blogs's People
Contributors
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")

Stargazers

Watchers

blogs's Issues
尘归尘,土归土——业务归业务,技术归技术。
随着分布式、微服务的火爆,跨系统的服务调用也变得常见起来。这使得我们在线上追查问题的时候,常常要查阅多个系统的日志。
这时候,问题就出现了。如何确定服务A中的某条日志,对应的是服务B中的一个操作呢?
我们的开发人员提出了一个简单的方案:每次服务调用时,调用方都将一些技术性的数据封装在header中;服务方从header中获取到数据后,记录到日志中(或者做其它必要的操作)。
初版
这个方案的思路无疑是正确的。不过其最初的实现方式么,我实在不敢苟同。因为它要求每次调用服务,都按这个格式来封装数据:
{
"header":{
"traceId":xxxx,// 一次请求的唯一键
"timestampe":zzzz, // 发起 请求的时间戳
"fromSystem":systemA,
"requestId":yyyy, // 业务数据的唯一键
"others":aaaa // 一些其它数据
},
"body":{
// 业务数据
}
} 这个方案的确解决了问题。但是同时它又引入了新的问题。
第一个问题出在requestId字段上。按照方案要求,它应该是业务数据的唯一键,一般就是数据库主键。最主要的问题是,不管用什么样的唯一键,这个字段都应属于业务数据,而非请求头中的技术数据——前者对于业务逻辑往往必不可少,后者则对业务可有可无、为技术上锦上添花。将业务数据放入请求头中,混淆了业务与技术的边界,为后续的变更、扩展带来不小的麻烦。
这套方案中“混淆业务与技术边界”的地方还不止这一处。它将header与body全部放在请求体中——例如http的RequestBody,或JMS的MessageBody中,使得每一段调用服务的业务代码中,都要处理header与body。这次,应当由技术框架承担的功能被写到业务代码中,技术与业务的边界再一次混淆。这次混淆不仅增加了业务代码的代码量和重复率,还导致大量的老代码无法顺利的接入,更为以后的扩展埋下了天坑——如果我们需要统一地再加一个字段怎么办?
说真的,这个方案让我回忆起很久以前在jsp页面上写代码的感觉。HTML标签、CSS样式、数据库事务、业务代码混杂在一起,熬成一锅大杂烩。虽然这样也能够实现业务功能,但是再想改动任何一个点,都难于上青天。
再版
第二套方案中,我们首先去掉了header中的requestId字段。这样,避免了业务代码对技术框架的入侵。
第二步,是避免技术框架入侵业务代码。我们的做法是将header字段放到http的请求头(header)或者JMS消息属性(MessageProperties)中。这样,业务代码仍如以前一样,只需要处理body内的数据。由技术框架提供header的写入和读取功能。这样,通过一些配置(如RestTemplate的拦截器等),就可以把旧代码全部按新规范进行处理。
完成这两步改造后,后续再修改、添加header字段时,只需要对框架代码进行修改即可。
后记
我与身边的开发同事讨论设计原则、设计模式时,常常被投以不理解的眼光:这种东西太理论/理想化了,实践中根本用不上、没必要用、性价比太低。
然而初版方案中,“单一职责”原则被无情的践踏——业务代码背负了技术框架的职责,技术框架也背上了业务代码的包袱。这是其低扩展性问题的根源。
但是,这个观点并没有得到同事们的认同。实际上,再版方案也并没有被通过施行——我们匆匆忙忙的上线了初版方案。
唉……
文件导入基础工具使用说明
基本思路和目标
把excel文件遍历工作抽取为通用工具,方便大家专注业务逻辑。
把excel数据转换为java对象的工作抽取为通用工具。
为excel数据和java对象的类型转换提供扩展,方便大家根据自己的特定需求进行扩展。
类结构
class diagram
FileImportService.java
FileImportService定义了顶层接口。使用字节数组作为入参有两个考虑。一是导入时的文件类型可能有File、MultipartFile、各种InpurtStream等,用byte[]可以统一接口;二是如果统一用InputStream,可能涉及到谁来关闭流、释放资源的问题。
这个类上声明的泛型类型 T,即文件数据转换后得到的java对象列表。
ImportFromFile.java
ImportFromFile算一个回调接口。在文件导入过程中,如果T实现了这个接口,那么会将importFile()方法参数中的UserInfo 写进对象中。这个接口主要目的是为java对象写入“创建人”属性。
FileImportServiceAsExcel.java
FileImportServiceAsExcel是处理excel文件导入的实现类。除接口方法和setters方法之外的几个方法(loopSheets()、loopRows()、validHeader()、loopCell()、fillField()等),基本都可以顾名思义的明白其含义(分别是遍历excel中的sheet、遍历sheet中的行、校验sheet中的表头各行、遍历一个row中的各个单元格、把单元格中的数据写入对象的字段中)。
需要说明的主要是几个字段的用法。
headerList
headerList是表头校验列表(实质是一个二维数组)。它定义了作为表头的第x行(x即第一维的下标)、第y列(y即第二维的下标)应该是什么名字。如果列表与excel中的名字不匹配,会报错。
例如,假定excel是这样的(可以参见测试类:FileImportServiceAsExcelTest.java):
林俊 29 19861224
那么,headerList就应当是这样:
List<String> headers = new ArrayList<>(2);
headers.add("姓名");
headers.add("年龄");
headers.add("生日");
List<List<String>> headerList = new ArrayList<>(1);
headerList.add(headers);
this.service.setHeaderList(headerList);cellList
cellList是单元格-字段名映射列表。它的下标是excel中单元格的列下标,它的值是对象中的字段名。
例如,假定上面那个excel需要映射到下面这个java类中(同样参见那个测试类):
public class ExcelModel implements ImportFromFile {
private String name;
private Integer age;
private UserInfo creater;
private Date birthday;
// setters && getters
}那么,cellList的定义就应当是:
List<String> cells = new ArrayList<>(2);
cells.add("name");
cells.add("age");
cells.add("birthday");
this.service.setCellList(cells);值得一提的是,cellList中的字段名支持“链式声明”。例如对象中有一个进件并且初始化时new了一个实例,而字段名声明为lendReqeust.id,那么这里是可以把对应单元格中的数值写入这个进件的id字段的。
claz
claz是类的泛型参数T的实际类型。额外定义一个claz的原因,是这里无法根据泛型参数获取实例。因此只能显式的声明一次claz,然后通过Class#getInstance()方法来获得实例。
// 虽然没有尝试过,但是推测,可以将T定义为超类,而将claz声明为子类。
helper是用来将单元格中数据解析为对象字段的帮助类。这个类在后面细说。
ExcelImportHelper.java
ExcelImportHelper是将单元格中数据解析为对象字段的帮助类。它会根据单元格的类型(Cell.getCellType()),和java对象中字段的类型,从transers中找到合适的转换器(CellValueTranser),然后借助转换器来获得数值、并完成设值。
通过这样的映射,可以做到无论单元格是数值类型、文本类型或其它excel类型,只要transers中有定义,都可以正确的转换到字段类型上来。
单元格类型、java对象中字段的类型和转换器之间的映射关系如下:
// cell.getCellType()即单元格类型,是int类型数据
// claz即java对象中字段的类型,这里取其全限定名(包名.类名)
CellValueTransfer transfer = this.transers[cell.getCellType()].get(claz.getName());
在构造方法中,transers被初始化为长度为6的一个数组,并且已经写入了部分转换器(CELL_TYPE_NUMERIC-> Integer/String/Date/BigDecimal,CELL_TYPE_STRING -> Integer/String/Date/BigDecimal等)。
对于当前没有实现的转换器,或者如果需要针对某个类型扩展特定的转换器,我们可以利用ExcelImportHelper中的一系列set方法来实现。以针对CELL_TYPE_NUMERIC的转换器为例:
/**
* 增加CELL_TYPE_NUMERIC的转换器映射
*
* @param transersMap
*/
public void setTransers4Numeric(Map<String, CellValueTransfer> transersMap) {
this.transers[Cell.CELL_TYPE_NUMERIC].putAll(transersMap);
}通过set方法设值以后,会向transers中加入指定的转换器,并用transersMap中的值覆盖transers中key值相同的转换器。
CellValueTranser.java
CellValueTranser接口,及其子类,都是用来完成实际的转换的。默认的转换操作都比较简单。这里不多赘述。
使用方法
首先,定义一个excel导入服务。其中需要声明:claz名称、headerList值和cellList值。
要注意的是:claz必须是类的全名;headerList是一个二维的list;cellList必须与excel的列长相等,如果excel中部分列不需要映射到类字段上,那么cellList中应将它声明为空字符串或者null。
<!-- // linjun 2016-01-08 THREAD-9674 还款日变更,excel导入服务 -->
<bean id="excelImporter4RepaydateChange"
class="********.common.service.system.FileImportServiceAsExcel">
<property name="claz"
value="********.common.model.credit.RepaydateChangeInfo" />
<property name="headerList">
<list>
<bean class="java.util.ArrayList">
<constructor-arg>
<list>
<value>友信交易号</value>
<value>姓名</value>
<value>身份证</value>
<value>人人贷标ID</value>
<value>标状态</value>
<value>导入时间</value>
<value>放标时间</value>
</list>
</constructor-arg>
</bean>
</list>
</property>
<property name="cellList">
<list>
<value>lendRequestId</value>
<value>name</value>
<value></value>
<value></value>
<value></value>
<value></value>
<value>actualLoanDate</value>
</list>
</property>
</bean>待导入的excel如下。其中只有“友信交易号”、“姓名”和“放标时间”这三列需要转换到java对象中。
*友信交易号 姓名 身份证 人人贷标ID 标状态 导入时间 放标时间
*822290 李忠 37068219780824241X 789061 还款中 2015-12-08 17:41:24.0 2015年12月19日
*822289 杨林 320222197906110018 789045 还款中 2015-12-08 17:32:25.0 2015年12月19日
*822288 郁保四 320222197906110018 789045 还款中 2015-12-08 17:32:25.0 2015年12月18日
*822287 扈三娘 320222197906110018 789045 还款中 2015-12-08 17:32:25.0 2015年12月18日
然后,就可以把这个bean注入并使用了。
/**
* 导入excel文件服务
*/
@Resource(name = "excelImporter4RepaydateChange")
private FileImportService<RepaydateChangeInfo> repaydateChangeImporter;
public void importRepaydateChange(MultipartFile file, Principal user)
throws ServiceException {
UserInfo userInfo = new UserInfo(user.getName());
// 将导入的文件转化为java对象
List<RepaydateChangeInfo> infoList = this.parstInfoList(file, userInfo);
// 处理infoList
……
}遗留问题
最主要的问题是,这个处理逻辑中存在“两次遍历”。将文件转换为java对象,是一次遍历;对java对象列表做业务逻辑操作,这又是一次遍历。无论时间、空间上,复杂度都有点高。这是以后的一个优化点。
不做需求复印机——批量操作流程设计
相信每个技术人员都不会甘心做“需求复印机”。
不做需求复印机,有两种简单的方式。一种是在代码/模块/系统的结构上下功夫,例如前面几篇设计方案(审批、分发等)。另一种则是直接对业务流程开刀,例如这篇文章要举的例子。
背景
大家一定都遇到过“批处理”这类需求。这次的背景就是一个批处理需求。按产品提出的需求,系统流程是这样的: 
如果将这个流程直接“复印”到系统、代码中,显而易见会有性能风险。
思路
这个需求的业务逻辑并不复杂,设计的关注点在于“性能”。性能风险的根源,看起来在于“一次提交N条数据”,实际上在于“同步请求”。因为同步请求会阻塞线程、占用资源,因此它对性能要求比较高。如果不是同步请求,而是异步响应,响应慢点儿其实也无所谓,性能风险自然消弭于无形。因此,我的方案就是用异步回调的方式来完成这个批处理请求。
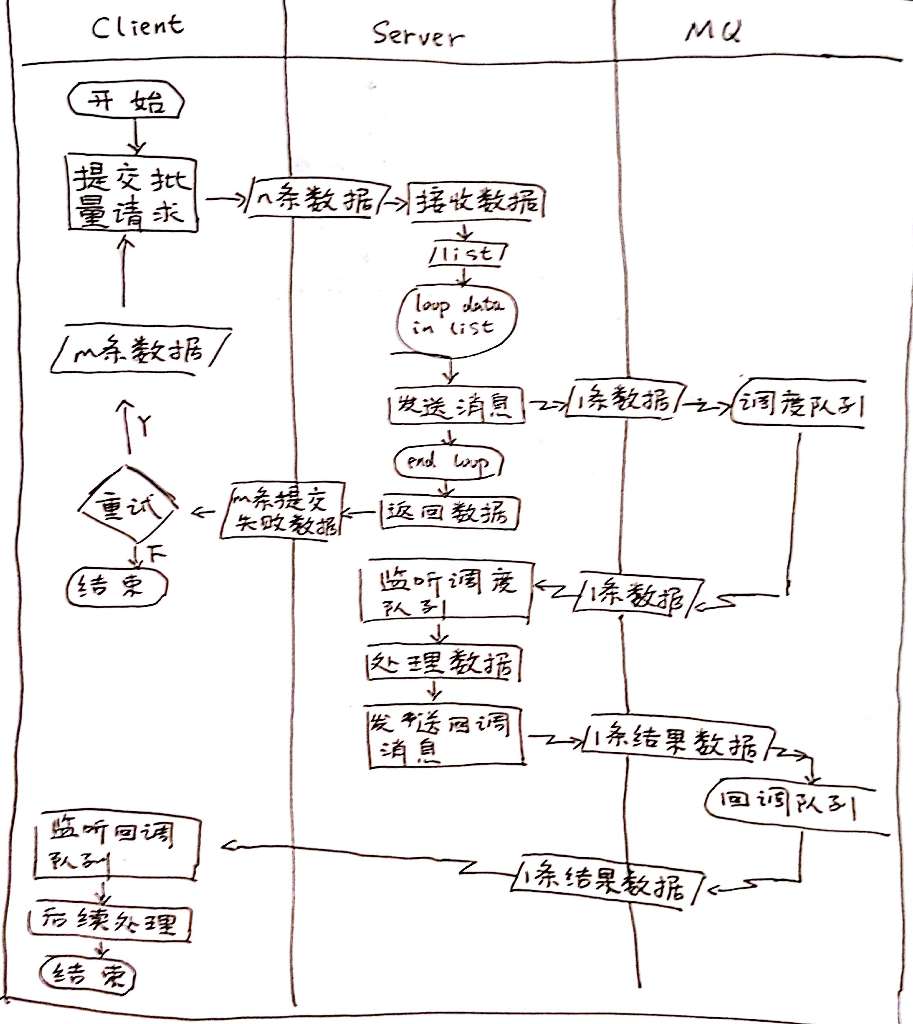
最简单的异步回调流程,就如下图所示。客户端向服务端批量地提交请求;服务端将异步任务提交给调度器后,立刻向客户端返回;然后异步任务再逐个地回调客户端接口,以告知真正的处理结果。

这个简单流程已经足以说明异步回调的思路,其中的问题也显而易见。例如,这个方案中没有对异步任务做持久化、判重、重试、限流的处理。这可能导致任务丢失、调度错误等问题,也可能导致客户端被回调请求压死。
因此,这个简单的异步回调流程中被加入了MQ,即利用消息服务来做异步任务的调度器,并借以解决持久化、重试、限流等问题。如下图所示:
类图与代码
这个方案的设计关键点并不是类结构,而是业务流程。因此,与其它方案的类图、哪怕只是与上面的流程图相比,这次的类图都朴素得多。所以,这次我就偷懒不上类图和代码了。
后记
这个方案其实并不出彩,它的起源只是我不想把产品需求“复印”到代码中而已。但是本质上,它也是一种技术驱动的思路:改变“怎么做”。尽管这个方案还没能进一步地改变“做什么”,但是,改变已从这里开始。
写给大家看的设计书——读后笔记
《写给大家看的设计书》介绍了设计的四个基本原则:亲密性、对齐、重复、对比。作为一个软件“设计师”,我也来聊聊读过这本书之后,我对这四个原则的一点理解。
亲密性
亲密性原则是指:内涵相关联的内容,在结构、关系上也应保持关联。
以软件设计的角度来说,一项业务所包含的功能、一个功能所包含的代码,应该在结构、关系上保持关联。例如把这些代码放到同一个包下、用同一套规则来命名。这样,当我们需要查阅、修改这个功能,需要处理哪些代码就“一望而知”了。
很明显,“亲密性”实际上就是软件工程中常说的“高内聚”。“高内聚”之于软件工程,就如空气之于人一样:重要,却常常被忽视。最常见的一种忽视“高内聚”原则而产生的bad smell,就是不通过继承或组合的方式来新增业务逻辑,而是在原有代码中用if-else/switch-case等方式来扩展。这样一来,新功能的代码就无法放到新功能的“群组”内,进而,在查阅、修改新功能的代码时,无法“一望而知”工作范围、也无法“一望而知”风险范围。
当然,上面的bad smell也可以说是违反了“低耦合”原则导致的。但是必须承认,违反了“高内聚”,则一定会违反“低耦合”。例如,操作Ecxel文件的Service类,却把POI组件泄露到接口之外——这是Excel操作代码不够内聚的缘故;这同时也导致了调用方与POI组件发生耦合,从而违反“低耦合”原则。
“低耦合”可以称为“私密性”原则,不过《写给大家看的设计书》中没有相关论述。这大概是因为,其它领域内的设计是为了充分表达自己的设计目标——要“一望而知”。而软件设计不仅要“一望而知”,还要“一望仅知”。只有这样,才能充分地拆分和管理复杂度。
对齐
“一望而知”各组件的内涵及范围,是“亲密性”原则的优点;而“一望而知”各组件之间的结构、关系,这是“对齐”原则带来的好处。标题对齐,“一望而知”全篇有几个标题;段落对齐,“一望而知”这个标题下有多少个段落。软件设计中会有这样的好事吗?
我有一个很切身的体会,也是一个很好的例子:文件后缀命名。例如,某个接口类命名为AlphaService,那么它的所有子类都在接口名后面缀上说明性单词,以此构成自己的名字。如命名为AlphaServiceAsChain、AlphaServiceAsDispatcher、AlphaService4English、AlphaService4Chinense,诸如此类。这样,由于IDE和操作系统的文件系统、查询功能默认都是字母顺序排列,因而这一系列类在“展示”上就非常紧凑——这就使得它们的关系“一望而知”。
“对齐”规则对现在的软件设计有很大的借鉴意义;规则如果执行得好,软件设计将会获益匪浅。这是因为,现代软件内部的逻辑复杂度一般都非常高。我们要通过设计来降低复杂度,一般只有一种办法:代码功能简单,而关系复杂。上面例子中提到的“接口-实现类”就是一种代码关系,而这种关系可以“一望而知”,这就是“对齐”原则给系统的裨益。
当然,软件中“对齐”的方式还有很多。略牵强一点来讲,同一个接口下的实现类都是向接口“对齐”;同一个模板类下的子类都是向模板“对齐”;符合里氏替换原则的都算“对齐”;等等。
重复
“重复”对其它领域的设计工作来说,也许确实是非常重要的一项原则。运用这项原则,可以把设计意图更加有效地表达出来。
但是,重复无疑是我们软件开发和设计人员最痛恨的:Don't Repeat Yourself! DON'T!!
也许这是软件设计与其它领域设计的一个不同之处。软件设计不仅要考虑表达设计意图,还要管理系统复杂度。“一望仅知”是一种方式,DRY也是同样的考虑。
对比
设计中进行“对比”,一般是为了突出核心设计目的。对软件设计来说,“对比”原则参考意义不大。
后记
最近的技术思考和积累,关注点都不在代码或系统的细节上,而是转向了一些业务系统或逻辑的设计上。这跟我的技术价值观有关:技术的价值是需要体现在业务系统中的。不过这可以另外展开,这里打住。
“设计”行业由来已久,建筑设计、时装设计、包装设计、城市规划设计、工业设计、平面设计……等等等等。这些设计门类都已经积累了很多经验,软件设计能否从中汲取一些营养呢?这也是我开始涉猎《写给大家看的设计书》的原因。
这本书偏“平面”设计——海报、广告、传单等。其设计目标与软件设计有些出入,因此,亲密性、对齐、重复和对比这四个原则,有些确实值得借鉴,有些只能说看看就好。
互联网
暂时关掉
introduction of Fish Eye
中文版参见附件。
THREAD-9175202-261215-1644-20.pdf
一种在旧代码上增加新需求的重构模式
应用场景
相信大家遇到过这种场景:
旧代码中已经有一堆的if-else或者switch-case了;产品却要求在这段流程里增加一个新的功能。
这种时候大家会怎么做?
我的建议是:
重构这段代码。在重构的基础上,加入新的功能。
肯定会有人说:
工期本来紧张,再对原有代码进行重构,岂不会更加捉襟见肘?
这里介绍的(也是我在实践中经常使用的)这种方式,我称之为“接口-分发器模式”。它可以在尽量减少重构工作量的同时,完成大部分重构工作。
类图
接口
这个模式首先将旧代码/功能抽取为一个接口(ServiceInterface.java)。这个接口的抽象能力,应该能够同时覆盖旧代码中的原有逻辑和新需求中的功能。换句话说就是新、旧代码都可以抽象为同一个接口。
如果这一点都无法做到,建议先回头想想这两段逻辑应不应该放到同一个抽象内。
例如我在一次重构中所做抽取的接口:
public interface RequestApprover {
void approveById(Integer id, Request requestInfo,
UserInfo approver) throws ServiceException;
}这个接口是对请求数据(Request)的审批操作的抽象。
请求数据一共有三类(其中旧类型两种,新需求一种);审批操作同样也有三类(同样,旧类型两种,新需求一种)。这样,最多会有九种审批逻辑(不过实际中只有六种)。而这些审批逻辑和代码,都可以用这一个接口来描述。
分发器
分发器(ServiceDispatcher.java)是服务的入口。但它本身并不提供任何业务服务,而只负责将请求分发给实际的服务处理类。
从这一点上看,分发器其实很像一个工厂。这么说也没错,不过这个分发器的重点在于“分发”,而不是“创建”。
另外,将它隐藏在对外接口之下,是因为我将这个分发器理解为接口的一种实现;它属于抽象之中,不需要被抽象之外的调用者感知。这是我个人偏好。
对应前面的接口,我用到的分发器是这样的。
class RequestApproverAsDispatcher RequestApprover {
private RequestApprover approver4First4NotLate;
private RequestApprover approver4First4PseudoOver;
private RequestApprover approver4Final4NotLate;
private RequestApprover approver4Final4M1;
private RequestApprover approver4Final4PseudoOver;
@Override
public void approveById(Integer id, Request requestInfo,
UserInfo approver) throws ServiceException {
RequestApprover requestApprover;
switch (some_field) {
case FIRST_APPROVED:
case FIRST_REJECTED:
requestApprover = xxx;
break;
case APPROVED:
case REJECTED:
requestApprover = yyy;
break;
default:
throw new UnsupportedOperationException();
}
requestApprover.approveById(id, requestInfo, approver);
}
}具体服务类
具体服务类承担实际上的业务逻辑。在类图中,它们被表示成了Service4Scene1.java ~ Service4Scene7.java。并且,我专门画了ServiceAsAdapter.java和ServiceAsSkeleton.java来表示:这些具体服务类还可以有自己的组织方式、应用自己应用的模式。
在我上面的例子中,我通过一个RequestApproverAsSkeleton.java定义了模板。而在另一项需求中,我用了组合和中介——至少我将那几个类理解为中介模式。
小结
本质上,这个所谓“接口-分发器模式”是一种策略模式。但是它比策略模式多一点东西——分发器。另外,在实践应用中,它不可能只有策略。在“具体服务类”的组织上,几乎都会用上更多的模式。
题外话,就设计模式的应用上,有策略则必有工厂,有工厂几乎必有单例,这似乎也自成一种“模式”。
重构
那么,这个“模式”要怎样应用到重构中呢?
很简单——让旧代码和新代码都成为“具体服务类”中的成员,并且是不同的成员。
仍以上面的例子来说,我将旧代码和新代码分别安排在这两个类中。再结合前面的分发器,很简单的就完成了这次重构,并同时完成了新需求。
class RequestApprover4First extends
RequestApproverAsSkeleton {
private static final Logger LOGGER = LoggerFactory
.getLogger(RequestApprover4First.class);
private RequestService service;
@Override
protected void approve(Request requestInfo,
Request request) throws InvalidDataException {
……
}
@Override
protected void reject(Request requestInfo,
Request request) {
// 不做处理
}
@Override
protected void configRequest(Request requestInfo,
Request request, UserInfo approver) {
……
}
}而新的业务在这个服务中:
class RequestApprover4Check extends
RequestApproverAsSkeleton {
private static final Logger LOGGER = LoggerFactory
.getLogger(RequestApprover4Check.class);
@Override
public void approveById(Integer id, Request requestInfo,
UserInfo approver) throws ServiceException {
……
// 这个方法中有额外处理
}
@Override
protected void approve(Request requestInfo,
Request request) throws ServiceException {
……
}
@Override
protected void reject(Request requestInfo,
Request request) {
// 不做任何操作
}
@Override
protected void configRequest(Request requestInfo,
Request request, UserInfo approver) {
……
}
}优点和缺点
优点应该说比较明显:新、旧逻辑和代码被隔离开了,也就完成了解耦合。并且后续如果还要加新的需求,也可以比较轻松的隔离到新的服务类中。相信接手过旧系统、旧代码的朋友们都能理解其中的意义。
缺点呢?一是容易造成“类爆炸”。虽然不一定变得太多,但是类的数量肯定比不用模式要多。二是这种模式有时候不会(也不需要)对旧代码做任何改动。这样一来,重构目标实际上并没有实现。
最后补充
做重构之前,一定要有用于验证旧代码功能的测试,并且尽可能的覆盖流程分支。
transaction in multi-thread in spring
The transaction introduce in spring.io
http://docs.spring.io/spring/docs/current/spring-framework-reference/htmlsingle/#transaction-intro
- Transaction Management
16.1 Introduction to Spring Framework transaction management
Comprehensive transaction support is among the most compelling reasons to use the Spring Framework. The Spring Framework provides a consistent abstraction for transaction management that delivers the following benefits:
Consistent programming model across different transaction APIs such as Java Transaction API (JTA), JDBC, Hibernate, Java Persistence API (JPA), and Java Data Objects (JDO).
Support for declarative transaction management.
Simpler API for programmatic transaction management than complex transaction APIs such as JTA.
Excellent integration with Spring’s data access abstractions.
The following sections describe the Spring Framework’s transaction value-adds and technologies. (The chapter also includes discussions of best practices, application server integration, and solutions to common problems.)
Advantages of the Spring Framework’s transaction support model describes why you would use the Spring Framework’s transaction abstraction instead of EJB Container-Managed Transactions (CMT) or choosing to drive local transactions through a proprietary API such as Hibernate.
Understanding the Spring Framework transaction abstraction outlines the core classes and describes how to configure and obtain DataSource instances from a variety of sources.
Synchronizing resources with transactionsdescribes how the application code ensures that resources are created, reused, and cleaned up properly.
Declarative transaction management describes support for declarative transaction management.
