SPAGRM is now implemented in the GRAB package. Please click here for download.
SPAGRM is a scalable, accurate, and universal analysis framework to control for sample relatedness in large-scale genome-wide association studies (GWAS). In the paper A scalable, accurate, and universal analysis framework to control for sample relatedness in large-scale genome-wide association studies and its application to 79 longitudinal traits in UK Biobank (to be updated), we applied SPAGRM to analyze 79 longitudinal traits extracted from UK Biobank primary care data. As a universal analysis framework, we also evaluated SPAGRM's performance in quantitative and binary trait analysis.
Like many other popular methods, such as BOLT-LMM, SAIGE, fastGWA, REGENIE, GATE, and POLMM, SPAGRM is also a two-step method to control for sample relatedness in large-scale cohort. It consists of:
-
In step 1, SPAGRM fits a null model to adjust for the effect of covariates on phenotypes and calculate model residuals. It is optional, rather than required, to incorporate the random effect into null model fitting to characterize the sample relatedness.
-
In step 2, SPAGRM associates the trait of interest to a single genetic variant and obtain GWAS results by a retrospective strategy: that is treating the genotypes as random variables. Unlike regular retrospective methods which solely rely on the genetic relationship matrix (GRM), SPAGRM calculates identity by descent (IBD)-sharing probabilities and then employs the Chow-Liu algorithm to approximate the joint distribution of genotypes. Saddlepoint approximation is applied in SPAGRM that can greatly increase the accuracy to analyze low-frequency and rare variants, especially if the phenotypic distribution is unbalanced.
-
To avoid redundant computations in step 2, SPAGRM uses the IBD-sharing probabilities and Chow-Liu algorithm to approximate the discrete joint distribution of genotype vectors in advance (illustrated as step 0).
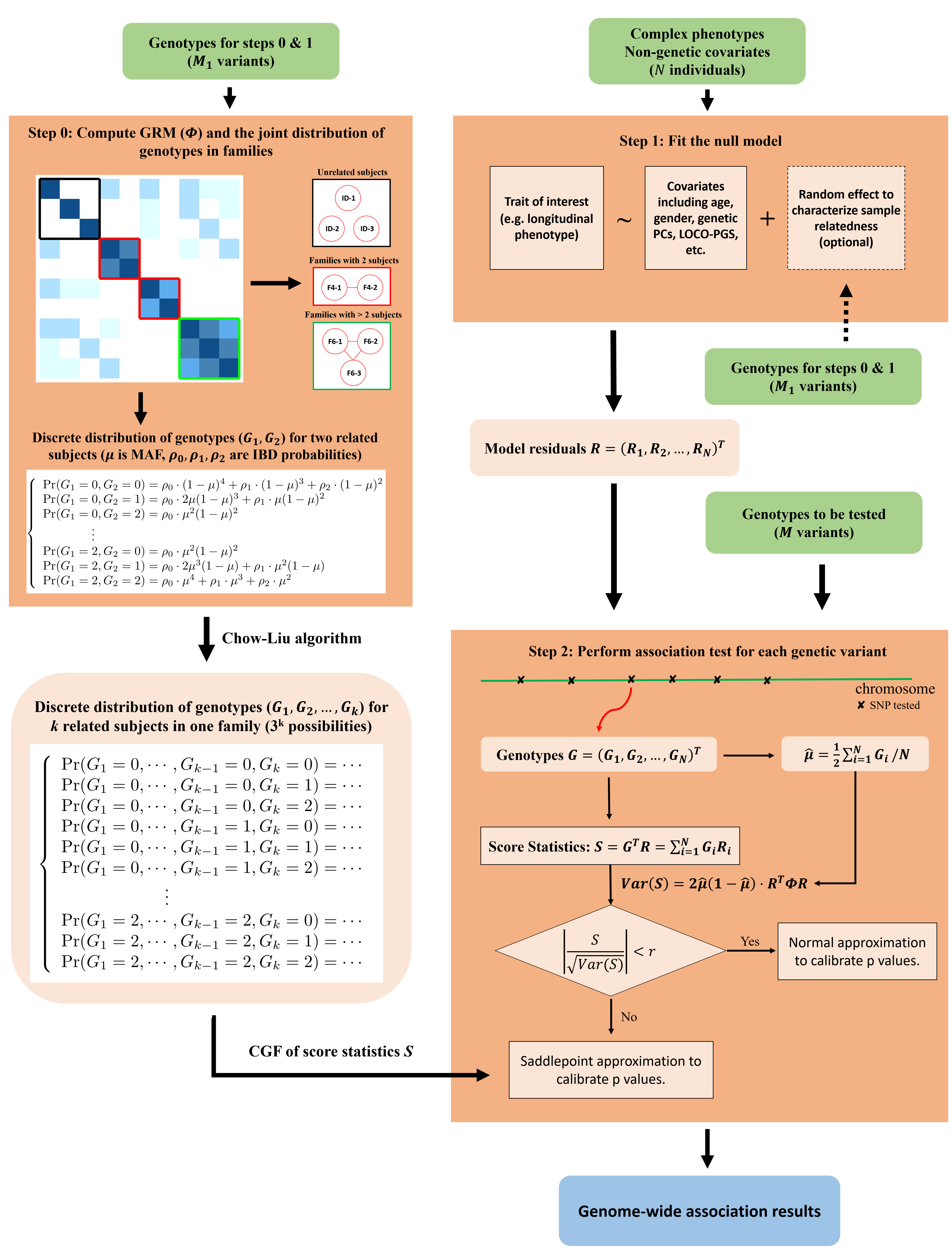
See A scalable, accurate, and universal analysis framework to control for sample relatedness in large-scale genome-wide association studies and its application to 79 longitudinal traits in UK Biobank (to be updated) for more details about the workflow of SPAGRM.
