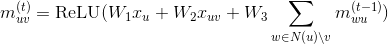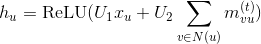Website | A Blitz Introduction to DGL | Documentation (Latest | Stable) | Official Examples | Discussion Forum | Slack Channel
DGL is an easy-to-use, high performance and scalable Python package for deep learning on graphs. DGL is framework agnostic, meaning if a deep graph model is a component of an end-to-end application, the rest of the logics can be implemented in any major frameworks, such as PyTorch, Apache MXNet or TensorFlow.

Figure: DGL Overall Architecture
DGL provides a powerful graph object that can reside on either CPU or GPU. It bundles structural data as well as features for better control. We provide a variety of functions for computing with graph objects including efficient and customizable message passing primitives for Graph Neural Networks.
The field of graph deep learning is still rapidly evolving and many research ideas emerge by standing on the shoulders of giants. To ease the process, DGl-Go is a command-line interface to get started with training, using and studying state-of-the-art GNNs. DGL collects a rich set of example implementations of popular GNN models of a wide range of topics. Researchers can search for related models to innovate new ideas from or use them as baselines for experiments. Moreover, DGL provides many state-of-the-art GNN layers and modules for users to build new model architectures. DGL is one of the preferred platforms for many standard graph deep learning benchmarks including OGB and GNNBenchmarks.
DGL provides plenty of learning materials for all kinds of users from ML researchers to domain experts. The Blitz Introduction to DGL is a 120-minute tour of the basics of graph machine learning. The User Guide explains in more details the concepts of graphs as well as the training methodology. All of them include code snippets in DGL that are runnable and ready to be plugged into one’s own pipeline.
It is convenient to train models using DGL on large-scale graphs across multiple GPUs or multiple machines. DGL extensively optimizes the whole stack to reduce the overhead in communication, memory consumption and synchronization. As a result, DGL can easily scale to billion-sized graphs. Get started with the tutorials and user guide for distributed training. See the system performance note for the comparison with other tools.
Users can install DGL from pip and conda. You can also download GPU enabled DGL docker containers (backended by PyTorch) from NVIDIA NGC for both x86 and ARM based linux systems. Advanced users can follow the instructions to install from source.
For absolute beginners, start with the Blitz Introduction to DGL. It covers the basic concepts of common graph machine learning tasks and a step-by-step on building Graph Neural Networks (GNNs) to solve them.
For acquainted users who wish to learn more,
- Experience state-of-the-art GNN models in only two command-lines using DGL-Go.
- Learn DGL by example implementations of popular GNN models.
- Read the User Guide (中文版链接), which explains the concepts and usage of DGL in much more details.
- Go through the tutorials for advanced features like stochastic training of GNNs, training on multi-GPU or multi-machine.
- Study classical papers on graph machine learning alongside DGL.
- Search for the usage of a specific API in the API reference manual, which organizes all DGL APIs by their namespace.
All the learning materials are available at our documentation site. If you are new to deep learning in general, check out the open source book Dive into Deep Learning.
We provide multiple channels to connect you to the community of the DGL developers, users, and the general GNN academic researchers:
- Our Slack channel, click to join
- Our discussion forum: https://discuss.dgl.ai/
- Our Zhihu blog (in Chinese)
- Monthly GNN User Group online seminar (event link | past videos)
Take the survey here and leave any feedback to make DGL better fit for your needs. Thanks!
