cvi-szu / linly Goto Github PK
View Code? Open in Web Editor NEWChinese-LLaMA 1&2、Chinese-Falcon 基础模型;ChatFlow中文对话模型;中文OpenLLaMA模型;NLP预训练/指令微调数据集
Chinese-LLaMA 1&2、Chinese-Falcon 基础模型;ChatFlow中文对话模型;中文OpenLLaMA模型;NLP预训练/指令微调数据集

























































































































































请问,项目里边发布的LLaMA-zh-7B和LLaMA-zh-7B,他们的max_length都是512吗?那在这个上边使用领域数据继续预训练,长度可以突破521吗?还是要想突破512,只能从头开始预训练呢?
如题所示,ChatLLaMA-zh-7B是在LLaMA-zh-7B基础上使用指令微调获得的吗?
Traceback (most recent call last):
File "scripts/generate_chatllama.py", line 82, in
args.tokenizer = str2tokenizerargs.tokenizer
File "/home/mo/llama/TencentPretrain/tencentpretrain/utils/tokenizers.py", line 255, in init
super().init(args, is_src)
File "/home/mo/llama/TencentPretrain/tencentpretrain/utils/tokenizers.py", line 30, in init
self.sp_model.Load(spm_model_path)
File "/home/mo/miniconda3/envs/llm_env/lib/python3.8/site-packages/sentencepiece/init.py", line 905, in Load
return self.LoadFromFile(model_file)
File "/home/mo/miniconda3/envs/llm_env/lib/python3.8/site-packages/sentencepiece/init.py", line 310, in LoadFromFile
return _sentencepiece.SentencePieceProcessor_LoadFromFile(self, arg)
RuntimeError: Internal: src/sentencepiece_processor.cc(1101) [model_proto->ParseFromArray(serialized.data(), serialized.size())]
我运行脚本后报错了,请问这个问题有谁遇到过嘛
大佬请教一下,1. 按照你的思路,相当于更新所有层参数对吗? 2. 中文词表没有扩充,这部分有影响吗?有的话 大概什么影响?
根据提示运行时报错如下:
/usr/local/cuda-11.2/include/thrust/detail/cpp11_required.h:23:6: error: #error C++11 is required for this Thrust feature; please upgrade your compiler or pass the appropriate -std=c++XX flag to it.
/usr/local/include/c++/5.2.0/bits/c++0x_warning.h:32:2: error: #error This file requires compiler and library support for the ISO C++ 2011 standard. This support is currently experimental, and must be enabled with the -std=c++11 or -std=gnu++11 co
我的gcc版本是5.2.0,请问需要哪个版本的gcc
我看pretrain.py任务里用到的deepspeed配置了fp16=true,而查看trainer.py里的优化参数args.fp16好像默认是不生效,需要同步配置它嘛?
TencentPretrain/tencentpretrain/utils/dataloader.py", line 187, in iter
yield torch.LongTensor(src),
TypeError: 'NoneType' object cannot be interpreted as an integer 请问这个是什么问题导致的,貌似预处理后的文件也没问题
请问中文预训练数据集有多大?训练了多久?多少个epoch?
我在单节点4*A800 80G上基于无监督的中午领域中文语料对llama进行增量预训练,相关配置如下:
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_config.json
--pretrained_model_path models/llama-7b.bin
--dataset_path dataset.pt --spm_model_path $LLaMA_7B_FOLDER/tokenizer.model
--config_path models/llama/7b_config.json
--output_model_path models/output_model.bin
--world_size 4 --learning_rate 1e-4
--data_processor lm --total_steps 10000 --save_checkpoint_steps 2000 --batch_size 48
但是当程序输出到4000个step后,大概12小时一直没有输出,如下图:

看了GPU使用情况是有显存占用和使用率的,如下图
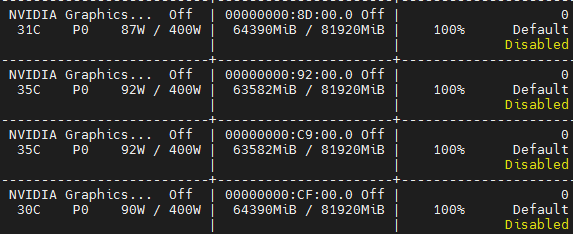
7b_config.json 能上传一下吗,缺少参数配置报错