Programmatic transaction management covers support for programmatic (that is, explicitly coded) transaction management.
Transaction bound event describes how you could use application events within a transaction.
16.2 Advantages of the Spring Framework’s transaction support model
Traditionally, Java EE developers have had two choices for transaction management: global or local transactions, both of which have profound limitations. Global and local transaction management is reviewed in the next two sections, followed by a discussion of how the Spring Framework’s transaction management support addresses the limitations of the global and local transaction models.
16.2.1 Global transactions
Global transactions enable you to work with multiple transactional resources, typically relational databases and message queues. The application server manages global transactions through the JTA, which is a cumbersome API to use (partly due to its exception model). Furthermore, a JTA UserTransaction normally needs to be sourced from JNDI, meaning that you also need to use JNDI in order to use JTA. Obviously the use of global transactions would limit any potential reuse of application code, as JTA is normally only available in an application server environment.
Previously, the preferred way to use global transactions was via EJB CMT (Container Managed Transaction): CMT is a form of declarative transaction management (as distinguished from programmatic transaction management). EJB CMT removes the need for transaction-related JNDI lookups, although of course the use of EJB itself necessitates the use of JNDI. It removes most but not all of the need to write Java code to control transactions. The significant downside is that CMT is tied to JTA and an application server environment. Also, it is only available if one chooses to implement business logic in EJBs, or at least behind a transactional EJB facade. The negatives of EJB in general are so great that this is not an attractive proposition, especially in the face of compelling alternatives for declarative transaction management.
16.2.2 Local transactions
Local transactions are resource-specific, such as a transaction associated with a JDBC connection. Local transactions may be easier to use, but have significant disadvantages: they cannot work across multiple transactional resources. For example, code that manages transactions using a JDBC connection cannot run within a global JTA transaction. Because the application server is not involved in transaction management, it cannot help ensure correctness across multiple resources. (It is worth noting that most applications use a single transaction resource.) Another downside is that local transactions are invasive to the programming model.
16.2.3 Spring Framework’s consistent programming model
Spring resolves the disadvantages of global and local transactions. It enables application developers to use a consistent programming model in any environment. You write your code once, and it can benefit from different transaction management strategies in different environments. The Spring Framework provides both declarative and programmatic transaction management. Most users prefer declarative transaction management, which is recommended in most cases.
With programmatic transaction management, developers work with the Spring Framework transaction abstraction, which can run over any underlying transaction infrastructure. With the preferred declarative model, developers typically write little or no code related to transaction management, and hence do not depend on the Spring Framework transaction API, or any other transaction API.
Do you need an application server for transaction management?
The Spring Framework’s transaction management support changes traditional rules as to when an enterprise Java application requires an application server.
In particular, you do not need an application server simply for declarative transactions through EJBs. In fact, even if your application server has powerful JTA capabilities, you may decide that the Spring Framework’s declarative transactions offer more power and a more productive programming model than EJB CMT.
Typically you need an application server’s JTA capability only if your application needs to handle transactions across multiple resources, which is not a requirement for many applications. Many high-end applications use a single, highly scalable database (such as Oracle RAC) instead. Standalone transaction managers such as Atomikos Transactions and JOTM are other options. Of course, you may need other application server capabilities such as Java Message Service (JMS) and Java EE Connector Architecture (JCA).
The Spring Framework gives you the choice of when to scale your application to a fully loaded application server. Gone are the days when the only alternative to using EJB CMT or JTA was to write code with local transactions such as those on JDBC connections, and face a hefty rework if you need that code to run within global, container-managed transactions. With the Spring Framework, only some of the bean definitions in your configuration file, rather than your code, need to change.
16.3 Understanding the Spring Framework transaction abstraction
The key to the Spring transaction abstraction is the notion of a transaction strategy. A transaction strategy is defined by the org.springframework.transaction.PlatformTransactionManager interface:
public interface PlatformTransactionManager {
TransactionStatus getTransaction(
TransactionDefinition definition) throws TransactionException;
void commit(TransactionStatus status) throws TransactionException;
void rollback(TransactionStatus status) throws TransactionException;
}
This is primarily a service provider interface (SPI), although it can be used programmatically from your application code. Because PlatformTransactionManager is an interface, it can be easily mocked or stubbed as necessary. It is not tied to a lookup strategy such as JNDI. PlatformTransactionManager implementations are defined like any other object (or bean) in the Spring Framework IoC container. This benefit alone makes Spring Framework transactions a worthwhile abstraction even when you work with JTA. Transactional code can be tested much more easily than if it used JTA directly.
Again in keeping with Spring’s philosophy, the TransactionException that can be thrown by any of the PlatformTransactionManager interface’s methods is unchecked (that is, it extends the java.lang.RuntimeException class). Transaction infrastructure failures are almost invariably fatal. In rare cases where application code can actually recover from a transaction failure, the application developer can still choose to catch and handle TransactionException. The salient point is that developers are not forced to do so.
The getTransaction(..) method returns a TransactionStatus object, depending on a TransactionDefinition parameter. The returned TransactionStatus might represent a new transaction, or can represent an existing transaction if a matching transaction exists in the current call stack. The implication in this latter case is that, as with Java EE transaction contexts, a TransactionStatus is associated with a thread of execution.
The TransactionDefinition interface specifies:
Isolation: The degree to which this transaction is isolated from the work of other transactions. For example, can this transaction see uncommitted writes from other transactions?
Propagation: Typically, all code executed within a transaction scope will run in that transaction. However, you have the option of specifying the behavior in the event that a transactional method is executed when a transaction context already exists. For example, code can continue running in the existing transaction (the common case); or the existing transaction can be suspended and a new transaction created. Spring offers all of the transaction propagation options familiar from EJB CMT. To read about the semantics of transaction propagation in Spring, see Section 16.5.7, “Transaction propagation”.
Timeout: How long this transaction runs before timing out and being rolled back automatically by the underlying transaction infrastructure.
Read-only status: A read-only transaction can be used when your code reads but does not modify data. Read-only transactions can be a useful optimization in some cases, such as when you are using Hibernate.
These settings reflect standard transactional concepts. If necessary, refer to resources that discuss transaction isolation levels and other core transaction concepts. Understanding these concepts is essential to using the Spring Framework or any transaction management solution.
The TransactionStatus interface provides a simple way for transactional code to control transaction execution and query transaction status. The concepts should be familiar, as they are common to all transaction APIs:
public interface TransactionStatus extends SavepointManager {
boolean isNewTransaction();
boolean hasSavepoint();
void setRollbackOnly();
boolean isRollbackOnly();
void flush();
boolean isCompleted();
}
Regardless of whether you opt for declarative or programmatic transaction management in Spring, defining the correct PlatformTransactionManager implementation is absolutely essential. You typically define this implementation through dependency injection.
PlatformTransactionManager implementations normally require knowledge of the environment in which they work: JDBC, JTA, Hibernate, and so on. The following examples show how you can define a local PlatformTransactionManager implementation. (This example works with plain JDBC.)
You define a JDBC DataSource
The related PlatformTransactionManager bean definition will then have a reference to the DataSource definition. It will look like this:
If you use JTA in a Java EE container then you use a container DataSource, obtained through JNDI, in conjunction with Spring’s JtaTransactionManager. This is what the JTA and JNDI lookup version would look like:
<jee:jndi-lookup id="dataSource" jndi-name="jdbc/jpetstore"/>
<bean id="txManager" class="org.springframework.transaction.jta.JtaTransactionManager" />
<!-- other <bean/> definitions here -->
The JtaTransactionManager does not need to know about the DataSource, or any other specific resources, because it uses the container’s global transaction management infrastructure.
[Note]
The above definition of the dataSource bean uses the tag from the jee namespace. For more information on schema-based configuration, see Chapter 40, XML Schema-based configuration, and for more information on the tags see the section entitled Section 40.2.3, “the jee schema”.
You can also use Hibernate local transactions easily, as shown in the following examples. In this case, you need to define a Hibernate LocalSessionFactoryBean, which your application code will use to obtain Hibernate Session instances.
The DataSource bean definition will be similar to the local JDBC example shown previously and thus is not shown in the following example.
[Note]
If the DataSource, used by any non-JTA transaction manager, is looked up via JNDI and managed by a Java EE container, then it should be non-transactional because the Spring Framework, rather than the Java EE container, will manage the transactions.
The txManager bean in this case is of the HibernateTransactionManager type. In the same way as the DataSourceTransactionManager needs a reference to the DataSource, the HibernateTransactionManager needs a reference to the SessionFactory.
org/springframework/samples/petclinic/hibernate/petclinic.hbm.xml hibernate.dialect=${hibernate.dialect}If you are using Hibernate and Java EE container-managed JTA transactions, then you should simply use the same JtaTransactionManager as in the previous JTA example for JDBC.
[Note]
If you use JTA , then your transaction manager definition will look the same regardless of what data access technology you use, be it JDBC, Hibernate JPA or any other supported technology. This is due to the fact that JTA transactions are global transactions, which can enlist any transactional resource.
In all these cases, application code does not need to change. You can change how transactions are managed merely by changing configuration, even if that change means moving from local to global transactions or vice versa.
16.4 Synchronizing resources with transactions
It should now be clear how you create different transaction managers, and how they are linked to related resources that need to be synchronized to transactions (for example DataSourceTransactionManager to a JDBC DataSource, HibernateTransactionManager to a Hibernate SessionFactory, and so forth). This section describes how the application code, directly or indirectly using a persistence API such as JDBC, Hibernate, or JDO, ensures that these resources are created, reused, and cleaned up properly. The section also discusses how transaction synchronization is triggered (optionally) through the relevant PlatformTransactionManager.
16.4.1 High-level synchronization approach
The preferred approach is to use Spring’s highest level template based persistence integration APIs or to use native ORM APIs with transaction- aware factory beans or proxies for managing the native resource factories. These transaction-aware solutions internally handle resource creation and reuse, cleanup, optional transaction synchronization of the resources, and exception mapping. Thus user data access code does not have to address these tasks, but can be focused purely on non-boilerplate persistence logic. Generally, you use the native ORM API or take a template approach for JDBC access by using the JdbcTemplate. These solutions are detailed in subsequent chapters of this reference documentation.
16.4.2 Low-level synchronization approach
Classes such as DataSourceUtils (for JDBC), EntityManagerFactoryUtils (for JPA), SessionFactoryUtils (for Hibernate), PersistenceManagerFactoryUtils (for JDO), and so on exist at a lower level. When you want the application code to deal directly with the resource types of the native persistence APIs, you use these classes to ensure that proper Spring Framework-managed instances are obtained, transactions are (optionally) synchronized, and exceptions that occur in the process are properly mapped to a consistent API.
For example, in the case of JDBC, instead of the traditional JDBC approach of calling the getConnection() method on the DataSource, you instead use Spring’s org.springframework.jdbc.datasource.DataSourceUtils class as follows:
Connection conn = DataSourceUtils.getConnection(dataSource);
If an existing transaction already has a connection synchronized (linked) to it, that instance is returned. Otherwise, the method call triggers the creation of a new connection, which is (optionally) synchronized to any existing transaction, and made available for subsequent reuse in that same transaction. As mentioned, any SQLException is wrapped in a Spring Framework CannotGetJdbcConnectionException, one of the Spring Framework’s hierarchy of unchecked DataAccessExceptions. This approach gives you more information than can be obtained easily from the SQLException, and ensures portability across databases, even across different persistence technologies.
This approach also works without Spring transaction management (transaction synchronization is optional), so you can use it whether or not you are using Spring for transaction management.
Of course, once you have used Spring’s JDBC support, JPA support or Hibernate support, you will generally prefer not to use DataSourceUtils or the other helper classes, because you will be much happier working through the Spring abstraction than directly with the relevant APIs. For example, if you use the Spring JdbcTemplate or jdbc.object package to simplify your use of JDBC, correct connection retrieval occurs behind the scenes and you won’t need to write any special code.
16.4.3 TransactionAwareDataSourceProxy
At the very lowest level exists the TransactionAwareDataSourceProxy class. This is a proxy for a target DataSource, which wraps the target DataSource to add awareness of Spring-managed transactions. In this respect, it is similar to a transactional JNDI DataSource as provided by a Java EE server.
It should almost never be necessary or desirable to use this class, except when existing code must be called and passed a standard JDBC DataSource interface implementation. In that case, it is possible that this code is usable, but participating in Spring managed transactions. It is preferable to write your new code by using the higher level abstractions mentioned above.
16.5 Declarative transaction management
[Note]
Most Spring Framework users choose declarative transaction management. This option has the least impact on application code, and hence is most consistent with the ideals of a non-invasive lightweight container.
The Spring Framework’s declarative transaction management is made possible with Spring aspect-oriented programming (AOP), although, as the transactional aspects code comes with the Spring Framework distribution and may be used in a boilerplate fashion, AOP concepts do not generally have to be understood to make effective use of this code.
The Spring Framework’s declarative transaction management is similar to EJB CMT in that you can specify transaction behavior (or lack of it) down to individual method level. It is possible to make a setRollbackOnly() call within a transaction context if necessary. The differences between the two types of transaction management are:
Unlike EJB CMT, which is tied to JTA, the Spring Framework’s declarative transaction management works in any environment. It can work with JTA transactions or local transactions using JDBC, JPA, Hibernate or JDO by simply adjusting the configuration files.
You can apply the Spring Framework declarative transaction management to any class, not merely special classes such as EJBs.
The Spring Framework offers declarative rollback rules,a feature with no EJB equivalent. Both programmatic and declarative support for rollback rules is provided.
The Spring Framework enables you to customize transactional behavior, by using AOP. For example, you can insert custom behavior in the case of transaction rollback. You can also add arbitrary advice, along with the transactional advice. With EJB CMT, you cannot influence the container’s transaction management except with setRollbackOnly().
The Spring Framework does not support propagation of transaction contexts across remote calls, as do high-end application servers. If you need this feature, we recommend that you use EJB. However, consider carefully before using such a feature, because normally, one does not want transactions to span remote calls.
Where is TransactionProxyFactoryBean?
Declarative transaction configuration in versions of Spring 2.0 and above differs considerably from previous versions of Spring. The main difference is that there is no longer any need to configure TransactionProxyFactoryBean beans.
The pre-Spring 2.0 configuration style is still 100% valid configuration; think of the new tx:tags/ as simply defining TransactionProxyFactoryBean beans on your behalf.
The concept of rollback rules is important: they enable you to specify which exceptions (and throwables) should cause automatic rollback. You specify this declaratively, in configuration, not in Java code. So, although you can still call setRollbackOnly() on the TransactionStatus object to roll back the current transaction back, most often you can specify a rule that MyApplicationException must always result in rollback. The significant advantage to this option is that business objects do not depend on the transaction infrastructure. For example, they typically do not need to import Spring transaction APIs or other Spring APIs.
Although EJB container default behavior automatically rolls back the transaction on a system exception (usually a runtime exception), EJB CMT does not roll back the transaction automatically on anapplication exception (that is, a checked exception other than java.rmi.RemoteException). While the Spring default behavior for declarative transaction management follows EJB convention (roll back is automatic only on unchecked exceptions), it is often useful to customize this behavior.
16.5.1 Understanding the Spring Framework’s declarative transaction implementation
It is not sufficient to tell you simply to annotate your classes with the @transactional annotation, add @EnableTransactionManagement to your configuration, and then expect you to understand how it all works. This section explains the inner workings of the Spring Framework’s declarative transaction infrastructure in the event of transaction-related issues.
The most important concepts to grasp with regard to the Spring Framework’s declarative transaction support are that this support is enabled via AOP proxies, and that the transactional advice is driven by metadata (currently XML- or annotation-based). The combination of AOP with transactional metadata yields an AOP proxy that uses a TransactionInterceptor in conjunction with an appropriate PlatformTransactionManager implementation to drive transactions around method invocations.
[Note]
Spring AOP is covered in Chapter 10, Aspect Oriented Programming with Spring.
Conceptually, calling a method on a transactional proxy looks like this…
tx
16.5.2 Example of declarative transaction implementation
Consider the following interface, and its attendant implementation. This example uses Foo and Bar classes as placeholders so that you can concentrate on the transaction usage without focusing on a particular domain model. For the purposes of this example, the fact that the DefaultFooService class throws UnsupportedOperationException instances in the body of each implemented method is good; it allows you to see transactions created and then rolled back in response to the UnsupportedOperationException instance.
// the service interface that we want to make transactional
package x.y.service;
public interface FooService {
Foo getFoo(String fooName);
Foo getFoo(String fooName, String barName);
void insertFoo(Foo foo);
void updateFoo(Foo foo);
}
// an implementation of the above interface
package x.y.service;
public class DefaultFooService implements FooService {
public Foo getFoo(String fooName) {
throw new UnsupportedOperationException();
}
public Foo getFoo(String fooName, String barName) {
throw new UnsupportedOperationException();
}
public void insertFoo(Foo foo) {
throw new UnsupportedOperationException();
}
public void updateFoo(Foo foo) {
throw new UnsupportedOperationException();
}
}
Assume that the first two methods of the FooService interface, getFoo(String) and getFoo(String, String), must execute in the context of a transaction with read-only semantics, and that the other methods, insertFoo(Foo) and updateFoo(Foo), must execute in the context of a transaction with read-write semantics. The following configuration is explained in detail in the next few paragraphs.
<!-- this is the service object that we want to make transactional -->
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<!-- the transactional advice (what 'happens'; see the <aop:advisor/> bean below) -->
<tx:advice id="txAdvice" transaction-manager="txManager">
<!-- the transactional semantics... -->
<tx:attributes>
<!-- all methods starting with 'get' are read-only -->
<tx:method name="get*" read-only="true"/>
<!-- other methods use the default transaction settings (see below) -->
<tx:method name="*"/>
</tx:attributes>
</tx:advice>
<!-- ensure that the above transactional advice runs for any execution
of an operation defined by the FooService interface -->
<aop:config>
<aop:pointcut id="fooServiceOperation" expression="execution(* x.y.service.FooService.*(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="fooServiceOperation"/>
</aop:config>
<!-- don't forget the DataSource -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@rj-t42:1521:elvis"/>
<property name="username" value="scott"/>
<property name="password" value="tiger"/>
</bean>
<!-- similarly, don't forget the PlatformTransactionManager -->
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- other <bean/> definitions here -->
Examine the preceding configuration. You want to make a service object, the fooService bean, transactional. The transaction semantics to apply are encapsulated in the tx:advice/ definition. The tx:advice/ definition reads as "… all methods on starting with 'get' are to execute in the context of a read-only transaction, and all other methods are to execute with the default transaction semantics". The transaction-manager attribute of the tx:advice/ tag is set to the name of the PlatformTransactionManager bean that is going to drive the transactions, in this case, the txManager bean.
[Tip]
You can omit the transaction-manager attribute in the transactional advice ( tx:advice/) if the bean name of the PlatformTransactionManager that you want to wire in has the name transactionManager. If the PlatformTransactionManager bean that you want to wire in has any other name, then you must use the transaction-manager attribute explicitly, as in the preceding example.
The aop:config/ definition ensures that the transactional advice defined by the txAdvice bean executes at the appropriate points in the program. First you define a pointcut that matches the execution of any operation defined in the FooService interface ( fooServiceOperation). Then you associate the pointcut with the txAdvice using an advisor. The result indicates that at the execution of a fooServiceOperation, the advice defined by txAdvice will be run.
The expression defined within the aop:pointcut/ element is an AspectJ pointcut expression; see Chapter 10, Aspect Oriented Programming with Spring for more details on pointcut expressions in Spring.
A common requirement is to make an entire service layer transactional. The best way to do this is simply to change the pointcut expression to match any operation in your service layer. For example:
aop:config
<aop:pointcut id="fooServiceMethods" expression="execution(* x.y.service..(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="fooServiceMethods"/>
/aop:config
[Note]
In this example it is assumed that all your service interfaces are defined in the x.y.service package; see Chapter 10, Aspect Oriented Programming with Spring for more details.
Now that we’ve analyzed the configuration, you may be asking yourself, "Okay… but what does all this configuration actually do?".
The above configuration will be used to create a transactional proxy around the object that is created from the fooService bean definition. The proxy will be configured with the transactional advice, so that when an appropriate method is invoked on the proxy, a transaction is started, suspended, marked as read-only, and so on, depending on the transaction configuration associated with that method. Consider the following program that test drives the above configuration:
public final class Boot {
public static void main(final String[] args) throws Exception {
ApplicationContext ctx = new ClassPathXmlApplicationContext("context.xml", Boot.class);
FooService fooService = (FooService) ctx.getBean("fooService");
fooService.insertFoo (new Foo());
}
}
The output from running the preceding program will resemble the following. (The Log4J output and the stack trace from the UnsupportedOperationException thrown by the insertFoo(..) method of the DefaultFooService class have been truncated for clarity.)
[AspectJInvocationContextExposingAdvisorAutoProxyCreator] - Creating implicit proxy for bean 'fooService' with 0 common interceptors and 1 specific interceptors
[JdkDynamicAopProxy] - Creating JDK dynamic proxy for [x.y.service.DefaultFooService]
[TransactionInterceptor] - Getting transaction for x.y.service.FooService.insertFoo
[DataSourceTransactionManager] - Creating new transaction with name [x.y.service.FooService.insertFoo]
[DataSourceTransactionManager] - Acquired Connection [org.apache.commons.dbcp.PoolableConnection@a53de4] for JDBC transaction
[RuleBasedTransactionAttribute] - Applying rules to determine whether transaction should rollback on java.lang.UnsupportedOperationException
[TransactionInterceptor] - Invoking rollback for transaction on x.y.service.FooService.insertFoo due to throwable [java.lang.UnsupportedOperationException]
[DataSourceTransactionManager] - Rolling back JDBC transaction on Connection [org.apache.commons.dbcp.PoolableConnection@a53de4]
[DataSourceTransactionManager] - Releasing JDBC Connection after transaction
[DataSourceUtils] - Returning JDBC Connection to DataSource
Exception in thread "main" java.lang.UnsupportedOperationException at x.y.service.DefaultFooService.insertFoo(DefaultFooService.java:14)
at $Proxy0.insertFoo(Unknown Source)
at Boot.main(Boot.java:11)
16.5.3 Rolling back a declarative transaction
The previous section outlined the basics of how to specify transactional settings for classes, typically service layer classes, declaratively in your application. This section describes how you can control the rollback of transactions in a simple declarative fashion.
The recommended way to indicate to the Spring Framework’s transaction infrastructure that a transaction’s work is to be rolled back is to throw an Exception from code that is currently executing in the context of a transaction. The Spring Framework’s transaction infrastructure code will catch any unhandled Exception as it bubbles up the call stack, and make a determination whether to mark the transaction for rollback.
In its default configuration, the Spring Framework’s transaction infrastructure code only marks a transaction for rollback in the case of runtime, unchecked exceptions; that is, when the thrown exception is an instance or subclass of RuntimeException. ( Errors will also - by default - result in a rollback). Checked exceptions that are thrown from a transactional method do not result in rollback in the default configuration.
You can configure exactly which Exception types mark a transaction for rollback, including checked exceptions. The following XML snippet demonstrates how you configure rollback for a checked, application-specific Exception type.
<tx:advice id="txAdvice" transaction-manager="txManager">
tx:attributes
<tx:method name="get*" read-only="true" rollback-for="NoProductInStockException"/>
<tx:method name="*"/>
/tx:attributes
/tx:advice
You can also specify 'no rollback rules', if you do not want a transaction rolled back when an exception is thrown. The following example tells the Spring Framework’s transaction infrastructure to commit the attendant transaction even in the face of an unhandled InstrumentNotFoundException.
<tx:advice id="txAdvice">
tx:attributes
<tx:method name="updateStock" no-rollback-for="InstrumentNotFoundException"/>
<tx:method name="*"/>
/tx:attributes
/tx:advice
When the Spring Framework’s transaction infrastructure catches an exception and is consults configured rollback rules to determine whether to mark the transaction for rollback, the strongest matching rule wins. So in the case of the following configuration, any exception other than an InstrumentNotFoundException results in a rollback of the attendant transaction.
<tx:advice id="txAdvice">
tx:attributes
<tx:method name="*" rollback-for="Throwable" no-rollback-for="InstrumentNotFoundException"/>
/tx:attributes
/tx:advice
You can also indicate a required rollback programmatically. Although very simple, this process is quite invasive, and tightly couples your code to the Spring Framework’s transaction infrastructure:
public void resolvePosition() {
try {
// some business logic...
} catch (NoProductInStockException ex) {
// trigger rollback programmatically
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
}
}
You are strongly encouraged to use the declarative approach to rollback if at all possible. Programmatic rollback is available should you absolutely need it, but its usage flies in the face of achieving a clean POJO-based architecture.
16.5.4 Configuring different transactional semantics for different beans
Consider the scenario where you have a number of service layer objects, and you want to apply a totally different transactional configuration to each of them. You do this by defining distinct aop:advisor/ elements with differing pointcut and advice-ref attribute values.
As a point of comparison, first assume that all of your service layer classes are defined in a root x.y.service package. To make all beans that are instances of classes defined in that package (or in subpackages) and that have names ending in Service have the default transactional configuration, you would write the following:
<aop:config>
<aop:pointcut id="serviceOperation"
expression="execution(* x.y.service..*Service.*(..))"/>
<aop:advisor pointcut-ref="serviceOperation" advice-ref="txAdvice"/>
</aop:config>
<!-- these two beans will be transactional... -->
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<bean id="barService" class="x.y.service.extras.SimpleBarService"/>
<!-- ... and these two beans won't -->
<bean id="anotherService" class="org.xyz.SomeService"/> <!-- (not in the right package) -->
<bean id="barManager" class="x.y.service.SimpleBarManager"/> <!-- (doesn't end in 'Service') -->
<tx:advice id="txAdvice">
<tx:attributes>
<tx:method name="get*" read-only="true"/>
<tx:method name="*"/>
</tx:attributes>
</tx:advice>
<!-- other transaction infrastructure beans such as a PlatformTransactionManager omitted... -->
The following example shows how to configure two distinct beans with totally different transactional settings.
<aop:config>
<aop:pointcut id="defaultServiceOperation"
expression="execution(* x.y.service.*Service.*(..))"/>
<aop:pointcut id="noTxServiceOperation"
expression="execution(* x.y.service.ddl.DefaultDdlManager.*(..))"/>
<aop:advisor pointcut-ref="defaultServiceOperation" advice-ref="defaultTxAdvice"/>
<aop:advisor pointcut-ref="noTxServiceOperation" advice-ref="noTxAdvice"/>
</aop:config>
<!-- this bean will be transactional (see the 'defaultServiceOperation' pointcut) -->
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<!-- this bean will also be transactional, but with totally different transactional settings -->
<bean id="anotherFooService" class="x.y.service.ddl.DefaultDdlManager"/>
<tx:advice id="defaultTxAdvice">
<tx:attributes>
<tx:method name="get*" read-only="true"/>
<tx:method name="*"/>
</tx:attributes>
</tx:advice>
<tx:advice id="noTxAdvice">
<tx:attributes>
<tx:method name="*" propagation="NEVER"/>
</tx:attributes>
</tx:advice>
<!-- other transaction infrastructure beans such as a PlatformTransactionManager omitted... -->
16.5.5 tx:advice/ settings
This section summarizes the various transactional settings that can be specified using the tx:advice/ tag. The default tx:advice/ settings are:
Propagation setting is REQUIRED.
