A Udacity Data Scientist Nanodegree Project
Beyond the Anaconda distribution of Python 3, the following packages need to be installed for nltk:
- punkt
- wordnet
- averaged_perceptron_tagger
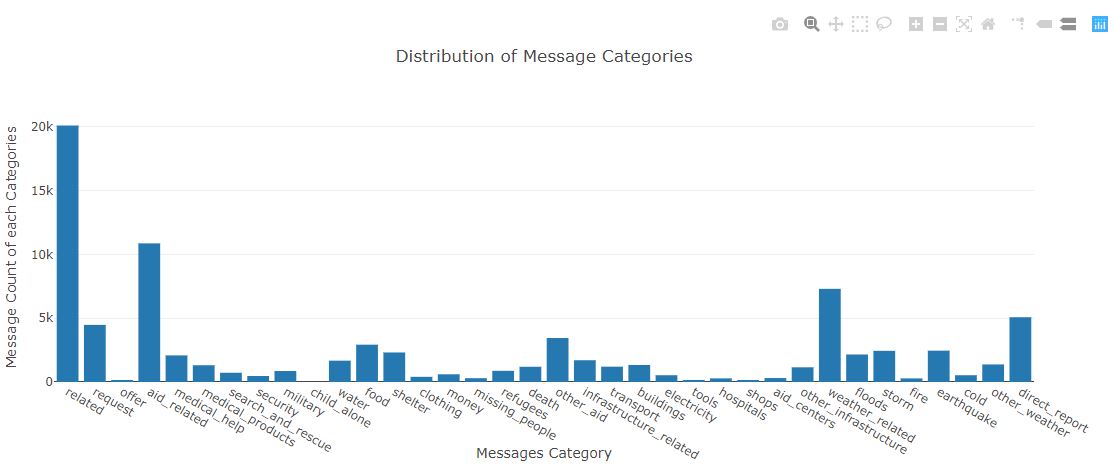
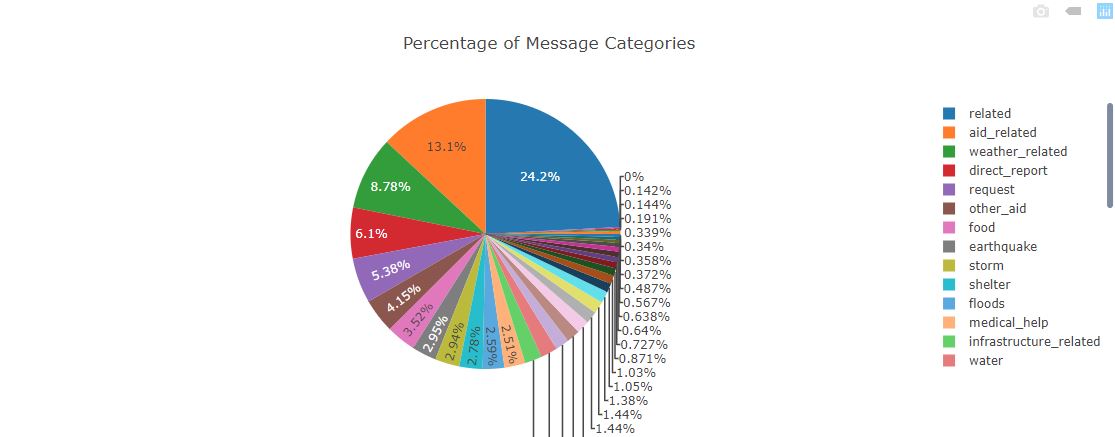
In this project I analyized thousands of real messages provided by Figure 8, sent during natural disasters either via social media or directly to disaster response organizations. I built an ETL pipeline that processes message and category data from csv files and load them into a SQLite database, which was fed to a machine learning pipeline to train, tune and save a multi-output supervised learning model. Then, my web app will extract data from this database to provide data visualizations and use the model to classify new messages for 36 categories.
Machine learning is critical to helping different organizations understand which messages are relevant to them and which messages to prioritize. During these disasters is when they have the least capacity to filter out messages that matter, and find basic methods such as using key word searches to provide trivial results. I learned the skills in ETL pipelines, natural language processing, and machine learning pipelines to create an amazing project with real world significance.