- DGL-LifeSci: a DGL-based package for various applications in life science with graph neural networks. https://github.com/awslabs/dgl-lifesci
- DGL-KE: a high performance, easy-to-use, and scalable package for learning large-scale knowledge graph embeddings. https://github.com/awslabs/dgl-ke
- Benchmarking GNN: https://github.com/graphdeeplearning/benchmarking-gnns
- OGB: a collection of realistic, large-scale, and diverse benchmark datasets for machine learning on graphs. https://ogb.stanford.edu/
- Graph4NLP: an easy-to-use library for R&D at the intersection of Deep Learning on Graphs and Natural Language Processing. https://github.com/graph4ai/graph4nlp
- GNN-RecSys: https://github.com/je-dbl/GNN-RecSys
- Amazon Neptune ML: a new capability of Neptune that uses Graph Neural Networks (GNNs), a machine learning technique purpose-built for graphs, to make easy, fast, and more accurate predictions using graph data. https://aws.amazon.com/cn/neptune/machine-learning/
- GNNLens2: Visualization tool for Graph Neural Networks. https://github.com/dmlc/GNNLens2
- RNAGlib: A package to facilitate construction, analysis, visualization and machine learning on RNA 2.5D Graphs. Includes a pre-built dataset: https://rnaglib.cs.mcgill.ca
- OpenHGNN: Model zoo and benchmarks for Heterogeneous Graph Neural Networks. https://github.com/BUPT-GAMMA/OpenHGNN
- TGL: A graph learning framework for large-scale temporal graphs. https://github.com/amazon-research/tgl
- gtrick: Bag of Tricks for Graph Neural Networks. https://github.com/sangyx/gtrick
- ArangoDB-DGL Adapter: Import ArangoDB graphs into DGL and vice-versa. https://github.com/arangoml/dgl-adapter
- DGLD: DGLD is an open-source library for Deep Graph Anomaly Detection based on pytorch and DGL.
-
Benchmarking Graph Neural Networks, Vijay Prakash Dwivedi, Chaitanya K. Joshi, Thomas Laurent, Yoshua Bengio, Xavier Bresson
-
Open Graph Benchmarks: Datasets for Machine Learning on Graphs, NeurIPS'20, Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, Jure Leskovec
-
DropEdge: Towards Deep Graph Convolutional Networks on Node Classification, ICLR'20, Yu Rong, Wenbing Huang, Tingyang Xu, Junzhou Huan
-
Discourse-Aware Neural Extractive Text Summarization, ACL'20, Jiacheng Xu, Zhe Gan, Yu Cheng, Jingjing Liu
-
GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training, KDD'20, Jiezhong Qiu, Qibin Chen, Yuxiao Dong, Jing Zhang, Hongxia Yang, Ming Ding, Kuansan Wang, Jie Tang
-
DGL-KE: Training Knowledge Graph Embeddings at Scale, SIGIR'20, Da Zheng, Xiang Song, Chao Ma, Zeyuan Tan, Zihao Ye, Jin Dong, Hao Xiong, Zheng Zhang, George Karypis
-
Improving Graph Neural Network Expressivity via Subgraph Isomorphism Counting, Giorgos Bouritsas, Fabrizio Frasca, Stefanos Zafeiriou, Michael M. Bronstein
-
INT: An Inequality Benchmark for Evaluating Generalization in Theorem Proving, Yuhuai Wu, Albert Q. Jiang, Jimmy Ba, Roger Grosse
-
Finding Patient Zero: Learning Contagion Source with Graph Neural Networks, Chintan Shah, Nima Dehmamy, Nicola Perra, Matteo Chinazzi, Albert-László Barabási, Alessandro Vespignani, Rose Yu
-
