This repository is now an historical artifact. It was the original LSP support for haskell, which is now provided by
https://github.com/haskell/haskell-language-server
![]()


This project aims to be the universal interface to a growing number of Haskell tools, providing a fully-featured Language Server Protocol server for editors and IDEs that require Haskell-specific functionality.
- Haskell IDE Engine (HIE)
- Features
- Installation
- Configuration
- Project Configuration
- Editor Integration
- Docs on hover/completion
- Contributing
- Documentation
- Troubleshooting
- Emacs
- DYLD on macOS
- macOS: Got error while installing GHC 8.6.1 or 8.6.2 - dyld: Library not loaded: /usr/local/opt/gmp/lib/libgmp.10.dylib
- macOS: Got error while processing diagnostics: unable to load package
integer-gmp-1.0.2.0 - cannot satisfy -package-id <package>
- Liquid Haskell
- Profiling
haskell-ide-engine.
-
Supports plain GHC projects, cabal projects(sandboxed and non sandboxed) and stack projects
-
Fast due to caching of compile info
-
Uses LSP, so should be easy to integrate with a wide selection of editors
-
Diagnostics via hlint and GHC warnings/errors
-
Code actions and quick fixes via apply-refact
-
Type information and documentation(via haddock) on hover
-
Jump to definition
-
List all top level definitions
-
Highlight references in document
-
Completion
-
Formatting via brittany
-
Renaming via HaRe (NOTE: HaRe is temporarily disabled)
-
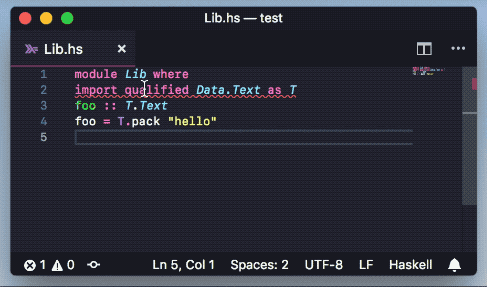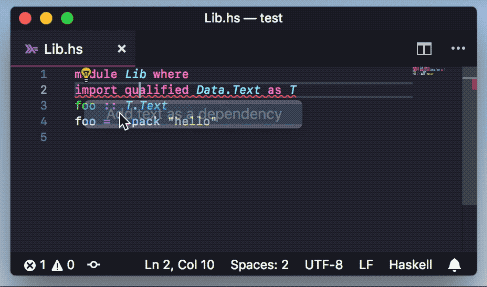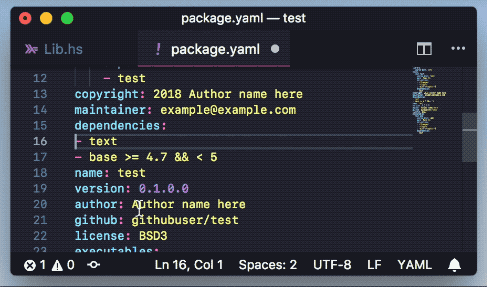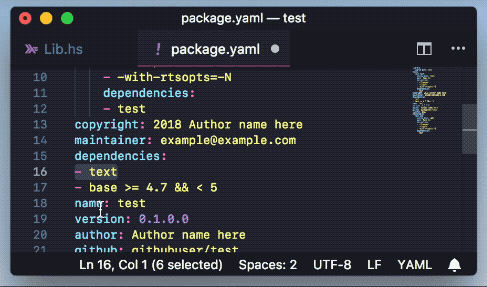
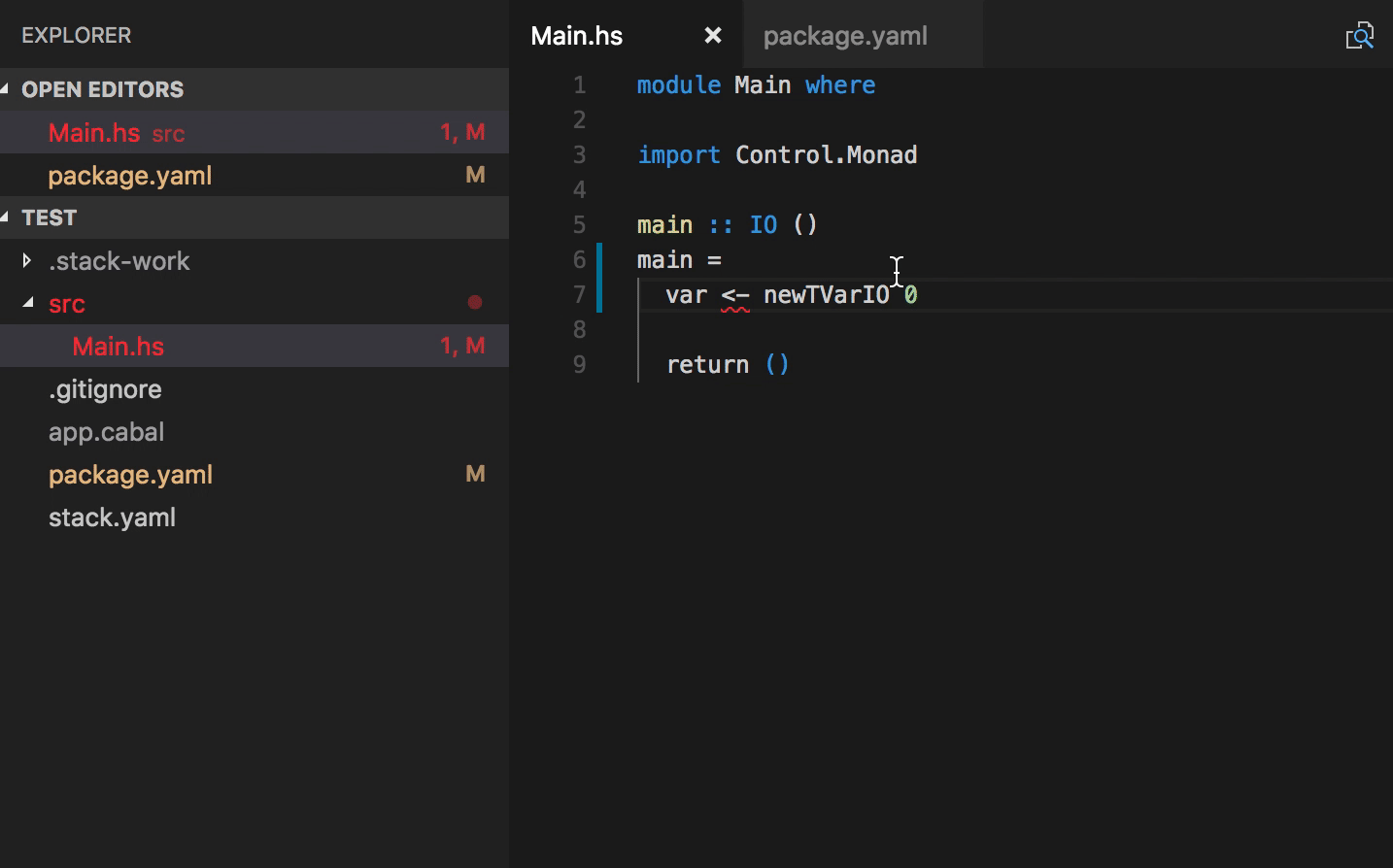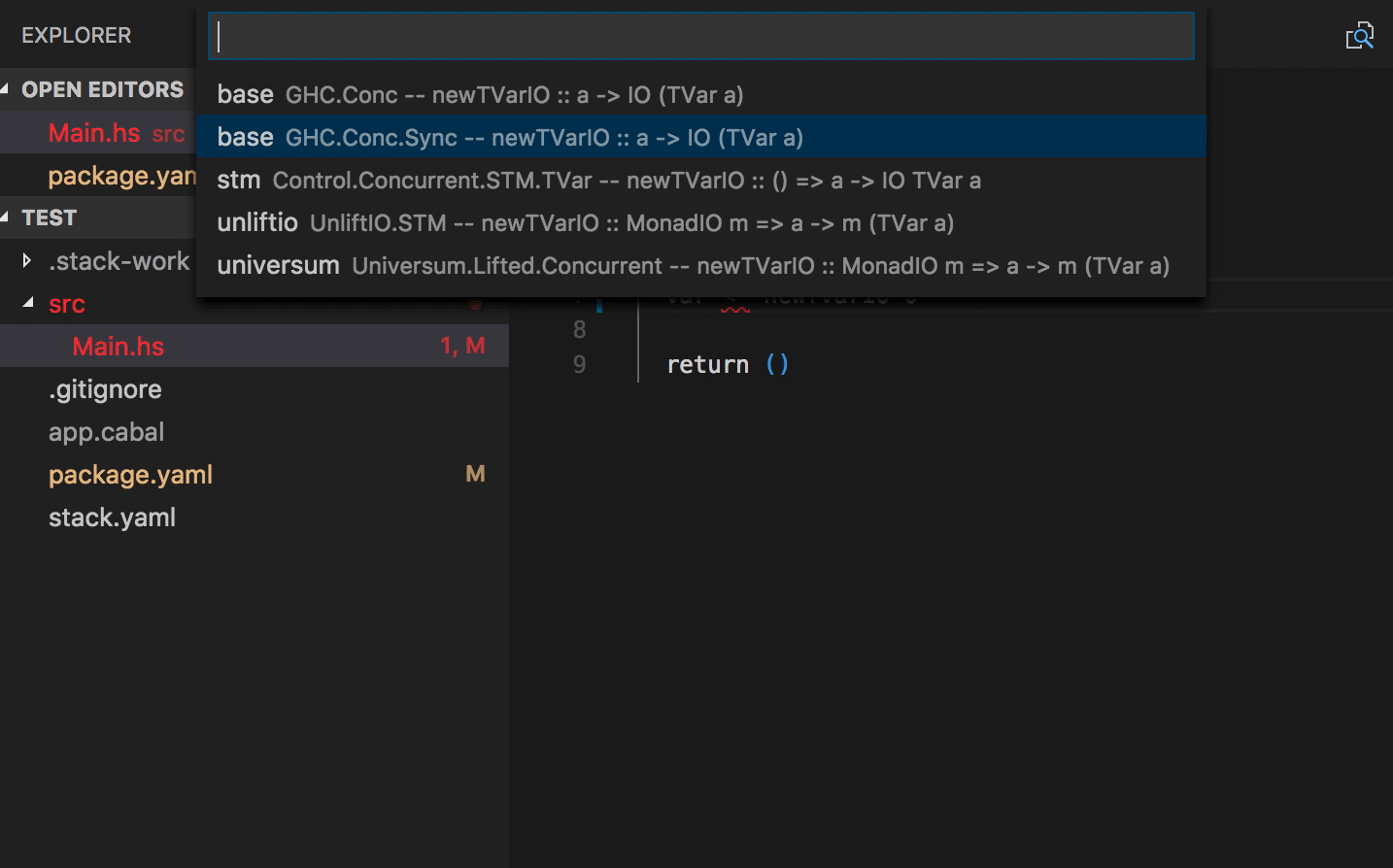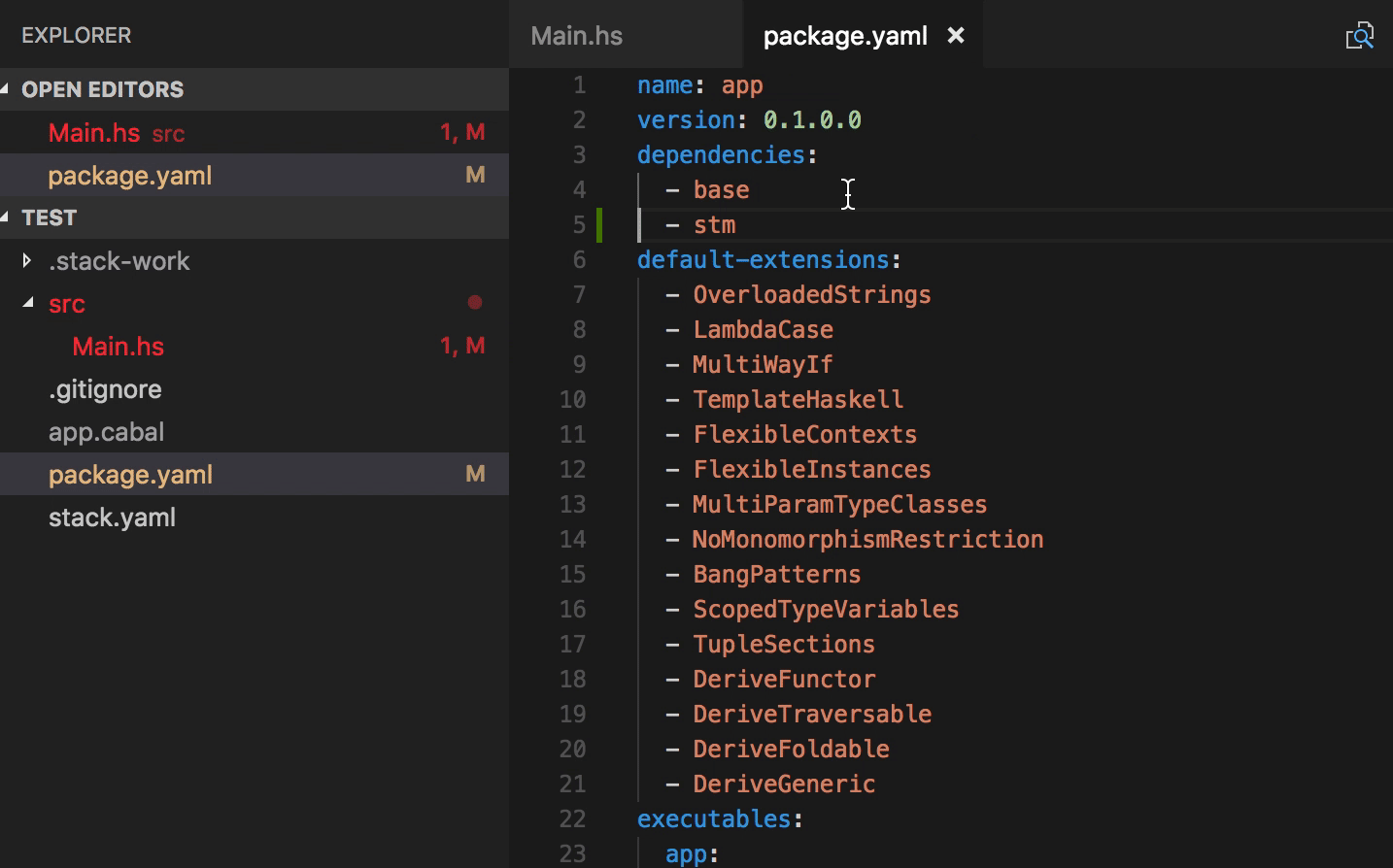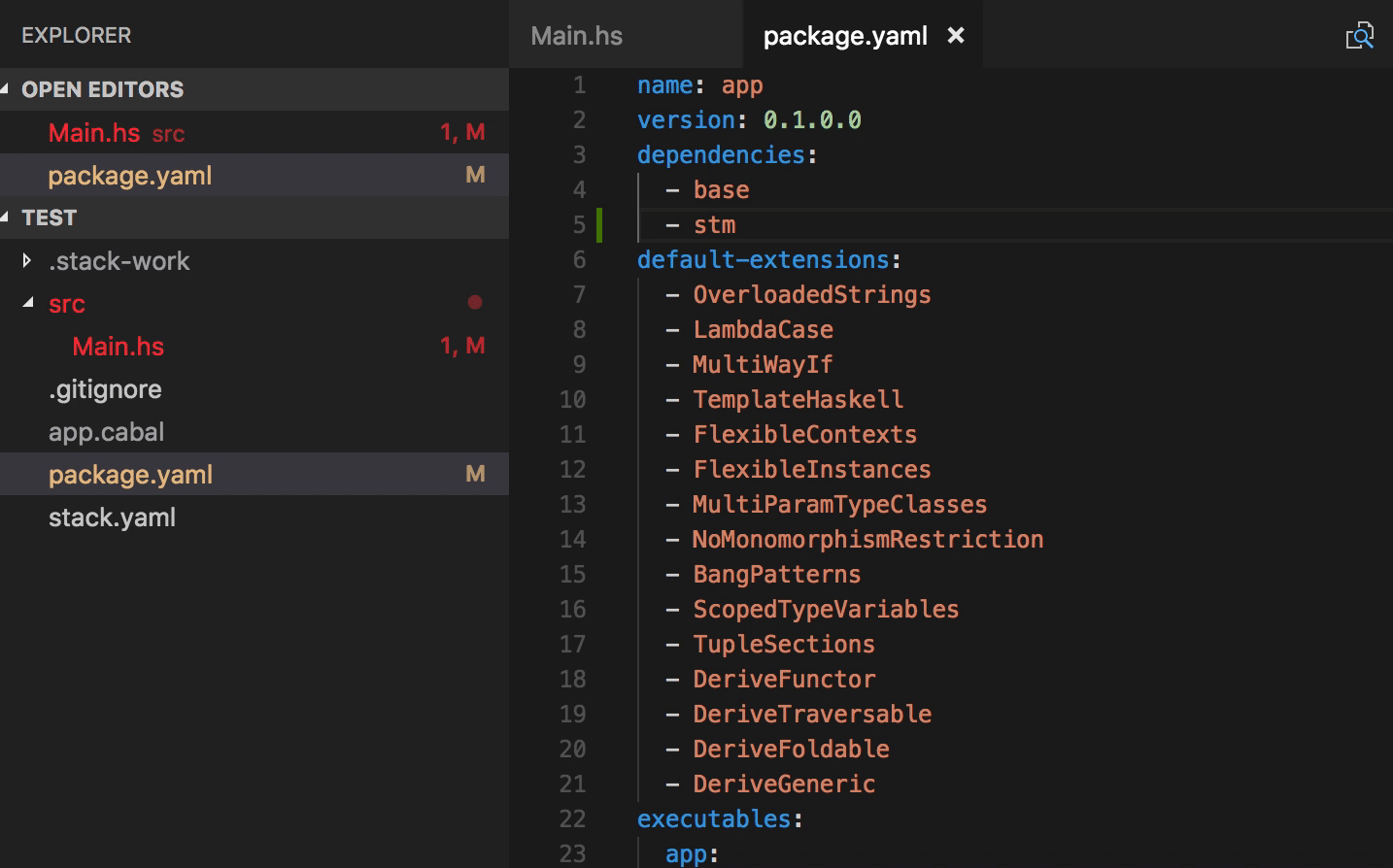
Add packages to cabal and hpack package files
-
Typo quick fixes
-
Add missing imports (via hsimport)








Follow the instructions at https://github.com/Infinisil/all-hies
A haskell-ide-engine package is available on the AUR.
Install it using Aura:
# aura -A haskell-ide-engine
To change which GHC versions are supported by HIE, use
# aura -A --hotedit haskell-ide-engine
and modify the value of _enabled_ghc_versions.
Reducing the number of supported GHC versions makes HIE compile faster.
