ivorysql / ivorysql Goto Github PK
View Code? Open in Web Editor NEWOpen Source Oracle Compatible PostgreSQL.
Home Page: https://ivorysql.org
License: Apache License 2.0
Open Source Oracle Compatible PostgreSQL.
Home Page: https://ivorysql.org
License: Apache License 2.0
1.1 and 1.2
Linux
When creating functions and packages using the PL/iSQL language, both the keywords IS and AS can be used, but stored procedures can only use the IS keyword.
Test SQL:
create or replace PROCEDURE xfunc (emp_id numeric) IS
BEGIN
raise notice '%', 'numeric';
END;
/
create or replace PROCEDURE xfunc (emp_id numeric) AS
BEGIN
raise notice '%', 'numeric';
END;
/
Test results:

PL/iSQL stored procedures, suggest adding support for the keyword "AS".
A package body can also be dropped without dropping the complete package. So IvorySQL should implement
DROP PACKAGE BODY command.
The ivorysql is expected to be compatible with oracle merge_into function.
the effect: to check whether the table T1 and table T2 meet the conditions in on or not.If yes, update the T1 table with T2 table. If not, insert T2 table into T1 table.
for example:
merge into tab1 t1 using (select xmccbh,jjbh from tab2 t2) t on (t.xmccbh =t1.xmccbh) when matched then update set t1.jjbh = t.jjbh where t1.jjbh is null;
Neither the Package Spec nor the Package Body compiles out of the box. At least in my build from source, the data types of NUMBER and VARCHAR2 are not defined. Even if you switch to PG data types of VARCHAR & NUMERIC it is still not close to working. There are also typos and inconsistencies in both the Spec and Body that also cause it not to work.
Also, the code in the samples should use spaces for the indenting. It seems to use a horrible combination of spaces and tabs that makes a mess when copy/paste into an editor no matter what your tab settings are.
I know it's early days, but, this is important. It's a users first impression & first experience.
The function (numtoyminterval) is inconsistent with oracle for decimal calculations
1.1
Linux
compatible_mode =oracle
Test SQL:
select timestamp'2022-02-18 10:55:20' + numtoyminterval(100.6,'year') from dual;
select timestamp'2022-02-18 10:55:20' + numtoyminterval(100.6,'month') from dual;
Test result:
IvorySQL V1.1:

Oracle:
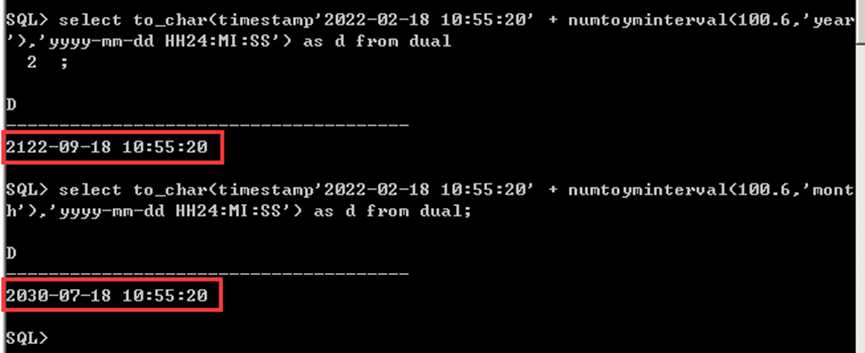
Consistent with Oracle's results
A random failure of some tests is noted in regression on Github and seems to go away after another run.
master branch
Bug Report
IvorySQL Version: 1.2
test=# select version();
version
PostgreSQL 14.2 (IvorySQL 1.2) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.0, 64-bit
(1 row)
OS Version : centos 7
Linux monitor 3.10.0-1062.el7.x86_64 #1 SMP Wed Aug 7 18:08:02 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
SQL:
1 create table and insert into some rows
create table h1(c1 integer, name varchar(23));
create table h2(c1 integer, name varchar(23));
insert into h1 values(1,'aa');
insert into h1 values(2,'bb');
insert into h1 values(3,'cc');
insert into h1 values(4,'dd');
insert into h2 values(1,'aa');
insert into h2 values(2,'bb');
insert into h2 values(3,'cc');
insert into h2 values(4,'dd');
2、Run the sql
select level, h1.c1, h2.c1 from h1 left join h2 on h1.c1 = h2.c1 connect by nocycle prior h1.c1 = prior h1.c1 start with h1.c1 = 1;
3 Get error:
ERROR: unrecognized node type: 153
ERROR: unrecognized node type: 153
Hierarchical queries are very useful to operate on hierarchical data. The PostgreSQL does not support it and It would be a good feature to add into the IvorySQL compatible list.
The usual clauses for a hierarchical query support are:
{
CONNECT BY [ NOCYCLE ] condition [AND condition]... [ START WITH condition ]
| START WITH condition CONNECT BY [ NOCYCLE ] condition [AND condition]...
}
CONNECT BY
The query syntax starts with CONNECT BY keywords which define the hierarchical interdependency between parent and child rows. The results must be further qualified by specifying the PRIOR keyword in the condition part for CONNECT BY clause.
The PRIOR keyword is a unary operator which links the previous row with the current one. The keyword can be used on the left or the right hand side of the equality condition. In case a loop is detected in the results, an error is returned to the user and the query aborted.
START WITH
This clause specified from which row to start the hierarchy.
NOCYCLE
This clause instructs to return data even if a cycle exists.