FeatGraph: A Flexible and Efficient Backend for Graph Neural Network Systems, SC'20, Yuwei Hu, Zihao Ye, Minjie Wang, Jiali Yu, Da Zheng, Mu Li, Zheng Zhang, Zhiru Zhang, Yida Wang
more
-
BP-Transformer: Modelling Long-Range Context via Binary Partitioning., Zihao Ye, Qipeng Guo, Quan Gan, Xipeng Qiu, Zheng Zhang
-
OptiMol: Optimization of Binding Affinities in Chemical Space for Drug Discovery, Jacques Boitreaud,Vincent Mallet, Carlos Oliver, Jérôme Waldispühl
-
JAKET: Joint Pre-training of Knowledge Graph and Language Understanding, Donghan Yu, Chenguang Zhu, Yiming Yang, Michael Zeng
-
Architectural Implications of Graph Neural Networks, Zhihui Zhang, Jingwen Leng, Lingxiao Ma, Youshan Miao, Chao Li, Minyi Guo
-
Combining Reinforcement Learning and Constraint Programming for Combinatorial Optimization, Quentin Cappart, Thierry Moisan, Louis-Martin Rousseau1, Isabeau Prémont-Schwarz, and Andre Cire
-
Therapeutics Data Commons: Machine Learning Datasets and Tasks for Therapeutics (code repo), Kexin Huang, Tianfan Fu, Wenhao Gao, Yue Zhao, Yusuf Roohani, Jure Leskovec, Connor W. Coley, Cao Xiao, Jimeng Sun, Marinka Zitnik
-
Sparse Graph Attention Networks, Yang Ye, Shihao Ji
-
On Self-Distilling Graph Neural Network, Yuzhao Chen, Yatao Bian, Xi Xiao, Yu Rong, Tingyang Xu, Junzhou Huang
-
Learning Robust Node Representations on Graphs, Xu Chen, Ya Zhang, Ivor Tsang, and Yuangang Pan
-
Recurrent Event Network: Autoregressive Structure Inference over Temporal Knowledge Graphs, Woojeong Jin, Meng Qu, Xisen Jin, Xiang Ren
-
Graph Neural Ordinary Differential Equations, Michael Poli, Stefano Massaroli, Junyoung Park, Atsushi Yamashita, Hajime Asama, Jinkyoo Park
-
FusedMM: A Unified SDDMM-SpMM Kernel for Graph Embedding and Graph Neural Networks, Md. Khaledur Rahman, Majedul Haque Sujon, , Ariful Azad
-
An Efficient Neighborhood-based Interaction Model for Recommendation on Heterogeneous Graph, KDD'20 Jiarui Jin, Jiarui Qin, Yuchen Fang, Kounianhua Du, Weinan Zhang, Yong Yu, Zheng Zhang, Alexander J. Smola
-
Learning Interaction Models of Structured Neighborhood on Heterogeneous Information Network, Jiarui Jin, Kounianhua Du, Weinan Zhang, Jiarui Qin, Yuchen Fang, Yong Yu, Zheng Zhang, Alexander J. Smola
-
Graphein - a Python Library for Geometric Deep Learning and Network Analysis on Protein Structures, Arian R. Jamasb, Pietro Lió, Tom L. Blundell
-
Graph Policy Gradients for Large Scale Robot Control, Arbaaz Khan, Ekaterina Tolstaya, Alejandro Ribeiro, Vijay Kumar
-
Heterogeneous Molecular Graph Neural Networks for Predicting Molecule Properties, Zeren Shui, George Karypis
-
Could Graph Neural Networks Learn Better Molecular Representation for Drug Discovery? A Comparison Study of Descriptor-based and Graph-based Models, Dejun Jiang, Zhenxing Wu, Chang-Yu Hsieh, Guangyong Chen, Ben Liao, Zhe Wang, Chao Shen, Dongsheng Cao, Jian Wu, Tingjun Hou
-
Principal Neighbourhood Aggregation for Graph Nets, Gabriele Corso, Luca Cavalleri, Dominique Beaini, Pietro Liò, Petar Veličković
-
Collective Multi-type Entity Alignment Between Knowledge Graphs, Qi Zhu, Hao Wei, Bunyamin Sisman, Da Zheng, Christos Faloutsos, Xin Luna Dong, Jiawei Han
-
