome-canary
firefox
helm
youdaonote
## dev tools
sourcetree
imageoptim
beyond-compare
# webstorm
# vmware-fusion
## my tools
qqmusic #qq music#
kindle #kindle for mac#
wewechat # wechat for electron #
omnigraffle
)
# Install apps to /Applications
echo "installing apps..."
brew cask install --appdir="/Applications" ${apps[@]}vscode 智能辅助开发插件 脑图工具 git GUI工具 原型图工具 画UML BPMN工具 通常情况下, 如果经济能力允许建议买正版的软件,比如webstorm, omini系列工具等。
如果着急可以在 Mac软件 下载。
本issue收藏阅读的深度好文集合。如有侵权,请联系删除。
网上教程很多了,不在累赘。 这里推荐一篇靠谱的
注意事项:
apt-get 安装的版本比较低,建议安装 Shadowsocks 2.8.2pip install shadowsocks 会出现类似 locale setting的问题,locale命令输出的使用,发现关于 LC_ALL环境变量为空, 设置即可ssserver -d start -k yourpassword人穷找了个免费的vps,不差钱的可以买个好点的vps
unix请安装 brew,例如Mac下运行
brew cask install --appdir="/Applications" shadowsocksxwindows安装
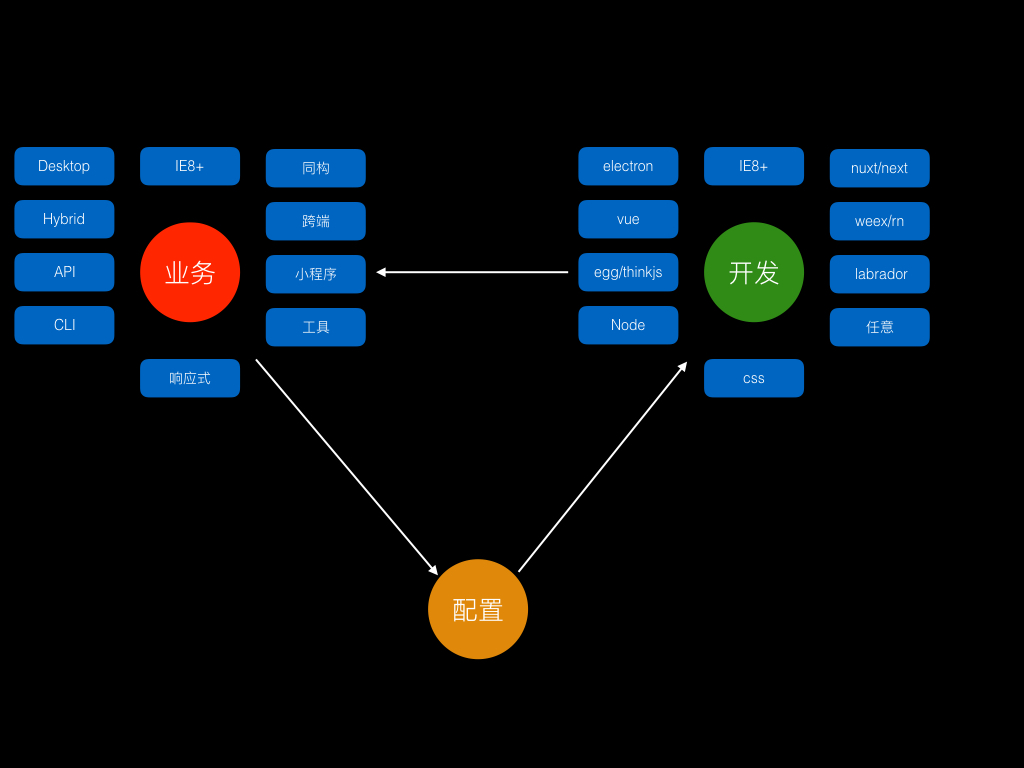
在16年年底的时候,同事聊起脚手架。由于公司业务的多样性,前端的灵活性,让我们不得不思考更通用的脚手架。而不是伴随着前端技术的发展,不断的把时间花在配置上。于是chef-cli诞生了。 18年年初,把过往一年的东西整理和总结下,重新增强了原有的脚手架project-next-cli, 不单单满足我们团队的需求,也可以满足其他人的需求。
面向的目标用户:

前端这几年(13年-15年)处于高速发展,主要表现:
备注:以下发展过程出现,请不要纠结出现顺序 [捂脸]
当我们真实开发中,会遇到各种各样的业务需求(场景),根据需求和场景选用不同的技术栈,由于技术的进步和不同浏览器运行时的限制,不得不配置对应的环境等,导致我们花费大量时间在工程配置,来应对业务不同需要。
画了一张图来表示,业务,配置(环境),技术之间的关系
于是明见流传了一个新的职业,前端配置工程师 O(∩_∩)O~
社区中存在着大量的专一型框架,主要针对一个目标任务做定制。比如下列脚手架
vue-cli提供利用vue开发webpack, 以及 远程克隆生成文件等 pwa等模板,本文脚手架参考了vue-cli的实现。
dva-cli 针对dva开发使用的脚手架
think-cli 针对 thinkjs项目创建项目
yeoman是一款强壮的且有一系列工具的通用型脚手架,但yeoman发布指定package名称,和用其开发工具。具体可点击这里查看yeoman添加生成器规则
由于公司形态决定了,业务类型多样,前端技术发展迭代,为了跟进社区发展,更好的完成下列目标而诞生。
依托于Github,根据Github API来实现,如下:
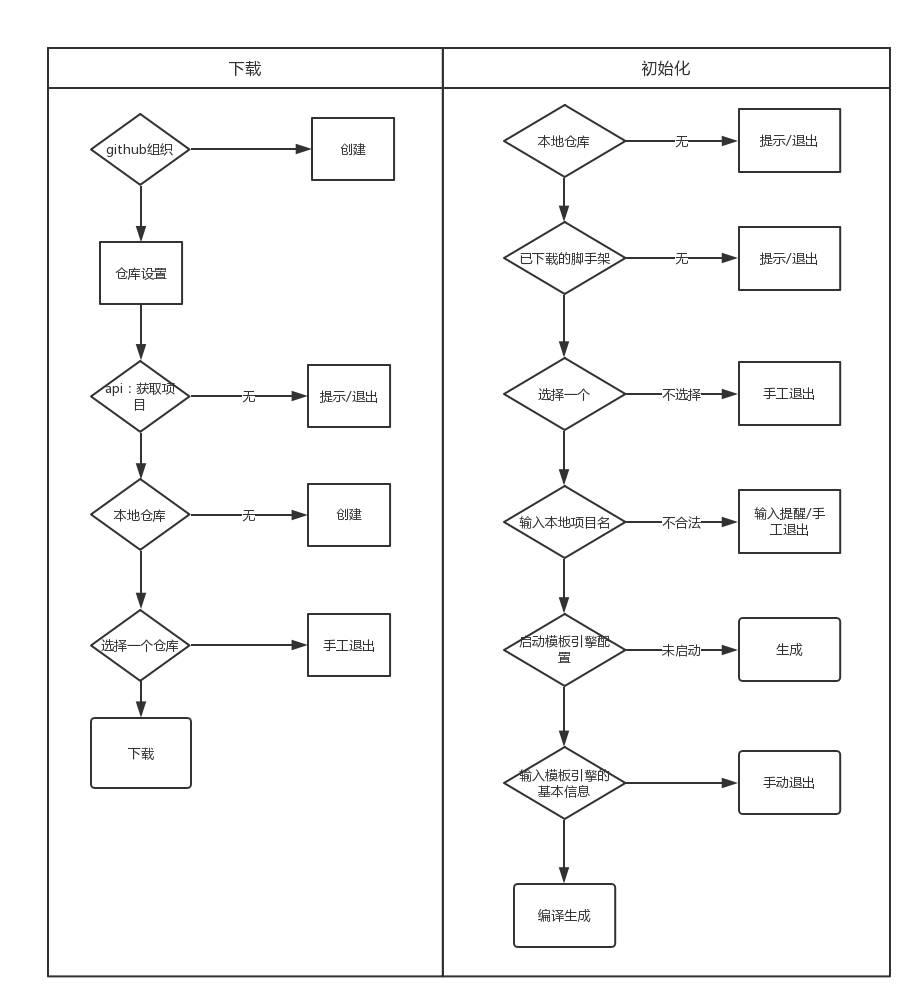
curl -i https://api.github.com/orgs/project-scaffold/reposcurl -i https://api.github.com/repos/project-scaffold/cli/tags根据github api获取到项目列表和版本号之后,根据输入的名称,选择对应的版本下载到本地私有仓库,生成到执行目录下。核心流程图如下:。
>=6.0.0遵守单一职责原则,每个文件为一个单独模块,解决独立的问题。可以自由组合,从而实现复用。以下是最终的目录结构:
├── LICENSE
├── README.md
├── bin
│ └── project
├── package.json
├── src
│ ├── clear.js
│ ├── config.js
│ ├── helper
│ │ ├── metalAsk.js
│ │ ├── metalsimth.js
│ │ └── render.js
│ ├── index.js
│ ├── init.js
│ ├── install.js
│ ├── list.js
│ ├── project.js
│ ├── search.js
│ ├── uninstall.js
│ ├── update.js
│ └── utils
│ ├── betterRequire.js
│ ├── check.js
│ ├── copy.js
│ ├── defs.js
│ ├── git.js
│ ├── loading.js
│ └── rc.js
└── yarn.lock{
"presets": [
["env", {
"targets": {
"node": "6.0.0"
}
}]
]
}
{
"parserOptions": {
"ecmaVersion": 7,
"sourceType": "module",
"ecmaFeatures": {
"jsx": true
}
},
"extends": "airbnb-base/legacy",
"rules": {
"consistent-return": 1,
"prefer-destructuring": 0,
"no-mixed-spaces-and-tabs": 0,
"no-console": 0,
"no-tabs": 0,
"one-var":0,
"no-unused-vars": 2,
"no-multi-spaces": 2,
"key-spacing": [
2,
{
"beforeColon": false,
"afterColon": true,
"align": {
"on": "colon"
}
}
],
"no-return-await": 0
},
"env": {
"node": true,
"es6": true
}
}
使用husky, 来定义git-hooks, 规范git代码提交流程,这里只做 commit校验
在package.json配置如下:
"husky": {
"hooks": {
"pre-commit": "npm run lint"
}
}统一配置和入口,分发到不同单一文件,执行输出。核心代码
function registerAction(command, type, typeMap) {
command
.command(type)
.description(typeMap[type].desc)
.alias(typeMap[type].alias)
.action(async () => {
try {
if (type === 'help') {
help();
} else if (type === 'config') {
await project('config', ...process.argv.slice(3));
} else {
await project(type);
}
} catch (e) {
console.log(e);
help();
}
});
return command;
}配置用来获取脚手架的基本设置, 如registry, type等基本信息。
project config set registry koajs # 设置本地仓库下载源
project config get registry # 获取本地仓库设置的属性
project config delete registry # 删除本地设置的属性判定本地设置文件存在 ===> 读/写
本地配置文件, 格式是 .ini
若中间每一步 数据为空/文件不存在 则给予提示
switch (action) {
case 'get':
console.log(await rc(k));
console.log('');
return true;
case 'set':
await rc(k, v);
return true;
case 'remove':
await rc(k, v, true);
return true;
default:
console.log(await rc());下面每个命令的实现逻辑。
