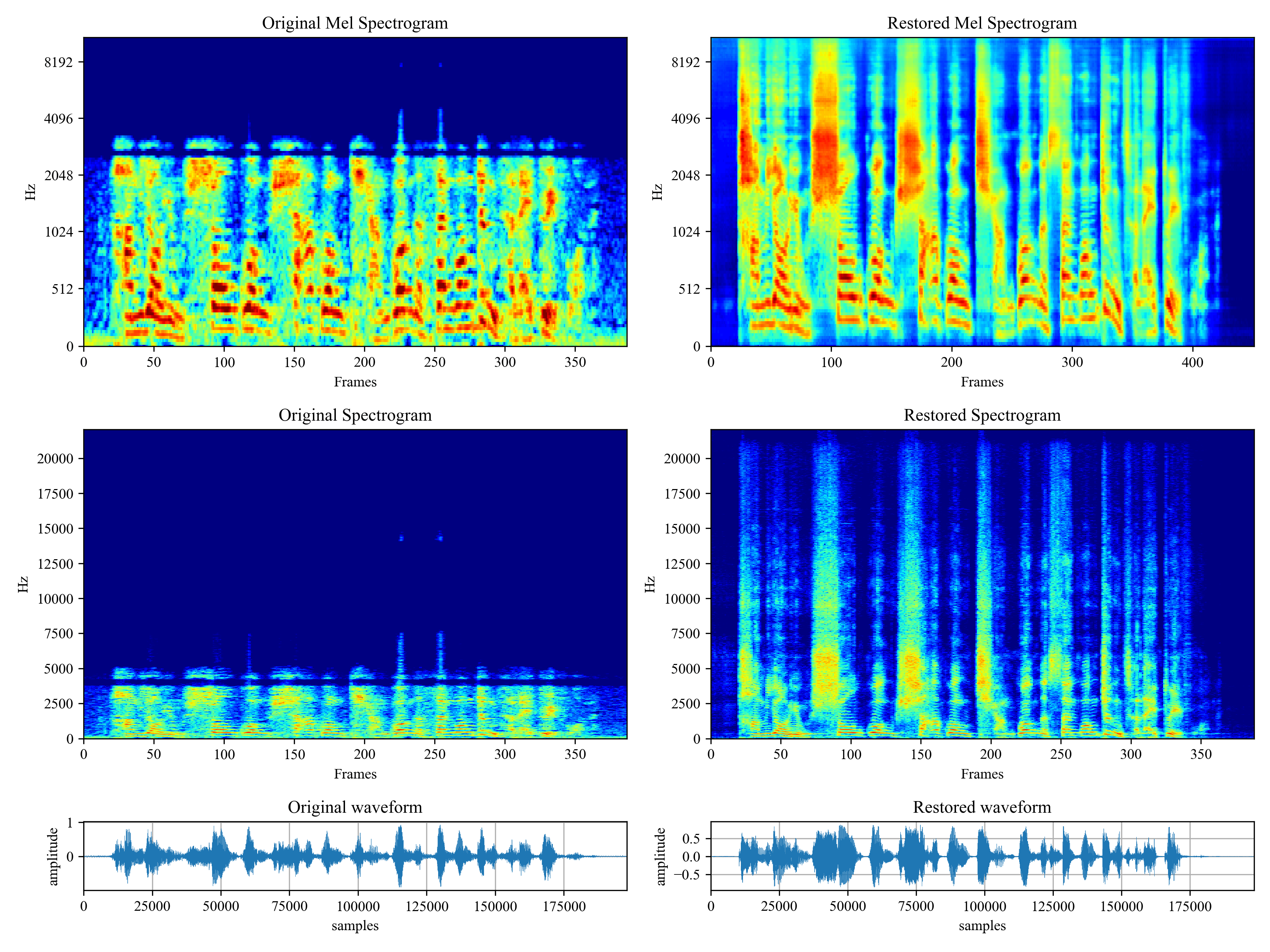
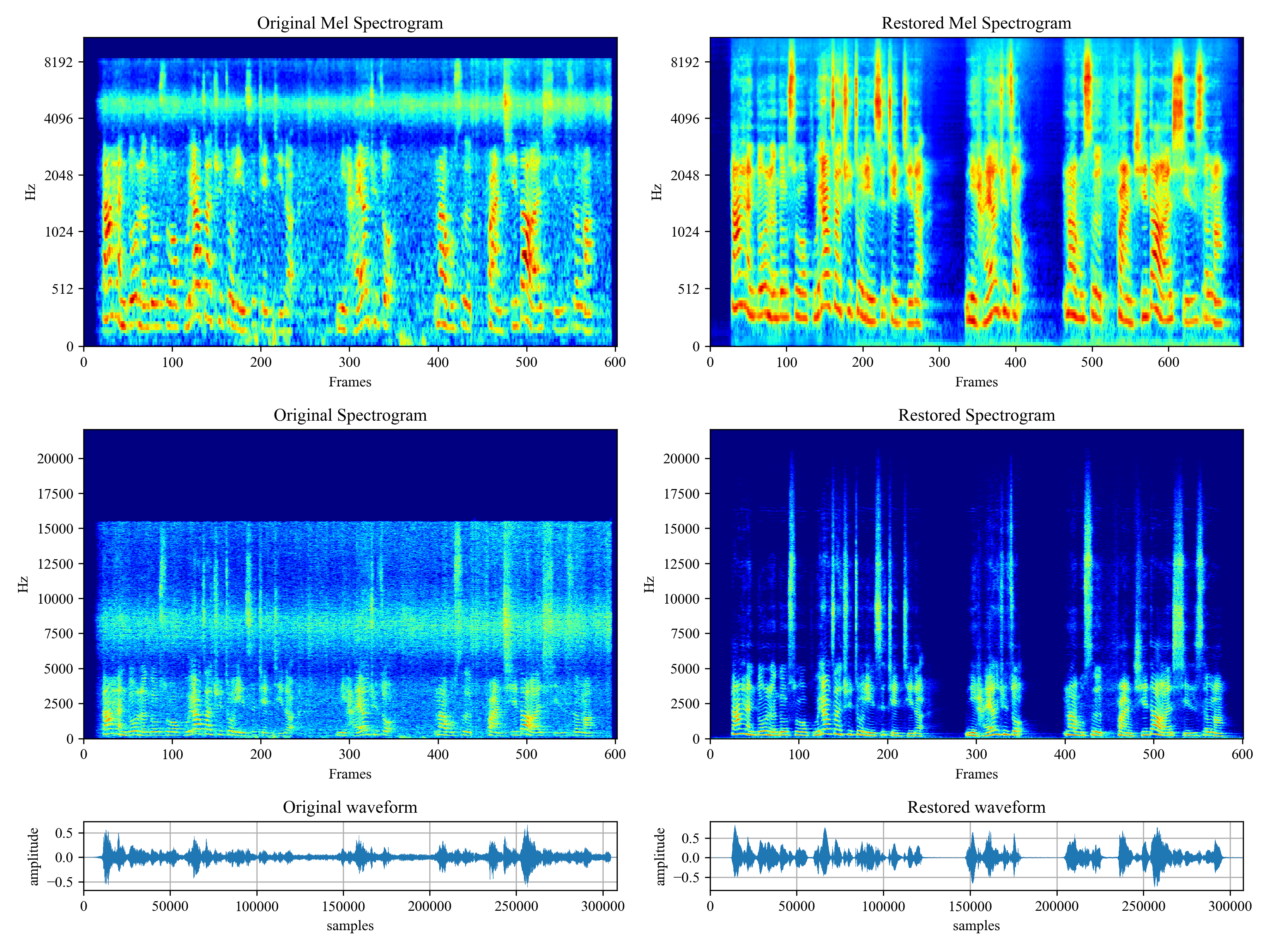
Collecting voicefixer==0.1.2
Using cached voicefixer-0.1.2-py3-none-any.whl (52 kB)
Requirement already satisfied: librosa<0.9.0,>=0.8.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from voicefixer==0.1.2) (0.8.1)
Requirement already satisfied: matplotlib in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from voicefixer==0.1.2) (3.7.1)
Requirement already satisfied: torch>=1.7.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from voicefixer==0.1.2) (2.0.1)
Collecting progressbar (from voicefixer==0.1.2)
Using cached progressbar-2.5-py3-none-any.whl
Collecting torchlibrosa==0.0.7 (from voicefixer==0.1.2)
Using cached torchlibrosa-0.0.7-py3-none-any.whl (10 kB)
Requirement already satisfied: GitPython in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from voicefixer==0.1.2) (3.1.32)
Requirement already satisfied: streamlit>=1.12.0pyyaml in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from voicefixer==0.1.2) (1.24.1)
Requirement already satisfied: audioread>=2.0.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (3.0.0)
Requirement already satisfied: numpy>=1.15.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (1.24.3)
Requirement already satisfied: scipy>=1.0.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (1.11.0)
Requirement already satisfied: scikit-learn!=0.19.0,>=0.14.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (1.2.2)
Requirement already satisfied: joblib>=0.14 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (1.2.0)
Requirement already satisfied: decorator>=3.0.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (5.1.1)
Requirement already satisfied: resampy>=0.2.2 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (0.4.2)
Requirement already satisfied: numba>=0.43.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (0.57.1)
Requirement already satisfied: soundfile>=0.10.2 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (0.12.1)
Requirement already satisfied: pooch>=1.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (1.7.0)
Requirement already satisfied: packaging>=20.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (23.1)
Requirement already satisfied: altair<6,>=4.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (5.0.1)
Requirement already satisfied: blinker<2,>=1.0.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (1.6.2)
Requirement already satisfied: cachetools<6,>=4.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (5.3.1)
Requirement already satisfied: click<9,>=7.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (8.1.3)
Requirement already satisfied: importlib-metadata<7,>=1.4 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (6.8.0)
Requirement already satisfied: pandas<3,>=0.25 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (2.0.3)
