greycode / technical-articles Goto Github PK
View Code? Open in Web Editor NEW写点东西的地方
License: MIT License
写点东西的地方
License: MIT License








先上模板代码
<!doctype html>
<html lang="en">
<head>
<!-- Required meta tags -->
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<title>Hello, Excel!</title>
</head>
<body>
<h1>Hello, Excel!</h1>
<div class="row">
<div class="col-sm-12">
<input type="file" id="file" />
<label for="file">... or click here to select a file</label>
</div>
</div>
<!-- https://sheetjs.com/sexql/index.html -->
<!-- https://docs.sheetjs.com/#parsing-workbooks -->
<!-- https://github.com/atlassian/jquery-handsontable -->
<!-- Optional JavaScript -->
<script src="https://code.jquery.com/jquery-3.2.1.slim.min.js" integrity="sha384-KJ3o2DKtIkvYIK3UENzmM7KCkRr/rE9/Qpg6aAZGJwFDMVNA/GpGFF93hXpG5KkN"
crossorigin="anonymous"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/xlsx/0.13.0/xlsx.full.min.js"></script>
<script>
var rABS = true; // true: readAsBinaryString ; false: readAsArrayBuffer
function handleFile(e) {
var files = e.target.files,
f = files[0];
var reader = new FileReader();
reader.onload = function (e) {
var data = e.target.result;
if (!rABS) data = new Uint8Array(data);
var workbook = XLSX.read(data, {
type: rABS ? 'binary' : 'array'
});
console.log(workbook)
/* DO SOMETHING WITH workbook HERE */
};
if (rABS) reader.readAsBinaryString(f);
else reader.readAsArrayBuffer(f);
}
var input_file = document.querySelector('#file');
input_file.addEventListener('change', handleFile, false);
</script>
</body>
</html>代码如下
import 'package:flutter/material.dart';
class WavyHeaderImage extends StatelessWidget {
@override
Widget build(BuildContext context) {
return new ClipPath(
child: new Image.asset('images/coffee_header.jpg'),
clipper: new BottomWaveClipper(),
);
}
}
class BottomWaveClipper extends CustomClipper<Path> {
@override
Path getClip(Size size) {
Path path = new Path();
path.lineTo(0.0, size.height - 20);
var firstControlPoint = new Offset(size.width / 4, size.height);
var firstEndPoint = new Offset(size.width / 2.25, size.height - 30.0);
path.quadraticBezierTo(firstControlPoint.dx, firstControlPoint.dy,
firstEndPoint.dx, firstEndPoint.dy);
var secondControlPoint =
new Offset(size.width - (size.width / 3.25), size.height - 65);
var secondEndPoint = new Offset(size.width, size.height - 40);
path.quadraticBezierTo(secondControlPoint.dx, secondControlPoint.dy,
secondEndPoint.dx, secondEndPoint.dy);
path.lineTo(size.width, size.height - 40);
path.lineTo(size.width, 0.0);
return path;
}
@override
bool shouldReclip(CustomClipper<Path> oldClipper) => false;
}
贝塞尔曲线 控制点 和 结束点如下:

最终结果如下:

use this command :
sudo npm install xxx --unsafe-perm=true --allow-root标签(空格分隔): antlr 词法分析 语法分析
支持多行、单行与 Javadoc 风格的注释
/**
* This grammar is an example illustrating the three kinds
* of comments.