The array variable can not be referenced when we call the package's function from the second time.
create or replace package pkg is
x int[] := array[1,2,3,4];
function tfunc return int;
end;
/
create or replace package body pkg is
function tfunc return int as
begin
raise info 'function tf called:%',x;
return x[1];
end;
end;
/
select pkg.tfunc; --ok
select pkg.tfunc; -- error
1.0
Linux mypg01 3.10.0-693.21.1.el7.x86_64 #1 SMP Wed Mar 7 19:03:37 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
./configure --prefix=/opt/IVORY --enable-debug --enable-cassert --with-pgport=5555 CFLAGS='-O0 -g' --enable-tap-tests
1
(1 row)
postgres=# select pkg.tfunc;
2022-01-20 15:04:14.322 CST [104318] ERROR: cache lookup failed for type 2139062143
2022-01-20 15:04:14.322 CST [104318] CONTEXT: PL/iSQL function tfunc() line 3 at RAISE
2022-01-20 15:04:14.322 CST [104318] STATEMENT: select pkg.tfunc;
ERROR: cache lookup failed for type 2139062143
CONTEXT: PL/iSQL function tfunc() line 3 at RAISE
select pkg.tfunc; --all calls are successful
I think supporting the pg_hintplan extension similar to how you have incorporated orafce by default will be important
A lot of PL/SQL programmers use this feature. In PL/pgSQL you've got to code a loop and there is lots of overhead
Multitable Inserts
Multitable inserts were introduced to allow a single INSERT INTO .. SELECT statement to conditionally, or unconditionally, insert into multiple tables. This statement reduces table scans and PL/SQL code necessary for performing multiple conditional inserts compared to previous versions. It's main use is for the ETL process in data warehouses where it can be parallelized and/or convert non-relational data into a relational format
Create and populate a test table to act as the source of the data for the basic examples, as well as three destination tables based on the source table, but with no rows.
CREATE TABLE source_tab AS
SELECT level AS id,
'Description of ' || level AS description
FROM dual
CONNECT BY level <= 10;
CREATE TABLE dest_tab1 AS
SELECT * FROM source_tab WHERE 1=2;
CREATE TABLE dest_tab2 AS
SELECT * FROM source_tab WHERE 1=2;
CREATE TABLE dest_tab3 AS
SELECT * FROM source_tab WHERE 1=2;
SELECT * FROM source_tab;
ID DESCRIPTION
---------- -------------------------------------------------------
1 Description of 1
2 Description of 2
3 Description of 3
4 Description of 4
5 Description of 5
6 Description of 6
7 Description of 7
8 Description of 8
9 Description of 9
10 Description of 10
10 rows selected.
SQL>
Create and populate a test table to act as the source for the pivot example, and an empty destination table.
CREATE TABLE pivot_source (
id NUMBER,
mon_val NUMBER,
tue_val NUMBER,
wed_val NUMBER,
thu_val NUMBER,
fri_val NUMBER
);
INSERT INTO pivot_source VALUES (1, 111, 222, 333, 444, 555);
INSERT INTO pivot_source VALUES (2, 111, 222, 333, 444, 555);
CREATE TABLE pivot_dest (
id NUMBER,
day VARCHAR2(3),
val NUMBER
);
### Unconditional INSERT ALL
When using an unconditional INSERT ALL statement, each row produced by the driving query results in a new row in each of the tables listed in the INTO clauses. In the example below, the driving query returns 10 rows, which means we will see 30 rows inserted, 10 in each table.
INSERT ALL
INTO dest_tab1 (id, description) VALUES (id, description)
INTO dest_tab2 (id, description) VALUES (id, description)
INTO dest_tab3 (id, description) VALUES (id, description)
SELECT id, description
FROM source_tab;
30 rows inserted.
SQL>
An unconditional INSERT ALL statement can be used to pivot or split data. In the following example we convert each single row representing a week of data into separate rows for each day.
INSERT ALL
INTO pivot_dest (id, day, val) VALUES (id, 'mon', mon_val)
INTO pivot_dest (id, day, val) VALUES (id, 'tue', tue_val)
INTO pivot_dest (id, day, val) VALUES (id, 'wed', wed_val)
INTO pivot_dest (id, day, val) VALUES (id, 'thu', thu_val)
INTO pivot_dest (id, day, val) VALUES (id, 'fri', fri_val)
SELECT *
FROM pivot_source;
10 rows inserted.
SQL>
SELECT *
FROM pivot_dest;
ID DAY VAL
---------- --- ----------
1 mon 111
2 mon 111
1 tue 222
2 tue 222
1 wed 333
2 wed 333
1 thu 444
2 thu 444
1 fri 555
2 fri 555
10 rows selected.
SQL>
In a conditional INSERT ALL statement, conditions can be added to the INTO clauses, which means the total number of rows inserted may be less that the number of source rows multiplied by the number of INTO clauses. It looks similar to a CASE expression, but each condition is always tested based on the current row from the driving query.
In the following example we insert into into different tables depending on the range of the ID value.
INSERT ALL
WHEN id <= 3 THEN
INTO dest_tab1 (id, description) VALUES (id, description)
WHEN id BETWEEN 4 AND 7 THEN
INTO dest_tab2 (id, description) VALUES (id, description)
WHEN id >= 8 THEN
INTO dest_tab3 (id, description) VALUES (id, description)
SELECT id, description
FROM source_tab;
10 rows inserted.
SQL>
A single condition can be used for multiple INTO clauses.
INSERT ALL
WHEN id <= 3 THEN
INTO dest_tab1 (id, description) VALUES (id, description)
WHEN id BETWEEN 4 AND 7 THEN
INTO dest_tab2 (id, description) VALUES (id, description)
INTO dest_tab3 (id, description) VALUES (id, description)
SELECT id, description
FROM source_tab;
11 rows inserted.
SQL>
You can use a condition of "1=1" to force all rows into a table.
INSERT ALL
WHEN id <= 3 THEN
INTO dest_tab1 (id, description) VALUES (id, description)
WHEN id BETWEEN 4 AND 7 THEN
INTO dest_tab2 (id, description) VALUES (id, description)
WHEN 1=1 THEN
INTO dest_tab3 (id, description) VALUES (id, description)
SELECT id, description
FROM source_tab;
17 rows inserted.
SQL>
Using INSERT FIRST makes the multitable insert work like a CASE expression, so the conditions are tested until the first match is found, and no further conditions are tested. We can also include an optional ELSE clause to catch any rows not already cause by a previous condition.
INSERT FIRST
WHEN id <= 3 THEN
INTO dest_tab1 (id, description) VALUES (id, description)
WHEN id <= 5 THEN
INTO dest_tab2 (id, description) VALUES (id, description)
ELSE
INTO dest_tab3 (id, description) VALUES (id, description)
SELECT id, description
FROM source_tab;
10 rows inserted.
SQL>
INSERT FIRST
WHEN id <= 3 THEN
INTO dest_tab1 (id, description) VALUES (id, description)
ELSE
INTO dest_tab2 (id, description) VALUES (id, description)
INTO dest_tab3 (id, description) VALUES (id, description)
SELECT id, description
FROM source_tab;
17 rows inserted.
