houjunjie / fe-learning Goto Github PK
View Code? Open in Web Editor NEW记录这段时间的学习
记录这段时间的学习


http: 超文本传输协议。http协议是基于TCP/IP通信协议进行通讯的。
通常一个http的请求消息包含,请求行,请求头,空行,主体
- 请求行:是用来说明请求类型,要访问的资源,以及所使用的http版本号,常用的请求类型:get,post,put,delete等
- 请求头:用来说明服务器要使用的一些信息
- 空行: 请求头部后面必须要加上空行,即时请求数据是空的,也要加上。
- 请求数据:也叫请求主体,可以添加任意的数据
http响应消息,通常服务器接受到客户端的请求消息,会返回一个http的响应信息,响应信息包含:状态行,报头,空行,响应正文
- 状态行:由http协议版本号,状态码,状态消息,三部分组成。
- 消息报头:用来说明客户端要使用的一些信息
- 消息报头后面的空行是必须的
- 响应正文:服务器返回给客户端的文本信息。
TCP:传输控制协议是位于传输层的通讯协议,TCP运行可分为三个阶段,
- 建立连接
- 传输数据
- 中断连接
建立连接需要进行三次握手,这也就是为什么http请求会有三次握手的行为,
- 第一次握手,客户端发送SYN(信号的一种)到服务端,告诉服务端,我想要建立连接
- 第二次握手,服务端接收到客户端发送的SYN,然后就会在SYN的基础上加上ACK发送给客户端,告诉客户端,我知道了
- 第三次握手,客户端接收到服务端发送过来的SYN-ACK,然后会发送ACK到服务端,告诉服务端好的,那我准备开始正式建立连接了
通过三次握手之后,TCP正式建立起连接。
tcp如果要断开链接,会触发四次挥手的过程:
由客户端发起关闭连接
- 客户端 ----> 服务端:FIN(请求关闭)
- 服务端 ----> 客户端:ACK(收到连接,但不会马上关闭,等报文都发送完再回复一个FIN)
- 服务端 ----> 客户端:FIN
- 客户端 ----> 服务端:ACK(收到关闭)
由服务端发起关闭:
- 当http设置了keepalive定时关闭,服务端会在数据传输完之后结束tcp连接
https 超文本传输安全协议。是经由http进行通信,然后通过ssl/tls来加密数据包。https主要的**就是在不安全的网络上构建一条安全的通道。通常,http是直接和tcp通信的,但使用了ssl之后,http先和ssl通信,然后再和tcp通信,简单来说就是http套了一层ssl的外壳。
共享密钥加密:加密解密用同一个密钥的加共享密钥加密,叫对称性加密。所以如果密钥被人知道了,就可以被任意的人加密。以这种方式加密的,必须密钥也要一起发送给对方,如果在发送过程中通信被人监听了,那么密钥就很有可能落入攻击者手上,这样加密就没有意义。
公开密钥加密:公开密钥加密是一种非对称加密方式,有一个私钥以及一个公钥。顾名思义,私钥是不能被人知道的。公钥是公开的所有人都知道,ssl采用的加密方式就是这种。
https采用的是混合加密的机制,也就是先使用公开密钥加密,把共享密钥发送给对方,之后的通讯就可以使用共享密钥加密的方式通信了。
- 应用层 访问网络服务的接口,例如为操作系统或网络应用提供访问网络服务的接口,如http,dns等
- 表现层 提供数据转换的服务,例如加密解密,图片解码转码,数据的压缩和解压
- 会话层 建立端连接,并提供访问验证和会话管理(session)
- 传输层 提供应用进程之间的逻辑通讯,例如建立连接,处理数据包错误,数据包次序(tcp,udp等)
- 网络层 为数据在结点之间传输创建逻辑链路,并分组转发数据(路由器,防护墙,多层交换机等)
- 链路层 在通讯实体之间建立数据链接链路(网卡等)
- 物理层 为数据端设备提供原始比特流的传输通路(网线等)
强制缓存:如果缓存数据库已有请求所需要的数据,就会直接读取缓存数据库的数据,不会再向服务端发起请求。
协商缓存:客户端会先从缓存数据库中获取一个缓存标识,拿到缓存标识后回去请求服务端该标识是否已经失效了,如果没失效就会返回304,然后从缓存数据库读取数据,如若失效,服务器会返回更新数据
两种缓存可以同时存在,强制缓存优先级比协商缓存高。
强制缓存在请求头中用两个字段表明 Express和cache-control
Express存储的是服务器返回数据的到期时间。当再次请求的时间小于到期时间,则不会再发起请求,直接在缓存数据库读取缓存。但是因为服务器时间与本地时间存在差异,所以导致了缓存命中的误差。而且Express是http1.0的产物,所以现在一般使用的是cache-control。
cache-control有多个属性
- max-age: 多少秒之后缓存失效
- private: 客户端可以缓存
- public 客户端服务器都可以缓存
- no-cache: 不缓存
- no-store: 不存储到存储数据库
两种缓存方案:
Last-Modified:服务器在响应请求时,会告诉浏览器资源的最后修改时间。
if-last-modifed:浏览器再次想服务器发送请求的时候,请求头会加上此字段,值就是之前获取到资源最后修改的时间。服务器接受到请求会用这个时间去和资源最后修改的时间比对,如果一样则返回304,客户端去缓存数据库读取数据。如果不一样则会返回新的数据
last-modified,有个不好的就是只要资源被修改了,但是里面的内容没有发生变化,都会重新发送资源到客户端
Etag:服务器响应请求时,会通过这个字段告诉浏览器当前资源在服务器生成的唯一标识(规则由服务器自己定)
If-Noth-Match: 再次请求的时候,浏览器的请求头会包含此字段,值是从缓存数据库获取的标识。当服务器接收到请求的时候,用这个值与被资源的唯一标识比对。
- 不同,则说明资源被修改过,则从新返回整个资源,状态码为 200
- 相同,则说明资源未修改过,服务器返回304状态码,客户端从缓存数据库获取数据。
缺点是,生成这些标识都是通过算法生成的,所以会占用服务器资源。
chunk(array, [size=1])
将目标数组分割成多个指定长度大小的块(数组),并将这些块组成一个新的数组,如果指定数组不能均匀的分割,则剩余的元素仍要形成一个块(数组)
该函数有两个参数
- array 目标数组,
- size 要分割的长度大小
先尝试了一下自己去实现:
function chunk_2 (array, size) {
size = size >= 0 ? size : 0;
const length = !array ? 0 : array.length;
if(!length || size < 1) {
return [];
}
let result = [];
let index = 0;
const resultLength = length % size > 0 ? parseInt(length/size) + 1 : length/size;
for(let i = 0; i < resultLength; i++) {
let start = i * size;
let end = start + size;
const temp = [].slice.call(array, start, end);
result.push(temp)
}
return result;
}
然后是lodash的实现
function chunk(array, size) {
// 保证将要进行分割的大小必须是大于等于0的。
size = Math.max(size, 0)
// 获取目标数组的长度,并做一个边界判断,
const length = array == null ? 0 : array.length
// 判断目标长度是否为零,或者分割大小是否小于1,是则返回空数组
if (!length || size < 1) {
return []
}
// 目标第一个元素的下标
let index = 0
// 新数组当前的下标
let resIndex = 0
// 创建要返回的新数组,并确定数组长度, ceil向上取整,确保不能均分也能得到最后数组的长度
const result = new Array(Math.ceil(length / size))
// 开始分割
while (index < length) {
// 这里使用的是lodash自身实现的slice 函数
result[resIndex++] = [].slice.call(array, index, (index += size))
}
return result
}
对比分割10w个元素的数组,性能上,lodash比自己实现的要好上不少,特别是如果传入的目标参数是字符串,更是2-3倍的提升(主要是因为lodash自己实现的slice对分割字符串有很大提升)。但就算抛去slice,性能上也是有一定的优势。主要在于lodash的实现上少了2个三目判断。
总结:
- 自己写的还不够健壮,有些边界处理不够完善
- 基础不够扎实,Math的一些方法忘记了
- `lodash`使用了`new`创建新数组,而我使用的是字面量创建,然后`push`进去,然后自己测试了一下。创建10W数据,性能差距可以忽略。所以不明白为什么要使用new
下面来学习一下slice方法
slice(array, [start=0], [end=array.length])
创建并返回一个切片数组,包含开始下标的元素,但不包含结束下标的元素
该函数的三个参数
- array 目标数组
- start 开始下标
- end 结束下标
自己实现的:
function slice_2(array, start, end) {
// 先获取array的长度
const length = !array ? 0 : array.length;
if(!length ){
return [];
}
// 下面这些其实都是一些规则
if(!start){
start = start || 0;
} else {
// 先判断开始下标是否为负数,
// 如果是负数,则判断绝对值是否大于数组的长度,是的话设置为0,
// 否则就用开始下标加上数组长度,
// 如若不是负数则无任何变化
start = start < 0 ? -start > length ? 0 : (start+length) : start;
}
if(!end) {
end = end || length;
} else {
// 如果结束下标小于零则,下标加length
end = end < 0 ? end += length : end;
}
let result = [];
// 当开始下标小于结束下标,并且开始下标小于数组长度,则添加到返回数组里
while (start < end && start < length) {
result.push(array[start])
start++;
}
return result
}
lodash 实现
function slice(array, start, end) {
// 获取array的length
let length = array == null ? 0 : array.length
// 如果没有length则返回空数组
if (!length) {
return []
}
// 如果开始下标或者结束下标不传,则开始下标为0,结束下标为length
start = start == null ? 0 : start
end = end === undefined ? length : end
// 如果下标为负数,则需要转为整数,
// 如果开始下标的绝对值大于length 则默认是0
if (start < 0) {
start = -start > length ? 0 : (length + start)
}
// 如果结束下标大于length,则结束下标设置为length
end = end > length ? length : end
// 如果end小于0,则与length进行相加
if (end < 0) {
end += length
}
length = start > end ? 0 : ((end - start) >>> 0)
start >>>= 0
let index = -1
const result = new Array(length)
while (++index < length) {
result[index] = array[index + start]
}
return result
}
总结:对比了一下自己实现的和lodash实现的,分别裁剪10w个元素的数组,发现自己的实现要比lodash的性能要好一点。好像是因为lodash使用了位运算符,但不太清楚为什么要这么做,也没搜索,可能自己的经验不够。画个重点。因为自己看了一下二进制,有点晕晕的。不太懂
接下来就学习一下compact吧
compact(array)
删除原数组所有的假值,并创建一个新数组。这些假值包括null,undefind,'',0,NaN,false
function compact(array) {
let resIndex = 0
const result = []
if (array == null) {
return result
}
for (const value of array) {
if (value) {
result[resIndex++] = value
}
}
return result
}
总结:源码跟自己想的不一样的地方在于,在脑海里想的是用for循环,但没考虑用for of。其他地方基本一致。
对于一直在小厂待的我,对于前端安全可以说是一无所知,因为每次涉及到安全问题的,总是后端大佬们在说,什么sql注入啊,DDoS啊,感觉好像跟我们前端一毛钱的关系都没有,渐渐地就认为安全这方面的事情只是后端的事。
其实现实中并不是这样,最容易发生安全事件的其实是跟前端有关系的,其中最经典的就是xss漏洞,而且这是最容易发生的。
所以我们就来聊聊前端安全的那些事。
前端安全主要有以下几块的内容:
1. xss
2. csrf
3. ssrf
4. hikjack
5. 其它
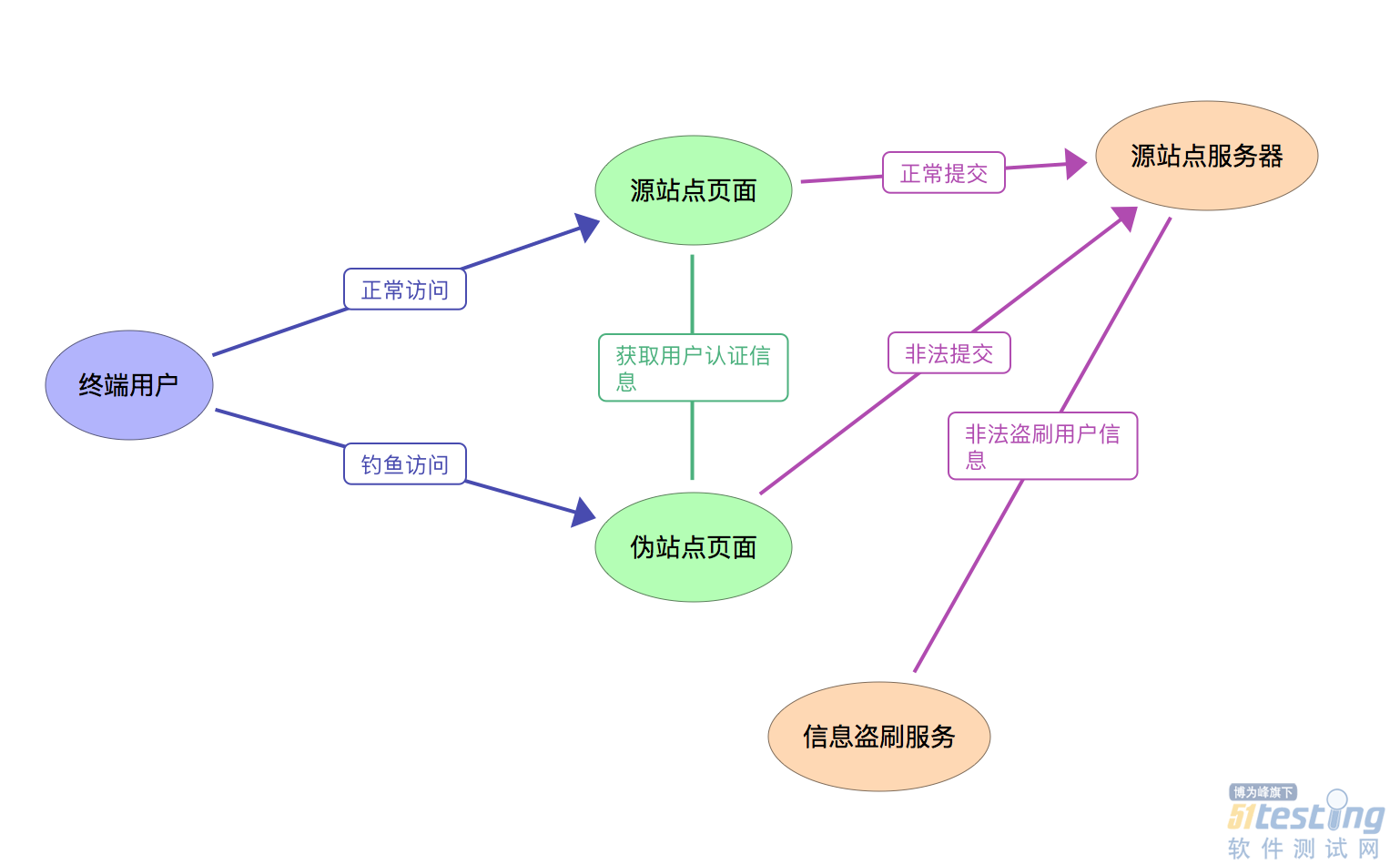
xss(跨站脚本攻击)指的是恶意攻击者在web页面上插入恶意的JavaScript代码,当用户浏览网页的时候,插入的JavaScript代码就会执行,从而造成攻击。
根据攻击脚本引入的位置,xss可以分成3类:
1. 反射型XSS
2. 存储型XSS
3. DOM Based XSS
非持久化,将用户输入的数据反射给浏览器,经过后端,但不会存储到数据库。需要欺骗用户点击链接,才会攻击成功。所以一般的攻击代码都会放在url上。
持久化,�将代码�储存到数据库中。比如在个人信息或者发表文章等地方,假如代码,没有过滤,或者过滤不严,那么这些代码将会储存到数据库当中,用户访问该页面的时候就会触发执行。�这种�XSS比较危险,容易造成蠕虫,盗窃cookie等。
例如在一个表单中,我们�输入内容,�然后前端直接把内容�展示到页面上,如果�没有进行xss�处理,假设输入:
<script>alert(1)</script>
在浏览器显示�这个内容的时候,就有可能会触发弹窗。所以在攻击的时候,有可能会触发各种行为,比如获取Cookie或所有本地存储并发送到某处,打开一个非法网址等等。
这种�和上面两种的区别在于,DOM XSS不需要服务端参与,可以认为是前端代码的漏洞导致的。
例如前端有一段这样的代码
<script>
eval(location.hash.substr(1));
</script>
然后攻击者就可以在网址后面加上恶意代码
http://www.xss.com#alert(document.cookie)
这样就完成攻击了,所以我们成说eval不安全的原因传入eval的字符串,天知道会是什么东西,但无论是什么,它都会去执行。
�
我们说了xss的三种攻击方式,现在来说一下防御方法。 总体的思路就是: �就是对输入(和url参数)进行过滤,对输出进行编码
1. & --> &
2. < --> <
3. > --> >
4. " --> "
5. ' --> '
6. / --> /
这个一方面是后端接收这些代码时候的转义存储,一方面是前端在显示的时候,需要把它们转成html实体。
�避免使用eval, new Function�等执行字符串的方法,除非确定字符串和用户输入无关。
使用innerHTML,document.write的时候,如果数据是用户输入的,那么需要对关键字符都进行过滤与转义。
对于非客户端的cookie,比如保存用户凭证的session,务必标识为http only,这样js就获取不到这个cookie值了。可以稍稍提高一丢丢的安全
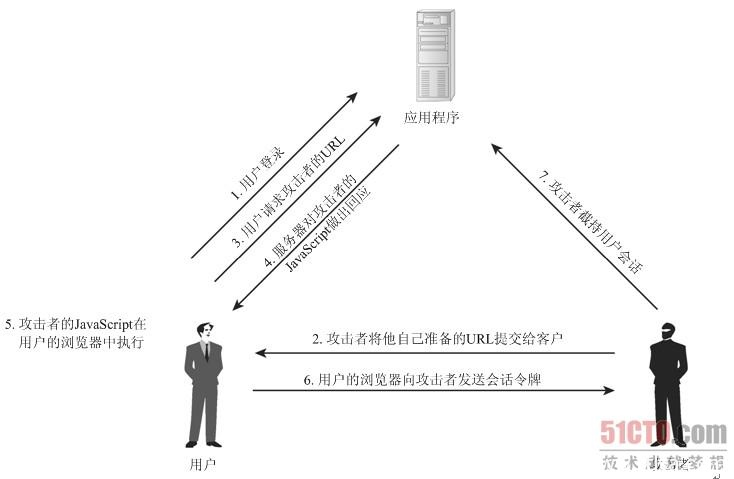
通过伪装来自受�信任用户的请求来利用受信任的网站。简单来说就是:攻击者通过一些技术手段,欺骗用户去访问一个自己曾经认证过�的网站进行一系列的操作(如发消息,发邮件,甚至一些财产操作如转账和购买商品等)。�由于浏览器曾经登录认证过,所以被访问的网站会认为是真正的用户在操作。就利用这个身份验证的漏洞:简单的身份验证,只能验证是来自真正用户的浏览器,并不能确定是否是真正用户的意愿
例如:
一个银行存在一个CSRF的漏洞。用户A转账给B用户2000元,执行转账操作后会给银行发送这样一个请求http://www.bank.com/money?user=A&num=2000&transfer=B,然后A用户就会把钱转到B的账号下。在发送这个请求给银行时,服务器首先会验证这个请求是否为一个合法的session,并且用户A确认登录过后才可以通过验证。
如果此时有一个恶意用户C想把A用户的钱转到C的账户下,那么�攻击者就可以构造http://www.bank.com/money?user=A&num=2000&transfer=C这个请求,但是这个请求必须�是A用户发出才有效。�此时�攻击者就可以搭建一个网站,在网站代码中写入如下代码:<img src="http://www.bank.com/money?user=A&num=2000&transfer=C">。
然后就会�诱导A点击这个网站,当A访问这个网站时,�网站就会把Img标签中的url发送到银行服务器,出了这个请求之外,还会把A用户的�cookie也一起发送过去,如果此时A用户浏览器和银行的session还没有过期的话,那么A就会在毫不知情下转账给了攻击者。
CSRF一般是在用户不知情的情况下发生的,所以我们可以增加验证码来�防止这种攻击。
因此在一些特定的业务场景下,比如银行转账等。如何使用验证码就要根据业务场景来使用了。
在http的�头中有一个Referer字段记录了请求的来源地址,比如从http://www.test.com 点击链接到 http://m.test.com 之后,那么referer就是 http://www.test.com 这个地址。所以在攻击者自己的�构建的网站上�构建恶意的攻击脚本,那么此时的Referer值就是攻击者自己的URL地址。因此服务端就可以知道�当前请求是否是自己网站发出的。这个方式在一定程度上可以防止攻击。