Isolation level is DEFAULT.
Transaction is read/write.
Transaction timeout defaults to the default timeout of the underlying transaction system, or none if timeouts are not supported.
Any RuntimeException triggers rollback, and any checked Exception does not.
You can change these default settings; the various attributes of the tx:method/ tags that are nested within tx:advice/ and tx:attributes/ tags are summarized below:
Table 16.1. tx:method/ settings
Attribute Required? Default Description
name
Yes
Method name(s) with which the transaction attributes are to be associated. The wildcard () character can be used to associate the same transaction attribute settings with a number of methods; for example, get, handle_, on_Event, and so forth.
propagation
No
REQUIRED
Transaction propagation behavior.
isolation
No
DEFAULT
Transaction isolation level.
timeout
No
-1
Transaction timeout value (in seconds).
read-only
No
false
Is this transaction read-only?
rollback-for
No
Exception(s) that trigger rollback; comma-delimited. For example, com.foo.MyBusinessException,ServletException.
no-rollback-for
No
Exception(s) that do not trigger rollback; comma-delimited. For example, com.foo.MyBusinessException,ServletException.
16.5.6 Using @transactional
In addition to the XML-based declarative approach to transaction configuration, you can use an annotation-based approach. Declaring transaction semantics directly in the Java source code puts the declarations much closer to the affected code. There is not much danger of undue coupling, because code that is meant to be used transactionally is almost always deployed that way anyway.
[Note]
The standard javax.transaction.Transactional annotation is also supported as a drop-in replacement to Spring’s own annotation. Please refer to JTA 1.2 documentation for more details.
The ease-of-use afforded by the use of the @transactional annotation is best illustrated with an example, which is explained in the text that follows. Consider the following class definition:
// the service class that we want to make transactional
@transactional
public class DefaultFooService implements FooService {
Foo getFoo(String fooName);
Foo getFoo(String fooName, String barName);
void insertFoo(Foo foo);
void updateFoo(Foo foo);
}
When the above POJO is defined as a bean in a Spring IoC container, the bean instance can be made transactional by adding merely one line of XML configuration:
<!-- this is the service object that we want to make transactional -->
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<!-- enable the configuration of transactional behavior based on annotations -->
<tx:annotation-driven transaction-manager="txManager"/><!-- a PlatformTransactionManager is still required -->
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<!-- (this dependency is defined somewhere else) -->
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- other <bean/> definitions here -->
[Tip]
You can omit the transaction-manager attribute in the tx:annotation-driven/ tag if the bean name of the PlatformTransactionManager that you want to wire in has the name transactionManager. If the PlatformTransactionManager bean that you want to dependency-inject has any other name, then you have to use the transaction-manager attribute explicitly, as in the preceding example.
[Note]
The @EnableTransactionManagement annotation provides equivalent support if you are using Java based configuration. Simply add the annotation to a @configuration class. See the javadocs for full details.
Method visibility and @transactional
When using proxies, you should apply the @transactional annotation only to methods with public visibility. If you do annotate protected, private or package-visible methods with the @transactional annotation, no error is raised, but the annotated method does not exhibit the configured transactional settings. Consider the use of AspectJ (see below) if you need to annotate non-public methods.
You can place the @transactional annotation before an interface definition, a method on an interface, a class definition, or a public method on a class. However, the mere presence of the @transactional annotation is not enough to activate the transactional behavior. The @transactional annotation is simply metadata that can be consumed by some runtime infrastructure that is @Transactional-aware and that can use the metadata to configure the appropriate beans with transactional behavior. In the preceding example, the tx:annotation-driven/ element switches on the transactional behavior.
[Tip]
Spring recommends that you only annotate concrete classes (and methods of concrete classes) with the @transactional annotation, as opposed to annotating interfaces. You certainly can place the @transactional annotation on an interface (or an interface method), but this works only as you would expect it to if you are using interface-based proxies. The fact that Java annotations are not inherited from interfaces means that if you are using class-based proxies ( proxy-target-class="true") or the weaving-based aspect ( mode="aspectj"), then the transaction settings are not recognized by the proxying and weaving infrastructure, and the object will not be wrapped in a transactional proxy, which would be decidedly bad.
[Note]
In proxy mode (which is the default), only external method calls coming in through the proxy are intercepted. This means that self-invocation, in effect, a method within the target object calling another method of the target object, will not lead to an actual transaction at runtime even if the invoked method is marked with @transactional. Also, the proxy must be fully initialized to provide the expected behaviour so you should not rely on this feature in your initialization code, i.e. @PostConstruct.
Consider the use of AspectJ mode (see mode attribute in table below) if you expect self-invocations to be wrapped with transactions as well. In this case, there will not be a proxy in the first place; instead, the target class will be weaved (that is, its byte code will be modified) in order to turn @transactional into runtime behavior on any kind of method.
Table 16.2. Annotation driven transaction settings
XML Attribute Annotation Attribute Default Description
transaction-manager
N/A (See TransactionManagementConfigurer javadocs)
transactionManager
Name of transaction manager to use. Only required if the name of the transaction manager is not transactionManager, as in the example above.
mode
mode
proxy
The default mode "proxy" processes annotated beans to be proxied using Spring’s AOP framework (following proxy semantics, as discussed above, applying to method calls coming in through the proxy only). The alternative mode "aspectj" instead weaves the affected classes with Spring’s AspectJ transaction aspect, modifying the target class byte code to apply to any kind of method call. AspectJ weaving requires spring-aspects.jar in the classpath as well as load-time weaving (or compile-time weaving) enabled. (See the section called “Spring configuration” for details on how to set up load-time weaving.)
proxy-target-class
proxyTargetClass
false
Applies to proxy mode only. Controls what type of transactional proxies are created for classes annotated with the @transactional annotation. If the proxy-target-class attribute is set to true, then class-based proxies are created. If proxy-target-class is false or if the attribute is omitted, then standard JDK interface-based proxies are created. (See Section 10.6, “Proxying mechanisms” for a detailed examination of the different proxy types.)
order
order
Ordered.LOWEST_PRECEDENCE
Defines the order of the transaction advice that is applied to beans annotated with @transactional. (For more information about the rules related to ordering of AOP advice, see the section called “Advice ordering”.) No specified ordering means that the AOP subsystem determines the order of the advice.
[Note]
The proxy-target-class attribute controls what type of transactional proxies are created for classes annotated with the @transactional annotation. If proxy-target-class is set to true, class-based proxies are created. If proxy-target-class is false or if the attribute is omitted, standard JDK interface-based proxies are created. (See Section 10.6, “Proxying mechanisms” for a discussion of the different proxy types.)
[Note]
@EnableTransactionManagement and tx:annotation-driven/ only looks for @transactional on beans in the same application context they are defined in. This means that, if you put annotation driven configuration in a WebApplicationContext for a DispatcherServlet, it only checks for @transactional beans in your controllers, and not your services. See Section 21.2, “The DispatcherServlet” for more information.
The most derived location takes precedence when evaluating the transactional settings for a method. In the case of the following example, the DefaultFooService class is annotated at the class level with the settings for a read-only transaction, but the @transactional annotation on the updateFoo(Foo) method in the same class takes precedence over the transactional settings defined at the class level.
@transactional(readOnly = true)
public class DefaultFooService implements FooService {
public Foo getFoo(String fooName) {
// do something
}
// these settings have precedence for this method
@Transactional(readOnly = false, propagation = Propagation.REQUIRES_NEW)
public void updateFoo(Foo foo) {
// do something
}
}
@transactional settings
The @transactional annotation is metadata that specifies that an interface, class, or method must have transactional semantics; for example, "start a brand new read-only transaction when this method is invoked, suspending any existing transaction". The default @transactional settings are as follows:
Propagation setting is PROPAGATION_REQUIRED.
Isolation level is ISOLATION_DEFAULT.
Transaction is read/write.
Transaction timeout defaults to the default timeout of the underlying transaction system, or to none if timeouts are not supported.
Any RuntimeException triggers rollback, and any checked Exception does not.
These default settings can be changed; the various properties of the @transactional annotation are summarized in the following table:
Table 16.3. @
Property Type Description
value
String
Optional qualifier specifying the transaction manager to be used.
propagation
enum: Propagation
Optional propagation setting.
isolation
enum: Isolation
Optional isolation level.
readOnly
boolean
Read/write vs. read-only transaction
timeout
int (in seconds granularity)
Transaction timeout.
rollbackFor
Array of Class objects, which must be derived from Throwable.
Optional array of exception classes that must cause rollback.
rollbackForClassName
Array of class names. Classes must be derived from Throwable.
Optional array of names of exception classes that must cause rollback.
noRollbackFor
Array of Class objects, which must be derived from Throwable.
Optional array of exception classes that must not cause rollback.
noRollbackForClassName
Array of String class names, which must be derived from Throwable.
Optional array of names of exception classes that must not cause rollback.
Currently you cannot have explicit control over the name of a transaction, where 'name' means the transaction name that will be shown in a transaction monitor, if applicable (for example, WebLogic’s transaction monitor), and in logging output. For declarative transactions, the transaction name is always the fully-qualified class name + "." + method name of the transactionally-advised class. For example, if the handlePayment(..) method of the BusinessService class started a transaction, the name of the transaction would be: com.foo.BusinessService.handlePayment.
Multiple Transaction Managers with @transactional
Most Spring applications only need a single transaction manager, but there may be situations where you want multiple independent transaction managers in a single application. The value attribute of the @transactional annotation can be used to optionally specify the identity of the PlatformTransactionManager to be used. This can either be the bean name or the qualifier value of the transaction manager bean. For example, using the qualifier notation, the following Java code
public class TransactionalService {
@Transactional("order")
public void setSomething(String name) { ... }
@Transactional("account")
public void doSomething() { ... }
}
could be combined with the following transaction manager bean declarations in the application context.
tx:annotation-driven/
<bean id="transactionManager1" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
...
<qualifier value="order"/>
</bean>
<bean id="transactionManager2" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
...
<qualifier value="account"/>
</bean>
In this case, the two methods on TransactionalService will run under separate transaction managers, differentiated by the "order" and "account" qualifiers. The default tx:annotation-driven target bean name transactionManager will still be used if no specifically qualified PlatformTransactionManager bean is found.
Custom shortcut annotations
If you find you are repeatedly using the same attributes with @transactional on many different methods, then Spring’s meta-annotation support allows you to define custom shortcut annotations for your specific use cases. For example, defining the following annotations
@target({ElementType.METHOD, ElementType.TYPE})
@retention(RetentionPolicy.RUNTIME)
@transactional("order")
public @interface OrderTx {
}
@target({ElementType.METHOD, ElementType.TYPE})
@retention(RetentionPolicy.RUNTIME)
@transactional("account")
public @interface AccountTx {
}
allows us to write the example from the previous section as
public class TransactionalService {
@OrderTx
public void setSomething(String name) { ... }
@AccountTx
public void doSomething() { ... }
}
Here we have used the syntax to define the transaction manager qualifier, but could also have included propagation behavior, rollback rules, timeouts etc.
16.5.7 Transaction propagation
This section describes some semantics of transaction propagation in Spring. Please note that this section is not an introduction to transaction propagation proper; rather it details some of the semantics regarding transaction propagation in Spring.
In Spring-managed transactions, be aware of the difference between physical and logical transactions, and how the propagation setting applies to this difference.
Required
tx prop required
PROPAGATION_REQUIRED
When the propagation setting is PROPAGATION_REQUIRED, a logical transaction scope is created for each method upon which the setting is applied. Each such logical transaction scope can determine rollback-only status individually, with an outer transaction scope being logically independent from the inner transaction scope. Of course, in case of standard PROPAGATION_REQUIRED behavior, all these scopes will be mapped to the same physical transaction. So a rollback-only marker set in the inner transaction scope does affect the outer transaction’s chance to actually commit (as you would expect it to).
However, in the case where an inner transaction scope sets the rollback-only marker, the outer transaction has not decided on the rollback itself, and so the rollback (silently triggered by the inner transaction scope) is unexpected. A corresponding UnexpectedRollbackException is thrown at that point. This is expected behavior so that the caller of a transaction can never be misled to assume that a commit was performed when it really was not. So if an inner transaction (of which the outer caller is not aware) silently marks a transaction as rollback-only, the outer caller still calls commit. The outer caller needs to receive an UnexpectedRollbackException to indicate clearly that a rollback was performed instead.
RequiresNew
tx prop requires new
PROPAGATION_REQUIRES_NEW
PROPAGATION_REQUIRES_NEW, in contrast to PROPAGATION_REQUIRED, uses a completely independent transaction for each affected transaction scope. In that case, the underlying physical transactions are different and hence can commit or roll back independently, with an outer transaction not affected by an inner transaction’s rollback status.
Nested
PROPAGATION_NESTED uses a single physical transaction with multiple savepoints that it can roll back to. Such partial rollbacks allow an inner transaction scope to trigger a rollback for its scope, with the outer transaction being able to continue the physical transaction despite some operations having been rolled back. This setting is typically mapped onto JDBC savepoints, so will only work with JDBC resource transactions. See Spring’s DataSourceTransactionManager.
16.5.8 Advising transactional operations
Suppose you want to execute both transactional and some basic profiling advice. How do you effect this in the context of tx:annotation-driven/?
When you invoke the updateFoo(Foo) method, you want to see the following actions:
Configured profiling aspect starts up.
Transactional advice executes.
Method on the advised object executes.
Transaction commits.
Profiling aspect reports exact duration of the whole transactional method invocation.
[Note]
This chapter is not concerned with explaining AOP in any great detail (except as it applies to transactions). See Chapter 10, Aspect Oriented Programming with Spring for detailed coverage of the following AOP configuration and AOP in general.
Here is the code for a simple profiling aspect discussed above. The ordering of advice is controlled through the Ordered interface. For full details on advice ordering, see the section called “Advice ordering”. .
package x.y;
import org.aspectj.lang.ProceedingJoinPoint;
import org.springframework.util.StopWatch;
import org.springframework.core.Ordered;
public class SimpleProfiler implements Ordered {
private int order;
// allows us to control the ordering of advice
public int getOrder() {
return this.order;
}
public void setOrder(int order) {
this.order = order;
}
// this method is the around advice
public Object profile(ProceedingJoinPoint call) throws Throwable {
Object returnValue;
StopWatch clock = new StopWatch(getClass().getName());
try {
clock.start(call.toShortString());
returnValue = call.proceed();
} finally {
clock.stop();
System.out.println(clock.prettyPrint());
}
return returnValue;
}
}
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<!-- this is the aspect -->
<bean id="profiler" class="x.y.SimpleProfiler">
<!-- execute before the transactional advice (hence the lower order number) -->
<property name="order" __value="1"__/>
</bean>
<tx:annotation-driven transaction-manager="txManager" __order="200"__/>
<aop:config>
<!-- this advice will execute around the transactional advice -->
<aop:aspect id="profilingAspect" ref="profiler">
<aop:pointcut id="serviceMethodWithReturnValue"
expression="execution(!void x.y..*Service.*(..))"/>
<aop:around method="profile" pointcut-ref="serviceMethodWithReturnValue"/>
</aop:aspect>
</aop:config>
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@rj-t42:1521:elvis"/>
<property name="username" value="scott"/>
<property name="password" value="tiger"/>
</bean>
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
The result of the above configuration is a fooService bean that has profiling and transactional aspects applied to it in the desired order. You configure any number of additional aspects in similar fashion.
The following example effects the same setup as above, but uses the purely XML declarative approach.
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<!-- the profiling advice -->
<bean id="profiler" class="x.y.SimpleProfiler">
<!-- execute before the transactional advice (hence the lower order number) -->
__<property name="order" value="1__"/>
</bean>
<aop:config>
<aop:pointcut id="entryPointMethod" expression="execution(* x.y..*Service.*(..))"/>
<!-- will execute after the profiling advice (c.f. the order attribute) -->
<aop:advisor advice-ref="txAdvice" pointcut-ref="entryPointMethod" __order="2__"/>
<!-- order value is higher than the profiling aspect -->
<aop:aspect id="profilingAspect" ref="profiler">
<aop:pointcut id="serviceMethodWithReturnValue"
expression="execution(!void x.y..*Service.*(..))"/>
<aop:around method="profile" pointcut-ref="serviceMethodWithReturnValue"/>
</aop:aspect>
</aop:config>
<tx:advice id="txAdvice" transaction-manager="txManager">
<tx:attributes>
<tx:method name="get*" read-only="true"/>
<tx:method name="*"/>
</tx:attributes>
</tx:advice>
<!-- other <bean/> definitions such as a DataSource and a PlatformTransactionManager here -->
The result of the above configuration will be a fooService bean that has profiling and transactional aspects applied to it in that order. If you want the profiling advice to execute after the transactional advice on the way in, and before the transactional advice on the way out, then you simply swap the value of the profiling aspect bean’s order property so that it is higher than the transactional advice’s order value.
You configure additional aspects in similar fashion.
16.5.9 Using @transactional with AspectJ
It is also possible to use the Spring Framework’s @transactional support outside of a Spring container by means of an AspectJ aspect. To do so, you first annotate your classes (and optionally your classes' methods) with the @transactional annotation, and then you link (weave) your application with the org.springframework.transaction.aspectj.AnnotationTransactionAspect defined in the spring-aspects.jar file. The aspect must also be configured with a transaction manager. You can of course use the Spring Framework’s IoC container to take care of dependency-injecting the aspect. The simplest way to configure the transaction management aspect is to use the tx:annotation-driven/ element and specify the mode attribute to aspectj as described in Section 16.5.6, “Using @transactional”. Because we’re focusing here on applications running outside of a Spring container, we’ll show you how to do it programmatically.
[Note]
Prior to continuing, you may want to read Section 16.5.6, “Using @transactional” and Chapter 10, Aspect Oriented Programming with Spring respectively.
// construct an appropriate transaction manager
DataSourceTransactionManager txManager = new DataSourceTransactionManager(getDataSource());
// configure the AnnotationTransactionAspect to use it; this must be done before executing any transactional methods
AnnotationTransactionAspect.aspectOf().setTransactionManager(txManager);
[Note]
When using this aspect, you must annotate the implementation class (and/or methods within that class), not the interface (if any) that the class implements. AspectJ follows Java’s rule that annotations on interfaces are not inherited.
The @transactional annotation on a class specifies the default transaction semantics for the execution of any method in the class.
The @transactional annotation on a method within the class overrides the default transaction semantics given by the class annotation (if present). Any method may be annotated, regardless of visibility.
To weave your applications with the AnnotationTransactionAspect you must either build your application with AspectJ (see the AspectJ Development Guide) or use load-time weaving. See Section 10.8.4, “Load-time weaving with AspectJ in the Spring Framework” for a discussion of load-time weaving with AspectJ.
16.6 Programmatic transaction management
The Spring Framework provides two means of programmatic transaction management:
Using the TransactionTemplate.
Using a PlatformTransactionManager implementation directly.
The Spring team generally recommends the TransactionTemplate for programmatic transaction management. The second approach is similar to using the JTA UserTransaction API, although exception handling is less cumbersome.
16.6.1 Using the TransactionTemplate
The TransactionTemplate adopts the same approach as other Spring templates such as the JdbcTemplate. It uses a callback approach, to free application code from having to do the boilerplate acquisition and release of transactional resources, and results in code that is intention driven, in that the code that is written focuses solely on what the developer wants to do.
[Note]
As you will see in the examples that follow, using the TransactionTemplate absolutely couples you to Spring’s transaction infrastructure and APIs. Whether or not programmatic transaction management is suitable for your development needs is a decision that you will have to make yourself.
Application code that must execute in a transactional context, and that will use the TransactionTemplate explicitly, looks like the following. You, as an application developer, write a TransactionCallback implementation (typically expressed as an anonymous inner class) that contains the code that you need to execute in the context of a transaction. You then pass an instance of your custom TransactionCallback to the execute(..) method exposed on the TransactionTemplate.
public class SimpleService implements Service {
// single TransactionTemplate shared amongst all methods in this instance
private final TransactionTemplate transactionTemplate;
// use constructor-injection to supply the PlatformTransactionManager
public SimpleService(PlatformTransactionManager transactionManager) {
Assert.notNull(transactionManager, "The ''transactionManager'' argument must not be null.");
this.transactionTemplate = new TransactionTemplate(transactionManager);
}
public Object someServiceMethod() {
return transactionTemplate.execute(new TransactionCallback() {
// the code in this method executes in a transactional context
public Object doInTransaction(TransactionStatus status) {
updateOperation1();
return resultOfUpdateOperation2();
}
});
}
}
If there is no return value, use the convenient TransactionCallbackWithoutResult class with an anonymous class as follows:
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus status) {
updateOperation1();
updateOperation2();
}
});
Code within the callback can roll the transaction back by calling the setRollbackOnly() method on the supplied TransactionStatus object:
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus status) {
try {
updateOperation1();
updateOperation2();
} catch (SomeBusinessExeption ex) {
status.setRollbackOnly();
}
}
});
Specifying transaction settings
You can specify transaction settings such as the propagation mode, the isolation level, the timeout, and so forth on the TransactionTemplate either programmatically or in configuration. TransactionTemplate instances by default have the default transactional settings. The following example shows the programmatic customization of the transactional settings for a specific TransactionTemplate:
public class SimpleService implements Service {
private final TransactionTemplate transactionTemplate;
public SimpleService(PlatformTransactionManager transactionManager) {
Assert.notNull(transactionManager, "The ''transactionManager'' argument must not be null.");
this.transactionTemplate = new TransactionTemplate(transactionManager);
// the transaction settings can be set here explicitly if so desired
this.transactionTemplate.setIsolationLevel(TransactionDefinition.ISOLATION_READ_UNCOMMITTED);
this.transactionTemplate.setTimeout(30); // 30 seconds
// and so forth...
}
}
The following example defines a TransactionTemplate with some custom transactional settings, using Spring XML configuration. The sharedTransactionTemplate can then be injected into as many services as are required.
"
Finally, instances of the TransactionTemplate class are threadsafe, in that instances do not maintain any conversational state. TransactionTemplate instances do however maintain configuration state, so while a number of classes may share a single instance of a TransactionTemplate, if a class needs to use a TransactionTemplate with different settings (for example, a different isolation level), then you need to create two distinct TransactionTemplate instances.
16.6.2 Using the PlatformTransactionManager
You can also use the org.springframework.transaction.PlatformTransactionManager directly to manage your transaction. Simply pass the implementation of the PlatformTransactionManager you are using to your bean through a bean reference. Then, using the TransactionDefinition and TransactionStatus objects you can initiate transactions, roll back, and commit.
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
// explicitly setting the transaction name is something that can only be done programmatically
def.setName("SomeTxName");
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
TransactionStatus status = txManager.getTransaction(def);
try {
// execute your business logic here
}
catch (MyException ex) {
txManager.rollback(status);
throw ex;
}
txManager.commit(status);
16.7 Choosing between programmatic and declarative transaction management
Programmatic transaction management is usually a good idea only if you have a small number of transactional operations. For example, if you have a web application that require transactions only for certain update operations, you may not want to set up transactional proxies using Spring or any other technology. In this case, using the TransactionTemplate may be a good approach. Being able to set the transaction name explicitly is also something that can only be done using the programmatic approach to transaction management.
On the other hand, if your application has numerous transactional operations, declarative transaction management is usually worthwhile. It keeps transaction management out of business logic, and is not difficult to configure. When using the Spring Framework, rather than EJB CMT, the configuration cost of declarative transaction management is greatly reduced.
16.8 Transaction bound event
As of Spring 4.2, the listener of an event can be bound to a phase of the transaction. The typical example is to handle the event when the transaction has completed successfully: this allows events to be used with more flexibility when the outcome of the current transaction actually matters to the listener.
Registering a regular event listener is done via the @eventlistener annotation. If you need to bind it to the transaction use @TransactionalEventListener. When you do so, the listener will be bound to the commit phase of the transaction by default.
Let’s take an example to illustrate this concept. Assume that a component publish an order created event and we want to define a listener that should only handle that event once the transaction in which it has been published as committed successfully:
@component
public class MyComponent {
@TransactionalEventListener
public void handleOrderCreatedEvent(CreationEvent<Order> creationEvent) {
...
}
}
The TransactionalEventListener annotation exposes a phase attribute that allows to customize to which phase of the transaction the listener should be bound to. The valid phases are BEFORE_COMMIT, AFTER_COMMIT (default), AFTER_ROLLBACK and AFTER_COMPLETION that aggregates the transaction completion (be it a commit or a rollback).
If no transaction is running, the listener is not invoked at all since we can’t honor the required semantics. It is however possible to override that behaviour by setting the fallbackExecution attribute of the annotation to true.
16.9 Application server-specific integration
Spring’s transaction abstraction generally is application server agnostic. Additionally, Spring’s JtaTransactionManager class, which can optionally perform a JNDI lookup for the JTA UserTransaction and TransactionManager objects, autodetects the location for the latter object, which varies by application server. Having access to the JTA TransactionManager allows for enhanced transaction semantics, in particular supporting transaction suspension. See the JtaTransactionManager javadocs for details.
Spring’s JtaTransactionManager is the standard choice to run on Java EE application servers, and is known to work on all common servers. Advanced functionality such as transaction suspension works on many servers as well — including GlassFish, JBoss and Geronimo — without any special configuration required. However, for fully supported transaction suspension and further advanced integration, Spring ships special adapters for WebLogic Server and WebSphere. These adapters are discussed in the following sections.
For standard scenarios, including WebLogic Server and WebSphere, consider using the convenient tx:jta-transaction-manager/ configuration element. When configured, this element automatically detects the underlying server and chooses the best transaction manager available for the platform. This means that you won’t have to configure server-specific adapter classes (as discussed in the following sections) explicitly; rather, they are chosen automatically, with the standard JtaTransactionManager as default fallback.
16.9.1 IBM WebSphere
On WebSphere 6.1.0.9 and above, the recommended Spring JTA transaction manager to use is WebSphereUowTransactionManager. This special adapter leverages IBM’s UOWManager API, which is available in WebSphere Application Server 6.0.2.19 and later and 6.1.0.9 and later. With this adapter, Spring-driven transaction suspension (suspend/resume as initiated by PROPAGATION_REQUIRES_NEW) is officially supported by IBM!
16.9.2 Oracle WebLogic Server
On WebLogic Server 9.0 or above, you typically would use the WebLogicJtaTransactionManager instead of the stock JtaTransactionManager class. This special WebLogic-specific subclass of the normal JtaTransactionManager supports the full power of Spring’s transaction definitions in a WebLogic-managed transaction environment, beyond standard JTA semantics: Features include transaction names, per-transaction isolation levels, and proper resuming of transactions in all cases.
16.10 Solutions to common problems
16.10.1 Use of the wrong transaction manager for a specific DataSource
Use the correct PlatformTransactionManager implementation based on your choice of transactional technologies and requirements. Used properly, the Spring Framework merely provides a straightforward and portable abstraction. If you are using global transactions, you must use the org.springframework.transaction.jta.JtaTransactionManager class (or an application server-specific subclass of it) for all your transactional operations. Otherwise the transaction infrastructure attempts to perform local transactions on resources such as container DataSource instances. Such local transactions do not make sense, and a good application server treats them as errors.
