We study reading comprehension questions generation for text, with the focus on controlling the difficulty level of questions. This work trains a confidence model, which scores the likelihood of correctly answering a question, as a measure of the difficulty, and uses it to guide the search for difficult questions. We test 2 different confidence algorithms, one which uses the output probabilities of a QA model as confidence, and another which uses a model trained specifically for QA error prediction. We also train an ensemble of 5 such models and use their internal probability qualities as measures of question difficulty. Examples of the generated question, using various decoding strategies, are included, and show some interesting results. Finally, we analyze the difficulty and relevance of 2 of the methods using Amazon Mechanical Turk.
Datasets:- Reading comprehension(RC) datasets include a text, a question and an answer. We use 3 RC datasets: Boolq, Race, and SWAG. The main efforts and all results included are on the Boolq datasets, a datasets of boolean questions collection from google search. Models - All models(qa,confidence and generation), are pre trained hugggingface models, which were pretrained on SQUAD and then fine tuned by us on boolq for their specific task. For question generation, we used t5-base-e2e-qg from huggingface, which was pretrained for generation on SQUAD for generation For confidence models, roberta-base. The data for error prediction model was the output of our trained qa model. I.e we took the boolq datasets and switched the labels with (1 - qa_prediction) For the ensemble, we used 2 roberta base and 3 distilled-bert.
More details on the training process and hyperparams can be found in https://github.com/DanielGlickmanTAU/QA-GRL/blob/main/experiments/results/runs.md
Code flows are divided into, and run as tests.
Confidence:https://github.com/DanielGlickmanTAU/QA-GRL/blob/main/experiments/tests/test_confidence.py
Generation:https://github.com/DanielGlickmanTAU/QA-GRL/blob/main/experiments/tests/question_generation_test.py
Ensemble: https://github.com/DanielGlickmanTAU/QA-GRL/blob/main/experiments/tests/test_ensemble.py
Scoring difficulty
Text generation is typically done by creating multiple possible outputs, using some decoding algorithm, such as beam search, and then selecting the most probable one. We use that fact to implement a simple generation strategy that simply generates multiple candidate questions per text and then uses the trained confidence model to select the best one.
We evaluate the 2 confidence scoring models on questions generated using various decoding strategies. We also evaluate the ensemble method on existing questions from the Boolq test set.
For each evaluation, a text file with the best and worst example, as judged by the model, is provided.
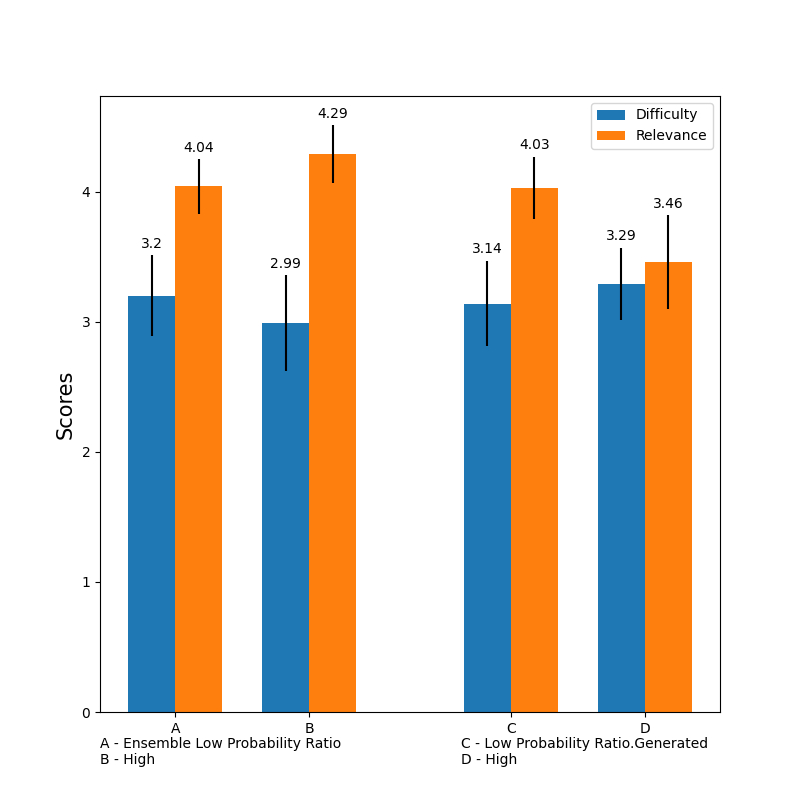
Finally, we conduct a survey, using Amazon Mechanical Turk, to quantify the difficulty and relevance of 2 of our methods.
Generated Examples
Ranked and sorted by error prediction: https://github.com/DanielGlickmanTAU/QA-GRL/blob/main/experiments/results/error_prediction_confidence
Ranked and sorted by probability ratio:https://github.com/DanielGlickmanTAU/QA-GRL/blob/main/experiments/results/probability_ratio_as_confidence
Generating multiple questions per text and sorting pairs of questions by difficulty. I.e show questions on the same texts with high differences in difficulty.
Confidence model beam search https://github.com/DanielGlickmanTAU/QA-GRL/blob/main/experiments/results/questions_confidence_diff_8_beams
p sampling:
https://github.com/DanielGlickmanTAU/QA-GRL/blob/main/experiments/results/question_confidence_diff_p_sampling_top_p_0.85_topk_25_return_seq_4
Results contain mostly “easy” questions which are nonsensical, such as “is paris the same as paris”. This was largely fixed by still taking the difference, but requiring that the difficulty of all questions will cross some difficulty threshold k=0.7.
https://github.com/DanielGlickmanTAU/QA-GRL/blob/main/experiments/results/take2/good_diff
Ensemble method
We also trained an ensemble of 2 roberta-base confidence(probability ratio) models and 3 smaller distilled-bert models. We evaluated their prediction on questions from the dataset(test) itself.
This is not simply an attempt to improve results by ensembling. We tried to use the disagreement between the models as a measure of difficulty, with the intuition that if the models do not score a question in the same way, it may serve as an indication for it being difficult.
Results: https://github.com/DanielGlickmanTAU/QA-GRL/tree/main/experiments/results/ensemble-results.
no_one_is_sure: vanilla ensemble method, taking the average of the 5 models confidence.
Smart_is_right_stupid_is_wrong: confidence given by the larger(roberta) models - confidence by smaller models
Entropy: entropy on all probabilities given.
https://s3.amazonaws.com/mturk_bulk/hits/456470764/aY0C4MQ9Giodq_gPsAfxgA.html