easily pull stats from sports-reference web sites
sportsref is designed to be used in an interactive python environment, such as IPython or JupyterNotebook
The api tries to mirror the web experience:
- each subject area (i.e. player, season, league) is represented by an class.
- each class has methods representing the pages available.
- for example Ozzie Albies player page has the following menu of pages
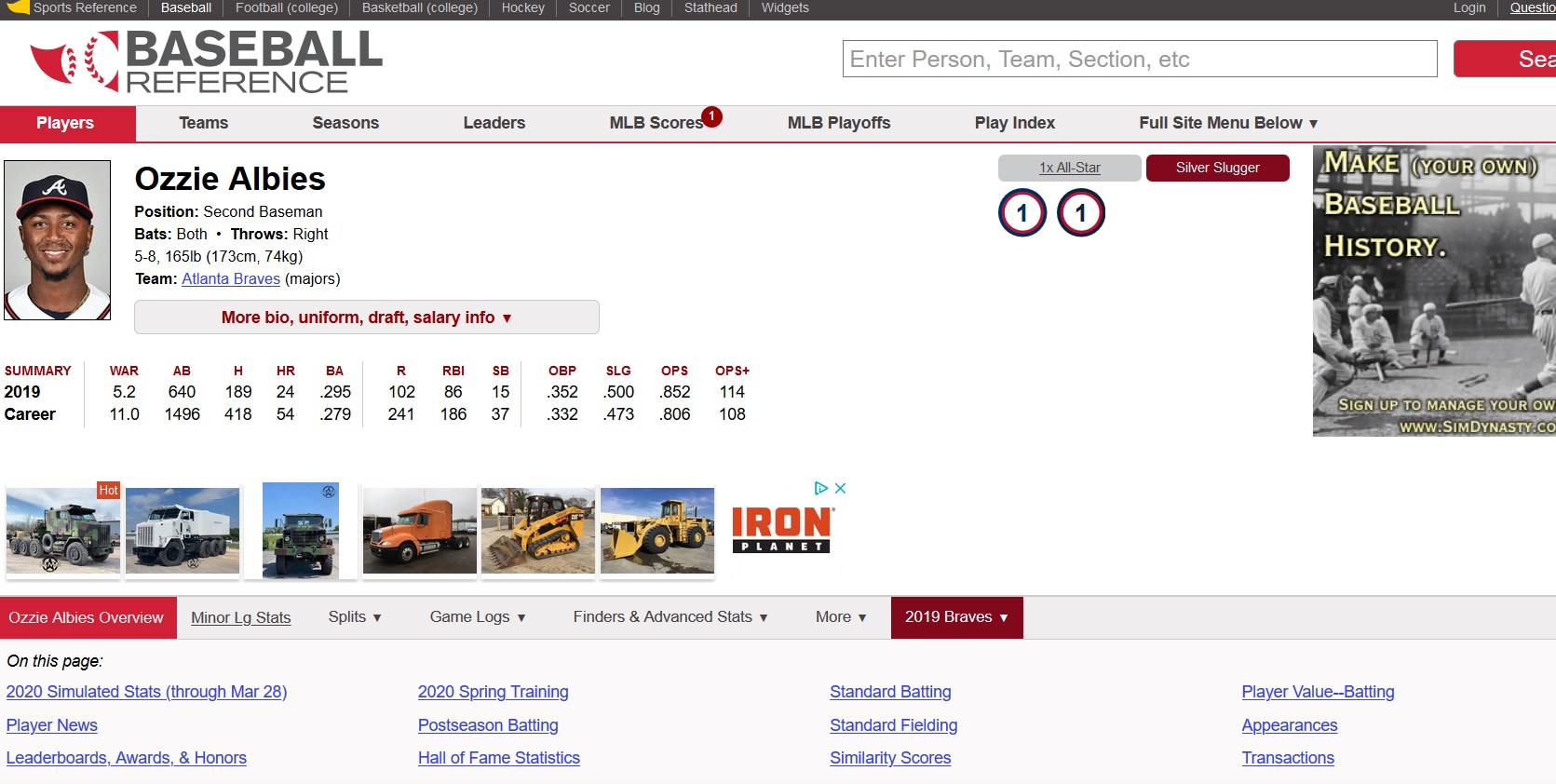
- if the menu is a dropdown,
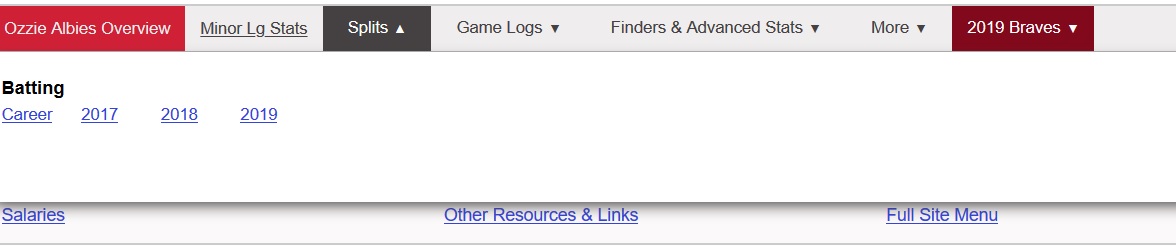 the method takes an additional parameter or two
the method takes an additional parameter or two
- for example Ozzie Albies player page has the following menu of pages
- the methods return a Page object which know about all the tables on that page
- use the Page.get_df("table_name") to get a pandas.DataFrame of the table you want.
The examples.ipynb JupyterNotebook has a few examples demonstrating a workflow.
clone the repo then
pip install .

