Pytorch Implementation of "A ConvNet for the 2020s", Liu et al. CVPR 2022
Paper | Official Implementation
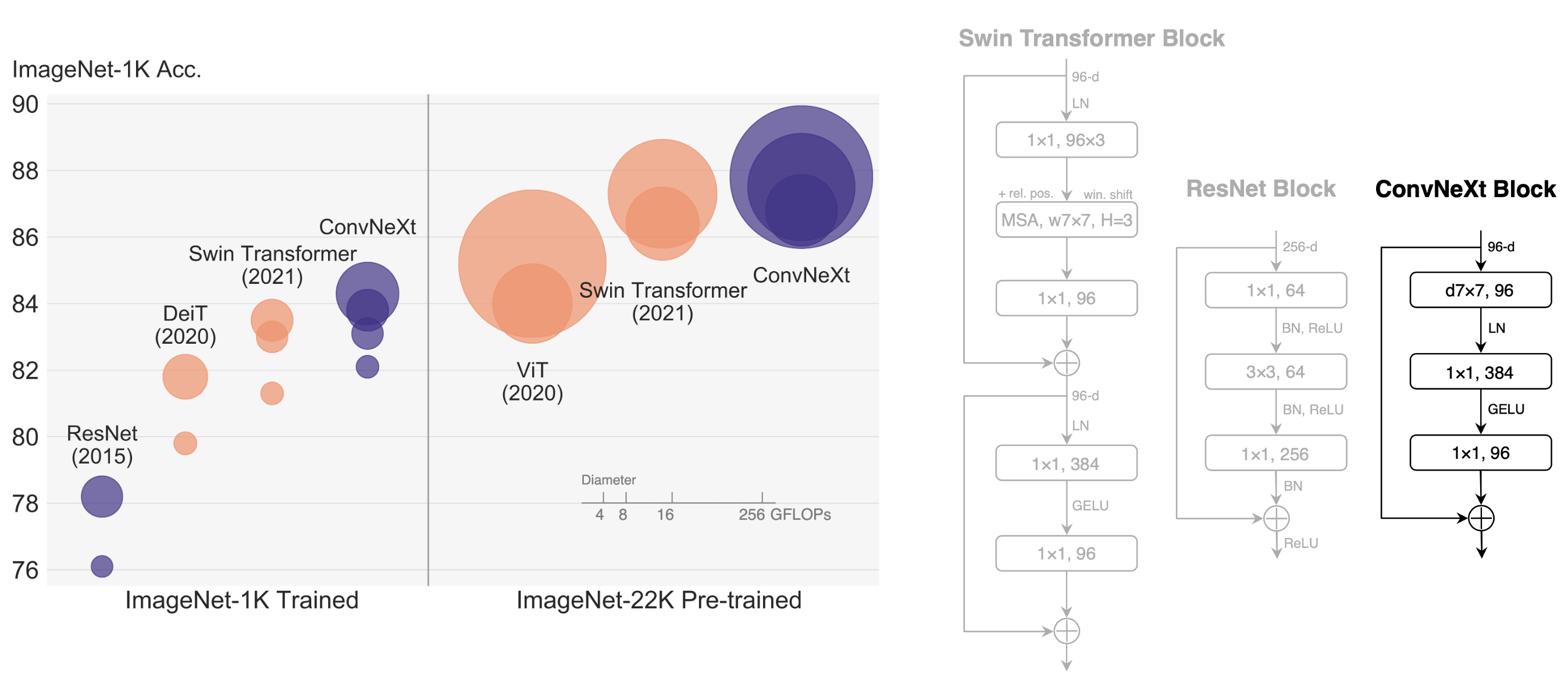
In the past few years, Vision Transformers has superseded ConvNets as the satte-of-the-art image classification model. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. But a lot of active research has been made on ConvNets, and ConvNets are still in use in many vision tasks. The major success of ConvNets is credited to their inherent inductive biases of the convolutions. Designing the ConvNets in a way similar to the transformers has shown signifcanct improvements in performance surpassing the Swin Transformers in terms of accuracy and stablilty, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
Looking back at the 2010s, the decade was marked by the monumental progress and impact of deep learning. The primary driver was the renaissance of neural networks, particularly convolutional neural networks (ConvNets). The introduction of AlexNet precipitated the “ImageNet moment”, ushering in a new era of computer vision. The field has since evolved at a rapid speed. Representative ConvNets like VGGNet, Inceptions, ResNe(X)t, DenseNet , MobileNet, EfficientNet and RegNet focused on different aspects of accuracy, efficiency and scalability, and popularized many useful design principles.
With the introduction of transformers, it completely altered the landscape of network architecture design. These Transformers can outperform standard ResNets by a significant margin. But Without the ConvNet inductive biases, a transformer model faces many challenges in being adopted as a generic vision backbone. The biggest challenge with transformers is the global attention design, which has a quadratic complexity with respect to the input size, which quickly becomes intractable with higer-resolution inputs.
ConvNets and hierarchical vision Transformers become different and similar at the same time: they are both equipped with similar inductive biases, but differ significantly in the training procedure and macro/micro-level architecture design. This Paper discover several key components that contribute to the performance difference between ConvNets and trnsformers and proposed a family of pure ConvNets dubbed ConvNeXt.

Various Design decisions are considered in the ConvNeXt architecture
- Macro Design :
- Changing the number of blocks from (3,4,6,3) as in ResNet-50 to (3,3,9,3)
- Changing the stem to "Patchify" with a patchify layer implemented using a 4x4, stride 4 convolution layer adopting the "patchify" strategy of the vision transformers.
- ResNeXt :

ResNeXt block
Adopting the idea of ResNeXt which has a better FLOPs/accuracy trade-off than a vanilla ResNet having the core component is grouped convolution, where the convolutional filters are separated into different groups. At a high level, ResNeXt’s guiding principle is to “use more groups, expand width”. Using depthwise convolution, a special case of grouped convolution where the number of groups equals the number of channels effectively reduces the network FLOPs.
- Inverted Bottleneck:

Inverted bottleneck Block
One important design in every Transformer block is that it creates an inverted bottleneck, i.e., the hidden dimension of the MLP block is four times wider than the input dimension. This Transformer design is connected to the inverted bottleneck design with an expansion ratio of 4 used in ConvNets.
- Large Kernel Size :

The position of the spatial depthwise conv layer is moved up
One of the most distinguishing aspects of vision Transformers is their non-local self-attention, which enables each layer to have a global receptive field. To explore large kernels, one prerequisite is to move up the position of the depthwise conv layer. That is a design decision also evident in Transformers: the MSA block is placed prior to the MLP layers. The network’s performance increases when 7x7 depthwise conv is used in each block.
- Layer-wise Micro Designs:

Block design comparisions of ResNet, a Swin Transformer, and ConvNeXt.
- Replacing ReLU with GELU
- Fewer activation functions
- Fewer normalization layers
- Substituting BN with LN
- Separate downsampling layers
Import any of the following variants of RegNet using
from convNeXt import convnext_large as convnext
from convNeXt import ConvNeXtIsotropic as convnext_iso # required of you want use the isotropic variantConvNeXt variants are available in the following sizes:
- convnext_base
- convnext_tiny
- convnext_small
- convnext_large
- convnext_xlarge
- convnext_isotropic_base
- convnext_isotropic_large
- convnext_isotropic_large
Import TrainingConfig and Trainer Classes from regnet and use them to train the model as follows
from convNeXt import TrainingConfig, Trainer
model = convnext(in_channels=3, num_classes=100, drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.)
trainig_config = TrainingConfig(max_epochs=100, batch_size=128, learning_rate=4e-3, weight_decay = 0.05)
trainer = Trainer(model=model, train_dataset=train_dataset, test_dataset=test_dataset, configs=trainig_config)
trainer.train()Note : you need not use TrainingConfig and Trainer classes if you want to write your own training loops. Just importing the respective models would suffice.
- Test if the isotropic variant is working
- Implement model checkpointing for every 'x' epochs
@Article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {arXiv preprint arXiv:2201.03545},
year = {2022},
}
MIT
