holoviz-topics / examples Goto Github PK
View Code? Open in Web Editor NEWVisualization-focused examples of using HoloViz for specific topics
Home Page: https://examples.holoviz.org
License: Creative Commons Attribution 4.0 International
Visualization-focused examples of using HoloViz for specific topics
Home Page: https://examples.holoviz.org
License: Creative Commons Attribution 4.0 International

























































































One of the main things that we mean to accomplish with pyviz-topics/examples is a set of stable urls that we can link to from all of our other projects. There should be some minimal index page, but more importantly there need to be static versions of all our topics suitable for iframing and linking. Since many of these topics require large datasets and/or take a long time to run, we will want to build these things locally. I am imagining that this will look a lot like the build process for earthml, where if the project falls under either of those categories (large data or slow to run), the maintainer is responsible for uploading an evaluated version to a specific branch. Then when we use nbsite to build the website on travis, it can grab the evaluated versions from that "blessed" branch first.
So there should be a command that the maintainer can run locally that will do this evaluation.
I guess there is also another case to think about which is the more-than-one notebook per project case. I think @jbednar's suggestion that we default to the notebook with the same name as the dir is a good one, but we might want to provide a mechanism for overriding that in the anaconda-project.yml.
I will start drafting what this will look like unless anyone has some requirements they'd like to add. @pyviz-topics/pyviz-dev
I'm running the portfolio optimizer off of the files downloaded from https://examples.pyviz.org/assets/portfolio_optimizer.zip . Everything appears to work fine, except when I upload a csv of stock prices, I get the stack trace below. This does not happen when I use https://portfolio-optimizer.pyviz.demo.anaconda.com/portfolio, which works fine with the same csv file. I also get the same error when I run from source (abc0167).
I'm using
% conda --version; anaconda-project --version
conda 4.7.12
0.8.3
on OSX.
Exception trace:
2019-11-25 09:42:26,235 Exception in callback functools.partial(<bound method IOLoop._discard_future_result of <tornado.platform.asyncio.AsyncIOMainLoop object at 0x7fd1e0572a58>>, <Future finished exception=RuntimeError('FileInput.filename is a readonly property',)>)
Traceback (most recent call last):
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/tornado/ioloop.py", line 743, in _run_callback
ret = callback()
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/tornado/ioloop.py", line 767, in _discard_future_result
future.result()
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/tornado/gen.py", line 748, in run
yielded = self.gen.send(value)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/bokeh/server/session.py", line 70, in _needs_document_lock_wrapper
result = yield yield_for_all_futures(func(self, *args, **kwargs))
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/bokeh/server/session.py", line 191, in with_document_locked
return func(*args, **kwargs)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/bokeh/document/document.py", line 1127, in wrapper
return doc._with_self_as_curdoc(invoke)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/bokeh/document/document.py", line 1113, in _with_self_as_curdoc
return f()
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/bokeh/document/document.py", line 1126, in invoke
return f(*args, **kwargs)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/bokeh/document/document.py", line 916, in remove_then_invoke
return callback(*args, **kwargs)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/panel/viewable.py", line 653, in _change_event
self.set_param(**self._process_property_change(events))
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/param/parameterized.py", line 1219, in inner
return fn(*args, **kwargs)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/param/parameterized.py", line 2573, in set_param
return self_or_cls.param.set_param(*args,**kwargs)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/param/parameterized.py", line 1365, in set_param
self_._batch_call_watchers()
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/param/parameterized.py", line 1480, in _batch_call_watchers
watcher.fn(*events)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/panel/viewable.py", line 604, in param_change
self._update_model(events, msg, root, model, doc, comm)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/panel/viewable.py", line 584, in _update_model
model.update(**msg)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/bokeh/core/has_props.py", line 376, in update
setattr(self, k, v)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/bokeh/core/has_props.py", line 280, in __setattr__
super(HasProps, self).__setattr__(name, value)
File "/private/tmp/portfolio_optimizer/envs/default/lib/python3.6/site-packages/bokeh/core/property/descriptors.py", line 543, in __set__
raise RuntimeError("%s.%s is a readonly property" % (obj.__class__.__name__, self.name))
RuntimeError: FileInput.filename is a readonly property
Update the ranges in datashader_dashboard to match the changes from holoviz/datashader#768
The opensky notebook is an example of a topic that requires a large data file (opensky.parq). I would like to suggest using intake in such cases instead of the current approach that will need updating anyway (right now it relies on datashader's system for getting data files).
This issue discusses a new monitoring dashboard that is being developed to track the deployments on examples.pyviz. This dashboard is being build with lumen and together with @jbednar @philippjfr we discussed ideas for improvements over the current state shown in the two screenshots below:

Starting with the detailed view, here were some of our comments:
Next we discussed the summary page which consists of the following table:

==, >=, <=, !=, > and <. One idea is that a conditional can specify a label (i.e an active predicate) that when active applies style or notification changes. This may be related to the existing 'filters' feature in Lumen.pyviz-topics/examples repo.There has been a discussion around how to expose which projects work with only the defaults channel.
This work has two parts:
Going through the projects in this repo and removing the pyviz channel dependency to see whether they can build with just defaults (estimate 2 days).
Displaying that in the static version of the site.
a. I think the right way of doing that would be to implement a labelling system which would then show up on the gallery page or generate new gallery pages for each label. This would requite changes in nbsite and making nbsite aware of anaconda-project.yml in a way that it isn't yet. But it would also allow us to label projects with 'datashader' or 'geoviews' which serves our long-term goals (estimate 4 days).
b. Instead of implementing the label system, we could cheat and make a .rst with static links to the right gallery assets (estimate 1 day).
The attractors_panel notebook works well generally, but it has a few open issues:
It could be useful to have examples have versions, this would be most useful if we could upload revisions directly to AE.
To-do items for the new https://examples.pyviz.org/ship_traffic example:
{list(groups.keys())[i]:tuple(int(e*255.) for e in v) for i,v in enumerate(colors[:(len(groups))][::-1])}? Seems awkward.In https://examples.pyviz.org/opensky there are various warnings that indicate that some library versions need to be updated or pinned, plus a couple of plots where the datashaded content does not appear:

I see that trimesh has support for dask from the table in the datashader performance page:

and there also an datashader trimesh notebook with a dask example
It would be great to add a similar dask example after the last cell in:
https://github.com/pyviz-topics/examples/blob/master/bay_trimesh/bay_trimesh.ipynb
to basically dask-enable this call:
datashade(hv.TriMesh((tris, points)), aggregator=ds.mean('z'), precompute=True)
When I try it, I get:
NotImplementedError: Dask dataframe does not support assigning non-scalar value.