VS Code provides the ability to develop applications inside of a Docker container (called Devcontainers) https://code.visualstudio.com/docs/remote/containers
There is a community Devcontainer setup which installs and configures GHC + HIE 8.6.5 and the necessary VS Code extensions to integrate them into the editor.
https://github.com/hmemcpy/haskell-hie-devcontainer
To install HIE, you need stack version >= 2.1.1.
HIE builds from source code, so there's a couple of extra steps.
stackmust be in your PATHgitmust be in your PATH- Stack local bin directory must be in your PATH. Get it with
stack path --local-bin
Tip: you can quickly check if some command is in your path by running the command. If you receive some meaningful output instead of "command not found"-like message then it means you have the command in PATH.
On Linux you will need install a couple of extra libraries (for Unicode (ICU) and NCURSES):
Debian 9/Ubuntu 18.04 or earlier:
sudo apt install libicu-dev libtinfo-dev libgmp-devDebian 10/Ubuntu 18.10 or later:
sudo apt install libicu-dev libncurses-dev libgmp-dev # also zlib1g-dev if not installedFedora:
sudo dnf install libicu-devel ncurses-devel # also zlib-devel if not already installedIn order to avoid problems with long paths on Windows you can do either one of the following:
-
Clone the
haskell-ide-engineto a short path, for example the root of your logical drive (e.g. toC:\hie). If this doesn't work or you want to use a longer path, try the second option. -
If the
Local Group Policy Editoris available on your system, go to:Local Computer Policy -> Computer Configuration -> Administrative Templates -> System -> FilesystemsetEnable Win32 long pathstoEnabled. If you don't have the policy editor you can use regedit by using the following instructions here. You also need to configure git to allow longer paths by using unicode paths. To set this for all your git repositories usegit config --system core.longpaths true(you probably need an administrative shell for this) or for just this one repository usegit config core.longpaths true.
In addition make sure hie.exe is not running by closing your editor, otherwise in case of an upgrade the executable can not be installed.
git clone https://github.com/haskell/haskell-ide-engine --recurse-submodules
cd haskell-ide-engineUses the shake build system for predictable builds.
Note, on first invocation of the build script, a GHC is being installed for execution.
The GHC used for the install.hs can be adjusted in shake.yaml by using a different resolver.
Available commands can be seen with:
stack ./install.hs helpRemember, this will take time to download a Stackage-LTS and an appropriate GHC. However, afterwards all commands should work as expected.
The install-script can be invoked via cabal instead of stack with the command
cabal v2-run ./install.hs --project-file install/shake.project <target>or using the existing alias script
./cabal-hie-install <target>Running the script with cabal on windows requires a cabal version greater or equal to 3.0.0.0.
For brevity, only the stack-based commands are presented in the following sections.
Install hie for the latest available and supported GHC version (and hoogle docs):
stack ./install.hs hieInstall hie for a specific GHC version (and hoogle docs):
stack ./install.hs hie-8.6.5
stack ./install.hs dataThe Haskell IDE Engine can also be built with cabal v2-build instead of stack build.
This has the advantage that you can decide how the GHC versions have been installed.
To see what GHC versions are available, the command cabal-hie-install ghcs can be used.
It will list all GHC versions that are on the path and their respective installation directory.
If you think, this list is incomplete, you can try to modify the PATH variable, such that the executables can be found.
Note, that the targets hie and data depend on the found GHC versions.
They install Haskell IDE Engine only for the found GHC versions.
An example output is:
> cabal-hie-install ghcs
******************************************************************
Found the following GHC paths:
ghc-8.4.4: /opt/bin/ghc-8.4.4
ghc-8.6.2: /opt/bin/ghc-8.6.2
******************************************************************If your desired ghc has been found, you use it to install Haskell IDE Engine.
cabal-hie-install hie-8.4.4
cabal-hie-install dataIn general, executing targets with cabal instead of stack have the same behaviour, except they do not install a GHC if it is missing but fail.
If you installed multiple versions of HIE then you will need to use a wrapper script. Wrapper script will analyze your project, find suitable version of HIE and launch it. Enable it by editing VS Code settings like this:
"haskell.useCustomHieWrapper": true,
"haskell.useCustomHieWrapperPath": "hie-wrapper",There are some settings that can be configured via a settings.json file:
{
"haskell": {
"hlintOn": Boolean,
"maxNumberOfProblems": Number
"diagnosticsDebounceDuration" : Number
"liquidOn" : Bool (default False)
"completionSnippetsOn" : Bool (default True)
"formatOnImportOn" : Bool (default True)
"formattingProvider" : String (default "brittany",
alternate "floskell")
}
}
- VS Code: These settings will show up in the settings window
- LanguageClient-neovim: Create this file in
$projectdir/.vim/settings.jsonor setg:LanguageClient_settingsPath
For a full explanation of possible configurations, refer to hie-bios/README.