16.11 Further Resources
For more information about the Spring Framework’s transaction support:
Distributed transactions in Spring, with and without XA is a JavaWorld presentation in which Spring’s David Syer guides you through seven patterns for distributed transactions in Spring applications, three of them with XA and four without.
Java Transaction Design Strategies is a book available from InfoQ that provides a well-paced introduction to transactions in Java. It also includes side-by-side examples of how to configure and use transactions with both the Spring Framework and EJB3.
设计模式怎么用?
好几位同事问我:你是怎么样把设计模式用到代码里去的?你在写代码的时候会去想“这里可以用这个模式”、“那里应该用哪个设计模式”吗?
我的答案是:理解设计模式。理解得越深刻,运用起来就越得心应手。
我对设计模式的最初理解,是“解耦合”。那时候我刚刚开始学习和理解“高内聚”、“低耦合”,看到什么都想要“解耦合”。对设计模式,我的理解就是“按照设计模式来做,这个功能和那个功能就彻底解耦了”。比如责任链,链上的每一环的功能都是相互独立的;又如工厂模式,“创建实例”和“使用实例”的功能就隔离开了;工厂再结合继承、泛型,还可以把不同的子类类型和操作也隔离开。这些东西“独立”、“隔离”了之后,代码之间的耦合程度自然就降低了。
后来我又开始学习OOD和OOP,结合五大设计原则——接口隔离,单一职责,开闭,里氏替换,依赖倒置等——再次回顾了设计模式。这些原则里,最核心的当属开闭原则。而从开闭的角度来看,设计模式几乎都是把“修改原有功能”变成了“新增一项功能”。以策略模式为例,如果不使用它,那么每一个“新的策略”或者说“新的流程”,都可能要在原有代码中加入一套if-else或者switch-case。但是使用了策略模式之后,我们无须修改原有代码,而只用增加一套策略类,就可以实现新需求,并保持原功能不变一。从其它原则的角度,同样也可以更加深入的理解设计模式。
顺带一说,不要小看“开闭”。只有面对“不知道影响范围有多大”的一段代码时,才能理解“把修改变成新增”的好处。我曾经遇到过的案例中,是修改一处,大约要影响12处;而这12处受影响代码只有4处需要使用新的逻辑。那么:修改12个地方,并把这12个地方全部覆盖到、测试一遍(而且可能还有没评估到的第13、第14处);与新增一套策略,并且只修改需要使用新逻辑的地方;这两种办法,哪一种更好?
接下来的两三年里,随着业务来越复杂,编码过程中接触到的问题场景也越来越多。因而,又能够从另一个角度——业务场景和扩展——来理解设计模式。设计模式本身就是针对一些特定的业务场景、问题提出的通用解决方案,结合相应的业务场景,能够更加深刻的理解使用模式的好处——以及缺点。仍以前述案例来说,它让我对策略模式的缺点有了进一步的理解:增加一个策略,往往需要面临“新策略在哪里接入”的问题。如果在整个流程开始时接入,就需要新增一整套流程;如果要在增加策略的那个功能点上接入,那么在那个接入点上又需要一个工厂。新增一整套流程,就可能要增加一个接口,但是几乎可以完全不动旧代码。增加一个工厂则需要对原代码做一点改动,但是不需要新的接口。
此外,那几年里不断壮大的我们的开发团队,又给了我一个新的视角来理解设计模式:是的,设计模式能够协助团队成员之间沟通设计和实现的思路。简单的一句“这就是一个责任链”或者“这就是一套状态”,就能够清晰、明确的描述一大段代码的设计和实现思路。
不谦虚的说,我对设计模式理解得已经比较深入了。加上在长期的编码中都在使用设计模式,并尝试改进自己的实现方式,因此,在编码的工作中,我并不需要专门去想“这里可以用这个模式”、“那里应该用哪个设计模式”这样的问题。从“看到业务场景、问题”到“决定用某种设计模式,已经从熟能生巧变成了自然而然的过程。例如,现在看到校验,我就想用责任链;看到类型,就想用策略和工厂……
顺带一提,也有很多刚毕业的同事问我:怎样可以提高自己的技术水平?我的回答也是一样:理解你要用的技术。理解得越深刻,运用起来就越得心应手。
最后值得一提,我听到的“不使用设计模式”的诸多原因中,最常出现的就是“增加了太多工作量”,或者说“太耗时间”。
但是就我的经验来说,如果从一开始就能够做出较好的设计、选用合适的设计模式,那么以后的开发工作量、开发时间一定会不增反降。而从头开始按设计模式编码,即使是复合模式,多出来的时间也不会超过四十分钟——包括全部的简单设计、开发和单元测试。
真正比较耗时间的,是把一团乱麻的代码梳理开、用更好的设计去重构。而在这项工作上浪费的时间,至少是当初不做设计所节约的时间的两三倍。
最后的最后,我希望这是我最后一次谈论设计模式、为设计模式写什么东西。
业务系统升级改造-I
“重构,一言以蔽之,就是在不改变外部行为的前提下,有条不紊地改善代码”。《重构——改善既有代码的设计》一书已经很充分的介绍了如何做重构。如果我们只需要对一小段流程、一小部分代码做重构,这本书已经提供了非常实用的工具。不过,如果我们要对整个系统做一个全面的升级改造,书中的技巧就有些“一叶障目不见泰山”了。
而且,技术升级其实并不难。首先,大多数情况下,技术方案都是比较通用的:你也用SpringCloud,我也用SpringCloud,我俩的方案即使不是一模一样,相去也不过毫厘之间。其次,技术升级一般会采用开发人员比较了解和掌握的技术,这样设计、实施起来会比较得心应手。因此,这类升级这里不多说。
但是业务升级却恰恰相反。首先,与通用的技术方案不同,业务逻辑就如孙悟空一般,同样的业务可以变化出七十二种不同的方案来。例如,同是账务系统的记账业务,就可能有单边账、双边账、会计科目账等不同的记录方法,账务系统A的设计方案与账务系统B的设计方案也许就是水火不容的。其次,开发人员对业务的了解和掌握程度,既不像对技术那样深入,也不像产品或业务人员那样熟悉。因此,由开发人员来升级业务系统,颇有点强人所难了。
尽管更加困难,业务升级有时比技术升级更加迫在眉睫。很多业务系统从立项伊始就伴随着业务的“野蛮生长”,因而不得不采取疯狂堆代码、先上线再说这样饮鸩止渴的策略。遵循这种策略开发出的代码,很快就会陷入高度冗余、高度耦合的泥潭中,并由此导致业务逻辑不清晰、改一个需求动一万行代码、天天加班需求还是搞不完、好不容易上线了却bug不断等种种问题。雪上加霜的是,由于陷入其中无法自拔,开发人员既没有精力去提高自身技术水平,也很难忙里偷闲来对系统做技术升级。何况,应对这些问题时,技术升级并不是对症的良方:由于对整个系统的理解上一叶障目不见泰山、或者改造时牵一发而动全身,技术升级往往只能得到局部最优解而非全局最优解。就更不要说技术升级有时还要依赖业务升级的成果了。
不知道算幸运还是算不幸😂,我做过好几个业务系统的升级改造。从这些工作中,我总结了一些业务系统全面升级改造的思路。
建立领域模型
大多数业务系统在建立之初都没有一个完整的模型,业务都是靠着一个一个的业务流程,甚至一个一个的功能点拼凑起来的。可以说这是业务系统的一个原罪。在业务开展和业务系统建立之初,用这种模式来开发系统无可厚非。但是在业务成熟之后,业务系统进行升级改造的时候,仍然沿用这种模式,可以说是一种治标不治本的行为。只要沿用这种模式,前面提到的业务系统的种种问题,一定会很快重现,甚至变本加厉。
要跳出这样的模式,我们就必须建立一个领域模型,并且必须由这个领域模型来全局地、统筹地管理业务,而不是一点、一线的拼凑业务。在设计出一个合理的领域模型之后,才有可能梳理出简洁的、清晰的、完整的业务逻辑,才有可能写出高内聚低耦合的代码,才有可能降低业务开发的工作量和bug率,才有可能放开手脚去做技术改造、让系统获得技术升级的同时,让开发人员提高开发水平。
大话说了这么多,怎样才能建立领域模型呢?
首先我们来想想,领域模型应该是什么样子的?从我的经验和理解来看,一个领域模型应该包含两套东西:一套数据结构,一套业务抽象。说到底,程序等于算法加数据结构嘛。
业务数据结构设计
一般来说,数据结构主要关注一对一、一对多、多对一、多对多等几种数据关系,以及类型、长度、主键、唯一键、外键等数据约束。熟悉数据库表设计的话,对上面这些一定驾轻就熟了。
但是,只有在业务非常简单的情况下,领域模型的数据结构设计才能与数据库表设计画上等号。在复杂的业务领域中,我们更应关注的是在内存中的数据结构。数据库表仅仅是业务数据在持久化时的一套映射关系,并不是数据本身。
举一个简单的例子。很多系统都会需要一个配置服务,即给定一个配置关键字,返回一个配置值。这个值有可能是一个数字,也可能是一个字符串、布尔值,甚至是一个复杂对象。这个值的实际类型就是我们在内存中使用的数据结构。但是对数据库设计来说,我们没有必要完全按照这个数据结构来设计库表,而可以借助NoSQL的方式、用Json或者Bson的格式将配置值存储在数据库中。这时候数据库表的结构与实际使用的数据结构之间就出现了差异,这种差异就是前面所说的业务数据在持久化时的映射关系。
再举一个复杂点的例子:如果要设计一个在线Excel系统,当一个公式涉及到多个单元格的时候,怎样能把这些单元格相互关联起来呢?链表是一种很容易想到的数据结构。但是链表结构要如何存储到数据库中呢?比较简单明了的方式是只在数据库中保存公式,从数据库读取数据并解析为单元格的时候,再根据公式中解析出链表关系。在这个例子中,我们使用的数据结构是列表,而存储的数据结构却只是一个字符串。二者借助公式解析功能来完成映射。
在实际工作中,不只是数据库表结构与业务数据结构之间存在差异和映射,接口出入参数与业务数据结构之间往往也有差异和映射。这里就不举例子了。但总的来说,我们在设计业务系统使用的数据结构时,虽然可以以数据库表或接口输入输出为基准,但不应该被他们束缚住思路。归根结底,业务数据结构才是业务系统的核心结构,数据库表或输入输出应当围绕业务数据结构来设计,而不是业务数据结构围绕数据库和输入输出来设计。
不与数据库表结构挂钩的话,业务数据结构应该如何设计呢?有一个比较简单的技巧,即现实业务的中数据是什么样的,我们的业务数据结构就设计成什么样。换句话说就是临摹。实际业务中的数据关系是一对多的,我们就用一对多的结构来表达,而不要为了图方便把多条数据压缩成一个字符串来表示。实际业务中的数据类型是整数,我们就不要把它设计为字符串。
这样做有什么好处呢?
首先业务逻辑是建立在业务数据上的。如果我们在操作业务数据时,需要引入额外的逻辑,等于是在为自己的业务逻辑增加额外的复杂度。例如还款计划表的每一期都有期初金额和期末金额这两个数据,并且当期的期初金额等于上一期期末金额。如果我们在设计它的业务数据结构时,每一期都只保存期初数据,那么当我们需要去获取期末数据时,就不得不查出下一期的期初数据。 只保存期末数据也有同样的问题。由于这种查询操作非常多,这样的额外操作也非常多,其中的性能浪费就很可观了。但如果我们为每一期都保留期初和期末两笔数据,就可以生成还款计划表时计算一次,此后都直接查询就可以了。
其次,附加在业务数据结构上的逻辑,往往只能匹配某些特定的业务需求。当业务需求发生变更时,这些逻辑往往就不能满足新的要求了。例如,我们曾经用一个数组来把一对多的关系压缩为一对一的关系。但是这样的压缩只能够满足一级的一对多,如果业务逻辑演变成多个层级的数据关联,如1对n对m,这个设计就满足不了要求了。
总的来说,数据结构的设计应当直接“临摹”业务数据结构。数据库、接口的设计应服务于数据结构,而非相反。
业务抽象模型设计
业务抽象的设计有点象做阅读理解:你需要钻进去,然后再跳出来。所谓钻进去,是指理解业务最核心的本质,并且对业务细节有充分的掌握。所谓跳出来则是从繁琐的细节中抽离出来,站在一定的高度上对业务进行抽象描述和设计。
其中最简单的就是掌握业务细节这一步骤。在这项工作上只要能肯花费足够的时间和精力,就能够有非常大的收获。理解业务核心本质和对业务进行抽象设计有异曲同工之处:我们都需要抹去一些细节上的差异,站在更全面的、更高层次的角度上去分析贯穿于不同细节之中的业务本质。
还用在线Excel系统举例子。Excel都需要支持哪些功能呢?我们输入一个文本,系统要能支持按不同格式展示出来。单元格要支持输入公式,输入公式后,要能计算出它的结果。某一个单元格改动后,所有与之相关的公式都要能自动重新计算。等等等等。把这些纷繁复杂的流程和功能分析过之后,我们可以发现Excel的核心逻辑是三项:展示、计算和传播。据此创建出三个模型,就可以实现我们所需的大部分功能了。
又比如我们要做一个还款系统,需要支持正常还款、逾期还款、提前还款、部分提前还款等等若干种不同的还款模式。虽然还款模式很多,但是他们的核心逻辑都是一样的:计算应还金额、记录收付款的账务、更新还款计划表。根据这三个核心逻辑,我们就可以创建三个模型,从而为上述不同的还款模式提供。
在设计业务抽象时,最重要、也许也是最困难的一点在于:要把业务抽象定义在合适的层次上。在这个合适的层次上,我们的业务抽象既不会过于抽象、也不会过于具体。过于抽象的设计,就像Java函数式接口Function一样,虽然包罗万象,但是大而无当。这种设计会失去业务逻辑中所包含的约束、隐喻等,因而无法为后续的开发提供实质性的指导。另一方面,过于具体的设计则很容易陷入纷繁复杂的细节之中,即使后期努力优化、重构,也很容易因为一叶障目而只能求得局部最优解,甚至连最优解都算不上、而只是补丁摞补丁。
其它方面设计
数据结构和业务抽象可以清楚地勾勒出一个系统有哪些业务功能,以及它要怎样实现这些功能。但是,除了业务功能需求之外,我们还应当关注一些其它需求,如扩展性、可用性、幂等性、请求响应时间、事务吞吐量、数据库锁性能、以及可监控、可运营等等。
从个人经验来看,业务系统的设计中,应当重点关注扩展性的设计。因为业务系统所面对的诸多问题中,最司空见惯、也最令人生厌的就是需求变化。上午时的业务流程还是“A-B-C”,开一个会之后就变成了“A-B-D”,再写几行代码又变成了“A-B-D-C”,随着测试介入,最后变成了“A-B-C-D”……类似的场景相信做业务系统的各位应该是见怪不怪了吧。如果在项目前期不能设计出一个高度可扩展的项目框架,那么当业务需求一变再变的时候,加班赶工、熬夜改bug等后续问题就会接踵而至了。一个扩展性高的系统,应该要做到当需求在同一维度上变化时,只改数据、不改代码就能支持;引入新的维度时,只需简单扩展,不必伤筋动骨就能支持。
可监控和可运营是很容易被忽视的两个设计要点。有一句话大家应该都听过:“用户输入是魔鬼”,如果我们对用户的操作、输入和输出没有充分的监控(有时甚至要监控到用户的一条完整操作链),有时我们完全无法想象用户会用什么样的方式来操作我们的系统、会提交什么样的数据,因而也无法想象我们遇到的bug和问题究竟是怎样产生的。我以前做过一个web系统,需要用户分两步提交一些数据,每个步骤对应一个web页面。系统上线后我们发现,从第二个页面提交过来的数据中,有很多都缺少第一页的数据。这是为什么呢?我们绞尽脑汁、查了大量的日志和数据,最后发现有些用户在填写完第一个页面后,会过好几天才打开第二页进行填写。然而几天过去了,这时提交的第二页数据就无法和第一页的数据关联上了,自然也就没有了那部分数据。推测是用户在填完第一个页面后,把第二页放进了收藏夹,后来直接从收藏夹进行访问。我们是怎么发现这个问题的呢?系统日志中记录下了用户请求系统的URL,我们经过分析后发现,这类问题数据都只有第二个页面的请求记录,而没有找到相关的第一个页面的请求记录。如果当时我们没有这个日志监控,想要发现这个问题的原因,简直天方夜谭。
监控的重要性已经被很多人认识到,并且在设计中会重点考虑。但是可运营性就真的很少被提及了。我所谓的“可运营性”,是指当需要对线上数据做修改时,可以通过系统中预定义的一些业务流程来执行操作,而非原始的修改数据库。与手工写SQL语句修改数据库相比,通过系统来执行业务操作有很多好处:保持业务数据一致性,不会漏改/错改某些数据;简单方便;可以通过系统权限控制来限制和追踪操作人及操作数据等等。例如,做过账务系统的朋友一定都遇到过改账(例如回滚或者对冲某笔账目)的需求吧。在我们的账务系统中,一个业务操作(例如放款、还款、垫付等)可能对应到上百个账户的余额、流水等数据,如果要手工改账,简直是impossible mission。所以我们设计了两个特殊的记账业务,分别用于指定对冲某一条账目和对冲某一笔业务引发的所有账目。这两个功能上线之后,相关的开发人员就从查账、写SQL的工作中解脱了出来,从而有更多时间和精力去做个人的技术提升和系统的技术优化工作了。
其它的可用性、幂等性、高性能等方面,相关的文章、讨论已经非常多了,这里不多赘述。
定时任务集群部署几种方案
很早以前跟嵩山聊过这事儿。这里稍微整理一下。
各方案综合比较
欢迎各位补充
ZooKeeper
分布式系统锁,可以用于监控锁的状态和当前持锁的服务器,后期可增加监控
框架较成熟
不能以job为单位进行调度,因此任务压力不能分散
需要单独部署zk,进而,可能需要有人负责服务器运维
姜作辉在canal系统中已经部署了一套zk。
调度机+执行机
任务压力分散方面最优
调度机单活
quartz
框架较成熟
需要把注解转换为xml配置,开发、测试工作量较大
以Sheduler为单位进行加锁、调度,也不能分散压力
自定义数据库锁
可以以job为单位调度,任务压力可以分散
目前来看工作量最小
可能因为未正常解锁而导致后续任务无法执行
ZOOKEEPER
对于步骤1和步骤2
创建Watcher - masterNode: 当stat=sync且event=none的时候,执行create path1,尝试创建,创建成功的系统持有锁。
不成功的使用watcher监听path1,当收到stat=sync且event=nodedeleted的响应后,重发
创建Watcher2 - running:当系统启动后,在路径path2下创建自己的node,用户其他系统获取children监听。
每个task模块创建开关(boolean),对于获取了master节点的状态,boolean为true,所有任务的执行需要先校验开关。
对于任务执行中的时候zkClient 与zkServer断开连接时,获取开关状态后的任务不取消。
有一个思路上的bug:当任务执行的时间超过任务间隔以后,可能会导致问题。
即:
1 - 任务T每5分钟执行一次,但是有可能执行时间超过5分钟。
2 - 服务器A获取锁,执行任务T(10:00),后ZK断开
3 - 服务器A丢失锁
4 - 服务器B获取锁,执行任务T(10:05),但此时T(10:00)的还未完成,此时会出现数据库锁或其他不可预料的问题。
需要一个很好的逻辑来确保执行且仅执行一次任务。
现有的想法是,仅仅判断主机,然后由这台主机做所有的任务执行。
需要满足的点有
1 - 任务将在某个条件下被触发 (例如时间)
2 - 同一个任务在同一条件下仅应当被执行一次,即在模块任务A中在条件1下被触发的任务A1失败后,再次被触发时任务为A2,并非A1。而其他模块可称为B...
3 - 任务失败后回滚 DONE Spring 代理回滚
4 - 失败回滚后此任务是否还可以重新触发(A1,并非A2或者A1‘ ) NEED 需要徐总帮忙确认
5 - A任务1启动后,连接断开,A的主机权易手到B,任务1不应启动(B1不启动,保持A1)
6 - 仅有A和B的情况下,A和B都未获取主机时,可以通过手动方案开启
7 - 仅有A和B的情况下,A和B都获取了主机,可以通过手动方案终止
8 - 每个任务在开始前需要备份(?)
9 - 确保任务完成后可回退(?)确保当出现任务1被执行了多次(A1 & B1),数据可以被修复
10 - 增加权重。
11 - 增加监控
调度机+执行机
这是跟别人聊天时听来的一种解决方案。调度机查出一次任务需要执行的数据集合;然后分发给执行机。
优点:执行机可以集群;并且可以做到类似map reduce的机制,让不同的执行机处理不同的数据子集,充分利用集群的优势。
缺点:调度机仍然是单活的。对现有的TASK模块来说,改造量太太太太大了
quartz
quartz自带有集群配置。按照它的要求在数据库中创建对应的表、并对配置和代码做相应的修改之后,就可以实现了。
建表语句: table_mysql.txt。 一共有11张表,QRTZ_LOCKS是其中数据库锁的核心表。
配置上的改造,可以参考http://tech.meituan.com/mt-crm-quartz.html。里面还有美团过往的task集群方案和quartz的原理分析。
代码上的改造,主要是需要自己重写一个QuartzJobBean,以避免quartz原生类无法序列化到数据库中去的问题。可以参考http://blog.csdn.net/lifetragedy/article/details/6212831
优点:quartz框架已经比较成熟了,可以认为值得信任。
缺点:从目前了解的情况来看,quartz还无法通过注解来和spring集成[1]。因此,TASK模块的改造(尤其是回归测试的工作量)会比较大。另外一个任务只能分配给一个服务。
注[1]:向姐说quartz支持注解,但我在开发手册和配置手册上都没找到相应的内容。不知道能否提供来源?附上两份手册:
开发手册:Quartz_Scheduler_Developer_Guide.pdf;配置手册:Quartz_Scheduler_Configuration_Guide.pdf
我看官方文档里有个提示:
Important: Never run clustering on separate machines, unless their clocks are synchronized using some form of time-sync service or daemon that runs very regularly (the clocks must be within a second of each other). See http://www.boulder.nist.gov/timefreq/service/its.htm if you are unfamiliar with how to do this.
即要求集群服务器之间有严格的时间同步;否则(目前推测)会出现:多个实例运行job;或者部分job错过运行时间等问题。
自定义数据库锁
参考quartz的机制,利用数据库锁自己写一个集群同步机制。
优点:改造量会最小。另外,可能可以根据咱们的job自定义更加精细的锁机制。
缺点:加锁容易解锁难。如果一个job正常加锁、但由于某些问题没有正常解锁,那么可能导致永久上锁。另外,以job为单位来加锁的话,一个任务同样只能分给一台服务。
下表是目前能掌握的、spring batch的BATCH_JOB_EXECUTION表中,job状态的几种情况。
运行中 STARTED UNKOWN
正常完成 COMPLEDTED COMPLEDTED
抛出异常 FAILED FAILED
运行中停机 STARTED UNKOWN
jvm错误(如内存溢出) 未重现,但估计是STARTED 未重现,但估计是UNKOWN
最要命的是,从spring batch的表中,无法区分“运行中”和“运行中停机”这两种情况。可能需要其它方式(超时机制,停机后清除锁等等)来保证正常解锁。不知道quartz是怎么解决这个问题的。
Redis
刘虓
通用的审批功能
为什么要给每个审批功能都写一套不同的代码呢?
虽然它们的待审批信息可能大不相同。但是,就审批本身而言——审批流程大可不必关心那些信息,这些信息是给审批人看的。而审批系统,只需要关注:
谁,执行某个操作,把某个待审批事件,从某个状态,更新为另一个状态。也许还会有一些其它操作。
基本上,这是一个状态模式。但是需要加入一些扩展点:审批人的权限设置,以及“其它操作”。
技术如何驱动业务?
技术如何驱动业务?
用新技术突破“怎么做”,进而推动“做什么”
这种方式就是我们最常说的“技术驱动”。利用更新、更快、更稳定的技术,创新业务的实现方式,从而推动业务的发展、创新和颠覆。
最著名、最具颠覆性的创新,大概当属移动支付。本质上,它只是利用移动互联网、NFC等技术,提供了一种新的支付方式。然而对“怎样付钱”的创新,催生出了余额宝、网约车、团购、外卖、共享单车等等一系列全新的、颠覆性的业务或行业。
不过,这种“技术驱动”模式并不适合于“业务驱动”的业务、公司或行业。在“业务驱动”下,“做什么”的业务需求是“主动轮”,而“怎么做”往往只能担当“从动轮”。也就是说,技术必须以满足业务需求为先,而将技术上的创新、突破则变得无关紧要、可有可无,更别谈驱动业务了。
那么,在“业务驱动”模式下,技术就无法反客为主了么?不,有办法。
理解业务
任何一项创新,都必须建立在对旧事物了如指掌的基础上。技术想要驱动业务,也必须通过全面、深入的理解业务来构建地基,才能万丈高楼平地起。
当然,技术人员理解业务,与产品人员一定会有不同,也一定要有不同。产品人员从业务的最终结果和表现上来理解业务,技术人员从内部结构、组织和实现方式上来理解。例如,产品人员理解的业务是“一个审批流程”,技术人员的理解则是“状态模式”、“工作流”;产品人员理解的是对某个渠道做某个处理、对另一个渠道做另一种处理,技术人员则会将其理解为策略模式。
从这两个例子上可以看到,设计模式是一种理解业务的不错的方式。设计模式本身就是用于“处理某一类业务问题/场景”的方法,很自然的有助于我们理解业务。此外,不少的技术架构,如工作流、权限、SSO等,也能够为我们理解业务提供帮助。
搭建高扩展性的基础架构
在理解业务的基础上,搭建出一套适合当前业务需求、以及未来业务发展的架构,这是技术真正开始驱动业务的第一步。
“业务驱动”的一大特点,就是业务需求在不断的变化。面对这种情况,如果技术实现也不断的随之变化,那么技术、技术人员一定会疲于应付——这种困境我们已经遭遇了太多了。
高扩展性的基础架构,能够在不断变化的业务需求面前,保持技术实现的相对稳定性,从而,一方面提高业务需求的实现效率,使得业务需求及其变化能够尽快的付诸实践;另一方面,也可以减少技术的债务和负担,从而有更多的资源来思考和实践“技术如何驱动业务”。
构建完备的领域模型
“高扩展性的基础架构”只是第一步。只有构建起了领域模型,技术才能够真正开始“驱动”业务。而只有完备的领域模型,才能够全面、深入地刻画出业务的本质属性。
领域模型实际上是“理解业务”与“技术架构”结合后的产物。只有充分理解了业务,才有可能构建起一套领域模型;而只有合理的技术架构才能够把业务完备的表达和实现出来。
突破模型、创新业务
构建领域模型的目的,不仅仅是描述现有业务、容纳新的业务。更重要的是,它勾勒出了已知业务的“边界”。而只有知道“边界”在哪里,才知道创新的“束缚”和目标在哪里,才能够有的放矢,完成业务上的突破和创新。
轮子除了开车,还能摊大饼——地址服务器的一个“另类”用法
地址服务器是软负载的一种实现方式。除了单纯做软负载,它还能做一点其它的事情。
背景
当时我们有两套系统和对应的首页,一套适用于PC端,一套适用于移动端。但是,总难免出现用户进错系统,例如使用PC版微信时打开了分享的链接。因此我们讨论了几版方案。
初版
起初的解决方案是在PC端和移动端分别做判断,如果用户进错了首页,那么将会重定向另一套系统上。就像这样:
这个版本的问题很明显:同一套代码重复出现在了两个地方。这个版本一定会在以后的扩展中,被“Don't Repeat Yourself”原则狠狠地打脸。
再版
这个方案显然有问题。因此我们改了一版:我们把判断逻辑放到了一个独立系统中。然后,PC端和移动端都先重定向到这个系统中,再重定向到对应的系统上。就像这样: 
这个版本的方案确实遵守了“DRY”原则。但是,它仍然存在一些问题。最主要的是:是它做了两次重定向。上图中实线、虚线(按从左到右的时序发生),以从移动端访问PC端的情况,说明了这一问题。两次客户端的重定向降低了响应性能、降低了用户体验。并且这样会将一个内部系统暴露了在公网上,增加了系统的安全性风险。
终版
终版的方案借鉴了地址服务器的思路。PC或移动端在接到客户端的请求后,通过内网的服务调用,从Judger上获取到正确的首页地址之后,再向客户端返回。如果是自己的首页,则直接返回;如果是另一个系统的地址,则向客户端发送重定向请求。如下图所示:
上图重现了一次再版方案中的流程。与再版方案不同,PC端访问Judger时是内网访问,这样就解决再版方案中的三个问题:性能、用户体验、安全风险。
后记
当时讨论方案的几位同事,其实都知道地址服务是怎么回事。但是为什么,在再版方案之后,大家讨论了很久都没有进展?