SQL>
The restrictions on multitable insertss are as follows.
Multitable inserts can only be performed on tables, not on views or materialized views.
You cannot perform a multitable insert via a DB link.
You cannot perform multitable inserts into nested tables.
The sum of all the INTO columns cannot exceed 999.
Sequences cannot be used in the multitable insert statement. It is considered a single statement, so only one sequence value will be generated and used for all rows.
Multitable inserts can't be used with plan stability.
If the PARALLEL hint is used for any target tables, the whole statement will be parallelized. If not, the statement will only be parallelized if the tables have PARALLEL defined.
Multitable statements will not be parallelized if any of the tables are index-organized, or have bitmap indexes defined on them.
The value of CONNECT_BY_ROOT in the hierarchical query is inconsistent with Oracle
1.2
Linux
compatible_mode =oracle
Test SQL:
create table city (
ID varchar2(10) primary key,
DSC varchar2(100),
PID varchar2(10)
);
Insert Into city values ('00001', '**', '-1');
Insert Into city values ('00011', '四川', '00001');
Insert Into city values ('00012', '贵州', '00001');
Insert Into city values ('00013', '广东', '00001');
Insert Into city values ('00111', '成都', '00011');
Insert Into city values ('00112', '绵阳', '00011');
Insert Into city values ('00113', '内江', '00011');
Insert Into city values ('01111', '武侯', '00111');
Insert Into city values ('01112', '双流', '00111');
Insert Into city values ('00131', '广州', '00013');
Insert Into city values ('00132', '珠海', '00013');
Test Statements:
select id, dsc, pid, sys_connect_by_path(dsc, '>'),LEVEL ,CONNECT_BY_ROOT id as root From city
start with id = '00001'
Connect By prior id = pid order by id;
IvorySQL:

Oracle:
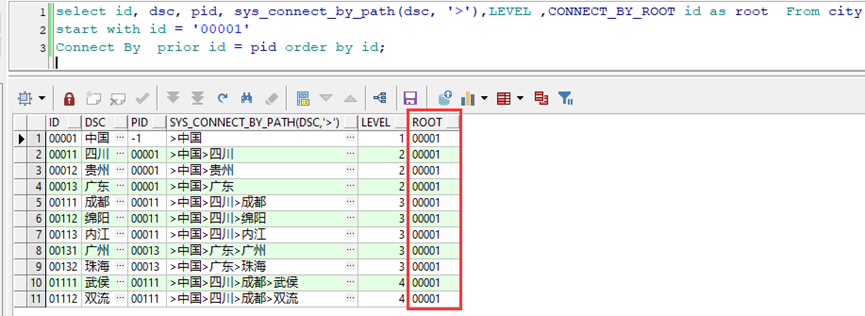
The value of CONNECT_BY_ROOT is inconsistent. is the result of IvorySQL correct? Or should it be consistent with Oracle?
IvorySQL's "CONNECT_BY_ROOT": parent node
Oracle's "CONNECT_BY_ROOT": root node
Please confirm.
In Oracle, PL / SQL goto statement is a sequence control structure available in Oracle. It unconditionally transfers the program to the specified statement label or block label. The statement or label name must be unique in the block.
Cannot be used in PL / ISQL:
oracle=> create or replace function test() return void is
oracle$> begin
oracle$> goto cmd1;
oracle$> select dbms_output.put_line('i am cmd.');
oracle$> <>
oracle$> select dbms_output.put_line('i am cmd1.');
oracle$> <>
oracle$> select dbms_output.put_line('i am cmd2.');
oracle$> end;
oracle$> /
ERROR: syntax error at or near "goto"
LINE 3: goto cmd1;
^
QUERY:
begin
goto cmd1;
select dbms_output.put_line('i am cmd.');
<>
select dbms_output.put_line('i am cmd1.');
<>
select dbms_output.put_line('i am cmd2.');
end;
1.1
linux
to_multi_byte(integer) succeeds in Oracle, but fails in IvorySQL V1.1
Oracle:

IvorySQL V1.1:

to_multi_byte(integer) is also executed successfully in IvorySQL.
As Per PL/iSQL the procedures should allow calling other procedures from within without using the call keyword.
But standalone PL/iSQL procedures are not allowing that.
postgres=# CREATE OR REPLACE PROCEDURE pro1 IS
postgres$# BEGIN
postgres$# DBMS_OUTPUT.PUT_LINE('some text');
postgres$# END;
postgres$# /
ERROR: syntax error at or near "DBMS_OUTPUT"
LINE 3: DBMS_OUTPUT.PUT_LINE('some text');
^
QUERY:
BEGIN
DBMS_OUTPUT.PUT_LINE('some text');
END;
However, calling the procedure from within the package procedure works without CALL keyword
postgres=# CREATE OR REPLACE PACKAGE pkg1 AS
PROCEDURE pro1;
end;
/
CREATE PACKAGE
postgres=# CREATE OR REPLACE PACKAGE BODY pgk1 AS
PROCEDURE pro1 AS
BEGIN
DBMS_OUTPUT.PUT_LINE('some text');
END;
END;
/
CREATE PACKAGE BODY
postgres=# \d pg_settings
ERROR: function pg_catalog.pg_table_is_visible(oid) does not exist
LINE 7: AND pg_catalog.pg_table_is_visible(c.oid)
^
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
not any error message
\d pg_settings
a package function should be able to return the defined type.
CREATE OR REPLACE PACKAGE example AS
TYPE extyp IS RECORD (a INT, b VARCHAR(100));
FUNCTION myfunc(x INT) RETURN extyp;
end;
/
1.0 and current master
Package should be created.
ivorysql=# CREATE OR REPLACE PACKAGE example AS
ivorysql$# TYPE extyp IS RECORD (a INT, b VARCHAR);
ivorysql$# FUNCTION myfunc(x INT) RETURN extyp; -- error here
ivorysql$# end;
ivorysql$# /
ERROR: type "extyp" does not exist
when we collect ddl statement to the log file,there will thow out WARNING infomation and package statement cannot be write into log file.
