hawtim.github.io's Issues
为什么往 call 和 apply 的 this 传入 null ?
笔者最近在学习 《JavaScript设计模式与开发实践》。
在 5.6 节的代码中,是一段表单验证的代码,如下,读者可以新开一个 tab在控制台运行一下的代码。
document.write(`<html>
<body>
<form action="http://example.com/register" id="registerForm" method="post">
<label htmlFor="">请输入用户名<input type="text" name="userName"/></label>
<label htmlFor="">请输入密码<input type="text" name="password"/></label>
<label htmlFor="">请输入手机号码<input type="text" name="phoneNumber"/></label>
<button>提交</button>
</form>
</body>
</html>`)
// 在一个Web项目中,注册、登录、修改用户信息等功能的实现都离不开提交表单
// 表单验证可以避免不合法的数据带来不必要的网络开销
var strategies = {
isNonEmpty: function(value, errorMsg) {
if (value === '') {
return errorMsg
}
},
minLength: function(value, length, errorMsg) {
if (value.length < length) {
return errorMsg
}
},
isMobile: function(value, errorMsg) {
if (!/(^1[3|5|7|8|9][0-9]{9}$)/.test(value)) {
return errorMsg
}
}
}
// 接下来实现 validator 类
var validateFunc = function() {
var validator = new Validator()
// registerForm 是 dom,做为表单的项,可以通过 registerForm.userName 取得 userName 输入框的 dom 引用
validator.add(registerForm.userName, 'isNonEmpty', '用户名不能为空')
validator.add(registerForm.password, 'minLength:6', '用户名不能为空')
validator.add(registerForm.phoneNumber, 'isMobile', '用户名不能为空')
var errorMsg = validator.start()
return errorMsg
}
var registerForm = document.getElementById('registerForm')
registerForm.onsubmit = function() {
var errorMsg = validateFunc()
if (errorMsg) {
console.log(errorMsg)
return false
}
return false
}
var Validator = function() {
this.cache = []
}
Validator.prototype.add = function(dom, rule, errorMsg) {
var ary = rule.split(':')
// 添加到缓存规则中
this.cache.push(function() {
var strategy = ary.shift()
ary.unshift(dom.value)
ary.push(errorMsg)
return strategies[strategy].apply(dom, ary)
})
}
Validator.prototype.start = function() {
for (var i = 0, validatorFunc; validatorFunc = this.cache[i++];) {
var msg = validatorFunc()
if (msg) { // 如果有确切的返回值,说明校验没有通过
return msg
}
}
}运行效果如图

我们注意到代码中 Validator 的 add 方法下
this.cache.push(function() {
var strategy = ary.shift()
ary.unshift(dom.value)
ary.push(errorMsg)
return strategies[strategy].apply(dom, ary)
})最后一行 apply 传入了 dom,我之前一直不解,这里传一个 dom 的引用和传 null 有什么差别?
运行效果不都是一样吗?读者可以试一下,控制台输出的都是”用户名不能为空“
那它们有什么差别呢?什么时候有差别呢?带着这两个疑问,我们在 strategies 下的 isNonEmpty 下添加一行打印。
有什么差别?
var strategies = {
isNonEmpty: function(value, errorMsg) {
console.log(this) // 打印下 this 的输出
if (value === '') {
return errorMsg
}
},
// ...
}我们重新运行,能发现,apply null 的话,在浏览器打印出来的值是 Window。

而如果是 apply dom 的话,this 指向的就是对应表单的输入框。

那么我们可能还有疑问,为什么传入的是 null,返回回来 this 的指向却是 window 对象呢?这里我们引用一下规范

可以看到规范里对 this 这个参数说明了,在非严格模式下,null 或者 undefined 都会变成指向全局对象(浏览器 Window,nodejs 下就是 global),基本类型值则会被包装成对象的形式。
所以我们试试 return strategies[strategy].apply('', ary) 传入字符串,会有什么效果。此时 this 指向的是

什么时候有差别?
看了上面 apply 的 this 指向了 null,dom,'' 代码都是一样的输出,什么时候会不一样呢?
查看下面的代码改动
var strategies = {
isNonEmpty: function(value, errorMsg) {
console.log(this.value) // 注意这里,打印 dom 的 value 属性值,如果指定错了 this,那么这里无疑不能拿到正确的值。
if (value === '') {
return errorMsg
}
},
// ...
}当我们要在 strategies 下的验证规则中获取 dom 的引用并访问数据时,指定正确的 this 就很关键了。这里我隐约感觉到,为什么 null 和 undefined 会变成指向全局对象,因为 this 变成了 window 了 this.value 也只是 undefined 而不会直接报错。至于是不是这样,等我翻了源码来补充一下哈哈。
结论
当你正在调用 .apply 方法,并且需要访问实例数据,则必须传递适合的对象作为第一个参数,以便该方法有权使用此指针来按预期方式执行工作。
Array.prototype.sort 是快排吗?
最近在写算法题,很多题解下说,数组的 sort 方法用的是快排,时间复杂度为 O(nlogn)
面试的时候被问到 sort 的时间复杂度,跟面试官说是内部是用快排实现的,面试官表示这个观点有问题,所以现在我自己来看这个问题了。
图片来自文章 https://segmentfault.com/a/1190000010648740
看图非常直观,感谢大佬的耐心整理,等我有空实际验证下结论。


网络模型之 OSI 七层模型、五层模型、TCP/IP 四层模型
MindMap

OSI 七层模型
-
应用层
- 例如 Chrome Skype 等应用程序
-
表示层
- 表示层管理数据的解密与加密,如系统口令的处理
-
会话层
- 网络中的两节点之间建立、维持和终止通信
-
传输层
- 进行流量控制、规定适当的发送速率、分割数据包,UDP TCP 负责在计算机之间进行点对点的传输,还会检测和修复错误
-
网络层
- 将网络地址翻译成对应的物理地址,并决定如何将数据从发送方路由到接收方
-
数据链路层
- 数据链路层有媒体访问控制地址(MAC),碰撞检测,指数退避,以及其他底层协议
-
物理层
- 物理层不提供纠错服务,但它能够设定数据传输速率并监测数据出错率
五层模型
- 应用层
- 运输层
- 网络层
- 数据链路层
- 物理层
TCP/IP 四层模型
-
应用层
- HTTP 数据
-
运输层
- TCP 头
-
网络层
- IP 头 + MAC 头
-
链路层
- 以太网头(报头,起始帧分界,帧校验序列)
Mac 软件推荐
系统:
- Tencent lemon lite 推荐网页版,不要 AppStore 版本,清理垃圾,释放内存,非常好用。
- alfred macos 上最有名的效率工具
- pock 替换 touchbar 为 程序坞
- pap.er 可使用 unsplash 上的壁纸
- Cheatsheet 显示当前软件快捷键
- Magnet 窗口布局
音视频及资源搜索:
开发:
- VScode 写代码
- SourceTree 项目 git 可视化管理
- Switchhost 切换 Host 必备
- electerm SSH/FTP/Terminal 客户端
效率
- Xmind Zen 思维导图
- Microsoft To Do 任务计划工具
- 微信小助手 拥有免扫码登录、自动回复等实用功能
如果帮助到你了,欢迎给我点个赞喔👍
在浏览器输入网址,到页面显示的过程中发生了什么?
总结三篇文章:(侧重点均不一样)
侧重底层《从输入 URL 到页面加载完成的过程中都发生了什么事情?》作者:nwind
http://fex.baidu.com/blog/2014/05/what-happen/
侧重网络《从你输入一个网址,到网页显示,其间发生了什么?》 作者:小林coding
https://mp.weixin.qq.com/s/tZ9-BoP1Oz3K4ZapLlnopQ
侧重前端《在浏览器输入 URL 回车之后发生了什么(超详细版)》作者:4Ark
https://zhuanlan.zhihu.com/p/80551769
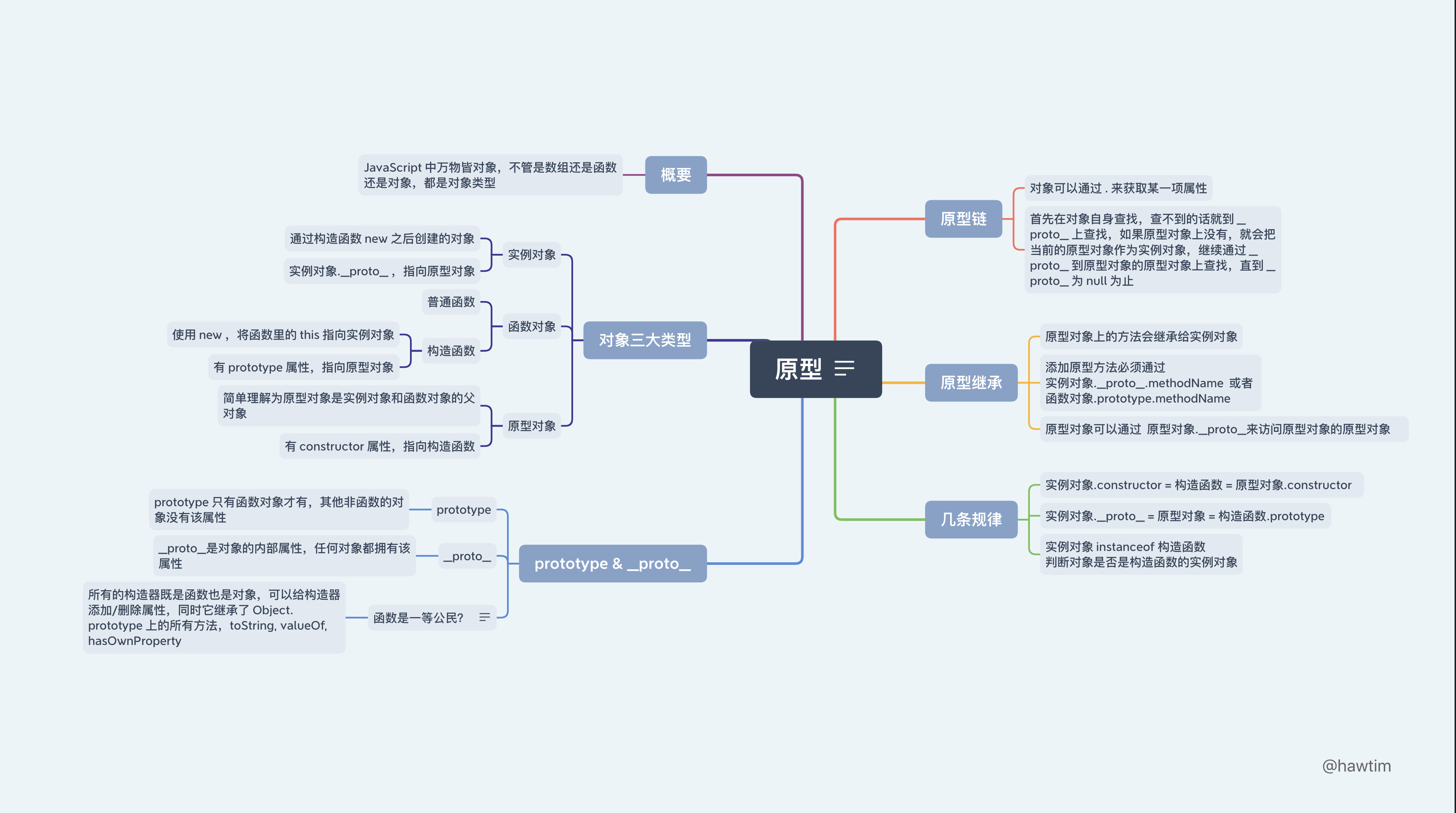
JavaScript 原型与原型链
脑图梳理
mac 配置 nginx 反向代理,配置本地域名
安装 Nginx
Mac 下安装 nginx 可以通过 brew 进行。
$ brew search nginx
$ brew install nginx出现如下的信息表示安装成功:
Docroot is: /usr/local/var/www
The default port has been set in /usr/local/etc/nginx/nginx.conf to 8080 so that nginx can run without sudo.
nginx will load all files in /usr/local/etc/nginx/servers/.
To have launchd start nginx now and restart at login: brew services start nginx
Or, if you don't want/need a background service you can just run: nginxNginx 启动
输入如下的命令来启动 Nginx:
$ nginx在浏览器中输入:http://localhost:8080 ,查看 Nginx 首页。
Nginx 操作
nginx -s reload:重新加载配置nginx -s reopen:重启nginx -s stop:停止nginx -s quit:退出
配置文件
其中 Nginx 配置文件路径在 /usr/local/etc/nginx/nginx.conf
vim /usr/local/etc/nginx/nginx.conf修改配置
最近在参与一个项目,我需要配置两个本地域名,目的如下:
- 把
yesplaymusic.com的请求转发到前端开发devServer服务localhost:8081 - 把
api.yesplaymusic.com的请求转发到本地运行接口服务localhost:3000
那么我们开始改动配置(带 # 为注释语句)
将 nginx 服务器默认监听的端口从 8080 改为 80
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
# ...
}添加 yesplaymusic.com 的服务器规则
server {
listen 80;
server_name yesplaymusic.com;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://localhost:8081;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}添加 api.yesplaymusic.com 的服务器规则
server {
listen 80;
server_name api.yesplaymusic.com;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://localhost:3000;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}完整的示例
# user hawtim;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name yesplaymusic.com;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://localhost:8081;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}
server {
listen 80;
server_name api.yesplaymusic.com;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://localhost:3000;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
# another virtual host using mix of IP-, name-, and port-based configuration
#
#server {
# listen 8000;
# listen somename:8080;
# server_name somename alias another.alias;
# location / {
# root html;
# index index.html index.htm;
# }
#}
# HTTPS server
#
#server {
# listen 443 ssl;
# server_name localhost;
# ssl_certificate cert.pem;
# ssl_certificate_key cert.key;
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 5m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
# location / {
# root html;
# index index.html index.htm;
# }
#}
include servers/*;
}
更新改动
nginx -t # 检查有无错误
nginx -s reload # 重新加载新的配置添加本地域名
这里使用 switchhosts 在 hosts 中添加上面设定好的两个域名
# develop
127.0.0.1 yesplaymusic.com
127.0.0.1 api.yesplaymusic.com测试
- 打开浏览器,确保前端 devServer 启动的情况下,输入
http://yesplaymusic.com,查看页面是否正常 - 打开浏览器,确保前端 devServer 启动的情况下,输入
http://yesplaymusic.com
浏览器返回空白,但是 CURL 却有内容
命令行中输入: 查看当前占用 80 端口的服务
lsof:i 80如下图,并没有 nginx 进程在使用 80 端口,就是有问题的。

彻底关闭 Google Chrome 和 Wechat 后,重新启动 nginx nginx -s stop && nginx,现在就能看到只有 nginx 在使用 80 端口了