My full notebook is here:
https://nbviewer.jupyter.org/gist/rsignell-usgs/cf853d43fd5e53ba90fbd4e0b9eb3da7
The existing format used in the anaconda-project yamls was designed to work as an environment yaml as well as a project specification. Unfortunately, this format no longer works properly with anaconda-project lock for newer versions of anaconda-project: Anaconda-Platform/anaconda-project#320
All new anaconda-project yamls should use the backwards compatible format suggested in that issue and old project yamls would ideally be updated too to avoid confusion when updating projects and their lock files.
@jlstevens and I were talking about test data and how it relates to #70. Currently, travis is configured to fail if a project requires data (either as a download in anaconda-project.yml or via an intake catalog). The idea behind this failure is to make the project author aware that test data should be used when possible. However, this can be kind of annoying if the data are remote, but not very large.
Perhaps this failure should become a warning instead. I ran into this in #71 as well.
I think originally https://github.com/pyviz-topics/EarthSim/blob/master/examples/topics/GrabCut.ipynb relied on some custom code for grabbing an ROI on a tile source as an image, but if I recall correctly there is now a good open-source tool for doing that. It would be great to port this example to use such a tool and then replace the EarthSim example with a fully archived one on this website.
I love the ship_traffic demo, and I'd like to customize and deploy my own panel app based on this example.
I would like to read the parquet datasets directly from S3 instead of downloading the zip file, and I have them in a requester pays bucket at:
vessels_file = 's3://esip-qhub/uscg/ship_traffic/AIS_2020_01_vessels.parq'
cache_file = 's3://esip-qhub/uscg/ship_traffic/AIS_2020_01_broadcast.parq'I can read the vessels file with
df = dd.read_parquet(vessels_file, storage_options={'requester_pays':True, 'profile':'esip-qhub'})but reading the cache file
gdf = dd.read_parquet(cache_file, storage_options={'requester_pays':True, 'profile':'esip-qhub'})gives:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x96 in position 2: invalid start byteIf I try to use the code in the notebook:
gdf = sp.io.read_parquet_dask(cache_file)I get:
/home/conda/store/d05c9ede5b971baf68a3777b3053fe561bc2f06dd4b6433f0f277e17dbf5129b-pangeo/lib/python3.8/site-packages/pyarrow/compat.py:24: FutureWarning: pyarrow.compat has been deprecated and will be removed in a future release
warnings.warn("pyarrow.compat has been deprecated and will be removed in a "
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-24-ea30c97c89a2> in <module>
----> 1 gdf = sp.io.read_parquet_dask(cache_file)
/home/conda/store/d05c9ede5b971baf68a3777b3053fe561bc2f06dd4b6433f0f277e17dbf5129b-pangeo/lib/python3.8/site-packages/spatialpandas/io/parquet.py in read_parquet_dask(path, columns, filesystem, load_divisions, geometry, bounds, categories)
228
229 # Perform read parquet
--> 230 result = _perform_read_parquet_dask(
231 path, columns, filesystem,
232 load_divisions=load_divisions, geometry=geometry, bounds=bounds,
/home/conda/store/d05c9ede5b971baf68a3777b3053fe561bc2f06dd4b6433f0f277e17dbf5129b-pangeo/lib/python3.8/site-packages/spatialpandas/io/parquet.py in _perform_read_parquet_dask(paths, columns, filesystem, load_divisions, geometry, bounds, categories)
319
320 # Import geometry columns in meta, not needed for pyarrow >= 0.16
--> 321 metadata = _load_parquet_pandas_metadata(paths[0], filesystem=filesystem)
322 geom_cols = _get_geometry_columns(metadata)
323 if geom_cols:
/home/conda/store/d05c9ede5b971baf68a3777b3053fe561bc2f06dd4b6433f0f277e17dbf5129b-pangeo/lib/python3.8/site-packages/spatialpandas/io/parquet.py in _load_parquet_pandas_metadata(path, filesystem)
45 filesystem = validate_coerce_filesystem(path, filesystem)
46 if not filesystem.exists(path):
---> 47 raise ValueError("Path not found: " + path)
48
49 if filesystem.isdir(path):
ValueError: Path not found: s3://esip-qhub/uscg/ship_traffic/AIS_2020_01_broadcast.parqwhich makes me spatialpandas is using pyarrow insead of fastparquet, and apparently doesn't have fsspec under the hood?
I also tried to use fsspec explicitly:
with fsspec.open(cache_file,requester_pays=True, profile='esip-qhub' ) as f:
gdf = sp.io.read_parquet_dask(f)and got back:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-29-7b6428120741> in <module>
1 with fsspec.open(cache_file,requester_pays=True, profile='esip-qhub' ) as f:
----> 2 gdf = sp.io.read_parquet_dask(f)
/home/conda/store/d05c9ede5b971baf68a3777b3053fe561bc2f06dd4b6433f0f277e17dbf5129b-pangeo/lib/python3.8/site-packages/spatialpandas/io/parquet.py in read_parquet_dask(path, columns, filesystem, load_divisions, geometry, bounds, categories)
217 path = list(path)
218 if not path:
--> 219 raise ValueError('Empty path specification')
220
221 # Infer filesystem
ValueError: Empty path specification@martindurant, I bet you know how I can read the parquet dataset: cache_file = s3://esip-qhub/uscg/ship_traffic/AIS_2020_01_broadcast.parq from a requester pays bucket into dask dataframe, am I right?
Not all of the dependencies in this repo need to be pegged at a specific version number, so I wanted to get thoughts on what could be a good way of separating the dependencies into direct and indirect dependencies to improve the anaconda-project.yml files.
cells [7] and [8] don't work on https://bay-trimesh.pyviz.demo.anaconda.com/notebooks/bay_trimesh.ipynb#
I wanted to share the notebook with output, but couldn't figure out how since saving the notebook was disabled.