*/
grammar T;
/* a multi-line
comment
*/
/** This rule matches a declarator for my language */
decl : ID ; // match a variable nameJavadoc 风格的注释会被 parser 忽略掉,只适合用在语法文件的开头。
标记(Token)名和词法解析规则(Lexer rules)名首字母必须大写,语法解析规则(Parser rule)首字母必须小写,其余字符可以使用大小写字母、数字和下划线。
ID, LPAREN, RIGHT_CURLY // token names/rules
expr, simpleDeclarator, d2, header_file // rule names
名称可使用 Unicode 字符:
grammer 外
a : '外'
ANTLR 的字面量不区分字符或字符串,不管一个或多个字符都是用单引号包裹起来,比如 ’;’ , ’if’ ,’>=’ 以及 ’\’’ ,字面量不能包含正则表达式。
字面量可包含 Unicode 转义序列,使用 ’\uXXXX’ 的形式可覆盖最大到 ’U+FFFF’ 或使用 ’\u{XXXXXX}’ 的形式覆盖所有 Unicode 码点,其中 XXXX 表示十六进制 Unicode 码点值。
还可以使用常见的特殊转义符:’\n’ (换行), ’\r’ (回车), ’\t’ (tab)
Actions 是用目标语言写的代码块——使用一对大括号包裹,可以插入到语法文件的各个地方。ANTLR 中字符串或注释或对称的大括号(比如代码块)是不需要转义的( "}" , /*}*/ , {...}),但其他情况下需要。
这种嵌入的代码可以用在 @header 和 @members 、语法解析规则和词法解析规则、异常捕获说明、语法解析规则的属性段等等。
ANTLR 只对动作中与语法属性(grammar attributes)相关的进行解释,嵌入在词法规则中的动作代码将不会经过任何解释或翻译直接放入生成的词法解释器中。
以下是 ANTLR 中的保留字
import, fragment, lexer, parser, grammar, returns,
locals, throws, catch, finally, mode, options, tokens
另外,rule 虽然不是关键词,不要将其用于规则名中,也不要在标记、标签或规则名中使用目标语言中的关键词。
语法本质上就是一个语法声明与一些规则的集合,通常如下:
/** Optional javadoc style comment */
grammar Name; ①
options {...}
import ... ;
tokens {...}
channels {...} // lexer only
@actionName {...}
rule1 // parser and lexer rules, possibly intermingled
...
ruleN语法名(grammar 后面的)必须跟文件名保持一致,比如上面的语法应该保存在 Name.g4 文件中。选项(options) ,引入语句(imports) ,标记规范(token specifications)与 动作(actions)可以以任意顺序出现,其中选项 、引入语句、标记规范最多只能出现一次或者没有。
语法文件的头部 ① 是必须的,而且至少要有一条规则,规则的基本形式为
ruleName : alternative1 | ... | alternativeN ;
语法解析规则(parser rule)名称必须以小写字母开头,词法解析规则(lexer rules)名称必须以大写字母开头。
grammar 头中不带有前缀的为组合语法,可同时包含词法解析和语法解析规则,如想限制语法文件中只能定义语法解析规则,可以如下:
parser grammar Name;
...
同理,一个纯词法解析语法文件可以如下:
lexer grammar Name;
...
仅限词法解析语法中可包含模式(mode)规范。
仅限词法解析语法中可包含自定义的频道(channel)规范:
channels {
WHITESPACE_CHANNEL,
COMMENTS_CHANNEL
}
定义的频道随后即可当做枚举常量一样用于词法解析规则中:
WS : [ \r\t\n]+ -> channel(WHITESPACE_CHANNEL) ;imports 的出现允许我们将语法文件按逻辑拆分成可重用的不同
部分。在 ANTLR 中 imports 有点类似于面向对象语言中的超类(superclass),一个语法文件会继承它所引入语法文件中的所有规则、标记规范和命名动作。主语法文件中的规则定义会覆盖引入语法文件中的同名定义。
下图展示了 imports 的作用:
被引入的语法文件中也可以再引入其他语法文件。
ANTLR 在合并被引入语法文件时将其中的规则定义置于主语法文件词法解析规则之后。因此主语法文件中的规则定义优先级要高于被引入中的规则定义,比如主语法文件中定义了 IF : ’if’ ; ,被引入语法文件中定义了 ID : [a-z]+ ; 也能识别 if ,但引入的 ID 规则不会掩盖掉主语法文件中的 IF(也就是 if 会优先匹配到 IF 而不是 ID) 。
标记段用来定义可在语法中使用的标记类型,基本语法为:
tokens { Token1, ..., TokenN }
这些标记类型多用于动作中:
// explicitly define keyword token types to avoid implicit definition warnings
tokens { BEGIN, END, IF, THEN, WHILE }
@lexer::members { // keywords map used in lexer to assign token types
Map<String,Integer> keywords = new HashMap<String,Integer>() {{
put("begin", KeywordsParser.BEGIN);
put("end", KeywordsParser.END);
...