Requirement already satisfied: pillow<10,>=6.2.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (9.5.0)
Requirement already satisfied: protobuf<5,>=3.20 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (4.23.3)
Requirement already satisfied: pyarrow>=4.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (12.0.1)
Requirement already satisfied: pympler<2,>=0.9 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (1.0.1)
Requirement already satisfied: python-dateutil<3,>=2 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (2.8.2)
Requirement already satisfied: requests<3,>=2.4 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (2.31.0)
Requirement already satisfied: rich<14,>=10.11.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (13.4.2)
Requirement already satisfied: tenacity<9,>=8.0.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (8.2.2)
Requirement already satisfied: toml<2 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (0.10.2)
Requirement already satisfied: typing-extensions<5,>=4.0.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (4.6.3)
Requirement already satisfied: tzlocal<5,>=1.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (4.3.1)
Requirement already satisfied: validators<1,>=0.2 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (0.20.0)
Requirement already satisfied: pydeck<1,>=0.1.dev5 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (0.8.1b0)
Requirement already satisfied: tornado<7,>=6.0.3 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (6.3.2)
Requirement already satisfied: watchdog in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (3.0.0)
Requirement already satisfied: gitdb<5,>=4.0.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from GitPython->voicefixer==0.1.2) (4.0.10)
Requirement already satisfied: filelock in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from torch>=1.7.0->voicefixer==0.1.2) (3.12.2)
Requirement already satisfied: sympy in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from torch>=1.7.0->voicefixer==0.1.2) (1.12)
Requirement already satisfied: networkx in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from torch>=1.7.0->voicefixer==0.1.2) (3.1)
Requirement already satisfied: jinja2 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from torch>=1.7.0->voicefixer==0.1.2) (3.1.2)
Requirement already satisfied: contourpy>=1.0.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from matplotlib->voicefixer==0.1.2) (1.1.0)
Requirement already satisfied: cycler>=0.10 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from matplotlib->voicefixer==0.1.2) (0.11.0)
Requirement already satisfied: fonttools>=4.22.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from matplotlib->voicefixer==0.1.2) (4.40.0)
Requirement already satisfied: kiwisolver>=1.0.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from matplotlib->voicefixer==0.1.2) (1.4.4)