1.0
Linux mypg01 3.10.0-693.21.1.el7.x86_64 #1 SMP Wed Mar 7 19:03:37 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
./configure --prefix=/opt/IVORY --enable-debug --enable-cassert --with-pgport=5555 CFLAGS='-O0 -g' --enable-tap-tests
set logging_collector = on and log_statement = 'ddl',Then the issues like follows:
postgres=# create or replace package pkg is
postgres$# x int;
postgres$# y varchar := 'test';
postgres$#
postgres$# -- no argument function creation
postgres$# function tfunc return int;
postgres$#
postgres$# -- no argument procedure creation
postgres$# procedure tpro;
postgres$#
postgres$# function tfunc2(x int) return int;
postgres$# procedure tpro(x int);
postgres$# end;
postgres$# /
WARNING: unrecognized node type: 432
CREATE PACKAGE
[postgres@mypg01 data]$ cat log/postgresql-2021-12-16_172125.log
2021-12-16 17:21:25.557 CST [126588] LOG: starting PostgreSQL 14.0 (IvorySQL 1.0) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-39), 64-bit
2021-12-16 17:21:25.557 CST [126588] LOG: listening on IPv4 address "127.0.0.1", port 5555
2021-12-16 17:21:25.558 CST [126588] LOG: could not bind IPv6 address "::1": Cannot assign requested address
2021-12-16 17:21:25.561 CST [126588] LOG: listening on Unix socket "/tmp/.s.PGSQL.5555"
2021-12-16 17:21:25.565 CST [126590] LOG: database system was shut down at 2021-12-16 17:21:25 CST
2021-12-16 17:21:25.568 CST [126588] LOG: database system is ready to accept connections
2021-12-16 17:21:32.473 CST [127046] WARNING: unrecognized node type: 432
postgres=# create or replace package pkg is
postgres$# x int;
postgres$# y varchar := 'test';
postgres$#
postgres$# -- no argument function creation
postgres$# function tfunc return int;
postgres$#
postgres$# -- no argument procedure creation
postgres$# procedure tpro;
postgres$#
postgres$# function tfunc2(x int) return int;
postgres$# procedure tpro(x int);
postgres$# end;
postgres$# /
CREATE PACKAGE
[postgres@mypg01 data]$ cat log/postgresql-2021-12-16_170737.log
2021-12-16 17:07:37.909 CST [36312] LOG: starting PostgreSQL 14.0 (IvorySQL 1.0) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-39), 64-bit
2021-12-16 17:07:37.909 CST [36312] LOG: listening on IPv4 address "127.0.0.1", port 5555
2021-12-16 17:07:37.910 CST [36312] LOG: could not bind IPv6 address "::1": Cannot assign requested address
2021-12-16 17:07:37.913 CST [36312] LOG: listening on Unix socket "/tmp/.s.PGSQL.5555"
2021-12-16 17:07:37.918 CST [36314] LOG: database system was shut down at 2021-12-16 17:05:37 CST
2021-12-16 17:07:37.921 CST [36312] LOG: database system is ready to accept connections
2021-12-16 17:10:04.016 CST [36782] LOG: statement: create or replace package pkg is
x int;
y varchar := 'test';
-- no argument function creation
function tfunc return int;
-- no argument procedure creation
procedure tpro;
function tfunc2(x int) return int;
procedure tpro(x int);
end;
The WARNING throw out at function GetCommandLogLevel, there is lack of CreatePackage TAG.
#20
Bug Report
IvorySQL Version: 1.2
PostgreSQL 14.2 (IvorySQL 1.2) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.0, 64-bit
(1 row)
OS Version : centos 7
Linux monitor 3.10.0-1062.el7.x86_64 #1 SMP Wed Aug 7 18:08:02 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
SQL:
create table hier
(parents char(20),
child char(20)
);
insert into hier values('Earth','Asia');
insert into hier values('Earth','Australia');
insert into hier values('Earth','Europe');
insert into hier values('Earth','North America');
insert into hier values('Asia','China');
insert into hier values('Asia','Japan');
insert into hier values('Australia','New South Wales');
insert into hier values('New South Wales','Sydney');
insert into hier values('California','Redwood Shores');
insert into hier values('Canada','Ontario');
insert into hier values('China','Beijing');
insert into hier values('England','London');
insert into hier values('Europe','United Kingdom');
insert into hier values('Japan','Osaka');
insert into hier values('Japan','Tokyo');
insert into hier values('North America','Canada');
insert into hier values('North America','USA');
insert into hier values('Ontario','Ottawa');
insert into hier values('Ontario','Toronto');
insert into hier values('USA','California');
insert into hier values('United Kingdom','England');
###2 Run this sql
select level,lpad(' ',level*3)||child child from hier start with parents ='Earth' connect by prior child = parents;
###3 Get error:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.
hges_test=# create table test(x int, y varchar(100));
CREATE TABLE
hges_test=# insert into test values(1, 'One');
INSERT 0 1
hges_test=# insert into test values(2, 'Two');
INSERT 0 1
hges_test=# insert into test values(3, 'Three');
INSERT 0 1
hges_test=#
hges_test=# create or replace package pkg is
hges_test$# function c_open return int;
hges_test$# function c_fetch return int;
hges_test$# end;
hges_test$# /
CREATE PACKAGE
hges_test=#
hges_test=# create or replace package body pkg
hges_test-# is
hges_test$# CURSOR c1 IS SELECT x,y FROM test;
hges_test$#
hges_test$# function c_open return int as
hges_test$# begin
hges_test$#hges_test$# OPEN c1;
hges_test$#hges_test$# return 0;
hges_test$# end;
hges_test$#
hges_test$# function c_fetch return int as
hges_test$#hges_test$# v_x test.x%TYPE;
hges_test$#hges_test$# v_y test.y%TYPE;
hges_test$# begin
hges_test$#hges_test$# LOOP
hges_test$# FETCH c1 INTO v_x, v_y;
hges_test$#hges_test$#
hges_test$# EXIT WHEN NOT FOUND;
hges_test$#hges_test$#
hges_test$# raise info '%, %', v_x, v_y;
hges_test$#hges_test$# END LOOP;
hges_test$#
hges_test$#hges_test$# CLOSE c1;
hges_test$#hges_test$# return 0;
hges_test$# end;
hges_test$#
hges_test$# begin
hges_test$# raise info 'initializer';
hges_test$# end;
hges_test$# /
CREATE PACKAGE BODY
hges_test=#
hges_test=# select * from pg_cursors ;
name | statement | is_holdable | is_binary | is_scrollable | creation_time
------+-----------+-------------+-----------+---------------+---------------
(0 rows)hges_test=#
hges_test=# select pkg.c_open();
INFO: initializer
c_open0(1 row)
hges_test=#
hges_test=# select * from pg_cursors ;
name | statement | is_holdable | is_binary | is_scrollable | creation_time
--------+----------------------+-------------+-----------+---------------+-------------------------------
pkg.c1 | SELECT x,y FROM test | t | f | t | 2022-01-20 15:01:36.117744+08
(1 row)
hges_test=#
hges_test=# drop package body pkg;
DROP PACKAGE BODY
hges_test=#
hges_test=# select * from pg_cursors ;
name | statement | is_holdable | is_binary | is_scrollable | creation_time
--------+----------------------+-------------+-----------+---------------+-------------------------------
pkg.c1 | SELECT x,y FROM test | t | f | t | 2022-01-20 15:01:36.117744+08
(1 row)
When Drop package body pkg, the opened cursor c1 defined in the package body should be closed at the same time.