如果遇到其他问题,建议查看这篇文章
ERR_CONTENT_LENGTH_MISMATCH
如果遇到前端 ERR_CONTENT_LENGTH_MISMATCH 报错,在前端的规则下 proxy_pass http://localhost:8081; 这行下加一行 proxy_buffering off;
server {
listen 80;
server_name yesplaymusic.com;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://localhost:8081;
proxy_buffering off;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}参考文档
深入浏览器的缓存机制
深入浏览器缓存机制
我们在开发过程中可能经常看到 200 (memory cache) 200 (disk cache) 304 Not Modified 的状态码,他们分别是什么意思?
这里先有个大体的概念,200 状态码是浏览器的强制缓存机制,304 则是协商缓存机制,这两个缓存机制是通过 HTTP 报文的缓存标识来生效的。
这里我们分析一个普通的 HTTP 请求的请求报文,省略了不影响缓存的消息头
第一次打开 hawtim.github.io/blog ,GET 请求
general
Request URL: https://hawtim.github.io/blog/
Request Method: GET
Status Code: 200
Remote Address: 185.199.111.153:443
Referrer Policy: no-referrer-when-downgraderequest headers
:authority: hawtim.github.io
:method: GET
accept: text/html
# 注意 cache-control 和 pragma
cache-control: no-cache
pragma: no-cache
#============================response headers
content-encoding: gzip
content-type: text/html; charset=utf-8
date: Thu, 21 May 2020 03:49:51 GMT
# 注意 cache-control etag expires last-modified
cache-control: max-age=600
etag: W/"5ec1ee1c-8ac"
expires: Thu, 21 May 2020 03:51:50 GMT
last-modified: Mon, 18 May 2020 02:08:28 GMT
#=============================================
server: GitHub.com
status: 200 # 现在的状态是 200第二次 GET 请求 (CTRL + R / Command + R)
general
Request URL: https://hawtim.github.io/blog/
Request Method: GET
Status Code: 304
Remote Address: 185.199.111.153:443
Referrer Policy: no-referrer-when-downgraderequest headers
:authority: hawtim.github.io
:method: GET
accept: text/html
# 注意 cache-control if-modified-since if-none-match
cache-control: max-age=0
if-modified-since: Mon, 18 May 2020 02:08:28 GMT
if-none-match: W/"5ec1ee1c-8ac"
# =================================================response headers
content-encoding: gzip
content-length: 924
content-type: text/html; charset=utf-8
date: Thu, 21 May 2020 04:13:25 GMT
# 注意 cache-control etag expires last-modified
cache-control: max-age=600
etag: W/"5ec1ee1c-8ac"
expires: Thu, 21 May 2020 04:23:25 GMT
last-modified: Mon, 18 May 2020 02:08:28 GMT
#=============================================
server: GitHub.com
status: 304 # 状态变成 304看完上面的例子,你可能还对上面注意的消息头,比如
cache-control expires
last-modified if-modified-since
etag if-none-match
有点懵,不知道它们是怎么在浏览器的缓存机制中生效的,没关系,我们下面来分析缓存过程
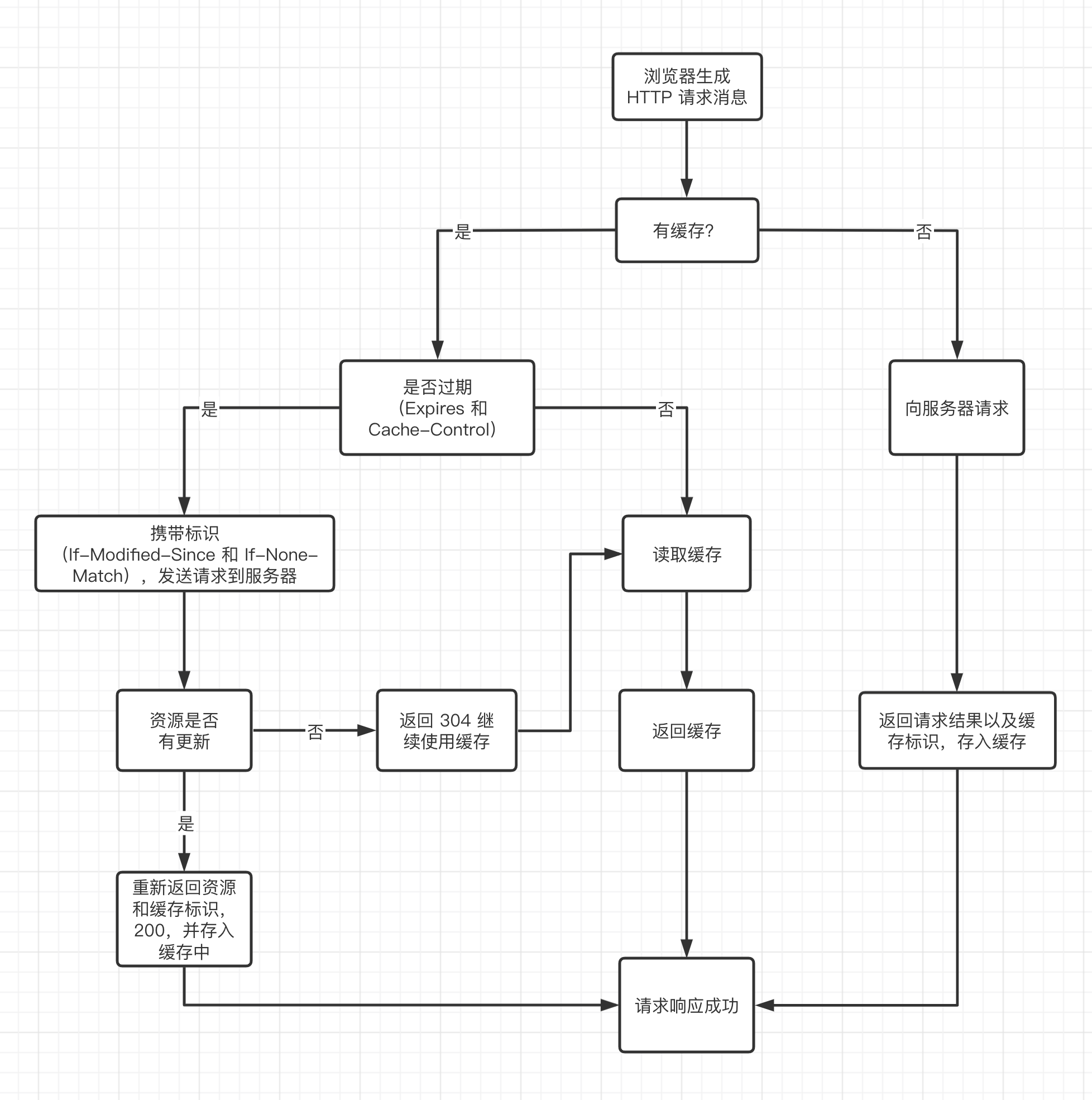
缓存过程分析

从图片可以看出
- 浏览器每次对资源发起请求的时候,会先在浏览器的缓存查找对应资源的请求结果和缓存标识
- 浏览器每次拿到返回的请求结果会将结果和缓存标识存入浏览器的缓存中
以上两点就是浏览器缓存机制的关键,确保了每个请求缓存存入与读取。根据是否需要向服务器重新发起 HTTP 请求,我们将缓存过程分为两部分,第一部分是强制缓存,第二部分是协商缓存。
强制缓存
强制缓存就是在浏览器的缓存中查找请求结果,并根据该结果的缓存标识决定是否使用该结果。有以下三种情况:
- 第一种情况,不存在缓存结果和缓存标识,直接向服务器发送请求,同上面的缓存过程分析

- 第二种情况,存在缓存结果和缓存标识,但是验证后已经失效,则使用
协商缓存

- 第三种情况,存在缓存结果和缓存标识,且验证有效,则直接返回该结果

强制缓存相关的请求头
- pragma
- expires
- cache-control
pragma
Pragma 是 HTTP/1.0 中规定的通用首部,它用来向后兼容只支持 HTTP/1.0 协议的缓存服务器,因为 那时候 HTTP/1.1 协议中的 Cache-Control 还没出来
Pragma: no-cache 与 Cache-Control: no-cache 效果一致
expires
Expires 是 HTTP/1.0 中规定的通用首部,它用来指指定资源缓存到期的时间。时间是绝对时间,受客户端时间影响。
cache-control
Cache-Control 是 HTTP/1.1中通用首部,同样用来指指定资源缓存到期的时间,max-age 设置的时间的单位为秒,是相对时间,不受客户端时间影响,优先级比 Expires 高,主要取值为:
public:所有内容都将被缓存(客户端和代理服务器都可缓存)private:所有内容只有客户端可以缓存,Cache-Control 的默认取值must-revalidate:如果超过了 max-age 的时间,浏览器必须向服务器发送请求,验证资源是否还有效。no-cache:客户端缓存内容,但是是否使用缓存则需要经过协商缓存来验证决定no-store:所有内容都不会被缓存,即不使用强制缓存,也不使用协商缓存max-age=600:缓存内容将在 600 秒 (任意正整型数字)后失效
使用场景
- 关闭缓存
Cache-Control: no-store - 缓存静态资源:
Cache-Control: public, max-age=31536000 - 重新验证缓存:
Cache-Control: no-store或max-age=0
细心的朋友可能发现了,一开始的例子里,第二次请求的时候 github 就是用了 max-age=0来向服务端校验我的文件是否有更改。
浏览器的缓存的存放位置

以 github 的博客请求为例,状态码是灰色 200 则代表使用了强制缓存,请求对应的 size 值则代表缓存存放的位置,分别为 memory cache 和 disk cache,那这两者有什么差别,什么情况用 memory 什么情况用 disk?
memory cache (内存缓存)
内存缓存会将编译解析后的文件,直接存入该进程的内存,占据一定的内存资源,方便下次使用时快速读取,但是一旦该进程关闭,则该进程的内存会被清空。
disk cache(硬盘缓存)
硬盘缓存是直接将缓存写入硬盘文件中,读取缓存需要进行 I/O 操作,读取该缓存并解析,速度比内存缓存慢。
使用的实际情况分析
还是以博客的页面为例,没有禁用缓存的情况下,多次刷新页面。就会如出现如 memory cache 和 disk cache 都有的情况。

然后关闭这个标签页,然后重新打开这个页面,则会出现全部都是从 disk cache 的情况。

这里有一点要注意的是,虽然 rem.js 是在 memory cache 中获取的,但实际上它也存在 disk cache,只是 memory cache 的优先级更高。
在浏览器中,浏览器会将 js 和 base64 的图片等文件解析执行后直接存入内存缓存中,那么当刷新页面时只需直接从内存缓存中读取(from memory cache);而 css 文件,图片后缀的图片文件则会存入硬盘文件中,所以每次渲染页面都需要从硬盘读取缓存(from disk cache)
协商缓存
下面我们来讲讲强制缓存的第二种情况,强制缓存标识失效,走协商缓存的过程。
在强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程,主要有以下两种情况:
- 协商缓存生效,返回 304 和 Not Modified

- 协商缓存失效,返回 200 和请求结果
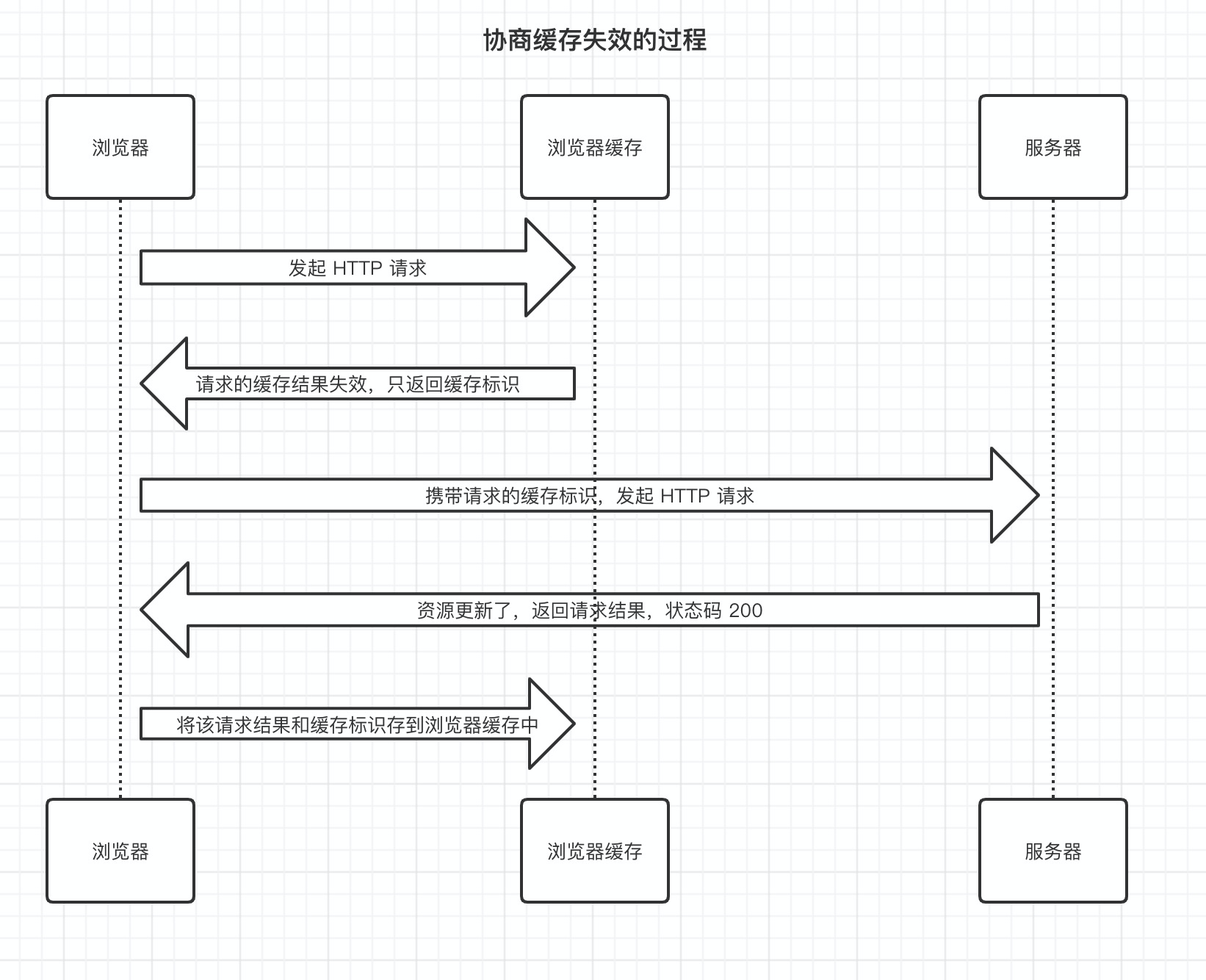
协商缓存的标识在响应报文的 HTTP 头中和请求结果一起返回给浏览器。
控制协商缓存的字段分别有:
Last-Modified / If-Modified-Since
下次请求时把上次返回的 Last-Modified 作为 If-Modified-Since 的值,服务端发现请求头中有 If-Modified-Since 字段,服务端将该值与资源的最后修改时间比对,大于则重新返回资源,否则返回 304 代表 资源无更新,可继续使用缓存。
Etag / If-None-Match
下次请求时把上次返回的 Etag 作为 If-None-Match 的值,服务端将 If-None-Match 的值与资源的 Etag 比对,一致则返回 304,代表资源无更新,继续使用缓存文件,不一致则重新返回资源文件,状态码 200
注 Etag / If-None-Match 优先级高于 Last-Modified / If-Modified-Since,同时存在则只有前者生效。
总结
综合上面的分析,现在看文章前面的第一次请求和第二次请求的变化,应该就能很好理解了。
在浏览器的缓存机制中,强制缓存优先于协商缓存。强制缓存的标识(Expires 和 Cache-Control),如果生效则使用缓存,如果不生效则发起请求进行协商缓存的标识验证。(Last-Modified / If-Modified-Since和 Etag / If-None-Match),若协商缓存失效,则重新获取请求结果,再传入浏览器缓存中;生效的话,则继续使用缓存。
参考文章
相关 UML 链接
深入 JS 的继承机制
首先是 JavaScript 继承机制的设计**
- new 来自于 C++ 和 java ,用来生成实例
- 不引入类的机制,否则就变成了面向对象语言
- new 从原型对象生成一个实例对象,new 调用的是构造函数
- 用构造函数生成对象的缺点就是,无法共享属性和方法
- 引入 prototype 属性,为构造函数设置一个 prototype 属性,所有对象实例需要共享的方法和属性,都放在这个对象下。不需要共享的属性和方法,就放在 构造函数内部
- 实例对象一旦创建,将自动引用 prototype 对象的属性和方法
来源:http://www.ruanyifeng.com/blog/2011/06/designing_ideas_of_inheritance_mechanism_in_javascript.html
webAssembly 入门介绍
之前的分享 《WebAssembly从入门到实践》
当你的 JS 不加分号的时候会发生什么
最近面试遇到一个代码题
题目大概是这样,问代码执行顺序,主要考察事件循环代码
setTimeout(() => {console.log('a')}, 0)
console.log('b')
new Promise(resolve => {
resolve(console.log('c'))
console.log('d')
}).then(() => console.log('e'))
(async () => console.log('f'))()平时 async 用的比较少,当时就说这个地方不是很理解,跳过了对 async 的分析
之后复盘的时候找了这个题,执行了上面的代码竟然报错了。如下:

看报错是这一行代码 (async () => console.log('f'))(),那我单独拿出来执行一遍看有没有问题。
结果执行结果又是正常的。
来 Google 一遍,Uncaught TypeError: (intermediate value)(…) is not a function,结果如同标题所说,就是分号的问题。
https://stackoverflow.com/questions/42036349/uncaught-typeerror-intermediate-value-is-not-a-function
按照高赞的回答,虽然 JS 有自动插入分号的机制,但是因为括号的下一行是括号,所以可以解释为函数参数的调用执行。
那么为了理解这句话,我们先精简一下以上代码,对现象进行复现:
(function test() {
console.log('c')
})
(async () => console.log('f'))()如果不加分号,等同于执行函数(所以执行上面的代码会报错)
(function test() {
console.log('c')
})(async () => console.log('f'))()这个问题给我这个不加分号党当头一棒,emmm 如果平时开发没有 babel 啥的,估计自己会踩不少坑吧。
OK 那我们老老实实加上分号,有兴趣的读者也可以试着回答一下:
setTimeout(() => {console.log('a')}, 0);
console.log('b');
new Promise(resolve => {
resolve(console.log('c'));
console.log('d');
}).then(() => console.log('e'));
(async () => console.log('f'))();最终的执行顺序是
b c d f e a
vscode 插件推荐
前端开发提效
- Auto Close Tag 自动闭合标签
- Auto Rename Tag 自动重命名对应标签
- Better Comments 统一、优雅的注释生成
- Bracket Pair Colorizer 高亮匹配的括号
- Color Highlight 显示对应的颜色
- HTML CSS Support 在 类 HTML 的文档提供 CSS 支持
- Image preview 显示所加载的图片预览图
- IntelliSense for CSS class names in HTML 智能提示类名
- Live Server 开启一个本地服务器,支持热更新
- Live Share 支持多人实时编辑代码
工程支持
- EditorConfig for VS Code 支持 editorConfig
- Project Manager 提供项目管理功能
- Code Spell Checker 检查单词检查
美化及格式化
Git 相关
配置同步
- Settings Sync 同步个人的 vscode 配置
SSH/SFTP
- Remote-SSH 使用 vscode 管理云服务器资源及命令行操作, 具体参考 #32
typescript 的 protect, private, public
谷歌浏览器插件推荐
通用插件
- 划词翻译 随选随翻译,准确度非常好
- The Great Suspender 自动冻结不用的页面,节省内存
- OneTab 节省高达95%的内存,并减轻标签页混乱现象
- Octotree 帮你在 github 的项目里生成 TOC (table of content)
- Emoji Keyboard by JoyPixels™ 最新最全的 emoji
- Stylish 为任意网站自定义主题
- Adblock Plus 免费的广告拦截器
tips: 组合搭配 2 和 3 可以最大化节省内存。
前端开发
- JSONView 格式化 json
- User-Agent Switcher for Chrome 切换 userAgent
- Vimium 支持 vim 快捷键
- Vue.js devtools
- React Developer Tools
- JavaScript and CSS Code Beautifier 美化代码
- Save All Resources 专业保存网站
- FeHelper 前端助手,丰富的工具,支持拓展
自备梯子的前提下, url 输入 chrome://extensions 即可进行拓展程序管理
没有的话,找国内的插件网站对应下载即可
手撕代码之——节流防抖
防抖
防抖,指事件多次触发的时候,只有在一定时间内没有再次触发的时候,事件才会执行一次。
场景
- 输入框联想:减少请求联想结果次数,用户在不断输入值时,用防抖来节约请求资源。
- 页面大小调整 resize: 避免不断触发 resize 的回调事件,等待最终浏览器视图大小确认下来之后再执行回调。
代码示例
防抖的核心在于重复触发进行定时器的清除,即 clearTimeout(timer)
Tips: 再次触发同一事件之后,上一次触发的定时器会被清除,新的定时器会被赋值给 timer,必须等到间隔大于 wait 的值时,才能触发 setTimeout 回调。
const debounce = (func, wait) => {
let timer = null
return (...args) => {
clearTimeout(timer)
timer = setTimeout(()=> {
fn.apply(this, args)
}, wait)
}
}节流
节流,指一定时间内,多次触发同一事件只执行一次。
Tips:
场景
- 快速点击按钮,对一个会发起 ajax 请求的接口快速的 click,会导致触发多个请求。
- 页面滚动,滚动的时候会多次且不规律的触发滚动事件回调,通过节流可以限定触发回调的间隔。
代码示例
节流的核心在于 timer 变量起到的作用。即 timer = setTimeout 及 timer = null。
Tips: 当 timer 为 setTimeout 返回的 number 时,内部的回调不会触发,直到回调执行后,timer 被重新设置回 null 的时候才会起作用。
const throttle = (func, wait = 500) => {
let timer = null
return (...args) => {
if (timer) return
timer = setTimeout(() => {
fn.apply(this, args)
timer = null
}, wait)
}
}go 语言速成课
视频地址:go tutorial
package main
// 导入所需要的依赖包
import (
"fmt"
"errors"
"math"
)
// 必须有的 main 函数
func main() {
// 变量定义
// x := 5
// y := 7
// sum := x + y
// fmt.Println("hello, world!", sum)
// if else 条件语句
// if sum >= 12 {
// fmt.Println("More than to 12")
// } else if x <= 5 {
// fmt.Println("x less than to 5")
// }
// 可拓展数组
// a := [] int {1, 2, 3, 4, 5}
// a = append(a, 13)
// fmt.Println("hello, world!", a)
// 可拓展 map
// vertices := make(map[string]int)
// vertices["triangle"] = 2
// vertices["square"] = 3
// vertices["dodecagon"] = 12
// delete(vertices, "triangle")
// fmt.Println(vertices)
// for 循环
// for i:= 0; i < 5; i++ {
// fmt.Println(i)
// }
// 遍历数组
// arr := []string{"a", "b", "c"}
// for index, value := range arr {
// fmt.Println(index, value)
// }
// 遍历 map
// m := make(map[string]string)
// m["a"] = "alpha"
// m["b"] = "beta"
// for key, value := range m {
// fmt.Println(key, value)
// }
// 函数调用
// result := sumfunc(1, 2)
// fmt.Println(result)
// 回调函数
// result, err := sqrt(-16)
// if err != nil {
// fmt.Println(err)
// } else {
// fmt.Println(result)
// }
// 构造函数/构造类
// p := person{name: "hawtim", age: 27}
// fmt.Println(p.age)
// 内存地址操作
// i := 7
// inc(&i)
// fmt.Println(i, &i)
}
// 一个普通函数
func sumfunc(x int, y int) int {
return x + y
}
// 定义一个函数和返回类型
func sqrt(x float64) (float64, error) {
if x < 0 {
return 0, errors.New("Undefined for negative numbers")
}
return math.Sqrt(x), nil
}
// 定义一个数据类型
type person struct {
name string
age int
}
func inc(x *int) {
*x++
}sessionStorage, localStorage, cookies 的差异及使用场景
DNS 解析过程
【读书笔记】认知红利
《认知红利》是笔者最近花了一些时间精读的一本书,书中有很多概念,但是概念并不十分抽象,书中会从现象分析入手,引导你思考更深,更高层次的问题,读起来不会枯燥,反而经常让我产生“噢,原来是这样的!”的感叹。有些看过类似的书的读者可能会说是把一些思维方式的书籍的观点整理起来讲。但我想讲这本书把这些概念和观点串联得真的很好,值得一看。
读书笔记我做了一个脑图,有点混乱,摘要我认为非常重要的 NLP 的概念。前面部分的内容就用h3标题带过了。
意识到自己拥有最宝贵的财富是“注意力”
善用每一份时间去做一个“时间商人”
学会围绕自己的“天赋”打造核心竞争力
使用“复利的思维”让财富和自己快速成长
通过“去角色化”看到那个陌生而又真实的自己
从“理解层次”的概念里发现,原来问题还可以从一个更高的维度快速地解决
NLP理解层次
环境
- 都是环境的错
行动
- 我还不够努力
能力
- 方法总比问题多!
BVR
- 什么才是更重要的
- B => Believe 信念
- V => Value 价值
- R => Rule 做人做事的原则
身份
- 因为我是×××,所以我会×××
精神/使命
- 人活着就是为了改变世界!
NLP的12条前提假设
-
没有两个人是一样的
-
一个人不能控制另外一个人
-
有效果比有道理更重要
-
只有由感官经验塑造出来的世界,没有绝对的真实世界
-
沟通的意义在于对方的回应
-
重复旧的做法,只会得到旧的结果
-
凡事必有至少三个解决方法
-
每一个人都选择给自己最佳利益的行为
-
每个人都已经具备使自己成功快乐的资源
-
在任何一个系统里,最灵活的部分便是最能影响大局的部分
-
没有失败,只有反馈
-
动机和情绪总不会错,只是行为没有效果而已
实现对人生的顶层设计
-
我的人生使命是什么?世界因为我会有什么不同
-
为了实现这个使命,五年后我会成为一个怎样的人,描述得越具体越好
-
一套怎样的价值观能帮助我达到这个身份,什么最重要,我应该坚持什么,放弃什么?我该相信一些什么原则和规律
-
为了实现这个身份,以及这套BVR,我应该学一些什么知识和技能,掌握什么方法和套路。什么可以做,什么不可以做。
-
具体怎么做,第一步是什么,今年的具体计划怎么实现
-
哪些人和资源可以帮助我实现目标,我如何去使用身边的资源。
另外跟大家分享书中我认为很重要的一个专注的观点。这部分看起来会很抽象,建议可以去看看原书。
为什么难以专注
- 天生爱分心
- 心猿意马
- 他人需要你
- 他事勾引你
如何专注
-
选择能专注的事情
-
对恐惧的逃避
-
对愉悦的追求
- 确定性的满足
- 不确定的奖励
-
-
设置一个威胁对象或者时间期限
- 让自己或者组织保持专注,一路狂奔
-
阻断外部干扰:创造纯净的环境
-
- 隔离噪声
- 进入不被打扰的环境
- 关闭各种 app 的提醒功能
- 带上降噪耳机
-
- 调控信道
- 调用多个信道做一件事情
- 用白噪音堵住听觉信道
-
- 摒除杂念
- 主动进入受拘束的环境
- 平时少看不相关的内容
- 冒出一个不相关的好想法,临时记录时候复盘
-
- 注意休息
-
- 短休息
-
- 中度休息
-
- 夜晚睡眠质量保证
-
前端知识图谱概览
如何通过思维导图将零散的碎片知识系统化?
笔者最近的工作中,前端资源很紧缺,日常招人,领导希望我整理一些前端面试的知识点,方便有些时候可以直接由他去面试。
然后我开始用思维导图来整理,基本上是从 HTML CSS JavaScript 的顺序来写的,想到什么就补充点什么,以工作中使用到的知识点来看的话,一个下午就搞定写完了。
思前想后,应该可以更加系统全面的整合前端的知识体系,第一点是先整理出哪些主要的模块,比如一开始我定的就是前端三板斧 HTML CSS JS,第二点是是根据前面的主要模块,在每一块里面找到经典的面试题目,由点及面,由浅到深的学习相关的知识和内容。帮助我做到以下三点:
- 查漏补缺
- 重难点攻克
- 培养脑图思维
我认为的前端知识点包括下面这些大模块
- HTML
- CSS
- JavaScript
- 浏览器
- 新技术
- 工程化
- 数据结构与算法
- 编译原理
- 设计模式
- 手撕代码
- 前端框架
- 性能和安全
- 计算机网络
我用 xmind zen 来完成这个工作
- HTML
- meta 标签,有哪些属性? 能做什么?
- 如何适配 iphoneX 的刘海屏,如何获取
- audio / video / canvas / svg
- 语义化标签
- CSS
- display 有哪些属性, flex 布局 grid 布局
- animation 属性
- 两栏布局 / 三栏布局
- 水平垂直居中
- FC (BFC / IFC / FFC / GFC)
- 文档流的类型
- 选择器优先级计算
- 重绘和回流,CSS 和 JavaScript 的规避方案吗?
- 盒模型类型,特点
- BEM 命名方式
- CSS 模块化、scoped
- JS
- ES6 有哪些新特性
- 闭包是什么?
- this 的指向
- JavaScript 的事件循环机制
- web worker / service worker
- 封装 Ajax
- Promise 的理解
- setTimeout / setInterval
- 线程和进程的差异
- prototype 、 proto 、 constructor 的关系
- 什么是原型链
- JS 的模块化实现
- 数组有哪些方法
- 基本类型和引用数据类型有什么差异
- 为什么 typeof null === ’object‘
- Object.defineProperty
- 内存泄露是什么,什么原因,怎么处理
- 严格模式的差异
- JS 如何实现继承
- 浏览器缓存
- 强缓存、协商缓存的原理
- cookie、localStorage、sessionStorage
- 上线发版本如何解决缓存的问题
- 浏览器读取缓存的顺序
- 浏览器事件周期, domcontentloaded、load、beforeunload、unload、readyState
- 浏览器事件冒泡、捕获、阻止冒泡、阻止默认事件
- 什么是跨域,如何解决
- 浏览器兼容问题
- 浏览器下载文件的方法
- 新技术/实现相关
- webAssembly 和 JavaScript 有什么差别
- 小程序的生命周期
- WebGL
- webRTC
- web worker
- JSbridge
- 工程构建
- webpack 的 loader plugins
- webpack 热更新
- webpack 构建优化
- git stash/rebase/merge
- git hook 能做什么
- npm 和 yarn 有什么差异
- docker 是什么,为什么使用
- 代码校验 eslint stylelint
- 提交规范 commitzen
- 如何封装一个组件
- 数据结构与算法
- 基本数据结构 堆 栈 链表 队列 集合 字典 二叉树
- 排序算法: 快排、基线排序、冒泡
- 动态规划的套路
- 大O表示法
- 编译原理
- 分词、语法分析、生成 AST
- 应用
- 常见的设计模式
单例模式、原型模式、工厂模式、观察者模式、策略模式、代理模式、发布订阅模式
- 手撕代码
- 防抖节流
- 设计一个 ajax 库
- jsonp
- instanceOf
- 柯里化
- new 做了什么
- 浅拷贝
- 深拷贝
- 前端框架(Vue)
- Vue 生命周期有哪些,执行顺序,父子组件的执行的先后顺序
- 如何实现数据劫持
- $nextTick 这个 API 用来做什么,原理是什么
- computed 和 watch 的差异
- 数据响应后是如何更新视图的?
- vue 的 diff 算法是怎样?
- vue hook 是什么?
- 性能和安全
- XSS
- CSRF
- Cookie 安全
- HTTP 劫持
- 性能分析和监控
- 网络
- 网络模型 OSI 七层模型、五层模型、TCP/IP 四层模型
- tcp 三次握手、四次挥手
- HTTP1.0 / HTTP1.1 / HTTP2.0 / HTTP3.0
- 常见状态码
- nginx 负载均衡是什么原理
- CDN 的原理
- Https 的全过程
- DNS 的解析过程
- 浏览器运行机制,从输入 url 到页面展示内容过程中做了什么?
- 合成 URL
- 解析 URL, 生成 HTTP 消息
- 进入浏览器缓存阶段
- DNS 域名解析,找到服务器地址
- 将 HTTP 的传输工作委托给系统的协议栈
- 服务器处理请求的过程
- 浏览器处理响应
- 解析文档
- 生成渲染树
- 客户端绘制
- 加载并执行js脚本
以上内容肯定不是前端的全部,大概才20%,主要是认为这些问题比较大,水平的区分度比较强。
脑图还在持续优化中,后续开源。
Vue 的 nextTick 用来做什么?原理是什么?
JSON.stringify的三个参数
JSON.stringify的三个参数
Created: Nov 25, 2020 12:32 PM
JSON.stringify 有三个参数
- 第一个参数是要序列化的对象
- 第二个参数是一个 replacer 参数
- 第三个参数是一个 space 参数
第一个参数是我们最常见的用法也最受关注的,比如在说简单的深拷贝的时候,可以用这种办法。
常见的问题有以下几个:
- undefined、任意的函数以及 symbol 值,在序列化过程中会被忽略
- 函数、undefined 被单独转换时,会返回 undefined,如JSON.stringify(function(){}) or JSON.stringify(undefined).
- 对包含循环引用的对象,会抛出错误
- Date 日期调用了 toJSON() 将其转换为了 string 字符串(同Date.toISOString()),因此会被当做字符串处理。
- NaN 和 Infinity 格式的数值及 null 都会被当做 null。
- 其他类型的对象,包括 Map/Set/WeakMap/WeakSet,仅会序列化可枚举的属性
- 非数组对象的属性不能保证以特定的顺序出现在序列化后的字符串中
- 转换值如果有 toJSON() 方法,该方法定义什么值将被序列化。所以我们可以通过改写 obj 的 toJSON 方法来修改 JSON.stringify 后的结果
我们主要后面看两个参数
replacer
如果该参数是一个函数,则在序列化过程中,被序列化的值的每个属性都会经过该函数的转换和处理。作为函数,它有两个参数,键(key)和值(value),它们都会被序列化。
传入一个 function
function replacer(key, value) {
if (typeof value === "string") {
return undefined;
}
return value;
}
var foo = {
foundation: "Mozilla",
model: "box",
week: 45,
transport: "car",
month: 7
};
var jsonString = JSON.stringify(foo, replacer);
// {"week":45,"month":7}传入一个数组
var foo = {
foundation: "Mozilla",
model: "box",
week: 45,
transport: "car",
month: 7
};
JSON.stringify(foo, ['week', 'month']);
// '{"week":45,"month":7}', 只保留 “week” 和 “month” 属性值。space
指定缩进用的空白字符串,用于美化输出(pretty-print)
- 如果是一个数字, 则在字符串化时每一级别会比上一级别缩进多这个数字值的空格(最多10个空格);
- 如果是一个字符串,则每一级别会比上一级别多缩进该字符串(或该字符串的前10个字符)
var foo = {
foundation: "Mozilla",
model: "box",
week: 45,
transport: "car",
month: 7
};
// 亲测最好用的
JSON.stringify(foo, null, '\t')
// or
JSON.stringify(foo, null, 4)
/**
输出结果
"{
"foundation": "Mozilla",
"model": "box",
"week": 45,
"transport": "car",
"month": 7
}"
*/注意事项:
- 针对循环引用对象,会抛出异常TypeError ("cyclic object value")(循环对象值)
- 当尝试去转换 BigInt 类型的值会抛出TypeError ("BigInt value can't be serialized in JSON")
Javascript 设计模式总结