但是此类方法并非万无一失,在低版本存在漏洞的浏览器中,黑客可以篡改referer值。另一种情况是CSRF结合XSS进行攻击,此时就不需要跨域发起,也可以绕过referer验证。
尽量对要修改数据的请求使用post而不是get。这样请求不能使用get,可以在一定程度上降低风险。
使用token验证机制,比如请求数据字段中添加一个token,响应请求时校验其有效性
�首先,在用户登录成功的时候,后端生成一个随机的token交给�前端页面。然后每次请求的时候,前端都带上这个token,然后后端进行验证,通过才返回数据,否则就报错。
注意:
CSRF的Token仅仅用于对抗CSRF攻击。当网站同时存在XSS漏洞时候,那这个方案也是空谈。所以XSS带来的问题,应该使用XSS的防御方案予以解决。
最后,CSRF攻击是攻击者利用用户的身份操作用户帐户的一种攻击方式,通常使用Anti CSRF Token来防御CSRF攻击,同时要注意Token的保密性和随机性。
ssrf�,攻击者可以伪造服务器端发起请求。从而获取客户端获取�不到的内容。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。
SSRF漏洞形成的原因主要是服务器端所提供的接口中包含了所要请求的内容的URL参数,并且未对客户端所传输过来的URL参数进行过滤。
类似于这样的形式:
ip:port/ssrf.php?url=xxxx
我们构建了一个url的请求,�服务端接收并访问传入的url,然后返回给客户端相应的数据(�如图片等)。正常情况下,�服务器希望我们传入的url是一个正常的链接,比如图片、网链,也可以是友链。
攻击者可以利用 SSRF 实现的攻击主要有 5 种:
1. 可以对外网、服务器所在内网、本地进行端口扫描,获取一些服务的 banner 信息
2. 攻击运行在内网或本地的应用程序(比如溢出)
3. 对内网web应用进行指纹识别,通过访问默认大文件
4. 攻击内外网的web应用,主要是使用`get�`参数就可以实现攻击
5. 利用`file`协议就可以获取本地文件等。
禁用不需要的协议。仅仅允许 HTTP 和 HTTPS 请求。可以防止类似于file://、gopher://和ftp://等引起的问题。
黑名单内网ip。避免应用被用来获取获取内网数据,攻击内网。
过滤返回信息,验证远程服务器对请求的响应是比较容易的方法。如果web应 用是去获取某一种类型的文件。那么在把返回结果展示给用户之前先验证返回的信息是否符合标准。
很多时候,我们的网站不是直接访问到我们的服务器上面去的,中间会经过很多层代理,如果在某一个环节,数据被中间代理层的劫持者�所截获,他们就能获取到你网站上的用户名和密码等一些保密数据。
HTTP劫持是指,在用户浏览器与访问的目的服务器之间所建立的网络数据传输通道中从网关或防火墙层上�监视特定数据,当满足一定条件时,就会在正常的数据包中插入或修改成为攻击者设计的网络数据包,目的是让用户浏览器解析错误的数据。或者以弹出新窗口的形式在使用者浏览器界面上展示宣传性广告或者直接显示某块其他的内容
�这种情况下,用户请求�源网站的IP地址以及网站加载的内容脚本都是正确的。但是在网站内容�请求返回过程中,可能被ISP(Internet Service Provider,互联网服务提供商)所劫持修改,最终在浏览器页面上添加显示一些广告等内容信息。
也有可能是我们在餐馆或其它地方接入一些奇奇怪怪的wifi,如果这些wifi是一些黑客所建立的热点,那么黑客就可以截获所有用户所有收发的数据。
对于这些情况,网站开发者常常无法�通过修改网站代码程序等手段来进行防范,请求劫持唯一可行的预防方法就是尽量使用https协议来访问�网站,还有就是尽量不蹭网。
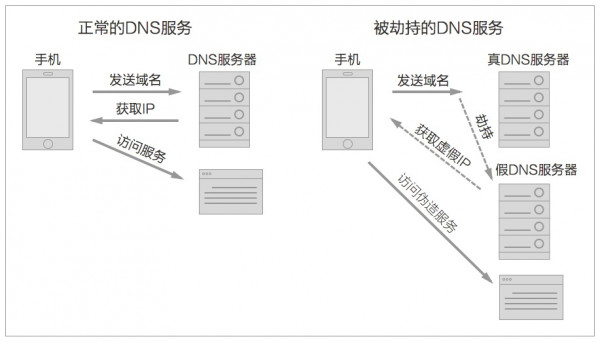
DNS劫持通常是指攻击者劫持了DNS服务器,通过某些手段取得某域名的解析记录控制权,进而修改此域名的解析结果。导致该用户对此域名地址的访问由原IP�地址转入到修改�后的指定IP地址。其结果就是让正确的网站不能解析,或者解析指向到�另一个网站IP上,实现获取用户资料或者破坏原有网站正常服务的目的。DNS劫持一般通过篡改DNS服务器上的�域名解析记录,来返回给用户一个错误的DNS查询结果。
DNS劫持也没有好的解决方法,尽量外出不蹭网,网站尽量使用HTTPS协议。
callback hell 是如何产生众所周知,JavaScript是单线程的方式运行的,所以线程是不能被阻塞的。所以我们在进行异步编程的时候,都是使用回调的。但是条件一多就很容易陷入回调地狱,我们在写代码的时候很可能遇到这样的情况:
$.ajax(url, (res) => {
if(res.xx) {
$.ajax(url2, (res2) => {
if(res2.xx) {
..... // 不断的嵌套
}
})
}
})
这样我们就陷入了回调地狱,这种回调地狱不仅看起来难看,可读性也很差。
我们先来了解一下什么是Promise。
Promise是一种对异步操作的封装,可以通过独立的接口添加在异步操作执行成功、失败时执行的方法。主流的规范是 Promises/A+。
Promise对象有三个状态。
1. pending 初始状态,既不是成功,也不是失败
2. fulfilled 意味着操作成功
3. rejected 意味着操作失败
Promise的状态一旦改变,就不会再发生任何的变化。它只有两种变化,一种是从pending->fulilled或者是pending -> rejected.
then这个方法then()接收两个函数作为参数,第一个是成功会触发的函数,第二个是失败触发的函数,但失败不建议写在then上,建议使用catch。then()返回的是一个Promise实例const p1 = new Promise((resolve, reject) => {
setTimeout(function(){
resolve("成功!"); //代码正常执行!
// reject("失败!"); //代码失败执行!
}, 250);
})
<!-- bad -->
p1.then((res) => {
//res的值是上面调用resolve(...)方法传入的值.
//res 参数不一定非要是字符串类型,这里只是举个例子
console.log(res);
}, (error) => {
<!-- 失败不建议这样写,应该使用catch -->
//error的值是上面调用reject(...)方法传入的值.
//error 参数不一定非要是字符串类型,这里只是举个例子
console.log(error);
});
<!-- good -->
p1.then((res) => {
//res的值是上面调用resolve(...)方法传入的值.
//res 参数不一定非要是字符串类型,这里只是举个例子
console.log(res);
})
.catch((error) => {
//error的值是上面调用reject(...)方法传入的值.
//error 参数不一定非要是字符串类型,这里只是举个例子
console.log(error);
})
在then中我们还可以返回一个Promise对象,然后再继续.then,形成一个联系调用
const p2 = new Promise((resolve, reject) => {
setTimeout(function(){
resolve("成功!");
}, 250);
})
p2.then(res => {
console.log(res);
return p1;
})
.then(res => {
console.log(res)
})
.catch(error => {
console.log(error)
})
虽然链式调用可以很好改善了回调地狱的问题,但还不能避免,要避免还是需要async/await;
async/await是什么
async/await是写异步代码的新方式,优于回调函数和Promise。async/await是基于Promise实现的,它不能用于普通的回调函数async/await使得异步代码看起来像同步代码,再也没有回调函数,但改变不了js单线程,异步的本质。用法
await,函数必须用async标识await后面跟的是一个Promise的实例try/catchfunction timeout(ms) {
return new Promise((resolve) => {
setTimeout(resolve, ms);
});
}
async function asyncPrint(value, ms) {
try{
await timeout(ms);
console.log(value);
} catch(error) {
console.error(error)
}
}
asyncPrint('hello world', 50); // 50 毫秒以后,输出hello world。
有了async/await我们就不需要些.then,不需要些匿名函数来处理Primise的值,还可以避免嵌套代码,从而避免回调地狱
并且使用了async/await,可以把异步方式写成了同步的方式,大大提高了我们的可读性
但有一点需要注意的是,使用async/await需要搭配babel-polyfill
未完待续。。。
这篇主要是让我了解一下基础的脚本错误以及上报方式。
脚本错误主要有两类::语法错误、脚本错误;
监控方式也主要有两种:try-catch、window.onerror