我们讨论设计模式时也常提出一个问题:我们已经把每一种设计模式都背得滚瓜烂熟了,为什么在实际工作中却不知道怎么应用?
我觉得,学设计有三种思路。一种是学设计如何应用;第二种是学设计是什么;第三种是学设计的核心**。
以设计模式来说,第一种思路是学哪种设计模式适用于哪种业务场景;第二种思路则是学这种模式与那种模式有什么区别;第三种思路则是从设计模式中学习开闭、里氏替换等设计原则。
过于专注“是什么”的人,也许更适合做科学而非技术。做技术的思路是优先“怎么用”、而后再“是什么”。而知道“怎么用”、“是什么”、并且还知道“为什么”,才能把技术做精、做专、做高。
外科手术式团队
我第一次听说“外科手术式团队”是在《人月神话》中:“Harlan Mills建议大型项目的每一个部分由一个团队解决,但是该队伍以类似外科手术的方式组建,而非一拥而上。也就是说,同每个成员截取问题某个部分的做法相反,由一个人来完成问题的分解,其他人给予他所需要的支持,以提高效率和生产力”。用下面这张图可以更直观的理解这个“外科手术团队”的组织方式(图中的“外科医生”、“副手”等的职责分工这里就不赘述了,翻翻《人月神话》或者上网查查就清楚了。):

当然,我们实际中的外科手术团队不会有这么多专门的角色,一般都是一人身兼多职。例如,有一个团队中,项目经理承担了“管理员”和“编辑”的角色,承担了几乎全部的对外工作——和“外科医生”一起与业务部门探讨核心业务方向与逻辑、与行政部门沟通职场/调休/考勤等问题、与领导沟通汇报项目进度等等,从而让其他人得以专注于自己所擅长的和承担的团队内部工作。有时候,团队成员也会在不同的角色之间“轮岗”,最常见的就是大家轮流来做“工具维护人员”或者“编辑”,我们也曾尝试过轮流来做“副手”甚至在某些比较小的功能需求上轮流做“外科医生”,以期锻炼团队、培养后备人才,效果也还不错。
不管怎样分配角色,既然是“外科手是团队”,就一定会有“外科医生”。《人月神话》将这个角色称为“首席程序员”,我们今天一般称为“架构师”。这个角色一般是由团队中技术最好、最熟悉业务的人来承担。这二者缺一不可。光是技术好却不熟悉业务,很容易做出技术华丽、但不适合业务的方案来。而熟悉业务但技术能力一般的话,则常有心有余而力不足之憾。“外科医生”往往也是“编程语言专家”,或者更宽泛一点来说,往往也是“技术专家”。一方面,如前所说,“外科医生”一般会由团队中技术最好的人来担任,技术最好的人很自然会成为“编程语言专家”或“技术专家”;另一方面,作为没有正式任命、因而也没有真正的上级对下属的权力的“外科医生”,出类拔萃的技术能力带来的权威和领导力是他一切权力的来源,因而他也必须让自己成为“编程语言专家”和“技术专家”。
但是,“外科医生”无法兼任“副手”。“副手”这个角色有两重意义:一方面是为“外科医生”提供参谋和建议,另一方面则是作为后备的“外科医生”,在必要时接手部分甚至全部的工作。这个角色适合团队中对技术或业务有一方面突出、但另一方面略有不足的成员。这样,他们可以用自己突出的一方面为“外科医生”提供帮助,也可以通过向“外科医生”学习来弥补自己不足的一面。有那么两个团队,那些出色的“副手”们在“外科医生”离开后顺利的接过了接力棒,不仅保证了项目有条不紊的继续推进,而且自己也多次获得公司的嘉奖(有些奖项甚至是原先的“外科医生”都没有得过的哈哈哈)。
对程序员来说,与人沟通常常是件非常麻烦而头疼的事情,比调试一万行代码都麻烦和头疼。跨团队甚至跨部门的沟通就更不用说了。如果是频繁的被打断,更加令人烦躁不安。因此,在团队中设立一个“管理员”角色是非常必要的。他需要负责团队成员内与团队之外的沟通与协调,从而把团队成员解放出来,使其能专注于自己在项目中的工作。这个角色一般也不适合由“外科医生”兼任,在我所接触过的团队中,一般是由产品经理甚至项目经理来扮演“管理员”的橘色——这时,除了报销、考勤等工作外,与沟通业务需求、对接其他项目团队、向领导汇报计划和进度等,也会由他们一并处理。但是这种情况下,“管理员”和“外科医生”必须合作无间,否则容易出现内耗。
外科手术团队的最大优点在于:“外科医生”可以把项目方向统一在一个正确的轨道上,把系统质量控制在较高的水平上,也能让团队成员水平芝麻开花节节高。总之,一个好的“外科医生”可以把项目、系统和团队带领到也许是前所未有的高度上。上次做业务系统优化改造时,我们团队就是一个外科手术团队。这位尽职尽责的“外科医生”花了一个月时间分析业务、老系统,并反复地与团队成员讨论技术和业务、讲解他的优化升级思路,最终提出了一个非常优秀的系统架构方案。在开发过程中,这位“外科医生”担纲编写了新系统的核心框架,并牵头推动团队的设计评审、代码评审和技术分享,不仅使得系统质量保持在一个较高水准,同时也让团队成员获益匪浅。可以说,没有这位“外科医生”,这个业务系统优化改造项目不会有最后的成功。
当然,要取得这样的成功,需要万事俱备、不欠东风:“外科医生”自身水平高、态度好,团队内、外工作能够顺利开展,团队成员也能积极跟上他的节奏,等等。如果这些条件有所欠缺——例如“外科医生”水平不行、做出了错误的设计,或者团队成员不配合、虽有好的方案却执行不下去,那么项目前途就一片灰暗了。我们有过一支团队,开始时还一切顺利,但是随着“外科医生”态度转变——她渐渐地倦怠了,对项目、系统和团队问题基本都以“嗯”“就这样吧”“都行”来应付——系统以肉眼可见的速度开始“腐化”,项目逐渐失去了方向和控制。这也算是“人治”这把双刃剑的效果吧。
但是,也有办法可以预防或者避免这类问题。首先,“外科医生”的选任上,应当选择技术、业务和工作态度都是团队内的顶尖的那位。这样一位人才,可以让项目和团队攀登到“人治”的巅峰。此外,团队里还有“副手”、还有“管理员”,他们是与“外科医生”一起工作的。预防“外科医生”犯下这样那样的错误,或在“外科医生”无法承担职责时接替他的工作,就是“副手”的职责之一,也许是最重要的职责了;而“外科医生”处理团队内外的协调、沟通工作时,有时需要“管理员”来充当润滑油。我们那位担任“管理员”的项目经理就为“外科医生”和业务部门之间的沟通协调做了很好的协调和缓冲,没有她的话我们那位脾气急的“外科医生”恐怕分分钟要和业务同事拍桌子吵起来。
外科手术团队还有其它的一些优点。这种团队成与大多数团队的人员组成是相似的:若干产品人员担任“管理员”,一位资深或高级研发担任“外科医生”,几位中级研发担任“副手”,几位中级和初级研发担任“程序职员”、“工具维护人员”,再加上几位QA同事充当“测试人员”。这种产品、资深、高/中/初级研发、QA的人员搭配可以说是大部分团队的标配了。因此,在现有团队基础上组织外科手术团队,可以说是水到渠成的。
之所以说是水到渠成,还有一个原因在于,组织外科手术团队不需要像敏捷或精益团队那样增加工作流程、提高管理成本。相反的,外科手术团队会把大部分全局性的、管理性的工作交给“外科医生”和“管理员”处理,其他人专注于分配给自己的工作,从而提高个人和团队的工作效率,也便于“外科医生”和“管理员”了解和把控项目进度。这也是外科手术团队的一个优点:整体上付出较小的管理成本,获得工作效率的大幅提升。当然,虽然整体上的管理成本不高,但是对“外科医生”和“管理员”来说,他们投入的时间精力可能要成倍地增加。这也是外科手术团队需要解决的一个问题。
对外科手术团队来说,最大的困难不是“外科医生”的选任。所谓“十室之邑必有忠信”,无论有没有正式任命,每一支团队必定都有一个这样的角色。也不是团队内、外的协调沟通,即使同层级上沟通不来,也可以由更高层来处理——就像孙悟空搞不定的妖怪可以请观世音如来佛出山一样。最困难的是让团队成员也能积极跟上“外科医生”,让团队成员——包括“副手”、“管理员”等——愿意主动的遵循他的要求、理解他的思路、跟上他的节奏:这是我过往的团队经验中最困难的一项工作。只有把这项工作做好,“外科医生”提出的一切的项目和系统的方向、规划才有可能变成现实。毕竟,仅靠“外科医生”一个人,写不完系统的全部代码、做不了项目的全部工作。
但是,在调动团队成员的积极性方面,据我的经验来看,外科医生团队往往不如敏捷团队做得好。不过这个下次再说吧。
Spring batch and Transactional
A task of spring batch was writen as following in my team:
public class XxxTask{
private Job xxJob;
private JobLauncher laucher;
public void execute(){
// get parameters
Map<String, Object> param =...
// execute the job
try{
laucher.execute( xxJob, param);
}catch(){
......
}
}
}If a database transaction was created when "get parameters", no matter it's reading from or writing to the database, then an exception will be thrown when "execute job". The exception is:
java.lang.IllegalStateException: Existing transaction detected in JobRepository. Please fix this and try again (e.g. remove @Transactional annotations from client).The internet said, the field named "validateTransactionState" of class "AbstractJobRepositoryFactoryBean" was set to TRUE, so the spring batch checked that whether a transaction was existed in the current thread. Then that exception happend as there is one transactoin already. The interrelated code is:
private void initializeProxy() throws Exception {
if (proxyFactory == null) {
proxyFactory = new ProxyFactory();
TransactionInterceptor advice = new TransactionInterceptor(transactionManager,
PropertiesConverter.stringToProperties("create*=PROPAGATION_REQUIRES_NEW,"
+ isolationLevelForCreate + "\ngetLastJobExecution*=PROPAGATION_REQUIRES_NEW,"
+ isolationLevelForCreate + "\n*=PROPAGATION_REQUIRED"));
if (validateTransactionState) {
DefaultPointcutAdvisor advisor = new DefaultPointcutAdvisor(new MethodInterceptor() {
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
if (TransactionSynchronizationManager.isActualTransactionActive()) {
throw new IllegalStateException(
"Existing transaction detected in JobRepository. "
+ "Please fix this and try again (e.g. remove @Transactional annotations from client).");
}
return invocation.proceed();
}
});
NameMatchMethodPointcut pointcut = new NameMatchMethodPointcut();
pointcut.addMethodName("create*");
advisor.setPointcut(pointcut);
proxyFactory.addAdvisor(advisor);
}
proxyFactory.addAdvice(advice);
proxyFactory.setProxyTargetClass(false);
proxyFactory.addInterface(JobRepository.class);
proxyFactory.setTarget(getTarget());
}
}So I configurate it by xml, like this:
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.JobRepositoryFactoryBean">
<property name="transactionManager" ref="transactionManager" />
<property name="dataSource" ref="dataSource" />
<property name="validateTransactionState" value="false" />
</bean>Well, one problem was resolved, and another one emerged:
十二月 28, 2015 6:40:05 下午 org.springframework.batch.core.job.AbstractJob execute
严重: Encountered fatal error executing job
org.springframework.dao.EmptyResultDataAccessException: Incorrect result size: expected 1, actual 0
at org.springframework.dao.support.DataAccessUtils.requiredSingleResult(DataAccessUtils.java:71)
at org.springframework.jdbc.core.JdbcTemplate.queryForObject(JdbcTemplate.java:791)
at org.springframework.jdbc.core.JdbcTemplate.queryForObject(JdbcTemplate.java:814)
at org.springframework.batch.core.repository.dao.JdbcJobExecutionDao.synchronizeStatus(JdbcJobExecutionDao.java:301)
at org.springframework.batch.core.repository.support.SimpleJobRepository.update(SimpleJobRepository.java:161)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:302)
at org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvocation.java:190)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:157)
at org.springframework.transaction.interceptor.TransactionInterceptor$1.proceedWithInvocation(TransactionInterceptor.java:99)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:281)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:96)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)
at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:207)
at com.sun.proxy.$Proxy97.update(Unknown Source)
at org.springframework.batch.core.job.AbstractJob.updateStatus(AbstractJob.java:416)
at org.springframework.batch.core.job.AbstractJob.execute(AbstractJob.java:299)
at org.springframework.batch.core.launch.support.SimpleJobLauncher$1.run(SimpleJobLauncher.java:135)
at org.springframework.core.task.SyncTaskExecutor.execute(SyncTaskExecutor.java:50)
at org.springframework.batch.core.launch.support.SimpleJobLauncher.run(SimpleJobLauncher.java:128)
at ********.common.task.TaskUtils.launchJob(TaskUtils.java:99)
at ********.task.auth.AuthSyncTask.syncGroupInfos(AuthSyncTask.java:89)
at ********.task.auth.AuthSyncTask$$FastClassBySpringCGLIB$$b0cb6150.invoke(<generated>)
at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:204)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.invokeJoinpoint(CglibAopProxy.java:717)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:157)
at org.springframework.transaction.interceptor.TransactionInterceptor$1.proceedWithInvocation(TransactionInterceptor.java:99)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:281)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:96)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:653)
at ********.task.auth.AuthSyncTask$$EnhancerBySpringCGLIB$$91744a87.syncGroupInfos(<generated>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.springframework.scheduling.support.ScheduledMethodRunnable.run(ScheduledMethodRunnable.java:65)
at org.springframework.scheduling.support.DelegatingErrorHandlingRunnable.run(DelegatingErrorHandlingRunnable.java:54)
at org.springframework.scheduling.concurrent.ReschedulingRunnable.run(ReschedulingRunnable.java:81)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)I'll try to resolve the second problem. And then, record the solution here.
“六神”——技术提高开发效率的一个方案
这个方案并不是我在系统设计方面的最早一次尝试。但它在提高开发效率方面,是效果最为显著的一个方案。
简介
“六神”框架提供了一套简单而通用的、从Web层到数据库操作(增加单个数据、删除单个数据、修改单个数据、查询单个数据、查分页列表、查不分页列表,六个操作,因此名为“六神”)的基础组件。并且,它为复杂的数据库操作留下了扩展点。
在当时的技术背景下,这套框架使用Struts2.0+Spring+myBatis来实现。但是它的设计思路是可以适用于其它技术的。
在应用了这套框架之后,我们那个系统在一个月时间上线14个功能模块,效率提升了近三倍。
背景
当时我们接下的项目是一个近似于OA系统的稽核系统。这个系统的主要功能有两类:一是各种数据、信息的增删改查;一是各种审批流程。审批流程的设计按下不表,“六神”就是为增删改查功能而开发的。
思路
在完成了几个增删改查的页面功能之后,我发现它们非常相似。
功能上,它们都是打开页面时查询一个分页列表;然后新建一条数据;按id查询出一条数据,并展示在弹出窗口上;弹出窗口上可以修改某些字段的值;某些页面上还需要提供删除数据的功能;部分配置数据、基础数据需要提供查询不分页列表的功能。
流程上,则几乎都是页面提交一个http请求,Struts 2.0的action从中解析出参数;service层调用对应的mapper;myBatis生成并执行SQL,将操作结果返回给service;service直接将参数交还action;action将返回值转为json字符串写入http响应中。
而它们之间的差异性,基本是入参和出参的封装类型、以及数据库操作的SQL上。
流程图

上述六个操作,都可以用下面这张流程图来描述。而不同的操作、不同的业务需求之间,基本上只有object以及SQL有所不同。
类图

“六神”的主要类图中,以接口定义居多。其中的BasicDbAction和BasicDbMapper,是当时Struts2.0和MyBatis框架中的两个实现类。
Service层上分出来了六个接口。这是为了保持接口的隔离性。但是默认类实现了全部接口,只是所有方法都直接抛出异常。实际上就只是提供了一个Adapter而已。
Dao层同样有六个接口,但不提供默认实现。需要使用时针对myBatis或者Hibernate,分别写自己的实现类。
原先的类结构上,Controller层只有一个Struts 2.0的action;Dao层只有一个myBatis的Mapper。两个接口都是后来提取出来,计划扩展到SpringMVC和Hibernate的。
Strust2.0一般会为每个HttpRequest创建一个action实例,并将HttpRequest中的参数根据action的setters/getters方法封装到action中。这就需要action在实例化的时候,同时生成一个参数容器、即类图中param: I的一个实例。然而,根据泛型参数无法直接做实例化。因此,需要为action配置一个参数claz并在Spring IoC中将它注入为I的具体类型。这样才能保证action初始化的同时实例化参数param,并成功读取到HttpRequest中的请求。
MyBatis一般会使用Mapper的类名+执行方法名作为需要执行的SQL-id,并据此id从xml文件中找到、生成实际的SQL。但是,如果直接注入、使用框架提供的MyBatis默认实现类,那么每一个查询请求都会按照“xxx.BasicDbMapper.select”这个id去查找SQL,因而也无法找到正确的SQL。为了避免这个问题,Basid
DbMapper中使用了入参param的类名+执行方法名作为SQL-id。这样,对“xx.ParamA”的查询请求就会使用“xx.ParamA.select”这个id了。
另外,除了Controller之外,计划扩展到Jms Listener。不过异步消息只有增删改三个操作,就算“半神”吧。
代码
https://github.com/winters1224/blogs/tree/master/code/src/main/java/net/loyintean/blog/sixgod
小结
这个小框架功能非常简单,设计上也非常简单。因为它太简单,少有开发团队愿意在这上面耗费资源。但是,这个框架能够把简单、重复的工作抽取出来,让团队把资源投放在更加复杂的工作中去。
另一方面,随着REST、微服务等概念的深入,我认为,每个系统中的每项资源都应该提供CURD的基本API。这个小框架,能够方便快捷的提供对应的Web API,也能为微服务的快速落地提供方便。
归并排序算法及一个问题分析
摘要
简单介绍了传统归并排序算法,以及Java API提供的TimSort优化后的归并排序算法。
并且分析了代码中出现的一个问题原因与解决方案。
敬请忽略文中的灵魂画风。
排序算法简析
代码入口
Collections.sort、List.sort、Arrays.sort方法是逐级调用的关系,最终的底层是Arrays.sort方法,其代码如下(这几个方法的javadoc都蔚然可观,大家不妨看一看):
public static <T> void sort(T[] a, Comparator<? super T> c) {
if (c == null) {
sort(a);
} else {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, c);
else
TimSort.sort(a, 0, a.length, c, null, 0, 0);
}
}其中的legacyMergeSort(a,c)方法已经被标记废弃;使用的主要是TimSort.sort()方法。这个方法是一个优化版的归并排序。
排序算法
这里简单描述一下核心算法,略过一些细节。
这里的描述出自个人理解(看代码和网上搜到的综合理解),可能与实际情况有出入。欢迎指正。
获取两个有序数组A和B
传统的归并排序中,A和B都是从“一个元素”开始的;“一个元素”天然有序。TimSort会通过插入排序等方法,先构建一些小的有序数组,以提高一点性能。
另外,在TimSort中,A和B都是入参a[]中的一个片段。这样可以节省一些内存空间。
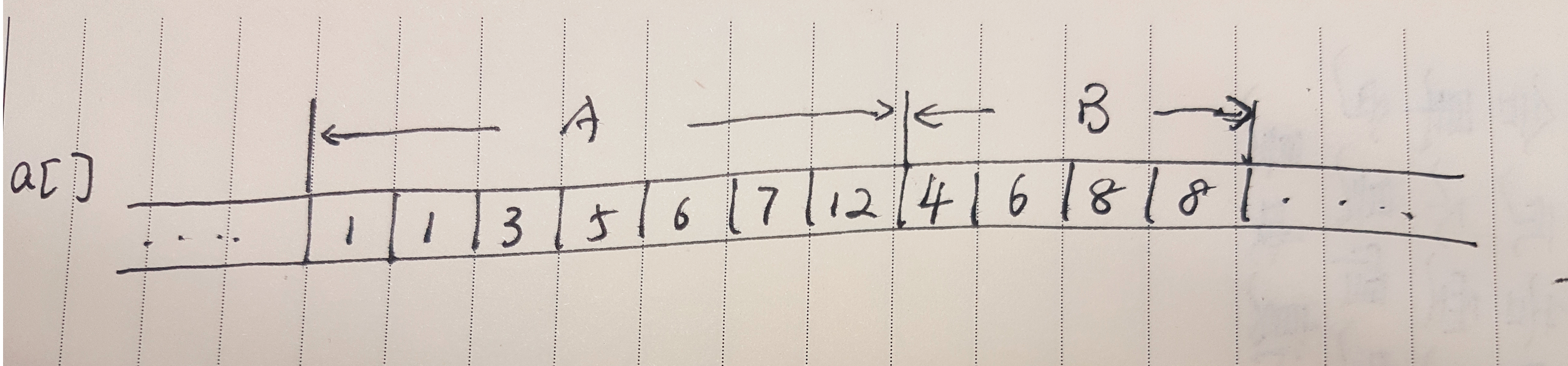
找到待归并区间
从数组A中,找到A[n-1]<B[0] && A[n]>B[0],以及A[m]<B[length-1] && A[m+1]>B[length-1]。
此时,待归并区间就是A[n,m]和B。

准备操作
在正式开始归并之前,会做一些准备操作。包括将非待归并区间的数据移动到合适的位置上;准备一个临时数组、初始化一些指针数据等。
数组B被复制到了临时数组temp中。因为数组B的空间会被其他元素覆盖。
原数组A中最后一个元素“12”被放到了原数组B的最后一个位置上。因为这个元素比待归并区间所有元素都更大。
指针B1指向数组A'的第一个元素;C1指向A'的最后一个元素;B2指向B'的第一个元素;C2指向B'的最后一个元素。这四个指针是用来确定两个数组中待比较和待移动的数据范围的
指针D指向的位置,是下一个“已排序”元素的位置。也就是从A'和B'中找到的最大的元素,将会放到这个位置上。

归并操作
归并操作相对比较简单。依次比较A'[C1]和B'[C2],将较大的数值移动到D的位置上,并将D和对应的C1/C2向左移动一位。重复执行此操作,直到C1<B1或者C2<B2,然后将另一数组中剩下的数据直接写入到数组中即可。
下图是示例数据从准备操作(左上角标记0)到四次排序(左上角标记依次从1到4)的归并步骤。
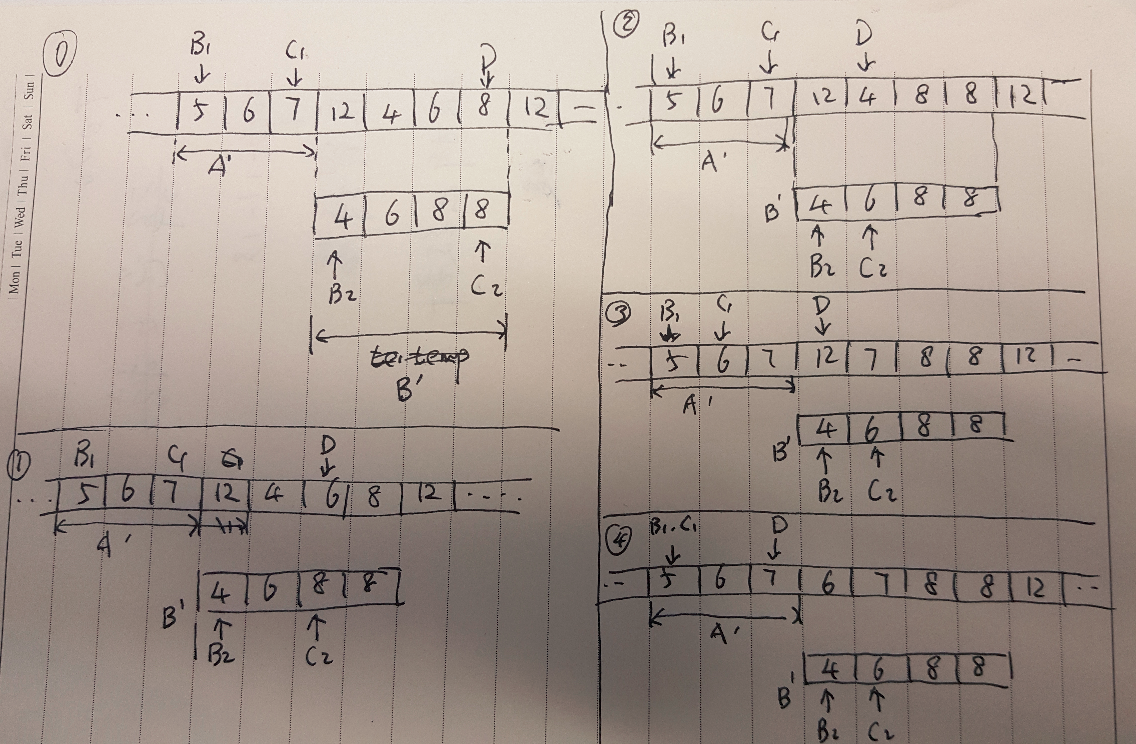
TimSort的优化归并操作
TimSort在某些情况(触发条件待考)下,会对上述归并操作做一个优化。主要的优化点在于:不是一次一个元素的移动,而是尝试着一次移动多个元素。
下图是按优化后的逻辑,同样的示例数据从准备操作(左上角标记0)到完成排序的归并步骤。注意第一步和第二步每次都移动了两个元素。这里只用了5步就完成了归并;而优化前需要7步。
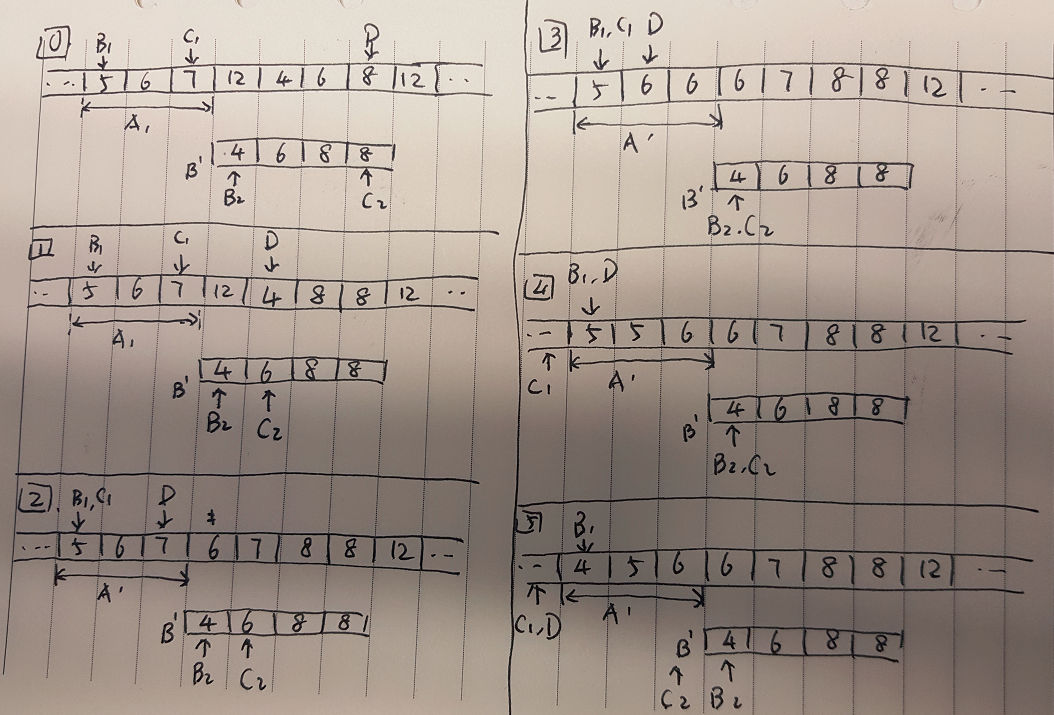
问题解析
问题现象
代码中有一处排序逻辑,代码是这样的:
List<BatchData> batchList = batchs.stream()
.sorted(new Comparator<Data>() {
@Override
public int compare(Data o1, Data o2) {
if (o1.getClass().getSimpleName()
.equals(o2.getClass().getSimpleName())) {
return o1.getId() - o2.getId();
}
return o1 instanceof BatchData ? 1 : -1;
}
}).collect(Collectors.toList());这段代码在某些特殊情况下,会引发这个问题:
java.lang.IllegalArgumentException: Comparison method violates its general contract!