Here's some of the cell [7] error:
WARNING:param.PlotSize: Use method 'params' via param namespace
WARNING:param.RangeXY: Use method 'params' via param namespace
WARNING:param.RangeXY: Use method 'get_param_values' via param namespace
WARNING:param.RangeXY: Use method 'params' via param namespace
WARNING:param.PlotSize: Use method 'get_param_values' via param namespace
WARNING:param.PlotSize: Use method 'get_param_values' via param namespace
WARNING:param.RangeXY: Use method 'get_param_values' via param namespace
WARNING:param.RangeXY: Use method 'get_param_values' via param namespace
WARNING:param.Layout: Use method 'params' via param namespace
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-7-33f439be71d1> in <module>
11 wireframe = datashade(hv.TriMesh((tris,verts), label="Wireframe"))
12 trimesh = datashade(hv.TriMesh((tris,hv.Points(verts, vdims='z')), label="TriMesh"), aggregator=ds.mean('z'))
---> 13 wireframe + trimesh
~/anaconda/envs/default/lib/python3.6/site-packages/holoviews/core/spaces.py in __add__(self, obj)
307 def __add__(self, obj):
308 "Composes HoloMap with other object into a Layout"
--> 309 return Layout([self, obj])
310
311
~/anaconda/envs/default/lib/python3.6/site-packages/holoviews/core/layout.py in __init__(self, items, identifier, parent, **kwargs)
435 def __init__(self, items=None, identifier=None, parent=None, **kwargs):
436 self.__dict__['_max_cols'] = 4
--> 437 super(Layout, self).__init__(items, identifier, parent, **kwargs)
438
439 @property
~/anaconda/envs/default/lib/python3.6/site-packages/holoviews/core/dimension.py in __init__(self, items, identifier, parent, **kwargs)
1327 if items and all(isinstance(item, Dimensioned) for item in items):
1328 items = self._process_items(items)
-> 1329 params = {p: kwargs.pop(p) for p in list(self.params().keys())+['id', 'plot_id'] if p in kwargs}
1330
1331 AttrTree.__init__(self, items, identifier, parent, **kwargs)
~/anaconda/envs/default/lib/python3.6/site-packages/param/parameterized.py in inner(*args, **kwargs)
1328 get_logger(name=args[0].__class__.__name__).log(
1329 WARNING, 'Use method %r via param namespace ' % fn.__name__)
-> 1330 return fn(*args, **kwargs)
1331
1332 inner.__doc__= "Inspect .param.%s method for the full docstring" % fn.__name__
~/anaconda/envs/default/lib/python3.6/site-packages/param/parameterized.py in params(cls, parameter_name)
2765 @Parameters.deprecate
2766 def params(cls,parameter_name=None):
-> 2767 return cls.param.params(parameter_name=parameter_name)
2768
2769 @classmethod
~/anaconda/envs/default/lib/python3.6/site-packages/param/parameterized.py in params(self_, parameter_name)
1422 superclasses.
1423 """
-> 1424 pdict = self_.objects(instance='existing')
1425 if parameter_name is None:
1426 return pdict
~/anaconda/envs/default/lib/python3.6/site-packages/param/parameterized.py in objects(self_, instance)
1511 if instance and self_.self is not None:
1512 if instance == 'existing':
-> 1513 if getattr(self_.self, 'initialized', False) and self_.self._instance__params:
1514 return dict(pdict, **self_.self._instance__params)
1515 return pdict
~/anaconda/envs/default/lib/python3.6/site-packages/holoviews/core/tree.py in __getattr__(self, identifier)
244 if identifier.startswith('_' + type(self).__name__) or identifier.startswith('__'):
245 raise AttributeError('Attribute %s not found.' % identifier)
--> 246 elif self.fixed==True:
247 raise AttributeError(self._fixed_error % identifier)
248
~/anaconda/envs/default/lib/python3.6/site-packages/holoviews/core/tree.py in fixed(self)
83 def fixed(self):
84 "If fixed, no new paths can be created via attribute access"
---> 85 return self.__dict__['_fixed']
86
87 @fixed.setter
KeyError: '_fixed'Using the monitoring dashboard, the following deployments seem to have memory leaks:
Voila example
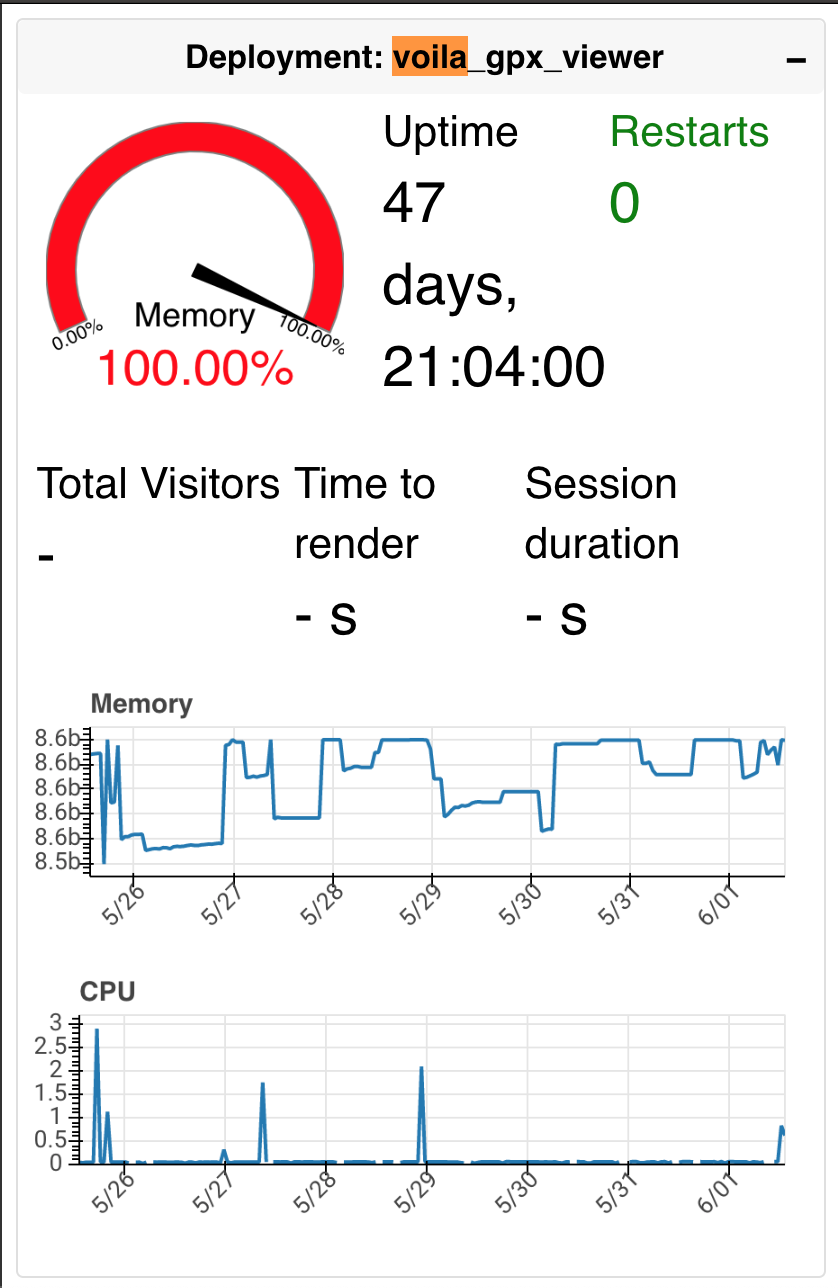
Attractors

Glaciers

Running anaconda project run in examples/nyc_taxi:
anaconda-project run
Potential issues with this project:
* anaconda-project.yml: Unknown field name 'maintainers'
* anaconda-project.yml: Unknown field name 'dependencies'
Error downloading https://s3.amazonaws.com/datashader-data/nyc_taxi_wide.parq: initialize() got an unexpected keyword argument 'io_loop'
missing requirement to run this project: NYC Taxi Data
Environment variable DATA is not set.