try-catch我们经常使用一种异常捕获的方式,通过给代码块进行try-catch进行包装后,当代码块发生错误时catch将能捕捉到错误信息,页面也将可以继续执行。
但是try-catch处理异常的能力有限,只能捕获到运行时的非异步错误,对于语法错误和异步错误就显得无能为力。
栗子: 运行时错误
try{
error // <- 未定义变量
} catch(e) {
console.log('捕获到错误');
console.log(e);
}
输出:
未捕获到错误
ReferenceError: error is not defined
栗子:语法错误
try {
var error = 'error'; // <-大写分号
} catch(e) {
console.log('捕获不到错误');
console.log(e);
}
输出:
Uncaught SyntaxError: Invalid or unexpected token
一般语法错误在编辑器就会体现出来,常表现的错误信息为: Uncaught SyntaxError: Invalid or unexpected token xxx 这样。但是这种错误会直接抛出异常,常使程序崩溃,一般在编码时候容易观察得到。
栗子:异步错误
try{
setTimeout(function () {
error // <- 异步错误
}, 0)
} catch(e) {
console.log('捕获不到错误');
console.log(e);
}
输出:
Uncaught ReferenceError: error is not defined
想要捕获异步错误,除非你在 setTimeout 函数中再套上一层 try-catch,否则就无法感知到其错误,但这样代码写起来比较啰嗦
window.onerror 捕获异常的能力比 try-catch稍强一点,无论是异步还是非异步的错误,onerror都能捕获到运行时的错误
栗子🌰:运行时同步错误
/**
* @param {String} msg 错误信息
* @param {String} url 出错文件
* @param {Number} row 行号
* @param {Number} col 列号
* @param {Object} error 错误详细信息
*/
window.onerror = function (msg, url, row, col, error) {
console.log('捕获到错误了');
console.log({
msg, url, row, col, error
})
return true;
};
error; // <- 未定义变量
输出:
捕获到错误了
{msg: "Uncaught ReferenceError: error is not defined", ...}
栗子🌰:捕获异步错误
window.onerror = function (msg, url, row, col, error) {
console.log('捕获到异步错误了');
console.log({
msg, url, row, col, error
})
return true;
};
setTimeout(() => {
error; // <- 未定义变量
});
输出:
捕获到异步错误了
{msg: "Uncaught ReferenceError: error is not defined", ...}
在实际使用中,onerror主要用来捕获预料之外的错误,try-catch则是用来在可预见情况下监控特定的错误,两者结合使用更加高效
但是对于语法错误,window.onerror还是捕获不了,所以我们在写代码的时候要尽可能避免语法错误,不过一般这种错误比较容易察觉。
除了语法错误不能捕获之外,网络异常的错误也是不能捕获的
栗子🌰:
<script>
window.onerror = function (msg, url, row, col, error) {
console.log('我知道错误了');
console.log({
msg, url, row, col, error
})
return true;
};
</script>
<img src="./404.jpg"/>
输出:
GET http://localhost:8081/404.jpg 404 (Not Found)
这是因为网络请求是没有事件冒泡的,所以需要在捕获阶段才能捕获到异常,虽然这样可以捕获到网络的异常,但无法判断http的状态,比如该异常是404还是500,想要知道这个状态就必须和服务日志一起排查了。
栗子🌰:
<script>
window.addEventListener('error', (msg, url, row, col, error) => {
console.log('我知道错误了');
console.log({
msg, url, row, col, error
})
return true;
}, true);
</script>
<img src="./404.jpg"/>
输出:
GET http://localhost:8081/404.jpg 404 (Not Found)
我知道错误了
{msg: Event, url: undefined, row: undefined, col: undefined, error: undefined}
Promise的错误没有使用catch去捕获的话,上述的方式都是不能捕获到错误的。但通过监听unhandledrejection事件,可以捕获未处理的Promise错误。但是需要注意的是,这个事件是有兼容问题的。
window.addEventListener("unhandledrejection", function(e){
e.preventDefault()
console.log('我知道 promise 的错误了');
console.log(e.reason);
return true;
});
new Promise((resolve, reject) => {
reject('promise error');
});
输出:
我知道 promise 的错误了
promise error
说完这些捕获异常的方式之后,该说说异常上报的常用方法了。
当我们拿到报错信息之后,就需要上报这些异常信息,我们上报的方式通常有两种方法:
1. 通过Ajax发送数据
2. 通过动态创建img标签的形式
img上报🌰:
function report(error) {
var reportUrl = 'http://xxxx/report';
new Image().src = reportUrl + 'error=' + error;
}
我们或多或少应该都看到过Script error这个错误,没有更详细的信息,只告诉我们是Script error。这是为什么,怎么产生的呢?
这是因为我们在一个域下引用了其他域的脚本,又没有去做额外的配资,就很容易产生Script error。说到最后这就是因为浏览器的同源策略产生的。
知道是跨域问题就好解决了,可以使用同源化,也就是放在同一个域名下面。但这样就不能做一些文件缓存啊。cdn等操作
所以最好我们还是使用跨源资源共享机制( CORS )
首先为页面上的 script 标签添加 crossOrigin 属性
// http://localhost:8080/index.html
<script>
window.onerror = function (msg, url, row, col, error) {
console.log('我知道错误了,也知道错误信息');
console.log({
msg, url, row, col, error
})
return true;
};
</script>
<script src="http://localhost:8081/test.js" crossorigin></script>
// http://localhost:8081/test.js
setTimeout(() => {
console.log(error);
});
然后需要服务端去配置Access-Control-Allow-Origin: localhost:8080 更具体就不说了,自行查看跨域的知识。
有人说你写测试代码会浪费很多时间,但是因为没有测试,然后出现了一些很明显的且低级的错误。去修改所浪费的时间要多的多。所以我觉得还是有必要好好了解一下测试,在项目中进行实践。
注意:
assert是Node的内置模块,提供了断言测试的函数,用于测试不变式
#####assert(value[, message])
assert.ok()的别名
assert.equal(actual, expected[, message])相等运算符(==)测试actual参数与expected参数是否相等assert.deepEqual(actual, expected[, message])参数与assert.equal一样
deepEqual方法是用来测试actual参数与expected参数是否深度相等。使用相等运算符==比较,只要它们的属性一一对应,且值都相等,就认为两个对象相等,否则抛出一个错误。
但是deepEqual只测试可枚举的自身属性,不测试对象的原型,连接符,或不可枚举的属性(这些情况要使用assert.deepStrictEqual方法)
assert.deepStrictEqual(actual, expected[, message////////// ])基本与上述的assert.deepEqual 相同,但还有一些区别