HTTP 发展史:从 HTTP1 到 HTTP3
http 的发展历史
http0.9
http1.0
http1.1
http2.0
http3.0(QUIC)
vue-cli@4 体验总结
前言
之前笔者只接触了 vue-cli@3,长期作为业务仔,自然没有使用最新的脚手架建立项目的机会。
不过没关系,最近有机会了。😁
基于某个公司的招聘项目,使用 vue-cli@4 的完成了一个小 demo,因为还没有走通前后台。
废话不多,开始了解。
安装
官网的东西不用细讲,安装链接
npm install -g @vue/cli 安装下来后在用 vue --version 检查即可
项目初始化
在 terminal 输入 vue create test-app 后,会出来几个选项。
你可以通过配置好的,或者选择自定义的选项来初始化项目,这部分根据项目的需求、特性、技术栈、性能、生态、用户场景等多个角度去考量。当然折腾能力强的,就直接选个最简单的组合就行了。比如 babel, sass/less, vue, vuex, vue-router, eslint 就行。pwa, ts, ssr, jest 和 cypress 就暂时先不考虑。

初始之后,会在 package.json 中帮你把对应的脚本,比如 eslint 的校验修复都处理好了,一行命令运行就行。
我们来看看官网上随口提了一下但没怎么细讲的 vue ui.
你可以通过 vue ui 命令使用 GUI 运行更多的特性脚本
vue ui
通过在当前项目 vue ui 你就可以启动当前项目的 cli 服务,基于一个页面的可视化操作。
在仪表盘下,默认只有一个杀掉端口,场景在于杀掉一个node进程后,这个端口还是被占用的。这时候再跑起前端代码会提示端口占用。这时候就要杀掉这个端口的进程占用。
通过右上角的自定义,可以把界面定制成这个样子:

可以注意到,除了可视化操作一些构建命令之外,还有依赖更新和插件更新正在 TODO 中,最后一个 Vue News 的面板,我试着点了一下设置,发现是可以自定义订阅内容的,只是我也没有合适的 rss 源来测试下替换后的效果。
整体感觉像是个玩具,事实上我并不会用这种方式去检查依赖版本,像 npm pnpm cnpm yarn 可能都已经内置了依赖版本检查,有需求的时候再去更新就好,何况一更新还经常会引起 bug。
优化版
根据一些通用的场景,我做了一个优化版的项目初始配置的,后续有需求的话也可以整合 ts,欢迎小伙伴留言。
涉及到的特性:
工程特性
.editorconfig 增加编辑器配置
.npmrc npm 设置 npm 和 node-sass 代理
.prettierrc 优化 prettier 选项
babel.config.js 实现 element-ui 按需加载
jsconfig.json 增加 vscode 文件跳转
jest.config.js 增加 identity-obj-proxy 用于含有 elementui 的组件测试
.eslintrc.js 增加全局变量配置
vue.config.js 增加 definePlugin 和 webpackBundleAnalyzer 的配置,自定义 loader(只是举例)
业务特性
dayjs 用于日期处理
normalize.css 用于 css reset
elementui 作为前端组件库
vchart 封装的 echart 作为数据可视化
CDN 详解
《CDN 详解》https://segmentfault.com/a/1190000010631404 作者 Pines_Cheng
JS 的模块化演变过程
CommonJS(同步)
Nodejs 代表,使用同步的方式加载模块
四个重要的环境变量
- module
- exports
- require
- global
实际使用的时候,使用 module.exports 定义当前模块对外输出的接口,用 require 加载模块
优缺点
- 更加适用于服务端,因为模块文件在服务器本地
- 在浏览器端,会受到网络的限制,更加使用异步加载
CMD(异步延迟加载)
依赖就近、延迟执行,代表 seajs
define
define(function(require, exports, module) {
var a = require('./a'); //在需要时申明
a.doSomething();
if (false) {
var b = require('./b');
b.doSomething();
}
});定义 math 模块
define(function(require, exports, module) {
var $ = require('jquery.js');
var add = function(a,b){
return a + b;
}
exports.add = add;
});
// 加载模块
seajs.use(['math.js'], function(math){
var sum = math.add(1 + 2);
});AMD(异步提前加载)
AMD 规范采用异步方式加载模块,模块加载不影响后面语句的运行
依赖相关模块的代码都定义在模块的回调函数中
代表 require.js
- require.config() 指定引用路径
- define() 定义模块
- require() 加载模块
依赖前置、提前执行
demo
/** 网页中引入require.js及main.js **/
<script src="js/require.js" data-main="js/main"></script>/** main.js 入口文件/主模块 **/
// 首先用config()指定各模块路径和引用名
require.config({
baseUrl: "js/lib",
paths: {
"jquery": "jquery.min", //实际路径为js/lib/jquery.min.js
"underscore": "underscore.min",
}
});
// 执行基本操作
require(["jquery","underscore"],function($,_){
// some code here
});ES6 模块系统(编译时引入)
export
- 规定模块对外暴露的接口
import
- 用于输入其他模块的功能
ES6 模块与 CommonJS 模块的差异
- CommonJS 输出的是值的拷贝,ES6 模块输出的是值的引用。前者一旦输出一个值之后,后续模块里的改变不会影响输出的值。而ES6 是动态引用,模块里的状态和输出的值是有关联的
- CommonJS 是运行时加载,ES6 模块是编译时加载
- CommonJS 模块就是对象,运行时,先加载整个模块,生成一个对象,然后再从这上面读取方法
- ES6 模块不是对象,在 import 的时候可加载某个指定的值,而不是加载整个模块
行为型模式-观察者模式
行为型模式-策略模式
定义
定义一系列算法,将每一个算法封装起来,并让它们可以相互替换。策略模式让算法独立于使用它的客户而变化
目的
目的是将算法的使用和算法的实现分离开。
组成
策略模式至少包含两个部分:
- 第一部分是一组策略类,封装了具体的算法,负责具体的计算过程。
- 第二个部分是环境类 context,接受客户的请求,随后把请求委托给某一个策略类。
一个计算奖金的例子
我们首先来看基于传统面向对象语言的模仿,各个类的职责体现得更加鲜明。
class performanceS {
calculate(salary) {
return salary * 4
}
}
class performanceA {
calculate(salary) {
return salary * 3
}
}
class performanceB {
calculate(salary) {
return salary * 2
}
}
class Bonus {
constructor() {
this.salary = null
this.strategy = null
}
setSalary(salary) {
this.salary = salary
}
setStrategy(strategy) {
this.strategy = strategy
}
getBonus() {
return this.strategy.calculate(this.salary)
}
}
let bonus = new Bonus()
bonus.setSalary(10000)
bonus.setStrategy(new performanceS())
console.log(bonus.getBonus()) // 输出 40000
bonus.setStrategy(new performanceA())
console.log(bonus.getBonus()) // 输出 30000JavaScript 版本的策略模式(不需要用到类的概念)
在JavaScript的策略模式中,策略类往往基于函数实现,因此策略模式在 JS 中是”隐形“的,我们通过高阶函数封装不同的行为,并把它传递到另一个函数(策略类)中,当我们调用这些高阶函数时,不同的函数调用返回不同的结果。
let strategies = {
"S": function(salary) {
return salary * 4
},
"A": function(salary) {
return salary * 3
},
"B": function(salary) {
return salary * 2
}
}
let calculateBonus = function(level, salary) {
return strategies[level](salary)
}
console.log(calculateBonus('S', 20000))
console.log(calculateBonus('A', 10000))优点:
- 策略模式有效避免多重条件选择语句
- 提供了对开放-封闭原则的完美支持,使得易于切换,理解、扩展。
- 利于算法复用,符合 DRY 原则
- 利用组合和委托让 Context(最终将算法执行的方法)拥有执行算法的能力
缺点:
- 会增加许多策略类或者策略对象,可以通过享元模式在一定程度上减少。
- 客户要使用策略模式,必须暴露所有策略的实现,违反了最少知识原则。
应用场景
- 如果许多类之间的区别仅在于它们的行为,那么使用策略模式可以动态地让对象在许多行为中选择一种行为。
- 一个系统需要动态地在几种算法中选择一种。
- 如果一个对象有很多的行为,如果不用恰当的模式,这些行为就只好使用多重的条件选择语句来实现。
- 不希望客户端知道复杂的、与算法相关的数据结构,在具体策略类中封装算法和相关的数据结构,提高算法的保密性与安全性。
总结
- 策略模式是一种行为型模式,也称为政策模式(Policy)。
- 策略模式包含三个角色:环境类在解决某个问题时可以采用多种策略,在环境类中维护一个对抽象策略类的引用实例;抽象策略类为所支持的算法声明了抽象方法,是所有策略类的父类;具体策略类实现了在抽象策略类中定义的算法(JavaScript中没有抽象类)
参考
AST 的基本原理和使用场景
AST
基本原理
-
读取 js 文件中的字符流
-
分词 token
-
标识符(Identifier)
- 沒有被引号括起來的连续字符,可以包含字母、数字、_、$,其中数字不能作为开头。
- 标识符可能是var,return,function 等关键字,也可能是true,false这样的内置常量,或是一個变量。具体是哪种语义,分词阶段不區分,只要正确拆分即可。
-
数字 (Numeric)
- 十六进制,十进制,八进制以及科学表达式等都是最小单元
-
运算符(operator)
- +、-、 *、/ 等
-
字符串 (string)
- 对计算机而言,字符串只會参与計算和展示
-
注释(comment)
- 不管是行注释還是块注释,对于计算机來说並不关心其內容,所以可以作为不可再拆分的最小单元
-
空格 (space)
- 连续的空格,换行,缩进等,只要不在字符串中都沒有实际的逻辑意义,所以连续的空格可以作为一個语法单元。
-
其他(paren)
- 大括号,中括号,小括号,冒号 等等
-
-
语法分析 Parser
- 主要是识别语句和表达式
-
生成 AST
-
生成机器码执行
应用
- 编辑器的错误提示、代码格式化、代码高亮、代码自动补全
- eslint、prettier 对代码错误或风格的检查
- webpack 通过 babel 转译 javascript 语法
- js 跨平台开发的实现
babel
-
Babylon.parse
- 现有 AST
-
babel-traverse
- 转换成新 AST
-
babel-generator
- 生成新代码
vue template
-
const ast = parse(template.trim(), options)
- 解析器是 vue 自己实现的
- AST 节点三种类型:1 为普通元素, 2 为表达式,3为纯文本
-
optimize(ast, options)
- 优化语法树
- 解析语法树都是深度优先遍历
- 针对非响应式的静态节点做优化,生成的 dom 也不需要再做改变,那样对运行时的模板更新起到极大的优化作用
-
const code = generate(ast, options)
- 通过 generate 方法将 ast 生成 render function
this 的指向总结,call apply new 对 this 指向的影响
// 作为对象的方法调用
var obj = {
a: 1,
getA: function() {
console.log(this === obj)
console.log(this.a)
}
}
obj.getA()
// 作为普通函数调用
window.name = 'global'
var getName = function() {
return this.name
}
console.log(getName()) // global
var myObject = {
name: 'sven',
getName: function() {
return this.name
}
}
var getName = myObject.getName
console.log(getName()) // global
// 函数构造器调用
var MyClass = function() {
this.name = 'sven'
}
var obj = new MyClass()
console.log(obj.name)
// 显式返回一个 object 类型的对象,则会指向返回的对象
// 但如果不返回,或者返回基本类型值,则 this 指向正常
var MyClass = function() {
this.name = 'sven'
return {
name: 'anne'
}
}
var obj = new MyClass()
console.log(obj.name)
// Function.prototype.call & Function.prototype.apply 调用
var obj1 = {
name: 'sven',
getName: function() {
return this.name
}
}
var obj2 = {
name: 'anne'
}
console.log('call & apply ' + obj1.getName()) // sven
console.log('call & apply ' + obj1.getName.call(obj2)) // anne
// 修正 document 方法的 this 指向
document.getElementById = (function(func) {
return function() {
return func.apply(document, arguments)
}
})(document.getElementById)
var getId = document.getElementById
var div = getId('div1')
console.log(div.id)总结
this 的指向大致可以分为
- 作为对象的方法调用
- 作为普通函数调用
- 构造器调用
- Function.prototype.call 或 Function.prototype.apply
Message record for vue3.0
《The process: Making Vue 3》 EVAN YOU
如何封装一个工具库
从 vue/examples/modal/index.html 调试理解 vue diff
思考
- vue diff 算法的过程。
- vue 的 diff 是如何从 O(n^3) => O(n),同层比较是怎样一个过程?
带着上面两个问题,我们开始调试吧。
Get start
- 打开 vue/examples/modal/index.html
- 修改
<script src="../../dist/vue.min.js"></script>为<script src="../../dist/vue.js"></script> - 安装项目依赖,
yarn install - 运行项目,
yarn dev - vscode live server 插件热更新
- 开始调试
打断点
在 patchVnode 和 updateChildren 下打断点。
example 的功能
点击展示一个弹窗,点击 OK 关闭。