Requirement already satisfied: pyparsing>=2.3.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from matplotlib->voicefixer==0.1.2) (3.1.0)
Requirement already satisfied: jsonschema>=3.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from altair<6,>=4.0->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (4.18.3)
Requirement already satisfied: toolz in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from altair<6,>=4.0->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (0.12.0)
Requirement already satisfied: colorama in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from click<9,>=7.0->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (0.4.6)
Requirement already satisfied: smmap<6,>=3.0.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from gitdb<5,>=4.0.1->GitPython->voicefixer==0.1.2) (5.0.0)
Requirement already satisfied: zipp>=0.5 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from importlib-metadata<7,>=1.4->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (3.16.2)
Requirement already satisfied: llvmlite<0.41,>=0.40.0dev0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from numba>=0.43.0->librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (0.40.1)
Requirement already satisfied: pytz>=2020.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from pandas<3,>=0.25->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (2023.3)
Requirement already satisfied: tzdata>=2022.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from pandas<3,>=0.25->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (2023.3)
Requirement already satisfied: platformdirs>=2.5.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from pooch>=1.0->librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (3.8.0)
Requirement already satisfied: MarkupSafe>=2.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from jinja2->torch>=1.7.0->voicefixer==0.1.2) (2.1.3)
Requirement already satisfied: six>=1.5 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from python-dateutil<3,>=2->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (1.16.0)
Requirement already satisfied: charset-normalizer<4,>=2 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from requests<3,>=2.4->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (3.1.0)
Requirement already satisfied: idna<4,>=2.5 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from requests<3,>=2.4->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (3.4)
Requirement already satisfied: urllib3<3,>=1.21.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from requests<3,>=2.4->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (1.26.16)
Requirement already satisfied: certifi>=2017.4.17 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from requests<3,>=2.4->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (2023.5.7)