HIE will attempt to automatically detect your project configuration and set up the environment for GHC.
cabal.project |
stack.yaml |
*.cabal |
Project selected |
|---|---|---|---|
| ✅ | - | - | Cabal v2 |
| ❌ | ✅ | - | Stack |
| ❌ | ❌ | ✅ | Cabal (v2 or v1) |
| ❌ | ❌ | ❌ | None |
However, you can also place a hie.yaml file in the root of the workspace to
explicitly describe how to setup the environment. For example, to state that
you want to use stack then the configuration file would look like:
cradle:
stack:
component: "haskell-ide-engine:lib"If you use cabal then you probably need to specify which component you want
to use.
cradle:
cabal:
component: "lib:haskell-ide-engine"If you have a project with multiple components, you can use a cabal-multi cradle:
cradle:
cabal:
- path: "./test/dispatcher/"
component: "test:dispatcher-test"
- path: "./test/functional/"
component: "test:func-test"
- path: "./test/unit/"
component: "test:unit-test"
- path: "./hie-plugin-api/"
component: "lib:hie-plugin-api"
- path: "./app/MainHie.hs"
component: "exe:hie"
- path: "./app/HieWrapper.hs"
component: "exe:hie-wrapper"
- path: "./"
component: "lib:haskell-ide-engine"Equivalently, you can use stack:
cradle:
stack:
- path: "./test/dispatcher/"
component: "haskell-ide-engine:test:dispatcher-test"
- path: "./test/functional/"
component: "haskell-ide-engine:test:func-test"
- path: "./test/unit/"
component: "haskell-ide-engine:test:unit-test"
- path: "./hie-plugin-api/"
component: "hie-plugin-api:lib"
- path: "./app/MainHie.hs"
component: "haskell-ide-engine:exe:hie"
- path: "./app/HieWrapper.hs"
component: "haskell-ide-engine:exe:hie-wrapper"
- path: "./"
component: "haskell-ide-engine:lib"Or you can explicitly state the program which should be used to collect the options by supplying the path to the program. It is interpreted relative to the current working directory if it is not an absolute path.
cradle:
bios:
program: ".hie-bios"The complete configuration is a subset of
cradle:
cabal:
component: "optional component name"
stack:
component: "optional component name"
bios:
program: "program to run"
dependency-program: "optional program to run"
direct:
arguments: ["list","of","ghc","arguments"]
default:
none:
dependencies:
- someDepThere is also support for multiple cradles in a single hie.yaml. An example configuration for Haskell IDE Engine:
cradle:
multi:
- path: ./test/dispatcher/
config:
cradle:
cabal:
component: "test:dispatcher-test"
- path: ./test/functional/
config:
cradle:
cabal:
component: "test:func-test"
- path: ./test/unit/
config:
cradle:
cabal:
component: "test:unit-test"
- path: ./hie-plugin-api/
config:
cradle:
cabal:
component: "lib:hie-plugin-api"
- path: ./app/MainHie.hs
config:
cradle:
cabal:
component: "exe:hie"
- path: ./app/HieWrapper.hs
config:
cradle:
cabal:
component: "exe:hie-wrapper"
- path: ./
config:
cradle:
cabal:
component: "lib:haskell-ide-engine"Note to editor integrators: there is now a hie-wrapper executable, which is installed alongside the hie executable. When this is invoked in the project root directory, it attempts to work out the GHC version used in the project, and then launch the matching hie executable.
All of the editor integrations assume that you have already installed HIE (see above) and that stack put the hie binary in your path (usually ~/.local/bin on linux and macOS).
Install from the VSCode marketplace, or manually from the repository vscode-hie-server.
.config/nixpkgs/config.nix sample:
with import <nixpkgs> {};
let
hie = (import (fetchFromGitHub {
owner="domenkozar";
repo="hie-nix";
rev="e3113da";
sha256="05rkzjvzywsg66iafm84xgjlkf27yfbagrdcb8sc9fd59hrzyiqk";
}) {}).hie84;
in
{
allowUnfree = true;
packageOverrides = pkgs: rec {
vscode = pkgs.vscode.overrideDerivation (old: {
postFixup = ''
wrapProgram $out/bin/code --prefix PATH : ${lib.makeBinPath [hie]}
'';
});
};
}- Make sure HIE is installed (see above) and that the directory stack put the
hiebinary in is in your path- (usually
~/.local/binon unix)
- (usually
- Install LSP using Package Control
- From Sublime Text, press Command+Shift+P and search for Preferences: LSP Settings
- Paste in these settings. Make sure to change the command path to your
hie
{
"clients": {
"haskell-ide-engine": {
"command": ["hie", "--lsp"],
"scopes": ["source.haskell"],
"syntaxes": ["Packages/Haskell/Haskell.sublime-syntax"],
"languageId": "haskell",
},
},
}
Now open a Haskell project with Sublime Text. You should have these features available to you:
- Errors are underlined in red
- LSP: Show Diagnostics will show a list of hints and errors
- LSP: Format Document will prettify the file
As above, make sure HIE is installed. Then you can use Coc, LanguageClient-neovim or any other vim Langauge server protocol client. Coc is recommend since it is the only complete LSP implementation for Vim and Neovim and offers snippets and floating documentation out of the box.