正式开始
首先我们点击 show modal 按钮,会进入 function patch (oldVnode, vnode, hydrating, removeOnly) 的断点。我们可以看到 vnode 和 oldVnode 的状态。
oldVnode 的 children

vnode 的 children

后者的 children 多了一个 vue-component-1-modal 的子节点。
进入 patchVnode
在 patchVnode 的逻辑中,对应了节点比对的逻辑:
oldVnode === vnode节点引用的位置一致,直接 returnif (oldCh && ch && oldCh !== ch),新旧子节点都存在并且两者不同,则检查新旧节点的子节点,调用updateChildren函数递归比较子节点if (ch),只有新子节点存在,调用addVnodes内部对应调用createEle来讲新的子节点添加到 vnode.el 上else if (oldCh),新节点没有子节点,老节点有子节点,调用removeVnodes移除子节点
在这个例子中,进入 patchVnode 之后,由于 oldCh 和 ch 都存在且不同,所以会进入上面的第二种情况,updateChildren 函数中。

进入 updateChildren
updateChildren 的逻辑很长,但花点时间看尤大还是写得很亲民了:
新旧子节点列表各自维护一对指针,即 oldStartIdx, oldEndIdx 和 newStartIdx, newEndIdx,不停的对新旧子节点列表的头部和尾部进行对比,将指针不断向内收缩。
如果是 sameVnode,递归进入 patchVnode 的过程,针对单个 vnode 进行 diff,如果 vnode 又有 children,则继续往进行 diff 算法,内部递归 updateChildren。
- isUndef(oldStartVnode)
- isUndef(oldEndVnode)
- sameVnode(oldStartVnode, newStartVnode) 旧首部和新首部
- sameVnode(oldEndVnode, newEndVnode) 旧尾部和新尾部
- sameVnode(oldStartVnode, newEndVnode) 旧首部和新尾部,即旧节点的第一个节点移动到最后的位置了
- sameVnode(oldEndVnode, newStartVnode) 旧尾部和新首部 ,即旧节点的最后节点移动到最前面的位置了
- 如果没有满足以上任意的情况,则把所有旧子节点的 key 做一个 { key: index } 映射 表,然后用新 vnode 的 key 去找出在旧节点中可以复用的位置。如果新 vnode 没有 key,则一个个比对。
在这个示例中,开始比对新旧节点的子节点列表。
-
新旧节点的子节点第一个都是 show modal 的 button,进入上面的第三种情况,
sameVnode(oldStartVnode, newStartVnode)旧首部和新首部,在这个条件下,会再次进入上面的 patchVnode 检查子节点是否相同,即检查 button 里的 #text 节点,由于两个 button 最终是相同的,所以检查 button 完毕之后会重新回到节点比对的过程。 -
紧接着检查新旧节点的子节点列表的第二个元素,是一个空格文本节点,同样的,新旧节点的子节点中,这个元素也是相同的,经过检查后来到第三个元素。

-
由于旧节点的子节点中,第三个元素是一个注释节点,用于 v-if 组件的切换显示,而新节点的子节点中,第三个元素则是 modal 组件,这时候满足了两个节点肯定不满足任意一种 sameVnode,所以会进入在旧子树中找复用的逻辑,这时候,复用逻辑也是不生效的,最终会满足
isUndef(idxInOld)的条件,进入 createElm 的逻辑。(生成节点这部分就不细讲了,有兴趣的读者可以去看看逻辑。检查当前的 vnode ,有子节点调用 createChildren 内部循环调用 createElm 再挂载到 parentElm 上,最终挂到 vnode.elm 下)
最后完成了节点的更新,此时页面出现了弹框内容。

