1.動機
貴為台灣軌道運輸主力的台鐵在不同領域仍有很大的改善空間,尤其在準點率這部分常被大眾詬病。 本次專題的機會,藉由機器學習以及資料探勘的相關理論,希望能夠找出造成台鐵誤點的真正原因, 以及各種不同外在因素對於台鐵誤點的影響,最後製作出一個動態網站來呈現結果。
陳彥安:整合所有任務分配、爬蟲、模型、特徵工程、鐵路相關知識
孫晧恩:網路爬蟲、各式模型製作
郭昭宏:MySQL資料庫管理與網頁部分
黃顗中:網路爬蟲、資料庫等
資料蒐集與預處理
利用網路爬蟲網站,包含「政府開放資料平台」上的多個資料、台鐵時刻表等,利用既有的資料來最大化、最佳化誤點的改善。
接著是資料預處理:將蒐集下來的資料作整理,製作成可用的資料表、csv檔、圖檔,內部的資料則做特徵工程和數據的處理,方便分析使用。
最後將爬蟲所爬取的資料放進SQL,資料庫除了做資料備份、方便管理以外,我們將資料庫的語法和內容整理製作成API讓組員方便使用。
改善方法:改良時刻表
利用統計學和多種機器學習的演算法將存於資料庫的資料進行分析,再進行驗證後選出最適合的演算法選作最終結果。
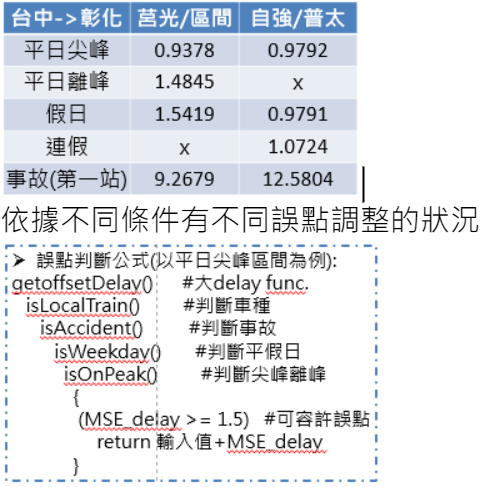
時刻表是少數能在台鐵、乘客雙方都能有所立足的資料。藉由時刻表,我們能透過不同車種、不同車站去方析誤點情況。
首先先將所有車次透過不同區段、不同時段、不同日期等條件分類,再利用XGBOOST演算法找出對應的誤點情況,另外在不同車站、事故發生、工程施工等特殊情況,找出適當的誤點加成時間,最後將以上綜合情況,將對應的誤點狀況做整合、整理、分析。
改善成果:時刻表網頁
透過已經更新、改善的時刻表內容來製作更新版的網頁,功能包含不同狀況的誤點模擬,以及建議改善的時刻表。
網路的進步、數據的累積讓我們新世代的人能用更有客觀、更便捷的方式去面對問題。透過這次實作,我們期待除了提升我們對於資料科學、智慧運輸的認識,也能開拓大家對於數據應用的視野。
https://www.iot.gov.tw/dl-6175-f153e123d9ea4faa8e33c5687813cb99.html https://www.railway.gov.tw/tra-tip-web/tip https://hdl.handle.net/11296/sznfue