Follow Coc's installation instructions,
Then issue :CocConfig and add the following to your Coc config file.
"languageserver": {
"haskell": {
"command": "hie-wrapper",
"args": ["--lsp"],
"rootPatterns": [
"*.cabal",
"stack.yaml",
"cabal.project",
"package.yaml"
],
"filetypes": [
"hs",
"lhs",
"haskell"
],
"initializationOptions": {
"haskell": {
}
}
}
}If you use vim-plug, then you can do this by e.g.,
including the following line in the Plug section of your init.vim or ~/.vimrc:
Plug 'autozimu/LanguageClient-neovim', {
\ 'branch': 'next',
\ 'do': './install.sh'
\ }
and issuing a :PlugInstall command within Neovim or Vim.
As an alternative to using vim-plug shown above, clone LanguageClient-neovim
into ~/.vim/pack/XXX/start/, where XXX is just a name for your "plugin suite".
set rtp+=~/.vim/pack/XXX/start/LanguageClient-neovim
let g:LanguageClient_serverCommands = { 'haskell': ['hie-wrapper', '--lsp'] }You'll probably want to add some mappings for common commands:
nnoremap <F5> :call LanguageClient_contextMenu()<CR>
map <Leader>lk :call LanguageClient#textDocument_hover()<CR>
map <Leader>lg :call LanguageClient#textDocument_definition()<CR>
map <Leader>lr :call LanguageClient#textDocument_rename()<CR>
map <Leader>lf :call LanguageClient#textDocument_formatting()<CR>
map <Leader>lb :call LanguageClient#textDocument_references()<CR>
map <Leader>la :call LanguageClient#textDocument_codeAction()<CR>
map <Leader>ls :call LanguageClient#textDocument_documentSymbol()<CR>Use Ctrl+xCtrl+o (<C-x><C-o>) to open up the auto-complete menu,
or for asynchronous auto-completion, follow the setup instructions on
LanguageClient.
If you'd like diagnostics to be highlighted, add a highlight group for ALEError/ALEWarning/ALEInfo,
or customize g:LanguageClient_diagnosticsDisplay:
hi link ALEError Error
hi Warning term=underline cterm=underline ctermfg=Yellow gui=undercurl guisp=Gold
hi link ALEWarning Warning
hi link ALEInfo SpellCapIf you're finding that the server isn't starting at the correct project root, it may also be helpful to also specify root markers:
let g:LanguageClient_rootMarkers = ['*.cabal', 'stack.yaml']Make sure HIE is installed, then install the two Atom packages atom-ide-ui and ide-haskell-hie,
$ apm install language-haskell atom-ide-ui ide-haskell-hieInstall HIE along with the following emacs packages:
Make sure to follow the instructions in the README of each of these packages.
Install HIE, and then add the following to your .spacemacs config,
(defun dotspacemacs/layers ()
"..."
(setq-default
;; ...
dotspacemacs-configuration-layers
'(
(haskell :variables haskell-completion-backend 'lsp)
lsp
)
))Now you should be able to use HIE in Spacemacs.
Oni (a Neovim GUI) added built-in support for HIE, using stack, in #1918. If you need to change the configuration for HIE, you can overwrite the following settings in your ~/.config/oni/config.tsx file (accessible via the command palette and Configuration: Edit User Config),
export const configuration = {
"language.haskell.languageServer.command": "stack",
"language.haskell.languageServer.arguments": ["exec", "--", "hie"],
"language.haskell.languageServer.rootFiles": [".git"],
"language.haskell.languageServer.configuration": {},
}HIE supports fetching docs from haddock on hover. It will fallback on using a hoogle db(generally located in ~/.hoogle on linux) if no haddock documentation is found.
To generate haddock documentation for stack projects:
$ cd your-project-directory
$ stack haddock --keep-goingTo enable documentation generation for cabal projects, add the following to your ~/.cabal/config
documentation: True
To generate a hoogle database that hie can use
$ cd haskell-ide-engine
$ stack --stack-yaml=<stack.yaml you used to build hie> exec hoogle generateOr you can set the environment variable HIE_HOOGLE_DATABASE to specify a specific database.
Please see the note above about the new haskell-language-server project.
This project is not started from scratch:
- See why we should supersede previous tools
- Check the list of existing tools and functionality
- See more other tools and IDEs for inspiration
❤️ Haskell tooling dream is near, we need your help! ❤️
- Register in our google group mailing list.
- Join our IRC channel at
#haskell-ide-engineonfreenode. - Fork this repo and hack as much as you can.
- Ask @alanz or @hvr to join the project.