Graph Representation Forecasting of Patient's Medical Conditions: towards A Digital Twin, Pietro Barbiero, Ramon Viñas Torné, Pietro Lió
-
Relational Graph Learning on Visual and Kinematics Embeddings for Accurate Gesture Recognition in Robotic Surgery, Yong-Hao Long, Jie-Ying Wu, Bo Lu, Yue-Ming Jin, Mathias Unberath, Yun-Hui Liu, Pheng-Ann Heng and Qi Dou
-
Dark Reciprocal-Rank: Boosting Graph-Convolutional Self-Localization Network via Teacher-to-student Knowledge Transfer, Takeda Koji, Tanaka Kanji
-
Graph InfoClust: Leveraging Cluster-Level Node Information For Unsupervised Graph Representation Learning, Costas Mavromatis, George Karypis
-
GraphSeam: Supervised Graph Learning Framework for Semantic UV Mapping, Fatemeh Teimury, Bruno Roy, Juan Sebastian Casallas, David macdonald, Mark Coates
-
Comprehensive Study on Molecular Supervised Learning with Graph Neural Networks, Doyeong Hwang, Soojung Yang, Yongchan Kwon, Kyung Hoon Lee, Grace Lee, Hanseok Jo, Seyeol Yoon, and Seongok Ryu
-
A graph auto-encoder model for miRNA-disease associations prediction, Zhengwei Li, Jiashu Li, Ru Nie, Zhu-Hong You, Wenzheng Bao
-
Graph convolutional regression of cardiac depolarization from sparse endocardial maps, STACOM 2020 workshop, Felix Meister, Tiziano Passerini, Chloé Audigier, Èric Lluch, Viorel Mihalef, Hiroshi Ashikaga, Andreas Maier, Henry Halperin, Tommaso Mansi
-
AttnIO: Knowledge Graph Exploration with In-and-Out Attention Flow for Knowledge-Grounded Dialogue, EMNLP'20, Jaehun Jung, Bokyung Son, Sungwon Lyu
-
Learning from Non-Binary Constituency Trees via Tensor Decomposition, COLING'20, Daniele Castellana, Davide Bacciu
-
Inducing Alignment Structure with Gated Graph Attention Networks for Sentence Matching, Peng Cui, Le Hu, Yuanchao Liu
-
Enhancing Extractive Text Summarization with Topic-Aware Graph Neural Networks, COLING'20, Peng Cui, Le Hu, Yuanchao Liu
-
Double Graph Based Reasoning for Document-level Relation Extraction, EMNLP'20, Shuang Zeng, Runxin Xu, Baobao Chang, Lei Li
-
Systematic Generalization on gSCAN with Language Conditioned Embedding, AACL-IJCNLP'20, Tong Gao, Qi Huang, Raymond J. Mooney
-
Automatic selection of clustering algorithms using supervised graph embedding, Noy Cohen-Shapira, Lior Rokach
-
Improving Learning to Branch via Reinforcement Learning, Haoran Sun, Wenbo Chen, Hui Li, Le Song
-
A Practical Guide to Graph Neural Networks, Isaac Ronald Ward, Jack Joyner, Casey Lickfold, Stash Rowe, Yulan Guo, Mohammed Bennamoun, code
-
APAN: Asynchronous Propagation Attention Network for Real-time Temporal Graph Embedding, SIGMOD'21, Xuhong Wang, Ding Lyu, Mengjian Li, Yang Xia, Qi Yang, Xinwen Wang, Xinguang Wang, Ping Cui, Yupu Yang, Bowen Sun, Zhenyu Guo, Junkui Li
-
Uncertainty-Matching Graph Neural Networks to Defend Against Poisoning Attacks, Uday Shankar Shanthamallu, Jayaraman J. Thiagarajan, Andreas Spanias
-
Computing Graph Neural Networks: A Survey from Algorithms to Accelerators, Sergi Abadal, Akshay Jain, Robert Guirado, Jorge López-Alonso, Eduard Alarcón
-
NHK_STRL at WNUT-2020 Task 2: GATs with Syntactic Dependencies as Edges and CTC-based Loss for Text Classification, Yuki Yasuda, Taichi Ishiwatari, Taro Miyazaki, Jun Goto