at java.util.TimSort.mergeHi(TimSort.java:899)
at java.util.TimSort.mergeAt(TimSort.java:516)
at java.util.TimSort.mergeForceCollapse(TimSort.java:457)
at java.util.TimSort.sort(TimSort.java:254)
at java.util.Arrays.sort(Arrays.java:1512)
问题原因
问题原因是,对某些数据来说,上述代码会导致compare(a,b)<0并且compare(b,a)<0,也就是a<b && b<a。当这类数据遇到某些特殊情况时,就会发生这个异常。
例如,我们假定:
- a<b && b<a,这是代码中出现的bug
- 假定输入数组a[] = {5,a,7,12,4,b,8,8},其中待归并的两个有序数组分别是{5,a,7,12}和{4,b,8,8}
- 假定b<7&&7>b。这样可以触发“特殊情况”,即:a和b在某一次归并操作后,会同时成为“是否移动元素”的临界条件。
这样,在“特殊情况”下,优化后的归并操作可能陷入死循环。用画图来表示是这样的。
获取两个有序数组A和B
首先,我们有两个有序数组A和B,如下图所示。
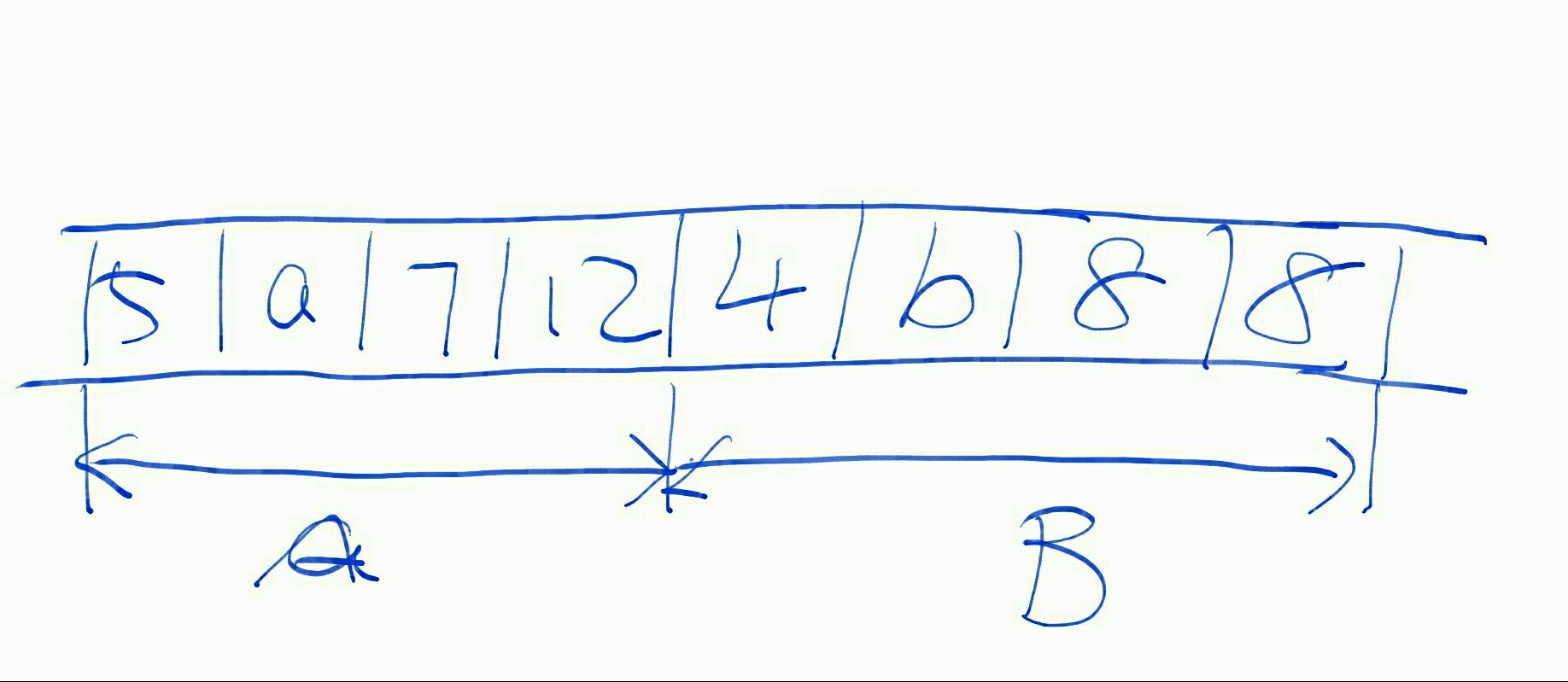
找到待归并区间、做好准备操作
这样,在划分完待归并区间后,得到的结果是这样的:
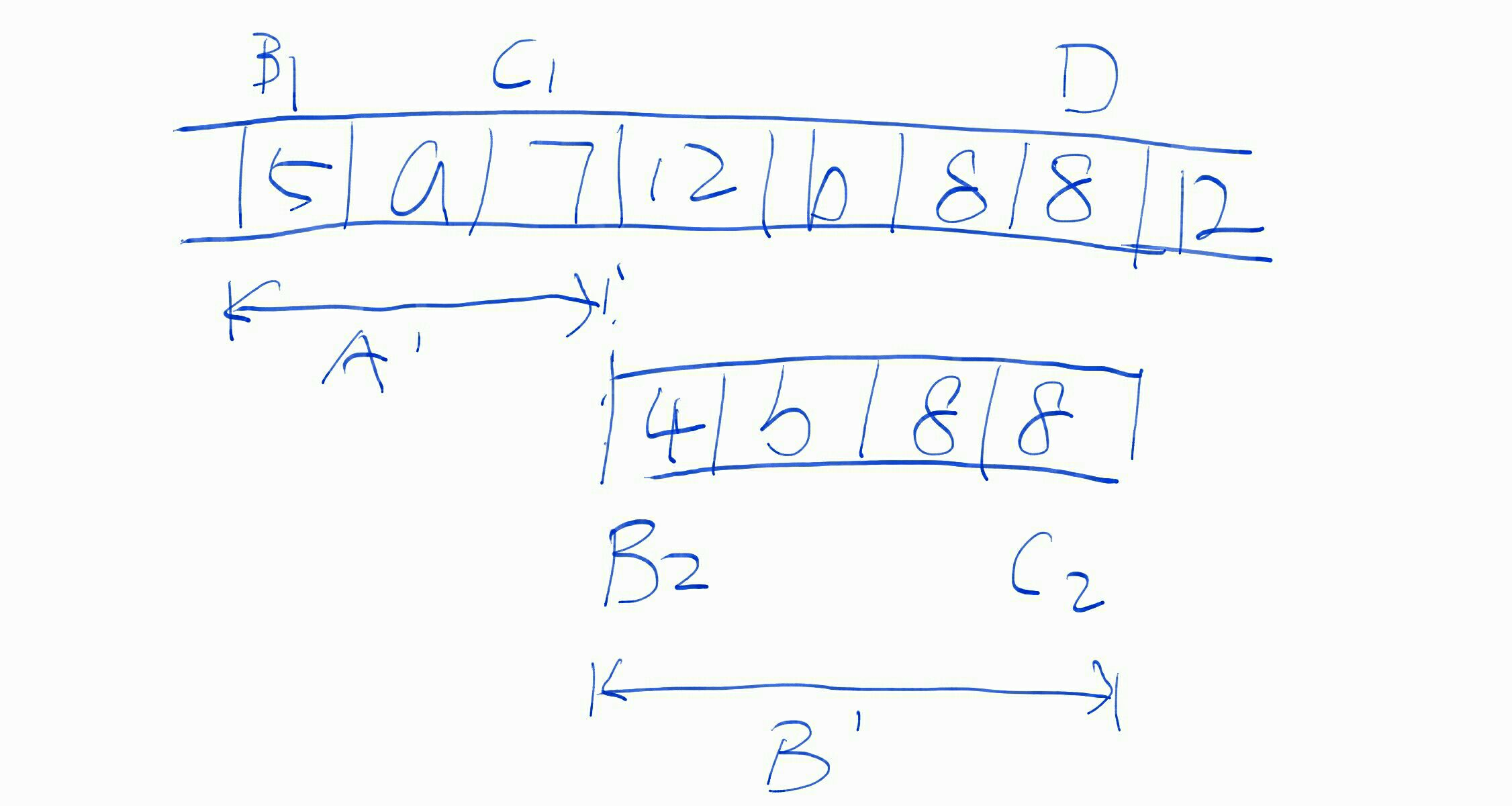
第一次归并操作:C2落在了元素b上
然后,开始第一次归并操作。由于B'[C2]>A'[C1],我们需要从C2开始,在数组B'中找到一个下标n,使得B'[n]<A'[C1]。找到之后,将B'(n,C2]复制到D的位置上。复制完成后,将C2和D都向左移动若干个位置。
这里需要注意两点:首先,临界点的比较条件是B'[n]<A'[C1],这是有顺序的;其次,复制的条件是B'(n,C2],这是个半包区间。
这样,第一轮归并完成后的结果是这样的:
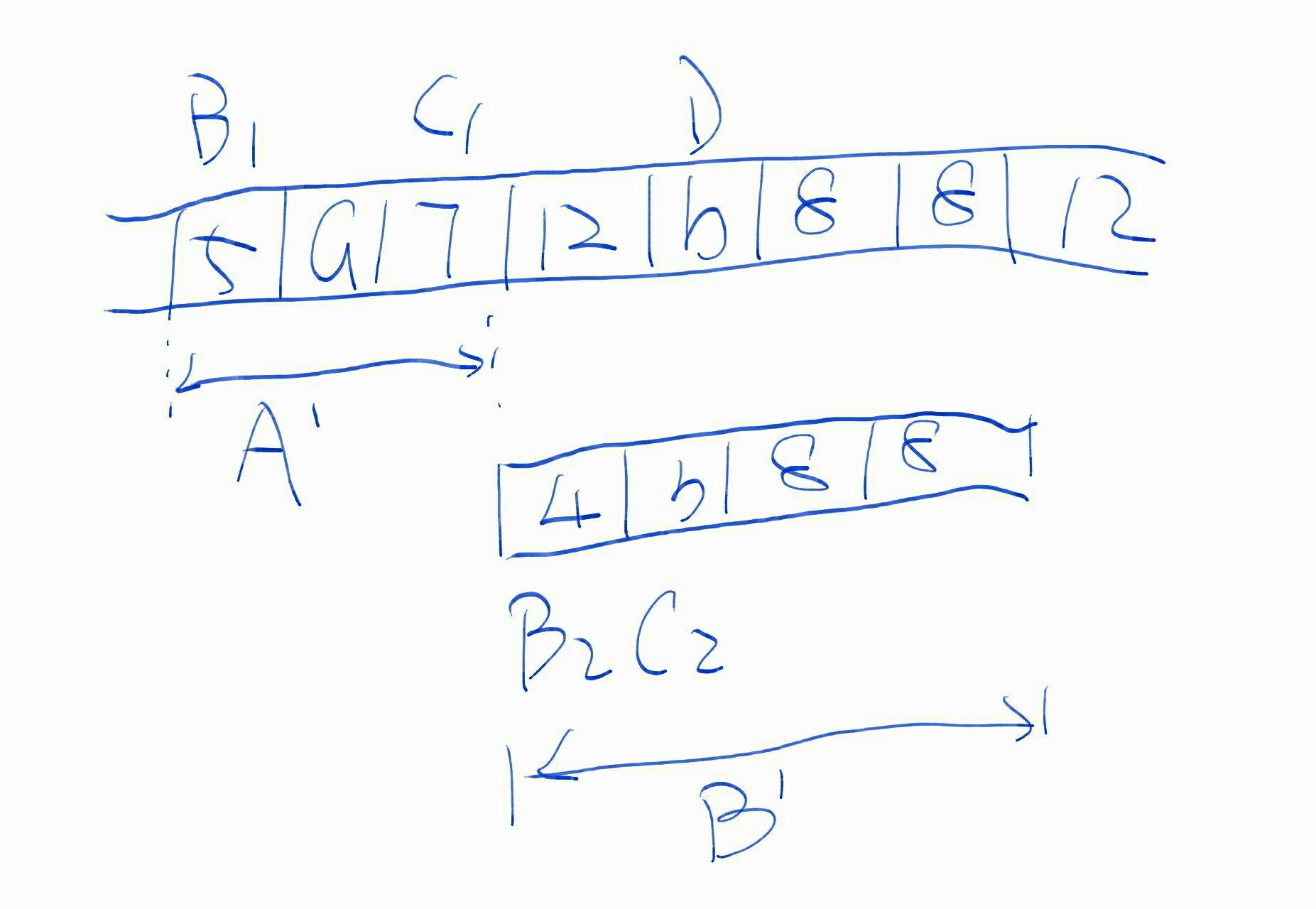
第二次归并操作:C1落在了元素a上
接下来做第二次归并操作。由于A'[C1]>B'[C2](这是先决条件里的第三点:b<7&&7>b),我们需要从C1开始,从A'中找到一个下标m,使得A'[m]<B'[C2]。找到之后,将A'(m,C1]复制到D的位置上。复制完成后,将C1和D都向左移动若干个位置。
这里需要注意比较的顺序性和区间半包性。
这一轮操作完,得到的结果是:
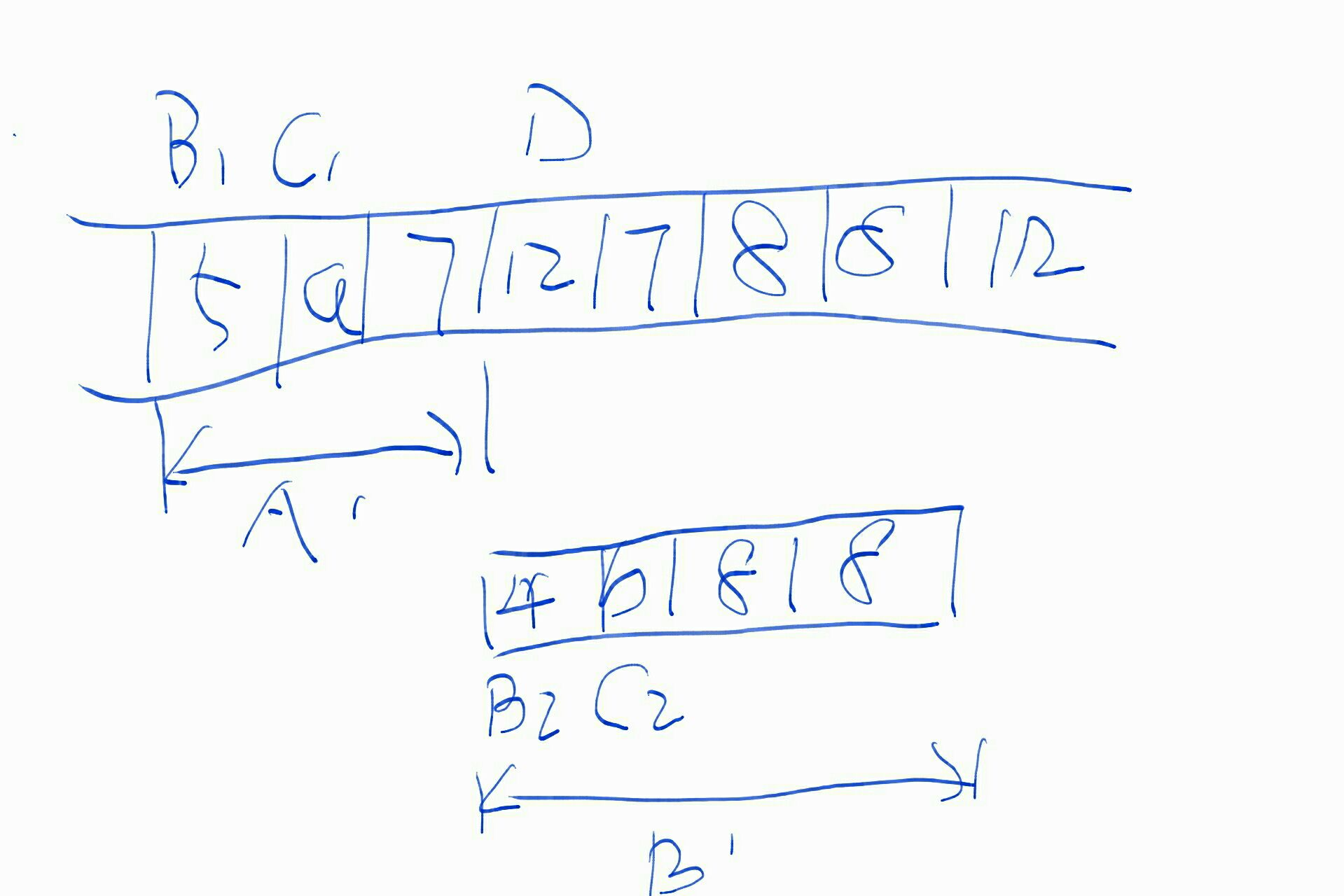
第三、四步操作:出现空集、死循环
由于此时A'[C1]<B'[C2],我们需要重复第一次归并操作。先C2开始,在数组B'中找到一个下标n,使得B'[n]<A'[C1]。但是,由于b<a(注意顺序),这一轮找到的n会等于C2。这就导致了需要复制到D中的元素集合B'(n,C2]是一个空集——或者用伪代码来说,我们需要将一个长度为0的数组复制到D的位置上去。
然后,由于B'[C2]<A'[C1],我们需要重复第二次归并操作。但是很显然,由于a<b(同样注意顺序),我们又会得到一个空集。
如果不加干预,排序操作会在这里无限循环下去。TimSort中的干预方式就是当检测到空集时,抛出异常。
解决方案
解决方案其实很简单,确保compare(a,b)操作中,如果a>b,那么b<a即可。
更严格点说,compareTo()或compare()操作,必须满足以下条件:
1. (x op y)的结果必须与(y op x)的结果相反。即,如果a>b,那么b<a。
2. 传递性。即,如果a>b, b>c,那么a>c。
3. x=y时,(x op z) = ( y op z )
顺带一说,在重写Java api的时候,如果没有十足把握的话,可以将它委托给另一个Java基础类(如String、Integer等)的对应api实现上。例如冯庆的解决方案,本质上就是将compare(a,b)操作委托给了int来实现。
参考
多线程环境下hibernate事务传播
方法(线程)调用堆栈是这样:
task调用calculater,calculator调用线程分发器;线程分发器把计算任务分发给若干子线程;子线程查询数据库;子线程全部结束后,线程分发器汇总数据,并更新数据库。
实际需要更新数据库的,只有最后一步。所以最初,我只在那个地方加了@transactional注解。但是这样就导致子线程执行中出现了异常:Could not obtain transaction-synchronized Session for current thread。
怎么看都是事务异常。
打开spring和业务日志后发现了问题。日志片段如下。
没有事务的日志
2015-12-16 12:59:39,615 [DEBUG] RMI TCP Connection(4)-10.255.8.131 org.springframework.orm.hibernate4.HibernateTransactionManager#?()@ - Participating in existing transaction
2015-12-16 12:59:39,632 [INFO ] RMI TCP Connection(4)-10.255.8.131 %%%%%Concurrent#calculate()@%%%%***TrustPayCalculateHelperByConcurrent.calculate(TrustPayCalculateHelperByConcurrent.java:62) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10
……
.TrustPayCalculateHelperByConcurrent#calculate()@c.TrustPayCalculateHelperByConcurrent.calculate(TrustPayCalculateHelperByConcurrent.java:68) - tpId=2,detailFutures=[java.util.concurrent.FutureTask@5fe038d5, java.util.concurrent.FutureTask@5f485bae, java.util.concurrent.FutureTask@711ffaa8, java.util.concurrent.FutureTask@1a00dc13, java.util.concurrent.FutureTask@44f87916, java.util.concurrent.FutureTask@59f0cf0c, java.util.concurrent.FutureTask@57b4a420, java.util.concurrent.FutureTask@4bc80a81, java.util.concurrent.FutureTask@4c7fea27, java.util.concurrent.FutureTask@13a8c40b, java.util.concurrent.FutureTask@61cff7fa]
2015-12-16 12:59:39,651 [INFO ] executor-2 .TrustPayCalculateHelper4UcRestPrcpNormal#calculate()@.TrustPayCalculateHelperAsSkeleton.calculate(TrustPayCalculateHelperAsSkeleton.java:70) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10
2015-12-16 12:59:39,653 [INFO ] executor-11 .TrustPayCalculateHelper4ClaimPrcpInte#calculate()@.TrustPayCalculateHelperAsSkeleton.calculate(TrustPayCalculateHelperAsSkeleton.java:70) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10
……
2015-12-16 12:59:39,653 [INFO ] executor-7 .TrustPayCalculateHelper4TrustMgmtLqud#calculate()@.TrustPayCalculateHelperAsSkeleton.calculate(TrustPayCalculateHelperAsSkeleton.java:70) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10
2015-12-16 12:59:39,653 [INFO ] executor-5 .TrustPayCalculateHelper4TrustRestPrcp#calculate()@.TrustPayCalculateHelperAsSkeleton.calculate(TrustPayCalculateHelperAsSkeleton.java:70) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10
2015-12-16 12:59:39,737 [ERROR] RMI TCP Connection(4)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#calculate()@.TrustPayCalculateHelperByConcurrent.calculate(TrustPayCalculateHelperByConcurrent.java:91) - trustProductId=2,计算信托支付明细数据时发生异常!,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10
java.util.concurrent.ExecutionException: org.hibernate.HibernateException: Could not obtain transaction-synchronized Session for current thread
at java.util.concurrent.FutureTask.report(Unknown Source)
at java.util.concurrent.FutureTask.get(Unknown Source)
两段粗体字是主线程( RMI TCP Connection(4)-10.255.8.131 );中间是子线程(executor-x)。很明显,除了主线程有 Participating in existing transaction之外,子线程中没有任何事务操作。
于是,在子线程的相关类上我也加上了@transactional注解:@transactional(readOnly = true)。这次的日志如下。
有事务的日志
2015-12-16 11:31:59,810 [DEBUG] RMI TCP Connection(2)-10.255.8.131 org.springframework.orm.hibernate4.HibernateTransactionManager#?()@ - Participating in existing transaction
2015-12-16 11:31:59,819 [INFO ] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#calculate()@.TrustPayCalculateHelperByConcurrent.calculate(TrustPayCalculateHelperByConcurrent.java:63) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10
2015-12-16 11:31:59,820 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:127) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10,helper=class ********.TrustPayCalculateHelper4UcRestPrcpOverDue$$EnhancerBySpringCGLIB$$54da0bf9
2015-12-16 11:31:59,823 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:127) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10,helper=class ********.TrustPayCalculateHelper4UcRestPrcpNormal$$EnhancerBySpringCGLIB$$d904f3fe
2015-12-16 11:31:59,825 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:127) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10,helper=class ********.TrustPayCalculateHelper4UcReserveRepaid$$EnhancerBySpringCGLIB$$18553f77
2015-12-16 11:31:59,827 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:127) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10,helper=class ********.TrustPayCalculateHelper4UcPrcpInte$$EnhancerBySpringCGLIB$$993f5ad9
2015-12-16 11:31:59,828 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:127) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10,helper=class ********.TrustPayCalculateHelper4TrustRestPrcp$$EnhancerBySpringCGLIB$$fd154f25
2015-12-16 11:31:59,829 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:127) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10,helper=class ********.TrustPayCalculateHelper4TrustPrcpInte$$EnhancerBySpringCGLIB$$a9b905e7
2015-12-16 11:31:59,830 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:127) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10,helper=class ********.TrustPayCalculateHelper4TrustMgmtLqud$$EnhancerBySpringCGLIB$$b0b8b637
2015-12-16 11:31:59,831 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:127) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10,helper=class ********.TrustPayCalculateHelper4Paid$$EnhancerBySpringCGLIB$$6c64e472
2015-12-16 11:31:59,832 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:127) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10,helper=class ********.TrustPayCalculateHelper4Distributed$$EnhancerBySpringCGLIB$$56f342ed
2015-12-16 11:31:59,833 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:127) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10,helper=class ********.TrustPayCalculateHelper4ClaimRestPrcp$$EnhancerBySpringCGLIB$$3b105c89
2015-12-16 11:31:59,834 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:127) - tpId=2,startDate=Sat Jul 09 00:00:00 GMT+08:00 2011,endDate=2011-07-10,helper=class ********.TrustPayCalculateHelper4ClaimPrcpInte$$EnhancerBySpringCGLIB$$e7b4134b
2015-12-16 11:32:00,070 [INFO ] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#submit()@.TrustPayCalculateHelperByConcurrent.submit(TrustPayCalculateHelperByConcurrent.java:143) - tpId=2,submitted!
