go-gorm / clickhouse Goto Github PK
View Code? Open in Web Editor NEWThis project forked from danielkurniadi/clickhouse
GORM clickhouse driver
License: MIT License
This project forked from danielkurniadi/clickhouse
GORM clickhouse driver
License: MIT License

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")


















































































































请问是进本地缓存还是到数据库?
如果进本地缓存的话在查询时如何查询这些在缓存区的数据?这一步需要自行实现吗
When I use gorm to operate the click house table which is running in the cluster mode, just like this:
database.db.Table(tableName).Set( "gorm:table_cluster_options", "on cluster hs_ch_cluster").AutoMigrate(&dto.User{})
The autoMigrate function is not working if we add new columns. I thought it is because the cluster clause is missing. The code is here.
The cluster clause is included in creating a table but is not included in adding a column.
craeting table
adding a column
And it seems that the issue exists for adding column, dropping column, and altering column
When i try use Create for batch as discribed in README it work fine. But when i run Create in two goroutines simultaneously this run transaction in second goroutne, and this broken. In logs i'm get
[clickhouse][connect=3][begin] tx=false, data=false
[clickhouse][connect=3][commit] tx=true, data=false
And got error
data request has already been prepared in transaction
If i'm disable transaction support via gorm. Just add
SkipDefaultTransaction: true
I can't use batch mode
insert statement supported only in the batch mode (use begin/commit)
But clickhouse not suport transaction. But if i try use batch fro clickhouse i should enable transaction. It's really strange thing.
Hi.
I am trying to create a table in the clickhouse database using gorm's auto migrator. I have defined the struct as below:
type Cost struct {
InfraId string `json:"infra_id" gorm:"primaryKey,index:idx_primary"`
Timestamp time.Time `json:"timestamp" gorm:"primaryKey,index:idx_primary"`
HourlyCost string `json:"hourly_cost"`
}When the automigrator runs, it sends the following SQL statement to the clickhouse DB.
CREATE TABLE `costs`(`infra_id` String,`timestamp` DateTime64(3),`hourly_cost` String ) ENGINE=MergeTree() ORDER BY tuple()As you can see, for some reason, it doesn't send any information about the primary keys. I have verified that it actually doesn't create any primary keys on the DB too. Why might this be happening?
Thanks.
If you have seen this issue, hope to make a version more than 0.2.1 to provide automigrate for distributed tables. Very grateful to you
^v^!!
err := h.DB.Model(&xxx{}).Where("xxx", xxx).
Where("xxx", xxx).Updates(updateMap).Error
When I looked at the code again, I didn't find a way to support cluster. How can CreateTable support ON CLUSTER syntax?
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = engine
model code:
type Test struct {
PartitionTime time.Time `gorm:"column:partition_time" json:"partition_time,omitempty"`
}
call CREATE method, DEBUG log:
INSERT INTO `test_dist` (`partition_time`) VALUES ('2021-02-22 15:00:00')
then call Find method, DEBUG log:
SELECT * FROM `test_dist`
&{2021-02-22 23:00:00 +0800 CST}
get &{2021-02-22 23:00:00 +0800 CST}
how to fix the issue? or any way to work around
When creating a new table, clickhouse fills in a few system columns.
The field of importance is character_octet_length
(Nullable(UInt64)) — Maximum length in bytes for binary data, character data, or text data and images. In ClickHouse makes sense only for FixedString data type. Otherwise, the
NULLvalue is returned.
Now, in most cases, when not using fixed strings and having DontSupportColumnPrecision in the dialector set to the default (false), all my columns should have NULL set in the system table.
Now, when migrating to this table, some issues arise. In go-gorm/clickhouse/migrator.go, there is a check to see if the scanned lengthValue (character_octet_length) is nil. Because of the previously stated conditions, it will be nil, as a result this field, lengthValue, will remain zero and invalid.
this causes issues down the line in gorm/migrator/migrator.go when calling AutoMigrate, which calls MigrateColumn. In this function, there is a check on the columns length value, which is the same as the aforementioned clickhouse system's chatacter_octet_length field (recall this is nil for every field in this case). This calls a check in gorm/migrator/column_type.go, which because LengthValue is invalid, the function will return ct.SQLColumnType.Length(). This calls go/sql.go which will have null pointer panic. This brings me to my next issue.