Haskell-ide-engine can be used on its own project. We have supplied
preset samples of hie.yaml files for stack and cabal, simply copy
the appropriate template to hie.yaml and it shoule work.
hie.yaml.cblfor cabalhie.yaml.stackfor stack
All the documentation is in the docs folder at the root of this project.
Have a look at
With the lsp-mode client for Emacs, it seems that the document can very easily get out of sync between, which leads to parse errors being displayed. To fix this, enable full document synchronization with
(setq lsp-document-sync-method 'full)emacs-direnv loads environment too late
emacs-direnv sometimes loads the environment too late, meaning lsp-mode won't be able to find correct GHC/cabal versions. To fix this, add a direnv update hook after adding the lsp hook for haskell-mode (meaning the direnv hook is executed first, because hooks are LIFO):
(add-hook 'haskell-mode-hook 'lsp)
(add-hook 'haskell-mode-hook 'direnv-update-environment)If you hit a problem that looks like can't load .so/.DLL for: libiconv.dylib (dlopen(libiconv.dylib, 5): image not found), it means that libraries cannot be found in the library path. We can hint where to look for them and append more paths to DYLD_LIBRARY_PATH.
export DYLD_LIBRARY_PATH="$DYLD_LIBRARY_PATH:/usr/lib:/usr/local/lib"
On practice /usr/local/lib is full of dylibs linked by brew. After you amend DYLD_LIBRARY_PATH, some of the previously compiled application might not work and yell about incorrect linking, for example, dyld: Symbol not found: __cg_jpeg_resync_to_restart. You may need to look up where it comes from and remove clashing links, in this case it were clashing images libs:
$ brew unlink libjpeg
$ brew unlink libtiff
$ brew unlink libpngRecompile.
macOS: Got error while installing GHC 8.6.1 or 8.6.2 - dyld: Library not loaded: /usr/local/opt/gmp/lib/libgmp.10.dylib
These builds have a dependency on homebrew's gmp library. Install with brew: brew install gmp.
Should be fixed in GHC 8.6.3.
Rename the file at ~/.stack/programs/x86_64-osx/ghc-8.4.3/lib/ghc-8.4.3/integer-gmp-1.0.2.0/HSinteger-gmp-1.0.2.0.o to a temporary name.
Should be fixed in GHC 8.8.1.
Make sure that the GHC version of HIE matches the one of the project. After that run
$ cabal configure
and then restart HIE (e.g. by restarting your editor).
Delete any .ghc.environment* files in your project root and try again. (At the time of writing, cabal new-style projects are not supported with ghc-mod)
Try running cabal update.
Liquid Haskell requires an SMT solver on the path. We do not take care of installing one, thus, Liquid Haskell will not run until one is installed. The recommended SMT solver is z3. To run the tests, it is also required to have an SMT solver on the path, otherwise the tests will fail for Liquid Haskell.
If you think haskell-ide-engine is using a lot of memory then the most useful
thing you can do is prepare a profile of the memory usage whilst you're using
the program.
- Add
profiling: Trueto the cabal.project file ofhaskell-ide-engine cabal new-build hie- (IMPORTANT) Add
profiling: Trueto thecabal.projectfile of the project you want to profile. - Make a wrapper script which calls the
hieyou built in step 2 with the additional options+RTS -hd -l-au - Modify your editor settings to call this wrapper script instead of looking for
hieon the path - Try using
h-i-eas normal and then process the*.eventlogwhich will be created usingeventlog2html. - Repeat the process again using different profiling options if you like.
haskell-ide-engine contains the necessary tracing functions to work with ghc-events-analyze. Each
request which is made will emit an event to the eventlog when it starts and finishes. This way you
can see if there are any requests which are taking a long time to complete or are blocking.
- Make sure that
hieis linked with the-eventlogoption. This can be achieved by adding the flag to theghc-optionsfield in the cabal file. - Run
hieas normal but with the addition of+RTS -l. This will produce an eventlog calledhie.eventlog. - Run
ghc-events-analyzeon thehie.eventlogfile to produce the rendered SVG. Warning, this might take a while and produce a big SVG file.
The default options for ghc-events-analyze will produce quite a wide chart which is difficult to view. You can try using less buckets in order
to make the chart quicker to generate and faster to render.
ghc-events-analyze hie.eventlog -b 100
This support is similar to the logging capabilities built into GHC.


















































































































































































