2015-12-16 11:32:00,120 [DEBUG] RMI TCP Connection(2)-10.255.8.131 .TrustPayCalculateHelperByConcurrent#calculate()@.TrustPayCalculateHelperByConcurrent.calculate(TrustPayCalculateHelperByConcurrent.java:69) - tpId=2,detailFutures=[java.util.concurrent.FutureTask@12198288, java.util.concurrent.FutureTask@2b4018bf, java.util.concurrent.FutureTask@6bebeb5, java.util.concurrent.FutureTask@32a9beca, java.util.concurrent.FutureTask@6c7a67d5, java.util.concurrent.FutureTask@47d40f05, java.util.concurrent.FutureTask@34ec5a5c, java.util.concurrent.FutureTask@4b4cede5, java.util.concurrent.FutureTask@74b77f96, java.util.concurrent.FutureTask@13fcfa22, java.util.concurrent.FutureTask@45946cbb]
2015-12-16 11:32:00,120 [DEBUG] executor-8 org.springframework.transaction.annotation.AnnotationTransactionAttributeSource#?()@ - Adding transactional method 'TrustPayCalculateHelper4Paid.calculate' with attribute: PROPAGATION_REQUIRED,ISOLATION_DEFAULT,readOnly; ''
2015-12-16 11:32:00,268 [DEBUG] executor-8 org.springframework.orm.hibernate4.HibernateTransactionManager#?()@ - Creating new transaction with name [****.TrustPayCalculateHelper4Paid.calculate]: PROPAGATION_REQUIRED,ISOLATION_DEFAULT,readOnly; ''
2015-12-16 11:32:00,268 [DEBUG] executor-8 org.springframework.orm.hibernate4.HibernateTransactionManager#?()@ - Opened new Session [SessionImpl(PersistenceContext[entityKeys=[],collectionKeys=[]];ActionQueue[insertions=org.hibernate.engine.spi.ExecutableList@7a7a2be7 updates=org.hibernate.engine.spi.ExecutableList@7e45b070 deletions=org.hibernate.engine.spi.ExecutableList@3b4721dc orphanRemovals=org.hibernate.engine.spi.ExecutableList@21b8886f collectionCreations=org.hibernate.engine.spi.ExecutableList@ab6baac collectionRemovals=org.hibernate.engine.spi.ExecutableList@59a34dba collectionUpdates=org.hibernate.engine.spi.ExecutableList@5b68de93 collectionQueuedOps=org.hibernate.engine.spi.ExecutableList@3e76de61 unresolvedInsertDependencies=UnresolvedEntityInsertActions[]])] for Hibernate transaction
第一段粗体字是主线程( RMI TCP Connection(2)-10.255.8.131)加入到了已有的事务中。由于整个流程是有spring batch的task发起的,其中有很多对batch_job_xxx表的读写,这个事务应该是由spring batch开启的。
第二段粗体字,是子线程(executor-8)启用了自己的事务。
至于为什么前面是Participating而后面是Creating new?我没太明白。但是翻前面的日志,两种记录都有。回头再细查吧。
CGLIB Can't Proxy for "final" Class or Method
I writed a class as template, habitually, I set the modifier of method as "finanl", as follow:
abstract class LoanProductChooseServiceAsSkeleton implements
LoanProductChooseService {
private LoanProductDAO loanProductDAO;
final public LoanProduct choose(LendRequest lendRequest, Boolean wholeSale) {
...
// here throws NullPointerException
correctProduct = this.loanProductDAO.getCorrectProduct(
product.getType(), product.getPeriod(),
new BigDecimal(tmpRate), wholeSale, product.isCycle());
...
}
public void setLoanProductDAO(LoanProductDAO _loanProductDAO) {
this.loanProductDAO = _loanProductDAO;
}
}Then an loanProductDAO was injected by Spring(xml).
But, an NullPointerException was thrown at the line of " here throws NullPointerException". According to logs, the loanProductionDAO was null.
However, the configurations were all right except this loanProductDAO, because the other fields were injencted correctly.
I was totally confused until I saw these lines in the logs recorded by spring:
2015-10-08 18:19:28,244 [DEBUG] ?#?()@? - Creating implicit proxy for bean 'loanProductChooseService36' with 0 common interceptors and 2 specific interceptors
2015-10-08 18:19:28,244 [DEBUG] ?#?()@? - Creating CGLIB proxy: target source is SingletonTargetSource for target object [****************.LoanProductChooseService36@4bd80dc9]
2015-10-08 18:19:28,244 [INFO ] ?#?()@? - Unable to proxy method [public final [****************.product.LoanProduct [****************.LoanProductChooseServiceAsSkeleton.choose([****************.LendRequest,java.lang.Boolean)] because it is final: All calls to this method via a proxy will NOT be routed to the target instance.
and the internet said:
http://blog.csdn.net/arlanhon/article/details/17622173
CGLIB proxy: CGLIB procy can proxy for not only interfaces, but also classes. Please pay attentions to following points:
* it can't proxy for methods modified by "final", as it can't override final methods( CGLIB proxy a class by inherited it).
* it calls constructor twice. the first time is for the target class, the second time is for the CGLIIB's proxy class. So, make sure the constructor is safe to called twice.
用图说话就是这样:
等我想法子把图弄上来吧
At last, I removed the "final" from the method.
业务系统中的开与闭——分发模式
“对新增开放,对修改关闭。”——开闭原则。
这里分享一个我在业务系统设计过程中常用的一个“复合模式”,用作一个在业务系统设计中运用“开闭原则”的例子。
背景
这是一个账务系统,负责处理各类业务流程中发生的若干个账户之间的转账相关逻辑,包括账户余额的变更、以及各账户的流水记录。
这个系统的复杂度在于:不同的业务流程,所需要操作的账户、金额的计算公式、以及流水的类型,都有很大的差异;即使是同一个业务,里面也会细分为多个子业务,账户、金额、流水类型又各不相同。而且,业务、子业务还会不断的新增和变更。这就要求我们在设计时,必须充分考虑扩展性。
思路
首先,业务流程虽然种类繁多,但是抽象、概括之后,其实核心逻辑非常简单。第一步当然是校验,然后是账户查找、计算金额等数据准备工作,准备好必要的数据之后就可以记账了,记账完成后做一些收尾的操作。
这样一来,所有的相关业务都可以放到这同一个“抽象”层次内来做处理了。如下图所示。
扩展性问题则是这样解决的。这个“抽象”层次内,最顶层的“服务提供者”只提供一个分发服务。它会根据外部传入的参数,选择对应的业务服务提供者,并将参数交给它来处理。
而“业务服务提供者”的最顶层,同样只提供分发服务。它会根据一些更细致的规则,选择对应的子业务服务提供者,然后将参数交给子业务服务提供者去处理。
这样的服务分发层级,在现实生活中可以找到很直观的例子。在一些大医院的门诊部大门口,会有一个分诊台。分诊台的护士会告诉你应该挂哪个科室的号。而在一些大科室的门口,又会有一名护士负责叫号,并指点被叫到的病人去找哪位医生。实际上,这也是我做这个“分发”服务的一个灵感来源。
在这个“分发”的框架下,新增一套业务是非常简单的。并且,由于真正处理业务功能的服务提供者只需要专注于自己的“一亩三分地”,与其它的业务之间很少发生耦合,因此,在必须对某些功能进行修改时,影响范围也会非常的小。
理论上,“分发”这个动作可以无限嵌套,因此无论多复杂的业务逻辑,都可以通过不断的分发处理来进行简化。只不过这样做会使得线程处理栈变得非常深,给理解系统和debug和trouble shooting增加不必要的麻烦。我们的系统做到二级分发,已经有“类爆炸”的困扰了。
类图
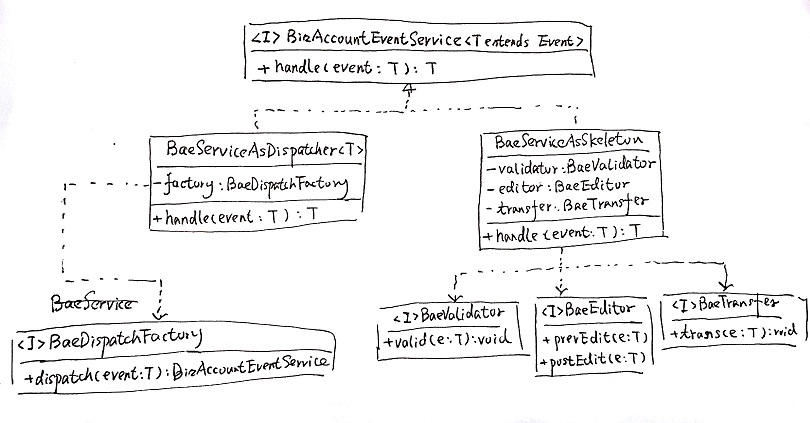
顶层的BizAccountEventService就是我们匹配“业务抽象”所建立起来的接口。所有的记账相关业务功能,无论是一级分发、二级分发,还是实际的业务功能处理,都是这个接口下的一个实现类。
只有两个类直接实现了BizAccountEventService接口,其中之一就是BaeServiceAsDispatcher,即业务抽象内最顶层的“服务提供者”——一级分发器。一级分发器需要一个服务工厂,以根据不同的参数提供不同的接口实现类。这个工厂既可以是一个简单的Map,也可以做得更复杂一些。我们单独创建了一个工厂类,这样可以方便地将一级分发扩展为二级分发。
在一级分发器中,服务工厂提供的类实际上都是二级分发器。二级分发器与一级分发器的逻辑实际上是一样的,也是利用工厂来根据不同的参数获得不同的接口实现。因而,二级分发器都继承自一级分发器,实例之间的差别基本上只是一个工厂。
直接实现BizAccountEventService接口的另一个类是BaeServiceAsSekeleton。这个类是一个模板类,它定义了真正的业务操作的核心步骤:校验、预处理、转账、后处理。所有的业务处理类,都必须是它、或者它的子类的实例。
但是,与教科书上的“模板模式”不同的是,BaeServiceAsSekeleton中的模板模式,并不是通过继承、而是通过组合来实现的。这个模板中的四个步骤,被分别委托给了三个接口(BaeValidator、BaeEditor、BaeTransfer)。这样做可以增加不同子业务之间的代码复用性。例如,业务甲的逻辑是ABCD,业务乙的逻辑是EFGH,而业务丙的则是ABGH。这种情况下,由于Java单继承的限制,业务丙无法通过继承甲或乙的类来完全复用代码,但是组合的方式却可以轻松做到。
关于这个接口,项目组内曾有过争论。有同事认为,应当为BaeServiceAsSkeleton类提供另一个接口,以便于保持BizAccountEventService接口的层次简单。这样做当然可以,不过我们没有把精力放在这件事上。
开闭
那么,回过头来看“开闭”。“对新增开放”很好理解,那么什么是“闭”呢?
实事求是的说,我们不可能完全地把“修改”关在门外。在这个“分发”方案里,我们也仍然需要通过修改分发相关代码,来增加新的业务、或变更原有业务。我们能够关闭的、也许也是我们真正想关闭的,是大量的、大范围的修改代码、是这样做所带来的不可控的风险。
以这个“分发”方案为例。当一种业务逻辑发生变化时,我们需要修改的仅仅是分发相关代码、以及这一种子业务所涉及的部分子类。这种修改的影响范围被牢牢锁定在业务抽象之下、甚至是单个子业务的相关抽象之下,因而,其中的风险是清晰明了的,因而也是可以有效控制住的。甚至于,我们可以保持原有业务代码完全变,而通过继承、多态等方式扩展出新的业务逻辑,从而用“废除+新增”的方式完全替代“修改”——当然,这种方式会带来很多冗余代码,值得商榷。
但是,把不可控的风险关在门外——我们做到了。
是银弹吗?业务基线方法论
Fred.Brooks在1987年就提出:没有银弹。没有任何一项技术或方法可以能让软件工程的生产力在十年内提高十倍。
我无意挑战这个理论,只想讨论一个方案,一个可能大幅提高业务系统开发效率的方案。
方案描述
我管这个方案叫做“由基线扩展业务线的方案”。从名字就可以看出,它至少包括两部分:基线;业务线。其实还有一部分隐藏在动词后面:扩展点。这三部分及相互之间的关系大体上是这样的:
基线
基线是一套领域模型、流程框架,但不包含任何业务的实际逻辑——即使是某种“通用”的、“默认”的逻辑。
基线中绝对不能混入业务逻辑,这是为了避免系统框架的“特化”。而系统一旦为了某种业务而进行“特化”,那么一定会在某一次业务变化中,系统要么像三叶虫、恐龙那样陷入死胡同;要么像总鳍鱼、库克逊蕨一样,大幅改造自己。无论哪一种都是代价昂贵、难以接受的。因此,基线中绝对不能混入业务逻辑。
业务基线中不做业务逻辑,做什么?领域模型和流程框架。
领域模型描述的是这个业务系统关注哪些数据,这些数据之间有什么样的关系、约束、依赖,必须在业务模型中描述清楚。这是整个业务系统的基石、首要问题:我们要做什么样的业务。就像人类仰望星空时的第一问“我是谁”一样,如何回答这个问题,决定了我们如何实现系统。
流程框架描述的是系统如何将数据组织、流转起来,使之成为我们期望的业务。这个流程可以是一级分发、二级分发、实际处理;可以是校验、预处理、核心逻辑、后处理;也可以是迭代、是递归、是链式、是并发……等等,这些都可以具体问题具体分析。
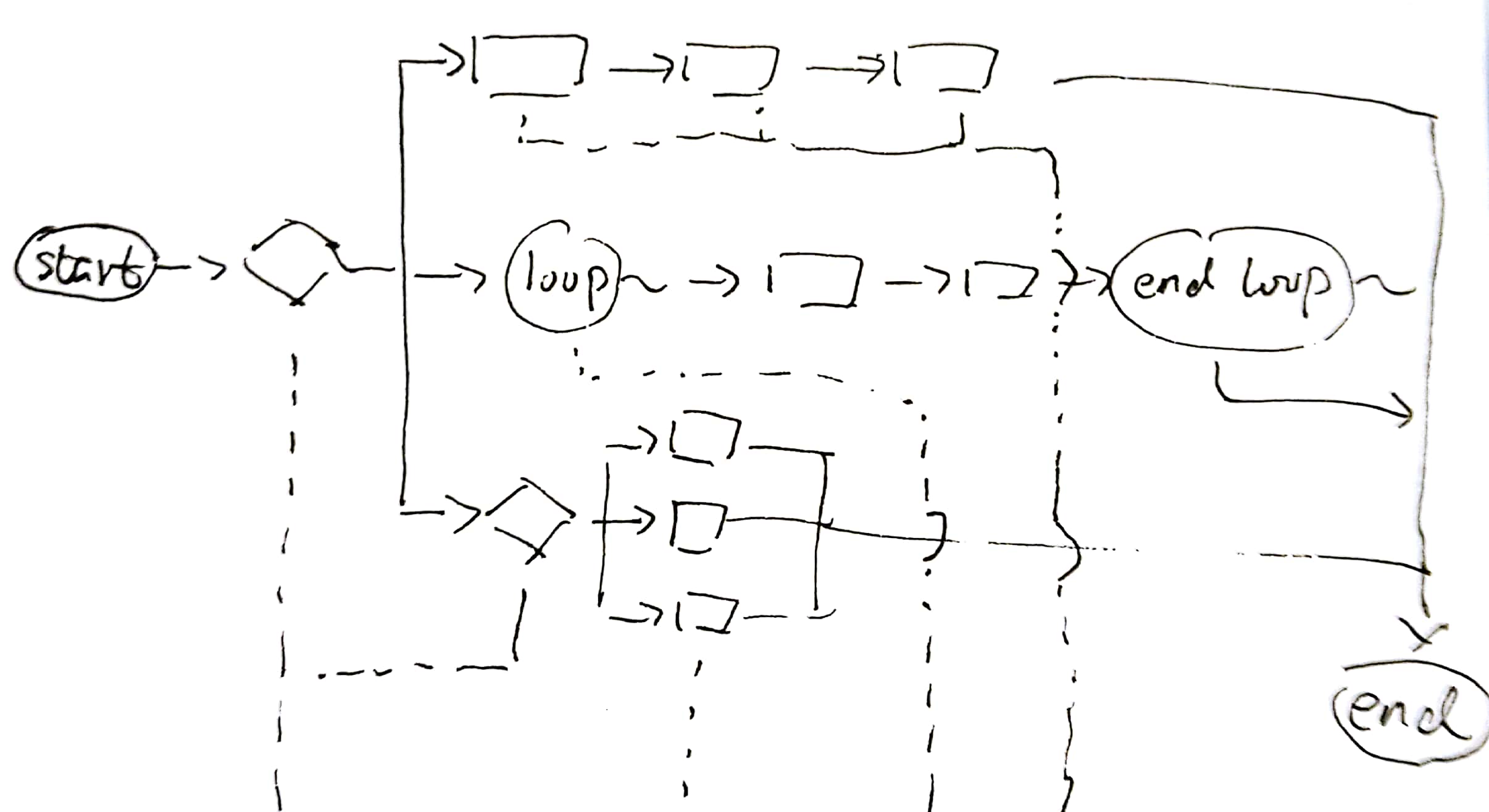
但是,尽管可以具体问题具体分析,无论是数据结构、还是流程框架,在实现上一定要保证高度的扩展性。这就是这个设计方案的第二部分:扩展点所重点关注的目标。
扩展点
由于基线中并不包含业务逻辑,我们必须在基线中埋入若干扩展点。否则,业务逻辑就无法按照基线中的流程来运转。
借助于面向对象的继承和泛型等特性,我们可以很便捷的扩展领域模型中的数据结构。但是流程框架中的扩展点,要更复杂一些。
从最简单的方面来考虑,我们同样可以利用继承、泛型和多态,以及各种设计模式,来将原有的一套代码扩展为另一套新的代码。然而,我们如何让基线代码执行到某个扩展点时,流转到特定的业务代码上去呢?
详细的解决办法可以有很多,比如我之前总结的分发模式。一般来说,都是利用一些依赖倒置(例如SpringIOC)或者服务注册等方式,在适当的位置上让业务流程走向不同的代码分支。
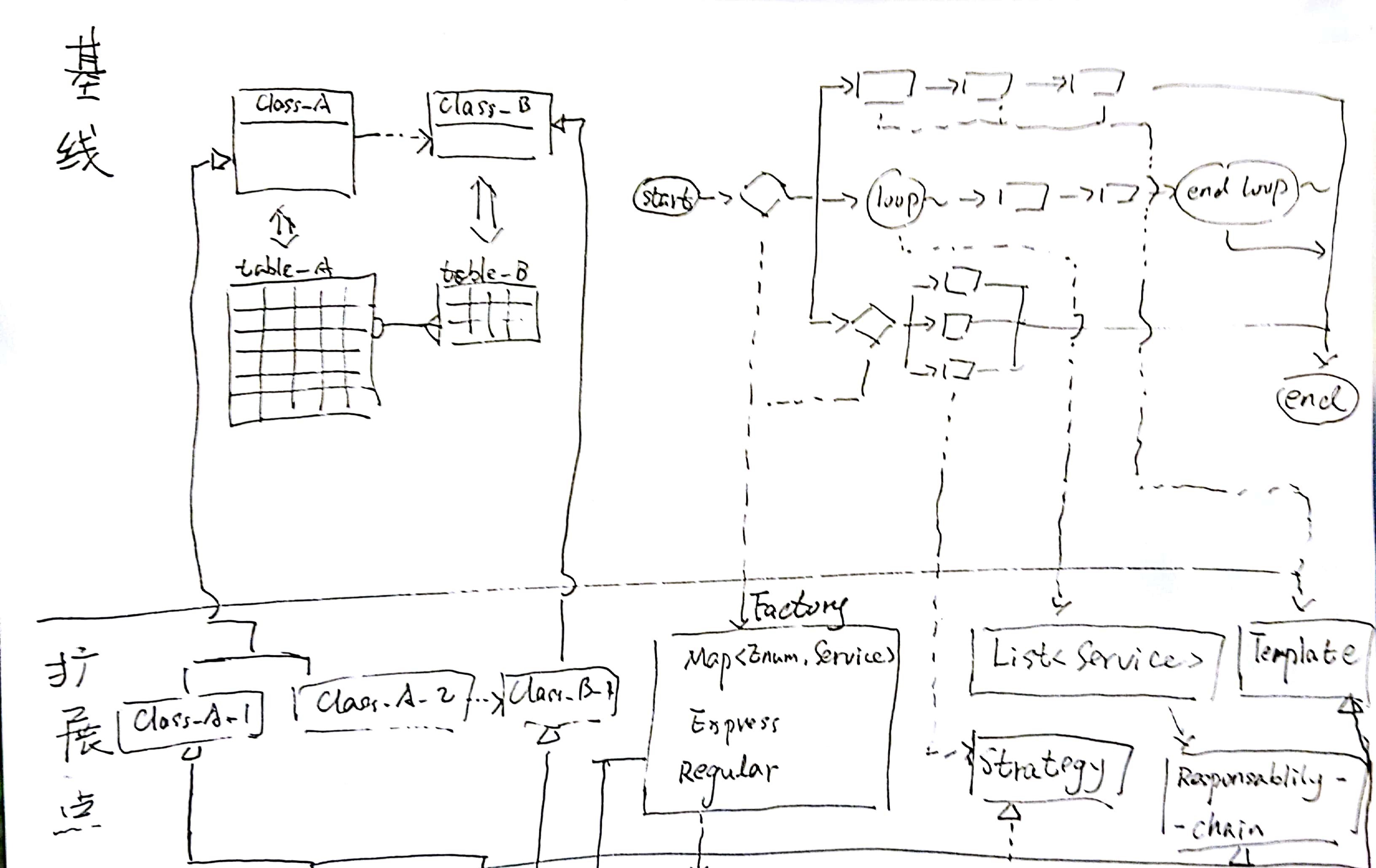
例如上图中,基线右侧的流程框架被分为三条分支。其中最上方的流程分为三个步骤;中间的流程以循环方式,依次执行两个逻辑;最下方的流程又再次被分为三个分支。
那么,这条基线的扩展点,就可以是一个工厂+策略(对应三个分支的分叉点)、一个模板(对应最上方流程)、一个责任链(对应中间流程)、以及又一个工厂+策略(对应最下方流程)。