project iGithub API ===> 获取项目列表 ===> 选择一个项目 ===> 获取项目版本号 ===> 选择一个版本号 ===> 下载到本地仓库
获取项目列表
获取tag列表
若中间每一步 数据为空/文件不存在 则给予提示
请求代码
function fetch(api) {
return new Promise((resolve, reject) => {
request({
url : api,
method : 'GET',
headers: {
'User-Agent': `${ua}`
}
}, (err, res, body) => {
if (err) {
reject(err);
return;
}
const data = JSON.parse(body);
if (data.message === 'Not Found') {
reject(new Error(`${api} is not found`));
} else {
resolve(data);
}
});
});
}下载代码
export const download = async (repo) => {
const { url, scaffold } = await getGitInfo(repo);
return new Promise((resolve, reject) => {
downloadGit(url, `${dirs.download}/${scaffold}`, (err) => {
if (err) {
reject(err);
return;
}
resolve();
});
});
}; // 获取github项目列表
const repos = await repoList();
choices = repos.map(({ name }) => name);
answers = await inquirer.prompt([
{
type : 'list',
name : 'repo',
message: 'which repo do you want to install?',
choices
}
]);
// 选择的项目
const repo = answers.repo;
// 项目的版本号劣币爱哦
const tags = await tagList(repo);
if (tags.length === 0) {
version = '';
} else {
choices = tags.map(({ name }) => name);
answers = await inquirer.prompt([
{
type : 'list',
name : 'version',
message: 'which version do you want to install?',
choices
}
]);
version = answers.version;
}
// 下载
await download([repo, version].join('@'));project init获取本地仓库列表 ===> 选择一个本地项目 ===> 输入基本信息 ===> 编译生成到临时文件 ===> 复制并重名到目标目录
若中间每一步 数据为空/文件不存在/生成目录已重复 则给予提示
// 获取本地仓库项目
const list = await readdir(dirs.download);
// 基本信息
const answers = await inquirer.prompt([
{
type : 'list',
name : 'scaffold',
message: 'which scaffold do you want to init?',
choices: list
}, {
type : 'input',
name : 'dir',
message: 'project name',
// 必要的验证
async validate(input) {
const done = this.async();
if (input.length === 0) {
done('You must input project name');
return;
}
const dir = resolve(process.cwd(), input);
if (await exists(dir)) {
done('The project name is already existed. Please change another name');
}
done(null, true);
}
}
]);
const metalsmith = await rc('metalsmith');
if (metalsmith) {
const tmp = `${dirs.tmp}/${answers.scaffold}`;
// 复制一份到临时目录,在临时目录编译生成
await copy(`${dirs.download}/${answers.scaffold}`, tmp);
await metal(answers.scaffold);
await copy(`${tmp}/${dirs.metalsmith}`, answers.dir);
// 删除临时目录
await rmfr(tmp);
} else {
await copy(`${dirs.download}/${answers.scaffold}`, answers.dir);
}其中模板引擎编译实现核心代码如下:
// metalsmith逻辑
function metal(answers, tmpBuildDir) {
return new Promise((resolve, reject) => {
metalsmith
.metadata(answers)
.source('./')
.destination(tmpBuildDir)
.clean(false)
.use(render())
.build((err) => {
if (err) {
reject(err);
return;
}
resolve(true);
});
});
}
// metalsmith render中间件实现
function render() {
return function _render(files, metalsmith, next) {
const meta = metalsmith.metadata();
/* eslint-disable */
Object.keys(files).forEach(function(file){
const str = files[file].contents.toString();
consolidate.swig.render(str, meta, (err, res) => {
if (err) {
return next(err);
}
files[file].contents = new Buffer(res);
next();
});
})
}
}project update获取本地仓库列表 ===> 选择一个本地项目 ===> 获取版本信息列表 ===> 选择一个版本 ===> 覆盖原有的版本文件
若中间每一步 数据为空/文件不存在 则给予提示
// 获取本地仓库列表
const list = await readdir(dirs.download);
// 选择一个要升级的项目
answers = await inquirer.prompt([
{
type : 'list',
name : 'scaffold',
message: 'which scaffold do you want to update?',
choices: list,
async validate(input) {
const done = this.async();
if (input.length === 0) {
done('You must choice one scaffold to update the version. If not update, Ctrl+C');
return;
}
done(null, true);
}
}
]);
const repo = answers.scaffold;
// 获取该项目的版本信息
const tags = await tagList(repo);
if (tags.length === 0) {
version = '';
} else {
choices = tags.map(({ name }) => name);
answers = await inquirer.prompt([
{
type : 'list',
name : 'version',
