
Many aspects of a person's life style and status can impact health outcomes. Multiple studies suggest that Social Determinents of Health (SDH) account for between 30-55% of health outcomes. [The WHO defines SDH as]((https://www.who.int/health-topics/social-determinants-of-health#tab=tab_1):
.. the non-medical factors that influence health outcomes. They are the conditions in which people are born,
grow, work, live, and age, and the wider set of forces and systems shaping the conditions of daily life.
These forces and systems include economic policies and systems, development agendas, social norms, social
policies and political systems.

Correlation between SDH and health outcomes is very clear: the lower the socioeconomic position, the worse the health, which in turn creates a negative feedback loop (poor health resulting in poor socioeconomic status) which results in widening the gap even more.
There are many public sources of SDH data with different levels of granularity (country level, state/province, county, or zipcode/postal code level) that can be used in analysis of the impact of SDH on health outcomes. One of the main challenegs for data analysis is finding the right data source and data cleaning.
To read shared data that has been shared with you using the Databricks-to-Databricks protocol, you must be a user on a Databricks workspace that is enabled for Unity Catalog.
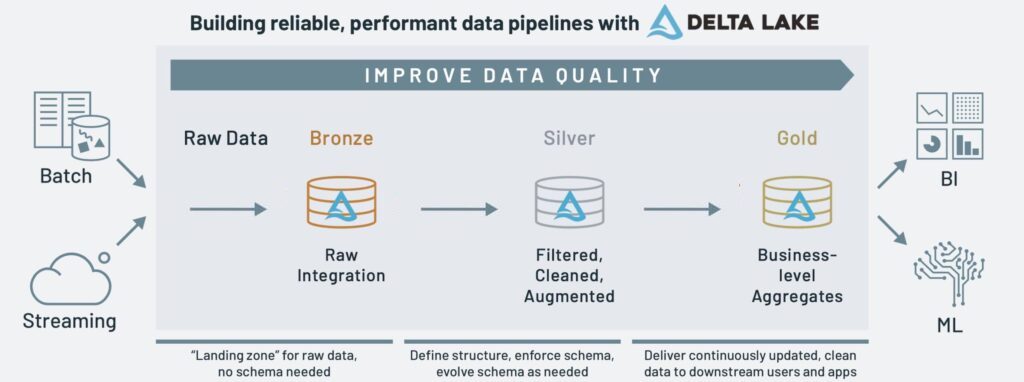
In this solution accelerator, we use pre-processed and cleansed tables that have been made available by Rearc via delta sharing protocol. We explore income, healthcare, education and other aspects affect counties vaccinations rates for COVID-19. Delta sharing allows us to offload the "bronze to silver" data prep step to a data provider or internal data team, beginning our analysis with "silver" or "gold" data. Using these data, we train a machine learning model to predict vaccination rates based on different SDH features and then use SHAP to offer insights into different factors impacting vaccination rates.
Copyright / License info of the notebook. Copyright [2021] the Notebook Authors. The source in this notebook is provided subject to the the Databricks License. All included or referenced third party libraries are subject to the licenses set forth below.
| Library Name | Library License | Library License URL | Library Source URL |
|---|---|---|---|
| Pandas | BSD 3-Clause License | https://github.com/pandas-dev/pandas/blob/master/LICENSE | https://github.com/pandas-dev/pandas |
| Numpy | BSD 3-Clause License | https://github.com/numpy/numpy/blob/main/LICENSE.txt | https://github.com/numpy/numpy |
| Apache Spark | Apache License 2.0 | https://github.com/apache/spark/blob/master/LICENSE | https://github.com/apache/spark/tree/master/python/pyspark |
| SHAP | MIT | https://github.com/slundberg/shap/blob/master/LICENSE | https://github.com/slundberg/shap/ |
| Plotly Express | MIT License | https://github.com/plotly/plotly_express/blob/master/LICENSE.txt | https://github.com/plotly/plotly_express/ |
| Author |
|---|
| Databricks Inc. |