其中,这两个分支判断所需工厂的具体实现,可以是Map<Enum,Service>、或者Express-Service、抑或Regular-Service。这些机制可以轻松地把我们为某个业务而扩展出来的Service注册、插入到由基线定义的流程框架中。
总之,有了扩展点,我们就可以把具体的业务代码加入到基线流程中,使之成为一条独立的业务线了。
业务线
就代码而言,业务线实际上并不是一条“线”。它往往只是针对一两个扩展点而开发的代码。实际上,只有在这些代码注册到基线中之后,它才能成为一条“业务线”。
尽管如此,我还是把它单独地画在了整个方案的最下方(扩展点的下方),就像这样:
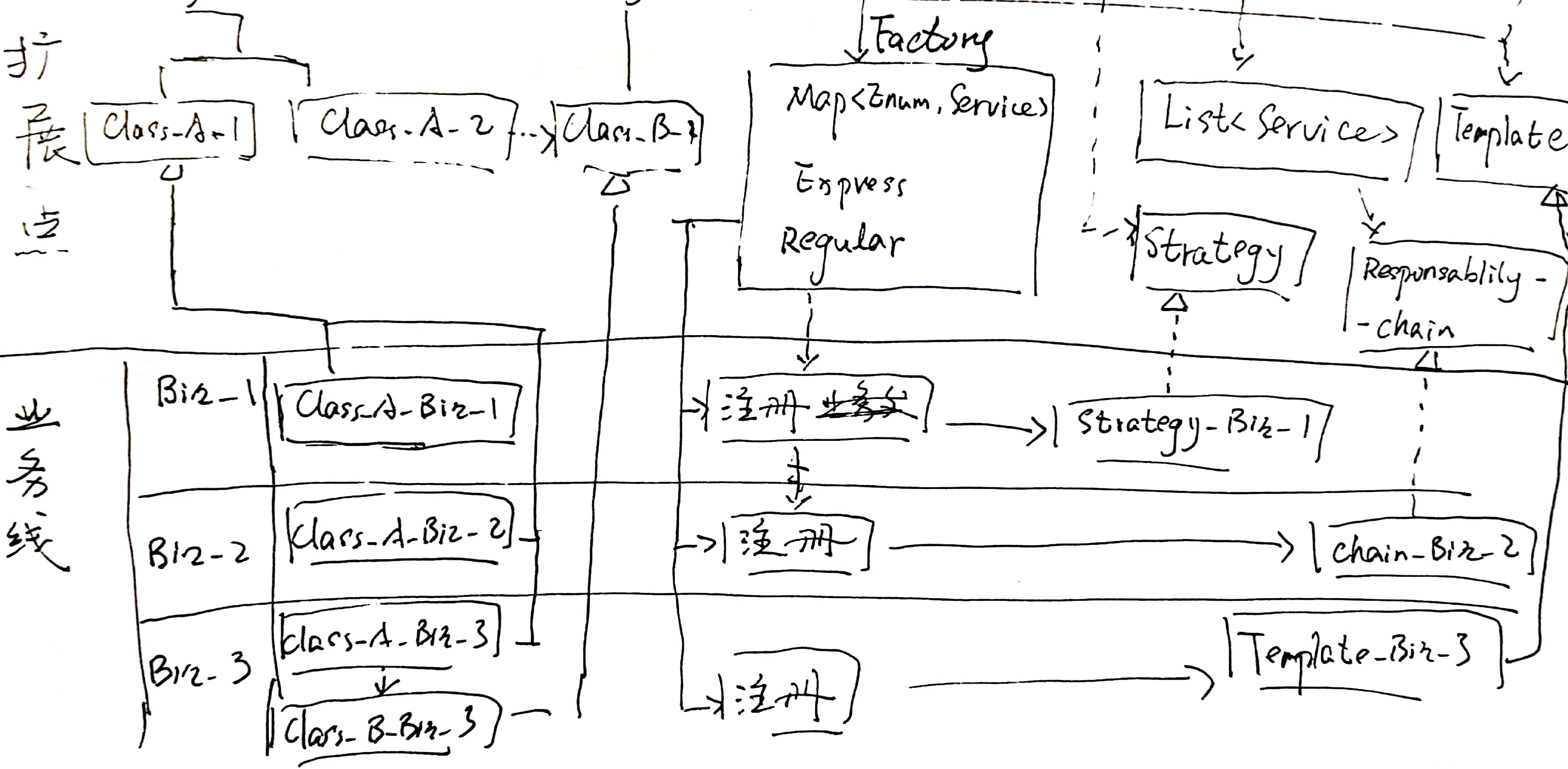
上图中展示了三条业务线分别扩展基线、并注册到基线中去的情况。如果再有新的业务线加入其中,可以依样画葫芦。
实践
实际上,这个方案是我在xx公司参加一个业务系统的改造开发过程中,逐步整理、积累出来的。所以,在这个业务系统中,我实践了这套方案的大部分想法。
没有实现的想法主要是基线中不能包含业务逻辑。一方面,基线的业务流程中包含有业务逻辑:这是一套“默认”逻辑。也就是说,如果一条业务线没有任何特殊的地方,那么它就会按照基线中的“默认”逻辑进行处理。但是,这导致了后期大量的业务代码以“默认逻辑”的名义涌入基线中,使得基线越来越特化、退化为一条“业务线”——尽管它是“默认”业务线。另一方面,领域模型中没有配置扩展点。这导致一套数据结构中包含了所有业务线所需数据。这也是“默认逻辑”不断扩大的一个“元凶”:数据结构中的每个字段都必须有“默认”值。
分析
“由基线扩展业务线”,这个方案的内容基本就是这样。这个方案的优缺点都有哪些呢?这里简单分析一下。
优点
这个方案的优点,基本都来自于它的高内聚低耦合特性。
高内聚低耦合
尽管高内聚低耦合在很多团队中只是一句口号,但是这个设计实实在在地践行了这一理念。基线对业务封闭,对扩展点开放;业务线对彼此封闭,对新业务开放。这样高度的封闭与有限的开放保证了基线和业务线自身的高内聚和相互的低耦合。
完整的业务模型
由于基线中包含了完整的领域模型和流程框架,它就能代表系统的业务模型。这是这个方案能成功的一个前提;同时,这也是使这个方案出类拔萃的一个产出。
在我们的实践中,这一点带来了很大的好处。在改造之前,系统中的业务非常混乱。产品不知道完整业务流程,经常出现需求只覆盖到一小部分流程、因而不断进行修改,甚至出现前后矛盾的需求。开发也不知道完整的代码流程,这导致了一个更严重的问题:产品怎么说开发怎么做,完全没有技术上的考虑和设计。测试同事反而是最熟悉完整流程的人,但是测试阶段太靠后,发现问题时往往为时已晚。
而完成改造后,变化首先出现在开发身上。开发人员对业务有了全局的掌控,开始和产品讨论、甚至是争论;此后产品给出的需求描述也更加准确、完善。
项目管理可控
项目管理的四个要点:范围、工期、成本、质量,都可以在高内聚、低耦合的特性下得到有力的控制。
这是我们的实践中改进最大的一点。在改造之前,产品提出需求之后,会问这样几个问题:开发同事们估计要改哪些地方?大概要多久?我们开发只能回答不知道,回去翻翻代码再说、问问老同事再说。在改造之前,我们代码质量非常糟糕,无数的巨型Java类、重复代码、超长的switch-case……
改造之后,我们对照基线梳理一遍,就能够清楚地知道需要写那些代码、大约需要多久。而且,基线和扩展点大量运用设计模式、泛型、接口等编程方式,有效的提高了代码质量。
技术易于演进
高内聚低耦合带来的是高度的模块化。在这样的模块化结构下,技术演进可以很轻松的推进。
在我们的实践中,基线中的一个内部模块前后经历过四次重构和优化,包括同步改异步(后来又改回了同步)、对接外部系统、SQL优化、以及数据库结构变更。尽管这个模块负责系统核心业务,但它每一次变化都没有影响到任何一个业务,并且都能顺利地达成目标。尤其是SQL优化这项工作:在改造之前我们就曾经尝试过,但因为代码质量太差、模块耦合度过高而放弃。
缺点
这个方案的缺点主要来自于它对业务模型的高要求。
建立和维护业务模型
建立模型本身就是一件困难的工作;让团队成员接受和理解这个模型,则是一项技术之外的工作;而让团队在后续的开发中维护这个模型,这几乎只能靠上帝保佑了。
这三个问题中,只有建模可以称得上技术工作;其它两项主要是团队中的组织和沟通工作。在这点上,“外科手术”式的团队也许比敏捷团队要更好一些。毕竟,“众不可户说”,将与模型有关的问题交给一两个人来决定,其他人只需参谋和执行,这样能减少一些建立和维护模型的问题。不过,如果能够像敏捷团队那样,每个人都“自组织”地接受、理解、维护甚至优化模型,那简直是求之不得的好事。
在我们的实践中,团队更类似于“外科手术”式。问题在于:团队内的两名权威——职级上的权威和技术上的权威——没有对模型达成根本上的一致。这导致了团队成员对模型的怀疑、误解,更导致了模型以及代码、系统的迅速腐化:基线中的业务代码越来越多;业务线不断突破彼此的边界;新代码的质量也大不如前。
代码流程不连贯
尽管我私底下认为,这个问题的根本原因是开发人员不了解模型及其中业务的运作方式,或者是开发人员不理解“面向接口”、“面向对象”等编程**。但是,鉴于这个问题在我们的实践中被反复地提出,我还是把它记录下来吧。
在这个模型下,实现业务的代码会零散的分布在业务线、扩展点和基线中。这会给我们阅读代码、断点追踪和trouble shooting带来一些麻烦。
束缚创新思维
这是一顶很大的帽子。一个业务模型规定了这项业务的处理方式——如何组织数据和流程。然而,这项业务就只能按照这种方式来处理吗?显然不是。然而,如果我们一味的泥于现有的业务模型,那么,迟早会出现这么一天:我们必须花费三倍、十倍的,才能把新的业务“塞进”这个模型中。这个问题已经很头疼了,更不用说当我们需要主动地对业务进行全面创新(而不仅仅是升级换代)时,这样“重”的一套模型会是多么大的一个负担。
幸运的是,我们的实践还完全没有走到这一步。悲观点想,也许根本就走不到这一步。
后记
我绝没有真的自大到认为这真的是一枚“银弹”,因为它甚至没能把我们团队的软件开发生产力提高三倍。
但我仍然认为这是一个好的思路。不是银弹——也许真的没有银弹——但是至少可以当颗大蒜。
数据与行为——状态模式与策略模式
我在另一篇博客里声称:做技术的思路是优先“怎么用”、而后再“是什么”。然而这里,我却想讨论一下状态模式与策略模式“是什么”,以及它们之间的区别。
这并不是打脸,而是我在经过长久的思考“怎么用”之后,终于明白了它们“是什么”。
状态机
让我想明白的契机,是“如何实现状态机(当然,是有限确定状态机)”这样一个问题。下图是一个简单的状态机:
策略与状态
我原本计划用这样一套类来实现这个状态机:

画好类图之后我发现,这是个典型的策略模式。但是从直觉上来看,状态模式才是状态机的天然盟友。因此我又尝试着画了一套状态模式的图:
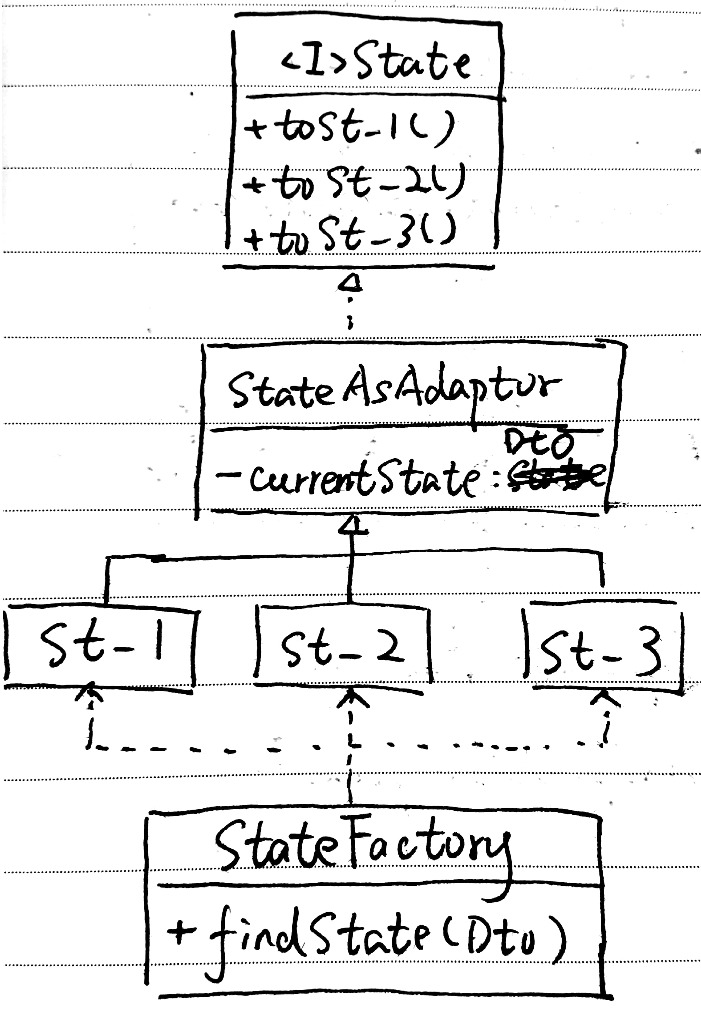
对比
一眼看上起,这两张类图一模一样。当然,仔细看看,一定能发现其中的区别。相同点会带来相同的优点,不同之处造就了各自的缺点。
相同点
这两张类图似乎一般无二:一个对外接口;若干个接口方法;一个基类;若干个子类;另外有一个工厂与之配合。
之所以有如此高的相似度,是因为这两种模式的基本思路都是一样的:对外提供一个抽象,对内扩展为不同的实现。
不同点
看起来,只有接口方法不同:策略模式用一个接口方法来处理所有的状态迁移;而状态模式则用不同方法来处理迁移到不同状态时的动作。
这个看起来不起眼的区别,实际上代表了这两种模式截然不同的“抽象”方式。策略模式将状态迁移的“操作”设计为抽象接口;而状态模式的抽象接口代表了“状态”本身。换句话说,策略模式是对行为的抽象,状态模式是对数据的抽象。
优点
面向接口的设计和编程方式可以带来数不尽的有点:接口对内高内聚,对外低耦合;实现类内部高内聚,彼此之间低耦合;对新增实现类保持开放,对修改现有类尽量封闭;等等等等。
缺点
用策略模式实现状态机,从代码还原到状态机时会遇到一些困难。在我实践过的代码中,团队成员都反应过这一点。用状态模式来做会更明白一些:因为状态模式同时封装了数据和行为,虽然也只是一个“片段”,但片段中包含的信息更多。
用状态模式实现,则会遇到实例化的问题。这是由于包含有数据,所以“状态”实例线程不安全。因而每次执行状态迁移操作时,系统都需要使用一个新的实例。当然,这个问题可以变通解决,但是相比天然只有行为、通常只需要单例实现的策略模式,这还是算得上一个缺点的。
Happy Chinese New Year!
新春快乐!
状态与策略——审批操作的两种方案
审批操作是ERP或OA系统中必不可少的功能之一。这里介绍两种我设计的用于审批操作的方案,并借此就“状态模式”与“策略模式”提出一点自己的理解。
别问我为什么不使用工作流引擎等工具来实现审批功能。做第一版方案时,我孤陋寡闻得并不知道有这个东西。后来引入工作流框架会导致学习曲线骤然上扬,不太划算。
背景
背景无需过多介绍,不外乎有一些数据/任务/请求,需要由领导们点一下头或者按钮。
思路
由于孤陋寡闻,在得到需求之后,我第一反应不是“工作流”,而是“状态机”。它从“提交”状态开始,流经“已初审”“已终审”或者“初审驳回”“终审驳回”等状态,进入终态。
这个状态机如下图所示:

当然,状态机中状态的名称、状态间的流转,是与业务需求紧密相关的。例如,有些业务会要求在“已终审”状态下执行“驳回”操作后进入“终审驳回”状态,而有些则要求返回“已初审”状态。不过万变不离其宗,种种流程最终都能归纳到“状态机”中来。
在这个思路下,我用了两种不同的设计模式来实现需求——状态模式和策略模式,它们都很好的完成了任务。需要多说一句的是,这是两个不同系统下独立的两次实现,而不是一个系统中的“原始版”和“改进版”。因而,两个方案之间并没有非常显著的优劣对比,本文的重点也不是二者的“优劣”对比。
方案一:状态模式
-
状态模式
首先来回顾一下我们常说的状态模式。简便起见,这里只提供类图。

其中的核心是“状态”接口。这个接口中有N个方法,对应的是状态机中的N个状态。每个方法负责从当前状态迁移到另一个状态上——一般是别的状态,也可以仍然是当前状态。
每个具体的状态都继承自这个接口,并在实现类中封装自己所需要的数据、重写自己的状态迁移操作。 -
我的方案
在我的设计方案中,类图则是这个样子的:
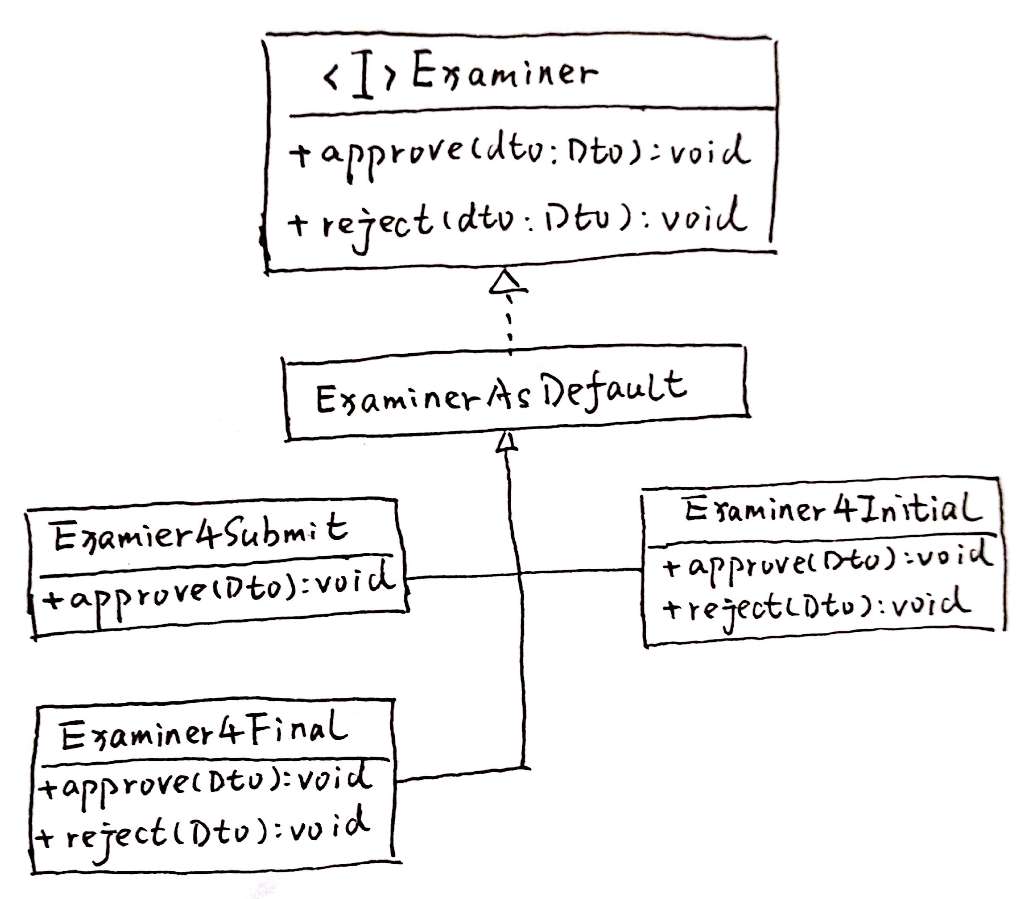
与“教科书”上的类图相似的,是“状态”接口(Examiner),以及各个实际状态所对应的子类。
与之不同的是,虽然我的状态机中有五个状态,但是由于每个状态最多都只有两个状态迁移操作(通过,或者驳回),因此,状态接口中我只定义了两个方法。
还有一点不同在于,我在Examiner接口下,加了一个默认的实现类(ExaminerAsDefault)。这个类实际上什么都不做,每个方法都直接抛出UnSupportedOperationException。这个类的作用是简化子类,使得每个子类只需要重写自己关心的方法,而不需要重写无关方法。当然,Java 8为接口引入的默认方法,可以实现同样的功能,这是后话。此外,由于业务需求中每次只做一步状态迁移,因此Examiner接口不需要再返回自己。还有一点不同的是,这个方案中,状态迁移操作与状态数据被拆开了——迁移操作由Examiner定义,状态数据则用Dto来封装。 -
扩展
当出现新的状态、或者新的迁移操作怎么办呢?
出现新的状态时,创建一个新的“状态”子类,并实现对应的“状态迁移”方法就行了。出现新的迁移操作时则更简单,只需要做第二步就可以了。
方案二:策略模式
-
策略模式
众所周知的策略模式一般都有这样的类图:
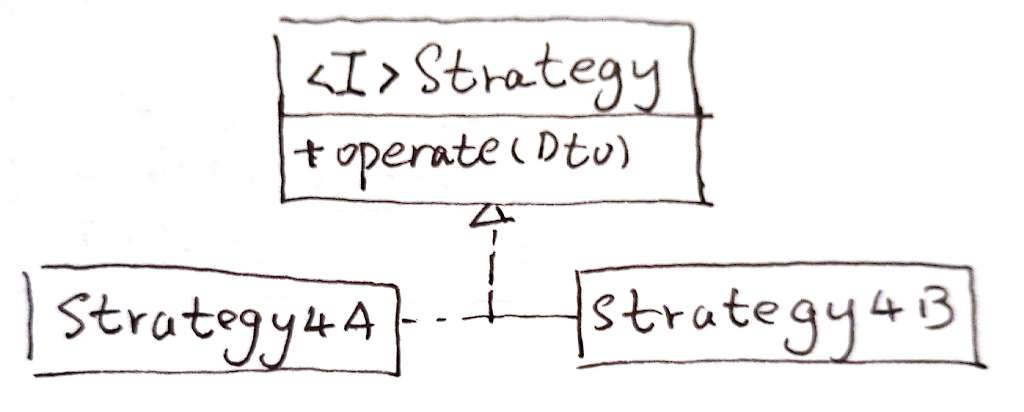
-
我的方案
在我的设计方案中,类图则是这样的:
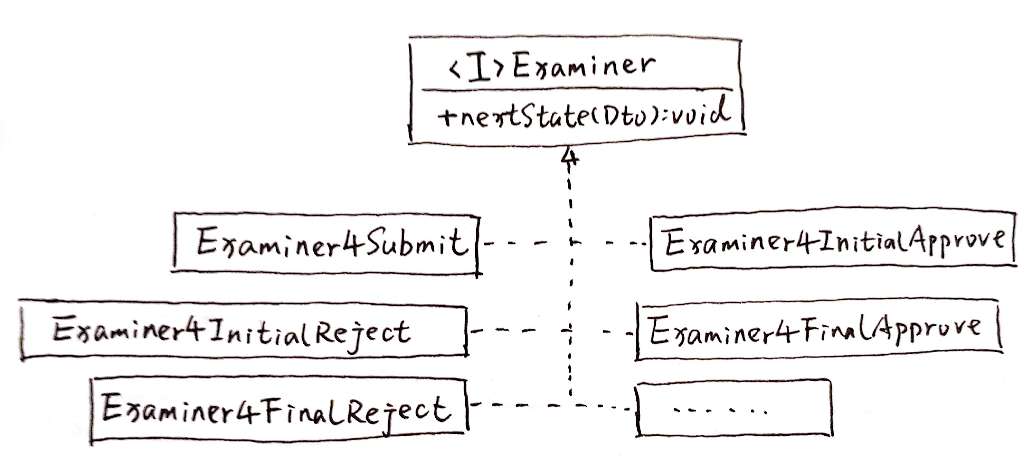
可以说这是一个“标准”的策略模式类图。接口定义从一个状态到另一个状态的迁移动作,不同的子类用不同的“策略”去实现它——例如从“已提交”到“已初审”,或者从“已初审”到“初审驳回”,等等。
状态相关的数据,仍然由单独的Dto来保存和传递。 -
扩展
策略模式下,如何增加新的状态、新的迁移操作呢?
由于策略模式仅仅定义了“状态迁移”动作,因此,无论是增加新的状态、还是增加新的迁移操作,都只需要增加对应的子类即可。
对比
我并不喜欢比较不同设计模式之间的区别。但这里仍可以多说几句。
用状态模式实现状态机,大概是一个最直观、最容易想到的设计。但是,标准的状态模式将状态数据也封装到状态类中。这使得这个类无法用单例实现。另外,由于状态接口中,对应每一个状态都有一个方法,这可能会使得部分子类非常的大。
用策略模式实现状态机,与状态机**是有冲突的。状态机是以“状态”为本,状态迁移操作为辅;而策略模式却专注于状态迁移操作,“状态”的概念淡化得几乎消失了。此外,与状态模式中的“超级类”相反,策略模式可能导致“类爆炸”。
两种模式之间的分界线,也许只是概念上的“以状态为本”或“以操作为本”。就实践上来说,像我的方案中那样,将状态模式中的数据与操作拆分开,那么整个方案与策略模式其实相去无几。
这是我不喜欢比较不同设计模式之间区别的原因。由于设计模式的变化、组合非常多,很多时候不同设计模式之间的界限仅仅存在于概念上、**上,而不在实践中。费尽心思去分析“如何区分23种设计模式”,只在学习阶段有一点意义。我们更应该关注设计模式适用的业务场景、业务问题,以及如何实现它们。
毕竟,科学可以满足于“认识世界”,技术必须要以“改造世界”为目标。
业务系统升级改造-II
最近看到了两篇文章,都是说系统重构/改造/升级的。一篇是《互联网架构实践:给飞机换引擎和安全意识十原则》,另一篇是《知乎社区核心业务 Golang 化实践》。这两篇虽然侧重点不同,但都涉及到一件事情:重构项目的项目路线。第一篇文章提出了三种重构方式:彻底重新做,直接从前到后抛弃老系统;大规模重构,保留对用户的这层皮,后面从服务到数据全部替换;小规模重构,保留对用户的这层皮以及数据结构,逐一替换核心逻辑到微服务。虽然原文是根据重构的彻底性来说的,但这三个划分其实也是三种项目路线。知乎的Golang改造选择了“大规模重构”的思路:保持新服务对外暴露的协议(HTTP 、RPC 接口定义和返回数据)与之前保持一致(保持协议一致很重要,之后迁移依赖方会更方便);并且在重构早期新的服务没有自己的资源,使用待重构服务的资源。然后通过功能验证、灰度放量等方式逐步将老服务切到新服务上。
如果是我,我也会选择这样的路线。因为我以前用第一和第三种方式做重构时,都遇到了很大的问题。
先说第三种方式。小规模重构会面临进退维谷的两个问题。如果我们没有一个完整的业务和系统架构设计,那么零敲碎打的重构改造对系统的优化作用和性价比实在有限:船都进水了,刷刷甲板擦擦灯罩也改变不了什么。而如果我们拿出了完整的架构设计,小规模重构往往就满足不了整体重构的需要,而必须升级为大规模重构了。所以,小规模重构在整个系统的层面上比较鸡肋;它比较适合于针对某个单独功能点的优化。当然,这种方式也并非一无是处。它能够延缓系统腐化的趋势,也能帮助项目团队提高能力和增加经验。总之,在系统架构稳定之后或是大规模重构之前,小规模重构还是大有可为的。我之前参与过的一个重构项目中,项目团队在系统级别的重构完成之后,还在持之以恒地对一些小功能、小细节进行重构,就我所知,这个系统目前无论在业务上还是在技术上,都非常的健康。
对系统级重构来说,小规模重构有点像缘木求鱼,虽然抓不到鱼,倒也没有什么大的坏处。彻底重做却有点像饮鸩止渴,很多时候不仅无法达成目标,还会埋下重大的隐患。最主要的隐患是新系统的技术、业务架构都要在全部开发完成后才能得到验证。这会导致风险都被压缩到了测试和验收阶段这两个阶段中:这时已经是上线前的倒计时阶段了,加上开发阶段在所难免的延期,时间往往非常紧张。在这样短的时间内尝试检查和解决大量风险,其中的问题是不言自明的。有个同事总结说,这个时候发现问题了,系统上线要延期;没发现问题,往往更要延期——因为积压了太多的功能和代码需要测试验收,没有问题比有问题更让人觉得心慌。此外,新系统上线之前老系统发生业务需求变更也是不容忽视的一个问题。新需求会扩大新系统的范围,进而影响开发、测试和验收的工期,最糟糕的情况下还可能迫使新系统修改技术或业务架构:这样的后果就不堪设想了。我参与和见识过两个这样的项目,在团队成员辛苦忙活了半年、一年以后,系统却因为种种问题、风险而一再延期。
曾经有同事在讨论中提出用最快的速度、最短的时间把新系统推上线。这样,测试验收的时间比较充足;通过快速试错的方式来修改发现的问题;而且这样还可以避免出现第二个问题。这样做似乎可行,但我认为这种“快速试错”的方案并不可取。首先,老系统为什么会腐化到非重构/重做不可的地步的?长期地只重速度不重质量、“先上线再说”的开发模式难辞其咎。在市场快速扩张、业务快速增长阶段这样取舍还情有可原,在专门拿出时间精力来做重构时仍然一味地“唯快不破”,岂不是要重蹈覆辙、欲速而不达?其次,快速试错是在市场方向、业务需求不明朗的情况下,有一丝“无奈的”试探性做法。但对业务系统重构项目来说,功能需求和性能指标都可以从老系统中总结、提炼出来。在可以看清楚道路的情况下还要闭着眼睛“快速试错”,非常的得不偿失。
彻底重做的方式有点类似瀑布式开发模式,可能只适合于一些规模较小、功能简单或者功能长期不变的系统。对大型的、复杂多变的业务系统来说,更合适的方式应该是更接近敏捷开发的大规模重构。这种重构的路线可以参考《知乎社区核心业务 Golang 化实践》。与小规模重构相比,大规模重构有一个更加全局的、完备的规划,每一个模块、每一个功能的重构既是对原有功能的优化改造,同时也是更大蓝图中的一块拼图。与彻底重做相比,大规模重构更加的敏捷:新系统的风险和问题会在逐步替换的过程中暴露和解决,从而避免了近在咫尺时才发现冰山的可怕场景。而且,在重构过程中遇到新需求,我们也有了更好的解决方案:我们可以先对相关模块做重构,然后在重构后的基础上做新需求。这样技术业务两不误,开发和产品也皆大欢喜。
哲学中有一个“忒修斯之船”的命题:把忒修斯乘坐过的船上的每一块木板都换成新的,最后这条船还是忒修斯的那条船吗?相比这个哲学命题,我更喜欢研究如何对那条船进行翻新修缮:小规模重构就像是在风雨飘摇的大海上刷洗甲板、修理护栏;彻底重做是在船坞里建造一条新船;大规模重构则是在航行过程中把小木船逐步升级改造成大航母。就我而言,无论是期望还是经验,我都愿意选择大规模重构的方式。
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.