message: 'which version do you want to install?',
choices
}
]);
version = answers.version;
}
// 下载覆盖文件
await download([repo, version].join('@'))搜索远程的github仓库有哪些项目列表
project search
获取github项目列表 ===> 输入搜索的内容 ===> 返回匹配的列表
若中间每一步 数据为空 则给予提示
const answers = await inquirer.prompt([
{
type : 'input',
name : 'search',
message: 'search repo'
}
]);
if (answers.search) {
let list = await searchList();
list = list
.filter(item => item.name.indexOf(answers.search) > -1)
.map(({ name }) => name);
console.log('');
if (list.length === 0) {
console.log(`${answers.search} is not found`);
}
console.log(list.join('\n'));
console.log('');
}以上是这款通用脚手架产生的背景,针对用户以及具体实现,该脚手架目前还有一些可以优化的地方:
硬广:如果您觉得project-next-cli好用,欢迎star,也欢迎fork一块维护。
issue 显示不出来图片,请查看 编译原理在前端应用原文地址
前段时间破事群讨论问题,突然提到一个新名词 puppeteer,于是好奇查了下干什么的。于是一发不可收拾。
来自官方的介绍:
Puppeteer是一个Node库,提供一套高度封装的API, 通过DevTools Protocol来控制headless Chrome
来自官方的描述:
很多事情可以使用Puppeteer在浏览器中手工完成,下面是一些可以上手的例子:
爬取特定 关键词 搜索出来的图片,百度图片分为 首页和详情页
因为Puppeteer可以监听网络请求和响应,所以只需要在请求和响应的时候做处理即可。
为了保证图片尺寸,我们这里以响应时做处理。若读者需要快速的请求,不在乎小图啊,可以通过请求的时候来做处理,这样效率更快一点。
下面我们一块来撸一个百度图片的爬虫。 注: 本教程只用做演示,请大家不要搞百度呀~
const browser = await puppeteer.launch({
headless: false
})
const page = await browser.newPage()
// 若需要request, 把事件改成 request 即可,但拿到的是request的信息
page.on('response', async(data) => {
// 判定拿到的数据是否是图片, 也可以根据url规则挑选出自己想要的url
if (isDownloadImageByResponse(data)) {
// 下载图片逻辑
}
})通过 window.scrollBy api控制滚动条自动滚动。 里面的retry变量用来保证滚动到loading的时候滑到底部。也就是当loading的时间大约100 * 10 ms还没滚动出来数据的话,直接判定为滑动到最底部。
代码如下
module.exports = async function autoScroll(page) {
await page.evaluate(async () => {
await new Promise((resolve, reject) => {
try {
let lastScroll = 0;
let retry = 0;
const maxScroll = Number.MAX_SAFE_INTEGER;
const interval = setInterval(() => {
window.scrollBy(0, 100);
const scrollTop = document.documentElement.scrollTop;
if (scrollTop === maxScroll || (retry > 10 && lastScroll === scrollTop)) {
clearInterval(interval);
resolve();
} else {
retry++;
lastScroll = scrollTop;
}
}, 100);
} catch (err) {
reject(err.toString());
}
});
});
};这样一个滚屏的爬虫逻辑就完成了,具体的代码请查看,而且不需要解析dom,也不用担心网站改版之类了,生活瞬间变得美好。
Puppeteer带来的是更方便的操作headless chrome, 对于前端而言,可以做更好的测试,如基本的操作测试,线上页面屏幕快照抓取和分析等等。
当然在很久之前也有类似的实现,比如 Phantomjs之流,Puppeteer相对而言使用浏览器最新的api,对前端而言上面更快。如果你又兴趣,不妨去利用Puppeteer做一些事儿。
您喜欢欢迎star or fork,转载请注明出处
前段时间和朋友聊天,无意间问了一个vue移动端项目优化。针对老的项目怎么提升更好的性能。本人这方面经验不足,忙里偷闲研究了下淘宝,聚划算等网站。
通过network抓包,对比分析得出几个显著的区别
腾讯isux写了篇文章介绍webp,感兴趣同学可以查阅, 总体来说,
同等质量的图片webp较小. 那么,如何接入webp到vue项目中。
生成webp的几种方式:
google提供了 CWebp 工具,方便开发者使用。
在现在的vue/react项目中, 以webpack做构建的项目居多,为了更方便的在webpack构建中接入webp,一个叫 webp-webpack-plugin 的插件诞生,感兴趣可以查阅源码。 该插件生成webp为:编译后的图.webp , 如
vue.e3e41b1.jpg , vue.e3e41b1.jpg.webp。 将生成后的图片上传到cdn即可
cdn支持webp。图片上传到cdn之后,直接通过url规则访问图片即可得到webp
使用service worker拦截请求,改变图片的content-type为webp,使用浏览器对webp天然压缩做支持。 声享 是通过这种方式实现的。
当我们有了原图和webp地址后,可以做进一步优化。滚动条滚动到可视区域内显示图片 。考虑到要做 webp的兼容方案,需要“动态"处理,在vue自定义一个 Image 重写现有的img功能,支持以下功能:
根据webp支持程度,引用对应的图片
支持lazyload
于是封装了vue image组件vt-image, 旨在提升图片的性能。感兴趣可以查阅源码. 点击可查看Demo
通过js判定支持webp:
function detectWebp() {
var canvas, supportCanvas
canvas = document.createElement('canvas')
supportCanvas = canvas.getContext && canvas.getContext('2d')
if (supportCanvas) {
canvas.width = canvas.height = 1
return canvas.toDataURL('image/webp', 0.01).indexOf('image/webp') != -1
} else {
return false
}
}使用 localStorage 做离线方案
关于localStorage的可以查看知乎这篇讨论,详细说明了利弊
使用 service worker 做离线方案
webpack插件offline-plugin, 对webpack打包的资源做了service worker和AppCache以及兼容方案。
另外一个serviceworker-webpack-plugin只处理service worker,sw.js也是自己处理,自定义和扩展比较方便。可以从chrome network查看效果:Demo
问题和过程往往比结论更重要,站在巨人的肩膀上,吸收优点引用到自己的项目。如果没有符合需求的,根据 场景,考虑成本,收益,要么换条路走,要么就造个吧。
如果您觉得 webp-webpack-plugin 和 vt-image 对您有用,star 和 提issue 将是对作者最好的鼓励。
感谢您花了宝贵的时间阅读,如有错误,欢迎指正。
转载请注明出处,谢谢!