如果点击了 OK
点击了 OK,弹框将开始隐藏。
这时候的 diff 过程其实就很相似了,旧子节点是 [button, ' ', modal],新子节点是 [button, ' ', 'comment']。跳过前两者的比较,我们直接到第三个子节点的比较。第三个子节点的比较,同样在旧节点中无法找到复用的节点,所以进入了创建一个 comment 节点的逻辑。
这时候我们发现 v-if 的组件在切换的时候,实际上是使用一个 comment 节点去切换挂载新的组件的。并且在这个 comment 节点之前,还会有一个 text 内容是一个空格的 node。这个地方的分析会在后边的题外话分析。
开头的问题
现在开头的问题应该比较清楚了,vue diff 算法的过程我们已经通过一个简单的例子分析了,那么 vue 的 diff 是如何从 O(n^3) 到 O(n) 的呢?同层比较是怎样一个过程?
这个问题要引用一个issue。Advanced-Frontend/Daily-Interview-Question#151 (comment) 。首先 O(n^3) 是怎么计算出来的。我的观点是 递归新树和旧树就是 O(n^2),修改树中的节点是 O(n),所以 O(n^3)。
那么 react 和 vue 是怎么优化的,在引用里 React 和 Vue 做优化的前提是“放弃了最优解“,本质上是一种权衡,有利有弊。这个前提是:
- 检测 vdom 的变化只发生在同一层,即避开了跨级比较。
- 检测 vdom 的变化依赖于用户指定的 key,即使用 key 可以更快速的找到复用的节点,加快 diff。
题外话
这次的探索中发现了一个很妙的地方,但是我没想明白,就是上面那行 紧接着检查新旧节点的子节点列表的第二个元素,是一个空格文本节点。设置了一个空格的文本节点会导致 diff 的时候检查比对这个节点,这样肯定是一种开销。如果有读者了解的话,欢迎评论区解答一下。
行为型模式-命令模式
命令模式是一种行为型模式。把对象之间的请求封装在命令对象中,将命令的调用者和命令的接收者完全解耦。
行为
当调用命令的 execute 方法时,不同的命令会做不同的事情,从而阐释不同的执行结果,此外还有 undo 和 redo 等操作。
电视遥控器例子
我们直接从代码入手,依次注释 命令的接收者、命令对象、命令的调用者
document.write(`<body>
<button id="execute">execute</button>
<button id="undo">undo</button>
</body>`)
// 命令的接收者
let Tv = {
open() {
console.log('open the tv')
},
close() {
console.log('close the tv')
}
}
// 命令对象
class OpenTvCommand {
constructor(receiver) {
this.receiver = receiver
}
// 行为 => 请求
execute() {
this.receiver.open()
}
undo() {
this.receiver.undo()
}
}
// 命令的调用者
let setCommand = (command) => {
document.getElementById('execute').onclick = () => {
command.execute()
}
document.getElementById('undo').onclick = () => {
command.undo()
}
}
// 实例化命令并解耦
setCommand(new OpenTvCommand(Tv))上述的简单的例子可以直观的理解命令模式的原理。
我们接下看另外一个例子,通过控制小球的移动,本质的模式是相同的,只是增加了更多的逻辑,更接近我们的业务代码。
一个控制小球移动的例子
// 补充 Animate 类
let tween = {
linear(t, b, c, d) {
return c * t / d + b
},
easeIn(t, b, c, d) {
return c * (t /= d) * t + b
}
// ...
}
class Animate {
constructor(dom) {
this.dom = dom // 进行运动的dom节点
this.startTime = 0 // 动画开始时间
this.endTime = 0
this.startPos = 0 // 动画开始时,dom节点的位置,即dom的初始位置
this.endPos = 0 // 动画开始时,dom节点的位置,即dom的目标位置
this.propertyName = null // dom 节点需要被改变的 CSS 的属性名
this.easing = null // 缓动算法
this.duration = null // 动画持续时间
}
start(propertyName, endPos, duration, easing) {
this.startTime = +new Date
this.startPos = this.dom.getBoundingClientRect()[propertyName]
this.propertyName = propertyName
this.endPos = endPos
this.duration = duration
this.easing = tween[easing]
let timeId = setInterval(() => {
if (this.step() === false) {
clearInterval(timeId)
}
}, 19)
}
step() {
let t = +new Date
if (t >= this.startTime + this.duration) {
this.update(this.endPos)
return false
}
let pos = this.easing(t - this.startTime, this.startPos, this.endPos - this.startPos, this.duration)
this.update(pos)
}
update(pos) {
this.dom.style[this.propertyName] = `${pos}px`
}
}
document.write(`<body>
<div id="ball" style="position: absolute;top: 50px; left: 0; background: #000; width: 50px; height: 50px;"></div>
输入小球移动后的位置: <input id="pos"/>
<button id="moveBtn">开始移动</button>
<button id="cancelBtn">撤销移动</button>
</body>`)
let ball = document.getElementById('ball')
let pos = document.getElementById('pos')
let moveBtn = document.getElementById('moveBtn')
let cancelBtn = document.getElementById('cancelBtn')
// 控制小球的命令对象
class MoveCommand {
constructor(receiver, pos) {
this.receiver = receiver
this.pos = pos
this.oldPos = null
}
execute() {
this.receiver.start('left', this.pos, 1000, 'linear')
this.oldPos = this.receiver.dom.getBoundingClientRect()[this.receiver.propertyName]
}
undo() {
this.receiver.start('left', this.oldPos, 1000, 'linear')
}
}
var moveCommand
moveBtn.onclick = () => {
var animate = new Animate(ball)
moveCommand = new MoveCommand(animate, pos.value)
moveCommand.execute()
}
cancelBtn.onclick = () => {
moveCommand.undo()
}优点
- 降低程序的耦合度
- 新的命令可以很容易的加入程序中
- 可以设计一个命令队列和宏命令(组合命令)(参考组合命令)
- 可以方便实现对请求的 undo 和 redo
缺点
- 可能会导致程序中有过多的命令类
使用场景
- 程序需要将请求调用者和请求接收者解耦,使得调用者和接收者不直接交互。
- 程序需要在不同的时间指定请求、将请求排队和执行请求。
- 程序需要支持命令的撤销(Undo)操作和恢复(Redo)操作。
- 程序需要将一组操作组合在一起,即支持宏命令。
比如 编辑器的实现、命令行的实现等等。
总结
- 命令模式是一种行为型模式,别名 动作模式 / 事务模式
- 命令模式的本质是对命令进行封装,将发出命令的责任和执行命令的责任分割开。
- 命令模式使请求本身成为一个对象,这个对象和其他对象一样可以被存储和传递。
nginx 主要知识点
负载均衡
充当着网络流中“交通指挥官”的角色,“站在”服务器前处理所有服务器端和客户端之间的请求,从而最大程度地提高响应速率和容量利用率,同时确保任何服务器都没有超负荷工作
正向代理 Forward Proxy
客户端非常明确要访问的服务器地址,它代理客户端,替客户端发出请求,比如 vpn
反向代理 Reverse Proxy
-
反向代理能够隐藏后端服务器
-
反向代理能够更快速地移除故障结点
-
反向代理服务器支持手动设定每台后端服务器的权重
相关模块
server 模块
- listen 80
- server_name www.baidu.com
- index
- charset utf-8
location 模块
- 指定根路径和访问默认文件
location / {
root /home/www/html;
index index.php index.html index.htm;
}- 反向代理
# 匹配到 /api 开头的路由时候,将请求转发到 http://192.168.0.1,
# 但是通常不是直接填写地址,而是设置一个 `upstream`配置,后面会提到
location /api {
# 请求转向地址192.168.0.1
proxy_pass http://192.168.0.1;
# 不修改被代理服务器返回的响应头中的 location 头
proxy_redirect off;
# 使用 nginx 反向代理后,如果要使服务获取真实的用户信息,用以下的设置
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
upstream 模块
- upstream
upstream backend {
server backend1.example.com weight=5;
server backend2.example.com:8080;
server unix:/tmp/backend3;
}
server {
location / {
proxy_pass http://backend;
}
}- weight 算法, 权重越高的机器访问占有的比例就越高
- ip_hash 为同一个 ip 的分配同一个后端服务器,这样我们不用解决session共享问题
http 模块
- http {
#开启gzip压缩
gzip on;
#IE6的某些版本对gzip的压缩支持很不好,故关闭
gzip_disable "MSIE [1-6]\.(?!.*SV1)";
#HTTP1.0以上的版本都启动gzip
gzip_http_version 1.0;
#指定哪些类型的相应才启用gzip压缩,多个用空格分隔
gzip_types
application/javascript
application/json
text/css
text/plain;
# 压缩等级,可选1-9,值越大压缩时间越长压缩率越高,
# 通常选5,能压缩到原来的1/4
gzip_comp_level 5;
gzip_min_length 1024;
}速读《永久记录》总结
永久记录这本书可以理解为作者本人的自传,书中前面一半讲述了他是如何利用校园及考试的规则来实现一些学业上的逃避及年级的跨越,后续是如何通过长达一年的安全测试,并在这期间遇见了他的女朋友。中间过程讲述了他在安全部门中的所见所闻及职业生涯的变化。在他的职业生涯过程中,通过不断的观察和一些无意的查看,逐渐在脑海中拼凑了出了国家层面的全民信息监听系统的模样。
后面一半大概是在他的癫痫症状出现之后,他的职业变动让他又接触到了一些信息,他渐渐地清楚了政府的行为,并对政府的行为感到失望,并最后决定揭发政府的行为。这个过程是十分漫长的, 而他也清楚这个行为的代价会有多大,但是他依然决定要去做这个事情。
通过长期的规划之后,充分获取了秘密数据之后并做好加密工作后,他最终选择在香港揭发美国政府的行为,他漫长的等待等到了记者的到来,后来随着对应的棱镜计划曝光,美国的民众也开始抵制政府的这些行为。
经过漫长的流亡,作者最后被留在了俄罗斯,而他最终也在非盈利机构工作,致力于数据安全领域。后来他的女朋友去俄罗斯找他,并在那里定居,最终结婚。并且在国际社会上获得极大的声望,happy ending。
不知道写这个书评会不会被封账号,能精简就精简,有资源的推荐大家去看看,非常精彩的一本书。
原本我的理解里,财富、权利、健康可能就是一切,但是这本书带给我第四个维度,正如他是“第四公民”一样,这个维度是自由。从小到大的环境导致了我们完全忽略了还有自由这个层面的存在,因为我们实际上处于非常严格的监管之下,只是我们完全没有去注意这个细节。外国人群体的意识里和我们不一样,他们注重这个维度,讲究人权。而不是选择忽略这个维度,因为一个人选择了忽略,其他的人可能就被迫被忽略,最终所有人都失去了这个维度的东西。而作者这本书,我觉得也就是希望大家去意识到这个事情,去重视和追求属于这个维度的东西。
书本是速读完的,概要中如果有错漏的地方,感谢指正。
iterator 遍历器总结
- 遍历器(Iterator)是一种接口,为各种不同的数据结构提供统一的访问机制
- 任何数据结构只要部署
iterator接口,就可以完成遍历操作 iterator接口默认部署在数据结构的Symbol.iterator属性- 一个数据结构只要具有
Symbol.iterator属性,就可以认为是“可遍历的”(iterable)
作用
- 为各种数据结构,提供一个统一的、简便的访问接口
- 使得数据结构的成员能够按某种次序排列
- Iterator 接口主要供
for...of消费
原生具备 iterator 接口的数据类型
ArrayMapSetStringTypedArray- 函数的
arguments对象 NodeList对象
理解 JavaScript 面向对象的 封装、继承、多态 三大特性
前言
最近学了 JavaScript 相关的设计模式,书名《JavaScript设计模式与开发实践》,为加深对 OOP 和设计模式的理解,分成三个部分来理解 JavaScript 的面向对象设计。
面向对象的 JavaScript (OOJS)
面向对象三大特性:
- 封装
- 继承
- 多态
封装
「封装」 把客观事物封装成抽象的类,隐藏属性和方法,仅对外公开接口。
私有属性和方法
只能在构造函数内访问不能被外部所访问(在构造函数内使用 var 声明的属性)
公有属性和方法(或实例方法)
对象外可以访问到对象内的属性和方法(在构造函数内使用 this 设置,或者设置在构造函数原型对象上比如 Person.prototype.xxx)
静态属性和方法
定义在构造函数上的方法(比如 Person.xxx),不需要实例就可以调用;
ES6 之前的封装(非 Class)
函数(function)
首先来看零散的语句
var oDiv = document.getElementsByTagName("div")[0];
var p = document.createElement("p");
body.style.backgroundColor = "green";
p.innerText ="我是新增的标签内容";
oDiv.appendChild(p);缺点很明显:
- 每次都会执行这段代码,造成浪费资源
- 用以被同名变量覆盖掉——因为是在全局作用域下申明的,所以容易被同名变量覆盖
接下来将零散的的语句写进函数的花括号内,成为函数体。
function createTag() {
var oDiv = document.getElementsByTagName("div")[0];
var p = document.createElement("p");
body.style.backgroundColor = "green";
p.innerText = "我是新增的标签内容";
oDiv.appendChild(p);
}优点也很明显
提高了代码的复用性;
按需执行——解析器读到此处,函数并不会立即执行,只有当被调用的时候才会执行;
避免全局变量——因为存在函数作用的问题。
原始模式
var p1 = {};
p1.name = 'a';
p2.sex = 'male';
var p2 = {};
p2.name = 'b';
p2.sex = 'female'优点:一把梭
缺点:生成几个实例,相似的对象,代码重复;而且实例与原型之间没有什么联系;
工厂模式
function Person(name, sex) {
// this.name = name
// this.sex = sex
return { name, sex }
}
var p1 = new Person('a', 'male')
var p2 = new Person('b', 'female')优点:解决代码重复的问题
缺点:p1 和 p2 没有内在联系,不能反映出是同一个原型的实例
构造函数模式
构造函数其实就是一个普通函数,但是内部有 this 指向,对构造函数使用 new 运算符就可以生成构造函数的实例。并且 this 会指向新生成的实例。
比如工厂模式中的 Person 改造成构造函数
function Person(name, sex) {
this.name = name;
this.sex = sex;
this.getName = function() {
console.log(this.name)
}
}
// 通过 new 运算符
var p1 = new Person('a','male');
var p2 = new Person('b','female');
p1.getName()
console.log(p1) //{name: "a", sex: "male"}
console.log(p2) //{name: "b", sex: "female"}优点:解决代码重复的问题,反映出 p1 和 p2 是同一个原型的实例。
缺点:多个实例有重复的属性和方法,占用内存。(所有的实例都会有 getName 方法)
Prototype 模式
每一个构造函数都有一个 prototype 属性,指向另一个对象。这个对象的所有属性和方法,都会被构造函数的实例继承。这意味着那些不变的属性和方法,可以直接定义在 prototype 对象上。
function Person(name, sex) {
this.name = name
this.sex = sex
}
Person.prototype.getName = function() {
console.log(this.name)
}
var p1 = new Person('a','male');
var p2 = new Person('b','female');
p1.getName()
console.log(p1) //{name: "a", sex: "male"}
console.log(p2) //{name: "b", sex: "female"}优点:所有实例的 getName 方法指向都是同一个内存地址,指向 prototype 对象,减少内存占用,提高效率。
一个完整的例子
function Person(name, sex) {
// !!! 私有属性和方法
var id = +new Date()
var getID = function() {
return id
}
// !!! 公有属性和方法
this.name = name
this.sex = sex
this.description = '我是公有属性'
this.getInfo = function() {
var id = getID()
return { id, name, sex }
}
}
// !!! 静态属性和方法
Person.description = '我是静态属性'
Person.work = function() {
return 'freelancer'
}
// !!! 原型上的属性和方法
Person.prototype.description = '我是原型上的属性'
Person.prototype.hobby = ['游泳', '跑步'];
Person.prototype.getHobby = function() {
console.log(this.hobby)
}
var p1 = new Person('小明','male');
// 试着输出私有属性 id
console.log(p1.id) // undefined
// 输出公有属性或方法
console.log(p1.name, p1.sex, p1.description, p1.getInfo())
// 输出静态属性或方法
console.log(Person.description, Person.work())
// 输出原型上的属性或方法
console.log(p1.hobby, p1.getHobby()注意 p1.description 输出的是 ”我是公有属性“
ES6 之后的封装
在 ES6 之后,新增了 class 这个关键字,代表传统面向对象语言的类的概念。但是并不是真的在 JavaScript 中实现了类的概念,还是一个构造函数的语法糖。存在只是为了让对象的原型功能更加清晰,更加符合面向对象语言的特点。
class Person {
constructor(name, sex) {
this.name = name
this.sex = sex
}
getInfo() {
console.log(this.name, this.sex)
}
}注意 class 内部的属性和方法都是不可枚举的
类的数据类型就是函数,类本身指向构造函数即 Person.prototype.constructor === Person 成立
类的公有属性和方法
class Person {
constructor(name, sex) {
// 公有属性和方法
this.name = name
this.sex = sex
this.getInfo = function() {
return { name, sex }
}
}
}类的私有属性和方法
class Person {
constructor(name, sex) {
this.name = name
this.sex = sex
this.getInfo = function() {
return { id, name, sex }
}
// 私有属性和方法
var id = +new Date()
var getID = function() {
return id
}
}
}
let p = new Person('小明','male')
console.log(p.getInfo())原型上的属性和方法
class Person {
constructor(name, sex) {
this.name = name
this.sex = sex
// 原型上的属性和方法
a = 1
getInfo() {
console.log(this.name, this.sex)
}
}
}
let p = new Person('小明','male')
console.log(p.a)静态属性和静态方法(static)
class Person {
constructor(name, age) {
this.name = name
this.age = age
}
static description = '我是一个静态属性'
static getDescription() {
console.log("我是一个静态方法")
}
}
// 或者
class Person {
constructor(name, age) {
this.name = name
this.age = age
}
}
Person.description = '我是一个静态属性'
Person.getDescription = function() {
console.log("我是一个静态方法")
}
// 我是一个静态属性
console.log(Person.description)
// 我是一个静态方法
Person.getDescription()类的实例属性
class Person {
constructor(name, age) {
this.name = name
this.age = age
this.getName = function() {
console.log(this.name)
}
}
// !!! 实例的属性和方法
myProp = '我是实例属性'
getMyProp = function() {
console.log(this.myProp + '=')
}
// !!! 类的原型上的方法
getMyProp() {
console.log(this.myProp)
}
getInfo() {
console.log('获取信息')
}
}
let p = new Person('小明','male')
// 我是实例属性
p.getMyProp() // 我是实例属性=,实例属性优先于类的原型的上的属性和方法
console.log(p.hasOwnProperty('getName')) // true
console.log(p.hasOwnProperty('getMyProp')) // true
console.log(p.hasOwnProperty('getInfo')) // false注意事项
- class 不会变量提升
new Foo();class Foo{}会报错; - class 中如果存在同名的属性或者方法,用 this 定义的方法会覆盖用”等号“定义的属性或方法;
继承
继承是面向对象语言中最有意思的概念。
许多面向对象语言都支持两种继承方式,继承通常包括"实现继承"和"接口继承"。
- 接口继承:继承方法签名
- 实现继承:继承实际方法
由于 JS 中没有签名,所以无法实现接口继承,只支持实现继承,依赖原型链实现。
原型和实例的关系
- 构造函数.prototype 指向原型对象
- 原型对象.constructor 指向构造函数
- 实例对象.proto 指向原型对象