[对象包装器][]时,其对象和里面的值要求相同。。。。。
更多api的信息,可以点击[查看]
作用是运行测试脚本,测试脚本就是用来测试源码的脚本
describe('Array', function() {
describe('#indexOf()', function() {
it('should return -1 when the value is not present', function() {
assert.equal(-1, [1, 2, 3].indexOf(4))
})
})
})
上述的代码就是测试脚本。
describe称之为“测试套件”,表示一组相关的测试。它是一个函数,第一个参数是套件的名称,第二个是实际执行的函数。
it称之为“测试用例”,表示一个单独的测试,是测试的最小单位。它也是一个函数,第一个参数是用例的名称。第二个是实例执行的函数
BDD的风格,跟我们日常用的语法几乎一模一样。例如Karma 是一个前端测试运行框架,它能可以让我们在真实的环境中测试 更多的可以自行查看
用于构建及测试在github上的代码
this在JavaScript中是一个很重要的一个知识点,字面上的意思指的自己本身。所以很多初学者就很容易把this理解成指向函数自身。但跟可惜这是不正确的。
对于this来说,它的指向不是一成不变的。也就是说它不是在函数声明的时候绑定的,是取决于函数在哪里被调用,然后调用的时候进行绑定。
也就是说,this完全取决于函数的调用位置(也就是函数的调用方法)。
例子1:
var name = 'window.ajie';
function fn1(){
fn1.name = 'fn1.ajie';
console.log(this.name);
}
fn1() // 'ajie'
上面的例子,最后输出的window.ajie,是因为我们是当我们执行fn1()的时候相当于是window.fn1()。
所以我们从这里可以看出,我们最后调用fn1这个函数时在window对象。所以this就是指向了window了。然后输出了window.ajie
例子2:
var name = 'window.name';
var user = {
name: 'user.ajie',
getName : function () {
console.log(this.name);
}
}
user.getName(); // user.ajie
window.user.getName(); // user.ajie
从例子2,我们也可以很清楚的看出。调用getName方法的是user,就算是window.user.getName,最终调用getName方法的也是user对象。
再来看看一个稍稍特殊一点的例子:
var name = 'window.name';
var user = {
name: 'user.ajie',
getName : function () {
console.log(this.name);
}
}
var o = user.getName
o(); // window.name
在这个例子中,最后调用getName方法的其实是window对象,因为var o = user.getName这只是一个单纯的赋值操作,并没有去调用。
上述的3个例子,已经很清晰明了的告诉我们,this的指向不是在函数创建的时候绑定的,是在函数调用的时候绑定的。
这种绑定方法叫做隐式绑定,因为这些this的绑定都是在调用的时候自动绑定的,那么有隐式必定有显式绑定
1. call, apply
2. bind
3. new
4. 箭头函数 (es6)
call和apply是Function的两个方法,它们的作用都是调用某一个方法,并改变该方法this的执行环境。
例:
var name = 'window.name'
var user = {
name: 'user.name'
}
function getName(){
console.log(this.name);
}
getName.call(user); // user.name
getName.apply(user) // user.name
getName.call(); // window.name
getName.apply() // window.name
在这个例子中我们可以看出当我们有传参数的时候,this会自动的绑定到该参数上面,如果不传的时候this就会跟隐式绑定一样,最终绑定到了
window上,其实我们的第一个参数如果传的是null,效果跟不传是一样的。
call和apply二者唯一的区别就是传参的不同,call传参是单个单个的传,apply是以数组的形式。
bind虽然都可以跟call和apply一样,可以绑定this的执行环境,但本质是不一样的,call和apply是会直接调用该方法,也就是立即执行函数。但是bind会返回一个新的函数
例如
var name = 'window.name'
var user = {
name: 'user.name'
}
var callUser = {
name: 'call.name'
}
function getName(){
console.log(this.name);
}
var userGetName = getName.bind(user);
userGetName(); // user.name
userGetName.call(callUser) // user.name
getName(); // window.name
从上述例子我们可以看出,bind也是可以改变this的指向,而且绑定之后使用call和apply都无法再改变其this
new本质是创建一个新的实例对象,并把this赋予这个新的实例对象。
例如
var name = 'window.name'
var user = {
name: 'user.name',
}
function getName() {
console.log(this.name)
}
var userGetName = getName.bind(user);
userGetName(); // user.name
var bindName = new userGetName(); // undefined
所以new才是老大,说一不二
箭头函数的作用是函数绑定上下文,
var name = 'window.name'
var user = {
name: 'user.name',
getName: () => {
console.log(this.name)
}
}
user.getName.call(user); // window.name
上述的例子虽然我们是在window下调用的,但是因为我们在创建这个函数的时候使用的是箭头函数,因为箭头函数不会创建新的context,它会在创建的时候就会自动绑定上下文(this),也就是绑定到了window上。
而且,使用箭头函数绑定了上下文之后,这个函数的上下文就不会再发生变化。
因为setTimeout的机制问题。当创建了一个setTimeout后,js就会自动把他丢到事件队列里面去,等所有js执行完毕后,再到事件队列里找出这个setTimeout然后执行,所以最后调用这个函数的是window对象
concat(array, [values])
创建一个新数组,将数组与任意的数组或值连接起来
照例,先自己实现一波
function concat2 () {
let length = arguments.length;
if(!length) return [];
let result = [];
for(let index = 0; index < length; index++) {
let value = arguments[index]
if(value instanceof Array) {
for(let valueIndex = 0; valueIndex < value.length; valueIndex++) {
result.push(value[valueIndex]);
}
} else {
result.push(value)
}
}
return result
}
lodash源码
function concat() {
var length = arguments.length;
if (!length) {
return [];
}
var args = Array(length - 1),
array = arguments[0],
index = length;
while (index--) {
args[index - 1] = arguments[index];
}
return arrayPush(isArray(array) ? copyArray(array) : [array], baseFlatten(args, 1));
}
源码很简单,我主要的疑惑是源码的实现,主要借助了两个工具函数arrayPush和baseFlatten。作用是什么?简单的和自己的实现做了一下对比。性能上差距不大。那我只能猜测是兼容,或者是一些边界的判断。让我们来看看他们的源码是怎么实现这两个函数的,到底是不是和我们想象的作用一样。
/**
* Appends the elements of `values` to `array`.
* 将values的元素添加到array,也可以说是把values拼接到array
* @private
* @param {Array} array The array to modify. 要改变的array