(Use Ctrl+C to quit.)
Value for DATA:
Potentially due to lack of tornado pinning? The URL is fine as I used wget to grab it...
I'm running locally the NYC taxi notebook and getting the error in the subject at the "Customizing datashader" section.
versions:
The user guide (https://examples.pyviz.org/user_guide) has a note that reads:
NOTE: If the notebook depends on data files, you will need to download them explicitly if you don’t use anaconda-project, by extracting the URLs defined in anaconda-project.yml and saving the file(s) to this directory.
I don't see any URLs in the yml file. If there is a single URL, would it not just be easier to place it in the markdown text in the example notebook itself?
Here is the file I obtained from the datashader_dashboard example:
name: datashader_dashboard
description: Interactive dashboard for making Datashader plots from any dataset that
has latitude and longitude
channels:
- conda-forge
- nodefaults
packages: &id001
- python=3.6
- notebook=5.7.8
- ipykernel=5.1.0
- nomkl
- anaconda-project=0.8.3
- colorcet=2.0.1
- datashader=0.7.0
- fastparquet=0.3.0
- holoviews=1.12.3
- hvplot=0.4.0
- intake=0.5.3
- intake-parquet=0.2.2
- panel=0.6.0
- param=1.9.1
- python-snappy=0.5.4
dependencies: *id001
commands:
dashboard:
unix: panel serve dashboard.ipynb
supports_http_options: true
census:
unix: 'anaconda-project prepare --directory ../census
DS_DATASET=census panel serve dashboard.ipynb
'
supports_http_options: true
nyc_taxi:
unix: 'anaconda-project prepare --directory ../nyc_taxi
DS_DATASET=nyc_taxi panel serve dashboard.ipynb
'
supports_http_options: true
opensky:
unix: 'anaconda-project prepare --directory ../opensky
DS_DATASET=opensky panel serve dashboard.ipynb
'
supports_http_options: true
osm:
unix: DS_DATASET=osm-1b panel serve dashboard.ipynb
supports_http_options: true
notebook:
notebook: dashboard.ipynb
variables:
DS_DATASET:
description: Choose a dataset from nyc_taxi, osm-1b, census, opensky, nyc_taxi_small
default: nyc_taxi_small
env_specs:
default: {}
The URLs that are generated for our examples are quite long and highly redundant. When there is only one item, the URL contains the project name four times (!):
https://examples.pyviz.org/bay_trimesh/bay_trimesh.html#bay-trimesh-gallery-bay-trimesh
For multiple targets in the same project, there is slightly less redundancy, but still there's no convenient link to pass around:
https://examples.pyviz.org/attractors/attractors.html#attractors-gallery-attractors
https://examples.pyviz.org/attractors/attractors_panel.html#attractors-gallery-attractors-panel
https://examples.pyviz.org/attractors/clifford_panel.html#attractors-gallery-clifford-panel
In each case the part after "#" can be omitted, but users may not know that, and in any case it's annoying to have to delete it.
Ideally, we could just pass around (and e.g. link to from other sites) the directory name (https://examples.pyviz.org/bay_trimesh or https://examples.pyviz.org/attractors), which is a convenient and readable URL without any redundant information. However, at the moment such URLs give a 404 (not found) error.
I propose that:
I am trying to capture all the projects that I think are still left to migrate, so that I can keep chipping away at them while working on some top-level infrastructure. Please add any that you can think of from other pyviz projects or from your own anaconda.org account. @pyviz-topics/pyviz-dev
geometry:
simulation:
Right now I have a developer env with nbrr, tornado<0.5, and anaconda-project (this should be captured in an env spec.
I have been doing something like:
mkdir attractors
mv strange_attractors.ipynb ./attractors/
cd attractors
nbrr env --directory "." --name default > environment.yml
anaconda-project init
rm environment.ymlThen I go into anaconda-project.yml, delete all the comments and reorganize it to look like the nice versions.
So I guess I should create a template that can be used by nbrr, anaconda-project, or pyctdev/doit.
There should be a top level environment.yml that can be used to create a master environment with all the necessary packages to run any of the notebooks.
There also needs to be a data acquisition mechanism. I'm wondering if we should maybe copy over the test data (doit small_data_setup - we'd need to extend this command to do all the projects if no project name is specified) and only really have people use that for playing with the projects in binder. The test data should be representative of the general data, but it won't be terribly impressive so if we do that we need to have a loud disclaimer telling people to pull the project down locally to use with full data, or pointing them to topics that use generated data.
At the moment we do an NSF mount to get large files on AE5, is there a good way to capture that config in the anaconda-project.yml? Possibly using env vars?
Prior to having https://examples.pyviz.org, we have been creating examples scattered over lots of different sites (anaconda.org, gists, nbviewer, various project repos, etc.) with many different purposes. This site lets us collect examples in a meaningful way, grouping related examples that share a dataset and an environment. E.g. the Attractors project includes:
Each of these three things is part of the same project (living in the same directory), and so we need a way to name them that clearly distinguishes them from each other. But they are also each individually meaningful, and can e.g. be tweeted about or linked one by one from a library website that they illustrate, and so the names also need to make sense on their own.
In this case, I propose these names:
I.e., in the specific case of having a "dashboard" version of the project created using Panel, I propose that we append "_panel" to a base name. The normal notebook version of this content then doesn't need any suffix. Projects using dash can then add "_dash", etc. Hopefully this will cover many of the typical reasons we'll have multiple endpoints per project. Please weigh in if you have any countersuggestions...
Hi,
Something does not look right with hosted boids demo.
https://boids.pyviz.demo.anaconda.com/notebooks/boids.ipynb
There are loads of warnings like
WARNING:param.ParameterizedMetaclass: Use method 'params' via param namespace
The result is that the final animation is not displaying.
On the main page for https://examples.pyviz.org/, there is a line directing the user to the user guide which explains how to use anaconda project for all the examples, but that link for the user guide isn't very noticeable. As a new user, my eyes are drawn to all the pictures and I immediately want to click on a picture, I don't notice the sentence at the top at all. I think the user guide sentence should stand out more to get attention. Another solution would be to have a link to the user guide on each example so hopefully a person would notice it there when looking at specific examples.
examples.pyviz.org already supports having groups of notebooks under one heading such as the three attractors notebooks:

This is already great but with one small feature we could allow these groups to act as mini examples of the dedicated topics websites (e.g earthsim or earthml). In the description (e.g 'Calculate and plot 2d attractors of various types' above), it would be very nice if we could put a link on that visits an index.ipynb (or overview.ipynb or similar).