The VARCHAR2 type cannot be used to create a package using the official documentation sample
PostgreSQL 14.2 (IvorySQL 1.2) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
(1 行记录)
oracle
(1 行记录)
oracle=# CREATE TABLE test(x INT, y VARCHAR2(100));
CREATE TABLE
oracle=# INSERT INTO test VALUES (1, 'One');
INSERT 0 1
oracle=# INSERT INTO test VALUES (2, 'Two');
INSERT 0 1
oracle=# INSERT INTO test VALUES (3, 'Three');
INSERT 0 1
oracle=# CREATE OR REPLACE PACKAGE example AUTHID DEFINER AS
oracle$# -- Declare public type, cursor, and exception:
oracle$# TYPE rectype IS RECORD (a INT, b VARCHAR2(100));
oracle$# CURSOR curtype RETURN rectype%rowtype;
oracle$#
oracle$# rec rectype;
oracle$#
oracle$# -- Declare public subprograms:
oracle$# FUNCTION somefunc (
oracle$# last_name VARCHAR2,
oracle$# first_name VARCHAR2,
oracle$# email VARCHAR2
oracle$# ) RETURN NUMBER;
oracle$#
oracle$# -- Overload preceding public subprogram:
oracle$# PROCEDURE xfunc (emp_id NUMBER);
oracle$# PROCEDURE xfunc (emp_email VARCHAR2);
oracle$# END example;
oracle$# /
错误: 类型 "varchar2" 不存在
When the first parameter of the function (to_date\to_timestamp\to_timestamp_tz) is passed only the value of the year, the converted result is different from the Oracle result.
1.1 and 1.2
Linux
compatible_mode =oracle
When the first parameter of the function (to_date\to_timestamp\to_timestamp_tz) is passed only the value of the year, the month part in IvorySQL is January, while the month part in Oracle is February (the current month).
Test SQL:
System time:2022/02/28
select to_date('2020','yyyy'),to_timestamp('2020','yyyy'),to_timestamp_tz('2020','yyyy') from dual;
Test result:
IvorySQL:The year, month and day are 2020-01-01

Oracle:The year, month and day are 2020-02-01
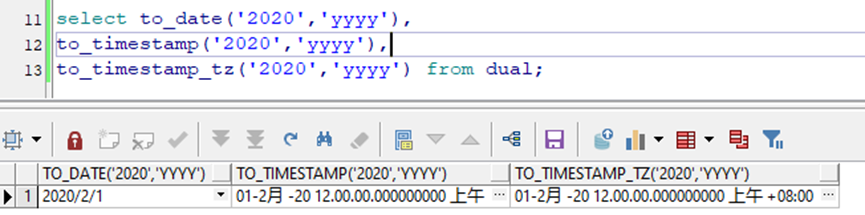
Please confirm the result of IvorySQL and Oracle, which one is correct.
Currently, PL/iSQL supports the named blocks i.e. FUNCTIONS, PROCEDURES ..that gets stored in the database
I want to request a feature to provide support for unnamed PL blocks in PL/iSQL (also known as anonymous blocks).
Unlike named blocks, An anonymous block should not get saved in the Database server and is just for one-time use.
Anonymous blocks can be very useful for testing purposes.
Describe the feature you'd like to propose:
An anonymous block can follow the same PL/iSQL program structure where the execution section is mandatory while it can have its own optional declaration and exception sections.
[DECLARE
declarations]
BEGIN
statements
[ EXCEPTION
WHEN <exception_condition> THEN
statements]
END;For example a minimal anonymous block can look like
BEGIN
NULL;
END;
/In Oracle, PL / SQL goto statement is a sequence control structure available in Oracle. It unconditionally transfers the program to the specified statement label or block label. The statement or label name must be unique in the block.
Cannot be used in PL / ISQL
oracle=> create or replace function test() return void is
oracle$> begin
oracle$> goto cmd1;
oracle$> select dbms_output.put_line('i am cmd.');
oracle$> <>
oracle$> select dbms_output.put_line('i am cmd1.');
oracle$> <>
oracle$> select dbms_output.put_line('i am cmd2.');
oracle$> end;
oracle$> /
ERROR: syntax error at or near "goto"
LINE 3: goto cmd1;
^
QUERY:
begin
goto cmd1;
select dbms_output.put_line('i am cmd.');
<>
select dbms_output.put_line('i am cmd1.');
<>
select dbms_output.put_line('i am cmd2.');
end;
When multiple columns of two or more tables are of type varchar2 and are compared, could not determine interpretation of row comparison operator =.
1.0
Linux localhost.localdomain 4.18.0-80.el8.x86_64 #1 SMP Tue Jun 4 09:19:46 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
./configure --prefix=/home/IVORYSQL --enable-debug --enable-cassert CFLAGS='-O0 -g' --enable-tap-tests
postgres=# select * from test_var where(c1,c2) not in (select * from test_tmp);
2021-12-21 15:02:21.648 CST [8344] ERROR: could not determine interpretation of row comparison operator = at character 37
2021-12-21 15:02:21.648 CST [8344] HINT: Row comparison operators must be associated with btree operator families.