* @param {Array} values The values to append. 要添加的value
* @returns {Array} Returns `array`. 返回一个数组
*/
function arrayPush(array, values) {
var index = -1, // 可以当做是当前的拼接次数 或 value下标
length = values.length, // 拼接总次数
offset = array.length; // 初始拼接的位置
// 判断当前拼接次数是否小于总次数,
while (++index < length) {
// 把value拼接到array中
array[offset + index] = values[index];
}
return array;
}
这个工具函数只是一个简单的数组拼接。貌似并没有什么特别。
接下来我们看看baseFlatten
/**
* The base implementation of `_.flatten` with support for restricting flattening.
_.flatten 就是基于这个函数实现的,可以减少数组的嵌套
*
* @private
* @param {Array} array The array to flatten. // 目标数组
* @param {number} depth The maximum recursion depth. // 最大的递归深度
* @param {boolean} [predicate=isFlattenable] The function invoked per iteration.
* @param {boolean} [isStrict] Restrict to values that pass `predicate` checks. // 是否限制values 必须通过 predicate 的校验
* @param {Array} [result=[]] The initial result value. // 期望放到指定的数组里,不传默认为一个空数组
* @returns {Array} Returns the new flattened array. // 返回一个被打平的新数组
*/
function baseFlatten(array, depth, predicate, isStrict, result) {
var index = -1, // 初始下标
length = array.length; // 目标数组的长度
// 当你没有传predicate,则设置一个默认的函数,主要作用是检验目标是否能打平
predicate || (predicate = isFlattenable);
// 返回的结果数组,如果不传,则默认是[]
result || (result = []);
//
while (++index < length) {
var value = array[index];
// 是否打平的判断,循环深度必须大于0,且value是可以被打平的
if (depth > 0 && predicate(value)) {
// 循环深度是否大于1, 大于1则进行递归打平
if (depth > 1) {
// Recursively flatten arrays (susceptible to call stack limits).
baseFlatten(value, depth - 1, predicate, isStrict, result);
} else {
// 将结果数组与当前的value进行拼接
arrayPush(result, value);
}
} else if (!isStrict) { // 如果没有通过predicate校验,则不把值添加到结果数组
result[result.length] = value;
}
}
return result;
}
看完这两个工具函数的源码。虽说这些工具函数对于一些边界判断确实存在,但我并没有感觉到是必要的。个人觉得更多是代码组织方面的问题。。可能也是自己能力还不足,没有一个更深的理解。。end
主要记录自己搭建前端脚手架,并且发布到npm上的过程。
之前重构了一个后台项目,从技术选型,到项目的开发。都是自己从0到1亲手弄完的。现在这个项目已经完成了,但是又有一个项目需要重构,就想着延用上一套的技术。当然了最简单的就是直接把上一个项目复制一份,然后把一些业务代码然后删掉。只留下一些与之前业务无关的代码。
但是这样有一个问题就是,如果下一个项目还是想用我这套技术,或者其他小伙伴想用我这套技术(其实也不是想了,因为之前说过新项目都准备用这个技术栈了),一直这样复制删除,岂不是很low。作为一个不想成为咸鱼的小开发,就准备花点时间把这个项目弄成一个脚手架,然后在写一个npm cli用来生成这个脚手架,这个cli还可以用来生成一些通用的模板,避免大量剪切复制的操作。提高开发效率。毕竟能偷懒,还是要偷懒的。
首先我们需要有自己的前端工程,也就是基本的脚手架,并上传至github,这步并没什么可以说的,就是按照自己实际的需求搭建一个基础的项目,用来给等会的cli工具生成。
搭建过程中我们依赖以下工具:
1. commander.js 终端输入处理框架
2. download-git-repo 拉取github上的文件
3. chalk 改变输出文字的颜色
4. ora 提示下载
5. Inquirer.js 命令行交互 提示文本
首先创建名为xxx-cli的文件夹,使用npm初始化,在文件夹内创建bin目录,并创建xxx.js,此时的项目结构:
xxx-cli
|- bin
| |- xxx.js
|- package.json
"bin": {
"xxx": "./bin/xxx.js"
}
在package.json增加bin,xxx就是命令号要输入的指令,./bin/xxx.js是命令执行时的文件。
�这是整个cli的核心。整个cli的流程就是根据终端输入的�命令,然后就去拉取我们�准备好的框架,下载到本地,然后我们还可以�对下载下来的文件进行操作,也就是node对文件的操作。
先来看看应该怎么写这个脚本文件:
#!/usr/bin/env node //告诉node使用终端运行
const fs = require('fs');
const program = require('commander'); //终端输入处理框架
const download = require('download-git-repo'); // 拉取github上的文件。
const chalk = require('chalk'); // 改变输出文字的颜色
const ora = require('ora'); // 小图标(loading、succeed、warn等
const package = require('../package.json'); //获取版本信息
const symbols = require('log-symbols'); //美化终端
const re = new RegExp("^[a-zA-Z\-]+$"); //检查文件名是否是英文,只支持英文
program
.version(package.version, '-v,--version')
// 定义参数。它接受四个参数,
// 在第一个参数中,它可输入短名字 -a和长名字–app ,
// 使用 | 或者,分隔,在命令行里使用时,这两个是等价的,区别是后者可以在程序里通过回调获取到;
// 第二个为描述, 会在 help 信息里展示出来;
// 第三个参数为回调函数,他接收的参数为一个string,有时候我们需要一个命令行创建多个模块,就需要一个回调来处理;
// 第四个参数为默认值
.option('-i, init [name]', '初始化 beidousat-admin 项目')
// 解析命令行
.parse(process.argv);
// 判断命令行是否是 init 命令
if(program.init){
// 获取要生成项目的名字
const name = program.init;
if (!re.test(name)) { //检查项目名字是否符合规定
console.log(symbols.error, chalk.red('错误!请输入英文名称'));
return
}
if (!fs.existsSync(name)) { //检查是否有该项目
console.log(symbols.success,chalk.green('开始创建..........,请稍候'));
const spinner = ora('正在下载模板...');
spinner.start();
// 下载脚手架
download(`你githun上的项目地址`, name, err => {
if (err) {
spinner.fail();
} else {
spinner.succeed();
console.log(symbols.success, chalk.green('模版创建成功'));
}
});
} else {
console.log(symbols.error, chalk.red('有相同名称模版'));
}
}
然后执行node bin/xxx.js init demo ,
node bin/xxx.js init demo
选择想要的选项,回车
输出:✔ 开始创建..........,请稍候
⠏ 正在下载模板...