Throughout the entire flow above, SQLColumnType in ColumnType is null. This is what causes the null pointer panic in sql.go. This value is set in go-gorm/clickhouse/migrator.go, in a for loop where the variable rawColumnTypes is iterated through. unfortunately, while stepping through this, it seems that rawColumnTypes is always empty, meaning that the contents in this for loop, which sets SQLColumnType, is never reached (resulting in the null panic).
It seems that this query
rows, err := m.DB.Session(&gorm.Session{}).Table(stmt.Table).Limit(1).Rows() in go-gorm/clickhouse/migrator.go returns a *sql.Rows type that has no columns. This affects the following query for the row's columns where an empty array is returned instead of the row's queries - resulting in the behavior mentioned above.
My table is empty, but exists. I am connecting to clickhouse through port 8443 (not the native port) due to hosting constraints. Is this the intended behavior? Are there any workarounds?
some related issues:
Parse and add GRANULARITY options when specifying index.
GRANULARITY is specified in constraintGRANULARITY is specified in the ALTER statementReference:
2022/03/25 09:12:20 /mnt/d/code/sidsa-service/pkg/database/clickhouse.go:24
[error] failed to initialize database, got error driver: bad connection
clickhouse conn fail:driver: bad connection
Error: clickhouse conn fail:driver: bad connection
我的gorm.io/driver/clickhouse包运营时会报错
错误如下
../../go/pkg/mod/github.com/!click!house/clickhouse-go/[email protected]/conn.go:31:2: //go:build comment without // +build comment
../../go/pkg/mod/github.com/!click!house/[email protected]/compress/reader.go:9:2: //go:build comment without // +build comment
../../go/pkg/mod/github.com/!click!house/[email protected]/proto/ipv4.go:5:2: package net/netip is not in GOROOT (/usr/local/go/src/net/netip)
not found net/netip package

Same username and password, can successfully connect to Clickhouse by HTTP but failed if using TCP.
Hi, I've filed an issue under the clickhouse-go repo, but this might be an issue with the clickhouse driver.
Is it expected for the output of a serializer to be its value (a string for example), or for it to be a *schema.serializer object?
It seems as though otherwise, DB clients need to explicitly handle this serializer object, which isn't the case with clickhouse-go.
For example, see this switch on types for FixedString inserts:
https://github.com/ClickHouse/clickhouse-go/blob/ca9c1f0265cec9aeb5cd54cabec31136adc2c9b3/lib/column/fixed_string.go#L140
`m := []UserTable{
{User: User{
Name: "tom1",
Age: 12,
Class: 10,
}},
{User: User{
Name: "li1",
Age: 22,
Class: 10,
}},
{User: User{
Name: "wang1",
Age: 22,
Class: 10,
}},
{User: User{
Name: "wan",
Age: 22,
Class: 10,
}},
}
if err = db.Model(&UserTable{}).CreateInBatches(&m,2).Error; err != nil {
fmt.Println("插入数据异常: ", err)
}`
当指定批量插入按照2条数据一组,进行批量插入,一共四条数据gorm底层库会分两批插入,但是发现clickhouse库会失败异常,具体原因可以使用的方式是: 如果指定批量插入的数据量必须大于总插入数据量进行一次性插入可以成功,一旦设置小于总量就会报错,请重点关注一下,这个异常不符合实际需求。
异常响应: code: 101, message: Unexpected packet Query received from client
gorm delet 时生成的sql 为“ELETE FROM 0test WHERE id = 1”不能运行
sql 为“alter table 0test delete WHERE id = 1“”
when prewhere support, in some cases, the performance of prewhere is better than where
Issue due to wrong SQL for ALTER TABLE ? ADD COLUMN ? as opposed to what is described in the official Clickhouse docs
Want Correct SQL:
ADD COLUMN [IF NOT EXISTS] name [type] [default_expr] [codec] [AFTER name_after]
Current SQL:
It doesn't has ...COLUMN... before the column name. So it will throw syntax error from the ClickHouse server.
ADD [IF NOT EXISTS] name [type] [default_expr] [codec] [AFTER name_after]
func(m Migrator) AddColumn(value interface{}, name string) error
for clickhouse,
dsn := fmt.Sprintf("tcp://%s:%d?database=%s&username=%s", "", 9000, "default", "default")
resultDb, err2 := gorm.Open(clickhouse.Open(dsn), &gorm.Config{NamingStrategy: schema.NamingStrategy{SingularTable: true}})
//ckDao := clickhouseDao.NewQueryDao()
err2 = resultDb.Exec("insert into ou(userId) values('123');").Error
fmt.Println(err2.Error())
是否可以升级到 clickhouse-go/v2 官方说性能会更好
Clickhouse, as OLAP database has different concepts when it comes to Table structure. It uses a special MergeTree data structure to perform fast and column-wise aggregate. The syntax for CREATE TABLE is also different; it has some options and engine syntax.