2021-12-21 15:02:21.648 CST [8344] STATEMENT: select * from test_var where(c1,c2) not in (select * from test_tmp);
ERROR: could not determine interpretation of row comparison operator =
LINE 1: select * from test_var where(c1,c2) not in (select * from te...
^
HINT: Row comparison operators must be associated with btree operator families.
postgres=# select * from test_var where(c1,c2) not in (select * from test_tmp);
c1 | c2
----+-------
2 | test2
(1 row)
set search_path to oracle,pg_catalog;
create table test_var(c1 varchar2,c2 varchar2);
insert into test_var values('1','test1'),('1','test1'),('2','test1'),('2','test2');
create table test_tmp(c1 varchar2,c2 varchar2);
insert into test_tmp values('1','test1'),('2','test1');
select * from test_var where(c1,c2) not in (select * from test_tmp);
Row comparison operators must be associated with btree operator families.
PG Version 14.2 has been released, we need to release the IvorySQL V1.2 based on PostgreSQL 14.2
1.0
Linux mypg01 3.10.0-693.21.1.el7.x86_64 #1 SMP Wed Mar 7 19:03:37 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
set nls_length_semantics to byte ;
select '我是一个**人'::char(5);
2022-01-04 11:00:18.204 CST [3010] ERROR: value too long for type character(5 byte)
2022-01-04 11:00:18.204 CST [3010] STATEMENT: select '我是一个**人'::char(5);
ERROR: value too long for type character(5 byte)
create table test_12 (id int, a oracle.nvarchar2(5));
CREATE TABLE
insert into test_12 values (1, 'abcde');
INSERT 0 1
insert into test_12 values (1, '少年张三丰');
2022-01-04 14:27:14.075 CST [3010] ERROR: input value too long for type nvarchar2(5 byte)
2022-01-04 14:27:14.075 CST [3010] STATEMENT: insert into test_12 values (1, '少年张三丰');
ERROR: input value too long for type nvarchar2(5 byte)
我
(1 row)
insert into test_12 values (1, '少年张三丰'); --expect succ
set nls_length_semantics to byte ;
select '我是一个**人'::char(5);
create table test_12 (id int, a oracle.nvarchar2(5));
insert into test_12 values (1, 'abcde');
insert into test_12 values (1, '少年张三丰');
Creating a table with an Oracle compatible data type like Varchar2 requires schema qualification that is not very intuitive and also conflicts with the IvorySQL documentation.
IvorySQL should allow using these types without schema qualification.
CREATE TABLE test_ora_typw(a varchar2);
ERROR: type "varchar2" does not exist
LINE 1: CREATE TABLE test_ora_typw(a varchar2);
^
-- Schema qualifying VARCHAR2 with Orcale works
CREATE TABLE test_ora_typw(a oracle.varchar2);
CREATE TABLE
postgres=# ###Proposed enhancement
-- Without schema qualification should work
CREATE TABLE test_ora_typw(a varchar2);About connectby using pg14's new feature depth-first traversal to solve the order problem of query results (pre-order traversal)
`
-- 创建表
create table player(keyid int,parent_keyid int,name varchar(16),salary int,sex varchar(4));
-- 添加数据
insert into player values(1,0,'zhangsan','1000000','f');
insert into player values(2,1,'lisi','50500','m');
insert into player values(3,1,'wangwu','60000','m');
insert into player values(4,1,'houzi','65000','m');
insert into player values(5,2,'maliu','30000','f');
insert into player values(6,2,'liuqi','25000','m');
insert into player values(7,4,'gouba','23000','m');
insert into player values(8,4,'dujiu','21000','f');
`
select keyid,parent_keyid,name,salary from player start with keyid=1 connect by prior keyid = parent_keyid;


tablefunc的sql函数 connectby 利用了函数的递归回调特性 也支持树状打印

cursor declaration is not able to use defined type with the RETURN.
CREATE OR REPLACE PACKAGE example AS
TYPE extyp IS RECORD (a INT, b VARCHAR(100));
CURSOR excur RETURN extyp;
FUNCTION myfunc(x INT) RETURN int;
end;
/
1.0 and current master
Package should be created.
ivorysql=# CREATE OR REPLACE PACKAGE example AS
ivorysql$# TYPE extyp IS RECORD (a INT, b VARCHAR(100));
ivorysql$# CURSOR excur RETURN extyp;
ivorysql$#
ivorysql$# FUNCTION myfunc(x INT) RETURN int;
ivorysql$# end;
ivorysql$# /
ERROR: syntax error at or near ";"
LINE 3: CURSOR excur RETURN extyp;
ROWNUM Pseudocolumn
For each row returned by a query, the ROWNUM pseudocolumn returns a number indicating the order in which Oracle selects the row from a table or set of joined rows. The first row selected has a ROWNUM of 1, the second has 2, and so on.
You can use ROWNUM to limit the number of rows returned by a query, as in this example:
SELECT * FROM employees WHERE ROWNUM < 10;
If an ORDER BY clause follows ROWNUM in the same query, then the rows will be reordered by the ORDER BY clause. The results can vary depending on the way the rows are accessed. For example, if the ORDER BY clause causes Oracle to use an index to access the data, then Oracle may retrieve the rows in a different order than without the index. Therefore, the following statement will not have the same effect as the preceding example:
SELECT * FROM employees WHERE ROWNUM < 11 ORDER BY last_name;
If you embed the ORDER BY clause in a subquery and place the ROWNUM condition in the top-level query, then you can force the ROWNUM condition to be applied after the ordering of the rows. For example, the following query returns the employees with the 10 smallest employee numbers. This is sometimes referred to as top-N reporting:
SELECT * FROM
(SELECT * FROM employees ORDER BY employee_id)
WHERE ROWNUM < 11;
In the preceding example, the ROWNUM values are those of the top-level SELECT statement, so they are generated after the rows have already been ordered by employee_id in the subquery.