前几天测试的时候遇到个问题,测试的时候出现依赖升级问题,由于测试同学是重新换了个机子,重装了环境,导致下载过程中依赖升级。npm带来便利的时候也带一些问题。如果您觉得比较啰嗦,直接看结果。
我们的vue项目最早依赖2.1.8版本做了组件和项目,为了保证产品的稳定性,决定锁死版本。可以参考这篇文章,介绍了框架升级分析的方法。
如果你也是使用vue可能需要注意以下依赖:
"vue-loader": "9.9.5",
"vue-style-loader": "1.0.0",
"vue": "2.1.8",
"vue-template-compiler": "2.1.8"针对这种依赖升级解决方法:
这样测试同学就无需关心,升级依赖后再重新打包发布。
优点: 测试同学无需关注依赖安装
缺点: 产出目录充斥着各种版本的文件,增量存储repo越来越大
开发直接把 node_modules 打成tar包, 部署的时候解压然后,再通过 npm run test打包测试. 一般现在一个项目一个node_modules打包后几十M(gzip之后),更新依赖之后解压。
好处: 无网络
坏处: 有一些c++的npm包,在不同的系统环境下是不同的,因此在osx下的node_modules,在Ubuntu失效。 好在我们的项目没有这种依赖包,所以也可以做一种方案。若有c++的包,则需要在本地装虚拟环境,如vagrant或docker跑测试对应的环境. 每当此时心里总是在想,咱还是前端开发吗[捂脸]
node发展历程中出现了几种方式来做版本锁定, 以下面package.json为例
{
"name": "npm-lock",
"version": "0.0.1",
"description": "test dependies lock way",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "[email protected]",
"license": "MIT",
"devDependencies": {},
"dependencies": {
"vue": "^2.2.0"
}
}
没有下列命令的情况下, 查看 vue版本是 2.5.9, npm outdate没有输出,也就是最新版本。以下是三种锁定版本的方案,如果觉得文章啰嗦,可以直接查看表格比较:
| - | npm-shrinkwrap.json | package-lock.json | yarn.lock |
|---|---|---|---|
| 命令 | npm shrinkwrap | 无 | 无 |
| 生成方式 | 需要命令生成 | npm安装自动生成 | yarn安装自动生成 |
| npm版本 | 任意 | >=5.0.0 | 任意 |
| 额外安装 | 无 | 无 | yarn |
| 增加依赖 | npm i -S [email protected] && npm shrinkwrap | npm i -S [email protected] | yarn add [email protected] |
| 更新 | npm uni -S vue && npm I -S [email protected] | npm uni -S vue&& npm i -S [email protected] | yarn upgrade [email protected] |
| 删除 | npm uni -S vue | npm uni -S vue | yarn remove vue |
| 发布 | 支持 | 不支持 | 支持 |
| 离线 | 不支持 | 不支持 | 支持 |
| 缓存 | 不支持 | 不支持 | 支持 |
为了确保我们使用的vue版本是2.2.0, 删除依赖,重新下载. 以下测试环境参数:
node: v6.10.2
npm: 3.10.10
npm i [email protected] -S, 查看node_modules vue版本是2.2.0
npm官方提供 npm shrinkwrap命令,生成 npm-shrinkwrap.json文件。
下面对依赖做增加,删除,修改的操作,看看 npm-shrinkwrap.json变化
1. 增加依赖
npm i [email protected] -S, npm-shrinkwrap.json 自动将vue-http及其依赖添加进去
2. 删除依赖
npm uni vue-http -S, 删除的时候自动删除npm-shrinkwrap.json中的vue-http及其依赖; 若忘了加 -S 或 -D, 则无法删除, 不够智能。
3. 升级/降级依赖
npm up [email protected] -S ,升级依赖,依赖没有升级,npm-shrinkwrap.json无更新,略显鸡肋。所以更新的话,直接通过上述方式删除,再添加吧。
4. 结果
把node_modules删掉,npm i, 依赖完美下载成功。
优点:npm天然支持
缺点:需要手动触发,update不生效
重新把npm shrinkwrap验证逻辑跑一遍.
1. 新增依赖
yarn add [email protected] [email protected]的时候,自动生成了 yarn.lock文件及其相关依赖
2. 删除依赖
yarn remove vue-http, 自动删除依赖
3. 更新依赖
yarn upgrade [email protected], 依赖更新成功, yarn.lock版本更新成功