This index notebook would help provide an overview of the group and help people visit the notebooks in the group in an appropriate order. The idea is that with by adding a bit of scaffolding and context around the whole group of notebooks (which can obviously still crosslink between each other), the topic becomes more of a cohesive unit just like earthsim and earthml) (though without Tutorial and FAQ sections).
Then examples.pyviz.org can serve the purpose of presenting isolated topic notebooks, disjointed topic notebooks that are in the same domain but without any meaningful story to link them as well as more cohesive sections that someone interested in a particular domain can work through in a well defined order.
Hope that makes sense!
Running the live version of the notebook gives the following error after running the import statements: AttributeError: module 'numba' has no attribute 'jitclass'. Running it locally gives a similar error and a few others, but mostly works — all the pictures show up correctly as far as I can tell.
/Users/adavis/development/examples/census/envs/default/lib/python3.6/site-packages/dask/dataframe/utils.py:14: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tm
/Users/adavis/development/examples/census/envs/default/lib/python3.6/site-packages/fastparquet/encoding.py:222: NumbaDeprecationWarning: The 'numba.jitclass' decorator has moved to 'numba.experimental.jitclass' to better reflect the experimental nature of the functionality. Please update your imports to accommodate this change and see http://numba.pydata.org/numba-doc/latest/reference/deprecation.html#change-of-jitclass-location for the time frame.
Numpy8 = numba.jitclass(spec8)(NumpyIO)
/Users/adavis/development/examples/census/envs/default/lib/python3.6/site-packages/fastparquet/encoding.py:224: NumbaDeprecationWarning: The 'numba.jitclass' decorator has moved to 'numba.experimental.jitclass' to better reflect the experimental nature of the functionality. Please update your imports to accommodate this change and see http://numba.pydata.org/numba-doc/latest/reference/deprecation.html#change-of-jitclass-location for the time frame.
Numpy32 = numba.jitclass(spec32)(NumpyIO)
/Users/adavis/development/examples/census/envs/default/lib/python3.6/site-packages/fastparquet/dataframe.py:5: FutureWarning: pandas.core.index is deprecated and will be removed in a future version. The public classes are available in the top-level namespace.
from pandas.core.index import CategoricalIndex, RangeIndex, Index, MultiIndex
/Users/adavis/development/examples/census/envs/default/lib/python3.6/site-packages/datashader/transfer_functions.py:21: FutureWarning: xarray subclass Image should explicitly define __slots__
class Image(xr.DataArray):
/Users/adavis/development/examples/census/envs/default/lib/python3.6/site-packages/numba/core/ir_utils.py:2031: NumbaPendingDeprecationWarning:
Encountered the use of a type that is scheduled for deprecation: type 'reflected list' found for argument 'dask_divisions' of function '_build_partition_grid'.
For more information visit http://numba.pydata.org/numba-doc/latest/reference/deprecation.html#deprecation-of-reflection-for-list-and-set-types
File "envs/default/lib/python3.6/site-packages/datashader/spatial/points.py", line 670:
@ngjit
def _build_partition_grid(dask_divisions, p):
^
warnings.warn(NumbaPendingDeprecationWarning(msg, loc=loc))
/Users/adavis/development/examples/census/envs/default/lib/python3.6/site-packages/numba/core/ir_utils.py:2031: NumbaPendingDeprecationWarning:
Encountered the use of a type that is scheduled for deprecation: type 'reflected list' found for argument 'iterable' of function 'list_constructor.<locals>.list_impl'.
For more information visit http://numba.pydata.org/numba-doc/latest/reference/deprecation.html#deprecation-of-reflection-for-list-and-set-types
File "envs/default/lib/python3.6/site-packages/numba/cpython/listobj.py", line 464:
def list_impl(iterable):
^
warnings.warn(NumbaPendingDeprecationWarning(msg, loc=loc))
Later, in the section where the different color palettes are compared, the matplotlib one gives this error: /Users/adavis/development/examples/census/envs/default/lib/python3.6/site-packages/matplotlib/colors.py:512: RuntimeWarning: invalid value encountered in less xa[xa < 0] = -1
In the last section, where interactivity is discussed, importing geoviews gives a really long error that seems to boil down to the following error for shapely: OSError: Could not find lib c or load any of its variants [].
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-31-d0b4ea3dfac7> in <module>
----> 1 import holoviews as hv, geoviews as gv, geoviews.tile_sources as gts
2 from holoviews.operation.datashader import datashade, dynspread
3 from holoviews import opts
4 hv.extension('bokeh')
5
~/development/examples/census/envs/default/lib/python3.6/site-packages/geoviews/__init__.py in <module>
11 pass
12
---> 13 from .element import (_Element, Feature, Tiles, # noqa (API import)
14 WMTS, LineContours, FilledContours, Text, Image,
15 Points, Path, Polygons, Shape, Dataset, RGB,
~/development/examples/census/envs/default/lib/python3.6/site-packages/geoviews/element/__init__.py in <module>
4 )
5
----> 6 from .geo import (_Element, Feature, Tiles, is_geographic, # noqa (API import)
7 WMTS, Points, Image, Text, LineContours, RGB,
8 FilledContours, Path, Polygons, Shape, Dataset,
~/development/examples/census/envs/default/lib/python3.6/site-packages/geoviews/element/geo.py in <module>
1 import param
2 import numpy as np
----> 3 from cartopy import crs as ccrs
4 from cartopy.feature import Feature as cFeature
5 from cartopy.io.img_tiles import GoogleTiles
~/development/examples/census/envs/default/lib/python3.6/site-packages/cartopy/__init__.py in <module>
105 # Commonly used sub-modules. Imported here to provide end-user
106 # convenience.
--> 107 import cartopy.crs
108 import cartopy.feature # noqa: F401 (flake8 = unused import)
~/development/examples/census/envs/default/lib/python3.6/site-packages/cartopy/crs.py in <module>
30
31 import numpy as np
---> 32 import shapely.geometry as sgeom
33 from shapely.prepared import prep
34 import six
~/development/examples/census/envs/default/lib/python3.6/site-packages/shapely/geometry/__init__.py in <module>
2 """
3
----> 4 from .base import CAP_STYLE, JOIN_STYLE
5 from .geo import box, shape, asShape, mapping
6 from .point import Point, asPoint
~/development/examples/census/envs/default/lib/python3.6/site-packages/shapely/geometry/base.py in <module>
15
16 from shapely.affinity import affine_transform
---> 17 from shapely.coords import CoordinateSequence
18 from shapely.errors import WKBReadingError, WKTReadingError
19 from shapely.ftools import wraps
~/development/examples/census/envs/default/lib/python3.6/site-packages/shapely/coords.py in <module>
6 from ctypes import byref, c_double, c_uint
7
----> 8 from shapely.geos import lgeos
9 from shapely.topology import Validating
10
~/development/examples/census/envs/default/lib/python3.6/site-packages/shapely/geos.py in <module>
111 _lgeos = load_dll('geos_c', fallbacks=alt_paths)
112
--> 113 free = load_dll('c').free
114 free.argtypes = [c_void_p]
115 free.restype = None
~/development/examples/census/envs/default/lib/python3.6/site-packages/shapely/geos.py in load_dll(libname, fallbacks, mode)
54 raise OSError(
55 "Could not find lib {0} or load any of its variants {1}.".format(
---> 56 libname, fallbacks or []))
57
58 _lgeos = None
OSError: Could not find lib c or load any of its variants [].