看一个简单的原型链实现继承的例子
function Father(name){
this.fatherName = name
}
Father.prototype.getFatherValue = function(){
return this.fatherName
}
function Son(name){
this.sonName = name
}
// 继承 Father
Son.prototype = new Father('Dad') // Son.prototype 被重写, 导致 Son.prototype.constructor 也一同被重写
Son.prototype.getSonValue = function() {
return this.sonName
}
// 实例化 son
var son = new Son('Son')
console.log(son.getFatherValue()) // Dad原型链实现继承存在的问题
- 当原型链中包含引用类型值的原型时,该引用类型值会被所有实例共享
- 在创建子类型时,不能向超类(例如父类)的构造函数中传递参数
实践中很少会单独使用原型链,有几种办法尝试弥补原型链的不足
借助构造函数 / 经典继承
在子类构造函数的内部调用超类构造函数
// 构造函数
function Father() {
this.colors = ['red', 'blue', 'green']
// 添加超类方法
this.test = function() {
console.log('测试添加超类方法')
}
}
function Son(name, age) {
this.name = name
this.age = age
// 相当于调用 Father 函数将父类的属性和方法添加到子类上,原型没有被修改
return Father.call(this) // 继承了 Father,且向父类型传递参数
}
var son1 = new Son('son1', 12)
son1.colors.push('black')
console.log(son1.colors) // "red,blue,green,black"
var son2 = new Son('son2', 13)
console.log(son2.colors) // "red,blue,green" 可见引用类型值是独立的优点:
- 原型链中引用类型值不再被所有实例共享
- 子类型创建的时候也能够向父类传递参数
缺点:
- 方法都在构造函数里定义,函数无法复用
- 超类中定义的方法,对子类是不可见的,即子类无法直接调用父类的方法
组合继承 / 伪经典继承
使用原型链实现对原型属性和方法的继承,通过借用构造函数来实现对实例属性的继承
function Father(name) {
this.name = name
this.colors = ['red', 'blue', 'green']
}
Father.prototype.sayName = function() {
console.log(this.name)
}
function Son(name, age) {
Father.call(this, name) // 第二次调用 Father() 使用构造函数来继承实例属性
this.age = age
}
// 第一次调用 Father() 使用原型链实现对原型属性和方法的继承
Son.prototype = new Father()
Son.prototype.sayAge = function() {
console.log(this.age)
}
var son1 = new Son('son1', 10)
son1.colors.push('black')
son1.sayName(), son1.sayAge()
console.log('son1.colors', son1.colors)
var son2 = new Son('son2', 12)
son2.sayName(), son2.sayAge()
console.log('son2.colors', son2.colors)组合继承避免了原型链和借用构造函数的缺陷,融合了它们的优点,成为 JavaScript 中最常用的继承模式。而且, instanceof 和 isPrototypeOf() 也能用于识别基于组合继承创建的对象。同时我们还注意到组合继承其实调用了两次父类构造函数,造成了不必要的消耗。
规范化原型继承
在 es5 中,通过 Object.create() 方法规范化了上面的原型式继承,接收了两个参数,一个用作新对象原型的对象、一个为新对象定义额外属性的对象(可选的)。
提醒:因为对传入的对象使用的是浅拷贝,所以包含引用类型值的属性始终都会共享相应的值,就像使用原型模式一样。
var person = {
friends: ["Van","Louis","Nick"]
}
var anotherPerson = Object.create(person, {
name: {
value: "Louis"
}
})
anotherPerson.friends.push("Rob")
// 在创建一个人,修改朋友列表
var yetAnotherPerson = Object.create(person)
yetAnotherPerson.friends.push("Style")
console.log(person.friends) // "Van,Louis,Nick,Rob,Style” 不同实例对象始终共享引用类型值寄生式继承
构造函数+工厂模式:创建一个仅用于封装继承过程的函数,该函数在内部以某种方式来增强对象,最后再像真的是它做了所有工作一样返回对象。
function createAnother(origin) {
var clone = Object.create(origin)
clone.sayHi = function() {
console.log('hi')
}
return clone
}
var a = {
test: 1
}
var a1 = createAnother(a)
console.log(a1)输出
a1: {
sayHi: f(),
__proto__: {
test: 1,
__proto__: {
constructor: f Object()
}
}
}使用寄生式继承来为对象添加函数,无法做到函数复用而降低效率。
寄生组合继承
组合继承是最常用的,但是会调用两次父类构造函数。
一是在创建子类型原型的时候,另一次是在子类型的构造函数内部。
寄生组合式继承就是为了降低父类构造函数的开销而出现的。
集寄生式继承和组合式继承的优点于一身,是最有效的实现类型继承的方法。
// 寄生继承
function extend(subClass, superClass) {
//基于超类(构造函数)的原型对象创建新的原型对象
var prototype = Object.create(superClass.prototype)
// 子类的原型对象指向新创建的原型对象
subClass.prototype = prototype // 指定对象
// 原型对象的构造函数指向子类
prototype.constructor = subClass // 增强对象
}
function Father(name){
console.log('调用了 father')
this.name = name;
this.colors = ["red","blue","green"];
}
Father.prototype.sayName = function(){
console.log(this.name);
};
// 组合继承
function Son(name, age){
Father.call(this, name); //继承实例属性,第一次调用Father()
this.age = age;
}
extend(Son, Father) // 继承父类方法,此处并不会第二次调用Father()
Son.prototype.sayAge = function(){
console.log(this.age);
}多态
看完了上面的封装和继承,到了多态这一步就没那么多复杂的代码了。
概念
同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。
在强类型语言中,如 C++、C#、Java
通常采用抽象类或者接口,进行更高一层的抽象,从而可以直接使用该抽象,即”向上转型“。本质上是为了弱化具体类型带来的限制。
在弱类型语言中,如 JavaScript
在 JavaScript 中,万物皆对象,对象的多态性是与生俱来的。多态可以把过程化的条件分支语句转化为对象的多态性,从而消除条件分支语句。
常见的两种实现方式
- 覆盖,子类重新定义父类方法,不同的子类可以自定义实现父类的方法。
- 重载,多个同名但参数不同的方法。
JavaScript 中的两种多态
通过子类重写父类方法的方式实现多态。
function Person(name, sex) {
this.name = name
this.sex = sex
}
Person.prototype.getInfo = function() {
return "I am " + this.name + " and sex is " + this.sex
}
function Employee(name, sex, age) {
this.name = name
this.sex = sex
this.age = age
}
Employee.prototype = new Person()
Employee.prototype.getInfo = function() {
return "I am " + this.name +
" and sex is " + this.sex +
" and age is " + this.age
}
var person = new Person('xiaoming', 'male')
var employee = new Employee('xiaoming', 'male', 12)
console.log(person.getInfo())
console.log(employee.getInfo())鸭子类型
一个 JavaScript 对象,既可以表示 Duck 类型的对象,又可以表示 Chicken 类型的对象,这意味着JavaScript 对象的多态性是与生俱来的。
var makeSound = function(animal) {
animal.sound()
}
var Duck = function() {}
Duck.prototype.sound = function() {
console.log('gagaga')
}
var Chicken = function() {}
Chicken.prototype.sound = function() {
console.log('gegege')
}
makeSound(new Duck())
makeSound(new Chicken())总结
在 JavaScript 中,会很难看到多态性的影响。因为 JavaScript 具有动态类型系统,因此在编译时没有函数重载或自动类型强制。由于语言的动态特性,我们甚至都不需要 JavaScript 中的参数多态性。
但是 JavaScript 仍具有两种多态的形式:
- 类型继承的形式,来模仿子类型多态性
- 鸭子类型(duck typing)的形式,关注的是对象的行为而不是对象本身。
总而言之,多态的设计是为了面向对象编程时共享对象的行为。
附录:
new 运算符里做了什么?
function myNew(func, ...args) {
// 创建一个空对象
let obj = {}
// 将对象与构造函数原型链接起来
Object.setPrototypeOf(obj, func.prototype)
// 将构造函数的 this 指向新生成的空对象
let result = func.apply(obj, args)
// 最后返回新对象的实例
return result
}- 创建一个空对象
- 将空对象的 proto 指向构造函数对象的 prototype 属性(即继承构造函数的原型)
- 将构造函数内部的 this 指针替换成 obj,然后再调用构造函数
- 将构造函数上的属性和方法添加到空对象上
- 最后返回这个改造后的对象
遍历实例对象属性的三种方法
- 使用
for...in...能获取到实例对象自身的属性和原型链上的属性; - 使用
Object.keys()和Object.getOwnPropertyNames()只能获取实例对象自身的属性; - 使用
hasOwnProperty()方法传入属性名来判断一个属性是不是实例自身的属性;
属性查找
instance.hasOwnProperty('property')检查属性是否在指定实例对象上Father.prototype.isPrototypeOf(instance)判断调用该方法的对象是不是参数实例对象的原型对象
模拟 Object.create()
先创建一个临时的构造函数,然后将传入的对象作为这个构造函数的原型,最后返回这个构造函数的一个新实例。
function objectCreate(o) {
var F = function() {}
F.prototype = o
return new F()
}
subClass.prototype = objectCreate(superClass.prototype)参考文章
通俗易懂讲解计算机编码知识
两个层面
分成两个层面来回答:
- 数据存储:说明一个字节,一个字符和一个字符串之间的区别。
- 字符编码:Unicode,UTF-8,UTF-16,GB2312 和 GB18030 之间的区别。
要说明这两个问题,我们先从计算机数据的基本单位——位,开始说起:
位 bit,是电脑存储的最小单位,一个位就代表二进制中的 0 或者 1。
那么一个字节,一个字符,一个字符串跟位的关系是怎样的呢?
- 字节 byte,是表示信息的最小单位,每八个位组成一个字节。
- 字符 char,字符是信息交换里的一种符号,根据编码的不同,一个字符可能代表1/2/4个字节。
- 字符串 string,字符串把多个字符串联起来的一种数据类型,可以存储一系列字符,占据多个字节。
接下来我们来看字符编码,计算机编码要从 ASCII 码说起:
起源
ASCII码 总共有 127 个包含英文字母和符号,但是不支持其他字符。ASCII码的标志是字节的第一位是 0,剩下的7位是ASCII码。为了满足信息交换,必须有新的编码方式来支持世界上的其他字符。
GB2312 => GBK => GB18030 的演变
因为 ASCII 码无法表示中文字符,所以需要通过拓展位数来表示中文字符,于是就有了 GB2312 字符集。
-
GB2312诞生于1980年,将所有的汉字字符都用2个字节(16位)表示。GB2312 字符集中除常用的简体汉字字符之外还有希腊字母,日文平假名和片假名、俄语西里尔字母等字符,未收录的繁体中文汉字和生僻字。 -
GBK首次出现在 Windows 95 简体中文版,因为 GB2312 还是不足以涵盖所有中文字符,所以微软对 GB2312 的进行了拓展,GBK 向下兼容 GB2312 和 ASCII。 -
GB180302000年,取代了 GBK 成为正式国家标准,该标准收录了27484个汉字,同时还收录了一些少数民族文字。它和前面两者的差别是,他是变长的字符集,意味着一个 GB18030 的字可能由 1个、2个或4个字节组成。兼容 GBK,GB2312,ASCII。
Unicode => UTF-8 => UTF-16 的演变
前面讲到的 GB 系列的编码虽然很好的解决了汉字编码问题,但是却无法形成世界统一的字符集,因此,世界需要一个统一的字符集,所以 Unicode 诞生了。
-
Unicode是一个统一的字符集,涵盖了世界上所有的字符,统一用两个字节来表示(后面诞生了4个字节的 unicode),包括 ASCII。虽然统一了字符集,但是 ASCII 字符也变成了2个字节的,这样数据在进行网络传输的时候就会造成流量浪费。所以诞生了 utf-8, utf-16, utf-32 等编码格式,横杠后面的数字代表尝试将单个 unicode 字符压缩成几 bit。 -
UTF-8是用一个字节来尝试表示一个 unicode 字符的编码格式。如果一个字节能容纳得了,那么Unicode 转成 UTF-8 就可以省下一个字节,当一个字节容纳不下的时候,会增加一个字节来尝试表示。所以可能会出现 unicode 只要两个字节,但是转换成 utf-8 会变成 3 或 4 个字节。因此出现了 utf-16。 -
UTF-16是用两个字节来尝试表示一个 unicode 字符的编码格式。当一个 unicode 字符转换UTF-8 需要 3 或 4 个字节的时候,用 UTF-16 的基本都能转换成 2 个字节,所以现在在 windows 下的 unicode 实现大多使用 utf-16 编码。
参考文章
vscode 插件之—— Remote-SSH
Remote-SSH

文档介绍(翻译)
Remote-SSH扩展使您可以将带有SSH服务器的任何远程计算机用作开发环境。这可以在各种情况下极大地简化开发和故障排除。您可以:
- 在您部署到本地操作系统的同一操作系统上进行开发,或使用比本地计算机更大,更快或更专业的硬件。
- 在不同的远程开发环境之间快速交换,并安全地进行更新,而不必担心会影响本地计算机。
- 从多台机器或位置访问现有的开发环境。
- 调试在其他位置(例如客户站点或云中)运行的应用程序。
上手过程演示
- 安装完插件之后,使用 command+shift+p,调出 Remote-SSH: Add New SSH Host

- 再输入 ssh root@你的服务器IP地址 -A

- 在选择你的 ssh 配置,笔者的 ssh 配置在对应路径下

- 右下角弹出 Host added! 的消息提醒,点击 Connect 即可连接

- 此时会打开一个新的 vscode 实例,需要输入服务器用户密码

- 经过一段时间的 Opening Remote 之后,连接上会变成 SSH: 你的 ip 地址
- 点击 Open folder,选择需要打开的服务器文件夹,顶部标题会变成 [SSH: 你的服务器 IP 地址],然后就可以愉快的开始折腾了

- 只要云服务器的带宽大的话,体验应该是很少有卡顿的,我用的是 1m 的云服务器,所以加载文件的时候会卡顿。
一些额外的技巧
- 笔者之前一直在用 sftp 工具来上传文件到服务器,通过这个插件,可以直接在其他 vscode 实例中复制文件并粘贴到服务器上。
- 连上 SSH 后,打开 terminal,对应的命令行也变成了 linux 自带的命令行,可以直接执行各种命令。
如何解决类似 curl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection refused 的问题
背景
笔者最近发现 github 的用户头像和自己文章中的图片显示不出来了。然后今天发现安装 homeBrew 和 nvm 出现了标题的报错信息。

以上是安装 pnpm 的报错信息,可以发现,脚本需要到 raw.githubusercontent.com 上拉取代码。
网上搜索了一下,发现是 github 的一些域名的 DNS 解析被污染,导致DNS 解析过程无法通过域名取得正确的IP地址。
DNS 污染
DNS 污染,感兴趣的朋友可以去了解一下。
解决方案
打开 https://www.ipaddress.com/ 输入访问不了的域名