}};
}本质上标记段就是在全局定义了一些标记:
$ cat Tok.g4
grammar Tok;
tokens { A, B, C }
a : X ;
$ antlr4 Tok.g4
warning(125): Tok.g4:3:4: implicit definition of token X in parser
$ cat Tok.tokens
A=1
B=2
C=3
X=4目前只定义了两种命名动作(named actions,仅用于目标语言为Java时):header 和 members 。前者用于在生成的识别程序(recognizer)类定义之前插入代码,后者用于在识别程序类定义之中插入代码。
对组合语法文件(同时包含语法解析和词法解析规则),ANTLR 会将动作代码同时插入生成的语法解析器和词法解析器中,若要限制动作代码的应用范围,要使用 @parser::name 或 @lexer::name 。
以下是个例子:
grammar Count;
@header {
package foo;
}
@members {
int count = 0;
}
list
@after {System.out.println(count+" ints");}
: INT {count++;} (',' INT {count++;} )*
;
INT : [0-9]+ ;
WS : [ \r\t\n]+ -> skip ;语法解析器最终包含所有的语法规则,ANTLR 生成的语法解析器会从起始规则开始,以深度优先顺序调用每条规则方法(每条语法规则会产生与该规则相关的方法)。
下面是一条最基本的语法解析规则:
/** Javadoc comment can precede rule */
retstat : 'return' expr ';' ;规则中若有其他的分支匹配项应使用 | 符号:
stat: retstat
| 'break' ';'
| 'continue' ';'
;匹配项中可包含一些规则元素或者为空,比如下面的例子中规则包含空的匹配项:
superClass
: 'extends' ID
| // empty means other alternative(s) are optional
;可以使用 # 符号为每条规则匹配项添加标签,这样会针对每个分支生成相关的语法树事件监听器,每个规则里的所有分支要么都有标签,要么都没有。
grammar T;
stat: 'return' e ';' # Return
| 'break' ';' # Break
;
e : e '*' e # Mult
| e '+' e # Add
| INT # Int
;
匹配项标签不一定要放在每行的最后, # 之后也不必非得加一个空格。ANTLR 会为每个标签生成一个规则上下文类,比如上面的语法生成的监听器(listener)代码为:
public interface AListener extends ParseTreeListener {
void enterReturn(AParser.ReturnContext ctx);
void exitReturn(AParser.ReturnContext ctx);
void enterBreak(AParser.BreakContext ctx);
void exitBreak(AParser.BreakContext ctx);
void enterMult(AParser.MultContext ctx);
void exitMult(AParser.MultContext ctx);
void enterAdd(AParser.AddContext ctx);
void exitAdd(AParser.AddContext ctx);
void enterInt(AParser.IntContext ctx);
void exitInt(AParser.IntContext ctx);
}每个匹配项的标签都会生成与之关联的 enter 和 exit 方法。
在多个可匹配项上可以使用相同的标签,这样在遍历语法树时这些匹配项将触发相同的事件:
e : e '*' e # BinaryOp
| e '+' e # BinaryOp
| INT # Int
;以上语法将生成如下代码:
void enterBinaryOp(AParser.BinaryOpContext ctx);
void exitBinaryOp(AParser.BinaryOpContext ctx);
void enterInt(AParser.IntContext ctx);
void exitInt(AParser.IntContext ctx);对规则定义中引用的其他规则,ANTLR 会生成方法获取与该引用规相关的上下文对象。只有一个引用规则的规则,ANTLR 生成没有参数的方法,比如如下的规则定义:
inc : e '++' ;
ANTLR 生成的上下文类为:
public static class IncContext extends ParserRuleContext {
public EContext e() { ... } // return context object associated with e
...