Requirement already satisfied: markdown-it-py>=2.2.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from rich<14,>=10.11.0->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (3.0.0)
Requirement already satisfied: pygments<3.0.0,>=2.13.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from rich<14,>=10.11.0->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (2.15.1)
Requirement already satisfied: threadpoolctl>=2.0.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from scikit-learn!=0.19.0,>=0.14.0->librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (3.1.0)
Requirement already satisfied: cffi>=1.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from soundfile>=0.10.2->librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (1.15.1)
Requirement already satisfied: pytz-deprecation-shim in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from tzlocal<5,>=1.1->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (0.1.0.post0)
Requirement already satisfied: mpmath>=0.19 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from sympy->torch>=1.7.0->voicefixer==0.1.2) (1.3.0)
Requirement already satisfied: pycparser in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from cffi>=1.0->soundfile>=0.10.2->librosa<0.9.0,>=0.8.1->voicefixer==0.1.2) (2.21)
Requirement already satisfied: attrs>=22.2.0 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from jsonschema>=3.0->altair<6,>=4.0->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (23.1.0)
Requirement already satisfied: jsonschema-specifications>=2023.03.6 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from jsonschema>=3.0->altair<6,>=4.0->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (2023.6.1)
Requirement already satisfied: referencing>=0.28.4 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from jsonschema>=3.0->altair<6,>=4.0->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (0.29.1)
Requirement already satisfied: rpds-py>=0.7.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from jsonschema>=3.0->altair<6,>=4.0->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (0.8.10)
Requirement already satisfied: mdurl~=0.1 in c:\users\beats\appdata\local\programs\python\python310\lib\site-packages (from markdown-it-py>=2.2.0->rich<14,>=10.11.0->streamlit>=1.12.0pyyaml->voicefixer==0.1.2) (0.1.2)
DEPRECATION: voicefixer 0.1.2 has a non-standard dependency specifier streamlit>=1.12.0pyyaml. pip 23.3 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of voicefixer or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
Installing collected packages: progressbar, torchlibrosa, voicefixer
Successfully installed progressbar-2.5 torchlibrosa-0.0.7 voicefixer-0.1.2
C:\Users\Beats>git clone https://github.com/haoheliu/voicefixer.git
Cloning into 'voicefixer'...