It would be great to add an example in this repo that access data directly from a Google Sheet, perhaps using the Python gsheets library. I think that would help people realize what's possible and how to "connect the dots" between their data and a dashboard.
Each of the examples on this site was created by a particular person at a particular time, and there is no expectation that the site maintainers will be updating those examples indefinitely into the future. To make that clear and to properly attribute the projects to their authors, the notebooks and web pages should all have authorship and a date (either first created or last updated, not sure; maybe both?) clearly and visibly indicated.
Right now, Jean-Luc is the only one who knows what should be deployed for which projects. Each anaconda-project.yml should declare what the live deployment targets are, e.g. by listing the command names under a user-defined field "live_deployments" with a dictionary command: endpoint.
By design, pyviz-topics/examples has a flat structure, because maintaining any hierarchical structure based on categories or other semantic groupings seems untenable over time. Many examples illustrate multiple libraries, multiple concepts, and so on, and as examples come and go, new hierarchical groupings and categories will emerge. We don't want the underlying URLs to ever have to change, and so we are using a single flat structure. Groupings can be provided by any site that links to these examples, and those groupings can change over time without breaking the URLs.
With that in mind, we need some sort of convention for how to name the projects. The same principle of needing to assign a static URL and not revisit that decision over time applies here; e.g. if some project is added and then another related one needs to be distinguished from it, then we shouldn't need to change the original URL to achieve that. E.g. if there is already an "attractors" project based on Datashader and a new one is added based on Vaex, we could rename the first one to "attractors_datashader" and the new one could be "attractors_vaex", but then links would break.
I think there are only two ways to avoid breaking links, only one of which is feasible. The infeasible way is to ensure that the name initially includes all the information that might vary in some subsequent project. E.g. the attractors project is based on Datashader and Panel, so it could be called attractors_datashader_panel, in anticipation of there someday being attractors_vaex_panel and attractors_datashader_dash and attractors_vaex_dash. I don't think that approach is feasible; there will always be some other thing that could vary between projects, and anticipating all of them seems doomed to failure. Plus, some examples already demonstrate lots of libraries (intake, dask, numba, datashader, bokeh, holoviews, hvplot, and panel, in at least one existing case), which would lead to a ridiculously long URL.
So I think the only feasible policy is:
Does anyone see any better approach than this?
Running the first cell in the Interactivity and Overlaying section on the bay-trimesh example gives the following error, which seems to have something to do with the version of Shapely:
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-7-33f439be71d1> in <module>
1 import holoviews as hv
----> 2 import geoviews as gv
3 from holoviews import opts
4 from holoviews.operation.datashader import datashade
5
~/development/examples/bay_trimesh/envs/default/lib/python3.6/site-packages/geoviews/__init__.py in <module>
11 pass
12
---> 13 from .element import (_Element, Feature, Tiles, # noqa (API import)
14 WMTS, LineContours, FilledContours, Text, Image,
15 Points, Path, Polygons, Shape, Dataset, RGB,
~/development/examples/bay_trimesh/envs/default/lib/python3.6/site-packages/geoviews/element/__init__.py in <module>
4 )
5
----> 6 from .geo import (_Element, Feature, Tiles, is_geographic, # noqa (API import)
7 WMTS, Points, Image, Text, LineContours, RGB,
8 FilledContours, Path, Polygons, Shape, Dataset,
~/development/examples/bay_trimesh/envs/default/lib/python3.6/site-packages/geoviews/element/geo.py in <module>
1 import param
2 import numpy as np
----> 3 from cartopy import crs as ccrs
4 from cartopy.feature import Feature as cFeature
5 from cartopy.io.img_tiles import GoogleTiles
~/development/examples/bay_trimesh/envs/default/lib/python3.6/site-packages/cartopy/__init__.py in <module>
105 # Commonly used sub-modules. Imported here to provide end-user
106 # convenience.
--> 107 import cartopy.crs
108 import cartopy.feature # noqa: F401 (flake8 = unused import)
~/development/examples/bay_trimesh/envs/default/lib/python3.6/site-packages/cartopy/crs.py in <module>
30
31 import numpy as np
---> 32 import shapely.geometry as sgeom
33 from shapely.prepared import prep
34 import six
~/development/examples/bay_trimesh/envs/default/lib/python3.6/site-packages/shapely/geometry/__init__.py in <module>
2 """
3
----> 4 from .base import CAP_STYLE, JOIN_STYLE
5 from .geo import box, shape, asShape, mapping
6 from .point import Point, asPoint
~/development/examples/bay_trimesh/envs/default/lib/python3.6/site-packages/shapely/geometry/base.py in <module>
15
16 from shapely.affinity import affine_transform
---> 17 from shapely.coords import CoordinateSequence
18 from shapely.errors import WKBReadingError, WKTReadingError
19 from shapely.ftools import wraps
~/development/examples/bay_trimesh/envs/default/lib/python3.6/site-packages/shapely/coords.py in <module>
6 from ctypes import byref, c_double, c_uint
7
----> 8 from shapely.geos import lgeos
9 from shapely.topology import Validating
10
~/development/examples/bay_trimesh/envs/default/lib/python3.6/site-packages/shapely/geos.py in <module>
111 _lgeos = load_dll('geos_c', fallbacks=alt_paths)
112
--> 113 free = load_dll('c').free
114 free.argtypes = [c_void_p]
115 free.restype = None
~/development/examples/bay_trimesh/envs/default/lib/python3.6/site-packages/shapely/geos.py in load_dll(libname, fallbacks, mode)
54 raise OSError(
55 "Could not find lib {0} or load any of its variants {1}.".format(
---> 56 libname, fallbacks or []))
57
58 _lgeos = None
OSError: Could not find lib c or load any of its variants [].
When setting up a deployed example on AE should the notebooks be executed before they are uploaded, or can the deployment be setup to run all the cells in the notebook before finishing?