}如果在一个规则定义中对另一个规则不止引用了一次,ANTLR 也提供相关方法支持:
field : e '.' e ;
ANTLR 会生成获取第x个引用规则上下文对象的方法以及获取所有规则应用上下文的列表方法:
public static class FieldContext extends ParserRuleContext {
public EContext e(int i) { ... } // get ith e context
public List<EContext> e() { ... } // return ALL e contexts
...
}如果有另外一个规则 s 定义中引用了上面的 field ,可以在嵌入动作中访问到规则 e 的列表:
s : field
{
List<EContext> x = $field.ctx.e();
...
}
;可以在规则定义中使用 = 为规则元素添加标签,添加了标签的元素会在所在规则生成的上下文对象中新增一个字段:
stat: 'return' value=e ';' # Return
| 'break' ';' # Break
;上面语法中 value 为规则 e 返回值的标签,标签会在合适的语法树节点类中生成代码。这里标签 value 将变成 ReturnContext 中的一个字段,因为正好有个 Return 匹配项标签:
public static class ReturnContext extends StatContext {
public EContext value;
...
}有时会需要跟踪一些标记(便于后续处理),那么可以使用 += 列表标签 ,比如下面的语法定义用于匹配一个数组:
array : '{' el+=INT (',' el+=INT)* '}' ;ANTLR 会在合适的规则上下文类中生成一个 List 字段:
public static class ArrayContext extends ParserRuleContext {
public List<Token> el = new ArrayList<Token>();
...
}列表标签同样适用于规则引用:
elist : exprs+=e (',' exprs+=e)* ;
以上 ANTLR 将生成一个包含上下文对象的列表字段:
public static class ElistContext extends ParserRuleContext {
public List<EContext> exprs = new ArrayList<EContext>();
...
}规则元素类似于编程语言中的语句(statements),指明解析器在某个时刻应该做什么。规则元素可以是规则、标记、字符串字面量(比如表达式、ID、'return'),以下是规则元素的完整列表:
| 语法 | 描述 |
|---|---|
| T | 在当前输入位置匹配标记 T。标记名总是以大写字母开头。 |
| ’literal’ | 在当前位置匹配字符串字面量 literal 。字符串字面量其实就是有固定值的标记 |
| r | 匹配规则 r ,即调用该规则——类似于函数调用。语法解析规则总是以小写字母开头。 |
| r[«args»] | 匹配规则 r ,带有参数传入。方括号中的参数使用目标语言的语法而且通常是以逗号分隔的表达式列表。 |
| {«action»} | 在匹配完前面的元素后立即执行动作。动作代码使用目标语言编写,ANTLR 将把动作代码直接拷贝到生成的类中——在拷贝前会先替换其中的规则引用和属性引用(比如 $x 、 $x.y)。 |
| {«p»}? | 对语义谓词 «p» 进行求值,如果值为 false ,将不再解析该谓词之后的内容。谓词通常用于 ANTLR 进行分支预测,使用谓词来开启或禁用某个匹配项。 |
| . | 匹配任意单个标记(除了文件结束符 EOF),点号操作符被称作通配符。 |
如果想匹配除了某个或某一些标记之外的任意标记,可以使用 ~ not 操作符。这个操作符用得很少却很有用。~INT 匹配除了 INT 之外任意标记, ~(INT|ID) 匹配除了 INT 或 ID 之外的任意标记。
规则可以包含被称作子规则的匹配块,子规则一共有四种形式(x、y、z代表语法片段):
| 语法 | 描述 |
|---|---|
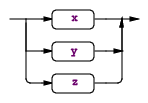 |
(x | y | z).,匹配该子规则中的任意一个匹配项。举例: returnType : (type | 'void') ; |
 |
(x | y | z)? ,完全不匹配或者匹配该子规则中的任一项。举例:classDeclaration : 'class' ID ('extends' type)? classBody ; |
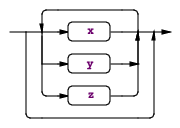 |
(x | y | z)* ,匹配子规则中的项目零或多次。举例:annotationName : ID ('.' ID)* ; |
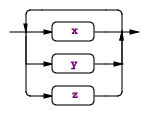 |
(x | y | z)+ ,匹配子规则中的项目一次或多次。举例:annotations : (annotation)+ ; |
可以给 ? 、 * 、 + 添加后缀——非贪婪操作符 ?? 。
对于比较简单的子规则,可以省略外面的括号比如 annotation+ 等同 (annotation)+ 。
当规则中出现语法错误,ANTLR 将捕获异常、报告错误并试图恢复,然后从规则中返回。每个规则都被包裹在 try/catch/finally 语句中:
void r() throws RecognitionException {
try {
rule-body
}
catch (RecognitionException re) {
_errHandler.reportError(this, re);
_errHandler.recover(this, re);
}
finally {
exitRule();
}
}使用策略对象可以改变 ANTLR 的错误处理行为,但这样会修改所有规则的错误处理方式。不过如要改变某一规则的异常处理,可以在规则定义之后指定异常:
r : ...