-
Relation-aware Graph Attention Networks with Relational Position Encodings for Emotion Recognition in Conversations, Taichi Ishiwatari, Yuki Yasuda, Taro Miyazaki, Jun Goto
-
PGM-Explainer: Probabilistic Graphical Model Explanations for Graph Neural Networks, Minh N. Vu, My T. Thai
-
A Generalization of Transformer Networks to Graphs, Vijay Prakash Dwivedi, Xavier Bresson
-
Discourse-Aware Neural Extractive Text Summarization, ACL'20, Jiacheng Xu, Zhe Gan, Yu Cheng, Jingjing Liu
-
Learning Robust Node Representations on Graphs, Xu Chen, Ya Zhang, Ivor Tsang, Yuangang Pan
-
Adaptive Graph Diffusion Networks with Hop-wise Attention, Chuxiong Sun, Guoshi Wu
-
The Photoswitch Dataset: A Molecular Machine Learning Benchmark for the Advancement of Synthetic Chemistry, Aditya R. Thawani, Ryan-Rhys Griffiths, Arian Jamasb, Anthony Bourached, Penelope Jones, William McCorkindale, Alexander A. Aldrick, Alpha A. Lee
-
A community-powered search of machine learning strategy space to find NMR property prediction models, Lars A. Bratholm, Will Gerrard, Brandon Anderson, Shaojie Bai, Sunghwan Choi, Lam Dang, Pavel Hanchar, Addison Howard, Guillaume Huard, Sanghoon Kim, Zico Kolter, Risi Kondor, Mordechai Kornbluth, Youhan Lee, Youngsoo Lee, Jonathan P. Mailoa, Thanh Tu Nguyen, Milos Popovic, Goran Rakocevic, Walter Reade, Wonho Song, Luka Stojanovic, Erik H. Thiede, Nebojsa Tijanic, Andres Torrubia, Devin Willmott, Craig P. Butts, David R. Glowacki, Kaggle participants
-
Adaptive Layout Decomposition with Graph Embedding Neural Networks, Wei Li, Jialu Xia, Yuzhe Ma, Jialu Li, Yibo Lin, Bei Yu, DAC'20
-
Transfer Learning with Graph Neural Networks for Optoelectronic Properties of Conjugated Oligomers, J. Chem. Phys. 154, Chee-Kong Lee, Chengqiang Lu, Yue Yu, Qiming Sun, Chang-Yu Hsieh, Shengyu Zhang, Qi Liu, and Liang Shi
-
Jet tagging in the Lund plane with graph networks, Journal of High Energy Physics 2021, Frédéric A. Dreyer and Huilin Qu
-
Global Attention Improves Graph Networks Generalization, Omri Puny, Heli Ben-Hamu, and Yaron Lipman
-
Learning over Families of Sets -- Hypergraph Representation Learning for Higher Order Tasks, SDM 2021, Balasubramaniam Srinivasan, Da Zheng, and George Karypis
-
SSFG: Stochastically Scaling Features and Gradients for Regularizing Graph Convolution Networks, Haimin Zhang, Min Xu
-
Application and evaluation of knowledge graph embeddings in biomedical data, PeerJ Computer Science 7:e341, Mona Alshahrani, Maha A. Thafar, Magbubah Essack
-
MoTSE: an interpretable task similarity estimator for small molecular property prediction tasks, bioRxiv 2021.01.13.426608, Han Li, Xinyi Zhao, Shuya Li, Fangping Wan, Dan Zhao, Jianyang Zeng
-
Reinforcement Learning For Data Poisoning on Graph Neural Networks, Jacob Dineen, A S M Ahsan-Ul Haque, Matthew Bielskas
-
Generalising Recursive Neural Models by Tensor Decomposition, IJCNN'20, Daniele Castellana, Davide Bacciu
-
Tensor Decompositions in Recursive Neural Networks for Tree-Structured Data, ESANN'20, Daniele Castellana, Davide Bacciu
-
Combining Self-Organizing and Graph Neural Networks for Modeling Deformable Objects in Robotic Manipulation, Frotiers in Robotics and AI, Valencia, Angel J., and Pierre Payeur