Conditions testing for ROWNUM values greater than a positive integer are always false. For example, this query returns no rows:
SELECT * FROM employees
WHERE ROWNUM > 1;
The first row fetched is assigned a ROWNUM of 1 and makes the condition false. The second row to be fetched is now the first row and is also assigned a ROWNUM of 1 and makes the condition false. All rows subsequently fail to satisfy the condition, so no rows are returned.
You can also use ROWNUM to assign unique values to each row of a table, as in this example:
UPDATE my_table
SET column1 = ROWNUM;
It only worked after I manually ran "CREATE EXTENSION orafce" in the database I was using.
I love that the pgisql extension is installed by default. I think you should also install orafce and define datatypes such as VARCHAR2 and NUMBER be default.
I would like to propose a small enhancement to add a \d.. command in psql to return the information of packages
PG Version 14.1 has been released, we need to release the IvorySQL V1.1 based on PostgreSQL 14.1
The declaration section of the WITH clause can be used to define PL/SQL functions, as shown below.
WITH
FUNCTION with_function(p_id IN NUMBER) RETURN NUMBER IS
BEGIN
RETURN p_id;
END;
SELECT with_function(id)
FROM t1
WHERE rownum = 1
/
WITH_FUNCTION(ID)
-----------------
1
SQL>
From a name resolution perspective, functions defined in the PL/SQL declaration section of the WITH clause take precedence over objects with the same name defined at the schema level.
We can also define procedures in the declaration section, even if they are not used.
SET SERVEROUTPUT ON
WITH
PROCEDURE with_procedure(p_id IN NUMBER) IS
BEGIN
DBMS_OUTPUT.put_line('p_id=' || p_id);
END;
SELECT id
FROM t1
WHERE rownum = 1
/
ID
----------
1
SQL>
In reality, you would only put a procedure into a WITH clause if you planned to call the procedure from a function in the declaration section.
WITH
PROCEDURE with_procedure(p_id IN NUMBER) IS
BEGIN
DBMS_OUTPUT.put_line('p_id=' || p_id);
END;
FUNCTION with_function(p_id IN NUMBER) RETURN NUMBER IS
BEGIN
with_procedure(p_id);
RETURN p_id;
END;
SELECT with_function(id)
FROM t1
WHERE rownum = 1
/
WITH_FUNCTION(ID)
-----------------
1
p_id=1
SQL>
(pivot row to column conversion function):
Grammar : pivot([any aggregation function] for [the column name which the value to be transferred belongs] in (the value to be converted to column name));
for example:
with temp as(
select '四川省' nation ,'成都市' city,'第一' ranking from dual union all
select '四川省' nation ,'绵阳市' city,'第二' ranking from dual union all
select '四川省' nation ,'德阳市' city,'第三' ranking from dual union all
select '四川省' nation ,'宜宾市' city,'第四' ranking from dual union all
select '湖北省' nation ,'武汉市' city,'第一' ranking from dual union all
select '湖北省' nation ,'宜昌市' city,'第二' ranking from dual union all
select '湖北省' nation ,'襄阳市' city,'第三' ranking from dual
)select * from (select nation,city,ranking from temp)pivot (max(city) for ranking in ('第一' as 第一,'第二' AS 第二,'第三' AS 第三,'第四' AS 第四));
(unpivot column to row conversion function):
Grammar : unpivot([the column name which the new-added value belongs] for [the new column name] in (the name of the column which should be converted to row)).
for example:
with temp as(
select '四川省' nation ,'成都市' 第一,'绵阳市' 第二,'德阳市' 第三,'宜宾市' 第四 from dual union all
select '湖北省' nation ,'武汉市' 第一,'宜昌市' 第二,'襄阳市' 第三,'' 第四 from dual
)select nation,name,title from temp
unpivot(name for title in (第一,第二,第三,第四)) t;
Describe the feature you'd like to propose:
compatible_mode=oracle, operator is not unique
1.1 and 1.2
Linux
compatible_mode =oracle
Test SQL:
select 1::numeric=2::varchar;
select 1::int=2::varchar;
select 1::bigint=2::varchar;
select 1::smallint=2::varchar;
error:
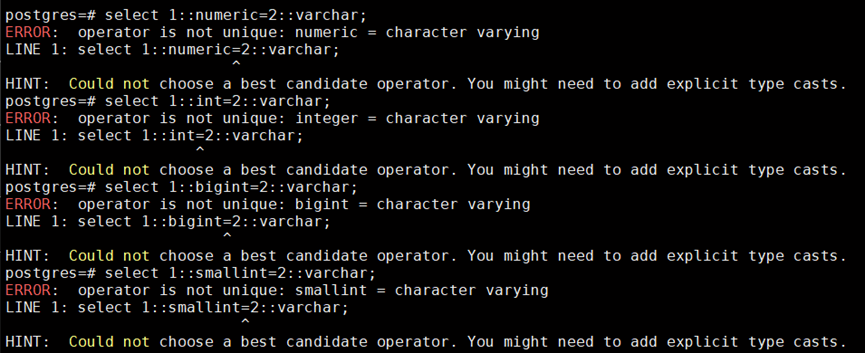
Successful execution
NCHAR is affected setting nls_length_semantics=byte as well as CHAR and VARCHAR2.
I think it is undesirable.
It may be caused by the native PostgreSQL behavior that accepts type NCHAR as CHAR.
1.0 and current master
V1.0 on RHEL 8.x (install from rpm package)
master on CentOS 6.x (source build with configure --enable-debug)
ivdb1=# CREATE EXTENSION orafce ;
ivdb1=# SET search_path TO "$user", oracle, pg_catalog, public;
ivdb1=# SET nls_length_semantics TO byte;
ivdb1=# SELECT NCHAR(10) 'あいうえお'; -- 5 chars, UTF8 3byte char x 5 = 15 bytes
ERROR: value too long for type character(10 byte)
CREATE SYNONYM ...
CREATE PUBLIC SYNONYM ....
##Current Status
In the document, the parameter (weekday) of the function (next_day) is noted as follows.
0 means Sunday.

However, when the parameter (weekday) is set to 0, there is an error in execution.

After verification, the integer value of the parameter (weekday) is 1 to 7, not 0 to 6, 1 represents Sunday, the document is incorrect. the value of Oracle is also 1 to 7.