remote: Enumerating objects: 452, done.
remote: Counting objects: 100% (31/31), done.
remote: Compressing objects: 100% (25/25), done.
Receiving objects: 100% (452/452), 784.00 KiB | 1.52 MiB/sed 421Receiving objects: 99% (448/452), 784.00 KiB | 1.52 MiB/s
Receiving objects: 100% (452/452), 3.83 MiB | 5.23 MiB/s, done.
Resolving deltas: 100% (246/246), done.
C:\Users\Beats>cd voicefixer
C:\Users\Beats\voicefixer>streamlit run test/streamlit.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://10.0.0.4:8501
2023-07-26 11:27:38.530 Uncaught app exception
Traceback (most recent call last):
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 552, in _run_script
exec(code, module.__dict__)
File "C:\Users\Beats\voicefixer\test\streamlit.py", line 4, in <module>
import librosa
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\librosa\__init__.py", line 211, in <module>
from . import core
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\librosa\core\__init__.py", line 9, in <module>
from .constantq import * # pylint: disable=wildcard-import
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\librosa\core\constantq.py", line 1059, in <module>
dtype=np.complex,
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\numpy\__init__.py", line 305, in __getattr__
raise AttributeError(__former_attrs__[attr])
AttributeError: module 'numpy' has no attribute 'complex'.
`np.complex` was a deprecated alias for the builtin `complex`. To avoid this error in existing code, use `complex` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.complex128` here.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
2023-07-26 11:27:46.792 Uncaught app exception
Traceback (most recent call last):
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 552, in _run_script
exec(code, module.__dict__)
File "C:\Users\Beats\voicefixer\test\streamlit.py", line 4, in <module>
import librosa
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\librosa\__init__.py", line 211, in <module>
from . import core
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\librosa\core\__init__.py", line 9, in <module>
from .constantq import * # pylint: disable=wildcard-import
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\librosa\core\constantq.py", line 1059, in <module>
dtype=np.complex,
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\numpy\__init__.py", line 305, in __getattr__
raise AttributeError(__former_attrs__[attr])
AttributeError: module 'numpy' has no attribute 'complex'.
`np.complex` was a deprecated alias for the builtin `complex`. To avoid this error in existing code, use `complex` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.complex128` here.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
2023-07-26 11:29:29.943 Uncaught app exception
Traceback (most recent call last):
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 552, in _run_script
exec(code, module.__dict__)
File "C:\Users\Beats\voicefixer\test\streamlit.py", line 4, in <module>
import librosa
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\librosa\__init__.py", line 211, in <module>
from . import core
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\librosa\core\__init__.py", line 9, in <module>
from .constantq import * # pylint: disable=wildcard-import
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\librosa\core\constantq.py", line 1059, in <module>
dtype=np.complex,
File "C:\Users\Beats\AppData\Local\Programs\Python\Python310\lib\site-packages\numpy\__init__.py", line 305, in __getattr__
raise AttributeError(__former_attrs__[attr])
AttributeError: module 'numpy' has no attribute 'complex'.
`np.complex` was a deprecated alias for the builtin `complex`. To avoid this error in existing code, use `complex` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.complex128` here.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations```
I'm new to this and have no idea what went wrong and how to fix it?