;
catch[RecognitionException e] { throw e; }
这个例子展示了如何避免 ANTLR 默认的错误处理和恢复机制。规则 r 重新抛出了异常,有利于更高层的规则来处理这个错误,指定一个异常语句后 ANTLR 将不在生成语句来处理 RecognitionException 。
还可以指定更多异常:
r : ...
;
catch[FailedPredicateException fpe] { ... }
catch[RecognitionException e] { ... }
大括号里的代码片段以及异常参数必须使用目标语言编写,这个例子使用了 Java。即便异常发生也需要执行的动作可以放在 finally 语句中:
r : ...
;
// catch blocks go first
finally { System.out.println("exit rule r"); }
finally 语句将在规则触发 exitRule 返回之前执行,如果希望动作在规则匹配完选项之后但在进行任何清理行为之前执行,可使用 after 动作。
以下是异常的列表:
| 异常名 | 描述 |
|---|---|
| RecognitionException | ANTLR 生成的识别器可能抛出的所有异常的超类,继承自 RuntimeException 。这个异常会记录识别器(词法或语法分析器)在输入流中的位置,在 ATN(一个内部用来表示语法的图数据结构)中的位置,规则调用堆栈信息以及错误的类型 |
| NoViableAltException | 表明语法解析器无法根据剩余的输入来决定该匹配两个或多个分支中的哪一个。该异常会记录出现歧义时的起始标记以及位置。 |
| LexerNoViableAltException | 同上,不过只用于词法解析器 |
| InputMismatchException | 当前输入标记不满足语法解析器的期望值 |
| FailedPredicateException | 语法解析器在预测阶段那些语义谓词为 false 的分支将不可见,而在正常的解析匹配阶段语义谓词值为 false 将抛出该异常。 |
规则可以像编程语言中的函数一样拥有参数、返回值和本地变量(还可以把动作嵌入规则元素之间)。ANTLR 会收集所有自定义的变量并将其存储到规则上下文对象中,这些变量就是属性。下面的语法展示了所有可能的属性定义位置:
rulename[args] returns [retvals] locals [localvars] : ... ;
下面是个实际的例子:
// Return the argument plus the integer value of the INT token
add[int x] returns [int result] : '+=' INT {$result = $x + $INT.int;} ;
参数、本地变量以及返回值通常使用目标语言编写,但也有一些限制。[...] 中为逗号分隔的声明,根据目标语言的不同可以有类型前缀或后缀声明,或者没有,声明中可以有初始化器比如 [int x = 32, float y] 。
可以指定规则级别的命名动作,规则级的命名动作只有 init 和 after ,解析器会分别在解析匹配动作之前执行和解析之后立即执行。
动作代码放在参数、本地变量以及返回值声明之后:
/** Derived from rule "row : field (',' field)* '\r'? '\n' ;" */
row[String[] columns]
returns [Map<String,String> values]
locals [int col=0]
@init {
$values = new HashMap<String,String>();
}
@after {
if ($values!=null && $values.size()>0) {
System.out.println("values = "+$values);
}
}
: ...