请问通过运行preprocess.py 发现 tokenizer 用的是bert 这个是对的嘛?
[2023-03-29 23:51:48,504] [INFO] [comm.py:634:init_distributed] Not using the DeepSpeed or dist launchers, attempting to detect MPI environment...
[2023-03-29 23:51:49,947] [INFO] [comm.py:688:mpi_discovery] Discovered MPI settings of world_rank=0, local_rank=0, world_size=1, master_addr=10.163.165.254, master_port=29500
[2023-03-29 23:51:49,947] [INFO] [comm.py:652:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl
[2023-03-29 23:51:50,194] [INFO] [logging.py:93:log_dist] [Rank 0] DeepSpeed info: version=0.8.3, git-hash=unknown, git-branch=unknown
Traceback (most recent call last):
File "scripts/generate_lm_deepspeed.py", line 46, in
model = deepspeed.init_inference(model=model, mp_size=args.mp_size, replace_method=None)
File "/home/hdp-nlu/xiebin1-data/chatglm-6b/miniconda3/envs/py38-chatLLaMA/lib/python3.8/site-packages/deepspeed/init.py", line 309, in init_inference
ds_inference_config = DeepSpeedInferenceConfig(**config_dict)
File "/home/hdp-nlu/xiebin1-data/chatglm-6b/miniconda3/envs/py38-chatLLaMA/lib/python3.8/site-packages/deepspeed/runtime/config_utils.py", line 62, in init
super().init(**data)
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.init
pydantic.error_wrappers.ValidationError: 1 validation error for DeepSpeedInferenceConfig
replace_method
none is not an allowed value (type=type_error.none.not_allowed)
你好!我在git clone时遇到问题:
(chatllama) lxj@6G-KIN-PlatformA:~/codespace$ git clone https://huggingface.co/P01son/ChatLLaMA-zh-7B
正克隆到 'ChatLLaMA-zh-7B'...
remote: Enumerating objects: 9, done.
remote: Total 9 (delta 0), reused 0 (delta 0), pack-reused 9
展开对象中: 100% (9/9), 1.09 KiB | 1.09 MiB/s, 完成.
Encountered 1 file(s) that may not have been copied correctly on Windows:
chatllama_7b.bin
See: git lfs help smudge for more details.
git clone TencentPretrain最新代码,在2*A100 80G GPU上进行DeepSpeed ZeRO-3预训练测试,执行脚本如下(参考:TencentPretrain 使用 DeepSpeed ZeRO-3 流水线并行训练):
CUDA_VISIBLE_DEVICES=6,7 deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_config.json
--pretrained_model_path models/llama-13b.bin
--dataset_path dataset.pt --spm_model_path /path_to_llama/tokenizer.model
--config_path models/llama/13b_config.json
--output_model_path models/output_model.llama_13.bin
--world_size 2 --data_processor lm --batch_size 2 --enable_zero3
不开启ZeRO-3正常,开启后报如下错误:

非常感谢您的开源!
请问指令微调中preprocess.py文件的位置在哪儿呢,有链接嘛,git中没有看到。
when I run pretrain.py of llama-7b model, it has exception below (not user zero3):
ExceptionException: : Current loss scale already at minimum - cannot decrease scale anymore. Exiting run.Current loss scale already at minimum - cannot decrease scale anymore. Exiting run.
what's problem? How to solve?
My GPU server configure:
GPU:single A100(80G)
memory: 128G
File "/opt/conda/lib/python3.8/site-packages/tensor_parallel/wrapper.py", line 71, in forward
output = self.tp_wrapped_module(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/bitsandbytes/nn/modules.py", line 313, in forward
if self.weight.CB is not None:
AttributeError: 'Parameter' object has no attribute 'CB'
按照【快速开始】来进行快速使用,python执行后,GenerateLm吃了95%的内存,然后load_model(model, args.load_model_path)运行到一半直接被kill了(我后来加了个20G虚拟内存依然被kill了),还是我操作有问题
能不能提供 llama.cpp 的 FP16 格式的权重文件下载。量化成int4之后感觉会有一些信息错误。
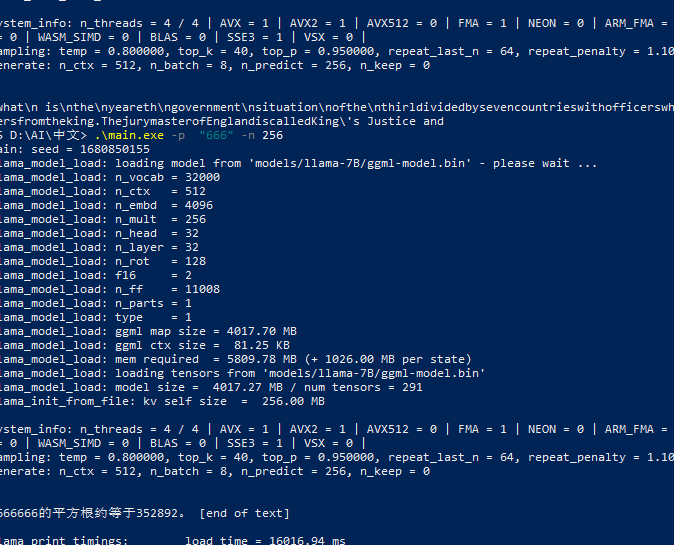
我再PowerShell下使用存在问题 我确认了路径是对的 但是我并不是加入 -p "中文" -n 256 中文参数 我希望设计成和其他模型差不多的双击main能成功运行 不再需要powershell 并且可以往复对话 目前对话用不了中文 而且不能连续对话 并且路径会令人混淆
分布式训练之后的模型格式是:
zero_pp_rank_0_mp_rank_00_model_states.pt
zero_pp_rank_0_mp_rank_00_optim_states.pt
zero_pp_rank_1_mp_rank_00_model_states.pt
zero_pp_rank_1_mp_rank_00_optim_states.pt
请问如何转化成适用于llama_inference推理的模型格式?https://github.com/fengyh3/llama_inference
如题,调用 convert_llama_weights_to_hf.py 后失败,显示如下:
FileNotFoundError: [Errno 2] No such file or directory: '../ChatLLaMA/7B/consolidated.00.pth'
如果通过GPTQ量化后可以在8G显卡上进行推理
如果使用你的参数会出现以下错误:
TypeError: load_model() takes 2 positional arguments but 3 were given
可以改为:
model = load_model(model, args.load_model_path)
因为在model_loader.py文件里,函数只需要两个输入:
def load_model(model, model_path)
可以改一下谢谢
https://github.com/oobabooga/text-generation-webui
我用的int4版本
加载模型时,提示
OSError: models/ChatLLaMA-zh-7B-int4 does not appear to have a file named config.json
需要一个config.json ?
结合此项目的示例方法成功进行预训练、增量训练,推理(generate_chatllama.py放不下,使用的generate_lm_deepspeed.py)环境应该是没有问题的。
由于保存的模型都是zero_pp_rank_XX_mp_rank_XX_optim_states.pt和zero_pp_rank_XX_mp_rank_XX_model_states.pt这种格式的,无法利用训练后的模型进行 推理 、增量训练。利用保存模型路径下的脚本zero_to_fp32.py进行转换python zero_to_fp32.py . pytorch_model.bin
这里使用的是7B的模型,cpu内存从16G增长到90多G,之后进程就死掉了。目前看着像是cpu内存不够导致的,模型保存文件-best是70多G,请问有什么方法能够转换成bin格式的模型么?
同时疑惑,现在可能是自己cpu内存不够导致的进程kill,如果之后用13B 30B 65B的模型(7B保存的模型75G,并且128G的cpu内存都不够用),难道要一直增加cpu内存来解决这个问题嘛。有没有大佬可以可以帮忙解决这个问题,感谢!
@ydli-ai
感谢分享!
请问一下:为什么推理速度比原版的llama要慢一些?
替换成int4模型后加载会报如下错误,请帮忙看下
Traceback (most recent call last):
File "scripts/generate_chatllama.py", line 86, in
model = load_model(model, args.load_model_path)
File "/workspace/TencentPretrain/tencentpretrain/model_loader.py", line 11, in load_model
model.load_state_dict(torch.load(model_path, map_location="cpu"), strict=False)
File "/opt/conda/lib/python3.7/site-packages/torch/serialization.py", line 795, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "/opt/conda/lib/python3.7/site-packages/torch/serialization.py", line 1002, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
我生成的结果:

readme中的结果:分词结果分别为:无线电,法国,别研究。
有些答非所问,不知道是什么原因
我计划在20G左右的领域数据(约9B token)上做增量预训练
learning_rate
max_seq_length
total_steps
save_checkpoint_steps
……
等超参数设置有啥推荐吗?
训练中文LLaMA大规模语言模型中的如下:
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_config.json
--pretrained_model_path models/llama-7b.bin
--dataset_path dataset.pt --spm_model_path $LLaMA_7B_FOLDER/tokenizer.model
--config_path models/llama/7b_config.json
--output_model_path models/output_model.bin
--world_size 8 --learning_rate 1e-4
--data_processor lm --total_steps 10000 --save_checkpoint_steps 2000 --batch_size 24
33b模型权重少了五份
https://huggingface.co/P01son/LLaMA-zh-33b-hf/tree/main
pytorch_model-00001-of-00007.bin
pytorch_model-00007-of-00007.bin
只有这两个
增量预训练时,统计训练数据大概有88873773个样本,instances_buffer_size默认值为25600。Dataloader类中_fill_buf方法中:
if len(self.buffer) >= self.instances_buffer_size:
break
我理解instances_buffer_size=88873773是不是才能遍历所有的训练样本,但是设置太多是不是内存会爆掉。如果是这样,有没有什么方法能保证遍历所有样本?
不知道理解对不对,请大佬指正~
RuntimeError:
CUDA Setup failed despite GPU being available. Inspect the CUDA SETUP outputs above to fix your environment!
If you cannot find any issues and suspect a bug, please open an issue with detals about your environment:
https://github.com/TimDettmers/bitsandbytes/issues
有人出现过这个问题吗?是怎么解决的呢?
根据readme操作,这个文件找不到
指令微调readme中提供了一个数据下载的超链接:https://huggingface.co/datasets/P01son/instructions
但对应repo内还没数据,请问后期会上传数据吗?大概什么时间?
如果超参都调最小,什么配置可以跑呢?

点击下载404如图

这个自己解决了 谢谢
Downloading model is too slow-_- Thanks

如果我有一批领域纯文本,不知可以通过chatllama来继续进行预训练吗,还是得从中英文增量预训练后的llama开始训练起?领域预训练完,再进行指令微调?
另外,领域上的指令微调训练集生成有什么指导意见不?
谢谢!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.