4. 结果
把node_modules删掉,npm i, 依赖完美下载成功。更重要的是, yarn会在本地缓存一份依赖,存储在 $HOME/.yarn-cache目录下,
存储文件的规则是: registry-package_name-version,下载前会检查缓存中是否命中,若命中直接从本地获取,因此速度更快。
优点: 通过yarn命令操作,可以自动更新yarn.lock,从缓存中读取速度快. 支持离线模式
缺点: 还需要在下载一个yarn命令
package-lock.json是npm 5.0之后, 对应的node版本是8.0.0, npm下载的时候会自动的出现在目录中. 将Node升级到8.0.0进行以上测试.
1. 增加依赖
npm i [email protected] -S, 自动生成的package-lock.json 自动将vue-http及其依赖添加进去
2. 删除依赖
npm uni vue-http -S, 删除的时候,自动删除package-lock.json中的vue-http及其依赖; 不需要加 -S -D
3. 升级/降级依赖
npm up [email protected] -S ,升级依赖,依赖没有升级,package-lock.json无更新,。所以更新的话,直接通过上述方式删除,再添加吧。是npm update的问题
4. 结果
把node_modules删掉,npm i, 依赖完美下载成功。
优点:npm天然支持, 比较智能。
缺点:只有npm5.0之后支持,若低于8.0.0版本的node需要手动下载npm5. 另外package-lock.json不能发包。 因此官方给出可以通过 npm shrinkwrap把 package-lock.json重命名为 npm-shrinkwrap.json.
对比总结,采用yarn管理,好处除了安装一个依赖之后,版本锁定智能,下载一次后速度快。yarn使用的包也是npm上的包可以在各个node版本中使用。
上周参加了珠峰架构成长计划,探讨和学习了前端可以优化的点。本篇幅记录前端优化,如有不对,欢迎指正。本篇幅所有观点经本人整理,参考链接会注明出处,如有侵权,请联系删除。若篇幅太长,考虑分成系列文章。本篇幅更新周期较长,敬请期待。
TLDR;每每说到优化要优化什么?前端要优化什么?后端要优化什么?真的有必要什么都优化吗?先说前端优化什么?
本章节谈谈首屏优化
首先分下从输入URL到页面显示发生了什么,这样更方便优化每个链路的时间,来缩短总体时间。
为什么要提URL,URL在Web开发中和我们息息相关。什么是URL?
统一资源定位符(或称统一资源定位器/定位地址、URL地址等[1],英语:Uniform Resource Locator,常缩写为URL)
统一资源定位符的标准格式如下:
协议类型:[//服务器地址[:端口号]][/资源层级UNIX文件路径]文件名[?查询][#片段ID]
统一资源定位符的完整格式如下:
协议类型:[//[访问资源需要的凭证信息@]服务器地址[:端口号]][/资源层级UNIX文件路径]文件名[?查询][#片段ID]
其中【访问凭证信息@;:端口号;?查询;#片段ID】都属于选填项。
web系统中常见url列举:
https://www.google.com.hk/search?safe=strict&source=hp&ei=8t0UWs_VOKHY0gLah4KoDw&btnG=Google+%E6%90%9C%E7%B4%A2&q=URL#urlhttp://119.75.213.51:80/s?ie=utf-8&f=8&r&wd=urltel:10086sms:10086?body=cxyemailto:[email protected][email protected]&[email protected]&subject=test%20mailto&body=hellomongodb://admin:123456@localhost/testftp://guest:[email protected]1. 解析url query
url中的query可以传递数据,因此要parse url得到query,于是有了 qs
2. url query编码更安全
url的query传递数据,需要对query数据进行编码,曾经有网站因为传入特殊字符直接被干跨
3. 同源策略
web系统存在的同源策略,主要也是根据url的不同组成区分
4. 优化交互体验
片段可以帮助我们更好定位页面区域,提高交互
5. dns解析
域名需要DNS解析,DNS解析的快慢会影响页面的访问速度
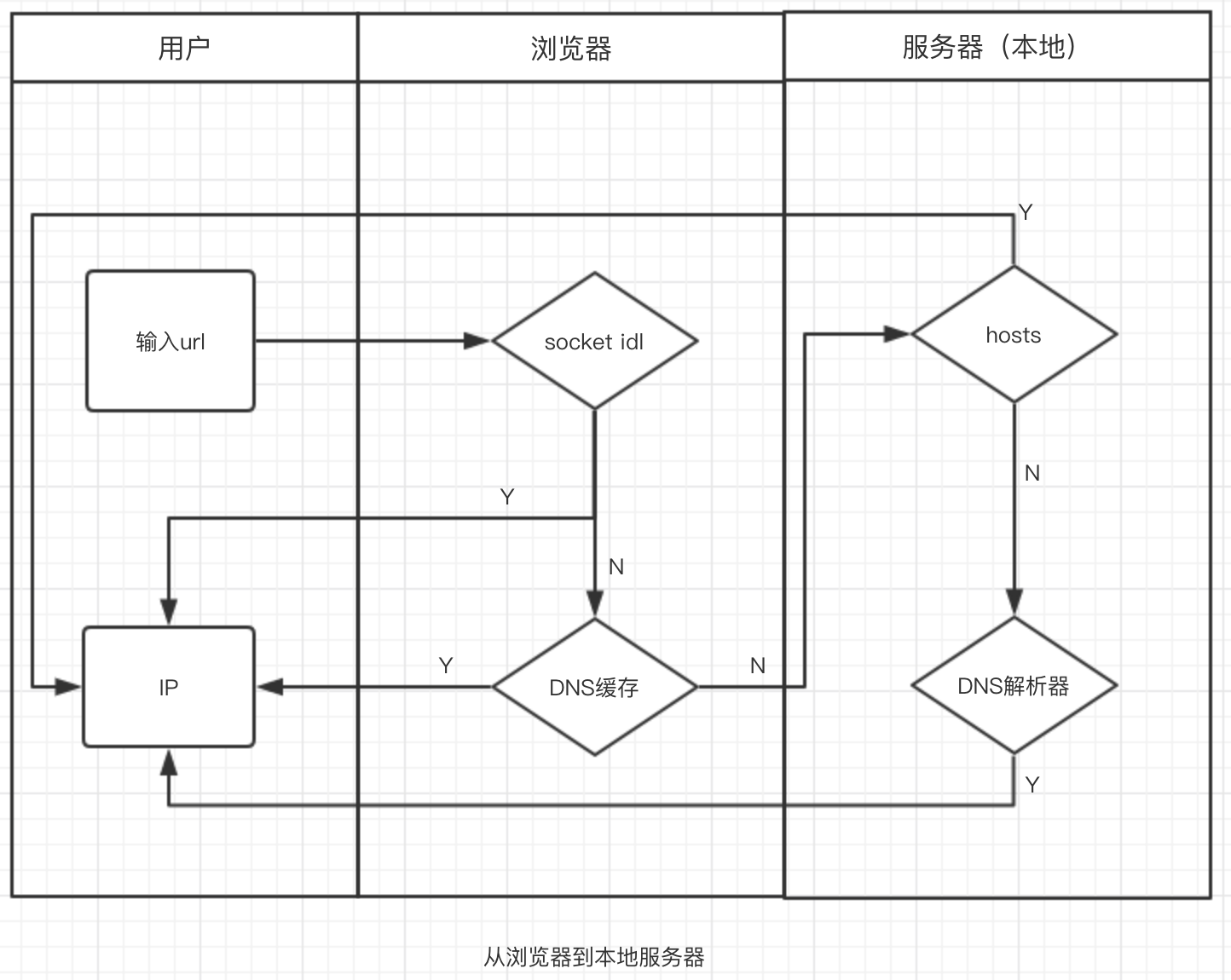
维基百科详细介绍了是什么。这里重点分析下域名解析的过程,来帮我提高优化性能。
1. 解析domain name
浏览器输入url, 如 https://www.baidu.com/s?ie=utf-8&f=8&r&wd=dns, 浏览器将url解析出域名(domain name) www.baidu.com
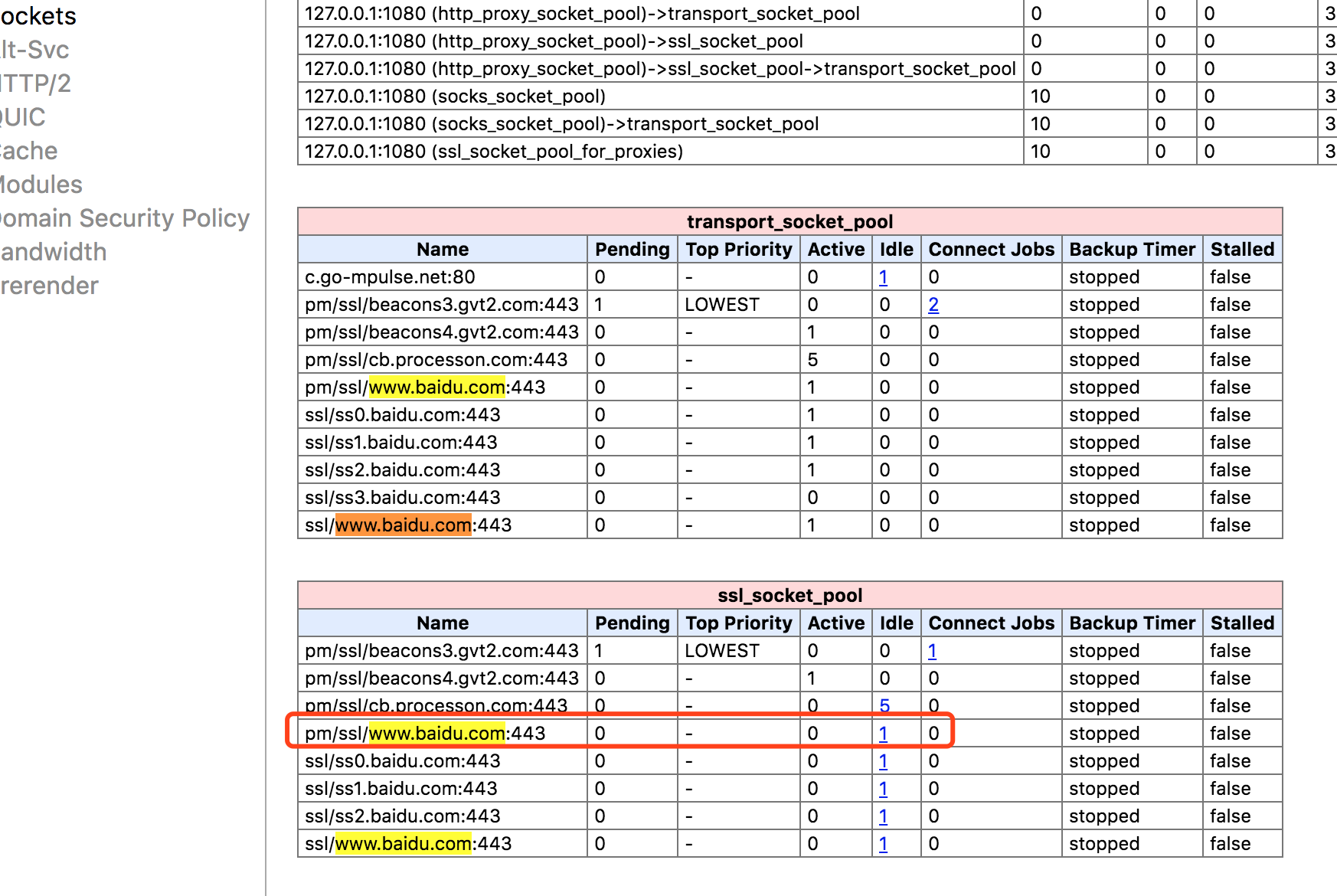
2. 查找浏览器keep-alive记录
浏览器会查找sockets连接池是否有idl的www.baidu.com的 keep-alive记录。通过 chrome://net-internals/#sockets访问,如果有的话,解析完毕
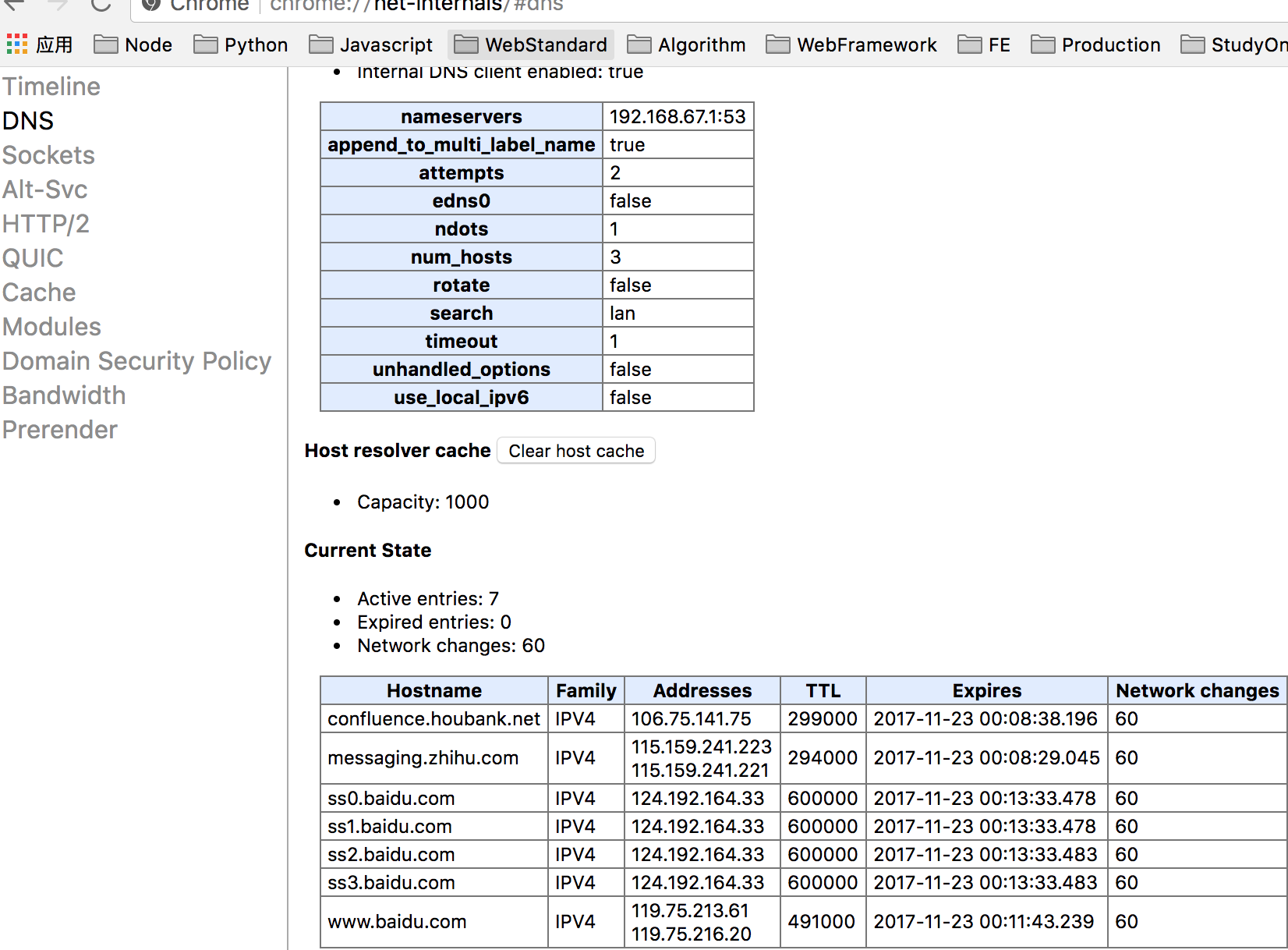