;
规则 row 接受参数 columns 数组,返回 values ,定义了本地变量 col , 方括号中的代码直接被拷贝到生成的代码中:
public class CSVParser extends Parser {
...
public static class RowContext extends ParserRuleContext {
public String [] columns;
public Map<String,String> values;
public int col=0;
...
}
...
}生成的规则函数指明规则参数为函数的参数,并将传入的参数拷贝给本地的 RowContext 对象:
public class CSVParser extends Parser {
...
public final RowContext row(String [] columns) throws RecognitionException {
RowContext _localctx = new RowContext(_ctx, 4, columns);
enterRule(_localctx, RULE_row);
...
}
...
}ANTLR 会跟踪 [...] 中的代码,所以 String[] 会被正确解析,同样它也会跟踪其中的尖括号,所以也能正确处理泛型:
a[Map<String,String> x, int y] : ... ;
ANTLR 解析后定义两个参数,x 和 y :
public final AContext a(Map<String,String> x, int y)
throws RecognitionException {
AContext _localctx = new AContext(_ctx, 0, x, y);
enterRule(_localctx, RULE_a);
...
}起始规则是被语法解析器处理的第一条规则,也是被语言应用所调用的规则函数。语法中的所有规则都可以作为起始规则。
起始规则不一定要匹配完所有的输入标记,除非使用预定义的标记 EOF :
file : element* EOF; // don't stop early. must match all input
左递归表达式通常是构造语言最自然的方式。下面是 ANTLR 4 语法中一个使用左递归表达式规则的例子:
stat: expr '=' expr ';' // e.g., x=y; or x=f(x);
| expr ';' // e.g., f(x); or f(g(x));
;
expr: expr '*' expr
| expr '+' expr
| expr '(' expr ')' // f(x)
| id
;
在直接上下文无关语法中这样的规则会产生歧义因为对于 1+2*3 这个表达式,任何一个操作符都可以优先匹配,但 ANTLR 会使用语义谓词将直接左递归重写为非左递归来消除这种歧义:
expr[int pr] : id
( {4 >= $pr}? '*' expr[5]
| {3 >= $pr}? '+' expr[4]
| {2 >= $pr}? '(' expr[0] ')'
)*
;
ANTLR 4.0,4.1 中对左递归的消除规则在 4.2 中做了调整,在 这里 可以查看。
ANTLR 的表达式默认使用左结合,如果要使用右结合,需要添加 <assoc=right> :
e : e '*' e
| e '+' e
|<assoc=right> e '?' e ':' e
|<assoc=right> e '=' e
| INT
;
[未完]
将以下内容添加到 librocksdb-sys\rocksdb_lib_sources.txt 文件的结尾:
port/win/port_win.cc port/win/env_win.cc port/win/env_default.cc port/win/win_logger.cc port/win/win_thread.cc port/win/io_win.cc port/win/xpress_win.ccerror LNK2019: unresolved external symbol
搜索无法解析的符号所在的静态库名,比如 __imp_PathIsRelativeA 在库 shlwapi.lib 中,修改 librocksdb-sys\build.rs 中 link("rpcrt4", false); 下面添加 link("shlwapi", false);
Froala editor 是一款非常不错的所见即所得web编辑器,并且是收费的,单个域名的授权是99美元~
个人感觉挺好用的编辑器,但是在没有购买正常的情况下,只能编辑10行,且有一个大大的未授权标识。
在 froala_editor.pkgd.min.js 文件中找到类似如下代码
return!0;return!1将其所在函数改成 function i(){return 1} 这样就可以绕过验证授权了,并且没有限制了。
froala_editor_2.8.1_cracked.zip 🔗
froala_editor_2.8.4_cracked.zip 🔗
froala_editor_2.9.1_cracked.zip 🔗
Node 应用请覆盖
node_modules/froala-editor/js中的froala_editor.pkgd.min.js
请勿在商业项目中使用,有条件请支持正版
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