See docs:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
MergeTree() as default Engine rather than Memory().gorm:"table_options"There is an issue with the QuoteTo method for the tuple data type of clickhouse, which resulted in the data not being written. An attempt was made to fix the issue, and the code is as follows:
func (dialector Dialector) QuoteTo(writer clause.Writer, str string) {
writer.WriteByte('`')
if strings.Contains(str, ".") {
for idx, str := range strings.Split(str, ".") {
if idx > 0 {
writer.WriteString(".")
}
writer.WriteString(str)
}
writer.WriteByte('`')
} else {
writer.WriteString(str)
writer.WriteByte('`')
}}


Please update the clickhouse-go in the clickhouse driver to the latest version
thank you :)
Seems like when gorm tries to insert in batches, clickhouse-go return an error:
data request has already been prepared in transaction
https://github.com/ClickHouse/clickhouse-go/blob/master/clickhouse.go#L69-L70
Workaround is just not to use batches, clickhouse can accept really large payloads. Posting just in case anyone encounters this
2023/04/26 10:58:22 main.go:32
[error] unsupported data type: &[]
Okgo version: go version go1.20.3 linux/amd64
clickhouse version: 23.3.1.2823
gorm version: [email protected]
driver clickhouse: v0.5.1
package main
import (
"fmt"
"gorm.io/driver/clickhouse"
"gorm.io/gorm"
)
type User struct {
Uniqid string `gorm:"column:uniqid;primaryKey"`
Name string `gorm:"column:name"`
}
func (User) TableName() string {
return "user"
}
func main() {
dsn := "clickhouse://gorm:gorm@localhost:9942/gorm?dial_timeout=10s&read_timeout=20s"
db, err := gorm.Open(clickhouse.Open(dsn), &gorm.Config{})
if err != nil {
panic("failed to connect database")
}
u := User{
Uniqid: "31502ca1839f3dccd849abdc49e2fa41",
Name: "gorm",
}
err = db.Table("user").Create(&u).Error
if err != nil {
panic(err)
}
fmt.Println("Ok")
}
// Output
// 2023/04/26 10:58:22 main.go:32
// [error] unsupported data type: &[]
// Oktype TaskLog struct {
gorm.Model
TaskID string
TaskStatus string
TaskResult string gorm:"type:text"
TaskLogDetails []*TaskLogDetail
}
dbClickhouse.Create(&TaskLog{})
deleted_at (DateTime64(3)): unexpected type
[387812.791ms] [rows:0] INSERT INTO task_logs (created_at,updated_at,deleted_at,task_id,task_status,task_result) VALUES ('2021-03-17 11:48:51.851','2021-03-17 11:48:51.851',NULL,'','test','ok')
--- PASS: TestDB (387.81s)
Most likely causes: ClickHouse/clickhouse-go#359
Suggest: That we constrain nil to escape NULL here
when using go-gorm/clickhouse with tag: v0.4.1,our Clickhouse version is 21.3.5.42, while AutoMigrate ColumnTypes, it throw an error message : "Missing columns: 'datetime_precision' 'numeric_scale' 'numeric_precision_radix' 'numeric_precision' 'character_octet_length'" and it fails. Actually there were no these coumns in system.columns table.
How should I migrate ?
把clickhouse driver 的引用去掉
将clickhouse driver 的引用去掉,由用户自己去选择使用哪个driver。
目前我想使用http的click house driver,发现这个包并不支持,因此想让这个包去掉clickhouse driver的引用。
使用gorm+clickhouse连接
DB连接
import(
"gorm.io/driver/clickhouse"
"gorm.io/driver/mysql")
db_ch, dberr = gorm.Open(clickhouse.Open(dsn), &gorm.Config{})
使用gorm连接clickhouse,读取数据,当读取到NullFloat字段时,报错,并且该字段索引后面的字段值也为空
字段如下:
Section2PdP1 float64 gorm:"section_2_pd_p1"
试了多种类型,包含float64,*float64,sql.NullFloat64, sql.RawBytes, interface{}.