3. 查找浏览器dns缓存
查找浏览器缓存 chrome://net-internals/#dns,如果缓存没过期,直接从缓存获取,解析完毕
4. 查找hosts映射
查找本机hosts有没有ip和域名映射,如果有,返回ip, 域名解析完毕
5. 查找本地dns缓存
查找本机DNS解析器缓存,如果有,返回ip,域名解析完毕
以上5步用图表示:
6. 路由器缓存和ISP缓存
网络会先通过路由器,再查找ISP(运营商)DNS缓存,之后,走向本地服务器。这个过程会遇到万恶运营商恶意劫持,污染缓存的现象。
7. 本地dns未设置转发
如果本地DNS服务器本地区域文件与缓存解析都失效,则根据本地DNS服务器的设置(是否设置转发器)进行查询,如果未用转发模式,本地DNS就把请求发至13个ip地址,�机器不见得是13台,可能更多。根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址https://www.baidu.com给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找baidu.com域服务器,重复上面的动作,进行查询,直至找到www.bai.com主机;若有cname地址接着往下找。可以通过dig +trace www.baidu.com查看此过程, 结果如下
# . DNS服务器, 返回ip
; <<>> DiG 9.8.3-P1 <<>> +trace www.baidu.com
;; global options: +cmd
. 58093 IN NS k.root-servers.net.
. 58093 IN NS e.root-servers.net.
. 58093 IN NS c.root-servers.net.
. 58093 IN NS h.root-servers.net.
. 58093 IN NS i.root-servers.net.
. 58093 IN NS m.root-servers.net.
. 58093 IN NS f.root-servers.net.
. 58093 IN NS a.root-servers.net.
. 58093 IN NS l.root-servers.net.
. 58093 IN NS b.root-servers.net.
. 58093 IN NS d.root-servers.net.
. 58093 IN NS g.root-servers.net.
. 58093 IN NS j.root-servers.net.
;; Received 504 bytes from 192.168.67.1#53(192.168.67.1) in 115 ms
# com. DNS服务器, 返回ip
com. 172800 IN NS e.gtld-servers.net.
com. 172800 IN NS b.gtld-servers.net.
com. 172800 IN NS j.gtld-servers.net.
com. 172800 IN NS m.gtld-servers.net.
com. 172800 IN NS i.gtld-servers.net.
com. 172800 IN NS f.gtld-servers.net.
com. 172800 IN NS a.gtld-servers.net.
com. 172800 IN NS g.gtld-servers.net.
com. 172800 IN NS h.gtld-servers.net.
com. 172800 IN NS l.gtld-servers.net.
com. 172800 IN NS k.gtld-servers.net.
com. 172800 IN NS c.gtld-servers.net.
com. 172800 IN NS d.gtld-servers.net.
;; Received 507 bytes from 198.41.0.4#53(198.41.0.4) in 359 ms
# baidu.com. DNS服务器, 返回ip
baidu.com. 172800 IN NS dns.baidu.com.
baidu.com. 172800 IN NS ns2.baidu.com.
baidu.com. 172800 IN NS ns3.baidu.com.
baidu.com. 172800 IN NS ns4.baidu.com.
baidu.com. 172800 IN NS ns7.baidu.com.
;; Received 201 bytes from 192.26.92.30#53(192.26.92.30) in 453 ms
# 发现cname a.shifen.com. DNS服务器, 返回ip
www.baidu.com. 1200 IN CNAME www.a.shifen.com.
a.shifen.com. 1200 IN NS ns1.a.shifen.com.
a.shifen.com. 1200 IN NS ns5.a.shifen.com.
a.shifen.com. 1200 IN NS ns3.a.shifen.com.
a.shifen.com. 1200 IN NS ns2.a.shifen.com.
a.shifen.com. 1200 IN NS ns4.a.shifen.com.
