![]()
Read res1d and xns11 files.
For other MIKE files (Dfs0, Dfs1, Dfs2, Dfsu,...) use the related package MIKE IO
- Windows operating system (Support for Linux is experimental)
- Python x64 3.6, 3.7 or 3.8
- VC++ redistributables (already installed if you have MIKE)
From PyPI:
pip install mikeio1d
Or development version:
pip install https://github.com/DHI/mikeio1d/archive/main.zip
For MIKE IO 1D to work .NET runtime environment (version 3.1 and above) is needed. On Linux operating systems this is not available per default. For example, on Ubuntu distribution to get .NET 7.0 runtime call:
sudo apt install dotnet-runtime-7.0
- New ideas and feature requests - GitHub Discussions
- Bugs - GitHub Issues
- General help, FAQ - Stackoverflow with the tag
mikeio
>>> from mikeio1d.res1d import Res1D, QueryDataReach
>>> df = Res1D(filename).read()
>>> query = QueryDataReach("WaterLevel", "104l1", 34.4131)
>>> df = res1d.read(query)For more Res1D examples see this notebook
>>> import matplotlib.pyplot as plt
>>> from mikeio1d import xns11
>>> # Query the geometry of chainage 58.68 of topoid1 at reach1
>>> q1 = xns11.QueryData('topoid1', 'reach1', 58.68)
>>> # Query the geometry of all chainages of topoid1 at reach2
>>> q2 = xns11.QueryData('topoid1', 'reach2')
>>> # Query the geometry of all chainages of topoid2
>>> q3 = xns11.QueryData('topoid2')
>>> # Combine the queries in a list
>>> queries = [q1, q2, q3]
>>> # The returned geometry object is a pandas DataFrame
>>> geometry = xns11.read('xsections.xns11', queries)
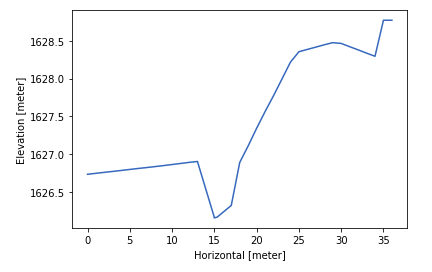
>>> # Plot geometry of chainage 58.68 of topoid1 at reach1
>>> plt.plot(geometry['x topoid1 reach1 58.68'],geometry['z topoid1 reach1 58.68'])
>>> plt.xlabel('Horizontal [meter]')
>>> plt.ylabel('Elevation [meter]')