等待下载完成
输出:✔ 模版创建成功
这样我们就完成了一个npm cli了。现在我们就可以把这个cli发布到npm上
npm官网中注册账号(如有忽略)发布之后,我们就可以使用全局安装这个npm包了。因为我们发布的npm包的名字是xxx-cli,所有我们全局安装是npm i xxx-cli -g,而且我们在pageage.json配置bin是xxx。所有我们的初始化命令是 xxx init demo
至此我们就完成了从开发到发布的整个流程了。
以下是我完整项目的连接
difference(array,[value])
检验一个数组,找出该数组中没有在其他数组中出现的元素,然后把这些元素组合成一个数组,并返回。
参数:
- array 要检验的数组
- [value] 要排除的值
返回值:一个新的数组
源码:
function difference(array, ...values) {
// 判断检验数组是否是一个类数组且对象,不是则返回空数组
// baseFlatten 这个函数在上一章已经聊过了,不清楚可找上一章来看 主要是减少数组的嵌套
return isArrayLikeObject(array)
? baseDifference(array, baseFlatten(values, 1, isArrayLikeObject, true))
: []
}
_.differenceBy(array, [values], [iteratee=_.identity])
该方法与difference方法类似,只是多了一个迭代器的参数,然后在比较的时候会先使用迭代器分别迭代array values的每一个元素。
参数:
- array 要检验的数组
- [value] 要排除的值
- [iteratee=_.identity] iteratee调用每一个元素
源码:
function differenceBy(array, ...values) {
// 要注意的是这里的迭代器是最后一个参数,所以这里用自己实现的last获取迭代器
let iteratee = last(values)
// 如果没有传入迭代器,则迭代器赋值为undefined
if (isArrayLikeObject(iteratee)) {
iteratee = undefined
}
return isArrayLikeObject(array)
? baseDifference(array, baseFlatten(values, 1, isArrayLikeObject, true), iteratee)
: []
}
_.differenceWith(array, [values], [comparator])
该方法与difference方法类似,只是多了一个比较器的参数,它调用比较array,values中的元素。 结果值是从第一数组中选择。
参数:
- array 要检验的数组
- [value] 要排除的值
- [comparator] comparator调用每一个元素
源码:
function differenceWith(array, ...values) {
// 要注意的是这里的迭代器是最后一个参数,所以这里用自己实现的last获取比较器comparator
let comparator = last(values)
// 如果没有传入比较器comparator,则迭代器赋值为undefined
if (isArrayLikeObject(comparator)) {
comparator = undefined
}
return isArrayLikeObject(array)
? baseDifference(array, baseFlatten(values, 1, isArrayLikeObject, true), undefined, comparator)
: []
}
// 类似 `difference` 方法的基本实现
/**
* The base implementation of methods like `_.difference` without support
* for excluding multiple arrays or iteratee shorthands.
*
* @private
* @param {Array} array The array to inspect. 检验的数组
* @param {Array} values The values to exclude. 要排除的值
* @param {Function} [iteratee] The iteratee invoked per element. 每一个元素都会调用iteratee
* @param {Function} [comparator] The comparator invoked per element. 每一个元素都会调用 comparator(比较)
* @returns {Array} Returns the new array of filtered values.
*/
function baseDifference(array, values, iteratee, comparator) {
var index = -1, // 初始下标
includes = arrayIncludes, // 这是一个lodash实现的方法,用来检验值是否存在数组中,实现用的是原生的indexOf
isCommon = true, // 是否是一个普通的数组
length = array.length, // 检验数组的长度
result = [], // 结果数组
valuesLength = values.length; // 有多少个排查数组
// 如果长度为0 或没有长度,则返回[]
if (!length) {
return result;
}
if (iteratee) {
// 要排除的每个值,都要去执行一遍 iteratee
// arrayMap 这是lodash 实现的一个特别的`_.map`函数,就是每个values的值都会用baseUnary执行一下,然后返回。有兴趣的可以自行去看一下源码
// baseUnary 是 `_.unary` 的基本实现, 参数接收一个函数,并返回一个函数,典型的柯理化函数
values = arrayMap(values, baseUnary(iteratee));
}
if (comparator) {
// arrayIncludesWith 跟arrayIncludes类似,只是多接收了一个比较函数
includes = arrayIncludesWith;
isCommon = false;
}
// LARGE_ARRAY_SIZE = 200 是否是大号数组
else if (values.length >= LARGE_ARRAY_SIZE) {
includes = cacheHas;
isCommon = false;
values = new SetCache(values);
}
outer:
while (++index < length) {
var value = array[index],
computed = computed == null ? value : iteratee(value);
value = (comparator || value !== 0) ? value : 0;
// 是一个普通的数组,并且要计算的值不是 NaN
if (isCommon && computed === computed) {
var valuesIndex = valuesLength;
// 循环比较,如果没有相同的值,则push到结果数组中
while (valuesIndex--) {
if (values[valuesIndex] === computed) {
continue outer;
}
}
result.push(value);
}
// 否则,如果不包含在values中,则push到结果数组
else if (!includes(values, computed, comparator)) {
result.push(value);
}
}
return result;
}
发布/订阅模式中的订阅,然后我们根据参赛选手的手机号码等信息,发短信这个操作就是发布。简单来说,就是我们需要一个缓存列表,来缓存订阅者的回调函数,然后有一个发布函数,这个发布函数的作用就是触发缓存列表中所有的回调函数。它们是一种一对多的依赖关系。
在我们做过的一些实际项目当中,肯定会遇到一种情况就是,很多东西都是必须依赖用户登录成功后,才可以进行下去的。。比如,用户登录成功后,我们去设置一些地方的用户头像啊,刷新消息列表啊,刷新收藏列表等等的操作,大家看到这个需求,脑子里肯定会想,这个简单,我们ajax中不是都有回调函数吗?直接在回调函数里面触发就好,可能代码是这样写的:
login.succ((res) => {
header.setAvatar(res.avatar); // 设置header的头像
message.refresh(); // 刷新消息列表
collect.refresh(); // 刷新收藏列表
// ...