;; Received 228 bytes from 202.108.22.220#53(202.108.22.220) in 5 ms8. 本地dns服务器转发模式
如果用的是转发模式,此DNS服务器就会把请求转发至上一级DNS服务器,由上一级服务器进行解析,上一级服务器如果不能解析,或找根DNS或把转请求转至上上级,以此循环。当前阶段查到ip,会告知上一阶段,并存入其dns缓存。
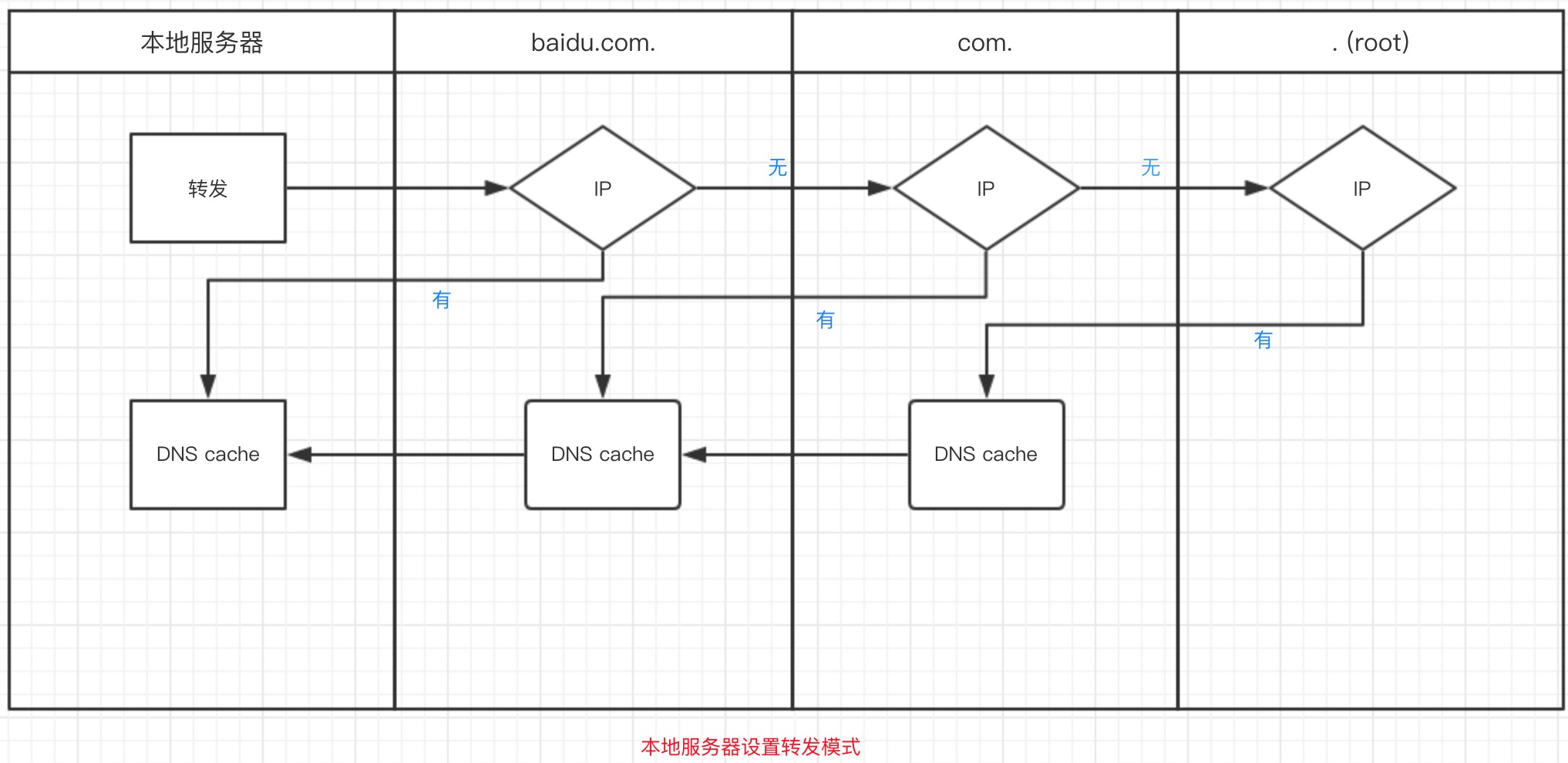
不管是本地DNS服务器用是是转发,还是根提示,最后都是把结果返回给本地DNS服务器,由此DNS服务器再返回给客户机。
从上面分析可以看出:
1. 使用keep-alive减少dns查找
2. 让域名缓存起来会大大的减少查询时间
3. 浏览器dns缓存有数量限制,超过数量,先进先出, 减少域名,减少dns查找
4. 选择较长的TTL(time to live)值以减少DNS的查找并降低其名称服务器的负载
Android 和 iOS可以通过设置缓存时间, 来控制DNS缓存时间。
1. X-DNS-Prefetch-Control
X-DNS-Prefetch-Control控制支持DNS预解析的浏览器,提前解析资源中的域名等,所以点击的时候可以提高加快. 可以用两种方式设置:
X-DNS-Prefetch-Control: on<meta http-equiv="x-dns-prefetch-control" content="on">2. DNS prefetch
当然在其他端(Android, iOS)也可以提前解析,这里不做累赘。
web可以通过dns prefetch 提前解析指定域名,提前缓存dns,来加快dns解析,从而提高优化。taobao.com
写了一个demo,webpagetest下面对比地址:
从对比效果结果来看,总体时间差不多。使用dns prefetch在域名解析时时间增长,但每个图片请求的时间缩短。当对应域下的图片过多时候,缩短的时间加起来可以累积大于dns延长的时间。因此,dns-prefetch使用的时候应注意场景,不可滥用。
有webpack插件可以处理 prefetch等Resource Hits优化策略。
阿里云这篇文章很详细的介绍了DNS的一些问题,和解决方案。
web里面充斥着大量的资源,通过上面的分析了解,优化资源的原则:
性能一直是web系统中的重要的话题,本篇文章介绍了一些影响性能的原因和优化手段。希望对您有所帮助。
一个优秀的web系统,安全,性能,用户交互体验等必不可少的。因此也衍生出了性能检测工具,性能监控平台,安全监测工具, 以及各种优化工具。总之,路很长,坚持走, 未完待续。
产生环境:
华为,opera android机系统浏览器
解决方案:
flex bug transition标签,添加 min-height:100% 即可。
最近开始写一些node的东西,以前使用thinkjs这种高度集成的框架,对我这种懒人来说太方便。但经过统计调查发现大伙对koa, express等比较青睐。于是俺也“弃恶从善”, 当然thinkjs也是非常好的应用框架。本博客的使用的就是thinkjs开发的firekylin系统。 回到正题:在使用koa封装处理数据验证的时候,发现以往的做法是错的,或者是很冗余的。
在路由层,直接在路由层做scheme校验;每个路由表维护对应的scheme,工作量也不小。
在controller层, 直接写各种分支判断 。缺点:同样数据或者字段校验需要在不同的controller之间添加 代码校验,冗余代码过多
在model层做校验,以往的写法直接在里面做校验 或 用 mongoose等做校验,但这种校验无法对复杂校验起作用。比如产品经理要验证 邮箱,电话,密码等等。要知道在某些厂特殊需求,规则复杂,当然数据库的数据也要符合规则,减少不必要的清理。 那直接写在model里面校验怎么样? 要知道老板和产品经理的思维变化很快,而model层那么关键和重要,这种侵入式的方式,耦合太强,牵一发而动全身。
decorators做验证那么, 有木有好的方式?
最近和同事调研发现,java 和 python 有 @, 也就是 修饰器。作用就是对方法进行修改返回新的方法, 听起来是不是很熟悉,木有错,就是高阶函数(higher order function). JavaScript 在ES7中支持decorators, babel是我们更好的使用这些特性。具体实现原理可查看这里
export function validate(vKey, message, validator) {
return (target, key, descriptor) => {
// descriptor中的属性,通过Object.defineProperty定义
const { set, get, value, writable, configurable, writable, enumerable} = descriptor
// 重写 descriptor
return descriptor
}
}由于Javascript中的decorators支持在类(class)中使用,不支持类之外的方法使用。因此期望代码是这样的。
class Model{
constructor(){
}
@validate('name', 'name is not a chinese name', validator.isChineseName)
@validate('age', 'age is out of [0, 100]', validator.isValidAge)
@validate('email', 'email is invalid email', validator.isEmail)
insert(obj){
// db insert with obj.
}
@validate('name', 'name is not a chinese name', validator.isChineseName)
@validate('age', 'age is out of [0, 100]', validator.isValidAge)
@validate('email', 'email is invalid email', validator.isEmail)
update(obj){
// db update with obj.
}
}预期结果发现上面的 validate 有大量的重复,利用getter 和 setter改进一下:
class Model{
constructor(){
this._scheme = null
}
@validate('name', 'name is not a chinese name', validator.isChineseName)
@validate('age', 'age is out of [0, 100]', validator.isValidAge)
@validate('email', 'email is invalid email', validator.isEmail)
set scheme(v){
this._scheme = v
}
get scheme(){
return this._scheme
}
insert(){
// db insert this.scheme.
}
update(){
// db update this.scheme.
}
}因此需要实现一个验证 setter的 decorators. 在这之前讨论下 setter decorators validate对外接口(验证字段错误处理)
对外每次构建实例之后,对scheme设置时需要try catch才能拿到错误信息
基于每个模块各司其职,Model层在Model层做处理,当不符合规则时候,返回统一格式给API层。
最终期望的结果:
class Model {
constructor(ctx, dbname) {
this.table = ctx.mongo.collection(dbname)
this._scheme = null
}
@validate('name', 'name is not a chinese name', validator.isChineseName)
@validate('age', 'age is out of [0, 100]', validator.isValidAge)
@validate('email', 'email is invalid email', validator.isEmail)
set scheme(v) {
this._scheme = v
}
get scheme() {
return this._scheme
}
insert() {
// 将验证错误信息方法在scheme中
if(this.scheme.validateResult && this.scheme.validateResult.invalid){
return this.scheme.validateResult
} else {
delete this.scheme.validateResult
// 执行db插入操作.