I am trying to follow the instructions in user guide (https://examples.pyviz.org/user_guide).
There are two different suggestions, and both of them don't work.
a) Using anaconda-project. I am not sure if this installation actually worked. Here is what happened:

anaconda-project run, it exited with the following error. I am not sure if this means it worked or not, since the user guide doesn't say what I should see after executing this step.
b) The option to create my own environment. This exited with the following error:

On the Clifford panel page, the link in the description to "Clifford attractor" gives a 404.
Also, this may just be my computer, but the final plot in the original Attractors notebook remains low resolution when I zoom in instead of updating to show the detailed trajectories, as below (even after waiting for 5+ minutes):

When I try to run the live boids example, I see all these warnings:
I am trying to go through these examples:
https://examples.pyviz.org/datashader_dashboard/dashboard.html
https://examples.pyviz.org/nyc_taxi/dashboard.html#nyc-taxi-gallery-dashboard
However, both of them call a file called nyc_taxi_wide.parq. I am not sure how to get this.
One of the examples sends me down this path:
notebook> https://anaconda.org/jbednar/nyc_taxi/notebook > https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page .
However, it is unclear which data file to get from there. Further, all the files are .csv's on the gov website, so not even sure how to convert to parq file. While the other one doesn't seem to mention anything about getting the data before hand.
Just to capture some conventions that need to be added to the docs:
If there are multiple notebooks in a project then the default command should be:
commands:
notebooks:
notebook: .UNLESS there are also panels, in which case it should be:
commands:
dashboard:
unix: panel serve *_panel.ipynb
supports_http_options: true
notebooks:
notebook: .The dashboard command should be deployed at .pyviz.demo.anaconda.com and the notebooks command at -notebooks.pyviz.demo.anaconda.com
I get a ValueError when trying to run the ship_traffic demo recently added. Hoping to make this work but debugging is a challenge.
Holoviews version:
import holoviews
print(holoviews.__version__)
1.14.1
Error results from the cell where the Matplotlib figures are supposed to be drawn:
hv.output(backend='matplotlib')
hv.opts.defaults(
hv.opts.RGB(xaxis=None, yaxis=None, axiswise=True, bgcolor='black'),
hv.opts.Layout(hspace=0.0, vspace=0.1, sublabel_format=None, framewise=True, fig_size=400))
plots = [hd.datashade(hv.Points(df), color_key=color_key, cmap=cc.fire, width=1000, height=600,
dynamic=True, x_range=ranges['x'], y_range=ranges['y']).relabel(region)
for region, ranges in loc.items()]
hv.Layout(plots).cols(1)
ValueError Traceback (most recent call last)
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/IPython/core/formatters.py in __call__(self, obj, include, exclude)
968
969 if method is not None:
--> 970 return method(include=include, exclude=exclude)
971 return None
972 else:
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/dimension.py in _repr_mimebundle_(self, include, exclude)
1314 combined and returned.
1315 """
-> 1316 return Store.render(self)
1317
1318
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/options.py in render(cls, obj)
1403 data, metadata = {}, {}
1404 for hook in hooks:
-> 1405 ret = hook(obj)
1406 if ret is None:
1407 continue
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/ipython/display_hooks.py in pprint_display(obj)
280 if not ip.display_formatter.formatters['text/plain'].pprint:
281 return None
--> 282 return display(obj, raw_output=True)
283
284
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/ipython/display_hooks.py in display(obj, raw_output, **kwargs)
253 elif isinstance(obj, (Layout, NdLayout, AdjointLayout)):
254 with option_state(obj):
--> 255 output = layout_display(obj)
256 elif isinstance(obj, (HoloMap, DynamicMap)):
257 with option_state(obj):
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/ipython/display_hooks.py in wrapped(element)
144 try:
145 max_frames = OutputSettings.options['max_frames']
--> 146 mimebundle = fn(element, max_frames=max_frames)
147 if mimebundle is None:
148 return {}, {}
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/ipython/display_hooks.py in layout_display(layout, max_frames)
218 return None
219
--> 220 return render(layout)
221
222
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/ipython/display_hooks.py in render(obj, **kwargs)
66 renderer = renderer.instance(fig='png')
67
---> 68 return renderer.components(obj, **kwargs)
69
70
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/plotting/renderer.py in components(self, obj, fmt, comm, **kwargs)
408 doc = Document()
409 with config.set(embed=embed):
--> 410 model = plot.layout._render_model(doc, comm)
411 if embed:
412 return render_model(model, comm)
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/panel/viewable.py in _render_model(self, doc, comm)
422 if comm is None:
423 comm = state._comm_manager.get_server_comm()
--> 424 model = self.get_root(doc, comm)
425
426 if config.embed:
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/panel/viewable.py in get_root(self, doc, comm, preprocess)
480 """
481 doc = init_doc(doc)
--> 482 root = self._get_model(doc, comm=comm)
483 if preprocess:
484 self._preprocess(root)
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/panel/layout/base.py in _get_model(self, doc, root, parent, comm)
110 if root is None:
111 root = model
--> 112 objects = self._get_objects(model, [], doc, root, comm)
113 props = dict(self._init_properties(), objects=objects)
114 model.update(**self._process_param_change(props))
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/panel/layout/base.py in _get_objects(self, model, old_objects, doc, root, comm)
100 else:
101 try:
--> 102 child = pane._get_model(doc, root, model, comm)
103 except RerenderError:
104 return self._get_objects(model, current_objects[:i], doc, root, comm)
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/panel/pane/holoviews.py in _get_model(self, doc, root, parent, comm)
239 plot = self.object
240 else:
--> 241 plot = self._render(doc, comm, root)
242
243 plot.pane = self
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/panel/pane/holoviews.py in _render(self, doc, comm, root)
304 kwargs['comm'] = comm
305
--> 306 return renderer.get_plot(self.object, **kwargs)
307
308 def _cleanup(self, root):
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/plotting/renderer.py in get_plot(self_or_cls, obj, doc, renderer, comm, **kwargs)
218
219 # Initialize DynamicMaps with first data item
--> 220 initialize_dynamic(obj)
221
222 if not renderer:
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/plotting/util.py in initialize_dynamic(obj)
250 continue
251 if not len(dmap):
--> 252 dmap[dmap._initial_key()]
253
254
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/spaces.py in __getitem__(self, key)
1329 # Not a cross product and nothing cached so compute element.