})
等以后可能有新需求了,也是需要在登录成功之后才能操作的,那我们能想象到的就是,找到这个函数,在回调函数里面再添加一个对象的操作,这样我们的代码的耦合性就非常严重了,也可能这段代码是A写的,但后来B需要添加一个登录后的操作,那么B就要去找这个函数,因为不是B写的。所以可能找很久B也找不到。这就很尴尬了。
那么我们使用了发布/订阅模式之后,我们就可以不关心登录模块里面的业务逻辑是什么了,我们只需要在登录成功后,去发布一个消息说,我登录成功啦。然后你们需要做什么的自己赶紧去做啊。可能代码如下:
$.ajax(url, (res) => {
login.trigger('loginSucc', res)
})
const header = (function () { // header模块
login.listen('lofinSucc', function (res) {
header.setAvatar(res.avatar);
})
return {
setAvatar: function (data) {
console.log('设置hearder模块的头像')
}
}
})()
const message = (function () { // 消息模块
login.listen('lofinSucc', function (res) {
message.refresh(res);
})
return {
refresh: function (data) {
console.log('设置hearder模块的头像')
}
}
})()
这样我们不论什么时候有新的需求在登录之后触发的,我们只需要在对应的模块中去订阅就好了,根本不用去关心登录模块内部的业务逻辑。进行解耦
以上的代码,参考javascript设计模式与开发实践
优点:时间上的解耦,对象之间的解耦。
缺点:创建订阅者本身需要消耗一定的内存,比如你订阅了一个事件后,但是该事件一直没有触发,那么这个订阅者就会一直常驻在内存之中。虽然这个设计模式可以在一定程度上的解耦,但是如果我们过渡使用的话,就很容易如果出问题了就难以追踪,其他人维护和理解也有可能会有一点困难
未完待续。。。。
.、\、|、[]、[^]、-{m,n}、+、*、?^、$、\b、\B、(?=p)、(?!p)\d、\D、\s、\S、\w、\Wg、i、m| 字符 | 含义 | 例子 |
|---|---|---|
\ |
可以将字符和特殊字符相互转换 | \d 匹配 [0-9] 的数字,a\*匹配的是"a*"字符串 |
^ |
匹配字符串开始的位置 | /^A/匹配的是"An E"的A,不会匹配"an A"的A |
$ |
匹配字符串结束的位置 | /t$/不会匹配"eater"的t,但会匹配"eat"的t |
* |
匹配前一个表达式0次或多次,等价于{0,} |
/bo*/能匹配boo或者b |
+ |
匹配前一个表达式1次或多次,等价于{1,} |
/bo+/能匹配bo或者boo,但不能匹配b |
? |
匹配签名一个表达式0次或者1次,等价于{0, 1}。如果紧跟在任何量词 *、 +、? 或 {} 的后面,将会使量词变为非贪婪的(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反 |
/do(es)?/能匹配到do或者does |
. |
匹配换行符之外的任何单个字符 | /.n/将会匹配nay,an apple is on the tree中的an和on,但不会匹配nay |
(x) |
匹配x并且记住匹配项,括号被称为捕获括号 |
/(foo) (bar) \1 \2/将会成功匹配foo bar foo bar,其中\1 \2分别代表(foo)和(bar) |
| (?:x) | 匹配x但不记住匹配项。也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符 `( |
)` 来组合一个模式的各个部分是很有用。 |
x(?=y) |
一般用法:××(?=y),它的意思就是 ×× 后面的条件限制是 ?= 后面的 y |
`Windows(?=95 |
x(?!y) |
类似于 x(?=y),表示不等于后面的 y。 |
/\d+(?!\.)/.exec("3.141")匹配‘141’但是不是‘3.141’ |
| `x | y` | 匹配x或y |
{n} |
n是一个正整数,匹配了前面一个字符刚好发生了n次 |
/a{2}/不会匹配“candy”中的'a',但是会匹配“caandy”中所有的a,以及“caaandy”中的前两个'a'。 |
{n,m} |
n和m都是整数,匹配签名的字符串至少n次,最多m次。如果n和m的值都是0,这个值被忽略。 |
/a{1, 3}/匹配“caandy”中的前两个a,也匹配“caaaaaaandy”中的前三个a |
[xyz] |
字符集合。匹配所包含的任意一个字符。 | [abc]可以匹配apple的a |
[^xyz] |
求反。匹配未包含的任意字符 | [^abc]可以匹配apple的p |
\b |
匹配一个单词的边界,也就是指单词和空间的位置。 | er\b 可以匹配 never 中的 er,但不能匹配 verb 中的 er。 |
\B |
匹配非单词边界 | er\B 能匹配 verb 中的 er,但不能匹配 never 中的 er。 |
\cx |
匹配由x指明的控制字符 |
例如,\cM 匹配一个 Control-M 或者回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 c字符。 |
\d |
匹配一个数字。等价于[0-9]。 |
/\d/或者[0-9]匹配A2中的2 |
\D |
匹配一个非数字,等价于[^0-9] |
/\D/或者[^0-9]匹配A2中的A |
\f |
匹配一个换页符 | --- |
\n |
匹配一个换行符 | --- |
\r |
匹配一个回车符 | --- |
\s |
匹配一个空白符,包括空格、制表符、换页符和换行符 | /\s\w*/匹配foo bar中的' bar' |
\S |
匹配一个非空白符 | /\S\w*/匹配foo bar中的'foo' |
\t |
匹配一个水平制表符 | --- |
\v |
匹配一个垂直制表符 | --- |
\w |
匹配一个单字字符(字母、数字或下划线),等价于[A-Za-z0-9_]。 |
ID A1.3 中的 I、D、A、1 和 3 |
\W |
匹配一个非单字字符。等价于 [^A-Za-z0-9_]。 | ID A1.3 中的 . |
exec,一个在字符串中执行查找匹配的RegExp方法,它返回一个数组(未匹配到则返回null)const str = 'foo bar';
const re = /^foo/;
console.log(re.exec(str)); //['foo',...]
test 一个字符串中测试是否匹配的RegExp方法,它返回true或falseconst str = 'foo bar';
const re = /^foo/;
console.log(re.test(str)) //true
match 一个字符串中执行查找匹配的String方法,它返回一个数组或者在未匹配到时返回nullconst str = 'foo bar';
const re = /^foo/;
console.log(str.match(re)) // ['foo',index: 0,...]
search 一个字符串中测试匹配的String方法,它返回匹配到的位置索引,或者在失败的时候返回-1const str = 'foo bar';
const re = /^foo/;
console.log(str.search(re)) // 0
replace 一个在字符串中执行查找匹配的String方法,并且使用替换字符串替换匹配到的子字符串。const str = 'foo bar';
const re = /^foo/;
console.log(str.replace(re, 'bar')) // 'bar bar'
split 一个使用正则表达式或者一个福鼎字符串分隔一个字符串,并将分隔后的字符串存储到数组中的String方法"Webkit Moz O ms Khtml".split( " " ) // ["Webkit", "Moz", "O", "ms", "Khtml"]
分组:主要是括号的使用
引用:正则中的第一个括号,我们可以使用$1,第二个$2,一直到$9;
例如:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-08-09";
var result = string.replace(regex, "$2/$3/$1");
console.log(result); // "08/09/2017"
等价
var result = string.replace(regex, function() {
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
console.log(result); // "08/09/2017"
没有宽度,匹配到的字符串不会被捕获
只是用来判断是否符合继续匹配的条件,并不会找到真正需要的字符串,终身不会匹配字符`
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.