}
}
update() {
// 将验证错误信息方法在scheme中
if(this.scheme.validateResult && this.scheme.validateResult.invalid){
return this.scheme.validateResult
} else {
delete this.scheme.validateResult
// 执行db更新操作.
}
}
}setter实现decorator, 需要自行处理异常拦截的问题以上是使用decorators实现model验证的思路和过程,查看validate decorator实现。
decorator给开发带来了很好的集中式处理。
如有不妥,欢迎指正。转载请写明出处。
转载请备注出处
17年年底接到一个中后台项目,主要用来解决金融行业线上问题:包含第三方调用失败,第三方调用次数,异常账单,用户核心信息修改等。由于涉及业务对权限要求极高。最近着手整理下跟权限相关的设计和思考。希望读者阅读可以受益,也防止记忆力不怎么好的自己,可以对权限有更好的理解。
某天。项目上线了,喜出望外,辛苦了一阵子的项目终于上线。结果,某位同事跟我说前端页面crash了,carsh了,crash了。。。心中一片翻腾。
在javascript单线程的世界里,没有异步寸步难行。本章节介绍异步编程的发展,从callback,Events到promise,generator,async/await.
在(javascript)单线程的世界里,如果有多个任务,就必须排队,前面一个完成,再继续后面的任务。就像一个ATM排队取钱似的,前面一个不取完,就不让后面的取。
为了这个问题,javascript提供了2种方式: 同步和异步。
异步就像银行取钱填了单子约了号,等着叫到号,再去做取钱,等待的时间里还可以干点其他的事儿~
举个例子:通过api拿到数据,数据里面有图片,图片加载成功渲染,那么代码如下:
// 伪代码
request(url, (data) => {
if(data){
loadImg(data.src, () => {
render();
})
}
})如果有在业务逻辑比较复杂或者NodeJS I/O操作比较频繁的时候,就成了下面这个样子:
doSth1((...args, callback) => {
doSth2((...args, callback) => {
doSth3((...args, callback) => {
doSth4((...args, callback) => {
doSth5((...args, callback) => {
})
})
})
})
})这样的维护性和可读性,整个人瞬间感觉不好了~
try {
setTimeout(() => {
throw new Error('unexpected error');
}, 100);
} catch (e) {
console.log('error2', e.message);
}以上代码运行抛出异常,但try catch不能得到未来时间段的异常。
流程控制只能通过维护各种状态来处理,不利于管理
不管浏览器还是NodeJS,提供了大量内置事件API来处理异步。
浏览器中如: websocket, ajax, canvas, img,FileReader等
NodeJS如: stream, http等
EventEmitter事件模型addEventListener,此外浏览器也提供一些自定义事件的API,但兼容性不好,具体可以这篇文章;也可以用Node中的EventEmitter;jquery中也对此做了封装,on,bind等方法支持自定义事件。事件一定程度上解决了解耦和提升了代码可维护性;对于异常处理,只有部分支持类似error事件才能处理。若想实现异常处理机制,只有自己模拟error事件,比较繁琐。
Promise严格来说不是一种新技术,它只是一种机制,一种代码结构和流程,用于管理异步回调。为了统一规范产生一个Promise/A+规范,点击查看Promise/A+中文版,cnode的William17实现了Promise/A+规范,有兴趣的可以点这里查看
promise状态由内部控制,外部不可变pending到resovled, rejected,一旦进行完成不可逆then/catch操作返回一个promise实例,可以进行链式操作
部分代码如下:
readFile(path1).then(function (data) {
console.log(data.toString());
return readFile(path2);
}).then(function (data) {
console.log(data.toString());
return readFile(errorPath);
}).then(function (data) {
console.log(data.toString());
}).catch(function (e) {
console.log('error', e);
return readFile(path1);
}).then(function (data) {
console.log(data.toString());
});Promise的缺陷:
promise.catch才能才能接收到Generator是ES6提供的方法,是生成器,最大的特点:可以暂停执行和恢复执行(可以交出函数的执行权),返回的是指针对象.
const run = function (generator) {
var g = generator()
var perform = function (result) {
if (result.done === true) {
return result.value
}
if (isPromise(result.value)) {
return result.value.then(function (v) {
return perform(g.next(v))
}).catch(function (e) {
return perform(g.throw(e))
})
} else {
return perform(g.next(result.value))
}
}
return perform(g.next())
}
const isPromise = f => f.constructor === Promise
function* g() {
var a = yield sleep(1000, _ => 1)
var b = yield sleep(1000, _ => 2)
return a + b
}
function sleep(d, fn) {
return new Promise((resolve, reject) => {
setTimeout(_ => resolve(fn()), d)
})
}由于以上问题,于是一个叫 co库诞生,支持thunk和Promise.
关于thunk可以查看阮一峰老师的thunk介绍和应用
ES7提供了async函数,使得异步操作变得更加方便。
yield只能是promise和thunk实例代码:
async function asyncReadFile() {
var p1 = readFile(path.join(__dirname, '../data/file1.txt'));
var p2 = readFile(path.join(__dirname, '../data/file2.txt'));
var [f1, f2] = await Promise.all([p1, p2]);
return `${f1.toString()}\n${f2.toString()}`;
}
(async function () {
try {
console.log(await asyncReadFile());
} catch (e) {
console.log(e.message)
}
})();Node8.0发布,全面支持 async/await, 推荐使用 async/await, 低版本node可以使用 babel来编译处理。 而 为了方便 接口设计时 返回 promise 更方面使用者. 当然依然使用 callback , 通过 promisify做转换, Node8.0已经内置 util.promisify方法。
异步编程在javascript中扮演者重要的角色,虽然现在需要通过babel,typescript等编译或转换代码,跟着规范和标准走,就没有跑偏。
如需转载,请备注出处。
奇舞周刊推荐了一篇文章Vue.js 中使用Mixin, 用了vue大半年时间,mixin不知道挺惭愧。
奇舞周刊文章中已经介绍了 vue mixin。
mixin这里再补充一个 通用业务(埋点) 来描述 mixin的优缺点。
在SPA实现埋点需求中比较通用的需求,进入页面 和 离开页面 需要记录用户在 当前页面的 停留时间。使用mixin, 简化代码如下
mixin.js
let cache = null // 确保进入和离开是一个page
export default {
methods: {
sendEnterPage() {
cache = this.$route
console.log('enter page', cache)
},
sendLeavePage() {
console.log('leave page', cache)
}
},
mounted(){
this.sendEnterPage()
},
destroyed() {
this.sendLeavePage()
}
}demo.vue 部分代码
<script>
import test from 'mixins/test'
export default {
data() {
return { text: 'Hello World' }
},
mixins: [test],
methods: {
logic() {
console.log('do the logic about hello page')
}
},
mounted() {
this.logic()
}
}运行结果图

从图中发现,使用局部mixin 使用 mounted, destroyed 等组件中的生成周期方法与 mixin 是 合并; 当然实验得出 methods中的方法是被覆盖的。具体是通过 mergeOtions function实现
埋点这部分需求 与 核心业务 关联, 代码少,尽可能的少侵入业务。
minxin中的方法 以及实现 逻辑 其他同事不知道,不直观。 只能通过约定和沟通来解决。
以上功能有种 “修饰” 的感觉。es7 decorator 支持修饰模式,当局限于 类和类的方法, vue官方提供了 vue-class-component 来解决这个问题。
在React当中已经废弃了 mixin,使用了 高阶组件 来解决这个问题,其实就是支持 class组件,结合decorator来
代替mixin。 关于react理解的不对,请指出。
前端时间闲暇的时候做了一个 vue-mount-time 用来记录,第一个组件mount开始时间到 最后一个mount组件结束时间,做了一个简单的尝试。
若需要做行为统计,可以通过 mixin 拦截到所有的方法, 对方法做统一收集。根据 页面地址 + 方法名 可以 确定对应的行为,从而做到无侵入的埋点解决方案
本篇是对mixin的看法和对业务的结合点,如有不对欢迎指正,转载请注明出处。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.