读取时均为如下报错:
sql: Scan error on column index 14, name "section_2_pd_p1": unsupported Scan, storing driver.Value type *float64 into type *sql.RawBytes
并且该字段index后面的字段值也为空,但是该字段前的字段值正常。

使用gorm的自动建表即使使用sql use database切换库名,在执行到ColumnTypes函数时,用CurrentDatabase打印出来的还是default
Wrong syntax in migrator.CreateTable produces trailing commas when Index or Constraint is not specified:
CREATE TABLE `companies` (`id` Int64,`name` String , ) ENGINE=MergeTree() ORDER BY tuple()
ClickHouse Version: 21.3.14.1.7
Conn Code:
url := fmt.Sprintf("http://%v:%v?database=%v&username=%v&password=%v&read_timeout=10&write_timeout=20",
cfg.Host, cfg.Port, cfg.Dbname, cfg.User, cfg.Password)
clickHouseDb, err := gorm.Open(clickhouse.Open(url), &gorm.Config{})
Err Info:
panic: runtime error: invalid memory address or nil pointer dereference
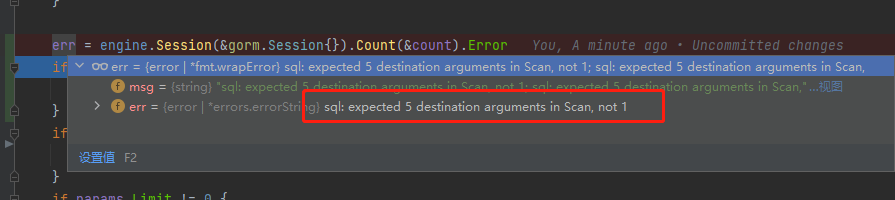
自定义 Selects 和 Group 的情况下查询 count 会抛出 sql: expected 5 destination arguments in Scan, not 1 错误

type SubProperties struct {
ID string
Contract string
Type string
Name string
}
type Properties struct {
Channel string
SubProperties
}
p := Properties{
Channel: "aaaa",
SubProperties: SubProperties{
ID: "ID3333",
Contract: "c3",
Type: "ty3",
Name: "n3",
},
}
Db.Table(strings.ToUpper(p.Channel) + "Attr").Create(p.SubProperties)
保存后 ID值为c3, Contract为ty3, Type为n3,Name为ID3333
当前版本0.5.0
表结构
CREATE TABLE FFAttr
(
id String,
contract String,
type String,
name String
)
ENGINE = MergeTree
PRIMARY KEY (contract, type)
ORDER BY (contract, type)
When i use createInBatch like global.GVA_CH.Model(v.Interface).CreateInBatch(datas,1000) OR specified BatchSize,an error will occured.
io.EOF error if gormConfig.SkipDefaultTransaction set to true and unpexted packet error if gormConfig.SkipDefaultTransaction set to false.
How can i use CreateInBatch in proper way.
github.com/ClickHouse/clickhouse-go/v2 has not been imported
package main
import (
"gorm.io/driver/clickhouse"
"gorm.io/gorm"
)
// should be github.com/ClickHouse/clickhouse-go/v2
sqlDB, err := clickhouse.OpenDB(&clickhouse.Options{
Addr: []string{"127.0.0.1:9999"},
Auth: clickhouse.Auth{
Database: "default",
Username: "default",
Password: "",
},
TLS: &tls.Config{
InsecureSkipVerify: true,
},
Settings: clickhouse.Settings{
"max_execution_time": 60,
},
DialTimeout: 5 * time.Second,
Compression: &clickhouse.Compression{
clickhouse.CompressionLZ4,
},
Debug: true,
})
func main() {
db, err := gorm.Open(clickhouse.New(click.Config{
Conn: sqlDB, // initialize with existing database conn
})
}
after update gorm version and clickhouse driver newest version, Count and Find method return error
sql: expected 1 arguments, got 2
I was wondering if it is possible to use GORM Auto-migration tools and setup Nullable columns in tables. All approaches I tried did not allow me to do that (either breaks with SIGs, or saying that null is not allowed). The only way I found (tried many approaches including null package, sql.NullStrings etc) is to create tables via raw sql. For example,
err = db.Exec(`
CREATE TABLE IF NOT EXISTS orders (
id UInt32,
completed_at DateTime,
datawarehoused_at Nullable(DateTime),
user_id Nullable(UInt32),
) engine=MergeTree PARTITION BY toYYYYMM(completed_at) ORDER BY completed_at SETTINGS index_granularity = 8192
`).ErrorAnd then in the GORM model I can use pointer in the struct fields
type Order struct {
ID int32 `json:"id" gorm:"primaryKey"`
CompletedAt time.Time `json:"completed_at"`
DatawarehousedAt time.Time `json:"datawarehoused_at"`
UserId *int32 `json:"user_id" `
}The only problem with this approach that I am missing AutoMigration tools, thus I need to write all migrations manually.
Is there a better way? Am I missing something?
I want:
driver clickhouse do not ignore creating index when using migrator gorm!
希望后期可以支持集群见表的功能,当前自动建表AutoMigrate不支持配置ON CLUSTER,只能单机建表,所以目前只能用EXEC手动写sql实现。后期希望可以增加该功能,对于clickhouse比较常用。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.