Please confirm and revise the description in the document.
This is important in Oracle Compatability mode
Two procedures of the same name with different parameter types are called with an error
1.1 and 1.2
Linux
compatible_mode=oracle
Test SQL:
set compatible_mode =oracle;
create or replace PROCEDURE xfunc (emp_id NUMBER) as
$$
BEGIN
raise notice '%','NUMBER';
END;
$$
language plpgsql;
create or replace PROCEDURE xfunc (emp_email VARCHAR2) as
$$
BEGIN
raise notice '%','VARCHAR2';
END;
$$
language plpgsql;
Execute "call xfunc(2);", An error has occurred
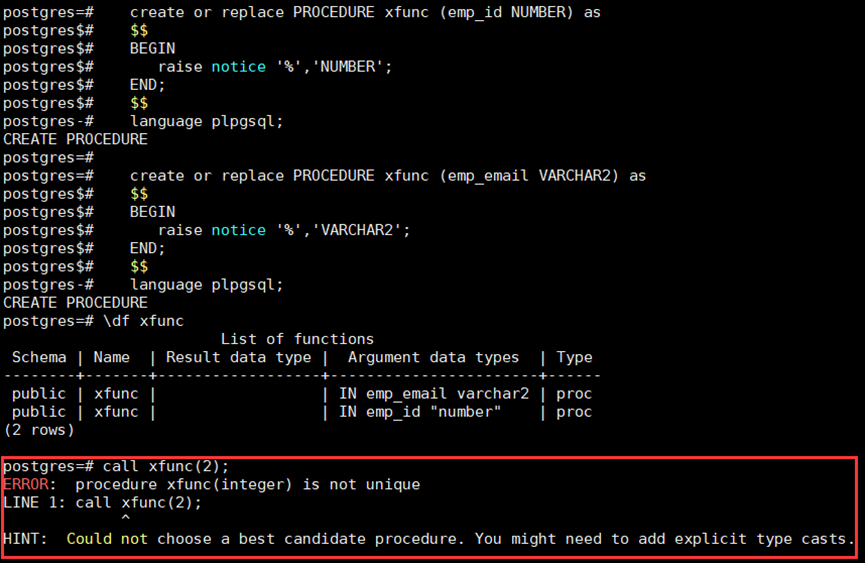
The procedure xfunc (emp_id NUMBER) should be called
Copying pg_config_os.h...
Generating configuration headers...
undefined symbol: PACKAGE_IVORYSQL_VERSION at src/include/pg_config.h line 795 at H:/VisualProject/vs2019/IvorySQL/IvorySQL-Ivory_REL_1_1/src/tools/msvc/Mkvcbuild.pm line 864.
1.1
Windows11
visual studio 2019
H:\VisualProject\vs2019\IvorySQL\IvorySQL-Ivory_REL_1_1\src\tools\msvc>perl build.pl DEBUG
##Current Status
In the document, the parameter (fmt) of the function (numtodsinterval) is noted as follows.
The parameter (fmt) does not contain year and month.

However, when the parameter (fmt) are year and month, no error is reported and the result is correct.
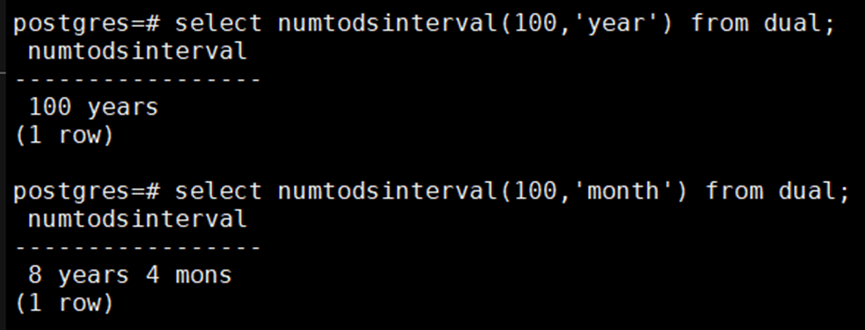
Please confirm whether it is an error of document or an error of the function's logic.
Pl/iSQL is not allowing to use of the 'name' as a variable name.
postgres=# CREATE OR REPLACE PROCEDURE test_proc ( name OUT TEXT) IS
postgres$# BEGIN
postgres$# name := 'IvorySQL';
postgres$# END;
postgres$# /
ERROR: syntax error at or near "name"
LINE 3: name := 'IvorySQL';
^
While Plpgsql does not complain about it.
postgres=# CREATE OR REPLACE PROCEDURE plpg_proc(name OUT TEXT)
LANGUAGE plpgsql
AS $$
BEGIN
name := 'IvorySQL';
END;$$ /
CREATE PROCEDURE
If the package is created in pg_catalog namespace (implicitly part of search_path), calling the package object without schema qualification throws function/procedure not found error.
CREATE OR REPLACE PACKAGE pg_catalog.pkg IS
FUNCTION f RETURN INT;
END;
/
CREATE PACKAGE
postgres=# CREATE OR REPLACE PACKAGE BODY pg_catalog.pkg IS
FUNCTION f RETURN INT IS
BEGIN
return 10;
END;
END;
postgres$# /
CREATE PACKAGE BODYTry selecting pkg.f()
postgres=# select pkg.f();
ERROR: schema "pkg" does not exist
LINE 1: select pkg.f();It workd with schema qualification
postgres=# select pg_catalog.pkg.f();
f
----
10
(1 row)Specifying the END label produces a syntax error
postgres=# CREATE OR REPLACE PROCEDURE pro1 as
BEGIN
NULL;
END pro1;
/
ERROR: end label "pro1" specified for unlabeled block
LINE 2: BEGIN
^
QUERY:
BEGIN
NULL;
END pro1
postgres=#
$ /opt/ipg/bin/pg_config |grep CONFIGURE
CONFIGURE = '--prefix=/opt/ipg' '--with-openssl' '--with-includes=/usr/include/openssl'
postgres=# CREATE TABLE test(x INT, y VARCHAR2(100));
ERROR: type "varchar2" does not exist
LINE 1: CREATE TABLE test(x INT, y VARCHAR2(100));
create table success
CREATE TABLE test(x INT, y VARCHAR2(100));
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.