-
Joint stroke classification and text line grouping in online handwritten documents with edge pooling attention networks, Pattern Recognition, Jun-Yu Ye, Yan-Ming Zhang, Qing Yang, Cheng-Lin Liu
-
Toward Accurate Predictions of Atomic Properties via Quantum Mechanics Descriptors Augmented Graph Convolutional Neural Network: Application of This Novel Approach in NMR Chemical Shifts Predictions, The Journal of Physical Chemistry Letters, Peng Gao, Jie Zhang, Yuzhu Sun, and Jianguo Yu
-
A Graph Neural Network to Model User Comfort in Robot Navigation, Pilar Bachiller, Daniel Rodriguez-Criado, Ronit R. Jorvekar, Pablo Bustos, Diego R. Faria, Luis J. Manso
-
Medical Entity Disambiguation Using Graph Neural Networks, Alina Vretinaris, Chuan Lei, Vasilis Efthymiou, Xiao Qin, Fatma Özcan
-
Chemistry-informed Macromolecule Graph Representation for Similarity Computation and Supervised Learning, Somesh Mohapatra, Joyce An, Rafael Gómez-Bombarelli
-
Characterizing and Forecasting User Engagement with In-app Action Graph: A Case Study of Snapchat, Yozen Liu, Xiaolin Shi, Lucas Pierce, Xiang Ren
-
GIPA: General Information Propagation Algorithm for Graph Learning, Qinkai Zheng, Houyi Li, Peng Zhang, Zhixiong Yang, Guowei Zhang, Xintan Zeng, Yongchao Liu
-
Graph Ensemble Learning over Multiple Dependency Trees for Aspect-level Sentiment Classification, NAACL'21, Xiaochen Hou, Peng Qi, Guangtao Wang, Rex Ying, Jing Huang, Xiaodong He, Bowen Zhou
-
Enhancing Scientific Papers Summarization with Citation Graph, AAAI'21, Chenxin An, Ming Zhong, Yiran Chen, Danqing Wang, Xipeng Qiu, Xuanjing Huang
-
Improving Graph Representation Learning by Contrastive Regularization, Kaili Ma, Haochen Yang, Han Yang, Tatiana Jin, Pengfei Chen, Yongqiang Chen, Barakeel Fanseu Kamhoua, James Cheng
-
Extract the Knowledge of Graph Neural Networks and Go Beyond it: An Effective Knowledge Distillation Framework, WWW'21, Cheng Yang, Jiawei Liu, Chuan Shi
-
VIKING: Adversarial Attack on Network Embeddings via Supervised Network Poisoning, PAKDD'21, Viresh Gupta, Tanmoy Chakraborty
-
Knowledge Graph Embedding using Graph Convolutional Networks with Relation-Aware Attention, Nasrullah Sheikh, Xiao Qin, Berthold Reinwald, Christoph Miksovic, Thomas Gschwind, Paolo Scotton
-
SLAPS: Self-Supervision Improves Structure Learning for Graph Neural Networks, Bahare Fatemi, Layla El Asri, Seyed Mehran Kazemi
-
Finding Needles in Heterogeneous Haystacks, AAAI'21, Bijaya Adhikari, Liangyue Li, Nikhil Rao, Karthik Subbian
-
RetCL: A Selection-based Approach for Retrosynthesis via Contrastive Learning, IJCAI 2021, Hankook Lee, Sungsoo Ahn, Seung-Woo Seo, You Young Song, Eunho Yang, Sung-Ju Hwang, Jinwoo Shin
-
Accurate Prediction of Free Solvation Energy of Organic Molecules via Graph Attention Network and Message Passing Neural Network from Pairwise Atomistic Interactions, Ramin Ansari, Amirata Ghorbani
-
DIPS-Plus: The Enhanced Database of Interacting Protein Structures for Interface Prediction, Alex Morehead, Chen Chen, Ada Sedova, Jianlin Cheng
-
Coreference-Aware Dialogue Summarization, SIGDIAL'21, Zhengyuan Liu, Ke Shi, Nancy F. Chen
