A library for burning through electronic health record data using Apache Spark™
Smolder provides an Apache Spark™ SQL data source for loading EHR data from HL7v2 message formats. Additionally, Smolder provides helper functions that can be used on a Spark SQL DataFrame to parse HL7 message text, and to extract segments, fields, and subfields, from a message.
Please note that all projects in the /databrickslabs github account are provided for your exploration only, and are not formally supported by Databricks with Service Level Agreements (SLAs). They are provided AS-IS and we do not make any guarantees of any kind. Please do not submit a support ticket relating to any issues arising from the use of these projects.
Any issues discovered through the use of this project should be filed as GitHub Issues on the Repo. They will be reviewed as time permits, but there are no formal SLAs for support.
This project is built using sbt and Java 8.
Start an sbt shell using the sbt command.
FYI: The following SBT projects are built on Spark 3.2.1/Scala 2.12.8 by default. To change the Spark version and Scala version, set the environment variables
SPARK_VERSIONandSCALA_VERSION.
To compile the main code:
compile
To run all Scala tests:
test
To test a specific suite:
testOnly *HL7FileFormatSuite
To create a JAR that can be run as part of an Apache Spark job or shell, run:
package
The JAR can be found under target/scala-<major-version>.
To load HL7 messages into an Apache Spark SQL
DataFrame,
simply invoke the hl7 reader:
scala> val df = spark.read.format("hl7").load("path/to/hl7/messages")
df: org.apache.spark.sql.DataFrame = [message: string, segments: array<struct<id:string,fields:array<string>>>]
The schema returned contains the message header in the message column. The
message segments are nested in the segments column, which is an array. This
array contains two nested fields: the string id for the segment (e.g., PID
for a patient identification segment
and an array of segment fields.
Smolder can also be used to parse raw message text. This might happen if you had
an HL7 message feed land in an intermediate source first (e.g., a Kafka stream).
To do this, we can use Smolder's parse_hl7_message helper function. First, we
start with a DataFrame containing HL7 message text:
scala> val textMessageDf = ...
textMessageDf: org.apache.spark.sql.DataFrame = [value: string]
scala> textMessageDf.show()
+--------------------+
| value|
+--------------------+
|MSH|^~\&|||||2020...|
+--------------------+
Then, we can import the parse_hl7_message message from the
com.databricks.labs.smolder.functions object and apply that to the column we
want to parse:
scala> import com.databricks.labs.smolder.functions.parse_hl7_message
import com.databricks.labs.smolder.functions.parse_hl7_message
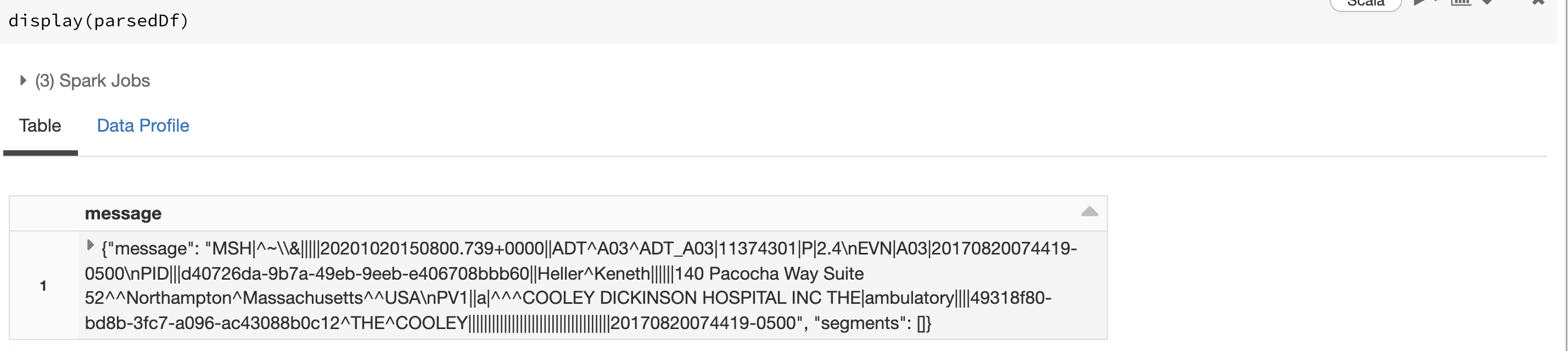
scala> val parsedDf = textMessageDf.select(parse_hl7_message($"value").as("message"))
parsedDf: org.apache.spark.sql.DataFrame = [message: struct<message: string, segments: array<struct<id:string,fields:array<string>>>>]
This yields the same schema as our hl7 data source.
While Smolder provides an easy-to-use schema for HL7 messages, we also provide
helper functions in com.databricks.labs.smolder.functions to extract subfields
of a message segment. For instance, let's say we want to get the patient's name,
which is the 5th field in the patient ID (PID) segment. We can extract this with
the segment_field function:
scala> import com.databricks.labs.smolder.functions.segment_field
import com.databricks.labs.smolder.functions.segment_field
scala> val nameDf = df.select(segment_field("PID", 4).alias("name"))
nameDf: org.apache.spark.sql.DataFrame = [name: string]
scala> nameDf.show()
+-------------+
| name|
+-------------+
|Heller^Keneth|
+-------------+
If we then wanted to get the patient's first name, we can use the subfield
function:
scala> import com.databricks.labs.smolder.functions.subfield
import com.databricks.labs.smolder.functions.subfield
scala> val firstNameDf = nameDf.select(subfield($"name", 1).alias("firstname"))
firstNameDf: org.apache.spark.sql.DataFrame = [firstname: string]
scala> firstNameDf.show()
+---------+
|firstname|
+---------+
| Keneth|
+---------+
Smolder is made available under an Apache 2.0 license, and we welcome contributions from the community. Please see our contibutor guidance for information about how to contribute to the project. To ensure that contributions to Smolder are properly licensed, we follow the Developer Certificate of Origin (DCO) for all contributions to the project.