There are 1 notebooks available here to showcase work related to the above questions. The notebooks is exploratory in searching through the data pertaining to the questions showcased by the notebook title. Markdown cells & comments were used to assist in walking through the thought process for individual steps.
-
In working_directory/data:
- process_data.py: ETL Pipeline Script to process data, it loads and merges the messages and categories datasets, splits the categories column into separate, clearly named columns, converts values to binary, and drops duplicates.
- ETL Pipeline Preparation HQ.ipynb: jupyter notebook records the progress of building the ETL Pipeline
- disaster_messages.csv: Input File 1, CSV file containing messages
- disaster_categories.csv: Input File 2, CSV file containing categories
- disaster_response_ETL.db: Output File, SQLite database, and also the input file of train_classifier.py
-
In working_directory/models:
- train_classifier.py: Machine Learning pipeline Script to fit, tune, evaluate, and export the model to a Python pickle file
- ML Pipeline Preparation_HQ.ipynb: jupyter notebook records the progress of building the Machine Learning Pipeline
- model.p: Output File, a pickle file of the trained Machine Learning Model
-
In working_directory/app:
- templates/*.html: HTML templates for the web app.
- run.py: Start the Python server for the web app and prepare visualizations.
-
Run the following commands in the project's root directory to set up your database and model.
- To run ETL pipeline that cleans data and stores in database
python data/process_data.py data/disaster_messages.csv data/disaster_categories.csv data/disaster_response_ETL.db - To run ML pipeline that trains classifier and saves
python models/train_classifier.py data/disaster_response_ETL.db models/model.p
- To run ETL pipeline that cleans data and stores in database
-
Run the following command in the app's directory to run your web app.
python run.py -
Go to http://0.0.0.0:3001/
The average overall accuracy is 94.79%, and the F1 score (custom definition): 93.69%
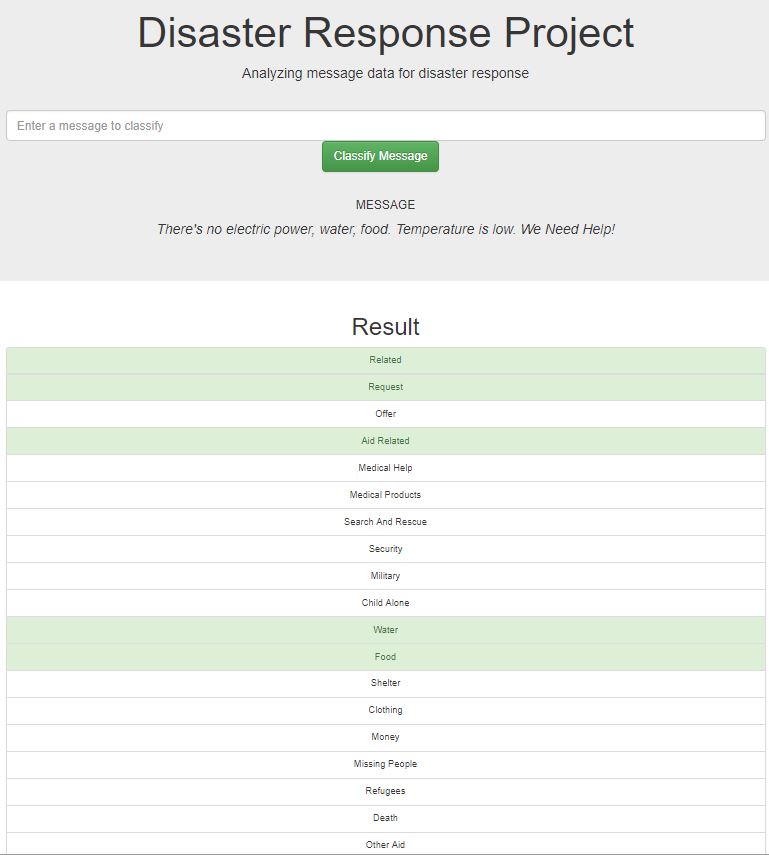
And the App works as expected: