dodger487 / dplython Goto Github PK
View Code? Open in Web Editor NEWdplyr for python
License: MIT License
dplyr for python
License: MIT License









































































































































There is a typing issue with spread, in that pandas doesn't retype columns that are pivoted. tidyr::spread doesn't retype columns by default, but can if you select the option.
Consider the following dataset:
| id | var | value |
|---|---|---|
| 1 | date | 1/12/12 |
| 1 | pop | 100 |
| 1 | country | USA |
If we spread on var/value, we get the following:
| id | date | pop | country |
|---|---|---|---|
| 1 | 1/12/12 | 100 | USA |
Now, in the first dataframe, the column value will be a string column, and by usual pandas behavior, all the new columns will also be strings, even though date should be a date, and pop should be numeric. In tidyr, if we used the convert option, these columns will be converted to what they should be.
pandas used to have a convert objects that would work on the whole dataframe, doing conversions like this, but it's been deprecated and replaced with specific methods that only specify a particular type (e.g. to_datetime). One sticky issue is that numbers can be converted to dates without errors, and dates (in some cases) can be converted to numbers without errors.
I see two directions to take:
tidyr, and the default behavior of pandas (spread here is just a wrapper for some functions where pandas.pivot is the main workhorse). If the user wants the correct typing, they can do that themselves after the data has been spread (while googling a possible solution to this problem, it came u a lot on stackoverflow, and the advice was to just do it themselves, although that was more of a specific problem, and not so much a development issue).tidyr does it.Note that this only an issue when there are mixed types in one column (in which case they'll almost always be strings). If the value column is say a date column, then the resulting spread columns will also be dates.
Really excited to use this more! One thing I noticed playing around today is that nrow breaks after the first call.
# this works
(diamonds >>
group_by(X.cut, X.color) >>
summarize(count = nrow()))
# this breaks
(diamonds >>
group_by(X.cut, X.clarity) >>
summarize(num_rows = nrow()))
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-6-9c32d69f8d9e> in <module>()
1 (diamonds >>
2 group_by(X.cut, X.clarity) >>
----> 3 summarize(num_rows = nrow()))
//anaconda/lib/python2.7/site-packages/dplython/dplython.pyc in __rshift__(self, delayedFcn)
300
301 if self._group_dict:
--> 302 outDf = self.apply_on_groups(delayedFcn, otherDf)
303 return outDf
304 else:
//anaconda/lib/python2.7/site-packages/dplython/dplython.pyc in apply_on_groups(self, delayedFcn, otherDf)
284 if len(subsetDf) > 0:
285 subsetDf._current_group = dict(zip(self._grouped_on, group_vals))
--> 286 groups.append(delayedFcn(subsetDf))
287
288 outDf = DplyFrame(pandas.concat(groups))
//anaconda/lib/python2.7/site-packages/dplython/dplython.pyc in CreateSummarizedDf(df)
393 def summarize(**kwargs):
394 def CreateSummarizedDf(df):
--> 395 input_dict = {k: val.applyFcns(df) for k, val in six.iteritems(kwargs)}
396 if len(input_dict) == 0:
397 return DplyFrame({}, index=index)
//anaconda/lib/python2.7/site-packages/dplython/dplython.pyc in <dictcomp>((k, val))
393 def summarize(**kwargs):
394 def CreateSummarizedDf(df):
--> 395 input_dict = {k: val.applyFcns(df) for k, val in six.iteritems(kwargs)}
396 if len(input_dict) == 0:
397 return DplyFrame({}, index=index)
//anaconda/lib/python2.7/site-packages/dplython/dplython.pyc in applyFcns(self, df)
183 stmt = df
184 for func in self.todo:
--> 185 stmt = func(stmt)
186 return stmt
187
//anaconda/lib/python2.7/site-packages/dplython/dplython.pyc in <lambda>(foo)
191
192 def __call__(self, *args, **kwargs):
--> 193 self.todo.append(lambda foo: foo.__call__(*args, **kwargs))
194 return self
195
AttributeError: 'int' object has no attribute '__call__'
How do I convert the dplyframe into DataFrame? My code is as follows.
newcalc=(dplython.DplyFrame(calc_order_emis) >>
arrange(X.mobile, X.emi_number, X.rank_f) >>
group_by(X.emi_number, X.mobile) >>
mutate(inter2=
X.inter1.cumsum()))
Now when I try to convert the newcalc to data frame it says constructor not properly called or sth. The type of newcalc is tuple.
pd.DataFrame(newcalc)
I have idea on a change and want to get feedback before making it.
In dplyr, you can call each function on the dataframe itself. So:
# with piping
df %>% mutate(foo=bar)
# same as
mutate(df, foo=bar)Currently in dplython, the dplython functions all return other functions which are then applied to the DataFrame. If you want to replicate the above, you would have to do something that looks like this:
# with piping
df >> mutate(foo=X.bar)
# same as
mutate(foo=X.bar)(df)My proposal is to modify the dplython functions to check the type of the first argument. If the first argument is a DataFrame (or inherits from DataFrame), then instead of returning a function, the function is applied to the dataframe. I think this will be more readable.
So:
# old
mutate(foo=X.bar)(df)
# new, also works
mutate(df, foo=X.bar)Note that this will not break the old way of doing things. I wanted to see what people think before making the change!
Currently, arrange only sorts in ascending columns. Functionality should be added so that arrange can sort both ascending and descending. Dplyr syntax uses an additional function, desc, to do this. Additionally, dplyr will sort the data frame based on the resulting values of the "Later". For example,
df %>% arrange(desc(foo))
is essentially equivalent to
df %>% arrange(-foo)
Users can also do stuff like:
df %>% arrange(foo**2) or df %>% arrange(abs(foo))
and it will sort by the largest absolute value of foo.
It'd be nice to have this functionality implemented in dplython as well.
if_else should take broadcastable things, much like np.where does.
Perhaps if_else should just be DelayFunction version of np.where
I'm working on adding python3 support (my fork, travis-ci). The only issue I find is the sporadic failures of this specific test.
The reason for the failure is that pd.DataFrame.equals compares, between other things, the columns of the data frames. On the other hand, your mutate function uses dict.iteritems internally to add columns. dict.iteritems, by definition, doesn't preserve any order, so there is no way to predict the order of the mutated data frame columns.
I'm not sure what the expected solution will be, but IMHO:
mutate function signature should be changed, so there is no way to get the columns in order.equals function can be override to be less restrictive.equals in the tests (or at least in this specific test).Having said that, I didn't notice any failure on python 2.7, but somehow it fails sporadically on python 3.3/4/5.
What do you think?
It would be nice to use select to get a DplyFrame with all columns but a set of columns to be left out.
For a lot of common use cases, column names could be passed as strings rather than properties of X:
This would slightly increase the interface complexity, but I think it would be easy (arguably easier) to read. It also is consistent with a clean (though verbose) style that uses mutate + group_by/arrange/filter rather than a "complex" group_by/arrange/filter that does an operation before grouping, arranging, or filtering.
for instance, if I have a table with 3 columns, (i.e. col1, col2, col3), can I do something like this:
df >> select(X.col1:X.col3)
In the current implementation of the join verbs, any grouping needs to be removed in order for the join to function correctly. In the existing code (not yet merged), it's done automatically, and the returned DplyFrame has no grouping. In Dplyr, the operation x %>% join(y) returns a dataframe with any grouping on x preserved. This wouldn't require too much work to implement, but it would require an additional attribute to serve as a swap variable (ungroup, do the operation, and then regroup) and an additional method. Also, while doing a mutating join returns a new dataframe, and hence we could ignore grouping theoretically, filtering joins return the original dataframe, so maintaining the grouping is probably desirable.
There are other issues regarding grouping as well.
Should summarise peel away any layers of grouping? In Dplython, x >> group_by(a, b) >> summarise() returns a dataframe grouped on a and b. In Dplyr, x %>% group_by(a, b) %>%> summarise() returns a dataframe grouped on a. This wouldn't be that hard to implement.
Should select statements have grouping variables implied? Currently, x >> group_by(a) >> select(b) throws an error in dplython, but returns x with columns a and b in Dplyr (still grouped on a).
while implementing spread(), how should grouping be handled? For example, if we have x >> group_by(a, b) >> spread(c, d), then it's easy enough to make it so that that the dataframe returned is still grouped on a and b, but something like x >> group_by(a, b) >> summarise(y = f(z)) >> spread(b, y), should that return a dataframe grouped on a? Dplyr would return a dataframe grouped on a, but if we had ... >> spread(a, y), that would return an ungrouped dataframe.
It gets a little more confusing with multiple variables.
x %>% group_by(a, b, c) %>% summarise(y=f(z)) %>% spread(a, y) gives a df grouped on b
x %>% group_by(a, b, c) %>% summarise(y=f(z)) %>% spread(b, y) gives a df grouped on a
x %>% group_by(a, b, c) %>% summarise(y=f(z)) %>% spread(c, y) gives a df grouped on a, b
Not sure what the pattern here is.
At any rate, I don't think any of these would be too difficult to do. But feel free to comment.
I'm a recent Python convert from R, so this is great to see. I have what could be a simple file I/O error when I run your example, but not sure:
/anaconda/bin/python /Users/myusername/code/dplyr_example1.py Traceback (most recent call last): File "/Users/myusername/code/dplyr_example1.py", line 1, in <module> from dplython import * File "/anaconda/lib/python3.4/site-packages/dplython/__init__.py", line 4, in <module> diamonds = DplyFrame(diamonds) NameError: name 'DplyFrame' is not defined
Any ideas what's wrong?
Count the number of unique combinations of columns with diamonds >> count(X.color, X.cut), creating a new column called n.
(Of the missing dplyr verbs, I think this is the single most important; it's one of the most frequent ones I use. It can be imitated with >> group_by(X.color, X.cut) >> summarize(n = X._.nrow())) (or whatever nrow equivalent is, but this is especially awkward until we have a n()-like solution)
Hi Chris R.
Thank you for making such a useful library. I'm really looking forward to using this!
There were a couple of things I tried on a lark, kind of hoping that they might work, but which gave me "wrong" results. I kind of expected these wouldn't work, but I think getting an error might be better. Of course it would be even more amazing if they magically worked as expected :) although I'm guessing that would be very hard or even impossible to implement.
# I tried to pass an if-else expression as the value in mutate()
# The results only used the color column, but not clarity column
diamonds = diamonds >> mutate(conditional_results = X.color if X.cut == "Premium" else X.clarity)
# I tried including an "or" in dfilter, but this only returned premium diamonds.
premium_and_ideal = diamonds >> dfilter(X.cut == "Premium" or X.cut == "Ideal")Currently, users can use functions with Later objects by decorating them / calling them with DelayFunction. It would be nice to have a module that calls DelayFunction on everything callable inside a module, so that other module's functions can be made to easily work with dplython.
I get this error
----> 1 df >> select(X.Month) >> head(5)
TypeError: unsupported operand type(s) for >>: 'DataFrame' and 'function'
Hi, maybe you already know about this, but just something important to have on your radar. When grouping on large number of keys, things can get very slow. I had to switch back to regular pandas when an operation was taking > 10 minutes.
# Grouping variable with 5 values -> Get results immediately
diamonds >> group_by(X.cut) >> mutate(m = X.x.mean()
# Grouping variable with 273 values -> Get results after 10 seconds.
# For larger data frames, can take more than 10 minutes
diamonds >> group_by(X.carat) >> mutate(m = X.x.mean())
# The same operation in standard pandas happens instantaneously
diamonds.groupby('carat').mean()This is a note mainly for me. Well, also for you to see, which will pressure me to do it quickly so I am not embarrassed by not having done it. So sort of for you, but mainly for me.
I need to add some good docs to pythonhosted or somewhere...
If you are interested in helping out with documentation, than this note can be for you even more! Just comment here or ping me on Twitter @dodger487
Currently, summarize returns a dataframe initialized with index=[0]. This is fine when summarize is used on an ungrouped dataframe and returns a dataframe with a single row, but it returns a dataframe with multiple rows, it initializes the index for every row to 0, which breaks a lot of behavior (including any subsequent arranges).
Also, if summarize is passed no arguments at all, it throws an error, because index is referenced on line 402 but not defined.
Later doesn't work when a method is called on a column before other operations.
In : diamonds >> mutate(foo=X.x.mean() + X.x) >> head() >> select(X.x, X.foo)
"""
Out:
x foo
0 3.95 NotImplemented
1 3.89 NotImplemented
2 4.05 NotImplemented
3 4.20 NotImplemented
4 4.34 NotImplemented
"""It works in many other cases though, notably,
In : diamonds >> mutate(foo=X.x + X.x.mean()) >> head() >> select(X.x, X.foo)
"""
Out:
x foo
0 3.95 9.681157
1 3.89 9.621157
2 4.05 9.781157
3 4.20 9.931157
4 4.34 10.071157
"""
In [84]: diamonds >> mutate(foo=X.x.mean()) >> head() >> select(X.x, X.foo)
"""
Out[84]:
x foo
0 3.95 5.731157
1 3.89 5.731157
2 4.05 5.731157
3 4.20 5.731157
4 4.34 5.731157
"""
In [85]: diamonds >> mutate(foo=X.x.mean() + 1) >> head() >> select(X.x, X.foo)
"""
Out[85]:
x foo
0 3.95 6.731157
1 3.89 6.731157
2 4.05 6.731157
3 4.20 6.731157
4 4.34 6.731157
"""
In : diamonds >> mutate(foo=X.x + X.x.mean() + X.x) >> head() >> select(X.x, X.foo)
"""
Out:
x foo
0 3.95 13.631157
1 3.89 13.511157
2 4.05 13.831157
3 4.20 14.131157
4 4.34 14.411157
"""Some external functions might enter an infinite loop when called incorrectly with Later arguments. For example, calling zip with Later arguments appears to enter one of these loops. It would help usability with other libraries if we could detect when code is being improperly used with Laters and return an error.
In a DplyFrame x with columns a and b, the following throws an error:
x >> group_by(a) >> select(b)
The correct result should be a dataframe with two columns, a and b, still grouped on a.
select and mutate are present, but there are two others that are variations on these:
rename is like select, but leaves other columns as they are: diamonds >> rename(Price = price) will just rename the one column.transmute is like select, but allows mutation in column definitions, e.g. diamonds >> transmute(carat, new_price = price / 1000) will have only two columns, with new_price manipulatedWildcard imports are discouraged by PEP 8 and obscures which functions actually came from the package.
Let's get this up on PyPI so users can install via pip
Hi,
I'm pulling in some data from a postgres database using sqlalchemy and pandas:
sic_codes_filtered = pandas.read_sql_query(query, con=db)This shows up as a DataFrame in my environment:

However, when I try to execute dplython code, e.g. the following:
(sic_codes_filtered >>
sample_n(10))I get the following error:

I'm not sure what I'm doing wrong. Could you point me in the right direction?
Thanks in advance!
J.
An enhancement request (if you are taking these) for an anti_join operation over multiple columns.
As I suggested in #22, I think we could safely "overload" the built-in filter function by testing whether it is called with a callable and an iterable in that order. Since neither DplyFrames nor DataFrames are callable, I think we'll be safe.
#48 factors out the Later object into its own class, and also mostly decouples it from DplyFrame-specific logic. Might it make sense to make "laters" its own package for handling arbitrary delayed-evaluation expressions in Python? (That will also help us weed out special-case inelegances and bugs.)
I'd be happy to work on that.
I attempted to import dplython:
import pandas
from dplython import (DplyFrame, X, diamonds, select, sift, sample_n,
sample_frac, head, arrange, mutate, group_by, summarize, DelayFunction)
This error was displayed:
Traceback (most recent call last):
File "C:\Users\Shane\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2862, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "", line 1, in
from dplython import (DplyFrame, X, diamonds, select, sift, sample_n,
File "C:\Program Files\JetBrains\PyCharm Community Edition 2017.2\helpers\pydev_pydev_bundle\pydev_import_hook.py", line 21, in do_import
module = sel
am Files\JetBrains\PyCharm Community Edition 2017.2\helpers\pydev_pydev_bundle\pydev_import_hook.py", line 21, in do_import
module = self.sy
ok.py", line 21, in do
o_import
module = self._system_import(name, *args, **kwargs)
ModuleNotFoundError: No module named 'dplython'
The dplython module appears to be installed, as I can see it in the list of packages in PyCharm. However, I cannot see it in the list of packages in Anaconda, which seems suspicious.
To install, I checking out the git repository, then used:
python setup.py install
Result:
E:\git\dplython>python setup.py install
running install
running bdist_egg
running egg_info
writing dplython.egg-info\PKG-INFO
writing dependency_links to dplython.egg-info\dependency_links.txt
writing requirements to dplython.egg-info\requires.txt
writing top-level names to dplython.egg-info\top_level.txt
reading manifest file 'dplython.egg-info\SOURCES.txt'
writing manifest file 'dplython.egg-info\SOURCES.txt'
installing library code to build\bdist.win-amd64\egg
running install_lib
warning: install_lib: 'build\lib' does not exist -- no Python modules to install
creating build\bdist.win-amd64\egg
creating build\bdist.win-amd64\egg\EGG-INFO
copying dplython.egg-info\PKG-INFO -> build\bdist.win-amd64\egg\EGG-INFO
copying dplython.egg-info\SOURCES.txt -> build\bdist.win-amd64\egg\EGG-INFO
copying dplython.egg-info\dependency_links.txt -> build\bdist.win-amd64\egg\EGG-INFO
copying dplython.egg-info\requires.txt -> build\bdist.win-amd64\egg\EGG-INFO
copying dplython.egg-info\top_level.txt -> build\bdist.win-amd64\egg\EGG-INFO
zip_safe flag not set; analyzing archive contents...
creating 'dist\dplython-0.0.7-py3.6.egg' and adding 'build\bdist.win-amd64\egg' to it
removing 'build\bdist.win-amd64\egg' (and everything under it)
Processing dplython-0.0.7-py3.6.egg
Removing c:\users\shane\anaconda3\lib\site-packages\dplython-0.0.7-py3.6.egg
Copying dplython-0.0.7-py3.6.egg to c:\users\shane\anaconda3\lib\site-packages
dplython 0.0.7 is already the active version in easy-install.pth
Installed c:\users\shane\anaconda3\lib\site-packages\dplython-0.0.7-py3.6.egg
Processing dependencies for dplython==0.0.7
Searching for six==1.10.0
Best match: six 1.10.0
Adding six 1.10.0 to easy-install.pth file
Using c:\users\shane\anaconda3\lib\site-packages
Searching for pandas==0.20.3
Best match: pandas 0.20.3
Adding pandas 0.20.3 to easy-install.pth file
Using c:\users\shane\anaconda3\lib\site-packages
Searching for numpy==1.12.1
Best match: numpy 1.12.1
Adding numpy 1.12.1 to easy-install.pth file
Using c:\users\shane\anaconda3\lib\site-packages
Searching for pytz==2017.2
Best match: pytz 2017.2
Adding pytz 2017.2 to easy-install.pth file
Using c:\users\shane\anaconda3\lib\site-packages
Searching for python-dateutil==2.6.1
Best match: python-dateutil 2.6.1
Adding python-dateutil 2.6.1 to easy-install.pth file
Using c:\users\shane\anaconda3\lib\site-packages
Finished processing dependencies for dplython==0.0.7
E:\git\dplython>
Currently, group_by only works on existing columns, not expressions. For example, group_by(X.carat + X.price) seems to only group by X.carat.
Dplyr's group_by allows group_by to be used on expressions.
I think it would make sense if group_by could take named arguments, like group_by(carat_plus_price=X.carat + X.price). This could probably be implemented fairly easily under the hood in group_by by checking for **kwargs and passing them to a mutate() before grouping.
It would be nice if ultimately it could autogenerate a column name, such as "carat_plus_price", if the user does not supply one.
As uncovered in #5.
In Dplyr, the user is able to add a column in a mutate statement derived from a column that he or she just wrote. I want to make this feature available in dplython. So:
diamonds_dp = self.diamonds >> mutate(foo=X.x, bar=X.foo.mean())
should be valid. foo should be the first column added, followed by bar.
This is difficult to accomplish though as python throws away the order information of *_kwargs. Currently, this example code would sometimes work and sometimes not work depending on the dictionary ordering of *_kwargs. There's a PEP out to accomplish this (https://www.python.org/dev/peps/pep-0468/) but it doesn't look like this feature is currently supported.
In a bad case, this will mean the user doesn't know what order to expect columns to be in. In a worse case, this will inconsistently cause errors when a use tries to create a column derived from another one.
Some potential solutions, none of which seem great:
The example listed on the README no longer works for ggplot.
from ggplot import ggplot, aes, geom_point, facet_wrap
ggplot = DelayFunction(ggplot) # Simple installation
(diamonds >> ggplot(aes(x="carat", y="price", color="cut"), data=X._) +
geom_point() + facet_wrap("color"))My guess is this is due to the Later refactor.
There's no "str" for a Later object right now. This makes it hard to interactively see what's going on. It also makes it more difficult to debug or know what a particular Later is. If we have this feature, it could enable other nice features! For example, dplyr does a nice job with this. As mentioned in #23, if you do something like df %>% mutate(x + 7) the output will be a dataframe with a column named x + 7.
It would be great to have a str method on a Later that could show you the expression that was written. So:
foo = X.x + X.y.mean()**2
str(foo)
# returns "X.x + X.y.mean()**2"I updated the README to include a video, and now the build is broken on a seemingly unrelated issue. My first guess is that something changed in pandas to make comparison between Series even more difficult, but I'm not sure yet. I will investigate but will hopefully resolve this soon. If anyone has issues with dplython breaking after the latest update please let me know.
(Quick note: After a bit of an absence due to talking on a very intense, temporary job for a few months, I'm back improving and updating dplython)
Here is a clear example of it

You would expect to have 5 different uuid
Since dplython deals with large dataset, it's important to make sure performance is as high as possible. To that end, we should set up benchmarks to see where our speed is improving (or getting worse!) over time.
transmute and select do very similar things: create a smaller dataframe that is just a few derived columns from the current one.
The different between transmute and select is a small one. transmute creates new columns, basically a mutate and then a select. select only uses existing columns. Why not put all of this functionality inside select?
diamonds >> select(X.carat * 2, X.color, chair=X.table) >> head()
# Out:
# X["carat"] * 2 color chair
# 8.01 I1 61
# 8.01 I1 62
One argument against this is that dplyr uses - to indicate "drop this". So diamonds %>% select(-carat) drops the carat row. This seems a little strange here, and separate from the SQL syntax, where a user might expect that this gives you the negative version of carat. To keep this functionality, we could make a new drop verb which drops rows.
I am trying to reshape this data, but I am getting this error
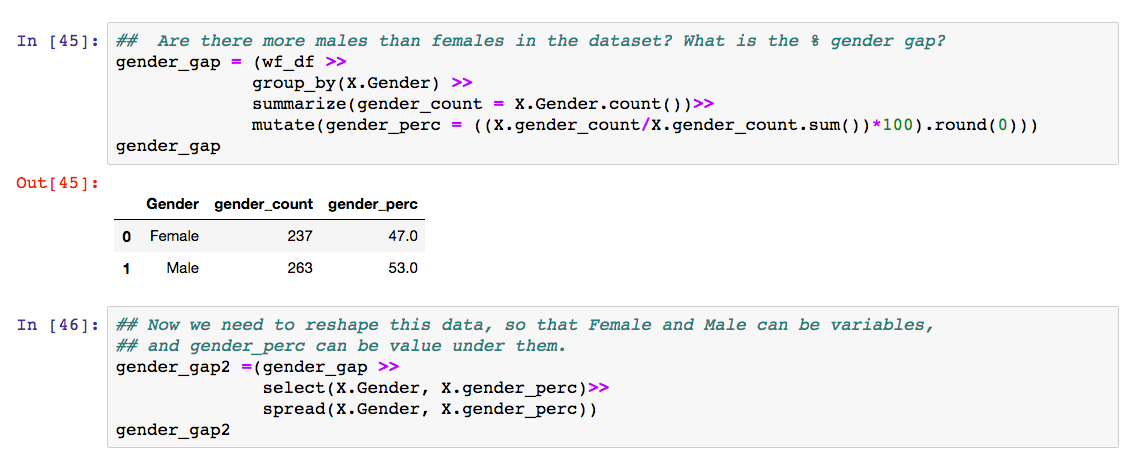
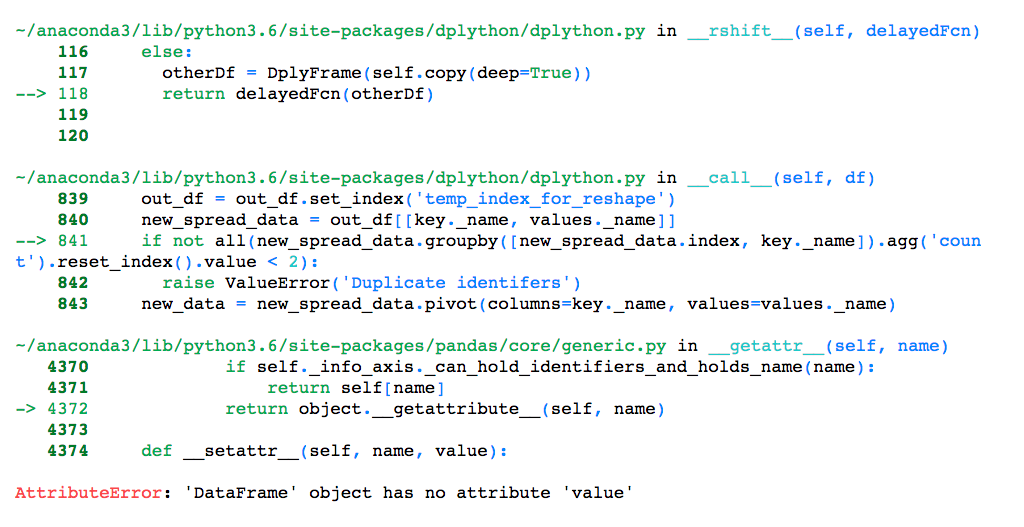
Hi all,
I've noticed an issue with mutate when you define variables using delay functions and group_by. I think the problem is actually just with mutating not working properly with group_by but I haven't extensively tested. For example:
@DelayFunction
def lead(series, i=1):
index = series.index
shifted = series.shift(i)
shifted.index = index
return shifted
diamonds >> group_by(X.cut) >> mutate(price_lead = lead(X.price)) >> head(6)
Unnamed: 0 carat cut color clarity depth table price x \
0 1 0.23 Ideal E SI2 61.5 55.0 326 3.95
1 2 0.21 Premium E SI1 59.8 61.0 326 3.89
2 3 0.23 Good E VS1 56.9 65.0 327 4.05
3 4 0.29 Premium I VS2 62.4 58.0 334 4.20
4 5 0.31 Good J SI2 63.3 58.0 335 4.34
5 6 0.24 Very Good J VVS2 62.8 57.0 336 3.94
y z price_lead
0 3.98 2.43 NaN
1 3.84 2.31 326.0
2 4.07 2.31 326.0
3 4.23 2.63 327.0
4 4.35 2.75 334.0
5 3.96 2.48 335.0 The lead delay function should operate independently on each group, but instead it is operating on the entire dataframe regardless of group.
I solved this in my own fork of dplython by removing mutate from the handled classes in the DplyFrame class. I assume however that you put it in handled classes for a reason, so I don't consider this a great fix (for example, arrange broke due to this and I had to change it to work again).
Curious to hear your opinion on this.
P.S. There are tons of changes and additions in that personal fork that I should make pull requests for, but a lot has changed including the formatting and so I've been lazy about it...
import pandas
from dplython import (DplyFrame, X, diamonds, select, sift, sample_n,
sample_frac, head, arrange, mutate, group_by, summarize, DelayFunction)
Yields:
ImportError: cannot import name 'DplyFrame'
If I remove DplyFrame, I get:
ImportError: cannot import name 'X'
Currently, dplython copies a new DataFrame whenever >> is used. The goal of this is to prevent dplython from inadvertently altering the contents of the original DataFrame when executing operations. See this pandas reference: http://pandas.pydata.org/pandas-docs/stable/indexing.html#returning-a-view-versus-a-copy
It would be great if we could restrict this behavior, or push it to key verbs (such as mutate), as it's very inefficient on large data sets.
Running your test suite after python setup.py install on a clean python 2.6 virtualenv fails. The failure occurs when importing pandas, as the latest pandas version (0.18.0) doesn't support python 2.6 anymore. Therefore, I think that it is legitimate to drop support for python 2.6 in this project as well.
I'm seeing this warning from Pandas:
.............../Users/nathangould/workspace/dplython/dplython/dplython.py:393: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
df[key] = val.applyFcns(df)
........................................
Since this happening inside mutate(), I think df[key] would be a new column, and therefore not be a copy. So I don't yet understand what pandas is complaining about, but it could be worth looking into.
We have already differed from dplyr by using sift instead of filter. mutate seems like a misnomer-- we're not mutating an existing column, but rather we're adding a new column. We're changing the dataframe that is output, but we're doing that with all of the verbs.
To make things a little easier to understand for new users, we could rename mutate to define. We could also keep around mutate for the hardcore dplyr users.

I am trying to generate a variable, based on conditions of another variable, but the mutate function is failing.
The dplyr select() function is nice because you can simultaneously select and rename columns. Do you offer this functionality? Alternatively, implementing the function dplyr::rename() would be sufficient.
These are verbs in dplyr
I tried these two commands and they produce different output:
df >> sift(X.a == 1)
df >> sift(X.a == 1 or X.b == 1) # this is equivalent to the line above
df >>sift(X.a == 1 | X.b == 1) # produces different results than the lines above and I don't know what the result represents
So is it possible to use the or condition inside sift at the moment?
Have you considered _? IMHO it feels more evocative (of member variables, for example) and invisible. The biggest downside is that it already has a meaning in the interactive interpreter (the last evaluated expression). If people want to use dplython in an interactive session and use the _ for that purpose, they could use from dplython import _ as X.
Are there any other names you considered? Assuming you want it to be a single character, I guess there are only 53 possibilities. I could see a case for x (lowercase is subtler and easier to type), d (for dataframe), s (for self), or c (for column).
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.