查询之后可以获得正确的 IP 地址
在本机的 host 文件中添加,建议使用 switchhosts 方便 host 管理
199.232.68.133 raw.githubusercontent.com
199.232.68.133 user-images.githubusercontent.com
199.232.68.133 avatars2.githubusercontent.com
199.232.68.133 avatars1.githubusercontent.com
添加以上几条 host 配置,页面的图片展示就正常了,homebrew 也能装了,nvm 也行动灵活了。
内存泄露是什么?如何定位和优化
JavaScript 内存泄露
程序未能释放已经不再使用的内存,即存在不需要的引用。
JavaScript 是垃圾回收语言,在代码中创建对象和变量会占用内存,但是 JavaScript 是有自己的内存回收机制,可以确定那些变量不再需要,并将其清除。
导致内存泄露的细节
意外的全局变量
- 通过 'use strict'; 指定严格模式,避免意外增加全局变量
- 尽量避免通过全局变量来存储大量数据 或者 完成后将其置空或重新分配
- 没有用变量定义声明
- 构造函数不小心被调用,内部的 this 指向了全局
被遗忘的计时器和回调函数
- setInterval / clearInterval
- addEventListener / removeEventListener
Set/Map
- add 之后需要显式 delete 再设置为 null 才能释放
- 否则使用 weakSet / weakMap 的弱引用特性,内存回收不会考虑这个值是否存在
订阅发布事件监听器
- 订阅发布事件有三个方法 emit 、on 、off
- 自定义的订阅发布事件没有 off 的话,该内存将无法回收
闭包
- 不恰当使用闭包,比如调用闭包函数返回一个方法,但不使用一个变量去保存闭包的返回的引用
脱离 dom 的引用
- 我们获取了一个 dom 并赋值到一个变量,删除了包含该 dom 的页面,但如果这个变量没有被回收,就会出现内存泄露
内存生命周期
分配你所需要的内存
- JavaScript 自动分配,定义常量,变量,函数,对象
使用分配到的内存(读、写)
- 获取定义的变量值,将变量传入函数参数内存区域
不需要时将其释放\归还
-
垃圾回收算法
-
引用计数
- 零引用的情况下,自动清除
- 有些场景下需要显式指定变量为 null
- 循环引用的情况下无法处理
-
标记清除
- 代码执行的时候,进入不同的作用域对变量进行不同的作用域的标记,离开对应的作用域的时候,对应的变量就可以被回收。
- 全局作用域只能在页面销毁的时候才会被回收或者显式的
delete window.a
内存泄露定位
- 泄漏引起内存使用的周期性增加
- 一次发生的泄漏,并且不会进一步增加内存
读前端早早聊-前端规划能力总结
前端规划体系
为何要做规划
不同的发展阶段要解决的问题不光是量的区别,问题的类型也发生了变化,那么所需的能力也自然会发生变化
如果我们提前知道每个阶段或者级别所需要的技能和能力,并且在练习和写代码的过程中刻意练习这些技能,那我们可以加速这个从当前阶段跨向下一个阶段的过程
规划有什么用?
价值层面
- 团队协作目标感更强更聚焦、协同性较好,更容易产出比较好的成果,减少重复建设
- 设计的解决方案考虑得更加完备
能力
- 从解决短期项目问题,到解决长期复杂问题
- 从解决自己的问题到解决大家的问题
- 锻炼自己从单点到横向,纵向,全局,长期,深入,多视角,多维度的思考能力
- 建立思考框架,让自己思考问题的过程更加完整有序
规划的思考方式
从发散到收敛的过程
- 分析各种数据
- 线上问题
- 各端的用户反馈
规划的思考框架
现象与问题的识别
-
先看现象和问题,它会决定我们做规划的完整性
-
问题变得更加的完整或者全面
-
追问法,一般要问三层
-
关键词联想
-
分维度思考
- 事情发展到什么阶段
- 数据分析发现的情况
- 用户价值的未来预判
-
问题不重复,不遗漏
-
-
定位
-
现象和问题明确清楚
-
做定位,做定位的时候我们就要去收敛了
- 收敛到一个问题域的交集
- 形成了解决问题域的范围
-
-
梳理定位的模板
- 面向和围绕什么样的场景
- 通过什么样的方式
- 构建什么样的解决方案或者产品
- 帮助什么样的用户提供什么样的价值?
-
找定位的过程
- 找差异化价值的过程
- 哪些事情再难你也一定要做,哪些事情再简单你也不做
目标
-
我们要做到什么程度,或者说在什么阶段做到什么程度,这个就是定目标的过程
-
目标拆解
- 树形子目标
- 里程碑目标
-
首先需要有一个聚焦的东西,让我们能一起往目标去走,之后才是走多远
技术架构/技术产品架构
-
步骤
- 之前梳理的出来的要解决的问题想解决方案,把这些解决方案根据不同的维度列出来
- 围绕你的架构目标去定义所需要解释的关系
- 逻辑自洽,内容、角色之间的关系能够讲得清楚
- 针对关系中的核心问题,设计解决方案
- 拿一个实际的案例或问题套进去
-
问题
- 照搬
- 逻辑自洽
- 目标不清晰
- 只有架没有构
打法与策略
项目计划
-
瀑布流 water fall
-
敏捷迭代 scrum
-
常见的项目管理工具
- WBS,Omniplan,Teambition,Redmine
原文链接
defer 和 async 以及 type="module" 的差异
defer 和 async 以及 type="module" 的差异
创建型模式-单例模式
定义
单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,它提供全局访问的方法。
场景
有一些对象我们往往只需要一个,比如 线程池,全局缓存,浏览器中的 window 对象。
在 javascript 中的单例模式
单例模式更加适合传统的面向对象语言中的类。在 javascript 中生搬单例模式的概念并无意义。
js 中两种单例模式的体现,本质都是减少全局变量,因为全局变量也可以理解为一种单例
- 使用命名空间
- 使用闭包封装私有变量
不透明的/标准的单例模式
class Singleton {
// 静态私有成员变量
// 提供全局访问的方法
static getInstance(name) {
// 确保一个类只有一个实例
if (!this.instance) {
// 自行实例化并提供这个实例
this.instance = new Singleton(name)
}
return this.instance
}
// 私有构造函数
constructor(name) {
this.name = name
this.instance = null
}
// 公有的静态工厂方法
getName() {
return this.name
}
}
// 简单的测试
let sven1 = Singleton.getInstance('sven1')
let sven2 = Singleton.getInstance('sven2')
console.log(sven1 === sven2) // true上述的例子中,不透明的地方体现在我们不知道这是一个单例类,并且跟以往通过 new XXX 的方式来获取对象不同,这里偏要使用 Singleton.getInstance 来获取对象。
透明的单例模式
要实现一个透明的单例模式就需要允许我们使用 new 操作符来获取对象。
我们来看一个在页面中创建唯一的 div 节点的例子。
let CreateDiv = (function() {
let instance
let CreateDiv = function(html) {
if (instance) {
return instance
}
this.html = html
this.init()
return instance = this
}
CreateDiv.prototype.init = function() {
let div = document.createElement('div')
div.innerHTML = this.html
document.body.appendChild(div)
}
// 使用闭包返回真正的 Singleton 构造方法
return CreateDiv
})()
let a = new CreateDiv('sven1')
let b = new CreateDiv('sven2')
console.log(a === b)上述的代码使用自执行的匿名函数和闭包,并且让这个匿名函数返回真正 Singleton 构造方法,增加了一些程序的复杂度,阅读起来也不是很舒服。
使用代理实现单例模式
把负责管理单例的逻辑移到了代理类 proxySingletonCreateDiv 中
// 改造成创建 div 的类,将控制唯一实例的逻辑在代理中实现
class CreateDiv {
constructor(html) {
this.html = html
this.init()
}
init() {
let div = document.createElement('div')
div.innerHTML = this.html
document.body.appendChild(div)
}
}
// 使用代理类实现 proxySingletonCreateDiv
let ProxySingletonCreateDiv = (function(){
let instance
return function(html) {
if (!instance) {
instance = new CreateDiv(html)
}
return instance
}
})()
let a = new ProxySingletonCreateDiv('sven1')
let b = new ProxySingletonCreateDiv('sven2')
console.log(a === b)构造一个通用的代理函数
class CreateDiv {
constructor(html) {
this.html = html
this.init()
}
init() {
let div = document.createElement('div')
div.innerHTML = this.html
document.body.appendChild(div)
}
}
// 通用的单例代理函数
function commonProxySingleton(funClass) {
let instance
let funClass = funClass
return function() {
if (!instance) {
instance = new funClass(arguments)
}
return instance
}
}
// 因为只是一个普通函数,所以不使用 new
let proxySingletonCreateDiv = commonProxySingleton(CreateDiv)
let a = proxySingletonCreateDiv('sven1')
let b = proxySingletonCreateDiv('sven2')
// 使用 new 的话 this 指向为 commonProxySingleton 的实例
// let ProxySingletonCreateDiv = new commonProxySingleton(CreateDiv)
// let c = ProxySingletonCreateDiv('sven3')
console.log(a === b)惰性单例
在需要实例化对象的时候才创建实例,将创建实例对象的职责和管理单例的职责分别开来,独立不互相影响。
利用闭包来实现。
// 惰性单例
let createLoginLayer = (function() {
let div
return function() {
if (!div) {
div = document.createElement('div')
div.innerHTML = '我是登录浮窗'
div.style.display = 'none'
document.body.appendChild(div)
}
return div
}
})()
document.getElementById('loginBtn').onclick = function() {
let loginLayer = createLoginLayer()
loginLayer.style.display = 'block'
}通用的惰性单例
let getSingle = function(fn) {
let result
return function() {
return result || (result = fn.apply(this, arguments))
}
}
// 创建登录浮窗
let createLoginLayer = function() {
let div = document.createElement('div')
div.innerHTML = '我是登录浮窗'
div.style.display = 'none'
document.body.appendChild(div)
return div
}
// 惰性函数包裹
let createSingleLoginLayer = getSingle(createLoginLayer)
document.getElementById('loginBtn').onclick = function() {
let loginLayer = createSingleLoginLayer()
loginLayer.style.display = 'block'
}
// 直接传入回调函数创建 iframe
let createSingleIFrame = getSingle(function() {
let iframe = document.createElement('iframe')
document.body.appendChild(iframe)
return iframe
})
document.getElementById('loginBtn').onclick = function() {
let loginLayer = createSingleIFrame()
loginLayer.src = 'http://baidu.com';
}优点
- 提供了对唯一实例的受控访问。可以严格控制客户怎样以及何时访问它。
- 减少资源的消耗。由于在系统内存中只存在一个对象,因此可以节约系统资源。对于需要频繁创建和销毁的对象,单例模式无疑可以提高系统的性能。
- 允许可变数目的实例。我们可以基于单例模式进行扩展,使用与单例控制相似的方法来获得指定个数的对象实例。
缺点
- 由于单例模式中没有抽象层,因此单例类的扩展有很大的困难。
- 单例类的职责过重,在一定程度上违背了“单一职责原则”,因为单例类既充当了工厂角色,提供了工厂方法,同时又充当了产品角色,包含一些业务方法。
- 滥用单例将带来一些负面问题,如为了节省资源将数据库连接池对象设计为单例类,可能会导致共享连接池对象的程序过多而出现连接池溢出;现在很多面向对象语言(如Java、C#)的运行环境都提供了自动垃圾回收的技术,因此,如果实例化的对象长时间不被利用,系统会认为它是垃圾,会自动销毁并回收资源,下次利用时又将重新实例化,这将导致对象状态的丢失。
使用场景
- 只需要一个实例对象,如要求提供一个唯一的序列号生成器,或者需要考虑资源消耗太大而只允许创建一个对象。
- 客户调用类的单个实例只允许使用一个公共访问点,除了该公共访问点,不能通过其他途径访问该实例。
- 要求一个类只有一个实例时才应当使用单例模式。反过来,如果一个类可以有几个实例共存,就需要对单例模式进行改进,使之成为多例模式
总结
- 单例模式是一种创建型模式。
- 单例模式的要点有三个:一是某个类只能有一个实例;二是它必须自行创建这个实例;三是它必须自行向整个系统提供这个实例。
- 单例类拥有一个私有构造函数,确保用户无法通过new关键字直接实例化它。除此之外,该模式中包含一个静态私有成员变量与静态公有的工厂方法。该工厂方法负责检验实例的存在性并实例化自己,然后存储在静态成员变量中,以确保只有一个实例被创建。
【读书笔记】小岛经济学

JavaScript 的事件循环机制 及 NodeJS 的差异
HTTPS全过程和中间人攻击
HTTPS 全过程
分两个阶段
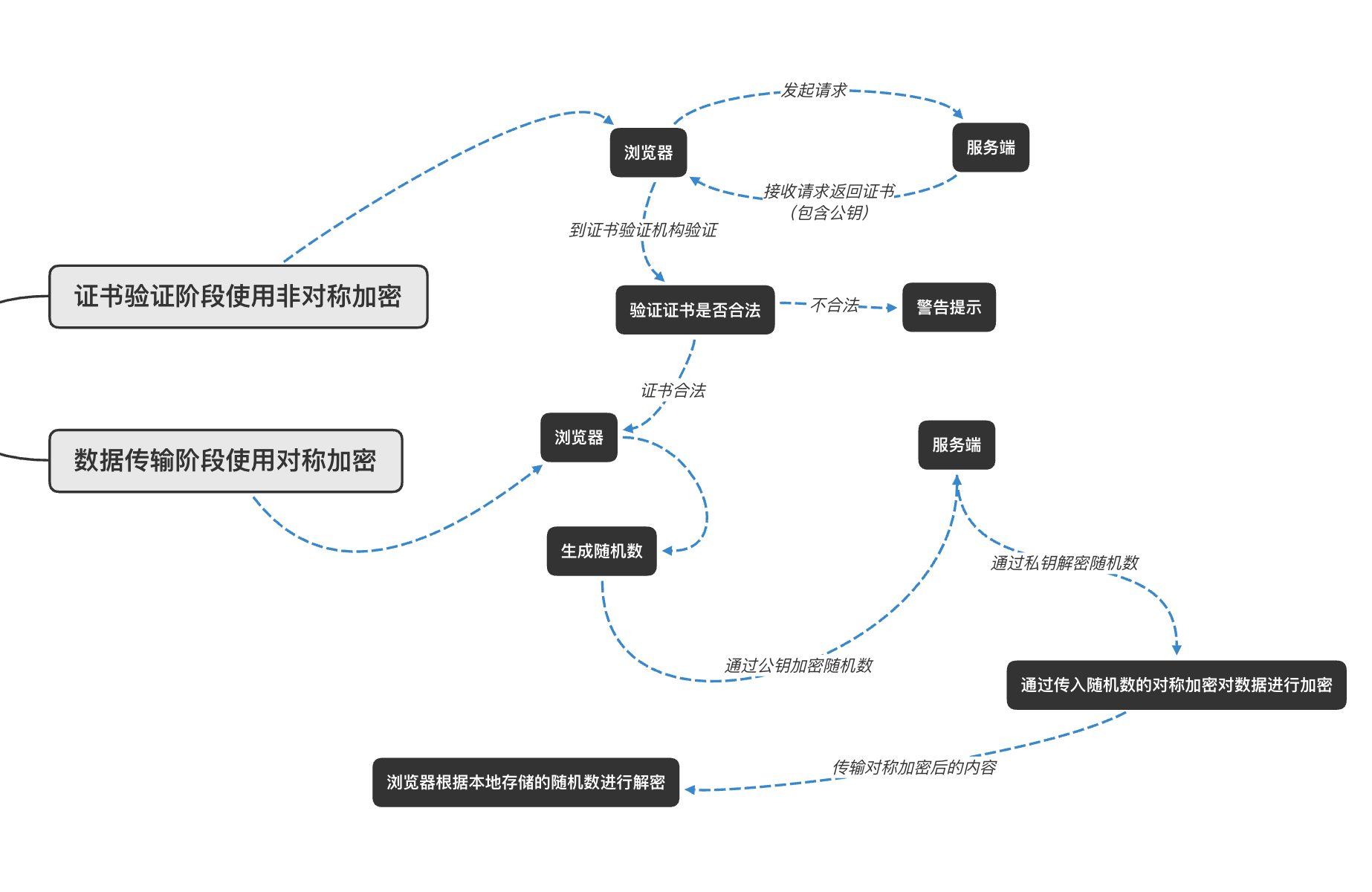
中间人攻击
在服务端和客户端之间存在一个中间人角色

常用的数组方法总结
判断数组类型
- Object.prototype.toString.call([]) === '[object Array]'
- Array.isArray
转换类数组
- Array.from
- Array.prototype.slice.call(arguments)
数组方法
-
push/pop 为一组
-
shift/unshift 为一组
-
some/every 为一组
-
map/filter 为一组
-
includes/find/findIndex为一组
-
slice/splice为一组
-
concat/join为一组
-
from/isArray 为一组
-
indexOf/lastIndexOf 为一组
-
reduce 单独一组,对数组中每个元素升序执行 reducer 函数,将结果汇总到累加器中最终返回
- accumulator
- currentValue
- currentIndex
- sourceArray
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.