-
Document Structure aware Relational Graph Convolutional Networks for Ontology Population, arXiv, Abhay M Shalghar, Ayush Kumar, Balaji Ganesan, Aswin Kannan, Shobha G
-
Covid-19 Detection from Chest X-ray and Patient Metadata using Graph Convolutional Neural Networks, Thosini Bamunu Mudiyanselage, Nipuna Senanayake, Chunyan Ji, Yi Pan, Yanqing Zhang
-
Rossmann-toolbox: a deep learning-based protocol for the prediction and design of cofactor specificity in Rossmann fold proteins, Briefings in Bioinformatics, Kamil Kaminski, Jan Ludwiczak, Maciej Jasinski, Adriana Bukala, Rafal Madaj, Krzysztof Szczepaniak, Stanislaw Dunin-Horkawicz
-
LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations, ACL'21, Ruisheng Cao, Lu Chen, Zhi Chen, Yanbin Zhao, Su Zhu, Kai Yu
-
Enhancing Graph Neural Networks via auxiliary training for semi-supervised node classification, Knowledge-Based System'21, Yao Wu, Yu Song, Hong Huang, Fanghua Ye, Xing Xie, Hai Jin
-
Modeling Graph Node Correlations with Neighbor Mixture Models, Linfeng Liu, Michael C. Hughes, Li-Ping Liu
-
COMBINING PHYSICS AND MACHINE LEARNING FOR NETWORK FLOW ESTIMATION, ICLR'21, Arlei Silva, Furkan Kocayusufoglu, Saber Jafarpour, Francesco Bullo, Ananthram Swami, Ambuj Singh
-
A Classification Method for Academic Resources Based on a Graph Attention Network, Future Internet'21, Jie Yu, Yaliu Li, Chenle Pan and Junwei Wang
-
Large Graph Convolutional Network Training with GPU-Oriented Data Communication Architecture, Seung Won Min, Kun Wu, Sitao Huang, Mert Hidayetoğlu, Jinjun Xiong, Eiman Ebrahimi, Deming Chen, Wen-mei Hwu
-
Graph Attention Multi-Layer Perception, Wentao Zhang, Ziqi Yin, Zeang Sheng, Wen Ouyang, Xiaosen Li, Yangyu Tao, Zhi Yang, Bin Cui
-
GNNLens: A Visual Analytics Approach for Prediction Error Diagnosis of Graph Neural Networks, Zhihua Jin, Yong Wang, Qianwen Wang, Yao Ming, Tengfei Ma, Huamin Qu
-
How Attentive are Graph Attention Networks?, Shaked Brody, Uri Alon, Eran Yahav, code
-
SCENE: Reasoning about Traffic Scenes using Heterogeneous Graph Neural Networks, Thomas Monninger*, Julian Schmidt*, Jan Rupprecht, David Raba, Julian Jordan, Daniel Frank, Steffen Staab, Klaus Dietmayer, code, *co-first authors
Please let us know if you encounter a bug or have any suggestions by filing an issue.
We welcome all contributions from bug fixes to new features and extensions.
We expect all contributions discussed in the issue tracker and going through PRs. Please refer to our contribution guide.
If you use DGL in a scientific publication, we would appreciate citations to the following paper:
@article{wang2019dgl,
title={Deep Graph Library: A Graph-Centric, Highly-Performant Package for Graph Neural Networks},
author={Minjie Wang and Da Zheng and Zihao Ye and Quan Gan and Mufei Li and Xiang Song and Jinjing Zhou and Chao Ma and Lingfan Yu and Yu Gai and Tianjun Xiao and Tong He and George Karypis and Jinyang Li and Zheng Zhang},
year={2019},
journal={arXiv preprint arXiv:1909.01315}
}
DGL is developed and maintained by NYU, NYU Shanghai, AWS Shanghai AI Lab, and AWS MXNet Science Team.
DGL uses Apache License 2.0.