1330 if cache is not None: return cache
-> 1331 val = self._execute_callback(*tuple_key)
1332 if data_slice:
1333 val = self._dataslice(val, data_slice)
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/spaces.py in _execute_callback(self, *args)
1098
1099 with dynamicmap_memoization(self.callback, self.streams):
-> 1100 retval = self.callback(*args, **kwargs)
1101 return self._style(retval)
1102
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/spaces.py in __call__(self, *args, **kwargs)
712
713 try:
--> 714 ret = self.callable(*args, **kwargs)
715 except KeyError:
716 # KeyError is caught separately because it is used to signal
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/util/__init__.py in dynamic_operation(*key, **kwargs)
1016
1017 def dynamic_operation(*key, **kwargs):
-> 1018 key, obj = resolve(key, kwargs)
1019 return apply(obj, *key, **kwargs)
1020
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/util/__init__.py in resolve(key, kwargs)
1005 elif isinstance(map_obj, DynamicMap) and map_obj._posarg_keys and not key:
1006 key = tuple(kwargs[k] for k in map_obj._posarg_keys)
-> 1007 return key, map_obj[key]
1008
1009 def apply(element, *key, **kwargs):
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/spaces.py in __getitem__(self, key)
1329 # Not a cross product and nothing cached so compute element.
1330 if cache is not None: return cache
-> 1331 val = self._execute_callback(*tuple_key)
1332 if data_slice:
1333 val = self._dataslice(val, data_slice)
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/spaces.py in _execute_callback(self, *args)
1098
1099 with dynamicmap_memoization(self.callback, self.streams):
-> 1100 retval = self.callback(*args, **kwargs)
1101 return self._style(retval)
1102
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/spaces.py in __call__(self, *args, **kwargs)
712
713 try:
--> 714 ret = self.callable(*args, **kwargs)
715 except KeyError:
716 # KeyError is caught separately because it is used to signal
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/util/__init__.py in dynamic_operation(*key, **kwargs)
1017 def dynamic_operation(*key, **kwargs):
1018 key, obj = resolve(key, kwargs)
-> 1019 return apply(obj, *key, **kwargs)
1020
1021 operation = self.p.operation
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/util/__init__.py in apply(element, *key, **kwargs)
1009 def apply(element, *key, **kwargs):
1010 kwargs = dict(util.resolve_dependent_kwargs(self.p.kwargs), **kwargs)
-> 1011 processed = self._process(element, key, kwargs)
1012 if (self.p.link_dataset and isinstance(element, Dataset) and
1013 isinstance(processed, Dataset) and processed._dataset is None):
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/util/__init__.py in _process(self, element, key, kwargs)
991 elif isinstance(self.p.operation, Operation):
992 kwargs = {k: v for k, v in kwargs.items() if k in self.p.operation.param}
--> 993 return self.p.operation.process_element(element, key, **kwargs)
994 else:
995 return self.p.operation(element, **kwargs)
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/operation.py in process_element(self, element, key, **params)
192 self.p = param.ParamOverrides(self, params,
193 allow_extra_keywords=self._allow_extra_keywords)
--> 194 return self._apply(element, key)
195
196
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/operation.py in _apply(self, element, key)
139 if not in_method:
140 element._in_method = True
--> 141 ret = self._process(element, key)
142 if hasattr(element, '_in_method') and not in_method:
143 element._in_method = in_method
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/operation/datashader.py in _process(self, element, key)
1496
1497 def _process(self, element, key=None):
-> 1498 agg = rasterize._process(self, element, key)
1499 shaded = shade._process(self, agg, key)
1500 return shaded
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/operation/datashader.py in _process(self, element, key)
1475 if k in transform.param})
1476 op._precomputed = self._precomputed
-> 1477 element = element.map(op, predicate)
1478 self._precomputed = op._precomputed
1479
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/data/__init__.py in pipelined_fn(*args, **kwargs)
199
200 try:
--> 201 result = method_fn(*args, **kwargs)
202 if PipelineMeta.disable:
203 return result
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/data/__init__.py in map(self, *args, **kwargs)
1214
1215 def map(self, *args, **kwargs):
-> 1216 return super(Dataset, self).map(*args, **kwargs)
1217 map.__doc__ = LabelledData.map.__doc__
1218
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/dimension.py in map(self, map_fn, specs, clone)
707 return deep_mapped
708 else:
--> 709 return map_fn(self) if applies else self
710
711
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/operation.py in __call__(self, element, **kwargs)
212 elif ((self._per_element and isinstance(element, Element)) or
213 (not self._per_element and isinstance(element, ViewableElement))):
--> 214 return self._apply(element)
215 elif 'streams' not in kwargs:
216 kwargs['streams'] = self.p.streams
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/core/operation.py in _apply(self, element, key)
139 if not in_method:
140 element._in_method = True
--> 141 ret = self._process(element, key)
142 if hasattr(element, '_in_method') and not in_method:
143 element._in_method = in_method
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/holoviews/operation/datashader.py in _process(self, element, key)
468
469 dfdata = PandasInterface.as_dframe(data)
--> 470 agg = getattr(cvs, glyph)(dfdata, x.name, y.name, agg_fn)
471 if 'x_axis' in agg.coords and 'y_axis' in agg.coords:
472 agg = agg.rename({'x_axis': x, 'y_axis': y})
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/datashader/core.py in points(self, source, x, y, agg, geometry)
222 glyph = MultiPointGeometry(geometry)
223
--> 224 return bypixel(source, self, glyph, agg)
225
226 def line(self, source, x=None, y=None, agg=None, axis=0, geometry=None):
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/datashader/core.py in bypixel(source, canvas, glyph, agg)
1152 raise ValueError("source must be a pandas or dask DataFrame")
1153 schema = dshape.measure
-> 1154 glyph.validate(schema)
1155 agg.validate(schema)
1156 canvas.validate()
~/miniconda3/envs/IOOS/lib/python3.8/site-packages/datashader/glyphs/points.py in validate(self, in_dshape)
93 def validate(self, in_dshape):
94 if not isreal(in_dshape.measure[str(self.x)]):
---> 95 raise ValueError('x must be real')
96 elif not isreal(in_dshape.measure[str(self.y)]):
97 raise ValueError('y must be real')
ValueError: x must be real
Everything else up to that point worked as expected (although I found there was an issue with the most recent numpy 1.20.0 release in the Parquet writing step - identical to this one for the pyarrow dependency). Downgrading to numpy 1.19.5 worked for me here as well.
Any advice? Debugging via Google for DataShader never seems too fruitful for me and the error isn't obvious to me either. There must be something wrong with my source data or perhaps a another dependency version issue?
I used the AIS data from 2020-01-01 when running. Thanks in advance!
This could be something with the way that we are cleaning metadata.
The NYC taxi - nongeo notebook gives the following error in the last cell:
No plotting class for Dataset found
:DynamicMap []
:Dataset [fare_amount]
versions:
This is needed for instance in the updated attractors project which now refers to a .py file in the project. For relative links to work to these assets, the project should be extracted to the correct directory on gh-pages: this should be fine as the projects should always be small (e.g we are not allowing large data files to be committed with projects). This would also allow you to link to the corresponding anaconda-project.yml for instance.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.